class Environment:\n",
+ " """Abstract class representing an Environment. 'Real' Environment classes\n",
+ " inherit from this. Your Environment will typically need to implement:\n",
+ " percept: Define the percept that an agent sees.\n",
+ " execute_action: Define the effects of executing an action.\n",
+ " Also update the agent.performance slot.\n",
+ " The environment keeps a list of .things and .agents (which is a subset\n",
+ " of .things). Each agent has a .performance slot, initialized to 0.\n",
+ " Each thing has a .location slot, even though some environments may not\n",
+ " need this."""\n",
+ "\n",
+ " def __init__(self):\n",
+ " self.things = []\n",
+ " self.agents = []\n",
+ "\n",
+ " def thing_classes(self):\n",
+ " return [] # List of classes that can go into environment\n",
+ "\n",
+ " def percept(self, agent):\n",
+ " """Return the percept that the agent sees at this point. (Implement this.)"""\n",
+ " raise NotImplementedError\n",
+ "\n",
+ " def execute_action(self, agent, action):\n",
+ " """Change the world to reflect this action. (Implement this.)"""\n",
+ " raise NotImplementedError\n",
+ "\n",
+ " def default_location(self, thing):\n",
+ " """Default location to place a new thing with unspecified location."""\n",
+ " return None\n",
+ "\n",
+ " def exogenous_change(self):\n",
+ " """If there is spontaneous change in the world, override this."""\n",
+ " pass\n",
+ "\n",
+ " def is_done(self):\n",
+ " """By default, we're done when we can't find a live agent."""\n",
+ " return not any(agent.is_alive() for agent in self.agents)\n",
+ "\n",
+ " def step(self):\n",
+ " """Run the environment for one time step. If the\n",
+ " actions and exogenous changes are independent, this method will\n",
+ " do. If there are interactions between them, you'll need to\n",
+ " override this method."""\n",
+ " if not self.is_done():\n",
+ " actions = []\n",
+ " for agent in self.agents:\n",
+ " if agent.alive:\n",
+ " actions.append(agent.program(self.percept(agent)))\n",
+ " else:\n",
+ " actions.append("")\n",
+ " for (agent, action) in zip(self.agents, actions):\n",
+ " self.execute_action(agent, action)\n",
+ " self.exogenous_change()\n",
+ "\n",
+ " def run(self, steps=1000):\n",
+ " """Run the Environment for given number of time steps."""\n",
+ " for step in range(steps):\n",
+ " if self.is_done():\n",
+ " return\n",
+ " self.step()\n",
+ "\n",
+ " def list_things_at(self, location, tclass=Thing):\n",
+ " """Return all things exactly at a given location."""\n",
+ " if isinstance(location, numbers.Number):\n",
+ " return [thing for thing in self.things\n",
+ " if thing.location == location and isinstance(thing, tclass)]\n",
+ " return [thing for thing in self.things\n",
+ " if all(x == y for x, y in zip(thing.location, location)) and isinstance(thing, tclass)]\n",
+ "\n",
+ " def some_things_at(self, location, tclass=Thing):\n",
+ " """Return true if at least one of the things at location\n",
+ " is an instance of class tclass (or a subclass)."""\n",
+ " return self.list_things_at(location, tclass) != []\n",
+ "\n",
+ " def add_thing(self, thing, location=None):\n",
+ " """Add a thing to the environment, setting its location. For\n",
+ " convenience, if thing is an agent program we make a new agent\n",
+ " for it. (Shouldn't need to override this.)"""\n",
+ " if not isinstance(thing, Thing):\n",
+ " thing = Agent(thing)\n",
+ " if thing in self.things:\n",
+ " print("Can't add the same thing twice")\n",
+ " else:\n",
+ " thing.location = location if location is not None else self.default_location(thing)\n",
+ " self.things.append(thing)\n",
+ " if isinstance(thing, Agent):\n",
+ " thing.performance = 0\n",
+ " self.agents.append(thing)\n",
+ "\n",
+ " def delete_thing(self, thing):\n",
+ " """Remove a thing from the environment."""\n",
+ " try:\n",
+ " self.things.remove(thing)\n",
+ " except ValueError as e:\n",
+ " print(e)\n",
+ " print(" in Environment delete_thing")\n",
+ " print(" Thing to be removed: {} at {}".format(thing, thing.location))\n",
+ " print(" from list: {}".format([(thing, thing.location) for thing in self.things]))\n",
+ " if thing in self.agents:\n",
+ " self.agents.remove(thing)\n",
+ "| Percept: | \n", + "Feel Food | \n", + "Feel Water | \n", + "Feel Nothing | \n", + "
| Action: | \n", + "eat | \n", + "drink | \n", + "move down | \n", + "
agent = architecture + program
" + ] + }, + { + "cell_type": "markdown", + "id": "d3f410d6", + "metadata": {}, + "source": [ + "## CONTENTS\n", + "\n", + "* Agent\n", + "* Table-Driven Agent Program\n", + "* Simple Reflex Agent Program\n", + "* Model-Based Reflex Agent Program" + ] + }, + { + "cell_type": "code", + "execution_count": 12, + "id": "29d9a4d8", + "metadata": {}, + "outputs": [], + "source": [ + "# from agents import *\n", + "from agents4e import *\n", + "from notebook import psource" + ] + }, + { + "cell_type": "markdown", + "id": "f230e074", + "metadata": {}, + "source": [ + "Let us first see how we define the TrivialVacuumEnvironment. Run the next cell to see how abstract class TrivialVacuumEnvironment is defined in agents module:" + ] + }, + { + "cell_type": "code", + "execution_count": 13, + "id": "5b27d516", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "class TrivialVacuumEnvironment(Environment):\n",
+ " """This environment has two locations, A and B. Each can be Dirty\n",
+ " or Clean. The agent perceives its location and the location's\n",
+ " status. This serves as an example of how to implement a simple\n",
+ " Environment."""\n",
+ "\n",
+ " def __init__(self):\n",
+ " super().__init__()\n",
+ " self.status = {loc_A: random.choice(['Clean', 'Dirty']),\n",
+ " loc_B: random.choice(['Clean', 'Dirty'])}\n",
+ "\n",
+ " def thing_classes(self):\n",
+ " return [Wall, Dirt, ReflexVacuumAgent, RandomVacuumAgent, TableDrivenVacuumAgent, ModelBasedVacuumAgent]\n",
+ "\n",
+ " def percept(self, agent):\n",
+ " """Returns the agent's location, and the location status (Dirty/Clean)."""\n",
+ " return agent.location, self.status[agent.location]\n",
+ "\n",
+ " def execute_action(self, agent, action):\n",
+ " """Change agent's location and/or location's status; track performance.\n",
+ " Score 10 for each dirt cleaned; -1 for each move."""\n",
+ " if action == 'Right':\n",
+ " agent.location = loc_B\n",
+ " agent.performance -= 1\n",
+ " elif action == 'Left':\n",
+ " agent.location = loc_A\n",
+ " agent.performance -= 1\n",
+ " elif action == 'Suck':\n",
+ " if self.status[agent.location] == 'Dirty':\n",
+ " agent.performance += 10\n",
+ " self.status[agent.location] = 'Clean'\n",
+ "\n",
+ " def default_location(self, thing):\n",
+ " """Agents start in either location at random."""\n",
+ " return random.choice([loc_A, loc_B])\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0c1e4de2",
+ "metadata": {},
+ "source": [
+ "We will now create a model-based reflex agent for the environment:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 24,
+ "id": "0c78878c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Delete the previously added simple reflex agent\n",
+ "trivial_vacuum_env.delete_thing(simple_reflex_agent)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1dc6a638",
+ "metadata": {},
+ "source": [
+ "We need another function UPDATE-STATE which will be responsible for creating a new state description."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 25,
+ "id": "868f49e9",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "ModelBasedVacuumAgent is located at (0, 0).\n"
+ ]
+ }
+ ],
+ "source": [
+ "# TODO: Implement this function for the two-dimensional environment\n",
+ "def update_state(state, action, percept, model):\n",
+ " pass\n",
+ "\n",
+ "# Create a model-based reflex agent\n",
+ "model_based_reflex_agent = ModelBasedVacuumAgent()\n",
+ "\n",
+ "# Add the agent to the environment\n",
+ "trivial_vacuum_env.add_thing(model_based_reflex_agent)\n",
+ "\n",
+ "print(\"ModelBasedVacuumAgent is located at {}.\".format(model_based_reflex_agent.location))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 26,
+ "id": "a3a6e727",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "State of the Environment: {(0, 0): 'Dirty', (1, 0): 'Dirty'}.\n",
+ "State of the Environment: {(0, 0): 'Clean', (1, 0): 'Dirty'}.\n",
+ "ModelBasedVacuumAgent is located at (0, 0).\n",
+ "State of the Environment: {(0, 0): 'Clean', (1, 0): 'Dirty'}.\n",
+ "ModelBasedVacuumAgent is located at (1, 0).\n",
+ "State of the Environment: {(0, 0): 'Clean', (1, 0): 'Clean'}.\n",
+ "ModelBasedVacuumAgent is located at (1, 0).\n"
+ ]
+ }
+ ],
+ "source": [
+ "trivial_vacuum_env.status = {(0, 0): 'Dirty', (1, 0): 'Dirty'}\n",
+ "print(\"State of the Environment: {}.\".format(trivial_vacuum_env.status))\n",
+ "\n",
+ "# Run the environment\n",
+ "trivial_vacuum_env.step()\n",
+ "# Check the current state of the environment\n",
+ "print(\"State of the Environment: {}.\".format(trivial_vacuum_env.status))\n",
+ "print(\"ModelBasedVacuumAgent is located at {}.\".format(model_based_reflex_agent.location))\n",
+ "\n",
+ "# Run the environment\n",
+ "trivial_vacuum_env.step()\n",
+ "# Check the current state of the environment\n",
+ "print(\"State of the Environment: {}.\".format(trivial_vacuum_env.status))\n",
+ "print(\"ModelBasedVacuumAgent is located at {}.\".format(model_based_reflex_agent.location))\n",
+ "\n",
+ "# Run the environment\n",
+ "trivial_vacuum_env.step()\n",
+ "# Check the current state of the environment\n",
+ "print(\"State of the Environment: {}.\".format(trivial_vacuum_env.status))\n",
+ "\n",
+ "print(\"ModelBasedVacuumAgent is located at {}.\".format(model_based_reflex_agent.location))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e7a0ae4d",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-03-Solving-Problems-Searching.ipynb b/Chapter-03-Solving-Problems-Searching.ipynb
new file mode 100644
index 000000000..c4bf062d4
--- /dev/null
+++ b/Chapter-03-Solving-Problems-Searching.ipynb
@@ -0,0 +1,868 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "d12f7cea",
+ "metadata": {},
+ "source": [
+ "# Search for AIMA 4th edition\n",
+ "\n",
+ "Implementation of search algorithms and search problems for AIMA.\n",
+ "\n",
+ "# Problems and Nodes\n",
+ "\n",
+ "We start by defining the abstract class for a `Problem`; specific problem domains will subclass this. To make it easier for algorithms that use a heuristic evaluation function, `Problem` has a default `h` function (uniformly zero), and subclasses can define their own default `h` function.\n",
+ "\n",
+ "We also define a `Node` in a search tree, and some functions on nodes: `expand` to generate successors; `path_actions` and `path_states` to recover aspects of the path from the node. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "a333c036",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%matplotlib inline\n",
+ "import matplotlib.pyplot as plt\n",
+ "import random\n",
+ "import heapq\n",
+ "import math\n",
+ "import sys\n",
+ "from collections import defaultdict, deque, Counter\n",
+ "from itertools import combinations\n",
+ "\n",
+ "\n",
+ "class Problem(object):\n",
+ " \"\"\"The abstract class for a formal problem. A new domain subclasses this,\n",
+ " overriding `actions` and `results`, and perhaps other methods.\n",
+ " The default heuristic is 0 and the default action cost is 1 for all states.\n",
+ " When yiou create an instance of a subclass, specify `initial`, and `goal` states \n",
+ " (or give an `is_goal` method) and perhaps other keyword args for the subclass.\"\"\"\n",
+ "\n",
+ " def __init__(self, initial=None, goal=None, **kwds): \n",
+ " self.__dict__.update(initial=initial, goal=goal, **kwds) \n",
+ " \n",
+ " def actions(self, state): raise NotImplementedError\n",
+ " def result(self, state, action): raise NotImplementedError\n",
+ " def is_goal(self, state): return state == self.goal\n",
+ " def action_cost(self, s, a, s1): return 1\n",
+ " def h(self, node): return 0\n",
+ " \n",
+ " def __str__(self):\n",
+ " return '{}({!r}, {!r})'.format(\n",
+ " type(self).__name__, self.initial, self.goal)\n",
+ " \n",
+ "\n",
+ "class Node:\n",
+ " \"A Node in a search tree.\"\n",
+ " def __init__(self, state, parent=None, action=None, path_cost=0):\n",
+ " self.__dict__.update(state=state, parent=parent, action=action, path_cost=path_cost)\n",
+ "\n",
+ " def __repr__(self): return '<{}>'.format(self.state)\n",
+ " def __len__(self): return 0 if self.parent is None else (1 + len(self.parent))\n",
+ " def __lt__(self, other): return self.path_cost < other.path_cost\n",
+ " \n",
+ " \n",
+ "failure = Node('failure', path_cost=math.inf) # Indicates an algorithm couldn't find a solution.\n",
+ "cutoff = Node('cutoff', path_cost=math.inf) # Indicates iterative deepening search was cut off.\n",
+ " \n",
+ " \n",
+ "def expand(problem, node):\n",
+ " \"Expand a node, generating the children nodes.\"\n",
+ " s = node.state\n",
+ " for action in problem.actions(s):\n",
+ " s1 = problem.result(s, action)\n",
+ " cost = node.path_cost + problem.action_cost(s, action, s1)\n",
+ " yield Node(s1, node, action, cost)\n",
+ " \n",
+ "\n",
+ "def path_actions(node):\n",
+ " \"The sequence of actions to get to this node.\"\n",
+ " if node.parent is None:\n",
+ " return [] \n",
+ " return path_actions(node.parent) + [node.action]\n",
+ "\n",
+ "\n",
+ "def path_states(node):\n",
+ " \"The sequence of states to get to this node.\"\n",
+ " if node in (cutoff, failure, None): \n",
+ " return []\n",
+ " return path_states(node.parent) + [node.state]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c3697d5a",
+ "metadata": {},
+ "source": [
+ "# Queues\n",
+ "\n",
+ "First-in-first-out and Last-in-first-out queues, and a `PriorityQueue`, which allows you to keep a collection of items, and continually remove from it the item with minimum `f(item)` score."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "457d5a0b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "FIFOQueue = deque\n",
+ "\n",
+ "LIFOQueue = list\n",
+ "\n",
+ "class PriorityQueue:\n",
+ " \"\"\"A queue in which the item with minimum f(item) is always popped first.\"\"\"\n",
+ "\n",
+ " def __init__(self, items=(), key=lambda x: x): \n",
+ " self.key = key\n",
+ " self.items = [] # a heap of (score, item) pairs\n",
+ " for item in items:\n",
+ " self.add(item)\n",
+ " \n",
+ " def add(self, item):\n",
+ " \"\"\"Add item to the queuez.\"\"\"\n",
+ " pair = (self.key(item), item)\n",
+ " heapq.heappush(self.items, pair)\n",
+ "\n",
+ " def pop(self):\n",
+ " \"\"\"Pop and return the item with min f(item) value.\"\"\"\n",
+ " return heapq.heappop(self.items)[1]\n",
+ " \n",
+ " def top(self): return self.items[0][1]\n",
+ "\n",
+ " def __len__(self): return len(self.items)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f9801f0",
+ "metadata": {},
+ "source": [
+ "# Search Algorithms: Best-First\n",
+ "\n",
+ "Best-first search with various *f(n)* functions gives us different search algorithms. Note that A\\*, weighted A\\* and greedy search can be given a heuristic function, `h`, but if `h` is not supplied they use the problem's default `h` function (if the problem does not define one, it is taken as *h(n)* = 0)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "3c7bc169",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def best_first_search(problem, f):\n",
+ " \"Search nodes with minimum f(node) value first.\"\n",
+ " node = Node(problem.initial)\n",
+ " frontier = PriorityQueue([node], key=f)\n",
+ " reached = {problem.initial: node}\n",
+ " while frontier:\n",
+ " node = frontier.pop()\n",
+ " if problem.is_goal(node.state):\n",
+ " return node\n",
+ " for child in expand(problem, node):\n",
+ " s = child.state\n",
+ " if s not in reached or child.path_cost < reached[s].path_cost:\n",
+ " reached[s] = child\n",
+ " frontier.add(child)\n",
+ " return failure\n",
+ "\n",
+ "\n",
+ "def best_first_tree_search(problem, f):\n",
+ " \"A version of best_first_search without the `reached` table.\"\n",
+ " frontier = PriorityQueue([Node(problem.initial)], key=f)\n",
+ " while frontier:\n",
+ " node = frontier.pop()\n",
+ " if problem.is_goal(node.state):\n",
+ " return node\n",
+ " for child in expand(problem, node):\n",
+ " if not is_cycle(child):\n",
+ " frontier.add(child)\n",
+ " return failure\n",
+ "\n",
+ "\n",
+ "def g(n): return n.path_cost\n",
+ "\n",
+ "\n",
+ "def astar_search(problem, h=None):\n",
+ " \"\"\"Search nodes with minimum f(n) = g(n) + h(n).\"\"\"\n",
+ " h = h or problem.h\n",
+ " return best_first_search(problem, f=lambda n: g(n) + h(n))\n",
+ "\n",
+ "\n",
+ "def astar_tree_search(problem, h=None):\n",
+ " \"\"\"Search nodes with minimum f(n) = g(n) + h(n), with no `reached` table.\"\"\"\n",
+ " h = h or problem.h\n",
+ " return best_first_tree_search(problem, f=lambda n: g(n) + h(n))\n",
+ "\n",
+ "\n",
+ "def weighted_astar_search(problem, h=None, weight=1.4):\n",
+ " \"\"\"Search nodes with minimum f(n) = g(n) + weight * h(n).\"\"\"\n",
+ " h = h or problem.h\n",
+ " return best_first_search(problem, f=lambda n: g(n) + weight * h(n))\n",
+ "\n",
+ " \n",
+ "def greedy_bfs(problem, h=None):\n",
+ " \"\"\"Search nodes with minimum h(n).\"\"\"\n",
+ " h = h or problem.h\n",
+ " return best_first_search(problem, f=h)\n",
+ "\n",
+ "\n",
+ "def uniform_cost_search(problem):\n",
+ " \"Search nodes with minimum path cost first.\"\n",
+ " return best_first_search(problem, f=g)\n",
+ "\n",
+ "\n",
+ "def breadth_first_bfs(problem):\n",
+ " \"Search shallowest nodes in the search tree first; using best-first.\"\n",
+ " return best_first_search(problem, f=len)\n",
+ "\n",
+ "\n",
+ "def depth_first_bfs(problem):\n",
+ " \"Search deepest nodes in the search tree first; using best-first.\"\n",
+ " return best_first_search(problem, f=lambda n: -len(n))\n",
+ "\n",
+ "\n",
+ "def is_cycle(node, k=30):\n",
+ " \"Does this node form a cycle of length k or less?\"\n",
+ " def find_cycle(ancestor, k):\n",
+ " return (ancestor is not None and k > 0 and\n",
+ " (ancestor.state == node.state or find_cycle(ancestor.parent, k - 1)))\n",
+ " return find_cycle(node.parent, k)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "448a13c5",
+ "metadata": {},
+ "source": [
+ "# Other Search Algorithms\n",
+ "\n",
+ "Here are the other search algorithms:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "191d3801",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def breadth_first_search(problem):\n",
+ " \"Search shallowest nodes in the search tree first.\"\n",
+ " node = Node(problem.initial)\n",
+ " if problem.is_goal(problem.initial):\n",
+ " return node\n",
+ " frontier = FIFOQueue([node])\n",
+ " reached = {problem.initial}\n",
+ " while frontier:\n",
+ " node = frontier.pop()\n",
+ " for child in expand(problem, node):\n",
+ " s = child.state\n",
+ " if problem.is_goal(s):\n",
+ " return child\n",
+ " if s not in reached:\n",
+ " reached.add(s)\n",
+ " frontier.appendleft(child)\n",
+ " return failure\n",
+ "\n",
+ "\n",
+ "def iterative_deepening_search(problem):\n",
+ " \"Do depth-limited search with increasing depth limits.\"\n",
+ " for limit in range(1, sys.maxsize):\n",
+ " result = depth_limited_search(problem, limit)\n",
+ " if result != cutoff:\n",
+ " return result\n",
+ " \n",
+ " \n",
+ "def depth_limited_search(problem, limit=10):\n",
+ " \"Search deepest nodes in the search tree first.\"\n",
+ " frontier = LIFOQueue([Node(problem.initial)])\n",
+ " result = failure\n",
+ " while frontier:\n",
+ " node = frontier.pop()\n",
+ " if problem.is_goal(node.state):\n",
+ " return node\n",
+ " elif len(node) >= limit:\n",
+ " result = cutoff\n",
+ " elif not is_cycle(node):\n",
+ " for child in expand(problem, node):\n",
+ " frontier.append(child)\n",
+ " return result\n",
+ "\n",
+ "\n",
+ "def depth_first_recursive_search(problem, node=None):\n",
+ " if node is None: \n",
+ " node = Node(problem.initial)\n",
+ " if problem.is_goal(node.state):\n",
+ " return node\n",
+ " elif is_cycle(node):\n",
+ " return failure\n",
+ " else:\n",
+ " for child in expand(problem, node):\n",
+ " result = depth_first_recursive_search(problem, child)\n",
+ " if result:\n",
+ " return result\n",
+ " return failure"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2dcbb1a1",
+ "metadata": {},
+ "source": [
+ "# 8 Puzzle Problems\n",
+ "\n",
+ "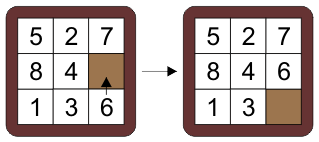\n",
+ "\n",
+ "A sliding tile puzzle where you can swap the blank with an adjacent piece, trying to reach a goal configuration. The cells are numbered 0 to 8, starting at the top left and going row by row left to right. The pieces are numebred 1 to 8, with 0 representing the blank. An action is the cell index number that is to be swapped with the blank (*not* the actual number to be swapped but the index into the state). So the diagram above left is the state `(5, 2, 7, 8, 4, 0, 1, 3, 6)`, and the action is `8`, because the cell number 8 (the 9th or last cell, the `6` in the bottom right) is swapped with the blank.\n",
+ "\n",
+ "There are two disjoint sets of states that cannot be reached from each other. One set has an even number of \"inversions\"; the other has an odd number. An inversion is when a piece in the state is larger than a piece that follows it.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "c0091daf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class EightPuzzle(Problem):\n",
+ " \"\"\" The problem of sliding tiles numbered from 1 to 8 on a 3x3 board,\n",
+ " where one of the squares is a blank, trying to reach a goal configuration.\n",
+ " A board state is represented as a tuple of length 9, where the element at index i \n",
+ " represents the tile number at index i, or 0 if for the empty square, e.g. the goal:\n",
+ " 1 2 3\n",
+ " 4 5 6 ==> (1, 2, 3, 4, 5, 6, 7, 8, 0)\n",
+ " 7 8 _\n",
+ " \"\"\"\n",
+ "\n",
+ " def __init__(self, initial, goal=(0, 1, 2, 3, 4, 5, 6, 7, 8)):\n",
+ " assert inversions(initial) % 2 == inversions(goal) % 2 # Parity check\n",
+ " self.initial, self.goal = initial, goal\n",
+ " \n",
+ " def actions(self, state):\n",
+ " \"\"\"The indexes of the squares that the blank can move to.\"\"\"\n",
+ " moves = ((1, 3), (0, 2, 4), (1, 5),\n",
+ " (0, 4, 6), (1, 3, 5, 7), (2, 4, 8),\n",
+ " (3, 7), (4, 6, 8), (7, 5))\n",
+ " blank = state.index(0)\n",
+ " return moves[blank]\n",
+ " \n",
+ " def result(self, state, action):\n",
+ " \"\"\"Swap the blank with the square numbered `action`.\"\"\"\n",
+ " s = list(state)\n",
+ " blank = state.index(0)\n",
+ " s[action], s[blank] = s[blank], s[action]\n",
+ " return tuple(s)\n",
+ " \n",
+ " def h1(self, node):\n",
+ " \"\"\"The misplaced tiles heuristic.\"\"\"\n",
+ " return hamming_distance(node.state, self.goal)\n",
+ " \n",
+ " def h2(self, node):\n",
+ " \"\"\"The Manhattan heuristic.\"\"\"\n",
+ " X = (0, 1, 2, 0, 1, 2, 0, 1, 2)\n",
+ " Y = (0, 0, 0, 1, 1, 1, 2, 2, 2)\n",
+ " return sum(abs(X[s] - X[g]) + abs(Y[s] - Y[g])\n",
+ " for (s, g) in zip(node.state, self.goal) if s != 0)\n",
+ " \n",
+ " def h(self, node): return self.h2(node)\n",
+ " \n",
+ " \n",
+ "def hamming_distance(A, B):\n",
+ " \"Number of positions where vectors A and B are different.\"\n",
+ " return sum(a != b for a, b in zip(A, B))\n",
+ " \n",
+ "\n",
+ "def inversions(board):\n",
+ " \"The number of times a piece is a smaller number than a following piece.\"\n",
+ " return sum((a > b and a != 0 and b != 0) for (a, b) in combinations(board, 2))\n",
+ " \n",
+ " \n",
+ "def board8(board, fmt=(3 * '{} {} {}\\n')):\n",
+ " \"A string representing an 8-puzzle board\"\n",
+ " return fmt.format(*board).replace('0', '_')\n",
+ "\n",
+ "class Board(defaultdict):\n",
+ " empty = '.'\n",
+ " off = '#'\n",
+ " def __init__(self, board=None, width=8, height=8, to_move=None, **kwds):\n",
+ " if board is not None:\n",
+ " self.update(board)\n",
+ " self.width, self.height = (board.width, board.height) \n",
+ " else:\n",
+ " self.width, self.height = (width, height)\n",
+ " self.to_move = to_move\n",
+ "\n",
+ " def __missing__(self, key):\n",
+ " x, y = key\n",
+ " if x < 0 or x >= self.width or y < 0 or y >= self.height:\n",
+ " return self.off\n",
+ " else:\n",
+ " return self.empty\n",
+ " \n",
+ " def __repr__(self):\n",
+ " def row(y): return ' '.join(self[x, y] for x in range(self.width))\n",
+ " return '\\n'.join(row(y) for y in range(self.height))\n",
+ " \n",
+ " def __hash__(self): \n",
+ " return hash(tuple(sorted(self.items()))) + hash(self.to_move)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "0580861b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Some specific EightPuzzle problems\n",
+ "\n",
+ "e1 = EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8))\n",
+ "e2 = EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0))\n",
+ "e3 = EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6))\n",
+ "e4 = EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1))\n",
+ "e5 = EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "785d61ba",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class CountCalls:\n",
+ " \"\"\"Delegate all attribute gets to the object, and count them in ._counts\"\"\"\n",
+ " def __init__(self, obj):\n",
+ " self._object = obj\n",
+ " self._counts = Counter()\n",
+ " \n",
+ " def __getattr__(self, attr):\n",
+ " \"Delegate to the original object, after incrementing a counter.\"\n",
+ " self._counts[attr] += 1\n",
+ " return getattr(self._object, attr)\n",
+ "\n",
+ " \n",
+ "def report(searchers, problems, verbose=True):\n",
+ " \"\"\"Show summary statistics for each searcher (and on each problem unless verbose is false).\"\"\"\n",
+ " for searcher in searchers:\n",
+ " print(searcher.__name__ + ':')\n",
+ " total_counts = Counter()\n",
+ " for p in problems:\n",
+ " prob = CountCalls(p)\n",
+ " soln = searcher(prob)\n",
+ " counts = prob._counts; \n",
+ " counts.update(actions=len(soln), cost=soln.path_cost)\n",
+ " total_counts += counts\n",
+ " if verbose: report_counts(counts, str(p)[:40])\n",
+ " report_counts(total_counts, 'TOTAL\\n')\n",
+ " \n",
+ "def report_counts(counts, name):\n",
+ " \"\"\"Print one line of the counts report.\"\"\"\n",
+ " print('{:9,d} nodes |{:9,d} goal |{:5.0f} cost |{:8,d} actions | {}'.format(\n",
+ " counts['result'], counts['is_goal'], counts['cost'], counts['actions'], name))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "5d51453f",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "breadth_first_search:\n",
+ " 81 nodes | 82 goal | 5 cost | 35 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 160,948 nodes | 160,949 goal | 22 cost | 59,960 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 218,263 nodes | 218,264 goal | 23 cost | 81,829 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 418,771 nodes | 418,772 goal | 26 cost | 156,533 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 448,667 nodes | 448,668 goal | 27 cost | 167,799 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ "1,246,730 nodes |1,246,735 goal | 103 cost | 466,156 actions | TOTAL\n",
+ "\n",
+ "uniform_cost_search:\n",
+ " 124 nodes | 46 goal | 5 cost | 50 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 214,952 nodes | 79,187 goal | 22 cost | 79,208 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 300,925 nodes | 112,082 goal | 23 cost | 112,104 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 457,766 nodes | 171,571 goal | 26 cost | 171,596 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 466,441 nodes | 174,474 goal | 27 cost | 174,500 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ "1,440,208 nodes | 537,360 goal | 103 cost | 537,458 actions | TOTAL\n",
+ "\n",
+ "depth_limited_search:\n",
+ " 351 nodes | 349 goal | 5 cost | 138 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 1,340 nodes | 1,341 goal | inf cost | 483 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 1,544 nodes | 1,545 goal | inf cost | 577 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 1,832 nodes | 1,833 goal | inf cost | 645 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 1,544 nodes | 1,545 goal | inf cost | 577 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ " 6,611 nodes | 6,613 goal | inf cost | 2,420 actions | TOTAL\n",
+ "\n",
+ "iterative_deepening_search:\n",
+ " 116 nodes | 118 goal | 5 cost | 47 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ "1,449,397 nodes |1,449,397 goal | 22 cost | 532,868 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ "4,398,813 nodes |4,398,818 goal | 23 cost |1,601,193 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ "23,139,541 nodes |23,139,544 goal | 26 cost |8,443,418 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ "33,561,413 nodes |33,561,419 goal | 27 cost |12,256,924 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ "62,549,280 nodes |62,549,296 goal | 103 cost |22,834,450 actions | TOTAL\n",
+ "\n",
+ "greedy_bfs:\n",
+ " 15 nodes | 6 goal | 5 cost | 10 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 1,569 nodes | 568 goal | 58 cost | 625 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 287 nodes | 109 goal | 33 cost | 141 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 1,128 nodes | 408 goal | 46 cost | 453 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 1,495 nodes | 543 goal | 63 cost | 605 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ " 4,494 nodes | 1,634 goal | 205 cost | 1,834 actions | TOTAL\n",
+ "\n",
+ "astar_search:\n",
+ " 15 nodes | 6 goal | 5 cost | 10 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 3,614 nodes | 1,349 goal | 22 cost | 1,370 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 5,373 nodes | 2,010 goal | 23 cost | 2,032 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 10,832 nodes | 4,086 goal | 26 cost | 4,111 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 11,669 nodes | 4,417 goal | 27 cost | 4,443 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ " 31,503 nodes | 11,868 goal | 103 cost | 11,966 actions | TOTAL\n",
+ "\n",
+ "weighted_astar_search:\n",
+ " 15 nodes | 6 goal | 5 cost | 10 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 2,082 nodes | 771 goal | 22 cost | 792 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 3,960 nodes | 1,475 goal | 25 cost | 1,499 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 1,992 nodes | 748 goal | 26 cost | 773 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 6,632 nodes | 2,480 goal | 29 cost | 2,508 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ " 14,681 nodes | 5,480 goal | 107 cost | 5,582 actions | TOTAL\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "report([breadth_first_search,uniform_cost_search,depth_limited_search,iterative_deepening_search,greedy_bfs,astar_search,weighted_astar_search], [e1, e2, e3, e4, e5])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "e193e911",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Solve an 8 puzzle problem and print out each action\n",
+ "for a in path_actions(depth_limited_search(e2)):\n",
+ " print(a)\n",
+ "\n",
+ "# Solve an 8 puzzle problem and print out each state\n",
+ "\n",
+ "for s in path_states(depth_limited_search(e2)):\n",
+ " print(board8(s))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "6ad94a70",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "6\n",
+ "7\n",
+ "4\n",
+ "1\n",
+ "0\n",
+ "1 4 2\n",
+ "_ 7 5\n",
+ "3 6 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 7 5\n",
+ "_ 6 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 7 5\n",
+ "6 _ 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 _ 5\n",
+ "6 7 8\n",
+ "\n",
+ "1 _ 2\n",
+ "3 4 5\n",
+ "6 7 8\n",
+ "\n",
+ "_ 1 2\n",
+ "3 4 5\n",
+ "6 7 8\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Solve an 8 puzzle problem and print out each action\n",
+ "\n",
+ "for a in path_actions(breadth_first_bfs(e1)):\n",
+ " print(a)\n",
+ "\n",
+ "# Solve an 8 puzzle problem and print out each state\n",
+ "\n",
+ "for s in path_states(breadth_first_bfs(e1)):\n",
+ " print(board8(s))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "446f14cd",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "1 4 2\n",
+ "_ 7 5\n",
+ "3 6 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 7 5\n",
+ "_ 6 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 7 5\n",
+ "6 _ 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 _ 5\n",
+ "6 7 8\n",
+ "\n",
+ "1 _ 2\n",
+ "3 4 5\n",
+ "6 7 8\n",
+ "\n",
+ "_ 1 2\n",
+ "3 4 5\n",
+ "6 7 8\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Solve an 8 puzzle problem and print out each state\n",
+ "\n",
+ "for s in path_states(astar_search(e1)):\n",
+ " print(board8(s))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "256ab048",
+ "metadata": {},
+ "source": [
+ "# Route Finding Problems\n",
+ "\n",
+ "\n",
+ "\n",
+ "In a `RouteProblem`, the states are names of \"cities\" (or other locations), like `'A'` for Arad. The actions are also city names; `'Z'` is the action to move to city `'Z'`. The layout of cities is given by a separate data structure, a `Map`, which is a graph where there are vertexes (cities), links between vertexes, distances (costs) of those links (if not specified, the default is 1 for every link), and optionally the 2D (x, y) location of each city can be specified. A `RouteProblem` takes this `Map` as input and allows actions to move between linked cities. The default heuristic is straight-line distance to the goal, or is uniformly zero if locations were not given."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "aa126eba",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class RouteProblem(Problem):\n",
+ " \"\"\"A problem to find a route between locations on a `Map`.\n",
+ " Create a problem with RouteProblem(start, goal, map=Map(...)}).\n",
+ " States are the vertexes in the Map graph; actions are destination states.\"\"\"\n",
+ " \n",
+ " def actions(self, state): \n",
+ " \"\"\"The places neighboring `state`.\"\"\"\n",
+ " return self.map.neighbors[state]\n",
+ " \n",
+ " def result(self, state, action):\n",
+ " \"\"\"Go to the `action` place, if the map says that is possible.\"\"\"\n",
+ " return action if action in self.map.neighbors[state] else state\n",
+ " \n",
+ " def action_cost(self, s, action, s1):\n",
+ " \"\"\"The distance (cost) to go from s to s1.\"\"\"\n",
+ " return self.map.distances[s, s1]\n",
+ " \n",
+ " def h(self, node):\n",
+ " \"Straight-line distance between state and the goal.\"\n",
+ " locs = self.map.locations\n",
+ " return straight_line_distance(locs[node.state], locs[self.goal])\n",
+ " \n",
+ " \n",
+ "def straight_line_distance(A, B):\n",
+ " \"Straight-line distance between two points.\"\n",
+ " return sum(abs(a - b)**2 for (a, b) in zip(A, B)) ** 0.5"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "4da0f76f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Map:\n",
+ " \"\"\"A map of places in a 2D world: a graph with vertexes and links between them. \n",
+ " In `Map(links, locations)`, `links` can be either [(v1, v2)...] pairs, \n",
+ " or a {(v1, v2): distance...} dict. Optional `locations` can be {v1: (x, y)} \n",
+ " If `directed=False` then for every (v1, v2) link, we add a (v2, v1) link.\"\"\"\n",
+ "\n",
+ " def __init__(self, links, locations=None, directed=False):\n",
+ " if not hasattr(links, 'items'): # Distances are 1 by default\n",
+ " links = {link: 1 for link in links}\n",
+ " if not directed:\n",
+ " for (v1, v2) in list(links):\n",
+ " links[v2, v1] = links[v1, v2]\n",
+ " self.distances = links\n",
+ " self.neighbors = multimap(links)\n",
+ " self.locations = locations or defaultdict(lambda: (0, 0))\n",
+ "\n",
+ " \n",
+ "def multimap(pairs) -> dict:\n",
+ " \"Given (key, val) pairs, make a dict of {key: [val,...]}.\"\n",
+ " result = defaultdict(list)\n",
+ " for key, val in pairs:\n",
+ " result[key].append(val)\n",
+ " return result"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "3fcad7fd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Some specific RouteProblems\n",
+ "\n",
+ "romania = Map(\n",
+ " {('O', 'Z'): 71, ('O', 'S'): 151, ('A', 'Z'): 75, ('A', 'S'): 140, ('A', 'T'): 118, \n",
+ " ('L', 'T'): 111, ('L', 'M'): 70, ('D', 'M'): 75, ('C', 'D'): 120, ('C', 'R'): 146, \n",
+ " ('C', 'P'): 138, ('R', 'S'): 80, ('F', 'S'): 99, ('B', 'F'): 211, ('B', 'P'): 101, \n",
+ " ('B', 'G'): 90, ('B', 'U'): 85, ('H', 'U'): 98, ('E', 'H'): 86, ('U', 'V'): 142, \n",
+ " ('I', 'V'): 92, ('I', 'N'): 87, ('P', 'R'): 97},\n",
+ " {'A': ( 76, 497), 'B': (400, 327), 'C': (246, 285), 'D': (160, 296), 'E': (558, 294), \n",
+ " 'F': (285, 460), 'G': (368, 257), 'H': (548, 355), 'I': (488, 535), 'L': (162, 379),\n",
+ " 'M': (160, 343), 'N': (407, 561), 'O': (117, 580), 'P': (311, 372), 'R': (227, 412),\n",
+ " 'S': (187, 463), 'T': ( 83, 414), 'U': (471, 363), 'V': (535, 473), 'Z': (92, 539)})\n",
+ "\n",
+ "\n",
+ "r0 = RouteProblem('A', 'A', map=romania)\n",
+ "r1 = RouteProblem('A', 'B', map=romania)\n",
+ "r2 = RouteProblem('N', 'L', map=romania)\n",
+ "r3 = RouteProblem('E', 'T', map=romania)\n",
+ "r4 = RouteProblem('O', 'M', map=romania)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "d06285b1",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "breadth_first_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 18 nodes | 19 goal | 450 cost | 10 actions | RouteProblem('A', 'B')\n",
+ " 42 nodes | 43 goal | 1085 cost | 27 actions | RouteProblem('N', 'L')\n",
+ " 36 nodes | 37 goal | 837 cost | 22 actions | RouteProblem('E', 'T')\n",
+ " 30 nodes | 31 goal | 445 cost | 16 actions | RouteProblem('O', 'M')\n",
+ " 126 nodes | 131 goal | 2817 cost | 75 actions | TOTAL\n",
+ "\n",
+ "uniform_cost_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 30 nodes | 13 goal | 418 cost | 16 actions | RouteProblem('A', 'B')\n",
+ " 42 nodes | 19 goal | 910 cost | 27 actions | RouteProblem('N', 'L')\n",
+ " 44 nodes | 20 goal | 805 cost | 27 actions | RouteProblem('E', 'T')\n",
+ " 30 nodes | 12 goal | 445 cost | 16 actions | RouteProblem('O', 'M')\n",
+ " 146 nodes | 65 goal | 2578 cost | 86 actions | TOTAL\n",
+ "\n",
+ "depth_limited_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 17 nodes | 8 goal | 733 cost | 14 actions | RouteProblem('A', 'B')\n",
+ " 40 nodes | 38 goal | 910 cost | 26 actions | RouteProblem('N', 'L')\n",
+ " 29 nodes | 23 goal | 992 cost | 20 actions | RouteProblem('E', 'T')\n",
+ " 35 nodes | 29 goal | 895 cost | 22 actions | RouteProblem('O', 'M')\n",
+ " 121 nodes | 99 goal | 3530 cost | 82 actions | TOTAL\n",
+ "\n",
+ "iterative_deepening_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 27 nodes | 25 goal | 450 cost | 13 actions | RouteProblem('A', 'B')\n",
+ " 167 nodes | 173 goal | 910 cost | 82 actions | RouteProblem('N', 'L')\n",
+ " 117 nodes | 120 goal | 837 cost | 56 actions | RouteProblem('E', 'T')\n",
+ " 108 nodes | 109 goal | 572 cost | 44 actions | RouteProblem('O', 'M')\n",
+ " 419 nodes | 428 goal | 2769 cost | 195 actions | TOTAL\n",
+ "\n",
+ "greedy_bfs:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 9 nodes | 4 goal | 450 cost | 6 actions | RouteProblem('A', 'B')\n",
+ " 28 nodes | 12 goal | 1207 cost | 22 actions | RouteProblem('N', 'L')\n",
+ " 19 nodes | 8 goal | 837 cost | 14 actions | RouteProblem('E', 'T')\n",
+ " 14 nodes | 6 goal | 572 cost | 10 actions | RouteProblem('O', 'M')\n",
+ " 70 nodes | 31 goal | 3066 cost | 52 actions | TOTAL\n",
+ "\n",
+ "astar_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 15 nodes | 6 goal | 418 cost | 9 actions | RouteProblem('A', 'B')\n",
+ " 34 nodes | 15 goal | 910 cost | 23 actions | RouteProblem('N', 'L')\n",
+ " 33 nodes | 14 goal | 805 cost | 21 actions | RouteProblem('E', 'T')\n",
+ " 20 nodes | 9 goal | 445 cost | 13 actions | RouteProblem('O', 'M')\n",
+ " 102 nodes | 45 goal | 2578 cost | 66 actions | TOTAL\n",
+ "\n",
+ "weighted_astar_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 9 nodes | 4 goal | 450 cost | 6 actions | RouteProblem('A', 'B')\n",
+ " 32 nodes | 14 goal | 910 cost | 22 actions | RouteProblem('N', 'L')\n",
+ " 28 nodes | 11 goal | 805 cost | 18 actions | RouteProblem('E', 'T')\n",
+ " 18 nodes | 8 goal | 445 cost | 12 actions | RouteProblem('O', 'M')\n",
+ " 87 nodes | 38 goal | 2610 cost | 58 actions | TOTAL\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "report([breadth_first_search,uniform_cost_search,depth_limited_search,iterative_deepening_search,greedy_bfs,astar_search,weighted_astar_search], [r0,r1, r2, r3, r4])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af534ace",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-04-Searchin-Complex-Enviroment.ipynb b/Chapter-04-Searchin-Complex-Enviroment.ipynb
new file mode 100644
index 000000000..8ab84b96b
--- /dev/null
+++ b/Chapter-04-Searchin-Complex-Enviroment.ipynb
@@ -0,0 +1,1874 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "cbd79869",
+ "metadata": {},
+ "source": [
+ "## HILL CLIMBING\n",
+ "\n",
+ "Hill Climbing is a heuristic search used for optimization problems.\n",
+ "Given a large set of inputs and a good heuristic function, it tries to find a sufficiently good solution to the problem. \n",
+ "This solution may or may not be the global optimum.\n",
+ "The algorithm is a variant of generate and test algorithm. \n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0c1e4de2",
+ "metadata": {},
+ "source": [
+ "We will now create a model-based reflex agent for the environment:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 24,
+ "id": "0c78878c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Delete the previously added simple reflex agent\n",
+ "trivial_vacuum_env.delete_thing(simple_reflex_agent)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1dc6a638",
+ "metadata": {},
+ "source": [
+ "We need another function UPDATE-STATE which will be responsible for creating a new state description."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 25,
+ "id": "868f49e9",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "ModelBasedVacuumAgent is located at (0, 0).\n"
+ ]
+ }
+ ],
+ "source": [
+ "# TODO: Implement this function for the two-dimensional environment\n",
+ "def update_state(state, action, percept, model):\n",
+ " pass\n",
+ "\n",
+ "# Create a model-based reflex agent\n",
+ "model_based_reflex_agent = ModelBasedVacuumAgent()\n",
+ "\n",
+ "# Add the agent to the environment\n",
+ "trivial_vacuum_env.add_thing(model_based_reflex_agent)\n",
+ "\n",
+ "print(\"ModelBasedVacuumAgent is located at {}.\".format(model_based_reflex_agent.location))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 26,
+ "id": "a3a6e727",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "State of the Environment: {(0, 0): 'Dirty', (1, 0): 'Dirty'}.\n",
+ "State of the Environment: {(0, 0): 'Clean', (1, 0): 'Dirty'}.\n",
+ "ModelBasedVacuumAgent is located at (0, 0).\n",
+ "State of the Environment: {(0, 0): 'Clean', (1, 0): 'Dirty'}.\n",
+ "ModelBasedVacuumAgent is located at (1, 0).\n",
+ "State of the Environment: {(0, 0): 'Clean', (1, 0): 'Clean'}.\n",
+ "ModelBasedVacuumAgent is located at (1, 0).\n"
+ ]
+ }
+ ],
+ "source": [
+ "trivial_vacuum_env.status = {(0, 0): 'Dirty', (1, 0): 'Dirty'}\n",
+ "print(\"State of the Environment: {}.\".format(trivial_vacuum_env.status))\n",
+ "\n",
+ "# Run the environment\n",
+ "trivial_vacuum_env.step()\n",
+ "# Check the current state of the environment\n",
+ "print(\"State of the Environment: {}.\".format(trivial_vacuum_env.status))\n",
+ "print(\"ModelBasedVacuumAgent is located at {}.\".format(model_based_reflex_agent.location))\n",
+ "\n",
+ "# Run the environment\n",
+ "trivial_vacuum_env.step()\n",
+ "# Check the current state of the environment\n",
+ "print(\"State of the Environment: {}.\".format(trivial_vacuum_env.status))\n",
+ "print(\"ModelBasedVacuumAgent is located at {}.\".format(model_based_reflex_agent.location))\n",
+ "\n",
+ "# Run the environment\n",
+ "trivial_vacuum_env.step()\n",
+ "# Check the current state of the environment\n",
+ "print(\"State of the Environment: {}.\".format(trivial_vacuum_env.status))\n",
+ "\n",
+ "print(\"ModelBasedVacuumAgent is located at {}.\".format(model_based_reflex_agent.location))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e7a0ae4d",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-03-Solving-Problems-Searching.ipynb b/Chapter-03-Solving-Problems-Searching.ipynb
new file mode 100644
index 000000000..c4bf062d4
--- /dev/null
+++ b/Chapter-03-Solving-Problems-Searching.ipynb
@@ -0,0 +1,868 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "d12f7cea",
+ "metadata": {},
+ "source": [
+ "# Search for AIMA 4th edition\n",
+ "\n",
+ "Implementation of search algorithms and search problems for AIMA.\n",
+ "\n",
+ "# Problems and Nodes\n",
+ "\n",
+ "We start by defining the abstract class for a `Problem`; specific problem domains will subclass this. To make it easier for algorithms that use a heuristic evaluation function, `Problem` has a default `h` function (uniformly zero), and subclasses can define their own default `h` function.\n",
+ "\n",
+ "We also define a `Node` in a search tree, and some functions on nodes: `expand` to generate successors; `path_actions` and `path_states` to recover aspects of the path from the node. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "a333c036",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%matplotlib inline\n",
+ "import matplotlib.pyplot as plt\n",
+ "import random\n",
+ "import heapq\n",
+ "import math\n",
+ "import sys\n",
+ "from collections import defaultdict, deque, Counter\n",
+ "from itertools import combinations\n",
+ "\n",
+ "\n",
+ "class Problem(object):\n",
+ " \"\"\"The abstract class for a formal problem. A new domain subclasses this,\n",
+ " overriding `actions` and `results`, and perhaps other methods.\n",
+ " The default heuristic is 0 and the default action cost is 1 for all states.\n",
+ " When yiou create an instance of a subclass, specify `initial`, and `goal` states \n",
+ " (or give an `is_goal` method) and perhaps other keyword args for the subclass.\"\"\"\n",
+ "\n",
+ " def __init__(self, initial=None, goal=None, **kwds): \n",
+ " self.__dict__.update(initial=initial, goal=goal, **kwds) \n",
+ " \n",
+ " def actions(self, state): raise NotImplementedError\n",
+ " def result(self, state, action): raise NotImplementedError\n",
+ " def is_goal(self, state): return state == self.goal\n",
+ " def action_cost(self, s, a, s1): return 1\n",
+ " def h(self, node): return 0\n",
+ " \n",
+ " def __str__(self):\n",
+ " return '{}({!r}, {!r})'.format(\n",
+ " type(self).__name__, self.initial, self.goal)\n",
+ " \n",
+ "\n",
+ "class Node:\n",
+ " \"A Node in a search tree.\"\n",
+ " def __init__(self, state, parent=None, action=None, path_cost=0):\n",
+ " self.__dict__.update(state=state, parent=parent, action=action, path_cost=path_cost)\n",
+ "\n",
+ " def __repr__(self): return '<{}>'.format(self.state)\n",
+ " def __len__(self): return 0 if self.parent is None else (1 + len(self.parent))\n",
+ " def __lt__(self, other): return self.path_cost < other.path_cost\n",
+ " \n",
+ " \n",
+ "failure = Node('failure', path_cost=math.inf) # Indicates an algorithm couldn't find a solution.\n",
+ "cutoff = Node('cutoff', path_cost=math.inf) # Indicates iterative deepening search was cut off.\n",
+ " \n",
+ " \n",
+ "def expand(problem, node):\n",
+ " \"Expand a node, generating the children nodes.\"\n",
+ " s = node.state\n",
+ " for action in problem.actions(s):\n",
+ " s1 = problem.result(s, action)\n",
+ " cost = node.path_cost + problem.action_cost(s, action, s1)\n",
+ " yield Node(s1, node, action, cost)\n",
+ " \n",
+ "\n",
+ "def path_actions(node):\n",
+ " \"The sequence of actions to get to this node.\"\n",
+ " if node.parent is None:\n",
+ " return [] \n",
+ " return path_actions(node.parent) + [node.action]\n",
+ "\n",
+ "\n",
+ "def path_states(node):\n",
+ " \"The sequence of states to get to this node.\"\n",
+ " if node in (cutoff, failure, None): \n",
+ " return []\n",
+ " return path_states(node.parent) + [node.state]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c3697d5a",
+ "metadata": {},
+ "source": [
+ "# Queues\n",
+ "\n",
+ "First-in-first-out and Last-in-first-out queues, and a `PriorityQueue`, which allows you to keep a collection of items, and continually remove from it the item with minimum `f(item)` score."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "457d5a0b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "FIFOQueue = deque\n",
+ "\n",
+ "LIFOQueue = list\n",
+ "\n",
+ "class PriorityQueue:\n",
+ " \"\"\"A queue in which the item with minimum f(item) is always popped first.\"\"\"\n",
+ "\n",
+ " def __init__(self, items=(), key=lambda x: x): \n",
+ " self.key = key\n",
+ " self.items = [] # a heap of (score, item) pairs\n",
+ " for item in items:\n",
+ " self.add(item)\n",
+ " \n",
+ " def add(self, item):\n",
+ " \"\"\"Add item to the queuez.\"\"\"\n",
+ " pair = (self.key(item), item)\n",
+ " heapq.heappush(self.items, pair)\n",
+ "\n",
+ " def pop(self):\n",
+ " \"\"\"Pop and return the item with min f(item) value.\"\"\"\n",
+ " return heapq.heappop(self.items)[1]\n",
+ " \n",
+ " def top(self): return self.items[0][1]\n",
+ "\n",
+ " def __len__(self): return len(self.items)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f9801f0",
+ "metadata": {},
+ "source": [
+ "# Search Algorithms: Best-First\n",
+ "\n",
+ "Best-first search with various *f(n)* functions gives us different search algorithms. Note that A\\*, weighted A\\* and greedy search can be given a heuristic function, `h`, but if `h` is not supplied they use the problem's default `h` function (if the problem does not define one, it is taken as *h(n)* = 0)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "3c7bc169",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def best_first_search(problem, f):\n",
+ " \"Search nodes with minimum f(node) value first.\"\n",
+ " node = Node(problem.initial)\n",
+ " frontier = PriorityQueue([node], key=f)\n",
+ " reached = {problem.initial: node}\n",
+ " while frontier:\n",
+ " node = frontier.pop()\n",
+ " if problem.is_goal(node.state):\n",
+ " return node\n",
+ " for child in expand(problem, node):\n",
+ " s = child.state\n",
+ " if s not in reached or child.path_cost < reached[s].path_cost:\n",
+ " reached[s] = child\n",
+ " frontier.add(child)\n",
+ " return failure\n",
+ "\n",
+ "\n",
+ "def best_first_tree_search(problem, f):\n",
+ " \"A version of best_first_search without the `reached` table.\"\n",
+ " frontier = PriorityQueue([Node(problem.initial)], key=f)\n",
+ " while frontier:\n",
+ " node = frontier.pop()\n",
+ " if problem.is_goal(node.state):\n",
+ " return node\n",
+ " for child in expand(problem, node):\n",
+ " if not is_cycle(child):\n",
+ " frontier.add(child)\n",
+ " return failure\n",
+ "\n",
+ "\n",
+ "def g(n): return n.path_cost\n",
+ "\n",
+ "\n",
+ "def astar_search(problem, h=None):\n",
+ " \"\"\"Search nodes with minimum f(n) = g(n) + h(n).\"\"\"\n",
+ " h = h or problem.h\n",
+ " return best_first_search(problem, f=lambda n: g(n) + h(n))\n",
+ "\n",
+ "\n",
+ "def astar_tree_search(problem, h=None):\n",
+ " \"\"\"Search nodes with minimum f(n) = g(n) + h(n), with no `reached` table.\"\"\"\n",
+ " h = h or problem.h\n",
+ " return best_first_tree_search(problem, f=lambda n: g(n) + h(n))\n",
+ "\n",
+ "\n",
+ "def weighted_astar_search(problem, h=None, weight=1.4):\n",
+ " \"\"\"Search nodes with minimum f(n) = g(n) + weight * h(n).\"\"\"\n",
+ " h = h or problem.h\n",
+ " return best_first_search(problem, f=lambda n: g(n) + weight * h(n))\n",
+ "\n",
+ " \n",
+ "def greedy_bfs(problem, h=None):\n",
+ " \"\"\"Search nodes with minimum h(n).\"\"\"\n",
+ " h = h or problem.h\n",
+ " return best_first_search(problem, f=h)\n",
+ "\n",
+ "\n",
+ "def uniform_cost_search(problem):\n",
+ " \"Search nodes with minimum path cost first.\"\n",
+ " return best_first_search(problem, f=g)\n",
+ "\n",
+ "\n",
+ "def breadth_first_bfs(problem):\n",
+ " \"Search shallowest nodes in the search tree first; using best-first.\"\n",
+ " return best_first_search(problem, f=len)\n",
+ "\n",
+ "\n",
+ "def depth_first_bfs(problem):\n",
+ " \"Search deepest nodes in the search tree first; using best-first.\"\n",
+ " return best_first_search(problem, f=lambda n: -len(n))\n",
+ "\n",
+ "\n",
+ "def is_cycle(node, k=30):\n",
+ " \"Does this node form a cycle of length k or less?\"\n",
+ " def find_cycle(ancestor, k):\n",
+ " return (ancestor is not None and k > 0 and\n",
+ " (ancestor.state == node.state or find_cycle(ancestor.parent, k - 1)))\n",
+ " return find_cycle(node.parent, k)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "448a13c5",
+ "metadata": {},
+ "source": [
+ "# Other Search Algorithms\n",
+ "\n",
+ "Here are the other search algorithms:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "191d3801",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def breadth_first_search(problem):\n",
+ " \"Search shallowest nodes in the search tree first.\"\n",
+ " node = Node(problem.initial)\n",
+ " if problem.is_goal(problem.initial):\n",
+ " return node\n",
+ " frontier = FIFOQueue([node])\n",
+ " reached = {problem.initial}\n",
+ " while frontier:\n",
+ " node = frontier.pop()\n",
+ " for child in expand(problem, node):\n",
+ " s = child.state\n",
+ " if problem.is_goal(s):\n",
+ " return child\n",
+ " if s not in reached:\n",
+ " reached.add(s)\n",
+ " frontier.appendleft(child)\n",
+ " return failure\n",
+ "\n",
+ "\n",
+ "def iterative_deepening_search(problem):\n",
+ " \"Do depth-limited search with increasing depth limits.\"\n",
+ " for limit in range(1, sys.maxsize):\n",
+ " result = depth_limited_search(problem, limit)\n",
+ " if result != cutoff:\n",
+ " return result\n",
+ " \n",
+ " \n",
+ "def depth_limited_search(problem, limit=10):\n",
+ " \"Search deepest nodes in the search tree first.\"\n",
+ " frontier = LIFOQueue([Node(problem.initial)])\n",
+ " result = failure\n",
+ " while frontier:\n",
+ " node = frontier.pop()\n",
+ " if problem.is_goal(node.state):\n",
+ " return node\n",
+ " elif len(node) >= limit:\n",
+ " result = cutoff\n",
+ " elif not is_cycle(node):\n",
+ " for child in expand(problem, node):\n",
+ " frontier.append(child)\n",
+ " return result\n",
+ "\n",
+ "\n",
+ "def depth_first_recursive_search(problem, node=None):\n",
+ " if node is None: \n",
+ " node = Node(problem.initial)\n",
+ " if problem.is_goal(node.state):\n",
+ " return node\n",
+ " elif is_cycle(node):\n",
+ " return failure\n",
+ " else:\n",
+ " for child in expand(problem, node):\n",
+ " result = depth_first_recursive_search(problem, child)\n",
+ " if result:\n",
+ " return result\n",
+ " return failure"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2dcbb1a1",
+ "metadata": {},
+ "source": [
+ "# 8 Puzzle Problems\n",
+ "\n",
+ "\n",
+ "\n",
+ "A sliding tile puzzle where you can swap the blank with an adjacent piece, trying to reach a goal configuration. The cells are numbered 0 to 8, starting at the top left and going row by row left to right. The pieces are numebred 1 to 8, with 0 representing the blank. An action is the cell index number that is to be swapped with the blank (*not* the actual number to be swapped but the index into the state). So the diagram above left is the state `(5, 2, 7, 8, 4, 0, 1, 3, 6)`, and the action is `8`, because the cell number 8 (the 9th or last cell, the `6` in the bottom right) is swapped with the blank.\n",
+ "\n",
+ "There are two disjoint sets of states that cannot be reached from each other. One set has an even number of \"inversions\"; the other has an odd number. An inversion is when a piece in the state is larger than a piece that follows it.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "c0091daf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class EightPuzzle(Problem):\n",
+ " \"\"\" The problem of sliding tiles numbered from 1 to 8 on a 3x3 board,\n",
+ " where one of the squares is a blank, trying to reach a goal configuration.\n",
+ " A board state is represented as a tuple of length 9, where the element at index i \n",
+ " represents the tile number at index i, or 0 if for the empty square, e.g. the goal:\n",
+ " 1 2 3\n",
+ " 4 5 6 ==> (1, 2, 3, 4, 5, 6, 7, 8, 0)\n",
+ " 7 8 _\n",
+ " \"\"\"\n",
+ "\n",
+ " def __init__(self, initial, goal=(0, 1, 2, 3, 4, 5, 6, 7, 8)):\n",
+ " assert inversions(initial) % 2 == inversions(goal) % 2 # Parity check\n",
+ " self.initial, self.goal = initial, goal\n",
+ " \n",
+ " def actions(self, state):\n",
+ " \"\"\"The indexes of the squares that the blank can move to.\"\"\"\n",
+ " moves = ((1, 3), (0, 2, 4), (1, 5),\n",
+ " (0, 4, 6), (1, 3, 5, 7), (2, 4, 8),\n",
+ " (3, 7), (4, 6, 8), (7, 5))\n",
+ " blank = state.index(0)\n",
+ " return moves[blank]\n",
+ " \n",
+ " def result(self, state, action):\n",
+ " \"\"\"Swap the blank with the square numbered `action`.\"\"\"\n",
+ " s = list(state)\n",
+ " blank = state.index(0)\n",
+ " s[action], s[blank] = s[blank], s[action]\n",
+ " return tuple(s)\n",
+ " \n",
+ " def h1(self, node):\n",
+ " \"\"\"The misplaced tiles heuristic.\"\"\"\n",
+ " return hamming_distance(node.state, self.goal)\n",
+ " \n",
+ " def h2(self, node):\n",
+ " \"\"\"The Manhattan heuristic.\"\"\"\n",
+ " X = (0, 1, 2, 0, 1, 2, 0, 1, 2)\n",
+ " Y = (0, 0, 0, 1, 1, 1, 2, 2, 2)\n",
+ " return sum(abs(X[s] - X[g]) + abs(Y[s] - Y[g])\n",
+ " for (s, g) in zip(node.state, self.goal) if s != 0)\n",
+ " \n",
+ " def h(self, node): return self.h2(node)\n",
+ " \n",
+ " \n",
+ "def hamming_distance(A, B):\n",
+ " \"Number of positions where vectors A and B are different.\"\n",
+ " return sum(a != b for a, b in zip(A, B))\n",
+ " \n",
+ "\n",
+ "def inversions(board):\n",
+ " \"The number of times a piece is a smaller number than a following piece.\"\n",
+ " return sum((a > b and a != 0 and b != 0) for (a, b) in combinations(board, 2))\n",
+ " \n",
+ " \n",
+ "def board8(board, fmt=(3 * '{} {} {}\\n')):\n",
+ " \"A string representing an 8-puzzle board\"\n",
+ " return fmt.format(*board).replace('0', '_')\n",
+ "\n",
+ "class Board(defaultdict):\n",
+ " empty = '.'\n",
+ " off = '#'\n",
+ " def __init__(self, board=None, width=8, height=8, to_move=None, **kwds):\n",
+ " if board is not None:\n",
+ " self.update(board)\n",
+ " self.width, self.height = (board.width, board.height) \n",
+ " else:\n",
+ " self.width, self.height = (width, height)\n",
+ " self.to_move = to_move\n",
+ "\n",
+ " def __missing__(self, key):\n",
+ " x, y = key\n",
+ " if x < 0 or x >= self.width or y < 0 or y >= self.height:\n",
+ " return self.off\n",
+ " else:\n",
+ " return self.empty\n",
+ " \n",
+ " def __repr__(self):\n",
+ " def row(y): return ' '.join(self[x, y] for x in range(self.width))\n",
+ " return '\\n'.join(row(y) for y in range(self.height))\n",
+ " \n",
+ " def __hash__(self): \n",
+ " return hash(tuple(sorted(self.items()))) + hash(self.to_move)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "0580861b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Some specific EightPuzzle problems\n",
+ "\n",
+ "e1 = EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8))\n",
+ "e2 = EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0))\n",
+ "e3 = EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6))\n",
+ "e4 = EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1))\n",
+ "e5 = EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "785d61ba",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class CountCalls:\n",
+ " \"\"\"Delegate all attribute gets to the object, and count them in ._counts\"\"\"\n",
+ " def __init__(self, obj):\n",
+ " self._object = obj\n",
+ " self._counts = Counter()\n",
+ " \n",
+ " def __getattr__(self, attr):\n",
+ " \"Delegate to the original object, after incrementing a counter.\"\n",
+ " self._counts[attr] += 1\n",
+ " return getattr(self._object, attr)\n",
+ "\n",
+ " \n",
+ "def report(searchers, problems, verbose=True):\n",
+ " \"\"\"Show summary statistics for each searcher (and on each problem unless verbose is false).\"\"\"\n",
+ " for searcher in searchers:\n",
+ " print(searcher.__name__ + ':')\n",
+ " total_counts = Counter()\n",
+ " for p in problems:\n",
+ " prob = CountCalls(p)\n",
+ " soln = searcher(prob)\n",
+ " counts = prob._counts; \n",
+ " counts.update(actions=len(soln), cost=soln.path_cost)\n",
+ " total_counts += counts\n",
+ " if verbose: report_counts(counts, str(p)[:40])\n",
+ " report_counts(total_counts, 'TOTAL\\n')\n",
+ " \n",
+ "def report_counts(counts, name):\n",
+ " \"\"\"Print one line of the counts report.\"\"\"\n",
+ " print('{:9,d} nodes |{:9,d} goal |{:5.0f} cost |{:8,d} actions | {}'.format(\n",
+ " counts['result'], counts['is_goal'], counts['cost'], counts['actions'], name))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "5d51453f",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "breadth_first_search:\n",
+ " 81 nodes | 82 goal | 5 cost | 35 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 160,948 nodes | 160,949 goal | 22 cost | 59,960 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 218,263 nodes | 218,264 goal | 23 cost | 81,829 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 418,771 nodes | 418,772 goal | 26 cost | 156,533 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 448,667 nodes | 448,668 goal | 27 cost | 167,799 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ "1,246,730 nodes |1,246,735 goal | 103 cost | 466,156 actions | TOTAL\n",
+ "\n",
+ "uniform_cost_search:\n",
+ " 124 nodes | 46 goal | 5 cost | 50 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 214,952 nodes | 79,187 goal | 22 cost | 79,208 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 300,925 nodes | 112,082 goal | 23 cost | 112,104 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 457,766 nodes | 171,571 goal | 26 cost | 171,596 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 466,441 nodes | 174,474 goal | 27 cost | 174,500 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ "1,440,208 nodes | 537,360 goal | 103 cost | 537,458 actions | TOTAL\n",
+ "\n",
+ "depth_limited_search:\n",
+ " 351 nodes | 349 goal | 5 cost | 138 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 1,340 nodes | 1,341 goal | inf cost | 483 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 1,544 nodes | 1,545 goal | inf cost | 577 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 1,832 nodes | 1,833 goal | inf cost | 645 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 1,544 nodes | 1,545 goal | inf cost | 577 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ " 6,611 nodes | 6,613 goal | inf cost | 2,420 actions | TOTAL\n",
+ "\n",
+ "iterative_deepening_search:\n",
+ " 116 nodes | 118 goal | 5 cost | 47 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ "1,449,397 nodes |1,449,397 goal | 22 cost | 532,868 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ "4,398,813 nodes |4,398,818 goal | 23 cost |1,601,193 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ "23,139,541 nodes |23,139,544 goal | 26 cost |8,443,418 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ "33,561,413 nodes |33,561,419 goal | 27 cost |12,256,924 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ "62,549,280 nodes |62,549,296 goal | 103 cost |22,834,450 actions | TOTAL\n",
+ "\n",
+ "greedy_bfs:\n",
+ " 15 nodes | 6 goal | 5 cost | 10 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 1,569 nodes | 568 goal | 58 cost | 625 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 287 nodes | 109 goal | 33 cost | 141 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 1,128 nodes | 408 goal | 46 cost | 453 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 1,495 nodes | 543 goal | 63 cost | 605 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ " 4,494 nodes | 1,634 goal | 205 cost | 1,834 actions | TOTAL\n",
+ "\n",
+ "astar_search:\n",
+ " 15 nodes | 6 goal | 5 cost | 10 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 3,614 nodes | 1,349 goal | 22 cost | 1,370 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 5,373 nodes | 2,010 goal | 23 cost | 2,032 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 10,832 nodes | 4,086 goal | 26 cost | 4,111 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 11,669 nodes | 4,417 goal | 27 cost | 4,443 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ " 31,503 nodes | 11,868 goal | 103 cost | 11,966 actions | TOTAL\n",
+ "\n",
+ "weighted_astar_search:\n",
+ " 15 nodes | 6 goal | 5 cost | 10 actions | EightPuzzle((1, 4, 2, 0, 7, 5, 3, 6, 8),\n",
+ " 2,082 nodes | 771 goal | 22 cost | 792 actions | EightPuzzle((1, 2, 3, 4, 5, 6, 7, 8, 0),\n",
+ " 3,960 nodes | 1,475 goal | 25 cost | 1,499 actions | EightPuzzle((4, 0, 2, 5, 1, 3, 7, 8, 6),\n",
+ " 1,992 nodes | 748 goal | 26 cost | 773 actions | EightPuzzle((7, 2, 4, 5, 0, 6, 8, 3, 1),\n",
+ " 6,632 nodes | 2,480 goal | 29 cost | 2,508 actions | EightPuzzle((8, 6, 7, 2, 5, 4, 3, 0, 1),\n",
+ " 14,681 nodes | 5,480 goal | 107 cost | 5,582 actions | TOTAL\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "report([breadth_first_search,uniform_cost_search,depth_limited_search,iterative_deepening_search,greedy_bfs,astar_search,weighted_astar_search], [e1, e2, e3, e4, e5])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "e193e911",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Solve an 8 puzzle problem and print out each action\n",
+ "for a in path_actions(depth_limited_search(e2)):\n",
+ " print(a)\n",
+ "\n",
+ "# Solve an 8 puzzle problem and print out each state\n",
+ "\n",
+ "for s in path_states(depth_limited_search(e2)):\n",
+ " print(board8(s))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "6ad94a70",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "6\n",
+ "7\n",
+ "4\n",
+ "1\n",
+ "0\n",
+ "1 4 2\n",
+ "_ 7 5\n",
+ "3 6 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 7 5\n",
+ "_ 6 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 7 5\n",
+ "6 _ 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 _ 5\n",
+ "6 7 8\n",
+ "\n",
+ "1 _ 2\n",
+ "3 4 5\n",
+ "6 7 8\n",
+ "\n",
+ "_ 1 2\n",
+ "3 4 5\n",
+ "6 7 8\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Solve an 8 puzzle problem and print out each action\n",
+ "\n",
+ "for a in path_actions(breadth_first_bfs(e1)):\n",
+ " print(a)\n",
+ "\n",
+ "# Solve an 8 puzzle problem and print out each state\n",
+ "\n",
+ "for s in path_states(breadth_first_bfs(e1)):\n",
+ " print(board8(s))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "446f14cd",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "1 4 2\n",
+ "_ 7 5\n",
+ "3 6 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 7 5\n",
+ "_ 6 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 7 5\n",
+ "6 _ 8\n",
+ "\n",
+ "1 4 2\n",
+ "3 _ 5\n",
+ "6 7 8\n",
+ "\n",
+ "1 _ 2\n",
+ "3 4 5\n",
+ "6 7 8\n",
+ "\n",
+ "_ 1 2\n",
+ "3 4 5\n",
+ "6 7 8\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Solve an 8 puzzle problem and print out each state\n",
+ "\n",
+ "for s in path_states(astar_search(e1)):\n",
+ " print(board8(s))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "256ab048",
+ "metadata": {},
+ "source": [
+ "# Route Finding Problems\n",
+ "\n",
+ "\n",
+ "\n",
+ "In a `RouteProblem`, the states are names of \"cities\" (or other locations), like `'A'` for Arad. The actions are also city names; `'Z'` is the action to move to city `'Z'`. The layout of cities is given by a separate data structure, a `Map`, which is a graph where there are vertexes (cities), links between vertexes, distances (costs) of those links (if not specified, the default is 1 for every link), and optionally the 2D (x, y) location of each city can be specified. A `RouteProblem` takes this `Map` as input and allows actions to move between linked cities. The default heuristic is straight-line distance to the goal, or is uniformly zero if locations were not given."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "aa126eba",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class RouteProblem(Problem):\n",
+ " \"\"\"A problem to find a route between locations on a `Map`.\n",
+ " Create a problem with RouteProblem(start, goal, map=Map(...)}).\n",
+ " States are the vertexes in the Map graph; actions are destination states.\"\"\"\n",
+ " \n",
+ " def actions(self, state): \n",
+ " \"\"\"The places neighboring `state`.\"\"\"\n",
+ " return self.map.neighbors[state]\n",
+ " \n",
+ " def result(self, state, action):\n",
+ " \"\"\"Go to the `action` place, if the map says that is possible.\"\"\"\n",
+ " return action if action in self.map.neighbors[state] else state\n",
+ " \n",
+ " def action_cost(self, s, action, s1):\n",
+ " \"\"\"The distance (cost) to go from s to s1.\"\"\"\n",
+ " return self.map.distances[s, s1]\n",
+ " \n",
+ " def h(self, node):\n",
+ " \"Straight-line distance between state and the goal.\"\n",
+ " locs = self.map.locations\n",
+ " return straight_line_distance(locs[node.state], locs[self.goal])\n",
+ " \n",
+ " \n",
+ "def straight_line_distance(A, B):\n",
+ " \"Straight-line distance between two points.\"\n",
+ " return sum(abs(a - b)**2 for (a, b) in zip(A, B)) ** 0.5"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "4da0f76f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Map:\n",
+ " \"\"\"A map of places in a 2D world: a graph with vertexes and links between them. \n",
+ " In `Map(links, locations)`, `links` can be either [(v1, v2)...] pairs, \n",
+ " or a {(v1, v2): distance...} dict. Optional `locations` can be {v1: (x, y)} \n",
+ " If `directed=False` then for every (v1, v2) link, we add a (v2, v1) link.\"\"\"\n",
+ "\n",
+ " def __init__(self, links, locations=None, directed=False):\n",
+ " if not hasattr(links, 'items'): # Distances are 1 by default\n",
+ " links = {link: 1 for link in links}\n",
+ " if not directed:\n",
+ " for (v1, v2) in list(links):\n",
+ " links[v2, v1] = links[v1, v2]\n",
+ " self.distances = links\n",
+ " self.neighbors = multimap(links)\n",
+ " self.locations = locations or defaultdict(lambda: (0, 0))\n",
+ "\n",
+ " \n",
+ "def multimap(pairs) -> dict:\n",
+ " \"Given (key, val) pairs, make a dict of {key: [val,...]}.\"\n",
+ " result = defaultdict(list)\n",
+ " for key, val in pairs:\n",
+ " result[key].append(val)\n",
+ " return result"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "3fcad7fd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Some specific RouteProblems\n",
+ "\n",
+ "romania = Map(\n",
+ " {('O', 'Z'): 71, ('O', 'S'): 151, ('A', 'Z'): 75, ('A', 'S'): 140, ('A', 'T'): 118, \n",
+ " ('L', 'T'): 111, ('L', 'M'): 70, ('D', 'M'): 75, ('C', 'D'): 120, ('C', 'R'): 146, \n",
+ " ('C', 'P'): 138, ('R', 'S'): 80, ('F', 'S'): 99, ('B', 'F'): 211, ('B', 'P'): 101, \n",
+ " ('B', 'G'): 90, ('B', 'U'): 85, ('H', 'U'): 98, ('E', 'H'): 86, ('U', 'V'): 142, \n",
+ " ('I', 'V'): 92, ('I', 'N'): 87, ('P', 'R'): 97},\n",
+ " {'A': ( 76, 497), 'B': (400, 327), 'C': (246, 285), 'D': (160, 296), 'E': (558, 294), \n",
+ " 'F': (285, 460), 'G': (368, 257), 'H': (548, 355), 'I': (488, 535), 'L': (162, 379),\n",
+ " 'M': (160, 343), 'N': (407, 561), 'O': (117, 580), 'P': (311, 372), 'R': (227, 412),\n",
+ " 'S': (187, 463), 'T': ( 83, 414), 'U': (471, 363), 'V': (535, 473), 'Z': (92, 539)})\n",
+ "\n",
+ "\n",
+ "r0 = RouteProblem('A', 'A', map=romania)\n",
+ "r1 = RouteProblem('A', 'B', map=romania)\n",
+ "r2 = RouteProblem('N', 'L', map=romania)\n",
+ "r3 = RouteProblem('E', 'T', map=romania)\n",
+ "r4 = RouteProblem('O', 'M', map=romania)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "d06285b1",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "breadth_first_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 18 nodes | 19 goal | 450 cost | 10 actions | RouteProblem('A', 'B')\n",
+ " 42 nodes | 43 goal | 1085 cost | 27 actions | RouteProblem('N', 'L')\n",
+ " 36 nodes | 37 goal | 837 cost | 22 actions | RouteProblem('E', 'T')\n",
+ " 30 nodes | 31 goal | 445 cost | 16 actions | RouteProblem('O', 'M')\n",
+ " 126 nodes | 131 goal | 2817 cost | 75 actions | TOTAL\n",
+ "\n",
+ "uniform_cost_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 30 nodes | 13 goal | 418 cost | 16 actions | RouteProblem('A', 'B')\n",
+ " 42 nodes | 19 goal | 910 cost | 27 actions | RouteProblem('N', 'L')\n",
+ " 44 nodes | 20 goal | 805 cost | 27 actions | RouteProblem('E', 'T')\n",
+ " 30 nodes | 12 goal | 445 cost | 16 actions | RouteProblem('O', 'M')\n",
+ " 146 nodes | 65 goal | 2578 cost | 86 actions | TOTAL\n",
+ "\n",
+ "depth_limited_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 17 nodes | 8 goal | 733 cost | 14 actions | RouteProblem('A', 'B')\n",
+ " 40 nodes | 38 goal | 910 cost | 26 actions | RouteProblem('N', 'L')\n",
+ " 29 nodes | 23 goal | 992 cost | 20 actions | RouteProblem('E', 'T')\n",
+ " 35 nodes | 29 goal | 895 cost | 22 actions | RouteProblem('O', 'M')\n",
+ " 121 nodes | 99 goal | 3530 cost | 82 actions | TOTAL\n",
+ "\n",
+ "iterative_deepening_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 27 nodes | 25 goal | 450 cost | 13 actions | RouteProblem('A', 'B')\n",
+ " 167 nodes | 173 goal | 910 cost | 82 actions | RouteProblem('N', 'L')\n",
+ " 117 nodes | 120 goal | 837 cost | 56 actions | RouteProblem('E', 'T')\n",
+ " 108 nodes | 109 goal | 572 cost | 44 actions | RouteProblem('O', 'M')\n",
+ " 419 nodes | 428 goal | 2769 cost | 195 actions | TOTAL\n",
+ "\n",
+ "greedy_bfs:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 9 nodes | 4 goal | 450 cost | 6 actions | RouteProblem('A', 'B')\n",
+ " 28 nodes | 12 goal | 1207 cost | 22 actions | RouteProblem('N', 'L')\n",
+ " 19 nodes | 8 goal | 837 cost | 14 actions | RouteProblem('E', 'T')\n",
+ " 14 nodes | 6 goal | 572 cost | 10 actions | RouteProblem('O', 'M')\n",
+ " 70 nodes | 31 goal | 3066 cost | 52 actions | TOTAL\n",
+ "\n",
+ "astar_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 15 nodes | 6 goal | 418 cost | 9 actions | RouteProblem('A', 'B')\n",
+ " 34 nodes | 15 goal | 910 cost | 23 actions | RouteProblem('N', 'L')\n",
+ " 33 nodes | 14 goal | 805 cost | 21 actions | RouteProblem('E', 'T')\n",
+ " 20 nodes | 9 goal | 445 cost | 13 actions | RouteProblem('O', 'M')\n",
+ " 102 nodes | 45 goal | 2578 cost | 66 actions | TOTAL\n",
+ "\n",
+ "weighted_astar_search:\n",
+ " 0 nodes | 1 goal | 0 cost | 0 actions | RouteProblem('A', 'A')\n",
+ " 9 nodes | 4 goal | 450 cost | 6 actions | RouteProblem('A', 'B')\n",
+ " 32 nodes | 14 goal | 910 cost | 22 actions | RouteProblem('N', 'L')\n",
+ " 28 nodes | 11 goal | 805 cost | 18 actions | RouteProblem('E', 'T')\n",
+ " 18 nodes | 8 goal | 445 cost | 12 actions | RouteProblem('O', 'M')\n",
+ " 87 nodes | 38 goal | 2610 cost | 58 actions | TOTAL\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "report([breadth_first_search,uniform_cost_search,depth_limited_search,iterative_deepening_search,greedy_bfs,astar_search,weighted_astar_search], [r0,r1, r2, r3, r4])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af534ace",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-04-Searchin-Complex-Enviroment.ipynb b/Chapter-04-Searchin-Complex-Enviroment.ipynb
new file mode 100644
index 000000000..8ab84b96b
--- /dev/null
+++ b/Chapter-04-Searchin-Complex-Enviroment.ipynb
@@ -0,0 +1,1874 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "cbd79869",
+ "metadata": {},
+ "source": [
+ "## HILL CLIMBING\n",
+ "\n",
+ "Hill Climbing is a heuristic search used for optimization problems.\n",
+ "Given a large set of inputs and a good heuristic function, it tries to find a sufficiently good solution to the problem. \n",
+ "This solution may or may not be the global optimum.\n",
+ "The algorithm is a variant of generate and test algorithm. \n",
+ "\n", + "As a whole, the algorithm works as follows:\n", + "- Evaluate the initial state.\n", + "- If it is equal to the goal state, return.\n", + "- Find a neighboring state (one which is heuristically similar to the current state)\n", + "- Evaluate this state. If it is closer to the goal state than before, replace the initial state with this state and repeat these steps.\n", + "
" + ] + }, + { + "cell_type": "code", + "execution_count": 1, + "id": "f98e6fed", + "metadata": {}, + "outputs": [], + "source": [ + "from search import *\n", + "from notebook import psource, heatmap, gaussian_kernel, show_map, final_path_colors, display_visual, plot_NQueens\n", + "\n", + "# Needed to hide warnings in the matplotlib sections\n", + "import warnings\n", + "warnings.filterwarnings(\"ignore\")" + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "d3922ef9", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def hill_climbing(problem):\n",
+ " """\n",
+ " [Figure 4.2]\n",
+ " From the initial node, keep choosing the neighbor with highest value,\n",
+ " stopping when no neighbor is better.\n",
+ " """\n",
+ " current = Node(problem.initial)\n",
+ " while True:\n",
+ " neighbors = current.expand(problem)\n",
+ " if not neighbors:\n",
+ " break\n",
+ " neighbor = argmax_random_tie(neighbors, key=lambda node: problem.value(node.state))\n",
+ " if problem.value(neighbor.state) <= problem.value(current.state):\n",
+ " break\n",
+ " current = neighbor\n",
+ " return current.state\n",
+ "\n", + "
\n", + "Let's now look at an algorithm that can deal with these situations.\n", + "
\n", + "Simulated Annealing is quite similar to Hill Climbing, \n", + "but instead of picking the _best_ move every iteration, it picks a _random_ move. \n", + "If this random move brings us closer to the global optimum, it will be accepted, \n", + "but if it doesn't, the algorithm may accept or reject the move based on a probability dictated by the _temperature_. \n", + "When the `temperature` is high, the algorithm is more likely to accept a random move even if it is bad.\n", + "At low temperatures, only good moves are accepted, with the occasional exception.\n", + "This allows exploration of the state space and prevents the algorithm from getting stuck at the local optimum.\n" + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "id": "bd52ba40", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def simulated_annealing(problem, schedule=exp_schedule()):\n",
+ " """[Figure 4.5] CAUTION: This differs from the pseudocode as it\n",
+ " returns a state instead of a Node."""\n",
+ " current = Node(problem.initial)\n",
+ " for t in range(sys.maxsize):\n",
+ " T = schedule(t)\n",
+ " if T == 0:\n",
+ " return current.state\n",
+ " neighbors = current.expand(problem)\n",
+ " if not neighbors:\n",
+ " return current.state\n",
+ " next_choice = random.choice(neighbors)\n",
+ " delta_e = problem.value(next_choice.state) - problem.value(current.state)\n",
+ " if delta_e > 0 or probability(np.exp(delta_e / T)):\n",
+ " current = next_choice\n",
+ "def exp_schedule(k=20, lam=0.005, limit=100):\n",
+ " """One possible schedule function for simulated annealing"""\n",
+ " return lambda t: (k * np.exp(-lam * t) if t < limit else 0)\n",
+ "class PeakFindingProblem(Problem):\n",
+ " """Problem of finding the highest peak in a limited grid"""\n",
+ "\n",
+ " def __init__(self, initial, grid, defined_actions=directions4):\n",
+ " """The grid is a 2 dimensional array/list whose state is specified by tuple of indices"""\n",
+ " super().__init__(initial)\n",
+ " self.grid = grid\n",
+ " self.defined_actions = defined_actions\n",
+ " self.n = len(grid)\n",
+ " assert self.n > 0\n",
+ " self.m = len(grid[0])\n",
+ " assert self.m > 0\n",
+ "\n",
+ " def actions(self, state):\n",
+ " """Returns the list of actions which are allowed to be taken from the given state"""\n",
+ " allowed_actions = []\n",
+ " for action in self.defined_actions:\n",
+ " next_state = vector_add(state, self.defined_actions[action])\n",
+ " if 0 <= next_state[0] <= self.n - 1 and 0 <= next_state[1] <= self.m - 1:\n",
+ " allowed_actions.append(action)\n",
+ "\n",
+ " return allowed_actions\n",
+ "\n",
+ " def result(self, state, action):\n",
+ " """Moves in the direction specified by action"""\n",
+ " return vector_add(state, self.defined_actions[action])\n",
+ "\n",
+ " def value(self, state):\n",
+ " """Value of a state is the value it is the index to"""\n",
+ " x, y = state\n",
+ " assert 0 <= x < self.n\n",
+ " assert 0 <= y < self.m\n",
+ " return self.grid[x][y]\n",
+ ""
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "heatmap(grid, cmap='jet', interpolation='spline16')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "24998ce8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "problem = PeakFindingProblem(initial, grid, directions8)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "60a26753",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "333 ms ± 6.71 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)\n"
+ ]
+ }
+ ],
+ "source": [
+ "%%timeit\n",
+ "solutions = {problem.value(simulated_annealing(problem)) for i in range(100)}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "71f882c8",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "1.0"
+ ]
+ },
+ "execution_count": 13,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "solutions = {problem.value(simulated_annealing(problem)) for i in range(100)}\n",
+ "max(solutions)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dae1c152",
+ "metadata": {},
+ "source": [
+ "The peak is at 1.0 which is how gaussian distributions are defined.\n",
+ "
\n", + "This could also be solved by Hill Climbing as follows." + ] + }, + { + "cell_type": "code", + "execution_count": 14, + "id": "b3b0c23c", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "118 µs ± 3.49 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)\n" + ] + } + ], + "source": [ + "%%timeit\n", + "solution = problem.value(hill_climbing(problem))" + ] + }, + { + "cell_type": "code", + "execution_count": 15, + "id": "34fdf3bd", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "1.0" + ] + }, + "execution_count": 15, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "solution = problem.value(hill_climbing(problem))\n", + "solution" + ] + }, + { + "cell_type": "markdown", + "id": "43310906", + "metadata": {}, + "source": [ + "Let's define a 2D surface as a matrix." + ] + }, + { + "cell_type": "code", + "execution_count": 16, + "id": "14622780", + "metadata": {}, + "outputs": [], + "source": [ + "grid = [[0, 0, 0, 1, 4], \n", + " [0, 0, 2, 8, 10], \n", + " [0, 0, 2, 4, 12], \n", + " [0, 2, 4, 8, 16], \n", + " [1, 4, 8, 16, 32]]" + ] + }, + { + "cell_type": "code", + "execution_count": 17, + "id": "95d0630e", + "metadata": {}, + "outputs": [ + { + "data": { + "image/png": "iVBORw0KGgoAAAANSUhEUgAAAd0AAAHwCAYAAADjD7WGAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAAB0oklEQVR4nO29f8h1XVrfd633ed53VMY6hQjN/EjGEpMiQrSdWIu0DZNKJ0ZiQqE1wUDalBeahozF1sZAf9G/SkHyR6UwVUkgISatSZvapMGSCVawxhmjQZ2kDDrBSSUTG0SHzrzz3s/s/nHufd/7rHP9Xtdae+19ri883Gevda219n2e5zmf873Wj12WZYFUKpVKpVL99dreN5BKpVKp1L0ooZtKpVKp1CAldFOpVCqVGqSEbiqVSqVSg5TQTaVSqVRqkBK6qVQqlUoNUkI3lUqlUqlBSuimUoNUSvlUKeXfqMr+aCnlxwP6Xkopv621n1Qq1VcJ3VQqlUqlBimhm0pNolLKu0spP1xK+SellF8qpfzJTd03lFJ+opTya6WUXyml/HellDce637sMexnSymfLaX8O6WU311K+XQp5btLKZ95bPMHSinfUkr5v0sp/7SU8qc1/T/WL6WUP1lK+cVSyq+WUv7bUkp+fqRSRuV/mlRqAj0C7H8FgJ8FgPcAwO8BgO8spfybjyGvAOA/AoDfBAD/ymP9HwcAWJblX3uM+Z3LsrxzWZa/9Hj9zwHAlzz2958DwP8AAN8BAP8SAPyrAPCflVK+Sup/oz8IAB8AgH8RAL4NAP69iN89lbonlTx7OZUao1LKp+ACtYdN8RsA8NMA8F0A8D8uy/JbNvHfAwC/fVmWfxfp6zsB4F9fluUPPl4vAPDVy7J88vH6dwPA3wCAdy7L8qqU8uUA8OsA8I3LsvzkY8zHAeC/Xpblf1b2/3uXZfnfH6//OAD8W8uy/B7n25FK3aVe7n0DqdSd6Q8sy/J/rBellD8KAP8+APxWAHh3KeXXNrEvAOD/fIz77QDwvXBxml8Gl/+7HxfG+n+XZXn1+Ppzjz//8ab+cwDwTkP/v7x5/Q8B4N3C+KlUqlKml1OpOfTLAPBLy7K8a/Pny5dl+ZbH+v8eAP4+XNzsPwMAfxoASuD4mv7ft3n9WwDg/wkcP5W6CyV0U6k59HcA4DdKKf9pKeVLSykvSilfW0r5XY/1a3r4s6WUfwEA/oOq/T8GgH++YXypfwCA/6SU8s+WUt4HAB8GgL+ExKRSKUYJ3VRqAj2mgb8VAL4OAH4JAH4VAL4fAL7iMeQ/BoA/DAC/AZcFUTXw/ksA+HOPq4//bcctSP0DAPwvcEk5/wwA/G8A8AOOcVKpu1YupEqlUqLqhVqpVMqndLqpVCqVSg1SQjeVSqVSqUHK9HIqlUqlUoOUTjeVSqVSqUHqcjhGKV+2ALyrR9epVCp1ANVbnC3X2jquDda+tV/PPXL3w8Vry7xjRsVS+hQsy6+iHXU6kepdAPBmn65TqVRqer1eXdcftVz960Q5V6dp4xlTU26pw+rra6wNFcfFa9ta+9Lod5E1mV5OpVKp08oCm1lkhV4kcPsroZtKpVK7au8j8OeC0r7q/3eR0E2lUqm7016g9wL+PF8MErqpVCoVqvMAor96v1ej53JlJXRTqVTqEOIWS0WJWxClaWOpu08ldFOpVKqrpNW7Kb+ioD7uy0FCN5VKpaaRx83O5IBbv1BYtgpFrVoe68YTuqlUKhUmK3R6fuC/TrzeSzPcQ63x6e+EbiqVSnVTVGo5ElieeVtNX5Y67di9Xe545Sx3KpVKhaj1g37vdGgrjHsC3KLR76Pt2MiEbiqVSnWR5ehHqS0lzTGNkTAc6dQ9LncEcNvOZs70ciqVSu2uUelQ7XnN1r6ssnwBidZ+wG0dPZVKpVIA0Bea2ocO9B7PohEp8Fqa98NzXxFPHWq7g1QqlUqx8j5VSKrTjEellls/7rVbhaxPFbI+UUgan5L194+FrfcuUqlUKnUl66PsvIp0uXumlr1qGdPStg9sVyV0U6lUyi0P/Ea5XI9aD+eQ6rwutyWtrP09+sJ2VUI3lUqlXNLAIWrBkAesngfeW/uq1TrnagHusWC7Klcvp1KplFlWN6ZRa5p3dpdbawbPNxa4AHP81qlUKnUgeZwmAO+CLXXWsan2nvOUez5RKMrlzulwVyV0U6lUSi3tgQ0ti6s8ANQehmFd5Rtxn9i15v3oBdx9YLsqoZtKpVIq9QKu1j163K+mfcSCLa5uFuDuC9tVCd1UKpViZfmgb33KUOu8KjV+z5XQFoxoYq3And/dbpXQTaVSKVRWV+VZzeyp87hcqtwzX9uSVpbirXHHcLdbJXRTqVTqRiOA60nXcn1a08etc8dSXURa2ZtOng+2q3LLUCqVSl0pYmVsj3ncWp7jHltXMmv68sZG9TcvcAHS6aZSqdSjvPtKWxdORad4NX23jmk9X5m7L+oePCnluYELkNBNpVJ3r5ZDHCKBy/WtvYdRJ09RbbBr6ctCxFGQ88N2VUI3lUrdqSJhi8VHHY7BjR0J1ojDOqzHXt4XcAESuqlU6q5kPRxC274XcCMWTrXu1dW2idifbIH2sWC7KqGbSqXuQL1gi7UbcRpV677biJXTW/VIs1PjHRO2qxK6qVTqxGqFrdTHHqdRaeOiT50CZV0Cl1NCN5VKnUxRW15a9+r22KdbX/dyshH3I/WD1WMxq44PXICEbiqVOo32gi3WZhbg1oo+jWoEcM8B21UJ3VQqdWBFHuTQA7ZSTG/g9mpj6cNTv+ogwK1v/0EfmkqlUpNLC1qANlfLtR+9ZejegDsZbANJmdBNpVKTywJZgHZXy/UxestQz/nY0XO4B0knd6ZiQjeVSk2oPUDL9eOFrRSTwH3WTrAdTMGEbiqVmkg9YKvpt8eBGHWMxf1aAYYpuo0nLU2NPQFwo+iH9fOq/7CpVCrlkBWyAGNAy7WP3i5U10fAba853Innb720C6ZkQjeVSg2UB7IAcaCV+mrdm4vF9Ujfjkope1dea+oHwNZKuAFEVD1Pt5TyoVLKPyilfLKU8qd631QqlTqLXq/+WPRy80c7jrcvqj3VDouv4+oYrJ6LrcfD6rT9e9q0bHXaEbiWfzYvwRYfIHGYUsoLAPg+APhmAPg0APxUKeWvLcvyC71vLpVKHU1eJ7sq0tFK/VldLdWmNd3cArdebSLuqa4D6A7biJiIdl9o6+obAOCTy7L8IgBAKeWHAODbACChm0qloA201k+z1vSx1MfIrUJS/F6p5l7zt52AK/11T5Zi1nT/HgD45c31pwHgX66DSilvAsCbl6uvCLi1VCo1r0Y5WstYe8IWi7UANxqqXN1JgBsF28Erm8KGW5blIwDwEQCAUt69RPWbSqX21kjAWsZrgSzX3gJaLL4HbL112jYHSSdHgLaVepr2zK+taf6PAOB9m+v3PpalUqlT6qiQlfryzO+2zO16YVvX9wSxJW5Hd8v91UWnl71tArv+KQD46lLKV8EFtt8OAH+43y2lUqmxaoUswPHcLNc2ErRYWXS6mKuLSCVbxgYIg+0I0A5OLauGXJbloZTyJwDgbwLACwD4wWVZfr77naVSqY5KN6tr512t3OISI1wv127yVDL1V7FnatnarjG9DMuy/HUA+OvGYVOp1DQaDVnLmEcFLRY7ArbeuhagcrDvCNsWt6uN8cQ2aAdznUqlxumsjlbqwwrbllXKVFkU1CLqJna3VmcbOYc7Y3o5lUodTQlaXZuI+NbFRr0XVx0Mtl5nO1NqeWx3qVRqP7XA9kwLobh2rY4WK9csphrteidOJVtg63W72hhPbKMSuqnU4eWFbYJWHyuBShPTC4QHdbZ7pJUjiKfpo3UhVSqVmk2jXO0RQdsjbawdyxoTVTcpbLWu1gPaHpAdQMSEbip1KI1wtTODduT8LNXes1+3x1xuZD8TwbYFtNp/5j3It+0znW4qdXTNAtujglabNra0bwGtVC+1jZj3xeqDYdvT6WrqtTERbfbvOpVKtWsW2Gr6jN5Le0ZXa60/URp5VFp5wpTyjsOlUimdZoHtEUG7h6vVxJzM2UankL2gHZFStrbN9HIqdRQdAbbeFPKsoJ3V9Uatdq7rJ3K1MyygSqebSt2jjg7b3q5WG6sda1bQ1teTuFqsu1lAO3LxlLaPdLqp1KyaAbY9Usi9QHtGR2uNt9TtsDAqArQjna4nvkEJ3VRqF43YZ7uHs41ICWtje4LWE9MTtHX9gV2tdT5Xqp/R6fbtIpVK2XRkdzuDsx0JUk1MwlaM0baNqLPERLSZb4hUKnXRkd1tL2d7VtDWMT338E6cQh61eGrvhVOGv5KEbirVXQlbf9xeEPXESPcfPS8cuN3HA9pWoPaGbDrdVOreNAK2mnGOBttR+2Q1Ma2OVupzR9BiZXvN3bZCduS8rqa/dLqp1GjN7m6ti6SiYdvL1e6x8rgum8jRYt31mre1ArUXgLUxLfENSuimUqGaHbZc+1lhuwdIpXrrF4Q7Am0kZCMBG0U7TT/pdFOp3rqXVHLUnKqm3Wz11jndOwdtD8ge3OXuMFwqdUYlcG0xvedaZ9rio6nfGbZ7z9uOms+1xrb0mU43leqlswG3ZaXx3inZSFAnaJuBehSn623jVEI3lXKpBbYA+87ftrjbHrDtuYe1xdUmaJvLuPKWOk29N7ZzPwndVMqsdLd4zMhVvZEg7pmq7rjFJwqie6eXpbromJb4ACV0UymT7mF1shUsWEwUFKNAfFDQRkC0N3itsS11lhhLXHT7nNNNpVp1NneLxUe42xHu1Ft3EtD2Aq+2naU/Tz+9YlriA5XQTaVEtc7fzjaOdqyzAjcyjb0jbGdIL3vKW+osMZa46D7S6aZSXt2jw7WmnEcD1ZtG9vYxMWhHgzeyXKqLjmmJD1RCN5UidTbgRszfRrnbnrCNHhdgatBGOte94Kup18ZY4qLbrkqnm0pZlcAdMz8aCeJokDtBa4XgqDnbmSAbAWBLnDW2RS8hoZtK2ZQrlPsAt9XBWmHrgXCQo90jbeyFqgWaewG2p8MdTMGEbip1pbMDV4JtHeM9PCISqlGw7exqz5hGHuluI2M8sZH9pNNNpTSaHbhc2wjgSvW90sIHg+3soD0CZO/M3U4ydCo1k2YHrrWNZg8uJ4vD1fQxA3Anhe3IVLK2r8jyqHprnDV2RD+xXaVSR9URgBuZUq5jOHcaOUerKZ8MthZYRsVi196YHmVS3eg0cjrdVOpImh24rXtwpZiewI0onwC2WnieIZU8Oo3cw7W2Ui2Cijmnm0phugfgahwoVt8DuNR4Fnc7AWz3BO/ekO0F315x3nir6v4TuqlUrVH7cL19zQJcDSit5a3uNhi2rXBtAafHze4N3pY6S0yPuKh2DUropu5Qo4ArjRP130+zD5er6wFcLzi1fQ2C7Qxu1xtjKfOUS3Waem1M79joPtLpplKj1QLc3gdfaOs0cVi5doFVXabtawBwI1zuXqlkCzxHu9yZALsT/RK6qTvTDPO4ewKXg6BlvjRiXrclnRwI25ld7ohUcg/A9kgLH8XlAqTTTaUuSuDiddZFU5Fw1rZpdLfRsB0J2lGQ3dvdntTZ1prkNlKp3ro34FrrsTgPRC3ttU62wd22wjYizWzpR9u+tcxT3lJnifHEeuJb2x1juFTqaDoqcD17cWcDLtaHI5XcCtuI1HKEm50FvBH11jhPfDTdLP1lejl13/K63BH/PaxbgzRxPYBLjRkBXC6+wd16wBqZWp4trRxZrq3XxvSOjWgXpIRuKtWsPbcGWWJagCutLObat8zfrgoArgeyFAj3hu1eoN3L4VrbRJLN01c63dT9qrfLnSmtbFmpLMmTao4ErtHhRoHV63gtdZ5rbYy2rVTeUmeJ8cSObhOsCW4hlbpHjQQu119rqrgVuNz4Tnfbw+W2QjjiurXMUy7VaeqtcaPio9tvlU43dZ+a2eVq4z0rlbk+vOnjCYHLgbIFvC2wPTJ4W+osMZa41nY9Ccf1ndBNpbTaM62skQbMFEwjVipr4izAda5Q1kDTWuet5+Ijrr0x3nKpTlOvjWmJ97ZpaReghG7qpGoBW8++W9PKUowGuFR76ZMcc6h1HOfMOwG3FcBSmabeUue51sZo20bUaeqtca3toojWkYwJ3VTqSb3/x+45jyvFSXC1bPMZ6HCjwNvqfOvXPa5by7jyljpLTEv86HE6abLbSaUitKfL7fWJYO03Yh6XK8P6o+o0Dnky4FogzMVHXHtjpPKWOk29Na613UwuN+d0U/ejPQ/C4Pqw3FdrWpkSBVzuE1y7j7Z2uRxwGxZNzQRe7euIa21MZLm2XhvTEt/SbjLKTXY7qdQe0v438AJ9dFpZM5eLtbXO2dZlXHtqDAG4GlB64KqFrAXGljrPtaXMUy7Vaeq1MRFtWtq1tpWUTjeV6q1e/5Uk4NYanVbmgCu53o7A7e1yZwOvNbalzhLjiW1tG/lf0dtXQjd1H/I40ZldrvWTz3vqVMtpUZSCgEsBr5cD9pTVry11muvWMq68pc4T542PaDsJ7Sa5jVTqyIr4xImex7WcOsX1xwFXO497EODOBF5vjLdcqrPEWOL2bhfVvlY63VQK014uVyPrf00PtKUyDdS5rUBBwmCHlc/idC2AjYRtD9BGgtgbH9F+ItJNdCupVIt6bhPidCSXay2r+7OANcjlRv/0xlrqrXWaa22Mp1yqs8RY4vZuF9V+7uFSqaMp0uVGfWrV9daTpzRlGsB2TiuP+mmt07621GmuLWVceUudJaYlPqJ9T7pJfWd6OXVu9VpAFX0QhmcMKcZ6cAVX1rJa+aDAtUK2FbxSrKa9pYwrl+o09da41jZ7tw1QQjeVcon7r6N1udFHPVoWT3nPUdbI2G5v0PZwvJY6zbU2xlMeVe+NjWwfRbTWftLpplJbRbjc6HZ7jxXpcut2hk+gBK89RttWW6ep18a0xEf1MRnlJrudVMqqPRZQRXzatLrcuq6Xy5WAK7UzPoh++3p28Hpee661MZ5yqU5Tb42bqW1Ee0zpdFOpEdprBXWrWu67oS0HNmubnsDlxudeW+o015YyrrylzhPnjY/sYyLSTXQrqdQIaf7JR8LT+wkWOZfL9YuNQbnZDi63BYrePlod7min2wpfrs7yRScqbqa2Ee0xpdNNpQD6ftVueYqQ9b68xz1iZS2rpxu2RbVA1NNmb/Ba6lpivOXaem1MS/xs43r6Tuimzqke6dwZUsQzuVzrFqFVik8dDZQ4AFrbtADXC15LnebaUsaVS3WaemtcVLuI9juSL6GbSqlldblYvNXl1vU9XG60FVEunto2iXCznjajnG4P2Ea63FkdrqePSKp1IGRCN3VQRcBntFoPwuBiW1xuHdPqchlZIaeNjQCvN0Y7vlSnubaUecq19dqYyHatfczwEQDT3EYqNYP2WEBlkea4R0m9/8s7XC5XR4GYi9X07x3T63QtddLYnjKuXFuvjfHERvYT/U/c01/O6aZSrbKmlj19ehdYUS6Xc6La1DK1H9iRova4XK69xaG2/pTKtK8tddi1pYwrl+o09da41jYR7Scg3gS3kEr11uh/5th4rS46woVz74OUMta8hwNcrseN9gDuDLCNTCnP6HL3TCG39pNON5WSZH1wQKtabIZmC08LYCUNcLktrpYbdw/gzuh0I1zuXm5zTxgHaKJbSaW0it7W0/vxfdELqKTxvP3WMA1+QD0HxzrGW6cBsOd+tMD1AnZ2pzvS5R4J5pTS6aZS0Ro5lzvjAirD6VMWqGFl0Q5YgpLH/XKvLXWea6rMU66t18ZEtGntYzLKTXY7qVS0Zvr665E27R2dWm5YMIXJCjBNXR1jGdeTZubuqTXN7Lm2lHHlUp0lxhIX2X62/+bpdFOpEfKmlnupJbVskWEBFTakt84LactYljG519KYEQCmynunlfdIB+/lsgM0yW2kUntp7wVUEUc+Su1bgMrdh+L90TpaTby1Tor1xmnG7ZVq1sZ4yqU6TX1r/N7jRfWxX/epVLRmPBt573Fa70f76dyYWubqvA6Rq2sBsTcNrn0t1Unx2jZSeUudJ661zV7jBUq8jVLKDwLAtwLAZ5Zl+dr+t5RKRWnk/zJNannk/VgeblC3ocqxPhoXUGnLeoDYIq2zTrfrj41oP3o8Ssx/i9cUzf8sAHwo6FZSqYk0OrUsje9JLUsp516pZaO0LpEr4/rypIQtLlejEcB9qYjh4rByqU5TX8dIsVwb71iaLwve8QIlDrMsy4+VUt4/4F5SqQNottRybwWtWtbWaeM9cOVkgbx0H3u5XUsZVy7Vaeq9sUcai9OI1cullDcB4M3L1VdEdZtKHVSzQNOrQV/7Z9EDHOtXtn5hae3bM473fjztRrUJUNiwy7J8BAA+AgBQyruXqH5TqfnVaqVGqk43z3JfqS6yutwW96uNaYkfPY6379ynm0odWdatQi0u+yAOfXWmmEPl6nrfz16KSCvPnm7u7bCj2u/bfSqVwrXnyuaJtTe8NLLc42y/TySINfXWuNn67iBx9XIp5S8CwE8AwO8opXy6lPLH+t9WKkXp7b1vYCJFutJODvehT7cmtd7DQ/XTO97e78Vo4LauYt6rb2tf2J+W9PKyLH+o4RZTqZRZUQCcyWIFiHONe7nP2ZzsqlaXOCLV3MuhjlzA5ZBmn24qlQKAw8x3HkWjnV89HnVtdbb3pL2Aa3G/1j5b3a9RM35HS6VS9y6vg/Qsoopyq9t+qD6pmJkccy+n2GOx1YgFXMF9zfLXnEpNpNb/FlZHzI2X7vpGFrBGAxUbWxrDcw/RELasbrb0oeknGqC9VzF3pmKml1OpUwmD9ATg5lK23ro6xjK+tNjJO25LSnqGdPYRFltF9VfHD0ozp9NNpZrUc2VHyqQWR9kjvatJJWvHnSn9vGqWxVa9na+nr8YHHqRSkym3DU3hXiV53ekoV6sV11/PRVczOF8Ae2paqot2tZoY78It6k+DErqp1HB5gdnT6khfZDoRICrt3AJj6adWHJQ9rzVjaa+9ipr31fYVAVtPynpgijmhm0qlNuqQRYgCgAes0dL2P5vzHeGaW9PNUbDVaPA2oa0SuqnU4dXj04P6lK6h7Hi2SXT62BLrXUildeLS4iqNq/U43wj1mhuNSje39NHiZF8u9j85p5tKpXyinK+DBpYUqCfWAyjLKmUNgKkyC5hb+tlLntXNrfOxkWlmABqgwUropk6smT6VUqQsMOs5d9syT0yVWdLQrXO7veZ1t7K4xF6LraLSzJ3hSg47bKRUKlRvw5wreGe8px1Vb3XRbH3RtKm3+njGsYgbjyvD+tC+1rSdQVEgbq3Xgtarl4ZvMYUeJ51uKjWVTgptz2rbyDaRblfrzC2rmTFFuF2uv57O2LtFx1MvtjW62ZcP+J8gJXRTqbvWzktiW9LHgbehGs8KYCxOUx+5wGqPGRbr/G5Pd+sBbWcldFOplKB1MdVDdb2qw3xYy/xqjzldrwPuucBqBrWueO7hbrXONgq0L1/d/snVy6nUPWvnE7y0qdueYJXaa+u5WE+Z1Hfra67fvdWy0Aot7wRaDKrbP0YldFMHVh4H6ZfmvRv0CW2dh6XaWcbQ1HscsLZPqT/utTSGtm0PWY+M1PaxlnPAZfs0gLYRqpISuqlUqpLly4zxE70HQHumlaUxqDpNPNY/VU/FaspbxuqlqHlfyd1qYNsZsrUSuqnUrppp70dL5kBwGlpQRIHSmj6OnteV7kXrcqNcsAfIkrwnSVFlHuCS4wqwdUL2tZevVH+4/w8J3VTqruS1NtJiqgBFuK4WF9jL+XrKsLGoeip2RoWlmgmoaWGrEA7TdiV0U6nUGHld6qifnCwA1sZbylphHNmWkjdpE+Vwg2HbSwndVKqrZkofe8R9Itfud9xRek+SnG0E0D2pZ+leejpfaxq6l1oeZBANXEHRbpYdq/sIqVRqcmEfWJ1Whvdyp5Jr1czNeuZzNTE9y4Aoa0mz91Lznl4EuFw6WXC3XtC+ePlK/FPyGMjUeZXbhmLFvZ+1sx2kPdPIGufaAt66LqpMU2/5gtJDlu1FFHDRWB1sNcKA2qqEbiql0sxnInttjfYLS3CKeQQke6SRtXClYqx9Yn1RZVo3TGlPByzJClxCWthGAha9jy69plJ3oaPP126186fuSNfakkbWxka5YW1fYCjb46+6/q+i3krUDlwNbCNA++Llw9OffMpQKnU3GpVu5z65HW635RYsQI5so+3HMoZWPVLP3oRJhDoCl5MXtFvAPoFWqYRuKnUX2sJY+wGBAZwra/x07ulMe7WJGtNaB0idpcwCY08fI5NADuBaYNsCWPS+mlqnUqkTCgOr1UYFu91eblYD3iioSrGRdVLZTGpxuQg4uXSyFrZRgMWU0E2lhmq2BVmedDTXxvkhFelQo2OlGItzbnW8tSKY0BvKmvncq/o24FKSYNsTtFsldFMn14xf7WcV9l5JUF7bYHEGt4uVtbhars7qQveAvOa+PHXa8TT1o9QIXMndWkH78uUr8U/J5+mmUimbtClmTMZPa2/6NxKGXH+a9paxou4r0gGPArDkemuXGwBcSlrY1kBtVUI3lUoJkhZUYW53LVMeDRnl5LwA52J6wBSTJVbTxvKeSGWzKAC4GthGQrZWQjeVOqRatwZ5P1kHfiK3Orkox6rp2wP5KLhaZAXwnmqYW+WAKw7b+fzlhG4qdWptP2QoUHu2E1H9BbpdqW6vVHFESjgyvex1tF51SzUL/06ULtcDXI+zzbOXU6nUo6IOyHibeI1J+iRuSDNHp565Og3kpPbamJ4O2OPWuRhvvVaaudxKWuBy6WQLaKPOYE7oplJhmm07kEUWUEvu2eucmWHqsha47uF0Nf16fnrkBXGkW7aqgpwFuGSXO53DnNBNpe5W1AcSBVWL23VuIaq70QARK/PGS1C1wFB6vddPq8LcbEw3rcCV3G0+8CCVatKZHkoQoajUMwVYySINBm+kC7bAjRpHAmB0udVpjxL337KGpeL85NsyGrhcP75zmJHH/+U+3VQq5RcFaumTujHNLPHbmgqNjKdiJMhpx4gqr+tnFLeASpFWruUFrlatc7sJ3VTqSvfsjDWQtK6Abkgzb7uypmq1ZR43LLUbnSa2AlX7BUDzZWNn1dCzAld/FnM+xD6V2ll7wNn7Kdjz09NirRxp5m0zC3h7wngkcOv748q8fVr+CfSG7RaagsvVApADLqdec7sJ3VTq7qSd16Ucq8btUuWDwIuVUbC0Ot2RwH1Arq19RMjbX6fvptp5XA9wey6iAkjoplKpK3kWWlFw1pR3Am9Pp0vFt/ys++XqNC7Yep9SvEYeMEsHYjxKfhi9DrgcUE3P2H3xiv1TmH/XCd3UnerIe2r3kmX70CoNeA3ioEi99jhdDlIzONr6tRQrqXfaWCMmtbyVZh6XAi7Vn2pedwPVFiV0UylRRwS097ALS51l8RQng9uth8LKtPVSnCW+Je3rgacFrLOlnjsvh7ACV1IEaLdK6KZS3XTUldAcNLUPsO+YZt42lRyvpp6Ki3a827Fb4GyBP6feMA7SNrUsudxI4EbDdlVCN5UapmjH3OJm67YRbper6wje7WtNqlmTsvUAWvrZkkK21llitG16QplILXNzuZonBnmA64HtC3i4+sP9W07oplIpRByU6zrtXO1A8FogTLXxuF/uJ3bfUcDl+sbUAlAPhAckfWqXi69wZhZSKWFbA/aF8c1M6KZSKYc8aWauLhi829cShCPKtBDVQFtbB0iZNp6qG5liVq5cXvXiKs0sp5W59lflCth6AYspoZtKhegMi62sKWhuNfNk4N2+bnW13tQydr8tALU6Ws2YE0lz5COl27lfGrhsP0Gg3Sqhm0o96agLn7Tq/ck6AXhbUswtZdHpYgmMESnnXulnTth/McVWIYvLjQBuC2xfwivueQcJ3dSZ1QuiZ4czJ8kNc/IsujKCl9JI8HLj94Jli3u1jj+xLIdbkHWGX/YlvLr5Iymhm7pDzZIK7g3v1tOlPH1YUtLaugXMJ1dRjleCniWdzJVp0tDasqgvDCCUTSRum9BW0lwuupiKAK7G3VoBiymhmzq4egN0FkD3kgaq1rnfHuAF6LLAylqvBTTXztIn1pfUH6UIh7wzrLepZU9aGQOuBNtWyNZK6KZS06oH8DWfmp5P1lbwPijrOq9sjnK60s9ouEq/JxW7l7CVy4aDLaQ4C3ApRYJ2q4RuKtVFZ5v3xSAa6Xjreq5uggVWmlQ199MzJvcaU7S7x/puBThywAW1aplzuddxMcC16AW8uvqTDzxIpQ6hVmfr/QTEUsxYX5454p7gHXCQhsXpakAr3QtWz7Xx9nUiaY5zvCkj3hSNu60B+8II6IRu6qSyOk0sXgtBTdxZ54YliHraaMHrkBdsdRl1G95UtHQPFuBqNBuUhdSy1+VagcvJA1hMCd3UgeUBWSv8zpA21rpYb5yUZta0qcEbtLK5bh7heC2p5Mj0MhjLPelozRg7yvqweQy4kruNgu2qhG4qdRgdCfjR4K3r67qdVja3AleCPXXPVL9cOdbPZCCVTqF6yWwlklwuBVxK0bBdldBNpQ4Fs56KdLtYXO1YsXYtq553OrNZM3drgawE7JbyPWX4b8adQCXFA7QBVwtbbG73uW0upEqdTnukliM1CvSexU+1otPRkeCt6zuubNaAV6qrY+o4C3C5PqWxPP14Rf1TX2HqOGNZejTf1bURuOy4zsVTWyV0UydUBNBaAH0E5xzxyToavDvM87aWjZqjbQXoKAADmJ4upFlAZZ3XxYDLgTQCtFsldFMptVpWOB9FlDOmPn2jwcuBFeu78zwv5n6t873Wtpa0c/0au8ZkhemA9LT2qUItLpcCLtlfzummUtEa4UrPBmaNvODFtBN4uXppLlVyoVaX6gHuCBh3EAZVjcuNBK7V2dYPtc+nDKVOJg5iFERHgc8L8ZnmqCPcLhXvSTVrYjossNLO8Xrmbrl67WvNWNY6jbTxjd9npQVUlrSyFbiSashalNBNpW40gzP13MOec8mtj/jzHDNpqe88x9sy/8u9pu5J26ZF3j65f4b1fO4jOFtTy5zL1QJXcrdeyNZK6KZSKkXO586y0Mrz4RFli7Sp5gOBVyqT+sZipXS2Rl4H3FOKbUBPocYHIUhQpIDL9dcK2q0SuqmDyZNajoq/J3HONSLNTMV7wftQ1XMrmw2SgErFattzr7XAnQWknJT/1VaYYqlljcuV5nEtwLXCdvsIwHzgQerOZXGk0VuF7u1c5pHg9S6wCgRvtAPmyrG6KAc8qawu96qtAFwqnex5mL3lqUQJ3VTKpdGg3MOVe9wu1y4avNxY0vgBq5q5Mkt6mYpp1QGg2irO5V7FKaGohW2LErqpA2mv1PKMaegZ3PGM4MVSzVT7hlXNmvK6TJMu9tZJsVQZpShgs4uqrhdRWVPL2BOEnofdwli7kAr/pT1ullNCN3VyzQCnrTQAH3nPrZ+uI8DbuqUoELx1Fy3pZSrGWoddSzpAGtqSWpZWK1/H3q509jx9iFfO6aYOr0iX6xlDijvrfG7r2c1Re35btxQFgVfrJiPnbiXoaaA4ApzSf8N1u5Bh5TKA7HI54GLzuNfXtLsV74t94AGthG7qxKKAtldqeY80dQTUJfBKH6K9wIv10fJcXqVa08tcH1Q/3lipvUeB/4yp1HLLAqqneAdwtc/WzQcepE6uvVzuLHO5s9wHJ+8n+Wjwcm0dqWbP3GnvNHJEG63IJwgpYhTyulwvcNF7yAcepFIaRbhcbb+RB2cc/cANSpH7flvPa+baK8GrAVvknC41hnRfEQpN9jzeoNW1YvANAi7lbj2gXdvk2cupA2vEnOde86qjwdwiDei8aWaurXZO2Uob7iEJDUNGzem2xEa08yoQ0NYVy2gfyjlcqR0VY5nLXZXQTU0sCS5H2ibk7W92B2tVFHijj4wM2EoUqdnSyB5dpZjp91Qzn3vTRulyqTZrO8+j/nJON3Wn4mDU6wSq3qnlaO1xH5pP9ZnAq61TNOm1kGpGlxswZ2t9yIHkcrm0svYxf1GP+uMkQreU8r5SykdLKb9QSvn5UsqHQ0ZOpVhFp15nc7nYfZ51PteqVvBKMZr53YFnNEesQI4GbMs/KXHrELYy+drlvqh+XsUq9uR6gEv143muLnf2suatfQCA71qW5adLKV8OAB8vpfzosiy/oL6TVCpUs2y96e1yW/rXxlney7eV/T4o+tX2pVHdl2Z8Si1tA7rVxHW6RVYiSBXlhocY3MQhLpdKK1uA632mbstTh0SnuyzLryzL8tOPr38DAD4BAO9xj5hKifJuEbK63Jm2Cc2Sko5Sq/WKXlg1wO1iw0r1oxc6UfL8s9e22c7nKp6fq3G5GuDe3IbyiUPSU4eGPk+3lPJ+APh6APhJpO7NUsrHSikfA/j/mm4qdc+aET4tLnfmOV+rLPd9tpQ3I89e3VR3RT4DN1Jq6JZS3gkAPwwA37ksy6/X9cuyfGRZlg8sy/IBgC+LvMfU3ahltXKEy91Le0H9jsCYsqv+52FJMRv+aUmrlq3bhDCNfK6uJBV0SymvwwW4f2FZlr8SNnoqpVbUamUuPhp0M7tcK3DT5U4jdVq3oe0A2Y91ROaElXO5ct/ygxS0ugC+YSFVKaUAwA8AwCeWZfle8x2kUqJ6geioj+/rDfWewI3STH8fHRX1a/Z6u1rc7lW5zylKC6g0sj4E4blcd8/W+9E43W8CgD8CAB8spfzM459vMY2SSpFqhUTPxVMjXO5ooPUGrrb/WRx/gCyOcoZVx6Oe4WEYR7NVqJbH5UY/zN7z6D/xbVmW5ccB2KMkUymnZgCute9Z5HG5swC3RVF/Lwd30q0wbWnf+NZpD8XYyjunan22rmas1ofZ54lUqYkVOY/rGUMT27JvduQ88EyQif5yoOlj9i9Rj+rx19T7r16bgmYOxdAP5QdexIlSrcC99JFKDVcvh8u1G+lyI/9b7bGX2PP77/lR0vr3FQjkkW/DEdwuc+ZylKjUcrTLjQDupZ9UaqhmAm4Pl9syl9vy3zHqmcO9gdtjW1gvBc6qBc19ho+vAa/m/oy/Azdnqzlr2fPIPak9Bdwo2K7K9HJqoHqsrPW267F4KloRYB6dW+Q0Cpotv/MAAlpXAEf9lUe/LWq3+wwzbD63XkRVS/84Pv9e2lHAvfSZSnVX1GENHse6d1p5T5d7JIcr9Ue11/Rbxwz62IvcsdbzlqNWODsPx9B3rz/QwvJQe8t4lOo+uRxJQjfVWb2B62kzKq285xhnAq5FO+1B1gDHAqUZtxY1/RP3LaKSDsRAhxKeh6sZQwNc78KshG6qkyKPIhwxj9sjrTxiX24LnEcsmIoAbqTL1d7HBLskNdDrvR/YCt6rLxb6RVT1/lzN0Y8tJ1C1t8uH2KemUiRYohYIcfGjVivP9FQjj/ZwkS3AxRT8fo92rD1WLLfI0Z/1+MfLMD7IeeDoWfVs6z+VClP0+bx7OVwqftT8cPRJWJp2knoBN3K1spWArzN1DrV+B9QC1VLWwx07v2hwi6i0ikwtW9PKEft8L2OkUs2K/nD0biuZ+cCMEUdK9gCu5yOiN3B7rzAPTi332C7UCtPWT37t/LTzzGUA/XGOVFwUJKP7SuimGjULcD1tRp3DPMNpSDO5W0/fnjG48TodiPESKeNuw1ovxbaC1wto418nt4gq4lF+N302uNxI4F7GSaXM6vUB3uPghAhX3GMudqTLPYq7lfrqNRXgXEDlBaSUVm5dNWwFLzZeyyKum7iNK0VXMfP7dFcYWlLLVlBGAHcbW1oe7ZdKPaunW5oBuKNWK7dMnln/DnoDd9Q8fsvfWUeXiw1Bud2R4LUqws0aVy5b53NXWVctSy63Fbh2wKdSKt0jcClFzh9GtI+a454VuBaNcPX+Zk1j9JibtYzfIOuThVYwelYtcxDUn26V+3RTu6nn1ozW+dvewG1NK49YPGUZm9LssI3MFnBjORZQSQuKWhdRecFrXbnsHZ918/pFVJb9uU9tFA83aFntTI+bW4ZSXdR7H2QPd8u1Gz3n23uFbUSfPedutf1bVylb+pKAO2Aut463pJwt41sg2wpkEbx4avl57vbhpkzSC+W8Lt9Hu8uNeTxgKnWlEYcOHBW4PaDZMs5I4PZwzl7gen5vCcgOYXO3mvlcqh8prm7TA7ItZZic87aXIXRpYmoBlcfl9gbuZdxUqst8onecUcC1jmH5oO+919YS19quxxypJ53M9d0K1ACXawGTFIsBu3XJATeuZjzrPW/02tXq5ce5WmRF85parh1pBOw0i6eocXLLUCpQR4Gt1IcHuBaIjgIuJW2s5z1qHdPSv6bPHtMAQWllrAsLjCyO1gO+Fmn61tzz02v/oRiUJPhZXK6276h+tkro3qVGwVY71gzAjYhtXXjVK60c/QXJ07fX3XJjaN6bQOBaoOPpTws+bxk1BiczePn5XKnsJkZ4KpDuaUC8y20Bru9s59Sd6R6A6xmv9XSqHodtRMwX9wJuZL97ALdBLalXcRGS8x5ayyzSOnbDfG6dWtbA1DOXq12tnFuGUo3qsUK2dbwW2HLte8/7toJplBu29LuXu5ViIr4gUfUBLtc7j2sFb+s8cqs7lsa+6efZWWrncyV5ASetWMaddD5lKOXWjLDV9Ot1t71XNu89j7s3cPeGLdXO6nAbgEvN5XpjvNecrJDWjG1x8wp5Hu8HID/U3uJyrcDN1cspQbOlkbX9nhW4lEa5Yc0YLf1Z+uz5dzUAuN56S91aX/c/cu62w3wudvQjlVrm9uZa53JbgJurl1OMRs8BWsbslU6W2kYA1zJua0q0hxv29h89Hxw5ZaB57xqBS8nqcrUOV5vebUkXW1LI9f1h12S7CnLIamar27W4XO1BGFhbTXmLErqn0VFTyZq+PMCNbKNdOBU5BynF9gTuzLCl4jsAtwWmlljM0VL9SOUjgMzeKz6fK4nam+t1uVz87QMQWh94cAv4fMrQ6TUylWwZr2c62XIfmjatwLWOp41tdcPW+JGpZG68CYGL1Xthq0ktc9ceadPQmrFZ8OILpV4Kj/C7dEUBMMblRj45yOqmVyV0D610tzHtIoA76zxutLvtDVuu7Q4pZcntckNbyzUOuMecrmb+VgSv/Cg/TNYH1re4XO08rrx6ue3gj4TuIXVk2Gr6GzV/a20TAe2R87gRW7csfWniesEWiws8bUrrdikwb8s5kGrTu71TyJ57E7YKXV7ful3LAqrnNrLLlQBtX70cc8pWQvdwmnFVsrbvlg9kqX1v4Eb0YQFuixs+Gmy59jsBV6rnnKAlhqqTHC7WBxVrKZMkgZhIHXOrliVpD8ywpJW187pSvx4ldA+jI7vbVgjMsI3oKAunooA7I2yp+A7A1bpYjRvunV7WSnN/2jGY1PJrwtwtVk65XO++XC6trF9IpYdt/YUgF1IdXjO62xGpZKl9VKpSatMLuC0g9fzXjXS3o79Iad+DzsDF2uydXrakkS1fACwwJh5wID07Vws26alAmkf9aa6192WdW75um5pYZ3a3LbDl2vd2t9Z+RgK3dZHXjLCl2gS527or0dUJP+syrSuOSC+/RGJbgWxx1sKq5W35NrVMbenhXK5nHlcD3J6wfe4jdVJZ/mqPNHervQdtm57ApdT6ZcrS5xFSyVzbnYBrcYna+tb+PPe0jYvqT5FarqVxuZpUsUUtj/qLuge8r9Sk8n4wz+xuNf3MOn/r6aeHc9X2yfWraWuJ2Qu2AN2Bq0kha+KltHMdh9VzMRZHau1PdP8VPJ/mdImUM7KA6taF3i6esrhc60MLKIcbCdvnPlMTagRwz+RuE7j6fqV21phRfy+B7rbuzuN2W9LLUgpYCz0NLL2p6roMHW/jchWrlrkFVE8xhtOhPPO4lpSy7nxnO5QTutPJA9wzu1upfe8FU1xf0XtmPf1a4/Z2tlz7Ae627rLF4WpisXiqnIMoBlCqbw2kvY755lq/Nxfg9uEGl9eyy6VipXoPcD37ey1K6E6lIwF3Vthy7bg2ewC3xQ1bwby3s+XaWn6XoHRyfe0Brrfe6mpreQHK9WW5p5dAulxpAdV1NzaXa108xQHX6m4jH3yQ0J1CM6WTR7jbWeYIpbperpXqO3IvriV+r7l4y3sT6G7raws8NXFaJ22p0zhaLUAtQObuIdDl1iuW6327W2nSylbgRsF2jc99uqfUrMDt6W6l9nsC1/L30eO/nfcLwkypZCp+MHClWE1/2jFER8lcY20oeVLH2phHaVyu9nSpm76Fpw1pVypHAzfndA+p3inlswC3x6rm3sDtsRgqyg3vsUiKa9cBtnW3kenlnuCV/hv1SC9LfV1d0wuoJJeLyeNytcDlnj7kgW1Emjmhu6tmAO7ssJXaez7ge6dCR8b2AK4Xtlxb6xeWQcDVlFOx0hhcPZderuuplHBketnqsl8+PAH3tZevXC7X+jg+6eCKVuCOepB9Qnc3JXDHw5ars/Y3A5ytwJ3ty88Ad1tfe19rXW8NSu61VFf3LbW3tNP2xbncShqXKz1JSHMGMw5t/RxuyzYlSrdfCHJO9wTS/lWNWp3cs32Ptr3drTV+JHDvBLZY16OAW8PTMg5Wp4Gh5GA17TTjBbpcTJZH+7UAV+tu83m6p5TV5UYCt7e7ne0D3tvnPQB3BtgCdAFuC3y19Roor6+lcuqerU6U68fsaus29JGPrS6Xc5/afbsW4O71LN3LvaQmV7TDbe2n5Z9MAtd2Ly2HZFDttf0cyN3W3be6Xa4eg6cUqynHHDMlL4ypviztiKMdAWwul5qn1Wzv0a0qjgGuF7bcv+yE7nBZ4HgWh9vyAd8ybtT8Lddmb4dLxfb4AjO5u62vo92u1cXW9fW9cG8nBmKtM+XaUf1IDrxasbx9Zq7H5V4PHzePa52/zUf7nV6zAnfGlHBL21HgGLnASttvwvbmWuM4reDl6i0Q1kCyvnesvRbIXDvx+nkuF8C2L/fymoaqJjXcAtzWx/rlU4YOqTMCd0ZnPJu7tca3zOFG/u7edp1hiw0R5W63r1shvC2THDLWtodj9bYzzOVKz8ul9uTW9XVbHLI43K3uNuIJQ3WfeSLVKTUzcO/N3UbFHwG4E8G2LmsBbguEMUBybSSnC1V9fa0BK9bG1e4RHojLXYH7slrBvD3usSWtHA3cCNjm4RiHUbTL7Q3cHm17prCj7+fswD2Zu62vNa+311rgep0u9Vqqk2CsaWMFMtrm+ozliLRyb+Ba3W1v0F6PlZpIswN3dDup7cj7GT3f2wLc6C8+B4Ftfe193ep0sbIIp9vkWJFxxLHwxVMAl7Tyy81iqqfyF6/Yoxq9DzvwAtcL29ZzlzO9vKuitvJo1dPhetolcONiNRrh7Lk2Bwcu1/+2DINxy3haF8zFSDDGJI1VbRHCHtG3lmPnK+v322qOgewP3N7nLl/GTU2iCJd7FofrhS3X754p6B6xUQ53QneLDaMFFhfbw+HWP6l2Url0rXGnXB8el7sCV3C50lOEsEMw7MdA6seIhK0HtFKbhG5XaV3uPQH3ntytNR6L7ZVSjgL0QNhK11b4tkBYA1zKRVpdqgekLYC+isEXT63XT6+JPbkt87jRwI06c7nV8SZ0d9cRgTsTbKW+j7KFKBq4vb9oDIZtXRblbqnXHvByZRScqTrNdT0O18YC6NXlMucrv9g6XWG1smcetxW4cSdSxS6iutxPqpNGzeUeHbijYcu16w2q1thW4EZ9aTiwu92+3svpeup6Ot2rfvg9udbVyltQeoFrOyhDf0CGpey6Xj4aMhdSTasIl+ttO8Lpecfp1eds7paKjwbuCWFbX8/odKXXlrrtdTSgb36Hi8vljnrcHoLBgXUtf2o7CLhW2I562AFAQndyzXR4heefSgLXHp/ANV9zzlcbH+F0Lfcm/T7S72SFLzXmVZvN4qlHUXtyAfB5XAB+e9D18OOBG3X2cj1OrXS6w9V7L63UfuaU8j2lk63xMwK3M2yxMi2cuFiPq8XKrOCl2nGu1+KCzSBV9PMSwLInt57HfYqrFk5dur52v1aHi8PcPnebZy+fWiPmcs8EH6mO61NqO+p9OgpwT+puuTqtE41wulwZ1p+lzgVSuBYFaMVRj8/X+MImasETtTVoWxYNXAtsW85d9i6ySujuohaXe0/A9f6u3ra9Hb0l1gvSA7jbXvDd2+nWZdJrS9322gtoFtK3Rz1yZytrnexafvnJbRvi53qxGGqc+jV+ncdAnkQRLreHU/b8NfcG7kzutjdsqXjLe1O3P4C7xYbo4Wa5uj2drracqrM4WU2behwAwA7B4M5W5uZxMWBGALdtny69srnuh+rDWg+Qc7qTqeUtPxJQuPhZFkp5240ErrZtK3DvzN1uX0c4XSt8KThGwFXdRp7H5fbjUiuVMZi2AtfzfN3n67EnUklK6A6V9HafxcFR8d7fr6XtiPQ51ab1vYkG7g6wxcp6uN0oyGrLNJCt67GY0W735hrfHsTtx5VSx1Q5BlzN/K3tUAza2bYckoH1xyud7gCNOgwjYtwZHJxm3Na20XPcnnE0sS3/dhK4XYHrqbM4Xamu7kdqr25zfeoUwDVc12tsPy4AvlJZKsd+1vIvquoD2+g9upf7SQ1SL7BY2xwJuLO0G+3+T+BwI6+tIPZAuMXpSv3P4HSvym5PnXpOIz+QD6W/NJdXKlPltrSzL53cckBG3b6WZdsQ978roTuFjgQJa9+Rqe/R7Xq/972BS93LwMfvSTFncLqUU9W8puq8cKVinsqutwdhwF0lzeNqVjC3ANfrblseZo/1QYlLRedCqu5qWYkbPWYCN6Zd70xBJHB3cLdWuFqvW+Ab7XSlWAqsmhgtjLF4awwC3FXSARjcSmULcLULpkY+yL5uex2bC6lOqNkOaaDie0FF6memdglctPue19GvvU5X85Mqk0CMtW8BMuuA8QMwNMBd52utwOWAqkkn94Jt34fYp9PtqF4ut/dfjRUU2tjIgzO80PS27e2IW7/MSMDtDFtsiCigeus8TrcHeKPdrgfILJSvz1XeHoDBPZB+JHD5/bk0nKnYOr5uU8dqyrX1Oac7rfZcedzat6XfkcAd2a4VuJbxNA631sTA5fruCVys3winy43B3ZP0e3Px6jb8ARgAQJ44BXANyEuX+j26l9ftj/fDYm/raWc70zN1E7pTKuqvJQKi2tgZHO6M7pYq1/ahff/ruB0XS/VwuxGvNXDl6no4XapOgrPa/doPwOBWJHN7caU5XC9wI542VMdh11J53T+nXEjVTT1SnJ7xLH+NewN3Fth62/UCbmRcEHAluFqvvbGRTrcXeNfXFJA5QGti63oTpOkDMCTgUquNrSll2+rlONjKq5cp8LY92i/ndA8l64e6JT6BK7eLcsSt74smDosZBFwrkFsBu72OcrdYmRfEVBx3f143q27zfACGdOIUthe3FbgYVL2P9pPmd6lYzTXWV92nRtt+c063i0a7XIusK4c1sdp77g2zPdr1creWWAm4B1md3MPdbl/3AO/6WlNucbRcnRfIBuBuVypHO1ztgqlW2EY+0m/UtqGE7lSKAFb0gh0qLmJbkTWea9Oj3Wh3i8XumE6OdLNcrDUuqt7jeDVul3qNjWkBMApXrAw/4hF7Nm4kcFueMqTZMrT2s425rdctrKr7oNpo62rlnG64Rm5XGbkYahRwR4KTaxfZZtR7vxNwW6498PW+tpZFAdjzutnNYu30W4Ok4x2lbUGWBVN4qlm3oIqL4V5v223bXtfbwFv3SSuhezJZ/tr2/CtO4OpiE7jdgIuNzf1T8jpd6TXnfLl6bdlLAO3WIGwvbg1Qyknewhmvk1PN2hXMsWcw13FcWd2PRutYOac7VCNcbo/YaJcbkX7m2vRo52lzYOByYPJc7wnfvRzu+lPjaC1ul6tH4263BkkPMZCAi6WHKXB6gTvi/OU6Dr+OedCBRglds3ovgpLU6nLPDtxRjnjUanIsZgBwrfWtgKXqjgBe6TVVp3G/KgjLZypjj+nTANeTUm45nYqq3/68fX0LaC5+22aryIVUTXO6pZQvAYAfA4B3PMb/T8uy/Bfmu7gLzeRyZwfuPbtbbewg4EZe93a01Oto8GrLtfDVABa7VsfQTw1qAS7lVCVHjLVZ6y+/gj3VjMVu46nY52v/QqrIFcwa2/QWAHxwWZbPllJeB4AfL6X8jWVZ/q+wuziMZnS52ns6M3DP5m6puEbgSu7Veh3paKnXe4DX89MKXI2blQCseEwfBdxVPYDLrU6OOnu517nL/Opl/fxuk9NdlmUBgM8+Xr7++Ifu8W4VCYse+2y9GgXcaHBGj7UncAe427psJHwtYJXaeWHcC7jA1FH1WEwN6Ubg1nCVXS8NVu9BGXKdnHKm4p7fRs75YtCNeoh94+rlUsoLAPg4APw2APi+ZVl+Eol5EwDevFx9hfrmUi0a6UB79n8m4EYvrDphOnl7Tf11HAW42z6lcu5a6263qvbiAgDUp00ByMB9itsAdBv3fN0OXP2qZeuCqriH2EtwbU01q6C7LMsrAPi6Usq7AOCvllK+dlmWn6tiPgIAHwEAKOXdJ3TCe55yFOlcqf4shz1IMRHAPRpsqfiW2MmAGw3fVleL1e/ldLXOl3Kuppjrwy/qvbjYecqUm5XLbh0uB1Rp7lZeRHUbs5Zf/5z7ebphh2Msy/JrpZSPAsCHAODnpPjzaNRc7qjFU5oYL/xbnDAXL7WLbrP3oSTB87dHg2+L07XUSW2k+B2BSz3AgFo0pQGoZv5Wmu+93Koetra5XZ3z3cbW8XhszAKqdcwCXyRjxE/RUspXAsDbj8D9UgD4ZgD4b0x3cmpFuy5NbGRa2QvcHtuHqPiRbQ6+WArrthdgudjo1xFlPX5agKsBLNvmGrjUHO560lQNUmz7j2f+VuOG17pt+W38bT3W5yrtfK5l6xBdxi+aklLQrYdj/GYA+HOP87qvAcBfXpblRxTtTiKvy7W22yutHHUfrcDd291a+7ozd1tfa1572liBitX3BrAVvi3AfSq/Be56lnINXD1ccYBq9+tq5m2jDsfAwCkBmWr3fN1vr27r6uW/BwBfbxrxNJLA6YGi5QMcU+QhC1ELp1pAszdsuTpLXy2xB3K3UVDVvLZClqvzAtga0wJYrIxYpcw9LciyQplzt7zjxUG8xuPlmjndWxBvX9vSy/hCq7o91pYqw4TBOx94MFwRc8AtfzU93Xnk4ipOZwQuFncg4HLj9njN1XNxnpiWtutr6X3E4qUygBvgboU5XAAbcJ/bXMduy6h+t2V1vHa+d2231l2X653v7euIOV3d3ty6/4SuS0d1uV6HGdX3Hg6X+7voOXdLxe80f3sWtxtRpnW6EkAtDpd6bXW8T+X6OVzJ4VJOlpvrrcue+7ac2SzD1grayDld65Yha5oZU0IXVQtw9148pZEHuJiigRv5vp54ZTLW7ayA3V73BK8HwJ6fGvhSMNXEMMDl5nDl9DG+YMqyWEo717vtZ1uHlW/7urxuOwpSC9ieR0C+gFdtq5dTFkWCIWp8DRilNlg7D5S58a3vUW/YUvGtsZ2BuweMI15HgjcKwB74agGLtWkELu1meYhKThgrr8vqfi+/ng+2GtBGHZZhKcP6ppSP9jOpR1rZIq+D8rpVzxytB8ojDseYJZWMxQ549m0vGFvHoGI8EI4CL9UmCsadgcstmpKcqJQiplPMdOpZ2mZU38O2j7UOi69/cm7WCllpHpeCqeX4x1XpdNUamVbutc+VU8Q8rge4lCKgJ7W5A3dbX0fFekDsAaul3gPelp/aulbgCquUuVOmWl2rFsxYWyx2W3b5dS1zvLaFVVgM/1qew+Vdrg7A6XSnU0ta2QtmT1q5lwum4rgxrfEnWSiFdd0DsFxsFHxbIIuV9QKvtc4CWKxsdbcAJHC5U6YsrlW7sMqyp/d2LBq2GEStoB25gtm/ejmdrkJHWTzl7Suib88/lwRukyRQamN717UCFxtjL6drqavLOQDXZVuHC0ACd5WUUt6KA+lTf8xK5ku9D7gtW4nWsuufvlXM2zZcfN2mfh8lYbBOpysqekGTdSztX4MGApqYiLTyiO1DM8GWiu8EXIsrra+jYnu+1ta3wFWK8bpezu1qHe8WuExK2epwpRXKFidsmee9jBm7lWituy6n53M1gJUOyajjNeWYcp8uK+9qXql961sb9UWgV1rZ2ke6W7V6QNMSu4fTjQbv+trjdj0Q5gCLlSmBy52j7JmXtezT9ax4rse9biuvVJYWVtXtV3EwrmPrOOy6bn9bxwM4odskD3At8S0f8p4FTBFbf7wLp6R74fqzbgXqBVsqtgNwR8A3Cqqa1xHg9QC4F2i3r6nruswIXAmIFEgBNKCm4GoD83M7Gbaa1DP+U38Ws/ZwDAyqGEx9q5cTuoR6bQ+yQsMjzyKniIVRvdLOWJwUf5KVyVjXES7VUqftMxK4o8GLgVCK5UBLvebKjMCVtgBJILW4Vkvc5VfTpJy5FHPMwios5vb1A1q+bUvVa+u2SuiiagXunidPeWJ6zeNK6gHcE+27xbqOAKW3TtNGUx4JWa5OauOBcgt8g4HrSRVHpp11+355p123v7w1t3Bf26z1a931T9vTh7b13CEZ1vQyAMDLVzSAE7rhikgr762Iv3ortK33YnnfRgI3UBJUtbFHBK6mf6yOeo+09xgFXKjKG4FLyQNcvI/otLP8uD+d473uay27/ql3vRhoJcii+3cZqL54EOZ0l4RupZFpZUvsSJcrjd3qglsc7h2mk+uykYDVxnlfW8Ec4XS9oOXqOjtcANsqZYvD5dLCvlXMvIN+vtbDFgNp7U45yFpXL9dQxUD64oHeb3sdd31dmGZ3CN3RaeXoLUJSTMRq5SigWu5B6quXY915sZR07Y0dDV9PfVSdBbD1tQW02zKpbyNwvauUI2Os41/iZWd8HScvqrq8jTiEt9em1csbwG7hikG1BuhzH3g5pkIb3XuDbmuat2da2eNGPf22AlP6J6MBWwRwT+hu6+toR7uHu20po2KkNhrAcnVSGfe6hjKACrjeVcojYgDoVc2XOnva+bnP6/ht+Rq/ltUx25/bWA1ga7DWQC3cdK7mkKqELkC//bhSO02s1w1HOM7WPq31Frd5p+5Wum6Fqqe/vZ1uj5/R8K2Byzy8QLNK+R3wBQZsr+Ad8NZNm5fwCt6AL2zKI6CsX4x1eTt4MG/bb+Prcgm0NWQlwIpgxWDKuVsOvplebgWup50WgK2nNln6loA6uh6L4cot73Vr7KDVydJ1T/hScWcEr7XO8/rpT/sq5RW4GMjegLdu2rwD3kJBt+1nC6834AsETGMWWfHldGqZA60GslsHu0L2Cq41KGuoYiDVHb983dd9O90I4EatPva+3RGLp44C3F5z5idyt1xdJIhbgesFbyuIvTEt8N0CV/HwAu5ZuBZQ9ks52/f2UrCty+r+1uvL20m44Qq0NWS3LhaF7CukjLqm3K0WvgD3Dl1JLW9BDxBo7ucMf22t24EOnk62tqfqtJBtae9xtdh4WqcrtddAWjNOJHBvxrVtCwK4Xa37XP4Mojr+Nq5e8ds3nayZ463Ltv1FwfYJtNu3hAItFVPXacqp2PuFboRD3XtPbsTJU7O53NaUcitwO8IW634Wh2vti4qPdr1RTjeyTgPZm9fyHC5A+7agreMFgMfreIfb4oKfy3EAv4BXULvetU4DWtbNagDLpZwpwBpWL98pdHunlS1vXU+X69mTa+mvVg/gnmT+lnNammsPYLVx0a9Hg7flp7ZOA+IG4Hq2BT0viroFbmRK+Y3HRVnaxVpcv9jvuJZhsN26WhVoKchKgOXgigG1xfXe30KqvYDb2+V6/rqsUOXaHwW4lj4nOOxCutb0MxLEkZDl6loAW19zIOXKVK/1q5QvTfTA3bZpAe660AoAW3jV57CNdawtbG9cMOJqX1zeSgAwgJZzuRq3i13X8bU4+N6X050NuF4ozJhWjuybKmuFaKaTTf1qyrVAxeotcNXEaF2rpk5TL8bjwKWkdZp4ClkHx3dstgxtVzrHpaC1KWcdbFfQAoDsaC2QjZrTlZwtVn8/TnemlcqasSxxo/+qPF8CKCVw0eu94et9HVGmjeGcq/ZniJutXgvbggCAXalcX2MpVyv46m1D2jT2G9V+YGz1NDVvvLap+yV/JwS2qKt9BbKbtbhdDq6tjhdrex9ONzq1i8nyYU8p6uSp3i6XU4tDpsY6GHCxrq0A9tTt/boHcKX22DVWF+FwpddX1xtiVLIAd7ttZguztWz7Wupj28a2JahOFV/XrzHyYRjX7vYKzI9zttv52htnq3G12zqqflu+LeNe122oGE39+aGrBUaLy7W+VT1d7ui540ggRwNXm9bv6G6xMq1rtcTODFmsfi+n293tPqeUAcC0F9ezShkANu5TdqxWhxu16plLJZNp5C0gKfiuP1vmdevXkXO7WLtzQ3cEcKPaRblcqU2rE/X2PQNwO7pbrPvI697wpfrs6XQ9jrflZzRwr66vU8oA/YBrhZ8EUCvA1+vbuebrOWKA61XJdSqZdLY1bCn4cqDlVihzTpiqB6KeK6N0Tui2Hq5g6Ytq32O/qBRjvdcWIEc64ARuM1S31xEA1bw+Ani1dVb4MsB97WreNh64twugbtus23m0wI1y1FwqmZu3JWGLpZQpt6ud18XqqPr6dR23lRa851tINQNwLfFekGjGjlzgZPldLUCO/v13nr/FhvIClosd9bonhHuB11pHlWnKiUVTANDJ4dYgw4HLARsAbhZE1fFSPbfSer1HgNuFUiRsa7jW15Tbpcq06Wasrq6v67BrqXyrczndSOC2tB+xcEsac8+0smVcT/xBgesFLFcXDVaqPAKyWFkUeL0xTa/HA1dahSwBVzpoQ9qjy9fLqeSbFcnb1cgUbKkFVBhoPXO63tOovI73HE639aQla58e4GrcmzYu+q+mBcgWqLZ+MaDu5eDp5Pq6B3x7gtoCTq5O2yYKxq3ARR5eACADF8D+xJ4t1CKBq0s/674wXO6hegKS5G7r18CUeVLNdTkg8dxrblEVVYa13er4TreHq9zDqVIasUWIUwtULV9OIv+5nQS43LjW15H9ecqoOi5WM4bUb12mAbNYfgvcVdu9uJReIJ/GLzdlHOSeY6StRdie2ds6qi/r9bXDvZ27fcdbwrwtBtLIed0ep1J5ne6xoTva4Up97LF4qlWRQOZkzRxEZgEOCtwR7jSiD6/r9cZ6na62L6PDBbhdNPVU5tqLK68atkKRmqNtc8D6dDLrbj2LqDTzup6FVVR9HYNdb8V97zomdD1ONOLXiQKuVjO7XKnfl0wd1w8WrxmP6mtS4I6Gb2Sstt4D3oifnjLu9dO1DritTwzy1lPP1G0FLjXfi93LO976wu2e288Dvf1HO69bt9leg1CmWTzlXbksuVqs/lhzut60r/ZXGZVW3svltgA5ygFL/Wic6+QLpuprL4yj4NsbyDOB1wJXqV4ALjWHC9D2iD5/vQzcFaA1cKn5YArk6/ztU19ed6tZRCXN67asXrbO5VrndbH+juF0W2AYBdyeLlcLFikmcp6Ua8vBmquLWFE9OXAtgOXatgC3N2Sl+lHgtcYcALjPW21sW3l4iNIpY2rPr8kdb4B7M3f7FujnbSXYSilmy5wuBlgKrpq5XA14V80L3QjXOSNwo9y65kQnrl7qr3ddL+BOmk6Wrq3w1ZSPdrVYWS/wWus6A3fVmL24fMo5GrikO371eADH599uc7d1HSD1QFxr53Q1Keb6tWVRVR3PaT7oRqV4RwDXqtYzgy2y3HfLFiFtXVTqWjteo6wAbelP2xcVh5X3criaMs0/kdafUh12n1rgPsXrVynXi6Yovag+rSkoP9dd119u8xaU277W19vYdWx6RTMH9gdk3Ien59w+vj0xwKXmcFsPy+Ccbuu8LhZD6QH2ntPtNYc6Crg9Fk9p+rO+b5EHYUTUSeNrvohgMYNSyr0cLlfXw6Fa6rHYVte7l9NVvfavUgbgt+5EbM+R517ltDB2rGPdz/aEqa3DZedv64VTrbCtna12Xle7elkCcB2DXVNlmMY73QJ9FyyNMugRaWUvXCLaeNqOcLmaLxgHBe4I+PYArheuXN3swH26/zjg2lcqW675tLEEXCyljK1QJoG7zt1KUH3r8X2VYEzBlpq/5eAbMa9LxdfSgHe+9LJX1tvtMY8bFd/SlwStmVxuAtdUNwq4MzvdUcBljnZctQXuU5kBuHVa2AvkGrJ1P9s53vVBCBbgPrlfasFUDcvPE+Ua56tdwSzBFwMtB1kKttZ53boNpmNtGaI0C3At99HL5VrGtOyt9dZJe3I1dVxMAHCxbnsB1hI7yqF66lvregLXDV/8aUEA18Ctj3e8NKdgSgOXWxhFbQ3CtvBIW3+41HQYcLdOl4LqmnaGqg4rl9LO22sQytcyQMqtble7T5dzvMd3ulHOzdOfpt1MLne0tG7Y+wXkRMCl4jTlXD+WNl7nao0f5WyxMiNwtynl52seuPVCKmmlMoB2QRN+rYUql1LevqaA+8bnv3g9f7umimvgYtuENKlkDWwpV8utVMbATNXXdXU5BlPO2WLxx3W6e9xez5XVnr5b7qfHXG5UFkDzewVuDdqqBbiWvj1vtzSWBEFtnOaLCFbXw+FK42D3Z/liggB3FQfc5+bX8HxqW7ne53LcBV//Ktf9vajGwNrezinb69b6K+BXD5u/cbgAODAjgGvdLqSBbeu87v06Xc+ttbpcD1C0UPQcexh57jQ3ltc9e13uwL24rYCNdrXW19HOtaWsB3BHOF0EuOs87ouXz5+c28MvAK6332BlVNr4MjS+hYdLK2sXTmGrj3V116uUt6dM3ThcaoUy53C38QB0OhqQPryLqiTQRjldDrCYCz4WdL231DOtbJVmHM+9WODYw7FHuNyTADeiLoF7q2jgPvVLA1c6bQoAXwh1GaZXWpk7SENX5wYuBlZs5fLnH99bLN7jgoEo49wvVwZI+baMe42BlANvHXOM9HLLrUQAN8rlYrERxz1K6uFyuT5b5nKBqU/guuuPCFzO6WrKxNcLCtynrhTHOwLQj9lbpZ2b1c7jcvt2t+B8Hpte4ewGLrVCmSu3whaIemBiAIkDoEGLuVwMxlTMVtKqZYV2hm7E8DMBV6veLreHvFuEuD46/fO7Z+BGw3ov4HpdrRK4mvOUV1HA1R6IgfVxKdNA9rrdduUytf2I2sO7HvWIArd2shhYsRiAvouqKABjQI1Yvaycz10k1zuf040adjbgjnK5lr2vvV0uF8fBGGvXYaXy0YAr9SGVtbQ9I3AfZTlP+akMgeeq6P24WjdMuV8KxtcAvl40pQJuDVYq/bxNOXsXVAFSvy0DuIUvVaZxu0TKuQbqQw3iR73NgPeL+83p9uo+yuVFukXt7xrhcjn1cMDcU4Sixk7gXr22AFnTthWuXJ33J1VnAS5g5foHGGgOv7gu5/fjXm7ldgWyPeVsS01j8L2Z38X24UrA1Sykok6qotLSwMRh9dw1ID+16Wa4BuwWrhhQHxjI1vFfHO90S7+umw6KsMjqcr2xrZCMArJlHlYji8vttBfXUm+J19bt4Xaj3DFVNwK8Ulldf1V+fbzjVtuVypfrV+atQdrtQ3VaGYvdjonVYU65vs96a9Bzu2snDABXRztePZpvCz7YvKacKeVQNQ63dq/UGMDEb68Bbu+7LttewzNoOcjWgKVcLeWCGaPb2+lGKxK4UftNoxX5eD4tHSKeAKTtYxBwLRDu4XglmGritUC2ul5tnAaYlnitq8X6VTldeWtQPY8LoN8aVAuDHrZ9CAdkRFqZOiayPk/5Ad7x1heuzlIm3Wy9zad2qq+IOKxcO8crwRjgFqgYVAnQcpDdwvUGvBVQ3wZZawxjdI8E3VHA9bTDxvPsy+2piN85Yi53gKIgaon1glXTj9WpWvvwAFfz+2rba2DMtbkql4G7yrI16DIUnVbG3KkmXXxp076NiFqp/DyPu3l4wRae1FzsW5ufADJwubncOi0NSHsLbBWLqGrQ1pDdAvYKxnAtDLRMllmlg0B3VErZ014br4mzulwt+Lx1nkMyLONOMI8bEWuFr6Ufa5m3jovv2Y9Upq7XbQ0CuH1qkARc+Vxl3MXSKWEcmJQz3r5+ozrKEUsl1/O4Nw+gr+GpcbsYcClXi4Fa43yBqIOqDJA2cAGtBFkKsNvXNVQph8vB98BON3KvqqZPrv1sc7mW/iIWP3nmfLk2EwDXC2AtcCXQzgJcbR0gcXWsxelq7kNqAwDYSuVVmoVTALep4udyGrh0zMOmz1soatLFHJi1i6+eF04hDpeCH7dKWQIu90CEbR0ADWNuURVUMXDtaCXQYpB9QMrqcqx+Kyz2oNA9AnCxNtoDM6R2Z3O5W00G3JZYShYnbKmvyzR1Erxb2knAtPYrOd2bcnml8ipu4RS3erleNFXHXbd5draXcvlMZM88LvZA+xuw11uDqPQxB0kNcDGnDEgsB1gqjczAdutqJdDWkKUA6wVvrQMupOq97eVsip6jjug/ejV0Q3cWh2sZy+p+LfBuBSbXp1Qm9S39xPq2At16ry9xMALozlS+dH8Nzqs+GDhyrnfbtu5rfY2NTUGbasPN45Yt9JC0LAlAzBVjAIWqvL7WApe6H3i+ppytFbYa0Hrnc9+GQzndiFW00e2jD8LA4kYd+ejtk4rbyeXWioSq1gH3fO11u17Iaepaf1rr6jL0NX4AhrRwaitPWpmCaA1Fi8ut55U1aWUy3VyllVGQru50+xOL4x7pZ30gQu2CubjqywHnbDnQtjpcz3wuwCGcbu8jFUfM43r617bp+bhBTK3jDXS5luuo2Fanre2z1dFGgVrraLXxdR0WT90fBtwqrQwAaFoZO77xFow0XGvxUNU+pIBegEUtkGJjsBOnMOfKlVHbhrzAtTwQAa6vMdhirlYDWgym2tQyl1bG6iZ1uqOA1iOtPJPLjVhApf3iQblcrRpdbgtwrX1TdR73a4ltcYPWGOzeNLFYuQa8nt8NLb8F7qqIZ+Pih1nwDyio+64XU9VjUPPBmjlebj8uegAG9YfbU0vVa4CLHR2pAa4BtjVo4fGaAq0HvD22CwEMh+4exy56+7CklT39a9tEbZfyuFxPapqC9M7A7eFqLRC19OF1vVZnbHGoksvV9oPFcoC+KcdPnNI+G3cr3QlT/DwuDlnuYQfcYRrWtDK/H/cKhtRCKKquBmGdjn4A/IEHLU8gArgCrga2FofLQfYEW4YK9F245AGIpQ/rvfdckNSjP0/6t9Xl7qgo4Fohq3Wz2FhSmQem2vba/jS/hyUWq0fbrVTh9+MC3D7IAAPZU+wNBG/ngLfCoHq51VcoGLftKLCu/T3HBWwP0i6Sqt0sBuF6TrgGa9234QlEVthiMNWC17N6WVq5vI2fNL3sVQRwe4+tje25TajjvCo5bicYt7ra6DptylXbVgtkL2ilGItbjQKvy+m27cel5mgpCD8Pz7neGqb1eDRA1/J6DGqx1raf+otB8zyupo5LF3NPJqohDNf9UankFbYAz5DlYKsFbV2+LavL6zoqptYBFlJpFXW7kS5XqyO4Q09qmdL2PQ5csSz9ExgBYE2cFq7e/rd1FtBqxpLaSFDF4rxO9+n1dVr5tat52+uPxa3TvXTDO9pa3PzuNgbrn5rn5V5fg5qCMf4ko8vb8djPA/Igg/on5Ww1dVwf29fA9A3VawB0+w/nbqm5XCtsWxwul1oGOA1093S43PhRh2FYdSepZQtkRzjgltfavr1OVhMbkV6uy7l+rS6eff2cVgYAVVp5KypdzLnX53bYXO2tk63jsXHrOO7kqdsFV7zLJYFJpXkpgGJ11LYi7VhVOZZO1rjbGrDYa22aeVvGldd1terYE6SXI29zVpd7ptRykMttgailL22dNcUsvda6Pg9greCOSCt7xqnL0NfyA+lXaU6dotLFW0mrlSn3qXHAlpOnuHHQQzC0rtWSVpYWRUkLsZC0NAfcVthKoLWAt66jYmod2Olab+8oLrdVPR4kb00t7/xPZ7SrtdyLtU+tE7WmfTVtuDGjAYzFi05X93xc66lTmCjA4rEPVTve5WLl6/1s73dbx69cJg7BoFyrBFXs4fXUAwuoxVQO4H7u87y7pcBbg9O7sGpbxpVHamLo9gDuHi5XM1aLy/WOS7nUWpq4Ds66l6uVYjVxXidsqafqNBDu4Wi97bE+pHtaX2+fj/so7WrlrbD5WS1cL7F4+pmbo8XmXz1bhK7v93olNLp4CoDfE8v90aSnpb23AnDfflxI9bnP29wt5my1+3Q1e3R7ARbTpNCdCbitLrc3zCOIslUkQJ2pZauLtbwFHAy8MPXEc/UR7jSqTd1WE6P9gkDVX5U/fiwih2Bs5TkEoxaeRuafMoS53Lo/aiVyvUVoraO2CF3dI3e2MgdCCqwWOGNArffvVmMuq6N9kNPJmvSylHoG4nqEk5U0IXQnvKWp1PvhBgdXRFo5YiwuNsLlasfzgLXFDbeA9+pe8FkxzuUCyIdgXA2BuFeLMJBu+11fY+V1mplKP1PO+sXjHpunXx9zuVC9flWV17F1P9u4uqzuox4LqY8AruZgDMtc7h6aiHDeW5nF5WplTS239E0p0gEHp5Z7ulxPXdRrbhwttKSYFrcrxbf0Y0kvK10ut3gKQN6Ti0l78hQf83DV37Z8C3jqkIs1/vJ23KahL2/Hs8sFANnl1jHS/O/6Z+tYqSMhMee77sXdzOF+7i07cGvwahdTcenmGTQBdFtuYaYFP71Sy97717br5YA7PE2oVg8AW6CpleT2NONFOldPbGsf2vQyAFiOetxKc8rU83C3KWNKkgvG3CgG0O09bevw+3qgy7cnT2EQBJBTzRhoNTHYwxCY9PW6aEoC7ucebxsDr7RXV+NyZ9KO0J2A98Ndbqu8C6wiH0jf8e8t0tV6IMspwuVayyJTwp42PdPL1Oun2AfQHPWInTwFQIOSO/DCskVIntul5mMpN3sNWsnlAlRzuQDX4AOQHe02RgNjDL41cDfueAUut2jqc4CDcwtcrh6Y17NqB/JFDNkzjeqR1uX2XLXc88uAddXyDi43IrbF5faAb11ngbG2D2t62Qteyek+lfFHPW5FnTyFrSKmF1TdrmzWqF78tB2fKsdgXN/r+noLZ8rlmh0sEDEa1yuNRTjctxmHuwWu1t1SqeMjwHbVACrN4Ggx7T2Xu5e2v9ss9wTHd7mesaxOUWrvcb3acS1tqXbatDMAtJw8BQBkGQdXi8u93PLtwqh6nDqVvH39EgXrq6u2V4uyapdLLWLiQLuNleCrBW71h9qHu4IWQAYuBVkOvEdRJyKWfl1P53L3kpYskallKn6rnV0uB4tIGHudrfefpRagLSlpqt5yD2pHi7WxnTx13Z00b3vtTDGYWlQvsKpfr9fXP+knCT23uU1Fr+VXK5a33yk4J0uBtF5ohbUBIMFK9VmfNFU73G23GuBq08pH0mt734BNUc7M+8g/bXzEAi8p9Wwdz6sB87wtLjdqTE1c5H1ogaXtRwtO6z1R5Zq/I+8XkJc0AGuXi8YgLvcynGZBlG4ud43H+sYPxqBh/Dw2NT/86vahBgDX4AO4hiVsYqCqf6jq6n4wcAPyE4M4wM2j+bA9tgC3dfcAXIDT2sEev1bvVGxU/xYbeED1SCVb08eacg+EqLqIvzZrylkbr0kVU3FXba735WoPwrAe9yiljD3SuNb6nurUMnbfN654fagBAL0laPuaSgUDUy/N/zLpaGqlMuVqtylmLg6IsqPqQJ/CUWnlSJer7T8a2NH3eaC5XUvb1jhNG2vCQirrMYfrSTlrYqlrqj/y9ea4R+VcLiZs648lhUy53Od+cCe81l9+Lby8hjHe/wPSbnW4r2735cLmGksT1/CEKobrqy6XFmoBkAunKKBqgLvewlmAC2BIL5dSXpRS/m4p5Ud63hCuvaFAjd86QSf1r62PbKeZDw6cz22BaoSpj8qYt7jcqFSzJKt7HeVyK2lXLFMLozSLpSyS0tLYcY7X5ddzvlg51s8T5LEFVAD06VNYDFZPuVzqGjY/t2/Jo8vl5nGp+VvNARlnAi6AbU73wwDwiV43QssCjpZPqJlMv+VeRi0s6zSf6xkSqxsFYAtcrelkTq0u1+NgLffBxbCvbx9qAHDrcq/qXtRpXG6xFA5mbp6Wais5YexeOKBK5Tcpcwqg63U9p4vBk3K5VLqaS1M/ltVpZW7/rOfnmYALoIRuKeW9APD7AOD7+95OrWiHu8e87MjUsvYTfe/MwaNaUsmWfqm6qO9ovVLMPb7P9IB2q8tVHPdYP7rv0gXucrm5XE6Uo5XaYgCttxNxKeftlqF6vO3j+64WUGHpYgygFJQpiFJOGQP34886rQxw61C9wN3u2T2LtE73zwDAdwPAF6mAUsqbpZSPlVI+BvDZgFuzgqGX44pOLc+mSQBcK8rJelxuL1Pvdb5aAI76J9nichuFnbFsao/My5rvYQtFcZ6YBjlWjy3EulKV1r2Ze63TwPXrtY+H6nqrug/m5/L4+uHx5xawQLw+I0gtEqFbSvlWAPjMsiwf5+KWZfnIsiwfWJblAwDvDLvBOPVeQKWVdT53pAbP53rVG8DeNi2gabk375ysNLbH7VrKGs9Yfr7us4BKfsbtNiV9nR7evsYeVF+X1yC/XkD1xetdVDVoAW5d7PoTSxdj6WWNM17Hefy53ZML8Oxyt04VkNd1jLRy+WzSON1vAoDfX0r5FAD8EAB8sJTy57ve1V273CgoRz79p4O16jEn6x3fuNAnLLXcI8Xscc6a+9L2oSnDUstwvYAKANjDMPBbot1r67ag2/54yGIp5Ot7uS2vr7d7cwEAd7WYa6UACnCbNsb60aah15DNXO7WxWILqQD04D2rROguy/I9y7K8d1mW9wPAtwPA31qW5Tv63VIP57eXyz3K3t6d1TK3O2L+VtNeGqv1S4V1zjUK3pp+XHO6tMvdijvy0QNSjYOl+q+3CVGudRu//SmfzYw4Z27VMlQ/MQdcu9m6jFp8tb6uYbz5ic3l1kPUgJX2354duADTnUh1ZIiMuPcIOxi1P3enOe1R87cRbXvAt1UtC6aoPqQ6MmOAzFnC7Tah2yH4dPO2zAJmadUy3e7atWJgrmEsbTMCgOuHG6yqgbn+pNzutp0EWArs2/rHP9stQgD4FiCoXksHXwCcH7gAxv/my7L8bQD4213uxK3RqeUWWe915JeQgfO5PZxsyxhYGy+YPelWqq7VnbbKOwXAgfemz8unvJRa1iygwrYOXdfxMNeqfqTf9qf03FzM6WIHY6yp5SdhqeW6jJvX5aBcr36WYAzPznb7up7DtYB32/7smsjpHsXlRkK+5VF+ln5bNNjR9p6/7dFnS/8tqWWpD2sKmurPmlKWVB35uIpLLQPcukLPHC33zFz0nph0tneOmIP/Vf/b1PIqbEgMyAC3FMNAjcVQYz3WbVcsb89XrptjsMVu/V7Syqsmga4XEpr/8bOsWo7WSZ62ZHGrHOhGp5Y9sT2deUQ7yxcAbZ1xAZXmmblX9UTq1/PkIArEUl/4SVK0A67LuW1DLyuHCQD4wiiqHJvnrcu51HIN6hWym7lcztla08v3oAmgexSHy2nEoRgn0ch5S2+bmVLLPRdAefrhYqky49jYCVRX1yiopAcc2B9UT97fFVRvU8jbuDoG23K01t1uFaoG5hxtDd+6HFvVDIC7WQbG29OnVkmLpbCVy/fmbrfaGbqzgmmG+VxL+9ZFVFbrsy0P3J/bY/42Kg3c2qcVvlRsK1RHLaQi29pXLQPwKdk6zvugeqmvel6YOuCiHq+OqU+fqrWdzy1UShhLIWvKV1HbgqSFVHC9L7deAKVJL1Nzv/eiHaHbCrY9Uss953Ot9dHtpPYdvoj0hqx2bM13i6jFXxHxeyliIRVA99Typc7uaqk5Xm7OF982pFvMRR0bCQC3B2IA0C4VW1BFlXMAx8oqGD8d8/hwHQ7Ap5S3r6n53XvRTtAdAdyjyfI7zZohOIEi50lnSy1rExqadhJYsTLFAqrZU8t1v89l12nm7WtqPrd+vfbz4mppMNCrj6GhHEtJC4usqCMfqQcTZHoZ1w7QPRswZp7P3X7iTXBP0QuJLH2OSi23pJulWO1qY2t/ln7C3kcmJas4fQp3knJq2ap6DhZ/YlG9fWi7pegWxttyrD0A3M7nAtBQxFLB2nJs8RWzkKpOLVMul0ol12X3qMHQHfnBv1d6NqVSz3Stpb+9F3a1jD/y3jsspKr35m5VPzfXImmOlXtE33bM63Rxu1PG5oi5ey41pYC4jiinHPI2BEktb5vUEKXmeblbugcNytMeeN9oiHouovIoahFVJ/Wez9W0t4C5h7v1qoejt8SI7xX+cYudQrVNLVsfVu+R5QQr+rm4tyDlzle+OZFq88B6AMC3Bq3X3AIpbj5XM6e7ff0KTy1v08PU4qh7PXWKU+ePgVld496LqKS+Le/biMVdASdR9YTlqD4t/UfPx0r9W+dlI1YvU2XofK+8armezwXgD6egyrblveZzAXTQx2Bct8WOhESTAPU8rFQOcJtipsrr1csIjOunCT2Vb5qs11jqGeC+53JXdUovF5gXuL2l+b17vTd39p6Pdph7Ot7o+VyPmjMJssvtOZ/rOyzjdp6Wuh/pMA3qgQfb1zeLqDSri6XybR3mmGshMK5TyxRYKdN87yuWt5rgcAyLtP/rzzyfe4R7FNRjPneGrUJSX1TdrDMm0auXN9LO51660KeWJbhyz86tY7Z90v3xY2Ex2CKqq3rNIirYXHPl2gVZVDp6G7YBLjYctTK5HuqeXS7A4aA7m04AQLc6PbR+dBq6te8Z53O1qWNPitnl0nVnLV/VKR5wEC2LG6a2AVGLvrhzo58ccn0oBiauXJNi1sznVjHL5hp7uAF2DUj9vcN2VUL3tJpsuxCl3rDroVmdqVY9V4M7x8DmcyV5HWiLtiuddQuudF8eUFhzi6hWad2vtj+i3+2KZSqVTHWB7d29Z50QuhJgZltEdSQNfh8igDx6e1DLOFGLqCJlTYGL894VhJj5XM1ThajTn9b29VOFrNI8VQh7zB91r/X93cRsVy4D8ClkCaLUIiquP2TLELZVCAPp9la57UL3rgNB96jgm227kKbv4DFn/KuLntvVur09F1F5xuTqLO8JcfSjfBsyqLA4q6RV0dIiKu6eNCuXr+q1K463ouZv6zph3vap/FHYVqFV1ElTUL3O1PK1DgTd3po4BUvK86lr3RYU/L7Mvj1otBsekeq1lEdnFzRNmQcf4EPx24Q0bbWLqNYybCzsmoKz5ijIF/VeHGmhFKaH6o+lP8GW1vO5dSh37GP9+p6V0A2VB1Ate3Qj2k2kiAU8I111T3fbKu3iqbpc06fpPnRPFdqqXkRllXc+17qIyjeni69cXhdR3axc3u6b3YqDK9a+FrZauR7ncauQZj6Xm0rmyu9RB4HujPnJO4ZjlO5tEVVPR94zg9CyZShAI1Yua8W53uvn5srumCozr1wGoOG6trMuoqoPwCDAy7lXakXzvesg0NWqxyKqmXRHwI74q9pjEZVX1m0+1PWBFLGIiuwbbh+X57pHYU+ttQ91P5rtP7U4uK71259C+VJdU6li7sjHdLi3Ohl0e+jAn2opWb0WUUVr77S5po5s4/vo1c2tyn17j4PUrFzWtufjiN9B87ZZ4Mq1eyDK4XkRFdeldK5yut1nJXRTDnU6GGOUIhZtt4B4r+9x0u8dme53nESlG0p/OpVF3H5arn9su5Cu/8r9Pry63S4EwB/fqIGrp26bSl5XLyO/lnS0Y7pdXAeA7j07zYhPwZOnpI+UQq7V+36ti6m4PqxjasOFxVV6t2h3sVgKWpuS9t6XarsQpRa4WldCM/1J2Wlq9XLqogNAd4R6gekoFNBsFwr4Xbzu7yhvo3flctTv12sbUkSfjQ53K85NSjDkYrSHZ2iOfMQfdq/0fBHOldt/q1whTT1NSLqNFK+Erksnd4+ROgowNTrT7yIp4suC8szlqwfWK7cLaR400EM4TPk9ulR8/fpKLeDlFlNRfRBO+OGBPolqu2CKO4Eq3e61JofuEU89OIoGnUYVrclvj9Rep0eNGu/Iaf7OkmC8fdDBlTTQlL5feLYZEfO32OuUXZND16K93efe42s00T32TiefGQIH/X20i6hcW2wGyOqgrQ9kQB/pByCDVXp7vPPESuWWIZtOBN0emvnTbeZ7O7j2Xl3sOds4+h4664VzG9FoWU6f4iTONWMrlwF0Tw2i6rX9IKr36BqapgQldHdVgnNXhcxbRtyIUntDduAe3VrWPbrRB2PQMbenUbWIPI0KQHa0XhF7dN9m7iX34/qV0J1KE6V/R+ro4Oo9RgQYe3156PR+Ruy9BaC3Bln7iFLrgRusJOfLHIDBOeHtKmbLmcsJYFwJ3aHqBdWE9dC+jpSg6LVebpIHO8TB2TaPrN9e5HD6LXOw2uGUcR63m+KV0E2lRmoUmA7wxcDzSL8e4k6jilSv+79R68pmpNyyRzdhzGti6I761LhTl5i6T3kc/U4A73UaVVRbDqJdz1223PLA1U+5R1eniaGb8ukAFqeH7vTXTvnFHXTBSYoZ5mgBplhSnGC1KaGbSkWo8xnFh9agIyBt/exHqz3HvhF1INYcW6NPqYRuaowmWx2bul9RgPY6VOkJQ11k4XYQ49PRxiihm0r10tm2Qp1Ae5xu5R6T2+KTOqwSuqlUKl7Eww5St3rRmsvdIVs9UYL8cEroHka5yjqVSqWOrrIs8d9ISyn/BAD+YXjHffWbAOBX976Jkyvf4zHK93mM8n0eoyO+z791WZavxCq6QPeIKqV8bFmWD+x9H2dWvsdjlO/zGOX7PEZne58zvZxKpVKp1CAldFOpVCqVGqSE7rM+svcN3IHyPR6jfJ/HKN/nMTrV+5xzuqlUKpVKDVI63VQqlUqlBimhm0qlUqnUIN09dEspHyql/INSyidLKX9q7/s5o0opP1hK+Uwp5ef2vpczq5TyvlLKR0spv1BK+flSyof3vqczqpTyJaWUv1NK+dnH9/m/2vuezqpSyotSyt8tpfzI3vcSpbuGbinlBQB8HwD8XgD4GgD4Q6WUr9n3rk6pPwsAH9r7Ju5ADwDwXcuyfA0AfCMA/If577mL3gKADy7L8jsB4OsA4EOllG/c95ZOqw8DwCf2volI3TV0AeAbAOCTy7L84rIsXwCAHwKAb9v5nk6nZVl+DAD+6d73cXYty/Iry7L89OPr34DLh9V79r2r82m56LOPl68//skVqcEqpbwXAH4fAHz/3vcSqXuH7nsA4Jc315+G/JBKnUCllPcDwNcDwE/ufCun1GPa82cA4DMA8KPLsuT7HK8/AwDfDQBf3Pk+QnXv0E2lTqdSyjsB4IcB4DuXZfn1ve/njFqW5dWyLF8HAO8FgG8opXztzrd0KpVSvhUAPrMsy8f3vpdo3Tt0/xEAvG9z/d7HslTqkCqlvA4X4P6FZVn+yt73c3Yty/JrAPBRyDUL0fomAPj9pZRPwWXa74OllD+/7y3F6N6h+1MA8NWllK8qpbwBAN8OAH9t53tKpVwqpRQA+AEA+MSyLN+79/2cVaWUryylvOvx9ZcCwDcDwN/f9aZOpmVZvmdZlvcuy/J+uHwu/61lWb5j59sK0V1Dd1mWBwD4EwDwN+Gy6OQvL8vy8/ve1flUSvmLAPATAPA7SimfLqX8sb3v6aT6JgD4I3BxBT/z+Odb9r6pE+o3A8BHSyl/Dy5f3H90WZbTbGlJ9VUeA5lKpVKp1CDdtdNNpVKpVGqkErqpVCqVSg1SQjeVSqVSqUFK6KZSqVQqNUgJ3VQqlUqlBimhm0qlUqnUICV0U6lUKpUapP8f1K+QjYD4lFsAAAAASUVORK5CYII=\n", + "text/plain": [ + "
\n", + "This could also be solved by Hill Climbing as follows." + ] + }, + { + "cell_type": "code", + "execution_count": 14, + "id": "b3b0c23c", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "118 µs ± 3.49 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)\n" + ] + } + ], + "source": [ + "%%timeit\n", + "solution = problem.value(hill_climbing(problem))" + ] + }, + { + "cell_type": "code", + "execution_count": 15, + "id": "34fdf3bd", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "1.0" + ] + }, + "execution_count": 15, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "solution = problem.value(hill_climbing(problem))\n", + "solution" + ] + }, + { + "cell_type": "markdown", + "id": "43310906", + "metadata": {}, + "source": [ + "Let's define a 2D surface as a matrix." + ] + }, + { + "cell_type": "code", + "execution_count": 16, + "id": "14622780", + "metadata": {}, + "outputs": [], + "source": [ + "grid = [[0, 0, 0, 1, 4], \n", + " [0, 0, 2, 8, 10], \n", + " [0, 0, 2, 4, 12], \n", + " [0, 2, 4, 8, 16], \n", + " [1, 4, 8, 16, 32]]" + ] + }, + { + "cell_type": "code", + "execution_count": 17, + "id": "95d0630e", + "metadata": {}, + "outputs": [ + { + "data": { + "image/png": "iVBORw0KGgoAAAANSUhEUgAAAd0AAAHwCAYAAADjD7WGAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAAB0oklEQVR4nO29f8h1XVrfd633ed53VMY6hQjN/EjGEpMiQrSdWIu0DZNKJ0ZiQqE1wUDalBeahozF1sZAf9G/SkHyR6UwVUkgISatSZvapMGSCVawxhmjQZ2kDDrBSSUTG0SHzrzz3s/s/nHufd/7rHP9Xtdae+19ri883Gevda219n2e5zmf873Wj12WZYFUKpVKpVL99dreN5BKpVKp1L0ooZtKpVKp1CAldFOpVCqVGqSEbiqVSqVSg5TQTaVSqVRqkBK6qVQqlUoNUkI3lUqlUqlBSuimUoNUSvlUKeXfqMr+aCnlxwP6Xkopv621n1Qq1VcJ3VQqlUqlBimhm0pNolLKu0spP1xK+SellF8qpfzJTd03lFJ+opTya6WUXyml/HellDce637sMexnSymfLaX8O6WU311K+XQp5btLKZ95bPMHSinfUkr5v0sp/7SU8qc1/T/WL6WUP1lK+cVSyq+WUv7bUkp+fqRSRuV/mlRqAj0C7H8FgJ8FgPcAwO8BgO8spfybjyGvAOA/AoDfBAD/ymP9HwcAWJblX3uM+Z3LsrxzWZa/9Hj9zwHAlzz2958DwP8AAN8BAP8SAPyrAPCflVK+Sup/oz8IAB8AgH8RAL4NAP69iN89lbonlTx7OZUao1LKp+ACtYdN8RsA8NMA8F0A8D8uy/JbNvHfAwC/fVmWfxfp6zsB4F9fluUPPl4vAPDVy7J88vH6dwPA3wCAdy7L8qqU8uUA8OsA8I3LsvzkY8zHAeC/Xpblf1b2/3uXZfnfH6//OAD8W8uy/B7n25FK3aVe7n0DqdSd6Q8sy/J/rBellD8KAP8+APxWAHh3KeXXNrEvAOD/fIz77QDwvXBxml8Gl/+7HxfG+n+XZXn1+Ppzjz//8ab+cwDwTkP/v7x5/Q8B4N3C+KlUqlKml1OpOfTLAPBLy7K8a/Pny5dl+ZbH+v8eAP4+XNzsPwMAfxoASuD4mv7ft3n9WwDg/wkcP5W6CyV0U6k59HcA4DdKKf9pKeVLSykvSilfW0r5XY/1a3r4s6WUfwEA/oOq/T8GgH++YXypfwCA/6SU8s+WUt4HAB8GgL+ExKRSKUYJ3VRqAj2mgb8VAL4OAH4JAH4VAL4fAL7iMeQ/BoA/DAC/AZcFUTXw/ksA+HOPq4//bcctSP0DAPwvcEk5/wwA/G8A8AOOcVKpu1YupEqlUqLqhVqpVMqndLqpVCqVSg1SQjeVSqVSqUHK9HIqlUqlUoOUTjeVSqVSqUHqcjhGKV+2ALyrR9epVCp1ANVbnC3X2jquDda+tV/PPXL3w8Vry7xjRsVS+hQsy6+iHXU6kepdAPBmn65TqVRqer1eXdcftVz960Q5V6dp4xlTU26pw+rra6wNFcfFa9ta+9Lod5E1mV5OpVKp08oCm1lkhV4kcPsroZtKpVK7au8j8OeC0r7q/3eR0E2lUqm7016g9wL+PF8MErqpVCoVqvMAor96v1ej53JlJXRTqVTqEOIWS0WJWxClaWOpu08ldFOpVKqrpNW7Kb+ioD7uy0FCN5VKpaaRx83O5IBbv1BYtgpFrVoe68YTuqlUKhUmK3R6fuC/TrzeSzPcQ63x6e+EbiqVSnVTVGo5ElieeVtNX5Y67di9Xe545Sx3KpVKhaj1g37vdGgrjHsC3KLR76Pt2MiEbiqVSnWR5ehHqS0lzTGNkTAc6dQ9LncEcNvOZs70ciqVSu2uUelQ7XnN1r6ssnwBidZ+wG0dPZVKpVIA0Bea2ocO9B7PohEp8Fqa98NzXxFPHWq7g1QqlUqx8j5VSKrTjEellls/7rVbhaxPFbI+UUgan5L194+FrfcuUqlUKnUl66PsvIp0uXumlr1qGdPStg9sVyV0U6lUyi0P/Ea5XI9aD+eQ6rwutyWtrP09+sJ2VUI3lUqlXNLAIWrBkAesngfeW/uq1TrnagHusWC7Klcvp1KplFlWN6ZRa5p3dpdbawbPNxa4AHP81qlUKnUgeZwmAO+CLXXWsan2nvOUez5RKMrlzulwVyV0U6lUSi3tgQ0ti6s8ANQehmFd5Rtxn9i15v3oBdx9YLsqoZtKpVIq9QKu1j163K+mfcSCLa5uFuDuC9tVCd1UKpViZfmgb33KUOu8KjV+z5XQFoxoYq3And/dbpXQTaVSKVRWV+VZzeyp87hcqtwzX9uSVpbirXHHcLdbJXRTqVTqRiOA60nXcn1a08etc8dSXURa2ZtOng+2q3LLUCqVSl0pYmVsj3ncWp7jHltXMmv68sZG9TcvcAHS6aZSqdSjvPtKWxdORad4NX23jmk9X5m7L+oePCnluYELkNBNpVJ3r5ZDHCKBy/WtvYdRJ09RbbBr6ctCxFGQ88N2VUI3lUrdqSJhi8VHHY7BjR0J1ojDOqzHXt4XcAESuqlU6q5kPRxC274XcCMWTrXu1dW2idifbIH2sWC7KqGbSqXuQL1gi7UbcRpV677biJXTW/VIs1PjHRO2qxK6qVTqxGqFrdTHHqdRaeOiT50CZV0Cl1NCN5VKnUxRW15a9+r22KdbX/dyshH3I/WD1WMxq44PXICEbiqVOo32gi3WZhbg1oo+jWoEcM8B21UJ3VQqdWBFHuTQA7ZSTG/g9mpj6cNTv+ogwK1v/0EfmkqlUpNLC1qANlfLtR+9ZejegDsZbANJmdBNpVKTywJZgHZXy/UxestQz/nY0XO4B0knd6ZiQjeVSk2oPUDL9eOFrRSTwH3WTrAdTMGEbiqVmkg9YKvpt8eBGHWMxf1aAYYpuo0nLU2NPQFwo+iH9fOq/7CpVCrlkBWyAGNAy7WP3i5U10fAba853Innb720C6ZkQjeVSg2UB7IAcaCV+mrdm4vF9Ujfjkope1dea+oHwNZKuAFEVD1Pt5TyoVLKPyilfLKU8qd631QqlTqLXq/+WPRy80c7jrcvqj3VDouv4+oYrJ6LrcfD6rT9e9q0bHXaEbiWfzYvwRYfIHGYUsoLAPg+APhmAPg0APxUKeWvLcvyC71vLpVKHU1eJ7sq0tFK/VldLdWmNd3cArdebSLuqa4D6A7biJiIdl9o6+obAOCTy7L8IgBAKeWHAODbACChm0qloA201k+z1vSx1MfIrUJS/F6p5l7zt52AK/11T5Zi1nT/HgD45c31pwHgX66DSilvAsCbl6uvCLi1VCo1r0Y5WstYe8IWi7UANxqqXN1JgBsF28Erm8KGW5blIwDwEQCAUt69RPWbSqX21kjAWsZrgSzX3gJaLL4HbL112jYHSSdHgLaVepr2zK+taf6PAOB9m+v3PpalUqlT6qiQlfryzO+2zO16YVvX9wSxJW5Hd8v91UWnl71tArv+KQD46lLKV8EFtt8OAH+43y2lUqmxaoUswPHcLNc2ErRYWXS6mKuLSCVbxgYIg+0I0A5OLauGXJbloZTyJwDgbwLACwD4wWVZfr77naVSqY5KN6tr512t3OISI1wv127yVDL1V7FnatnarjG9DMuy/HUA+OvGYVOp1DQaDVnLmEcFLRY7ArbeuhagcrDvCNsWt6uN8cQ2aAdznUqlxumsjlbqwwrbllXKVFkU1CLqJna3VmcbOYc7Y3o5lUodTQlaXZuI+NbFRr0XVx0Mtl5nO1NqeWx3qVRqP7XA9kwLobh2rY4WK9csphrteidOJVtg63W72hhPbKMSuqnU4eWFbYJWHyuBShPTC4QHdbZ7pJUjiKfpo3UhVSqVmk2jXO0RQdsjbawdyxoTVTcpbLWu1gPaHpAdQMSEbip1KI1wtTODduT8LNXes1+3x1xuZD8TwbYFtNp/5j3It+0znW4qdXTNAtujglabNra0bwGtVC+1jZj3xeqDYdvT6WrqtTERbfbvOpVKtWsW2Gr6jN5Le0ZXa60/URp5VFp5wpTyjsOlUimdZoHtEUG7h6vVxJzM2UankL2gHZFStrbN9HIqdRQdAbbeFPKsoJ3V9Uatdq7rJ3K1MyygSqebSt2jjg7b3q5WG6sda1bQ1teTuFqsu1lAO3LxlLaPdLqp1KyaAbY9Usi9QHtGR2uNt9TtsDAqArQjna4nvkEJ3VRqF43YZ7uHs41ICWtje4LWE9MTtHX9gV2tdT5Xqp/R6fbtIpVK2XRkdzuDsx0JUk1MwlaM0baNqLPERLSZb4hUKnXRkd1tL2d7VtDWMT338E6cQh61eGrvhVOGv5KEbirVXQlbf9xeEPXESPcfPS8cuN3HA9pWoPaGbDrdVOreNAK2mnGOBttR+2Q1Ma2OVupzR9BiZXvN3bZCduS8rqa/dLqp1GjN7m6ti6SiYdvL1e6x8rgum8jRYt31mre1ArUXgLUxLfENSuimUqGaHbZc+1lhuwdIpXrrF4Q7Am0kZCMBG0U7TT/pdFOp3rqXVHLUnKqm3Wz11jndOwdtD8ge3OXuMFwqdUYlcG0xvedaZ9rio6nfGbZ7z9uOms+1xrb0mU43leqlswG3ZaXx3inZSFAnaJuBehSn623jVEI3lXKpBbYA+87ftrjbHrDtuYe1xdUmaJvLuPKWOk29N7ZzPwndVMqsdLd4zMhVvZEg7pmq7rjFJwqie6eXpbromJb4ACV0UymT7mF1shUsWEwUFKNAfFDQRkC0N3itsS11lhhLXHT7nNNNpVp1NneLxUe42xHu1Ft3EtD2Aq+2naU/Tz+9YlriA5XQTaVEtc7fzjaOdqyzAjcyjb0jbGdIL3vKW+osMZa46D7S6aZSXt2jw7WmnEcD1ZtG9vYxMWhHgzeyXKqLjmmJD1RCN5UidTbgRszfRrnbnrCNHhdgatBGOte94Kup18ZY4qLbrkqnm0pZlcAdMz8aCeJokDtBa4XgqDnbmSAbAWBLnDW2RS8hoZtK2ZQrlPsAt9XBWmHrgXCQo90jbeyFqgWaewG2p8MdTMGEbip1pbMDV4JtHeM9PCISqlGw7exqz5hGHuluI2M8sZH9pNNNpTSaHbhc2wjgSvW90sIHg+3soD0CZO/M3U4ydCo1k2YHrrWNZg8uJ4vD1fQxA3Anhe3IVLK2r8jyqHprnDV2RD+xXaVSR9URgBuZUq5jOHcaOUerKZ8MthZYRsVi196YHmVS3eg0cjrdVOpImh24rXtwpZiewI0onwC2WnieIZU8Oo3cw7W2Ui2Cijmnm0phugfgahwoVt8DuNR4Fnc7AWz3BO/ekO0F315x3nir6v4TuqlUrVH7cL19zQJcDSit5a3uNhi2rXBtAafHze4N3pY6S0yPuKh2DUropu5Qo4ArjRP130+zD5er6wFcLzi1fQ2C7Qxu1xtjKfOUS3Waem1M79joPtLpplKj1QLc3gdfaOs0cVi5doFVXabtawBwI1zuXqlkCzxHu9yZALsT/RK6qTvTDPO4ewKXg6BlvjRiXrclnRwI25ld7ohUcg/A9kgLH8XlAqTTTaUuSuDiddZFU5Fw1rZpdLfRsB0J2lGQ3dvdntTZ1prkNlKp3ro34FrrsTgPRC3ttU62wd22wjYizWzpR9u+tcxT3lJnifHEeuJb2x1juFTqaDoqcD17cWcDLtaHI5XcCtuI1HKEm50FvBH11jhPfDTdLP1lejl13/K63BH/PaxbgzRxPYBLjRkBXC6+wd16wBqZWp4trRxZrq3XxvSOjWgXpIRuKtWsPbcGWWJagCutLObat8zfrgoArgeyFAj3hu1eoN3L4VrbRJLN01c63dT9qrfLnSmtbFmpLMmTao4ErtHhRoHV63gtdZ5rbYy2rVTeUmeJ8cSObhOsCW4hlbpHjQQu119rqrgVuNz4Tnfbw+W2QjjiurXMUy7VaeqtcaPio9tvlU43dZ+a2eVq4z0rlbk+vOnjCYHLgbIFvC2wPTJ4W+osMZa41nY9Ccf1ndBNpbTaM62skQbMFEwjVipr4izAda5Q1kDTWuet5+Ijrr0x3nKpTlOvjWmJ97ZpaReghG7qpGoBW8++W9PKUowGuFR76ZMcc6h1HOfMOwG3FcBSmabeUue51sZo20bUaeqtca3toojWkYwJ3VTqSb3/x+45jyvFSXC1bPMZ6HCjwNvqfOvXPa5by7jyljpLTEv86HE6abLbSaUitKfL7fWJYO03Yh6XK8P6o+o0Dnky4FogzMVHXHtjpPKWOk29Na613UwuN+d0U/ejPQ/C4Pqw3FdrWpkSBVzuE1y7j7Z2uRxwGxZNzQRe7euIa21MZLm2XhvTEt/SbjLKTXY7qdQe0v438AJ9dFpZM5eLtbXO2dZlXHtqDAG4GlB64KqFrAXGljrPtaXMUy7Vaeq1MRFtWtq1tpWUTjeV6q1e/5Uk4NYanVbmgCu53o7A7e1yZwOvNbalzhLjiW1tG/lf0dtXQjd1H/I40ZldrvWTz3vqVMtpUZSCgEsBr5cD9pTVry11muvWMq68pc4T542PaDsJ7Sa5jVTqyIr4xImex7WcOsX1xwFXO497EODOBF5vjLdcqrPEWOL2bhfVvlY63VQK014uVyPrf00PtKUyDdS5rUBBwmCHlc/idC2AjYRtD9BGgtgbH9F+ItJNdCupVIt6bhPidCSXay2r+7OANcjlRv/0xlrqrXWaa22Mp1yqs8RY4vZuF9V+7uFSqaMp0uVGfWrV9daTpzRlGsB2TiuP+mmt07621GmuLWVceUudJaYlPqJ9T7pJfWd6OXVu9VpAFX0QhmcMKcZ6cAVX1rJa+aDAtUK2FbxSrKa9pYwrl+o09da41jZ7tw1QQjeVcon7r6N1udFHPVoWT3nPUdbI2G5v0PZwvJY6zbU2xlMeVe+NjWwfRbTWftLpplJbRbjc6HZ7jxXpcut2hk+gBK89RttWW6ep18a0xEf1MRnlJrudVMqqPRZQRXzatLrcuq6Xy5WAK7UzPoh++3p28Hpee661MZ5yqU5Tb42bqW1Ee0zpdFOpEdprBXWrWu67oS0HNmubnsDlxudeW+o015YyrrylzhPnjY/sYyLSTXQrqdQIaf7JR8LT+wkWOZfL9YuNQbnZDi63BYrePlod7min2wpfrs7yRScqbqa2Ee0xpdNNpQD6ftVueYqQ9b68xz1iZS2rpxu2RbVA1NNmb/Ba6lpivOXaem1MS/xs43r6Tuimzqke6dwZUsQzuVzrFqFVik8dDZQ4AFrbtADXC15LnebaUsaVS3WaemtcVLuI9juSL6GbSqlldblYvNXl1vU9XG60FVEunto2iXCznjajnG4P2Ea63FkdrqePSKp1IGRCN3VQRcBntFoPwuBiW1xuHdPqchlZIaeNjQCvN0Y7vlSnubaUecq19dqYyHatfczwEQDT3EYqNYP2WEBlkea4R0m9/8s7XC5XR4GYi9X07x3T63QtddLYnjKuXFuvjfHERvYT/U/c01/O6aZSrbKmlj19ehdYUS6Xc6La1DK1H9iRova4XK69xaG2/pTKtK8tddi1pYwrl+o09da41jYR7Scg3gS3kEr11uh/5th4rS46woVz74OUMta8hwNcrseN9gDuDLCNTCnP6HL3TCG39pNON5WSZH1wQKtabIZmC08LYCUNcLktrpYbdw/gzuh0I1zuXm5zTxgHaKJbSaW0it7W0/vxfdELqKTxvP3WMA1+QD0HxzrGW6cBsOd+tMD1AnZ2pzvS5R4J5pTS6aZS0Ro5lzvjAirD6VMWqGFl0Q5YgpLH/XKvLXWea6rMU66t18ZEtGntYzLKTXY7qVS0Zvr665E27R2dWm5YMIXJCjBNXR1jGdeTZubuqTXN7Lm2lHHlUp0lxhIX2X62/+bpdFOpEfKmlnupJbVskWEBFTakt84LactYljG519KYEQCmynunlfdIB+/lsgM0yW2kUntp7wVUEUc+Su1bgMrdh+L90TpaTby1Tor1xmnG7ZVq1sZ4yqU6TX1r/N7jRfWxX/epVLRmPBt573Fa70f76dyYWubqvA6Rq2sBsTcNrn0t1Unx2jZSeUudJ661zV7jBUq8jVLKDwLAtwLAZ5Zl+dr+t5RKRWnk/zJNannk/VgeblC3ocqxPhoXUGnLeoDYIq2zTrfrj41oP3o8Ssx/i9cUzf8sAHwo6FZSqYk0OrUsje9JLUsp516pZaO0LpEr4/rypIQtLlejEcB9qYjh4rByqU5TX8dIsVwb71iaLwve8QIlDrMsy4+VUt4/4F5SqQNottRybwWtWtbWaeM9cOVkgbx0H3u5XUsZVy7Vaeq9sUcai9OI1cullDcB4M3L1VdEdZtKHVSzQNOrQV/7Z9EDHOtXtn5hae3bM473fjztRrUJUNiwy7J8BAA+AgBQyruXqH5TqfnVaqVGqk43z3JfqS6yutwW96uNaYkfPY6379ynm0odWdatQi0u+yAOfXWmmEPl6nrfz16KSCvPnm7u7bCj2u/bfSqVwrXnyuaJtTe8NLLc42y/TySINfXWuNn67iBx9XIp5S8CwE8AwO8opXy6lPLH+t9WKkXp7b1vYCJFutJODvehT7cmtd7DQ/XTO97e78Vo4LauYt6rb2tf2J+W9PKyLH+o4RZTqZRZUQCcyWIFiHONe7nP2ZzsqlaXOCLV3MuhjlzA5ZBmn24qlQKAw8x3HkWjnV89HnVtdbb3pL2Aa3G/1j5b3a9RM35HS6VS9y6vg/Qsoopyq9t+qD6pmJkccy+n2GOx1YgFXMF9zfLXnEpNpNb/FlZHzI2X7vpGFrBGAxUbWxrDcw/RELasbrb0oeknGqC9VzF3pmKml1OpUwmD9ATg5lK23ro6xjK+tNjJO25LSnqGdPYRFltF9VfHD0ozp9NNpZrUc2VHyqQWR9kjvatJJWvHnSn9vGqWxVa9na+nr8YHHqRSkym3DU3hXiV53ekoV6sV11/PRVczOF8Ae2paqot2tZoY78It6k+DErqp1HB5gdnT6khfZDoRICrt3AJj6adWHJQ9rzVjaa+9ipr31fYVAVtPynpgijmhm0qlNuqQRYgCgAes0dL2P5vzHeGaW9PNUbDVaPA2oa0SuqnU4dXj04P6lK6h7Hi2SXT62BLrXUildeLS4iqNq/U43wj1mhuNSje39NHiZF8u9j85p5tKpXyinK+DBpYUqCfWAyjLKmUNgKkyC5hb+tlLntXNrfOxkWlmABqgwUropk6smT6VUqQsMOs5d9syT0yVWdLQrXO7veZ1t7K4xF6LraLSzJ3hSg47bKRUKlRvw5wreGe8px1Vb3XRbH3RtKm3+njGsYgbjyvD+tC+1rSdQVEgbq3Xgtarl4ZvMYUeJ51uKjWVTgptz2rbyDaRblfrzC2rmTFFuF2uv57O2LtFx1MvtjW62ZcP+J8gJXRTqbvWzktiW9LHgbehGs8KYCxOUx+5wGqPGRbr/G5Pd+sBbWcldFOplKB1MdVDdb2qw3xYy/xqjzldrwPuucBqBrWueO7hbrXONgq0L1/d/snVy6nUPWvnE7y0qdueYJXaa+u5WE+Z1Hfra67fvdWy0Aot7wRaDKrbP0YldFMHVh4H6ZfmvRv0CW2dh6XaWcbQ1HscsLZPqT/utTSGtm0PWY+M1PaxlnPAZfs0gLYRqpISuqlUqpLly4zxE70HQHumlaUxqDpNPNY/VU/FaspbxuqlqHlfyd1qYNsZsrUSuqnUrppp70dL5kBwGlpQRIHSmj6OnteV7kXrcqNcsAfIkrwnSVFlHuCS4wqwdUL2tZevVH+4/w8J3VTqruS1NtJiqgBFuK4WF9jL+XrKsLGoeip2RoWlmgmoaWGrEA7TdiV0U6nUGHld6qifnCwA1sZbylphHNmWkjdpE+Vwg2HbSwndVKqrZkofe8R9Itfud9xRek+SnG0E0D2pZ+leejpfaxq6l1oeZBANXEHRbpYdq/sIqVRqcmEfWJ1Whvdyp5Jr1czNeuZzNTE9y4Aoa0mz91Lznl4EuFw6WXC3XtC+ePlK/FPyGMjUeZXbhmLFvZ+1sx2kPdPIGufaAt66LqpMU2/5gtJDlu1FFHDRWB1sNcKA2qqEbiql0sxnInttjfYLS3CKeQQke6SRtXClYqx9Yn1RZVo3TGlPByzJClxCWthGAha9jy69plJ3oaPP126186fuSNfakkbWxka5YW1fYCjb46+6/q+i3krUDlwNbCNA++Llw9OffMpQKnU3GpVu5z65HW635RYsQI5so+3HMoZWPVLP3oRJhDoCl5MXtFvAPoFWqYRuKnUX2sJY+wGBAZwra/x07ulMe7WJGtNaB0idpcwCY08fI5NADuBaYNsCWPS+mlqnUqkTCgOr1UYFu91eblYD3iioSrGRdVLZTGpxuQg4uXSyFrZRgMWU0E2lhmq2BVmedDTXxvkhFelQo2OlGItzbnW8tSKY0BvKmvncq/o24FKSYNsTtFsldFMn14xf7WcV9l5JUF7bYHEGt4uVtbhars7qQveAvOa+PHXa8TT1o9QIXMndWkH78uUr8U/J5+mmUimbtClmTMZPa2/6NxKGXH+a9paxou4r0gGPArDkemuXGwBcSlrY1kBtVUI3lUoJkhZUYW53LVMeDRnl5LwA52J6wBSTJVbTxvKeSGWzKAC4GthGQrZWQjeVOqRatwZ5P1kHfiK3Orkox6rp2wP5KLhaZAXwnmqYW+WAKw7b+fzlhG4qdWptP2QoUHu2E1H9BbpdqW6vVHFESjgyvex1tF51SzUL/06ULtcDXI+zzbOXU6nUo6IOyHibeI1J+iRuSDNHp565Og3kpPbamJ4O2OPWuRhvvVaaudxKWuBy6WQLaKPOYE7oplJhmm07kEUWUEvu2eucmWHqsha47uF0Nf16fnrkBXGkW7aqgpwFuGSXO53DnNBNpe5W1AcSBVWL23VuIaq70QARK/PGS1C1wFB6vddPq8LcbEw3rcCV3G0+8CCVatKZHkoQoajUMwVYySINBm+kC7bAjRpHAmB0udVpjxL337KGpeL85NsyGrhcP75zmJHH/+U+3VQq5RcFaumTujHNLPHbmgqNjKdiJMhpx4gqr+tnFLeASpFWruUFrlatc7sJ3VTqSvfsjDWQtK6Abkgzb7uypmq1ZR43LLUbnSa2AlX7BUDzZWNn1dCzAld/FnM+xD6V2ll7wNn7Kdjz09NirRxp5m0zC3h7wngkcOv748q8fVr+CfSG7RaagsvVApADLqdec7sJ3VTq7qSd16Ucq8btUuWDwIuVUbC0Ot2RwH1Arq19RMjbX6fvptp5XA9wey6iAkjoplKpK3kWWlFw1pR3Am9Pp0vFt/ys++XqNC7Yep9SvEYeMEsHYjxKfhi9DrgcUE3P2H3xiv1TmH/XCd3UnerIe2r3kmX70CoNeA3ioEi99jhdDlIzONr6tRQrqXfaWCMmtbyVZh6XAi7Vn2pedwPVFiV0UylRRwS097ALS51l8RQng9uth8LKtPVSnCW+Je3rgacFrLOlnjsvh7ACV1IEaLdK6KZS3XTUldAcNLUPsO+YZt42lRyvpp6Ki3a827Fb4GyBP6feMA7SNrUsudxI4EbDdlVCN5UapmjH3OJm67YRbper6wje7WtNqlmTsvUAWvrZkkK21llitG16QplILXNzuZonBnmA64HtC3i4+sP9W07oplIpRByU6zrtXO1A8FogTLXxuF/uJ3bfUcDl+sbUAlAPhAckfWqXi69wZhZSKWFbA/aF8c1M6KZSKYc8aWauLhi829cShCPKtBDVQFtbB0iZNp6qG5liVq5cXvXiKs0sp5W59lflCth6AYspoZtKhegMi62sKWhuNfNk4N2+bnW13tQydr8tALU6Ws2YE0lz5COl27lfGrhsP0Gg3Sqhm0o96agLn7Tq/ck6AXhbUswtZdHpYgmMESnnXulnTth/McVWIYvLjQBuC2xfwivueQcJ3dSZ1QuiZ4czJ8kNc/IsujKCl9JI8HLj94Jli3u1jj+xLIdbkHWGX/YlvLr5Iymhm7pDzZIK7g3v1tOlPH1YUtLaugXMJ1dRjleCniWdzJVp0tDasqgvDCCUTSRum9BW0lwuupiKAK7G3VoBiymhmzq4egN0FkD3kgaq1rnfHuAF6LLAylqvBTTXztIn1pfUH6UIh7wzrLepZU9aGQOuBNtWyNZK6KZS06oH8DWfmp5P1lbwPijrOq9sjnK60s9ouEq/JxW7l7CVy4aDLaQ4C3ApRYJ2q4RuKtVFZ5v3xSAa6Xjreq5uggVWmlQ199MzJvcaU7S7x/puBThywAW1aplzuddxMcC16AW8uvqTDzxIpQ6hVmfr/QTEUsxYX5454p7gHXCQhsXpakAr3QtWz7Xx9nUiaY5zvCkj3hSNu60B+8II6IRu6qSyOk0sXgtBTdxZ54YliHraaMHrkBdsdRl1G95UtHQPFuBqNBuUhdSy1+VagcvJA1hMCd3UgeUBWSv8zpA21rpYb5yUZta0qcEbtLK5bh7heC2p5Mj0MhjLPelozRg7yvqweQy4kruNgu2qhG4qdRgdCfjR4K3r67qdVja3AleCPXXPVL9cOdbPZCCVTqF6yWwlklwuBVxK0bBdldBNpQ4Fs56KdLtYXO1YsXYtq553OrNZM3drgawE7JbyPWX4b8adQCXFA7QBVwtbbG73uW0upEqdTnukliM1CvSexU+1otPRkeCt6zuubNaAV6qrY+o4C3C5PqWxPP14Rf1TX2HqOGNZejTf1bURuOy4zsVTWyV0UydUBNBaAH0E5xzxyToavDvM87aWjZqjbQXoKAADmJ4upFlAZZ3XxYDLgTQCtFsldFMptVpWOB9FlDOmPn2jwcuBFeu78zwv5n6t873Wtpa0c/0au8ZkhemA9LT2qUItLpcCLtlfzummUtEa4UrPBmaNvODFtBN4uXppLlVyoVaX6gHuCBh3EAZVjcuNBK7V2dYPtc+nDKVOJg5iFERHgc8L8ZnmqCPcLhXvSTVrYjossNLO8Xrmbrl67WvNWNY6jbTxjd9npQVUlrSyFbiSashalNBNpW40gzP13MOec8mtj/jzHDNpqe88x9sy/8u9pu5J26ZF3j65f4b1fO4jOFtTy5zL1QJXcrdeyNZK6KZSKkXO586y0Mrz4RFli7Sp5gOBVyqT+sZipXS2Rl4H3FOKbUBPocYHIUhQpIDL9dcK2q0SuqmDyZNajoq/J3HONSLNTMV7wftQ1XMrmw2SgErFattzr7XAnQWknJT/1VaYYqlljcuV5nEtwLXCdvsIwHzgQerOZXGk0VuF7u1c5pHg9S6wCgRvtAPmyrG6KAc8qawu96qtAFwqnex5mL3lqUQJ3VTKpdGg3MOVe9wu1y4avNxY0vgBq5q5Mkt6mYpp1QGg2irO5V7FKaGohW2LErqpA2mv1PKMaegZ3PGM4MVSzVT7hlXNmvK6TJMu9tZJsVQZpShgs4uqrhdRWVPL2BOEnofdwli7kAr/pT1ullNCN3VyzQCnrTQAH3nPrZ+uI8DbuqUoELx1Fy3pZSrGWoddSzpAGtqSWpZWK1/H3q509jx9iFfO6aYOr0iX6xlDijvrfG7r2c1Re35btxQFgVfrJiPnbiXoaaA4ApzSf8N1u5Bh5TKA7HI54GLzuNfXtLsV74t94AGthG7qxKKAtldqeY80dQTUJfBKH6K9wIv10fJcXqVa08tcH1Q/3lipvUeB/4yp1HLLAqqneAdwtc/WzQcepE6uvVzuLHO5s9wHJ+8n+Wjwcm0dqWbP3GnvNHJEG63IJwgpYhTyulwvcNF7yAcepFIaRbhcbb+RB2cc/cANSpH7flvPa+baK8GrAVvknC41hnRfEQpN9jzeoNW1YvANAi7lbj2gXdvk2cupA2vEnOde86qjwdwiDei8aWaurXZO2Uob7iEJDUNGzem2xEa08yoQ0NYVy2gfyjlcqR0VY5nLXZXQTU0sCS5H2ibk7W92B2tVFHijj4wM2EoUqdnSyB5dpZjp91Qzn3vTRulyqTZrO8+j/nJON3Wn4mDU6wSq3qnlaO1xH5pP9ZnAq61TNOm1kGpGlxswZ2t9yIHkcrm0svYxf1GP+uMkQreU8r5SykdLKb9QSvn5UsqHQ0ZOpVhFp15nc7nYfZ51PteqVvBKMZr53YFnNEesQI4GbMs/KXHrELYy+drlvqh+XsUq9uR6gEv143muLnf2suatfQCA71qW5adLKV8OAB8vpfzosiy/oL6TVCpUs2y96e1yW/rXxlney7eV/T4o+tX2pVHdl2Z8Si1tA7rVxHW6RVYiSBXlhocY3MQhLpdKK1uA632mbstTh0SnuyzLryzL8tOPr38DAD4BAO9xj5hKifJuEbK63Jm2Cc2Sko5Sq/WKXlg1wO1iw0r1oxc6UfL8s9e22c7nKp6fq3G5GuDe3IbyiUPSU4eGPk+3lPJ+APh6APhJpO7NUsrHSikfA/j/mm4qdc+aET4tLnfmOV+rLPd9tpQ3I89e3VR3RT4DN1Jq6JZS3gkAPwwA37ksy6/X9cuyfGRZlg8sy/IBgC+LvMfU3ahltXKEy91Le0H9jsCYsqv+52FJMRv+aUmrlq3bhDCNfK6uJBV0SymvwwW4f2FZlr8SNnoqpVbUamUuPhp0M7tcK3DT5U4jdVq3oe0A2Y91ROaElXO5ct/ygxS0ugC+YSFVKaUAwA8AwCeWZfle8x2kUqJ6geioj+/rDfWewI3STH8fHRX1a/Z6u1rc7lW5zylKC6g0sj4E4blcd8/W+9E43W8CgD8CAB8spfzM459vMY2SSpFqhUTPxVMjXO5ooPUGrrb/WRx/gCyOcoZVx6Oe4WEYR7NVqJbH5UY/zN7z6D/xbVmW5ccB2KMkUymnZgCute9Z5HG5swC3RVF/Lwd30q0wbWnf+NZpD8XYyjunan22rmas1ofZ54lUqYkVOY/rGUMT27JvduQ88EyQif5yoOlj9i9Rj+rx19T7r16bgmYOxdAP5QdexIlSrcC99JFKDVcvh8u1G+lyI/9b7bGX2PP77/lR0vr3FQjkkW/DEdwuc+ZylKjUcrTLjQDupZ9UaqhmAm4Pl9syl9vy3zHqmcO9gdtjW1gvBc6qBc19ho+vAa/m/oy/Azdnqzlr2fPIPak9Bdwo2K7K9HJqoHqsrPW267F4KloRYB6dW+Q0Cpotv/MAAlpXAEf9lUe/LWq3+wwzbD63XkRVS/84Pv9e2lHAvfSZSnVX1GENHse6d1p5T5d7JIcr9Ue11/Rbxwz62IvcsdbzlqNWODsPx9B3rz/QwvJQe8t4lOo+uRxJQjfVWb2B62kzKq285xhnAq5FO+1B1gDHAqUZtxY1/RP3LaKSDsRAhxKeh6sZQwNc78KshG6qkyKPIhwxj9sjrTxiX24LnEcsmIoAbqTL1d7HBLskNdDrvR/YCt6rLxb6RVT1/lzN0Y8tJ1C1t8uH2KemUiRYohYIcfGjVivP9FQjj/ZwkS3AxRT8fo92rD1WLLfI0Z/1+MfLMD7IeeDoWfVs6z+VClP0+bx7OVwqftT8cPRJWJp2knoBN3K1spWArzN1DrV+B9QC1VLWwx07v2hwi6i0ikwtW9PKEft8L2OkUs2K/nD0biuZ+cCMEUdK9gCu5yOiN3B7rzAPTi332C7UCtPWT37t/LTzzGUA/XGOVFwUJKP7SuimGjULcD1tRp3DPMNpSDO5W0/fnjG48TodiPESKeNuw1ovxbaC1wto418nt4gq4lF+N302uNxI4F7GSaXM6vUB3uPghAhX3GMudqTLPYq7lfrqNRXgXEDlBaSUVm5dNWwFLzZeyyKum7iNK0VXMfP7dFcYWlLLVlBGAHcbW1oe7ZdKPaunW5oBuKNWK7dMnln/DnoDd9Q8fsvfWUeXiw1Bud2R4LUqws0aVy5b53NXWVctSy63Fbh2wKdSKt0jcClFzh9GtI+a454VuBaNcPX+Zk1j9JibtYzfIOuThVYwelYtcxDUn26V+3RTu6nn1ozW+dvewG1NK49YPGUZm9LssI3MFnBjORZQSQuKWhdRecFrXbnsHZ918/pFVJb9uU9tFA83aFntTI+bW4ZSXdR7H2QPd8u1Gz3n23uFbUSfPedutf1bVylb+pKAO2Aut463pJwt41sg2wpkEbx4avl57vbhpkzSC+W8Lt9Hu8uNeTxgKnWlEYcOHBW4PaDZMs5I4PZwzl7gen5vCcgOYXO3mvlcqh8prm7TA7ItZZic87aXIXRpYmoBlcfl9gbuZdxUqst8onecUcC1jmH5oO+919YS19quxxypJ53M9d0K1ACXawGTFIsBu3XJATeuZjzrPW/02tXq5ce5WmRF85parh1pBOw0i6eocXLLUCpQR4Gt1IcHuBaIjgIuJW2s5z1qHdPSv6bPHtMAQWllrAsLjCyO1gO+Fmn61tzz02v/oRiUJPhZXK6276h+tkro3qVGwVY71gzAjYhtXXjVK60c/QXJ07fX3XJjaN6bQOBaoOPpTws+bxk1BiczePn5XKnsJkZ4KpDuaUC8y20Bru9s59Sd6R6A6xmv9XSqHodtRMwX9wJuZL97ALdBLalXcRGS8x5ayyzSOnbDfG6dWtbA1DOXq12tnFuGUo3qsUK2dbwW2HLte8/7toJplBu29LuXu5ViIr4gUfUBLtc7j2sFb+s8cqs7lsa+6efZWWrncyV5ASetWMaddD5lKOXWjLDV9Ot1t71XNu89j7s3cPeGLdXO6nAbgEvN5XpjvNecrJDWjG1x8wp5Hu8HID/U3uJyrcDN1cspQbOlkbX9nhW4lEa5Yc0YLf1Z+uz5dzUAuN56S91aX/c/cu62w3wudvQjlVrm9uZa53JbgJurl1OMRs8BWsbslU6W2kYA1zJua0q0hxv29h89Hxw5ZaB57xqBS8nqcrUOV5vebUkXW1LI9f1h12S7CnLIamar27W4XO1BGFhbTXmLErqn0VFTyZq+PMCNbKNdOBU5BynF9gTuzLCl4jsAtwWmlljM0VL9SOUjgMzeKz6fK4nam+t1uVz87QMQWh94cAv4fMrQ6TUylWwZr2c62XIfmjatwLWOp41tdcPW+JGpZG68CYGL1Xthq0ktc9ceadPQmrFZ8OILpV4Kj/C7dEUBMMblRj45yOqmVyV0D610tzHtIoA76zxutLvtDVuu7Q4pZcntckNbyzUOuMecrmb+VgSv/Cg/TNYH1re4XO08rrx6ue3gj4TuIXVk2Gr6GzV/a20TAe2R87gRW7csfWniesEWiws8bUrrdikwb8s5kGrTu71TyJ57E7YKXV7ful3LAqrnNrLLlQBtX70cc8pWQvdwmnFVsrbvlg9kqX1v4Eb0YQFuixs+Gmy59jsBV6rnnKAlhqqTHC7WBxVrKZMkgZhIHXOrliVpD8ywpJW187pSvx4ldA+jI7vbVgjMsI3oKAunooA7I2yp+A7A1bpYjRvunV7WSnN/2jGY1PJrwtwtVk65XO++XC6trF9IpYdt/YUgF1IdXjO62xGpZKl9VKpSatMLuC0g9fzXjXS3o79Iad+DzsDF2uydXrakkS1fACwwJh5wID07Vws26alAmkf9aa6192WdW75um5pYZ3a3LbDl2vd2t9Z+RgK3dZHXjLCl2gS527or0dUJP+syrSuOSC+/RGJbgWxx1sKq5W35NrVMbenhXK5nHlcD3J6wfe4jdVJZ/mqPNHervQdtm57ApdT6ZcrS5xFSyVzbnYBrcYna+tb+PPe0jYvqT5FarqVxuZpUsUUtj/qLuge8r9Sk8n4wz+xuNf3MOn/r6aeHc9X2yfWraWuJ2Qu2AN2Bq0kha+KltHMdh9VzMRZHau1PdP8VPJ/mdImUM7KA6taF3i6esrhc60MLKIcbCdvnPlMTagRwz+RuE7j6fqV21phRfy+B7rbuzuN2W9LLUgpYCz0NLL2p6roMHW/jchWrlrkFVE8xhtOhPPO4lpSy7nxnO5QTutPJA9wzu1upfe8FU1xf0XtmPf1a4/Z2tlz7Ae627rLF4WpisXiqnIMoBlCqbw2kvY755lq/Nxfg9uEGl9eyy6VipXoPcD37ey1K6E6lIwF3Vthy7bg2ewC3xQ1bwby3s+XaWn6XoHRyfe0Brrfe6mpreQHK9WW5p5dAulxpAdV1NzaXa108xQHX6m4jH3yQ0J1CM6WTR7jbWeYIpbperpXqO3IvriV+r7l4y3sT6G7raws8NXFaJ22p0zhaLUAtQObuIdDl1iuW6327W2nSylbgRsF2jc99uqfUrMDt6W6l9nsC1/L30eO/nfcLwkypZCp+MHClWE1/2jFER8lcY20oeVLH2phHaVyu9nSpm76Fpw1pVypHAzfndA+p3inlswC3x6rm3sDtsRgqyg3vsUiKa9cBtnW3kenlnuCV/hv1SC9LfV1d0wuoJJeLyeNytcDlnj7kgW1Emjmhu6tmAO7ssJXaez7ge6dCR8b2AK4Xtlxb6xeWQcDVlFOx0hhcPZderuuplHBketnqsl8+PAH3tZevXC7X+jg+6eCKVuCOepB9Qnc3JXDHw5ars/Y3A5ytwJ3ty88Ad1tfe19rXW8NSu61VFf3LbW3tNP2xbncShqXKz1JSHMGMw5t/RxuyzYlSrdfCHJO9wTS/lWNWp3cs32Ptr3drTV+JHDvBLZY16OAW8PTMg5Wp4Gh5GA17TTjBbpcTJZH+7UAV+tu83m6p5TV5UYCt7e7ne0D3tvnPQB3BtgCdAFuC3y19Roor6+lcuqerU6U68fsaus29JGPrS6Xc5/afbsW4O71LN3LvaQmV7TDbe2n5Z9MAtd2Ly2HZFDttf0cyN3W3be6Xa4eg6cUqynHHDMlL4ypviztiKMdAWwul5qn1Wzv0a0qjgGuF7bcv+yE7nBZ4HgWh9vyAd8ybtT8Lddmb4dLxfb4AjO5u62vo92u1cXW9fW9cG8nBmKtM+XaUf1IDrxasbx9Zq7H5V4PHzePa52/zUf7nV6zAnfGlHBL21HgGLnASttvwvbmWuM4reDl6i0Q1kCyvnesvRbIXDvx+nkuF8C2L/fymoaqJjXcAtzWx/rlU4YOqTMCd0ZnPJu7tca3zOFG/u7edp1hiw0R5W63r1shvC2THDLWtodj9bYzzOVKz8ul9uTW9XVbHLI43K3uNuIJQ3WfeSLVKTUzcO/N3UbFHwG4E8G2LmsBbguEMUBybSSnC1V9fa0BK9bG1e4RHojLXYH7slrBvD3usSWtHA3cCNjm4RiHUbTL7Q3cHm17prCj7+fswD2Zu62vNa+311rgep0u9Vqqk2CsaWMFMtrm+ozliLRyb+Ba3W1v0F6PlZpIswN3dDup7cj7GT3f2wLc6C8+B4Ftfe193ep0sbIIp9vkWJFxxLHwxVMAl7Tyy81iqqfyF6/Yoxq9DzvwAtcL29ZzlzO9vKuitvJo1dPhetolcONiNRrh7Lk2Bwcu1/+2DINxy3haF8zFSDDGJI1VbRHCHtG3lmPnK+v322qOgewP3N7nLl/GTU2iCJd7FofrhS3X754p6B6xUQ53QneLDaMFFhfbw+HWP6l2Url0rXGnXB8el7sCV3C50lOEsEMw7MdA6seIhK0HtFKbhG5XaV3uPQH3ntytNR6L7ZVSjgL0QNhK11b4tkBYA1zKRVpdqgekLYC+isEXT63XT6+JPbkt87jRwI06c7nV8SZ0d9cRgTsTbKW+j7KFKBq4vb9oDIZtXRblbqnXHvByZRScqTrNdT0O18YC6NXlMucrv9g6XWG1smcetxW4cSdSxS6iutxPqpNGzeUeHbijYcu16w2q1thW4EZ9aTiwu92+3svpeup6Ot2rfvg9udbVyltQeoFrOyhDf0CGpey6Xj4aMhdSTasIl+ttO8Lpecfp1eds7paKjwbuCWFbX8/odKXXlrrtdTSgb36Hi8vljnrcHoLBgXUtf2o7CLhW2I562AFAQndyzXR4heefSgLXHp/ANV9zzlcbH+F0Lfcm/T7S72SFLzXmVZvN4qlHUXtyAfB5XAB+e9D18OOBG3X2cj1OrXS6w9V7L63UfuaU8j2lk63xMwK3M2yxMi2cuFiPq8XKrOCl2nGu1+KCzSBV9PMSwLInt57HfYqrFk5dur52v1aHi8PcPnebZy+fWiPmcs8EH6mO61NqO+p9OgpwT+puuTqtE41wulwZ1p+lzgVSuBYFaMVRj8/X+MImasETtTVoWxYNXAtsW85d9i6ySujuohaXe0/A9f6u3ra9Hb0l1gvSA7jbXvDd2+nWZdJrS9322gtoFtK3Rz1yZytrnexafvnJbRvi53qxGGqc+jV+ncdAnkQRLreHU/b8NfcG7kzutjdsqXjLe1O3P4C7xYbo4Wa5uj2drracqrM4WU2behwAwA7B4M5W5uZxMWBGALdtny69srnuh+rDWg+Qc7qTqeUtPxJQuPhZFkp5240ErrZtK3DvzN1uX0c4XSt8KThGwFXdRp7H5fbjUiuVMZi2AtfzfN3n67EnUklK6A6V9HafxcFR8d7fr6XtiPQ51ab1vYkG7g6wxcp6uN0oyGrLNJCt67GY0W735hrfHsTtx5VSx1Q5BlzN/K3tUAza2bYckoH1xyud7gCNOgwjYtwZHJxm3Na20XPcnnE0sS3/dhK4XYHrqbM4Xamu7kdqr25zfeoUwDVc12tsPy4AvlJZKsd+1vIvquoD2+g9upf7SQ1SL7BY2xwJuLO0G+3+T+BwI6+tIPZAuMXpSv3P4HSvym5PnXpOIz+QD6W/NJdXKlPltrSzL53cckBG3b6WZdsQ978roTuFjgQJa9+Rqe/R7Xq/972BS93LwMfvSTFncLqUU9W8puq8cKVinsqutwdhwF0lzeNqVjC3ANfrblseZo/1QYlLRedCqu5qWYkbPWYCN6Zd70xBJHB3cLdWuFqvW+Ab7XSlWAqsmhgtjLF4awwC3FXSARjcSmULcLULpkY+yL5uex2bC6lOqNkOaaDie0FF6memdglctPue19GvvU5X85Mqk0CMtW8BMuuA8QMwNMBd52utwOWAqkkn94Jt34fYp9PtqF4ut/dfjRUU2tjIgzO80PS27e2IW7/MSMDtDFtsiCigeus8TrcHeKPdrgfILJSvz1XeHoDBPZB+JHD5/bk0nKnYOr5uU8dqyrX1Oac7rfZcedzat6XfkcAd2a4VuJbxNA631sTA5fruCVys3winy43B3ZP0e3Px6jb8ARgAQJ44BXANyEuX+j26l9ftj/fDYm/raWc70zN1E7pTKuqvJQKi2tgZHO6M7pYq1/ahff/ruB0XS/VwuxGvNXDl6no4XapOgrPa/doPwOBWJHN7caU5XC9wI542VMdh11J53T+nXEjVTT1SnJ7xLH+NewN3Fth62/UCbmRcEHAluFqvvbGRTrcXeNfXFJA5QGti63oTpOkDMCTgUquNrSll2+rlONjKq5cp8LY92i/ndA8l64e6JT6BK7eLcsSt74smDosZBFwrkFsBu72OcrdYmRfEVBx3f143q27zfACGdOIUthe3FbgYVL2P9pPmd6lYzTXWV92nRtt+c063i0a7XIusK4c1sdp77g2zPdr1creWWAm4B1md3MPdbl/3AO/6WlNucbRcnRfIBuBuVypHO1ztgqlW2EY+0m/UtqGE7lSKAFb0gh0qLmJbkTWea9Oj3Wh3i8XumE6OdLNcrDUuqt7jeDVul3qNjWkBMApXrAw/4hF7Nm4kcFueMqTZMrT2s425rdctrKr7oNpo62rlnG64Rm5XGbkYahRwR4KTaxfZZtR7vxNwW6498PW+tpZFAdjzutnNYu30W4Ok4x2lbUGWBVN4qlm3oIqL4V5v223bXtfbwFv3SSuhezJZ/tr2/CtO4OpiE7jdgIuNzf1T8jpd6TXnfLl6bdlLAO3WIGwvbg1Qyknewhmvk1PN2hXMsWcw13FcWd2PRutYOac7VCNcbo/YaJcbkX7m2vRo52lzYOByYPJc7wnfvRzu+lPjaC1ul6tH4263BkkPMZCAi6WHKXB6gTvi/OU6Dr+OedCBRglds3ovgpLU6nLPDtxRjnjUanIsZgBwrfWtgKXqjgBe6TVVp3G/KgjLZypjj+nTANeTUm45nYqq3/68fX0LaC5+22aryIVUTXO6pZQvAYAfA4B3PMb/T8uy/Bfmu7gLzeRyZwfuPbtbbewg4EZe93a01Oto8GrLtfDVABa7VsfQTw1qAS7lVCVHjLVZ6y+/gj3VjMVu46nY52v/QqrIFcwa2/QWAHxwWZbPllJeB4AfL6X8jWVZ/q+wuziMZnS52ns6M3DP5m6puEbgSu7Veh3paKnXe4DX89MKXI2blQCseEwfBdxVPYDLrU6OOnu517nL/Opl/fxuk9NdlmUBgM8+Xr7++Ifu8W4VCYse+2y9GgXcaHBGj7UncAe427psJHwtYJXaeWHcC7jA1FH1WEwN6Ubg1nCVXS8NVu9BGXKdnHKm4p7fRs75YtCNeoh94+rlUsoLAPg4APw2APi+ZVl+Eol5EwDevFx9hfrmUi0a6UB79n8m4EYvrDphOnl7Tf11HAW42z6lcu5a6263qvbiAgDUp00ByMB9itsAdBv3fN0OXP2qZeuCqriH2EtwbU01q6C7LMsrAPi6Usq7AOCvllK+dlmWn6tiPgIAHwEAKOXdJ3TCe55yFOlcqf4shz1IMRHAPRpsqfiW2MmAGw3fVleL1e/ldLXOl3Kuppjrwy/qvbjYecqUm5XLbh0uB1Rp7lZeRHUbs5Zf/5z7ebphh2Msy/JrpZSPAsCHAODnpPjzaNRc7qjFU5oYL/xbnDAXL7WLbrP3oSTB87dHg2+L07XUSW2k+B2BSz3AgFo0pQGoZv5Wmu+93Koetra5XZ3z3cbW8XhszAKqdcwCXyRjxE/RUspXAsDbj8D9UgD4ZgD4b0x3cmpFuy5NbGRa2QvcHtuHqPiRbQ6+WArrthdgudjo1xFlPX5agKsBLNvmGrjUHO560lQNUmz7j2f+VuOG17pt+W38bT3W5yrtfK5l6xBdxi+aklLQrYdj/GYA+HOP87qvAcBfXpblRxTtTiKvy7W22yutHHUfrcDd291a+7ozd1tfa1572liBitX3BrAVvi3AfSq/Be56lnINXD1ccYBq9+tq5m2jDsfAwCkBmWr3fN1vr27r6uW/BwBfbxrxNJLA6YGi5QMcU+QhC1ELp1pAszdsuTpLXy2xB3K3UVDVvLZClqvzAtga0wJYrIxYpcw9LciyQplzt7zjxUG8xuPlmjndWxBvX9vSy/hCq7o91pYqw4TBOx94MFwRc8AtfzU93Xnk4ipOZwQuFncg4HLj9njN1XNxnpiWtutr6X3E4qUygBvgboU5XAAbcJ/bXMduy6h+t2V1vHa+d2231l2X653v7euIOV3d3ty6/4SuS0d1uV6HGdX3Hg6X+7voOXdLxe80f3sWtxtRpnW6EkAtDpd6bXW8T+X6OVzJ4VJOlpvrrcue+7ac2SzD1grayDld65Yha5oZU0IXVQtw9148pZEHuJiigRv5vp54ZTLW7ayA3V73BK8HwJ6fGvhSMNXEMMDl5nDl9DG+YMqyWEo717vtZ1uHlW/7urxuOwpSC9ieR0C+gFdtq5dTFkWCIWp8DRilNlg7D5S58a3vUW/YUvGtsZ2BuweMI15HgjcKwB74agGLtWkELu1meYhKThgrr8vqfi+/ng+2GtBGHZZhKcP6ppSP9jOpR1rZIq+D8rpVzxytB8ojDseYJZWMxQ549m0vGFvHoGI8EI4CL9UmCsadgcstmpKcqJQiplPMdOpZ2mZU38O2j7UOi69/cm7WCllpHpeCqeX4x1XpdNUamVbutc+VU8Q8rge4lCKgJ7W5A3dbX0fFekDsAaul3gPelp/aulbgCquUuVOmWl2rFsxYWyx2W3b5dS1zvLaFVVgM/1qew+Vdrg7A6XSnU0ta2QtmT1q5lwum4rgxrfEnWSiFdd0DsFxsFHxbIIuV9QKvtc4CWKxsdbcAJHC5U6YsrlW7sMqyp/d2LBq2GEStoB25gtm/ejmdrkJHWTzl7Suib88/lwRukyRQamN717UCFxtjL6drqavLOQDXZVuHC0ACd5WUUt6KA+lTf8xK5ku9D7gtW4nWsuufvlXM2zZcfN2mfh8lYbBOpysqekGTdSztX4MGApqYiLTyiO1DM8GWiu8EXIsrra+jYnu+1ta3wFWK8bpezu1qHe8WuExK2epwpRXKFidsmee9jBm7lWituy6n53M1gJUOyajjNeWYcp8uK+9qXql961sb9UWgV1rZ2ke6W7V6QNMSu4fTjQbv+trjdj0Q5gCLlSmBy52j7JmXtezT9ax4rse9biuvVJYWVtXtV3EwrmPrOOy6bn9bxwM4odskD3At8S0f8p4FTBFbf7wLp6R74fqzbgXqBVsqtgNwR8A3Cqqa1xHg9QC4F2i3r6nruswIXAmIFEgBNKCm4GoD83M7Gbaa1DP+U38Ws/ZwDAyqGEx9q5cTuoR6bQ+yQsMjzyKniIVRvdLOWJwUf5KVyVjXES7VUqftMxK4o8GLgVCK5UBLvebKjMCVtgBJILW4Vkvc5VfTpJy5FHPMwios5vb1A1q+bUvVa+u2SuiiagXunidPeWJ6zeNK6gHcE+27xbqOAKW3TtNGUx4JWa5OauOBcgt8g4HrSRVHpp11+355p123v7w1t3Bf26z1a931T9vTh7b13CEZ1vQyAMDLVzSAE7rhikgr762Iv3ortK33YnnfRgI3UBJUtbFHBK6mf6yOeo+09xgFXKjKG4FLyQNcvI/otLP8uD+d473uay27/ql3vRhoJcii+3cZqL54EOZ0l4RupZFpZUvsSJcrjd3qglsc7h2mk+uykYDVxnlfW8Ec4XS9oOXqOjtcANsqZYvD5dLCvlXMvIN+vtbDFgNp7U45yFpXL9dQxUD64oHeb3sdd31dmGZ3CN3RaeXoLUJSTMRq5SigWu5B6quXY915sZR07Y0dDV9PfVSdBbD1tQW02zKpbyNwvauUI2Os41/iZWd8HScvqrq8jTiEt9em1csbwG7hikG1BuhzH3g5pkIb3XuDbmuat2da2eNGPf22AlP6J6MBWwRwT+hu6+toR7uHu20po2KkNhrAcnVSGfe6hjKACrjeVcojYgDoVc2XOnva+bnP6/ht+Rq/ltUx25/bWA1ga7DWQC3cdK7mkKqELkC//bhSO02s1w1HOM7WPq31Frd5p+5Wum6Fqqe/vZ1uj5/R8K2Byzy8QLNK+R3wBQZsr+Ad8NZNm5fwCt6AL2zKI6CsX4x1eTt4MG/bb+Prcgm0NWQlwIpgxWDKuVsOvplebgWup50WgK2nNln6loA6uh6L4cot73Vr7KDVydJ1T/hScWcEr7XO8/rpT/sq5RW4GMjegLdu2rwD3kJBt+1nC6834AsETGMWWfHldGqZA60GslsHu0L2Cq41KGuoYiDVHb983dd9O90I4EatPva+3RGLp44C3F5z5idyt1xdJIhbgesFbyuIvTEt8N0CV/HwAu5ZuBZQ9ks52/f2UrCty+r+1uvL20m44Qq0NWS3LhaF7CukjLqm3K0WvgD3Dl1JLW9BDxBo7ucMf22t24EOnk62tqfqtJBtae9xtdh4WqcrtddAWjNOJHBvxrVtCwK4Xa37XP4Mojr+Nq5e8ds3nayZ463Ltv1FwfYJtNu3hAItFVPXacqp2PuFboRD3XtPbsTJU7O53NaUcitwO8IW634Wh2vti4qPdr1RTjeyTgPZm9fyHC5A+7agreMFgMfreIfb4oKfy3EAv4BXULvetU4DWtbNagDLpZwpwBpWL98pdHunlS1vXU+X69mTa+mvVg/gnmT+lnNammsPYLVx0a9Hg7flp7ZOA+IG4Hq2BT0viroFbmRK+Y3HRVnaxVpcv9jvuJZhsN26WhVoKchKgOXgigG1xfXe30KqvYDb2+V6/rqsUOXaHwW4lj4nOOxCutb0MxLEkZDl6loAW19zIOXKVK/1q5QvTfTA3bZpAe660AoAW3jV57CNdawtbG9cMOJqX1zeSgAwgJZzuRq3i13X8bU4+N6X050NuF4ozJhWjuybKmuFaKaTTf1qyrVAxeotcNXEaF2rpk5TL8bjwKWkdZp4ClkHx3dstgxtVzrHpaC1KWcdbFfQAoDsaC2QjZrTlZwtVn8/TnemlcqasSxxo/+qPF8CKCVw0eu94et9HVGmjeGcq/ZniJutXgvbggCAXalcX2MpVyv46m1D2jT2G9V+YGz1NDVvvLap+yV/JwS2qKt9BbKbtbhdDq6tjhdrex9ONzq1i8nyYU8p6uSp3i6XU4tDpsY6GHCxrq0A9tTt/boHcKX22DVWF+FwpddX1xtiVLIAd7ttZguztWz7Wupj28a2JahOFV/XrzHyYRjX7vYKzI9zttv52htnq3G12zqqflu+LeNe122oGE39+aGrBUaLy7W+VT1d7ui540ggRwNXm9bv6G6xMq1rtcTODFmsfi+n293tPqeUAcC0F9ezShkANu5TdqxWhxu16plLJZNp5C0gKfiuP1vmdevXkXO7WLtzQ3cEcKPaRblcqU2rE/X2PQNwO7pbrPvI697wpfrs6XQ9jrflZzRwr66vU8oA/YBrhZ8EUCvA1+vbuebrOWKA61XJdSqZdLY1bCn4cqDlVihzTpiqB6KeK6N0Tui2Hq5g6Ytq32O/qBRjvdcWIEc64ARuM1S31xEA1bw+Ani1dVb4MsB97WreNh64twugbtus23m0wI1y1FwqmZu3JWGLpZQpt6ud18XqqPr6dR23lRa851tINQNwLfFekGjGjlzgZPldLUCO/v13nr/FhvIClosd9bonhHuB11pHlWnKiUVTANDJ4dYgw4HLARsAbhZE1fFSPbfSer1HgNuFUiRsa7jW15Tbpcq06Wasrq6v67BrqXyrczndSOC2tB+xcEsac8+0smVcT/xBgesFLFcXDVaqPAKyWFkUeL0xTa/HA1dahSwBVzpoQ9qjy9fLqeSbFcnb1cgUbKkFVBhoPXO63tOovI73HE639aQla58e4GrcmzYu+q+mBcgWqLZ+MaDu5eDp5Pq6B3x7gtoCTq5O2yYKxq3ARR5eACADF8D+xJ4t1CKBq0s/674wXO6hegKS5G7r18CUeVLNdTkg8dxrblEVVYa13er4TreHq9zDqVIasUWIUwtULV9OIv+5nQS43LjW15H9ecqoOi5WM4bUb12mAbNYfgvcVdu9uJReIJ/GLzdlHOSeY6StRdie2ds6qi/r9bXDvZ27fcdbwrwtBtLIed0ep1J5ne6xoTva4Up97LF4qlWRQOZkzRxEZgEOCtwR7jSiD6/r9cZ6na62L6PDBbhdNPVU5tqLK68atkKRmqNtc8D6dDLrbj2LqDTzup6FVVR9HYNdb8V97zomdD1ONOLXiQKuVjO7XKnfl0wd1w8WrxmP6mtS4I6Gb2Sstt4D3oifnjLu9dO1DritTwzy1lPP1G0FLjXfi93LO976wu2e288Dvf1HO69bt9leg1CmWTzlXbksuVqs/lhzut60r/ZXGZVW3svltgA5ygFL/Wic6+QLpuprL4yj4NsbyDOB1wJXqV4ALjWHC9D2iD5/vQzcFaA1cKn5YArk6/ztU19ed6tZRCXN67asXrbO5VrndbH+juF0W2AYBdyeLlcLFikmcp6Ua8vBmquLWFE9OXAtgOXatgC3N2Sl+lHgtcYcALjPW21sW3l4iNIpY2rPr8kdb4B7M3f7FujnbSXYSilmy5wuBlgKrpq5XA14V80L3QjXOSNwo9y65kQnrl7qr3ddL+BOmk6Wrq3w1ZSPdrVYWS/wWus6A3fVmL24fMo5GrikO371eADH599uc7d1HSD1QFxr53Q1Keb6tWVRVR3PaT7oRqV4RwDXqtYzgy2y3HfLFiFtXVTqWjteo6wAbelP2xcVh5X3criaMs0/kdafUh12n1rgPsXrVynXi6Yovag+rSkoP9dd119u8xaU277W19vYdWx6RTMH9gdk3Ien59w+vj0xwKXmcFsPy+Ccbuu8LhZD6QH2ntPtNYc6Crg9Fk9p+rO+b5EHYUTUSeNrvohgMYNSyr0cLlfXw6Fa6rHYVte7l9NVvfavUgbgt+5EbM+R517ltDB2rGPdz/aEqa3DZedv64VTrbCtna12Xle7elkCcB2DXVNlmMY73QJ9FyyNMugRaWUvXCLaeNqOcLmaLxgHBe4I+PYArheuXN3swH26/zjg2lcqW675tLEEXCyljK1QJoG7zt1KUH3r8X2VYEzBlpq/5eAbMa9LxdfSgHe+9LJX1tvtMY8bFd/SlwStmVxuAtdUNwq4MzvdUcBljnZctQXuU5kBuHVa2AvkGrJ1P9s53vVBCBbgPrlfasFUDcvPE+Ua56tdwSzBFwMtB1kKttZ53boNpmNtGaI0C3At99HL5VrGtOyt9dZJe3I1dVxMAHCxbnsB1hI7yqF66lvregLXDV/8aUEA18Ctj3e8NKdgSgOXWxhFbQ3CtvBIW3+41HQYcLdOl4LqmnaGqg4rl9LO22sQytcyQMqtble7T5dzvMd3ulHOzdOfpt1MLne0tG7Y+wXkRMCl4jTlXD+WNl7nao0f5WyxMiNwtynl52seuPVCKmmlMoB2QRN+rYUql1LevqaA+8bnv3g9f7umimvgYtuENKlkDWwpV8utVMbATNXXdXU5BlPO2WLxx3W6e9xez5XVnr5b7qfHXG5UFkDzewVuDdqqBbiWvj1vtzSWBEFtnOaLCFbXw+FK42D3Z/liggB3FQfc5+bX8HxqW7ne53LcBV//Ktf9vajGwNrezinb69b6K+BXD5u/cbgAODAjgGvdLqSBbeu87v06Xc+ttbpcD1C0UPQcexh57jQ3ltc9e13uwL24rYCNdrXW19HOtaWsB3BHOF0EuOs87ouXz5+c28MvAK6332BlVNr4MjS+hYdLK2sXTmGrj3V116uUt6dM3ThcaoUy53C38QB0OhqQPryLqiTQRjldDrCYCz4WdL231DOtbJVmHM+9WODYw7FHuNyTADeiLoF7q2jgPvVLA1c6bQoAXwh1GaZXWpk7SENX5wYuBlZs5fLnH99bLN7jgoEo49wvVwZI+baMe42BlANvHXOM9HLLrUQAN8rlYrERxz1K6uFyuT5b5nKBqU/guuuPCFzO6WrKxNcLCtynrhTHOwLQj9lbpZ2b1c7jcvt2t+B8Hpte4ewGLrVCmSu3whaIemBiAIkDoEGLuVwMxlTMVtKqZYV2hm7E8DMBV6veLreHvFuEuD46/fO7Z+BGw3ov4HpdrRK4mvOUV1HA1R6IgfVxKdNA9rrdduUytf2I2sO7HvWIArd2shhYsRiAvouqKABjQI1Yvaycz10k1zuf040adjbgjnK5lr2vvV0uF8fBGGvXYaXy0YAr9SGVtbQ9I3AfZTlP+akMgeeq6P24WjdMuV8KxtcAvl40pQJuDVYq/bxNOXsXVAFSvy0DuIUvVaZxu0TKuQbqQw3iR73NgPeL+83p9uo+yuVFukXt7xrhcjn1cMDcU4Sixk7gXr22AFnTthWuXJ33J1VnAS5g5foHGGgOv7gu5/fjXm7ldgWyPeVsS01j8L2Z38X24UrA1Sykok6qotLSwMRh9dw1ID+16Wa4BuwWrhhQHxjI1vFfHO90S7+umw6KsMjqcr2xrZCMArJlHlYji8vttBfXUm+J19bt4Xaj3DFVNwK8Ulldf1V+fbzjVtuVypfrV+atQdrtQ3VaGYvdjonVYU65vs96a9Bzu2snDABXRztePZpvCz7YvKacKeVQNQ63dq/UGMDEb68Bbu+7LttewzNoOcjWgKVcLeWCGaPb2+lGKxK4UftNoxX5eD4tHSKeAKTtYxBwLRDu4XglmGritUC2ul5tnAaYlnitq8X6VTldeWtQPY8LoN8aVAuDHrZ9CAdkRFqZOiayPk/5Ad7x1heuzlIm3Wy9zad2qq+IOKxcO8crwRjgFqgYVAnQcpDdwvUGvBVQ3wZZawxjdI8E3VHA9bTDxvPsy+2piN85Yi53gKIgaon1glXTj9WpWvvwAFfz+2rba2DMtbkql4G7yrI16DIUnVbG3KkmXXxp076NiFqp/DyPu3l4wRae1FzsW5ufADJwubncOi0NSHsLbBWLqGrQ1pDdAvYKxnAtDLRMllmlg0B3VErZ014br4mzulwt+Lx1nkMyLONOMI8bEWuFr6Ufa5m3jovv2Y9Upq7XbQ0CuH1qkARc+Vxl3MXSKWEcmJQz3r5+ozrKEUsl1/O4Nw+gr+GpcbsYcClXi4Fa43yBqIOqDJA2cAGtBFkKsNvXNVQph8vB98BON3KvqqZPrv1sc7mW/iIWP3nmfLk2EwDXC2AtcCXQzgJcbR0gcXWsxelq7kNqAwDYSuVVmoVTALep4udyGrh0zMOmz1soatLFHJi1i6+eF04hDpeCH7dKWQIu90CEbR0ADWNuURVUMXDtaCXQYpB9QMrqcqx+Kyz2oNA9AnCxNtoDM6R2Z3O5W00G3JZYShYnbKmvyzR1Erxb2knAtPYrOd2bcnml8ipu4RS3erleNFXHXbd5draXcvlMZM88LvZA+xuw11uDqPQxB0kNcDGnDEgsB1gqjczAdutqJdDWkKUA6wVvrQMupOq97eVsip6jjug/ejV0Q3cWh2sZy+p+LfBuBSbXp1Qm9S39xPq2At16ry9xMALozlS+dH8Nzqs+GDhyrnfbtu5rfY2NTUGbasPN45Yt9JC0LAlAzBVjAIWqvL7WApe6H3i+ppytFbYa0Hrnc9+GQzndiFW00e2jD8LA4kYd+ejtk4rbyeXWioSq1gH3fO11u17Iaepaf1rr6jL0NX4AhrRwaitPWpmCaA1Fi8ut55U1aWUy3VyllVGQru50+xOL4x7pZ30gQu2CubjqywHnbDnQtjpcz3wuwCGcbu8jFUfM43r617bp+bhBTK3jDXS5luuo2Fanre2z1dFGgVrraLXxdR0WT90fBtwqrQwAaFoZO77xFow0XGvxUNU+pIBegEUtkGJjsBOnMOfKlVHbhrzAtTwQAa6vMdhirlYDWgym2tQyl1bG6iZ1uqOA1iOtPJPLjVhApf3iQblcrRpdbgtwrX1TdR73a4ltcYPWGOzeNLFYuQa8nt8NLb8F7qqIZ+Pih1nwDyio+64XU9VjUPPBmjlebj8uegAG9YfbU0vVa4CLHR2pAa4BtjVo4fGaAq0HvD22CwEMh+4exy56+7CklT39a9tEbZfyuFxPapqC9M7A7eFqLRC19OF1vVZnbHGoksvV9oPFcoC+KcdPnNI+G3cr3QlT/DwuDlnuYQfcYRrWtDK/H/cKhtRCKKquBmGdjn4A/IEHLU8gArgCrga2FofLQfYEW4YK9F245AGIpQ/rvfdckNSjP0/6t9Xl7qgo4Fohq3Wz2FhSmQem2vba/jS/hyUWq0fbrVTh9+MC3D7IAAPZU+wNBG/ngLfCoHq51VcoGLftKLCu/T3HBWwP0i6Sqt0sBuF6TrgGa9234QlEVthiMNWC17N6WVq5vI2fNL3sVQRwe4+tje25TajjvCo5bicYt7ra6DptylXbVgtkL2ilGItbjQKvy+m27cel5mgpCD8Pz7neGqb1eDRA1/J6DGqx1raf+otB8zyupo5LF3NPJqohDNf9UankFbYAz5DlYKsFbV2+LavL6zoqptYBFlJpFXW7kS5XqyO4Q09qmdL2PQ5csSz9ExgBYE2cFq7e/rd1FtBqxpLaSFDF4rxO9+n1dVr5tat52+uPxa3TvXTDO9pa3PzuNgbrn5rn5V5fg5qCMf4ko8vb8djPA/Igg/on5Ww1dVwf29fA9A3VawB0+w/nbqm5XCtsWxwul1oGOA1093S43PhRh2FYdSepZQtkRzjgltfavr1OVhMbkV6uy7l+rS6eff2cVgYAVVp5KypdzLnX53bYXO2tk63jsXHrOO7kqdsFV7zLJYFJpXkpgGJ11LYi7VhVOZZO1rjbGrDYa22aeVvGldd1terYE6SXI29zVpd7ptRykMttgailL22dNcUsvda6Pg9greCOSCt7xqnL0NfyA+lXaU6dotLFW0mrlSn3qXHAlpOnuHHQQzC0rtWSVpYWRUkLsZC0NAfcVthKoLWAt66jYmod2Olab+8oLrdVPR4kb00t7/xPZ7SrtdyLtU+tE7WmfTVtuDGjAYzFi05X93xc66lTmCjA4rEPVTve5WLl6/1s73dbx69cJg7BoFyrBFXs4fXUAwuoxVQO4H7u87y7pcBbg9O7sGpbxpVHamLo9gDuHi5XM1aLy/WOS7nUWpq4Ds66l6uVYjVxXidsqafqNBDu4Wi97bE+pHtaX2+fj/so7WrlrbD5WS1cL7F4+pmbo8XmXz1bhK7v93olNLp4CoDfE8v90aSnpb23AnDfflxI9bnP29wt5my1+3Q1e3R7ARbTpNCdCbitLrc3zCOIslUkQJ2pZauLtbwFHAy8MPXEc/UR7jSqTd1WE6P9gkDVX5U/fiwih2Bs5TkEoxaeRuafMoS53Lo/aiVyvUVoraO2CF3dI3e2MgdCCqwWOGNArffvVmMuq6N9kNPJmvSylHoG4nqEk5U0IXQnvKWp1PvhBgdXRFo5YiwuNsLlasfzgLXFDbeA9+pe8FkxzuUCyIdgXA2BuFeLMJBu+11fY+V1mplKP1PO+sXjHpunXx9zuVC9flWV17F1P9u4uqzuox4LqY8AruZgDMtc7h6aiHDeW5nF5WplTS239E0p0gEHp5Z7ulxPXdRrbhwttKSYFrcrxbf0Y0kvK10ut3gKQN6Ti0l78hQf83DV37Z8C3jqkIs1/vJ23KahL2/Hs8sFANnl1jHS/O/6Z+tYqSMhMee77sXdzOF+7i07cGvwahdTcenmGTQBdFtuYaYFP71Sy97717br5YA7PE2oVg8AW6CpleT2NONFOldPbGsf2vQyAFiOetxKc8rU83C3KWNKkgvG3CgG0O09bevw+3qgy7cnT2EQBJBTzRhoNTHYwxCY9PW6aEoC7ucebxsDr7RXV+NyZ9KO0J2A98Ndbqu8C6wiH0jf8e8t0tV6IMspwuVayyJTwp42PdPL1Oun2AfQHPWInTwFQIOSO/DCskVIntul5mMpN3sNWsnlAlRzuQDX4AOQHe02RgNjDL41cDfueAUut2jqc4CDcwtcrh6Y17NqB/JFDNkzjeqR1uX2XLXc88uAddXyDi43IrbF5faAb11ngbG2D2t62Qteyek+lfFHPW5FnTyFrSKmF1TdrmzWqF78tB2fKsdgXN/r+noLZ8rlmh0sEDEa1yuNRTjctxmHuwWu1t1SqeMjwHbVACrN4Ggx7T2Xu5e2v9ss9wTHd7mesaxOUWrvcb3acS1tqXbatDMAtJw8BQBkGQdXi8u93PLtwqh6nDqVvH39EgXrq6u2V4uyapdLLWLiQLuNleCrBW71h9qHu4IWQAYuBVkOvEdRJyKWfl1P53L3kpYskallKn6rnV0uB4tIGHudrfefpRagLSlpqt5yD2pHi7WxnTx13Z00b3vtTDGYWlQvsKpfr9fXP+knCT23uU1Fr+VXK5a33yk4J0uBtF5ohbUBIMFK9VmfNFU73G23GuBq08pH0mt734BNUc7M+8g/bXzEAi8p9Wwdz6sB87wtLjdqTE1c5H1ogaXtRwtO6z1R5Zq/I+8XkJc0AGuXi8YgLvcynGZBlG4ud43H+sYPxqBh/Dw2NT/86vahBgDX4AO4hiVsYqCqf6jq6n4wcAPyE4M4wM2j+bA9tgC3dfcAXIDT2sEev1bvVGxU/xYbeED1SCVb08eacg+EqLqIvzZrylkbr0kVU3FXba735WoPwrAe9yiljD3SuNb6nurUMnbfN654fagBAL0laPuaSgUDUy/N/zLpaGqlMuVqtylmLg6IsqPqQJ/CUWnlSJer7T8a2NH3eaC5XUvb1jhNG2vCQirrMYfrSTlrYqlrqj/y9ea4R+VcLiZs648lhUy53Od+cCe81l9+Lby8hjHe/wPSbnW4r2735cLmGksT1/CEKobrqy6XFmoBkAunKKBqgLvewlmAC2BIL5dSXpRS/m4p5Ud63hCuvaFAjd86QSf1r62PbKeZDw6cz22BaoSpj8qYt7jcqFSzJKt7HeVyK2lXLFMLozSLpSyS0tLYcY7X5ddzvlg51s8T5LEFVAD06VNYDFZPuVzqGjY/t2/Jo8vl5nGp+VvNARlnAi6AbU73wwDwiV43QssCjpZPqJlMv+VeRi0s6zSf6xkSqxsFYAtcrelkTq0u1+NgLffBxbCvbx9qAHDrcq/qXtRpXG6xFA5mbp6Wais5YexeOKBK5Tcpcwqg63U9p4vBk3K5VLqaS1M/ltVpZW7/rOfnmYALoIRuKeW9APD7AOD7+95OrWiHu8e87MjUsvYTfe/MwaNaUsmWfqm6qO9ovVLMPb7P9IB2q8tVHPdYP7rv0gXucrm5XE6Uo5XaYgCttxNxKeftlqF6vO3j+64WUGHpYgygFJQpiFJOGQP34886rQxw61C9wN3u2T2LtE73zwDAdwPAF6mAUsqbpZSPlVI+BvDZgFuzgqGX44pOLc+mSQBcK8rJelxuL1Pvdb5aAI76J9nichuFnbFsao/My5rvYQtFcZ6YBjlWjy3EulKV1r2Ze63TwPXrtY+H6nqrug/m5/L4+uHx5xawQLw+I0gtEqFbSvlWAPjMsiwf5+KWZfnIsiwfWJblAwDvDLvBOPVeQKWVdT53pAbP53rVG8DeNi2gabk375ysNLbH7VrKGs9Yfr7us4BKfsbtNiV9nR7evsYeVF+X1yC/XkD1xetdVDVoAW5d7PoTSxdj6WWNM17Hefy53ZML8Oxyt04VkNd1jLRy+WzSON1vAoDfX0r5FAD8EAB8sJTy57ve1V273CgoRz79p4O16jEn6x3fuNAnLLXcI8Xscc6a+9L2oSnDUstwvYAKANjDMPBbot1r67ag2/54yGIp5Ot7uS2vr7d7cwEAd7WYa6UACnCbNsb60aah15DNXO7WxWILqQD04D2rROguy/I9y7K8d1mW9wPAtwPA31qW5Tv63VIP57eXyz3K3t6d1TK3O2L+VtNeGqv1S4V1zjUK3pp+XHO6tMvdijvy0QNSjYOl+q+3CVGudRu//SmfzYw4Z27VMlQ/MQdcu9m6jFp8tb6uYbz5ic3l1kPUgJX2354duADTnUh1ZIiMuPcIOxi1P3enOe1R87cRbXvAt1UtC6aoPqQ6MmOAzFnC7Tah2yH4dPO2zAJmadUy3e7atWJgrmEsbTMCgOuHG6yqgbn+pNzutp0EWArs2/rHP9stQgD4FiCoXksHXwCcH7gAxv/my7L8bQD4213uxK3RqeUWWe915JeQgfO5PZxsyxhYGy+YPelWqq7VnbbKOwXAgfemz8unvJRa1iygwrYOXdfxMNeqfqTf9qf03FzM6WIHY6yp5SdhqeW6jJvX5aBcr36WYAzPznb7up7DtYB32/7smsjpHsXlRkK+5VF+ln5bNNjR9p6/7dFnS/8tqWWpD2sKmurPmlKWVB35uIpLLQPcukLPHC33zFz0nph0tneOmIP/Vf/b1PIqbEgMyAC3FMNAjcVQYz3WbVcsb89XrptjsMVu/V7Syqsmga4XEpr/8bOsWo7WSZ62ZHGrHOhGp5Y9sT2deUQ7yxcAbZ1xAZXmmblX9UTq1/PkIArEUl/4SVK0A67LuW1DLyuHCQD4wiiqHJvnrcu51HIN6hWym7lcztla08v3oAmgexSHy2nEoRgn0ch5S2+bmVLLPRdAefrhYqky49jYCVRX1yiopAcc2B9UT97fFVRvU8jbuDoG23K01t1uFaoG5hxtDd+6HFvVDIC7WQbG29OnVkmLpbCVy/fmbrfaGbqzgmmG+VxL+9ZFVFbrsy0P3J/bY/42Kg3c2qcVvlRsK1RHLaQi29pXLQPwKdk6zvugeqmvel6YOuCiHq+OqU+fqrWdzy1UShhLIWvKV1HbgqSFVHC9L7deAKVJL1Nzv/eiHaHbCrY9Uss953Ot9dHtpPYdvoj0hqx2bM13i6jFXxHxeyliIRVA99Typc7uaqk5Xm7OF982pFvMRR0bCQC3B2IA0C4VW1BFlXMAx8oqGD8d8/hwHQ7Ap5S3r6n53XvRTtAdAdyjyfI7zZohOIEi50lnSy1rExqadhJYsTLFAqrZU8t1v89l12nm7WtqPrd+vfbz4mppMNCrj6GhHEtJC4usqCMfqQcTZHoZ1w7QPRswZp7P3X7iTXBP0QuJLH2OSi23pJulWO1qY2t/ln7C3kcmJas4fQp3knJq2ap6DhZ/YlG9fWi7pegWxttyrD0A3M7nAtBQxFLB2nJs8RWzkKpOLVMul0ol12X3qMHQHfnBv1d6NqVSz3Stpb+9F3a1jD/y3jsspKr35m5VPzfXImmOlXtE33bM63Rxu1PG5oi5ey41pYC4jiinHPI2BEktb5vUEKXmeblbugcNytMeeN9oiHouovIoahFVJ/Wez9W0t4C5h7v1qoejt8SI7xX+cYudQrVNLVsfVu+R5QQr+rm4tyDlzle+OZFq88B6AMC3Bq3X3AIpbj5XM6e7ff0KTy1v08PU4qh7PXWKU+ePgVld496LqKS+Le/biMVdASdR9YTlqD4t/UfPx0r9W+dlI1YvU2XofK+8armezwXgD6egyrblveZzAXTQx2Bct8WOhESTAPU8rFQOcJtipsrr1csIjOunCT2Vb5qs11jqGeC+53JXdUovF5gXuL2l+b17vTd39p6Pdph7Ot7o+VyPmjMJssvtOZ/rOyzjdp6Wuh/pMA3qgQfb1zeLqDSri6XybR3mmGshMK5TyxRYKdN87yuWt5rgcAyLtP/rzzyfe4R7FNRjPneGrUJSX1TdrDMm0auXN9LO51660KeWJbhyz86tY7Z90v3xY2Ex2CKqq3rNIirYXHPl2gVZVDp6G7YBLjYctTK5HuqeXS7A4aA7m04AQLc6PbR+dBq6te8Z53O1qWNPitnl0nVnLV/VKR5wEC2LG6a2AVGLvrhzo58ccn0oBiauXJNi1sznVjHL5hp7uAF2DUj9vcN2VUL3tJpsuxCl3rDroVmdqVY9V4M7x8DmcyV5HWiLtiuddQuudF8eUFhzi6hWad2vtj+i3+2KZSqVTHWB7d29Z50QuhJgZltEdSQNfh8igDx6e1DLOFGLqCJlTYGL894VhJj5XM1ThajTn9b29VOFrNI8VQh7zB91r/X93cRsVy4D8ClkCaLUIiquP2TLELZVCAPp9la57UL3rgNB96jgm227kKbv4DFn/KuLntvVur09F1F5xuTqLO8JcfSjfBsyqLA4q6RV0dIiKu6eNCuXr+q1K463ouZv6zph3vap/FHYVqFV1ElTUL3O1PK1DgTd3po4BUvK86lr3RYU/L7Mvj1otBsekeq1lEdnFzRNmQcf4EPx24Q0bbWLqNYybCzsmoKz5ijIF/VeHGmhFKaH6o+lP8GW1vO5dSh37GP9+p6V0A2VB1Ate3Qj2k2kiAU8I111T3fbKu3iqbpc06fpPnRPFdqqXkRllXc+17qIyjeni69cXhdR3axc3u6b3YqDK9a+FrZauR7ncauQZj6Xm0rmyu9RB4HujPnJO4ZjlO5tEVVPR94zg9CyZShAI1Yua8W53uvn5srumCozr1wGoOG6trMuoqoPwCDAy7lXakXzvesg0NWqxyKqmXRHwI74q9pjEZVX1m0+1PWBFLGIiuwbbh+X57pHYU+ttQ91P5rtP7U4uK71259C+VJdU6li7sjHdLi3Ohl0e+jAn2opWb0WUUVr77S5po5s4/vo1c2tyn17j4PUrFzWtufjiN9B87ZZ4Mq1eyDK4XkRFdeldK5yut1nJXRTDnU6GGOUIhZtt4B4r+9x0u8dme53nESlG0p/OpVF3H5arn9su5Cu/8r9Pry63S4EwB/fqIGrp26bSl5XLyO/lnS0Y7pdXAeA7j07zYhPwZOnpI+UQq7V+36ti6m4PqxjasOFxVV6t2h3sVgKWpuS9t6XarsQpRa4WldCM/1J2Wlq9XLqogNAd4R6gekoFNBsFwr4Xbzu7yhvo3flctTv12sbUkSfjQ53K85NSjDkYrSHZ2iOfMQfdq/0fBHOldt/q1whTT1NSLqNFK+Erksnd4+ROgowNTrT7yIp4suC8szlqwfWK7cLaR400EM4TPk9ulR8/fpKLeDlFlNRfRBO+OGBPolqu2CKO4Eq3e61JofuEU89OIoGnUYVrclvj9Rep0eNGu/Iaf7OkmC8fdDBlTTQlL5feLYZEfO32OuUXZND16K93efe42s00T32TiefGQIH/X20i6hcW2wGyOqgrQ9kQB/pByCDVXp7vPPESuWWIZtOBN0emvnTbeZ7O7j2Xl3sOds4+h4664VzG9FoWU6f4iTONWMrlwF0Tw2i6rX9IKr36BqapgQldHdVgnNXhcxbRtyIUntDduAe3VrWPbrRB2PQMbenUbWIPI0KQHa0XhF7dN9m7iX34/qV0J1KE6V/R+ro4Oo9RgQYe3156PR+Ruy9BaC3Bln7iFLrgRusJOfLHIDBOeHtKmbLmcsJYFwJ3aHqBdWE9dC+jpSg6LVebpIHO8TB2TaPrN9e5HD6LXOw2uGUcR63m+KV0E2lRmoUmA7wxcDzSL8e4k6jilSv+79R68pmpNyyRzdhzGti6I761LhTl5i6T3kc/U4A73UaVVRbDqJdz1223PLA1U+5R1eniaGb8ukAFqeH7vTXTvnFHXTBSYoZ5mgBplhSnGC1KaGbSkWo8xnFh9agIyBt/exHqz3HvhF1INYcW6NPqYRuaowmWx2bul9RgPY6VOkJQ11k4XYQ49PRxiihm0r10tm2Qp1Ae5xu5R6T2+KTOqwSuqlUKl7Eww5St3rRmsvdIVs9UYL8cEroHka5yjqVSqWOrrIs8d9ISyn/BAD+YXjHffWbAOBX976Jkyvf4zHK93mM8n0eoyO+z791WZavxCq6QPeIKqV8bFmWD+x9H2dWvsdjlO/zGOX7PEZne58zvZxKpVKp1CAldFOpVCqVGqSE7rM+svcN3IHyPR6jfJ/HKN/nMTrV+5xzuqlUKpVKDVI63VQqlUqlBimhm0qlUqnUIN09dEspHyql/INSyidLKX9q7/s5o0opP1hK+Uwp5ef2vpczq5TyvlLKR0spv1BK+flSyof3vqczqpTyJaWUv1NK+dnH9/m/2vuezqpSyotSyt8tpfzI3vcSpbuGbinlBQB8HwD8XgD4GgD4Q6WUr9n3rk6pPwsAH9r7Ju5ADwDwXcuyfA0AfCMA/If577mL3gKADy7L8jsB4OsA4EOllG/c95ZOqw8DwCf2volI3TV0AeAbAOCTy7L84rIsXwCAHwKAb9v5nk6nZVl+DAD+6d73cXYty/Iry7L89OPr34DLh9V79r2r82m56LOPl68//skVqcEqpbwXAH4fAHz/3vcSqXuH7nsA4Jc315+G/JBKnUCllPcDwNcDwE/ufCun1GPa82cA4DMA8KPLsuT7HK8/AwDfDQBf3Pk+QnXv0E2lTqdSyjsB4IcB4DuXZfn1ve/njFqW5dWyLF8HAO8FgG8opXztzrd0KpVSvhUAPrMsy8f3vpdo3Tt0/xEAvG9z/d7HslTqkCqlvA4X4P6FZVn+yt73c3Yty/JrAPBRyDUL0fomAPj9pZRPwWXa74OllD+/7y3F6N6h+1MA8NWllK8qpbwBAN8OAH9t53tKpVwqpRQA+AEA+MSyLN+79/2cVaWUryylvOvx9ZcCwDcDwN/f9aZOpmVZvmdZlvcuy/J+uHwu/61lWb5j59sK0V1Dd1mWBwD4EwDwN+Gy6OQvL8vy8/ve1flUSvmLAPATAPA7SimfLqX8sb3v6aT6JgD4I3BxBT/z+Odb9r6pE+o3A8BHSyl/Dy5f3H90WZbTbGlJ9VUeA5lKpVKp1CDdtdNNpVKpVGqkErqpVCqVSg1SQjeVSqVSqUFK6KZSqVQqNUgJ3VQqlUqlBimhm0qlUqnUICV0U6lUKpUapP8f1K+QjYD4lFsAAAAASUVORK5CYII=\n", + "text/plain": [ + "
"
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "heatmap(grid, cmap='jet', interpolation='spline16')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e5db98cd",
+ "metadata": {},
+ "source": [
+ "The peak value is 32 at the lower right corner.\n",
+ "
\n", + "The region at the upper left corner is planar." + ] + }, + { + "cell_type": "code", + "execution_count": 18, + "id": "fbb77637", + "metadata": {}, + "outputs": [], + "source": [ + "problem = PeakFindingProblem(initial, grid, directions8)" + ] + }, + { + "cell_type": "markdown", + "id": "cc0c2498", + "metadata": {}, + "source": [ + "Solution by Hill Climbing" + ] + }, + { + "cell_type": "code", + "execution_count": 19, + "id": "236cde2b", + "metadata": {}, + "outputs": [], + "source": [ + "solution = problem.value(hill_climbing(problem))" + ] + }, + { + "cell_type": "code", + "execution_count": 20, + "id": "1f97a239", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "0" + ] + }, + "execution_count": 20, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "solution" + ] + }, + { + "cell_type": "markdown", + "id": "535af367", + "metadata": {}, + "source": [ + "Solution by Simulated Annealing" + ] + }, + { + "cell_type": "code", + "execution_count": 21, + "id": "653741be", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "32" + ] + }, + "execution_count": 21, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "solutions = {problem.value(simulated_annealing(problem)) for i in range(100)}\n", + "max(solutions)" + ] + }, + { + "cell_type": "markdown", + "id": "ccb84314", + "metadata": {}, + "source": [ + "Notice that even though both algorithms started at the same initial state, \n", + "Hill Climbing could never escape from the planar region and gave a locally optimum solution of **0**,\n", + "whereas Simulated Annealing could reach the peak at **32**.\n", + "
\n", + "A very similar situation arises when there are two peaks of different heights.\n", + "One should carefully consider the possible search space before choosing the algorithm for the task." + ] + }, + { + "cell_type": "markdown", + "id": "9c80a23e", + "metadata": {}, + "source": [ + "## GENETIC ALGORITHM\n", + "\n", + "Genetic algorithms (or GA) are inspired by natural evolution and are particularly useful in optimization and search problems with large state spaces.\n", + "\n", + "Given a problem, algorithms in the domain make use of a *population* of solutions (also called *states*), where each solution/state represents a feasible solution. At each iteration (often called *generation*), the population gets updated using methods inspired by biology and evolution, like *crossover*, *mutation* and *natural selection*." + ] + }, + { + "cell_type": "markdown", + "id": "96577df8", + "metadata": {}, + "source": [ + "### Overview\n", + "\n", + "A genetic algorithm works in the following way:\n", + "\n", + "1) Initialize random population.\n", + "\n", + "2) Calculate population fitness.\n", + "\n", + "3) Select individuals for mating.\n", + "\n", + "4) Mate selected individuals to produce new population.\n", + "\n", + " * Random chance to mutate individuals.\n", + "\n", + "5) Repeat from step 2) until an individual is fit enough or the maximum number of iterations is reached." + ] + }, + { + "cell_type": "markdown", + "id": "cf94ed1f", + "metadata": {}, + "source": [ + "### Glossary\n", + "\n", + "Before we continue, we will lay the basic terminology of the algorithm.\n", + "\n", + "* Individual/State: A list of elements (called *genes*) that represent possible solutions.\n", + "\n", + "* Population: The list of all the individuals/states.\n", + "\n", + "* Gene pool: The alphabet of possible values for an individual's genes.\n", + "\n", + "* Generation/Iteration: The number of times the population will be updated.\n", + "\n", + "* Fitness: An individual's score, calculated by a function specific to the problem." + ] + }, + { + "cell_type": "markdown", + "id": "24eeae15", + "metadata": {}, + "source": [ + "### Crossover\n", + "\n", + "Two individuals/states can \"mate\" and produce one child. This offspring bears characteristics from both of its parents. There are many ways we can implement this crossover. Here we will take a look at the most common ones. Most other methods are variations of those below.\n", + "\n", + "* Point Crossover: The crossover occurs around one (or more) point. The parents get \"split\" at the chosen point or points and then get merged. In the example below we see two parents get split and merged at the 3rd digit, producing the following offspring after the crossover.\n", + "\n", + "\n", + "\n", + "* Uniform Crossover: This type of crossover chooses randomly the genes to get merged. Here the genes 1, 2 and 5 were chosen from the first parent, so the genes 3, 4 were added by the second parent.\n", + "\n", + "" + ] + }, + { + "cell_type": "markdown", + "id": "84c973b1", + "metadata": {}, + "source": [ + "### Mutation\n", + "\n", + "When an offspring is produced, there is a chance it will mutate, having one (or more, depending on the implementation) of its genes altered.\n", + "\n", + "For example, let's say the new individual to undergo mutation is \"abcde\". Randomly we pick to change its third gene to 'z'. The individual now becomes \"abzde\" and is added to the population." + ] + }, + { + "cell_type": "markdown", + "id": "8e29418d", + "metadata": {}, + "source": [ + "### Selection\n", + "\n", + "At each iteration, the fittest individuals are picked randomly to mate and produce offsprings. We measure an individual's fitness with a *fitness function*. That function depends on the given problem and it is used to score an individual. Usually the higher the better.\n", + "\n", + "The selection process is this:\n", + "\n", + "1) Individuals are scored by the fitness function.\n", + "\n", + "2) Individuals are picked randomly, according to their score (higher score means higher chance to get picked). Usually the formula to calculate the chance to pick an individual is the following (for population *P* and individual *i*):\n", + "\n", + "$$ chance(i) = \\dfrac{fitness(i)}{\\sum_{k \\, in \\, P}{fitness(k)}} $$" + ] + }, + { + "cell_type": "markdown", + "id": "743ac5c6", + "metadata": {}, + "source": [ + "### Implementation\n", + "\n", + "Below we look over the implementation of the algorithm in the `search` module.\n", + "\n", + "First the implementation of the main core of the algorithm:" + ] + }, + { + "cell_type": "code", + "execution_count": 22, + "id": "a0e885e5", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(genetic_algorithm)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "446d7ae9",
+ "metadata": {},
+ "source": [
+ "The algorithm takes the following input:\n",
+ "\n",
+ "* `population`: The initial population.\n",
+ "\n",
+ "* `fitness_fn`: The problem's fitness function.\n",
+ "\n",
+ "* `gene_pool`: The gene pool of the states/individuals. By default 0 and 1.\n",
+ "\n",
+ "* `f_thres`: The fitness threshold. If an individual reaches that score, iteration stops. By default 'None', which means the algorithm will not halt until the generations are ran.\n",
+ "\n",
+ "* `ngen`: The number of iterations/generations.\n",
+ "\n",
+ "* `pmut`: The probability of mutation.\n",
+ "\n",
+ "The algorithm gives as output the state with the largest score."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "557e25cf",
+ "metadata": {},
+ "source": [
+ "For each generation, the algorithm updates the population. First it calculates the fitnesses of the individuals, then it selects the most fit ones and finally crosses them over to produce offsprings. There is a chance that the offspring will be mutated, given by `pmut`. If at the end of the generation an individual meets the fitness threshold, the algorithm halts and returns that individual.\n",
+ "\n",
+ "The function of mating is accomplished by the method `recombine`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 23,
+ "id": "c853c47c",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(recombine)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4005c889",
+ "metadata": {},
+ "source": [
+ "The method picks at random a point and merges the parents (`x` and `y`) around it.\n",
+ "\n",
+ "The mutation is done in the method `mutate`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 24,
+ "id": "543db2e2",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(mutate)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4cfb1898",
+ "metadata": {},
+ "source": [
+ "We pick a gene in `x` to mutate and a gene from the gene pool to replace it with.\n",
+ "\n",
+ "To help initializing the population we have the helper function `init_population`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 25,
+ "id": "7d684797",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(init_population)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92f71dbf",
+ "metadata": {},
+ "source": [
+ "The function takes as input the number of individuals in the population, the gene pool and the length of each individual/state. It creates individuals with random genes and returns the population when done."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6c19b2c6",
+ "metadata": {},
+ "source": [
+ "#### Eight Queens\n",
+ "\n",
+ "Let's take a look at a more complicated problem.\n",
+ "\n",
+ "In the *Eight Queens* problem, we are tasked with placing eight queens on an 8x8 chessboard without any queen threatening the others (aka queens should not be in the same row, column or diagonal). In its general form the problem is defined as placing *N* queens in an NxN chessboard without any conflicts.\n",
+ "\n",
+ "First we need to think about the representation of each solution. We can go the naive route of representing the whole chessboard with the queens' placements on it. That is definitely one way to go about it, but for the purpose of this tutorial we will do something different. We have eight queens, so we will have a gene for each of them. The gene pool will be numbers from 0 to 7, for the different columns. The *position* of the gene in the state will denote the row the particular queen is placed in.\n",
+ "\n",
+ "For example, we can have the state \"03304577\". Here the first gene with a value of 0 means \"the queen at row 0 is placed at column 0\", for the second gene \"the queen at row 1 is placed at column 3\" and so forth.\n",
+ "\n",
+ "We now need to think about the fitness function. On the graph coloring problem we counted the valid edges. The same thought process can be applied here. Instead of edges though, we have positioning between queens. If two queens are not threatening each other, we say they are at a \"non-attacking\" positioning. We can, therefore, count how many such positionings are there.\n",
+ "\n",
+ "Let's dive right in and initialize our population:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 26,
+ "id": "021b6756",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[[0, 2, 1, 2, 7, 2, 4, 5], [1, 6, 7, 0, 1, 3, 6, 0], [5, 1, 7, 6, 1, 4, 6, 6], [6, 4, 3, 7, 4, 1, 4, 4], [7, 7, 2, 3, 1, 4, 2, 4]]\n"
+ ]
+ }
+ ],
+ "source": [
+ "population = init_population(100, range(8), 8)\n",
+ "print(population[:5])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "46632d29",
+ "metadata": {},
+ "source": [
+ "We have a population of 100 and each individual has 8 genes. The gene pool is the integers from 0 to 7, in string form. Above you can see the first five individuals.\n",
+ "\n",
+ "Next we need to write our fitness function. Remember, queens threaten each other if they are at the same row, column or diagonal.\n",
+ "\n",
+ "Since positionings are mutual, we must take care not to count them twice. Therefore for each queen, we will only check for conflicts for the queens after her.\n",
+ "\n",
+ "A gene's value in an individual `q` denotes the queen's column, and the position of the gene denotes its row. We can check if the aforementioned values between two genes are the same. We also need to check for diagonals. A queen *a* is in the diagonal of another queen, *b*, if the difference of the rows between them is equal to either their difference in columns (for the diagonal on the right of *a*) or equal to the negative difference of their columns (for the left diagonal of *a*). Below is given the fitness function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 27,
+ "id": "eb80278a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def fitness(q):\n",
+ " non_attacking = 0\n",
+ " for row1 in range(len(q)):\n",
+ " for row2 in range(row1+1, len(q)):\n",
+ " col1 = int(q[row1])\n",
+ " col2 = int(q[row2])\n",
+ " row_diff = row1 - row2\n",
+ " col_diff = col1 - col2\n",
+ "\n",
+ " if col1 != col2 and row_diff != col_diff and row_diff != -col_diff:\n",
+ " non_attacking += 1\n",
+ "\n",
+ " return non_attacking"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c0f83006",
+ "metadata": {},
+ "source": [
+ "Note that the best score achievable is 28. That is because for each queen we only check for the queens after her. For the first queen we check 7 other queens, for the second queen 6 others and so on. In short, the number of checks we make is the sum 7+6+5+...+1. Which is equal to 7\\*(7+1)/2 = 28.\n",
+ "\n",
+ "Because it is very hard and will take long to find a perfect solution, we will set the fitness threshold at 25. If we find an individual with a score greater or equal to that, we will halt. Let's see how the genetic algorithm will fare."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 28,
+ "id": "2270e60a",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[4, 0, 7, 5, 2, 6, 1, 3]\n",
+ "28\n"
+ ]
+ }
+ ],
+ "source": [
+ "solution = genetic_algorithm(population, fitness, f_thres=28, gene_pool=range(8))\n",
+ "print(solution)\n",
+ "print(fitness(solution))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 29,
+ "id": "35c80bf2",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Figure(504x504)\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAd0AAAHwCAYAAADjD7WGAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAACTdElEQVR4nOz9eXyU5b3/jz+vmclGVkiAsKOAILITQKsUS7VatbZae7Qq9mit2p/V6qdFPerp0dZatVb9Ha0eW1TqWgsqFYrFBVFwAcKi7EsgYQ0Jgez7zPX9430Pc88S1iRkeT8fjzxm7mWu+7rnJrzyvt6bsdaiKIqiKErL4znZE1AURVGUzoKKrqIoiqK0Eiq6iqIoitJKqOgqiqIoSiuhoqsoiqIorYSKrqIoiqK0Eiq6iqIoitJKqOgqiqIoSiuhoqsorYAxZqAxZr4x5qAxptAY84wxxneY8zOMMc8551YbY9YYY37SmnNWFKX5UdFVlNbhWaAI6AWMAaYA/79YJxpj4oEPgQHAWUA6MB14zBhze2tMVlGUlkFFV1Fah1OAf1hra621hcC/gTOaOHca0B/4kbV2u7W2wVr7b+B24CFjTAqAMcYaYwYHP2SMmWmMeci1fYkxZrUxptQY87kxZpTrWG9jzFvGmGJjzHa3mBtjHjDG/MMY87IxpsIYs84Yk+M6frcxZrdzbJMx5tvN8xUpSsdHRVdRWoengKuMMV2MMX2A7yLCG4vzgfestVUR+98CuiDW72ExxowFXgRuBjKB54F3jTEJxhgPMBf4CugDfBu4wxhzgWuIS4G/AxnAu8AzzrhDgV8AE6y1qcAFQP6R5qMoiqCiqyitw6eIZVsO7AJygTlNnJsF7I3caa1tBPYD3Y/iejcBz1trl1pr/dbavwF1wJnABKC7tfa31tp6a+024K/AVa7PL7HWzrfW+oFXgNHOfj+QAAw3xsRZa/OttXlHMR9FUVDRVZQWx7Es/w28DSQjotoVeLSJj+xHfL+R4/icz+4/issOAH7lLC2XGmNKgX5Ab+dY74hj9wI9XZ8vdL2vBhKNMT5r7VbgDuABoMgY83djTO+jmI+iKKjoKkpr0A3x0T5jra2z1pYALwEXNXH+h8B3jTHJEft/CNQDS53tamS5OUi26/1O4PfW2gzXTxdr7RvOse0Rx1KttU3NJwxr7evW2nMQ8bY0/ceDoigRqOgqSgtjrd0PbAd+bozxGWMygJ8AXzfxkVeQJehZTqpRnONv/V/gj9baMue81cDVxhivMeZCJCI6yF+BW4wxk4yQbIy52BiTCiwDKpyAqCTn8yOMMROOdC/GmKHGmKnGmASgFqgBAsf4lShKp0VFV1Fah8uBC4FiYCvQANwZ60RrbR1wHmKRLkWE7d9IMNaDrlN/CXwPKAWuweUjttbmAj9DAqAOOtf8T+eYH7gESV3ajixXz0BSk45EAvCI85lCoAfwX0fxOUVRAGOtPdlzUBTlMBhj4oD3gN3Af1r9pVWUdotauorSxrHWNiD+3Dxg6EmejqIoJ4BauoqiKIrSSqilqyiKoiitRJMF10+ErKwsO3DgwJYYuk2wYsWKkz2FFmX8+PEnewotjj7D9o0+v/ZPR3+G1loTa3+LLC/n5OTY3NzcZh+3rWBMzO/yqPF4YGh/+Mkl8INvwSm9wecBjxfJegy9ONdzdhgI+KExAPl74d1P4aV3YWM+BJoxaaMzuBxO9Bm2dTr6M9Tn1/7pBM9QRbe5ON5/LHE+uOAsuPcGyBkG3qDQwiFRDXvvfiViHyLA/gCs3AgPvwTvfQ4Njcc1tTD0F77909GfoT6/9k8neIYxb1B9uq2AAb4xCpbOhDmPw1kjRIA9HsIF1Y2NeDURr1Y+H+eDSSPg7T/CspfhnDGOZawoiqK0OVR0W5jULvD8ffDx8zB2KHiDlq1bRG3ET3C/IVyM3ccjxvB6YMwQWPgcvPDfkBZZQFBRFEU56ajotiAjBsOKV+Gnl0J8HNHWbJDI/ZFC7N5/hDHifPCTi+W6o4cc99QVRVGUFkBFt4W44Ez4bAYM6uNaRm7CN3vovVtUI7djWcJNjOHxwql9YPEMuOjsFrk9RVEU5ThQ0W0BrrxQfKwpSU6gVOQSMU1vWwsVVTB/CTz9JvxrCZRXR5x2hDGw4DGQnASzH4VrLj6Bm1EURVGajRbJ0+3MXHAmvHgfdEkkZuSxhbAgKeM6x1rYXQzXPwCLVkCjX3zAU8bCSw9Av54Rq8uRfuGIYx4DSQnw1/+C0jIRcEVRFOXkoZZuMzJiMPzjEUiMJ8r3ai0crIAZc+Cm38M9z0DuBie/NpgCZOHBv8CHy0RwAfx+WJgL//N8+LnWQkkZzP0U/jYPVm6SdCHrEvTgknNSIrzxMIzRqr2KoignFbV0m4m0ZHj7MUjpIhZmpOVZUgbX3A8fLhVxBfjr2/Dne+Cq74jFW1YBHyyNGhqAj5aJaGdlyNCrNsFPfwtfbxUxTk6Cmy6D398KSfGuDzrXSk6A2Y/A+GlQVtm8964oiqIcHWrpNgMG+NOdrqCpCCxi4X7gElwQEb3/WSg+KCf5A2LZxqLR71i6Fqpq4LbHYPXmUCWqqhrxAf99gaOzEZa2xyOVr576lebxKoqinCxUdJuBs0ZJmk6Y4LqELRCAj3NdS78udhTClh3yPiNVCl3EYuIZ0DVNxt28Q6pQRdLoh7cWhgu7ex4eL1xzoRTQUBRFUVofFd0TJM4Hz9wFPh/sL4N5i+GV98QKbQz6YI3j542B1wMJjg/Y54UHb4ERg8LPOeNUeOjnchygvkGs4ljU1DnibuX6X22GV9+DuYvFovb54OnpMm9FURSlddH/ek+QC86CUUNg+Xq48XewbptYtqld4Oc/ggdvhoQ4uHwqzP8sFCAVZOxQGDpA3hsDw0+BBc/As7PgsZfhV9fCL/4DencPLQsP7gcDe8GWneFjGeDc8SLkdQ0SlPXMP6CiWqzw4afAX++HCcPh4nNgzqKW/nYURVEUN2rpngAeD9x3A1TWwK2PwJqtIR9rRTU8+Rq89ZFs/8f5cPtVEvAEIqCjh8Azd0vwVTDa2BgR2AnDZazxw6BPd2eV2Fk2zkyXgKnM9NBcjIFvTYCbL5ftdxbB46/KPEDGWpsHtz4q++67QcRZURRFaT30v90TYGh/EcX12ySKOJKGRnj7Y1nuTYyHR26DRc+LlZmSBDMfgHHDogObrIX122UJeW1ezBRcfjgVXvmd5OGOGATP3gOzHoHuXeXz7yyM3XFozVYZc/QQOH1g83wPiqIoytGhonsC/OeloaXcpnystXWhCo1xXhh/OgzoJdbx8vXOSTEKaKzLk11r8yICsJzBjIHiA1BbDxPOEAu3W1pIwGvrY88nEJD5er1ww/eP/94VRVGUY0dF9zjxeeEH58oS87AB0LdH9DnGiI/VE1FHubxShPSthdE+XpBAqU0F8n7LDpeAusbw+2H2QhmnvDK66f25ObFTg/r0EAvX44HvfTMUnKUoiqK0PCq6x0nPbhLMhIGemRJdnJEaOm6A8ybC9Ze6snasI5JVsrl0LWzbTXhOrYHScti5TzZ3F0thDVxjABQUwudfyfuKarAuS9sY+MklcOFZ4UOnp8Bvb4FeWbI9IFv8x4qiKErroKJ7nIwcAj7n2zMGrr5Qoo6nT5Oc2jgfTL/OCXZy1UgOWKh0gptKK+C9z5zlY5c67iySYyACvWNv+BjWwoIv4IAjxpXVzvK2a4yuqXDXddJScPzp8Otp8O+n4dqLQhaw1wOjT2vub0ZRFEVpChXd4+Sc0U4HISfq2GNg4nB49Ha448cSxPTyPJev1znPHxB/bpB3PpblZHfrvk354ncFGWdjfij3FusEaC0MLSlX1jjXseHXmTlPxrntSnjsdjhzJHhdJSo9HrkPRVEUpXVQ0T1Oxg933kT4TY2Bvj0lUOndTyVa+JAla8QX6xbdlRthY0Fo2wJr8sLHPLTtjLF1pysIC6iuhUZXpHIwEGvOIplHWHcid49eJHpaURRFaR1UdI+T0UOcNzEa0PfMlFSe8ip4blaoZnLQSq2pC41TWQPzPg3VSw4EQpHLQdZvC1my1sK8JSG/MEiEdF1DaA4BC8/NlsYGifEhH67bEsa53ojBzfSFKIqiKEdERfc4SU+OUUvZEbRuadJ1CCRCeWNBSOfqG0Qk3cz5JCTE1XWQtyv8+LbdIT9wbb0sSbupqXOWqJE5bSqAWU5RjtQuLr+y2yp3BDyty7HctaIoinIiHJXoGmMuNMZsMsZsNcbc09KTag8UH2zigJGqU1kZsnmgHJ5/KyTQdfXRObTr8mQZOjhu4f7w40UHYN8BGXv9Nvh6S/jxepf1bK1cLxhklZURXvEqcjl8f+mR71VRFEVpHo4ousYYL/Bn4LvAcODHxpjhh/9Ux6dHN+dNUMRczePjfeGpOH9/H7buknOr66IrRdXUif/VWti+Gypqwo9X1Yr1ay38c5H4cN00Nob25e2S9n5BemdJBHMYLuHt3vUoblZRFEVpFo7G0p0IbLXWbrPW1gN/Bzp9LaPSyvB6yG48HuifHdouPgj/N1v8tZFBT0HmLZZ823XbonvqBusmV9VIcFYkjX45FrDSt7fIZYX3y46oseyarwHKXL5hRVEUpWU5GtHtA7j72exy9oVhjLnJGJNrjMktLi5urvm1WcKWeGP0rx3YO/z81/4tVmh1TewqVJt3wIoN0UvHQdZscSKd86OPBdOQCvbCK/PDjw3sFWMw1zLz2rwYxxVFUZQWodkCqay1f7HW5lhrc7p37/hljlZsIDo4ycEgYuc+VHQgFFEciGEd1zfAa+81LYLrt0tf3GD+rptgKcgX5sDeCH/wgN4x0oWCuboGVm06zE0qiqIozcrR9NPdDfRzbfd19nVqlqyGgN8pkOESseBr357SMN7tv335X9AlMUbUs8OsD2NbwQAbtkt+biyslQCrmfPC9/ucHF2ImKOzHfDDklVHulNFURSluTgaS3c5MMQYc4oxJh64Cni3ZafV9lmzFRqD+bcQZfH2zITEhPB9JWXw1BtNi255VXSQVJCauvDc3Ehm/BN2F4Xvi8rRjUgZ8gdg9eamx1QURVGalyOKrrW2EfgFsADYAPzDWruupSfW1iksgfxgTeSIghMgubrpydGfq6qJ3tccFOyN3peeGlH72T1PpKnCno7vflcURWkzHJVP11o731p7mrV2kLX29y09qfZAox/eXeRUm3LjCFtaMkweexIm5uJb4yEjJfaxgJVI6KaWsxVFUZTm52h8ukoTvDQPfvlj8PiI8pn6vPDwrbJ8u2F702P4vNJyr1eW+F97ZYl1mtxFjjX6oapalqb37Idd+yRYqqzy8IJ5Wn9p4+cN9st1NTrASlrSi3NP9BtQFEVRjgUV3RNgY76k8Uwa4drpCJsxMKAX/PluuOIuqUwFon1d02DsUJg6Ac4aBYP7ifAGAlKxqr5R/L7WyjheLyTESdENjAju1p3wxRr4eLnM4WB5SFPTU+DpuyRtKaqRvbP91VZYr+lCiqIorYqK7gkQCMDDL8Hbf3QsyogoZmNgyjixOO98AoYNhJ9dBhedDdmZkka0ciM8tVgs4p2FUF4txTPcouvxSFWptGSpMDX8VBHrH50Hv7xK/MvzP4MZ78CGfPjNz+C8iY7guqOqHfx+ePhFV9tBRVEUpVUwtqlQ2hMgJyfH5ubmNvu4bQXjMh/jfLDsZRgTbAYf4+usqYebHoKbLofUZHj/C5j/uRS8KK2Inbd75DmIRTtqCHz3G2I1V9VIWtKzd0uXo+gPycuaLTB+WnQ5yiAt8W+irWGilgA6Fh39Gerza/90gmcY8wZVdI+DyH8s54yBhc+JAMsJroNWdHjZOrjmfrFKIyOYE+KhV6aUbOzbQ6zgrmkh4ayuldKO+Xtgc4FEHUc2TUiMh57d4O3HZenaxJgHBhoa4Pxb4ZOVTd+f/sK3fzr6M9Tn1/7pBM8w5g3q8nIz8NlXUk3quoudYhkRvy/GSLP4UYNDbfsS48VK/d5kOP9M8et6PFJZqrQiJKpJCZCWIkvLSQni892yEz5YCnM/kWXpWqdz0ajTYORgl+BGzCPghzc/gE+1IIaiKMpJQS3d4yDWX2hpybDiVTi1j4jnIWzoZcEX8MO74PxJcMfVMP50acG3ZDW89zms2iiWcHVdqOmBzwmiSk+B7CwYOgC+cyZ8c6xYwys3wpOvy9hv/gEumRwjeAoR3IJCGHeNNGs4HPpXdvunoz9DfX7tn07wDNXSbUnKq0RQl8yQfroeV7lFAGPF2p06Af53Ony1BW78HSzKheLSpqtUNTi9cksrRTSXrpWmBj26wrk5cOX58Ojt4hfOGe4Kngpe23lfVQuXTT+y4CqKoigth4puM/L1FrjqXpj9qOOPdYmeRVJ8PloGk2+USlCNfvEDZ2VI/91+PeU1Mx1SkiQi2u+07Sspk88Eq0gdKIc334fZH0rlqepasZiv+Ha0P7emHq75b/hKSz4qiqKcVFR0m5n5n8GND8OMeyEpMbS/0Q8z54rvtaYWzpsEU3Ng0kgY1Ees47p6sUTLKsW6tVZShVK7yPJ1arIsN1dUS7P7pWth4XJYvl4+++K78P0pTj6vI/Y19XDLIzA3Rh9eRVEUpXVR0W0BXp8PpWXwxsOQkig+3m27Yfk6+NOdcNm5IqLb94hgznwX1m6D3ftkmbq+MVReMlgcIykhVLlq2EA4e7SkCt38QygphSdeE1HfVAAjB8nnq+okYloFV1EUpW2gottCzP8MzvkpvPNHOKW3CGN8nBTEePJ1iT7O3yMW7ZFoaITaOqk6lb8HvvhahDqli0RAXzJZxk2Ih+KDIrgFhXDF3RJopSiKorQNmq2JvRLNmq0w/lopWDH+dPjgWchIFSEsOiAW7YlQVSvXmLNIUoWWzICzR8HrCyRKWQVXURSlbaEpQ8fBsYa6GyMFNJ6eDiMGiX+3sETybfcWi7Xb4Cwp+yPa7wXLQHo9odf4OMnzzUiV+sr9s8WPu2E7/OIxycM9kceq6Qrtn47+DPX5tX86wTPUlKGThbWweBVMuA4uPgfuvV7KRvbr6eT0xmgwH9YDlxjHcUQ6IM0LHn4R5i1uurSjoiiKcvJR0W1FGhplKXjup3D6QLj+Urh0iliqPseSxciP+w9dA1FCu3MfzF0ML7wr3YK0eYGiKErbR5eXj4PmXBbxeaVz0OjT4JzRMO50WYJOS4b9pdC9q6QQrc2D1VvEYl69SZalG1qoAb0ubbV/Ovoz1OfX/ukEz1CXl9sijX7YsU9+5i4+2bNRFEVRWhKNXlYURVGUVkJFV1EURVFaCRVdRVEURWklVHQVRVEUpZVokUCqFStWdOjItI4eWdiRn10QfYbtG31+7Z+O/AxzcnKaPKbRy4qiKB0crxeyu8HIIZKaOH44jB4C6cnSz7t7BpRVSXvSFRvgs6/kfWGJZFgozYeKrqIoSgfE44Gh/eEnl8APviWNV3we8HgJ6/PdP1ved0mCXplwwVkQ8ENjAPL3wrufwkvvwsb8UPcz5fhpkeIYxpiOu25Ax14WAV3a6gh09Geoz69p4nwinPfeADnDnLrtXudgZIlZE/FKxD5EgP0BaaDy8Evw3ufNU262Iz/DnJwccnNzYz5EDaRSFEXpABjgG6Ng6UyY8zicNUIE+FB99+BJbmzEq4l4tfL5OB9MGgFv/xGWvSwNXDr433UthoquoihKOye1Czx/H3z8PIwdKj5cIFxEbcRPcL8huqGK2wh1jeH1wJghsPA5eOG/pVytcmyo6CqKorRjRgyGFa/CTy+Vtp9R1myQyP2RQuzef4Qx4nzwk4vluqOHHPfUOyUquoqiKO2UC86Ez2bAoD6uZeQmfLOH3rtFNXI7liXcxBgeL5zaBxbPgIvObpHb65Co6CqKorRDrrxQfKwpSU6gVIye201tWwsVVTB/CTz9JvxrCZRXR5x2hDGw4DGQnASzH4VrLj6Bm+lEaMqQoihKO+OCM+HF+6BLIjEjjy2EBUkZ1znWwu5iuP4BWLRC8nC9XpgyFl56APr1jFhdjvQLRxzzGEhKgL/+F5SWiYArTaOWrqIoSjtixGD4xyOQGE+U79VaOFgBM+bATb+He56B3A1Ofm0wBcjCg3+BD5eFCl/4/bAwF/7n+fBzrYWSMpj7KfxtHqzcJOlC1iXowSXnpER442EYM7SFv4B2jlq6iqIo7YS0ZHj7MUjpIhZmpOVZUgbX3A8fLhVxBfjr2/Dne+Cq74jFW1YBHyyNPf5Hy0S0szJk6FWb4Ke/ha+3ihgnJ8FNl8Hvb4WkeNcHnWslJ8DsR2D8NCirbN577yiopasoitIOMMCf7nQFTUVgEQv3A5fggojo/c9C8UE5yR8QyzYWjX7H0rVQVQO3PQarN4cqUVXViA/47wscnY2wtD0eqXz11K80j7cpVHQVRVHaAWeNkjSdMMF1CVsgAB/nupZ+XewohC075H1GqhS6iMXEM6Brmoy7eYdUoYqk0Q9vLQwXdvc8PF645kIpoKFEo6KrKIrSxonzwTN3gc8H+8tg3mJ45T2xQhuDPljj+Hlj4PVAguMD9nnhwVtgxKDwc844FR76uRwHqG8QqzgWNXWOuFu5/leb4dX3YO5isah9Pnh6usxbCUe/EkVRlDbOBWfBqCGwfD3c+DtYt00s29Qu8PMfwYM3Q0IcXD4V5n8W3Rlo7FAYOkDeGwPDT4EFz8Czs+Cxl+FX18Iv/gN6dw8tCw/uBwN7wZad4WMZ4NzxIuR1DRKU9cw/oKJarPDhp8Bf74cJw+Hic2DOopb+dtoXaukqiqK0YTweuO8GqKyBWx+BNVtDPtaKanjyNXjrI9n+j/Ph9qsk4AlEQEcPgWfuluCrYLSxMSKwE4bLWOOHQZ/uziqxs2ycmS4BU5npobkYA9+aADdfLtvvLILHX5V5gIy1Ng9ufVT23XeDiLMSQr8ORVGUNszQ/iKK67dJFHEkDY3w9sey3JsYD4/cBoueFyszJQlmPgDjhkUHNlkL67fLEvLavJgpuPxwKrzyO8nDHTEInr0HZj0C3bvK599ZGLvj0JqtMuboIXD6wOb5HjoKKrqKoihtmP+8NLSU25SPtbYuVKExzgvjT4cBvcQ6Xr7eOSlGAY11ebJrbV5EAJYzmDFQfABq62HCGWLhdksLCXhtfez5BAIyX68Xbvj+8d97R0RFV1EUpY3i88IPzpUl5mEDoG+P6HOMER+rJ6KOcnmlCOlbC6N9vCCBUpsK5P2WHS4BdY3h98PshTJOeWVEXwQD5+bETg3q00MsXI8HvvfNUHCWoqKrKIrSZunZTYKZMNAzU6KLM1JDxw1w3kS4/lJX1o51RLJKNpeuhW27Cc+pNVBaDjv3yebuYimsgWsMgIJC+PwreV9RDdZlaRsDP7kELjwrfOj0FPjtLdArS7YHZIv/WBFUdBVFUdooI4eAz/lf2hi4+kKJOp4+TXJq43ww/Ton2MlVIzlgodIJbiqtgPc+c5aPXeq4s0iOgQj0jr3hY1gLC76AA44YV1Y7y9uuMbqmwl3XSUvB8afDr6fBv5+Gay8KWcBeD4w+rbm/mfaLiq6iKEob5ZzRTgchJ+rYY2DicHj0drjjxxLE9PI8l6/XOc8fEH9ukHc+luVkd+u+TfnidwUZZ2N+KPcW6wRoLQwtKVfWONex4deZOU/Gue1KeOx2OHMkeF0lKj0euQ9FUNFVFEVpo4wf7ryJ8JsaA317SqDSu59KtPAhS9aIL9Ytuis3wsaC0LYF1uSFj3lo2xlj605XEBZQXQuNrkjlYCDWnEUyj7DuRO4evUj0tCKo6CqKorRRRg9x3sRoQN8zU1J5yqvguVmhmslBK7WmLjROZQ3M+zRULzkQCEUuB1m/LWTJWgvzloT8wiAR0nUNoTkELDw3WxobJMaHfLhuSxjneiMGN9MX0gE4ougaY140xhQZY9a2xoQURVEUIT05Ri1lR9C6pUnXIZAI5Y0FIZ2rbxCRdDPnk5AQV9dB3q7w49t2h/zAtfWyJO2mps5ZokbmtKkAZjlFOVK7uPzKbqvcEfC0Lsdy1x2bo7F0ZwIXtvA8FEVRlAiKDzZxwEjVqawM2TxQDs+/FRLouvroHNp1ebIMHRy3cH/48aIDsO+AjL1+G3y9Jfx4vct6tlauFwyyysoIr3gVuRy+v/TI99pZOKLoWms/BQ60wlwURVEUFz26OW+CIuZqHh/vC0/F+fv7sHWXnFtdF10pqqZO/K/WwvbdUFETfryqVqxfa+Gfi8SH66axMbQvb5e09wvSO0simMNwCW/3rkdxs50E9ekqiqK0UUorw+shu/F4oH92aLv4IPzfbPHXRgY9BZm3WPJt122L7qkbrJtcVSPBWZE0+uVYwErf3iKXFd4vO6LGsmu+Bihz+YY7O80musaYm4wxucaY3OYaU1EUpTMTtsQbo3/twN7h57/2b7FCq2tiV6HavANWbIheOg6yZosT6ZwffSyYhlSwF16ZH35sYK8Yg7mWmdfmxTjeSWk20bXW/sVam2OtzWmuMRVFUTozKzYQHZzkYBCxcx8qOhCKKA7EsI7rG+C195oWwfXbpS9uMH/XTbAU5AtzYG+EP3hA7xjpQsFcXQOrNh3mJjsZ2k9XURSljbJkNQT8ToEMl4gFX/v2lIbxbv/ty/+CLokxop4dZn0Y2woG2LBd8nNjYa0EWM2cF77f5+ToQsQcne2AH5asOtKddh6OJmXoDeALYKgxZpcx5qctPy1FURRlzVZoDObfQpTF2zMTEhPC95WUwVNvNC265VXRQVJBaurCc3MjmfFP2F0Uvi8qRzciZcgfgNWbmx6zs3FES9da++PWmIiiKIoSTmEJ5O+F0/oTLryOsHVLk1zeigihrIqITG4uCvZG70tPdeXoRhTFAGmqsKe4ZebTHtHoZUVRlDZKox/eXeRUm3LjiFtaMkweexIm5uJb4yEjJfaxgJVI6KaWszsj6tNVFEVpw7w0D375Y/D4iPKZ+rzw8K2yfLthe9Nj+LzScq9Xlvhfe2WJdZrcRY41+qGqWpam9+yHXfskWKqs8vCCeVp/aePnDfbLdTU6wEpa0otzT/Qb6Fio6CqKorRhNuZLGs+kEa6djrAZAwN6wZ/vhivukspUINrXNQ3GDoWpE+CsUTC4nwhvICAVq+obxe9rrYzj9UJCnBTdwIjgbt0JX6yBj5fLHA6WhzQ1PQWevkvSlqIa2TvbX22F9ZouFIaKrqIoShsmEICHX4K3/+hYlBFRzMbAlHFicd75BAwbCD+7DC46G7IzJY1o5UZ4arFYxDsLobxaime4RdfjkapSaclSYWr4qSLWPzoPfnmV+JfnfwYz3oEN+fCbn8F5Ex3BdUdVO/j98PCLrraDCgDGNhXidiKDGtP8g7YhWuI7a0uYqD9bOx76DNs3ne35xflg2cswJtgMPsbt19TDTQ/BTZdDajK8/wXM/1wKXpRWxM7bPfI8xKIdNQS++w2xmqtqJC3p2buly1H0h+RlzRYYPy26HGWQjvwMc3JyyM3NjflLqKJ7HHTkfyzQ8f/DBn2G7Z3O+PzOGQMLnxMBlpNcB63o8LJ1cM39YpVGRjAnxEOvTCnZ2LeHWMFd00LCWV0rpR3z98DmAok6jmyakBgPPbvB24/L0rWJMQ8MNDTA+bfCJyubvseO/AwPJ7q6vKwoitIO+OwrqSZ13cVOsYwIzTJGmsWPGhxq25cYL1bq9ybD+WeKX9fjkcpSpRUhUU1KgLQUWVpOShCf75ad8MFSmPuJLEvXOp2LRp0GIwe7BDdiHgE/vPkBfKoFMWKilu5x0JH/QoOObyWBPsP2Tmd9fmnJsOJVOLWPiOchbOhlwRfww7vg/Elwx9Uw/nRpwbdkNbz3OazaKJZwdV2o6YHPCaJKT4HsLBg6AL5zJnxzrFjDKzfCk6/L2G/+AS6ZHCN4ChHcgkIYd400azgcHfkZqqWrKIrSASivEkFdMkP66Xpc5RYBjBVrd+oE+N/p8NUWuPF3sCgXikubrlLV4PTKLa0U0Vy6Vpoa9OgK5+bAlefDo7eLXzhnuCt4Knht531VLVw2/ciC25lR0VUURWlHfL0FrroXZj/q+GNdomeRFJ+PlsHkG6USVKNf/MBZGdJ/t19Pec1Mh5QkiYj2O237SsrkM8EqUgfK4c33YfaHUnmqulYs5iu+He3PramHa/4bvtKSj4dFRVdRFKWdMf8zuPFhmHEvJCWG9jf6YeZc8b3W1MJ5k2BqDkwaCYP6iHVcVy+WaFmlWLfWSqpQahdZvk5NluXmimppdr90LSxcDsvXy2dffBe+P8XJ53XEvqYebnkE5sbow6uEo6KrKIrSDnl9PpSWwRsPQ0qi+Hi37Ybl6+BPd8Jl54qIbt8jgjnzXVi7DXbvk2Xq+sZQeclgcYykhFDlqmED4ezRkip08w+hpBSeeE1EfVMBjBwkn6+qk4hpFdyjQ0VXURSlnTL/Mzjnp/DOH+GU3iKM8XFSEOPJ1yX6OH+PWLRHoqERauuk6lT+HvjiaxHqlC4SAX3JZBk3IR6KD4rgFhTCFXdLoJVydGjDA0VRlHbMmq0w/lopWDH+dPjgWchIFSEsOiAW7YlQVSvXmLNIUoWWzICzR8HrCyRKWQX32NCUoeOgI4e6Q8dPNwF9hu0dfX6xPiMFNJ6eDiMGiX+3sETybfcWi7Xb4Cwp+90t+AiVgfR6Qq/xcZLnm5Eq9ZX7Z4sfd8N2+MVjkod7Io+hIz9DTRlSFEXp4FgLi1fBhOvg4nPg3uulbGS/nk5Ob4wG84e2I3rguvcFAlI/+autUkt53uKmSzsqR0ZFV1EUpQPR0ChLwXM/hdMHwvWXwqVTxFL1OZYsRn7cxqaBKKHduQ/mLoYX3pVuQdq84MTR5eXjoCMvi0DHX5oEfYbtHX1+x4bPK52DRp8G54yGcafLEnRaMuwvhe5dJYVobR6s3iIW8+pNsizd0EIN6DvyM9TlZUVRlE5Mox927JOfuYtP9mw6Nxq9rCiKoiithIquoiiKorQSKrqKoiiK0kq0iE93/Pjx5ObmtsTQbQINUmn/6DNs3+jza/909GfYFGrpKoqiKEorodHLiqJEUVJSzI5NH5BSN5vspC9JiSvGWL80bHW1kQtyqL+qAazBGi+VDVkU1kykMuFH9B96AZmZ3Vv/RhSljaGiqyjKIfYV7mLPxpfo53uZMYnbMfEBEVo3jsCGC637BIuhkdS4QlJ9c7H8iwMbBrKqYRq9ht1Adq9+rXU7itLmaJHiGDk5OVZ9uu0X9Se1f471GVZVVrJx5UsM8j1BenwBhhhCG3aBGIMc4RyLoayhP3n1dzJ0/A2kpKQe0xzDLqXPr93TCZ5hzBtUn66idHLyNq9mX+4PGJf8/8iIz+dQQbngfxlBS9b9E9xviK7XG7buHHo1WDLiChiX/CuKcy9l66aVLXNDitKGUdFVlE6K3+9n9Zev0vPAdzk1ZSGGxmhrNUjk/kghdu8/whgGP6ekfEL2wYtY/cXfaGzU6vlK50FFV1E6IfX19az65BFG+m4mxbcPsNFWbGQXmkjLNnI7liXc5BiWlLgiRsb9nNWfPExd3VF0WVeUDoAGUilKJ6O+vp4NXz7A2NQ/4aUhFCgVFMtYLeDcmxYqq6Uoft5uOLUPTB4LqV1cHzvCGLJt8ZpaxqY9xLqlVQyd9FsSEhKa4xYVpc2ioqsonQi/38/XS/4ogmvqwyOPnfeOHgruKGVEcHcXw/UPwKIVUkjf64UpY+GlB6R3a9jqcqRfOOqYxWsaOCPpSVYt6cKYKffh8+l/S0rHRZeXFaUTsWb5G4xNexivaYjyvVoLBytgxhy46fdwzzOQu0F6qwbPDVh48C/w4TIRXAC/Hxbmwv88H36utVBSJn1d/zYPVm6SXq/WbVE7FrHX08DYjEdZu/zVThG5q3Re9E9KRekk5G1exWCm4zU1onwR2lZSBtfcDx8uFXEF+Ovb8Od74KrviMVbVgEfLI09/kfLRLSzMmToVZvgp7+Fr7eKGCcnwU2Xwe9vhaR41weda3mpZYi5h62bRjBkWE4z372itA3U0lWUTkBlRQWePb8OBU1FYBEL9wOX4IKI6P3PQvFBOckfEMs2Fo1+x9K1UFUDtz0Gqzc7+5B9T78Jf1/gzCAqytmS7CsirvDXVFSUn9gNK0obRUVXUToBm1bNZGDKJ4QJrkv0AgH4ONe19OtiRyFs2SHvM1Jh0ojY15h4BnRNk3E374CVG6PPafTDWwvDhT1MfI1lQMoStqx88ehuTFHaGSq6itLB2Ve4i0G+JwA/+8tg3mJ45T2xQhuDPlgDifGxP+/1QEK8nOPzwoO3wIhB4eeccSo89HM5DlDfIFZxLGrqHHG3cv2vNsOr78HcxY5FjZ9B8U9RuHdnM9y9orQtVHQVpYOzZ8OLpMcXsHw9TL0Fvv8ruO438M0b4b5nobYePAYunxoSTTdjh8LQAfLeGBh+Cix4Bu67AeJ8cM9/yvYZg5xIZ2BwPxjYK3osA5w7XoS8rgF+8xxMvhGm/QZ+8GuZ39K1kBa3g8KNM1rqK1GUk4aKrqJ0YEpKiukX9zLlVZZbH4E1W0M+1opqePI1eOsj2f6P8+H2qyTgCURARw+BZ+6GlC4cijY2Bnp3hwnDZazxw6BP90MZQABkpkvAVGZ6aC7GwLcmwM2Xy/Y7i+DxV2UeIGOtzYNbH4WySku/+Fco2V/Uot+PorQ2KrqK0oHZsekDMhPzWb9NoogjaWiEtz+W5d7EeHjkNlj0PFx8DqQkwcwHYNywkAUbxFpYv12WkNfmxU7B/eFUeOV3kJQgy9HP3gOzHoHuXeXz7yyU60eyZquM2S1hBzs2L2imb0JR2gYquorSQfH7/aTUzcIQoO4wPtbaulABqTgvjD8dBvSCyhpYvt45KUYBjXV5smttXkQAljOYMVB8QJavJ5whFm63tJCA19bHnk8gIEvPxgRIrZuFv6lwaUVph6joKkoHpWT/PrKTvgQswwZA3x7R5xgjPlZPRB3l8koR0rcWhopguKlvgE0F8n7LDpeAusbw+2H2QhmnvDK66f25OdEWNECfHnD6QABLdtIyiov2HvO9K0pbRUVXUToo+3Z9TUrcfjDQM1OiizNcLWwNcN5EuP7S8JrJ1kJ5lWwuXQvbdhOR1gOl5bBzn2zuLpbCGrjGACgohM+/kvcV1WBdlrYx8JNL4MKzwodOT4Hf3gK9smQ72befot2rj/9LUJQ2hoquonRQakuXY6yYqcbA1RdKlPH0aZJTG+eD6dc5wU6uGskBp6EBQGkFvPeZs3zsUsedRXIMRKB37A0fw1pY8AUccMS4stpZ3naN0TUV7roO4uNkSfvX0+DfT8O1F4UsYEOA+tJlzf7dKMrJQkVXUTooaZ6vpYOQE3XsMTBxODx6O9zxYwlienmey9frnOcPiD83yDsfy3Kyu3Xfpnzxu4KMszE/lHuLdQK0FoaWlCtrnOvY8OvMnCfj3HYlPHY7nDkSvGHNESzpnjUt9h0pSmujoqsoHZSMOCdcOcJvagz07Sndgd79VKKFD1myRnyxbtFduRE2FoS2LbAmL3zMQ9vOGFt3uoKwgOpacPeqDwZizVkk8wjrTuTu0QukJ2w7lttWlDaNiq6idFB6pDgBSDEa0PfMlFSe8ip4blaoZnLQSq1x9ZSvrIF5n4bqJQcCocjlIOu3hSxZa2HekpBfGCRCuq4hNIeAhedmQ1mlpCoFfbhuSxjnet1TCpvrK1GUk46KrqJ0VPxl0bWUHUHrlgZpybLrrYViyQZPrW8QkXQz55OQEFfXQd6u8OPbdof8wLX1siTtpqbOWaJGRHlTAcxyinKkdnH5lSMa31sLNGrzA6XjcETRNcb0M8Z8bIxZb4xZZ4z5ZWtMTFGUE2P3viYSYY1UncrKkM0D5fD8W6Fc27r66BzadXmyDA1SH7lwf/jxogOw74CMvX4bfL0l/Hi9y3q2Vq4XDLLKygiveBW5HL6nqIn7UJR2yNFYuo3Ar6y1w4EzgVuNMcNbdlqKopwofXrGyZugiLmax8f7pJRjkL+/D1t3ybnVddGVomrqxP9qLWzfDRU14cerasX6tRb+uUh8uG4aG0P78nZJe78gvbMkgjkMl/D27hF5UFHaL0cUXWvtXmvtSud9BbAB6NPSE1MU5QTxZoTVQ3bj8UD/7NB28UH4v9nir40Megoyb7Hk267bFt1TN1g3uapGgrMiafTLsYCVvr1FB0PH+mVLA4RDRHYf9LkKOCtKO+eYfLrGmIHAWGBpjGM3GWNyjTG5xcXFzTQ9RVGOl+JKV5ufGP1rB/YOP/+1f4sVWl0TuwrV5h2wYkP00nGQNVucSOf86GPBNKSCvfDK/PBjsboRuZeZiyuzY5ygKO2ToxZdY0wK8BZwh7U2KrLBWvsXa22OtTane/fu0QMoitKqlNYPig5OcjCI2LkPFR0IRRQHYljH9Q3w2nti0cZi/XbpixvM33UTLAX5whzYG+EPHtA7RrpQMFfXQFnjqYe7TUVpV/iO5iRjTBwiuK9Za99u2SkpitIclAVGgX1bCmS4RCz42rcn+Hzh/tuX/wVdEomOenaY9WFsKxhgw3bJz42FtRJgNXNe+H6fk6ML4XMLbRvKGkYe8V4Vpb1wRNE1xhjgBWCDtfaJlp+SoijNQWLXCVi8GNsY0+LtmQmJCeGiW1IGT73RtOi6c28jqakLz++NZMY/YXdEe9yoHN3IlCE8xGdMbHpQRWlnHM3y8tnANGCqMWa183NRC89LUZQTpGff0VQ2ZIUsSHd7PiRXNz05+nNVNdH7moOCGM2C0lMjaj+75wlUN2bSo8+YlpmQopwEjiZ6eYm11lhrR1lrxzg/84/0OUVRTi6ZWT0prJlElInrCFtaMkweezJmFuJb4yEjpYmDxrC3diJZ3TWQSuk4HJVPV1GU9ofX66Uy4QqsnYfBH+Uz9Xnh4Vth9WbxxzaFzyst93plif+1V5ZYp8ld5FijH6qqZWl6z37YtU+Cpcoqm/b/ApzWX9r4eb3ODnejA2dpuTz+Cnw+/W9K6Tjov2ZF6cD0H3oBBzYMJDPRFXLsCJsxMKAX/PluuOIuqUwFon1d02DsUJg6Ac4aBYP7ifAGAlKxqr5R/L7WyjheLyTESdENjAju1p3wxRr4eLmkEh0sD2lqego8fZekLUU1sne2D9b2p/9pF7bcl6MoJwEVXUXpwGRmdmdVwzS6JT6IITqK2RiYMk4szjufgGED4WeXwUVnQ3ampBGt3AhPLRaLeGchlFdL8Qy36Ho8UlUqLVkqTA0/VcT6R+fBL6+CwhKY/xnMeAc25MNvfgbnTXQE1x1V7WCtYUf9tYzp3jP6phSlHWNsU2GKJ0BOTo7Nzc1t9nHbCibqT/OORUv8m2hrdKZnWLh3J4n5k8mId/rzxXi8NfVw00Nw0+WQmgzvfwHzP5eCF6UVsfN2j4QxYtGOGgLf/YZYzVU1kpb07N3S5Sj6Q/JSVt+fmgGLye7dv4mxO8/z66h0gmcY8wbV0lWUDk52r36s3HwnY+N+Jb5diErNSYyHX1wJ19wvVmlkBHNCPPTKlJKNfXuIFdw1LSSc1bVS2jF/D2wugJ37pGlCaQV8ulJ+EuOhZzd4+3FJVYo1DwBrveTV/5JxTQiuorRnVHQVpRNw2vgbKMidw8CUT6RYRoQhZQyMGwajBofa9iXGi5X6vclw/pni1/V4pLJUaUWoE1FSAqSlyNJyUoL4fLfshA+WwtxPZFm61ulcNOo0GDnY0dqIJWUArGFH1TcYMu7Glv1CFOUkoaKrKJ2AlJRUCrMfp7L0YlLiikR4gzgpRD6vLC8v+BLOnwR3XA3jT5cWfEtWw9NvwqqNYglX14WaHvicIKr0FMjOgqED4DtnwrTvwu1Xik/4yddhwRfwsx/I+WFVpw7Nw1Dl7059jz+RmprWGl+LorQ6KrqK0kkYPGw8q798jJH2FrymNlR2yhE+Y8XanToB/nc6fLUFbvwdLMqF4tKmq1Q1OL1ySyuhoBCWrpWmBj26wrk5cOX58Ojt4hfOGe4Kngpe23nvJ5FNDX9g7LCclvsSFOUko6KrKJ2IETlXs+qTfMamPYTXNISJnkVSfD5aBpNvhD3Fkmcb55NG8727S55u7+6Sp5uSJKlCfqdtX0mZfGbnPnk9UA5vvg+zP5TKU9W1YjFf8W3X8rKDnzhWl01n9JTrOnyAjdK5UdFVlE6Ez+dj5Dl3s25pNWckPSHC69Doh5lzxfdaUwvnTYKpOTBpJAzqA8lJ4q8trZQ83Jo6sX7j4yC1i/h0U5Nl+biiWprdL10LC5fD8vXy2Rffhe9PcfJ5D1m4cayvvp0R59yrhTCUDo/+C1eUTkZCQgJDJz3IqiVdGJP+CD5qAcu23bB8HfzpTrjsXBHR7XtEMGe+C2u3we590vSgvlEKZUCoOEZSQqhy1bCBcPZoSRW6+YdQUgpPvCaivqkARg4CMPhNIqtLpzPinHtJSIiVQ6QoHQsVXUXphCQkJDBmyr18vXQAQ713k+wroqTUEh8nBTGefF2ij/P3HL5zUJCGRqitk6pT+Xvgi69FqFO6SAT0JZNl3IR4KD4IIEFTW/x/YPSU69TCVToNR93EXlGUjoXP52Pc2T9hb9d/kV85hUkjvXzwLGSkSsRx0QGxaE+EqlpYsxXmLJJUoSUzYMo4LwVV57AnbR6jz7peBVfpVGhFquOgowd6aDWc9s+xPsPKygo2r3iBQfFPkRa3g/oGS2GJ5NvuLRZrt8FZUvZHtN8LloH0ekKv8XGS55uRKvWV+2dDYryhvKEvefV3MGTcjSeUFqTPr/3TCZ5hzBtU0T0OOsE/lpM9hRZHn2FsCvfupHDTC/SLe4VuCQUYE8Bp+RNdPcrdA5cYx52dFg8H6/qzo/5asofe2GRpx2NBn1/7pxM8QxXd5qIT/GM52VNocfQZHp6S/UXs2LyA1LrZZCctJTmuBGP9EGyaQHjebvi3KUJb3ZjJ3poJlCf8iP5DLiSrGZsX6PNr/3SCZ6i1lxVFOToys3qQmTUNv/9qiov2sm3XaurLlpPuXUN6fB7dkwvBX86eonp694jDetMprsqmrOEUyhpHEpc+kZ79xzCwRy/12SqKC/1tUBSlSbxeL9m9+pLdqy9wSdTxPq73PZwfRVGaRqOXFUVRFKWVUNFVFEVRlFZCRVdRFEVRWgkVXUVRFEVpJVokkGrFihUdOhy8o4fzd+RnF0SfYftGn1/7pyM/w5ycpttTavSyoiiK0m7x+/2UlBSxb+dX1JYuJ83zNRlxW+mRuhcay9hdVE+fHvHgTae4shelDYMo848ksetEevYdTWZWT7xeb6vNt0WKYxhjOu6fMHTsv9BA/8ruCHT0Z6jPr/1zwgVcSorZsekDUupmk530JSlxxVLAxdiwHtFBTLB3tAGswRovlQ1ZFNZMpDLhR/QfegGZmd1PaE5BcnJyyM3N1eIYiqIoSvtmX+Eu9mx8iX6+lxmTuB0THxChdeMIbLjQuk+wGBpJjSsk1TcXy784sGEgqxqm0WvYDWT36tdi81dL9zjQv7LbP/oM2zf6/No/x/oMqyor2bjyJQb5niA9vgBDDKENu0CMQY5wjsVQ1tCfvPo7GTr+BlJSUo9pjkEOZ+lq9LKiKIrSpsnbvJp9uT9gXPL/IyM+n0N2XVDWgpas+ye430BUM46wdefQq8GSEVfAuORfUZx7KVs3rWz2e1HRVRRFUdokfr+f1V++Ss8D3+XUlIUYGqOt1SCR+yOF2L3/CGMY/JyS8gnZBy9i9Rd/o7HxBBtLu1DRVRRFUdoc9fX1rPrkEUb6bibFt49DLSbdVmxki8lIyzZyO5Yl3OQYlpS4IkbG/ZzVnzxMXV1ds9yXBlIpiqIobYr6+no2fPkAY1P/hJeGUKBUUCxj9Xd2b1qorIbFqyBvN5zaByaPhdQuro8dYQzZtnhNLWPTHmLd0iqGTvotCQkJJ3RvKrqKoihKm8Hv9/P1kj+K4Jr68Mhj572jh4I7ShkR3N3FcP0DsGgFNPrB64UpY+GlB6Bfz4jV5Ui/cNQxi9c0cEbSk6xa0oUxU+47oXaVurysKIqitBnWLH+DsWkP4zUNUb5Xa+FgBcyYAzf9Hu55BnI3QCDAoXMDFh78C3y4TAQXwO+HhbnwP8+Hn2stlJTB3E/hb/Ng5SZoaJT9cgKHLGKvp4GxGY+ydvmrJxQ9r5auoiiK0ibI27yKwUzHa2pE+SK0raQMrrkfPlwq4grw17fhz/fAVd8Ri7esAj5YGnv8j5aJaGdlyNCrNsFPfwtfbxUxTk6Cmy6D398KSfGuDzrX8lLLEHMPWzeNYMiwpks9Hg61dBVFUZSTTmVFBZ49vw4FTUVgEQv3A5fggojo/c9C8UE5yR8QyzYWjX7H0rVQVQO3PQarNzv7kH1Pvwl/X+DMICrK2ZLsKyKu8NdUVJQf132q6CqKoignnU2rZjIw5RPCBNcleoEAfJzrWvp1saMQtuyQ9xmpMGlE7GtMPAO6psm4m3fAyo3R5zT64a2F4cIeJr7GMiBlCVtWvnh0NxaBiq6iKIpyUtlXuItBvicAP/vLYN5ieOU9sUIbgz5YA4nxsT/v9UBCvJzj88KDt8CIQeHnnHEqPPRzOQ5Q3yBWcSxq6hxxt3L9rzbDq+/B3MWORY2fQfFPUbh35zHfq4quoiiKclLZs+FF0uMLWL4ept4C3/8VXPcb+OaNcN+zUFsPHgOXTw2JppuxQ2HoAHlvDAw/BRY8A/fdAHE+uOc/ZfuMQU6kMzC4HwzsFT2WAc4dL0Je1wC/eQ4m3wjTfgM/+LXMb+laSIvbQeHGGcd8ryq6iqIoykmjpKSYfnEvU15lufURWLM15GOtqIYnX4O3PpLt/zgfbr9KAp5ABHT0EHjmbkjpwqFoY2Ogd3eYMFzGGj8M+nQ/lAEEQGa6BExlpofmYgx8awLcfLlsv7MIHn9V5gEy1to8uPVRKKu09It/hZL9Rcd0vyq6iqIoykljx6YPyEzMZ/02iSKOpKER3v5YlnsT4+GR22DR83DxOZCSBDMfgHHDQhZsEGth/XZZQl6bFzsF94dT4ZXfQVKCLEc/ew/MegS6d5XPv7NQrh/Jmq0yZreEHezYvOCY7ldFV1EURTkp+P1+UupmYQhQdxgfa21dqIBUnBfGnw4DekFlDSxf75wUo4DGujzZtTYvIgDLGcwYKD4gy9cTzhALt1taSMBr62PPJxCQpWdjAqTWzcLfVLh0DFR0FUVRlJNCyf59ZCd9CViGDYC+PaLPMUZ8rJ6IOsrllSKkby0MFcFwU98Amwrk/ZYdLgF1jeH3w+yFMk55ZXTT+3Nzoi1ogD494PSBAJbspGUUF+096ntW0VUURVFOCvt2fU1K3H4w0DNTooszXC1sDXDeRLj+0vCaydZCeZVsLl0L23YTkdYDpeWwc59s7i6Wwhq4xgAoKITPv5L3FdVgXZa2MfCTS+DCs8KHTk+B394CvbJkO9m3n6Ldq4/6nlV0FUVRlJNCbelyjBUz1Ri4+kKJMp4+TXJq43ww/Ton2MlVIzngNDQAKK2A9z5zlo9d6rizSI6BCPSOveFjWAsLvoADjhhXVjvL264xuqbCXddBfJwsaf96Gvz7abj2opAFbAhQX7rsqO9ZRVdRFEU5KaR5vpYOQk7UscfAxOHw6O1wx48liOnleS5fr3OePyD+3CDvfCzLye7WfZvyxe8KMs7G/FDuLdYJ0FoYWlKurHGuY8OvM3OejHPblfDY7XDmSPCGNUewpHvWHPU9q+gqiqIoJ4WMOCdcOcJvagz07Sndgd79VKKFD1myRnyxbtFduRE2FoS2LbAmL3zMQ9vOGFt3uoKwgOpacPeqDwZizVkk8wjrTuTu0QukJ2w76ntW0VUURVFOCj1SnACkGA3oe2ZKKk95FTw3K1QzOWil1rh6ylfWwLxPQ/WSA4FQ5HKQ9dtClqy1MG9JyC8MEiFd1xCaQ8DCc7OhrFJSlYI+XLcljHO97imFR33PRxRdY0yiMWaZMeYrY8w6Y8yDRz26oiiKojSFvyy6lrIjaN3SIC1Zdr21UCzZ4Kn1DSKSbuZ8EhLi6jrI2xV+fNvukB+4tl6WpN3U1DlL1IgobyqAWU5RjtQuLr9yRON7a4HGo29+cDSWbh0w1Vo7GhgDXGiMOfOor6AoiqIoMdi9r4lEWCNVp7IyZPNAOTz/VijXtq4+Ood2XZ4sQ4PURy7cH3686ADsOyBjr98GX28JP17vsp6tlesFg6yyMsIrXkUuh+8pauI+YnBE0bVCpbMZ5/wcfwdfRVEURQH69IyTN0ERczWPj/dJKccgf38ftu6Sc6vroitF1dSJ/9Va2L4bKmrCj1fVivVrLfxzkfhw3TQ2hvbl7ZL2fkF6Z0kEcxgu4e3dI/Jg0xyVT9cY4zXGrAaKgA+stVEtgo0xNxljco0xuUd9dUVRFKXz4s0Iq4fsxuOB/tmh7eKD8H+zxV8bGfQUZN5iybddty26p26wbnJVjQRnRdLol2MBK317iw6GjvXLlgYIh4jsPuhzFXA+AkclutZav7V2DNAXmGiMiepWaK39i7U2x1qbc9RXVxRFUTotxZWuNj8x+tcO7B1+/mv/Fiu0uiZ2FarNO2DFhuil4yBrtjiRzvnRx4JpSAV74ZX54cdidSNyLzMXV2bHOCE2xxS9bK0tBT4GLjyWzymKoihKJKX1g6KDkxwMInbuQ0UHQhHFgRjWcX0DvPaeWLSxWL9d+uIG83fdBEtBvjAH9kb4gwf0jpEuFMzVNVDWeOrhbjMM35FOMMZ0BxqstaXGmCTgfODRo76CoiiKosSgLDAK7NtSIMMlYsHXvj3B5wv33778L+iSSHTUs8OsD2NbwQAbtkt+biyslQCrmfPC9/ucHF0In1to21DWMPKI93povKM4pxfwN2OMF7GM/2GtnXeEzyiKoijKYUnsOgGLF2MbY1q8PTMhMSFcdEvK4Kk3mhZdd+5tJDV14fm9kcz4J+yOaI8blaMbmTKEh/iMiU0PGsERRdda+zUw9qhHVBRFUZSjoGff0VRuzyI1rjC8NZ8jbN3SID0ZKiKEtCoiMrm5KIjRLCg91ZWjG1EUA6C6MZMeA8Yc9TW0IpWiKIpyUsjM6klhzSSiTFxH3NKSYfJJNvm+NR4yUpo4aAx7ayeS1f3oA6mOZnlZURRFUZodr9dLZcIVWDsPgz/KZ+rzwsO3wurN4o9tCp9XWu71yhL/a68ssU6Tu8ixRj9UVcvS9J79sGufBEuVVTbt/wU4rb+08fN6nR3uRgfO0nJ5/BX4fEcvpSq6iqIoykmj/9ALOLBhIJmJrpBjR9iMgQG94M93wxV3SWUqEO3rmgZjh8LUCXDWKBjcT4Q3EJCKVfWN4ve1VsbxeiEhTopuYERwt+6EL9bAx8sllehgeUhT01Pg6bskbSmqkb2zfbC2P/1PO7ZkHhVdRVEU5aSRmdmdVQ3T6Jb4IIboKGZjYMo4sTjvfAKGDYSfXQYXnQ3ZmZJGtHIjPLVYLOKdhVBeLcUz3KLr8UhVqbRkqTA1/FQR6x+dB7+8CgpLYP5nMOMd2JAPv/kZnDfREVx3VLWDtYYd9dcypnvP6Js6DMY2FQJ2AhhjOnSZyJb4ztoSJurPuo6HPsP2jT6/9o/7GRbu3Uli/mQy4p3+fDEeb0093PQQ3HQ5pCbD+1/A/M+l4EVpRey83SNhjFi0o4bAd78hVnNVjaQlPXu3dDmK/pC8lNX3p2bAYrJ79486JScnh9zc3JgPUS1dRVEU5aSS3asfKzffydi4X4lvF6JScxLj4RdXwjX3i1UaGcGcEA+9MqVkY98eYgV3TQsJZ3WtlHbM3wObC2DnPmmaUFoBn66Un8R46NkN3n5cUpVizQPAWi959b9kXAzBPRIquoqiKMpJ57TxN1CQO4eBKZ9IsYwIy9UYGDcMRg0Ote1LjBcr9XuT4fwzxa/r8UhlqdKKUCeipARIS5Gl5aQE8flu2QkfLIW5n8iydK3TuWjUaTBysKO1EUvKAFjDjqpvMGTcjcd1nyq6iqIoykknJSWVwuzHqSy9mJS4IhHeIE4Kkc8ry8sLvoTzJ8EdV8P406UF35LV8PSbsGqjWMLVdaGmBz4niCo9BbKzYOgA+M6ZMO27cPuV4hN+8nVY8AX87AdyfljVqUPzMFT5u1Pf40+kpqYd132q6CqKoihtgsHDxrP6y8cYaW/Ba2pDZacc4TNWrN2pE+B/p8NXW+DG38GiXCgubbpKVYPTK7e0EgoKYelaaWrQoyucmwNXng+P3i5+4ZzhruCp4LWd934S2dTwB8YOO/6+Piq6iqIoSpthRM7VrPokn7FpD+E1DWGiZ5EUn4+WweQbYU+x5NnG+aTRfO/ukqfbu7vk6aYkSaqQ32nbV1Imn9m5T14PlMOb78PsD6XyVHWtWMxXfNu1vOzgJ47VZdMZPeW6Ewp0U9FVFEVR2gw+n4+R59zNuqXVnJH0hAivQ6MfZs4V32tNLZw3CabmwKSRMKgPJCeJv7a0UvJwa+rE+o2Pg9Qu4tNNTZbl44pqaXa/dC0sXA7L18tnX3wXvj/Fyec9ZOHGsb76dkacc+8xFcKIeX8n9GlFURRFaWYSEhIYOulBVi3pwpj0R/BRC1i27Ybl6+BPd8Jl54qIbt8jgjnzXVi7DXbvk6YH9Y1SKANCxTGSEkKVq4YNhLNHS6rQzT+EklJ44jUR9U0FMHIQgMFvElldOp0R59xLQkKsHKJjQ0VXURRFaXMkJCQwZsq9fL10AEO9d5PsK6Kk1BIfJwUxnnxdoo/z9xy+c1CQhkaorZOqU/l74IuvRahTukgE9CWTZdyEeCg+CCBBU1v8f2D0lOtO2MINog0PFEVRlDaJz+dj3Nk/YW/Xf5FfOYVJI7188CxkpErEcdEBsWhPhKpaWLMV5iySVKElM2DKOC8FVeewJ20eo8+6vtkEF7Qi1XGh1XDaP/oM2zf6/No/x/oMKysr2LziBQbFP0Va3A7qGyyFJZJvu7dYrN0GZ0nZ727BR6gMpNcTeo2PkzzfjFSpr9w/GxLjDeUNfcmrv4Mh42487rSgw1WkUtE9DvQXvv2jz7B9o8+v/XO8z7Bw704KN71Av7hX6JZQgDEBnJY/0dWjjOs9MY47Oy0eDtb1Z0f9tWQPvTFmacdjQUW3mdFf+PaPPsP2jT6/9s+JPsOS/UXs2LyA1LrZZCctJTmuBGP9EGyaQHjebvg3KkJb3ZjJ3poJlCf8iP5DLiTrGJsXNIXWXlYURVE6FJlZPcjMmobffzXFRXvZtms19WXLSfeuIT0+j+7JheAvZ09RPb17xGG96RRXZVPWcApljSOJS59Iz/5jGNijV7P6bI+Eiq6iKIrSbvF6vWT36kt2r77AJVHH+7je93B+TiYavawoiqIorYSKrqIoiqK0Eiq6iqIoitJKtIhPd/z48eTm5rbE0G2Cjh5Z2NEjQ0GfYXtHn1/7p6M/w6ZQS1dRFEVRWok2F71cUlLMjk0fkFI3m+ykL0mJK5bcK2PD2jsFOdT30ADWYI2XyoYsCmsmUpnwI/oPvYDMzO6tfyOKoiiKEkGbEd19hbvYs/El+vleZkzidkx8QITWjSOw4ULrPsFiaCQ1rpBU31ws/+LAhoGsaphGr2E3kN2rX2vdjqIoiqJE0SIVqXJycuzR+nSrKivZuPIlBvmeID2+AEMMoXUTa7pHOMdiKGvoT179nQwdfwMpKalHNbem6Oi+CPUntX86+jPU59f+6QTPMOYNnlSfbt7m1ezL/QHjkv8fGfH5HKoeGZxq0JJ1/wT3G4iqoxm27hx6NVgy4goYl/wrinMvZeumlS1zQ4qiKIpyGE6K6Pr9flZ/+So9D3yXU1MWYmiMtlaDRO6PFGL3/iOMYfBzSsonZB+8iNVf/I3GxhPsCaUoiqIox0Cri259fT2rPnmEkb6bSfHt41B3CLcVG9kdItKyjdyOZQk3OYYlJa6IkXE/Z/UnD1NXdxTdjxVFURSlGWjVQKr6+no2fPkAY1P/hJeGUKBUUCxjtWZyb1qorIbFqyBvN5zaByaPhdQuro8dYQzZtnhNLWPTHmLd0iqGTvotCQkJzXGLiqIoitIkrSa6fr+fr5f8UQTX1IdHHjvvHT0U3FHKiODuLobrH4BFK6DRD14vTBkLLz0A/XpGrC5H+oWjjlm8poEzkp5k1ZIujJlyX6t2mlAURVE6H622vLxm+RuMTXsYr2mI8r1aCwcrYMYcuOn3cM8zkLsBAgEOnRuw8OBf4MNlIrgAfj8szIX/eT78XGuhpAzmfgp/mwcrN0FDo6u3YnAp2oDX08DYjEdZu/zVThExqCiKopw8WsW0y9u8isFMx2tqRPkitK2kDK65Hz5cKuIK8Ne34c/3wFXfEYu3rAI+WBp7/I+WiWhnZcjQqzbBT38LX28VMU5Ogpsug9/fCknxrg861/JSyxBzD1s3jWDIsJxmvntFURRFEVrc0q2sqMCz59ehoKkILGLhfuASXBARvf9ZKD4oJ/kDYtnGotHvWLoWqmrgtsdg9WZnH7Lv6Tfh7wucGURFOVuSfUXEFf6aioryE7thRVEURWmCFhfdTatmMjDlE8IE1yV6gQB8nOta+nWxoxC27JD3GakwaUTsa0w8A7qmybibd8DKjdHnNPrhrYXhwh4mvsYyIGUJW1a+eHQ3piiKoijHSIuK7r7CXQzyPQH42V8G8xbDK++JFdoY9MEaSIyP/XmvBxLi5RyfFx68BUYMCj/njFPhoZ/LcYD6BrGKY1FT54i7let/tRlefQ/mLnYsavwMin+Kwr07m+HuFUVRFCWcFhXdPRteJD2+gOXrYeot8P1fwXW/gW/eCPc9C7X14DFw+dSQaLoZOxSGDpD3xsDwU2DBM3DfDRDng3v+U7bPGOREOgOD+8HAXtFjGeDc8SLkdQ3wm+dg8o0w7Tfwg1/L/JauhbS4HRRunNFSX4miKIrSiWkx0S0pKaZf3MuUV1lufQTWbA35WCuq4cnX4K2PZPs/zofbr5KAJxABHT0EnrkbUrpwKNrYGOjdHSYMl7HGD4M+3Q9lAAGQmS4BU5npobkYA9+aADdfLtvvLILHX5V5gIy1Ng9ufRTKKi394l+hZH9RS301iqIoSielxUR3x6YPyEzMZ/02iSKOpKER3v5YlnsT4+GR22DR83DxOZCSBDMfgHHDQhZsEGth/XZZQl6bFzsF94dT4ZXfQVKCLEc/ew/MegS6d5XPv7NQrh/Jmq0yZreEHezYvKCZvglFURRFEVpEdK21pNTNwhCg7jA+1tq6UAGpOC+MPx0G9ILKGli+PjiY8+oqoLEuT3atzYsIwHIGMwaKD8jy9YQzxMLtlhYS8Nr62PMJBGTp2ZgAqXWz8DcVLq0oiqIox0ELiW4D2UlfApZhA6Bvj+hzjBEfqyeijnJ5pQjpWwtDRTDc1DfApgJ5v2WHS0BdY/j9MHuhjFNeGd30/tycaAsaoE8POH0ggCU7aRnFRXuP+d4VRVEUpSlaRHTTkmpIidsPBnpmSnRxhquFrQHOmwjXXxpeM9laKK+SzaVrYdtuItJ6oLQcdu6Tzd3FUlgD1xgABYXw+VfyvqIarMvSNgZ+cglceFb40Okp8NtboFeWbCf79lO0e/XxfwmKoiiKEkGLiO6g3tUYK2aqMXD1hRJlPH2a5NTG+WD6dU6wk6tGcsBpaABQWgHvfeYsH7vUcWeRHAMR6B17w8ewFhZ8AQccMa6sdpa3XWN0TYW7roP4OFnS/vU0+PfTcO1FIQvYEKC+dFmzfzeKoihK56VFRHf8adXSQciJOvYYmDgcHr0d7vixBDG9PM/l63XO8wfEnxvknY9lOdndum9TvvhdQcbZmB/KvcU6AVoLQ0vKlTXOdWz4dWbOk3FuuxIeux3OHAnesOYIlnTPmpb4ehRFUZROSouI7ohBTo/aCL+pMdC3p3QHevdTiRY+ZMka8cW6RXflRthYENq2wJq88DEPbTtjbN3pCsICqmvB3as+GIg1Z5HMI6w7kbtHL5CesO1YbltRFEVRDkuLiO7wAY4pGqMBfc9MSeUpr4LnZoVqJget1BpXT/nKGpj3aaheciAQilwOsn5byJK1FuYtCfmFQSKk6xpCcwhYeG42lFVKqlLQh+u2hHGu1z2lsLm+EkVRFEU5etE1xniNMauMMfOOdG5ykj+6lrIjaN3SIC1Zdr21UCzZ4Kn1DSKSbuZ8EhLi6jrI2xV+fNvukB+4tl6WpN3U1DlL1IgobyqAWU5RjtQuLr9yRON7a4FGbX6gKIqiNB/HYun+EthwNCcWHWiiL62RqlNZGbJ5oByefyuUa1tXH51Duy5PlqFB6iMX7o+8Fuw7IGOv3wZfbwk/Xu+ynq2V6wWDrLIywiteRS6H7ylqIqFXURRFUY6DoxJdY0xf4GLgqIoS98w8FAIsuJrHx/uklGOQv78PW3fJudV10ZWiaurE/2otbN8NFTXhx6tqxfq1Fv65SHy4bhobQ/vydkl7vyC9sySCOfxmXcd7RB5UFEVRlOPnaC3dp4C7gCZqS4Ex5iZjTK4xJre80oTVQw67oAf6Z4e2iw/C/80Wf21k0FOQeYsl33bdtuieusG6yVU1EpwVSaNfjgWs9O0tOhg61i9bGiAcIrL7oM9VwFlRFEVRTpAjiq4x5hKgyFq74nDnWWv/Yq3NsdbmbNqZ4DrgHkxeBvYO/+xr/xYrtLomdhWqzTtgxYbopeMga7Y4kc750ceCaUgFe+GV+eHHYnUjci8zF1dmxzhBURRFUY6Po7F0zwYuNcbkA38HphpjXj3cB9bmJUQHJzkYROzch4oOhCKKAzGs4/oGeO09sWhjsX679MUN5u+6CZaCfGEO7I3wBw/oHSNdKJira6Cs8dTD3aaiKIqiHBO+I51grf0v4L8AjDHnAr+21l57uM+s2JwEtkwKZLhELPjatyf4fOH+25f/BV0SiY56dpj1YWwrGGDDdsnPjT1/CbCaGRFz7XNydCF8bqFtQ1nDyMPdpqIoiqIcE0cU3eMhb08y1ngxtjGmxdszExITwkW3pAyeeqNp0XXn3kZSUxee3xvJjH/C7oj2uFE5upEpQ3iIz5jY9KCKoiiKcowcU3EMa+0ia+0lRzqvrCaJyoaskAXpbs+H5OqmJ0d/rqomel9zUBCjWVB6akTtZ/c8gerGTHr0GdMyE1IURVE6JS1SkcqYOAprJhFl4jrClpYMk8e2xJWPnm+Nh4yUJg4aw97aiWR110AqRVEUpflokeVlYwyVCVdg7TwM/iifqc8LD98KqzeLP7bJyXml5V6vLPG/9soS6zS5ixxr9ENVtSxN79kPu/ZJsFRZZdP+X4DT+ksbP683OGHCcoktHsrjr8Dna5GvR1EURemktJiq9B96AQc2DCQz0RVy7AibMTCgF/z5brjiLqlMBaJ9XdNg7FCYOgHOGgWD+4nwBgJSsaq+Ufy+1so4Xi8kxEnRDYwI7tad8MUa+Hi5pBIdLA9panoKPH2XpC1FNbJ3tg/W9qf/aRe21FejKIqidFJaTHQzM7uzqmEa3RIfxBAdxWwMTBknFuedT8CwgfCzy+CisyE7U9KIVm6EpxaLRbyzEMqrpXiGW3Q9HqkqlZYsFaaGnypi/aPz4JdXQWEJzP8MZrwDG/LhNz+D8yY6guuOqnaw1rCj/lrGdO8ZfVOKoiiKcgIY21S48AmQk5Njc3NzKdy7k8T8yWTEO/35Ylyqph5ueghuuhxSk+H9L2D+51LworQidt7ukTBGLNpRQ+C73xCruapG0pKevVu6HEV/SF7K6vtTM2Ax2b37H2b8GAnIHYiW+DfR1tBn2L7R59f+6QTPMOYNtqjTMrtXP1ZuvpOxcb8S3y5EpeYkxsMvroRr7herNDKCOSEeemVKyca+PcQK7poWEs7qWintmL8HNhfAzn3SNKG0Aj5dKT+J8dCzG7z9uKQqxZoHgLVe8up/ybjDCK6iKIqiHC8tHil02vgbKMidw8CUT6RYRsQfcMbAuGEwanCobV9ivFip35sM558pfl2PRypLlVaEOhElJUBaiiwtJyWIz3fLTvhgKcz9RJala53ORaNOg5GDHa2NWFIGwBp2VH2DIeNubNkvRFEURem0tLjopqSkUpj9OJWlF5MSVyTCG8RJIfJ5ZXl5wZdw/iS442oYf7q04FuyGp5+E1ZtFEu4ui7U9MDnBFGlp0B2FgwdAN85E6Z9F26/UnzCT74OC76An/1Azg+rOnVoHoYqf3fqe/yJ1NS0lv5KFEVRlE5Kq+TEDB42ntVfPsZIewteUxsqOxXsAGjF2p06Af53Ony1BW78HSzKheLSpqtUNTi9cksroaAQlq6VpgY9usK5OXDl+fDo7eIXzhnuCp4KXtt57yeRTQ1/YOywnJb7EhRFUZROT6sloo7IuZpVn+QzNu0hvKYhTPQskuLz0TKYfCPsKZY82zifNJrv3V3ydHt3lzzdlCRJFfI7bftKyuQzO/fJ64FyePN9mP2hVJ6qrhWL+Ypvu5aXHfzEsbpsOqOnXNfhHfuKoijKyaXVRNfn8zHynLtZt7SaM5KeEOF1aPTDzLnie62phfMmwdQcmDQSBvWB5CTx15ZWSh5uTZ1Yv/FxkNpFfLqpybJ8XFEtze6XroWFy2H5evnsi+/C96c4+byHLNw41lffzohz7tVCGIqiKEqL06pKk5CQwNBJD7JqSRfGpD+Cj1rAsm03LF8Hf7oTLjtXRHT7HhHMme/C2m2we580PahvlEIZECqOkZQQqlw1bCCcPVpShW7+IZSUwhOviahvKoCRgwAMfpPI6tLpjDjnXhISYuUQKYqiKErz0urmXUJCAmOm3MvXSwcw1Hs3yb4iSkot8XFSEOPJ1yX6OH/P4TsHBWlohNo6qTqVvwe++FqEOqWLREBfMlnGTYiH4oMAEjS1xf8HRk+5Ti1cRVEUpdVokYYHR8Ln8zHu7J+wt+u/yK+cwqSRXj54FjJSJeK46IBYtCdCVS2s2QpzFkmq0JIZMGWcl4Kqc9iTNo/RZ12vgqsoiqK0Ki1akepoqKysYPOKFxgU/xRpcTuob7AUlki+7d5isXYbnCVlf0T7vWAZSK8n9BofJ3m+GalSX7l/NiTGG8ob+pJXfwdDxt14wmlBHT3gSqvhtH86+jPU59f+6QTPMOYNnnTRDVK4dyeFm16gX9wrdEsowJgATsuf6OpR7h64xDju7LR4OFjXnx3115I99MbDlnY8FjrBP5aTPYUWR59h+0afX/unEzzDti26QUr2F7Fj8wJS62aTnbSU5LgSjPVDsGkC4Xm74XclQlvdmMnemgmUJ/yI/kMuJKuZmxd0gn8sJ3sKLY4+w/aNPr/2Tyd4hq1fe/l4yMzqQWbWNPz+qyku2su2XaupL1tOuncN6fF5dE8uBH85e4rq6d0jDutNp7gqm7KGUyhrHElc+kR69h/DwB691GerKIqitCnarCp5vV6ye/Ulu1df4JKo431c73s4P4qiKIrSljkp0cuKoiiK0hlR0VUURVGUVkJFV1EURVFaiRbx6a5YsaJDR6Z19MjCjvzsgugzbN/o82v/dORnmJPTdMc6tXQVRVEUpZVos9HLitKWKSkpZsemD0ipm0120pekxBVLPrmxYS0rgxzq5WwAa7DGS2VDFoU1E6lM+BH9h15AZmb31r8RRVFaFRVdRTkG9hXuYs/Gl+jne5kxidsx8QERWjeOwIYLrfsEi6GR1LhCUn1zsfyLAxsGsqphGr2G3UB2r36tdTuKorQyLVKRypjI/4U6Fh3ZFwHqT4pFVWUlG1e+xCDfE6THF2CIIbRhF4gxyBHOsRjKGvqTV38nQ8ffQEpK6jHNMexSHfwZ6u9g+6cjP8OcnBxyc3NjPkT16SrKEcjbvJp9uT9gXPL/IyM+n0N/UwZ/pYKWrPsnuN9AVG3wsHXn0KvBkhFXwLjkX1GceylbN61smRtSFOWkoaKrKE3g9/tZ/eWr9DzwXU5NWYihMdpaDRK5P1KI3fuPMIbBzykpn5B98CJWf/E3GhtPsM+loihtBhVdRYlBfX09qz55hJG+m0nx7eNQxyu3FRvZ8SrSso3cjmUJNzmGJSWuiJFxP2f1Jw9TV1fXErepKEoro4FUihJBfX09G758gLGpf8JLQyhQKiiWsdpNujctVFbD4lWQtxtO7QOTx0JqF9fHjjCGbFu8ppaxaQ+xbmkVQyf9loSEhOa4RUVRThIquoriwu/38/WSP4rgmvrwyGPnvaOHgjtKGRHc3cVw/QOwaAU0+sHrhSlj4aUHoF/PiNXlSL9w1DGL1zRwRtKTrFrShTFT7tPuWYrSjtHlZUVxsWb5G4xNexivaYjyvVoLBytgxhy46fdwzzOQuwECAQ6dG7Dw4F/gw2UiuAB+PyzMhf95Pvxca6GkDOZ+Cn+bBys3QUOjq190cCnagNfTwNiMR1m7/NUOHfWpKB0d/ZNZURzyNq9iMNPxmhpRvghtKymDa+6HD5eKuAL89W348z1w1XfE4i2rgA+Wxh7/o2Ui2lkZMvSqTfDT38LXW0WMk5Pgpsvg97dCUrzrg861vNQyxNzD1k0jGDKs6TJziqK0XdTSVRSgsqICz55fh4KmIrCIhfuBS3BBRPT+Z6H4oJzkD4hlG4tGv2PpWqiqgdseg9WbnX3IvqffhL8vcGYQFeVsSfYVEVf4ayoqyk/shhVFOSmo6CoKsGnVTAamfEKY4LpELxCAj3NdS78udhTClh3yPiMVJo2IfY2JZ0DXNBl38w5YuTH6nEY/vLUwXNjDxNdYBqQsYcvKF4/uxhRFaVOo6Cqdnn2FuxjkewLws78M5i2GV94TK7Qx6IM1kBgf+/NeDyTEyzk+Lzx4C4wYFH7OGafCQz+X4wD1DWIVx6KmzhF3K9f/ajO8+h7MXexY1PgZFP8UhXt3NsPdK4rSmqjoKp2ePRteJD2+gOXrYeot8P1fwXW/gW/eCPc9C7X14DFw+dSQaLoZOxSGDpD3xsDwU2DBM3DfDRDng3v+U7bPGOREOgOD+8HAXtFjGeDc8SLkdQ3wm+dg8o0w7Tfwg1/L/JauhbS4HRRunNFSX4miKC2Eiq7SqSkpKaZf3MuUV1lufQTWbA35WCuq4cnX4K2PZPs/zofbr5KAJxABHT0EnrkbUrpwKNrYGOjdHSYMl7HGD4M+3Q9lAAGQmS4BU5npobkYA9+aADdfLtvvLILHX5V5gIy1Ng9ufRTKKi394l+hZH9Ri34/iqI0Lyq6Sqdmx6YPyEzMZ/02iSKOpKER3v5YlnsT4+GR22DR83DxOZCSBDMfgHHDQhZsEGth/XZZQl6bFzsF94dT4ZXfQVKCLEc/ew/MegS6d5XPv7NQrh/Jmq0yZreEHezYvKCZvglFUVoDFV2l0+L3+0mpm4UhQN1hfKy1daECUnFeGH86DOgFlTWwfL1zUowCGuvyZNfavIgALGcwY6D4gCxfTzhDLNxuaSEBr62PPZ9AQJaejQmQWjcLf1Ph0oqitDlUdJVOS8n+fWQnfQlYhg2Avj2izzFGfKyeiDrK5ZUipG8tDBXBcFPfAJsK5P2WHS4BdY3h98PshTJOeWV00/tzc6ItaIA+PeD0gQCW7KRlFBftPeZ7VxTl5KCiq3Ra9u36mpS4/WCgZ6ZEF2e4Wtga4LyJcP2l4TWTrYXyKtlcuha27SYirQdKy2HnPtncXSyFNXCNAVBQCJ9/Je8rqsG6LG1j4CeXwIVnhQ+dngK/vQV6Zcl2sm8/RbtXH/+XoChKq6Kiq3RaakuXY6yYqcbA1RdKlPH0aZJTG+eD6dc5wU6uGskBp6EBQGkFvPeZs3zsUsedRXIMRKB37A0fw1pY8AUccMS4stpZ3naN0TUV7roO4uNkSfvX0+DfT8O1F4UsYEOA+tJlzf7dKIrSMqjoKp2WNM/X0kHIiTr2GJg4HB69He74sQQxvTzP5et1zvMHxJ8b5J2PZTnZ3bpvU774XUHG2Zgfyr3FOgFaC0NLypU1znVs+HVmzpNxbrsSHrsdzhwJ3rDmCJZ0z5oW+44URWleVHSVTktGnBOuHOE3NQb69pTuQO9+KtHChyxZI75Yt+iu3AgbC0LbFliTFz7moW1njK07XUFYQHUtuHvVBwOx5iySeYR1J3L36AXSE7Ydy20rinISUdFVOi09UpwApBgN6HtmSipPeRU8NytUMzlopda4espX1sC8T0P1kgOBUORykPXbQpastTBvScgvDBIhXdcQmkPAwnOzoaxSUpWCPly3JYxzve4phc31lSiK0sIclegaY/KNMWuMMauNMbktPSlFaRX8ZdG1lB1B65YGacmy662FYskGT61vEJF0M+eTkBBX10HervDj23aH/MC19bIk7aamzlmiRkR5UwHMcopypHZx+ZUjGt9bCzRq8wNFaS8ci6X7LWvtGGut9hRTOgS79zWRCGuk6lRWhmweKIfn3wrl2tbVR+fQrsuTZWiQ+siF+8OPFx2AfQdk7PXb4Ost4cfrXdaztXK9YJBVVkZ4xavI5fA9RU3ch6IobQ5dXlY6LX16xsmboIi5msfH+6SUY5C/vw9bd8m51XXRlaJq6sT/ai1s3w0VNeHHq2rF+rUW/rlIfLhuGhtD+/J2SXu/IL2zJII5DJfw9u4ReVBRlLbK0YquBd43xqwwxtwU6wRjzE3GmFxdflbaDd6MsHrIbjwe6J8d2i4+CP83W/y1kUFPQeYtlnzbdduie+oG6yZX1UhwViSNfjkWsNK3t+hg6Fi/bGmAcIjI7oM+VwFnRVHaNEcruudYa8cB3wVuNcZ8M/IEa+1frLU5uvystBeKK11tfmL0rx3YO/z81/4tVmh1TewqVJt3wIoN0UvHQdZscSKd86OPBdOQCvbCK/PDj8XqRuReZi6uzI5xgqIobZGjEl1r7W7ntQh4B5jYkpNSlNagtH5QdHCSg0HEzn2o6EAoojgQwzqub4DX3hOLNhbrt0tf3GD+rptgKcgX5sDeCH/wgN4x0oWCuboGyhpPPdxtKorShvAd6QRjTDLgsdZWOO+/A/y2xWemKC1MWWAU2LelQIZLxIKvfXuCzxfuv335X9AlkeioZ4dZH8a2ggE2bJf83FhYKwFWM+eF7/c5OboQPrfQtqGsYeQR71VRlLbBEUUX6Am8Y6TunA943Vr77xadlaK0AoldJ2DxYmxjTIu3ZyYkJoSLbkkZPPVG06Lrzr2NpKYuPL83khn/hN0R7XGjcnQjU4bwEJ+hC0+K0l44ouhaa7cBo1thLorSqvTsO5rK7VmkxhWGt+ZzhK1bGqQnQ0WEkFZFRCY3FwUxmgWlp7pydCOKYgBUN2bSY8CYlpmQoijNjqYMKZ2WzKyeFNZMIsrEdcQtLRkmjz0ZMwvxrfGQkdLEQWPYWzuRrO4aSKUo7YWjWV5WlA6J1+ulMuEKrJ2HwR/lM/V54eFbYfVm8cc2hc8rLfd6ZYn/tVeWWKfJXeRYox+qqmVpes9+2LVPgqXKKpv2/wKc1l/a+Hm9zg53owNnabk8/gp8Pv01VpT2gv62Kp2a/kMv4MCGgWQmukKOHWEzBgb0gj/fDVfcJZWpQLSvaxqMHQpTJ8BZo2BwPxHeQEAqVtU3it/XWhnH64WEOCm6gRHB3boTvlgDHy+XVKKD5SFNTU+Bp++StKWoRvbO9sHa/vQ/7cKW+3IURWl2VHSVTk1mZndWNUyjW+KDGKKjmI2BKePE4rzzCRg2EH52GVx0NmRnShrRyo3w1GKxiHcWQnm1FM9wi67HI1Wl0pKlwtTwU0Wsf3Qe/PIqKCyB+Z/BjHdgQz785mdw3kRHcN1R1Q7WGnbUX8uY7j2jb0pRlDaLsU2FYZ7IoMY0/6BtiJb4ztoSJsq06ni4n2Hh3p0k5k8mI97pzxfj8dbUw00PwU2XQ2oyvP8FzP9cCl6UVsTO2z0SxohFO2oIfPcbYjVX1Uha0rN3S5ej6A/JS1l9f2oGLCa7d/8mxu7Yz1B/B9s/HfkZ5uTkkJubG/MhqqWrdHqye/Vj5eY7GRv3K/HtQlRqTmI8/OJKuOZ+sUojI5gT4qFXppRs7NtDrOCuaSHhrK6V0o75e2BzAezcJ00TSivg05XykxgPPbvB249LqlKseQBY6yWv/peMa0JwFUVpu6joKgpw2vgbKMidw8CUT6RYRsQf4cbAuGEwanCobV9ivFip35sM558pfl2PRypLlVaEOhElJUBaiiwtJyWIz3fLTvhgKcz9RJala53ORaNOg5GDHa2NWFIGwBp2VH2DIeNubNkvRFGUFkFFV1GAlJRUCrMfp7L0YlLiikR4gzgpRD6vLC8v+BLOnwR3XA3jT5cWfEtWw9NvwqqNYglX14WaHvicIKr0FMjOgqED4DtnwrTvwu1Xik/4yddhwRfwsx/I+WFVpw7Nw1Dl7059jz+RmprWGl+LoijNjIquojgMHjae1V8+xkh7C15TGyo75QifsWLtTp0A/zsdvtoCN/4OFuVCcWnTVaoanF65pZVQUAhL10pTgx5d4dwcuPJ8ePR28QvnDHcFTwWv7bz3k8imhj8wdpj2FFGU9oqKrqK4GJFzNas+yWds2kN4TUOY6FkkxeejZTD5RthTLHm2cT5pNN+7u+Tp9u4uebopSZIq5Hfa9pWUyWd27pPXA+Xw5vsw+0OpPFVdKxbzFd92LS87+Iljddl0Rk+5rlME2ShKR0VFV1Fc+Hw+Rp5zN+uWVnNG0hMivA6Nfpg5V3yvNbVw3iSYmgOTRsKgPpCcJP7a0krJw62pE+s3Pg5Su4hPNzVZlo8rqqXZ/dK1sHA5LF8vn33xXfj+FCef95CFG8f66tsZcc69WghDUdo5+husKBEkJCQwdNKDrFrShTHpj+CjFrBs2w3L18Gf7oTLzhUR3b5HBHPmu7B2G+zeJ00P6hulUAaEimMkJYQqVw0bCGePllShm38IJaXwxGsi6psKYOQgAIPfJLK6dDojzrmXhIRYOUSKorQnVHQVJQYJCQmMmXIvXy8dwFDv3ST7iigptcTHSUGMJ1+X6OP8PYfvHBSkoRFq66TqVP4e+OJrEeqULhIBfclkGTchHooPAkjQ1Bb/Hxg95Tq1cBWlg6ANDxSlCXw+H+PO/gl7u/6L/MopTBrp5YNnISNVIo6LDohFeyJU1cKarTBnkaQKLZkBU8Z5Kag6hz1p8xh91vUquIrSgdCKVMdBR66kAloNJxaVlRVsXvECg+KfIi1uB/UNlsISybfdWyzWboOzpOx3t+AjVAbS6wm9xsdJnm9GqtRX7p8NifGG8oa+5NXfwZBxN55QWlBHf4b6O9j+6cjP8HAVqVR0j4OO/I8F9Bf+cBTu3UnhphfoF/cK3RIKMCaA0/InunqUcb0nxnFnp8XDwbr+7Ki/luyhNzZZ2vFY6OjPUH8H2z8d+Rmq6DYzHfkfC+gv/NFQsr+IHZsXkFo3m+ykpSTHlWCsH4JNEwjP2w3/RkVoqxsz2VszgfKEH9F/yIVkNWPzgo7+DPV3sP3TkZ+h1l5WlGYmM6sHmVnT8PuvprhoL9t2raa+bDnp3jWkx+fRPbkQ/OXsKaqnd484rDed4qpsyhpOoaxxJHHpE+nZfwwDe/RSn62idCL0t11RTgCv10t2r75k9+oLXBJ1vI/rfQ/nR1GUzotGLyuKoihKK6GiqyiKoiithIquoiiKorQSLeLTHT9+PLm5uS0xdJugo0cWduSowiD6DNs3+vzaPx39GTaFWrqKoiiK0kqo6CqKoihKK6EpQ4qidEo8HhjaH35yCfzgW3BKb/B5wOMlrIdyEBPsrWwg4IfGAOTvhXc/hZfehY35oc5SitIULVKRKicnx6pPt/2i/qT2T0d/hify/OJ8cMFZcO8NkDPMqYntdQ5Glu80Ea9E7EME2B+QJhgPvwTvfS51uE+Ejv78oFP8Dsa8QV1eVhSlU2CAb4yCpTNhzuNw1ggRYI+H2PWxce2PPO4SZo9Hxpk0At7+Iyx7Gc4Z41jGihKBiq6iKB2e1C7w/H3w8fMwdih4g5atW0RtxE9wv4GoZhVh686hV68HxgyBhc/BC/8NacktcjtKO0ZFV1GUDs2IwbDiVfjppdJSMcqaDRK5P1KI3fuPMEacD35ysVx39JDjnrrSAVHRVRSlw3LBmfDZDBjUx7WM3IRv9tB7t6hGbseyhJsYw+OFU/vA4hlw0dktcntKO0RFV1GUDsmVF4qPNSXJCZSK2c849ra1UFEF85fA02/Cv5ZAeXXEaUcYAwseA8lJMPtRuObiE7gZpcOgKUOKonQ4LjgTXrwPuiQSM/LYQliQlHGdYy3sLobrH4BFK6DRLz7gKWPhpQegX8+I1eVIv3DEMY+BpAT4639BaZkIuNJ5UUtXUZQOxYjB8I9HIDGeKN+rtXCwAmbMgZt+D/c8A7kbnPzaYAqQhQf/Ah8uE8EF8PthYS78z/Ph51oLJWUw91P42zxYuUnShaxL0INLzkmJ8MbDMGZoC38BSptGLV1FUToMacnw9mOQ0kUszEjLs6QMrrkfPlwq4grw17fhz/fAVd8Ri7esAj5YGnv8j5aJaGdlyNCrNsFPfwtfbxUxTk6Cmy6D398KSfGuDzrXSk6A2Y/A+GlQVtm89660D9TSVRSlQ2CAP93pCpqKwCIW7gcuwQUR0fufheKDcpI/IJZtLBr9jqVroaoGbnsMVm8OVaKqqhEf8N8XODobYWl7PFL56qlfaR5vZ0VFV1GUDsFZoyRNJ0xwXcIWCMDHua6lXxc7CmHLDnmfkSqFLmIx8Qzomibjbt4hVagiafTDWwvDhd09D48XrrlQCmgonQ8VXUVR2j1xPnjmLvD5YH8ZzFsMr7wnVmhj0AdrHD9vDLweSHB8wD4vPHgLjBgUfs4Zp8JDP5fjAPUNYhXHoqbOEXcr1/9qM7z6HsxdLBa1zwdPT5d5K50LfeSKorR7LjgLRg2B5evhxt/Bum1i2aZ2gZ//CB68GRLi4PKpMP+zUIBUkLFDYegAeW8MDD8FFjwDz86Cx16GX10Lv/gP6N09tCw8uB8M7AVbdoaPZYBzx4uQ1zVIUNYz/4CKarHCh58Cf70fJgyHi8+BOYta+ttR2hJq6SqK0q7xeOC+G6CyBm59BNZsDflYK6rhydfgrY9k+z/Oh9uvkoAnEAEdPQSeuVuCr4LRxsaIwE4YLmONHwZ9ujurxM6ycWa6BExlpofmYgx8awLcfLlsv7MIHn9V5gEy1to8uPVR2XffDSLOSudBH7eiKO2aof1FFNdvkyjiSBoa4e2PZbk3MR4euQ0WPS9WZkoSzHwAxg2LDmyyFtZvlyXktXkxU3D54VR45XeShztiEDx7D8x6BLp3lc+/szB2x6E1W2XM0UPg9IHN8z0o7QMVXUVR2jX/eWloKbcpH2ttXahCY5wXxp8OA3qJdbx8vXNSjAIa6/Jk19q8iAAsZzBjoPgA1NbDhDPEwu2WFhLw2vrY8wkEZL5eL9zw/eO/d6X9oaKrKEq7xeeFH5wrS8zDBkDfHtHnGCM+Vk9EHeXyShHStxZG+3hBAqU2Fcj7LTtcAuoaw++H2QtlnPLK6Kb35+bETg3q00MsXI8HvvfNUHCW0vFR0VUUpd3Ss5sEM2GgZ6ZEF2ekho4b4LyJcP2lrqwd64hklWwuXQvbdhOeU2ugtBx27pPN3cVSWAPXGAAFhfD5V/K+ohqsy9I2Bn5yCVx4VvjQ6Snw21ugV5ZsD8gW/7HSOVDRVRSl3TJyCPic/8WMgasvlKjj6dMkpzbOB9Ovc4KdXDWSAxYqneCm0gp47zNn+diljjuL5BiIQO/YGz6GtbDgCzjgiHFltbO87RqjayrcdZ20FBx/Ovx6Gvz7abj2opAF7PXA6NOa+5tR2ioquoqitFvOGe10EHKijj0GJg6HR2+HO34sQUwvz3P5ep3z/AHx5wZ552NZTna37tuUL35XkHE25odyb7FOgNbC0JJyZY1zHRt+nZnzZJzbroTHboczR4LXVaLS45H7UDoHKrqKorRbxg933kT4TY2Bvj0lUOndTyVa+JAla8QX6xbdlRthY0Fo2wJr8sLHPLTtjLF1pysIC6iuhUZXpHIwEGvOIplHWHcid49eJHpa6RwclegaYzKMMbONMRuNMRuMMWe19MQURVGOxOghzpsYDeh7ZkoqT3kVPDcrVDM5aKXW1IXGqayBeZ+G6iUHAqHI5SDrt4UsWWth3pKQXxgkQrquITSHgIXnZktjg8T4kA/XbQnjXG/E4Gb6QpQ2z9Fauv9/4N/W2mHAaGBDy01JURTl6EhPjlFL2RG0bmnSdQgkQnljQUjn6htEJN3M+SQkxNV1kLcr/Pi23SE/cG29LEm7qalzlqiROW0qgFlOUY7ULi6/stsqdwQ8rcux3LXSnjmi6Bpj0oFvAi8AWGvrrbWlLTwvRVGUI1J8sIkDRqpOZWXI5oFyeP6tkEDX1Ufn0K7Lk2Xo4LiF+8OPFx2AfQdk7PXb4Ost4cfrXdaztXK9YJBVVkZ4xavI5fD9pUe+V6VjcDSW7ilAMfCSMWaVMWaGMSa5heelKIpyRHp0c94ERczVPD7eF56K8/f3YesuObe6LrpSVE2d+F+the27oaIm/HhVrVi/1sI/F4kP101jY2hf3i5p7xekd5ZEMIfhEt7uXY/iZpUOwdGIrg8YBzxnrR0LVAH3RJ5kjLnJGJNrjMktLi5u5mkqiqJEU1oZXg/ZjccD/bND28UH4f9mi782MugpyLzFkm+7blt0T91g3eSqGgnOiqTRL8cCVvr2Frms8H7ZETWWXfM1QJnLN6x0bI5GdHcBu6y1S53t2YgIh2Gt/Yu1Nsdam9O9u2Z6K4rS8oQt8cboXzuwd/j5r/1brNDqmthVqDbvgBUbopeOg6zZ4kQ650cfC6YhFeyFV+aHHxvYK8ZgrmXmtXkxjisdkiOKrrW2ENhpjBnq7Po2sP4wH1EURWkVVmwgOjjJwSBi5z5UdCAUURyIYR3XN8Br7zUtguu3S1/cYP6um2ApyBfmwN4If/CA3jHShYK5ugZWbTrMTSodiqPtp3sb8JoxJh7YBlzfclNSFEU5OpashoDfKZDhErHga9+e0jDe7b99+V/QJTFG1LPDrA9jW8EAG7ZLfm4srJUAq5nzwvf7nBxdiJijsx3ww5JVR7pTpaNwVKJrrV0N5LTsVBRFUY6NNVuhMQDxHmJavD0zITEhXHRLyuCpN5oW3fLD+Fdr6sLzeyOZ8U/YXRS+LypHNyJlyB+A1ZubHlPpWGhFKkVR2i2FJZAfrIkcUXACJFc3PUauRVVN9L7moGBv9L701Ijaz+55Ik0V9mjsaadBRVdRlHZLox/eXeRUm3LjCFtaMkweexIm5uJb4yEjJfaxgJVI6KaWs5WOx9H6dBVFUdokL82DX/4YPD6ifKY+Lzx8qyzfbtje9Bg+r7Tc65Ul/tdeWWKdJneRY41+qKqWpek9+2HXPgmWKqs8vGCe1l/a+HmD/XJdjQ6wkpb04twT/QaU9oSKrqIo7ZqN+ZLGM2mEa6cjbMbAgF7w57vhirukMhWI9nVNg7FDYeoEOGsUDO4nwhsISMWq+kbx+1or43i9kBAnRTcwIrhbd8IXa+Dj5TKHg+UhTU1PgafvkrSlqEb2zvZXW2G9pgt1KlR0FUVp1wQC8PBL8PYfHYsyIorZGJgyTizOO5+AYQPhZ5fBRWdDdqakEa3cCE8tFot4ZyGUV0vxDLfoejxSVSotWSpMDT9VxPpH58EvrxL/8vzPYMY7sCEffvMzOG+iI7juqGoHvx8eftHVdlDpFBjbVAjfCZCTk2Nzc3Obfdy2gon6s7Vj0RL/Jtoa+gzbN5HPL84Hy16GMcFm8DFuv6YebnoIbrocUpPh/S9g/udS8KK0Inbe7pHnIRbtqCHw3W+I1VxVI2lJz94tXY6iPyQva7bA+GnR5Sih4z8/6BS/gzFvUEX3OOgE/1hO9hRaHH2G7ZtYz++cMbDwORFgOcl10IoOL1sH19wvVmlkBHNCPPTKlJKNfXuIFdw1LSSc1bVS2jF/D2wukKjjyKYJifHQsxu8/bgsXZsY88BAQwOcfyt8sjL2/XX05wed4ncw5g3q8rKiKB2Cz76SalLXXewUy4jQLWOkWfyowaG2fYnxYqV+bzKcf6b4dT0eqSxVWhES1aQESEuRpeWkBPH5btkJHyyFuZ/IsnSt07lo1GkwcrBLcCPmEfDDmx/Ap1oQo1Oilu5x0An+QjvZU2hx9Bm2b5p6fmnJsOJVOLWPiOchbOhlwRfww7vg/Elwx9Uw/nRpwbdkNbz3OazaKJZwdV2o6YHPCaJKT4HsLBg6AL5zJnxzrFjDKzfCk6/L2G/+AS6ZHCN4ChHcgkIYd400a2iKjv78oFP8DqqlqyhKx6a8SgR1yQzpp+txlVsEMFas3akT4H+nw1db4MbfwaJcKC5tukpVg9Mrt7RSRHPpWmlq0KMrnJsDV54Pj94ufuGc4a7gqeC1nfdVtXDZ9MMLrtKxUdFVFKVD8fUWuOpemP2o4491iZ5FUnw+WgaTb5RKUI1+8QNnZUj/3X495TUzHVKSJCLa77TtKymTzwSrSB0ohzffh9kfSuWp6lqxmK/4drQ/t6Yervlv+EpLPnZqVHQVRelwzP8MbnwYZtwLSYmh/Y1+mDlXfK81tXDeJJiaA5NGwqA+Yh3X1YslWlYp1q21kiqU2kWWr1OTZbm5olqa3S9dCwuXw/L18tkX34XvT3HyeR2xr6mHWx6BuTH68CqdCxVdRVE6JK/Ph9IyeONhSEkUH++23bB8HfzpTrjsXBHR7XtEMGe+C2u3we59skxd3xgqLxksjpGUEKpcNWwgnD1aUoVu/iGUlMITr4mobyqAkYPk81V1EjGtgquAiq6iKB2Y+Z/BOT+Fd/4Ip/QWYYyPk4IYT74u0cf5ew7fOShIQyPU1knVqfw98MXXItQpXSQC+pLJMm5CPBQfFMEtKIQr7pZAK0UBbXigKEoHZ81WGH+tFKwYfzp88CxkpIoQFh0Qi/ZEqKqVa8xZJKlCS2bA2aPg9QUSpayCq7jRlKHjoBOEup/sKbQ4+gzbN8fz/IyRAhpPT4cRg8S/W1gi+bZ7i8XabXCWlP0R7feCZSC9ntBrfJzk+WakSn3l/tnix92wHX7xmOThHu9j6OjPDzrF76CmDCmK0nmxFhavggnXwcXnwL3XS9nIfj2dnN4YDebDeuAS4ziOSAekecHDL8K8xbFLOyoKqOgqitLJaGiUpeC5n8LpA+H6S+HSKWKp+hxLFiM/boPTQJTQ7twHcxfDC+9KtyBtXqAcCV1ePg46wbLIyZ5Ci6PPsH3T3M/P55XOQaNPg3NGw7jTZQk6LRn2l0L3rpJCtDYPVm8Ri3n1JlmWbmiBBvQd/flBp/gd1OVlRVGUWDT6Ycc++Zm7+GTPRunIaPSyoiiKorQSKrqKoiiK0kqo6CqKoihKK9EiPt0VK1Z0aCd5Rw9y6MjPLog+w/aNPr/2T0d+hjk5OU0eU0tXURRFUVoJjV5Wmh2PB4b2h59cAj/4ltS89XnA4yWsxVqQQ71HjTT5bgxA/l5491N46V3YmB8qPK8oitKeaZE8XWNMx103oGMvi8DxL23F+eCCs+DeGyBnmFMyz+scjKzuYyJeidiHCLA/ILVrH34J3vu8+Sr96DNs3+jza/905GeYk5NDbm5uzIeoy8vKCWOAb4yCpTNhzuNw1ggR4EOl9YInubERrybi1crn43wwaQS8/UdY9rLUzu0E/x8pitJBUdFVTojULvD8ffDx8zB2qPQcBcJF1Eb8BPcbiKplG7buHHr1emDMEFj4HLzw31IpSFEUpb2hoqscNyMGw4pX4aeXSseVKGs2SOT+SCF27z/CGHE++MnFct3RQ4576oqiKCcFFV3luLjgTPhsBgzq41pGbsI3e+i9W1Qjt2NZwk2M4fHCqX1g8Qy46OwWuT1FUZQWQUVXOWauvFB8rClJTqBUjHZnTW1bCxVVMH8JPP0m/GsJlFdHnHaEMbDgMZCcBLMfhWsuPoGbURRFaUU0ZUg5Ji44E168D7okEjPy2EJYkJRxnWMt7C6G6x+ARSukyLzXC1PGwksPSF/TsNXlSL9wxDGPgaQE+Ot/QWmZCLiiKEpbRi1d5agZMRj+8QgkxhPle7UWDlbAjDlw0+/hnmcgd4OTXxtMAbLw4F/gw2UiuAB+PyzMhf95Pvxca6GkTHqe/m0erNwk6ULWJejBJeekRHjjYRgztIW/AEVRlBNELV3lqEhLhrcfg5QuYmFGWp4lZXDN/fDhUhFXgL++DX++B676jli8ZRXwwdLY43+0TEQ7K0OGXrUJfvpb+HqriHFyEtx0Gfz+VkiKd33QuVZyAsx+BMZPk76niqIobRG1dJUjYoA/3ekKmorAIhbuBy7BBRHR+5+F4oNykj8glm0sGv2OpWuhqgZuewxWbw5VoqqqER/w3xc4OhthaXs8UvnqqV9pHq+iKG0XFV3liJw1StJ0wgTXJWyBAHyc61r6dbGjELbskPcZqVLoIhYTz4CuaTLu5h1ShSqSRj+8tTBc2N3z8HjhmgulgIaiKEpbREVXOSxxPnjmLvD5YH8ZzFsMr7wnVmhj0AdrHD9vDLweSHB8wD4vPHgLjBgUfs4Zp8JDP5fjAPUNYhXHoqbOEXcr1/9qM7z6HsxdLBa1zwdPT5d5K4qitDX0vyblsFxwFowaAsvXw42/g3XbxLJN7QI//xE8eDMkxMHlU2H+Z6EAqSBjh8LQAfLeGBh+Cix4Bp6dBY+9DL+6Fn7xH9C7e2hZeHA/GNgLtuwMH8sA544XIa9rkKCsZ/4BFdVihQ8/Bf56P0wYDhefA3MWtfS3oyiKcmyopas0iccD990AlTVw6yOwZmvIx1pRDU++Bm99JNv/cT7cfpUEPIEI6Ogh8MzdEnwVjDY2RgR2wnAZa/ww6NPdWSV2lo0z0yVgKjM9NBdj4FsT4ObLZfudRfD4qzIPkLHW5sGtj8q++24QcVYURWlL6H9LSpMM7S+iuH6bRBFH0tAIb38sy72J8fDIbbDoebEyU5Jg5gMwblh0YJO1sH67LCGvzYuZgssPp8Irv5M83BGD4Nl7YNYj0L2rfP6dhbE7Dq3ZKmOOHgKnD2ye70FRFKW5UNFVmuQ/Lw0t5TblY62tC1VojPPC+NNhQC+xjpevd06KUUBjXZ7sWpsXEYDlDGYMFB+A2nqYcIZYuN3SQgJeWx97PoGAzNfrhRu+f/z3riiK0hKo6Cox8XnhB+fKEvOwAdC3R/Q5xoiP1RNRR7m8UoT0rYXRPl6QQKlNBfJ+yw6XgLrG8Pth9kIZp7wyuun9uTmxU4P69BAL1+OB730zFJylKIrSFlDRVWLSs5sEM2GgZ6ZEF2ekho4b4LyJcP2lrqwd64hklWwuXQvbdhOeU2ugtBx27pPN3cVSWAPXGAAFhfD5V/K+ohqsy9I2Bn5yCVx4VvjQ6Snw21ugV5ZsD8gW/7GiKEpbQUVXicnIIeBz/nUYA1dfKFHH06dJTm2cD6Zf5wQ7uWokByxUOsFNpRXw3mfO8rFLHXcWyTEQgd6xN3wMa2HBF3DAEePKamd52zVG11S46zppKTj+dPj1NPj303DtRSEL2OuB0ac19zejKIpy/KjoKjE5Z7TTQciJOvYYmDgcHr0d7vixBDG9PM/l63XO8wfEnxvknY9lOdndum9TvvhdQcbZmB/KvcU6AVoLQ0vKlTXOdWz4dWbOk3FuuxIeux3OHAleV4lKj0fuQ1EUpa2goqvEZPxw502E39QY6NtTApXe/VSihQ9ZskZ8sW7RXbkRNhaEti2wJi98zEPbzhhbd7qCsIDqWmh0RSoHA7HmLJJ5hHUncvfoRaKnFUVR2goqukpMRg9x3sRoQN8zU1J5yqvguVmhmslBK7WmLjROZQ3M+zRULzkQCEUuB1m/LWTJWgvzloT8wiAR0nUNoTkELDw3WxobJMaHfLhuSxjneiMGN9MXoiiK0gwcUXSNMUONMatdP+XGmDtaYW7KSSQ9OUYtZUfQuqVJ1yGQCOWNBSGdq28QkXQz55OQEFfXQd6u8OPbdof8wLX1siTtpqbOWaJG5rSpAGY5RTlSu7j8ym6r3BHwtC7HcteKoigtyxFF11q7yVo7xlo7BhgPVAPvtPTElJNL8cEmDhipOpWVIZsHyuH5t0ICXVcfnUO7Lk+WoYPjFu4PP150APYdkLHXb4Ovt4Qfr3dZz9bK9YJBVlkZ4RWvIpfD95ce+V4VRVFai2NdXv42kGetLTjimUq7pkc3501QxFzN4+N94ak4f38ftu6Sc6vroitF1dSJ/9Va2L4bKmrCj1fVivVrLfxzkfhw3TQ2hvbl7ZL2fkF6Z0kEcxgu4e3e9ShuVlEUpZU4VtG9Cngj1gFjzE3GmFxjTO6JT0s52ZRWhtdDduPxQP/s0HbxQfi/2eKvjQx6CjJvseTbrtsW3VM3WDe5qkaCsyJp9MuxgJW+vUUuK7xfdkSNZdd8DVDm8g0riqKcbI5adI0x8cClwKxYx621f7HW5lhrc5prcsrJI2yJN0b/2oG9w89/7d9ihVbXxK5CtXkHrNgQvXQcZM0WJ9I5P/pYMA2pYC+8Mj/82MBeMQZzLTOvzYtxXFEU5SRxLJbud4GV1tp9LTUZpe2wYgPRwUkOBhE796GiA6GI4kAM67i+AV57r2kRXL9d+uIG83fdBEtBvjAH9kb4gwf0jpEuFMzVNbBq02FuUlEUpZU5ln66P6aJpWWl47FkNQT8ToEMl4gFX/v2lIbxbv/ty/+CLokxop4dZn0Y2woG2LBd8nNjYa0EWM2cF77f5+ToQsQcne2AH5asOtKdKoqitB5HZekaY5KB84G3W3Y6SlthzVZoDObfQpTF2zMTEhPC95WUwVNvNC265VXRQVJBaurCc3MjmfFP2F0Uvi8qRzciZcgfgNWbmx5TURSltTkq0bXWVllrM621ZUc+W+kIFJZAfrAmckTBCZBc3fTk6M9V1UTvaw4K9kbvS0+NqP3snifSVGFPccvMR1EU5XjQilRKTBr98O4ip9qUG0fY0pJh8tiTMDEX3xoPGSmxjwWsREI3tZytKIpyMjgWn67SyXhpHvzyx+DxEeUz9Xnh4Vtl+XbD9qbH8Hml5V6vLPG/9soS6zS5ixxr9ENVtSxN79kPu/ZJsFRZ5eEF87T+0sbPG+yX62p0gJW0pBfnnug3oCiK0ryo6CpNsjFf0ngmjXDtdITNGBjQC/58N1xxl1SmAtG+rmkwdihMnQBnjYLB/UR4AwGpWFXfKH5fa2UcrxcS4qToBkYEd+tO+GINfLxc5nCwPKSp6Snw9F2SthTVyN7Z/morrNd0IUVR2hgqukqTBALw8Evw9h8dizIiitkYmDJOLM47n4BhA+Fnl8FFZ0N2pqQRrdwITy0Wi3hnIZRXS/EMt+h6PFJVKi1ZKkwNP1XE+kfnwS+vEv/y/M9gxjuwIR9+8zM4b6IjuO6oage/Hx5+0dV2UFEUpY1gbFOhpicyqDHNP2gboiW+s7aEcZmPcT5Y9jKMCTaDj3HrNfVw00Nw0+WQmgzvfwHzP5eCF6UVsfN2jzwHsWhHDYHvfkOs5qoaSUt69m7pchT9IXlZswXGT4suR+mmMz3Djog+v/ZPR36GOTk55ObmxnyIKrrHQUf+xwLRv/DnjIGFz4kAywmug1Z0eNk6uOZ+sUojI5gT4qFXppRs7NtDrOCuaSHhrK6V0o75e2BzgUQdRzZNSIyHnt3g7cdl6drEmAcGGhrg/Fvhk5WHv8fO9gw7Gvr82j8d+RkeTnR1eVk5Ip99JdWkrrvYKZYR8btijDSLHzU41LYvMV6s1O9NhvPPFL+uxyOVpUorQqKalABpKbK0nJQgPt8tO+GDpTD3E1mWrnU6F406DUYOdgluxDwCfnjzA/hUC2IoitJGUUv3OOjIf6FB7L+y05Jhxatwah8Rz0PY0MuCL+CHd8H5k+COq2H86dKCb8lqeO9zWLVRLOHqulDTA58TRJWeAtlZMHQAfOdM+OZYsYZXboQnX5ex3/wDXDI5RvAUIrgFhTDuGmnWcCQ64zPsSOjza/905Geolq5ywpRXiaAumSH9dD2ucosAxoq1O3UC/O90+GoL3Pg7WJQLxaVNV6lqcHrlllaKaC5dK00NenSFc3PgyvPh0dvFL5wz3BU8Fby2876qFi6bfnSCqyiKcrJQ0VWOmq+3wFX3wuxHHX+sS/QskuLz0TKYfKNUgmr0ix84K0P67/brKa+Z6ZCSJBHRfqdtX0mZfCZYRepAObz5Psz+UCpPVdeKxXzFt6P9uTX1cM1/w1da8lFRlDaOiq5yTMz/DG58GGbcC0mJof2Nfpg5V3yvNbVw3iSYmgOTRsKgPmId19WLJVpWKdattZIqlNpFlq9Tk2W5uaJamt0vXQsLl8Py9fLZF9+F709x8nkdsa+ph1segbkx+vAqiqK0NVR0lWPm9flQWgZvPAwpieLj3bYblq+DP90Jl50rIrp9jwjmzHdh7TbYvU+WqesbQ+Ulg8UxkhJClauGDYSzR0uq0M0/hJJSeOI1EfVNBTBykHy+qk4iplVwFUVpL6joKsfF/M/gnJ/CO3+EU3qLMMbHSUGMJ1+X6OP8PWLRHomGRqitk6pT+Xvgi69FqFO6SAT0JZNl3IR4KD4ogltQCFfcLYFWiqIo7QVteKAcN/9fe/cWYlUVx3H8+3NUKtMMFBO1lCgRJPOSEYpFYiiK9ahggS/1kKEERfkSvfTQQwRBQYyGkRdKM1QiEzIcHyqv4b3ULEfU0URMIbz9e9hb0tJA3Xsv9+73gcPMOQMzv8XizP/sddlr214YOSO7YcXIIbDmfejZPSuEHSeyK9qbcebP7G988W22VWh9K4x5CBatzlYpu+CaWd14y9ANaPJSd7j+7QpSdgON916Bofdn87tHfs/22x4+ll3tnsuHlC/84/i9S7eBbOn099euXbJ9vj27Z/dXvveebB531y8w6+1sH+7NdoH7sN7cf/XX5D70liErVQS0bYFHnoPJY2HuzOy2kQP65Ht6r3LA/BVn4HKVn5MX6YvZ4QVvzYdVbf99a0czs1udi64V5tz5bCh45ToYMhBmToWpj2dXqp3zK1mUPS7/kCv4V6E9eBRWtsG8FdlpQT68wMyawMPLN6DJwyJQ7NBW55bs5KBhD8LYYTBiSDYE3aMbHD8Jve/OthBt3wdbf86umLfuyYalz5V4AL37sN7cf/XX5D708LIlc/4C/HY0e6xsS53GzCwtr142MzOriIuumZlZRVx0zczMKlLWnO5x4NeSfvfV9Mr/ZiUSLHKotH0JVN6+ivvQ/VcwvwcL1/Q+rLp9913rB6WsXq6apI0RMSp1jrK4ffXm9tVf09vo9lXHw8tmZmYVcdE1MzOrSFOK7oepA5TM7as3t6/+mt5Gt68ijZjTNTMzq4OmXOmamZnd8lx0zczMKlLroitpoqQ9kvZKei11nqJJmi+pQ9L21FnKIGmApLWSdkraIWl26kxFknSbpB8k/Zi3783UmcogqUXSFkmrUmcpmqQDkrZJ2ippY+o8RZPUU9JSSbsl7ZL0WOpMRZI0OO+7S49TkuYkzVTXOV1JLcBPwASgHdgATI+InUmDFUjSOOA08HFEDE2dp2iS+gJ9I2KzpO7AJuCZpvShst3/3SLitKQuwHpgdkR8lzhaoSS9DIwCekTElNR5iiTpADAqIhp5YwxJC4C2iGiV1BW4IyJOJo5VirxmHAIejYgqb950hTpf6Y4G9kbE/og4CywBnk6cqVARsQ44kTpHWSLicERszr//A9gF9EubqjiROZ0/7ZI/6vkp9xok9QcmA62ps9j1kXQXMA6YBxARZ5tacHPjgX0pCy7Uu+j2Aw5e9rydBv3D/r+RNBAYDnyfOEqh8qHXrUAHsCYiGtU+4F3gVeBi4hxlCeBrSZskPZ86TMEGAceAj/LpgVZJ3VKHKtE0YHHqEHUuutYQku4ElgFzIuJU6jxFiogLEfEw0B8YLakx0wSSpgAdEbEpdZYSjY2IEcAk4MV8yqcpOgMjgA8iYjhwBmjc2hiAfOh8KvBZ6ix1LrqHgAGXPe+fv2Y1ks91LgMWRsTnqfOUJR+2WwtMTBylSGOAqfm85xLgSUmfpI1UrIg4lH/tAJaTTWs1RTvQftnoy1KyItxEk4DNEXE0dZA6F90NwAOSBuWfYqYBKxJnsuuQLzSaB+yKiHdS5ymapN6Seubf30626G930lAFiojXI6J/RAwke/99ExEzEscqjKRu+QI/8mHXp4DG7CSIiCPAQUmD85fGA41YxHgV07kFhpahvKP9ShcR5yXNAlYDLcD8iNiROFahJC0GngB6SWoH3oiIeWlTFWoM8CywLZ/3BJgbEV+mi1SovsCCfNVkJ+DTiGjctpoG6wMsz4+g6wwsioiv0kYq3EvAwvzCZT8wM3GewuUfmCYAL6TOAjXeMmRmZlY3dR5eNjMzqxUXXTMzs4q46JqZmVXERdfMzKwiLrpmZmYVcdE1MzOriIuumZlZRf4CDqtE3abGTy8AAAAASUVORK5CYII=\n",
+ "text/plain": [
+ "
\n", + "The region at the upper left corner is planar." + ] + }, + { + "cell_type": "code", + "execution_count": 18, + "id": "fbb77637", + "metadata": {}, + "outputs": [], + "source": [ + "problem = PeakFindingProblem(initial, grid, directions8)" + ] + }, + { + "cell_type": "markdown", + "id": "cc0c2498", + "metadata": {}, + "source": [ + "Solution by Hill Climbing" + ] + }, + { + "cell_type": "code", + "execution_count": 19, + "id": "236cde2b", + "metadata": {}, + "outputs": [], + "source": [ + "solution = problem.value(hill_climbing(problem))" + ] + }, + { + "cell_type": "code", + "execution_count": 20, + "id": "1f97a239", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "0" + ] + }, + "execution_count": 20, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "solution" + ] + }, + { + "cell_type": "markdown", + "id": "535af367", + "metadata": {}, + "source": [ + "Solution by Simulated Annealing" + ] + }, + { + "cell_type": "code", + "execution_count": 21, + "id": "653741be", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "32" + ] + }, + "execution_count": 21, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "solutions = {problem.value(simulated_annealing(problem)) for i in range(100)}\n", + "max(solutions)" + ] + }, + { + "cell_type": "markdown", + "id": "ccb84314", + "metadata": {}, + "source": [ + "Notice that even though both algorithms started at the same initial state, \n", + "Hill Climbing could never escape from the planar region and gave a locally optimum solution of **0**,\n", + "whereas Simulated Annealing could reach the peak at **32**.\n", + "
\n", + "A very similar situation arises when there are two peaks of different heights.\n", + "One should carefully consider the possible search space before choosing the algorithm for the task." + ] + }, + { + "cell_type": "markdown", + "id": "9c80a23e", + "metadata": {}, + "source": [ + "## GENETIC ALGORITHM\n", + "\n", + "Genetic algorithms (or GA) are inspired by natural evolution and are particularly useful in optimization and search problems with large state spaces.\n", + "\n", + "Given a problem, algorithms in the domain make use of a *population* of solutions (also called *states*), where each solution/state represents a feasible solution. At each iteration (often called *generation*), the population gets updated using methods inspired by biology and evolution, like *crossover*, *mutation* and *natural selection*." + ] + }, + { + "cell_type": "markdown", + "id": "96577df8", + "metadata": {}, + "source": [ + "### Overview\n", + "\n", + "A genetic algorithm works in the following way:\n", + "\n", + "1) Initialize random population.\n", + "\n", + "2) Calculate population fitness.\n", + "\n", + "3) Select individuals for mating.\n", + "\n", + "4) Mate selected individuals to produce new population.\n", + "\n", + " * Random chance to mutate individuals.\n", + "\n", + "5) Repeat from step 2) until an individual is fit enough or the maximum number of iterations is reached." + ] + }, + { + "cell_type": "markdown", + "id": "cf94ed1f", + "metadata": {}, + "source": [ + "### Glossary\n", + "\n", + "Before we continue, we will lay the basic terminology of the algorithm.\n", + "\n", + "* Individual/State: A list of elements (called *genes*) that represent possible solutions.\n", + "\n", + "* Population: The list of all the individuals/states.\n", + "\n", + "* Gene pool: The alphabet of possible values for an individual's genes.\n", + "\n", + "* Generation/Iteration: The number of times the population will be updated.\n", + "\n", + "* Fitness: An individual's score, calculated by a function specific to the problem." + ] + }, + { + "cell_type": "markdown", + "id": "24eeae15", + "metadata": {}, + "source": [ + "### Crossover\n", + "\n", + "Two individuals/states can \"mate\" and produce one child. This offspring bears characteristics from both of its parents. There are many ways we can implement this crossover. Here we will take a look at the most common ones. Most other methods are variations of those below.\n", + "\n", + "* Point Crossover: The crossover occurs around one (or more) point. The parents get \"split\" at the chosen point or points and then get merged. In the example below we see two parents get split and merged at the 3rd digit, producing the following offspring after the crossover.\n", + "\n", + "\n", + "\n", + "* Uniform Crossover: This type of crossover chooses randomly the genes to get merged. Here the genes 1, 2 and 5 were chosen from the first parent, so the genes 3, 4 were added by the second parent.\n", + "\n", + "" + ] + }, + { + "cell_type": "markdown", + "id": "84c973b1", + "metadata": {}, + "source": [ + "### Mutation\n", + "\n", + "When an offspring is produced, there is a chance it will mutate, having one (or more, depending on the implementation) of its genes altered.\n", + "\n", + "For example, let's say the new individual to undergo mutation is \"abcde\". Randomly we pick to change its third gene to 'z'. The individual now becomes \"abzde\" and is added to the population." + ] + }, + { + "cell_type": "markdown", + "id": "8e29418d", + "metadata": {}, + "source": [ + "### Selection\n", + "\n", + "At each iteration, the fittest individuals are picked randomly to mate and produce offsprings. We measure an individual's fitness with a *fitness function*. That function depends on the given problem and it is used to score an individual. Usually the higher the better.\n", + "\n", + "The selection process is this:\n", + "\n", + "1) Individuals are scored by the fitness function.\n", + "\n", + "2) Individuals are picked randomly, according to their score (higher score means higher chance to get picked). Usually the formula to calculate the chance to pick an individual is the following (for population *P* and individual *i*):\n", + "\n", + "$$ chance(i) = \\dfrac{fitness(i)}{\\sum_{k \\, in \\, P}{fitness(k)}} $$" + ] + }, + { + "cell_type": "markdown", + "id": "743ac5c6", + "metadata": {}, + "source": [ + "### Implementation\n", + "\n", + "Below we look over the implementation of the algorithm in the `search` module.\n", + "\n", + "First the implementation of the main core of the algorithm:" + ] + }, + { + "cell_type": "code", + "execution_count": 22, + "id": "a0e885e5", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def genetic_algorithm(population, fitness_fn, gene_pool=[0, 1], f_thres=None, ngen=1000, pmut=0.1):\n",
+ " """[Figure 4.8]"""\n",
+ " for i in range(ngen):\n",
+ " population = [mutate(recombine(*select(2, population, fitness_fn)), gene_pool, pmut)\n",
+ " for i in range(len(population))]\n",
+ "\n",
+ " fittest_individual = fitness_threshold(fitness_fn, f_thres, population)\n",
+ " if fittest_individual:\n",
+ " return fittest_individual\n",
+ "\n",
+ " return max(population, key=fitness_fn)\n",
+ "def recombine(x, y):\n",
+ " n = len(x)\n",
+ " c = random.randrange(0, n)\n",
+ " return x[:c] + y[c:]\n",
+ "def mutate(x, gene_pool, pmut):\n",
+ " if random.uniform(0, 1) >= pmut:\n",
+ " return x\n",
+ "\n",
+ " n = len(x)\n",
+ " g = len(gene_pool)\n",
+ " c = random.randrange(0, n)\n",
+ " r = random.randrange(0, g)\n",
+ "\n",
+ " new_gene = gene_pool[r]\n",
+ " return x[:c] + [new_gene] + x[c + 1:]\n",
+ "def init_population(pop_number, gene_pool, state_length):\n",
+ " """Initializes population for genetic algorithm\n",
+ " pop_number : Number of individuals in population\n",
+ " gene_pool : List of possible values for individuals\n",
+ " state_length: The length of each individual"""\n",
+ " g = len(gene_pool)\n",
+ " population = []\n",
+ " for i in range(pop_number):\n",
+ " new_individual = [gene_pool[random.randrange(0, g)] for j in range(state_length)]\n",
+ " population.append(new_individual)\n",
+ "\n",
+ " return population\n",
+ ""
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "plot_NQueens(solution)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-05-Adversarial-Search-Games.ipynb b/Chapter-05-Adversarial-Search-Games.ipynb
new file mode 100644
index 000000000..9c34c11a6
--- /dev/null
+++ b/Chapter-05-Adversarial-Search-Games.ipynb
@@ -0,0 +1,537 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "922c90cd",
+ "metadata": {},
+ "source": [
+ "# Game Tree Search\n",
+ "\n",
+ "We start with defining the abstract class `Game`, for turn-taking *n*-player games. We rely on, but do not define yet, the concept of a `state` of the game; we'll see later how individual games define states. For now, all we require is that a state has a `state.to_move` attribute, which gives the name of the player whose turn it is. (\"Name\" will be something like `'X'` or `'O'` for tic-tac-toe.) \n",
+ "\n",
+ "We also define `play_game`, which takes a game and a dictionary of `{player_name: strategy_function}` pairs, and plays out the game, on each turn checking `state.to_move` to see whose turn it is, and then getting the strategy function for that player and applying it to the game and the state to get a move."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "68e4f9db",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from collections import namedtuple, Counter, defaultdict\n",
+ "import random\n",
+ "import math\n",
+ "import functools \n",
+ "cache = functools.lru_cache(10**6)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "1171ce1c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Game:\n",
+ " \"\"\"A game is similar to a problem, but it has a terminal test instead of \n",
+ " a goal test, and a utility for each terminal state. To create a game, \n",
+ " subclass this class and implement `actions`, `result`, `is_terminal`, \n",
+ " and `utility`. You will also need to set the .initial attribute to the \n",
+ " initial state; this can be done in the constructor.\"\"\"\n",
+ "\n",
+ " def actions(self, state):\n",
+ " \"\"\"Return a collection of the allowable moves from this state.\"\"\"\n",
+ " raise NotImplementedError\n",
+ "\n",
+ " def result(self, state, move):\n",
+ " \"\"\"Return the state that results from making a move from a state.\"\"\"\n",
+ " raise NotImplementedError\n",
+ "\n",
+ " def is_terminal(self, state):\n",
+ " \"\"\"Return True if this is a final state for the game.\"\"\"\n",
+ " return not self.actions(state)\n",
+ " \n",
+ " def utility(self, state, player):\n",
+ " \"\"\"Return the value of this final state to player.\"\"\"\n",
+ " raise NotImplementedError\n",
+ " \n",
+ "\n",
+ "def play_game(game, strategies: dict, verbose=False):\n",
+ " \"\"\"Play a turn-taking game. `strategies` is a {player_name: function} dict,\n",
+ " where function(state, game) is used to get the player's move.\"\"\"\n",
+ " state = game.initial\n",
+ " while not game.is_terminal(state):\n",
+ " player = state.to_move\n",
+ " move = strategies[player](game, state)\n",
+ " state = game.result(state, move)\n",
+ " if verbose: \n",
+ " print('Player', player, 'move:', move)\n",
+ " print(state)\n",
+ " return state"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2955b585",
+ "metadata": {},
+ "source": [
+ "# Minimax-Based Game Search Algorithms\n",
+ "\n",
+ "We will define several game search algorithms. Each takes two inputs, the game we are playing and the current state of the game, and returns a a `(value, move)` pair, where `value` is the utility that the algorithm computes for the player whose turn it is to move, and `move` is the move itself.\n",
+ "\n",
+ "First we define `minimax_search`, which exhaustively searches the game tree to find an optimal move (assuming both players play optimally), and `alphabeta_search`, which does the same computation, but prunes parts of the tree that could not possibly have an affect on the optimnal move. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "0db76c52",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def minimax_search(game, state):\n",
+ " \"\"\"Search game tree to determine best move; return (value, move) pair.\"\"\"\n",
+ "\n",
+ " player = state.to_move\n",
+ "\n",
+ " def max_value(state):\n",
+ " if game.is_terminal(state):\n",
+ " return game.utility(state, player), None\n",
+ " v, move = -infinity, None\n",
+ " for a in game.actions(state):\n",
+ " v2, _ = min_value(game.result(state, a))\n",
+ " if v2 > v:\n",
+ " v, move = v2, a\n",
+ " return v, move\n",
+ "\n",
+ " def min_value(state):\n",
+ " if game.is_terminal(state):\n",
+ " return game.utility(state, player), None\n",
+ " v, move = +infinity, None\n",
+ " for a in game.actions(state):\n",
+ " v2, _ = max_value(game.result(state, a))\n",
+ " if v2 < v:\n",
+ " v, move = v2, a\n",
+ " return v, move\n",
+ "\n",
+ " return max_value(state)\n",
+ "\n",
+ "infinity = math.inf\n",
+ "\n",
+ "def alphabeta_search(game, state):\n",
+ " \"\"\"Search game to determine best action; use alpha-beta pruning.\n",
+ " As in [Figure 5.7], this version searches all the way to the leaves.\"\"\"\n",
+ "\n",
+ " player = state.to_move\n",
+ "\n",
+ " def max_value(state, alpha, beta):\n",
+ " if game.is_terminal(state):\n",
+ " return game.utility(state, player), None\n",
+ " v, move = -infinity, None\n",
+ " for a in game.actions(state):\n",
+ " v2, _ = min_value(game.result(state, a), alpha, beta)\n",
+ " if v2 > v:\n",
+ " v, move = v2, a\n",
+ " alpha = max(alpha, v)\n",
+ " if v >= beta:\n",
+ " return v, move\n",
+ " return v, move\n",
+ "\n",
+ " def min_value(state, alpha, beta):\n",
+ " if game.is_terminal(state):\n",
+ " return game.utility(state, player), None\n",
+ " v, move = +infinity, None\n",
+ " for a in game.actions(state):\n",
+ " v2, _ = max_value(game.result(state, a), alpha, beta)\n",
+ " if v2 < v:\n",
+ " v, move = v2, a\n",
+ " beta = min(beta, v)\n",
+ " if v <= alpha:\n",
+ " return v, move\n",
+ " return v, move\n",
+ "\n",
+ " return max_value(state, -infinity, +infinity)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "883d9991",
+ "metadata": {},
+ "source": [
+ "# A Simple Game: Tic-Tac-Toe\n",
+ "\n",
+ "We have the notion of an abstract game, we have some search functions; now it is time to define a real game; a simple one, tic-tac-toe. Moves are `(x, y)` pairs denoting squares, where `(0, 0)` is the top left, and `(2, 2)` is the bottom right (on a board of size `height=width=3`)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "b38b2d2e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class TicTacToe(Game):\n",
+ " \"\"\"Play TicTacToe on an `height` by `width` board, needing `k` in a row to win.\n",
+ " 'X' plays first against 'O'.\"\"\"\n",
+ "\n",
+ " def __init__(self, height=3, width=3, k=3):\n",
+ " self.k = k # k in a row\n",
+ " self.squares = {(x, y) for x in range(width) for y in range(height)}\n",
+ " self.initial = Board(height=height, width=width, to_move='X', utility=0)\n",
+ "\n",
+ " def actions(self, board):\n",
+ " \"\"\"Legal moves are any square not yet taken.\"\"\"\n",
+ " return self.squares - set(board)\n",
+ "\n",
+ " def result(self, board, square):\n",
+ " \"\"\"Place a marker for current player on square.\"\"\"\n",
+ " player = board.to_move\n",
+ " board = board.new({square: player}, to_move=('O' if player == 'X' else 'X'))\n",
+ " win = k_in_row(board, player, square, self.k)\n",
+ " board.utility = (0 if not win else +1 if player == 'X' else -1)\n",
+ " return board\n",
+ "\n",
+ " def utility(self, board, player):\n",
+ " \"\"\"Return the value to player; 1 for win, -1 for loss, 0 otherwise.\"\"\"\n",
+ " return board.utility if player == 'X' else -board.utility\n",
+ "\n",
+ " def is_terminal(self, board):\n",
+ " \"\"\"A board is a terminal state if it is won or there are no empty squares.\"\"\"\n",
+ " return board.utility != 0 or len(self.squares) == len(board)\n",
+ "\n",
+ " def display(self, board): print(board) \n",
+ "\n",
+ "\n",
+ "def k_in_row(board, player, square, k):\n",
+ " \"\"\"True if player has k pieces in a line through square.\"\"\"\n",
+ " def in_row(x, y, dx, dy): return 0 if board[x, y] != player else 1 + in_row(x + dx, y + dy, dx, dy)\n",
+ " return any(in_row(*square, dx, dy) + in_row(*square, -dx, -dy) - 1 >= k\n",
+ " for (dx, dy) in ((0, 1), (1, 0), (1, 1), (1, -1)))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d3dd8c0f",
+ "metadata": {},
+ "source": [
+ "States in tic-tac-toe (and other games) will be represented as a `Board`, which is a subclass of `defaultdict` that in general will consist of `{(x, y): contents}` pairs, for example `{(0, 0): 'X', (1, 1): 'O'}` might be the state of the board after two moves. Besides the contents of squares, a board also has some attributes: \n",
+ "- `.to_move` to name the player whose move it is; \n",
+ "- `.width` and `.height` to give the size of the board (both 3 in tic-tac-toe, but other numbers in related games);\n",
+ "- possibly other attributes, as specified by keywords. \n",
+ "\n",
+ "As a `defaultdict`, the `Board` class has a `__missing__` method, which returns `empty` for squares that have no been assigned but are within the `width` × `height` boundaries, or `off` otherwise. The class has a `__hash__` method, so instances can be stored in hash tables."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "5918c22a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Board(defaultdict):\n",
+ " \"\"\"A board has the player to move, a cached utility value, \n",
+ " and a dict of {(x, y): player} entries, where player is 'X' or 'O'.\"\"\"\n",
+ " empty = '.'\n",
+ " off = '#'\n",
+ " \n",
+ " def __init__(self, width=8, height=8, to_move=None, **kwds):\n",
+ " self.__dict__.update(width=width, height=height, to_move=to_move, **kwds)\n",
+ " \n",
+ " def new(self, changes: dict, **kwds) -> 'Board':\n",
+ " \"Given a dict of {(x, y): contents} changes, return a new Board with the changes.\"\n",
+ " board = Board(width=self.width, height=self.height, **kwds)\n",
+ " board.update(self)\n",
+ " board.update(changes)\n",
+ " return board\n",
+ "\n",
+ " def __missing__(self, loc):\n",
+ " x, y = loc\n",
+ " if 0 <= x < self.width and 0 <= y < self.height:\n",
+ " return self.empty\n",
+ " else:\n",
+ " return self.off\n",
+ " \n",
+ " def __hash__(self): \n",
+ " return hash(tuple(sorted(self.items()))) + hash(self.to_move)\n",
+ " \n",
+ " def __repr__(self):\n",
+ " def row(y): return ' '.join(self[x, y] for x in range(self.width))\n",
+ " return '\\n'.join(map(row, range(self.height))) + '\\n'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6f0a9d7c",
+ "metadata": {},
+ "source": [
+ "# Players\n",
+ "\n",
+ "We need an interface for players. I'll represent a player as a `callable` that will be passed two arguments: `(game, state)` and will return a `move`.\n",
+ "The function `player` creates a player out of a search algorithm, but you can create your own players as functions, as is done with `random_player` below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "3dcc2288",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def random_player(game, state): return random.choice(list(game.actions(state)))\n",
+ "\n",
+ "def player(search_algorithm):\n",
+ " \"\"\"A game player who uses the specified search algorithm\"\"\"\n",
+ " return lambda game, state: search_algorithm(game, state)[1]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e5297660",
+ "metadata": {},
+ "source": [
+ "# Playing a Game\n",
+ "\n",
+ "We're ready to play a game. I'll set up a match between a `random_player` (who chooses randomly from the legal moves) and a `player(alphabeta_search)` (who makes the optimal alpha-beta move; practical for tic-tac-toe, but not for large games). The `player(alphabeta_search)` will never lose, but if `random_player` is lucky, it will be a tie."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "009231c5",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Player X move: (2, 2)\n",
+ ". . .\n",
+ ". . .\n",
+ ". . X\n",
+ "\n",
+ "Player O move: (1, 1)\n",
+ ". . .\n",
+ ". O .\n",
+ ". . X\n",
+ "\n",
+ "Player X move: (1, 0)\n",
+ ". X .\n",
+ ". O .\n",
+ ". . X\n",
+ "\n",
+ "Player O move: (0, 1)\n",
+ ". X .\n",
+ "O O .\n",
+ ". . X\n",
+ "\n",
+ "Player X move: (2, 0)\n",
+ ". X X\n",
+ "O O .\n",
+ ". . X\n",
+ "\n",
+ "Player O move: (2, 1)\n",
+ ". X X\n",
+ "O O O\n",
+ ". . X\n",
+ "\n",
+ "CPU times: user 851 ms, sys: 7.08 ms, total: 859 ms\n",
+ "Wall time: 857 ms\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "-1"
+ ]
+ },
+ "execution_count": 7,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "%time play_game(TicTacToe(), dict(X=random_player, O=player(minimax_search)), verbose=True).utility"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "51662ca9",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Player X move: (2, 2)\n",
+ ". . .\n",
+ ". . .\n",
+ ". . X\n",
+ "\n",
+ "Player O move: (1, 1)\n",
+ ". . .\n",
+ ". O .\n",
+ ". . X\n",
+ "\n",
+ "Player X move: (0, 0)\n",
+ "X . .\n",
+ ". O .\n",
+ ". . X\n",
+ "\n",
+ "Player O move: (0, 1)\n",
+ "X . .\n",
+ "O O .\n",
+ ". . X\n",
+ "\n",
+ "Player X move: (1, 0)\n",
+ "X X .\n",
+ "O O .\n",
+ ". . X\n",
+ "\n",
+ "Player O move: (2, 0)\n",
+ "X X O\n",
+ "O O .\n",
+ ". . X\n",
+ "\n",
+ "Player X move: (0, 2)\n",
+ "X X O\n",
+ "O O .\n",
+ "X . X\n",
+ "\n",
+ "Player O move: (2, 1)\n",
+ "X X O\n",
+ "O O O\n",
+ "X . X\n",
+ "\n",
+ "CPU times: user 84.4 ms, sys: 0 ns, total: 84.4 ms\n",
+ "Wall time: 83.1 ms\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "-1"
+ ]
+ },
+ "execution_count": 8,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "%time play_game(TicTacToe(), dict(X=random_player, O=player(alphabeta_search)), verbose=True).utility"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "28b41a8d",
+ "metadata": {},
+ "source": [
+ "The alpha-beta player will never lose, but sometimes the random player can stumble into a draw. When two optimal (alpha-beta or minimax) players compete, it will always be a draw:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "a5ac7867",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Player X move: (0, 1)\n",
+ ". . .\n",
+ "X . .\n",
+ ". . .\n",
+ "\n",
+ "Player O move: (0, 0)\n",
+ "O . .\n",
+ "X . .\n",
+ ". . .\n",
+ "\n",
+ "Player X move: (2, 0)\n",
+ "O . X\n",
+ "X . .\n",
+ ". . .\n",
+ "\n",
+ "Player O move: (2, 1)\n",
+ "O . X\n",
+ "X . O\n",
+ ". . .\n",
+ "\n",
+ "Player X move: (1, 2)\n",
+ "O . X\n",
+ "X . O\n",
+ ". X .\n",
+ "\n",
+ "Player O move: (0, 2)\n",
+ "O . X\n",
+ "X . O\n",
+ "O X .\n",
+ "\n",
+ "Player X move: (1, 0)\n",
+ "O X X\n",
+ "X . O\n",
+ "O X .\n",
+ "\n",
+ "Player O move: (1, 1)\n",
+ "O X X\n",
+ "X O O\n",
+ "O X .\n",
+ "\n",
+ "Player X move: (2, 2)\n",
+ "O X X\n",
+ "X O O\n",
+ "O X X\n",
+ "\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "0"
+ ]
+ },
+ "execution_count": 9,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "play_game(TicTacToe(), dict(X=player(minimax_search), O=player(alphabeta_search)), verbose=True).utility"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b7d28958",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-06-Constraint-Satisfaction-Problems.ipynb b/Chapter-06-Constraint-Satisfaction-Problems.ipynb
new file mode 100644
index 000000000..d6f40db7c
--- /dev/null
+++ b/Chapter-06-Constraint-Satisfaction-Problems.ipynb
@@ -0,0 +1,927 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "9eb4175b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from csp import *\n",
+ "from notebook import psource, plot_NQueens\n",
+ "%matplotlib inline\n",
+ "\n",
+ "# Hide warnings in the matplotlib sections\n",
+ "import warnings\n",
+ "warnings.filterwarnings(\"ignore\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "6587e509",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "neighbors = parse_neighbors('A:B; B:')\n",
+ "domains = {'A': [0, 1, 2, 3, 4], 'B': [0, 1, 2, 3, 4]}\n",
+ "constraints = lambda X, x, Y, y: x % 2 == 0 and (x + y) == 4 and y % 2 !=0\n",
+ "removals = []"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "dc60700d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "csp = CSP(variables=None, domains=domains, neighbors=neighbors, constraints=constraints)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "203c44bb",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(False, 25)"
+ ]
+ },
+ "execution_count": 4,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "AC3(csp, removals=removals)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "b7e9def2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "constraints = lambda X, x, Y, y: (x % 2) == 0 and (x + y) == 4\n",
+ "removals = []\n",
+ "csp = CSP(variables=None, domains=domains, neighbors=neighbors, constraints=constraints)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "c4290879",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(True, 31)"
+ ]
+ },
+ "execution_count": 6,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "AC3(csp, removals=removals)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d2d45786",
+ "metadata": {},
+ "source": [
+ "## Sudoku"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "839e08a2",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ ". . 3 | . 2 . | 6 . .\n",
+ "9 . . | 3 . 5 | . . 1\n",
+ ". . 1 | 8 . 6 | 4 . .\n",
+ "------+-------+------\n",
+ ". . 8 | 1 . 2 | 9 . .\n",
+ "7 . . | . . . | . . 8\n",
+ ". . 6 | 7 . 8 | 2 . .\n",
+ "------+-------+------\n",
+ ". . 2 | 6 . 9 | 5 . .\n",
+ "8 . . | 2 . 3 | . . 9\n",
+ ". . 5 | . 1 . | 3 . .\n"
+ ]
+ }
+ ],
+ "source": [
+ "sudoku = Sudoku(easy1)\n",
+ "sudoku.display(sudoku.infer_assignment())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "03b4d8d8",
+ "metadata": {},
+ "source": [
+ "### First, Check CSP with AC3"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "3332a76e",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "CPU times: user 8.26 ms, sys: 81 µs, total: 8.34 ms\n",
+ "Wall time: 8.3 ms\n",
+ "Check Results:True\n",
+ "AC3 needs 11322 consistency-checks\n"
+ ]
+ }
+ ],
+ "source": [
+ "%time results, checks = AC3(sudoku, arc_heuristic=no_arc_heuristic)\n",
+ "print(f\"Check Results:{results}\")\n",
+ "print(f\"AC3 needs {checks} consistency-checks\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "93f1e97b",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ ". . 3 | . 2 . | 6 . .\n",
+ "9 . . | 3 . 5 | . . 1\n",
+ ". . 1 | 8 . 6 | 4 . .\n",
+ "------+-------+------\n",
+ ". . 8 | 1 . 2 | 9 . .\n",
+ "7 . . | . . . | . . 8\n",
+ ". . 6 | 7 . 8 | 2 . .\n",
+ "------+-------+------\n",
+ ". . 2 | 6 . 9 | 5 . .\n",
+ "8 . . | 2 . 3 | . . 9\n",
+ ". . 5 | . 1 . | 3 . .\n",
+ "CPU times: user 6.89 ms, sys: 166 µs, total: 7.05 ms\n",
+ "Wall time: 6.9 ms\n",
+ "4 8 3 | 9 2 1 | 6 5 7\n",
+ "9 6 7 | 3 4 5 | 8 2 1\n",
+ "2 5 1 | 8 7 6 | 4 9 3\n",
+ "------+-------+------\n",
+ "5 4 8 | 1 3 2 | 9 7 6\n",
+ "7 2 9 | 5 6 4 | 1 3 8\n",
+ "1 3 6 | 7 9 8 | 2 4 5\n",
+ "------+-------+------\n",
+ "3 7 2 | 6 8 9 | 5 1 4\n",
+ "8 1 4 | 2 5 3 | 7 6 9\n",
+ "6 9 5 | 4 1 7 | 3 8 2\n"
+ ]
+ }
+ ],
+ "source": [
+ "sudoku = Sudoku(easy1)\n",
+ "sudoku.display(sudoku.infer_assignment())\n",
+ "%time backtracking_search(sudoku, select_unassigned_variable=mrv, inference=forward_checking)\n",
+ "sudoku.display(sudoku.infer_assignment())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "657c2c53",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "4 1 7 | 3 6 9 | 8 . 5\n",
+ ". 3 . | . . . | . . .\n",
+ ". . . | 7 . . | . . .\n",
+ "------+-------+------\n",
+ ". 2 . | . . . | . 6 .\n",
+ ". . . | . 8 . | 4 . .\n",
+ ". . . | . 1 . | . . .\n",
+ "------+-------+------\n",
+ ". . . | 6 . 3 | . 7 .\n",
+ "5 . . | 2 . . | . . .\n",
+ "1 . 4 | . . . | . . .\n"
+ ]
+ }
+ ],
+ "source": [
+ "sudoku = Sudoku(harder1)\n",
+ "sudoku.display(sudoku.infer_assignment())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "7dc4193c",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "CPU times: user 8.79 ms, sys: 0 ns, total: 8.79 ms\n",
+ "Wall time: 9.04 ms\n",
+ "Check Results:True\n",
+ "AC3 needs 12837 consistency-checks\n"
+ ]
+ }
+ ],
+ "source": [
+ "%time results, checks = AC3(sudoku, arc_heuristic=no_arc_heuristic)\n",
+ "print(f\"Check Results:{results}\")\n",
+ "print(f\"AC3 needs {checks} consistency-checks\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "83e94714",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "4 1 7 | 3 6 9 | 8 . 5\n",
+ ". 3 . | . . . | . . .\n",
+ ". . . | 7 . . | . . .\n",
+ "------+-------+------\n",
+ ". 2 . | . . . | . 6 .\n",
+ ". . . | . 8 . | 4 . .\n",
+ ". . . | . 1 . | . . .\n",
+ "------+-------+------\n",
+ ". . . | 6 . 3 | . 7 .\n",
+ "5 . . | 2 . . | . . .\n",
+ "1 . 4 | . . . | . . .\n",
+ "CPU times: user 7.44 ms, sys: 3.87 ms, total: 11.3 ms\n",
+ "Wall time: 11.2 ms\n",
+ "4 1 7 | 3 6 9 | 8 2 5\n",
+ "6 3 2 | 1 5 8 | 9 4 7\n",
+ "9 5 8 | 7 2 4 | 3 1 6\n",
+ "------+-------+------\n",
+ "8 2 5 | 4 3 7 | 1 6 9\n",
+ "7 9 1 | 5 8 6 | 4 3 2\n",
+ "3 4 6 | 9 1 2 | 7 5 8\n",
+ "------+-------+------\n",
+ "2 8 9 | 6 4 3 | 5 7 1\n",
+ "5 7 3 | 2 9 1 | 6 8 4\n",
+ "1 6 4 | 8 7 5 | 2 9 3\n"
+ ]
+ }
+ ],
+ "source": [
+ "sudoku = Sudoku(harder1)\n",
+ "sudoku.display(sudoku.infer_assignment())\n",
+ "%time backtracking_search(sudoku, select_unassigned_variable=mrv, inference=forward_checking)\n",
+ "sudoku.display(sudoku.infer_assignment())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bbc63694",
+ "metadata": {},
+ "source": [
+ "## 8-queens"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "a4ffae94",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "eight_queens = NQueensCSP(8)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "66529d8c",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "CPU times: user 760 µs, sys: 0 ns, total: 760 µs\n",
+ "Wall time: 766 µs\n",
+ "Check Results:True\n",
+ "AC3 needs 666 consistency-checks\n"
+ ]
+ }
+ ],
+ "source": [
+ "%time results, checks = AC3(eight_queens, arc_heuristic=no_arc_heuristic)\n",
+ "print(f\"Check Results:{results}\")\n",
+ "print(f\"AC3 needs {checks} consistency-checks\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "30c4ccf2",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{0: 2, 1: 4, 2: 1, 3: 7, 4: 0, 5: 6, 6: 3, 7: 5}\n",
+ "Figure(504x504)\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAd0AAAHwCAYAAADjD7WGAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAACTV0lEQVR4nOz9eXyU5b3/jz+vmclGVkiAsKOAILITQCsUS7VatbZae7RuPVqr9me1+mlRj3p6tLVWrVV/R6vHFpW61oJKhWJxQRRcgLAo+xJIWAMhkH2fub5/vO9h7lkCAZKQ5f18PPKYuZe57uuem/DK+3pvxlqLoiiKoigtj+dkT0BRFEVROgsquoqiKIrSSqjoKoqiKEoroaKrKIqiKK2Eiq6iKIqitBIquoqiKIrSSqjoKoqiKEoroaKrKIqiKK2Eiq6itALGmIHGmPnGmEPGmEJjzDPGGN8Rzs8wxjznnFtljFljjPlJa85ZUZTmR0VXUVqHZ4H9QC9gDDAV+P/FOtEYEw98CAwAzgLSgenAY8aY21tjsoqitAwquorSOpwC/MNaW2OtLQT+DZzRyLnXAv2BH1lrt1tr6621/wZuBx4yxqQAGGOsMWZw8EPGmJnGmIdc2xcbY1YbY0qMMZ8bY0a5jvU2xrxljCkyxmx3i7kx5gFjzD+MMS8bY8qNMeuMMTmu43cbY3Y7xzYZY77dPF+RonR8VHQVpXV4CrjSGNPFGNMH+C4ivLE4D3jPWlsZsf8toAti/R4RY8xY4EXgZiATeB541xiTYIzxAHOBr4A+wLeBO4wx57uGuAT4O5ABvAs844w7FPgFMMFamwqcD+QfbT6KoggquorSOnyKWLZlwC4gF5jTyLlZwN7IndbaBuAA0L0J17sJeN5au9Ra67fW/g2oBc4EJgDdrbW/tdbWWWu3AX8FrnR9fom1dr611g+8Aox29vuBBGC4MSbOWptvrc1rwnwURUFFV1FaHMey/DfwNpCMiGpX4NFGPnIA8f1GjuNzPnugCZcdAPzKWVouMcaUAP2A3s6x3hHH7gV6uj5f6HpfBSQaY3zW2q3AHcADwH5jzN+NMb2bMB9FUVDRVZTWoBvio33GWltrrS0GXgIubOT8D4HvGmOSI/b/EKgDljrbVchyc5Bs1/udwO+ttRmuny7W2jecY9sjjqVaaxubTxjW2tettZMR8bY0/seDoigRqOgqSgtjrT0AbAd+bozxGWMygJ8AXzfykVeQJehZTqpRnONv/V/gj9baUue81cBVxhivMeYCJCI6yF+BW4wxk4yQbIy5yBiTCiwDyp2AqCTn8yOMMROOdi/GmKHGmGnGmASgBqgGAsf4lShKp0VFV1Fah8uAC4AiYCtQD9wZ60RrbS1wLmKRLkWE7d9IMNaDrlN/CXwPKAGuxuUjttbmAj9DAqAOOdf8T+eYH7gYSV3ajixXz0BSk45GAvCI85lCoAfwX034nKIogLHWnuw5KIpyBIwxccB7wG7gP63+0ipKu0UtXUVp41hr6xF/bh4w9CRPR1GUE0AtXUVRFEVpJdTSVRRFUZRWotGC6ydCVlaWHThwYEsM3SZYsWLFyZ5CizJ+/PiTPYUWR59h+0afX/unoz9Da62Jtb9FlpdzcnJsbm5us4/bVjAm5nfZYegMLgd9hkemuLiIHZs+IKV2NtlJX5ISV4SxfjBWMnM5/AKAMc4OA1iDNV4q6rMorJ5IRcKP6D/0fDIzm1JIq2no82v/dIJnGPMGW8TSVRSlfbKvcBd7Nr5EP9/LjEncjokPiNC6cQQ2XGjdJ1gMDaTGFZLqm4vlXxzcMJBV9dfSa9gNZPfq11q3oyhtDrV0j4NO8BfayZ5Ci6PPMJzKigo2rnyJQb4nSI8vwBBDaMMuEGOQo5xjMZTW9yev7k6Gjr+BlJTUY5pj2KX0+bV7OsEzjHmDGkilKJ2cvM2r2Zf7A8Yl/z8y4vMxQcs2+F9G0JJ1/wT3G8LF1n08YgyDJSOugHHJv6Io9xK2blrZMjekKG0YFV1F6aT4/X5Wf/kqPQ9+l1NTFmJoiLZWg0TujxRi9/6jjGHwc0rKJ2QfupDVX/yNhoaG478JRWlnqOgqSiekrq6OVZ88wkjfzaT49gE22ooN+mtxvXeLauR2LEu40TEsKXH7GRn3c1Z/8jC1tbUtcZuK0ubQQCpF6WTU1dWx4csHGJv6J7zUhwKlgmLpFkr3/uCmhYoqWLwK8nbDqX1gylhI7eL62FHGkG2L19QwNu0h1i2tZOik35KQkNAct6gobRYVXUXpRPj9fr5e8kcRXFMXHnnsvHf0UHBHKSOCu7sIrn8AFq2ABj94vTB1LLz0APTrGbG6HOkXjjpm8Zp6zkh6klVLujBm6n34fPrfktJx0eVlRelErFn+BmPTHsZr6qN8r9bCoXKYMQdu+j3c8wzkboBAgMPnBiw8+Bf4cJkILoDfDwtz4X+eDz/XWiguhbmfwt/mwcpNUN8g++UEDlvEXk89YzMeZe3yVztF5K7SedE/KRWlk5C3eRWDmY7XVIvyRWhbcSlcfT98uFTEFeCvb8Of74ErvyMWb2k5fLA09vgfLRPRzsqQoVdtgp/+Fr7eKmKcnAQ3XQq/vxWS4l0fdK7lpYYh5h62bhrBkGE5zXz3itI2UEtXUToBFeXlePb8OhQ0FYFFLNwPXIILIqL3PwtFh+Qkf0As21g0+B1L10JlNdz2GKze7OxD9j39Jvx9gTODqChnS7JvP3GFv6a8vOzEblhR2igquorSCdi0aiYDUz4hTHBdohcIwMe5rqVfFzsKYcsOeZ+RCpNGxL7GxDOga5qMu3kHrNwYfU6DH95aGC7sYeJrLANSlrBl5YtNuzFFaWeo6CpKB2df4S4G+Z4A/BwohXmL4ZX3xAptCPpgDSTGx/681wMJ8XKOzwsP3gIjBoWfc8ap8NDP5ThAXb1YxbGornXE3cr1v9oMr74Hcxc7FjV+BsU/ReHenc1w94rStlDRVZQOzp4NL5IeX8Dy9TDtFvj+r+C638A3b4T7noWaOvAYuGxaSDTdjB0KQwfIe2Ng+Cmw4Bm47waI88E9/ynbZwxyIp2Bwf1gYK/osQxwzngR8tp6+M1zMOVGuPY38INfy/yWroW0uB0UbpzRUl+Jopw0VHQVpQNTXFxEv7iXKau03PoIrNka8rGWV8GTr8FbH8n2f5wHt18pAU8gAjp6CDxzN6R04XC0sTHQuztMGC5jjR8GfbofzgACIDNdAqYy00NzMQa+NQFuvky231kEj78q8wAZa20e3PoolFZY+sW/QvGB/S36/ShKa6OiqygdmB2bPiAzMZ/12ySKOJL6Bnj7Y1nuTYyHR26DRc/DRZMhJQlmPgDjhoUs2CDWwvrtsoS8Ni92Cu4Pp8Erv4OkBFmOfvYemPUIdO8qn39noVw/kjVbZcxuCTvYsXlBM30TitI2UNFVlA6K3+8npXYWhgC1R/Cx1tSGCkjFeWH86TCgF1RUw/L1zkkxCmisy5Nda/MiArCcwYyBooOyfD3hDLFwu6WFBLymLvZ8AgFZejYmQGrtLPyNhUsrSjtERVdROijFB/aRnfQlYBk2APr2iD7HGPGxeiLqKJdViJC+tTBUBMNNXT1sKpD3W3a4BNQ1ht8PsxfKOGUV0U3vz8mJtqAB+vSA0wcCWLKTllG0f+8x37uitFVUdBWlg7Jv19ekxB0AAz0zJbo4w9XC1gDnToTrLwmvmWwtlFXK5tK1sG03EWk9UFIGO/fJ5u4iKayBawyAgkL4/Ct5X14F1mVpGwM/uRguOCt86PQU+O0t0CtLtpN9B9i/e/XxfwmK0sZQ0VWUDkpNyXKMFTPVGLjqAokynn6t5NTG+WD6dU6wk6tGcsBpaABQUg7vfeYsH7vUced+OQYi0Dv2ho9hLSz4Ag46YlxR5Sxvu8bomgp3XQfxcbKk/etr4d9PwzUXhixgQ4C6kmXN/t0oyslCRVdROihpnq+lg5ATdewxMHE4PHo73PFjCWJ6eZ7L1+uc5w+IPzfIOx/LcrK7dd+mfPG7goyzMT+Ue4t1ArQWhpaUK6qd69jw68ycJ+PcdgU8djucORK8Yc0RLOmeNS32HSlKa6OiqygdlIw4J1w5wm9qDPTtKd2B3v1UooUPW7JGfLFu0V25ETYWhLYtsCYvfMzD284YW3e6grCAqhpw96oPBmLNWSTzCOtO5O7RC6QnbDuW21aUNo2KrqJ0UHqkOAFIMRrQ98yUVJ6ySnhuVqhmctBKrXb1lK+ohnmfhuolBwKhyOUg67eFLFlrYd6SkF8YJEK6tj40h4CF52ZDaYWkKgV9uG5LGOd63VMKm+srUZSTjoquonRU/KXRtZQdQeuWBmnJsuuthWLJBk+tqxeRdDPnk5AQV9VC3q7w49t2h/zANXWyJO2mutZZokZEeVMBzHKKcqR2cfmVIxrfWws0aPMDpePQJNE1xlxgjNlkjNlqjLmnpSelKMqJs3tfI4mwRqpOZWXI5sEyeP6tUK5tbV10Du26PFmGBqmPXHgg/Pj+g7DvoIy9fht8vSX8eJ3LerZWrhcMssrKCK94Fbkcvmd/I/ehKO2Qo4quMcYL/Bn4LjAc+LExZnhLT0xRlBOjT884eRMUMVfz+HiflHIM8vf3YesuObeqNrpSVHWt+F+the27obw6/HhljVi/1sI/F4kP101DQ2hf3i5p7xekd5ZEMIfhEt7ePSIPKkr7pSmW7kRgq7V2m7W2Dvg78P2WnZaiKCeMNyOsHrIbjwf6Z4e2iw7B/80Wf21k0FOQeYsl33bdtuieusG6yZXVEpwVSYNfjgWs9O3dfyh0rF+2NEA4TGT3QZ+rgLOitHOaIrp9AHePrV3OvjCMMTcZY3KNMblFRUXNNT9FUY6TogpXm58Y/WsH9g4//7V/ixVaVR27CtXmHbBiQ/TScZA1W5xI5/zoY8E0pIK98Mr88GOxuhG5l5mLKrJjnKAo7ZNmC6Sy1v7FWptjrc3p3r370T+gKEqLUlI3KDo4ycEgYuc+tP9gKKI4EMM6rquH194TizYW67dLX9xg/q6bYCnIF+bA3gh/8IDeMdKFgrm6BkobTj3SbSpKu8LXhHN2A/1c232dfYqitGFKA6PAvi0FMlwiFnzt2xN8vnD/7cv/gi6JREc9O8z6MLYVDLBhu+TnxsJaCbCaOS98v8/J0YXwuYW2DaX1I496r4rSXmiKpbscGGKMOcUYEw9cCbzbstNSFOVESew6AWu84R2CXPTMhMSE8H3FpfDUG42LbllldJBUkOra8NzcSGb8E3ZHtMeNytGNTBnCQ3zGxMYHVZR2xlFF11rbAPwCWABsAP5hrV3X0hNTFOXE6Nl3NBX1WSELMkJ8u6VBenL05yqro/c1BwUxmgWlp0bUfnbPE6hqyKRHnzEtMyFFOQk0yadrrZ1vrT3NWjvIWvv7lp6UoignTmZWTwqrJxFl4jrClpYMU8aejJmF+NZ4yEhp5KAx7K2ZSFZ3DaRSOg5N8ekqitIO8Xq9VCRcjrXzMPijfKY+Lzx8K6zeLP7YxvB5peVeryzxv/bKEus0uYsca/BDZZUsTe85ALv2SbBUaUXj/l+A0/pLGz+v19nhbnTgLC2XxV+Oz6f/TSkdB/3XrCgdmP5Dz+fghoFkJrpCjh1hMwYG9II/3w2X3yWVqUC0r2sajB0K0ybAWaNgcD8R3kBAKlbVNYjf11oZx+uFhDgpuoERwd26E75YAx8vl1SiQ2UhTU1PgafvkrSlqEb2zvahmv70P+2ClvtyFOUkoKKrKB2YzMzurKq/lm6JD2KIjmI2BqaOE4vzzidg2ED42aVw4dmQnSlpRCs3wlOLxSLeWQhlVVI8wy26Ho9UlUpLlgpTw08Vsf7RufDLK6GwGOZ/BjPegQ358JufwbkTHcF1R1U7WGvYUXcNY7r3jL4pRWnHGNtYmOIJkJOTY3Nzc5t93LaCifrTvGPREv8m2hqd6RkW7t1JYv4UMuKd/nwxHm91Hdz0ENx0GaQmw/tfwPzPpeBFSXnsvN2jYYxYtKOGwHe/IVZzZbWkJT17t3Q5iv6QvJTW9ad6wGKye/dvZOzO8/w6Kp3gGca8QbV0FaWDk92rHys338nYuF+JbxeiUnMS4+EXV8DV94tVGhnBnBAPvTKlZGPfHmIFd00LCWdVjZR2zN8Dmwtg5z5pmlBSDp+ulJ/EeOjZDd5+3JWqFDEPAGu95NX9knGNCK6itGdUdBWlE3Da+BsoyJ3DwJRPpFhGhCFlDIwbBqMGh9r2JcaLlfq9KXDemeLX9XikslRJeagTUVICpKXI0nJSgvh8t+yED5bC3E9kWbrG6Vw06jQYOdjR2oglZQCsYUflNxgy7saW/UIU5SShoqsonYCUlFQKsx+nouQiUuL2i/AGcVKIfF5ZXl7wJZw3Ce64CsafLi34lqyGp9+EVRvFEq6qDTU98DlBVOkpkJ0FQwfAd86Ea78Lt18hPuEnX4cFX8DPfiDnh1WdOjwPQ6W/O3U9/kRqalprfC2K0uqo6CpKJ2HwsPGs/vIxRtpb8JqaUNkpR/iMFWt32gT43+nw1Ra48XewKBeKShqvUlXv9MotqYCCQli6Vpoa9OgK5+TAFefBo7eLXzhnuCt4Knht572fRDbV/4Gxw3Ja7ktQlJOMiq6idCJG5FzFqk/yGZv2EF5THyZ6Fknx+WgZTLkR9hRJnm2cTxrN9+4uebq9u0uebkqSpAr5nbZ9xaXymZ375PVgGbz5Psz+UCpPVdWIxXz5t13Lyw5+4lhdOp3RU6/r8AE2SudGRVdROhE+n4+Rk+9m3dIqzkh6QoTXocEPM+eK77W6Bs6dBNNyYNJIGNQHkpPEX1tSIXm41bVi/cbHQWoX8emmJsvycXmVNLtfuhYWLofl6+WzL74L35/q5PMetnDjWF91OyMm36uFMJQOj/4LV5RORkJCAkMnPciqJV0Yk/4IPmoAy7bdsHwd/OlOuPQcEdHte0QwZ74La7fB7n3S1KCuQQplQKg4RlJCqHLVsIFw9mhJFbr5h1BcAk+8JqK+qQBGDgIw+E0iq0umM2LyvSQkxMohUpSOhYquonRCEhISGDP1Xr5eOoCh3rtJ9u2nuMQSHycFMZ58XaKP8/eIRXs06hugplaqTuXvgS++FqFO6SIR0BdPkXET4qHoEIAETW3x/4HRU69TC1fpNDRbE3tFUdoXPp+PcWf/hL1d/0V+xVQmjfTywbOQkSoRx/sPikV7IlTWwJqtMGeRpAotmQFTx3kpqJzMnrR5jD7rehVcpVOhFamOg44e6KHVcNo/x/oMKyrK2bziBQbFP0Va3A7q6i2FxZJvu7dIrN16Z0nZH9F+L1gG0usJvcbHSZ5vRqrUV+6fDYnxhrL6vuTV3cGQcTeeUFqQPr/2Tyd4hjFvUEX3OOgE/1hO9hRaHH2GsSncu5PCTS/QL+4VuiUUYEwAp+VPdPUodw9cYhx3dlo8HKrtz466a8geemOjpR2PBX1+7Z9O8AxVdJuLTvCP5WRPocXRZ3hkig/sZ8fmBaTWziY7aSnJccUY64dg0wTC83bDv00R2qqGTPZWT6As4Uf0H3IBWc3YvECfX/unEzxDrb2sKErTyMzqQWbWtfj9V1G0fy/bdq2mrnQ56d41pMfn0T25EPxl7NlfR+8ecVhvOkWV2ZTWn0Jpw0ji0ifSs/8YBvbopT5bRXGhvw2KojSK1+slu1dfsnv1BS6OOt7H9b6H86MoSuNo9LKiKIqitBIquoqiKIrSSqjoKoqiKEoroaKrKIqiKK1EiwRSrVixokOHg3f0cP6O/OyC6DNs3+jza/905GeYk9N4e0qNXlZaFK8XsrvByCEweTSMHw6jh0B6svRo7Z4BpZXw9RZYsQE++0reFxZL1xtFUZSOhIqu0ux4PDC0P/zkYvjBt+CU3uDzgMdLWO/W/tnyvksS9MqE88+CgB8aApC/F979FF56FzbmhzraKIqitGdapCKVMabjrhvQsZdF4PiXtuJ8Ipz33gA5w5xavF7nYGTZQBPxSsQ+RID9ASm+//BL8N7nUv+3OdBn2L7R59f+6cjPMCcnh9zc3JgPUQOplBPGAN8YBUtnwpzH4awRIsAeD7Hr8uLaH3ncJcwej4wzaQS8/UdY9jJMHiMF9hVFUdojKrrKCZHaBZ6/Dz5+HsYOFR8uEC6iNuInuN9AVJF89x+/rjG8HhgzBBY+By/8tzRYVxRFaW+o6CrHzYjBsOJV+Okl0sotypoNErk/Uojd+48yRpwPfnKRXHf0kOOeuqIoyklBRVc5Ls4/Ez6bAYP6uJaRG/HNHn7vFtXI7ViWcCNjeLxwah9YPAMuPLtFbk9RFKVFUNFVjpkrLhAfa0qSEygVs49q7G1robwS5i+Bp9+Efy2BsqqI044yBhY8BpKTYPajcPVFJ3AziqIorYimDCnHxPlnwov3QZdEYkYeWwgLkjKuc6yF3UVw/QOwaIXk4Xq9MHUsvPQA9OsZsboc6ReOOOYxkJQAf/0vKCkVAVcURWnLqKWrNJkRg+Efj0BiPFG+V2vhUDnMmAM3/R7ueQZyNzj5tcEUIAsP/gU+XBYqfOH3w8Jc+J/nw8+1FopLYe6n8Ld5sHKTpAtZl6AHl5yTEuGNh2HM0Bb+AhRFUU4QtXSVJpGWDG8/BildxMKMtDyLS+Hq++HDpSKuAH99G/58D1z5HbF4S8vhg6Wxx/9omYh2VoYMvWoT/PS38PVWEePkJLjpUvj9rZAU7/qgc63kBJj9CIy/FkormvfeFUVRmgu1dJWjYoA/3ekKmorAIhbuBy7BBRHR+5+FokNykj8glm0sGvyOpWuhshpuewxWbw5VoqqsFh/w3xc4OhthaXs8UvnqqV9pHq+iKG0XFV3lqJw1StJ0wgTXJWyBAHyc61r6dbGjELbskPcZqVLoIhYTz4CuaTLu5h1ShSqSBj+8tTBc2N3z8Hjh6gukgIaiKEpbREVXOSJxPnjmLvD54EApzFsMr7wnVmhD0AdrHD9vDLweSHB8wD4vPHgLjBgUfs4Zp8JDP5fjAHX1YhXHorrWEXcr1/9qM7z6HsxdLBa1zwdPT5d5K4qitDX0vybliJx/FowaAsvXw42/g3XbxLJN7QI//xE8eDMkxMFl02D+Z9GdgcYOhaED5L0xMPwUWPAMPDsLHnsZfnUN/OI/oHf30LLw4H4wsBds2Rk+lgHOGS9CXlsvQVnP/APKq8QKH34K/PV+mDAcLpoMcxa19LejKIpybKilqzSKxwP33QAV1XDrI7Bma8jHWl4FT74Gb30k2/9xHtx+pQQ8gQjo6CHwzN0SfBWMNjZGBHbCcBlr/DDo091ZJXaWjTPTJWAqMz00F2PgWxPg5stk+51F8PirMg+Qsdbmwa2Pyr77bhBxVhRFaUvof0tKowztL6K4fptEEUdS3wBvfyzLvYnx8MhtsOh5sTJTkmDmAzBuWHRgk7WwfrssIa/Ni5mCyw+nwSu/kzzcEYPg2Xtg1iPQvat8/p2FsTsOrdkqY44eAqcPbJ7vQVEUpblQ0VUa5T8vCS3lNuZjrakNVWiM88L402FAL7GOl693TopRQGNdnuxamxcRgOUMZgwUHYSaOphwhli43dJCAl5TF3s+gYDM1+uFG75//PeuKIrSEqjoKjHxeeEH58gS87AB0LdH9DnGiI/VE1FHuaxChPSthdE+XpBAqU0F8n7LDpeAusbw+2H2QhmnrCKiL4KBc3Jipwb16SEWrscD3/tmKDhLURSlLaCiq8SkZzcJZsJAz0yJLs5IDR03wLkT4fpLXFk71hHJStlcuha27SY8p9ZASRns3Cebu4uksAauMQAKCuHzr+R9eRVYl6VtDPzkYrjgrPCh01Pgt7dAryzZHpAt/mNFUZS2goquEpORQ8Dn/OswBq66QKKOp18rObVxPph+nRPs5KqRHLBQ4QQ3lZTDe585y8cuddy5X46BCPSOveFjWAsLvoCDjhhXVDnL264xuqbCXddJS8Hxp8Ovr4V/Pw3XXBiygL0eGH1ac38ziqIox4+KrhKTyaOdDkJO1LHHwMTh8OjtcMePJYjp5XkuX69znj8g/twg73wsy8nu1n2b8sXvCjLOxvxQ7i3WCdBaGFpSrqh2rmPDrzNznoxz2xXw2O1w5kjwukpUejxyH4qiKG0FFV0lJuOHO28i/KbGQN+eEqj07qcSLXzYkjXii3WL7sqNsLEgtG2BNXnhYx7edsbYutMVhAVU1UCDK1I5GIg1Z5HMI6w7kbtHLxI9rSiK0lZQ0VViMnqI8yZGA/qemZLKU1YJz80K1UwOWqnVtaFxKqph3qehesmBQChyOcj6bSFL1lqYtyTkFwaJkK6tD80hYOG52dLYIDE+5MN1W8I41xsxuJm+EEVRlGbgqKJrjHnRGLPfGLO2NSaktA3Sk2PUUnYErVuadB0CiVDeWBDSubp6EUk3cz4JCXFVLeTtCj++bXfID1xTJ0vSbqprnSVqZE6bCmCWU5QjtYvLr+y2yh0BT+tyLHetKIrSsjTF0p0JXNDC81DaGEWHGjlgpOpUVoZsHiyD598KCXRtXXQO7bo8WYYOjlt4IPz4/oOw76CMvX4bfL0l/Hidy3q2Vq4XDLLKygiveBW5HH6g5Oj3qiiK0locVXSttZ8CB1thLkobokc3501QxFzN4+N94ak4f38ftu6Sc6tqoytFVdeK/9Va2L4byqvDj1fWiPVrLfxzkfhw3TQ0hPbl7ZL2fkF6Z0kEcxgu4e3etQk3qyiK0kqoT1eJSUlFeD1kNx4P9M8ObRcdgv+bLf7ayKCnIPMWS77tum3RPXWDdZMrqyU4K5IGvxwLWOnbu99lhffLjqix7JqvAUpdvmFFUZSTTbOJrjHmJmNMrjEmt7nGVE4eYUu8MfrXDuwdfv5r/xYrtKo6dhWqzTtgxYbopeMga7Y4kc750ceCaUgFe+GV+eHHBvaKMZhrmXltXozjiqIoJ4lmE11r7V+stTnW2pzmGlM5eazYQHRwkoNBxM59aP/BUERxIIZ1XFcPr73XuAiu3y59cYP5u26CpSBfmAN7I/zBA3rHSBcK5uoaWLXpCDepKIrSymg/XSUmS1ZDwO8UyHCJWPC1b09pGO/23778L+iSGCPq2WHWh7GtYIAN2yU/NxbWSoDVzHnh+31Oji5EzNHZDvhhyaqj3amiKErr0ZSUoTeAL4Chxphdxpiftvy0lJPNmq3QEMy/hSiLt2cmJCaE7ysuhafeaFx0yyqjg6SCVNeG5+ZGMuOfsHt/+L6oHN2IlCF/AFZvbnxMRVGU1uaolq619setMRGlbVFYDPl74bT+hAuvI2zd0iSXtzxCKCsjIpObi4K90fvSU105uhFFMUCaKuwpapn5KIqiHA8avazEpMEP7y5yqk25ccQtLRmmjD0JE3PxrfGQkRL7WMBKJHRjy9mKoignA/XpKo3y0jz45Y/B4yPKZ+rzwsO3yvLthu2Nj+HzSsu9Xlnif+2VJdZpchc51uCHyipZmt5zAHbtk2Cp0oojC+Zp/aWNnzfYL9fV6AAraUkvzj3Rb0BRFKV5UdFVGmVjvqTxTBrh2ukImzEwoBf8+W64/C6pTAWifV3TYOxQmDYBzhoFg/uJ8AYCUrGqrkH8vtbKOF4vJMRJ0Q2MCO7WnfDFGvh4uczhUFlIU9NT4Om7JG0pqpG9s/3VVliv6UKKorQxVHSVRgkE4OGX4O0/OhZlRBSzMTB1nFicdz4BwwbCzy6FC8+G7ExJI1q5EZ5aLBbxzkIoq5LiGW7R9XikqlRaslSYGn6qiPWPzoVfXin+5fmfwYx3YEM+/OZncO5ER3DdUdUOfj88/KKr7aCiKEobwdjGQk1PZFBjmn/QNkRLfGdtCeMyH+N8sOxlGBNsBh/j1qvr4KaH4KbLIDUZ3v8C5n8uBS9KymPn7R59DmLRjhoC3/2GWM2V1ZKW9Ozd0uUo+kPysmYLjL82uhylm870DDsi+vzaPx35Gebk5JCbmxvzIaroHgcd+R8LRP/CTx4DC58TAZYTXAet6PCydXD1/WKVRkYwJ8RDr0wp2di3h1jBXdNCwllVI6Ud8/fA5gKJOo5smpAYDz27wduPy9K1iTEPDNTXw3m3wicrj3yPne0ZdjT0+bV/OvIzPJLo6vKyclQ++0qqSV13kVMsI+J3xRhpFj9qcKhtX2K8WKnfmwLnnSl+XY9HKkuVlIdENSkB0lJkaTkpQXy+W3bCB0th7ieyLF3jdC4adRqMHOwS3Ih5BPzw5gfwqRbEUBSljaKW7nHQkf9Cg9h/Zaclw4pX4dQ+Ip6HsaGXBV/AD++C8ybBHVfB+NOlBd+S1fDe57Bqo1jCVbWhpgc+J4gqPQWys2DoAPjOmfDNsWINr9wIT74uY7/5B7h4SozgKURwCwph3NXSrOFodMZn2JHQ59f+6cjPUC1d5YQpqxRBXTJD+ul6XOUWAYwVa3faBPjf6fDVFrjxd7AoF4pKGq9SVe/0yi2pENFculaaGvToCufkwBXnwaO3i184Z7greCp4bed9ZQ1cOr1pgqsoinKyUNFVmszXW+DKe2H2o44/1iV6Fknx+WgZTLlRKkE1+MUPnJUh/Xf79ZTXzHRISZKIaL/Ttq+4VD4TrCJ1sAzefB9mfyiVp6pqxGK+/NvR/tzqOrj6v+ErLfmoKEobR0VXOSbmfwY3Pgwz7oWkxND+Bj/MnCu+1+oaOHcSTMuBSSNhUB+xjmvrxBItrRDr1lpJFUrtIsvXqcmy3FxeJc3ul66Fhcth+Xr57IvvwvenOvm8jthX18Etj8DcGH14FUVR2hoqusox8/p8KCmFNx6GlETx8W7bDcvXwZ/uhEvPERHdvkcEc+a7sHYb7N4ny9R1DaHyksHiGEkJocpVwwbC2aMlVejmH0JxCTzxmoj6pgIYOUg+X1krEdMquIqitBdUdJXjYv5nMPmn8M4f4ZTeIozxcVIQ48nXJfo4f49YtEejvgFqaqXqVP4e+OJrEeqULhIBffEUGTchHooOieAWFMLld0uglaIoSntBGx4ox82arTD+GilYMf50+OBZyEgVIdx/UCzaE6GyRq4xZ5GkCi2ZAWePgtcXSJSyCq6iKO0NTRk6DjpyqDsce7qCMVJA4+npMGKQ+HcLiyXfdm+RWLv1zpKy392Cj1AZSK8n9BofJ3m+GalSX7l/tvhxN2yHXzwmebgn+gj0GbZv9Pm1fzryM9SUIaVFsRYWr4IJ18FFk+He66VsZL+eTk5vjAbzh7cjeuC69wUCUj/5q61SS3ne4iOXdlQURWnrqOgqzUZ9gywFz/0UTh8I118Cl0wVS9XnWLIY+XH/kWsgSmh37oO5i+GFd6VbkDYvUBSlI6DLy8dBR14WgeZd2vJ5pXPQ6NNg8mgYd7osQaclw4ES6N5VUojW5sHqLWIxr94ky9L1LdiAXp9h+0afX/unIz9DXV5WThoNftixT37mLj7Zs1EURTm5aPSyoiiKorQSKrqKoiiK0kqo6CqKoihKK9EiPt3x48eTm5vbEkO3CTp6kENHDnAIos+wfaPPr/3T0Z9hY6ilqyiKoiitRJuLXi4uLmLHpg9IqZ1NdtKXpMQVYaxfGra62sgFOdxf1QDWYI2XivosCqsnUpHwI/oPPZ/MzO6tfyOKoiiKEkGbEd19hbvYs/El+vleZkzidkx8QITWjSOw4ULrPsFiaCA1rpBU31ws/+LghoGsqr+WXsNuILtXv9a6HUVRFEWJokWKY+Tk5Nim+nQrKyrYuPIlBvmeID2+AEMMoXUTa7pHOcdiKK3vT17dnQwdfwMpKalNmltjdHRfhPqT2j8d/Rnq82v/dIJnGPMGT6pPN2/zavbl/oBxyf+PjPh8DheyCk41aMm6f4L7DdH1esPWnUOvBktGXAHjkn9FUe4lbN20smVuSFEURVGOwEkRXb/fz+ovX6Xnwe9yaspCDA3R1mqQyP2RQuzef5QxDH5OSfmE7EMXsvqLv9HQoNXzFUVRlNaj1UW3rq6OVZ88wkjfzaT49gE22oqN7EITadlGbseyhBsdw5ISt5+RcT9n9ScPU1vbhC7riqIoitIMtGogVV1dHRu+fICxqX/CS30oUCoolrFawLk3LVRUSVH8vN1wah+YMhZSu7g+dpQxZNviNTWMTXuIdUsrGTrptyQkJDTHLSqKoihKo7Sa6Pr9fr5e8kcRXFMXHnnsvHf0UHBHKSOCu7sIrn8AFq2QQvpeL0wdCy89IL1bw1aXI/3CUccsXlPPGUlPsmpJF8ZMvQ+fr80EcyuKoigdkFZbXl6z/A3Gpj2M19RH+V6thUPlMGMO3PR7uOcZyN0gvVWD5wYsPPgX+HCZCC6A3w8Lc+F/ng8/11ooLpW+rn+bBys3Sa9X67aoHYvY66lnbMajrF3+aqeIGFQURVFOHq1i2uVtXsVgpuM11aJ8EdpWXApX3w8fLhVxBfjr2/Dne+DK74jFW1oOHyyNPf5Hy0S0szJk6FWb4Ke/ha+3ihgnJ8FNl8Lvb4WkeNcHnWt5qWGIuYetm0YwZFhOM9+9oiiKoggtbulWlJfj2fPrUNBUBBaxcD9wCS6IiN7/LBQdkpP8AbFsY9HgdyxdC5XVcNtjsHqzsw/Z9/Sb8PcFzgyiopwtyb79xBX+mvLyshO7YUVRFEVphBYX3U2rZjIw5RPCBNcleoEAfJzrWvp1saMQtuyQ9xmpMGlE7GtMPAO6psm4m3fAyo3R5zT44a2F4cIeJr7GMiBlCVtWvti0G1MURVGUY6RFRXdf4S4G+Z4A/BwohXmL4ZX3xAptCPpgDSTGx/681wMJ8XKOzwsP3gIjBoWfc8ap8NDP5ThAXb1YxbGornXE3cr1v9oMr74Hcxc7FjV+BsU/ReHenc1w94qiKIoSTouK7p4NL5IeX8Dy9TDtFvj+r+C638A3b4T7noWaOvAYuGxaSDTdjB0KQwfIe2Ng+Cmw4Bm47waI88E9/ynbZwxyIp2Bwf1gYK/osQxwzngR8tp6+M1zMOVGuPY38INfy/yWroW0uB0UbpzRUl+JoiiK0olpMdEtLi6iX9zLlFVabn0E1mwN+VjLq+DJ1+Ctj2T7P86D26+UgCcQAR09BJ65G1K6cDja2Bjo3R0mDJexxg+DPt0PZwABkJkuAVOZ6aG5GAPfmgA3Xybb7yyCx1+VeYCMtTYPbn0USiss/eJfofjA/pb6ahRFUZROSouJ7o5NH5CZmM/6bRJFHEl9A7z9sSz3JsbDI7fBoufhosmQkgQzH4Bxw0IWbBBrYf12WUJemxc7BfeH0+CV30FSgixHP3sPzHoEuneVz7+zUK4fyZqtMma3hB3s2Lygmb4JRVEURRFaRHSttaTUzsIQoPYIPtaa2lABqTgvjD8dBvSCimpYvj44mPPqKqCxLk92rc2LCMByBjMGig7K8vWEM8TC7ZYWEvCautjzCQRk6dmYAKm1s/A3Fi6tKIqiKMdBC4luPdlJXwKWYQOgb4/oc4wRH6snoo5yWYUI6VsLQ0Uw3NTVw6YCeb9lh0tAXWP4/TB7oYxTVhHd9P6cnGgLGqBPDzh9IIAlO2kZRfv3HvO9K4qiKEpjtIjopiVVkxJ3AAz0zJTo4gxXC1sDnDsRrr8kvGaytVBWKZtL18K23USk9UBJGezcJ5u7i6SwBq4xAAoK4fOv5H15FViXpW0M/ORiuOCs8KHTU+C3t0CvLNlO9h1g/+7Vx/8lKIqiKEoELSK6g3pXYayYqcbAVRdIlPH0ayWnNs4H069zgp1cNZIDTkMDgJJyeO8zZ/nYpY4798sxEIHesTd8DGthwRdw0BHjiipneds1RtdUuOs6iI+TJe1fXwv/fhquuTBkARsC1JUsa/bvRlEURem8tIjojj+tSjoIOVHHHgMTh8Ojt8MdP5YgppfnuXy9znn+gPhzg7zzsSwnu1v3bcoXvyvIOBvzQ7m3WCdAa2FoSbmi2rmODb/OzHkyzm1XwGO3w5kjwRvWHMGS7lnTEl+PoiiK0klpEdEdMcjpURvhNzUG+vaU7kDvfirRwoctWSO+WLfortwIGwtC2xZYkxc+5uFtZ4ytO11BWEBVDbh71QcDseYsknmEdSdy9+gF0hO2HcttK4qiKMoRaRHRHT7AMUVjNKDvmSmpPGWV8NysUM3koJVa7eopX1EN8z4N1UsOBEKRy0HWbwtZstbCvCUhvzBIhHRtfWgOAQvPzYbSCklVCvpw3ZYwzvW6pxQ211eiKIqiKC0juslJ/uhayo6gdUuDtGTZ9dZCsWSDp9bVi0i6mfNJSIiraiFvV/jxbbtDfuCaOlmSdlNd6yxRI6K8qQBmOUU5Uru4/MoRje+tBRq0+YGiKIrSfBxVdI0x/YwxHxtj1htj1hljfnm0z+w/2EhfWiNVp7IyZPNgGTz/VijXtrYuOod2XZ4sQ4PURy48EHkt2HdQxl6/Db7eEn68zmU9WyvXCwZZZWWEV7yKXA7fs7+RhF5FURRFOQ6aYuk2AL+y1g4HzgRuNcYMP9IHemYeDgEWXM3j431SyjHI39+Hrbvk3Kra6EpR1bXif7UWtu+G8urw45U1Yv1aC/9cJD7csMk3hPbl7ZL2fkF6Z0kEcxgu4e3dI/KgoiiKohw/RxVda+1ea+1K5305sAHoc6TPVFR5w+ohh13QA/2zQ9tFh+D/Zou/NjLoKci8xZJvu25bdE/dYN3kymoJzoqkwS/HAlb69u4/FDrWL1saIIRuNvTWAPhcBZwVRVEU5QQ5Jp+uMWYgMBZYGuPYTcaYXGNM7pqtLnMxRv/agb3DP/vav8UKraqOXYVq8w5YsSF66TjImi1OpHN+9LFgGlLBXnhlfvixWN2I3MvMRRXZMU5QFEVRlOOjyaJrjEkB3gLusNZGRRhZa/9irc2x1uZs3JEcHZwUHAcRO/eh/QdDEcWBGNZxXT289p5YtLFYv1364gbzd8PnJaUgX5gDeyP8wQN6x0gXCubqGihtODX2BRVFURTlOPA15SRjTBwiuK9Za98+2vkrNieBLZUCGS4RC7727Qk+X7j/9uV/QZdEoqOeHWZ9GNsKBtiwXfJzY2GtBFjNnBe+3+fk6MoNEh5IZQBrKK0febRbVRRFUZQmc1TRNcYY4AVgg7X2iaYMmrcnGWu8GNsQ0+LtmQmJCeGiW1wKT73RuOi6c28jqa4Nz++NZMY/YXdEe9yoHN3IlCE8xGdMbHxQRVEURTlGmrK8fDZwLTDNGLPa+bnwSB8orU6ioj4rZEG62/MhubrpydGfq6yO3tccFMRoFpSeGlH72T1PoKohkx59xrTMhBRFUZROSVOil5dYa421dpS1dozzM/9InzEmjsLqSUSZuI6wpSXDlLEnMu0T51vjISOlkYPGsLdmIlndNZBKURRFaT6a5NM9VowxVCRcjrXzMPijfKY+Lzx8K6zeLP7YRifnlZZ7vbLE/9orS6zT5C5yrMEPlVWyNL3nAOzaJ8FSpRWN+38BTusvbfy83uCECcsltngoi78cn69Fvh5FURSlk9JiqtJ/6Pkc3DCQzERXyLEjbMbAgF7w57vh8rukMhWI9nVNg7FDYdoEOGsUDO4nwhsISMWqugbx+1or43i9kBAnRTcwIrhbd8IXa+Dj5ZJKdKgspKnpKfD0XZK2FNXI3tk+VNOf/qdd0FJfjaIoitJJaTHRzczszqr6a+mW+CCG6ChmY2DqOLE473wChg2En10KF54N2ZmSRrRyIzy1WCzinYVQViXFM9yi6/FIVam0ZKkwNfxUEesfnQu/vBIKi2H+ZzDjHdiQD7/5GZw70RFcd1S1g7WGHXXXMKZ7z+ibUhRFUZQTwNjGwoVPgJycHJubm0vh3p0k5k8hI97pzxfjUtV1cNNDcNNlkJoM738B8z+Xghcl5bHzdo+GMWLRjhoC3/2GWM2V1ZKW9Ozd0uUo+kPyUlrXn+oBi8nu3f8I48dIQO5AtMS/ibaGPsP2jT6/9k8neIYxb7BFnZbZvfqxcvOdjI37lfh2ISo1JzEefnEFXH2/WKWREcwJ8dArU0o29u0hVnDXtJBwVtVIacf8PbC5AHbuk6YJJeXw6Ur5SYyHnt3g7cclVSnWPACs9ZJX90vGHUFwFUVRFOV4afFIodPG30BB7hwGpnwixTIi/oAzBsYNg1GDQ237EuPFSv3eFDjvTPHrejxSWaqkPNSJKCkB0lJkaTkpQXy+W3bCB0th7ieyLF3jdC4adRqMHOxobcSSMgDWsKPyGwwZd2PLfiGKoihKp6XFRTclJZXC7MepKLmIlLj9IrxBnBQin1eWlxd8CedNgjuugvGnSwu+Javh6Tdh1UaxhKtqQ00PfE4QVXoKZGfB0AHwnTPh2u/C7VeIT/jJ12HBF/CzH8j5YVWnDs/DUOnvTl2PP5GamtbSX4miKIrSSWmVnJjBw8az+svHGGlvwWtqQmWngh0ArVi70ybA/06Hr7bAjb+DRblQVNJ4lap6p1duSQUUFMLStdLUoEdXOCcHrjgPHr1d/MI5w13BU8FrO+/9JLKp/g+MHZbTcl+CoiiK0ulptUTUETlXseqTfMamPYTX1IeJnkVSfD5aBlNuhD1Fkmcb55NG8727S55u7+6Sp5uSJKlCfqdtX3GpfGbnPnk9WAZvvg+zP5TKU1U1YjFf/m3X8rKDnzhWl05n9NTrOrxjX1EURTm5tJro+nw+Rk6+m3VLqzgj6QkRXocGP8ycK77X6ho4dxJMy4FJI2FQH0hOEn9tSYXk4VbXivUbHwepXcSnm5osy8flVdLsfulaWLgclq+Xz774Lnx/qpPPe9jCjWN91e2MmHyvFsJQFEVRWpxWVZqEhASGTnqQVUu6MCb9EXzUAJZtu2H5OvjTnXDpOSKi2/eIYM58F9Zug937pOlBXYMUyoBQcYykhFDlqmED4ezRkip08w+huASeeE1EfVMBjBwEYPCbRFaXTGfE5HtJSIiVQ6QoiqIozUurm3cJCQmMmXovXy8dwFDv3ST79lNcYomPk4IYT74u0cf5e47cOShIfQPU1ErVqfw98MXXItQpXSQC+uIpMm5CPBQdApCgqS3+PzB66nVq4SqKoiitRpOb2DcnPp+PcWf/hL1d/0V+xVQmjfTywbOQkSoRx/sPikV7IlTWwJqtMGeRpAotmQFTx3kpqJzMnrR5jD7rehVcRVEUpVVp0YpUTaGiopzNK15gUPxTpMXtoK7eUlgs+bZ7i8TarXeWlP0R7feCZSC9ntBrfJzk+WakSn3l/tmQGG8oq+9LXt0dDBl34wmnBXX0gCuthtP+6ejPUJ9f+6cTPMOYN3jSRTdI4d6dFG56gX5xr9AtoQBjAjgtf6KrR7l74BLjuLPT4uFQbX921F1D9tAbj1ja8VjoBP9YTvYUWhx9hu0bfX7tn07wDNu26AYpPrCfHZsXkFo7m+ykpSTHFWOsH4JNEwjP2w2/KxHaqoZM9lZPoCzhR/QfcgFZzdy8oBP8YznZU2hx9Bm2b/T5tX86wTNs/drLx0NmVg8ys67F77+Kov172bZrNXWly0n3riE9Po/uyYXgL2PP/jp694jDetMpqsymtP4UShtGEpc+kZ79xzCwRy/12SqKoihtijarSl6vl+xefcnu1Re4OOp4H9f7Hs6PoiiKorRlTkr0sqIoiqJ0RlR0FUVRFKWVUNFVFEVRlFZCRVdRFEVRWokWCaRasWJFhw4H7+jh/B352QXRZ9i+0efX/unIzzAnp/E2sW02ellRFEVpHrxeyO4GI4fA5NEwfjiMHgLpydKzvHsGlFbC11tgxQb47Ct5X1gsXeCU5kNFV1EUpQPi8cDQ/vCTi+EH34JTeoPPAx4vYb3M+2fL+y5J0CsTzj8LAn5oCED+Xnj3U3jpXdiYH+rwphw/LVKRyhjTcdcN6NjLIqBLWx2Bjv4M9fk1TpxPhPPeGyBnmFOb3uscjCyjayJeidiHCLA/IM1oHn4J3vtc6uGfKB35Gebk5JCbmxvzIWoglaIoSgfAAN8YBUtnwpzH4awRIsAeD7Hr1OPaH3ncJcwej4wzaQS8/UdY9jJMHiMNZ5RjR0VXURSlnZPaBZ6/Dz5+HsYOFR8uEC6iNuInuN9AVNMYtxHqGsPrgTFDYOFz8MJ/Q1pyi9xOh0ZFV1EUpR0zYjCseBV+eom0No2yZoNE7o8UYvf+o4wR54OfXCTXHT3kuKfeKVHRVRRFaaecfyZ8NgMG9XEtIzfimz383i2qkduxLOFGxvB44dQ+sHgGXHh2i9xeh0RFV1EUpR1yxQXiY01JcgKlYvYVj71tLZRXwvwl8PSb8K8lUFYVcdpRxsCCx0ByEsx+FK6+6ARuphOhKUOKoijtjPPPhBfvgy6JxIw8thAWJGVc51gLu4vg+gdg0QrJw/V6YepYeOkB6NczYnU50i8cccxjICkB/vpfUFIqAq40jlq6iqIo7YgRg+Efj0BiPFG+V2vhUDnMmAM3/R7ueQZyNzj5tcEUIAsP/gU+XBYqfOH3w8Jc+J/nw8+1FopLYe6n8Ld5sHKTpAtZl6AHl5yTEuGNh2HM0Bb+Ato5aukqiqK0E9KS4e3HIKWLWJiRlmdxKVx9P3y4VMQV4K9vw5/vgSu/IxZvaTl8sDT2+B8tE9HOypChV22Cn/4Wvt4qYpycBDddCr+/FZLiXR90rpWcALMfgfHXQmlF8957R0EtXUVRlHaAAf50pytoKgKLWLgfuAQXRETvfxaKDslJ/oBYtrFo8DuWroXKarjtMVi9OVSJqrJafMB/X+DobISl7fFI5aunfqV5vI2hoqsoitIOOGuUpOmECa5L2AIB+DjXtfTrYkchbNkh7zNSpdBFLCaeAV3TZNzNO6QKVSQNfnhrYbiwu+fh8cLVF0gBDSUaFV1FUZQ2TpwPnrkLfD44UArzFsMr74kV2hD0wRrHzxsDrwcSHB+wzwsP3gIjBoWfc8ap8NDP5ThAXb1YxbGornXE3cr1v9oMr74HcxeLRe3zwdPTZd5KOPqVKIqitHHOPwtGDYHl6+HG38G6bWLZpnaBn/8IHrwZEuLgsmkw/7PozkBjh8LQAfLeGBh+Cix4Bp6dBY+9DL+6Bn7xH9C7e2hZeHA/GNgLtuwMH8sA54wXIa+tl6CsZ/4B5VVihQ8/Bf56P0wYDhdNhjmLWvrbaV+opasoitKG8XjgvhugohpufQTWbA35WMur4MnX4K2PZPs/zoPbr5SAJxABHT0Enrlbgq+C0cbGiMBOGC5jjR8Gfbo7q8TOsnFmugRMZaaH5mIMfGsC3HyZbL+zCB5/VeYBMtbaPLj1Udl33w0izkoI/ToURVHaMEP7iyiu3yZRxJHUN8DbH8tyb2I8PHIbLHperMyUJJj5AIwbFh3YZC2s3y5LyGvzYqbg8sNp8MrvJA93xCB49h6Y9Qh07yqff2dh7I5Da7bKmKOHwOkDm+d76Cio6CqKorRh/vOS0FJuYz7WmtpQhcY4L4w/HQb0Eut4+XrnpBgFNNblya61eREBWM5gxkDRQaipgwlniIXbLS0k4DV1secTCMh8vV644fvHf+8dERVdRVGUNorPCz84R5aYhw2Avj2izzFGfKyeiDrKZRUipG8tjPbxggRKbSqQ91t2uATUNYbfD7MXyjhlFRF9EQyckxM7NahPD7FwPR743jdDwVmKiq6iKEqbpWc3CWbCQM9MiS7OSA0dN8C5E+H6S1xZO9YRyUrZXLoWtu0mPKfWQEkZ7Nwnm7uLpLAGrjEACgrh86/kfXkVWJelbQz85GK44KzwodNT4Le3QK8s2R6QLf5jRVDRVRRFaaOMHAI+539pY+CqCyTqePq1klMb54Pp1znBTq4ayQELFU5wU0k5vPeZs3zsUsed++UYiEDv2Bs+hrWw4As46IhxRZWzvO0ao2sq3HWdtBQcfzr8+lr499NwzYUhC9jrgdGnNfc3035R0VUURWmjTB7tdBByoo49BiYOh0dvhzt+LEFML89z+Xqd8/wB8ecGeedjWU52t+7blC9+V5BxNuaHcm+xToDWwtCSckW1cx0bfp2Z82Sc266Ax26HM0eC11Wi0uOR+1AEFV1FUZQ2yvjhzpsIv6kx0LenBCq9+6lECx+2ZI34Yt2iu3IjbCwIbVtgTV74mIe3nTG27nQFYQFVNdDgilQOBmLNWSTzCOtO5O7Ri0RPK4KKrqIoShtl9BDnTYwG9D0zJZWnrBKemxWqmRy0UqtrQ+NUVMO8T0P1kgOBUORykPXbQpastTBvScgvDBIhXVsfmkPAwnOzpbFBYnzIh+u2hHGuN2JwM30hHYCjiq4xJtEYs8wY85UxZp0x5sHWmJiiKEpnJz05Ri1lR9C6pUnXIZAI5Y0FIZ2rqxeRdDPnk5AQV9VC3q7w49t2h/zANXWyJO2mutZZokbmtKkAZjlFOVK7uPzKbqvcEfC0Lsdy1x2bpli6tcA0a+1oYAxwgTHmzBadlaIoiiKdgWJhpOpUVoZsHiyD598KCXRtXXQO7bo8WYYOjlt4IPz4/oOw76CMvX4bfL0l/Hidy3q2Vq4XDLLKygiveBW5HH6g5Oj32lk4quhaIdgZMc75idHHQlEURWlOenRz3gRFzNU8Pt4Xnorz9/dh6y45t6o2ulJUda34X62F7buhvDr8eGWNWL/Wwj8XiQ/XTUNDaF/eLmnvF6R3lkQwh+ES3u5dm3CznYQm+XSNMV5jzGpgP/CBtTaqBbIx5iZjTK4xJreZ56goitIpKakIr4fsxuOB/tmh7aJD8H+zxV8bGfQUZN5iybddty26p26wbnJltQRnRdLgl2MBK31797us8H7ZETWWXfM1QKnLN9zZaZLoWmv91toxQF9gojEmqhujtfYv1toca21OM89RURSlUxK2xBujf+3A3uHnv/ZvsUKrqmNXodq8A1ZsiF46DrJmixPpnB99LJiGVLAXXpkffmxgrxiDuZaZ1+bFON5JOaboZWttCfAxcEGLzEZRFEU5zIoNRAcnORhE7NyH9h8MRRQHYljHdfXw2nuNi+D67dIXN5i/6yZYCvKFObA3wh88oHeMdKFgrq6BVZuOcJOdjKP20zXGdAfqrbUlxpgk4Dzg0RafmaIoSidnyWoI+J0CGS4RC7727SkN493+25f/BV0SY0Q9O8z6MLYVDLBhu+TnxsJaCbCaOS98v8/J0YWIOTrbAT8sWXW0O+08NKWJfS/gb8YYL2IZ/8NaO+8on1EURVFOkDVboSEA8R5iWrw9MyExIVx0i0vhqTcaF92yI/hXq2vD83sjmfFP2L0/fF9Ujm5EypA/AKs3Nz5mZ+Ooomut/RoY2wpzURRFUVwUFkP+XjitP+Gt+Rxh65YmubzlEUJaGRGZ3FwU7I3el57qytGNKIoB0lRhT1HLzKc9ohWpFEVR2igNfnh3kVNtyo0jbmnJMOUkm0TfGg8ZKbGPBaxEQje2nN0ZacrysqIoinKSeGke/PLH4PER5TP1eeHhW2X5dsP2xsfweaXlXq8s8b/2yhLrNLmLHGvwQ2WVLE3vOQC79kmwVGnFkQXztP7Sxs8b7JfranSAlbSkF+ee6DfQsVDRVRRFacNszJc0nknuRE1H2IyBAb3gz3fD5XdJZSoQ7euaBmOHwrQJcNYoGNxPhDcQkIpVdQ3i97VWxvF6ISFOim5gRHC37oQv1sDHy2UOh8pCmpqeAk/fJWlLUY3sne2vtsJ6TRcKQ0VXURSlDRMIwMMvwdt/dCzKiChmY2DqOLE473wChg2En10KF54N2ZmSRrRyIzy1WCzinYVQViXFM9yi6/FIVam0ZKkwNfxUEesfnQu/vFL8y/M/gxnvwIZ8+M3P4NyJjuC6o6od/H54+EVX20EFAGMbC3E7kUGN6dBlIlviO2tLmKg/Wzse+gzbN53t+cX5YNnLMCbYDD7G7VfXwU0PwU2XQWoyvP8FzP9cCl6UlMfO2z36PMSiHTUEvvsNsZorqyUt6dm7pctR9IfkZc0WGH9tdDnKIB35Gebk5JCbmxvzl1BF9zjoyP9YoOP/hw36DNs7nfH5TR4DC58TAZaTXAet6PCydXD1/WKVRkYwJ8RDr0wp2di3h1jBXdNCwllVI6Ud8/fA5gKJOo5smpAYDz27wduPy9K1iTEPDNTXw3m3wicrG7/HjvwMjyS6urysKIrSDvjsK6kmdd1FTrGMCM0yRprFjxocatuXGC9W6vemwHlnil/X45HKUiXlIVFNSoC0FFlaTkoQn++WnfDBUpj7iSxL1zidi0adBiMHuwQ3Yh4BP7z5AXyqBTFiopbucdCR/0KDjm8lgT7D9k5nfX5pybDiVTi1j4jnYWzoZcEX8MO74LxJcMdVMP50acG3ZDW89zms2iiWcFVtqOmBzwmiSk+B7CwYOgC+cyZ8c6xYwys3wpOvy9hv/gEunhIjeAoR3IJCGHe1NGs4Eh35GaqlqyiK0gEoqxRBXTJD+ul6XOUWAYwVa3faBPjf6fDVFrjxd7AoF4pKGq9SVe/0yi2pENFculaaGvToCufkwBXnwaO3i184Z7greCp4bed9ZQ1cOv3ogtuZUdFVFEVpR3y9Ba68F2Y/6vhjXaJnkRSfj5bBlBulElSDX/zAWRnSf7dfT3nNTIeUJImI9jtt+4pL5TPBKlIHy+DN92H2h1J5qqpGLObLvx3tz62ug6v/G77Sko9HREVXURSlnTH/M7jxYZhxLyQlhvY3+GHmXPG9VtfAuZNgWg5MGgmD+oh1XFsnlmhphVi31kqqUGoXWb5OTZbl5vIqaXa/dC0sXA7L18tnX3wXvj/Vyed1xL66Dm55BObG6MOrhKOiqyiK0g55fT6UlMIbD0NKovh4t+2G5evgT3fCpeeIiG7fI4I5811Yuw1275Nl6rqGUHnJYHGMpIRQ5aphA+Hs0ZIqdPMPobgEnnhNRH1TAYwcJJ+vrJWIaRXcpqGiqyiK0k6Z/xlM/im880c4pbcIY3ycFMR48nWJPs7fc+TOQUHqG6CmVqpO5e+BL74WoU7pIhHQF0+RcRPioeiQCG5BIVx+twRaKU1DGx4oiqK0Y9ZshfHXSMGK8afDB89CRqoI4f6DYtGeCJU1co05iyRVaMkMOHsUvL5AopRVcI8NTRk6DjpyqDt0/HQT0GfY3tHnF+szUkDj6ekwYpD4dwuLJd92b5FYu/XOkrLf3YKPUBlIryf0Gh8neb4ZqVJfuX+2+HE3bIdfPCZ5uCfyGDryM9SUIUVRlA6OtbB4FUy4Di6aDPdeL2Uj+/V0cnpjNJg/vB3RA9e9LxCQ+slfbZVayvMWN17aUTk6KrqKoigdiPoGWQqe+ymcPhCuvwQumSqWqs+xZDHy4zY2DUQJ7c59MHcxvPCudAvS5gUnji4vHwcdeVkEOv7SJOgzbO/o8zs2fF7pHDT6NJg8GsadLkvQaclwoAS6d5UUorV5sHqLWMyrN8mydH0LNaDvyM9Ql5cVRVE6MQ1+2LFPfuYuPtmz6dxo9LKiKIqitBIquoqiKIrSSqjoKoqiKEor0SI+3fHjx5Obm9sSQ7cJNEil/aPPsH2jz6/909GfYWOopasoiqIorYRGL58EPB4Y2h9+cjH84FtSM9XnAY+XsBZdQQ73rjTSJLohAPl74d1P4aV3YWN+qHC5oiiK0nZpkTzdnJwcq8vL0cT54Pyz4N4bIGeYU3LN6xyMrA5jIl6J2IcIsD8gtU8ffgne+7x5KsXo0lb7p6M/Q31+7Z9O8Axj3qAuL7cCBvjGKFg6E+Y8DmeNEAE+XJoteJIbG/FqIl6tfD7OB5NGwNt/hGUvS+3VDv5vWVEUpd2iotvCpHaB5++Dj5+HsUOlZyUQLqI24ie430BULdSwdefQq9cDY4bAwufghf+WSjOKoihK20JFtwUZMRhWvAo/vUQ6dkRZs0Ei90cKsXv/UcaI88FPLpLrjh5y3FNXFEVRWgAV3Rbi/DPhsxkwqI9rGbkR3+zh925RjdyOZQk3MobHC6f2gcUz4MKzW+T2FEVRlONARbcFuOIC8bGmJDmBUjHaZTW2bS2UV8L8JfD0m/CvJVBWFXHaUcbAgsdAchLMfhSuvugEbkZRFEVpNjRlqJk5/0x48T7okkjMyGMLYUFSxnWOtbC7CK5/ABatkCLlXi9MHQsvPSB9McNWlyP9whHHPAaSEuCv/wUlpSLgiqIoyslDLd1mZMRg+McjkBhPlO/VWjhUDjPmwE2/h3uegdwNTn5tMAXIwoN/gQ+XieAC+P2wMBf+5/nwc62F4lLpmfm3ebByk6QLWZegB5eckxLhjYdhzNAW/gIURVGUI6KWbjORlgxvPwYpXcTCjLQ8i0vh6vvhw6UirgB/fRv+fA9c+R2xeEvL4YOlscf/aJmIdlaGDL1qE/z0t/D1VhHj5CS46VL4/a2QFO/6oHOt5ASY/QiMv1b6ZiqKoiitj1q6zYAB/nSnK2gqAotYuB+4BBdERO9/FooOyUn+gFi2sWjwO5auhcpquO0xWL05VImqslp8wH9f4OhshKXt8Ujlq6d+pXm8iqIoJwsV3WbgrFGSphMmuC5hCwTg41zX0q+LHYWwZYe8z0iVQhexmHgGdE2TcTfvkCpUkTT44a2F4cLunofHC1dfIAU0FEVRlNZHRfcEifPBM3eBzwcHSmHeYnjlPbFCG4I+WOP4eWPg9UCC4wP2eeHBW2DEoPBzzjgVHvq5HAeoqxerOBbVtY64W7n+V5vh1fdg7mKxqH0+eHq6zFtRFEVpXfS/3hPk/LNg1BBYvh5u/B2s2yaWbWoX+PmP4MGbISEOLpsG8z8LBUgFGTsUhg6Q98bA8FNgwTPw7Cx47GX41TXwi/+A3t1Dy8KD+8HAXrBlZ/hYBjhnvAh5bb0EZT3zDyivEit8+Cnw1/thwnC4aDLMWdTS346iKIriRi3dE8DjgftugIpquPURWLM15GMtr4InX4O3PpLt/zgPbr9SAp5ABHT0EHjmbgm+CkYbGyMCO2G4jDV+GPTp7qwSO8vGmekSMJWZHpqLMfCtCXDzZbL9ziJ4/FWZB8hYa/Pg1kdl3303iDgriqIorYf+t3sCDO0vorh+m0QRR1LfAG9/LMu9ifHwyG2w6HmxMlOSYOYDMG5YdGCTtbB+uywhr82LmYLLD6fBK7+TPNwRg+DZe2DWI9C9q3z+nYWxOw6t2Spjjh4Cpw9snu9BURRFaRoquifAf14SWsptzMdaUxuq0BjnhfGnw4BeYh0vX++cFKOAxro82bU2LyIAyxnMGCg6CDV1MOEMsXC7pYUEvKYu9nwCAZmv1ws3fP/4711RFEU5dlR0jxOfF35wjiwxDxsAfXtEn2OM+Fg9EXWUyypESN9aGO3jBQmU2lQg77fscAmoawy/H2YvlHHKKqKb3p+TEzs1qE8PsXA9HvjeN0PBWYqiKErLo6J7nPTsJsFMGOiZKdHFGamh4wY4dyJcf4kra8c6Ilkpm0vXwrbdhOfUGigpg537ZHN3kRTWwDUGQEEhfP6VvC+vAuuytI2Bn1wMF5wVPnR6Cvz2FuiVJdsDssV/rCiKorQOKrrHycgh4HO+PWPgqgsk6nj6tZJTG+eD6dc5wU6uGskBCxVOcFNJObz3mbN87FLHnfvlGIhA79gbPoa1sOALOOiIcUWVs7ztGqNrKtx1nbQUHH86/Ppa+PfTcM2FIQvY64HRpzX3N6MoiqI0horucTJ5tNNByIk69hiYOBwevR3u+LEEMb08z+Xrdc7zB8SfG+Sdj2U52d26b1O++F1BxtmYH8q9xToBWgtDS8oV1c51bPh1Zs6TcW67Ah67Hc4cCV5XiUqPR+5DURRFaR1UdI+T8cOdNxF+U2Ogb08JVHr3U4kWPmzJGvHFukV35UbYWBDatsCavPAxD287Y2zd6QrCAqpqoMEVqRwMxJqzSOYR1p3I3aMXiZ5WFEVRWgcV3eNk9BDnTYwG9D0zJZWnrBKemxWqmRy0UqtrQ+NUVMO8T0P1kgOBUORykPXbQpastTBvScgvDBIhXVsfmkPAwnOzpbFBYnzIh+u2hHGuN2JwM30hiqIoylFpsugaY7zGmFXGmHktOaH2QnpyjFrKjqB1S5OuQyARyhsLQjpXVy8i6WbOJyEhrqqFvF3hx7ftDvmBa+pkSdpNda2zRI3MaVMBzHKKcqR2cfmV3Va5I+BpXY7lrhVFUZQT4Vgs3V8CG1pqIu2NokONHDBSdSorQzYPlsHzb4UEurYuOod2XZ4sQwfHLTwQfnz/Qdh3UMZevw2+3hJ+vM5lPVsr1wsGWWVlhFe8ilwOP1By9HtVFEVRmocmia4xpi9wETCjZafTfujRzXkTFDFX8/h4X3gqzt/fh6275Nyq2uhKUdW14n+1FrbvhvLq8OOVNWL9Wgv/XCQ+XDcNDaF9ebukvV+Q3lkSwRyGS3i7d23CzSqKoijNQlMt3aeAu4BG6i6BMeYmY0yuMSa3qKioOebWpimpCK+H7Mbjgf7Zoe2iQ/B/s8VfGxn0FGTeYsm3XbctuqdusG5yZbUEZ0XS4JdjASt9e/e7rPB+2RE1ll3zNUCpyzesKIqitCxHFV1jzMXAfmvtiiOdZ639i7U2x1qb0717x6+4ELbEG6N/7cDe4ee/9m+xQquqY1eh2rwDVmyIXjoOsmaLE+mcH30smIZUsBdemR9+bGCvGIO5lpnX5sU4riiKorQITbF0zwYuMcbkA38HphljXm3RWbUDVmwgOjjJwSBi5z60/2AoojgQwzquq4fX3mtcBNdvl764wfxdN8FSkC/Mgb0R/uABvWOkCwVzdQ2s2nSEm1QURVGalaP207XW/hfwXwDGmHOAX1trr2nZabV9lqyGgN8pkOESseBr357SMN7tv335X9AlMUbUs8OsD2NbwQAbtkt+biyslQCrmRFx5T4nRxci5uhsB/ywZNXR7lRRFEVpLrSJ/XGyZis0BCDeQ0yLt2cmJCaEi25xKTz1RuOiW3YE/2p1bXh+byQz/gm794fvi8rRjUgZ8gdg9ebGx1QURVGal2MqjmGtXWStvbilJtOeKCyG/GBN5IiCEyC5uunJ0Z+rrI7e1xwU7I3el54aUfvZPU+kqcKejh/zpiiK0mbQilTHSYMf3l3kVJty4whbWjJMGXsSJubiW+MhIyX2sYCVSOjGlrMVRVGU5keXl0+Al+bBL38MHh9RPlOfFx6+VZZvN2xvfAyfV1ru9coS/2uvLLFOk7vIsQY/VFbJ0vSeA7BrnwRLlVYcWTBP6y9t/LzBfrmuRgdYSUt6ce6JfgOKoijKsaCiewJszJc0nkkjXDsdYTMGBvSCP98Nl98llalAtK9rGowdCtMmwFmjYHA/Ed5AQCpW1TWI39daGcfrhYQ4KbqBEcHduhO+WAMfL5c5HCoLaWp6Cjx9l6QtRTWyd7a/2grrNV1IURSlVVHRPQECAXj4JXj7j45FGRHFbAxMHScW551PwLCB8LNL4cKzITtT0ohWboSnFotFvLMQyqqkeIZbdD0eqSqVliwVpoafKmL9o3Phl1eKf3n+ZzDjHdiQD7/5GZw70RFcd1S1g98PD7/oajuoKIqitArGNhZKewLk5OTY3NzcZh+3rWBc5mOcD5a9DGOCzeBjfJ3VdXDTQ3DTZZCaDO9/AfM/l4IXJeWx83aPPgexaEcNge9+Q6zmympJS3r2bulyFP0heVmzBcZfG12OMkhL/Jtoa5ioJYCORUd/hvr82j+d4BnGvEEV3eMg8h/L5DGw8DkRYDnBddCKDi9bB1ffL1ZpZARzQjz0ypSSjX17iBXcNS0knFU1Utoxfw9sLpCo48imCYnx0LMbvP24LF2bGPPAQH09nHcrfLKy8fvTX/j2T0d/hvr82j+d4BnGvEFdXm4GPvtKqkldd5FTLCPi98UYaRY/anCobV9ivFip35sC550pfl2PRypLlZSHRDUpAdJSZGk5KUF8vlt2wgdLYe4nsixd43QuGnUajBzsEtyIeQT88OYH8KkWxFAURTkpqKV7HMT6Cy0tGVa8Cqf2EfE8jA29LPgCfngXnDcJ7rgKxp8uLfiWrIb3PodVG8USrqoNNT3wOUFU6SmQnQVDB8B3zoRvjhVreOVGePJ1GfvNP8DFU2IETyGCW1AI466WZg1HQv/Kbv909Geoz6/90wmeoVq6LUlZpQjqkhnST9fjKrcIYKxYu9MmwP9Oh6+2wI2/g0W5UFTSeJWqeqdXbkmFiObStdLUoEdXOCcHrjgPHr1d/MI5w13BU8FrO+8ra+DS6UcXXEVRFKXlUNFtRr7eAlfeC7MfdfyxLtGzSIrPR8tgyo1SCarBL37grAzpv9uvp7xmpkNKkkRE+522fcWl8plgFamDZfDm+zD7Q6k8VVUjFvPl347251bXwdX/DV9pyUdFUZSTiopuMzP/M7jxYZhxLyQlhvY3+GHmXPG9VtfAuZNgWg5MGgmD+oh1XFsnlmhphVi31kqqUGoXWb5OTZbl5vIqaXa/dC0sXA7L18tnX3wXvj/Vyed1xL66Dm55BObG6MOrKIqitC4qui3A6/OhpBTeeBhSEsXHu203LF8Hf7oTLj1HRHT7HhHMme/C2m2we58sU9c1hMpLBotjJCWEKlcNGwhnj5ZUoZt/CMUl8MRrIuqbCmDkIPl8Za1ETKvgKoqitA1UdFuI+Z/B5J/CO3+EU3qLMMbHSUGMJ1+X6OP8PUfuHBSkvgFqaqXqVP4e+OJrEeqULhIBffEUGTchHooOieAWFMLld0uglaIoitI20IYHLciarTD+GilYMf50+OBZyEgVIdx/UCzaE6GyRq4xZ5GkCi2ZAWePgtcXSJSyCq6iKErbQlOGjoNjDXU3RgpoPD0dRgwS/25hseTb7i0Sa7feWVL2R7TfC5aB9HpCr/FxkuebkSr1lftnix93w3b4xWOSh3sij1XTFdo/Hf0Z6vNr/3SCZ6gpQycLa2HxKphwHVw0Ge69XspG9uvp5PTGaDAf1gOXGMdxRDogzQsefhHmLW68tKOiKIpy8lHRbUXqG2QpeO6ncPpAuP4SuGSqWKo+x5LFyI/7D10DUUK7cx/MXQwvvCvdgrR5gaIoSttHl5ePg+ZcFvF5pXPQ6NNg8mgYd7osQaclw4ES6N5VUojW5sHqLWIxr94ky9L1LdSAXpe22j8d/Rnq82v/dIJnqMvLbZEGP+zYJz9zF5/s2SiKoigtiUYvK4qiKEoroaKrKIqiKK2Eiq6iKIqitBIt4tNdsWJFh3aSd/Qgh4787ILoM2zf6PNr/3TkZ5iTk9PoMbV0FUVRFKWV0OhlRVEUpd1RXFzEjk0fkFI7m+ykL0mJK8JYvzQvd7VUDXK417gBrMEaLxX1WRRWT6Qi4Uf0H3o+mZndW3zeKrqKoihKu2Ff4S72bHyJfr6XGZO4HRMfEKF14whsuNC6T7AYGkiNKyTVNxfLvzi4YSCr6q+l17AbyO7Vr8Xm3yLFMYyJ/AY6Fh3ZFwHqT+oIdPRnqM+v/XOsz7CyooKNK19ikO8J0uMLMMQQ2rALxBjkKOdYDKX1/cmru5Oh428gJSX1mOYYJCcnh9zc3JgPUX26iqIoSpsmb/Nq9uX+gHHJ/4+M+HwO23VBWQtasu6f4H5DdO36sHXn0KvBkhFXwLjkX1GUewlbN61s9ntR0VUURVHaJH6/n9VfvkrPg9/l1JSFGBqirdUgkfsjhdi9/yhjGPyckvIJ2YcuZPUXf6Ohofk6yajoKoqiKG2Ouro6Vn3yCCN9N5Pi2wfYaCs2siNbpGUbuR3LEm50DEtK3H5Gxv2c1Z88TG1tbbPclwZSKYqiKG2Kuro6Nnz5AGNT/4SX+lCgVFAsY7VDdW9aqKiSBjF5u+HUPjBlLKR2cX3sKGPItsVrahib9hDrllYydNJvSUhIOKF7U9FVFEVR2gx+v5+vl/xRBNfUhUceO+8dPRTcUcqI4O4ugusfgEUrpKmM1wtTx8JLD0gf87DV5Ui/cNQxi9fUc0bSk6xa0oUxU+/D5zt+6dTlZUVRFKXNsGb5G4xNexivqY/yvVoLh8phxhy46fdwzzOQu0H6jAfPDVh48C/w4TIRXAC/Hxbmwv88H36utVBcKj3O/zYPVm6SvufWbVE7FrHXU8/YjEdZu/zVE4qeV0tXURRFaRPkbV7FYKbjNdWifBHaVlwKV98PHy4VcQX469vw53vgyu+IxVtaDh8sjT3+R8tEtLMyZOhVm+Cnv4Wvt4oYJyfBTZfC72+FpHjXB51realhiLmHrZtGMGRY46Uej4RauoqiKMpJp6K8HM+eX4eCpiKwiIX7gUtwQUT0/meh6JCc5A+IZRuLBr9j6VqorIbbHoPVm519yL6n34S/L3BmEBXlbEn27Seu8NeUl5cd132q6CqKoignnU2rZjIw5RPCBNcleoEAfJzrWvp1saMQtuyQ9xmpMGlE7GtMPAO6psm4m3fAyo3R5zT44a2F4cIeJr7GMiBlCVtWvti0G4tARVdRFEU5qewr3MUg3xOAnwOlMG8xvPKeWKENQR+sgcT42J/3eiAhXs7xeeHBW2DEoPBzzjgVHvq5HAeoqxerOBbVtY64W7n+V5vh1fdg7mLHosbPoPinKNy785jvVUVXURRFOans2fAi6fEFLF8P026B7/8KrvsNfPNGuO9ZqKkDj4HLpoVE083YoTB0gLw3BoafAguegftugDgf3POfsn3GICfSGRjcDwb2ih7LAOeMFyGvrYffPAdTboRrfwM/+LXMb+laSIvbQeHGGcd8ryq6iqIoykmjuLiIfnEvU1ZpufURWLM15GMtr4InX4O3PpLt/zgPbr9SAp5ABHT0EHjmbkjpwuFoY2Ogd3eYMFzGGj8M+nQ/nAEEQGa6BExlpofmYgx8awLcfJlsv7MIHn9V5gEy1to8uPVRKK2w9It/heID+4/pflV0FUVRlJPGjk0fkJmYz/ptEkUcSX0DvP2xLPcmxsMjt8Gi5+GiyZCSBDMfgHHDQhZsEGth/XZZQl6bFzsF94fT4JXfQVKCLEc/ew/MegS6d5XPv7NQrh/Jmq0yZreEHezYvOCY7ldFV1EURTkp+P1+UmpnYQhQewQfa01tqIBUnBfGnw4DekFFNSxf75wUo4DGujzZtTYvIgDLGcwYKDooy9cTzhALt1taSMBr6mLPJxCQpWdjAqTWzsLfWLh0DFR0FUVRlJNC8YF9ZCd9CViGDYC+PaLPMUZ8rJ6IOsplFSKkby0MFcFwU1cPmwrk/ZYdLgF1jeH3w+yFMk5ZRXTT+3Nyoi1ogD494PSBAJbspGUU7d/b5HtW0VUURVFOCvt2fU1K3AEw0DNTooszXC1sDXDuRLj+kvCaydZCWaVsLl0L23YTkdYDJWWwc59s7i6Swhq4xgAoKITPv5L35VVgXZa2MfCTi+GCs8KHTk+B394CvbJkO9l3gP27Vzf5nlV0FUVRlJNCTclyjBUz1Ri46gKJMp5+reTUxvlg+nVOsJOrRnLAaWgAUFIO733mLB+71HHnfjkGItA79oaPYS0s+AIOOmJcUeUsb7vG6JoKd10H8XGypP3ra+HfT8M1F4YsYEOAupJlTb5nFV1FURTlpJDm+Vo6CDlRxx4DE4fDo7fDHT+WIKaX57l8vc55/oD4c4O887EsJ7tb923KF78ryDgb80O5t1gnQGthaEm5otq5jg2/zsx5Ms5tV8Bjt8OZI8Eb1hzBku5Z0+R7VtFVFEVRTgoZcU64coTf1Bjo21O6A737qUQLH7Zkjfhi3aK7ciNsLAhtW2BNXviYh7edMbbudAVhAVU14O5VHwzEmrNI5hHWncjdoxdIT9jW5HtW0VUURVFOCj1SnACkGA3oe2ZKKk9ZJTw3K1QzOWilVrt6yldUw7xPQ/WSA4FQ5HKQ9dtClqy1MG9JyC8MEiFdWx+aQ8DCc7OhtEJSlYI+XLcljHO97imFTb7nJomuMSbfGLPGGLPaGJPb5NEVRVEUpTH8pdG1lB1B65YGacmy662FYskGT62rF5F0M+eTkBBX1ULervDj23aH/MA1dbIk7aa61lmiRkR5UwHMcopypHZx+ZUjGt9bCzQ0vfnBsVi637LWjrHWHl8/I0VRFEVxsXtfI4mwRqpOZWXI5sEyeP6tUK5tbV10Du26PFmGBqmPXHgg/Pj+g7DvoIy9fht8vSX8eJ3LerZWrhcMssrKCK94Fbkcvmd/I/cRA11eVhRFUU4KfXrGyZugiLmax8f7pJRjkL+/D1t3yblVtdGVoqprxf9qLWzfDeXV4ccra8T6tRb+uUh8uG4aGkL78nZJe78gvbMkgjkMl/D27hF5sHGaKroWeN8Ys8IYc1OsE4wxNxljcnX5WVEURWkS3oyweshuPB7onx3aLjoE/zdb/LWRQU9B5i2WfNt126J76gbrJldWS3BWJA1+ORaw0rd3/6HQsX7Z0gDhMJHdB32uAs5HoamiO9laOw74LnCrMeabkSdYa/9irc3R5WdFURSlKRRVuNr8xOhfO7B3+Pmv/Vus0Krq2FWoNu+AFRuil46DrNniRDrnRx8LpiEV7IVX5ocfi9WNyL3MXFSRHeOE2DRJdK21u53X/cA7wMQmX0FRFEVRYlBSNyg6OMnBIGLnPrT/YCiiOBDDOq6rh9feE4s2Fuu3S1/cYP6um2ApyBfmwN4If/CA3jHShYK5ugZKG0490m2G4TvaCcaYZMBjrS133n8H+G2Tr6AoiqIoMSgNjAL7thTIcIlY8LVvT/D5wv23L/8LuiQSHfXsMOvD2FYwwIbtkp8bC2slwGrmvPD9PidHF8LnFto2lNaPPOq9Hh6vCef0BN4xUvPKB7xurf13k6+gKIqiKDFI7DoBixdjG2JavD0zITEhXHSLS+GpNxoXXXfubSTVteH5vZHM+CfsjmiPG5WjG5kyhIf4jKYv/h5VdK2124DRTR5RURRFUZpAz76jqdieRWpcYXhrPkfYuqVBejKURwhpZURkcnNREKNZUHqqK0c3oigGQFVDJj0GjGnyNTRlSFEURTkpZGb1pLB6ElEmriNuackwZezJmFmIb42HjJRGDhrD3pqJZHVveiBVU5aXFUVRFKXZ8Xq9VCRcjrXzMPijfKY+Lzx8K6zeLP7YxvB5peVeryzxv/bKEus0uYsca/BDZZUsTe85ALv2SbBUaUXj/l+A0/pLGz+v19nhbnTgLC2XxV+Oz9d0KVXRVRRFUU4a/Yeez8ENA8lMdIUcO8JmDAzoBX++Gy6/SypTgWhf1zQYOxSmTYCzRsHgfiK8gYBUrKprEL+vtTKO1wsJcVJ0AyOCu3UnfLEGPl4uqUSHykKamp4CT98laUtRjeyd7UM1/el/2gXHdL8quoqiKMpJIzOzO6vqr6Vb4oMYoqOYjYGp48TivPMJGDYQfnYpXHg2ZGdKGtHKjfDUYrGIdxZCWZUUz3CLrscjVaXSkqXC1PBTRax/dC788kooLIb5n8GMd2BDPvzmZ3DuREdw3VHVDtYadtRdw5juPaNv6ggY21gI2AlgjGn+QdsQLfGdtSVM1J91HQ99hu0bfX7tH/czLNy7k8T8KWTEO/35Yjze6jq46SG46TJITYb3v4D5n0vBi5Ly2Hm7R8MYsWhHDYHvfkOs5spqSUt69m7pchT9IXkpretP9YDFZPfuH3VKTk4Oubm5MR+iWrqKoijKSSW7Vz9Wbr6TsXG/Et8uRKXmJMbDL66Aq+8XqzQygjkhHnplSsnGvj3ECu6aFhLOqhop7Zi/BzYXwM590jShpBw+XSk/ifHQsxu8/bikKsWaB4C1XvLqfsm4GIJ7NFR0FUVRlJPOaeNvoCB3DgNTPpFiGRGWqzEwbhiMGhxq25cYL1bq96bAeWeKX9fjkcpSJeWhTkRJCZCWIkvLSQni892yEz5YCnM/kWXpGqdz0ajTYORgR2sjlpQBsIYdld9gyLgbj+s+VXQVRVGUk05KSiqF2Y9TUXIRKXH7RXiDOClEPq8sLy/4Es6bBHdcBeNPlxZ8S1bD02/Cqo1iCVfVhpoe+JwgqvQUyM6CoQPgO2fCtd+F268Qn/CTr8OCL+BnP5Dzw6pOHZ6HodLfnboefyI1Ne247lNFV1EURWkTDB42ntVfPsZIewteUxMqO+UIn7Fi7U6bAP87Hb7aAjf+DhblQlFJ41Wq6p1euSUVUFAIS9dKU4MeXeGcHLjiPHj0dvEL5wx3BU8Fr+2895PIpvo/MHbY8ff1UdFVFEVR2gwjcq5i1Sf5jE17CK+pDxM9i6T4fLQMptwIe4okzzbOJ43me3eXPN3e3SVPNyVJUoX8Ttu+4lL5zM598nqwDN58H2Z/KJWnqmrEYr78267lZQc/cawunc7oqdedUKCbiq6iKIrSZvD5fIycfDfrllZxRtITIrwODX6YOVd8r9U1cO4kmJYDk0bCoD6QnCT+2pIKycOtrhXrNz4OUruITzc1WZaPy6uk2f3StbBwOSxfL5998V34/lQnn/ewhRvH+qrbGTH53mMqhBHz/k7o04qiKIrSzCQkJDB00oOsWtKFMemP4KMGsGzbDcvXwZ/uhEvPERHdvkcEc+a7sHYb7N4nTQ/qGqRQBoSKYyQlhCpXDRsIZ4+WVKGbfwjFJfDEayLqmwpg5CAAg98ksrpkOiMm30tCQqwcomNDRVdRFEVpcyQkJDBm6r18vXQAQ713k+zbT3GJJT5OCmI8+bpEH+fvOXLnoCD1DVBTK1Wn8vfAF1+LUKd0kQjoi6fIuAnxUHQIQIKmtvj/wOip152whRtEGx4oiqIobRKfz8e4s3/C3q7/Ir9iKpNGevngWchIlYjj/QfFoj0RKmtgzVaYs0hShZbMgKnjvBRUTmZP2jxGn3V9swkuaEWq40Kr4bR/9Bm2b/T5tX+O9RlWVJSzecULDIp/irS4HdTVWwqLJd92b5FYu/XOkrLf3YKPUBlIryf0Gh8neb4ZqVJfuX82JMYbyur7kld3B0PG3XjcaUFHqkilonsc6C98+0efYftGn1/753ifYeHenRRueoF+ca/QLaEAYwI4LX+iq0cZ13tiHHd2Wjwcqu3PjrpryB56Y8zSjseCim4zo7/w7R99hu0bfX7tnxN9hsUH9rNj8wJSa2eTnbSU5LhijPVDsGkC4Xm74d+oCG1VQyZ7qydQlvAj+g+5gKxjbF7QGFp7WVEURelQZGb1IDPrWvz+qyjav5dtu1ZTV7qcdO8a0uPz6J5cCP4y9uyvo3ePOKw3naLKbErrT6G0YSRx6RPp2X8MA3v0alaf7dFQ0VUURVHaLV6vl+xefcnu1Re4OOp4H9f7Hs7PyUSjlxVFURSllVDRVRRFUZRWQkVXURRFUVqJFvHpjh8/ntzc3JYYuk3Q0SMLO3pkKOgzbO/o82v/dPRn2Bhq6SqKoihKK6GiqyiKoiithKYMKYrSKfF4YGh/+MnF8INvwSm9wecBj5ew/q1BDjc2NxDwQ0MA8vfCu5/CS+/CxvxQVxtFaYwWqUiVk5Nj1afbflF/Uvunoz/DE3l+cT44/yy49wbIGebU4/U6ByNLB5qIVyL2IQLsD0gB/odfgvc+lxrAJ0JHf37QKX4HY96gLi8ritIpMMA3RsHSmTDncThrhAiwx0Ps2ry49kcedwmzxyPjTBoBb/8Rlr0Mk8c4lrGiRKCiqyhKhye1Czx/H3z8PIwdKg3NgXARtRE/wf0Gogrlh607h169HhgzBBY+By/8tzRZVxQ3KrqKonRoRgyGFa/CTy+Rdm5R1myQyP2RQuzef5Qx4nzwk4vkuqOHHPfUlQ6Iiq6iKB2W88+Ez2bAoD6uZeRGfLOH37tFNXI7liXcyBgeL5zaBxbPgAvPbpHbU9ohKrqKonRIrrhAfKwpSU6gVMxeqrG3rYXySpi/BJ5+E/61BMqqIk47yhhY8BhIToLZj8LVF53AzSgdBk0ZUhSlw3H+mfDifdAlkZiRxxbCgqSM6xxrYXcRXP8ALFoBDX7xAU8dCy89AP16RqwuR/qFI455DCQlwF//C0pKRcCVzotauoqidChGDIZ/PAKJ8UT5Xq2FQ+UwYw7c9Hu45xnI3eDk1wZTgCw8+Bf4cJkILoDfDwtz4X+eDz/XWiguhbmfwt/mwcpNki5kXYIeXHJOSoQ3HoYxQ1v4C1DaNGrpKorSYUhLhrcfg5QuYmFGWp7FpXD1/fDhUhFXgL++DX++B678jli8peXwwdLY43+0TEQ7K0OGXrUJfvpb+HqriHFyEtx0Kfz+VkiKd33QuVZyAsx+BMZfC6UVzXvvSvtALV1FUToEBvjTna6gqQgsYuF+4BJcEBG9/1koOiQn+QNi2caiwe9YuhYqq+G2x2D15lAlqspq8QH/fYGjsxGWtscjla+e+pXm8XZWVHQVRekQnDVK0nTCBNclbIEAfJzrWvp1saMQtuyQ9xmpUugiFhPPgK5pMu7mHVKFKpIGP7y1MFzY3fPweOHqC6SAhtL5UNFVFKXdE+eDZ+4Cnw8OlMK8xfDKe2KFNgR9sMbx88bA64EExwfs88KDt8CIQeHnnHEqPPRzOQ5QVy9WcSyqax1xt3L9rzbDq+/B3MViUft88PR0mbfSudBHrihKu+f8s2DUEFi+Hm78HazbJpZtahf4+Y/gwZshIQ4umwbzPwsFSAUZOxSGDpD3xsDwU2DBM/DsLHjsZfjVNfCL/4De3UPLwoP7wcBesGVn+FgGOGe8CHltvQRlPfMPKK8SK3z4KfDX+2HCcLhoMsxZ1NLfjtKWUEtXUZR2jccD990AFdVw6yOwZmvIx1peBU++Bm99JNv/cR7cfqUEPIEI6Ogh8MzdEnwVjDY2RgR2wnAZa/ww6NPdWSV2lo0z0yVgKjM9NBdj4FsT4ObLZPudRfD4qzIPkLHW5sGtj8q++24QcVY6D/q4FUVp1wztL6K4fptEEUdS3wBvfyzLvYnx8MhtsOh5sTJTkmDmAzBuWHRgk7WwfrssIa/Ni5mCyw+nwSu/kzzcEYPg2Xtg1iPQvat8/p2FsTsOrdkqY44eAqcPbJ7vQWkfqOgqitKu+c9LQku5jflYa2pDFRrjvDD+dBjQS6zj5eudk2IU0FiXJ7vW5kUEYDmDGQNFB6GmDiacIRZut7SQgNfUxZ5PICDz9Xrhhu8f/70r7Q8VXUVR2i0+L/zgHFliHjYA+vaIPscY8bF6Iuool1WIkL61MNrHCxIotalA3m/Z4RJQ1xh+P8xeKOOUVUQ3vT8nJ3ZqUJ8eYuF6PPC9b4aCs5SOj4quoijtlp7dJJgJAz0zJbo4IzV03ADnToTrL3Fl7VhHJCtlc+la2Lab8JxaAyVlsHOfbO4uksIauMYAKCiEz7+S9+VVYF2WtjHwk4vhgrPCh05Pgd/eAr2yZHtAtviPlc6Biq6iKO2WkUPA5/wvZgxcdYFEHU+/VnJq43ww/Ton2MlVIzlgocIJbioph/c+c5aPXeq4c78cAxHoHXvDx7AWFnwBBx0xrqhylrddY3RNhbuuk5aC40+HX18L/34arrkwZAF7PTD6tOb+ZpS2ioquoijtlsmjnQ5CTtSxx8DE4fDo7XDHjyWI6eV5Ll+vc54/IP7cIO98LMvJ7tZ9m/LF7woyzsb8UO4t1gnQWhhaUq6odq5jw68zc56Mc9sV8NjtcOZI8LpKVHo8ch9K50BFV1GUdsv44c6bCL+pMdC3pwQqvfupRAsftmSN+GLdortyI2wsCG1bYE1e+JiHt50xtu50BWEBVTXQ4IpUDgZizVkk8wjrTuTu0YtETyudgyaJrjEmwxgz2xiz0RizwRhzVktPTFEU5WiMHuK8idGAvmempPKUVcJzs0I1k4NWanVtaJyKapj3aaheciAQilwOsn5byJK1FuYtCfmFQSKka+tDcwhYeG62NDZIjA/5cN2WMM71Rgxupi9EafM01dL9/wP/ttYOA0YDG1puSoqiKE0jPTlGLWVH0LqlSdchkAjljQUhnaurF5F0M+eTkBBX1ULervDj23aH/MA1dbIk7aa61lmiRua0qQBmOUU5Uru4/Mpuq9wR8LQux3LXSnvmqKJrjEkHvgm8AGCtrbPWlrTwvBRFUY5K0aFGDhipOpWVIZsHy+D5t0ICXVsXnUO7Lk+WoYPjFh4IP77/IOw7KGOv3wZfbwk/Xueynq2V6wWDrLIywiteRS6HHyg5+r0qHYOmWLqnAEXAS8aYVcaYGcaY5Bael6IoylHp0c15ExQxV/P4eF94Ks7f34etu+TcqtroSlHVteJ/tRa274by6vDjlTVi/VoL/1wkPlw3DQ2hfXm7pL1fkN5ZEsEchkt4u3dtws0qHYKmiK4PGAc8Z60dC1QC90SeZIy5yRiTa4zJLSoqauZpKoqiRFNSEV4P2Y3HA/2zQ9tFh+D/Zou/NjLoKci8xZJvu25bdE/dYN3kymoJzoqkwS/HAlb69u53WeH9siNqLLvma4BSl29Y6dg0RXR3AbustUud7dmICIdhrf2LtTbHWpvTvbtmeiuK0vKELfHG6F87sHf4+a/9W6zQqurYVag274AVG6KXjoOs2eJEOudHHwumIRXshVfmhx8b2CvGYK5l5rV5MY4rHZKjiq61thDYaYwZ6uz6NrD+CB9RFEVpFVZsIDo4ycEgYuc+tP9gKKI4EMM6rquH195rXATXb5e+uMH8XTfBUpAvzIG9Ef7gAb1jpAsFc3UNrNp0hJtUOhRN7ad7G/CaMSYe2AZc33JTUhRFaRpLVkPA7xTIcIlY8LVvT2kY7/bfvvwv6JIYI+rZYdaHsa1ggA3bJT83FtZKgNXMeeH7fU6OLkTM0dkO+GHJqqPdqdJRaJLoWmtXAzktOxVFUZRjY81WaAhAvIeYFm/PTEhMCBfd4lJ46o3GRbfsCP7V6trw/N5IZvwTdu8P3xeVoxuRMuQPwOrNjY+pdCy0IpWiKO2WwmLID9ZEjig4AZKrmx4j16KyOnpfc1CwN3pfempE7Wf3PJGmCns09rTToKKrKEq7pcEP7y5yqk25cYQtLRmmjD0JE3PxrfGQkRL7WMBKJHRjy9lKx6OpPl1FUZQ2yUvz4Jc/Bo+PKJ+pzwsP3yrLtxu2Nz6Gzyst93plif+1V5ZYp8ld5FiDHyqrZGl6zwHYtU+CpUorjiyYp/WXNn7eYL9cV6MDrKQlvTj3RL8BpT2hoqsoSrtmY76k8Uwa4drpCJsxMKAX/PluuPwuqUwFon1d02DsUJg2Ac4aBYP7ifAGAlKxqq5B/L7WyjheLyTESdENjAju1p3wxRr4eLnM4VBZSFPTU+DpuyRtKaqRvbP91VZYr+lCnQoVXUVR2jWBADz8Erz9R8eijIhiNgamjhOL884nYNhA+NmlcOHZkJ0paUQrN8JTi8Ui3lkIZVVSPMMtuh6PVJVKS5YKU8NPFbH+0bnwyyvFvzz/M5jxDmzIh9/8DM6d6AiuO6rawe+Hh190tR1UOgXGNhbCdwLk5OTY3NzcZh+3rWCi/mztWLTEv4m2hj7D9k3k84vzwbKXYUywGXyM26+ug5segpsug9RkeP8LmP+5FLwoKY+dt3v0eYhFO2oIfPcbYjVXVkta0rN3S5ej6A/Jy5otMP7a6HKU0PGfH3SK38GYN6iiexx0gn8sJ3sKLY4+w/ZNrOc3eQwsfE4EWE5yHbSiw8vWwdX3i1UaGcGcEA+9MqVkY98eYgV3TQsJZ1WNlHbM3wObCyTqOLJpQmI89OwGbz8uS9cmxjwwUF8P590Kn6yMfX8d/flBp/gdjHmDurysKEqH4LOvpJrUdRc5xTIidMsYaRY/anCobV9ivFip35sC550pfl2PRypLlZSHRDUpAdJSZGk5KUF8vlt2wgdLYe4nsixd43QuGnUajBzsEtyIeQT88OYH8KkWxOiUqKV7HHSCv9BO9hRaHH2G7ZvGnl9aMqx4FU7tI+J5GBt6WfAF/PAuOG8S3HEVjD9dWvAtWQ3vfQ6rNoolXFUbanrgc4Ko0lMgOwuGDoDvnAnfHCvW8MqN8OTrMvabf4CLp8QInkIEt6AQxl0tzRoao6M/P+gUv4Nq6SqK0rEpqxRBXTJD+ul6XOUWAYwVa3faBPjf6fDVFrjxd7AoF4pKGq9SVe/0yi2pENFculaaGvToCufkwBXnwaO3i184Z7greCp4bed9ZQ1cOv3Igqt0bFR0FUXpUHy9Ba68F2Y/6vhjXaJnkRSfj5bBlBulElSDX/zAWRnSf7dfT3nNTIeUJImI9jtt+4pL5TPBKlIHy+DN92H2h1J5qqpGLObLvx3tz62ug6v/G77Sko+dGhVdRVE6HPM/gxsfhhn3QlJiaH+DH2bOFd9rdQ2cOwmm5cCkkTCoj1jHtXViiZZWiHVrraQKpXaR5evUZFluLq+SZvdL18LC5bB8vXz2xXfh+1OdfF5H7Kvr4JZHYG6MPrxK50JFV1GUDsnr86GkFN54GFISxce7bTcsXwd/uhMuPUdEdPseEcyZ78LabbB7nyxT1zWEyksGi2MkJYQqVw0bCGePllShm38IxSXwxGsi6psKYOQg+XxlrURMq+AqoKKrKEoHZv5nMPmn8M4f4ZTeIozxcVIQ48nXJfo4f8+ROwcFqW+AmlqpOpW/B774WoQ6pYtEQF88RcZNiIeiQyK4BYVw+d0SaKUooA0PFEXp4KzZCuOvkYIV40+HD56FjFQRwv0HxaI9ESpr5BpzFkmq0JIZcPYoeH2BRCmr4CpuNGXoOOgEoe4newotjj7D9s3xPD9jpIDG09NhxCDx7xYWS77t3iKxduudJWV/RPu9YBlIryf0Gh8neb4ZqVJfuX+2+HE3bIdfPCZ5uMf7GDr684NO8TuoKUOKonRerIXFq2DCdXDRZLj3eikb2a+nk9Mbo8F8WA9cYhzHEemANC94+EWYtzh2aUdFARVdRVE6GfUNshQ891M4fSBcfwlcMlUsVZ9jyWLkx21wGogS2p37YO5ieOFd6RakzQuUo6HLy8dBJ1gWOdlTaHH0GbZvmvv5+bzSOWj0aTB5NIw7XZag05LhQAl07yopRGvzYPUWsZhXb5Jl6foWaEDf0Z8fdIrfQV1eVhRFiUWDH3bsk5+5i0/2bJSOjEYvK4qiKEoroaKrKIqiKK2Eiq6iKIqitBIt4tNdsWJFh3aSd/Qgh4787ILoM2zf6PNr/3TkZ5iTk9PoMbV0FUVRFKWV0OhlRTkOiouL2LHpA1JqZ5Od9CUpcUUY65eGra42ckEO91c1gDVY46WiPovC6olUJPyI/kPPJzOze+vfiKIorYqKrqIcA/sKd7Fn40v0873MmMTtmPiACK0bR2DDhdZ9gsXQQGpcIam+uVj+xcENA1lVfy29ht1Adq9+rXU7iqK0Mi1SHMOYyP+FOhYd2RcB6k+KRWVFBRtXvsQg3xOkxxdgiCG0YReIMchRzrEYSuv7k1d3J0PH30BKSuoxzTHsUh38GervYPunIz/DnJwccnNzYz5E9ekqylHI27yafbk/YFzy/yMjPp/Df1MGf6WClqz7J7jfEF2vN2zdOfRqsGTEFTAu+VcU5V7C1k0rW+aGFEU5aajoKkoj+P1+Vn/5Kj0PfpdTUxZiaIi2VoNE7o8UYvf+o4xh8HNKyidkH7qQ1V/8jYYGrZ6vKB0FFV1FiUFdXR2rPnmEkb6bSfHtA2y0FRvZhSbSso3cjmUJNzqGJSVuPyPjfs7qTx6mtrYJXdYVRWnzaCCVokRQV1fHhi8fYGzqn/BSHwqUCoplrBZw7k0LFVVSFD9vN5zaB6aMhdQuro8dZQzZtnhNDWPTHmLd0kqGTvotCQkJzXGLiqKcJFR0FcWF3+/n6yV/FME1deGRx857Rw8Fd5QyIri7i+D6B2DRCimk7/XC1LHw0gPSuzVsdTnSLxx1zOI19ZyR9CSrlnRhzNT78Pn011ZR2iu6vKwoLtYsf4OxaQ/jNfVRvldr4VA5zJgDN/0e7nkGcjdIb9XguQELD/4FPlwmggvg98PCXPif58PPtRaKS6Wv69/mwcpN0uvVui1qxyL2euoZm/Eoa5e/2qGjPhWlo6N/MiuKQ97mVQxmOl5TLcoXoW3FpXD1/fDhUhFXgL++DX++B678jli8peXwwdLY43+0TEQ7K0OGXrUJfvpb+HqriHFyEtx0Kfz+VkiKd33QuZaXGoaYe9i6aQRDhjVeZk5RlLaLWrqKAlSUl+PZ8+tQ0FQEFrFwP3AJLoiI3v8sFB2Sk/wBsWxj0eB3LF0LldVw22OwerOzD9n39Jvw9wXODKKinC3Jvv3EFf6a8vKyE7thRVFOCiq6igJsWjWTgSmfECa4LtELBODjXNfSr4sdhbBlh7zPSIVJI2JfY+IZ0DVNxt28A1ZujD6nwQ9vLQwX9jDxNZYBKUvYsvLFpt2YoihtChVdpdOzr3AXg3xPAH4OlMK8xfDKe2KFNgR9sAYS42N/3uuBhHg5x+eFB2+BEYPCzznjVHjo53IcoK5erOJYVNc64m7l+l9thlffg7mLHYsaP4Pin6Jw785muHtFUVoTFV2l07Nnw4ukxxewfD1MuwW+/yu47jfwzRvhvmehpg48Bi6bFhJNN2OHwtAB8t4YGH4KLHgG7rsB4nxwz3/K9hmDnEhnYHA/GNgreiwDnDNehLy2Hn7zHEy5Ea79Dfzg1zK/pWshLW4HhRtntNRXoihKC6Giq3RqiouL6Bf3MmWVllsfgTVbQz7W8ip48jV46yPZ/o/z4PYrJeAJREBHD4Fn7oaULhyONjYGeneHCcNlrPHDoE/3wxlAAGSmS8BUZnpoLsbAtybAzZfJ9juL4PFXZR4gY63Ng1sfhdIKS7/4Vyg+sL9Fvx9FUZoXFV2lU7Nj0wdkJuazfptEEUdS3wBvfyzLvYnx8MhtsOh5uGgypCTBzAdg3LCQBRvEWli/XZaQ1+bFTsH94TR45XeQlCDL0c/eA7Mege5d5fPvLJTrR7Jmq4zZLWEHOzYvaKZvQlGU1kBFV+m0+P1+UmpnYQhQewQfa01tqIBUnBfGnw4DekFFNSxf75wUo4DGujzZtTYvIgDLGcwYKDooy9cTzhALt1taSMBr6mLPJxCQpWdjAqTWzsLfWLi0oihtDhVdpdNSfGAf2UlfApZhA6Bvj+hzjBEfqyeijnJZhQjpWwtDRTDc1NXDpgJ5v2WHS0BdY/j9MHuhjFNWEd30/pycaAsaoE8POH0ggCU7aRlF+/ce870rinJyUNFVOi37dn1NStwBMNAzU6KLM1wtbA1w7kS4/pLwmsnWQlmlbC5dC9t2E5HWAyVlsHOfbO4uksIauMYAKCiEz7+S9+VVYF2WtjHwk4vhgrPCh05Pgd/eAr2yZDvZd4D9u1cf/5egKEqroqKrdFpqSpZjrJipxsBVF0iU8fRrJac2zgfTr3OCnVw1kgNOQwOAknJ47zNn+diljjv3yzEQgd6xN3wMa2HBF3DQEeOKKmd52zVG11S46zqIj5Ml7V9fC/9+Gq65MGQBGwLUlSxr9u9GUZSWQUVX6bSkeb6WDkJO1LHHwMTh8OjtcMePJYjp5XkuX69znj8g/twg73wsy8nu1n2b8sXvCjLOxvxQ7i3WCdBaGFpSrqh2rmPDrzNznoxz2xXw2O1w5kjwhjVHsKR71rTYd6QoSvOioqt0WjLinHDlCL+pMdC3p3QHevdTiRY+bMka8cW6RXflRthYENq2wJq88DEPbztjbN3pCsICqmrA3as+GIg1Z5HMI6w7kbtHL5CesO1YbltRlJOIiq7SaemR4gQgxWhA3zNTUnnKKuG5WaGayUErtdrVU76iGuZ9GqqXHAiEIpeDrN8WsmSthXlLQn5hkAjp2vrQHAIWnpsNpRWSqhT04botYZzrdU8pbK6vRFGUFuaoomuMGWqMWe36KTPG3NEKc1OUlsVfGl1L2RG0bmmQliy73loolmzw1Lp6EUk3cz4JCXFVLeTtCj++bXfID1xTJ0vSbqprnSVqRJQ3FcAspyhHaheXXzmi8b21QIM2P1CU9sJRRddau8laO8ZaOwYYD1QB77T0xBSlpdm9r5FEWCNVp7IyZPNgGTz/VijXtrYuOod2XZ4sQ4PURy48EH58/0HYd1DGXr8Nvt4SfrzOZT1bK9cLBlllZYRXvIpcDt+zv5H7UBSlzXGsy8vfBvKstQVHPVNR2jh9esbJm6CIuZrHx/uklGOQv78PW3fJuVW10ZWiqmvF/2otbN8N5dXhxytrxPq1Fv65SHy4bhoaQvvydkl7vyC9sySCOQyX8PbuEXlQUZS2yrGK7pXAG7EOGGNuMsbkGmNyT3xaitIKeDPC6iG78Xigf3Zou+gQ/N9s8ddGBj0FmbdY8m3XbYvuqRusm1xZLcFZkTT45VjASt/e/YdCx/plSwOEw0R2H/S5CjgritKmabLoGmPigUuAWbGOW2v/Yq3NsdbmNNfkFKUlKapwtfmJ0b92YO/w81/7t1ihVdWxq1Bt3gErNkQvHQdZs8WJdM6PPhZMQyrYC6/MDz8WqxuRe5m5qCI7xgmKorRFjsXS/S6w0lq7r6UmoyitSUndoOjgJAeDiJ370P6DoYjiQAzruK4eXntPLNpYrN8ufXGD+btugqUgX5gDeyP8wQN6x0gXCubqGihtOPVIt6koShvCdwzn/phGlpYVpT1SGhgF9m0pkOESseBr357g84X7b1/+F3RJJDrq2WHWh7GtYIAN2yU/NxbWSoDVzHnh+31Oji6Ezy20bSitH3nUe1UUpW3QJEvXGJMMnAe83bLTUZTWI7HrBKzxhncIctEzExITwvcVl8JTbzQuumWV0UFSQaprw3NzI5nxT9gd0R43Kkc3MmUID/EZExsfVFGUNkWTRNdaW2mtzbTWlh79bEVpH/TsO5qK+qyQBRkhvt3SID05+nOV1dH7moOCGM2C0lMjaj+75wlUNWTSo8+YlpmQoijNjlakUjotmVk9KayeRJSJ6whbWjJMGXsyZhbiW+MhI6WRg8awt2YiWd01kEpR2gvH4tNVlA6F1+ulIuFyrJ2HwR/lM/V54eFbYfVm8cc2hs8rLfd6ZYn/tVeWWKfJXeRYgx8qq2Rpes8B2LVPgqVKKxr3/wKc1l/a+Hm9zg53owNnabks/nJ8Pv01VpT2gv62Kp2a/kPP5+CGgWQmukKOHWEzBgb0gj/fDZffJZWpQLSvaxqMHQrTJsBZo2BwPxHeQEAqVtU1iN/XWhnH64WEOCm6gRHB3boTvlgDHy+XVKJDZSFNTU+Bp++StKWoRvbO9qGa/vQ/7YKW+3IURWl2VHSVTk1mZndW1V9Lt8QHMURHMRsDU8eJxXnnEzBsIPzsUrjwbMjOlDSilRvhqcViEe8shLIqKZ7hFl2PR6pKpSVLhanhp4pY/+hc+OWVUFgM8z+DGe/Ahnz4zc/g3ImO4Lqjqh2sNeyou4Yx3XtG35SiKG0WYxsLwzyRQY1p/kHbEC3xnbUlTJRp1fFwP8PCvTtJzJ9CRrxT3TTG462ug5segpsug9RkeP8LmP+5FLwoKY+dt3s0jBGLdtQQ+O43xGqurJa0pGfvli5H0R+Sl9K6/lQPWEx27/6NjN2xn6H+DrZ/OvIzzMnJITc3N+ZDVEtX6fRk9+rHys13MjbuV+LbhajUnMR4+MUVcPX9YpVGRjAnxEOvTCnZ2LeHWMFd00LCWVUjpR3z98DmAti5T5omlJTDpyvlJzEeenaDtx93pSpFzAPAWi95db9kXCOCqyhK20VFV1GA08bfQEHuHAamfCLFMiL+CDcGxg2DUYNDbfsS48VK/d4UOO9M8et6PFJZqqQ81IkoKQHSUmRpOSlBfL5bdsIHS2HuJ7IsXeN0Lhp1Gowc7GhtxJIyANawo/IbDBl3Y8t+IYqitAgquooCpKSkUpj9OBUlF5ESt1+EN4iTQuTzyvLygi/hvElwx1Uw/nRpwbdkNTz9JqzaKJZwVW2o6YHPCaJKT4HsLBg6AL5zJlz7Xbj9CvEJP/k6LPgCfvYDOT+s6tTheRgq/d2p6/EnUlPTWuNrURSlmVHRVRSHwcPGs/rLxxhpb8FrakJlpxzhM1as3WkT4H+nw1db4MbfwaJcKCppvEpVvdMrt6QCCgph6VppatCjK5yTA1ecB4/eLn7hnOGu4KngtZ33fhLZVP8Hxg7TniKK0l5R0VUUFyNyrmLVJ/mMTXsIr6kPEz2LpPh8tAym3Ah7iiTPNs4njeZ7d5c83d7dJU83JUlShfxO277iUvnMzn3yerAM3nwfZn8olaeqasRivvzbruVlBz9xrC6dzuip13WKIBtF6aio6CqKC5/Px8jJd7NuaRVnJD0hwuvQ4IeZc8X3Wl0D506CaTkwaSQM6gPJSeKvLamQPNzqWrF+4+MgtYv4dFOTZfm4vEqa3S9dCwuXw/L18tkX34XvT3XyeQ9buHGsr7qdEZPv1UIYitLO0d9gRYkgISGBoZMeZNWSLoxJfwQfNYBl225Yvg7+dCdceo6I6PY9Ipgz34W122D3PmlqUNcghTIgVBwjKSFUuWrYQDh7tKQK3fxDKC6BJ14TUd9UACMHARj8JpHVJdMZMfleEhJi5RApitKeUNFVlBgkJCQwZuq9fL10AEO9d5Ps209xiSU+TgpiPPm6RB/n7xGL9mjUN0BNrVSdyt8DX3wtQp3SRSKgL54i4ybEQ9EhAAma2uL/A6OnXqcWrqJ0ELThgaI0gs/nY9zZP2Fv13+RXzGVSSO9fPAsZKRKxPH+g2LRngiVNbBmK8xZJKlCS2bA1HFeCionsydtHqPPul4FV1E6EFqR6jjoyJVUQKvhxKKiopzNK15gUPxTpMXtoK7eUlgs+bZ7i8TarXeWlP0R7feCZSC9ntBrfJzk+WakSn3l/tmQGG8oq+9LXt0dDBl34wmlBXX0Z6i/g+2fjvwMj1SRSkX3OOjI/1hAf+GPROHenRRueoF+ca/QLaHg/2vv7l6squIwjn8fj1PZZCM46kyOphfiTYGKGWFIJIaSWDeBhl4EURcVShdR3UT/QHQXhBpGppQmREQWJFQXmS8Z5kuiYjqmjVo5aeHk+OtiljCDCkn77OXePh84zHmBmWfNmj2/c9Zaey+kS6Qtf668etTgPXC5yuvpyWAYv1+YyNG+pXRMffqal3a8HnXvQx+D1VfnPnTRLVid/1jAB/x/ceZ0D0cPbGbkhQ10jNhKa8sZFP1wedMEhp63O/Q3OlBo/7o4mhN/30fvrU8wccp82gvcvKDufehjsPrq3Ie+9rJZwUa3j2V0+zL6+5/kVM8JDnfvou/sNtoau2m75RBjWk9Cfy+/9PRx19gWotHGqfMdnP1nMmcv3ktL2yzGTZzGpLGdnrM1u4n4aDf7HxqNBh2dXXR0dgELr3h9/KD7Y9PNzG5eXr1sZmZWEhddMzOzkrjompmZlaRZc7qngZ+b9L2vpj39zFJkWFlYavsyKL19Jfeh+69gPgYLV/c+LLt9d1/rhaacMlQ2Sdsjorb7nbl91eb2VV/d2+j2lcfDy2ZmZiVx0TUzMytJXYru27kDNJnbV21uX/XVvY1uX0lqMadrZmZWBXX5pGtmZnbDc9E1MzMrSaWLrqT5kn6SdFDSy7nzFE3Sakk9kn7MnaUZJE2QtEXSXkl7JC3PnalIkm6T9J2kH1L7Xs+dqRkkNSR9L+mT3FmKJumIpN2SdknanjtP0SSNkrRB0n5J+yQ9kDtTkSRNTX13+dYraUXWTFWd05XUAA4A84BuYBuwJCL2Zg1WIElzgHPAuxFxT+48RZPUCXRGxE5JI4EdwON16UMNnP3fGhHnJLUA3wDLI+LbzNEKJelFYCZwZ0RcuetDhUk6AsyMiFpeGEPSGuDriFgp6Rbg9oj4I3Ospkg14zhwf0SUefGmIar8SXcWcDAiDkdEH7AeeCxzpkJFxFfAb7lzNEtEnIiInen+n8A+hm7MU2kx4Fx62JJu1XyXew2SuoBHgZW5s9j1kdQGzAFWAUREX10LbjIXOJSz4EK1i+544Nigx93U6B/2zUbSJGA6sDVzlEKlodddQA/wRUTUqn3Am8BLwKXMOZolgM8l7ZD0TO4wBZsMnALeSdMDKyW15g7VRIuBdblDVLnoWk1IugPYCKyIiN7ceYoUEf0RMQ3oAmZJqs00gaSFQE9E7MidpYkejIgZwALguTTlUxfDgRnAWxExHTgP1G5tDEAaOl8EfJg7S5WL7nFgwqDHXek5q5A017kRWBsRH+XO0yxp2G4LMD9zlCLNBhalec/1wMOS3ssbqVgRcTx97QE2MTCtVRfdQPeg0ZcNDBThOloA7IyIX3MHqXLR3QZMkTQ5vYtZDHycOZNdh7TQaBWwLyLeyJ2naJLGSBqV7o9gYNHf/qyhChQRr0REV0RMYuD4+zIilmaOVRhJrWmBH2nY9RGgNmcSRMRJ4JikqempuUAtFjFexRJugKFlaN7Wfk0XERclPQ9sBhrA6ojYkzlWoSStAx4C2iV1A69FxKq8qQo1G1gG7E7zngCvRsSn+SIVqhNYk1ZNDgM+iIjanVZTY+OATWkLuuHA+xHxWd5IhXsBWJs+uBwGnsqcp3DpDdM84NncWaDCpwyZmZlVTZWHl83MzCrFRdfMzKwkLrpmZmYlcdE1MzMriYuumZlZSVx0zczMSuKia2ZmVpJ/AbcdI1K7/Eb7AAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "solution = min_conflicts(eight_queens)\n",
+ "print(solution)\n",
+ "plot_NQueens(solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "id": "660fef79",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import copy\n",
+ "class InstruCSP(CSP):\n",
+ " \n",
+ " def __init__(self, variables, domains, neighbors, constraints):\n",
+ " super().__init__(variables, domains, neighbors, constraints)\n",
+ " self.assignment_history = []\n",
+ " \n",
+ " def assign(self, var, val, assignment):\n",
+ " super().assign(var,val, assignment)\n",
+ " self.assignment_history.append(copy.deepcopy(assignment))\n",
+ " \n",
+ " def unassign(self, var, assignment):\n",
+ " super().unassign(var,assignment)\n",
+ " self.assignment_history.append(copy.deepcopy(assignment))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "id": "12cd427f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def make_instru(csp):\n",
+ " return InstruCSP(csp.variables, csp.domains, csp.neighbors, csp.constraints)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "id": "71b65c4a",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Figure(504x504)\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAd0AAAHwCAYAAADjD7WGAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAACTcElEQVR4nOz9eXyU5b3/jz+vmclGVkiAsKOAILITQCsUS7VatbZae7RuPVqr9me1+mlRj3p6tLVWrVV/R6vHFpW61opKhWJxQRRcgLDIvgUS1pAQyL7PXN8/3vcw9yxhTUKW9/PxyGPmXua6r3tuwivv670Zay2KoiiKorQ8npM9AUVRFEXpLKjoKoqiKEoroaKrKIqiKK2Eiq6iKIqitBIquoqiKIrSSqjoKoqiKEoroaKrKIqiKK2Eiq6iKIqitBIquorSChhjBhpj5hljDhpjCo0xzxhjfIc5P8MY85xzbrUxZo0x5ietOWdFUZofFV1FaR2eBYqAXsAYYCrw/4t1ojEmHvgIGACcBaQD04HHjDG3t8ZkFUVpGVR0FaV1OAX4h7W21lpbCPwbOKOJc68F+gM/stZut9Y2WGv/DdwOPGSMSQEwxlhjzODgh4wxM40xD7m2LzbGrDLGlBpjvjDGjHId622MedsYU2yM2e4Wc2PMA8aYfxhjXjbGVBhj1hljclzH7zbG7HaObTLGfLt5viJF6fio6CpK6/AUcKUxposxpg/wXUR4Y3Ee8L61tipi/9tAF8T6PSzGmLHAi8DNQCbwPPCeMSbBGOMB5gBfA32AbwN3GGPOdw1xCfB3IAN4D3jGGXco8AtggrU2FTgfyD/SfBRFEVR0FaV1+AyxbMuBXUAuMLuJc7OAvZE7rbWNwH6g+1Fc7ybgeWvtEmut31r7N6AOOBOYAHS31v7WWltvrd0G/BW40vX5xdbaedZaP/AKMNrZ7wcSgOHGmDhrbb61Nu8o5qMoCiq6itLiOJblv4F3gGREVLsCjzbxkf2I7zdyHJ/z2f1HcdkBwK+cpeVSY0wp0A/o7RzrHXHsXqCn6/OFrvfVQKIxxmet3QrcATwAFBlj/m6M6X0U81EUBRVdRWkNuiE+2mestXXW2hLgJeDCJs7/CPiuMSY5Yv8PgXpgibNdjSw3B8l2vd8J/N5am+H66WKtfcM5tj3iWKq1tqn5hGGtfd1aOxkRb0vTfzwoihKBiq6itDDW2v3AduDnxhifMSYD+AmwuomPvIIsQb/lpBrFOf7W/wX+aK0tc85bBVxljPEaYy5AIqKD/BW4xRgzyQjJxpiLjDGpwFKgwgmISnI+P8IYM+FI92KMGWqMmWaMSQBqgRogcIxfiaJ0WlR0FaV1uAy4ACgGtgINwJ2xTrTW1gHnIhbpEkTY/o0EYz3oOvWXwPeAUuBqXD5ia20u8DMkAOqgc83/dI75gYuR1KXtyHL1DCQ16UgkAI84nykEegD/dRSfUxQFMNbakz0HRVEOgzEmDngf2A38p9VfWkVpt6ilqyhtHGttA+LPzQOGnuTpKIpyAqilqyiKoiithFq6iqIoitJKNFlw/UTIysqyAwcObImh2wTLly8/2VNoUcaPH3+yp9Di6DNs3+jza/909GdorTWx9rfI8nJOTo7Nzc09rs+WlBSzY9OHpNTNIjvpK1LiijHWD8ZKRiCHXgAwxtlhAGuwxktlQxaFNROpTPgR/YeeT2bm0RTwOXqMiflddhg6g8tBn2H7Rp9f+6cTPMOYN9gilu7xsK9wF3s2vkQ/38uMSdyOiQ+I0LpxBDZcaN0nWAyNpMYVkuqbg+VfHNgwkJUN19Jr2A1k9+rXWrejKIqiKFGcdEu3qrKSjSteYpDvCdLjCzDEEFo3saZ7hHMshrKG/uTV38nQ8TeQkpJ6VHNrik7wF9rJnkKLo8+wfaPPr/3TCZ5hzBs8qYFUeZtXsS/3B4xL/n9kxOdjgpZtcKpBS9b9E9xvCBdb9/GIMQyWjLgCxiX/iuLcS9i6aUXL3JCiKIqiHIaTIrp+v59VX71KzwPf5dSUBRgao63VIJH7I4XYvf8IYxj8nJLyKdkHL2TVl3+jsbHx+G9CURRFUY6RVhfd+vp6Vn76CCN9N5Pi2wfYaCs26K/F9d4tqpHbsSzhJsewpMQVMTLu56z69GHq6upa4jYVRVEUJYpWDaSqr69nw1cPMDb1T3hpCAVKBcXSLZTu/cFNC5XVsGgl5O2GU/vAlLGQ2sX1sSOMIdsWr6llbNpDrFtSxdBJvyUhIaE5blFRFEVRmqTVRNfv97N68R9FcE19eOSx897RQ8EdpYwI7u5iuP4BWLgcGv3g9cLUsfDSA9CvZ8TqcqRfOOqYxWsaOCPpSVYu7sKYqffh87WZYG5FURSlA9Jqy8trlr3B2LSH8ZqGKN+rtXCwAmbMhpt+D/c8A7kbIBDg0LkBCw/+BT5aKoIL4PfDglz4n+fDz7UWSspgzmfwt7mwYhM0NMp+OYFDFrHX08DYjEdZu+zVThExqCiKopw8WsW0y9u8ksFMx2tqRPkitK2kDK6+Hz5aIuIK8Nd34M/3wJXfEYu3rAI+XBI9NsDHS0W0szJk6JWb4Ke/hdVbRYyTk+CmS+H3t0JSvOuDzrW81DLE3MPWTSMYMiynme9eURRFUYQWt3QrKyrw7Pl1KGgqAotYuB+6BBdERO9/FooPykn+gFi2sWj0O5auhaoauO0xWLXZ2Yfse/pN+Pt8ZwZRUc6WZF8RcYW/pqKi/MRuWFEURVGaoMVFd9PKmQxM+ZQwwXWJXiAAn+S6ln5d7CiELTvkfUYqTBoR+xoTz4CuaTLu5h2wYmP0OY1+eHtBuLCHia+xDEhZzJYVLx7djSmKoijKMdKioruvcBeDfE8AfvaXwdxF8Mr7YoU2Bn2wBhLjY3/e64GEeDnH54UHb4ERg8LPOeNUeOjnchygvkGs4ljU1DnibuX6X2+GV9+HOYscixo/g+KfonDvzma4e0VRFEUJp0VFd8+GF0mPL2DZeph2C3z/V3Ddb+CbN8J9z0JtPXgMXDYtJJpuxg6FoQPkvTEw/BSY/wzcdwPE+eCe/5TtMwY5kc7A4H4wsFf0WAY4Z7wIeV0D/OY5mHIjXPsb+MGvZX5L1kJa3A4KN85oqa9EURRF6cS0mOiWlBTTL+5lyqsstz4Ca7aGfKwV1fDka/D2x7L9H+fB7VdKwBOIgI4eAs/cDSldOBRtbAz07g4ThstY44dBn+6HMoAAyEyXgKnM9NBcjIFvTYCbL5PtdxfC46/KPEDGWpsHtz4KZZWWfvGvULK/qKW+GkVRFKWT0mKiu2PTh2Qm5rN+m0QRR9LQCO98Isu9ifHwyG2w8Hm4aDKkJMHMB2DcsJAFG8RaWL9dlpDX5sVOwf3hNHjld5CUIMvRz94Dbz0C3bvK599dINePZM1WGbNbwg52bJ7fTN+EoiiKoggtIrrWWlLq3sIQoO4wPtbaulABqTgvjD8dBvSCyhpYtj44mPPqKqCxLk92rc2LCMByBjMGig/I8vWEM8TC7ZYWEvDa+tjzCQRk6dmYAKl1b+FvKlxaURRFUY6DFhLdBrKTvgIswwZA3x7R5xgjPlZPRB3l8koR0rcXhIpguKlvgE0F8n7LDpeAusbw+2HWAhmnvDK66f05OdEWNECfHnD6QABLdtJSiov2HvO9K4qiKEpTtIjopiXVkBK3Hwz0zJTo4gxXC1sDnDsRrr8kvGaytVBeJZtL1sK23USk9UBpOezcJ5u7i6WwBq4xAAoK4Yuv5X1FNViXpW0M/ORiuOCs8KHTU+C3t0CvLNlO9u2naPeq4/8SFEVRFCWCFhHdQb2rMVbMVGPgqgskynj6tZJTG+eD6dc5wU6uGskBp6EBQGkFvP+5s3zsUsedRXIMRKB37A0fw1qY/yUccMS4stpZ3naN0TUV7roO4uNkSfvX18K/n4ZrLgxZwIYA9aVLm/27URRFUTovLSK640+rlg5CTtSxx8DE4fDo7XDHjyWI6eW5Ll+vc54/IP7cIO9+IsvJ7tZ9m/LF7woyzsb8UO4t1gnQWhBaUq6sca5jw68zc66Mc9sV8NjtcOZI8IY1R7Cke9a0xNejKIqidFJaRHRHDHJ61Eb4TY2Bvj2lO9B7n0m08CFL1ogv1i26KzbCxoLQtgXW5IWPeWjbGWPrTlcQFlBdC+5e9cFArNkLZR5h3YncPXqB9IRtx3LbiqIoinJYWkR0hw9wTNEYDeh7ZkoqT3kVPPdWqGZy0EqtcfWUr6yBuZ+F6iUHAqHI5SDrt4UsWWth7uKQXxgkQrquITSHgIXnZkFZpaQqBX24bksY53rdUwqb6ytRFEVRlJYR3eQkf3QtZUfQuqVBWrLsenuBWLLBU+sbRCTdzP40JMTVdZC3K/z4tt0hP3BtvSxJu6mpc5aoEVHeVABvOUU5Uru4/MoRje+tBRq1+YGiKIrSfByV6BpjLjDGbDLGbDXG3HOk84sONNGX1kjVqawM2TxQDs+/Hcq1rauPzqFdlyfL0CD1kQv3R14L9h2Qsddvg9Vbwo/Xu6xna+V6wSCrrIzwileRy+F7ippI6FUURVGU4+CIomuM8QJ/Br4LDAd+bIwZfrjP9Mw8FAIsuJrHx/uklGOQv38AW3fJudV10ZWiaurE/2otbN8NFTXhx6tqxfq1Fv65UHy4bhobQ/vydkl7vyC9sySCOfyGXcd7RB5UFEVRlOPnaCzdicBWa+02a2098Hfg+4f7QGW1N6wectgFPdA/O7RdfBD+b5b4ayODnoLMXST5tuu2RffUDdZNrqqR4KxIGv1yLGClb2/RwdCxftnSAOEQkd0Hfa4CzoqiKIpyghyN6PYB3L3udjn7wjDG3GSMyTXG5K7Z6jIXY/SvHdg7/LOv/Vus0Oqa2FWoNu+A5Ruil46DrNniRDrnRx8LpiEV7IVX5oUfi9WNyL3MXFyZHeMERVEURTk+mi2Qylr7F2ttjrU2Z+OO5OjgJAeDiJ37UNGBUERxIIZ1XN8Ar70vFm0s1m+XvrjB/N3weUkpyBdmw94If/CA3jHShYK5ugbKGk893C0riqIoyjHhO4pzdgP9XNt9nX1NsnxzEtgyKZDhErHga9+e4POF+29f/hd0SSQ66tnhrY9iW8EAG7ZLfm4srJUAq5lzw/f7nBxdCJ9baNtQ1jDycLepKIqiKMfE0Vi6y4AhxphTjDHxwJXAe4f7QN6eZKzxhncIctEzExITwveVlMFTbzQtuuVV0UFSQWrqwnNzI5nxT9gd0R43Kkc3MmUID/EZE5seVFEURVGOkSOKrrW2EfgFMB/YAPzDWrvucJ8pq0misiErZEFGiG+3NEhPjv5cVU30vuagIEazoPTUiNrP7nkC1Y2Z9OgzpmUmpCiKonRKjsqna62dZ609zVo7yFr7+yOdb0wchTWTiDJxHWFLS4YpY49nus3Ht8ZDRkoTB41hb+1EsrprIJWiKIrSfByNT/eYMcZQmXA51s7F4I/ymfq88PCtsGqz+GObnJxXWu71yhL/a68ssU6Tu8ixRj9UVcvS9J79sGufBEuVVTbt/wU4rb+08fN6gxMmLJfY4qE8/nJ8vhb5ehRFUZROSoupSv+h53Ngw0AyE10hx46wGQMDesGf74bL75LKVCDa1zUNxg6FaRPgrFEwuJ8IbyAgFavqG8Xva62M4/VCQpwU3cCI4G7dCV+ugU+WSSrRwfKQpqanwNN3SdpSVCN7Z/tgbX/6n3ZBS301iqIoSielxUQ3M7M7KxuupVvigxiio5iNganjxOK88wkYNhB+dilceDZkZ0oa0YqN8NQisYh3FkJ5tRTPcIuuxyNVpdKSpcLU8FNFrH90LvzySigsgXmfw4x3YUM+/OZncO5ER3DdUdUO1hp21F/DmO49o29KURRFUU4AY5sKFz4BcnJybG5uLoV7d5KYP4WMeKc/X4xL1dTDTQ/BTZdBajJ88CXM+0IKXpRWxM7bPRLGiEU7agh89xtiNVfVSFrSs3dLl6PoD8lLWX1/agYsIrt3/8OMHyMBuQPREv8m2hr6DNs3+vzaP53gGca8wRZ1Wmb36seKzXcyNu5X4tuFqNScxHj4xRVw9f1ilUZGMCfEQ69MKdnYt4dYwV3TQsJZXSulHfP3wOYC2LlPmiaUVsBnK+QnMR56doN3HnelKkXMA8BaL3n1v2TcYQRXURRFUY6XFo8UOm38DRTkzmZgyqdSLCPiDzhjYNwwGDU41LYvMV6s1O9NgfPOFL+uxyOVpUorQp2IkhIgLUWWlpMSxOe7ZSd8uATmfCrL0rVO56JRp8HIwY7WRiwpA2ANO6q+wZBxN7bsF6IoiqJ0WlpcdFNSUinMfpzK0otIiSsS4Q3ipBD5vLK8PP8rOG8S3HEVjD9dWvAtXgVPvwkrN4olXF0Xanrgc4Ko0lMgOwuGDoDvnAnXfhduv0J8wk++DvO/hJ/9QM4Pqzp1aB6GKn936nv8idTUtJb+ShRFUZROSqvkxAweNp5VXz3GSHsLXlMbKjsV7ABoxdqdNgH+dzp8vQVu/B0szIXi0qarVDU4vXJLK6GgEJaslaYGPbrCOTlwxXnw6O3iF84Z7gqeCl7bee8nkU0Nf2DssJyW+xIURVGUTk+rJaKOyLmKlZ/mMzbtIbymIUz0LJLi8/FSmHIj7CmWPNs4nzSa791d8nR7d5c83ZQkSRXyO237SsrkMzv3yeuBcnjzA5j1kVSeqq4Vi/nyb7uWlx38xLGqbDqjp17X4R37iqIoysml1UTX5/MxcvLdrFtSzRlJT4jwOjT6YeYc8b3W1MK5k2BaDkwaCYP6QHKS+GtLKyUPt6ZOrN/4OEjtIj7d1GRZPq6olmb3S9bCgmWwbL189sX34PtTnXzeQxZuHOurb2fE5Hu1EIaiKIrS4rSq0iQkJDB00oOsXNyFMemP4KMWsGzbDcvWwZ/uhEvPERHdvkcEc+Z7sHYb7N4nTQ3qG6VQBoSKYyQlhCpXDRsIZ4+WVKGbfwglpfDEayLqmwpg5CAAg98ksqp0OiMm30tCQqwcIkVRFEVpXlrdvEtISGDM1HtZvWQAQ713k+wroqTUEh8nBTGefF2ij/P3iEV7JBoaobZOqk7l74EvV4tQp3SRCOiLp8i4CfFQfBBAgqa2+P/A6KnXqYWrKIqitBrN1sT+WPD5fIw7+yfs7fov8iunMmmklw+fhYxUiTguOiAW7YlQVQtrtsLshZIqtHgGTB3npaBqMnvS5jL6rOtVcBVFUZRWpUUrUh0NlZUVbF7+AoPinyItbgf1DZbCEsm33Vss1m6Ds6Tsj2i/FywD6fWEXuPjJM83I1XqK/fPhsR4Q3lDX/Lq72DIuBtPOC2oowdcaTWc9k9Hf4b6/No/neAZxrzBky66QQr37qRw0wv0i3uFbgkFGBPAafkTXT3K3QOXGMednRYPB+v6s6P+GrKH3njY0o7HQif4x3Kyp9Di6DNs3+jza/90gmfYtkU3SMn+InZsnk9q3Syyk5aQHFeCsX4INk0gPG83/K5EaKsbM9lbM4HyhB/Rf8gFZDVz84JO8I/lZE+hxdFn2L7R59f+6QTPsPVrLx8PmVk9yMy6Fr//KoqL9rJt1yrqy5aR7l1Denwe3ZMLwV/OnqJ6eveIw3rTKa7KpqzhFMoaRxKXPpGe/ccwsEcv9dkqiqIobYo2q0per5fsXn3J7tUXuDjqeB/X+x7Oj6IoiqK0ZU5K9LKiKIqidEZUdBVFURSllVDRVRRFUZRWQkVXURRFUVqJFgmkWr58eYcOB+/o4fwd+dkF0WfYvtHn1/7pyM8wJ6fpNrFtNnpZURRFaR68XsjuBiOHwOTRMH44jB4C6cnSs7x7BpRVweotsHwDfP61vC8skS5wSvOhoqsoitIB8XhgaH/4ycXwg2/BKb3B5wGPl7Be5v2z5X2XJOiVCeefBQE/NAYgfy+89xm89B5szA91eFOOnxapSGWM6bjrBnTsZRHQpa2OQEd/hvr8mibOJ8J57w2QM8ypTe91DkaW0TURr0TsQwTYH5BmNA+/BO9/IfXwT5SO/AxzcnLIzc2N+RA1kEpRFKUDYIBvjIIlM2H243DWCBFgj4fYdepx7Y887hJmj0fGmTQC3vkjLH0ZJo+RhjPKsaOiqyiK0s5J7QLP3wefPA9jh4oPFwgXURvxE9xvIKppjNsIdY3h9cCYIbDgOXjhvyEtuUVup0OjoqsoitKOGTEYlr8KP71EWptGWbNBIvdHCrF7/xHGiPPBTy6S644ectxT75So6CqKorRTzj8TPp8Bg/q4lpGb8M0eeu8W1cjtWJZwE2N4vHBqH1g0Ay48u0Vur0OioqsoitIOueIC8bGmJDmBUjH7isfethYqqmDeYnj6TfjXYiivjjjtCGNgwWMgOQlmPQpXX3QCN9OJ0JQhRVGUdsb5Z8KL90GXRGJGHlsIC5IyrnOshd3FcP0DsHC55OF6vTB1LLz0APTrGbG6HOkXjjjmMZCUAH/9LygtEwFXmkYtXUVRlHbEiMHwj0cgMZ4o36u1cLACZsyGm34P9zwDuRuc/NpgCpCFB/8CHy0NFb7w+2FBLvzP8+HnWgslZTDnM/jbXFixSdKFrEvQg0vOSYnwxsMwZmgLfwHtHLV0FUVR2glpyfDOY5DSRSzMSMuzpAyuvh8+WiLiCvDXd+DP98CV3xGLt6wCPlwSe/yPl4poZ2XI0Cs3wU9/C6u3ihgnJ8FNl8Lvb4WkeNcHnWslJ8CsR2D8tVBW2bz33lFQS1dRFKUdYIA/3ekKmorAIhbuhy7BBRHR+5+F4oNykj8glm0sGv2OpWuhqgZuewxWbQ5VoqqqER/w3+c7OhthaXs8UvnqqV9pHm9TqOgqiqK0A84aJWk6YYLrErZAAD7JdS39uthRCFt2yPuMVCl0EYuJZ0DXNBl38w6pQhVJox/eXhAu7O55eLxw9QVSQEOJRkVXURSljRPng2fuAp8P9pfB3EXwyvtihTYGfbDG8fPGwOuBBMcH7PPCg7fAiEHh55xxKjz0czkOUN8gVnEsauoccbdy/a83w6vvw5xFYlH7fPD0dJm3Eo5+JYqiKG2c88+CUUNg2Xq48XewbptYtqld4Oc/ggdvhoQ4uGwazPs8ujPQ2KEwdIC8NwaGnwLzn4Fn34LHXoZfXQO/+A/o3T20LDy4HwzsBVt2ho9lgHPGi5DXNUhQ1jP/gIpqscKHnwJ/vR8mDIeLJsPshS397bQv1NJVFEVpw3g8cN8NUFkDtz4Ca7aGfKwV1fDka/D2x7L9H+fB7VdKwBOIgI4eAs/cLcFXwWhjY0RgJwyXscYPgz7dnVViZ9k4M10CpjLTQ3MxBr41AW6+TLbfXQiPvyrzABlrbR7c+qjsu+8GEWclhH4diqIobZih/UUU12+TKOJIGhrhnU9kuTcxHh65DRY+L1ZmShLMfADGDYsObLIW1m+XJeS1eTFTcPnhNHjld5KHO2IQPHsPvPUIdO8qn393QeyOQ2u2ypijh8DpA5vne+goqOgqiqK0Yf7zktBSblM+1tq6UIXGOC+MPx0G9BLreNl656QYBTTW5cmutXkRAVjOYMZA8QGorYcJZ4iF2y0tJOC19bHnEwjIfL1euOH7x3/vHREVXUVRlDaKzws/OEeWmIcNgL49os8xRnysnog6yuWVIqRvL4j28YIESm0qkPdbdrgE1DWG3w+zFsg45ZURfREMnJMTOzWoTw+xcD0e+N43Q8FZioquoihKm6VnNwlmwkDPTIkuzkgNHTfAuRPh+ktcWTvWEckq2VyyFrbtJjyn1kBpOezcJ5u7i6WwBq4xAAoK4Yuv5X1FNViXpW0M/ORiuOCs8KHTU+C3t0CvLNkekC3+Y0VQ0VUURWmjjBwCPud/aWPgqgsk6nj6tZJTG+eD6dc5wU6uGskBC5VOcFNpBbz/ubN87FLHnUVyDESgd+wNH8NamP8lHHDEuLLaWd52jdE1Fe66TloKjj8dfn0t/PtpuObCkAXs9cDo05r7m2m/qOgqiqK0USaPdjoIOVHHHgMTh8Ojt8MdP5Ygppfnuny9znn+gPhzg7z7iSwnu1v3bcoXvyvIOBvzQ7m3WCdAa0FoSbmyxrmODb/OzLkyzm1XwGO3w5kjwesqUenxyH0ogoquoihKG2X8cOdNhN/UGOjbUwKV3vtMooUPWbJGfLFu0V2xETYWhLYtsCYvfMxD284YW3e6grCA6lpodEUqBwOxZi+UeYR1J3L36EWipxVBRVdRFKWNMnqI8yZGA/qemZLKU14Fz70VqpkctFJr6kLjVNbA3M9C9ZIDgVDkcpD120KWrLUwd3HILwwSIV3XEJpDwMJzs6SxQWJ8yIfrtoRxrjdicDN9IR2AI4quMeZFY0yRMWZta0xIURRFEdKTY9RSdgStW5p0HQKJUN5YENK5+gYRSTezPw0JcXUd5O0KP75td8gPXFsvS9JuauqcJWpkTpsK4C2nKEdqF5df2W2VOwKe1uVY7rpjczSW7kzgghaeh6IoihJB8cEmDhipOpWVIZsHyuH5t0MCXVcfnUO7Lk+WoYPjFu4PP150APYdkLHXb4PVW8KP17usZ2vlesEgq6yM8IpXkcvh+0uPfK+dhSOKrrX2M+BAK8xFURRFcdGjm/MmKGKu5vHxvvBUnL9/AFt3ybnVddGVomrqxP9qLWzfDRU14cerasX6tRb+uVB8uG4aG0P78nZJe78gvbMkgjkMl/B273oUN9tJUJ+uoihKG6W0MrweshuPB/pnh7aLD8L/zRJ/bWTQU5C5iyTfdt226J66wbrJVTUSnBVJo1+OBaz07S1yWeH9siNqLLvma4Ayl2+4s9NsomuMuckYk2uMyW2uMRVFUTozYUu8MfrXDuwdfv5r/xYrtLomdhWqzTtg+YbopeMga7Y4kc750ceCaUgFe+GVeeHHBvaKMZhrmXltXozjnZRmE11r7V+stTnW2pzmGlNRFKUzs3wD0cFJDgYRO/ehogOhiOJADOu4vgFee79pEVy/XfriBvN33QRLQb4wG/ZG+IMH9I6RLhTM1TWwctNhbrKTof10FUVR2iiLV0HA7xTIcIlY8LVvT2kY7/bfvvwv6JIYI+rZ4a2PYlvBABu2S35uLKyVAKuZc8P3+5wcXYiYo7Md8MPilUe6087D0aQMvQF8CQw1xuwyxvy05aelKIqirNkKjcH8W4iyeHtmQmJC+L6SMnjqjaZFt7wqOkgqSE1deG5uJDP+CbuLwvdF5ehGpAz5A7Bqc9NjdjaOaOlaa3/cGhNRFEVRwiksgfy9cFp/woXXEbZuaZLLWxEhlFURkcnNRcHe6H3pqa4c3YiiGCBNFfYUt8x82iMavawoitJGafTDewudalNuHHFLS4YpY0/CxFx8azxkpMQ+FrASCd3UcnZnRH26iqIobZiX5sIvfwweH1E+U58XHr5Vlm83bG96DJ9XWu71yhL/a68ssU6Tu8ixRj9UVcvS9J79sGufBEuVVR5eME/rL238vMF+ua5GB1hJS3pxzol+Ax0LFV1FUZQ2zMZ8SeOZNMK10xE2Y2BAL/jz3XD5XVKZCkT7uqbB2KEwbQKcNQoG9xPhDQSkYlV9o/h9rZVxvF5IiJOiGxgR3K074cs18MkymcPB8pCmpqfA03dJ2lJUI3tn++utsF7ThcJQ0VUURWnDBALw8Evwzh8dizIiitkYmDpOLM47n4BhA+Fnl8KFZ0N2pqQRrdgITy0Si3hnIZRXS/EMt+h6PFJVKi1ZKkwNP1XE+kfnwi+vFP/yvM9hxruwIR9+8zM4d6IjuO6oage/Hx5+0dV2UAHA2KZC3E5kUGOaf9A2REt8Z20JE/Vna8dDn2H7prM9vzgfLH0ZxgSbwce4/Zp6uOkhuOkySE2GD76EeV9IwYvSith5u0eeh1i0o4bAd78hVnNVjaQlPXu3dDmK/pC8rNkC46+NLkcZpCM/w5ycHHJzc2P+EqroHgcd+R8LdPz/sEGfYXunMz6/yWNgwXMiwHKS66AVHV66Dq6+X6zSyAjmhHjolSklG/v2ECu4a1pIOKtrpbRj/h7YXCBRx5FNExLjoWc3eOdxWbo2MeaBgYYGOO9W+HRF0/fYkZ/h4URXl5cVRVHaAZ9/LdWkrrvIKZYRoVnGSLP4UYNDbfsS48VK/d4UOO9M8et6PFJZqrQiJKpJCZCWIkvLSQni892yEz5cAnM+lWXpWqdz0ajTYORgl+BGzCPghzc/hM+0IEZM1NI9DjryX2jQ8a0k0GfY3umszy8tGZa/Cqf2EfE8hA29zP8SfngXnDcJ7rgKxp8uLfgWr4L3v4CVG8USrq4LNT3wOUFU6SmQnQVDB8B3zoRvjhVreMVGePJ1GfvNP8DFU2IETyGCW1AI466WZg2HoyM/Q7V0FUVROgDlVSKoi2dIP12Pq9wigLFi7U6bAP87Hb7eAjf+DhbmQnFp01WqGpxeuaWVIppL1kpTgx5d4ZwcuOI8ePR28QvnDHcFTwWv7byvqoVLpx9ZcDszKrqKoijtiNVb4Mp7Ydajjj/WJXoWSfH5eClMuVEqQTX6xQ+clSH9d/v1lNfMdEhJkohov9O2r6RMPhOsInWgHN78AGZ9JJWnqmvFYr7829H+3Jp6uPq/4Wst+XhYVHQVRVHaGfM+hxsfhhn3QlJiaH+jH2bOEd9rTS2cOwmm5cCkkTCoj1jHdfViiZZVinVrraQKpXaR5evUZFlurqiWZvdL1sKCZbBsvXz2xffg+1OdfF5H7Gvq4ZZHYE6MPrxKOCq6iqIo7ZDX50FpGbzxMKQkio93225Ytg7+dCdceo6I6PY9Ipgz34O122D3Plmmrm8MlZcMFsdISghVrho2EM4eLalCN/8QSkrhiddE1DcVwMhB8vmqOomYVsE9OlR0FUVR2inzPofJP4V3/win9BZhjI+TghhPvi7Rx/l7xKI9Eg2NUFsnVafy98CXq0WoU7pIBPTFU2TchHgoPiiCW1AIl98tgVbK0aENDxRFUdoxa7bC+GukYMX40+HDZyEjVYSw6IBYtCdCVa1cY/ZCSRVaPAPOHgWvz5coZRXcY0NTho6DjhzqDh0/3QT0GbZ39PnF+owU0Hh6OowYJP7dwhLJt91bLNZug7Ok7He34CNUBtLrCb3Gx0meb0aq1Ffuny1+3A3b4RePSR7uiTyGjvwMNWVIURSlg2MtLFoJE66DiybDvddL2ch+PZ2c3hgN5g9tR/TAde8LBKR+8tdbpZby3EVNl3ZUjoyKrqIoSgeioVGWgud8BqcPhOsvgUumiqXqcyxZjPy4jU0DUUK7cx/MWQQvvCfdgrR5wYmjy8vHQUdeFoGOvzQJ+gzbO/r8jg2fVzoHjT4NJo+GcafLEnRaMuwvhe5dJYVobR6s2iIW86pNsizd0EIN6DvyM9TlZUVRlE5Mox927JOfOYtO9mw6Nxq9rCiKoiithIquoiiKorQSKrqKoiiK0kq0iE93/Pjx5ObmtsTQbQINUmn/6DNs3+jza/909GfYFGrpKoqiKEorodHLiqJEUVJSzI5NH5JSN4vspK9IiSvGWL80bHW1kQtyqL+qAazBGi+VDVkU1kykMuFH9B96PpmZ3Vv/RhSljaGiqyjKIfYV7mLPxpfo53uZMYnbMfEBEVo3jsCGC637BIuhkdS4QlJ9c7D8iwMbBrKy4Vp6DbuB7F79Wut2FKXN0SLFMXJycqz6dNsv6k9q/xzrM6yqrGTjipcY5HuC9PgCDDGENuwCMQY5wjkWQ1lDf/Lq72To+BtISUk9pjmGXUqfX7unEzzDmDeoPl1F6eTkbV7FvtwfMC75/5ERn8+hgnLB/zKClqz7J7jfEF2vN2zdOfRqsGTEFTAu+VcU517C1k0rWuaGFKUNo6KrKJ0Uv9/Pqq9epeeB73JqygIMjdHWapDI/ZFC7N5/hDEMfk5J+ZTsgxey6su/0dio1fOVzoOKrqJ0Qurr61n56SOM9N1Mim8fYKOt2MguNJGWbeR2LEu4yTEsKXFFjIz7Oas+fZi6uqPosq4oHQANpFKUTkZ9fT0bvnqAsal/wktDKFAqKJaxWsC5Ny1UVktR/LzdcGofmDIWUru4PnaEMWTb4jW1jE17iHVLqhg66bckJCQ0xy0qSptFRVdROhF+v5/Vi/8ogmvqwyOPnfeOHgruKGVEcHcXw/UPwMLlUkjf64WpY+GlB6R3a9jqcqRfOOqYxWsaOCPpSVYu7sKYqffh8+l/S0rHRZeXFaUTsWbZG4xNexivaYjyvVoLBytgxmy46fdwzzOQu0F6qwbPDVh48C/w0VIRXAC/Hxbkwv88H36utVBSJn1d/zYXVmySXq/WbVE7FrHX08DYjEdZu+zVThG5q3Re9E9KRekk5G1eyWCm4zU1onwR2lZSBlffDx8tEXEF+Os78Od74MrviMVbVgEfLok9/sdLRbSzMmTolZvgp7+F1VtFjJOT4KZL4fe3QlK864POtbzUMsTcw9ZNIxgyLKeZ715R2gZq6SpKJ6CyogLPnl+HgqYisIiF+6FLcEFE9P5nofignOQPiGUbi0a/Y+laqKqB2x6DVZudfci+p9+Ev893ZhAV5WxJ9hURV/hrKirKT+yGFaWNoqKrKJ2ATStnMjDlU8IE1yV6gQB8kuta+nWxoxC27JD3GakwaUTsa0w8A7qmybibd8CKjdHnNPrh7QXhwh4mvsYyIGUxW1a8eHQ3pijtDBVdReng7CvcxSDfE4Cf/WUwdxG88r5YoY1BH6yBxPjYn/d6ICFezvF54cFbYMSg8HPOOBUe+rkcB6hvEKs4FjV1jrhbuf7Xm+HV92HOIseixs+g+Kco3LuzGe5eUdoWKrqK0sHZs+FF0uMLWLYept0C3/8VXPcb+OaNcN+zUFsPHgOXTQuJppuxQ2HoAHlvDAw/BeY/A/fdAHE+uOc/ZfuMQU6kMzC4HwzsFT2WAc4ZL0Je1wC/eQ6m3AjX/gZ+8GuZ35K1kBa3g8KNM1rqK1GUk4aKrqJ0YEpKiukX9zLlVZZbH4E1W0M+1opqePI1ePtj2f6P8+D2KyXgCURARw+BZ+6GlC4cijY2Bnp3hwnDZazxw6BP90MZQABkpkvAVGZ6aC7GwLcmwM2Xyfa7C+HxV2UeIGOtzYNbH4WySku/+Fco2V/Uot+PorQ2KrqK0oHZselDMhPzWb9NoogjaWiEdz6R5d7EeHjkNlj4PFw0GVKSYOYDMG5YyIINYi2s3y5LyGvzYqfg/nAavPI7SEqQ5ehn74G3HoHuXeXz7y6Q60eyZquM2S1hBzs2z2+mb0JR2gYquorSQfH7/aTUvYUhQN1hfKy1daECUnFeGH86DOgFlTWwbL1zUowCGuvyZNfavIgALGcwY6D4gCxfTzhDLNxuaSEBr62PPZ9AQJaejQmQWvcW/qbCpRWlHaKiqygdlJL9+8hO+gqwDBsAfXtEn2OM+Fg9EXWUyytFSN9eECqC4aa+ATYVyPstO1wC6hrD74dZC2Sc8sropvfn5ERb0AB9esDpAwEs2UlLKS7ae8z3rihtFRVdRemg7Nu1mpS4/WCgZ6ZEF2e4Wtga4NyJcP0l4TWTrYXyKtlcsha27SYirQdKy2HnPtncXSyFNXCNAVBQCF98Le8rqsG6LG1j4CcXwwVnhQ+dngK/vQV6Zcl2sm8/RbtXHf+XoChtDBVdRemg1JYuw1gxU42Bqy6QKOPp10pObZwPpl/nBDu5aiQHnIYGAKUV8P7nzvKxSx13FskxEIHesTd8DGth/pdwwBHjympneds1RtdUuOs6iI+TJe1fXwv/fhquuTBkARsC1JcubfbvRlFOFiq6itJBSfOslg5CTtSxx8DE4fDo7XDHjyWI6eW5Ll+vc54/IP7cIO9+IsvJ7tZ9m/LF7woyzsb8UO4t1gnQWhBaUq6sca5jw68zc66Mc9sV8NjtcOZI8IY1R7Cke9a02HekKK2Niq6idFAy4pxw5Qi/qTHQt6d0B3rvM4kWPmTJGvHFukV3xUbYWBDatsCavPAxD207Y2zd6QrCAqprwd2rPhiINXuhzCOsO5G7Ry+QnrDtWG5bUdo0KrqK0kHpkeIEIMVoQN8zU1J5yqvgubdCNZODVmqNq6d8ZQ3M/SxULzkQCEUuB1m/LWTJWgtzF4f8wiAR0nUNoTkELDw3C8oqJVUp6MN1W8I41+ueUthcX4minHRUdBWlo+Ivi66l7AhatzRIS5Zdby8QSzZ4an2DiKSb2Z+GhLi6DvJ2hR/ftjvkB66tlyVpNzV1zhI1IsqbCuAtpyhHaheXXzmi8b21QKM2P1A6DkcUXWNMP2PMJ8aY9caYdcaYX7bGxBRFOTF272siEdZI1amsDNk8UA7Pvx3Kta2rj86hXZcny9Ag9ZEL94cfLzoA+w7I2Ou3weot4cfrXdaztXK9YJBVVkZ4xavI5fA9RU3ch6K0Q47G0m0EfmWtHQ6cCdxqjBnestNSFOVE6dMzTt4ERczVPD7eJ6Ucg/z9A9i6S86trouuFFVTJ/5Xa2H7bqioCT9eVSvWr7Xwz4Xiw3XT2Bjal7dL2vsF6Z0lEcxhuIS3d4/Ig4rSfjmi6Fpr91prVzjvK4ANQJ+WnpiiKCeINyOsHrIbjwf6Z4e2iw/C/80Sf21k0FOQuYsk33bdtuieusG6yVU1EpwVSaNfjgWs9O0tOhg61i9bGiAcIrL7oM9VwFlR2jnH5NM1xgwExgJLYhy7yRiTa4zJLS4ubqbpKYpyvBRXutr8xOhfO7B3+Pmv/Vus0Oqa2FWoNu+A5Ruil46DrNniRDrnRx8LpiEV7IVX5oUfi9WNyL3MXFyZHeMERWmfHLXoGmNSgLeBO6y1UZEN1tq/WGtzrLU53bt3jx5AUZRWpbR+UHRwkoNBxM59qOhAKKI4EMM6rm+A194XizYW67dLX9xg/q6bYCnIF2bD3gh/8IDeMdKFgrm6BsoaTz3cbSpKu8J3NCcZY+IQwX3NWvtOy05JUZTmoCwwCuw7UiDDJWLB1749wecL99++/C/okkh01LPDWx/FtoIBNmyX/NxYWCsBVjPnhu/3OTm6ED630LahrGHkEe9VUdoLRxRdY4wBXgA2WGufaPkpKYrSHCR2nYDFi7GNMS3enpmQmBAuuiVl8NQbTYuuO/c2kpq68PzeSGb8E3ZHtMeNytGNTBnCQ3zGxKYHVZR2xtEsL58NXAtMM8ascn4ubOF5KYpygvTsO5rKhqyQBeluz4fk6qYnR3+uqiZ6X3NQEKNZUHpqRO1n9zyB6sZMevQZ0zITUpSTwNFELy+21hpr7Shr7RjnZ96RPqcoysklM6snhTWTiDJxHWFLS4YpY0/GzEJ8azxkpDRx0Bj21k4kq7sGUikdh6Py6SqK0v7wer1UJlyOtXMx+KN8pj4vPHwrrNos/tim8Hml5V6vLPG/9soS6zS5ixxr9ENVtSxN79kPu/ZJsFRZZdP+X4DT+ksbP6/X2eFudOAsLZfHX47Pp/9NKR0H/desKB2Y/kPP58CGgWQmukKOHWEzBgb0gj/fDZffJZWpQLSvaxqMHQrTJsBZo2BwPxHeQEAqVtU3it/XWhnH64WEOCm6gRHB3boTvlwDnyyTVKKD5SFNTU+Bp++StKWoRvbO9sHa/vQ/7YKW+3IU5SSgoqsoHZjMzO6sbLiWbokPYoiOYjYGpo4Ti/POJ2DYQPjZpXDh2ZCdKWlEKzbCU4vEIt5ZCOXVUjzDLboej1SVSkuWClPDTxWx/tG58MsrobAE5n0OM96FDfnwm5/BuRMdwXVHVTtYa9hRfw1juveMvilFaccY21SY4gmQk5Njc3Nzm33ctoKJ+tO8Y9ES/ybaGp3pGRbu3Uli/hQy4p3+fDEeb0093PQQ3HQZpCbDB1/CvC+k4EVpRey83SNhjFi0o4bAd78hVnNVjaQlPXu3dDmK/pC8lNX3p2bAIrJ7929i7M7z/DoqneAZxrxBtXQVpYOT3asfKzbfydi4X4lvF6JScxLj4RdXwNX3i1UaGcGcEA+9MqVkY98eYgV3TQsJZ3WtlHbM3wObC2DnPmmaUFoBn62Qn8R46NkN3nlcUpVizQPAWi959b9kXBOCqyjtGRVdRekEnDb+BgpyZzMw5VMplhFhSBkD44bBqMGhtn2J8WKlfm8KnHem+HU9HqksVVoR6kSUlABpKbK0nJQgPt8tO+HDJTDnU1mWrnU6F406DUYOdrQ2YkkZAGvYUfUNhoy7sWW/EEU5SajoKkonICUllcLsx6ksvYiUuCIR3iBOCpHPK8vL87+C8ybBHVfB+NOlBd/iVfD0m7Byo1jC1XWhpgc+J4gqPQWys2DoAPjOmXDtd+H2K8Qn/OTrMP9L+NkP5PywqlOH5mGo8nenvsefSE1Na42vRVFaHRVdRekkDB42nlVfPcZIewteUxsqO+UIn7Fi7U6bAP87Hb7eAjf+DhbmQnFp01WqGpxeuaWVUFAIS9ZKU4MeXeGcHLjiPHj0dvEL5wx3BU8Fr+2895PIpoY/MHZYTst9CYpyklHRVZROxIicq1j5aT5j0x7CaxrCRM8iKT4fL4UpN8KeYsmzjfNJo/ne3SVPt3d3ydNNSZJUIb/Ttq+kTD6zc5+8HiiHNz+AWR9J5anqWrGYL/+2a3nZwU8cq8qmM3rqdR0+wEbp3KjoKkonwufzMXLy3axbUs0ZSU+I8Do0+mHmHPG91tTCuZNgWg5MGgmD+kBykvhrSyslD7emTqzf+DhI7SI+3dRkWT6uqJZm90vWwoJlsGy9fPbF9+D7U5183kMWbhzrq29nxOR7tRCG0uHRf+GK0slISEhg6KQHWbm4C2PSH8FHLWDZthuWrYM/3QmXniMiun2PCObM92DtNti9T5oe1DdKoQwIFcdISghVrho2EM4eLalCN/8QSkrhiddE1DcVwMhBAAa/SWRV6XRGTL6XhIRYOUSK0rFQ0VWUTkhCQgJjpt7L6iUDGOq9m2RfESWllvg4KYjx5OsSfZy/5/Cdg4I0NEJtnVSdyt8DX64WoU7pIhHQF0+RcRPiofgggARNbfH/gdFTr1MLV+k0HHUTe0VROhY+n49xZ/+EvV3/RX7lVCaN9PLhs5CRKhHHRQfEoj0RqmphzVaYvVBShRbPgKnjvBRUTWZP2lxGn3W9Cq7SqdCKVMdBRw/00Go47Z9jfYaVlRVsXv4Cg+KfIi1uB/UNlsISybfdWyzWboOzpOyPaL8XLAPp9YRe4+MkzzcjVeor98+GxHhDeUNf8urvYMi4G08oLUifX/unEzzDmDeoonscdIJ/LCd7Ci2OPsPYFO7dSeGmF+gX9wrdEgowJoDT8ie6epS7By4xjjs7LR4O1vVnR/01ZA+9scnSjseCPr/2Tyd4hiq6zUUn+MdysqfQ4ugzPDwl+4vYsXk+qXWzyE5aQnJcCcb6Idg0gfC83fBvU4S2ujGTvTUTKE/4Ef2HXEBWMzYv0OfX/ukEz1BrLyuKcnRkZvUgM+ta/P6rKC7ay7Zdq6gvW0a6dw3p8Xl0Ty4Efzl7iurp3SMO602nuCqbsoZTKGscSVz6RHr2H8PAHr3UZ6soLvS3QVGUJvF6vWT36kt2r77AxVHH+7je93B+FEVpGo1eVhRFUZRWQkVXURRFUVoJFV1FURRFaSVUdBVFURSllWiRQKrly5d36HDwjh7O35GfXRB9hu0bfX7tn478DHNymm5PqdHLiqIoSrvF7/dTUlLEvp1fU1u6jDTPajLittIjdS80lrG7qJ4+PeLBm05xZS9KGwZR5h9JYteJ9Ow7msysnni93labb4sUxzDGdNw/YejYf6GB/pXdEejoz1CfX/vnhAu4lBSzY9OHpNTNIjvpK1LiiqWAi7FhPaKDmGDvaANYgzVeKhuyKKyZSGXCj+g/9HwyM7uf0JyC5OTkkJubq8UxFEVRlPbNvsJd7Nn4Ev18LzMmcTsmPiBC68YR2HChdZ9gMTSSGldIqm8Oln9xYMNAVjZcS69hN5Ddq1+LzV8t3eNA/8pu/+gzbN/o82v/HOszrKqsZOOKlxjke4L0+AIMMYQ27AIxBjnCORZDWUN/8urvZOj4G0hJST2mOQY5nKWr0cuKoihKmyZv8yr25f6Accn/j4z4fA7ZdUFZC1qy7p/gfgNRzTjC1p1DrwZLRlwB45J/RXHuJWzdtKLZ70VFV1EURWmT+P1+Vn31Kj0PfJdTUxZgaIy2VoNE7o8UYvf+I4xh8HNKyqdkH7yQVV/+jcbGE2ws7UJFV1EURWlz1NfXs/LTRxjpu5kU3z4OtZh0W7GRLSYjLdvI7ViWcJNjWFLiihgZ93NWffowdXV1zXJfGkilKIqitCnq6+vZ8NUDjE39E14aQoFSQbGM1d/ZvWmhshoWrYS83XBqH5gyFlK7uD52hDFk2+I1tYxNe4h1S6oYOum3JCQknNC9qegqiqIobQa/38/qxX8UwTX14ZHHzntHDwV3lDIiuLuL4foHYOFyaPSD1wtTx8JLD0C/nhGry5F+4ahjFq9p4IykJ1m5uAtjpt53Qu0qdXlZURRFaTOsWfYGY9Mexmsaonyv1sLBCpgxG276PdzzDORugECAQ+cGLDz4F/hoqQgugN8PC3Lhf54PP9daKCmDOZ/B3+bCik3Q0Cj75QQOWcReTwNjMx5l7bJXTyh6Xi1dRVEUpU2Qt3klg5mO19SI8kVoW0kZXH0/fLRExBXgr+/An++BK78jFm9ZBXy4JPb4Hy8V0c7KkKFXboKf/hZWbxUxTk6Cmy6F398KSfGuDzrX8lLLEHMPWzeNYMiwpks9Hg61dBVFUZSTTmVFBZ49vw4FTUVgEQv3Q5fggojo/c9C8UE5yR8QyzYWjX7H0rVQVQO3PQarNjv7kH1Pvwl/n+/MICrK2ZLsKyKu8NdUVJQf132q6CqKoignnU0rZzIw5VPCBNcleoEAfJLrWvp1saMQtuyQ9xmpMGlE7GtMPAO6psm4m3fAio3R5zT64e0F4cIeJr7GMiBlMVtWvHh0NxaBiq6iKIpyUtlXuItBvicAP/vLYO4ieOV9sUIbgz5YA4nxsT/v9UBCvJzj88KDt8CIQeHnnHEqPPRzOQ5Q3yBWcSxq6hxxt3L9rzfDq+/DnEWORY2fQfFPUbh35zHfq4quoiiKclLZs+FF0uMLWLYept0C3/8VXPcb+OaNcN+zUFsPHgOXTQuJppuxQ2HoAHlvDAw/BeY/A/fdAHE+uOc/ZfuMQU6kMzC4HwzsFT2WAc4ZL0Je1wC/eQ6m3AjX/gZ+8GuZ35K1kBa3g8KNM475XlV0FUVRlJNGSUkx/eJeprzKcusjsGZryMdaUQ1PvgZvfyzb/3Ee3H6lBDyBCOjoIfDM3ZDShUPRxsZA7+4wYbiMNX4Y9Ol+KAMIgMx0CZjKTA/NxRj41gS4+TLZfnchPP6qzANkrLV5cOujUFZp6Rf/CiX7i47pflV0FUVRlJPGjk0fkpmYz/ptEkUcSUMjvPOJLPcmxsMjt8HC5+GiyZCSBDMfgHHDQhZsEGth/XZZQl6bFzsF94fT4JXfQVKCLEc/ew+89Qh07yqff3eBXD+SNVtlzG4JO9ixef4x3a+KrqIoinJS8Pv9pNS9hSFA3WF8rLV1oQJScV4YfzoM6AWVNbBsvXNSjAIa6/Jk19q8iAAsZzBjoPiALF9POEMs3G5pIQGvrY89n0BAlp6NCZBa9xb+psKlY6CiqyiKopwUSvbvIzvpK8AybAD07RF9jjHiY/VE1FEurxQhfXtBqAiGm/oG2FQg77fscAmoawy/H2YtkHHKK6Ob3p+TE21BA/TpAacPBLBkJy2luGjvUd+ziq6iKIpyUti3azUpcfvBQM9MiS7OcLWwNcC5E+H6S8JrJlsL5VWyuWQtbNtNRFoPlJbDzn2yubtYCmvgGgOgoBC++FreV1SDdVnaxsBPLoYLzgofOj0FfnsL9MqS7WTffop2rzrqe1bRVRRFUU4KtaXLMFbMVGPgqgskynj6tZJTG+eD6dc5wU6uGskBp6EBQGkFvP+5s3zsUsedRXIMRKB37A0fw1qY/yUccMS4stpZ3naN0TUV7roO4uNkSfvX18K/n4ZrLgxZwIYA9aVLj/qeVXQVRVGUk0KaZ7V0EHKijj0GJg6HR2+HO34sQUwvz3X5ep3z/AHx5wZ59xNZTna37tuUL35XkHE25odyb7FOgNaC0JJyZY1zHRt+nZlzZZzbroDHboczR4I3rDmCJd2z5qjvWUVXURRFOSlkxDnhyhF+U2Ogb0/pDvTeZxItfMiSNeKLdYvuio2wsSC0bYE1eeFjHtp2xti60xWEBVTXgrtXfTAQa/ZCmUdYdyJ3j14gPWHbUd+ziq6iKIpyUuiR4gQgxWhA3zNTUnnKq+C5t0I1k4NWao2rp3xlDcz9LFQvORAIRS4HWb8tZMlaC3MXh/zCIBHSdQ2hOQQsPDcLyiolVSnow3VbwjjX655SeNT3fETRNcYkGmOWGmO+NsasM8Y8eNSjK4qiKEpT+Muiayk7gtYtDdKSZdfbC8SSDZ5a3yAi6Wb2pyEhrq6DvF3hx7ftDvmBa+tlSdpNTZ2zRI2I8qYCeMspypHaxeVXjmh8by3QePTND47G0q0DpllrRwNjgAuMMWce9RUURVEUJQa79zWRCGuk6lRWhmweKIfn3w7l2tbVR+fQrsuTZWiQ+siF+8OPFx2AfQdk7PXbYPWW8OP1LuvZWrleMMgqKyO84lXkcvieoibuIwZHFF0rVDqbcc7P8XfwVRRFURSgT884eRMUMVfz+HiflHIM8vcPYOsuObe6LrpSVE2d+F+the27oaIm/HhVrVi/1sI/F4oP101jY2hf3i5p7xekd5ZEMIfhEt7ePSIPNs1R+XSNMV5jzCqgCPjQWhvVItgYc5MxJtcYk3vUV1cURVE6L96MsHrIbjwe6J8d2i4+CP83S/y1kUFPQeYuknzbdduie+oG6yZX1UhwViSNfjkWsNK3t+hg6Fi/bGmAcIjI7oM+VwHnI3BUomut9VtrxwB9gYnGmKhuhdbav1hrc6y1OUd9dUVRFKXTUlzpavMTo3/twN7h57/2b7FCq2tiV6HavAOWb4heOg6yZosT6ZwffSyYhlSwF16ZF34sVjci9zJzcWV2jBNic0zRy9baUuAT4IJj+ZyiKIqiRFJaPyg6OMnBIGLnPlR0IBRRHIhhHdc3wGvvi0Ubi/XbpS9uMH/XTbAU5AuzYW+EP3hA7xjpQsFcXQNljace7jbD8B3pBGNMd6DBWltqjEkCzgMePeorKIqiKEoMygKjwL4jBTJcIhZ87dsTfL5w/+3L/4IuiURHPTu89VFsKxhgw3bJz42FtRJgNXNu+H6fk6ML4XMLbRvKGkYe8V4PjXcU5/QC/maM8SKW8T+stXOP8BlFURRFOSyJXSdg8WJsY0yLt2cmJCaEi25JGTz1RtOi6869jaSmLjy/N5IZ/4TdEe1xo3J0I1OG8BCfMbHpQSM4ouhaa1cDY496REVRFEU5Cnr2HU3l9ixS4wrDW/M5wtYtDdKToSJCSKsiIpObi4IYzYLSU105uhFFMQCqGzPpMWDMUV9DK1IpiqIoJ4XMrJ4U1kwiysR1xC0tGaacZJPvW+MhI6WJg8awt3YiWd2PPpDqaJaXFUVRFKXZ8Xq9VCZcjrVzMfijfKY+Lzx8K6zaLP7YpvB5peVeryzxv/bKEus0uYsca/RDVbUsTe/ZD7v2SbBUWWXT/l+A0/pLGz+v19nhbnTgLC2Xx1+Oz3f0UqqiqyiKopw0+g89nwMbBpKZ6Ao5doTNGBjQC/58N1x+l1SmAtG+rmkwdihMmwBnjYLB/UR4AwGpWFXfKH5fa2UcrxcS4qToBkYEd+tO+HINfLJMUokOloc0NT0Fnr5L0paiGtk72wdr+9P/tGNL5lHRVRRFUU4amZndWdlwLd0SH8QQHcVsDEwdJxbnnU/AsIHws0vhwrMhO1PSiFZshKcWiUW8sxDKq6V4hlt0PR6pKpWWLBWmhp8qYv2jc+GXV0JhCcz7HGa8Cxvy4Tc/g3MnOoLrjqp2sNawo/4axnTvGX1Th8HYpkLATgBjTIcuE9kS31lbwkT9Wdfx0GfYvtHn1/5xP8PCvTtJzJ9CRrzTny/G462ph5segpsug9Rk+OBLmPeFFLworYidt3skjBGLdtQQ+O43xGquqpG0pGfvli5H0R+Sl7L6/tQMWER27/5Rp+Tk5JCbmxvzIaqlqyiKopxUsnv1Y8XmOxkb9yvx7UJUak5iPPziCrj6frFKIyOYE+KhV6aUbOzbQ6zgrmkh4ayuldKO+XtgcwHs3CdNE0or4LMV8pMYDz27wTuPS6pSrHkAWOslr/6XjIshuEdCRVdRFEU56Zw2/gYKcmczMOVTKZYRYbkaA+OGwajBobZ9ifFipX5vCpx3pvh1PR6pLFVaEepElJQAaSmytJyUID7fLTvhwyUw51NZlq51OheNOg1GDna0NmJJGQBr2FH1DYaMu/G47lNFV1EURTnppKSkUpj9OJWlF5ESVyTCG8RJIfJ5ZXl5/ldw3iS44yoYf7q04Fu8Cp5+E1ZuFEu4ui7U9MDnBFGlp0B2FgwdAN85E679Ltx+hfiEn3wd5n8JP/uBnB9WderQPAxV/u7U9/gTqalpx3WfKrqKoihKm2DwsPGs+uoxRtpb8JraUNkpR/iMFWt32gT43+nw9Ra48XewMBeKS5uuUtXg9MotrYSCQliyVpoa9OgK5+TAFefBo7eLXzhnuCt4Knht572fRDY1/IGxw46/r4+KrqIoitJmGJFzFSs/zWds2kN4TUOY6FkkxefjpTDlRthTLHm2cT5pNN+7u+Tp9u4uebopSZIq5Hfa9pWUyWd27pPXA+Xw5gcw6yOpPFVdKxbz5d92LS87+IljVdl0Rk+97oQC3VR0FUVRlDaDz+dj5OS7WbekmjOSnhDhdWj0w8w54nutqYVzJ8G0HJg0Egb1geQk8deWVkoebk2dWL/xcZDaRXy6qcmyfFxRLc3ul6yFBctg2Xr57IvvwfenOvm8hyzcONZX386IyfceUyGMmPd3Qp9WFEVRlGYmISGBoZMeZOXiLoxJfwQftYBl225Ytg7+dCdceo6I6PY9Ipgz34O122D3Pml6UN8ohTIgVBwjKSFUuWrYQDh7tKQK3fxDKCmFJ14TUd9UACMHARj8JpFVpdMZMfleEhJi5RAdGyq6iqIoSpsjISGBMVPvZfWSAQz13k2yr4iSUkt8nBTEePJ1iT7O33P4zkFBGhqhtk6qTuXvgS9Xi1CndJEI6IunyLgJ8VB8EECCprb4/8DoqdedsIUbRBseKIqiKG0Sn8/HuLN/wt6u/yK/ciqTRnr58FnISJWI46IDYtGeCFW1sGYrzF4oqUKLZ8DUcV4KqiazJ20uo8+6vtkEF7Qi1XGh1XDaP/oM2zf6/No/x/oMKysr2Lz8BQbFP0Va3A7qGyyFJZJvu7dYrN0GZ0nZ727BR6gMpNcTeo2PkzzfjFSpr9w/GxLjDeUNfcmrv4Mh42487rSgw1WkUtE9DvQXvv2jz7B9o8+v/XO8z7Bw704KN71Av7hX6JZQgDEBnJY/0dWjjOs9MY47Oy0eDtb1Z0f9NWQPvTFmacdjQUW3mdFf+PaPPsP2jT6/9s+JPsOS/UXs2Dyf1LpZZCctITmuBGP9EGyaQHjebvg3KkJb3ZjJ3poJlCf8iP5DLiDrGJsXNIXWXlYURVE6FJlZPcjMuha//yqKi/aybdcq6suWke5dQ3p8Ht2TC8Ffzp6ienr3iMN60ymuyqas4RTKGkcSlz6Rnv3HMLBHr2b12R4JFV1FURSl3eL1esnu1ZfsXn2Bi6OO93G97+H8nEw0ellRFEVRWgkVXUVRFEVpJVR0FUVRFKWVaBGf7vjx48nNzW2JodsEHT2ysKNHhoI+w/aOPr/2T0d/hk2hlq6iKIqitBIavXwS8HhgaH/4ycXwg2/BKb3B5wGPl7AWVkEO9XY0EPBDYwDy98J7n8FL78HG/FBhb0VRFKXt0iLFMXJycqwuL0cT54Pzz4J7b4CcYU5JMq9zMLJ6iol4JWIfIsD+gNQgffgleP8LKYN2oujSVvunoz9DfX7tn07wDGPeoC4vtwIG+MYoWDITZj8OZ40QAfZ4iF2eDNf+yOMuYfZ4ZJxJI+CdP8LSl2HyGMcyVhRFUdocKrotTGoXeP4++OR5GDtUejoC4SJqI36C+w1E1QoNW3cOvXo9MGYILHgOXvhv6TOpKIqitC1UdFuQEYNh+avw00uko0WUNRskcn+kELv3H2GMOB/85CK57ughxz11RVEUpQVQ0W0hzj8TPp8Bg/q4lpGb8M0eeu8W1cjtWJZwE2N4vHBqH1g0Ay48u0VuT1EURTkOVHRbgCsuEB9rSpITKBWznVTsbWuhogrmLYan34R/LYby6ojTjjAGFjwGkpNg1qNw9UUncDOKoihKs6EpQ83M+WfCi/dBl0RiRh5bCAuSMq5zrIXdxXD9A7BwOTT6xQc8dSy89AD06xmxuhzpF4445jGQlAB//S8oLRMBVxRFUU4eauk2IyMGwz8egcR4onyv1sLBCpgxG276PdzzDORucPJrgylAFh78C3y0VAQXwO+HBbnwP8+Hn2stlJTBnM/gb3NhxSZJF7IuQQ8uOSclwhsPw5ihLfwFKIqiKIdFLd1mIi0Z3nkMUrqIhRlpeZaUwdX3w0dLRFwB/voO/PkeuPI7YvGWVcCHS2KP//FSEe2sDBl65Sb46W9h9VYR4+QkuOlS+P2tkBTv+qBzreQEmPUIjL8Wyiqb994VRVGUo0Mt3WbAAH+60xU0FYFFLNwPXYILIqL3PwvFB+Ukf0As21g0+h1L10JVDdz2GKzaHKpEVVUjPuC/z3d0NsLS9nik8tVTv9I8XkVRlJOFim4zcNYoSdMJE1yXsAUC8Emua+nXxY5C2LJD3mekSqGLWEw8A7qmybibd0gVqkga/fD2gnBhd8/D44WrL5ACGoqiKErro6J7gsT54Jm7wOeD/WUwdxG88r5YoY1BH6xx/Lwx8HogwfEB+7zw4C0wYlD4OWecCg/9XI4D1DeIVRyLmjpH3K1c/+vN8Or7MGeRWNQ+Hzw9XeatKIqitC76X+8Jcv5ZMGoILFsPN/4O1m0Tyza1C/z8R/DgzZAQB5dNg3mfhwKkgowdCkMHyHtjYPgpMP8ZePYteOxl+NU18Iv/gN7dQ8vCg/vBwF6wZWf4WAY4Z7wIeV2DBGU98w+oqBYrfPgp8Nf7YcJwuGgyzF7Y0t+OoiiK4kYt3RPA44H7boDKGrj1EVizNeRjraiGJ1+Dtz+W7f84D26/UgKeQAR09BB45m4JvgpGGxsjAjthuIw1fhj06e6sEjvLxpnpEjCVmR6aizHwrQlw82Wy/e5CePxVmQfIWGvz4NZHZd99N4g4K4qiKK2H/rd7AgztL6K4fptEEUfS0AjvfCLLvYnx8MhtsPB5sTJTkmDmAzBuWHRgk7WwfrssIa/Ni5mCyw+nwSu/kzzcEYPg2XvgrUege1f5/LsLYnccWrNVxhw9BE4f2Dzfg6IoinJ0qOieAP95SWgptykfa21dqEJjnBfGnw4Deol1vGy9c1KMAhrr8mTX2ryIACxnMGOg+ADU1sOEM8TC7ZYWEvDa+tjzCQRkvl4v3PD94793RVEU5dhR0T1OfF74wTmyxDxsAPTtEX2OMeJj9UTUUS6vFCF9e0G0jxckUGpTgbzfssMloK4x/H6YtUDGKa+Mbnp/Tk7s1KA+PcTC9Xjge98MBWcpiqIoLY+K7nHSs5sEM2GgZ6ZEF2ekho4b4NyJcP0lrqwd64hklWwuWQvbdhOeU2ugtBx27pPN3cVSWAPXGAAFhfDF1/K+ohqsy9I2Bn5yMVxwVvjQ6Snw21ugV5ZsD8gW/7GiKIrSOqjoHicjh4DP+faMgasukKjj6ddKTm2cD6Zf5wQ7uWokByxUOsFNpRXw/ufO8rFLHXcWyTEQgd6xN3wMa2H+l3DAEePKamd52zVG11S46zppKTj+dPj1tfDvp+GaC0MWsNcDo09r7m9GURRFaQoV3eNk8ming5ATdewxMHE4PHo73PFjCWJ6ea7L1+uc5w+IPzfIu5/IcrK7dd+mfPG7goyzMT+Ue4t1ArQWhJaUK2uc69jw68ycK+PcdgU8djucORK8rhKVHo/ch6IoitI6qOgeJ+OHO28i/KbGQN+eEqj03mcSLXzIkjXii3WL7oqNsLEgtG2BNXnhYx7adsbYutMVhAVU10KjK1I5GIg1e6HMI6w7kbtHLxI9rSiKorQOKrrHyeghzpsYDeh7ZkoqT3kVPPdWqGZy0EqtqQuNU1kDcz8L1UsOBEKRy0HWbwtZstbC3MUhvzBIhHRdQ2gOAQvPzZLGBonxIR+u2xLGud6Iwc30hSiKoihH5KhF1xjjNcasNMbMbckJtRfSk2PUUnYErVuadB0CiVDeWBDSufoGEUk3sz8NCXF1HeTtCj++bXfID1xbL0vSbmrqnCVqZE6bCuAtpyhHaheXX9ltlTsCntblWO5aURRFORGOxdL9JbChpSbS3ig+2MQBI1WnsjJk80A5PP92SKDr6qNzaNflyTJ0cNzC/eHHiw7AvgMy9vptsHpL+PF6l/VsrVwvGGSVlRFe8SpyOXx/6ZHvVVEURWkejkp0jTF9gYuAGS07nfZDj27Om6CIuZrHx/vCU3H+/gFs3SXnVtdFV4qqqRP/q7WwfTdU1IQfr6oV69da+OdC8eG6aWwM7cvbJe39gvTOkgjmMFzC273rUdysoiiK0iwcraX7FHAX0ETdJTDG3GSMyTXG5BYXFzfH3No0pZXh9ZDdeDzQPzu0XXwQ/m+W+Gsjg56CzF0k+bbrtkX31A3WTa6qkeCsSBr9cixgpW9vkcsK75cdUWPZNV8DlLl8w4qiKErLckTRNcZcDBRZa5cf7jxr7V+stTnW2pzu3Tt+xYWwJd4Y/WsH9g4//7V/ixVaXRO7CtXmHbB8Q/TScZA1W5xI5/zoY8E0pIK98Mq88GMDe8UYzLXMvDYvxnFFURSlRTgaS/ds4BJjTD7wd2CaMebVFp1VO2D5BqKDkxwMInbuQ0UHQhHFgRjWcX0DvPZ+0yK4frv0xQ3m77oJloJ8YTbsjfAHD+gdI10omKtrYOWmw9ykoiiK0qwcsZ+utfa/gP8CMMacA/zaWntNy06r7bN4FQT8ToEMl4gFX/v2lIbxbv/ty/+CLokxop4d3voothUMsGG75OfGwloJsJoZEVfuc3J0IWKOznbAD4tXHulOFUVRlOZCm9gfJ2u2QmMA4j3EtHh7ZkJiQrjolpTBU280Lbrlh/Gv1tSF5/dGMuOfsLsofF9Ujm5EypA/AKs2Nz2moiiK0rwcU3EMa+1Ca+3FLTWZ9kRhCeQHayJHFJwAydVNT47+XFVN9L7moGBv9L701Ijaz+55Ik0V9nT8mDdFUZQ2g1akOk4a/fDeQqfalBtH2NKSYcrYkzAxF98aDxkpsY8FrERCN7WcrSiKojQ/urx8Arw0F375Y/D4iPKZ+rzw8K2yfLthe9Nj+LzScq9Xlvhfe2WJdZrcRY41+qGqWpam9+yHXfskWKqs8vCCeVp/aePnDfbLdTU6wEpa0otzTvQbUBRFUY4FFd0TYGO+pPFMGuHa6QibMTCgF/z5brj8LqlMBaJ9XdNg7FCYNgHOGgWD+4nwBgJSsaq+Ufy+1so4Xi8kxEnRDYwI7tad8OUa+GSZzOFgeUhT01Pg6bskbSmqkb2z/fVWWK/pQoqiKK2Kiu4JEAjAwy/BO390LMqIKGZjYOo4sTjvfAKGDYSfXQoXng3ZmZJGtGIjPLVILOKdhVBeLcUz3KLr8UhVqbRkqTA1/FQR6x+dC7+8UvzL8z6HGe/Chnz4zc/g3ImO4Lqjqh38fnj4RVfbQUVRFKVVMLapUNoTICcnx+bm5jb7uG0F4zIf43yw9GUYE2wGH+PrrKmHmx6Cmy6D1GT44EuY94UUvCitiJ23e+Q5iEU7agh89xtiNVfVSFrSs3dLl6PoD8nLmi0w/trocpRBWuLfRFvDRC0BdCw6+jPU59f+6QTPMOYNqugeB5H/WCaPgQXPiQDLCa6DVnR46Tq4+n6xSiMjmBPioVemlGzs20Os4K5pIeGsrpXSjvl7YHOBRB1HNk1IjIee3eCdx2Xp2sSYBwYaGuC8W+HTFU3fn/7Ct386+jPU59f+6QTPMOYN6vJyM/D511JN6rqLnGIZEb8vxkiz+FGDQ237EuPFSv3eFDjvTPHrejxSWaq0IiSqSQmQliJLy0kJ4vPdshM+XAJzPpVl6Vqnc9Go02DkYJfgRswj4Ic3P4TPtCCGoijKSUEt3eMg1l9oacmw/FU4tY+I5yFs6GX+l/DDu+C8SXDHVTD+dGnBt3gVvP8FrNwolnB1Xajpgc8JokpPgewsGDoAvnMmfHOsWMMrNsKTr8vYb/4BLp4SI3gKEdyCQhh3tTRrOBz6V3b7p6M/Q31+7Z9O8AzV0m1JyqtEUBfPkH66Hle5RQBjxdqdNgH+dzp8vQVu/B0szIXi0qarVDU4vXJLK0U0l6yVpgY9usI5OXDFefDo7eIXzhnuCp4KXtt5X1ULl04/suAqiqIoLYeKbjOyegtceS/MetTxx7pEzyIpPh8vhSk3SiWoRr/4gbMypP9uv57ympkOKUkSEe132vaVlMlnglWkDpTDmx/ArI+k8lR1rVjMl3872p9bUw9X/zd8rSUfFUVRTioqus3MvM/hxodhxr2QlBja3+iHmXPE91pTC+dOgmk5MGkkDOoj1nFdvViiZZVi3VorqUKpXWT5OjVZlpsrqqXZ/ZK1sGAZLFsvn33xPfj+VCef1xH7mnq45RGYE6MPr6IoitK6qOi2AK/Pg9IyeONhSEkUH++23bBsHfzpTrj0HBHR7XtEMGe+B2u3we59skxd3xgqLxksjpGUEKpcNWwgnD1aUoVu/iGUlMITr4mobyqAkYPk81V1EjGtgqsoitI2UNFtIeZ9DpN/Cu/+EU7pLcIYHycFMZ58XaKP8/ccvnNQkIZGqK2TqlP5e+DL1SLUKV0kAvriKTJuQjwUHxTBLSiEy++WQCtFURSlbaAND1qQNVth/DVSsGL86fDhs5CRKkJYdEAs2hOhqlauMXuhpAotngFnj4LX50uUsgquoihK20JTho6DYw11N0YKaDw9HUYMEv9uYYnk2+4tFmu3wVlS9ke03wuWgfR6Qq/xcZLnm5Eq9ZX7Z4sfd8N2+MVjkod7Io9V0xXaPx39Gerza/90gmeoKUMnC2th0UqYcB1cNBnuvV7KRvbr6eT0xmgwH9YDlxjHcUQ6IM0LHn4R5i5qurSjoiiKcvJR0W1FGhplKXjOZ3D6QLj+ErhkqliqPseSxciP+w9dA1FCu3MfzFkEL7wn3YK0eYGiKErbR5eXj4PmXBbxeaVz0OjTYPJoGHe6LEGnJcP+UujeVVKI1ubBqi1iMa/aJMvSDS3UgF6Xtto/Hf0Z6vNr/3SCZ6jLy22RRj/s2Cc/cxad7NkoiqIoLYlGLyuKoihKK6GiqyiKoiithIquoiiKorQSLeLTXb58eYd2knf0IIeO/OyC6DNs3+jza/905GeYk5PT5DG1dBVFURSlldDoZUU5DkpKitmx6UNS6maRnfQVKXHFGOuXxsmudo5BDvU5NoA1WOOlsiGLwpqJVCb8iP5Dzyczs3vr34iiKK2Kiq6iHAP7CnexZ+NL9PO9zJjE7Zj4gAitG0dgw4XWfYLF0EhqXCGpvjlY/sWBDQNZ2XAtvYbdQHavfq11O4qitDItUhzDmMj/hToWHdkXAepPikVVZSUbV7zEIN8TpMcXYIghtGEXiDHIEc6xGMoa+pNXfydDx99ASkrqMc0x7FId/Bnq72D7pyM/w5ycHHJzc2M+RPXpKsoRyNu8in25P2Bc8v8jIz6fQ39TBn+lgpas+ye43xBdNzts3Tn0arBkxBUwLvlXFOdewtZNK1rmhhRFOWmo6CpKE/j9flZ99So9D3yXU1MWYGiMtlaDRO6PFGL3/iOMYfBzSsqnZB+8kFVf/o3GRu1ioSgdBRVdRYlBfX09Kz99hJG+m0nx7QNstBUb2Q0q0rKN3I5lCTc5hiUlroiRcT9n1acPU1dX1xK3qShKK6OBVIoSQX19PRu+eoCxqX/CS0MoUCoolrFaMbo3LVRWS3OKvN1wah+YMhZSu7g+doQxZNviNbWMTXuIdUuqGDrptyQkJDTHLSqKcpJQ0VUUF36/n9WL/yiCa+rDI4+d944eCu4oZURwdxfD9Q/AwuXS0MLrhalj4aUHpIdy2OpypF846pjFaxo4I+lJVi7uwpip9+Hz6a+torRXdHlZUVysWfYGY9Mexmsaonyv1sLBCpgxG276PdzzDORukB7HwXMDFh78C3y0VAQXwO+HBbnwP8+Hn2stlJRJf+W/zYUVm6TnsnVb1I5F7PU0MDbjUdYue7VDR30qSkdH/2RWFIe8zSsZzHS8pkaUL0LbSsrg6vvhoyUirgB/fQf+fA9c+R2xeMsq4MMlscf/eKmIdlaGDL1yE/z0t7B6q4hxchLcdCn8/lZIind90LmWl1qGmHvYumkEQ4Y1XWZOUZS2i1q6igJUVlTg2fPrUNBUBBaxcD90CS6IiN7/LBQflJP8AbFsY9HodyxdC1U1cNtjsGqzsw/Z9/Sb8Pf5zgyiopwtyb4i4gp/TUVF+YndsKIoJwUVXUUBNq2cycCUTwkTXJfoBQLwSa5r6dfFjkLYskPeZ6TCpBGxrzHxDOiaJuNu3gErNkaf0+iHtxeEC3uY+BrLgJTFbFnx4tHdmKIobQoVXaXTs69wF4N8TwB+9pfB3EXwyvtihTYGfbAGEuNjf97rgYR4OcfnhQdvgRGDws8541R46OdyHKC+QaziWNTUOeJu5fpfb4ZX34c5ixyLGj+D4p+icO/OZrh7RVFaExVdpdOzZ8OLpMcXsGw9TLsFvv8ruO438M0b4b5nobYePAYumxYSTTdjh8LQAfLeGBh+Csx/Bu67AeJ8cM9/yvYZg5xIZ2BwPxjYK3osA5wzXoS8rgF+8xxMuRGu/Q384NcyvyVrIS1uB4UbZ7TUV6IoSguhoqt0akpKiukX9zLlVZZbH4E1W0M+1opqePI1ePtj2f6P8+D2KyXgCURARw+BZ+6GlC4cijY2Bnp3hwnDZazxw6BP90MZQABkpkvAVGZ6aC7GwLcmwM2Xyfa7C+HxV2UeIGOtzYNbH4WySku/+Fco2V/Uot+PoijNi4qu0qnZselDMhPzWb9NoogjaWiEdz6R5d7EeHjkNlj4PFw0GVKSYOYDMG5YyIINYi2s3y5LyGvzYqfg/nAavPI7SEqQ5ehn74G3HoHuXeXz7y6Q60eyZquM2S1hBzs2z2+mb0JRlNZARVfptPj9flLq3sIQoO4wPtbaulABqTgvjD8dBvSCyhpYtt45KUYBjXV5smttXkQAljOYMVB8QJavJ5whFm63tJCA19bHnk8gIEvPxgRIrXsLf1Ph0oqitDlUdJVOS8n+fWQnfQVYhg2Avj2izzFGfKyeiDrK5ZUipG8vCBXBcFPfAJsK5P2WHS4BdY3h98OsBTJOeWV00/tzcqItaIA+PeD0gQCW7KSlFBftPeZ7VxTl5KCiq3Ra9u1aTUrcfjDQM1OiizNcLWwNcO5EuP6S8JrJ1kJ5lWwuWQvbdhOR1gOl5bBzn2zuLpbCGrjGACgohC++lvcV1WBdlrYx8JOL4YKzwodOT4Hf3gK9smQ72befot2rjv9LUBSlVVHRVTottaXLMFbMVGPgqgskynj6tZJTG+eD6dc5wU6uGskBp6EBQGkFvP+5s3zsUsedRXIMRKB37A0fw1qY/yUccMS4stpZ3naN0TUV7roO4uNkSfvX18K/n4ZrLgxZwIYA9aVLm/27URSlZVDRVTotaZ7V0kHIiTr2GJg4HB69He74sQQxvTzX5et1zvMHxJ8b5N1PZDnZ3bpvU774XUHG2Zgfyr3FOgFaC0JLypU1znVs+HVmzpVxbrsCHrsdzhwJ3rDmCJZ0z5oW+44URWleVHSVTktGnBOuHOE3NQb69pTuQO99JtHChyxZI75Yt+iu2AgbC0LbFliTFz7moW1njK07XUFYQHUtuHvVBwOxZi+UeYR1J3L36AXSE7Ydy20rinISUdFVOi09UpwApBgN6HtmSipPeRU891aoZnLQSq1x9ZSvrIG5n4XqJQcCocjlIOu3hSxZa2Hu4pBfGCRCuq4hNIeAhedmQVmlpCoFfbhuSxjnet1TCpvrK1EUpYU5KtE1xuQbY9YYY1YZY3JbelKK0ir4y6JrKTuC1i0N0pJl19sLxJINnlrfICLpZvanISGuroO8XeHHt+0O+YFr62VJ2k1NnbNEjYjypgJ4yynKkdrF5VeOaHxvLdCozQ8Upb1wLJbut6y1Y6y12lNM6RDs3tdEIqyRqlNZGbJ5oByefzuUa1tXH51Duy5PlqFB6iMX7g8/XnQA9h2Qsddvg9Vbwo/Xu6xna+V6wSCrrIzwileRy+F7ipq4D0VR2hy6vKx0Wvr0jJM3QRFzNY+P90kpxyB//wC27pJzq+uiK0XV1In/1VrYvhsqasKPV9WK9Wst/HOh+HDdNDaG9uXtkvZ+QXpnSQRzGC7h7d0j8qCiKG2VoxVdC3xgjFlujLkp1gnGmJuMMbm6/Ky0G7wZYfWQ3Xg80D87tF18EP5vlvhrI4OegsxdJPm267ZF99QN1k2uqpHgrEga/XIsYKVvb9HB0LF+2dIA4RCR3Qd9rgLOiqK0aY5WdCdba8cB3wVuNcZ8M/IEa+1frLU5uvystBeKK11tfmL0rx3YO/z81/4tVmh1TewqVJt3wPIN0UvHQdZscSKd86OPBdOQCvbCK/PCj8XqRuReZi6uzI5xgqIobZGjEl1r7W7ntQh4F5jYkpNSlNagtH5QdHCSg0HEzn2o6EAoojgQwzqub4DX3heLNhbrt0tf3GD+rptgKcgXZsPeCH/wgN4x0oWCuboGyhpPPdxtKorShvAd6QRjTDLgsdZWOO+/A/y2xWemKC1MWWAU2HekQIZLxIKvfXuCzxfuv335X9AlkeioZ4e3PoptBQNs2C75ubGwVgKsZs4N3+9zcnQhfG6hbUNZw8gj3quiKG2DI4ou0BN410jdOR/wurX23y06K0VpBRK7TsDixdjGmBZvz0xITAgX3ZIyeOqNpkXXnXsbSU1deH5vJDP+Cbsj2uNG5ehGpgzhIT5DF54Upb1wRNG11m4DRrfCXBSlVenZdzSV27NIjSsMb83nCFu3NEhPhooIIa2KiExuLgpiNAtKT3Xl6EYUxQCobsykx4AxLTMhRVGaHU0ZUjotmVk9KayZRJSJ64hbWjJMGXsyZhbiW+MhI6WJg8awt3YiWd01kEpR2gtHs7ysKB0Sr9dLZcLlWDsXgz/KZ+rzwsO3wqrN4o9tCp9XWu71yhL/a68ssU6Tu8ixRj9UVcvS9J79sGufBEuVVTbt/wU4rb+08fN6nR3uRgfO0nJ5/OX4fPprrCjtBf1tVTo1/Yeez4ENA8lMdIUcO8JmDAzoBX++Gy6/SypTgWhf1zQYOxSmTYCzRsHgfiK8gYBUrKpvFL+vtTKO1wsJcVJ0AyOCu3UnfLkGPlkmqUQHy0Oamp4CT98laUtRjeyd7YO1/el/2gUt9+UoitLsqOgqnZrMzO6sbLiWbokPYoiOYjYGpo4Ti/POJ2DYQPjZpXDh2ZCdKWlEKzbCU4vEIt5ZCOXVUjzDLboej1SVSkuWClPDTxWx/tG58MsrobAE5n0OM96FDfnwm5/BuRMdwXVHVTtYa9hRfw1juveMvilFUdosxjYVhnkigxrT/IO2IVriO2tLmCjTquPhfoaFe3eSmD+FjHinP1+Mx1tTDzc9BDddBqnJ8MGXMO8LKXhRWhE7b/dIGCMW7agh8N1viNVcVSNpSc/eLV2Ooj8kL2X1/akZsIjs3v2bGLtjP0P9HWz/dORnmJOTQ25ubsyHqJau0unJ7tWPFZvvZGzcr8S3C1GpOYnx8Isr4Or7xSqNjGBOiIdemVKysW8PsYK7poWEs7pWSjvm74HNBbBznzRNKK2Az1bIT2I89OwG7zwuqUqx5gFgrZe8+l8yrgnBVRSl7aKiqyjAaeNvoCB3NgNTPpViGRF/hBsD44bBqMGhtn2J8WKlfm8KnHem+HU9HqksVVoR6kSUlABpKbK0nJQgPt8tO+HDJTDnU1mWrnU6F406DUYOdrQ2YkkZAGvYUfUNhoy7sWW/EEVRWgQVXUUBUlJSKcx+nMrSi0iJKxLhDeKkEPm8srw8/ys4bxLccRWMP11a8C1eBU+/CSs3iiVcXRdqeuBzgqjSUyA7C4YOgO+cCdd+F26/QnzCT74O87+En/1Azg+rOnVoHoYqf3fqe/yJ1NS01vhaFEVpZlR0FcVh8LDxrPrqMUbaW/Ca2lDZKUf4jBVrd9oE+N/p8PUWuPF3sDAXikubrlLV4PTKLa2EgkJYslaaGvToCufkwBXnwaO3i184Z7greCp4bee9n0Q2NfyBscO0p4iitFdUdBXFxYicq1j5aT5j0x7CaxrCRM8iKT4fL4UpN8KeYsmzjfNJo/ne3SVPt3d3ydNNSZJUIb/Ttq+kTD6zc5+8HiiHNz+AWR9J5anqWrGYL/+2a3nZwU8cq8qmM3rqdZ0iyEZROioquoriwufzMXLy3axbUs0ZSU+I8Do0+mHmHPG91tTCuZNgWg5MGgmD+kBykvhrSyslD7emTqzf+DhI7SI+3dRkWT6uqJZm90vWwoJlsGy9fPbF9+D7U5183kMWbhzrq29nxOR7tRCGorRz9DdYUSJISEhg6KQHWbm4C2PSH8FHLWDZthuWrYM/3QmXniMiun2PCObM92DtNti9T5oe1DdKoQwIFcdISghVrho2EM4eLalCN/8QSkrhiddE1DcVwMhBAAa/SWRV6XRGTL6XhIRYOUSKorQnVHQVJQYJCQmMmXovq5cMYKj3bpJ9RZSUWuLjpCDGk69L9HH+nsN3DgrS0Ai1dVJ1Kn8PfLlahDqli0RAXzxFxk2Ih+KDABI0tcX/B0ZPvU4tXEXpIGjDA0VpAp/Px7izf8Lerv8iv3Iqk0Z6+fBZyEiViOOiA2LRnghVtbBmK8xeKKlCi2fA1HFeCqomsydtLqPPul4FV1E6EFqR6jjoyJVUQKvhxKKysoLNy19gUPxTpMXtoL7BUlgi+bZ7i8XabXCWlP3uFnyEykB6PaHX+DjJ881IlfrK/bMhMd5Q3tCXvPo7GDLuxhNKC+roz1B/B9s/HfkZHq4ilYrucdCR/7GA/sIfjsK9Oync9AL94l6hW0IBxgRwWv5EV48yrvfEOO7stHg4WNefHfXXkD30xiZLOx4LHf0Z6u9g+6cjP0MV3WamI/9jAf2FPxpK9hexY/N8UutmkZ20hOS4Eoz1Q7BpAuF5u+HfqAhtdWMme2smUJ7wI/oPuYCsZmxe0NGfof4Otn868jPU2suK0sxkZvUgM+ta/P6rKC7ay7Zdq6gvW0a6dw3p8Xl0Ty4Efzl7iurp3SMO602nuCqbsoZTKGscSVz6RHr2H8PAHr3UZ6sonQj9bVeUE8Dr9ZLdqy/ZvfoCF0cd7+N638P5URSl86LRy4qiKIrSSqjoKoqiKEoroaKrKIqiKK1Ei/h0x48fT25ubksM3Sbo6JGFHTmqMIg+w/aNPr/2T0d/hk2hlq6iKIqitBIquoqiKIrSSmjKkKIonRKPB4b2h59cDD/4FpzSG3we8HgJ66EcxAR7KxsI+KExAPl74b3P4KX3YGN+qLOUojRFi1SkysnJserTbb+oP6n909Gf4Yk8vzgfnH8W3HsD5AxzamJ7nYOR5TtNxCsR+xAB9gekCcbDL8H7X0gd7hOhoz8/6BS/gzFvUJeXFUXpFBjgG6NgyUyY/TicNUIE2OMhdn1sXPsjj7uE2eORcSaNgHf+CEtfhsljHMtYUSJQ0VUUpcOT2gWevw8+eR7GDgVv0LJ1i6iN+AnuNxDVrCJs3Tn06vXAmCGw4Dl44b8hLblFbkdpx6joKorSoRkxGJa/Cj+9RFoqRlmzQSL3Rwqxe/8RxojzwU8ukuuOHnLcU1c6ICq6iqJ0WM4/Ez6fAYP6uJaRm/DNHnrvFtXI7ViWcBNjeLxwah9YNAMuPLtFbk9ph6joKorSIbniAvGxpiQ5gVIx+xnH3rYWKqpg3mJ4+k3412Ior4447QhjYMFjIDkJZj0KV190AjejdBg0ZUhRlA7H+WfCi/dBl0RiRh5bCAuSMq5zrIXdxXD9A7BwOTT6xQc8dSy89AD06xmxuhzpF4445jGQlAB//S8oLRMBVzovaukqitKhGDEY/vEIJMYT5Xu1Fg5WwIzZcNPv4Z5nIHeDk18bTAGy8OBf4KOlIrgAfj8syIX/eT78XGuhpAzmfAZ/mwsrNkm6kHUJenDJOSkR3ngYxgxt4S9AadOopasoSochLRneeQxSuoiFGWl5lpTB1ffDR0tEXAH++g78+R648jti8ZZVwIdLYo//8VIR7awMGXrlJvjpb2H1VhHj5CS46VL4/a2QFO/6oHOt5ASY9QiMvxbKKpv33pX2gVq6iqJ0CAzwpztdQVMRWMTC/dAluCAiev+zUHxQTvIHxLKNRaPfsXQtVNXAbY/Bqs2hSlRVNeID/vt8R2cjLG2PRypfPfUrzePtrKjoKorSIThrlKTphAmuS9gCAfgk17X062JHIWzZIe8zUqXQRSwmngFd02TczTukClUkjX54e0G4sLvn4fHC1RdIAQ2l86GiqyhKuyfOB8/cBT4f7C+DuYvglffFCm0M+mCN4+eNgdcDCY4P2OeFB2+BEYPCzznjVHjo53IcoL5BrOJY1NQ54m7l+l9vhlffhzmLxKL2+eDp6TJvpXOhj1xRlHbP+WfBqCGwbD3c+DtYt00s29Qu8PMfwYM3Q0IcXDYN5n0eCpAKMnYoDB0g742B4afA/Gfg2bfgsZfhV9fAL/4DencPLQsP7gcDe8GWneFjGeCc8SLkdQ0SlPXMP6CiWqzw4afAX++HCcPhoskwe2FLfztKW0ItXUVR2jUeD9x3A1TWwK2PwJqtIR9rRTU8+Rq8/bFs/8d5cPuVEvAEIqCjh8Azd0vwVTDa2BgR2AnDZazxw6BPd2eV2Fk2zkyXgKnM9NBcjIFvTYCbL5PtdxfC46/KPEDGWpsHtz4q++67QcRZ6Tzo41YUpV0ztL+I4vptEkUcSUMjvPOJLPcmxsMjt8HC58XKTEmCmQ/AuGHRgU3WwvrtsoS8Ni9mCi4/nAav/E7ycEcMgmfvgbcege5d5fPvLojdcWjNVhlz9BA4fWDzfA9K+0BFV1GUds1/XhJaym3Kx1pbF6rQGOeF8afDgF5iHS9b75wUo4DGujzZtTYvIgDLGcwYKD4AtfUw4QyxcLulhQS8tj72fAIBma/XCzd8//jvXWl/qOgqitJu8XnhB+fIEvOwAdC3R/Q5xoiP1RNRR7m8UoT07QXRPl6QQKlNBfJ+yw6XgLrG8Pth1gIZp7wyuun9OTmxU4P69BAL1+OB730zFJyldHxUdBVFabf07CbBTBjomSnRxRmpoeMGOHciXH+JK2vHOiJZJZtL1sK23YTn1BooLYed+2Rzd7EU1sA1BkBBIXzxtbyvqAbrsrSNgZ9cDBecFT50egr89hbolSXbA7LFf6x0DlR0FUVpt4wcAj7nfzFj4KoLJOp4+rWSUxvng+nXOcFOrhrJAQuVTnBTaQW8/7mzfOxSx51FcgxEoHfsDR/DWpj/JRxwxLiy2lnedo3RNRXuuk5aCo4/HX59Lfz7abjmwpAF7PXA6NOa+5tR2ioquoqitFsmj3Y6CDlRxx4DE4fDo7fDHT+WIKaX57p8vc55/oD4c4O8+4ksJ7tb923KF78ryDgb80O5t1gnQGtBaEm5ssa5jg2/zsy5Ms5tV8Bjt8OZI8HrKlHp8ch9KJ0DFV1FUdot44c7byL8psZA354SqPTeZxItfMiSNeKLdYvuio2wsSC0bYE1eeFjHtp2xti60xWEBVTXQqMrUjkYiDV7ocwjrDuRu0cvEj2tdA6OSnSNMRnGmFnGmI3GmA3GmLNaemKKoihHYvQQ502MBvQ9MyWVp7wKnnsrVDM5aKXW1IXGqayBuZ+F6iUHAqHI5SDrt4UsWWth7uKQXxgkQrquITSHgIXnZkljg8T4kA/XbQnjXG/E4Gb6QpQ2z9Fauv9/4N/W2mHAaGBDy01JURTl6EhPjlFL2RG0bmnSdQgkQnljQUjn6htEJN3M/jQkxNV1kLcr/Pi23SE/cG29LEm7qalzlqiROW0qgLecohypXVx+ZbdV7gh4WpdjuWulPXNE0TXGpAPfBF4AsNbWW2tLW3heiqIoR6T4YBMHjFSdysqQzQPl8PzbIYGuq4/OoV2XJ8vQwXEL94cfLzoA+w7I2Ou3weot4cfrXdaztXK9YJBVVkZ4xavI5fD9pUe+V6VjcDSW7ilAMfCSMWalMWaGMSa5heelKIpyRHp0c94ERczVPD7eF56K8/cPYOsuObe6LrpSVE2d+F+the27oaIm/HhVrVi/1sI/F4oP101jY2hf3i5p7xekd5ZEMIfhEt7uXY/iZpUOwdGIrg8YBzxnrR0LVAH3RJ5kjLnJGJNrjMktLi5u5mkqiqJEU1oZXg/ZjccD/bND28UH4f9mib82MugpyNxFkm+7blt0T91g3eSqGgnOiqTRL8cCVvr2Frms8H7ZETWWXfM1QJnLN6x0bI5GdHcBu6y1S5ztWYgIh2Gt/Yu1Nsdam9O9u2Z6K4rS8oQt8cboXzuwd/j5r/1brNDqmthVqDbvgOUbopeOg6zZ4kQ650cfC6YhFeyFV+aFHxvYK8ZgrmXmtXkxjisdkiOKrrW2ENhpjBnq7Po2sP4wH1EURWkVlm8gOjjJwSBi5z5UdCAUURyIYR3XN8Br7zctguu3S1/cYP6um2ApyBdmw94If/CA3jHShYK5ugZWbjrMTSodiqPtp3sb8JoxJh7YBlzfclNSFEU5OhavgoDfKZDhErHga9+e0jDe7b99+V/QJTFG1LPDWx/FtoIBNmyX/NxYWCsBVjPnhu/3OTm6EDFHZzvgh8Urj3SnSkfhqETXWrsKyGnZqSiKohwba7ZCYwDiPcS0eHtmQmJCuOiWlMFTbzQtuuWH8a/W1IXn90Yy45+wuyh8X1SObkTKkD8AqzY3PabSsdCKVIqitFsKSyA/WBM5ouAESK5ueoxci6qa6H3NQcHe6H3pqRG1n93zRJoq7NHY006Diq6iKO2WRj+8t9CpNuXGEba0ZJgy9iRMzMW3xkNGSuxjASuR0E0tZysdj6P16SqKorRJXpoLv/wxeHxE+Ux9Xnj4Vlm+3bC96TF8Xmm51ytL/K+9ssQ6Te4ixxr9UFUtS9N79sOufRIsVVZ5eME8rb+08fMG++W6Gh1gJS3pxTkn+g0o7QkVXUVR2jUb8yWNZ9II105H2IyBAb3gz3fD5XdJZSoQ7euaBmOHwrQJcNYoGNxPhDcQkIpV9Y3i97VWxvF6ISFOim5gRHC37oQv18Any2QOB8tDmpqeAk/fJWlLUY3sne2vt8J6TRfqVKjoKorSrgkE4OGX4J0/OhZlRBSzMTB1nFicdz4BwwbCzy6FC8+G7ExJI1qxEZ5aJBbxzkIor5biGW7R9XikqlRaslSYGn6qiPWPzoVfXin+5Xmfw4x3YUM+/OZncO5ER3DdUdUOfj88/KKr7aDSKTC2qRC+EyAnJ8fm5uY2+7htBRP1Z2vHoiX+TbQ19Bm2byKfX5wPlr4MY4LN4GPcfk093PQQ3HQZpCbDB1/CvC+k4EVpRey83SPPQyzaUUPgu98Qq7mqRtKSnr1buhxFf0he1myB8ddGl6OEjv/8oFP8Dsa8QRXd46AT/GM52VNocfQZtm9iPb/JY2DBcyLAcpLroBUdXroOrr5frNLICOaEeOiVKSUb+/YQK7hrWkg4q2ultGP+HthcIFHHkU0TEuOhZzd453FZujYx5oGBhgY471b4dEXs++vozw86xe9gzBvU5WVFUToEn38t1aSuu8gplhGhW8ZIs/hRg0Nt+xLjxUr93hQ470zx63o8UlmqtCIkqkkJkJYiS8tJCeLz3bITPlwCcz6VZelap3PRqNNg5GCX4EbMI+CHNz+Ez7QgRqdELd3joBP8hXayp9Di6DNs3zT1/NKSYfmrcGofEc9D2NDL/C/hh3fBeZPgjqtg/OnSgm/xKnj/C1i5USzh6rpQ0wOfE0SVngLZWTB0AHznTPjmWLGGV2yEJ1+Xsd/8A1w8JUbwFCK4BYUw7mpp1tAUHf35Qaf4HVRLV1GUjk15lQjq4hnST9fjKrcIYKxYu9MmwP9Oh6+3wI2/g4W5UFzadJWqBqdXbmmliOaStdLUoEdXOCcHrjgPHr1d/MI5w13BU8FrO++rauHS6YcXXKVjo6KrKEqHYvUWuPJemPWo4491iZ5FUnw+XgpTbpRKUI1+8QNnZUj/3X495TUzHVKSJCLa77TtKymTzwSrSB0ohzc/gFkfSeWp6lqxmC//drQ/t6Yerv5v+FpLPnZqVHQVRelwzPscbnwYZtwLSYmh/Y1+mDlHfK81tXDuJJiWA5NGwqA+Yh3X1YslWlYp1q21kiqU2kWWr1OTZbm5olqa3S9ZCwuWwbL18tkX34PvT3XyeR2xr6mHWx6BOTH68CqdCxVdRVE6JK/Pg9IyeONhSEkUH++23bBsHfzpTrj0HBHR7XtEMGe+B2u3we59skxd3xgqLxksjpGUEKpcNWwgnD1aUoVu/iGUlMITr4mobyqAkYPk81V1EjGtgquAiq6iKB2YeZ/D5J/Cu3+EU3qLMMbHSUGMJ1+X6OP8PYfvHBSkoRFq66TqVP4e+HK1CHVKF4mAvniKjJsQD8UHRXALCuHyuyXQSlFAGx4oitLBWbMVxl8jBSvGnw4fPgsZqSKERQfEoj0RqmrlGrMXSqrQ4hlw9ih4fb5EKavgKm40Zeg46ASh7id7Ci2OPsP2zfE8P2OkgMbT02HEIPHvFpZIvu3eYrF2G5wlZX9E+71gGUivJ/QaHyd5vhmpUl+5f7b4cTdsh188Jnm4x/sYOvrzg07xO6gpQ4qidF6shUUrYcJ1cNFkuPd6KRvZr6eT0xujwXxYD1xiHMcR6YA0L3j4RZi7KHZpR0UBFV1FUToZDY2yFDznMzh9IFx/CVwyVSxVn2PJYuTHbXAaiBLanftgziJ44T3pFqTNC5QjocvLx0EnWBY52VNocfQZtm+a+/n5vNI5aPRpMHk0jDtdlqDTkmF/KXTvKilEa/Ng1RaxmFdtkmXphhZoQN/Rnx90it9BXV5WFEWJRaMfduyTnzmLTvZslI6MRi8riqIoSiuhoqsoiqIorYSKrqIoiqK0Ei3i012+fHmHdpJ39CCHjvzsgugzbN/o82v/dORnmJOT0+QxtXQVRVEUpZXQ6GWl2fF4YGh/+MnF8INvSc1bnwc8XsJarAU51HvUSJPvxgDk74X3PoOX3oON+aHC84qiKO2ZFsnTNcZ03HUDOvayCBz/0lacD84/C+69AXKGOSXzvM7ByOo+JuKViH2IAPsDUrv24Zfg/S+ar9KPPsP2jT6/9k9HfoY5OTnk5ubGfIi6vKycMAb4xihYMhNmPw5njRABPlRaL3iSGxvxaiJerXw+zgeTRsA7f4SlL0vt3E7w/5GiKB0UFV3lhEjtAs/fB588D2OHSs9RIFxEbcRPcL+BqFq2YevOoVevB8YMgQXPwQv/LZWCFEVR2hsquspxM2IwLH8VfnqJdFyJsmaDRO6PFGL3/iOMEeeDn1wk1x095LinriiKclJQ0VWOi/PPhM9nwKA+rmXkJnyzh967RTVyO5Yl3MQYHi+c2gcWzYALz26R21MURWkRVHSVY+aKC8THmpLkBErFaHfW1La1UFEF8xbD02/CvxZDeXXEaUcYAwseA8lJMOtRuPqiE7gZRVGUVkRThpRj4vwz4cX7oEsiMSOPLYQFSRnXOdbC7mK4/gFYuFyKzHu9MHUsvPSA9DUNW12O9AtHHPMYSEqAv/4XlJaJgCuKorRl1NJVjpoRg+Efj0BiPFG+V2vhYAXMmA03/R7ueQZyNzj5tcEUIAsP/gU+WiqCC+D3w4Jc+J/nw8+1FkrKpOfp3+bCik2SLmRdgh5cck5KhDcehjFDW/gLUBRFOUHU0lWOirRkeOcxSOkiFmak5VlSBlffDx8tEXEF+Os78Od74MrviMVbVgEfLok9/sdLRbSzMmTolZvgp7+F1VtFjJOT4KZL4fe3QlK864POtZITYNYjMP5a6XuqKIrSFlFLVzkiBvjTna6gqQgsYuF+6BJcEBG9/1koPign+QNi2cai0e9YuhaqauC2x2DV5lAlqqoa8QH/fb6jsxGWtscjla+e+pXm8SqK0nZR0VWOyFmjJE0nTHBdwhYIwCe5rqVfFzsKYcsOeZ+RKoUuYjHxDOiaJuNu3iFVqCJp9MPbC8KF3T0PjxeuvkAKaCiKorRFVHSVwxLng2fuAp8P9pfB3EXwyvtihTYGfbDG8fPGwOuBBMcH7PPCg7fAiEHh55xxKjz0czkOUN8gVnEsauoccbdy/a83w6vvw5xFYlH7fPD0dJm3oihKW0P/a1IOy/lnwaghsGw93Pg7WLdNLNvULvDzH8GDN0NCHFw2DeZ9HgqQCjJ2KAwdIO+NgeGnwPxn4Nm34LGX4VfXwC/+A3p3Dy0LD+4HA3vBlp3hYxngnPEi5HUNEpT1zD+golqs8OGnwF/vhwnD4aLJMHthS387iqIox4ZaukqTeDxw3w1QWQO3PgJrtoZ8rBXV8ORr8PbHsv0f58HtV0rAE4iAjh4Cz9wtwVfBaGNjRGAnDJexxg+DPt2dVWJn2TgzXQKmMtNDczEGvjUBbr5Mtt9dCI+/KvMAGWttHtz6qOy77wYRZ0VRlLaE/rekNMnQ/iKK67dJFHEkDY3wziey3JsYD4/cBgufFyszJQlmPgDjhkUHNlkL67fLEvLavJgpuPxwGrzyO8nDHTEInr0H3noEuneVz7+7IHbHoTVbZczRQ+D0gc3zPSiKojQXKrpKk/znJaGl3KZ8rLV1oQqNcV4YfzoM6CXW8bL1zkkxCmisy5Nda/MiArCcwYyB4gNQWw8TzhALt1taSMBr62PPJxCQ+Xq9cMP3j//eFUVRWgIVXSUmPi/84BxZYh42APr2iD7HGPGxeiLqKJdXipC+vSDaxwsSKLWpQN5v2eESUNcYfj/MWiDjlFdGN70/Jyd2alCfHmLhejzwvW+GgrMURVHaAiq6Skx6dpNgJgz0zJTo4ozU0HEDnDsRrr/ElbVjHZGsks0la2HbbsJzag2UlsPOfbK5u1gKa+AaA6CgEL74Wt5XVIN1WdrGwE8uhgvOCh86PQV+ewv0ypLtAdniP1YURWkrqOgqMRk5BHzOvw5j4KoLJOp4+rWSUxvng+nXOcFOrhrJAQuVTnBTaQW8/7mzfOxSx51FcgxEoHfsDR/DWpj/JRxwxLiy2lnedo3RNRXuuk5aCo4/HX59Lfz7abjmwpAF7PXA6NOa+5tRFEU5flR0lZhMHu10EHKijj0GJg6HR2+HO34sQUwvz3X5ep3z/AHx5wZ59xNZTna37tuUL35XkHE25odyb7FOgNaC0JJyZY1zHRt+nZlzZZzbroDHboczR4LXVaLS45H7UBRFaSuo6CoxGT/ceRPhNzUG+vaUQKX3PpNo4UOWrBFfrFt0V2yEjQWhbQusyQsf89C2M8bWna4gLKC6FhpdkcrBQKzZC2UeYd2J3D16kehpRVGUtoKKrhKT0UOcNzEa0PfMlFSe8ip47q1QzeSglVpTFxqnsgbmfhaqlxwIhCKXg6zfFrJkrYW5i0N+YZAI6bqG0BwCFp6bJY0NEuNDPly3JYxzvRGDm+kLURRFaQaOKLrGmKHGmFWun3JjzB2tMDflJJKeHKOWsiNo3dKk6xBIhPLGgpDO1TeISLqZ/WlIiKvrIG9X+PFtu0N+4Np6WZJ2U1PnLFEjc9pUAG85RTlSu7j8ym6r3BHwtC7HcteKoigtyxFF11q7yVo7xlo7BhgPVAPvtvTElJNL8cEmDhipOpWVIZsHyuH5t0MCXVcfnUO7Lk+WoYPjFu4PP150APYdkLHXb4PVW8KP17usZ2vlesEgq6yM8IpXkcvh+0uPfK+KoiitxbEuL38byLPWFhzxTKVd06Ob8yYoYq7m8fG+8FScv38AW3fJudV10ZWiaurE/2otbN8NFTXhx6tqxfq1Fv65UHy4bhobQ/vydkl7vyC9sySCOQyX8HbvehQ3qyiK0kocq+heCbwR64Ax5iZjTK4xJvfEp6WcbEorw+shu/F4oH92aLv4IPzfLPHXRgY9BZm7SPJt122L7qkbrJtcVSPBWZE0+uVYwErf3iKXFd4vO6LGsmu+Bihz+YYVRVFONkctusaYeOAS4K1Yx621f7HW5lhrc5prcsrJI2yJN0b/2oG9w89/7d9ihVbXxK5CtXkHLN8QvXQcZM0WJ9I5P/pYMA2pYC+8Mi/82MBeMQZzLTOvzYtxXFEU5SRxLJbud4EV1tp9LTUZpe2wfAPRwUkOBhE796GiA6GI4kAM67i+AV57v2kRXL9d+uIG83fdBEtBvjAb9kb4gwf0jpEuFMzVNbBy02FuUlEUpZU5ln66P6aJpWWl47F4FQT8ToEMl4gFX/v2lIbxbv/ty/+CLokxop4d3voothUMsGG75OfGwloJsJo5N3y/z8nRhYg5OtsBPyxeeaQ7VRRFaT2OytI1xiQD5wHvtOx0lLbCmq3QGMy/hSiLt2cmJCaE7yspg6feaFp0y6uig6SC1NSF5+ZGMuOfsLsofF9Ujm5EypA/AKs2Nz2moihKa3NUomutrbLWZlpry458ttIRKCyB/GBN5IiCEyC5uunJ0Z+rqone1xwU7I3el54aUfvZPU+kqcKe4paZj6IoyvGgFamUmDT64b2FTrUpN46wpSXDlLEnYWIuvjUeMlJiHwtYiYRuajlbURTlZHAsPl2lk/HSXPjlj8HjI8pn6vPCw7fK8u2G7U2P4fNKy71eWeJ/7ZUl1mlyFznW6Ieqalma3rMfdu2TYKmyysML5mn9pY2fN9gv19XoACtpSS/OOdFvQFEUpXlR0VWaZGO+pPFMGuHa6QibMTCgF/z5brj8LqlMBaJ9XdNg7FCYNgHOGgWD+4nwBgJSsaq+Ufy+1so4Xi8kxEnRDYwI7tad8OUa+GSZzOFgeUhT01Pg6bskbSmqkb2z/fVWWK/pQoqitDFUdJUmCQTg4ZfgnT86FmVEFLMxMHWcWJx3PgHDBsLPLoULz4bsTEkjWrERnlokFvHOQiivluIZbtH1eKSqVFqyVJgafqqI9Y/OhV9eKf7leZ/DjHdhQz785mdw7kRHcN1R1Q5+Pzz8oqvtoKIoShvB2KZCTU9kUGOaf9A2REt8Z20J4zIf43yw9GUYE2wGH+PWa+rhpofgpssgNRk++BLmfSEFL0orYuftHnkOYtGOGgLf/YZYzVU1kpb07N3S5Sj6Q/KyZguMvza6HKWbzvQMOyL6/No/HfkZ5uTkkJubG/MhqugeBx35HwtE/8JPHgMLnhMBlhNcB63o8NJ1cPX9YpVGRjAnxEOvTCnZ2LeHWMFd00LCWV0rpR3z98DmAok6jmyakBgPPbvBO4/L0rWJMQ8MNDTAebfCpysOf4+d7Rl2NPT5tX868jM8nOjq8rJyRD7/WqpJXXeRUywj4nfFGGkWP2pwqG1fYrxYqd+bAuedKX5dj0cqS5VWhEQ1KQHSUmRpOSlBfL5bdsKHS2DOp7IsXet0Lhp1Gowc7BLciHkE/PDmh/CZFsRQFKWNopbucdCR/0KD2H9lpyXD8lfh1D4inoewoZf5X8IP74LzJsEdV8H406UF3+JV8P4XsHKjWMLVdaGmBz4niCo9BbKzYOgA+M6Z8M2xYg2v2AhPvi5jv/kHuHhKjOApRHALCmHc1dKs4Uh0xmfYkdDn1/7pyM9QLV3lhCmvEkFdPEP66Xpc5RYBjBVrd9oE+N/p8PUWuPF3sDAXikubrlLV4PTKLa0U0VyyVpoa9OgK5+TAFefBo7eLXzhnuCt4Knht531VLVw6/egEV1EU5WShoqscNau3wJX3wqxHHX+sS/QskuLz8VKYcqNUgmr0ix84K0P67/brKa+Z6ZCSJBHRfqdtX0mZfCZYRepAObz5Acz6SCpPVdeKxXz5t6P9uTX1cPV/w9da8lFRlDaOiq5yTMz7HG58GGbcC0mJof2Nfpg5R3yvNbVw7iSYlgOTRsKgPmId19WLJVpWKdattZIqlNpFlq9Tk2W5uaJamt0vWQsLlsGy9fLZF9+D70918nkdsa+ph1segTkx+vAqiqK0NVR0lWPm9XlQWgZvPAwpieLj3bYblq2DP90Jl54jIrp9jwjmzPdg7TbYvU+WqesbQ+Ulg8UxkhJClauGDYSzR0uq0M0/hJJSeOI1EfVNBTBykHy+qk4iplVwFUVpL6joKsfFvM9h8k/h3T/CKb1FGOPjpCDGk69L9HH+HrFoj0RDI9TWSdWp/D3w5WoR6pQuEgF98RQZNyEeig+K4BYUwuV3S6CVoihKe0EbHij/X3v3FmJVFcdx/PtzVCrTDBQTtZQoESTzkhGKRWIoivWoYIEv9ZChBEX5Er300EMEQUGMhpEXSjNUIhMyHB8qr+G91CxH1NFETCG8/XvYW9LSQN17L/fu94HDzDkDM7/F4sz/7HXZ64Zt2wsjZ2Q3rBg5BNa8Dz27Z4Ww40R2RXszzvyZ/Y0vvs22Cq1vhTEPwaLV2SplF1wzqxtvGboBTV7qDte/XUHKbqDx3isw9P5sfvfI79l+28PHsqvdc/mQ8oV/HL936TaQLZ3+/tq1S7bPt2f37P7K996TzePu+gVmvZ3tw73ZLnAf1pv7r/6a3IfeMmSlioC2LfDIczB5LMydmd02ckCffE/vVQ6Yv+IMXK7yc/IifTE7vOCt+bCq7b9v7Whmdqtz0bXCnDufDQWvXAdDBsLMqTD18exKtXN+JYuyx+UfcgX/KrQHj8LKNpi3IjstyIcXmFkTeHj5BjR5WASKHdrq3JKdHDTsQRg7DEYMyYage3SD4yeh993ZFqLt+2Drz9kV89Y92bD0uRIPoHcf1pv7r/6a3IceXrZkzl+A345mj5VtqdOYmaXl1ctmZmYVcdE1MzOriIuumZlZRcqa0z0O/FrS776aXvnfrESCRQ6Vti+ByttXcR+6/wrm92Dhmt6HVbfvvmv9oJTVy1WTtDEiRqXOURa3r97cvvprehvdvup4eNnMzKwiLrpmZmYVaUrR/TB1gJK5ffXm9tVf09vo9lWkEXO6ZmZmddCUK10zM7NbnouumZlZRWpddCVNlLRH0l5Jr6XOUzRJ8yV1SNqeOksZJA2QtFbSTkk7JM1OnalIkm6T9IOkH/P2vZk6UxkktUjaImlV6ixFk3RA0jZJWyVtTJ2naJJ6SloqabekXZIeS52pSJIG53136XFK0pykmeo6pyupBfgJmAC0AxuA6RGxM2mwAkkaB5wGPo6IoanzFE1SX6BvRGyW1B3YBDzTlD5Utvu/W0ScltQFWA/MjojvEkcrlKSXgVFAj4iYkjpPkSQdAEZFRCNvjCFpAdAWEa2SugJ3RMTJxLFKkdeMQ8CjEVHlzZuuUOcr3dHA3ojYHxFngSXA04kzFSoi1gEnUucoS0QcjojN+fd/ALuAfmlTFScyp/OnXfJHPT/lXoOk/sBkoDV1Frs+ku4CxgHzACLibFMLbm48sC9lwYV6F91+wMHLnrfToH/Y/zeSBgLDge8TRylUPvS6FegA1kREo9oHvAu8ClxMnKMsAXwtaZOk51OHKdgg4BjwUT490CqpW+pQJZoGLE4dos5F1xpC0p3AMmBORJxKnadIEXEhIh4G+gOjJTVmmkDSFKAjIjalzlKisRExApgEvJhP+TRFZ2AE8EFEDAfOAI1bGwOQD51PBT5LnaXORfcQMOCy5/3z16xG8rnOZcDCiPg8dZ6y5MN2a4GJiaMUaQwwNZ/3XAI8KemTtJGKFRGH8q8dwHKyaa2maAfaLxt9WUpWhJtoErA5Io6mDlLnorsBeEDSoPxTzDRgReJMdh3yhUbzgF0R8U7qPEWT1FtSz/z728kW/e1OGqpAEfF6RPSPiIFk779vImJG4liFkdQtX+BHPuz6FNCYnQQRcQQ4KGlw/tJ4oBGLGK9iOrfA0DKUd7Rf6SLivKRZwGqgBZgfETsSxyqUpMXAE0AvSe3AGxExL22qQo0BngW25fOeAHMj4st0kQrVF1iQr5rsBHwaEY3bVtNgfYDl+RF0nYFFEfFV2kiFewlYmF+47AdmJs5TuPwD0wTghdRZoMZbhszMzOqmzsPLZmZmteKia2ZmVhEXXTMzs4q46JqZmVXERdfMzKwiLrpmZmYVcdE1MzOryF8MAELp1mbYYAAAAABJRU5ErkJggg==\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "eight_queens = NQueensCSP(8)\n",
+ "backtracking_instru_queen = make_instru(eight_queens)\n",
+ "result = backtracking_search(backtracking_instru_queen)\n",
+ "plot_NQueens(result)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 19,
+ "id": "10c87b7a",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "None\n"
+ ]
+ }
+ ],
+ "source": [
+ "from notebook import plot_NQueens\n",
+ "eight_queens = NQueensCSP(8)\n",
+ "result = tree_csp_solver(eight_queens)\n",
+ "print(result)\n",
+ "# plot_NQueens(result)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f96c9fd7",
+ "metadata": {},
+ "source": [
+ "## Graph Coloring"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 20,
+ "id": "e0ff2c3a",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "['R', 'G', 'B']"
+ ]
+ },
+ "execution_count": 20,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "s = UniversalDict(['R','G','B'])\n",
+ "s[5]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 21,
+ "id": "e594d6a5",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(,\n",
+ " ,\n",
+ " )"
+ ]
+ },
+ "execution_count": 21,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "australia_csp, usa_csp, france_csp"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 22,
+ "id": "f30530c0",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "CPU times: user 41 µs, sys: 13 µs, total: 54 µs\n",
+ "Wall time: 58.4 µs\n",
+ "Check Results:True\n",
+ "AC3 needs 72 consistency-checks\n"
+ ]
+ }
+ ],
+ "source": [
+ "%time results, checks = AC3(australia_csp, arc_heuristic=no_arc_heuristic)\n",
+ "print(f\"Check Results:{results}\")\n",
+ "print(f\"AC3 needs {checks} consistency-checks\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 23,
+ "id": "aecd9dfc",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "CPU times: user 299 µs, sys: 96 µs, total: 395 µs\n",
+ "Wall time: 399 µs\n",
+ "Check Results:True\n",
+ "AC3 needs 1070 consistency-checks\n"
+ ]
+ }
+ ],
+ "source": [
+ "%time results, checks = AC3(usa_csp, arc_heuristic=no_arc_heuristic)\n",
+ "print(f\"Check Results:{results}\")\n",
+ "print(f\"AC3 needs {checks} consistency-checks\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 24,
+ "id": "a9563f4f",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "CPU times: user 210 µs, sys: 67 µs, total: 277 µs\n",
+ "Wall time: 282 µs\n",
+ "Check Results:True\n",
+ "AC3 needs 430 consistency-checks\n"
+ ]
+ }
+ ],
+ "source": [
+ "%time results, checks = AC3(france_csp, arc_heuristic=no_arc_heuristic)\n",
+ "print(f\"Check Results:{results}\")\n",
+ "print(f\"AC3 needs {checks} consistency-checks\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 25,
+ "id": "b02a1901",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'SA': 'G', 'WA': 'R', 'NT': 'B', 'Q': 'R', 'NSW': 'B', 'V': 'R'}\n"
+ ]
+ }
+ ],
+ "source": [
+ "solution = min_conflicts(australia_csp)\n",
+ "print(solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 26,
+ "id": "578ae79d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import networkx as nx\n",
+ "def draw_graph(csp, solution, node_size=1000):\n",
+ " graph = csp.neighbors\n",
+ " G=nx.Graph(graph)\n",
+ " pos = nx.spring_layout(G,k=0.15)\n",
+ " colors = [solution[node] for node in G.nodes]\n",
+ " colors_dict = {'G':'Green', 'B':'Blue', 'R':'Red', 'Y':'Yellow'}\n",
+ " colors = [colors_dict[c] for c in colors]\n",
+ " nx.draw(G, pos, node_color=colors, node_size=node_size, with_labels=True)\n",
+ " return None"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 27,
+ "id": "6c9b0699",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'SA': 'B', 'WA': 'G', 'NT': 'R', 'Q': 'G', 'NSW': 'R', 'V': 'G'}\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAb4AAAEuCAYAAADx63eqAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAABLw0lEQVR4nO3dd1yV9d/H8ddhgzhwj1BEBXGBOyea2xwI5S4t1DLLPdpl5dbM6s7MSo3UtACNn2mpmRslBVTEjYoDlFzI5nDdfxwlV8o451xnfJ6Ph49+Hs65vh/uW33z3RpFURSEEEIIK2GjdgFCCCGEMUnwCSGEsCoSfEIIIayKBJ8QQgirIsEnhBDCqkjwCSGEsCoSfEIIIayKBJ8QQgirIsEnhBDCqkjwCSGEsCoSfEIIIayKBJ8QQgirIsEnhBDCqkjwCSGEsCp2ahcghKGkZacRkxRDdFI0/6T/Q05eDk52TniU8aBplaZ4lfPC1sZW7TKFEEYmwScsyu3s2/x46EcW7l3ImRtncLF3IVubTWZuJgAaNLg6uJKn5JGbl0unmp2Y0mYK/jX80Wg0KlcvhDAGjVxEKyxBRk4G7217j6+ivsJGY0NaTlqBPqdBg4u9C+VcyvF/Pf+PXl69DFypEEJtEnzC7EVeiOT5n5/nn/R/yMjNKPJzXOxdeLbOsyzptQQ3Zzc9ViiEMCUSfMKsfbHvC6ZtmVaswLuXo60jpRxLseOlHdQtX1cvzxRCmBYJPmG25u2ex4fbPyQ9J12vz9WgoZRjKfYG78Wngo9eny2EUJ8EnzBLqw+vZkTECL2H3l0aNJR1Lkv8mHgqlKhgkDaEEOqQfXzC7FxKvcSo/40yWOgBKCjcyrrFS+tfMlgbQgh1SPAJs6IoCkPDhuZvTzCknLwc/jr7Fz/H/WzwtoQQxiPBJ8zK1oSt7L+4n9y8XKO0l5aTxugNo43WnhDC8CT4hFmZu3tugffo6Uu2NpsNJzYYtU0hhOFI8AmzceHWBXac22H0dlOzU5m9e7bR2xVCGIYcWSbMRsTxCGw0RfhZLRrYC1wDHAEfoDPgVPBHHLh0gNSsVEo6lix8+0IIkyI9PmE2dp7fWfiN6nuALUAX4C1gBHADCAG0BX+Ms70z0UnRhWtbCGGSJPiE2Yi8EFm4D2QC24AeQB3AFnADngeuA4cL/qis3CwOXDpQuPaFECZJgk+YjYupFwv3gUQgF93Q5r0c0QXh6YI/KkubxeErhUhKIYTJkuATZqPQWwrSARd0Pb0HuQKFXBx6O/t24T4ghDBJEnzCbGgo5H15LujC71FzebfvfL0Q7G3sC/cBIYRJkuATZsPFvpBJ5Y5u3XL8A69nAScBj8I9rrxL+cJ9QAhhkiT4hNnwKV/ImxKcAH9gI7qg06Jb1PIzut5eo4I/ytXBlebVmheufSGESZJ9fMJstPdoz9+X/yZPySv4h9qiC7k/0O3j0wI1gBcBh8K137RK08J9QAhhkqTHJ8xGu+rtKGFfovAfbAKMAd4D+qLr9RUiOwHS0tP44bMfOHjwIHKTlxDmTYJPmI3utbsX7eSWezUGOqHb6lBA9jb2BHkGkZebR//+/fH09GTSpEns3r2bvLxCJqgQQnVyEa0wK29teYuFkQvJ0mYZrU0nOycOvXqIOuXqoCgKhw8fJiwsjNDQUFJSUujXrx9BQUH4+/tjZyezB0KYOgk+YVYu3rqI15deBr2E9l52Nnb41/Bny4tbHvn1EydO5IdgQkICffr0ITAwkC5duuDo6GiUGoUQhSPBJ8zO3B1zeWfrO+TaGP6OvBL2JYgfE497afcnvvf8+fOEhYURFhbGoUOH6NGjB0FBQXTv3h1XV1eD1yqEKBgJPmFWYmJiGDhoIFcDrnLT+SZapRAnTRdSCfsSLOy+kJFNRhb6s0lJSaxfv57Q0FAiIyPp1KkTgYGB9O7dmzJlyui/WCFEgUnwCbOQl5fHokWLmDlzJp999hn+vf1psqQJKekpKOj/j7CLvQt9vPuwKnAVGk0hT4x5wLVr14iIiCAsLIxt27bRunVrgoKC6Nu3LxUrVtRTxUKIgpLgEyYvOTmZ4cOHc/36dVatWoWnpycAp66dotV3rbiecV2vPT8Xexe61erG2ufXYmej38UqqampbNy4kdDQUH7//Xf8/PwICgqiX79+PPXUU3ptSwjxaBJ8wqRt3LiR4OBggoODef/997G3v/+8zPM3z/PsqmdJuJ5AWk4hT51+BGc7Z15p9goLui4o/taJJ8jIyGDz5s2EhYURERFBnTp1CAwMJCgoiFq1ahm0bSGsmQSfMElZWVlMmzaNsLAwQkJC8Pf3/8/3avO0zN0zl4+3f0yONodcpfCLXlzsXXBzcmPt82tp7d66OKUXSU5ODn/99RehoaGsW7eOSpUqERQURGBgIPXr1y/2cKsQ4l8SfMLkxMfHM2jQIGrVqsXSpUspW7ZsgT536top5u2eR8ihEGw0Nk/sAWrQ4GLvQjmXckxuNZkRTUbgbO+sj2+hWLRaLXv27MlfIerk5JTfE2zatKmEoBDFJMEnTIaiKHzzzTe8++67zJo1i+Dg4CL9I387+zY/x/3M5jObibwQSeKtRGw1tthobHRzgQo43nQkuEswfb374l/D32TDRFEUDhw4QGhoKKGhoWRlZREYGEhgYCCtW7fG1vZRlw0KIR5Hgk+YhH/++YeRI0eSkJDA6tWrqVu3rt6ena3NJjUrlZy8HBxtHcm8kUmDBg1ISUkx2cB7FEVRiIuLy98wn5ycTEBAAEFBQXTo0OGh+U8hxKNJ8AnVbdu2jRdffJH+/fszc+ZMo5x4UqlSJf7++2/c3Z+8Md1UnTp1Kj8ET506Re/evQkMDKRr1644OTmpXZ4QJkuCT6gmJyeHDz74gOXLl/P999/TvXt3o7XdrVs33njjDXr16mW0Ng0pMTGR8PBwwsLCiImJoXv37gQGBtKzZ085NUaIB8jtDEIVp0+fpm3btsTExBAdHW3U0APw9fUlJibGqG0akru7O2PHjuWvv/7ixIkTdOrUie+//56qVavSt29ffvjhB65fv652mUKYBAk+YXQhISE8/fTTDBkyhA0bNlCpUiWj1+Dn50dsbKzR2zWGihUrMnLkSDZt2sT58+d57rnnCA8Px8PDg27durFkyRKSk5PVLlMI1chQpzCamzdvMmbMGA4ePMjq1avx9fVVrZa4uDgCAgI4efKkajUY2+3bt9m0aROhoaFs3LiRRo0a5e8VNOe5TiEKS4JPGEVkZCSDBw+mW7duLFiwABcXF1Xryc3NpVSpUiQnJ1OyZElVa1FDZmYmW7ZsISwsjF9//RVPT8/8vYJ16tRRuzwhDEqCTxiUVqtl1qxZfPHFFyxZsoSAgAC1S8rXrFkzPv/8c1q3Nv5JLaYkJyeHHTt2EBoaSnh4OOXLl8/vCTZs2NCstnwIURASfMJgEhMTGTp0KDY2NoSEhJjcIcwjRoygadOmjB49Wu1STEZeXh579+7N3yZhb2+f3xNs3ry5hKCwCLK4RRhEaGgozZo1o0ePHmzZssXkQg8sb2WnPtjY2NCmTRsWLFhAQkICa9aswc7OjhdffJHq1aszbtw4duzYgVZruHsQhTA06fEJvUpLS2PChAls3bqV1atX06JFC7VL+k87d+5kypQpREZGql2KWTh69CihoaGEhYVx6dIlAgICCAwMpGPHjjg4OKhdnhAFJsEn9CY6OppBgwbRsmVLvvjiC0qVKqV2SY918+ZNqlWrxs2bN+XMy0I6ffp0/ob5Y8eO0atXL4KCgujatSvOzuof9C3E40jwiWK7ezv6rFmz+Oyzzxg8eLDaJRWYp6cnGzduxNvbW+1SzNbFixdZt24doaGhHDx4kK5duxIUFETPnj2tcsWsMH0SfKJYkpKSGD58ODdv3mTVqlXUrFlT7ZIKJTAwkAEDBjBgwAC1S7EIV69e5ddffyU0NJRdu3bRoUMHAgMD6d27N+XKlVO7PCEAWdwiiuG3336jcePGtGjRgh07dphd6IFugYulnuCihgoVKhAcHMxvv/1GYmIiAwYMICIiAk9PT7p06cLixYtJSkpSu0xh5aTHJwotMzOTN998k/DwcEJCQmjfvr3aJRXZ+vXrWbJkCb/99pvapVi0tLQ0fv/9d0JDQ/ntt9+oX79+/l7BGjVqqF2esDISfKJQjh49yqBBg6hTpw5Lly7Fzc1N7ZKK5ezZs7Rp04aLFy+qXYrVyMrKYuvWrYSFhbF+/Xpq1KiRH4Iy1yqMQYJPFIi+bkc3NYqi4ObmxsmTJ6lQoYLa5Vid3Nxcdu7cmX9qjJubW/6G+UaNGlnEnzFheiT4xBP9888/jBgxgrNnz+r9dnRT4O/vz3vvvUfnzp3VLsWq5eXlsW/fvvxTY2xsbAgMDCQwMJAWLVpgY2PiSxJiYmDXLtixA/7+G27cAK0W7O3B3R3at4enn4bOnUF+yFKVBJ94rLu3ow8YMIAZM2YY5XZ0Yxs3bhzu7u5MnjxZ7VLEHYqiEBsbS2hoKKGhody6dYt+/foRFBREu3btTGffZUYG/PQTzJkDFy5AXp7utUfRaMDVFXJyoEcPmDwZWrXSvS6MSoJPPNK9t6MvW7aMbt26qV2SwXz//fds27aNkJAQtUsR/yE+Pp7w8HBCQ0NJTEykb9++BAYG0qlTJ/VOjfnjDxgyBDIz4fbtwn1WowEXF13whYRA5cqGqVE8kgSfeMipU6cYPHgwFSpUYNmyZVSsWFHtkgzq4MGDDBs2jMOHD6tdiiiAs2fPEhYWRlhYGEePHqVnz54EBQXRrVs341x3lZYGo0dDaCikpxfvWfb24OQE33wDAwfqpz7xRBJ8Ip+iKISEhDBp0iTee+893njjDatYXJCZmYmbmxvXr1/HyclJ7XJEIVy+fDn/6LSoqCi6dOlCUFAQzz77rGGOzLtxAzp0gOPHdT09fXFxgXfegbff1t8zxX+S4BOA7tzK1157jZiYGFavXk2jRo3ULsmoGjZsyIoVK2jSpInapYgiSklJISIigtDQUHbs2EH79u0JDAykb9+++jk1Ji0NWreGY8cgO7v4z3uQiwt8+CFMmaL/Z4v7mPgyKWEMe/fupXHjxpQqVYqoqCirCz2QE1wsQfny5XnppZf43//+x4ULFxgyZAgbN27E09OTTp068dVXX3Hp0qWiN/DSS3DihGFCD3TDph9+CFu2GOb5Ip/0+KyYVqtl5syZfPnllyZ3O7qxzZ8/n8TERBYtWqR2KULP0tPT+eOPPwgNDWXDhg34+Pjkb5Mo8DF7ERG6ObjizukVRIUKcPo0yAHfBiPBZ6XOnz/P0KFDsbOzIyQkhGrVqqldkqo2b97MjBkz+Ouvv9QuRRhQdnY2f/75J2FhYaxbt46nnnqKoKAggoKC/nt/6q1b4OEB168bp0gnJxg8GL77zjjtWSEJPiv0yy+/8NprrzFx4kSmTJliOnuiVHTlyhW8vLy4fv26VSzoEboRj127duVfrluqVKn8o9P8/Pz+/XOwaJFu0Ykxent3OTnBuXNg4Suq1SLBZ0XS0tIYP34827ZtY9WqVSZ9O7oaqlatyp49e/Dw8FC7FGFkeXl5REVF5Z8ak5eXpxsO7dePVgMGoDH2Wa5OTrpVnu++a9x2rYQsbrESBw8epEmTJmRnZxMdHS2h9wh+fn6ywMVK2djY0LJlS+bMmcPJkydZt24dJUqUYOkLL5D2hAUxHkBFIO2e174FPAHXe35pgBL3/H7n4x6amanraUq/xCAk+CxcXl4eCxYsoFu3bnzwwQesWLFCbsX+D76+vsTExKhdhlCZRqOhUaNGTJ8+nWUvvkiJApwRqgUeXBZVHbh9zy+A2Ht+3+5JD01Lg8TEwpQuCshO7QKE4SQlJTFs2DBSU1PZv3+/WV4Ua0x+fn6sWbNG7TKEKdm+HY1W+8S3TQHmAq8BZfTVtr09HDgA1avr64niDunxWagNGzbQuHFjWrZsaba3oxub9PjEQwo49N0M6ADM12fbt2/D/v36fKK4Q3p8FiYzM5OpU6eyfv161qxZY9a3oxtbnTp1SE5O5ubNm5QuXVrtcoQpSE0t8Fs/AtoA4/TVdl6e7sYHoXfS47MgcXFxtGjRgsuXLxMTEyOhV0i2trY0aNCAQ4cOqV2KMBUFGOa8qwHQC5itz/azsvT5NHGHBJ8FUBSFxYsX4+/vz7hx41i7di1ubm5ql2WWZGWnuE8h97hOB5YCetv8YIzbJqyQDHWauZSUFEaMGMH58+fZvXs33t7eapdk1nx9fTl48KDaZQhTUb48JCUV+O21gQHA50DD4rZtbw+1axf3KeIRpMdnxv7880/8/PyoXbs2e/fuldDTA+nxifs0bVroj7zP/Xv6iszFBZo318eTxAOkx2eGcnJyeO+99wgJCWHZsmV07dpV7ZIsRsOGDYmLiyM3Nxc7O/nrYfU6dIDNmx97I8PZB37vDjzqpr5Cb0XPyChS8Ionkx6fmTl16hRt2rThyJEjREdHS+jpWcmSJalWrRonTpxQuxRhCrp1K/Q8n95Ur64bahV6J8FnJhRFYcWKFbRq1YoXXniBiIgIKsoBtgYh+/lEvoYNwcvL+O26usK0acZv10pI8JmBmzdvMnjwYObOncvWrVt544035AYBA5J5PnGfadN0QWRMeXkwaJBx27QiEnwmbs+ePfj5+eHm5sbff/9tlbejG5ufn5/0+MS/nnsOqlRBMdYPmyVK6G5lKFHCOO1ZIQk+E5Wbm8tHH31Ev379+Oyzz/jqq69wdnZWuyyr4OvrKz0+8S97e34PDibTGDcl2NhAzZowdarh27JismzNBJ0/f54hQ4bg4ODAwYMHrf52dGN76qmnyMnJISkpicqVK6tdjlBRamoqb7zxBnv27GFbcDDVVq827IW0Tk6wdq16C2qshPT4TMzPP/9Ms2bN6NWrF5s3b5bQU4FGo5Fen2D//v00btwYW1tb3Q+g33wDffoY7jQVFxcIDQUfH8M8X+ST4DMRaWlpBAcH8/bbb7NhwwamTZuGTQHuAROGIfN81kur1TJz5kx69erFrFmz+O6773B1ddUNQ/74IwQG6nf+TaPRPS80FLp3199zxX+Sf1lNwN3b0bVaLQcPHqS5nNagOunxWafExEQ6derEH3/8wYEDB3j++efvf4OtLfzwA8yfrwur4g5JurhAnTqwZ4+EnhFJ8KkoLy+P+fPn061bNz788EOWL18ut6ObCOnxWZ+ff/6Zpk2b0rVrV7Zu3Yq7u/uj36jRwKuvQlwctG6tC69CBmA6kOfoCJMmwZEjIKu1jUqjKMZYqiQedPnyZYYNG0ZaWhorV67Ew8ND7ZLEPbKzsyldujTXrl2T1bQW7vbt24wdO5YdO3awatUqWrRoUbgHHDoECxfCmjW6g6VzcnTHjd1Lo9HtBdRqoUwZNtarx5bq1Vnw3Xf6+0ZEgUnwqeB///sfI0eOZNSoUbz33ntyJqSJ8vPzY+nSpTL0bMGioqIYPHgwbdu25fPPPy/eiEtGhu7G9gMHYNcuSE7WhaCzs27BSqtWurM3a9cmKTkZHx8fTp06Rbly5fT3DYkCkeAzoszMTKZMmcKvv/7Kjz/+SLt27dQuSTzGsGHDaNeuHSNGjFC7FKFnWq2WefPm8emnn/Lll1/Sv39/o9fw0ksvUadOHd5++22jt23tpKthJHFxcQwcOBAfHx9iYmLkolgzIPN8lunChQu88MILaLVaoqKiqFGjhip1TJgwge7duzNp0iQcHR1VqcFayeIWA1MUha+++ooOHTowYcIE1qxZI6FnJmRlp+UJDQ2ladOmdOrUiW3btqkWegCNGjWifv36rFmzRrUarJUMdRpQSkoKwcHBXLhwgVWrVslFsWbmn3/+oWbNmty4cUP2VJq5tLQ0xo8fz59//snKlSt5+umn1S4JgI0bN/LWW28RHR0tB88bkfxtNpCtW7fi5+eHl5eX3I5upsqVK0fp0qU5e/as2qWIYjhw4ABNmjQhOzub6Ohokwk9gG7dupGdnc22bdvULsWqSPDpWXZ2Nm+++SYvvvgiy5YtY968eTg4OKhdligimeczX3l5ecydO5cePXowffp0VqxYQalSpdQu6z42NjZMmDCBTz/9VO1SrIoEnx6dPHmSNm3aEBcXR0xMDF26dFG7JFFMMs9nni5evEiXLl2IiIggKiqKgQMHql3Sfxo6dChRUVEcO3ZM7VKshgSfHty9Hb1169YMGzaMX3/9lQoVKqhdltAD6fGZn/DwcJo0aUKHDh1UX8BSEM7Ozrz66qt89tlnapdiNWRxSzHduHGD0aNHc/jwYVavXk3Dhg3VLkno0cmTJ+ncuTPnzp1TuxTxBGlpaUycOJHNmzezcuVKWrVqpXZJBZacnEzdunU5efIk5cuXV7sciyc9vmLYvXs3jRs3ply5ckRFRUnoWaBatWpx7do1rl+/rnYp4jGio6Np2rQp6enpxMTEmFXoAVSqVInAwEC+/vprtUuxCpYZfIoCFy/C4cMQHQ1Hj8Lt23p7/N3b0YOCgli0aBFffvmlnOdooWxsbGjYsKHM85mouwe9d+3alffff5+QkBCTW8BSUBMmTOD//u//yMrKUrsUi2c5J7dcuADffQe//64LvNxcuLuaUlF05+hVrgzNm8PAgRAQ8O/XC+HcuXMMHToUR0dHDh48SNWqVfX7fQiT4+fnR2xsLB06dFC7FHGPS5cuMWzYMNLT09m/fz81a9ZUu6RiadCgAY0aNWL16tUMHz5c7XIsmvn3+Pbsga5doXZtmDUL9u7V9e4yM+HWLd2v1FRdEF64AOHhMGIEVKwIb74JhRjCWrt2Lc2bN6d379788ccfEnpWwtfXVxa4mJj169fTpEkT2rZty/bt280+9O6aOHEin376KbL0wsAUc3X7tqKMHKkozs6KouvTFf6Xo6OiuLkpyq+/Prap1NRU5eWXX1Zq166t7N+/30jfoDAVkZGRSuPGjdUuQyiKkpaWprzyyiuKh4eHsnv3brXL0bu8vDylXr16yubNm9UuxaKZZ48vNlbXw/vxx4fvvSqMrCxdj2/gQBg0CLKzH3rL3VMfFEUhOjparqixQg0aNCA+Pp6cnBy1S7FqdxewpKamEhMTQ+vWrdUuSe80Gk1+r08YkNrJW2iRkYri6lr0Xt5//XJ2VhR/f0XJyFAURVG0Wq0yb948pUKFCsrq1avV/Z6F6ry9vZVDhw6pXYZV0mq1yoIFC5Ty5csrISEhapdjcBkZGUqlSpWUuLg4tUuxWOa1uCUuDrp00esKzXwZGbB/P/Tty+Xvv+fF4cPzJ83ldnRxd55PtqwY1+XLlxk+fDi3bt1i3759eHp6ql2SwTk5OTF69Gg+++wzvvnmG7XLsUjmM9SZnQ19+ugWqhhKRga527fzdd26tGnThu3bt0voCeDflZ3CeCIiImjcuDFPP/00O3futIrQu2v06NH8/PPPXL16Ve1SLJL5BN8HH0BSksGbscvK4v2cHD4cMgQ7O/PqEAvDkZWdxpOens5rr73GG2+8wS+//ML06dOt7u9ixYoVee6551i8eLHapVgk8ziy7PhxaNy4eAtZCsPGBlq21G2VEALdnjFfX1+uXLki96YZUGxsLIMGDcLX15fFixdTpkwZtUtSTVxcHJ06deLs2bM4OTmpXY5FMY8e36efgjFX1OXlQUyM7sQXIYAqVaqg0Wi4dOmS2qVYpLy8PBYuXEjnzp158803WbVqlVWHHkD9+vVp3Lgxq1atUrsUi2P6wZeWptu2kJtr3HZzcmDRIuO2KUyWRqORK4oMJCkpiZ49e7JmzRoiIyN58cUXpVd9h2xoNwzTD77163VDj4AHUBFIu+fL3wId7r4V8ANKAeWBZ4AE4DKgAZLv+dyM/3it+93f5OZCSAhotfr6ToSZkyuK9G/Dhg00btyYZs2asXPnTmrVqqV2SSalc+fOaDQaNm/erHYpFsX0g2/Hjvu2L2iBR/XDTgEvAguAm+gCbwxgC1QBagM77n0sUPcRr7W/96G2tnDiRLG/BWEZpMenPxkZGbz++uu89tprrFmzhk8++QR7e3u1yzI5sqHdMEw/+Hbvvu+3U4D5wI0H3hYD1AQ6oevJlQSCgOp3vt6ef0NOCxwExj3w2l4eCD6AAweKVb6wHNLj04/Dhw/TvHlzrl69SkxMDO3bP/S3Ttxj8ODBxMbGcuTIEbVLsRimH3wnT97322bohjbnP/C2JsAxYAKwDXhwi/u9wRcN+KALyXtfywFa3Puh27fh4MHiVC8siLe3N4mJiaSlpT35zeIhiqLw+eef88wzzzB58mR++ukn3Nzc1C7L5Dk6OvLaa6/JDe16ZNrBpyi68zQf8BHwBXDv1k5P4C/gItAf3RzfcP4NQH/gCLqe4k6gHVDnzjPuvvY08NBFRdeuFfvbEJbB3t4eHx8fDh8+rHYpZic5OZlnn32WH3/8kb179zJ8+HBZwFIIr776KqGhoSQnJz/5zeKJTD/4HqEB0AuY/cDrTwNr0YXZTnS9uRl3vuYBVLvn9XZ3Xm99z2uPHHCRxS3iHjLPV3i//fYbfn5+NG7cmN27d1O7dm21SzI7FSpUoH///rKhXU9MO/hsbOA/TmyYDixF18N7lOZAILpe3l13hzv3ogs80AXgDmAX/xF8ZnqbszAMmecruMzMTMaOHcurr77K6tWrmTFjhixgKYbx48ezePFiMox1kIcFM+3gA3B3f+TLtYEBwOd3fr8LXRBeufP7Y8Cv6HqBd7UHfgCqotvyAND2zms3gVYPNuLiAo0aFat8YVmkx1cwR44coUWLFly+fJmYmBi5vV4PfHx8aNasGStXrlS7FLNn+sH39NP/+aX3+XdPXxl0QdcQcEW3H68fMPWe9/ujC8a297zmB2QATQGXBxuwtYWmTYtaubBAvr6+HD58mLy8PLVLMUmKovDll1/SsWNHxo8fz9q1aylbtqzaZVkM2dCuH6Z/8mv79rBuHWRkcPaBL7kDmff8PuIJj/IGHvzjYgvc+o/3596+zfoTJ+jq7U3JkiULWrGwYGXKlKFcuXKcPn2aOnXqqF2OSbly5Qovv/wyycnJ7NmzR/7vYwDPPPMM9vb2/P7773Tv3v3JHxCPZPo9vr59dWdnGpmi0XCxXj2W/vAD1apVo1evXnz77bdcuXLlyR8WFk3m+R62adMm/Pz8aNiwIbt375bQMxDZ0K4fph98VapA585g5KXPmhIlqPHll2zatInExESGDBnC5s2b8fLyol27dixYsIAzZ84YtSZhGmSe71+ZmZmMHz+ekSNHsnLlSmbNmoWDw0ObgoQeDRw4kCNHjsi2mmIw/eADmDpVt9DEmMqVA39/AEqXLs2gQYNYs2YNycnJvPXWWxw/fpxWrVrRqFEj3n//faKjo2Xc3UpIj08nLi6Oli1bkpiYSGxsLB07dlS7JKvg6OjImDFjWLhwodqlmC3zuI8PdLev//677iZ2Q3NxgQ0b4Akr0bRaLZGRkaxbt47w8HBycnIICAigX79+tG3b1uouz7QWZ86cwd/fn8TERLVLUYWiKCxevJj333+f2bNnExwcLJvRjSwlJYU6deoQHx9P5cqV1S7H7JhP8KWkQO3acPOmYdtxcoIhQ+Dbbwv1MUVRiIuLyw/B8+fP06tXLwICAujSpQsuxu6xCoPJy8vDzc2NM2fOUK5cObXLMaqrV68SHBzMxYsXWbVqFd7e3mqXZLVGjx5NhQoV+Oijj9QuxeyYx1AnQPnyunv5nJ0N14adHVSuDEU4E0+j0dCgQQPeffddDhw4wIEDB2jSpAmLFi2iSpUqBAYG8sMPP3BNjkAzezY2NjRq1Mjq5vn++OMP/Pz88PHxYe/evRJ6Khs/fjxff/21bGgvAvMJPoBeveCLLwwTfnZ2ULGi7jYIV9diP6569eq88cYb/Pnnn5w5c4aAgADCw8Px8PCgU6dOfPHFF5w/f14PhQs1WNM8X1ZWFhMnTiQ4OJiQkBDmzJkjC1hMgLe3Ny1btiQkJETtUsyOeQUfQHAwfPedLvz0Na/g4gI1a8Lff0PVqvp55j3KlSvHiy++SHh4OElJSYwdOza/R9isWTM++eQTjhw5IotjzIivr69VBN/Ro0dp2bIlZ8+eJSYmhmeeeUbtksQ9Jk6cyMKFC+VAhUIyv+ADGDRId11QgwbFX+3p7AxjxsDhw7qtEwbm4uJC3759Wb58OUlJScyfP5+rV6/y7LPP4uXlxZQpU9i9e7f8QTZxfn5+Fj3UeXcBS/v27XnttdcIDQ21uvlMc9ChQwecnJzYtGmT2qWYFfNZ3PIoWq1uPm7WLN1qz9TUgn3O3l43tOnrqxs6bdbMoGUWhKIoREdHs27dOtatW8eVK1fo06cP/fr145lnnsHR0VHtEsU9MjIyKFu2LDdu3LC4/9+kpKQQHBxMYmIiq1atom7dumqXJB4jJCSEFStWsGXLFrVLMRvmHXx35ebqth98+ilERYFGQ5ZWi0arxcHe/t9bHtLTdfvzgoJg3Dgw4dMlTp06xfr161m3bh2HDx+mW7du9OvXjx49elC6dGm1yxNA/fr1WblyJX5+fmqXojdbtmxh+PDhDBo0iE8++cTiQt0SZWdnU7NmTX777Td8fX3VLscsWEbw3UtRICGBHydNoizQs0sX3RaFmjWhSRMww9BITk4mIiKCdevWsWPHDlq3bk2/fv3o06cPVYwwPCsebfDgwXTt2pXhw4erXUqxZWVl8c4777B69WqWL19Oly5d1C5JFMKsWbM4fvw4y5cvV7sUs2B5wXfHiBEjaNmyJSNHjlS7FL1KTU1l06ZNhIeHs3HjRurWrUu/fv0ICAjAy8tL7fKsyty5c7l8+bLZn6Bx7NgxBg8ejLu7O9999x3ly5dXuyRRSNeuXaNWrVocPXpUfhguAPNc3FIAV69epUKFCmqXoXclS5bk+eefZ9WqVSQnJzN9+nQSEhLo0KED9erV45133iEqKkpWiBqBua/sVBSFJUuW0LZtW0aNGsW6desk9MxU2bJlGTx4MP/3f/+ndilmwWJ7fK1bt2bu3Lm0bdv2yW+2AHl5eURFRREeHk54eDhpaWkEBAQQEBCAv7+/3HxtAMnJyfj4+PDPP/+Y3ZFd//zzDyNGjCAhIYHVq1fj4+OjdkmimE6cOEGbNm04d+6cnBT1BNLjsxA2Nja0bNmS2bNnc/z4cbZs2UK1atV45513qFSpEi+88AKhoaGkpaU9+WGiQCpVqoSDg4PZndm5detWfH198fT0ZN++fRJ6FsLLy4vWrVvzww8/qF2KybPYHp+bmxunT5+W25+Bixcv5q8QjYyMpEOHDgQEBNC7d2+r+uHAELp3786YMWPo3bu32qU8UXZ2Nu+++y4rV65k2bJldO3aVe2ShJ5t376dUaNGER8fj42NxfZris0i/y+Tk5PD7du3KVOmjNqlmIRq1arx2muv8ccff3Du3DkGDBjAxo0bqV27Nv7+/ixcuJCEhAS1yzRL5jLPd/z4cVq3bk18fDwxMTESehaqffv2uLq68ttvv6ldikmzyOBLSUmhbNmy8hPPI7i5uTFkyBB+/vlnkpKSmDJlSv69an5+fnz44YfExsbK4pgCMvUTXBRF4dtvv6Vt27a8/PLL/Prrr9LLt2ByQ3vBWORQ5+HDhxk0aBBHjhxRuxSzodVq2bNnT/61SkD+4pg2bdpga2urcoWmKT4+nt69e3Pq1Cm1S3nItWvXGDlyJKdOnWLVqlXUr19f7ZKEEWRnZ+Pp6UlERASNGzdWuxyTZJFdoqtXr8qy7EKytbWlXbt2LFiwgNOnT7Nu3TpKly7NuHHjqFKlCsHBwURERMgVKA+oU6cOly9fJrWgx+UZybZt2/D19aV69ers27dPQs+KODg48MYbb5j9/lJDstjgk+GcotNoNDRq1IgPPviA6Oho9u/fT8OGDVmwYAGVK1fmueee48cff+T69etql6o6Ozs76tevz6FDh9QuBdD9tP/mm28yZMgQli5dysKFC3FyclK7LGFko0aNIiIigosXL6pdikmyyOBLSUmR4NMjDw8Pxo8fz19//cXp06d59tln+fnnn6lRowZdunTh//7v/7hw4YLaZarG19fXJOb5Tpw4QevWrTly5AgxMTF0795d7ZKEStzc3Bg6dKhsaP8PFhl8MtRpOOXLl+ell15i/fr1XL58mdGjR7Nv3z58fX1p0aIFM2fO5OjRo1a1OEbtS2kVReH777+ndevWDB8+nIiICCpWrKhaPcI0jBs3jm+++Ub27j6CxQaf9PgMr0SJEgQGBvLDDz+QlJTErFmzuHz5Mt26daNu3bpMmzaNyMhIi79bUM0e3/Xr1+nfvz8LFy7kr7/+4vXXXze7U2SEYdSuXZt27dqxYsUKtUsxORYZfDLUaXz29vZ06tSJL774gvPnz7Ny5Urs7e0JDg6mWrVqvPrqq/z+++9kZ2erXareNWrUiCNHjqDVao3a7vbt2/H19aVq1apERUXRoEEDo7YvTJ/c0P5oFhl80uNTl0ajoVmzZnzyySfExcWxfft2atWqxfTp06lUqRKDBg1i7dq13Lp1S+1S9aJUqVJUrlyZkydPGqW9nJwc3n77bQYNGsSSJUtYtGiRLGARj9S2bVvKlCnD//73P7VLMSkWG3wyx2c6vLy8mDJlCnv27OHo0aN07NiRZcuW8dRTT9GzZ0+WLl1KcnKy2mUWi7Hm+U6dOkWbNm2IiYkhOjqaHj16GLxNYb5kQ/ujWeQG9ipVqnDgwAGqVq2qdiniMW7dusVvv/3GunXr2LRpE/Xr18+/W7B27dpql1dg167BhAk/cu5cedzcunPrlu4+5NKloXlzaNYMmjaFcuWK3oaiKCxfvpypU6fy/vvvy1yeKLCcnBw8PT1Zt24dTZs2Vbsck2BxwacoCg4ODqSlpeHg4KB2OaKAsrKy+PPPP1m3bh3r16+nQoUK+SfHNGnSxOT+kddq4fffYc4ciIwEO7scMjJAUe6//sneHlxcICNDF4LTpkHPnlCYg3CuX7/OK6+8wtGjR1m9ejUNGzbU83cjLN28efOIjY3lxx9/VLsUk2BxwXf9+nU8PDy4efOm2qWIIsrLyyMyMjL/+LSsrKz8EGzfvj12dnaq1rd1K7zwAty+DYU9sKVkSShRApYvh27dnvz+HTt28MILL9CnTx/mzp2Ls7NzkWoW1u3GjRt4enpy6NAhnnrqKbXLUZ3FBd+JEyfo2bOnSZ6dKApPURSOHj2aH4IJCQn06tWLgIAAunXrZtQLN1NTYexYWLNG14MrDhcXCAyEL7/UDYk+KCcnh+nTp/Pdd9/x7bff8uyzzxavQWH1xo0bh7OzM7Nnz1a7FNVZXPDt2bOHSZMmsXfvXrVLEQaQmJjI+vXrCQ8PJyoqimeeeSb/bsFyxZlEe4LkZGjbFi5cgMxM/TzTyQkqV4bdu+He6ejTp08zZMgQ3NzcWLZsGZUrV9ZPg8KqnTlzhhYtWnD27FlcXV3VLkdVFreqU1Z0WjZ3d3def/11tm7dytmzZwkKCuLXX3+lZs2adOzYkc8//5xz587ptc2rV6FFCzh7Vn+hB7pnXbige3Zysq53u2LFCp5++mkGDhzIhg0bJPSE3nh6euLv78/y5cvVLkV1Ftfj+/bbb9mzZw/ff/+92qUII0pPT2fLli2Eh4cTERFB9erVCQgIoF+/fjRo0KDIi2O0Wt2KzKNHISdHz0XfYWcHtWppadToReLiYli1ahW+vr6GaUxYtd27dzNs2DCOHz9u1VeNWVyPT05tsU4uLi706dOHZcuWkZSUxMKFC7l27Rq9e/emdu3aTJ48mV27dhX6dJW5c+HUKcOFHkBuLpw4kUVCwiD+/vtvCT1hMK1bt6ZcuXJERESoXYqqLC74ZKhT2NnZ4e/vz2effUZCQgK//PILJUqUYMyYMVStWpWRI0eyYcMGMp8wbnnsGHz8MRjjjF9FcSEurhenT8uqTWE4sqFdxyKDT3p84i6NRkPjxo2ZPn06sbGx7NmzBx8fH+bMmUPlypXp378/q1at4saNGw999q23ICvLeLVmZur2+QlhSEFBQZw7d46oqCi1S1GNxQWfDHWKx6lVqxYTJ05kx44dnDhxgm7durF69WqqV69Ot27dWLx4MZcuXeLKFdi0CYx5tq+i6PYIXrpkvDaF9bGzs2Ps2LFWfUO7xQWfDHWKgqpYsSLBwcH5N1WPHDmSXbt2Ub9+fZo0+ZrcXANO7D3G11+r0qywIiNGjGDTpk0kJiaqXYoqLG5Vp4eHB3/++Seenp5qlyLMVHZ2NvXqZXL6dKkCvHsXMBWIA2wBH+AzoPmdr98GKgPtgI0Far9ePYiLK2TRQhTShAkTsLe3Z+7cuWqXYnQWF3yurq5cvnyZkiVLql2KMFN5ebpjxZ68Z+8WUB1YDPQHsoGd6IKu0Z33rAAmAjeBC3e+9ngODroFNSqfzCYsXEJCAs2aNePs2bNW9++lRQ11ZmRkkJOTY/WnEojiOXmyoIdIn7jz30HoenvOQFf+DT3QBd+rd14r2AHBDg66FaVCGFLNmjV55plnWLZsmdqlGJ1FBd/dFZ2mdpK/MC+JiQXtbXmhC7xh6IYxrz/w9XPAX8CQO79+KFD7trZw/nwBixWiGCZOnMhnn31W6P2t5s6igk9WdAp9KPgWhlLo5vg0wEigAtAHuHupbgi6nl49YCC6ecDoJz5VUYy7jUJYr1atWlGpUiXWr1+vdilGZVHBJys6hT7Y2z/5Pf/yAZajm787AlwCxt/52g/oenoA1QB/dEOfj6fR6IY7hTAGa9zQbnHBJz0+UVwVKhR1/15dYDi6ANwDnARmoVvQUhnYB6wCch/7FEVRkJ/fhLH069ePCxcusG/fPrVLMRoJPiEeUK9eQW9hOAYsQNfbA0gEVgNPo+vZdQGOAjF3fh0BMnjStoZbt3KZMKETY8eO5fvvvyc6Oprs7OzCfyNCFICdnR3jxo2zqg3tFhV8Mscn9MHREWrUKMg7S6LrxbUESqALvAbownAt8Ab/9vYqAzWBF3jScKe7uw2ffPIOHh4ebNu2jRdeeIEyZcrg5+fHSy+9xOeff86OHTu4detWEb9DIe4XHBzM5s2b9X6ll6myqH18o0aNokmTJrz66qtqlyLM3Jgx8M03upsTjMnWFoYPh2+/vf/1jIwMjhw5QnR0NDExMURHR3P48GEqVapE48aN83/5+flRpUoVWdksCm3SpEloNBrmz5+vdikGZ1HB169fP4YOHUpQUJDapQgzd+wYNGkCGRnGbdfZGfbtg4YNn/xerVbLyZMniY6Ovi8QbWxs8kPwbiDWrl0bGxuLGuARenbu3DmaNGlCQkICpUoV5NQi82VRwdeuXTtmzJhB+/bt1S5FWIDmzfP4+2/jhoWfH0Q/ecfDf1IUhYsXL+aH4N1AvHr1Ko0aNbovEOvXr4+Tk5Peahfmb8CAAbRq1Yrx48erXYpBWVTw1a1bl7CwMOrVq6d2KcKMKYpCaGgoY8f+ypUr36DVGiccXFzgl1+gRw/9P/vGjRvExMTcF4inTp2idu3a94Whn58fZcqU0X8Bwizs27ePgQMHcvLkSews+Mw8iwq+cuXKcezYMVngIops7969TJo0iczMTObPn8933z1DWFhBV3kWnaMj9OkDa9catp17ZWZmEhcXd98w6aFDhyhfvvx9c4aNGzemWrVqMm9oJdq0acOECRN47rnn1C7FYCwm+HJzc3FyciIrKwvbgh20KES+M2fO8NZbb7Fnzx5mzJjB0KFDsbGx4eZNqF0bUlIM237ZsnDqFLi5GbadJ9FqtZw+ffqhecO8vLz75gz9/Pzw8vKSv2sWKDQ0lAULFrBnzx61SzEYiwm+K1euUK9ePVIM/S+UsCjXr19nxowZLF++nAkTJjBhwgRcXFzue8/Bg+DvD7dvG6aGEiVg2zZo3vzJ71WDoigkJSU9FIZJSUk0bNjwvkBs0KABzs7OapcsikGr1VKnTh1WrlxJq1at1C7HICwm+OLi4njuueeIj49XuxRhBrKzs1m8eDEzZswgMDCQDz/8kMqV//vKoH37oEsXXfjp82+Mq6vupvc2bfT3TGO5efMmhw4dui8Qjx8/jqen50O9w7Jly6pdriiERYsWsXv3btYac+zdiCwm+LZv3857773Hjh071C5FmDBFUQgLC2PatGl4e3szd+5c6tevX6DPxsdDv3662xvS04tXh4sLVK0K4eHQoEHxnmVKsrKyOHr06H2LaGJjY3Fzc3toi4W7u7vMG5qo1NRUPDw8OHDgAB4eHmqXo3cWE3y//PILq1atIiwsTO1ShInat28fkyZN4vbt28yfP5/OnTsX+hk5OTBjBsydC1otFPYkMQcH3Sb1CRPggw+s4zDqvLw8zpw5c98w6d1j2B7sGXp7e1v0akJzMmXKFLRarUUeYG0xwbd48WJiYmJYsmSJ2qUIE5OQkMBbb73Frl27+OSTT3jhhReKvSjj/Hn48kv4+mvdbQppabogfBRbW908nqLAqFHw+utggT9EF1pSUlJ+EN7978WLF6lfv/59YdioUaOH5l2F4Z0/fx4/Pz8SEhIoXbq02uXolcUE30cffUR2djaffPKJ2qUIE3Hjxg1mzJjBsmXLGDduHBMnTqREiRJ6bSMrC7Zu1c0Bbt+uGw7NzNSFnJMT+PjoFsa0aKGbI3R01GvzFic1NTV/3vBuGMbHx+Ph4fFQ71CuIDO8QYMG0bx5cyZOnKh2KXplMcE3duxYPD09Lf7EAfFk2dnZfP3118yYMYO+ffvy0UcfPXbhijBt2dnZHDt2LH+I9G4olipV6qF5wxo1asi8oR7t37+f559/ntOnT1vUELTFBN+gQYPo1asXQ4YMefKbhUVSFIV169Yxbdo0atWqxbx582hgSStHRD5FUUhISHjoaLa0tLT7TqFp3LgxdevWxb5wtwuLe7Rr14433niD/v37q12K3lhM8HXu3JmpU6fStWtXtUsRKti/fz+TJ0/m5s2bzJs3T/4cWKkrV648dDTb+fPnqVev3kPzhq6urmqXaxbCw8OZPXs2kZGRj+xNa/O02GhszKqnbTHB5+fnx/fff0+TJk3ULkUY0dmzZ3n77bfZvn07H3/8McOGDZPTRMR90tLSHpo3jIuLw93d/aGj2SpWrKh2uSZHq9Xi5eVFSEgIZb3KEnE8gu3ntnPg8gGupF0hT8kDwMXeBZ/yPrSv0R7/Gv70rNMTe1vT7GlbTPBVq1aNyMhI3N3d1S5FGMGNGzeYNWsW3377LWPHjmXy5Ml6X7giLFdOTg7Hjx9/6DQaFxeXhxbReHp6mlVvRt+0eVpGLRxF+JVwMktlolW0ZGv/ex+PBg2uDq7Y2tgypvkYxjQfQ5WSVYxY8ZNZRPApioKjoyM3b96U45IsXE5ODkuWLOHjjz+md+/efPzxx1SpYlp/qYR5UhSFc+fOPTRveOvWLXx9fe8LRB8fHxysYBPm8ZTj9P+lP6evnSYtJ63Qn3e0dcTOxo4FXRcwqukok/kBwiKC79atW1StWpXbhjpMUahOURR+/fVXpk6dioeHB/PmzaNRo0ZqlyWsQEpKCrGxsfeFYUJCAnXr1r1vmNTX15eSJUuqXa5eKIrCwsiFvPvnu2Rps/KHM4uqhH0J/Cr7Edo/lEqulfRUZdFZRPCdPn2azp07k5CQoHYpwgD+/vtvJk2axLVr15g/fz7dunVTuyRh5dLT0zl8+PB9vcMjR45QtWrVh+YNzW0rjaIojNs0ju+ivyM9p5hn893DzsaOSiUqsSd4D9VLV9fbc4vCIoIvMjKSsWPHsn//frVLEXp07tw53nnnHbZt28ZHH33E8OHDZeGKMFm5ubmcOHHioaPZHBwcHpo3rFWrFjY2NmqX/EhTNk/hq6iv9Bp6d9lqbKnsWpkDow6o2vOziOD73//+x+LFi9mwYYPapQg9uHnzJrNnz2bp0qW8/vrrTJ48WZaeC7OkKAoXLlx4aBHNtWvXHpo3rFevHo4qH+2z/th6BocNNkjo3WVnY0eLqi3Y9fIu1eb8LGIr/tWrV+X4IguQk5PD0qVL+eijj3j22WeJjY2lWrVqapclRJFpNBrc3d1xd3enT58++a9fu3Ytf95w27ZtLFy4kNOnT+Pl5XVfGPr6+hrtnMxrGdcYvm64QUMPIDcvl9jkWJYeXMqopqMM2tZ/sZjgq1ChgtpliCJSFIWIiAimTp2Ku7s7v//+O76+vmqXJYTBlC1blo4dO9KxY8f81zIyMjhy5Eh+r/Cnn37i8OHDVKpU6aGj2apUqaL33tJrG14jPdewoXdXWk4aE3+fSG+v3qpsdbCI4EtJSZHgM1MHDhxg8uTJXLlyhYULF9K9e3eTWfIshDE5OzvTvHlzmjdvnv+aVqvl5MmT+cOkixYtIjo6Go1G89Aimjp16hR53vBy6mXWH1//2P15+pabl8tXUV/x8TMfG63Nuyxiju+ll16ibdu2BAcHq12KKKDExETefvtttm7dyvTp03nppZcs6hBcIQxFURQuXbr00Lzh1atXadiw4X2B2KBBA5ycnJ74zPe3vc+8PfPIzM00wnfwrzJOZbgy+YrRT3ixiH9pZKjTfNy6dYvZs2ezZMkSxowZw/Hjxy1m75MQxqDRaKhWrRrVqlWjV69e+a/fuHEjf95w165dfPHFF5w8eZLatWs/NG/o5uaW/zlFUfgq6qtHh95O4Bww9J7XPgfKPuK1jkBDYBuwHRgBPPX470Wbp2XjqY308e7z+DfqmQSfMIrc3FyWLl3K9OnT6dGjB4cOHZKFK0LoUZkyZfD398ff3z//tczMTI4ePZrfOwwNDSU2Npby5cvn9wqfqv8Uadn/cSpLDWAXkAfYAKmAFrj8wGvX7rxXAWIB5zv/fULw3c6+zbaz2yT4iiIlJUVWdZooRVHYsGEDU6ZMoVq1amzatAk/Pz+1yxLCKjg5OdGkSZP7Du/Py8vj1KlT+UOkX4R+QZZHFjxqJ0VVdEGXdOd/nwNqAtcfeM0NKAWcBW4DfYCNQDcemzIKCjvP7Szut1loFhF80uMzTdHR0UyaNImkpCQWLFhAjx49ZOGKECqzsbHBy8sLLy8v+vfvj81WGw7tPsQjl3vYoeu1nePfkKsOlHzgtRp33h8LeAH10QXfCaDe4+uJT4kv/jdVSKZ5dEAhZGVlkZmZabS9LuLJEhMTGTZsGD179mTAgAEcOnSInj17SugJYYLuvVrokWqgCzeA83d+X/2B1zyAbCAO3TyfLbrAi31y++k56Y8OXQMy++BLSUmhXLly8o+qCUhNTeXdd9/Fz88Pd3d3Tpw4wSuvvCKrNYUwYTl5OY9/Qw104ZYOpAHlAHcg8c5rV+685xi6RKlz53MNgZN3PvMYGjRoFW0Rqy8as/8XSYY51Zebm8t3333Hhx9+SNeuXYmNjeWpp54wqy2EMAku9i6Pf4M7kAkcRNfTA3BCN9x58M5/3YAIdL2+hfd8Ng84DDz934/XaDTY2Rg3iiT4RJEpisLGjRuZMmUKlSpVYsOGDfdNogshTJ93OW+c7Jz+ew+fPbq5vL1Au3ter37nNU/gFpAADAHuPXs6Et1w52OCr2IJ4996b/bBJys61RETE8PkyZO5ePEi8+bN49lnn5XhZiHMUNOqTXGwdXj85nUP4AL/9vi487/3oxvmjAUqA7Uf+FxLdOGYzP2BeG/7VZoWqe7iMPvgkx6fcV28eJF3332XjRs38sEHHzBy5EiZwxPCjPlV9nvywdSd7/y6V4M7v+5qx8NKAe//92MdbB3wr+H/328wELNf3CLBZxypqam8//77NGrUiKpVq3LixAlGjx4toSeEmXN1cKVJFXWmKGw1tvTy6vXkN+qZ2QefDHUa1t0TV7y9vTl79izR0dHMmDGDUqVKqV2aEEJPprWZRkkH4x8d2KBiA3wq+Bi9XbP/cV16fIahKAqbNm1iypQplC9fnoiICJo2Nf5YvBDC8Pp49zH6QdGuDq5MbTPVqG3eZfY9Pgk+/YuNjaVr165MmDCBmTNnsm3bNgk9ISyYnY0dn3X7jBL2JYzSno3GhlputehXt59R2nuofVVa1SMJPv25dOkSL7/8Ml27diUgIIDDhw/Tp08fWa0phBUY2mgoTz/1NPY2hu/5Odo6sua5Ndja2Bq8rUcx++CTOb7iu337Nh988AENGzakUqVKnDhxgjFjxmBvb9yhDyGEejQaDT/0++HJG9qLycXehY+f+Rjv8t4GbedxzDr48vLyuHbtGuXKlVO7FLOk1Wr59ttv8fb25vTp0xw8eJBZs2bJuadCWKmqJauybdg2gy10cbF34WW/l5n49ESDPL+gzHpxy7Vr1yhVqpT0TIrg999/Z/LkyZQtW5b169fTrFkztUsSQpiAxlUas+OlHXRc0ZG07LQnn+VZQC72LoxuNpp5XeapPn1i1sEnw5yFd/jwYSZPnszZs2eZO3euzOEJIR7iV9mPo68d5YXwF4i8EElazhNOmn4MB1sHXOxdWBGwwugXzv4Xsx7qlIUtBXfp0iVGjBhB586d6d27N0eOHKFv374SekKIR6pSsgqbX9jMV89+hZuTW6GHP53snHC0dSSgbgCnx542mdADCT6Ll5aWxvTp02nYsCHlypXj+PHjvP766zI8LIR4Io1Gw4u+L3JlyhVWBKygRbUW2NnYUcqxFE52Tve91wYbSjmWwtnOmbLOZZncajJnxp1hzXNrKOtcVqXv4NFkqNNCabVaVqxYwXvvvYe/vz8HDhzAw8ND7bKEEGbIzsaOfj796OfTj7TsNGKSYjhw+QDxV+NJz0nHwdaBiiUq0qxqM5pWbYp7KXeTHk0y6+CTHt+jbd68mcmTJ1OqVCnCw8Np0aKF2iUJISxECYcStKnehjbV26hdSpGZffBVr179yW+0EkeOHGHKlCmcOnWKuXPnEhAQYNI/dQkhhBrMeo5Phjp1kpKSGDVqFJ06daJHjx7ExcXRr18/CT0hhHgEsw4+ax/qTEtL4+OPP6ZBgwaULl2a48ePM3bsWBwcHNQuTQghTJYEnxnSarUsX74cb29vjh49SlRUFPPmzaNMmTJqlyaEECbPrOf4rHGoc8uWLUyePBlXV1dCQ0Np2bKl2iUJIYRZMdvgUxTFqnp8cXFxTJkyhRMnTjBnzhwCAwNlDk8IIYrAbIc609LS0Gg0lChhnPuj1JKcnMwrr7xCx44d6dq1K0ePHiUoKEhCTwghishsg+/q1asWPcyZnp7OJ598Qv369XF1deX48eOMHz9eFq4IIUQxme1QZ0pKikUOc+bl5RESEsK7775L69at2b9/P56enmqXJYQQFsNsg88S5/f+/PNPJk2ahLOzM2vXrqVVq1ZqlySEEBbHrIPPUoY64+PjmTJlCvHx8cyZM0fm8IQQwoDMdo7PEoY6k5OTGT16NP7+/nTq1ImjR4/y3HPPSegJIYQBmW3wmfNQZ0ZGBjNnzqR+/fo4Oztz7NgxJkyYgKOjo9qlCSGExZPgM6K7C1e8vb2Jjo4mMjKSTz/9lLJlTeuuKiGEsGRmO8dnbqe2bNu2jcmTJ+Pg4MBPP/1E69at1S5JCCGsktkGn7n0+I4dO8bUqVM5cuQIs2fP5vnnn5c5PCGEUJEMdRrIlStXGDNmDO3atcPf35/4+Hj69+8voSeEECoz2+Az1aHOjIwMZs+eTb169bC3t+fYsWNMmjRJFq4IIYSJMMuhzpycHG7fvo2bm5vapeTLy8tj9erVvP322zRr1oy9e/dSp04dtcsSQgjxALMMvpSUFMqWLYuNjWl0WLdv386kSZOwtbVl5cqVtG3bVu2ShBBC/AezDT5TGOY8fvw4U6dO5dChQ8yaNYv+/fubTBgLIYR4NLP8V1rthS1Xr17l9ddfp23btrRt25b4+HgGDhwooSeEEGbALP+lViv4MjMzmTNnDj4+PtjY2OSfsenk5GT0WoQQQhSNWQ51GvuA6ry8PH766SfefvttmjRpwp49e/Dy8jJa+0IIIfTH5INPURROXz/NgUsHOHvjLJm5mWxP2Y5zRWf2XdiHb2VfnOwM1+PasWMHkydPRlEUfvjhB9q3b2+wtoQQQhieRlEURe0iHqQoCnsS9zBvzzz+OP0HNhobbDQ2ZORkkKvkggL2GnucHZ1Jz0mnTtk6TGo1iUENB+Fi76KXGk6cOMG0adOIjo5m5syZMocnhBAWwuSCb9OpTYzZMIbktGTSc9JRKFh5rg6uKIrCmOZjmN5xepF7gSkpKXz00UesWrWKqVOnMnbsWJnDE0IIC2IyXZibmTcZHDqYoLVBnLlxhrSctAKHHsDt7Nuk5aTxxf4vqPtlXfZf3F+o9jMzM5k3bx4+Pj4oikJ8fDxTp06V0BNCCAtjEj2+k/+cpN2ydtzIvEGWNksvz3S2c2Ze13mMaT7mse9TFIU1a9bw1ltv4evry5w5c/D29tZLDUIIIUyP6otbjqccp9V3rbiReaNQPbwnycjNYOrmqWTmZjKp1aRHvmfXrl1MmjQJrVbLsmXL6NChg97aF0IIYZpU7fGlpKdQ7//qkZKeotfQu5eLvQvf9/meAQ0G5L928uRJ3nzzTaKiopg5cyaDBw+WhStCCGElVP3XPvjXYG5m3TRY6AGk56QzImIEl1Mv888//zB+/HhatWpF8+bNOX78OEOHDpXQE0IIK6LaUGdYfBhbzmwhW5tt8LaycrPwX+TPtUXXGNB/AEePHqVixYoGb1cIIYTpUWWoU5unpcqCKlxNv2q0Nm21tizttJSX/F8yWptCCCFMjypjfL+d/I3M3Eyjtqm11bImcY1R2xRCCGF6VAm+ObvnkJqdavR2t5/dzsVbF43erhBCCNNh9OC7nX270JvLCQH+fMTrx4B5gLZgj7HR2BBxIqJwbQshhLAoRg++mKQYnO2dC/chP+AQPLT4MxZoBNgW7DHpuensPL+zcG0LIYSwKEYPvr8v/U1WbiFPZ6kLZADn7nktAzgB+BbuUZGJkYX7gBBCCIti9OA7cuVI4Y8lswfqo+vh3RUHlAcqF+5RF1IvFO4DQgghLIrRgy81q4iLWnyBo0DOnd/HohsCLaQcbc6T3ySEEMJiGT347GyKuGe+BuCCbkHLNeAi0LDwj7HRyCktQghhzYx+ckuFEhWK/mFfdD29f4BagGvhH1HohTVCCCEsitG7P82qNsPVoQiJBbrgOwMcoEjDnAA+5X2K9kEhhBAWwejB17RK04e3JRSUG+CObp6vCFfmadDQvkb7IjYuhBDCEhh9qNOrnFfxbmMoxlGbrg6utK3etugPEEIIYfaM3uOztbHlRd8XsbexN3bTaDQaetbpafR2hRBCmA5VljiOazkOW5sCHreiJw62Drza9FUcbB2M2q4QQgjTokrweZf3ptVTrYq+taEI7DR2vN7idaO1J4QQwjSptqltecByHG0djdJWCfsSfNTxI9xLuxulPSGEEKZLteCrXro687vOp4R9CYO2Y6uxxaucFxNaTTBoO0IIIcyDqseYvNL0FXrU6YGLvYtBnq9BQxmnMoQPCJcTW4QQQgAqB59Go2F10Go61eyk9/Cz0dhQ1rksu17eRY0yNfT6bCGEEOZL9W6QnY0d4QPCCW4crLfwc7F3waucF1Ejo6hbvq5enimEEMIyaBRFKcZucv3aeW4nA34ZwM2sm6TnpBf687YaWxxsHXiz7Zu83e5to64aFUIIYR5MKvgA0nPSWfL3EhbsXcDNrJukZac98aSXEvYlyFPyGNhgINPaTMO7fBHOMxNCCGEVTC747lIUhT8T/mTdsXXsPL+TYynHAN3JL4qikJOXQxXXKrSo1oJutboxoMEASjmWUrlqIYQQps5kg+9BeUoe1zKukZGTgb2tPaUdS8sVQ0IIIQrNbIJPCCGE0AfVV3UKIYQQxiTBJ4QQwqpI8AkhhLAqEnxCCCGsigSfEEIIqyLBJ4QQwqpI8AkhhLAqEnxCCCGsigSfEEIIqyLBJ4QQwqpI8AkhhLAqEnxCCCGsigSfEEIIqyLBJ4QQwqr8P8LqKitJCVG2AAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "solution = min_conflicts(australia_csp)\n",
+ "print(solution)\n",
+ "draw_graph(australia_csp, solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 28,
+ "id": "f8dae006",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'SA': 'R', 'WA': 'G', 'NT': 'B', 'Q': 'G', 'NSW': 'B', 'V': 'G'}\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAb4AAAEuCAYAAADx63eqAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAABDWUlEQVR4nO3dd3yN5//H8ddJTvayKTUigiqNvSJG7aL1s6lNjZq1OhRV2m/Vbqm2aY2KqFBUbWqXIrEa42unZikZsnNyzu+PG18jyEnOOfcZn+fjkUfjjPv6pNW8z3Xd19AYDAYDQgghhINwUrsAIYQQwpIk+IQQQjgUCT4hhBAORYJPCCGEQ5HgE0II4VAk+IQQQjgUCT4hhBAORYJPCCGEQ5HgE0II4VAk+IQQQjgUCT4hhBAORYJPCCGEQ5HgE0II4VAk+IQQQjgUrdoFCPuVmQlnzkBUFPz9N6SkgKsrFCwIVapAUBB4eqpdpRDC0UjwCZPS62HHDvjyS9i9Wwk6gKQkeHDyo4cHuLhAcjIEBsKYMdCli4SgEMIyNHIQrTCVX36B4cMhIQESE7P/Pm9vJRSHD4dJk8DNzXw1CiGEBJ/Itdu3oW9f2LlT6dnllKcnFC4MK1dCtWqmq08IIR4lwSdy5fhxeP11pYeXnm6aa3p4wNdfQ79+prmeEEI8Su7xiRw7dgzq14d790x73ZQUZdgzLQ3efde01xZCCOnxiRy5dg0qVoS4OPO14ekJy5fDm2+arw0hhOOR4BNGMxigYUPYvx90OvO25ecH589DgQLmbUcI4ThkAbsw2qJFyto8c4ceKMOeffuavx0hhOOQHp8wSlqasgDd1Pf1nsfLC7Ztgzp1LNemEMJ+SY9PGGXVqv8tRLeUlBSYOdOybQoh7Jf0+IRRXnsN/vrL8u26uyvbnhUsaPm2hRD2RZYziGy7dQvOns3OK0sBycAlwOv+Yz8AnwO3HnldEuAJaO7/eRMQkuUVtVrYvBl69DC6bCEAyNRncvrf00Rdj2L/1f3ExMWQlpmGm7MbpfKUom7xulR7qRrlC5TH2clZ7XKFGUnwiWyLilJ6Xmlp2Xl1JjAX+OiRx0oAFx/5swY4DpR54dUSE+HAAQk+YbyrCVf55vA3LDi8AJ1BBwZIzHh6T71lfy0DQOukZWiNoQyuMZiiPkUtXa6wALnHJ7Lt0CFjtiQbC8wA4kzW/t69JruUcAAJaQn0WtuLwK8CmXVgFnFpcSSmJ2YZeoDyXHoicalxTN8/ndJzS9P3177cS7PgTC5hERJ8IttOnDBmCUN1oCFK+JlGTIzJLiXs3LYL2wj4KoCI6AhSM1NJy8zWMMVDaZlppGWmsTx6OWW+LsPvF383U6VCDRJ8ItuM34D6U+Br4LZJ2jfVXqDCvs06MIu2K9ryb/K/pGam5upaqbpUbiXdos3yNnx98GsTVSjUJvf4RLZpjf7bUhFoDXwBvJLr9jMz05k06TPy589Pvnz5yJcv32Pf58mTB2dnmZTgyGbsn8GkXZNIzkg26XVTdCl88PsH6A16RtQeYdJrC8uT4BPZlrOlBJOBqsDoXLfv7q5Do9Fw/vx57ty5w927d7l79+7D7xMSEvD19X1mMGb1ff78+fHz88PJSQY/bN26/64zS+g9kJyRzEc7PiIwfyBvBL5hljaEZcg6PpFt330Ho0YpJ6c/XymU5QtN7v/5HWA1UAnY9cjrNMA5sjOrE6BxY9i+/dnPZ2ZmEhcX91gYZuf7e/fu4efnl62QfPQxX19fCUwrcSf5DmW+KkNcWpzZ28rnkY/zw86T1yOv2dsS5iE9PpFt1arlZLgTYCKwNFdta7XQoMHzX+Ps7Ez+/PnJnz8/gYGB2b62Tqd7bmCeOXPm4fePPp+YmEiePHmyFZJPBqZGo3lxYSLb3vntHVJ0KRZpKyk9iUEbBrGiwwqLtCdMT3p8ItvS0iBPHkjN3XyBHPHxgbVrlUNvrYVOpyM2NvaZgfmsnmZycnKOAtPHx0cCMwsnb52kRmgNiwUfgIfWg6MDj1KuQDmLtSlMR4JPGKVnTwgPh8xMy7ZbqBBcvw72MHclIyPjqcDMztBsSkoKefPmzVZIPvq9t7e3XQdm/3X9WXxsMZkGy/2l1DppeafqO3zT6huLtSlMR4JPGOXYMQgOzs59PtPx8ICJE+GDDyzXpjVKT0/PUWCmpaXlKDC9vLysPjAT0xMpNL2QRXt7D3i6eHJ77G08XTwt3rbIHbnHJ4xSubJy8npkJOj1lmnTyQn697dMW9bM1dWVwoULU7hwYaPel5aWRmxs7DODMSYmJsvHMzIyHgZhdmfI5suXD09PT4sF5oErB3BxdjE++I4CB4C7gBvKapsmgHv2L6F10nLo2iEalmpoXNtCdRJ8wmjLlsFrrxlISTH/LzcvL5g7V05gzw03NzeKFClCkSJFjHpfamrqcwPz0qVLWd7XzMzMNHqGbL58+fDw8DA6MCOvR5KSYWTo7Qf+ANoCpYEEYAPK/Ku+QDaH01N1qURdj5Lgs0ESfMJoCQlH8PDYREbGGHQ6N7O1o9UqM0nlBHZ1uLu789JLL/HSSy8Z9b6UlJTnBuaFCxeyHJo1GAxGT/j5/eLvZOgzsl9cKrATeAt4MPE3L9ARZU/1v4DK2btUemY6uy7vYnTd3K9RFZYlwSeyzWAw8O233zJx4kTmzZvH8uVubN+uHBRrak5OyoSWiAiw8ttM4gkeHh54eHhQtKhxJxukpKQ8d4bsuXPnnnr+RvsbkN+IRq4AOp7eSMgNJQgvkO3gA7gUd8mIxoW1kOAT2XLv3j3eeecdzpw5w/79+wkMDKR9e2jTBvbtM+1kF61W2SVm/34w8naWsGEeHh4UK1aMYsWKZfs9/nP9uRx3OfuNJKMcAZnVcKY3cCP7lwKM3vxaWAfZdkK80IkTJ6hevTp+fn4cOHDg4eJwV1fYsAG6dwdPk01sSyIwMIWoKChZ0lTXFPbKxcnFuDd4ooRfVisfEu8/bwRXJ1fj3iCsggSfeCaDwcAPP/xA48aNmThxIt999x0eHh6PvUarVbYy27BB6Z3lNABdXJT3dukSjbNzbfLmVWGVvLA5Bb2M3EC2OMo41+knHk9D2T2vlJnbF1ZBgk9kKTExkZ49ezJnzhz27t3L22+//dzXN2wI58/D1KlQtCh4e2fv3py3tzJzc+BAOHkSwsNrEhgYwMcff2yaH0TYtZASITgZ82vMHWgAbEIJukwgFliJ0tt7LfuXctY406DkC/bRE1ZJ7vGJp5w8eZIOHTpQp04dDh06hGc2u3He3vDeezByJOzYAb/+qtz/O31aWfPn7Kz8MzNTGcasUweaNYP27R/tKWr4/vvvCQoKolWrVjRq1MhcP6awA7WK1cLbzZuEtITsv6keSshtRVnHlwmUBHoCRoxcerl6UaNYDSOqFdZCdm4Rj1myZAljxoxh+vTp9O7d2yTX1OshPl7Z69PFRdl30/UFv2A2bdrEwIEDOXHiBHny5DFJHcL+/JP4D6XmliJVl4uh8aMoSxz6Anmy/zZ3Z3eujLpCAU9ZZGprJPgEAMnJyQwdOpQDBw6wcuVKKlasqHZJDB06lNjYWJYtW6Z2KcKKtQhrwZYLW3J3keMoN34qZe/lGjS0KtuK37r+lrt2hSrkHp/gzJkz1KpVi4yMDA4fPmwVoQfw5ZdfcuTIEZYvX652KcKKja07Fm8X79xdJIhshx4ow5xj647NXZtCNRJ8Di48PJyQkBBGjBjBTz/9hLd3Ln+BmJCnpydhYWGMGDGCK1euqF2OsFKv+79OqTyl0GCZnQ6cNE4E5A0gpESIRdoTpidDnQ4qJSWFkSNHsnPnTlauXElQUJDaJT3TZ599xu+//8727dvlxHORpVO3T1H9++oWOaXBQ+vBsUHHKJu/rNnbEuYhv0Uc0Llz56hTpw7x8fFERkZadegBvP/++6SlpTFnzhy1SxFWqkLBCowPGW/2I4I8XTyZ3HCyhJ6Nkx6fg4mIiGDIkCFMnjyZwYMHW/15aw9cvHiRWrVqsWPHDipVMuJmjHAYeoOeDhEd2HJ+C8k60x8Y6an1pFXZVvzc4WecNNJnsGUSfA4iLS2N0aNHs2nTJiIiIqhWrZraJRlt0aJFzJ49m8OHD+PmZr5TIYTtysjMoOPKjmw4swGdRmey63q6eNKyTEt+7vAzWidZ/mzr5GOLA7h48SLBwcHcuHGDI0eO2GToAfTu3ZsyZcrIri7imVycXejq1BWvE164O7vnesKLBg3ooFOxTkR0jJDQsxMSfHZuzZo11K5dm549e7Jq1Sr8/PzULinHNBplV5fw8HB27typdjnCCp08eZKhQ4ayc8JODvQ/QEC+ALxdczZT2dvVm8D8gcytOJddn+ziXsI9E1cr1CJDnXYqPT2dcePG8euvv7JixQpq1qypdkkmI7u6iKzExcVRs2ZNJkyYQI8ePQDQ6XWs++86pv0xjRP/nMBJ40RyxrPv/3m6eGIwGAgqEsT7we/TumxrtE5aBg0aRFJSEkuXLrXUjyPMSILPDsXExNCpUycKFy7M4sWLyZcvn9olmdyQIUOIi4uTXV0EAHq9nrZt21KyZEm+/vrrLF9z9s5Zdl3exd6/9/LnlT/5N+VfdHodWictBT0LUvvl2tQrUY9GpRoRmD/wsfcmJSVRtWpVJk+eTJcuXSzxIwkzkuCzM7/99hv9+/dn3LhxjBo1ymZmbRorOTmZqlWr8sknn8gvIsGUKVPYsmULO3bswPVFG8HmUFRUFC1btiQyMpISJUqYpQ1hGRJ8diIjI4Px48fz888/8/PPP1O3bl21SzK7yMhI3njjDaKioihevLja5QiVbNy4kQEDBnD48GFeeukls7b1xRdfsHnzZn7//XecnbM6xl3YApncYgeuXLlCw4YNiY6O5siRIw4RegDVq1dnxIgR9O7dG71er3Y5QgXnz5+nT58+REREmD30AMaOHYvBYGDGjBlmb0uYjwSfjdu0aRM1atSgTZs2rF+/ngIFHOuIlPfff5/U1FTZ1cUBJSUl0a5dOyZNmmSxD3vOzs4sXbqUmTNnEhUVZZE2henJUKeN0ul0TJw4kZ9++onw8HDq16+vdkmqkV1dHI/BYODtt9/G1dWVRYsWWfxe9vLly5k8eTJHjhzJ9kHNwnpI8Nmg69ev07VrV9zc3AgLC6NQoUJql6S6hQsXMmfOHNnVxUHMnj2bsLAw9u3bh4eHhyo1dO/eHR8fHxYsWKBK+yLnZKjTxmzfvp1q1arRpEkTNm3aJKF3X58+fQgICJBdXRzArl27mDZtGqtXr1Yt9ADmz5/Ppk2b+O03OYzW1kiPz0ZkZmYyZcoUQkNDWbp0Ka+//rraJVmdf//9l6CgIJYtW0bDhg3VLkeYwdWrV6lZsyY//fQTTZo0Ubsc9u7dS6dOnTh27BiFCxdWuxyRTRJ8NuDmzZu8/fbbGAwGwsPDKVKkiNolWa1NmzYxaNAgjh8/Lru62Jm0tDTq169P+/btGTdunNrlPPTxxx9z9OhR1q9fb7frZu2NDHVauZ07d1KtWjWCg4PZtm2bhN4LtGzZktatWzNkyBC1SxEmNmzYMIoXL87YsWPVLuUxkyZN4vbt23zzzTdqlyKySXp8Vkqv1/P5558zf/58lixZQrNmzdQuyWbIri72JzQ0lDlz5vDnn3/i4+OjdjlPOXv2LMHBwezevZsKFSqoXY54AQk+K3T79m26d+9OSkoKy5cvp1ixYmqXZHNkVxf7cejQIVq3bs3evXspV66c2uU8U2hoKPPnz+fgwYMys9jKyVCnldm3bx9Vq1alatWq7NixQ0Ivh6pXr87w4cNlVxcbd+vWLTp06EBoaKhVhx5A//79KVWqlMwstgHS47MSer2e6dOnM3v2bBYuXMgbb7yhdkk2T6fT0aBBAzp06MB7772ndjnCSDqdjiZNmhASEsKUKVPULidbHswslpnX1k2CzwrcuXOHnj17Ehsby4oVK2RozoRkVxfbNXr0aE6dOsX69ettakPoLVu20L9/f44fP26XR4LZAxnqVNmBAweoWrUqr7zyCrt375bQM7HSpUszbdo03n77bdLS0tQuR2TT8uXLWbt2LcuWLbOp0ANo3rw57du3Z9CgQUi/wjpJj08lBoOB2bNnM23aNEJDQ3nzzTfVLsluGQwG2rVrR5kyZZg+fbra5YgXOHHiBI0bN2b79u0EBQWpXU6OpKamUqNGDcaMGUOvXr3ULkc8QYJPBbGxsfTp04fr168TERFBqVKl1C7J7t2+fZugoCDCw8NlVxcrFhsbS40aNfj000/p1q2b2uXkyoMAP3jwIKVLl1a7HPEIGeq0sMOHD1O1alVKlizJvn37JPQspGDBgvzwww/06tWLuLg4tcsRWdDr9XTv3p02bdrYfOgBvPbaa3z00Ud0794dnU6ndjniEdLjsxCDwcDXX3/N1KlTWbBgAe3bt1e7JIc0ZMgQ4uPjCQsLU7sU8YRJkyaxa9cutm/fjouLi9rlmIRer6d58+bUq1ePSZMmqV2OuE+CzwLi4+Pp168fly5dIiIigoCAALVLcliyq4t1+u2333j33XeJjIy0u82er1+/TpUqVfj111+pXbu22uUIZKjT7I4cOUK1atUoXLgwf/zxh4Seyjw9PQkLC2P48OFcuXJF7XIEcO7cOfr168eqVavsLvQAihYtyoIFC+jevTv37t1TuxyB9PjMxmAw8N133zFhwgTmzZtH586d1S5JPGLq1Kns3LmTbdu24eQkn//UkpiYSK1atRgxYgQDBgxQuxyz6tevHwaDgYULF6pdisOT4DODe/fuMWDAAE6dOsXKlSspW7as2iWJJ+h0OurXr0/Hjh1lVxeVGAwGOnfujK+vL6GhoXZ/pE9iYiJVqlThiy++kHv8KpOPuiZ24sQJqlevjre3N3/++aeEnpXSarUsXbqUzz//nOjoaLXLcUgzZ87k8uXLzJs3z+5DD8Db25uwsDDeffddrl27pnY5Dk2Cz0QMBgM//PADjRs3ZsKECYSGhuLh4aF2WeI5AgICZFcXlfz+++/MnDmTX375BXd3d7XLsZhatWoxdOhQevXqJZunq0iGOk0gKSmJwYMHc+TIEVauXMkrr7yidkkimx7s6hIYGMiXX36pdjkOISYmhlq1arF8+XIaNWqkdjkW92Dz9Pbt2zNq1Ci1y3FI0uPLpZMnT1KjRg2cnZ05ePCghJ6N0Wg0fP/994SFhbFr1y61y7F7qamptG/fnrFjxzpk6IEyzB4WFsZ//vMfjh8/rnY5DkmCLxeWLFlCw4YNGTt2LIsWLcLLy0vtkkQOyK4ulmEwGHj33XcpU6aMw/d0/P39mTlzJt26dSMlJUXtchyODHXmQHJyMsOGDeOPP/5g1apVVKxYUe2ShAm8++67JCQkyK4uZvLtt98yf/58/vzzT/mQiPJBoEuXLhQuXJivvvpK7XIcivT4jHTmzBlq1apFamoqkZGREnp2ZMaMGRw+fJgVK1aoXYrdOXDgABMnTmT16tUSevdpNBq+/fZb1q5dy+bNm9Uux6FI8BkhPDyckJAQhg0bRlhYGN7e3mqXJEzI09OTZcuWMXz4cK5evap2OXbj5s2bdOrUiYULFxIYGKh2OVYlb968LFmyhH79+nH79m21y3EYMtSZDampqYwYMYIdO3awcuVKKleurHZJwoymTp3Krl272Lp1q+zqkksZGRk0btyYxo0byybNz/H+++9z5swZ1q5d6xBrGtUm/1e/wPnz56lTpw5xcXFERUVJ6DmADz74gOTkZObOnat2KTZvzJgx+Pn5MWHCBLVLsWpTpkzhypUrhIaGql2KQ5Ae33OsXLmSd999l8mTJzN48GD5JOZALly4QO3atdm5c6fcx82hsLAwJk+ezOHDh8mTJ4/a5Vi906dPU79+ffbt20e5cuXULseuSfBlIS0tjdGjR7Np0yYiIiKoVq2a2iUJFfz444989dVXHDp0CDc3N7XLsSnHjh2jadOm8sHBSN988w0LFy5k//79uLq6ql2O3ZKhzidcvHiR4OBgrl+/TlRUlISeA+vbty+lS5eWYToj3b17l3bt2jFv3jwJPSMNHjyYIkWK8Mknn6hdil2THt8j1qxZw8CBAxk/fjzDhw+XoU3B7du3CQoKYvny5TRo0EDtcqxeZmYmrVq1omLFisyYMUPtcmzSP//8Q+XKlVmxYgX169dXuxy7JMEHpKen8/7777NmzRoiIiKoWbOm2iUJK7Jx40YGDx7M8ePH5V7VC4wfP54DBw6wdetWtFqt2uXYrPXr1zN06FCOHTsmf+fMwKqDLyMzg6M3jxJ1PYq9f+/lv3f+S5ouDa2TloKeBQkpGUKNojWoWawm+T3z56iNmJgYOnfuTKFChVi8eDH58uUz8U8h7IHs6vJia9asYeTIkURGRlKwYEG1y7F5Q4YMIS4ujmXLlqldit2xyuC7lnCNbw5/wzeHvyHTkIlOryNF9/R+dlonLZ4unqTp0mhSugnjgscRUiIk20OU69evp1+/fowdO5bRo0fL0KZ4puTkZKpUqcKnn35K586d1S7H6pw5c4b69euzYcMGatSooXY5diE5OZlq1aoxYcIEunXrpnY5dsWqgi85I5lx28bx49EfMRgMpGVm/4w0DRo8XTzxz+PPio4rqFCwwjNfm5GRwfjx4/n5559Zvnw5wcHBpihf2LnDhw/TqlUrjhw5wssvv6x2OVbj3r171KxZkzFjxtCvXz+1y7ErR48epXnz5hw6dIhSpUqpXY7dsJrgO3DlAB1XduRuyt0se3fZpUGDu9ad8SHj+aDeBzg7OT/2/NWrV+ncuTO+vr4sXbqUAgUK5LZ04UCmTJnC7t27ZVeX+wwGAx06dKBgwYJ8++23apdjl7788kvWr1/Pzp07cXZ2fvEbxAtZxf+5K6JX0GRpE67du5ar0AMwYCBFl8Ln+z6n7c9tSc9Mf/jc5s2bqV69Oq1bt2bDhg0SesJoH374IcnJybKb/n3Tpk3j2rVrssuNGY0ePRpnZ2emTZumdil2Q/Ue38qTK+m1tleuAy8rHloPGpRqwJqOa5gyeQpLliwhPDxcpgiLXJFdXRRbt26ld+/eHDp0SIZ+zezKlStUq1aNjRs3Ur16dbXLsXmqBt+xm8cIXhhMckay2drw0HqQ71I+Xol5hWXLllGoUCGztSUch6Pv6nLp0iXq1KlDRESEfJC0kBUrVjBx4kSOHDkiRzvlkmrBl56ZToX5FbgQe8HsbWnRsqv3LoJLyiQWYRoGg4F27doRGBjIl19+qXY5FpWcnExwcDC9e/dmxIgRapfjUHr27ImHhwffffed2qXYNNWCb/zv45lzcI5Ze3uPetn3Zc4NO4e71t0i7Qn754i7uhgMBnr16kVmZiZhYWGyBMjCEhISqFy5MrNnz+att95SuxybpcrkloS0BGb/OdtioQcQmxLLimg5WVuYTsGCBQkNDaVnz57Ex8erXY5FfPPNN5w4cYLQ0FAJPRU8mI0+cOBAbt68qXY5NkuV4Ft6fClOGss2nZSRxLQ/ZFaUMK1WrVrRqlUrhg4dqnYpZrdv3z4+/fRTVq9ejaenp9rlOKzg4GAGDBhA79690ev1apdjk1QJvun7p5OUkfT0E3uBJ3eE+uoZj/11//udwCfA1Re3GxMfQ9T1KKNqFeJFZsyYwaFDh1ixwn5HFK5fv07nzp1ZvHgxpUuXVrschzdhwgRiY2OZN2+e2qXYJIsH3z+J/3Az8Rld9JLAFeDBh5h7QCZw44nH7t5/rQE4Dnjc/+cL6PQ6tl/cnuPahciKp6cnYWFhDBs2jKtXs/EJzMakp6fTsWNHBg8eTMuWLdUuRwAuLi4sW7aMKVOmEB0drXY5NsfiwRd1I+rZE0yKogTdg1yMAfyBAk88lhfwvf99ItASiAZ0z287PTOd3TG7c1O+EFmqUaMGw4YNs8vhp/fee4+CBQvy0UcfqV2KeESZMmX44osvePvtt0lLy/72jkKF4Dt07RBJ6VkMcwJogZdRAo37/yxx/+vRx0re//44UBZ49f6fz764/agbMtQpzOPDDz8kKSnJrnZ1Wbx4Mdu3b2fJkiWyRZsV6tu3LwEBAfKhxEgW/5t8KfYSOsNzumYl+V/I/X3/zyWeeKwUkA6cBCoBzkAFsjXceTflbk7KFuKFtFotYWFhTJ061S6Gn44cOcK4ceNYs2YNfn5+apcjsqDRaAgNDWXFihVs3y63cbLL4sH3wq3JSqKEWzKQBOQHiqPc+0sGbt1/zRmU6gPvv68ScO7+e54jU5+Zw8qFeLGAgACmTZtG9+7dbXr46d9//6Vdu3YsWLCAChWefdKJUF/+/PlZtGgRffr04c6dO2qXYxMsHnweWo/nv6A4kAocQenpAbgDPvcf80G5x3cMpdc3G5gOrESZAPMXz/XkaQ1CmFrfvn3x9/dn4sSJapeSIzqdji5dutClSxfat2+vdjkiG5o2bUrHjh0ZOHAgVnLgjlWzePAV9yuOs+Y54eOCMsnlAP8LPu5/fwClt5cAXAK6AYMe+QrmhcOdnk6e3L59O6flC/FCGo2G77//nqVLl7J7t+1Npvr444/RaDRMnTpV7VKEET7//HPOnj3L4sWL1S7F6mkt3WDNYjXxcvUiIS3h2S8qhbIu78ngO4QSfMeBIkCZJ95XCyUc/wEKZ31pzT8aAgMDcXNzo2LFio99vfrqq/j6+ubo5xLiUY/u6nLixAmbuUf2yy+/8PPPPxMZGYlWa/FfDyIX3N3dCQ8Pp1GjRoSEhFCmzJO/IMUDFt+r81rCNcp8XYZUXaolmwXAxcmFSQ0m8VHIR1y7do3o6OjHvk6fPk2BAgWeCsRXXnkFd3fZ41MYb/DgwSQmJrJ06VK1S3mhU6dO0bBhQzZv3kzVqlXVLkfk0Ny5c1m+fDl79+7FxcVF7XKsksWDz2AwUGxWMW4k3rBkswB4uXixrcc26hSvk+XzmZmZXLp06alAvHDhAiVLlnwqEMuUKSOfisVzJSUlUaVKFaZOnUqnTp3ULueZ4uPjqVmzJh999BG9evVSuxyRC3q9npYtW1K7dm0mT56sdjlWSZXTGWbsn8HEnRPNcvjs8/jn8efC8AtGb66bnp7O2bNnnwrEa9euUa5cuacCsUSJErLmSTx0+PBhWrduzZEjRyhWrJja5TxFr9fTrl07ihUrxvz589UuR5jAjRs3qFKlCqtXr6Zu3bpql2N1VAm+uyl3KTarmEWHO71cvJjRbAaDqg8y2TWTkpI4ffr0U4EYHx/Pq6+++lQgFi5cWHa0d1BTpkxhz549bNmyxeo+FE2dOpVNmzaxc+dOXF1d1S5HmMjatWsZNWoUx44dk7kLT1DtPL7hm4bzw5EfLNbrK+RViIvDL+Llav6Ti2NjYzl58iTR0dH89ddfDwNRo9FkOaEmb968Zq9JqEun0xESEkLnzp0ZOXKk2uU8tGnTJvr378/hw4cpWrSo2uUIExswYADp6eky0/MJqgVfSkYKgV8Hcu3eNbO35an15Lduv/G6/+tmb+tZDAYDN2/efKp3ePLkSfLkyfNUIFaoUEGOfrEzFy5coFatWuzatYuKFSuqXQ4XLlygbt26/PLLL9SrV0/tcoQZPLjH/Nlnn9GxY0e1y7EaqgUfwP4r+2nyUxOz9vo8tB50frUzi9ouMlsbuaHX64mJiXkqEM+ePUuxYsUeC8NKlSoRGBgow1E27IcffmDevHkcPHgQNzc31epISkqibt26DBgwgCFDhqhWhzC/B/eYIyMjKV68uNrlWAVVgw8gNCqUkVtGmuU0dnetO1VfqsqOnjtw06r3SyYnMjIyOH/+/FOB+Pfff1OmTJmneoj+/v5Wd+9IPM1gMNC2bVvKly/PtGnqHIxsMBjo3r07Wq2WxYsXy31nB/DZZ5/x+++/s337dvk9gRUEH8CCyAWM3jLapD0/D60H1V6qxubumy1yX89SUlJSOHPmzFOB+O+//1KhQoWnArFo0aLyi83K3Lp1i8qVK7N8+XIaNGhg8fbnzp3L4sWL2b9/Px4eL9hCUNiFzMxMGjZsyJtvvsnYsWPVLkd1VhF8AJvPb6bbL91IzkgmLTN3m/t6aD0YUG0A05pMs7meXk7Fx8dz6tSpx8Lwr7/+IiMj46kwrFixIvnz51e7ZIe2YcMGhgwZwvHjxy26q8vu3bvp3Lkzf/75J6VKlbJYu0J9ly9fpkaNGmzdupUqVaqoXY6qrCb4AGJTYhm0YRC//fc3MjIznn98URZ8XH3I456HiI4R1H65tpmqtC23bt16qncYHR2Nl5dXlhNqfHx81C7ZYVh6V5erV69Ss2ZNlixZQtOmTS3SprAuYWFhfP7550RGRjr05DmrCr4HTt0+xZw/5xB2IgwXZxeSM5LR6bMOQW9Xb3R6HZWLVOb94PdpXbY1WifZTeV5DAYDV65ceSoMz5w5Q+HChZ8KxPLly6s6EcNeWXJXl7S0NBo0aEDbtm354IMPzNqWsF4Gg4Fu3bqRP39+5s2bp3Y5qrHK4HsgMT2RfX/v4/C1w+yO2c3F2IukZaahddKSzz0fwSWCqfNyHeoWr4t/Xn+1y7V5mZmZXLhw4alAvHjxIv7+/lSqVOmxQAwICMDZWY55yo1Dhw7RunVrjh49atZdXQYNGsTt27dZtWqV3PN1cHFxcQQFBbFgwQLeeOMNtctRhVUHn7AOaWlp/Pe//30qEG/evEn58uWf6iEWL15cfrka4dNPP2Xv3r3P3tXl+nWIioLISIiJgdRU8PCA0qWhenWoVg0KFXrm9X/88UdmzJjBoUOHZChbAMq93q5du3Ls2DEKPefvjr2S4BM5lpiY+NSEmujoaJKSkrLcss0R/wfLjge7unTp0oURI0YoD8bGwsKFMGsW3L0Lrq6QlASZmf97o1YLnp5KEBYrBmPHQvfu8Ei4PehR7tmzh/Lly1v4JxPW7MMPPyQ6Opp169Y53AdVCT5hcnfu3OHkyZOPbdcWHR2Ni4tLllu22cpZdeZ0/vx56tSpw+7Nm6mwZAmEhoKTEyQbsb7Vywv0ehgzBiZM4FZsLDVq1GDu3Lm0bdvWbLUL25Senk6dOnXo378/gwcPVrsci5LgExZhMBi4fv36U73DU6dOkT9//izPQHS0NWbrPviAWrNmUUirRZOSizWtnp4Yihblnbx5KdKsmZykLp7pzJkz1KtXj3379jnUiIAEn1CVXq/P8gzE8+fPU6JEiSzPQLTLwzVDQzGMGJG7wHuEHkh3csIlIgLn9u1Nck1hn7799ltCQ0M5cOCAw2yHKMEnrFJ6ejrnzp17KhCvXr1K2bJlnwrEkiVL2u5WTN98o9yfM2ZYM7s8POCnn6BDB9NfW9gFg8HAW2+9RYUKFfjiiy/ULsciJPiETUlOTs7yDMTY2NgsJ9QUKVLEum/cb9wIHTuaJ/Qe8PSE33+H2rKpg8jag230wsPDadiwodrlmJ0En7ALcXFxD89AfPQcRIPBkOWWbVZxBmJsLAQEKP80t5dfhrNnlR6gEFnYtGkTgwYN4tixY9bx/4cZSfAJu2UwGPjnn3+yPAPR19c3yy3bvLwsuKF5p06wbh2k5W5v2mzx8IB33oG5c83flrBZw4YN499//yU8PNy6R0pySYJPOBy9Xs/ff//9VCD+97//pWjRok8FYrly5Ux/0z86GmrWBBNNZskWNze4eBHkpHXxDCkpKVSvXp0PP/yQ7t27q12O2UjwCXGfTqfL8gzEmJgYAgICsjwDMcdbtvXrB0uWPL4g3dzc3ZVJNJ9+ark2hc05duwYTZs25dChQ/j7P74V5N27yu3igwdh9274+29ITwdnZ/Dzgxo1ICQEgoOhcmV16s8OCT4hXiA1NTXLMxBv377NK6+88lQgFitW7PnDRPfuQeHClu3tPZA3L9y6pez6IsQzzJgxg7Vr17Jr1y60Wi2HD8PMmfDrr+DiAomJ8Kzk8PBQ9l4oVgzefx+6dFHmV1kTCT4hcighISHLLdtSU1OznFBToEAB5Y0bN0LXrpCQ8Nzr7wPGAScBZ+AVYA5Q4/7ziUARIATYlN2ifXxg505lf08hnkGv19O0aVNq1mxFdPQoduxQdsbT6427jre3MsK+bBk0b26eWnNCgk8IE7t9+3aWZyB6eHhQsWJFRiUm0uLwYZye81skASgBLAA6AenAXpSge+3+a5YAo4B44Or9517I0xNmz4YBA3L88wnHEBr6LwMHuqLVepORkbs1sp6e8H//B99+q4Sh2iT4hLAAg8HA1atXiY6O5tWhQylx8eJzXx8JNAHinvOa14E6KL29bsCY7BbTvTtY6PBbYZtmz4aPPzbt8lJ3dwgMVO4Nqr1aQoJPCEvz94fLl5/7kgTAH2gNdAFqA4/+roi5/3w0SvAtAU5kt/0aNeDQIaNKFo5j3jzl3pw59lRwdYWyZeHAAXV7fja6x5MQNiwb6/Z8Ue7xaYB3gILAm8A/959fijLkWQElGE8CR7PbvhqTaoRN2LsXxo0z30ZC6elw7pwy6KAm6fEJYWnFi8PVq0a95QzQHQgElgNlUQJx7P3nX0cJwjnZuFa0qyu9KlbEz8/vqa88efJk+fiD59zd3Y2qW9iO5GQoUwZu3DB/W56eEBam3PdTgwSfEJYWFAQnsj0w+dA84Lv7X8EoQ58PltXfA7yA68CLFiokBQdzes4c4uPjs/yKi4t75uPAc4MxO8+5ubkZ/bML8xs6VDn72FIDAn5+cOmSOvf7ZDGPEJZWp84Lg+8MsAHoDLwMXEHp6dVGuZ/XFPjpkdenoPT4NgFtnndhFxe8WrakevXqOSo9NTX1hYEZExPz3CB1cnLKUWA++uUox+dYSmws/PijsmTBUtLT4YcflD0VLE2CTwhLq1tXWdiUmPjMl/gAB4FZKDM786BMdJkOlEQJvSeXL/RACcXnBp+nJ+Qw9ADc3d1xd3encOHCOXq/wWB4LDyf1bu8dOnSM5+Lj49Hq9XmKDAffU4ri/gfWrhQWXRuSSkpMGsWjB5t+bZlqFMIS7twASpVUmeSiZsbXL8O+fJZvm0TMRgMJCcn52io9sH3CQkJuLm55Xi41s/PD19fX7sJz5dfhmvXHvypFJAMXEIZQAf4AQgDdgG/ApOAiyiD7a8BPwLuQFHgJvDgg9FnwMdZPLYX2IyPD6xeDU2amOkHewb7+K8mhC0JCIBXX4XISMu2q9Eo22fYcOgBaDQavLy88PLyomgON9w2GAwkJSW9MCxv3rz5zOcSEhLw8PDI8XDtg/DM8X6vJnLzJvz775OPZgJzgY+eePw80BNYjTKlKhHYirK30EtAGWAP0PH+6/cA5bN4rAEASUmwY4cEnxCO4f33oU+f5w53mpynJ4zJ9jJ3u6bRaPD29sbb25tixYrl6Bp6vZ7ExMQX9jyvXbv2zJ5nYmIiXl5eRgfmo8/7+PjglIuxwqgoZSDg8VU2Y4EvgXdRBtofOIaygrTx/T/7AO0feb4+/wu5TOAIMOWJxw4AE+7/O1QWtFuaBJ8QanjrLWVam6WCT6OB0qWhXj3LtOcAnJyc8PX1xdfXl+LFi+foGnq9nnv37r2w5/n3338/87mkpCS8vb1zPGT7xx8FSU52Q1k1+kB1oCEwA5j6yONVUaZevYeysrQG8OhK9Pood6ZBWVn6CkpILnjksQyg5sN3/PVXjv7V5YoEnxBqcHGBiAhljMcS9/rc3WHFCiUAhdV4dIZrTmVmZpKQkPDcnufdu3e5dOlSlj3PW7emoNP1zeLKn6IsnBnxyGOlUe7zzULZRfYeyhYK81ACsAHQF2VK1l6ULdQDgduPPFab/y3E+d9JD5b8qynBJ4Ra6taFvn3Nv3jKyws++gheecV8bQjVODs7kzdvXvLmcEFcr17w009ZPVMRZS7xFyg9twdqAxH3vz+MsujmM+A/KBNjiqEE3B5g4P3X1X3ksfpPtZSZadmTsmTLMiHUNHOmcmKnmXZE0bm5QaNGyj1FIbLg4fG8ZycDocC1ZzxfA2iHsmvsAw/u8x1ACTxQen57UDbiezr4LD2/R4JPCDW5ucHWrcpuLiYOv0x3d3bp9ex77z3L/2YRNqN0aWXz6KyVQenRfXX/z/tQgvDW/T+fAdah9AIfqI+y0rQoyq6zAPXuPxaPcqbI/+TPb/kReAk+IdTm7Q27dkGnTqY7qtrDA+eBA2HdOtp16cKRI0dMc11hd6pXf9FnrolA0v3v86AEXSWUe3otgP9DOTL5gQYowfjoRKrKKPsLVQMe/zteuXIOC88FWcAuhDXZtg26dVN2DM7JFvleXsrmhytXQm3lU/jq1asZMmQIO3fupHz58iYuWNi6uDgoVAgyMizftlYLn3wC48dbtl3p8QlhTZo2VXbunT4dSpZUeoMvuuvv4qIEXvnyymFq5849DD2Adu3a8Z///IdmzZoRExNj5h9A2Jo8eZQDYtXg5qbsqWBp0uMTwloZDPDHH8rWFrt3w7FjEB//vylwefNC1arQoIESmC/Yg3Pu3LnMnz+fvXv35nivTWGffvoJhgyx7H4KoHxWO33asm2CBJ8QticXi54mT57MmjVr2LlzZ46nvwv7k5oKBQtaNvi8vJQBit69LdfmAzLUKYStycUUuIkTJ9KoUSNatWpFUlLSi98gHIK7u3KvzcvrhS81mQIFoGtXy7X3KOnxCeFg9Ho9/fr14/r166xbt04OhhWAMoJevbpyVKReb962PDyUicw1a77wpWYhPT4hHIyTkxOhoaF4e3vz9ttvo9Pp1C5JWAFnZ2VXu+cvaM89T0/lfqJaoQcSfEI4JK1WS3h4OAkJCQwYMAC9uT/iC5tQtiysWWO65aRP8vRUtqf94gvzXD+7JPiEcFBubm6sWbOGM2fOMHr0aOSuhwBlgvDq1UpImXJHFS8vaNkSVq1SfyMhCT4hHJiXlxcbNmxgx44dTJkyRe1yhJVo3hwOHoRy5XLf+3NyUq4xdapyIImLi2lqzFVNahcghFBX3rx52bp1K0uXLuWrr7568RuEQ6hYUZnoMm4cuLpmotEYd4LIg8CrVk25zsiRymPWQGZ1CiEAiImJISQkhClTptCrVy+1yxFWpEGDthQtOp49e2oQH68E2INz9B7l5qZ8pafD//0fjB6tBJ+1kfP4hBAAlCxZkq1bt9KoUSN8fX35v//7P7VLElbgyJEjXLgQybZtQbi4wNmzEBUFBw7AyZPK4ncXF2UBfL16StBVqaLstmetpMcnhHjMkSNHaNGiBeHh4TRp0kTtcoTKunXrRpUqVRg7dqzapZiMBJ8Q4il79+6lXbt2rFu3jjp16rz4DcIuxcTEULVqVS5evIifn5/a5ZiMldxqFEJYk5CQEJYsWULbtm05ceKE2uUIlcyZM4e+ffvaVeiB9PiEEM+xYsUKRo0axe7duylTpoza5QgLio2NJSAggBMnTvDyyy+rXY5JyeQWIcQzde7cmYSEBJo2bcrevXvt7hegeLZvv/2WNm3a2OV/c+nxCSFeaPr06SxcuJA9e/ZQsGBBtcsRZpaWloa/vz9btmyhUqVKapdjcnKPTwjxQmPHjqVdu3a0aNGC+Ph4tcsRZhYWFkZQUJBdhh5Ij08IkU0Gg4GhQ4cSHR3N5s2b8TD3Nv5CFXq9nldffZX58+fz+uuvq12OWUiPTwiRLRqNhq+//prixYvToUMH0tPT1S5JmMGGDRvw9PSkUaNGapdiNhJ8Qohsc3JyYtGiRTg7O9OzZ08yMzPVLkmY2PTp0xk7diwaUx7NYGUk+IQQRnFxcSEiIoJbt27x7rvvynFGduTgwYP8/fffdOjQQe1SzEqCTwhhNHd3d3799VeOHj3Khx9+qHY5wkSmT5/Oe++9h1Zr3yvdZHKLECLH7ty5Q/369enRowcffPCB2uWIXDh//jy1a9fm8uXLeFvzDtMmYN+xLoQwq/z587Nt2zZCQkLw8/Nj8ODBapckcmjWrFkMHDjQ7kMPJPiEELlUtGhRtm3bRv369fHz86Nbt25qlySMdPv2bZYvX87p06fVLsUiJPiEELlWunRpNm/eTJMmTfDx8aFNmzZqlySM8M0339ChQweKFCmidikWIff4hBAmc+jQIVq1asXKlStp2LCh2uWIbEhOTsbf35/du3dTvnx5tcuxCJnVKYQwmZo1axIREUGnTp04fPiw2uWIbFiyZAm1a9d2mNAD6fEJIcxg3bp1DBgwgB07dlChQgW1yxHPkJmZSbly5Vi8eDH16tVTuxyLkXt8QgiTe/PNN0lISKB58+bs2bMHf39/tUsSWVi7di0FCxYkODhY7VIsSoJPCGEW3bt3Jz4+niZNmrBv3z5eeukltUsSjzAYDEyfPp1x48bZ9fZkWZHgE0KYzZAhQ4iPj6dZs2bs3r2bfPnyqV2SuG/fvn3cuXOHt956S+1SLE4mtwghzOrDDz+kRYsWtGzZknv37qldjrhv+vTpjB49GmdnZ7VLsTiZ3CKEMDuDwcCAAQO4ePEiGzZswN3dXe2SHNrp06dp2LAhly9fdshzFSX4hBAWkZmZSbdu3UhLS2PVqlV2vxGyNevfvz8lSpRg4sSJapeiCgk+IYTFpKen89Zbb1GwYEEWL16Mk5PcbbG0GzduUKFCBc6dO0eBAgXULkcV8rdOCGExrq6u/PLLL1y6dIkRI0bIWX4q+Prrr+nWrZvDhh5Ij08IoYL4+HgaNWpEq1atmDJlitrlOIx79+7h7+/PwYMHCQgIULsc1cgguxDC4vz8/Ni8eTP169cnT548jB49Wu2SHMKPP/5Io0aNHDr0QIJPCKGSQoUKPTzLL0+ePPTr10/tkuxaRkYGs2fPZuXKlWqXojoJPiGEaooXL862bdto0KABvr6+dOzYUe2S7NaqVasoVaoUNWvWVLsU1UnwCSFUFRgYyKZNm2jWrBk+Pj60aNFC7ZLszoPtyT799FO1S7EKMqtTCKG6oKAg1qxZQ48ePdi3b5/a5didHTt2kJqayhtvvKF2KVZBgk8IYRXq1q1LeHg47dq14+jRo2qXY1emT5/OmDFjZN3kfbKcQQhhVX755ReGDh3Krl27KFeunNrl2LwTJ07QokULLl26hJubm9rlWAW5xyeEsCrt27cnISGBZs2asXfvXkqUKKF2STZtxowZDB8+XELvEdLjE0JYpTlz5rBgwQL27NlD4cKF1S7HJl25coWgoCAuXrxInjx51C7HakiPTwhhlUaOHElcXBzNmzdn165d8os7B+bOnUvv3r3l390TpMcnhLBaBoOBkSNHEhkZydatW/Hy8lK7JJsRHx9P6dKlOXr0qAwXP0Gm+AghrJZGo2H27NkEBgbSrl070tLS1C7JZnz33Xe0bNlSQi8L0uMTQlg9nU5Hp06dcHZ25ueff3bIU8ONkZ6ejr+/Pxs2bKBy5cpql2N1pMcnhLB6Wq2W5cuXExcXx4ABA+Q4oxcIDw+nQoUKEnrPIMEnhLAJbm5urFmzhlOnTjF69GgJv2cwGAzMmDGDsWPHql2K1ZLgE0LYDG9vbzZu3Mj27duZOnWq2uVYpU2bNqHVamnatKnapVgtWc4ghLApefPmZevWrQ+PMxo2bJjaJVmVB9uTaTQatUuxWhJ8QgibU6RIEbZt20b9+vXx8/OjZ8+eapdkFSIjI7lw4QKdO3dWuxSrJsEnhLBJpUqVYsuWLbz++uv4+vrStm1btUtS3YwZMxg5ciQuLi5ql2LVZDmDEMKmRUVF0bJlS5YvX07jxo3VLkc1ly5dokaNGly6dAkfHx+1y7FqMrlFCGHTqlWrxqpVq+jatSt//vmn2uWoZvbs2fTv319CLxukxyeEsAsbN26kT58+bN++nUqVKqldjkXduXOHwMBAoqOjKVq0qNrlWD3p8Qkh7MIbb7zB3LlzadGiBefPn1e7HItasGABbdu2ldDLJpncIoSwG126dCEhIYGmTZuyb98+ihUrpnZJZpeamsq8efPYsWOH2qXYDAk+IYRdGTBgAHFxcTRt2pQ9e/ZQoEABtUsyq59++onq1atToUIFtUuxGXKPTwhhlz766CO2bt3Kjh078PX1Vbscs9Dr9bzyyit8//33NGjQQO1ybIbc4xNC2KXPPvuMmjVr0qZNG1JSUtQuxyzWrVuHr68v9evXV7sUmyI9PiGE3dLr9fTo0YP4+HjWrFljdwu7g4ODGTFiBJ06dVK7FJsiPT4hhN1ycnJi8eLFaDQaevbsSWZmptolmcz+/fu5ceMG7dq1U7sUmyPBJ4Sway4uLkRERHDjxg2GDBliN8cZTZ8+nVGjRqHVyhxFY8lQpxDCISQkJNC4cWOaNGnCf/7zH7XLyZWzZ89Sr149Ll26hJeXl9rl2Bzp8QkhHIKvry+bNm1i3bp1fPHFF2qXkyuzZs1i0KBBEno5JH1kIYTDKFCgwGNn+Q0aNEjtkox269YtIiIiOHPmjNql2CwJPiGEQylWrBjbtm2jQYMG+Pn50bVrV7VLMsq8efPo1KkThQoVUrsUmyX3+IQQDik6OpomTZrw448/0qpVK7XLyZakpCT8/f35448/CAwMVLscmyX3+IQQDqlixYr8+uuv9OnTh927d6tdTrYsWrSIevXqSejlkvT4hBAObceOHXTp0oWNGzdSvXp1tct5Jp1OR9myZVm2bBl16tRRuxybJj0+IYRDe/311wkNDaV169acOnVK7XKeafXq1RQtWlRCzwRkcosQwuG99dZb3Lt3j+bNm7Nnzx78/f3VLukxBoOB6dOn8/HHH6tdil2Q4BNCCKB79+4PjzPau3cvL730ktolPbR7927u3btHmzZt1C7FLkjwCSHEfUOHDiUuLo5mzZqxe/du8uXLp3ZJgLI92ejRo3FykrtTpiCTW4QQ4hEGg4GxY8eyb98+tm/fjre3t6r1nDx5ksaNG3P58mXc3d1VrcVeSPAJIcQTDAYD77zzDpcvX2b9+vWqBk6fPn0ICAiQ+3smJMEnhBBZyMzMpGvXrmRkZLBy5UpVTkG4du0alSpV4ty5c+TPn9/i7dsrGTAWQogsODs7ExYWRmpqKv369UOv11u8hq+++oru3btL6JmY9PiEEOI5kpOTad68OVWqVGHu3LloNBqLtJuQkIC/vz+RkZFWt7zC1kmPTwghnsPT05PffvuNvXv38sknn1is3R9++IGmTZtK6JmB9PiEECIbbt26RUhICAMHDmTUqFFmbSsjI4OAgADWrFlDtWrVzNqWI5J1fEIIkQ2FChVi27ZtD8/y69u3r9naWrFiBWXKlJHQMxMJPiGEyKYSJUqwbds2GjZsiK+vLx06dDB5Gw+2J7P1U+KtmQSfEEIYoWzZsmzcuJFmzZrh4+ND8+bNX/geg8HA1YSrRN2I4tydcyRnJOPs5Iyfmx9BRYKoUqQKPm4+AGzbtg29Xk+LFi3M/aM4LAk+IYQwUuXKlVmzZg1t27Zl7dq1BAcHZ/m6v/75i9l/zmbVqVXo9DpcnF1IyUghQ5+BBg1uWjfcnN1IzkimqE9RhtYcyvrZ6xkzZozFZo86IpncIoQQObRlyxZ69OjB1q1bqVy58sPHI69HMuC3AZz59wwZ+gx0el22rufu5E5qeio9qvTgqze+Io97HvMU7uAk+IQQIhdWrVrF8OHD2bVrFyVLl+TjnR8z/9B8UnQpOb6mm7MbXq5eLP2/pbwR+IYJqxUgwSeEELm2cOFCJk2bhPtgd64nXSdZl2yS63q6eDKw2kBmNpspQ58mJMEnhBC5dDvpNuVmliNWFwvOpr22p4sn3St159vW30r4mYjs3CKEELmQnplOg8UNSNQkmjz0AJIzkgn7K4xP93xq+os7KAk+IYTIhQk7JhATH0OGPsNsbSRnJDNt3zSO3TxmtjYciQx1CiFEDkVdjyJkUUiuJrIYo0zeMpwcchJXZ1eLtGevpMcnhBA5NGj9IIuFHsD1xOssPLrQYu3ZKwk+IYTIgVO3T3Hy9kmLtpmckcyXf3yJDNTljgSfEELkwOw/Z5ORab77es9yK+kWB64esHi79kSCTwghcmDVqVXoDNnbkQWApcCOLB4/A0wHMrN3meSMZH6O/jn77YqnSPAJIYSRbty7QUqGkff2KgMngCdHKY8Dr5HtpRAGDOz7e59xbYvHSPAJIYSRom5E4aZ1M+5N5YEUIOaRx1KAs0CQcZc6/e9p9Aa9cW8SD0nwCSGEkc7fPU+qLtW4N7kAr6L08B44CRQAihhfw62kW8a/SQASfEIIYbTkjORsn7jwmCDgFPBgTsxxlCFQIzlrnI0fahUPSfAJIYSRnDXOOOXk12dJwBNlQstd4BpQyfjLGDDg7GSG/dEchBxEK4QQRsrjngdXrSu6jBz2+o4Dd4AAwNv4S2RkZuDn5mf8GwUgPT4hhDBaUJEgtE457DcEAReBKHI0zAng5+6Hn7sEX05J8AkhhJGCCgeRnJHDM/fyAsVR7vOVy9klqhapmrM3CkCGOoUQwmgeLh745/Hn3N1zObtAn5y37e7sTpPSTXJ+ASE9PiGEyInhtYbj5eJl8XYNGOgR1MPi7doTCT4hhMiBnkE9Lb6IXIOGpgFNKeKdg4V/4iEJPiGEyAFfN196BfXCXetusTY9XDwYHzLeYu3ZKwk+IYTIoS+bfomvm69F2nLXutO1Yldqv1zbIu3ZMwk+IYTIIR83H8LbhePp4mn2tvzc/JjTYo7Z23EEEnxCCJELjUs35r3a75k1/LxcvFjfbT3erjlY7S6eIsEnhBC5NKXRFAZWG2iW8PNy8WLj2xupXrS6ya/tqDQGOcNeCCFMYub+mUzYOYFUXSqGpw7eM46H1gM/dz9+6/qbhJ6JSfAJIYQJnbp9io4rOxITF0NSRpLR79egwV3rTo/XejCr+Sy8XC2/VtDeSfAJIYSJ6fQ6wk6EMW3fNK4kXCElIwU9z1/z92BZRIuAFnwY8iE1i9W0RKkOSYJPCCHMKPJ6JBEnI9gTs4foW9Fk6DPQOmkxGAxk6DMo4FGAqkWr0sS/CW+/9jaFvAqpXbLdk+ATQggLMRgM3E25S4ouBWeNMz5uPjJTUwUSfEIIIRyKLGcQQgjhUCT4hBBCOBQJPiGEEA5Fgk8IIYRDkeATQgjhUCT4hBBCOBQJPiGEEA5Fgk8IIYRDkeATQgjhUCT4hBBCOBQJPiGEEA5Fgk8IIYRDkeATQgjhUCT4hBBCOJT/B0a/X35M1ISPAAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "solution = backtracking_search(australia_csp)\n",
+ "print(solution)\n",
+ "draw_graph(australia_csp, solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 29,
+ "id": "701b3bb7",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'SA': 'R', 'WA': 'G', 'NT': 'B', 'Q': 'G', 'NSW': 'B', 'V': 'G'}\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAb4AAAEuCAYAAADx63eqAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAABG50lEQVR4nO3dd3gU5d7G8e+W9EDoCIReQkeB0Akt0oLShAABRBBQRJQkgBQ5yiud0BQRISr9QBREOiItQICEKiUBjXSkSU3f7L5/LHgQk5Cyu7Pl97muXCab3XnuaMy9M88zMyqDwWBACCGEcBBqpQMIIYQQliTFJ4QQwqFI8QkhhHAoUnxCCCEcihSfEEIIhyLFJ4QQwqFI8QkhhHAoUnxCCCEcihSfEEIIhyLFJ4QQwqFI8QkhhHAoUnxCCCEcihSfEEIIhyLFJ4QQwqFolQ4ghDC6cweOHoVff4WHD8FgAA8PqFoV6teHUqVApVI6pRC2T4pPCAVduwYLF8LixXD/Pri6QlISpKUZv6/Vgrs7pKaCszP07g0jR4KPj6KxhbBpKrkRrRCWd/06vPMO/Pyzcc8uJSV7r9NqwckJ6tSBJUugRg3z5hTCHll18d1Luseei3s4cu0Iey/t5dL9S6TqU9GoNBR0K0ijUo1oWqYpTUs3pVrRakrHFeKFDAZYtgyGD4fkZNDpcrcdlcq4dzh2rPFDK8duhMg2qyy+YzeOERYVxrpz63DWOPM45TF69Bk+193JHYBKhSrxUdOP6FatGy5aF0vGFSJbdDoICoLNmyEhwTTb9PCA6tVh507In9802xTC3llV8d1JvMOgnwaxM34nKboU0g3pOXq9p7Mn+Zzzsbr7alqUa2GmlELknE4HnTvDnj2QmGjabbu4QKVKEBUF+fKZdttC2COrKb4NsRt488c3SdIlkZqemqdtuWnd6Fe7H3Pbz8XNyc1ECYXIvcGDYdUq05feUy4uUK8eREaCWk5SEiJLVvG/yOyo2fRZ14cHKQ/yXHoASboklp9ajt93fjxMeWiChELk3o4d5i09MC6OOXkS5s833xhC2AvF9/jmH57P2F/Gkphm+r8KLhoXahWrxb639smen1DEgwfGw5B37lhmPHd3OHUKKla0zHhC2CJF9/j2XdrH2J3mKT2AlPQUztw+w+CNg82yfSFeZOZMePzYcuMlJ8MHH1huPCFskWJ7fAmpCVT+vDI3Ht8w+1juTu6s67mOdpXamX0sIZ5KS4NixYwnpluSiwv88QeUKGHZcYWwFYrt8YXuCOV+8n2LjJWYlkjQuiAepTyyyHhCAPz4I6TnbGGySahUxqvBCCEypkjx3Um8w3cnvyNJl2SxMZN0SSw7ucxi4wmxfDk8+vu9VjmgGPDsCXxLgJZPPt8AvAzkB4oArYE/gBuACrj5zOsmZ/JYe8B4uHPVKlP9FELYH0WKL/xYOCose7XdxLREZh6ciZWcvSEcQEzM84+kA/MyeOZvQH8gDHiAsfDeAzRACaASsO+Z5+8DqmbwmN/fX12+nP3LoAnhaCxefAaDgTmH5uRsb285sCuDx2OBmRj/nmTD3aS7HLhyIPvjCpFLDx9mtJJzFDALuP/c4yeA8kAbjHty+YDuQJkn3/fjfyWXDhwDPnjusSieLT5XV+NdHoQQ/2bx4rv68GrOz617GTgFPL+zdhKojfGNcTYk65LZ9UdGDSqEacXHg9u/zqCpj/HQ5qznHq+L8V3cSGA38Pwy0GeL7zhQDWNJPvtYGtDgH6+6cCG36YWwbxa/tO3RG0dx0jjlbI+vKrAJuIRxqgQgCTgP5OBMBZ1ex95Le7P/AmGT9Ho9Op2O9PT0f/wzs8/N8f34+OKkpAQCrs+lmwQ0xbjH9lQFYA8wG+gJPAJ6AV8AnkALYCDGPcVIoDlQGbj9zGONAOdn/h0Yb28khPg3ixdf9LVoHqfm8MQmJ6AGxj28ck8eO4NxDcBLOdvUiT9P5OwFVspgMGT5h1eJP/am/H5etmUwGNBqtWi1WjQaTZafm+v7SUke/PsQBUBNoBMwDeOe21ONgLVPPo8GAjEuWJmK8Ze+FMaC2wcMffK8Js885sezVCq5Y4MQmbH4/xqXH15Gb8j4TgtZqgOsAjpiLMKTGA+B5tD9pPts2LDB5v/Y6/V6NBqNyf6A5/WPvbOzM25uboqWzdPP1VZwscrz52HduswWmHyK8fBmSCav9gW6Aaefeezp4c4oYOmTx5o/eWw/MPwfW1Crwcsrt+mFsG8WL75UXS6vxVkWcMc4FVIKuIbxTXEO6Q16wsPDc/3H1t3dXZE/5s8/ptFoUKksuzJWZF/Fiv+7i/q/VcL4yzsfqIWxuM4BnTGe8hAL/AS8+cxr/ICPMf7yP73/UDOM7wQfAI3/MUJaGrz8ct5/DiHskcWLL0/XzKyDcU/vLlAR4/RHDjlpnPjpp59yn0GIbNBooHJlOH06s2dMxLhcGaAAxqKbgPE8vyIYi3H0M89vAdzin+/2XsY42V0P47vC/1GroUwZhBAZsHjxVShYAa1ai06fi1tP18F4ZOcmT8/VzbHCboVz90Ihcqh1a4iNfXqX9YvPfbc0kPzM1xtfsDUf/j1nqAEyXiFdv75xnk8I8W8WnwzxLemLh5NH7l5cEOPfizSMfwdyoV7Jerl7oRA5NHQoODlZftx8+eRC1UJkxeJ7fPVK1iNZl/ziJ2bmrdy/1FnjjF9Zvxc/UQgTqF7d+HH0qGXHdXKC116z7JhC2BKL7/EV8yhGqfylLD0sAFq1lrYV2yoytnBMn3wCHrk8wJEb7u4QGiqnMgiRFUXWfY9qMir3hzvzoEKBCrz80ssWH1c4rk6doGVLcHZ+4VPzTKWC0qWNxSeEyJwixde3dt/cncuXB57OnoxpNsaiYwoB8O23GV2+zPRcXSEiQpl5RSFsiSLF5+nsyUfNPsLdyf3FTzaRIu5F6FG9h8XGE+KpokVh/Xrzlp9KlcTYsX9Sq5b5xhDCXih2iYtxzcdRJn8Zi9yeyEXjQkSPCFy0LmYfS4iMtGpl3BtzN8N7PTc3CAw8xcKFdTl16pTpBxDCzihWfFq1loieEXk7oT0bnFXOqKPVXIq6ZNZxhHiRgADYsgUKFQIXE7wH02qNC2e+/hpWr27InDlzaNu2LdHR0XnfuBB2TNGLGtYsVpPV3VfjpjVP+bk7udOhSgf2fLyHkJAQxowZg06XixPnhTCRFi3g99+ha1fj3l9uTzL38IBGjeDsWejb1/hYYGAgixcvJiAggMjISNOFFsLOqAxWcEvyDbEb6LOuD4lpiSbbpoeTBx0qd2B199Vo1Vru3LlD7969MRgMrF69mqJFi5psLCFyIzISpk6FXbsA9KSkZP0+VKs1ftSuDR99BF26ZFycO3fupE+fPqxYsYK2beX0HSGeZxXFB3D0+lHeiHiDW49vkajLfQGqVWpcNC581vozPmz0IWrV//6YpKen8/HHH7Ny5Up++OEH6tevb4roQuTJtWswcuQR9u93Qq9/hTt3/rcyU6czXomlTh3jaRGBgVC16ou3eeDAAbp27crixYvp3LmzWfMLYWuspvgAUnQpTNg9gS+OfIEKVY5uVqtWqXHTulGtSDVWdV9F5cKVM33uunXreOedd5g2bRoDBw40RXQh8qR///40bdqUoUOHkpgICQnGm8m6uxuLLzeOHj1KQEAAc+bMoXfv3qYNLIQNs6rie+pWwi0WH13M3MNzSdYlYzAYSEhL+NfznDXOuGpdSU1P5XWf1wltHIpvKd9sjREbG0vXrl3x8/Nj/vz5uJhitYEQuWAwGChbtiw7d+6kSpUqJt326dOnadeuHZMmTWLQoEEm3bYQtsoqi++pdH06Z2+fJeZ6DAevHCT2TixJuiScNE4U8yhGs9LNqF+yPvVK1iO/S/4Xb/A5jx49YsCAAVy9epUffvgBb29vM/wUQmQtPj6eZs2ace3aNbPcY/HChQv4+/sTHBzMB3L1aiGsu/gswWAwMGPGDObNm8eqVato2bKl0pGEgwkPD+eXX35h1apVZhvj0qVL+Pv789ZbbzFu3DizjSOELVD0dAZroFKpGDNmDMuWLaNXr17Mnj0bB38vICxsz549Zn/DVbZsWfbt28fKlSsZN26c/I4Lh+bwe3zPunTpEt27d6dSpUosWbIET89c3OJdiBwwGAyUKVOGXbt2Ubly5guyTOXOnTu0a9eOZs2aMWfOHNRqh3/vKxyQ/NY/o2zZsuzfvx93d3caNWrEhQsXlI4k7Fx8fDx6vZ5KlSpZZLwiRYqwa9cuYmJiGDx4MOnp6RYZVwhrIsX3HFdXV8LDw3n//fdp2rQpGzduVDqSsGO7d++mZcuWZlnUkhkvLy+2b9/OxYsX6du3L2lpaRYbWwhrIMWXAZVKxdChQ/npp58YNmwYEydOlHfGwiwsMb+XEU9PTzZv3syjR4944403SE5OtngGIZQic3wvcPPmTQIDA3F3d2fFihUUKlRI6UjCThgMBkqXLs2ePXssdqjzeampqfTt25f79++zfv16PCx5u3ghFCJ7fC9QvHhxfv75Z6pVq4avry8nT55UOpKwE7/99hsAFStWVCyDs7Mzq1evplSpUrRv354HDx4olkUIS5HiywYnJyfCwsKYPHky/v7+rFixQulIwg48Pcxpyfm9jGg0GsLDw6lTpw7+/v7cvXtX0TxCmJsUXw706tWLXbt28emnnzJixAhZFCDyRKn5vYyo1Wo+//xzWrduTcuWLfnzzz+VjiSE2Ujx5VCtWrWIjo7mjz/+oHXr1ty4cUPpSMIGGQwG9uzZQ6tWrZSO8jeVSsW0adMIDAzEz8+PK1euKB1JCLOQ4suFAgUKsGHDBl599VV8fX05ePCg0pGEjblw4QJqtZoKFSooHeUfVCoVEyZM4N1338XPz+/veUgh7IkUXy6p1WomTpzI119/TZcuXViwYIFcBkpkm7XM72Vm5MiRjB07lpYtW3L27Fml4whhUlJ8edSxY0eioqJYtGgRAwYMICkp+/cQFI7Lmub3MjNkyBCmTZtGmzZtOHbsmNJxhDAZKT4TqFixIlFRUeh0Opo0acIff/yhdCRhxaxxfi8zffv2ZcGCBbRv356oqCil4whhElJ8JuLh4cGKFSsYMGAAjRo1Yvv27UpHElbq/PnzaLVaypcvr3SUbOnWrRvLli2jc+fO7Nq1S+k4QuSZFJ8JqVQqPvjgAyIiInjrrbeYPHkyer1e6VjCylj7/F5G2rdvT0REBL169WLz5s1KxxEiT6T4zMDPz4/o6Gg2bdpEt27d5GoY4h9s5TDn81q0aMHGjRsZOHAg33//vdJxhMg1KT4zKVWqFHv37qVUqVI0aNBAVsYJ4H/ze9a+sCUzDRs2ZMeOHbz//vssW7ZM6ThC5IoUnxk5OzuzYMECxo4dS4sWLYiIiFA6klBYXFwczs7OlCtXTukouVanTh12797N+PHjWbhwodJxhMgxrdIBHMGAAQOoXbs23bt358iRI0ydOhWtVv7VOyJbnN/LSNWqVdm7dy/+/v4kJCQQGhqqdCQhsk32+Cykbt26xMTEcPLkSdq2bcvt27eVjiQUYKvzexmpUKEC+/btY8mSJXzyySdyAQdhM6T4LKhw4cJs3bqVRo0aUb9+faKjo5WOJCzI1uf3MuLt7c3evXtZv349o0aNkvITNkGKz8I0Gg1Tpkxh7ty5dOzYkSVLligdSVhIbGwsrq6uNj2/l5HixYuze/duIiMjGTZsmJzCI6yeFJ9CunbtSmRkJGFhYQwZMoSUlBSlIwkzs7e9vWcVKlSIn3/+mbNnzzJgwAB0Op3SkYTIlBSfgqpWrcqRI0f466+/5DYwDsCe5vcykj9/frZu3cqtW7fo1asXqampSkcSIkNSfArLly8fERERdO/enQYNGrB7926lIwkzeDq/16JFC6WjmJW7uzsbNmwgPT2dLl26yEXbhVWS4rMCKpWK0aNHs2LFCnr37k1YWJgsErAz586dw93d3e7m9zLi4uLC2rVrKViwIB07duTRo0dKRxLiH6T4rEibNm04fPgwq1evplevXjx+/FjpSMJE7Hl+LyNOTk4sW7aMypUr07ZtW+7du6d0JCH+JsVnZcqWLcv+/fvx9PSkUaNGnD9/XulIwgTsfX4vIxqNhkWLFtGoUSNat24t564KqyHFZ4VcXV1ZsmQJI0aMoFmzZvz0009KRxJ54CjzexlRqVTMnj2bTp064efnx7Vr15SOJIRcssxaqVQqhgwZQp06dejRowfR0dF88sknaDQapaOJHDp79iyenp6ULVtW6SiKUKlU/N///R+enp74+fnxyy+/OMRcp7Bessdn5Ro2bEh0dDSRkZF06tSJv/76S+lIIocc8TBnRsaMGcPIkSPx8/MjLi5O6TjCgUnx2YDixYuzc+dOqlevjq+vLydOnFA6ksgBR1vYkpXhw4fz6aef0qpVK06dOqV0HOGgVAZZN29T1qxZw/Dhw5kzZw59+/ZVOo54AYPBQPHixYmJiaFMmTJKx7Eaa9as4YMPPmDjxo34+voqHUc4GJnjszGBgYHUqFGDrl27cuTIEWbNmoWzs7PSsUQmzpw5Q758+aT0nhMYGIi7uzsBAQH88MMPNG/eXOlIwoHIoU4bVLNmTaKjo7l48SKtW7fmxo0bSkcSmZD5vcy99tprrFq1iu7du7Njxw6l4wgHIsVnowoUKMCPP/5Iu3bt8PX15cCBA0pHEhmQ+b2s+fv7s379evr27cuGDRuUjiMchMzx2YEtW7bw1ltv8fHHH/Pee+/Z/N297YVer6d48eIcO3aM0qVLKx3Hqh09epSAgADmzJlD7969lY4j7Jzs8dmBjh07cvDgQRYvXsybb75JYmKi0pEExvk9Ly8vKb1sqFevHjt37iQ0NJTw8HCl4wg7J8VnJypWrEhUVBTp6ek0adKE+Ph4pSM5PJnfy5maNWuyZ88eJk2axLx585SOI+yYFJ8dcXd3Z8WKFQwcOJDGjRuzbds2pSM5NJnfy7nKlSuzb98+vvjiC6ZMmaJ0HGGnZI7PTkVGRtKrVy/effddxo0bh1ot73EsSa/XU6xYMU6cOIG3t7fScWzOjRs38Pf3p3PnzkyePFnmrYVJyV9DO9W8eXOio6PZsmULXbt25cGDB0pHciinT5+mYMGCUnq5VKJECfbu3cv27dv58MMP0ev1SkcSdkSKz46VLFmSPXv24O3tja+vL2fOnFE6ksOQ+b28K1KkCLt27SImJobBgweTnp6udCRhJ6T47JyzszMLFixg/PjxtGzZkrVr1yodySHI/J5peHl5sX37di5evEjfvn1JS0tTOpKwAzLH50COHz9Ot27deOONN5g6dSparVyxzhz0ej1Fixbl1KlTlCpVSuk4diE5OZk33ngDjUbDmjVrcHV1VTqSsGGyx+dAXnnlFWJiYjh16hRt27bl1q1bSkeyS7/++iuFCxeW0jMhV1dX1q1bh4uLC6+//joJCQlKRxI2TIrPwRQuXJgtW7bQuHFj6tevz5EjR5SOZHdkfs88nJ2dWb16NaVKlaJ9+/ayYEvkmhSfA9JoNEyePJn58+fTqVMnFi9erHQkuyLze+aj0WgIDw+nTp06+Pv7c/fuXaUjCRskc3wOLi4ujq5du9K0aVM+//xzmTvJI71eT5EiRThz5gwlSpRQOo7dMhgMfPTRR2zZsoWff/6Zl156SelIwobIHp+D8/Hx4fDhw9y/fx8/Pz+uXLmidCSbdurUKYoVKyalZ2YqlYpp06YRGBgov7cix6T4BPny5WPt2rX06NGDBg0asGvXLqUj2Sw5zGk5KpWKCRMm8O677+Ln58dvv/2mdCRhI6T4BGD8IzJq1ChWrFhBUFAQs2bNQo6C55wUn+WNHDmSsWPH0rJlS86ePat0HGEDZI5P/Mvly5fp3r075cuXJzw8nHz58ikdySakp6dTtGhRmd9TyIoVKxg1ahSbN2+mbt26SscRVkz2+MS/lClThsjISPLnz0+jRo2Ii4tTOpJNOHXqFMWLF5fSU0jfvn358ssv6dChA1FRUUrHEVZMik9kyNXVlSVLlvDhhx/SvHlzfvzxR6UjWT05zKm8rl27snTpUjp37ixz1SJTUnwiS4MHD2bjxo2MGDGCCRMmyIWCsyDFZx3at29PREQEvXr1YvPmzUrHEVZI5vhEtty6dYvAwEBcXFxYtWoVhQoVUjqSVUlPT6dIkSKcO3dOzimzEocPH+b1119nwYIFvPHGG0rHEVZE9vhEthQrVoyff/6ZmjVrUr9+fU6cOKF0JKty8uRJSpQoIaVnRRo2bMiOHTsYMWIEy5YtUzqOsCJSfCLbtFots2bNYurUqbz66qssX75c6UhWQw5zWqc6deqwa9cuxo8fz8KFC5WOI6yE3JdG5FhgYCA1atSgW7duHDlyhLCwMJydnZWOpag9e/bQt29fpWOIDFStWpW9e/fi7+9PQkICoaGhSkcSCpM5PpFrDx48oH///ty5c4eIiAhKliypdCRFPJ3fi42NpXjx4krHEZm4evUq/v7+9OrVi//85z+oVCqlIwmFyKFOkWteXl6sX7+eDh064Ovry/79+5WOpIgTJ05QsmRJKT0r5+3tzb59+1i/fj2jRo2SKxM5MCk+kSdqtZoJEyawZMkSunfvzueff+5wf1Bkfs92FCtWjN27dxMZGcmwYcPQ6/VKRxIKkOITJtGhQwcOHjzIkiVL6N+/P4mJiUpHshgpPttSqFAhdu7cydmzZxkwYAA6nU7pSMLCpPiEyVSsWJGoqCgMBgNNmjQhPj5e6Uhmp9PpiIyMpEWLFkpHETmQL18+tm7dyq1bt+jVqxepqalKRxIWJMUnTMrd3Z3ly5czaNAgGjduzNatW5WOZFYnTpzA29ubYsWKKR1F5JC7uzsbNmxAr9fTpUsXkpKSlI4kLESKT5icSqXi/fff54cffuDtt9/ms88+s9u5FDnMadtcXFxYu3YthQoVomPHjjx69EjpSMICpPiE2TRr1ozo6Gi2bt1Kly5dePDggdKRTE6Kz/ZptVqWLl1K5cqVadu2Lffu3VM6kjAzKT5hViVLlmT37t2UKVMGX19fTp8+rXQkk9HpdOzfv1/m9+yARqNh0aJFNGrUiNatW3P79m2lIwkzkuITZufs7MwXX3zBhAkTaNWqFWvXrlU6kkkcP36c0qVLU7RoUaWjCBNQqVTMnj2b1157DT8/P65du6Z0JGEmcskyYTH9+/enVq1af1/qbNq0aWi1tvsrKIc57Y9KpWLSpEl4eHjg5+fHL7/8Qrly5XK8HYPBwOPUxyTpktCoNHg6e+KidTF9YJErcskyYXF3794lKCiIlJQU1qxZY7MrIgMCAhg4cCDdu3dXOoowgwULFjB9+nR+/vlnfHx8Xvj8YzeO8cPZH9h7aS+nbp4iSZeEVq3FYDCg0+soma8kDUo1wL+CP4E1AinoVtACP4XIiBSfUER6ejr/+c9/WLZsGRERETRs2FDpSDmi0+koXLgwv//+O0WKFFE6jjCT7777jnHjxrFt2zZq1679r+/r9DpW/7qa6Qem88f9P0jRpZBuyPpmze5O7ugNerpV68ZHTT+iVvFa5oovMiHFJxS1YcMGBg8ezOTJkxk8eLDScbLtyJEjvP3225w6dUrpKMLM1q5dy4gRI9i4cSO+vr5/P37u9jl6RPTg4v2LJKQl5Hi7GpUGZ40zw3yHMbn1ZDkUakGyuEUoqnPnzkRGRjJ37lzefvttkpOTlY6ULTK/5zh69uzJkiVLCAgIIDIyEoPBQNjBMOp9XY+zt8/mqvQA0g3pJOmSWBizEJ8vfDhz64yJk4vMSPEJxfn4+HDo0CEePHhA8+bNuXz5stKRXkiKz7F06tSJ1atX0617N7p93Y2JeyaSpEvCQN4PmCWmJXL5wWWahDch+lq0CdKKF5FDncJqGAwGwsLCmDVrFitXrqRNmzZKR8pQWloaRYoUIT4+nsKFCysdR1hQ/6X9WX5hOTiZZ/v5nfNzcNBBahSrYZ4BBCB7fMKKqFQqQkNDWbVqFX379mXmzJlWeYujY8eOUa5cOSk9B7Pj9x38cO0Hs5UewKPURwSsCiBZZxuH/G2VFJ+wOq1bt+bw4cNERETQs2dPq7t+ohzmdDwPkh8QtC6IxDTz3m7LgIHbibcZv2u8WcdxdFJ8wiqVKVOGffv2UaBAARo2bEhcXJzSkf4mxed4QneE8jjlsUXGSkxLZGH0Qk7+edIi4zkiKT5htVxdXVm8eDEjR46kefPm/Pjjj0pHIi0tjQMHDsj1OR3IvaR7rPh1Bcnpljv8mJKewvQD0y02nqOR4hNWb/DgwWzatIkRI0Ywfvx40tOzPkHYnI4ePUqFChUoVKiQYhmEZX174lvUFv5TqTfoWR+7nntJcqcIc5DiEzahQYMGxMTEEBUVRceOHbl7964iOeQwp+P5/PDnJOrMO7eXETVqVp9ebfFxHYEUn7AZxYoVY8eOHdSuXZv69etz7Ngxi2fYvXs3rVq1svi4QhkPUx5y7VEu79JwHPgS+AyYCWwCcnC0NFGXyM74nbkbW2RJik/YFK1Wy8yZM5k+fTrt2rVj6dKlFhs7LS2NqKgomjdvbrExhbKO3ziOu5N7zl94ENgJvAqMBd4G7gPLgRwcqY++Lie0m4MUn7BJPXv2ZM+ePUyePJn33nuP1NRUs48ZExNDxYoVZX7PgZy8eTLn59QlA7uBDkBlQAMUBHoA94Bfs7+pPx//SVJaUs7GFy8kxSdsVo0aNYiOjubq1au0bNmS69evm3U8md9zPPeS7pGSnpKzF10BdEC15x53wViEv2d/U1q1lkep1nUeqz2w3buACgF4eXmxfv16pkyZgq+vL//9739zdyjSYIALF+DoUTh0CE6fhqQk0GqhSBFo2pS7P/yAf2io6X8IYbV0el3OX5QIuGPc03ueJ3Aj+5tSocpdBpElKT5h89RqNRMmTKBevXq88cYbTJgwgeHDh6NSqV784gcPYOlSmDUL7t4FjQYePzYW4TMMW7bwcUoK+QcMgO+/h9BQaNgQsjOGsBk6nY4bN25w5coVrly5wtHfj6IyqDCocnDpPHeM5ZfOv8vv8ZPvZ1O6IR03rVv2XyCyRS5SLexKfHw83bp1o2bNmnz99de4u2fyVyY9HWbOhEmTjOWVmIPl6mo1uLlBpUrw3/9C1aqmCS/MSq/Xc/Pmzb9L7erVq39//vTj5s2bFClShNKlS1O6dGmSKiTxi8cvpJCDw53JQBjQGaj5zOMpwDygNVA/e5vycPLg0dhH2XsTJ7JNik/YncTERIYOHcqvv/7KunXrqFChwj+fEBcHPXpAfDwk5O5eaoCxMF1d4eOPYfRo496iUITBYODOnTuZFtqVK1e4fv06Xl5ef5da6dKl8fb2/sfXJUuWxNnZ+e/txt+Lp9bCWjm/Rud+IAroAlQAHgKbMa7sHAI4Z/bCf2pYqiGH3j6Us7HFC8mhTmF33N3dWbZsGQsWLKBx48Z89913dOjQwfjNPXvgtdeMe3h6fd4GMhiM84CffQaRkbB+PbjIXbRNzWAwcP/+/UwL7WnZubm5/avU2rVr94+vXV1dczR2+QLlcxe6GcZDmjuAvzAe9iwL9CfbpadGjV9Zv9yNL7Ike3zCru3fv5/AwEDeeecdxjdvjjogIGeHNbPLzQ2aNYPNm8HJjPetsUOPHz/OtNCefqjV6iz31Ly9vfH09DRLvl7f9yLibAR6Qx7eKB3HeIrDQKBA9l7i4eTBrjd30aBUg9yPKzIkxSfs3o0bNxj+2musOHECN3Ne59PdHfr1g6++Mt8YNiYpKSnLPbUrV66QmpqaaaE9/fDy8lLsZ4i5HkOL71rk/ZZEJzGeQFYre0/3KexD7PDYvI0pMiTFJ+yfwYC+cWMMR46gMfevu5sbbN0KDnD3htTUVK5du5bpoccrV67w6NEjSpUqlWmhlS5dmkKFCln94o3qC6pz7s45i43n4eTB/A7zGfjKQIuN6Uik+IT9W7QIQkLytpAlJ156CX77DTw8LDOeGTy/rD+jUrt79y4lSpTIstSKFi2KWm3718mIvBRJuxXtSNKZ/yoqKlRUKVyFX9/9FSeNHDY3Byk+Yd/S0qBYMbh/33JjurvD9OkwfLjlxsyB55f1Z7S8//ll/Rl9vPTSS2gcaCXru5veZenJpWYvPzetG4ffPkyt4tk8JipyTIpP2Lfvv4eBA+GRhS/7VKYMXLxo8RPcn13Wn9n5ahkt63/+o2TJkjjJIp1/SExLpMaXNbj68KrZrqbi7uTOuObjGN98vFm2L4yk+IR9a9AAol98hfv9wGjgDMaLbVQD5gK+T77/GHgJaA5szc64Hh7GFZ4mnOt7uqw/q3PVMlrW//xHqVKlcrysXxhde3iN+ovrczvhNukG0y6Ucndyp3/t/nwZ8KXVz3naOik+Yb+SkiB/ftBl/e78IVAGWAj0BFKBSIxFV/vJc5YCwcAD4OqT72VJrYZRo2DatGzHffTo0QtXQD6/rP/5D29vbzxseG7RFlx7eI2Gixpy7cE1MNFOsbuTO+/Ue4dZbWdJ6VmAFJ+wX4cPQ9u28PBhlk+LAfwxXlQjM62Bxhj39voA2bpUdaNGEBUF5HxZf0aFpvSyfmH06NEj6jWqh/cgbw4lHcrTnJ+LxgV3J3eWd11OQJUAE6YUWZHiE/bryy+NF5NOyvoP00OgPNAJ6AU0wnj7tKcuPfn+aYzFtxQ4lY3hkzQamtSsyZWrV3n8+DGlSpXKstRsYVm/ozMYDPTp0wdPT08WL17Mvkv7GLJxCFcfXiVJl5Ttk9zdtG4YMNCzRk/mtptLQbeCL36RMBm5ZJmwXxcvvrD0APJjnOObDgwG/gQ6AouB4hhvml0bqA54YZwLPA688oLtuur1LPnyS7wrVrSbZf2ObtGiRZw9e5ZDh4zXz/Qr60fs8Fiir0Uz6+AsNp7fiFqlRq1S8zj1MQaM+xXOamdcnVxJSkuiuGdx3m/wPoNeGURh98JK/jgOS/b4hP0aPhwWLMjxy2KBvhjvGboaqIKxEEc9+X5rjEU490UbcnKCO3eM84zC5h07dox27dpx4MABqlSpkuFz9AY98ffiOXr9KBf+ukBCagJOGicKuBbg5Zdepm6JuhRwLWDZ4OJfZI9P2K9crlysCgwAFgEHgQvAVIx3mgF4hPGw5yxe8D+QXg/O2bwisbBqDx48oEePHnzxxReZlh6AWqWmUqFKVCpUyYLpRE7JsRdhv0qWzFbxxGIstatPvr6CcU+vEcb5vFeBs8CJJx+ngSSycVqDVit3a7ADBoOBgQMH0qFDBwIDA5WOI0xA9viE/apb17jXl5qa5dPyAYeB2RhXdhbAuNBlJsY7ySzj36cv9MNYiq9lteGqVeUO7XZg/vz5XLp0iVWrVikdRZiIzPEJ+/XgARQtarxsmaWpVDBsGHzxheXHFiZz6NAhXn/9dQ4fPkz58rm8N5+wOnKoU9gvLy8oW1aZsT094dVXlRlbmMTdu3cJDAzk66+/ltKzM1J8wr6FhChzlwStFgLkhGRbpdfr6d+/P2+88QZdunRROo4wMSk+Yd/69jWurrSgdGdn46kUWplCt1UzZ87k3r17TMvBJeeE7ZDiE/bN0xNGjDDeKshCktLSCIyM5PTp0xYbU5hOZGQkc+bMYc2aNXKHCjslxSfs36efQvHilhnLwwPXb76hadeutGnThqFDh3Lz5k3LjC3y7NatW/Tu3Ztvv/2W0qVLKx1HmIkUn7B/Li6wdi24uZl3HGdnaNwY7ZtvMmLECGJjY/H09KRGjRpMmTKFpGxcPk0oJz09naCgIN588006dOigdBxhRlJ8wjHUr2+8fJm5ys/JybiCNCLi73P3ChYsSFhYGIcPH+bYsWNUrVqVlStXorfwnKPInsmTJ5OWlsann36qdBRhZnIen3AsX38NI0dCYqLptuniYiy9/fuN5w1mYv/+/QQHBwMwe/ZsmjVrZroMIk9++eUX+vXrx9GjRylRooTScYSZSfEJx7Nli3G1Z2IipKTkbVvu7tChA4SHG88bfAG9Xs/q1asZN24cvr6+TJ8+nYoVK+Ytg8iT69evU79+fZYvX06bNm2UjiMsQA51CsfTsSP8/ju8/rqxuDSaHG8iWauFggVh9Wr4/vtslR6AWq0mKCiI2NhY6tWrR8OGDQkJCeHevXs5ziDyTqfT0bt3b9555x0pPQcixSccU8GCxgUvBw5Anz7Ga3rmzw9Z3TPP1RU8PNCVK8dHTk78dfKksTxzwc3NjbFjx3LmzBkSEhLw8fFh/vz5pClxeTUH9p///AcXFxfGjx+vdBRhQXKoUwiA+/dh1y44fBj27jXexDY11ViE+fMbF8f4+UHjxlC3Lm8NHEjlypUZN26cSYY/ffo0oaGhxMfHM3PmTF5//XW5G7uZbd26lSFDhnD06FGKFSumdBxhQVJ8QuTC6dOnadu2LX/88QcuJrz10Pbt2wkJCaFIkSLMnj2bunXrmmzb4n+uXLmCr68vERERNG/eXOk4wsLkUKcQuVCzZk1q165t8lvVtGvXjhMnTtCnTx8CAgJ48803uXr16otfKLItNTWVnj17EhwcLKXnoKT4hMil0NBQwsLCMPVBE61Wy5AhQ4iLi8Pb25s6deowceJEHj9+bNJxHNXYsWMpXLgwoaGhSkcRCpHiEyKX2rRpg0ajYfv27WbZfv78+Zk8eTLHjx8nPj4eHx8fwsPDSU9PN8t4jmD9+vX88MMPLF26FHVWC5mEXZM5PiHyYPny5SxdupSdO3eafazo6GiCg4N5+PAhYWFh+Pv7m31MexIfH0+jRo3YuHEjDRs2VDqOUJAUnxB5kJqaSoUKFdi0aRMvv/yy2cczGAysW7eOMWPGULVqVWbOnEm1atXMPq6tS0lJoWnTpvTr148PPvhA6ThCYbKvL0QeODs7M2LECMLCwiwynkqlonv37pw5c4bWrVvj5+fHe++9x+3bty0yvq0KCQmhbNmyjBgxQukowgpI8QmRR0OGDGHz5s0WXX3p4uJCcHAwsbGxODk5Ua1aNWbMmEFycrLFMtiKNWvWsG3bNr755hs5N1IAUnxC5FmBAgV48803mT9/vsXHLly4MHPnzuXgwYMcPHiQatWqsWbNGpOvNLVV58+fZ/jw4axduxavbF5WTtg/meMTwgQuXrxIvXr1+OOPP8ifP79iOfbs2UNwcDAuLi7Mnj2bxo0bK5ZFaUlJSTRs2JBhw4bxzjvvKB1HWBHZ4xPCBMqVK8err75KeHi4ojlatmxJTEwM7777Lj179qRXr1788ccfimZSyvvvv0/NmjUZOnSo0lGElZHiE8JEQkJCmDt3LjqdTtEcarWa/v37ExcXR40aNahfvz5jxozhwYMHiuaypGXLlrF//34WLVok83riX6T4hDARX19fypUrx/fff690FADc3d35+OOPOX36NHfv3sXHx4cFCxbY/R0gzpw5Q0hICBEREeTLl0/pOMIKSfEJYUIhISHMmjXLqhaXlChRgiVLlrB9+3bWr19P7dq12bx5s1VlNJXHjx/To0cPZs6cSa1atZSOI6yULG4RwoT0ej3VqlXj66+/pkWLFkrH+ReDwcCWLVsIDQ2lVKlShIWFUadOHaVjmYTBYKBfv344OzvzzTffKB1HWDHZ4xPChNRqNcHBwRY7oT2nVCoVAQEBnDp1im7dutGuXTsGDRrE9evXlY6WZ0uWLOHkyZN88cUXSkcRVk6KTwgT69+/P4cPHyY2NlbpKJlycnJi2LBhxMXFUaRIEWrVqsWkSZNISEhQOlqunDhxgnHjxhEREYG7u7vScYSVk+ITwsTc3Nx49913mTNnjtJRXsjLy4vp06cTExPD2bNnqVq1KkuXLkWv1ysdLdsePnxIjx49mDdvHlWrVlU6jrABMscnhBncunULHx8f4uLiKFasmNJxsi0qKorg4GBSUlIICwujVatWSkfKksFgIDAwkMKFC7Nw4UKl4wgbIXt8QphBsWLF6NmzJ19++aXSUXKkcePGHDx4kDFjxjBw4EC6dOnC+fPnlY6VqQULFvDbb7/ZxN61sB6yxyeEmcTFxeHn58fFixdxc3NTOk6OJScnM3/+fGbMmEFQUBATJ06kcOHCSsf6W3R0NAEBAURFRVGxYkWl4wgbInt8QpiJj48PDRs2ZNmyZUpHyRVXV1dGjx7NuXPn0Ol0VK1albCwMFJSUpSOxr179+jZsycLFy6U0hM5Jnt8QpjRvn37GDx4MOfOnUOttu33mefOnWPUqFGcO3eOGTNm0K1bN0UuB2YwGOjcuTMVKlRg7ty5Fh9f2D7b/j9RCCvXvHlz8ufPz6ZNm5SOkmfVqlVj06ZNLFq0iEmTJuHn58eRI0csniMsLIybN28yY8YMi48t7IMUnxBmpFKpCA0NtdoT2nPD39+fY8eO8dZbb9G1a1eCgoK4fPmyRcY+cOAAM2fOZO3atTg7O1tkTGF/pPiEMLPu3btz6dIloqOjlY5iMhqNhoEDBxIXF0elSpV45ZVXGDduHA8fPjTbmLdv36Z3796Eh4dTtmxZs40j7J8UnxBmptVq+fDDD+1qr+8pT09PPv30U06ePMn169fx8fFh0aJFJr81k16vp1+/fvTp04dOnTqZdNvC8cjiFiEs4NGjR5QvX56YmBjKlSundByzOXbsGCEhIdy+fZuwsDDatWtnku1OnjyZ7du3s2vXLrRarUm2KRyXFJ8QFjJmzBhSU1Pt/mRrg8HATz/9xKhRo6hQoQKzZs2iZs2aud7e7t276dOnDzExMZQqVcqESYWjkuITwkKuXr1K7dq1iY+Pp0CBAkrHMbvU1FS++uorPvvsM7p27cqkSZMoXrx4jrbx559/Uq9ePb799lvatm1rpqTC0cgcnxAW4u3tTadOnfj666+VjmIRzs7OjBgxgri4ODw9PalRowZTpkwhKSkpW69PT0+nT58+vP3221J6wqRkj08ICzp58iQBAQHEx8c73HL833//nTFjxhAdHc2UKVPo3bt3lif1T5w4kQMHDrBjxw40Go0Fkwp7J8UnhIW9+uqr9O/fn379+ikdRRH79+8nODgYMJ6M3rx58389Z/v27QwcOJBjx47l+PCoEC8ixSeEhW3bto0xY8Zw4sQJRS75ZQ30ej2rV69m3Lhx+Pr6Mn369L+vuXn16lV8fX3573//S4sWLRROKuyRzPEJYWHt2rVDr9fzyy+/KB1FMWq1mqCgIGJjY6lXrx4NGzYkJCSEW7du0atXL0aMGCGlJ8xGik8IC1OpVAQHBzNr1iyloyjOzc2NsWPHcubMGR4/fky5cuX466+/GDlypNLRhB2T4hNCAX369OHUqVOcPn1a6ShWoXjx4gQEBODl5cVLL71E7dq12bBhAzITI8xB5viEUMiUKVO4cOEC3377rdJRFHfx4kUaNmzI+vXradKkCdu2bSM0NJQiRYowe/Zs6tatq3REYUek+IRQyF9//UWlSpU4c+YMJUqUUDqOYlJTU2nWrBm9evX6e7UngE6n45tvvuE///kPbdu2ZfLkyXh7eyuYVNgLOdQphEIKFSpEUFAQn3/+udJRFDVq1ChKliz5r3k9rVbLkCFDiIuLw9vbmzp16jBx4kQeP36sUFJhL6T4hFDQhx9+yOLFix32j/n333/Pxo0b+fbbbzM9tSN//vxMnjyZ48ePEx8fj4+PD+Hh4aSnp1s4rbAXcqhTCIW98cYbtGjRgvfff1/pKBb122+/0bhxY7Zu3Ur9+vWz/bojR44QEhLCw4cPCQsLw9/f34wphT2S4hNCYVFRUQQFBXHhwgWHuTRXUlISTZo04e233+a9997L8esNBgPr1q1jzJgxVK1alZkzZ1KtWjUzJBX2SA51CqGwxo0bU6JECdavX690FIv58MMPqVKlCsOGDcvV61UqFd27d+fMmTO0bt0aPz8/3nvvPW7fvm3ipMIeSfEJYQVCQkKYNWuWQ5y3tnLlSnbv3s3ixYvzfMk2FxcXgoODiY2NRavVUq1aNWbMmEFycrKJ0gp7JMUnhBXo3Lkzd+7c4eDBg0pHMatz587x4YcfEhERQf78+U223cKFCzNv3jwOHjzIwYMHqVatGmvWrHGINxIi52SOTwgrsWDBAn755RfWrVundBSzSEhIoGHDhowcOZJBgwaZdaw9e/YQHByMi4sLs2fPpnHjxmYdT9gWKT4hrERCQgLlypXj4MGDVK5cWek4JmUwGBgwYAAA3333nUXuSqHX61mxYgXjx4+nSZMmTJs2jfLly5t9XGH95FCnEFbCw8ODoUOHMnfuXKWjmNy3335LTEwMX375pcVuxaRWq+nfvz9xcXHUrFmT+vXrM3r0aB48eGCR8YX1kj0+IazIn3/+SfXq1blw4QKFCxdWOo5JnDp1ijZt2rB3716qV6+uWI7r16/z8ccfs3nzZj7++GOGDBmCk5OTYnmEcmSPTwgr8tJLL9G1a1cWLlyodBSTePToET169GDOnDmKlh5AyZIlCQ8PZ/v27axfv57atWuzadMmWQDjgGSPTwgrc+bMGdq0acPFixdxdXVVOk6uGQwG+vTpQ758+fj666+VjvMPBoOBLVu2EBoaSqlSpQgLC6NOnTpKxxIWInt8QliZGjVqULduXVauXKl0lDz56quvOHfuHPPmzVM6yr+oVCoCAgI4deoU3bp1o23btgwaNIjr168rHU1YgBSfEFYoNDSUsLAw9Hq90lFy5ejRo0ycOJGIiAjc3NyUjpMpJycnhg0bxvnz5ylSpAi1atVi0qRJJCQkKB1NmJEUnxBWqFWrVri4uLBt2zalo+TY/fv36dmzJ19++aXNnJbh5eXF9OnTiYmJ4ezZs1StWpWlS5fa7BsPkTWZ4xPCSq1cuZLw8HB27dqldJRsMxgMdOvWDW9vb5u+z2BUVBTBwcGkpKQQFhZGq1atlI4kTEiKTwgrlZaWRoUKFdiwYQN169ZVOk62zJkzh1WrVrF//35cXFyUjpMnBoOBtWvX8tFHH1GnTh1mzJhBlSpVlI4lTEAOdQphpZycnPjggw8ICwtTOkq2HDp0iKlTp7J27VqbLz0wLoAJDAzk3LlzNGnShCZNmvDBBx9w9+5dpaOJPJLiE8KKDR48mG3btnHlyhWlo2Tp7t27BAYGsmTJEru7LJirqyujR4/m3Llz6HQ6qlatSlhYGCkpKUpHE7kkxSeEFfPy8mLAgAFWeUrAU3q9nv79+9OzZ09ef/11peOYTdGiRVmwYAH79u1j9+7dVK9enR9++EFOgLdBMscnhJW7fPkyr7zyCvHx8Xh5eSkd51+mTZvGxo0b2bNnj0NdAmznzp2EhISQP39+wsLCaNCggdKRRDbJHp8QVq5MmTK0a9eOJUuWKB3lX/bu3cvcuXNZs2aNQ5UegL+/P8eOHeOtt96ia9euBAUFcfnyZaVjiWyQ4hPCBoSEhDBv3jzS0tKUjvK3mzdvEhQUxHfffYe3t7fScRSh0WgYOHAgcXFxVKpUiVdeeYVx48bx8OFDpaOJLEjxCWED6tWrR8WKFYmIiFA6CgDp6ekEBQUxYMAA2rdvr3QcxXl6evLpp59y8uRJrl27ho+PD4sWLUKn0ykdTWRAik8IGxESEkJYWJhVLKb4v//7P9LT0/nkk0+UjmJVvL29Wbp0KZs3b+a///0vL7/8sk1efcfeyeIWIWyEXq+nRo0afPnll4peSWTnzp3079+fo0ePUqJECcVyWDuDwcBPP/3EqFGjqFChArNmzaJmzZpKxxLIHp8QNkOtVhMcHKzoCe3Xr1+nX79+rFy5UkrvBVQqFZ07d+b06dN07NiR1q1bM3ToUG7evKl0NIcnxSeEDenXrx8xMTGcO3fO4mPrdDp69erFe++9J9euzAFnZ2dGjBhBXFwcnp6e1KhRgylTppCUlKR0NIclxSeEDXF1dWXYsGHMnj3b4mN//PHHuLm5MW7cOIuPbQ8KFixIWFgYhw8f5tixY/j4+LBy5Uq5A4QCZI5PCBtz584dKleuTGxsLMWLF7fImJs3b+add97h2LFjFC1a1CJj2rvIyEhCQkIACAsLo3nz5gonchyyxyeEjSlSpAi9evViwYIFFhnv8uXLDBw4kNWrV0vpmVDz5s05dOgQH3zwAUFBQXTv3p3ffvtN6VgOQYpPCBs0cuRIvvrqKxITE806TmpqKoGBgYSGhtKsWTOzjuWI1Go1QUFBxMXFUa9ePRo1akRwcDD37t1TOppdk+ITwgZVqVKFJk2asHTpUrOO89FHH1G0aNG/D8kJ83g6d3rmzBkSEhLw8fFh3rx5pKamKh3NLskcnxA2av/+/bz11lvExsai0WhMvv3169cTHBzM0aNHKVSokMm3LzJ3+vRpQkNDiY+PZ8aMGXTu3BmVSqV0LLshxSeEjTIYDDRq1IixY8fSpUsXk277999/p3HjxmzatEnuOqCgbdu2ERoaSpEiRZg9ezZ169ZVOpJdkEOdQtgolUpFaGgos2bNMul2k5OT6dmzJxMmTJDSU1j79u05ceIEffr0ISAggDfffJOrV68qHcvmSfEJYcO6du3KtWvXOHTokMm2GRwcTPny5Xn//fdNtk2Re1qtliFDhhAXF4e3tzd16tRh4sSJPH78WOloNkuKTwgbptVqGTly5JOLV0NkJEydCu3bw0svgYcHuLlBvnxQrRq8/TZ8+y3cuJHx9lavXs2OHTsIDw+XOSUrkz9/fiZPnszx48eJj4+nSpUqhIeHk56ernQ0myNzfELYuKtXH+PjM5V8+T4lIUFLSgpkdds+Dw/Q6cDfH0aNAj8/UKkgLi6OZs2asWPHDl555RXL/QAiV44cOUJISAgPHz4kLCwMf39/pSPZDCk+IWxYRAQMHgwJCanodM45eq1KBe7u0KABLF6cRNeuDRk+fDhDhgwxU1phagaDgXXr1jF69GiqVq3KzJkzqV69utKxrJ4UnxA26N496NcP9uyBhIS8bUurBUimQYNw9u8fJoc4bVBKSgoLFixg6tSp9OzZk08++cRsV9kxGAzE34vn6I2j/HHvD5J1yWjVWgq5FeKVEq9Qp3gd3JzczDK2qUjxCWFjbt6EJk3g6lUw5fnNbm4Gxo9XMX686bYpLOvu3btMmjSJlStXMnr0aEaMGIGrq2uet2swGDh09RCzDs5i2+/GG+tqVVoSdYno9DrUqHHRuuCkcSIxLZGKBSsystFIgmoH4ensmefxTU2KTwgb8tdfUL8+XLlinKczNXd3+OQT49yfsF3nz59n9OjRnDx5kqlTpxIYGJjrPfmd8Tt5d9O73Hh8g8S0RAxkrzI8nDwwYODd+u/yf63+z6r2AqX4hLARBgO0bQv79pl2T+95bm6weTPILfds3549ewgODsbFxYXZs2fTuHHjbL/2YcpD3t/yPt+f+57EtNxfE9ZN60Zh98KsfWMtjUtnf3xzkuITwkYsXw7vvpv3Ob3sKF4cfvsNPK3vKJXIIb1ez/Llyxk/fjxNmzZl2rRplC9fPsvXxN+Lp9k3zbiXdI/k9GST5HDTujGlzRQ+bPShSbaXF3IenxA24NYteO89y5QewIMHEBpqmbGEeanVat58803i4uKoUaMG9evXZ/To0Tx48CDD5//+1+/4LvblZsJNk5UeQJIuifG7xjM1cqrJtplbUnxC2ICFC7M+N8/UkpNh6VLjnKKwDx4eHkycOJFff/2Vu3fv4uPjw4IFC0h75hfrXtI9mn7TlPvJ99EbTH9n+MS0RD6L/IxlJ5eZfNs5IcUnhJXT6WD+fGMZWZJaDeHhlh1TmF/JkiUJDw9n+/btrF+/ntq1a7Np0yYMBgNDNw01W+k9lZiWyLDNw7j6ULlrjsocnxBWbtMm6NMHHj3K6lnlgETgD8DjyWNLgCnArWeelwC4A09X+G0Fmme61ZIl4dq1XMUWNsBgMLBlyxZCQ0NxruXM+drnTXp4MzNatZbG3o3ZO2CvIueNyh6fEFbul18ge9cjTgfmPfdYGeDxMx8AJ5/5OvPSA7h71zi/KOyTSqUiICCAEydPcLHWRYuUHoBOr+P4jeNs+22bRcZ7nhSfEFYuMtJ4KsOLjQJmAfdNNraLCxw9arLNCSu15/IeDFrLHvx7nPaYmQdnWnTMp6T4hLBy585l95n1gZYYy880EhMhJsZkmxNWasaBGTxKzfJYullEXY3i4v2LFh9Xik8IK5aebiyf7JsEfA7cNsn4Oh38+adJNiWsVLIumcjLkRl/MxJY8dxj8zN57Ncnn+8GPgGys3bFABtiN2Q3qsloLT6iECLb0tKMqyv12V5kVxPoBEwDqpkkQ0TET5w5MxtnZ2ecnZ1xcnL6+/OMvs7LY1k9x8nJCbVa3qub2qmbp3BzciMtJYPzZcoC+wE9xt2kRxinkm8899hfT55rwDiF7Pbkn95Zj52cnsy+S/v4oNEHpvlhskmKTwgr5uKSk9J76lOgLhBikgx+fvUZPvwTUlNT//5IS0v7x9fPP5aQkMC9e/f+9bwXve5Fj2m1WpOWrzlf5+TkhEajMcl/A3OKuR5DWnomJ4mWxFh0fz75/BJQHrj33GMFgfzARYxrpl7HuGC4HS9smSPXj+T1R8gxKT4hrJhKBYUK5fRE8kpAIMbjT7XyNL6rKzRvXpKWLUvmaTumYDAY0Ol0eS7RjJ6TnJzMw4cPc/y6Fz2mUqmsvqCPXztOki4p43/pWox7bZf4X8mVAfI991jZJ88/CVQBamAsvvPAC24PeP3R9bz9YuSCFJ8QVu7ll2HXrpy+aiKwPM9jOzsb7wZhDVQqFU5OTjg5OeHh4fHiFyjMYDCQnp5u0oJ+9rHHjx+bpKDvt7pvLKrMlMVYbo2By0AjjMV39JnHGgOpwBmgK6DBWHgneWHxGQwGdHodWrXl6kiKTwgr16KF8Y4MWd+G6OJzX5cGMjonK2dL1hMTjcUrck6lUqHVatFqtbi5Wc8teZ436KdBfHP8m8yfUBaIxnh9hASgMMZrJPz45LFbT54Ti3HOr/KT19UClj15TRbvUwwY0Kgse0hYZoqFsHIBAcY9LyXUrg02sHMl8qCoe1FUZHH1lKfvoY5hPMwJ4Ipxr+/Yk38WBE5g3OubA8wEIjAugPmVLLlqXS1+9RbZ4xPCytWrB2XL5uR8PtPIlw8++siyYwrLq1uiLvmc8/Ew9WHGT3DCOJcXxT8v9FPmyWMVgIcYr5YXBBR/5jmHMB7ubJT5+FUKV8l19tySPT4hbMCYMZbf89JooEsXy44pLK9eiXroDFkeRzdeCjaB/+3x8eTzBIyHOU8CL2FcV5XvmY+GwM0nH5loVrpZLpPnnlykWggbkJoK1apBfLxlxvPwgFmz4J13LDOeUI7BYKDAtAKZ7/GZUT7nfCx5fQk9a/S06LiyxyeEDXB2hogIsMQaCa0W6tSBoUPNP5ZQnkqlYlDdQThrLD+RbMDA6z6vW3xcKT4hbETduvDhh+Dubt5x3Nxg9WrjOYTCMbzf4H3UKsvWgZPaiUGvDMJV62rRcUGKTwib8tln0KmT+crP3R22bYMyZV78XGE/yhcsT8uyLS16Lp2T2okPGlr2UmVPSfEJYUPUali1Crp1M+1iF40GPD1hxw5o0sR02xW2Y8nrS3DRuFhkLA8nD8b7jad8wfIWGe95UnxC2BiNBpYtgzlzjOWnzeObdA8P40nqJ05A06amSChsUan8pfi8w+d4OJl3+bBapaZ8gfKMaTrGrONkmUGxkYUQuaZSweDBxnP7mjc3zsvltAA9PIyHNj/7DI4cgYoVzZNV2I4BLw+gS9UuuDuZbyLZy8WLDb03oFErdwFvOZ1BCDtw9izMmwfLlxsLMKP7+Gk0xrJLSTHO4X30EfTqZf7FMsK2pOvTCfw+kK2/bSUxLUc3g8ySWqXGy8WLyLciqVEsq4uDmp8UnxB2JDUVzpyBo0chKgpu3zY+5u4ONWpAgwbGK8GUVP5mC8KK6Q16QneE8lXMV5nfuSEH3J3cKZWvFFuCtlCpUCUTJMwbKT4hhBAZiroSRc/ve/JX0l+52vvTqDQ4a5wJaRzCxBYTcdI4mSFlzknxCSGEyFRSWhKLjy1m1sFZ3Eu+R0JqAoYX3OXD3ckdvUFPj+o9+KjZR1Qv+oJ7E1mYFJ8QQogXMhgM7L20l3Xn1rH/8n7O3TmHwWBAo9ZgMBhI06fxkudLNCjZgLYV29KrZi+8XL2Ujp0hKT4hhBA5pjfo+SvpL5LSknDSOOHl4oWbk/Xed/BZUnxCCCEcipzHJ4QQwqFI8QkhhHAoUnxCCCEcihSfEEIIhyLFJ4QQwqFI8QkhhHAoUnxCCCEcihSfEEIIhyLFJ4QQwqFI8QkhhHAoUnxCCCEcihSfEEIIhyLFJ4QQwqFI8QkhhHAo/w98uGPsej+IGQAAAABJRU5ErkJggg==\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "solution = tree_csp_solver(australia_csp)\n",
+ "print(solution)\n",
+ "draw_graph(australia_csp, solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 30,
+ "id": "0ec15ed2",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'WA': 'Y', 'OR': 'R', 'ID': 'G', 'NV': 'Y', 'CA': 'G', 'AZ': 'R', 'UT': 'B', 'MT': 'Y', 'WY': 'R', 'CO': 'Y', 'ND': 'R', 'SD': 'B', 'NE': 'G', 'KA': 'B', 'OK': 'R', 'NM': 'G', 'TX': 'B', 'MN': 'Y', 'IA': 'R', 'MO': 'Y', 'AR': 'G', 'LA': 'R', 'WI': 'G', 'IL': 'B', 'KY': 'R', 'TN': 'B', 'MS': 'Y', 'MI': 'R', 'IN': 'Y', 'OH': 'B', 'AL': 'R', 'GA': 'Y', 'FL': 'B', 'PA': 'G', 'WV': 'Y', 'VA': 'G', 'NC': 'R', 'SC': 'B', 'NY': 'B', 'NJ': 'R', 'DE': 'Y', 'MD': 'B', 'DC': 'Y', 'VT': 'G', 'MA': 'Y', 'CT': 'R', 'NH': 'R', 'RI': 'B', 'ME': 'G'}\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAb4AAAEuCAYAAADx63eqAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAACp+klEQVR4nOydd3hT1RvHP+luOoBCKZuyt+yhTNlLQIb8HKg4EERAcKGiooCKIsPBUJANAoogCMhG9t5DQMqeZZTukby/P05H0qZtmg5aOZ/nuU+TO07OTXPv9573vMMgIoJGo9FoNA8JTg+6AxqNRqPR5CRa+DQajUbzUKGFT6PRaDQPFVr4NBqNRvNQoYVPo9FoNA8VWvg0Go1G81ChhU+j0Wg0DxVa+DQajUbzUKGFT6PRaDQPFVr4NBqNRvNQoYVPo9FoNA8VWvg0Go1G81ChhU+j0Wg0DxVa+DQajUbzUKGFT6PRaDQPFVr4NBqNRvNQoYVPo9FoNA8VWvg0Go1G81ChhU+j0Wg0DxVa+DQajUbzUOHyoDug0WQHV6/CmjWwfTv8+y+IQNmy0LgxtGsHJUs+6B5qNJoHhUFE5EF3QqPJKk6fhjffhE2bwNkZwsOttxuNYDJBkyYwaRJUq/ZAuqnRaB4gWvg0/wlE4Ntv4f33IToazOa09zcYwMMDPvoIhg9X7zUazcOBFj7Nf4J33oHJkyEiImPHGY3w3HMwdaoWP43mYUE7t2jyPHPmOCZ6oI6ZP18dr9FoHg70iE+Tp7l2DSpWhLCwzLVjNMLx4xAYmCXd0mg0uRg94tPkacaNg5iY5GsDAU/AGygCvAgkKOOLwIgU7cTEwOefZ1MnNRpNrkILnybPEhMDP/1kS/gAVqDE7hBwEPgizbbi4mDevJReoBqN5r+HFj5NnuXoUXv2KgK0Qwlg2ri5wf79meuTRqPJ/Wjh0+RZDh5MP2wBLgOrgfLpthcVpdrUaDT/bbTwafIswcFKrGzTDfABSgKFgU/TbS86Gm7dyqreaTSa3IoWPk2exdkZnFL9BS8DQoHNwCkg2K42XXQSP43mP0+eucxFhEv3L3Ev6h6uTq6ULVAWdxf3B92trMdshg0bYP162LYN7t5Vd+Nq1aB5c+jeHQoXftC9zBWULw+enhAbm9ZezVGenG+jxDB1fHxUmxqN5r9NrhY+s5hZc3YN43eOZ+flnSDg4uyCiBAVF0Vg/kBeq/saL9V+iQKeBR50dzOHCMycCR98oKKqw8OtJ7COHoU//oChQ6FTJ/juOyha9MH1NxdQr15qHp3JeRMV4nA4zb1MJtUmly/Dxo2waxdcvKiGllWrQsOG0KqVUkiNRpNnybUB7EdvHOWpX5/i8v3LhMWkHp1sdDViwMC4tuN4re5rGPJi3qk7d+DJJ5VLoT3+9K6u4O4Os2ZBjx7Z3r3sR4A9wExgK3ABMKHi8B4BOgMvAH4pjqxRA44dS742EJgOtLZYNwC4iZr3KwGMTtFWmeLR/FupE4Yd29Uo2zIq3skJvL3V8PLZZ1XQn7+/Iyer0WgeMLlS+BYeXcjLf7xMVFwUgn3d83L1onlgc5Y+tTRvmUDv3IEGDeDSJXuHL0l4esKUKfDCC9nTtxxhP9AHuAhEArbcNI3x618Gvop/r1iwAPr1E8LDM/fA4+UazXgZRr84O3KXubmp737OHOjSJVOfq9Focp5cJ3zLTi3jmd+eITIuMsPHerp48niZx1n59Mq8MfITgZYtYceOjIteAp6equhc7dpZ27dsR1BB5aNRgmcPnqhR33qgMgB79uyjWTN3YmKqIuLsUE8MmKhq+IdD8ggumOw/0NNTmZxfftmhz9VoNA+GXOXVeS30Gs///rxDogcQGRfJlvNb+HH/j1ncs2xi9mzYu9dx0QOIjIRevVTqkTzFx8AY7Bc94ve9CjxKXNwJRo8ezRNPdOKrry7g6+uY6AF4Ec4S6ZEx0QP13Q8erJyQNBpNniFXjfh6LOrBitMriP0mVnmivwV4WewwFbgODEF5qR8FLO93fsAAZfa8NPRS7nZ4MZuhRAm4do1AIAIIIul0pwPzUKdpAM5gHYI9Ejgbvw/e3srs9uSTOdL1zLMWeBJ11hlHxMDly2688spjzJgxhxIlSnDoEDz+uJoiTdvLMwkXZzOepjDW0YaG7HGoLwAUKwZnzqhM1xqNJteTa0Z8N8JusOrMKmLN8XetAoCl08INIPkNrTHwocUyQK0WhJmHZmZvhzPL5s0QGpr41gRMcrStsDD4+uss6FROEAk8S2BgBG5uKgjdktq1VV288+eT1o0cqdbt3q3eGwxCkSJmVq9uRokSJQCoVQtOnFARH15e6dfW8/aGRr4nOE51K9FbANRDudUUBTqgXGS84xc3wNXifQeAe/fUg4dGo8kT5BrhW3JiifW83CNYe58fAmra11ZEbATT9k3Lus5lBxs3KlNZPO8A44B7jra3f7/yx39AxJnjOH7zOJvPb2bbxW1cDb2ayp6LAZVupUwZWLgwacvRoylr6okoTfHzs9YWV9dYnJwmANGJ64oWhbVrYeVK6NBBOb56e0O+fGrx9lZ+Ka1bw9Lpd/g7vB4luZR4/HhU4MMHqOesi8DrQG1Uuuuw+G29Ld6vBtXpPPPgodFoco3wbT6/2XpurwTqnnYL5dB3DCWGdhJ0L4jouOj0d3xQbN9uJVT1gBYo8XMINzdlbstBTGYTf/zzB01nNsU4xkijGY3o9ks3Oi/oTNlJZSnwZQEGrBzAP8H/WBw1gYQSQX36WIvZ7Nnw/PPWn7F1q6q59+238MsvyadDBVhptb/BAC1awJ9/KrPn7t2weDEsWgQ7d6p169ZBG9ZhcHdLPC4ENev4A9AdZXJ2BZ4A7JK0y5dTDl81Gk2uJNcEsB+/eTzlyoRRX2nAHxWCZckOsJqaqYyaOgJccOHnZT9TzLUYZrMZk8mEyWRKfJ3e36zeN/m6bw4cIDDZ6XyGst4OsfH91MH6KSUK6Gn5PjaWJZMmcbtSJTw8PHB3d8fDwyPV17bWubi42O0Ne+LWCZ5a8hQXQi4kxlnGxljboqNN0Uw/OJ3Zh2fzcu2X+arNGDxdTyRub9QI5s6FkydVMdlfflHPAyMsyuXNng1PPAFPPaX8SFassAxdDAO2ALZjGRPizqtWtbFx926rOL2d8d+pw7Oknp5w4AC0betoCxqNJofINcIXY7bh2VgTFdN8F9tmzseAVrbbi42JZeGiheSPzo+zszNOTk44OztbvU7vb2rr3Nzc7No3rXbzHToE9+9b9bk6KlT7S6BKsvM5gG3nFkvuhocTFBREdHQ0UVFRREVFJb62tS75axGxSyTvBdxjf5n9mAwm5XmTBnHmOOLMcfy470eOXV3M2hedcXVJEsiEUV/z5lClChQvnnRsRAQsWaK2u7pCz57qdZLwCZGRmzh9+jAxMTHExsYmLpbvbW1rv2EDlSz8um4DhcjEBWEywc2bjh6t0WhykFwjfPnd89tYGb+cAbpmrD1XD1fmTZ9HqXylMtu17OHPP+HcuRSrP0WN7t7KYHNO0dFsuXqVSiVK0LRpU2rXrk3ZsmUzFM8YFxdHdHR0miK5+8ZuPv7nY0ySsfnEGIkhwnyT8FjIb/Gr69MHmjWDoKCUZs7ff1cJVDp2VO+ffVbNz926lZQ05erV0/Tp0wc3NzdcXV1xdXW1ep38fcLr8GhrM3hBVBrrOBy8KAwGNcTUaDS5nlwjfI+WfJSD1w+mzNTSFeUI6AYZCbNyMjhR0rdkFvYwi2nSRE0+JUtRVh7lPPEtUCMDzTkHBPDC4MEcPHiQuXPnMnToUEJDQ6lVqxZ16tShTp061K5dm0qVKuGSSgkCFxcXXFxc8PLysrk9JCqEnt/2JEYcizuMMKWsplC6tHJyWbUKZsyw3jZ7trJGlop/dhFRoQoLFsCQeHtwuXI1OHJkX8Y7M2aMcheNj398FHBHpbHumfpRqWMwQLlyjhyp0WhymFwjfG3KtmHO4TmExoRab0iZnjGJ7cAui/cuwHvq5aMlH83d2Vu6dYOBA21u+hiYm5G23N1x7tePLl260MUihdatW7c4ePAgBw8eZMWKFXz22WdcvXqV6tWrJwphnTp1qF69Ou7u6ad5G7FxhJrPmwsUB1om2+EU8AvKKwSSHlTiB0InaoFHv5TtzpihilB4eSXF4V+5oopUrF4Nj1g4NU2cqMydQxInQuul22+b1K+v4u7izc35UHOsA1E/o7bxp7Ee2IRKlJYmkZHWHdVoNLmWXBPAHmuKpfC4wtyLupfptrzdvFnSawnty7fPfMeykz591KgvM5lbQDlWnD2rAqnT4f79+xw+fJgDBw5w4MABDh48yJkzZ6hUqVKiENauXZuaNWviY1GFIDwmnMLjChMRG6ESB2xAeeFYPlssQpmm28W//x3wxWoe9uRAqFwIAgNh+nRlurQkLk7N533xhZrf27/fevvVq2qUePAgVK/uDUwDnrHjS0pGVJQq7xRq/aA1H+V3ehLlS1UXFSL6WPz2kVgkDrCkTRsVS6HRaHI9uUb4ACbsnMBHmz4iPNaOCgWpYMBApUKVOP76cZwMuSZawza3bkGFChAS4ngbRqNyg3z/fYebiIyM5NixY4lCeODAAY4fP06JEiUShTCidATf/PsNYbFhKpHAOOBpSHRNjYxf9ypQJH6dDeF7vR6MbQPeSZEEmcCIqrhg2zSbLm+/DT/8kFYZd/vw8oJly1KquEajyZXkKuEzmU3U/6k+R28eJc7sWO5JTxdP9ry6h+qFq2dx77KJVatUrs3kkdv24OEBderA339nuWNFbGwsp06dShTD30J+43Kpy0kxFX+gwugSnI72AXtJzJ4D2BQ+Hze4NBTyeWSuf5GRBjZtqkCNGuspWdLBudyQEFV5NjPxd25uKtH4qlXpp4vRaDS5glw1JHJ2cubPZ/7E3+iPi1PGpx89XTyZ0WVG3hE9UC6Ls2apkVtGbpxeXkr01q7NFm9CV1dXatSowQsvvMDEiROp1qqa9a+lJnCCpDRyh4Fa6bcbGgOvroDwTFp33d0DOHCgO7Vq1WL06NFERjqQ2DxfPhXZ7unpWCcMBlWUdtYsLXoaTR4iVwkfQFGfouzrt48ahWvg5WqfCcvVyRUfNx8W9FjA0zWezuYeZgO9esGePSqQzds77X09PNSN+qOP1EgvFQ/MrCbFCLw0ytJ4CrgDXMFuN9QlJ+C3k67EmR2tm+iFk9MKRoz4gv3793Po0CGqVq3K0qVLybABo2VL5S2T0QTTbm5QsKCKuA8IyNixGo3mgZLrhA+gmE8x9vXbx+iWoyngUQAfNx8MNiKlPV088XD2oEulLpwedJpulbvlfGezimrV4MgRNQJ5/HElbl5ealTi66s8PkqWhOHDVfzfe+/laNxYgJeNm3tN1EjvCFAOlbXZToas9uRWeAcsi8qmjxvKe2Y9Cd6cgYGB/Prrr8yYMYOPP/6Y1q1bcyxlSfa06dlT5UYrWzb9BwmDQe3Tpg0cPw6VKmXsszQazQMnV83x2SLWFMuqM6tYH7SenZd2cjfqLm7OblT3r06LwBb0rNqTAO//4BO32axKFNy+rUYX5cqlPxrMRibvnczba9+2zqd6F/gO5VvSHqiW7CAbc3wJGMwGPnb/mKd7+FGx4hgMhkhULSpbuKJiItoDP6FyrKQkLi6OqVOn8tlnn/G///2PTz/9lAIFMlCaKiZGedl+9RWcOgWenkTHxGA2mfD08FBOMG3awDvvqISgGo0mT5LrhU+TOzhx6wT1fqyXskjwTFQpg7dJGRWahvCV9ChJ92vd2bBhA9euXeKttyrx9NOhlChxHWfnEAwGJ1SsRDmU4A3EOmlb6gQHB/PRRx+xdOlSPvvsM1555RWcMzg6vnMhlH+XHmbH71u5dCWYhk8/T8l2ValZz9XhKUGNRpM70MKnsZva02pz6PqhTLfj5erF9x2/58VaLwJw/fp1Nm7cyIYNG9iwYQMi0bRp04ImTdrQqlUbh702Dx06xODBgwkNDeXbb7+ladOm6R6zaROMHq2Kqnt6QkSEibg4wcPDBVdXNSjs1Qs++AAqV3aoWxqN5gGjhU9jN+vPrafrL11VEHsmKO5TnLODz+LhkjKmQUQ4d+5coghu3LiRAgUK0KpVK1q1asXjjz9OwYIF7f4sEWHx4sW88847NG7cmK+++sqmkN67B/36qRSq6UWWODsr6/Pw4UoAU8kAp9Focila+DQZ4vnfn2fJiSVExTkW9G10MbK2z1oal2ps1/5ms5kjR44kCuG2bduoUKFCohA2adIk1dyiloSHhzN27Fh++OEHhg4dyttvv42HhxLeGzdUiaRr1yA6AyUcjUZVVWL5cuV7pNFo8gZa+DQZIiouisdnP86h64cyLH6eLp6Mbzee/vX6O/z5MTEx7Nmzhw0bNrB+/XoOHjxI3bp1adWqFa1bt6Z+/fq4pqFCQUFBvP322xw8eJBvvvmGjh27UbOmgX//TcoTmhGMRuUUOnu2w6ek0WhyGC18mgwTGRvJy3+8zPJ/lttl9nRxcsHDxYPpT0ynd/XeWdqXsLAwtm7dmjgiPHfuHE2bNk0cEVavXh2n5CUhgA0bNjBkyBDCwj7kxo2niIpyPDTEaIRff4UOHTJzJhqNJqfQwqdxmNVnVjNs7TAuhlwkzhxHjMk6HYuXqxdx5ji6VOrCxPYTKeaTfhLtzBIcHMymTZsShTAkJCRRBFu1akWZMmUS9718OY4yZSAuzgWVdDQCCCIp9+d0VCkKQbmmfmLxSXNQ1ROPAkZKloQLF3QCF40mL6CFT5Np9l/dz4agDfx94W9uhN/AxeBC1cJVaVyyMV0qdaGQ0XbcXU5w4cKFRBHcsGEDRqMx0Sx64EBnvv3WKz5HdSAqjvAt4IP4o6ej6jD8CDRA1cGqBtwCqgKLgccBFWK5fLlKBKPRaHI3Wvg0Dw0iwokTJxLnB//882vM5oTMK4FAf1TlvXOoDDEJwrcZ+Br4DdgBPIuq4Dc1sW2DAV5/Hb7/PmfORaPROI4WPs1DSWwseHkJsbEJtslAlNBNRo3mRmMtfCZUVb7iqFIUx1EV+5KoWRMOHcr+vms0msyhI5A0DyXBweDiYiA2NvmWz4DGqCq7ljgDPwPVgWUkFz1QVeM1Gk3uJ1cmqdZospvU7RzVgc7Alza2VUv21942NRpNbkILn+ahpFChtOL2PkUlw87YEK5IkfT30Wg0Dx4tfJqHEjc3KF06ta3lgd7Atxlqs7F9yWg0Gs0DRs/xaR5aevaECRNSS1P2MSqGzz48PGLp2tWZTD9L3r6tihIfOQL376vo+GrVoEEDKJb9cZAazcOA9urUPLRcvgwVKhAfx5c5XFyCKVu2Ke+++zbPPfcc7u4ZrC6/Zw98+ils2ADu7ipTdlwcODmpIMGYGKhdGz7+GNq3z3yHNZqHGG3q1Dy0lCgBL79MpuvrGY2wcGFBpkz5gSVLllC2bFm++uorQkJC0j84KgoGDlSFbVevVsPP+/eTJiDNZvU+Kgp27lTD1K5d4c6dzHVao3mI0SM+zUNNZCRUqaJGfyZTxo83GCKpUuUix45VxBCfr+zw4cN8/fXXrF69mldeeYUhQ4ZQzJaZMiICHn8cjh5VHbEXNzflSbN7t/ao0WgcQI/4NA81np7w99/g75/x0kKenlCvnhPOzn0YOHAgpnjlrFmzJvPmzePAgQNERUVRvXp1Xn75ZU6ePJl0sAj06KHm8jIieqDMnteuqVFiTEy6u2s0Gmu08GkeekqVUhlXmjcHO0r7YTAo0Xv1Vdi61Z1t29Zz5swZunfvToRFFdvSpUszadIkzpw5Q2BgIC1atKBbt27s2LEDFiyArVsdn2CMjYVLl2DkSMeO12geYrSpU6OJRwSWLYNRo+DUKTUCDA1V611clChGR0OrVvDJJ1C/ftKxMTExvPrqq/zzzz+sWLECf3//FO1HREQwa9YsJnz9NfsuXyafRSBhILZrQyQkTAuMf986eaMeHnDxohqyajQau9DCp9HY4MIF5Wh5/LiaiitQAGrVUlEFBQvaPkZE+Oijj1i0aBFr1qyhXLlyNvcz/for5j59cLUY7QWSem2IzaQhfJ6e8NFH8P77Dp2nRvMwouP4NBoblC6tll697D/GYDAwevRoSpYsSZMmTVi+fDkNGjRIsZ/z77/jbMPE+Q6qNsTrqNoQdhEZCYsWaeHTaDKAnuPTaLKY1157jZ9++onOnTuzYsWKlDvs2mXzuHpAC2BcRj/w1CkV9qDRaOxCC59Gkw107tyZlStX8tprrzFt2jTrjTdvpnrcZ8B3qFK3diOiYv00Go1daOHTaLKJBg0asHXrVr755hs+/PBDEqfTDYZUj0mrNkSqiKTZpkajsUYLn0aTjZQrV47t27ezYcMGXnzxRWJiYiAgIM1jEmtDeNj5Ic7O4JOyPqBGo7GNFj6NJpvx9/dn48aN3Lt3j06dOhFTt27KnQxAd+AAlI+A3n3hWyPQDFXsPT/gl8oHVKmicnpqNBq70FeLRpMDGI1Gli5dSoUKFXh7927MCZHyTsB7QEmgL1Ab8ISPP4XwcJQgVgV8wTAXmAh4WDUMTz+dcyei0fwH0HF8Gk0OIiJ8/eWXvDxiBAV9zbAeqAR4p32cnx9s3Ai1KqA8X5oDF1EB7FeuqB00Go1d6BGfRpODGAwG3n3/fU4Oew3zNpQ3Szqit3atSqBdoQIqrUsJYBdQxlPF72nR02gyhA5g12geAE2+jsMcbQD3tA0u//ufKsLw008WeURdgILAL05QRweuazQZRY/4NJocZw8wDyd3ITBQZR3z8YH8+eGxx2Dq1KR49ARL5ksvqXq03t5QsybgBtQXcPn9gZ2FRpNX0cKn0eQ4XwBJKctWrFDJsC9cgOHDYexYVSA3gXffhbCwpOXw4fgNhghgVE52XKP5T6CFT6PJUcKBVUBKE2e+fNCli0q9OXs2HDuWfmsRscfosegRPt38KVdDr2Z5bzWa/yJa+DSaHOUQ1vEIKWnQAEqUUOX60iPODJ6uR/ly+5eUnVSWF5e9yP1onb5Mo0kLLXwaTY5yAohLd69ixeDOHfV63Dg1/5ewvPBC0n7eblCjMETFRRFtimbRsUWU/7Y8R24cyYa+azT/DbTwaTQ5SiRgSncvy9C8t9+Ge/eSltmzk/ZzMijxSyDKFMWtiFs0+bkJx28ez8J+azT/HbTwaTQ5ig/pRRHt3auEr0mT9FszmeFuytJ+hMaE0mlBJ6Ljoh3rpkbzH0YLn0aTo9Qktcvu/n1YuVLF7j33HNSoodZ/950KefD2VvmtX3xReXcCTJsBHzUHbDjC3Iq4xadbPs2Ok9Bo8jRa+DSaHKU6yef4nnhCxfGVLAljxsCwYTBzZtJ2y1J7YWEwbx6MHq3eL5oPBiNwmBRExEbw3Z7viIqzMSTUaB5itPBpNDmKG/AcCebO8+chMlLF8YWEwM6dMHCgqjQEMGsWlC6tYv3CwlTi6qFDVajDhQuw9W+QzsBZIDTlpxkwsOIfG1XgNZqHGC18Gk2O8w7g6tCRly7BqlVQuzZMnwnegajqDf7A0ZT7h8WE8ffFvx3vqkbzH0Tn6tRocpwKwAhgDBBh1xHduoGLiwpy79QJhr4DVapDaNX4HWqgzJ2PWR8nCHsu78mqjms0/wn0iE+jeSC8BzyOiNGuvZctU6EMFy7AN5Ng+Wa4eQU1ZQhK+G4A11IeGxYblgX91Wj+O+gRn0bzQHAGfufff1tQvPhOPD3tK4sZFgO7r0C/0aisZ1OT7XAYKGq9yts1nbpHGs1Dhh7xaTQPiNOng3j00dPcuPE9UAzwJrWy0OExcCcSBq2C1jMg7gjwBNDfYumImueziI83YKBBiQbZeh4aTV5DC59Gk4WcO6cqLNStq+LuXFxUDF7VqjBgABw8qPaLiYnhmWeeYeTIkQQGvg5cAn7DYHiZf++4cS8KQqLg7B0Ij4VxOyBgHMw6DJxC+cbURMXDJyy1ATPKwzMebzdvmpVqloPfgEaT+zGIpPaMqdFo7OXGDXjlFVi/XtXSi4lJuY+zM7i7Q5UqUKvW19y8uZXly5djMBis9pu6bypv/fUWEXH2Ob6khbebN7feuYWHS9qJsTWahwk9x6fRZJKNG+HJJ1U8Xmxs6vuZTBARAQcOmDlwYCDjx/dPIXpRUVFcX3udyLDI9Io4pIuHsweDGgzSoqfRJEObOjWaTLBpk8q8cv9+2qJniYgTIkY+/NCHH39MWCf89ttvVK1alcN7DzO53WSMrvZ5fKZGzN0YAi8Eoo06Go01esSn0ThIcLAa6UU4aJGMiIA334T8+U8xeXJ/7ty5w/Tp02nZsiUAxyOP8/PBn4mIzfgH+Lr7Mqv7LEb0G8GWDVuYMmUKvr6+jnVUo/mPoUd8Go2DDBgAISGBqDRkwcm21gYMwHngxfh9ErxQqgPvAyFERpp55hkn/ve/pzlw4ECi6AF82/5bBtYfiKeLp9198nD2wN/oz9a+W3my8ZPs3bsXb29vateuzd69ex0+V43mv4QWPs1/iASXxv2ocgXZl5z5yhWVP1NRBlhosfUoKTOyvItKpnkLmAnsAhoDkXh4VKBy5ddwcbE2wBgMBr5q8xVrnltDSd+SeLulHo/n4eKBu7M7vav35uzgszwS8AgARqORadOm8eWXX9KpUyfGjRuH2Wx2+Lw1mv8CWvg0eZw4YCnQBDACtYCWqNxdPqj0YN8Ad7P0Uy2LwUIfYI7lVuD5VI70AOoDfwC3gZlERBj47rvUP6tZ6Wacf/M8S59aSu9qvSmdrzTOBmcQ8HL1on6x+gxvPJxzQ84xq9ssfN1TmjR79erFnj17WLp0KR07duTGjRsZOl+N5r+EDmfQ5GH2Ak+hzIxppeUyosyOE4BX4l9njscfh82bAQKB6cBAYBlQESgNbI/fFgSMBEoAo5O18jwQDSyiSBG4ZiPdWGqcPHmS7t27c/LkyQz1OzY2lpEjRzJr1ixmzZpFmzZtMnS8RvNfQI/4NHmUqUBz1BxaerkoI4BwYCjQDbARZJdBjh9PviZh1LcOqAIUt6OVYsAdAG7dypiTjMFgcMhk6erqypgxY5gzZw4vvvgiw4cPJ9Zed1SN5j+CFj5NHmQOMAyIzOBx4ShhegqV6NJxolJMH/YBFgCzSN3MmZwrgB+gMrxkRPicnJwyFabQqlUrDh06xNGjR2natClBQUEOt6XR5DW08GnyGOeBAWRc9BKIBNYDczPVCze35KOt0ignl1VAdztaCIvvR1NABbd72u+86fCIzxJ/f39WrFhB7969adiwIYsWLcpUexpNXkELnyaP0Q+IJjBQCYWPD+TPD489BlOnqnRhCezZAx07qu1+ftCgAcycCWrkNxCbJcttcOfOHTZs2MDXX3/NM888Q+XKlbl7d4eNPWcAGwGvNFqLRnmddgMKAH0B1T+vtA4DkuYLm1G2bEMOHjyHKsXQFuXAc8uu87HEycmJoUOHsnr1akaMGMGrr75KhKOBiRpNHkELnyYPEQRsJaH8wIoVEBqqatQNHw5jx8LLL6s9d+6Eli2heXM4exZu34YpU2D16oS2BJiX4hOuXbvGn3/+yejRo+nevTuBgYEEBgby6aefcvnyZdq1a8eSJUv46KNHcXNLfnQ5oF4qff8K5WVaEGUKrQvsIEEkH300rfO+AnRAlVr/AtiKs/NdfHwEuI4y334ElETFDIak1ZhN6taty4EDB4iKiqJevXocOXIkw21oNHkF7dWpyUN8CXwCxBAYCNOnQ+vWSVv37IFGjeDIEejfH2rWhB9+SL216OjK/PnnGA4cOMCBAwc4ePAgsbGx1K5dmzp16lCnTh1q165N+fLlcXKyfka8eBEqVbI115dxPDxiWb7cmbZtbT2HLgOeQ40U4+xpDSWmqwDHyhHNmTOHt956i08//ZQBAwakyCeq0eR1tPBp8hDtgLUANoUPoFQpeO89GDxYVUp4/PHUW4uOhqee6kStWnUTRa5kyZJ23+i7dlUjyMw5RQru7pepUqUbX3wxhnbt2ll8/hLgBRybz/QCNgANHerV6dOn+d///kdgYCDTp0/Hz8/PoXY0mtyIztWpyUOcSnePYsXg3j0111e0aNr7ursbWb58MlDKod78+CNUqJA54fP0NLB1awnOn/+AoUOHEhAQwBdffMGjj/qjzJaOOvGEA52Af4F8GT66YsWK7Ny5k+HDh1O7dm3mz59PkyZNHOyLRpO70HN8mjxE+qa+K1eUM4uTkz0B4U5kJqYvIACWLAEPD8e8K41G+OILqFvXQI8ePTh69CjPP/88vXs/xVtvVad9e2snkwoVoEMHUqyrXBl+/jll+5Mm3aNevbIO9Q3A3d2dCRMm8MMPP9CzZ09GjRqFyWRK85jLl9U5tWqlHjz8/KB4cdXv8ePh5k2Hu6PRZB2i0eQZqogIIoKULo2sW0fiexFkzx7EYECOHEEaN0YGDrTennJxE5HgTPXoypUr4u//gri7x4iLiwikvxgMIp6eIt9+a7vNqKgtsmmTi/j6InFxqq9Xr6pzDgiwXgfI6NFI8+Ypz69uXeTbb11E5EamzlFE5PLly9KiRQtp0aKFXL58OcX269dFunUT8fAQcXe3fd6enmp7nz4id+9muksajcPoEZ8mD2F7vur+fVi5Ev73P3juOahRA776CmbNgq+/Vh6dAIcPq32S8EZ5WTpGWFgYTzzxBEOGVODsWVeaNVMhFi6pTCAYDCpkoXJl2LULBg2yvZ+7+4889piJ2Fg4dEit27pVzVdWqmS9rlw5eOEF2LZNebcmcOKEcvJ5+mlnVFB95ihevDjr16+ndevW1K1blxVJGbr56y+oWBFWrVLOPtHRttuIjFTbFy9W/d65M9Pd0mgc40Err0ZjPwtFxFsSRnweHoi3N+LrizRqhHz/fdJoSATZvRtp315tL1AAadAAmT07YbtBRJ50uCdxcXHyxBNPyEsvvSRmszlx/fHjIm+8IVKlioirqxrpODmJlCmjRjo7dohY7J4KJUQEadECGT9e9XfgQGTGDOSDD6zX9e2rXrdujYwalXTuw4cjXbsmvG/p8HnaYtu2bVKqVCkZPHiwLFsWI0ajfSPd5IuXl8i2bVnaNY3GLrTwafIQUSLiI2mbL+1dvERkq0O9MJvN8sYbb0jr1q0lJiYmzX3j4uwROkuiRMRZRJBPPkG6dVP9feQR5PRpZPVq63WzZqnXc+ciFSuq1yYTUrIksnRpwrn6O3SeaXHnzh1p376fODmFOyR6CUuBAiK3b2d59zSaNNGmTk0ewh1VwDXdFCfp4IRKJN3YoaMnTZrEpk2b+PXXX3F1dU1zX2dnZeK0n3DAGYBmzZQJ884dlcS6QgWVoWbHDrXu2DG1D0D37sqZZ9cuVTUiIgI6dUpo01HP0NQpUKAAkZFTUf8TxwkPVzGXGk1OouP4NHmMOFTNvVMkZHDJOEbgCCrTSsZYtmwZAwcOZMeOHZQuXdrBz0+LCMAXMBEZCfnywahRsG+f8iAFqF1bzVV+/z1cupR05EsvgYeHmkvz8lLbAUJDXfnoo9cpXbo0pUuXJjAwkNKlS+Pn5+dwcPqRIypZQGSips5CpU37N77/T6KyzORHpVk7S8pMOQbgDB4e5TlzBkqUcKgrGk2G0XF8mjyGC7AGlRosmIyKn8nkjrPzL0A57kXdY/ah2Sz7ZxmHrx/mfvR9DAYDRb2L0rBEQ16o+QIdynfA2UmNwPbu3Uu/fv1YtWpVNome6p/Z7IOr6z08PaFePRUG8OGHSfs0aaLWJQ/ef+EFNfKLjYUNG5LWx8SUoVSpUgQFBbF582YuXLjA+fPniYuLSxTB5KJYunRpAgICUmSsSeCHHyAmMRLkG1RKttlAK1SKtdeBNqi6hGkjosIxPv7Yzi9Jo8kkesSnyaNcQQVon0WZB9PDjdhYN555xoVRn+9k9oXZTNw9ESeDExGxtpMy+7j54Onqyc9dfqaaWzUee+wxpk6dSpcuXbLwPODChQusXbuWtWvXsmHDBn7/PY7mzVUC7fffhy+/hP37oU4dtf/ixdC7t0rK/dprSe2IKG9JDw/l1alwBd4GPk/xuSEhIVy4cCFRCJO/Dg0NpWTJkjZF8YUXHuX8eVfgPqqu4M+ock8JhKGqVYwFLpLWiA/K89hjsD19jdRosgQtfJo8jAmYhKpsHoe62Sb/OXvF79cLmMjobycz6uIonAs4Exln39yXp4snbmfc+KT2JwwdMjTTvQ4LC2Pz5s2sXbuWv/76i7t379KmTRvatm1LmzZtKFbsEPA/7K0ekTYewFGgfIaPjIiI4OLFiylE8fz5i+zcuZmk0XdnIIqUBqQXUAkCKpGe8OXLpzLuaDQ5gRY+zX+AWGA1sAlV8SAEcEPNBTZD1cfz42roVepMq8PNsJuIIWM/exdxoWvVrizutRgnQ8Z8wkwmEwcPHkwc1e3fv58GDRrQtm1b2rZtS82aNZOZFM1AIHDJdoN244w6/42ZbMeayEhVDkolcZmHGlFet7HncFQJpsaoEacx2fYQEoTPzS31+D+NJqvRwqd5KBARGv/cmD1X9mASx5xivFy9+KrNV7xe//V097106RLr1q1j7dq1rF+/noCAgESha9asGV7pFt/bjpojy4xHphdwHFUkN+swmcDNLaH2YdaM+Ly8ICwsS7up0aSKDmfQPBT8fOhnjtw4gmmOyfYA6BTwNcoqmlDvdZv1LuGx4byz7h2uhl5NcXh4eDirVq3izTffpGrVqtSuXZt169bRrl07Dh06xPHjx5kwYQIdOnSwQ/RAjZLeI+UoyV48UfNuWe+E4+xsmQD8UVRIw9Jke4WhRuGt7GqzfMYtsRqNw2jh0/znERE+2/IZ4bHhyvp5hJRTgYeBR1DWwcMo3Ticsi2T2cQPe37AbDZz4MABvvzyS1q2bEmRIkX46quvCAgIYO7cudy8eZOFCxfSt29fSjjsp/8x8G58Z+zFKX7/H7F2Nslakgrn5kPVSByEGv3FAufjP7sE0MeO1uK4cmU+n3zyCQcPHkQboTTZjQ5nyAAxMXDqFISEKFNPpUqqEoAmd7Pnyh7uRN5RbyoDK4ELqGk0UNbE08CrKMvcCeAJ4HeU82jxpLaiTdGM2zKOH5/+kYJ+BWnbti3Dhg2jefPm+Pj4ZHHPDShRaQU8jZoTs+3wYjaDk5MXKjZxEepEs4/+/WHNmgTz5LuonKdvkxTH1w2Yjz0B7p6eznz9dWWOHj1Ar169iI2NpWvXrnTt2pVmzZqlmyRAo8koeo4vHaKj4bffYNw4lSnDw0OVvBFRk/yFCsHLL8OAAaoWnCb3MXHXRIavH060Kd574g/UiK9r/A77gL3AANQobx0wDPgFFX/d0bo9V1z5u9ffNKraKPs7n4gJNaL6Pr6zIajn1jhiYvKxYUMMHTqsBh5DCWb2IgLFikVw/boHmTEcOTmpWMXduxPaFU6cOMGyZctYvnw5Z8+epWPHjnTt2pX27dtnw8OF5mFEmzrTYMcOFRf12mtw8KAKDA4NVSO++/fV+2vXlCiWL68qAaRTrkzzANh1eVeS6AHURI3qEgrIHkaZQAEOAdVQV0YN4BgpYuSN7kbuuN7Jvg7bxBkVt7gaFbh/BxUfF4KLy01efNGToKBi5ITo3bp1i+eeexYnp2dwc8vcc7O7uzB3btJ7g8FAtWrV+PDDD9mzZw9Hjx6lcePGzJgxg+LFi9OxY0emTZvGtfSLLWo0qaKFLxW+/x7atFGFTdPzNouKUqO/Tz9VBTgjsz41Ys5gNqth7ezZMGYMjB4NM2eq/FR5WNFDo5OZB0ujfEZOofTjCkrkQlDTU4/E71cJFR542vpwESE8xp6g+ezEB/AHjDg5OdGhQwdWrVqVrZ8oIsyZM4fq1atTtGhRTp+ez8iRzhgd9L9xcoqiatXJlC6dehxD8eJODBhQnDVrHufmzTcYM8afW7cW07BhFRo1asQXX3zBiRMncn5eUATOn4d161Q9pl27VIJUTZ5Az/HZYNYseO+9jP+Ow8OVyaZTJ1i/Xplx8gTh4fDddzBhQtJJR0Soi9toVFmWPTxg8GB4800VxJVHCAsLIzrMxo21Jmqkdxs1LeYN/I0ygS6w2C8ufr8qSasMBgNGV0e9LbOHTp06MXPmTAYOHJgt7Z87d47+/fsTHBzMqlWrqFu3LqAyy5jN6jnJ3ge+hJ/TuHHObNy4iY4dl7Js2bJkZsw/gVGoL98NiMDDI47atd2pXduDDz+M4sYNd37++Qjt2k3G09MzcV7w0UcfxdnZOWu/gAROnVLXycKFEBenJvtBXSsREWri/513VGodD4/s6YMm0+g5vmScPw/VqmXu4c3LS90IhgzJsm5lH1u3qov03r3071yenkr0Fi6Eli1zpHv2EhMTwz///MOxY8c4duwYR48e5dixY1y/fh2/Tn5cq3oNs5M56YC7wHeoULf2KPPmd0B1VBrQBK4AS4C3SIwscDO4ceiVQ1QpZqGGD5h79+5RqlQprl+/jtHRIZgN4uLimDhxIl9++SXvvfceQ4cOxcVGpd0dO1Ti7Hv31HRAanh7Q/HiKu3aI4+o4P7XX3+dAwcOsGrVKvz9Daj4vy2kn4rOCXBH5E0OHOjK8uV/snz5cq5fv07nzp3p2rUrbdq0wdMzI16xqRAZqZ6Gp09XcxxxcWmfZL586iQfeyzzn63JcrTwJaNtW9i4McGytw3lsXYcNcdSBZgI1AeuASOAVaiYpeJA7/j9vTAa4eJFKOh4ge/sZ9Ei6Ns347ZZT0+YPBlefDFbupUWJpOJoKAgK3E7duwY586dIzAwkOrVq1st5cqVY++1vbSd15awmGQ265nADZQz4jVUgYFhpKx69ANKDOMLwLvEuuA+yZ1GDRvRrl072rdvT/Xq1R2udJBVtGjRgnfeeYdOSfWIMsWBAwd49dVXKVCgANOmTaNcubSrWZhMytPzu+9gzx41ReDiojQif34VAjFkiKokb/lViQgjRoxg27Zf2LAhHBeXOyRNwNqDERX3uBJwIygoiOXLl7N8+XIOHDhAy5Yt6dq1K507d6ZQoUIZ/h64fRuaNlVPxRm5Vjw9VTZxXXcp16GFz4ILF6ByZTVnp5LvlgKmoGKSYoCtQBFUfFIdlAfd5ySllxoHvAw8gqenmvN7552cPgs72bZNqbyjE5JGIyxfnrJEQBYhIly9ejWFwJ08eRJ/f38rcatRowaVKlXCIxXTkohQckJJroReyXS/3JzdGNJwCB81+ohNmzbx119/sXr1aqKjo2nfvj3t2rWjdevW+Pn5ZfqzMsqEzz/HZccOBjVqBCdPKhtkYCA0aADNm4OdfYqIiOCTTz5hzpw5fPXVVzz//PMOiXpIiLKceHmBr296e0cSElICo/EOjkUveKJKIc23Wnv79m3+/FONBNevX0+tWrUSTaLpCTmg3Lrr1IEzZ9RIL8Pd8lTz5L17Z/xYTbahhc+CceNgxIiEnIH7gNbAPRt7jgCWo+YfUp/Iq1ABTp9OdfODIzxcdS6znnGFCsG//9pzV0uT27dvJwqb5eLm5mYlbtWrV6dq1ar4OvB5U/dN5e21b6sg9kxgdDFy6o1TlMxXMnGdiHD27FnWrFnDX3/9xd9//0316tUTR4P16tXLvjknUCOSkSMxz5hBWFQUPi4uGBJu0k5OyvQWEwNPPAGff55mmpR169bRv39/GjZsyMSJEylcuHD29duKQcAMMpeizQgsRnm/piQyMpINGzawfPly/vjjDwoXLpwogvXq1bMt7m+/DVOmZG7uw9sb/vlHxzvlIrTwWdC5M/z5Z8K7+6iyKp1RmfIbAQXitzUC2gGfptmeq6ua73DPXJHqrOfrr+GTTyAykkBU6dMgkix801FZFTejfD2+Q+UBCUJ9A4+icorU8PCA4cNVW3YQFhbGiRMnUghceHh4ChNltWrVsvSmaxYzDX9qyMHrBzOVq3NUy1EMbZR2hYaoqCi2bduWKITXrl2jTZs2tGvXjnbt2lE0Kd9X5vnzT3juOXVjTiqQZxsnJ/Vj/OIL5ahkcaO/ffs2w4YNY8uWLUyZMoUOHTpkXR/T5TJQAZXvUxEYqKbTLl9W1vixY+Hdd5OOKFEC5s2DFi2St1UCFeaR9gjVZDKxe/duli9fzrJlywgPD6dLly507dqVxx9/HDc3Nzh3DqpXt7KKBAJX4xdLo2ltVCRMQra7EqiaIYCy93btCr/+asd3ockJtPBZUL68GsAkcRJVT2w9Kvt8R+AnoAnK2yFt2723t6qjVrFitnTXMcxm5V1wXWXTD0TlAnkL+CB+F0vhG4zyr/sJNYtiQiU0uYTKvU/BgqotC4eH5I4mCcu1a9eoXLlyCpErWbJkjsyPXQy5SN0f63I74jaSImdZ2ni6eNKyTEv+ePqPDFdnuHz5Mn/99Rdr1qxhw4YNlCpVKtEs2rhxY3WTdYQZM2DQoIybq41GVa7922+VE+uCBbz11ls8/fTTjBo1Cm9vb8f64zDvAxOAJO9bS+F76y2l0UFBSQ7FqQufNypDweMZ6sGpU6cS5wVPnjxJu3bt+DQkhIobNiSNnlHXizvwBmqMCqroU09U1ItN4QPl4XnxIvj7Z6hfmuxBC58FgYFqns82p4DnUE+mQdgz4nNyCqdBgyEUKXIbHx8fvL29E5e03ie89vLysulBlylOnoT69ZW5E3Uh90fVzz6HSlSSIHw/oRJf7QQapNKcycuLvz/9lO2RkYnzcWk5mmT5+WSQmctm8uq2V3HL70akyT7BMLoa6VyhM/O6z8PVOXPps+Li4tizZ0/iaPDUqVO0aNEiUQjLli1rX0NbtkCHDpmao739zjs8t3s3V69eZfr06dSvX9+xtjJNeVSqsyQshW/6dChQQGV4STAupC58BmAgyk7hGNevX2fFihU8NXAg+ZLN6wUCr6AmOvbGr3sbZQkZQRrC5+UFEyfCK6843C9N1qGFz4LateHQobT2+B6Yhsp19QfKuJH607+bm5nZs//Gze0OYWFhhIaGEhYWluJ1WFgYMTH3CAy8SZky9yhYMILIyBj++SeOw4dd+fdfX4xGn3QFMzUBtXzv9fvvOA0cmBiVH4gSuslAVdTFmiB8/wO+QKW1TI1wg4Gfq1fnSseOifNwaTmaPEhOnz5NkyZN+OXXX1gesZwf9/+IAUOqBWl93HxwcXLhpyd+okfVHtnSp+DgYNatW5cohL6+vrRv35727dvTvHlz25UcwsOVeeK6rRp49hMBzH7nHV4ZM+YB5sOMRgXjJxOYQGvh+/575Q3677/KRyd14QOVhudg5rp165b6kGTm40DU9TEQWAZUROVD2B6/LVXhA3jhBRUkrHng6AB2Cxo3thS+UygjX2/Uz/gSsBA1vzcMJQ0voH7epVEBX98AL5KQ+sPT04n//a9FOp96FRWouwn174hCeZCCiBFwQsTM3btduXKlN6GhplQF9NatWykENfm+g8LD+QxIfpv7DGXKtAw9vA2kNxvlJcKg7t1h5Mh09nyw3L9/n27dujF69GhaNmtJS1oyoukIph+YzvJ/lnPs5jHCY8MxYKCwV2HqFq1L39p96Vqpa6ZHeWlRqFAhnn76aZ5++mnMZjNHjhxhzZo1fPXVV/Tu3ZtGjRoljgarVaumTMIzZqicefEEom7GCf61v6DSjt4DbpE0FxWNkoQhqFG+h5MTA65exUE3yiziJurXmLbHZK1aKpPS2LFqSYvw8LP8+OMEDAYDTk5OGAwGq9f2rPM/e5bHnZ1JzQjdB5gDNEcFORVPZT8rjh+3Zy9NDqCFz4K2bWHOnIQAXB9gNzAedQvJj3J0+RqVfX4HyrjREBVoWxyVQV95zBkMQrNm6c1bzUE9O0ahUoRYYzBExP+FggWnUbDgIlQ0dXuHz9H8xRcYPv44RQBuddTZfUlSkpKCqPC29Bs1p7/PA8RsNvPcc8/RvHlz+vXrl7je38uf95u+z/tN3wdUySEng9MDi8dzcnKiVq1a1KpVi+HDh3P//n02bdrEmjVr+P7774mNjaV9u3Z8u3w5xlS8DGejHsv+RPlIDiHJwX806kHmtYTPM5tVBvbvv8+WMiNRUVHcvn07zcVguMzkyVHYE2P+2WcqMmPYsLT3M5vNXLx4EbPZjIgk/rV8nd66Cjdu0CQuLk3ha4Ya4T1v7xeSVtC7JkfRwmdBx46WD7/FUa7RqVEMVejTNiLhuLvP4sqVJyle3Nbz4EcoUbXXTToyfmmDeqbvYudx1jiVLIl4eNhMQPopKjrxrfj3rVCyvA/rZCZWeHlByZKpbc0VjBw5knv37vFrOl51zk7ZGHLgAL6+vonu9iLCmTNn2PbLLzjfvWtz/2nAh8BfqP9XNZT5+k+UTeJ7YD/J/B3d3VXalY7JSlBYYDabCQkJSVfEki+xsbEULFiQggULUqhQocTXBQsWpGjRolSvXh1/f1/c3Tfb9X1Urgzdu6usSGnh41ORCRMm2NVmqpw6pebCU4ndK43y+V6FesCwi4CAzPVJk2Vo4bPAxQVGjVJu0+GZCPdydoZq1dwoUeIcNWrUoHfv3rz33nsEBgbG7/EzGRM9SyJRI8utKJmyj3///Zd169Zx4rff+CIsLEVyElBj1d7At6iczRWA1+M/7SdUuL4ZNbdxnnivTicniM/bmBv57bffmD17Nnv37nXcezIXYDAYqFixIhVr1lTuwhamTlBpFrYBG1BpSEGViJ2KMmsWRVX2S+46Yw4N5cCUKaw7fDhVAbt79y5eXl5WwmW5VK1a1eZ6b29vO0fPgSR3bkmNTz5Rqc5S90wwoLyuM0mFCukGrM9AZb7zwpa9JhmurtCsWeb7pckStPAlo39/VZwgoQyRI7i7w9KlbpQrN54PPnifiRMnUrduXZ544gk++uhFypUbjGOil0AE0AsVbmH7Zn7nzh02btzIunXrWLduHVFRUbRp04Y2ffrgcfiwmry3wceARZUYvo1fBpIUx9ckfj+AsJgY/hVJvNnmJo4ePUr//v1Zs2ZNDgZiZzM3btg0ma1DOfDXSLb+CZRBPQgVmpIcJ7OZyH/+4V7VqhQuXJgqVaqkEDA/P79sdn7pRfJwhtQoUwb69FEx5bbxArpnvkvOztCokfKeTQU78r4k4eamSrdocgfyHyE2VuTkSZFdu0QOHRIJD3e8rZs3RUqXFnF1FVHPlvYvnp4if/6Zss27d+/KqFGjZOFCd4mNNUj8VIIsXIg0aIAYjYi/v3r9ww+IxXSDfPIJAsiuXUnrRLxEZEZi+9HR0bJ582b58MMPpUGDBuLj4yMdOnSQ8ePHy9GjR8VsNid15quvVEczenLJFpO7u2xp0UJKlCghjRs3lgULFkh0dLTjX3wWEhwcLGXLlpX58+c/6K5kLT/9JGaj0er/UBpkHkhlkL4g5mT/p09Ank3rf9mv3wM+qUsi4iFJv+3MLCVFxCxZwooVIt7emb5OBETKlxcxZ1G/NJkmTwtfdLTIwoUi9eqJuLmp32i+fCI+PiIuLiJly6p7/O3bGW/75k2RJk1EvLzs+127u4v4+Yls3JhWqyFiNidd4OPGIYULI0uWIPfvK7E7cAB55hkkKkrtYzYjZcogfn7I669bX+RRUYEyceJE6dixo/j4+Ei9evXk/fffl02bNklUVFTq3QgLEylaNPMXc6FCIiEhEhsbK0uXLpVWrVpJQECAfPjhh3LhwoWMf+l2cOeOyP79Irt3iwQF2b6XxMbGSqtWreSdd97Jlj7kFHFxcfLPP//Ib7/9Jp999pk89dRT8lLp0nIv2f+hNMg6kCsg5UH6Z0T43N1Fxo9/0KcqIoNExFMyJ3pGEbHx1OkocXEi1aqJGAyZu06MRpHly7OuX5pMk2eFb9s2keLF038gMxqVeE2blvEHLrNZZMYMpRHe3iLOzinb9/ZWg6d+/UTu3k2vxZUi4isiyL17apT3669pX8xbtiAeHsi8eUr8oqMthQ8ZOrSPLF68WIKDgzN2cn//nblRn9EosnZtimZPnjwpgwcPFj8/P+natausXbtWTCZTxvqWjHPnRIYOFQkIUKNwX1/1gGM0qqVjR/XAkfD/ffPNN6Vdu3YSFxeXqc/NKUwmk5w7d05WrFghX3zxhTz77LNSq1Yt8fT0lDJlysgTTzwhw4cPl3nz5smRLVvE7OZmU/gE5AJIIMibdgpfmLOz/DZkiFy8ePEBfwsRIlJGRJzFMdHzFJFns75bJ06oH5mj14mHh0j37lnfL02myJPCN3Fixu/ZXl4iXbuKxMRk/PNMJnVj/eQTkZYtRWrVEmnUSGTAAJF580Tu37e3pU9ExEVEkNWrEWdnJDY27Qv6pZeQXr2QmBglfJZCaTbnE5E1GT+hBBYudOyiNhpFZs5Ms+mwsDCZNm2aPPLII1KhQgWZMGGC3LlzJ0Pdi4oSeestde9Idq+3+f9t2FBk3LjfpHz58hn+rJzAbDbLpUuXZM2aNTJu3Djp27ev1K9fX7y9vaVEiRLSvn17eeutt2TmzJmyZ88eCQ0Ntd1QvXqpCp+AnAMpATLcDuGLMRql77PPip+fn9SpU0c+/fRTOXz4sLVpPMe4JCLFRcRNMiZ6RhFpIyLZZGZfvtyhh8Q4NzeROnUyN++iyRbynPD9+KPjD2BGo3r4enCm9ucl4WKdOxcJCLC+gB99FMmXT43wtmxBwsMRHx/k99/V9n79kC5dLI+xnudziC1bRIoUse/C9vAQ8fcXWb/e7ubNZrNs375dnnnmGcmfP7+8/PLLcuDAgXSPu3VLpEqVjP2vnZ1NAmEyY8b5zHwjWcKNGzdkw4YNMmnSJOnXr5889thjki9fPgkICJCWLVvK4MGD5ccff5Tt27fL3fRNBdb8+qv9Nvj0/p/Dh4uIMg9v2rRJ3nzzTQkMDJTAwEAZMmSIbNq0SWJjY7P+C0qVWyLSSdRvOz3BcxI10vtQRLK5jxs2qLkMd3e7vttYd3f5w2iU25cuZW+/NA6Rp1KWnT2rXJkdTU8IKuxs6lSV0D6nEBFu3LiBk9NLFC68GoDVq1WVmKgoq/zOQFI6pitXVA7i69eVU9jff6vyd1euqFy3UVEurF/fheDgJyhWrFjiUqBAgYwFYYeHw7ffqlyCCYHRCfEcRmNSVv/Bg1UlUQfLEN28eZPp06czdepUihcvzsCBA+nZs2eK9GYRESp9XFCQY561RqMqJtywoUPdzBB37tzh+PHjHD9+nGPHjiX+NZlMVpUmEv46VAg1OWazquq6f39CxWTH8PdXOcASMj/HIyIcPXo0sXLBhQsX6NixI926daNt27Y5lMR6FSrk/gAi7ohEAHGIuAMeODlFYzB0RSWRqJ4D/UGVl//wQ5V2zNlZXSOWyRs8PNS1UqYMfPUVw9av59y5c/z+++8PvEixxpo8JXzNm6v6qUm/tUBUCW3LwOO1qORbsaQWreHjo0rR2UqD6Ch3794lKCjIajl//nziXy8vLz791J1XX72Kq6tw754qkjBnDvRIlgYyQfg+/xw2b06qHyoCN28qfRoyBKKjPZg7txtbt7px9erVxCUyMpKiRYtaiaGtxdfX1/qCNJtVWqX9+1WSRBHVyXr1oFo1dbFnAXFxcfz5559MnjyZQ4cO8dJLL/Haa68lxjkOGKBCSjLzgFO0qHpQMhqzpMuEhoZalVRKELiwsDArYUv4W6RIkey92QUFqTxeyeL57MbTU5U0ejz9KgaXLl3ijz/+YNmyZezevZtmzZrRrVs3nnjiCQKyKSjbZFLdmz79Ok5O+6hR4wROTveIiirMwYO1OXq0Du3a+fDWW1AjeQxHdhMerkrN79ql4p5iYlRwetOm6iZVsyYA0dHRNG7cmL59+zJw4MAc7qQmLfKM8J05o0Z7UVGWawOxzlIIKrS6DGkJn7c3fPMNWGSvSpeIiAgrMUu+mM1mypQpY7UEBgYm/vXx8UGJci9UrT/46ivVjx9+gHbtlBAfOaLuRd9/D88/r0aGjzyS1I+JE2HdOqVNiCsYbpBUJzCpr9euXbMSw+TLlStXEJF0xbFYsWK2EyVnEWfOnGHKlCnMmTOHRx99lI4d3+OttxoTGWk5ColAFYNJEN5pwBlUrplFwFPx6+NQeR+D8PQM5M031cNDRoiMjOTkyZNW4nb8+HFu3bpFlSpVUohcTpVUssn+/So2LCwsYyM/T0/1ZNGrV4Y/8t69e6xevZply5bx119/UbVqVbp27Uq3bt2oVKlShtuzxalTqmvnz9tMMJSIs7MyRPTurQwWOV5NyQ7Onj3Lo48+yrp166hVq9aD7o4mnjwjfJ9+qlIVWZu+AnFE+ADq1IkXj3hiY2O5ePGiTVELCgri/v37lC5d2krQLBc/Pz87boCRgD8qt6di/nyYNAmOHVPCV7YsvPyyMm8uX27dR4CrV6F0afWgWV1cwOeMSmXvAKGhoWmKY8Li5uaWrjgWLVo0UxUZIiIiWLhwIe+8U5i7dztg/b8LJOX/eSSq9Exh4BhKFJOEDwLx9VVx+rYStiTUDEwQtwSBu3z5MhUrVkwhcIGBgdlbRd1RLlyAp5+Go0fTVglQPzB/f1iyRI3iM0l0dDSbN29OrGPn4+OTKIINGzbEySljdQsBVq1SohcVZX8KWA8PKFwYtm9X1pLcxvz58xk1ahT79+/P1odIjf3kGeFr0cJWEoVAHBU+F5dYnnmmH+fPnyMoKIgbN25QtGjRFIKWsBQpUsShCzklg1D1zNOplp0eoUA/A+woqR6R7cny6wAiwr179xJFMLWR5LVr1/D29rYpiJbvixQpkmrqMLMZvLyEqKjkDxCB2Ba+MyjRG4aqlJFS+ObPN1G+/JkUc3BBQUGJNQMtRa58+fIPsESPg4jAH3/Al1+qJyVPTzCbMYsQGhFBPldX9XD07rtqctvdPcu7YDab2b9/f+K8YHBwME888QTdunWjVatWdj0Ubd0K7dsnTTNnBGdnKFZM6X++fA6cQDbTt29fDAYDP/+cen5fTc6RZ4SveHE12rEmEAgmSeBaABOxV/i+/PJXatcOoEyZMpQoUSKHbnjBqKyYIY43YQKOoDIRu3uqIeJ3jhfezArMZjN37txJd/R448YNChQoYHPUaDZX5O23mxMZmXxkFYht4TuLMnO+CfyDytOYJHwQi4vLl5QuPTuFwFWqVAn3bBCAB05YmKqtFRSE2WSi62uvsfD0abxLl87Rbpw9ezZxJHj48GFat25Nt27d6NSpE34Jk9bJul2unJrDdhQPD5XEev789PfNacLCwqhXrx4ff/wxzzzzDGYxs/7cehYcXcCOSzu4FnYNs5jx8/SjfrH6dK/SnZ5Ve+LhkvvqWv4XyDPCFxBg66IIxNERn7t7HDNn7uGRR/IREBCAn59fFo3o7GE5yNNgSOm90aIFHD6sTJ0J9+UXX1QmnNEJlS1DgbqoAQ+oK/7cOeXRkcsxmUzcunXLpigePFiCAweGYjb7JDsqkNSFbx6qNNSLwKtYCx906hTHypUPb0raatWqsXDhQh6xnCjOYW7dusXKlStZvnw5GzdupG7dunTr1o2uXbsmOjS9+656drOew4ek//3l+L/b0vwsoxE2bVLli3Ibhw4dok2bNnz565d8vP9j7kffJyzGtnna280bAwZGtRzFoAaDcDLk1L3p4SDP3BHy5cvc02ByYmLghx/GcPv2OW7evMn9+/cpVKgQAQEBiUvhwoWt3ies8/f3z+TosCvs6Q01ZoGF1+H588rcky+fslyl8D0wofw8OpAkeglMnaomQnMJIkJERAT3798nNDSU0NDQNF/HxcXh4mLE4NAFPhroi6qSZo3JlGd+4tlCuXLl+Pfffx+o8Pn7+9O3b1/69u1LREQE69atY/ny5YwZM4aiRYvSuXMPJk/+kKiozM+hRkXB11+raczcRvVHqlNuWDn6re+H2SXtCcwEQfxww4csOLKA1c+txs8z5UhZ4xh55q7QoIHy7LSfaKyLhbgBSTfVwoVd2Lbtz8T3MTEx3Lp1ixs3bnDjxg1u3rzJjRs3uH79OocPH7Zad/v2bfLly5euQCa8tjm/8dV9NXKbj0oob1ShDY0aqfizFE53MahiDL1QxeEtiYqC33/PtPCZzWbCwsJSFaj0xMvydVhYGO7u7vj4+ODr64uPj0/iYvne19c30eu1RInyHDni5sAcTxuU+Xhyii0Pewm0cuXKce7cuQfdjUSMRmNijUGTycSOHTuYOPEUERERqOLPmcNsVg+NcXEp42MfJGYx02txL46aj6YrepaEx4Zz6MYhGk1vxJ5X95DfI3/2dfIhIhf9NNKmQwfl5Zie41oSyX2b15FgKnNyUiZFS9zc3ChevHgqRWOtMZlM3L5920oME5azZ89avb958yYeHh4pxPGL9evJdx9V2+R1YBjMmQ3DXoeGj0Kj5nDjDASUQE0HHkCV8EvFa13++YfjR44QGh6eIYGyfB0ZGYnRaExVoCxfFylSJM19fHx8cMngnefOHRg7NkOHWDAG6JpsXTgHD85i/PhomjdvTq1atXKnZ2Y2Uq5cOU6cOPGgu2ETZ2dnmjZtyqZNTfnjD8myAuVubnDy5AOI70uDibsmsu7cOiLiMu65E2OK4ULIBfou78vvvX/Pht49fOQZ4evRQ9XKs+a8jT0DgbSnLT09Ydgwx/vi7OxM4cKF7arxJiKEhIRYieGNGzfwTIjODgXGwraxcAF4ajsUugTlfGBBNxh6D0jh1JOS2JgY+vbqhXOBAjaFqECBApQqVSpNsfL29s7Bec6U+PlBkSImLl50RJwaAw2A1YlrPDw8ef75QM6cWcn06dO5evUqjRs3pnnz5jRv3pw6derkPQ/ODFKuXDlWrFjxoLuRJocPQ1xc1sVCOjkp61BuEb4L9y7w0caPlOhtRV3olpmjvgX8bKx7HPgNGAQxBWNY++9aVp5eSeeKnXOs7/9V8ozweXjAe+/BF1845u6cgIuLSniRU5PfBoOB/Pnzkz9/fusA3/fftwpKnA20BQrFP9A9A8y+C0Pt/Bw3Fxf27tuXIv1UXuH48eNMmjSJmzfz4eIyirg4S/PweRtHjLSxbpXVu6pVnXjrrU5AJ0ClTPv777/ZsmULr776KufPn+fRRx+lRYsWNG/enHr16uXpKu22KFu2LP/+a1918weFowWfUyMqKorlyzcQEXGXQoUKWS1eXl45nnBg/M7xxJrjT7I0yj/HjJp5CUVZca4lW3cnfl8LImIj+HjTx1r4soA8I3wAw4fDggVw+rTjKQrd3VUbD5yiRRMnLSOBxajff5H4zdHAPeCwve25u2dD6oobwH7gEmoUXRzlTlosS1o3m82sWbOGiRMncvToUQYMGMCxY/1p2NCD27cz17bRqMLaLClcuDA9e/akZ8+eAAQHB7N161a2bNnCwIEDOXv2LA0bNkwcETZo0CBTQfm5gcDAQC5duhTvPJQ7L/esdkY2GCA09Dxr1uzk1q1bBAcHJy4mk8lKCP39/VOIY/IlM2EvZjHz86Gfk4SvGOpCvx7/+gLKCf1usnUFABspcU8Fn+LM7TNUKFjB4T5p8pjwubjAX3+ppBO3b2dc/IxGWLoUSpXKnv5liMceSxS+Zai8I0dRLjgJPAXMiX9tAiw9vZ2S7RtXpQouWfIkG4fyuBkLnAM8SAq2d41/XQx4FxVCkPGbQlhYGHPmzGHSpEl4eXnx5ptv0rt378QbzIIF8OSTjo/sE+K52rRJe79ChQrx5JNP8uSTTwIq3+q2bdvYsmULb731FidPnqRevXqJQtioUSOMWZX8M4dwd3enSJEiXLx4kbJlyz7o7tikSpUQ3N2NREenZ3YWrK8CUL/PZHuJBz/9NJCCBVPmx4yIiOD27dtWYpiwnDhxIoVQBgcH4+7ubrdIFipUCD8/v8SHjNO3T1t3wAUogRK3BJErhfLrsVyXStils5MzOy7t0MKXSfJMHJ8lly9D584qCXF4ePr7u7urbE1Ll6ocsrmCtWvVxGVYGO2BasA3yXZZDAxGueQkj8ltTFJEU6SzMx+6unKtWzf69OlD27ZtHXy6P4ZyG72EZVo12xhR6cKWoCLp0+fixYt8//33/PzzzzRr1ow333yTpk2b2jQ9jR0Ln32WcfHz8FBzO1u2ZD6Zzf3799m+fTtbtmxhy5YtHD16lFq1aiUK4WOPPZZDlQoyR8uWLXn//fdpk96TQA5y+vRpli1bxrJlyzh2LJzw8L2YzbbMzIEkxfH1tbE9Zbxu2bKq6ERWICKEhobaFMrg4GCbQnn37l18fX3x9/eHanCu+jninC08dzahjCn/A6agnnDvoIwrCeseBWqhLPqDgIJJh7/R4A2+6/BgE1bkeXKwBFKWEhcnMn68KpHl4yPi5JSyLFZCdfRXXxW5d+9B9zgZJpNIsWKZr6kWX2gwOChIfvjhB2nUqJEEBATIm2++Kfv3789AQdH1ogp6GiT9OmiWi1FElqXaqtlslm3btknPnj3Fz89Phg4dKv/++69dPZo2TdXjc3bOWL3F7Kr7GRoaKmvXrpUPP/xQmjRpIl5eXtKwYUN599135c8//5SQkJDs+eBM0r9/X/nll49FZL+InBURU473wWQyyc6dO2X48OFSuXJlKVq0qPTv319Wr14tUVFR0rhxll0KMnlyjp+eFXFxcRIcHCynTp2S4YuGi/un7sJIkpbnEYwI7yJ4x68bjuAVv86AMCR+PQiDsDr+2d+yodL8Q0aeHPFZEhenKoRs3gw7dkBIiBrh1a4NzZopk5mD5eOyn9WroWfPzHnreHmpyaw33khcdebMGebOncu8efPw9PSkT58+PPvss5QsWTKVRo4Aj5H+KC81PIH18W0oYmJiWLJkCRMnTuTu3bsMGTKEF198Mb5Khf2cOwevv67+v05OKUsVubiA2RxBoULCjz960TV5REM2EhkZya5du9iyZQubN29m3759VKlSJXFE2LRpU/Lnz59zHbLiHsplajIm01liY13i5ytN8UsdVI7TLigTdtYTHR3Nxo0bE1OX+fn5JSaxrlevnpUH8Y4dqtZkZkpRAfj7mwkKcsrSkmOZYcHRBfRf2Z/QmNCklbHAF0BLlMd2QnGRqajSgntQ/xqwOeJ7re5rTO08NXs7/h8nzwtfnueFF+DXXx0TP3d3qF9f2fVshCGICNu3b2fu3Ln8+uuv1KxZkz59+tCjRw98E58GYlGG1rOkFwaSNsWAMwQHRzBt2jQmT55M5cqVefPNN+nYsWOm4+cuXYJly1Qx3n/+UfO7AQHq4SYubjX793/H6tWr0m0nO4mKimLPnj2JptHdu3dTvnz5RCFs1qwZBQsWTL+hTCEowRuEchNM63fljfKjX4xK+5Z57t27x6pVq1i2bBlr166levXqiQHrFStWTPPYN96An392XPycnWMICHiJlSvfonbt2o41ksUcvn6YpjObWgsfKOvtXaAp0Ch+3SrgOFAWSKjRORIr4TO6GpnYbiKv1n01m3v+H+eBjjc1IrGxIl26KBtNRmw6np4ideuK3L9v18dERkbKkiVLpEuXLpIvXz55+umnZdWqVRIXN1lEvKR0acTVFbl1y9qUWauWMrcEBSGXLiHduyMFCyK+vki1asjMmWo/k8ldfvutnuTPn19eeuklOXz4cPZ9Z8kIDw8XPz8/uXjxYo59pj1ER0fL9u3b5fPPP5d27dqJj4+PVK9eXQYOHCiLFy+W69evZ/EnxopITxHxkoyZqz1F5HuHP/XixYvy/fffS+vWrcXHx0c6d+4s06dPz/D5xcSItGqlftoZNXF6eop8+63IggULpFChQjJ58uQMmPmzj5i4GPEY7WFt6hyJ0CTejNnPYl3P+HWdLdYlM3V6jfGSw9dz7tr6r6JHfLkBsxkmTICPPlK227QCm5ydVWqKAQNUgUIH3O2Dg4NZtGgRc+fOYdGifZQubSYwUA0g33gDBg1S+x09qiyxp0+rgt99+6ri0mPGqH2PHlXJtDt0UPuHh3sRHn6GwoVzPln2wIEDCQgI4OOPP87xz7aXuLg4Dhw4kDgi3LZtG0WLFk0cETZv3pxixRwNFRGUZ8RK0h7lpYYR+B7bDiTJPkmEY8eOsWzZMpYvX05QUBCdOnWiW7dutG3bNlMOPzExMHCgqrBgz8jPxUVdAtOmwTPPqHWnT5/mqaeeolKlSvz0008W1o0Hwwu/v8D8o/MxiYMxWBaUK1COM4POPLjix/8RtPDlJoKCYPx4mDlTBSMZDMqm5+SkXsfEKCV6770sSksRhNlcFSenKAID4ZVXVFq4vXvV1rffhgIFYMQI1bXq1WHbNpUAwDbewN9AzpuZDh48SLdu3Th37lyeSUtmMpk4fPhwohD+/fffFCxY0EoIS9kde7MQVZ3C0XlaUOJ3BJVHz5q4uDh27NiR6IlpNpsTKyw0bdo0y2MEN2+GoUOVWdtshuho6+1eXuoZ8YknYOJEVbbMksjISIYOHcqGDRtYvHjxAzN9mkwmPp3yKaOuj8r0VKqXqxc/dPyBF2q9kDWde4jRwpcbMZnUFX/4sEpO6ukJ1aqpJUszi/wKvAzcJzAQpk9XT9vLlkHFiqrS+/btqoZpUJASxshINSJ87DFb8ZBGYBLwShb20X7q1avHmDFjaNeu3QP5/MxiNps5evSolRD6+PhYCWFgYKCNp/0IoAiBgaFcvarqVhYqlLS1du3EEn0EBipHkhEj1AOOk5OaJx07FqpWdQaaAJtVqxERrF27luXLl7Ny5UpKlCiRKHY1a9bMkVHHsWOwYYOa2712TfW3WjX1++vUyfo8bbFw4UIGDx7MZ599Rv/+/dPuc1QUrFsHu3bBwYPqQbNQIWjcWMVBZbDCxd9//83gwYPJly8fZfqVYcmFJUTEOubIZhADDUs0ZMfLO/RoLwvQwvdQMw74AIhNFL5du1RsZPPm8M03yvHU1VXdNPPlUzfIFStU0fcaNeCnn5R/TRLvA58/iJNhypQpLNy1kEo9K7Hj0g6u3L+CIBTyLETDEg15svKTdKvcDVfnvJGfU0Q4ceJEohBu2bIFNzc3KyEsX748BsPPwBACA8PTNVdfu6YC+8eMgZdeUlb18ePhhx9U8fYyZdz57bdPmTdvJxs3bqRevXp069aNLl26JNbOy2uka/oMC1OVTaZOVcoaFqaGmQl4eKj1ZcqoC6BTpzQ/79KlS7zzzjvs2LGDcePG0atXL2JMMTSd2ZQjN44QbYpO8/jkOBmccI52psU/LVg2Z1meS6KQG9HC91DzNUr44hKFr0IFNQJ49FF1fT/9dJLwWd73goOVKXTdOpVQIOkhdDjKVztn+evsX7y8/GWu3LlindLGAh83H5wNzoxtM5ZX67ya556cRYTTp09bCaHZbGbr1ijKlbtrl7m6Tx/1wDI5WQWnDh3A3189yPz+e1ViY4enWi09L5Kq6XPHDpVI4t49W1VwU2I0QseOMGsWyWMmIiMjGTduHBMnTuSNN97gvffesxKp8JhwOi3oxL6r+wiPtc8k7eniib/Rn3XPrmPMO2P4559/WLFihQqO1ziMFr6HmnnAACAsUfhat1Ylmw4cUKMDd3fbwgfKDFWjhhLBggUhNtaFf/99jcKFP8uxG2acOY5+K/qx6Pgiu81IXq5e1C1WlxVPr8DXPbcGeaaPiHDu3FlKl66Gi0tsuubq48fV/2v9enj8ceu2Zs6EDz5Q/3NVFmBjTp9OjvDLL78waNAgZfosVw6DI7nx3N2hcmU14e3tjYiwbNkyhg0bRt26dRk3blyqo2MRYcq+Kbyz7h0MGFIVQA8XD0SEV+q8wtdtvsbT1RMR4eOPP2bhwoWsWbOG8uXLZ/DsNQnkqVydmqymrs21M2bA3btJDgQJvPeeGjFUrqzm+qZMgfLllegBxMU58e2325k7tzQBAQHUr18/caldu3aWp/dKKO659tzaDM2dhMeGs/vybhr/3JidL+/E2y33px2zhcFgoFw5b9RlnOQJ3KePKmrcvDlUqZLk+HHnjrLg2UoKXbSoeoBR/JPNPX9w/O9//6NOnTq82bUrfc+cwcORbPfR0WoO/n//4/jYsQwZMoTr168zY8YMWrZsmeahBoOB1+u/zvM1n2f+kfnMOjyLYzePERUXhQEDTgYnKhasyJOVn6R/vf4U9SlqdeyoUaMoWbIkTZs2ZdmyZTRsmDXxlw8bWvgeaiqhkvxaV/ctl9KpD1APxk8+qUYFnp6qUvwffyRt9/R0Y/LkXXz3nQunTp1i79697Nu3j0WLFnH06FHKli1rJYaPPPJIpjLfj985XhX3dMBhINoUzdk7Z+m3oh8LeuSGch0ZIy4ujlu3bnH79gEqVzZbVRvv00eZq4OC4Pnnk9YXKKCmqq5dUw8vlly7luQoEh4ewvz5P1KwYEEKFiyIn59f4l/PzCZAzQVUrFCBFd7e1vN4GSUqiui//uKbrVvpOno0AwYMyJBnq7ebN6/Ve43X6r2GiBARG4FZzHi5eeFkSLsmZr9+/ShevDhPPPEE06dPp0uXLo6fx0OKNnU+9IxGVS+3Y34jTdxQZtOJNrfGxMRw9OjRRDHcu3cvZ86coWrVqlZiWKVKFbtuIEF3g6g2uRqRcRbBXjNRyX/fJumR7ndU2Qvn+KUY0AGInyIxuhpZ/r/ltC7b2oFzzlpEhLt373L9+nWuX7/OjRs3El8nX+7cuUPBggUpV64QmzefwNVV7DJXP/ecck60NcdXsCDMmwfBwfl5//2e3L59m9u3b3Pnzp3E187OzolCmFwUU1vn5+eXuwr+btoEXbooJxYLAlEJVRJ+CZtRRt8vgfdSacpUrBjO1pPcOca+ffvo0qULI0aM4PXXX7exRzSqku0vwD4gYUhfEGXt6Y1KSp+3S285gha+h577qBxJmSyAhy9wBlWxwT4iIiI4ePCglRheuXKFWrVqWYmh8ly0vrG8seoNftz/Y1Kds7uoqtXuwBOoLGyghM8XaIWyBq5EZcJ/OamtRiUasfPlnQ6cs32Eh4fbJWY3btzA09OTIkWKpLsUKlTI4gEhALhpJXz//qvM1fXqKXN1gvBdvgzt2qmCzn37qm3ffAPff68cYipUAFUGOXk9ECXMCWV9EsTQUhRTW3f37l08PT3tFsqE1/nz58+emMxOnZS7crJbXyDWwtcX+ANVI/N4am15e8PKlQ+s7Mu5c+fo0KEDTz75JJ9//nl8/lMBZgBvodLWhaVytDdgQJUg6x//+uFAC58GWAt0Q5XEdQQjKj9kz0z35N69e+zfv99KDO/fv0/dunWT5gvr1qbG/BrWjgGbgX9RtXJvA8/Gr7cUPoDTqEpKHyYd6uHiwamBpyidv7Td/YyJieHmzZtpClnCEhcXZ5eYBQQEOFj4tjfwK4GB5kThs8RS+AIDlU/GiBGwb58yfTZtqrz0q1cHk8kTZ+dpQB8H+mEbs9lMaGhougKZfF1oaCi+vr52C2XCX19f39Q9dkXAx8dmPbNAkoQvHCV4PwHPAztIpfiWs7Oa/B4zJiu+KocIDg6mS5culClThp9//hZ3916oTNf2JjPwQiUtX4nN6rf/QbTwaeKZikoJn0HxizDAkS7wyALl6p0N3LhxI1EE9+3bx85/d3K3+13EzeKnOwlVw6wE6u41DPVAayl8Mahr+wbKKhuPj5sPPz7xI09VfYrbt2/bJWYhISH4+/vbJWg+Pj7ZHDqxi6TbdeYIDzfQpUsjBg58m65duz7QLDgmk4m7d+/aNaq0/BsVFYWfn59Nk2sZZ2f6T5yIi420gIEkCd9cVKnly6hHwkAg1Qp4TZuqCPsHSGRkJH37/o9PP91ExYoxGAwZixVUppJKKInPJaUtshEtfBoL/gBeQIlfOhdOTPwurwIrvVR0+6JF0KRJdneSeUfm0X9l/6QR3wXUgPMt1DX7Herx/FGU8B1DzflFA/lRKS2LWDQo4HXEi+gV0fj6+tolZgULFrQqq/NgEeAxRPZiMGQmH6QRk+ktli6twfjx47lx4wZDhgzhpZdeynA5qQdJdHQ0d+/etSmQHseP8/KCBRjTEb7WqApBE1HJ4AajKgjZnKmsXBlOnsyek8kAZvPrxMX9iJubo78BD5SpZHoW9ip3ooVPk4zbcPtNcJ+nyra5kzT3HY3ygXEB5gCfAdctDvX0VClA+qaf6DgzTN03lWF/DUtybPkDCCXJvLkZOIka1VmO+O6hQhcfJ2kOMJ7eFXozu8fsTHmZPkgiIk7g5PQIHh6O3vScUTk6j5Fwe9+1axcTJkxg/fr19O3bl0GDBlG6tP3m4FzJoUNqPu7+/RSbAlG3/Erxr3cB9VEJ4QJQo8BuNpq8WqAAs95+m+LFi1OiRAlKlChB8eLFszx8J232As0JDIxMN23dyJEwezbs3g0NGqjtZ8+q+V0RI2rqo3EO9j3n0eEMGmuux0K1Vepqb4Ry/iqPmvc+B+wHdmK7AEBkpIqeLlRIZQ/OJkzRJjVnD8ph5Tjq/dcJO6AE+nqyA/OjPDp/Bypi9fgeUCAgz4relStX6NKlD88++zhDh27HYMjoXK0zUAB1w0v6Uho1asSiRYu4cOEC3333HXXq1KFVq1YMGzaMRo0apdZY7qZMmXTLPsxF/Zwsf8FRKKNCNxv7R5YqRWhoKOvXr+fy5ctcuXKFy5cv4+bmliiECWKY/H2BAgWyyAw+igTP7DJlYOFC67R1yWP0/fzUPO/atcnbiUA90f6VBX3KvegRnyYJEeXyt3lz2qWR0iNfPuVWmMmiq9HR0Zw8eZKjR49aLXc87xDTOwaTq0mFKvyJckqznI5agnJ0icDauQVgGlCTxAKgXq5efNfhO/rWzt6RanZw4MABunbtysCBA3nvvfcwGDahnIwiSNdcDcTGuuHqWgH1JaY9mgsNDeXnn39m0qRJBAQEMGzYMJ588sksr8yQ7RQvroZEyQhEjfgGAk+jflIJ7EE5/l/Fqhi6yuM5diwMHmzVVkJoiqUQJiyW72NiYlIVxYTXhQsXTsesHoIak0bblbZu5EglfAsWqNmJ5s0tR3ygzDyXgXQygOdhtPBpktiwAbp2TfR4C8TavdsSQRnGPIATyTe6uakMyFOm2PWxZrOZoKAgK3E7duwYQUFBlCtXjho1alC9enVq1KhBjRo1CCgegN9XfirZ71xUBEXyggzHgNWoSI38WAvfMdQD7RDARcXy7XllD9UKJ7N/5nKWLVvGq6++ytSpU+nRo4fFljso755FqKeB5E4vBsCbuDhh7Fgnhg69hNFovzefyWRi+fLlTJgwgUuXLjFo0CBeeeUV8uXLl9lTyhneew8mTUpR6ygQVVdkNHCJxFDPRKqhrOdvWK50d1eqUaKEQ10JCwtLUxgvX77MvXv3KFq0aKojx3LlLlC4cH8MBvuqrIwcqbpbuDAsXqy8fK2FLx8q9q+9Q+eUF9DCp0mibVuVdTqeQFIXvi1AJyAO2IqaC7HCaISbN1Mk8r1161aKEdyJEycoUKBAorAlLJUqVUrV/Nh7SW9+PfkrZslE9o14nO86847xHV4f8DolS5bMdHvZjYgwbtw4Jk2axLJly6hXz6ajPSq48TdUjcRDKFNYPpTXT0ugE716PUOdOnV4//33AVWJ5+RJFQPo6qpunGnlQ967dy8TJkxgzZo1PP/88wwePJiyZctm2blmC5cuIRUrYrAnKXUaiLMzhtatYc2aLOqYbaKjo7l69Wqqwti+/SmGDw/BwwO7qqwkCN9HHymxmzZN/U0SPhdUUot3s/W8HiR5zEahyTaio5WJ005mA11R/p+zSSl84uzM2WnT2FaggJXIRUVFJQpb3bp1efHFF6levTr58+fPUHeHNxnOitMrrDO3OICXqxefdPiEy6suU7NmTVq2bMmgQYNo1qxZrqzeEBMTw+uvv87+/fvZtWsXJdIcaRRAjWFSr4/4+eef06hRMwoVGsiPP/py+HBSFR5Q02E+PvDCC6rcUZky1sfXr1+fBQsWcOnSJb7//nsaNGhA8+bNGTp0KI0bN86V3+EVJyf+LlqUbhcu4JmJtGVRZjPnBw+mShb2zRbu7u6UKVOGMsm//ETGIPIxSRPfqaets25Xid9HH8Evv1huiUN5i/13yS3+2JoHzdGj6o5nBxGoErbPxi+/oKIbLDGFhrJx7Fg2bNhAQEAAQ4cOZe/evdy9e5etW7cyefJkBgwYQJMmTTIsegC1i9amb62+eLo4njvS2eBMrSK1eLvt20yaNIkLFy7w+OOP079/f2rVqsVPP/1EREYz92cjd+/epX379ty8eZOtW7emI3r2ce9eBWJjjzFwoBv79qmp3dBQCAlRS0wM3L6tMrtUq6bmiWxN/5YsWZKxY8dy/vx5WrZsSd++fWnYsCELFy4kNjPzxRZcCrnEkuNLGLFxBINXD2bExhEsOb6ESyGX7G5j0aJF1KlTh7PPPot7Zgo7G40c7NuXZi+8wKRJk3iwhjMjBoP1GKZ0afWQsmoVdO+e+pF9+6qKTEuXWq514T8fyycajYjI4sUivr4iytohAlIaZJ3F+4RlLkghkFiQSBBfkKU29pPu3bO1yxExEfLIlEfEfZS7MJIMLU6fOon/V/5yOeRyinbNZrOsXbtWOnfuLAULFpS3335bgoKCMt/hyEiRuXNFunYVKV5cxNNTxGgUKVdO5NlnRVauFImLs3nomTNnpGLFijJs2DCJS2WfjPLzz6oLYE7xr0ttMRpFatcWuXcv7bbj4uJk+fLl0rx5cylZsqSMHTtW7ty541A/15xZIw1/aigeoz3E93NfMYw0CCMRw0iD+H7hKx6jPaTR9Eay5syaVNu4ffu2PP3001KpUiXZs2ePWnnnjkj16glfgv2L0Sjy9dciov4v9evXl44dO8qNGzccOr/Ms1ZEfEUEKV0aWbcOEUHOnkX27lWvY2MRQIKCkBdeQD78UK0XQebNQ/z81Ha1zldEVj6gc8kZ9IhPozCbU+QuTI3ZwFOo50IPoEf8uhRY1jTKBjxdPfn7xb+pWaQmXq72P6F6unhSzKcYu1/ZTXHf4im2GwwG2rRpw4oVK9i9ezdmszmxEvmGDRsy/nRvNsO33ypvggEDlMvdlSvKjhgRoTxg589XVX+LF7cueQFs2bKFJk2a8NZbb/HNN99kSTaVX39VDhDKs99+c2REBJw4AS1bpu346+zsTJcuXdi8eTPLli3j2LFjlCtXjkGDBnH27Fm7Pute1D16LO5B98Xd2X1lN1FxUdyPuY+gvn9BuB99n6i4KHZd3kX3xd3pubgn96LuWbWzdu1aatasib+/PwcOHKB+/XjDfIECyvWxf38Vg5qed6qXl/ofrlihXCWB8uXLs23bNh555BFq167NOos58pyjHrY8eMuVU7la0+Ppp5OXqorBxqz9f4sHrbyaXMKmTXaN+C6BOMWP8gLiFx8QV5BblvsaDCJvvJEjXY8zxcnX278Wz9GeYhxjTHWU5z7KXTxGe8iAlQMkPCY8Q58RFhYmU6dOlWrVqknVqlVl8uTJEhoamv6Bd+6INGwo4uWVsRHF00+LxMTIzJkzpXDhwrJu3ToHv52UXL0q4u2dsUGOrS5+9FHGPvfKlSvywQcfSKFChaRr166yefNmMZvNNve9FX5Lyk0ql+HRvPsodyn/bXkJDg+W8PBwGThwoJQsWTL97+/kSZF+/dT/yWgUyZdPXQ/58om4uopUqCAydapIWFiqTaxfv16KFy8ub7/9tkRHR2fsy8k07SRhBJf55fEc7nvOo706NYqQEOW+Z/EYHwhMQSU6SeBrYAGwKdnhjwFDgfiYWWI9PDBNnoxHNmZxuX8ffv8dtmxRJXjC4u4RXWU2N4p8i7ngZZxdwIABs5gp71ee7lW6M6DeAJujPHsRETZv3sx3333Hli1beP755xk4cKDtatj376vUGEFBarIsI59jNPJPkSJ0Af74808qJy+glwl69VKDTvWvDsTad/cXlNP+MqA5aRXn8fCA06cho46wERERzJkzh4kTJ+Ll5cXQoUN56qmncIufbzOZTdT7qR4nbp4gxpyx7w3A1cmVMt5lkGlCg3oN+O677yhQoIB9B4vA+fOq0GxMjBoV1qwJvvaFewQHB/PSSy9x9epVFi5cSAVV7iIH2I7Z3AYnp8w5e6mE8yuxvur/gzxg4dXkJqpWTTHiI9lSDuRbG0OAsSB1Ld5HOzlJRW9v6dGjhyxcuFDu37+fZd28f1+kf381NWN75GISL+9Y8S50R94beVsiomKz7LMtOX/+vLz33ntSqFAh6dixo6xZs0ZMJlPSDr16ibi7OzysinBykrARI7K0zzdvinh4WH5MaYF18a9nCfgJbLfY/mL8uqopuujmJvLee473xWQyycqVK6VVq1ZSrFgx+fzzz+X27dvyxdYvxGuMV4bnba2WD5FnJz+bdV9cBjCbzfLdd99JoUKFZObMmamOahO4dk1NGbZrp6Z+CxYUKVFCpFMnkYkTRW7dSv8zly9fLgsWeEhMjIs4OtKLjnaS2NinHD7vvIQWPk0Ss2ZlzCSX2mIwiHToIMHBwfLzzz9Lhw4dxMfHR7p27Spz586Ve+l5RqTBjh0i/v7Jb95pm+QqVBA5cyYLv6dkREREyIwZM6RWrVpSsWJF+fbbbyXst9/Uh8d3ZCZIdRBPlHm4P8jd+G2fgDxr0enLIJVABoGYPTyytPM//mjVLQvhmypQUGCvxbYwAW+BhQKuybappUiRrOnXoUOH5MUXX5T8hfOL8yfOSrzyIRgRPrAQtCcQSse/BsE12dI6aV/jaKOERtthjs4mDh8+LFWrVpX//e9/Nn/zt24lPRul9nv29FTbXnzRtkNReHi49O/fXwIDA2XHjrUiUk1E3CSjomc2u8mVKz7SunUDuXnzZrZ8H7kJLXyaJKKjRcqUybzweXqKHD1q1fSdO3dk9uzZ8sQTT4iPj4907txZZs2alSFPvy1bkt+07VucnEQKFBD555+s/sKsMZvNsnXrVunVq5fsc3ZO7MA4kMIgq0FiQIJAOoDUA4lOJnznQcqCvJPQeRcXkddey7I+9umT/PspLdBdoLDAoWTb5ggUEYgT6CzwRorv1tVVTWNmFV+u/1JcP3FNEj5PhJZpCN+g1Ed9XmO8ZOreqVnXOQeIiIiQAQMGxAvTjsT169er6UM3N/t+wx4eaiS4c2dS2wcOHJDKlSvLM888YyGsd0WkgYh4if3C5yUidcRkuiUffPCBlCtXTv6x52KJi1MX1a5dIvv3K1NMHkELn8aavXsdU5eExctL5NNP0/yIkJAQmT9/vjz55JPi6+sr7du3l+nTp8utNGw6166J+Pg43i2DQaRUKRVRkO2cOyem+Ef4EBAvkEXJOhSKCgmZYSF8Z0FKgXyUvPNGo0hs1phra9e2JXw+Al0ETMm2tRIYEv96gUAhgRirffLlE0mIDsgKWsxqkSRe+RBaIXggvJdx4WMk0nJ2y6zrXCb4/fffpXDhwjJq1ChZtSrO4UvMaBTZutUk48aNk0KFCsm8efNsfJpJRMaLiFHSFkAvEfEUkS9FJClEZvr06RIQECB///13yqZjY0V+/12kcWM1VPX2TnIEcnVVttqPP1YeVLkY7dyiScnixfDii+lmsU+B0aiiZWfPTkr9kQ6hoaGsWrWKX3/9lbVr19KgQQN69epFt27dKFy4cOJ+7dvDxo2Zy53t6amiCb75xvE27GLBAuUiHxrKGqAzSdWcLHkB5TheCVUX4QIqQfIHydvz8VEJFR95xObHmc1mwsLCuHfvHiEhIYmLrfe//PI+ISGlLY4ORKWnGo1KZTYDFd5wCXuK8zg53ad8+cEEBJzDy8sr00vRiUW5G3VXNT4B6IKquOOPyre6HzgC9AVGoryp0siF7ufpx+13b6e+Qw5y+fJlnnpqKHv2zMZkcrxos4tLKLVr92LRoilpZHMBCEPV4VoIHEYlszYAPsAjqMKUz8e/t2bdunU8++yzTJw4kWeeeUatPHRIeUZdvw5hYal/rIcHGAzwyScq7OMBFjNODS18Gtts2AD/+59K4xGdTpZ/g0H92N9/Hz780G7RS054eDhr1qzh119/ZfXq1dSpU4eePXtStWovOnb0j9dhyxpnEahM8gkX1jTgAKpkg2W9lTeBs8BKPDzUdZut+ZTffhvGjwcR5gFvk7JCEsBw1H28MTAelUZpPyr5tyXRbm780qwZ64sUsSlmoaGheHl5kS9fvsQlf/78Nl9///2TnDhhWYU3EOXVWRXlxdka5cv7OfAhSuwSuI2S8d8T1xiNZmbPPo6//x3Cw8MztYSFhxH3QVxSWGGC8HkDP6OqwZ7CWvjcsA5D7IUqoxWPk8EJ08eZKc6btbRqJWzebMZsdlwMnJ3j6N7dicWLM3qdJXwP9n32sWPH6Ny5M6+++ioflCqF4bXXICpKDT7twcsL6tRRiUK9clcmGJ2rU2ObVq1UyvZRo+DHH5W4RUYmDbmcnMDbW7l8t2kDX3yhclplAi8vL3r06EGPHj2IjIxk7dq1LFmyhKFDPYiJeR71c7V80gwkZRrtJ1FPszNRd8edqPD6o4ndnjtX5Z3MSsxmMyEhIdy5cwff06fxj785FAKCUdkPk19s10gq/NIFVWSiJSqltOWYzGA2U8rPj7Zt29oUM19fX7uD2m/cgNGjwZRCC4oBG1DiNxRYBXyC7eI8t0kYZplMTnTvXsPRZx0rRATnz5wTA9QTCUDVT9xGyko5r5HmiM9sNtO3b18KFy6Mv78/hQsXTlz8/f3x9/fHw85UfZnlxAnYudNgIXrbUImgj6PEqAqq5vtx4GUgIR2fP9ACeB+oiMnkwh9/wOXLGS0KkTGxrV69Ojt37mRc48bEXLyIe8ofTdqEh6sEAR06wKZNuWrkp4VPkzr58sG4cTBmDPz9N+zbB8ePq4wsJUuqGLXmzVU2iyzG09OTrl270rVrV7ZvF86ftze7iBH4CVWTriXwEioGTd0hIiJU/sLUhC8uLo579+5x584dm8vt27dtrg8JCcHHxwc/Pz9GhYURbxziUdSYdCkq200CYaiqSZ+jKp+BGvVFkyR+CdGGbh4ePN6xo8o8nElatlSmXtuWqlLARpTKxKEMr5alGbqghlMLSSjO07ChwwP8FBgMBgoZC3Er4lbKjS1QA/rHMtZmftf8NG3alJs3b3Lt2jUOHz7MzZs3E5dbt27h6emZqjBavi9cuDAFCxZ0uP7gDz9Ymurvo0bPU1C/jBhUnZOEaiSPooTRBJwHvkFVhd4JVAdUFYaRIx3qit0UNRgYd+sWhoyKXgJRUSrIdvx4eOedrO1cJtCmTk2uJjZWTR3azn4WSOqFk15DleSpgbqZJwmnl1coL7ww3KaAhYaGki9fPvz8/FIsBQsWtLnez8+P/PnzJ90QZ81S5a/j1eUr1G1rNmqa6grwOsr8uRP4AmWInQcI8CrqlrcFNdgRHx8MmzZB3boOf48JiKgExpfsz+ucKt7eqtJ3586ZbyuB9vPa89e/8dW/E0ydCbbfP4CTqKGxnXN8Hcp3YNWzq1LdLiKEhIRYCWFyYbR8f/fuXfLly5eqOCZ/nz9//sQispUqqYB/xT7U7/aejV7NQv2utyVb3xmVJPBXQD107NqV+rlnCfHZDgJjY4kAgkhKXz0d9ZvdjLq6jPF/3YFaQD+gd0I7np4qkUOApen8waFHfJpcTViYoyOKpsCPwDMkz0UZG+tGlSpVUhWwtKtd20GjRio/Zzzvou7NbwP/ogrCdwPmk/R8n4Ahvtcvom6LmwCf0FA+mDmTruHhNG7cOFO5Og0G+OorVaU7PHl92gy2U7KksmJlJc/WeJbtF7cTFmtjSNoc5aNhydRk7+sA8X3ydvPmmRrPkBYGg4H8+fOTP39+KlasmG7/TCYTd+7csSmMhw8fTiGUYWFhFCpUCH//wpw5s5+kW25FlOnxBZSTSSNUGam06I4ydypOnky3u5nj5k1YuTJxmGoCJmHD+Sqewyh7QDDKmvEGakr2E1BPXD/+qGog5QL0iE+TqwkLU1mjMjbiu42ql/00KgXXSVQZdkX+/KrQarZStWqW3JnE2ZmQdu34rlEjli5dytWrV+nWrRs9evTg8ccfx9XVNeNtihKszZvT91tKDaMRdu+G6tUdO94WJpOJ2fNn88rpVxDXzN+WfN18ufnOTdxdbBczzgliYmIIDg7m8uVbNGr0CCKWD2EngbHAetT4vyPKTL8a2yO+NcATgBIiZ2czW7futpr3NRqNWVcDcdo0GDYMIiIIRM32fgWcQ11NyUd8Z7DyK+JX4DmUhaMgQKlScOFC1vQtk2jh0+R6ChRQNcNSEoht4euDepqehTK2+MTvp6hTB/bvz/p+WrFoEbz8cuaGVaBMRDt3qnyRwL///svvv//O0qVL+eeff+jcuTPdu3enbdu2eHraX5vw/n149FFVGCKj4ufpaWbOnK307LkTdcsriaoQUIGMVHpIQET4448/GDFiBN7e3jQZ3IQpQVMIj3X8u/Ny9WJSh0m8XPtlh9vISsxmVQE99bq3p1AyUQFoh23hm4Eab90AwMkpivr1W1iFrsTGxqbr3ZveuoScqTzzjLJlk3SlTUb5/44mfeGLRbnnrCB+EO7ioi7kXODhqYVPk+tp1UrF8KUkkJTCtwrl0HIC8ANuoi7VJcDjODsLgwYZmDAhW7ushlUtW6r4O0fLM3l6qnjA8eNtbr5y5QrLli1j6dKl7N+/n7Zt29K9e3c6duyIrx1Jle/fVyVptmyxT59dXKLx9o5i4cIXaN9+AxCJuuV5oqp/50cZdPuj5qLSZ9OmTXzwwQeEh4czZswYOsdPGLaZ24btl7YTFRdlVztWxEKtgrU48OaBXFUBvmRJ5YmZOt+jPHjewp45vmrV4Ngx6z1iYmJSxHFahsDYs87NzY18+fKx+c4dKsUnVw+M71ERVPjNWWA5aQsf8ft/gypYja+vcpKLf4h7oDyAoHmNJkMsWpRaMurSkpRgWQTuC5QUWJRsv1kC5QUiBMJlwIBpOVM09No1lczSIn2Z3Yu7u0jdunanmrl165bMmDFDOnbsmJgS7ueff5bg4OB0j12yRCQwUCXdcXVN2RVv71jx8IiQ556bIcHBfpJ2+iujiJQUkV1pfubevXulTZs2UrZsWZk3b551cm8RCYsOk4Y/NRTP0Z4ZSk7tOdpTqk2oJoWLF5aFCxfa9d3lFL16WX6vJwXGCVyKf39R4DGBVwRmCjSOXx8ncE5UujgvgSMC6if1+utZ30ez2SxhYWFy+fJlibJIX1iapBJlz4AMA/kJpHn8OkDOJPvhxKBKmK2yTPOzd2/Wd9oBtPBpcj3R0SpPoSMpniwXg0GkcuUIeeWVVyR//vzywgsvyIEDB7K38xcvqvynGclR5eUl0qSJw7kP7927J/Pnz5cePXqIr6+vtGrVSn744Qe5mkYaKbNZJQD//HORDh2U5j72mMiAASdl7ty+cu+eqvBt/2IUkeUpPufEiRPSvXt3KVasmEyZMkViYmJS7VNUbJQMXTNUPEd7itOnTmkKntOnTuI52lOG/TVMomKj5MiRI1K8eHGZOvXB5uq0ZMMGywe4ywK9BIoJGOP/9hMIiRc+p3ihMwqUEnhe4ETiT8RoFDl4MJs7/NhjNoXvDKoG58h0hG8JiBtIsGWn//03mzttH1r4NHmClSszl0IUrHNnBwcHyxdffCElSpSQpk2bypIlSyQ2i/JhpiAyUmTo0LTT8CcIntEo8u23IslGQI4SHh4uS5culeeee04KFCggjz32mHzzzTdy7tw5O45eK0rAMiJ4ycVvt4iIBAUFyYsvvij+/v4yduxYCQ+3vxDwwWsH5aklT4n7KHfx/cJXjKON4jbKTYxjjOL7ha+4j3KX3kt6y6Frh6yOO3v2rJQpU0a++OILuz8rO7lw4aJ4eV2TlDlRM7Y4OYnUqZMDHX73XfVhpCxK/QqIXyrCdxtkHioxu1XeWU9P9YSVC9DCp8kzvPKK4+JnNIqMH5+yzZiYGFm8eLE0btxYSpUqJWPHjpXbt29nzwncuCEyapRIrVoS5eQkJmdnZbPy8VFP15Mni9hT1d1BoqOjZfXq1fLqq6+Kv7+/1K5dW0aPHi0nTpywsfc9ESkojoueWuLiisvQoQPEz89PRowYkamSVOEx4bLj4g6Ztm+aTNg5QabtmyY7L+2U8JjURfTy5ctStWpVee+999Kti5ddREZGyujRo6VgwYLy8svTxMPDnOkHOJv/sqzmr78SM8MnF76LIO7JhM+ISsheAKQFyPzkHW/ePAc6bR9a+DR5hrg4kRdeyHjJQE9PkTFj0m9/37598vzzz0v+/PmlX79+cuzYsSzr+/Gbx2X6/ukyYOUAefa3Z6XAcwVk5JL35fiFfQ/kKTguLk42b94sgwcPlhIlSkjlypXlww8/lP3798cLxAgR8ZAEAZs/H6lbF/HyQooUQdq3R7ZuVduOH0eeeALx9UW8vZEWLZDt29W2sDBkyZJmcv369Rw/xwSCg4Olfv368tprr0lcXFz6B2QhK1eulHLlykm3bt0SR9ljxmTmAc4sU6bkUOdNJjEXLuy4Qlsu3t7KbJNL0MKnyVOYzcrZxdc3fQH09la+JZs3Z+wzrl+/LiNHjpQiRYpIq1at5I8//kjhfGFfX82y5PgSqfJ9FTGOMaaoKm4cbRTjGKNU+b6KLD62+IGNSEwmk+zevVveffddKVeunJQvX1rCw90lQfS++Qbx90d++00JWUwM8scfyNtvI2fPIvnzIx98gNy+jdy/j0yapARyx46EkV8pEXmwJq779+/L448/Lr1795bo6OiUO5jNqq7cyJEiLVuKVK2qlq5dlakgg3NTZ86ckU6dOknFihVlzZo1KbaPGqUeyOzXDrMYDJHSs+cmx74AB1i/fr2MKFpUIuLNnQ4vanJdPbnmErTwafIk9++L/PCDup5cXZVFxtdXiZ2bm0i9eiILFohERTn+GdHR0TJ37lypV6+elCtXTiZMmGC3qe5m2E1pPbt1CrFLq2hq69mt5UZYDnibpoHZbJYzZ+ZLZKSq4n3vnhKxxYttmzKfew7p0CHl+v79kaZNE94bReTsAzkfSyIjI6Vr167SoUMH6znG1atFypdXT1IuLilv3Alzs82bi5w8meZnhIWFyQcffCAFCxaUsWPH2hbZeLZuVeXr0qsz6eMjUq6cyPLll6Rw4cKyZcsWG62ZROQfEVktIn+KyF4Rcaz45IULF6RXr14SGBgovy9dKuYmTWy7+2bE5JKsMPWDRgufJs8THS1y/LjIvn2qIHRWP1iazWbZsWOH9O7dWwoUKCBvvPFGmhWqr96/KiXHlxTXz1wz5Irv+pmrlPimhFy9/6CLeP4gqkApsno14uyMxMbaFr6AAOTnn1Ou37gRcXJCIiIQER8RWfRAziQ5sbGx0qdPH2nSpIncu3FD5Nln7bc7Ojmpm7iNyWKz2Sy//PKLlCxZUp555hm5fPmyXf2JixNZvlykdeukiuxGo/pboIDysF2zJsnX6a+//pKiRYvKxYsX41vYKyJPifp/eYlIvvjFV0RcRKSeiCwWkfQdtyznIj/55BOJiIhQG4KDlWeyI+Ln6Snyyy92fRc5iQ5g12gywOXLl5kyZQo//fQT9evXZ8iQIbRp0yYxUDrWFEvNqTU5c+cMceaMB667OLlQ3q88R/ofwdU54+nIsob3UMmpYP58eOstVcPQFi4uKp1j+/bW60+dgipVVMB28eJuqFTcw7Kz03ZjNpt56403eG7OHOqYTBiiMhgkbzTC4MGqFBeqbt2gQYO4c+cO3333Hc2aNXO4b7dvq+pfXl4qY5EtvvrqK1avXsi6dRVwcfkTVeY41ZQwqIKGxVFJHGrY3OPPP/9kyJAh1KhRg/Hjx6cscHv7Njz5pKq0YE+2A1dXlYBh/vyszWKeRWRRQRGN5uGgRIkSjBkzhgsXLtCjRw/eeecdqlatypQpUwgLC2PM1jFcCLngkOgBxJnjuBhykVF/j8rinqdPREQE//zzD0FBQYnrChaE4ODUk88UKgTXrqVcf+2aSi5eoIDKwXnp0kVu3bpFbnjOdnJyYrwINaKjMy56oGpbffst4XPn8uabb9KyZUt69uzJ/v37MyV6oL7vEiVSFz2Ad955it9+O4XZ/BuqGHNaogeqCNZpVCLsZVZbzp49S+fOnRk2bBg//PADv//+u+2q7gULqhQ/334LRYqAj4/t7PFeXqooda9eqp5nLhQ90CnLNJpMISJs2bKFSZMmsXnXZsJeCyNuYpxKVPgmqkI4qNLqlpXDjajMVAmFFkyo3E4RaruHiwfX37pOPo98WdJPk8nE9evXuXjxIpcuXeLixYtWy6VLlwgNDaVkyZIMGuRE//7/4uZmIiQEihWD2bOhZ8+U7T73HNy5o2ocWjJgABw9qjK2RUS48Nlnxfnxx/tER0dTunRpqyUwMDDxddGiRTNfHSM9duyA1q3V0CoT3DcY+Pi55/jwm2/w9/dP/4As4S5QDZEbGAzpCZ4tPIE/CQ9vwBdffMHUqVN59913efPNN5NydKaH2axyCG7cCNu3qycjd3eoUQOaNlUjw4Jp1IrKBeiyRBpNJjAYDLRo0YIWLVrwyapP+HzP52qDALuA1AYAnqiEh5Xi35+JXxeh3joZnJh9eDaDGw62qx8hISFpitrVq1fx8/OjVKlSlCxZklKlSlG2bFlatGiRuM7f3z9edHahEiXfJ18++OwzGDhQmTXbtlVWrPXrVVHtTz6B+vXhww+VSdTVVZUjnDMH1q5VfTMa3fjyy/V8+WV5QkNDuXDhAufPn+fChQtcuHCBQ4cOJa67e/cuJUqUsBJDS4EsUaKEQxUprHj/fb6IjORvVB2EBCqgck0mX2dA5Zr8xGL9HOBTEY6WLYsxx0QPVJW7Ow6KHkAk0dFdadAgHzVrNuXw4cMUL148/cMscXJSDw6tbdXBzBvoEZ9Gk0U0n9mcvy/+rQqo1gO2A0NQgpZ8xPc4Ksl+Qln2RUBRVM3ckWpV01JN+bvv38TGxnLlyhWbgpbw2mQyUapUqRRLgsiVKFECd3d7y/PEoCqv309cM38+TJigKi35+KiauB9+CI89phIlDx+u8g+bzVCvHoweDU2aJBxdDFVnPv2E0VFRUVy8eDFRFC0F8sKFC1y7do2AgIAUI0XLJc0qFRcvQqVKbI+KoiNwBzXovoaqeR6FKqOTsK4YqiBwF9S/sxpwC5X2fDHwuL8/3LihChRmOzuANgQGRnD1Kly9qkzNCdSuDYcOqfnWrVvVuuho1bWEwdxzz8GkSQZu3uxJyZKLc6DPuRM94tNosogjN48kvSmGSmm/A1V2PTmVgT2oAgcAF4EWKOGLZ8e/OyhevDi3bt2iSJEiVmJWo0YNOnXqlLguf/78WViJwA1VYWESoGoWPfusWmxRvbpycLGNJ8qpxb6+eXh4ULFixVSLwiY8BFiK4e7du1m8eDEXLlzg0qVL5MuXL1VTavnduzG6ulI/KopY4BBQF9iKehY5l2xdOdSg/UPgZdS/czDQI35/wsJUOftSpew6v8wxloQfTJkyqmLQoEFqy9GjauoRYMoUCAxUr198Uc0Zjh5t2Y5QsuRqlMzbV0Xjv4YWPo0mi7gffd96xePAzyifguS4oIpwH0eZRSuR4mo0uZrYsUOJn4tLTl+q76FqwTtYqTaRAsCAzHcnHldXVwIDAwlMuLMnw2w2c+PGDauR4okTJ1i9ejXnz5/n9dOnGRAXhxvQEPgbJXJ/A01RzyuW6xIs1cNQxYB6AvtQ/7b4DqlhVrYLXyzKCKsMdH36KHNygvDNng3PPw8jRtjbnhPqKatjlvc0L6CFT6PJLgJQ4rYNKGRje01gA+pe1iblZieDE6VLl87GDqaFHzAXZYt1zAkkKsoJk+lnvLyMWdmxNHFycqJo0aIULVqURx99NMV2efppDL/8AkBzlLgNRY3uhqCEb5rFuoQADGfUM0x1lF+kT/z6mMhINi5YwLnLl/Hw8EhcPD09rd7bWufu7p6BUfpx1OhMVV9v1AjmzlWm54oV4ZdflJ+J/cIXAexFC59Go8kUhY2FuR6eLOCtBepO+piNA0oDoSgrYCnUhJMF/sacdJqwRWeUq+lbZFT8RDyZP78xP/zwPqtX1yIgICA7OphhDBbznM2AH1Bf+y2UI0sA8EL8umNY+yZVS/YXwGwwEHz/PseOHSMqKorIyEiioqKsltTWxcbG4u7ubpdgNmt2k1dfjcJo8QyRMOpr3lzFTGbMRyUONen8cKKFT6PJIuoVr8fK08kmuwqihgm7gcLJDjAAz1i8TkbdonWzuosOMACl0M+hRgnpmT49gXwYDIt46aWmXLr0KU2aNOGvv/6i7P/bO/PoKKtsbz81ZKgMTDLIHEEggEkzRAKIERVFUDQISABtv4siODXNIJ/IxeZe4bYKigoCNmKLMiheRAYRpUFEWwhCggkzYVamjmEIGSpVqff+sZNUVeZKAjbJftaqFeodTp0Ka72/7HP2b+9Wra72ZMumUycJj+x2egCXgIVIV3GAWkjUtzDvZzGONi8CAwN59JVXeLSr7/9XLpcLu91eLsFs1GgLVutO8iM+EOGLiYFjx2SZ03cq5jWtDqjwKUoV8VjkY3x3/DvSSfc+cQfwcwk3FRbDPEL9Q3m80+NVOb1K0B84AswE5iOmw1wKvBcEI8odiCwY/hkIwWSCadOm0bBhQ2JiYli/fj2RkZHXfPZeREVJiqPdjg1Jvn0TSV7Jp1fesXIl62dlSXZPBTCbzdhsNmw2G3VLc6wDUAdZenYb7lu2lCSX9eth0aKKzMBHG0M1QoVPUaqI2PBYxqwbIxtEntQGpnq8n1bCADe4z1nMFmLDY6t2gpWiLvA/wH8hKr4Lt0WhJZIOEoHbke/mmWeeoX79+vTp04eVK1dy++23X7NZFya3WzccuHMZ7wC2IWKXz+3AXEq2YBZgMkllknLbRCpDZ4pbbl60CC5ckIIpJVXXKZ4Qis+6qhloyTJFqSL8Lf682/9dgvwql8xhdpqZ3n06/pZyVtK4pvghcdJo4BXgv5FE/04UJ3r5PPLIIyxbtoxBgwaxZs2aYq9xOmHNGhg7VgKzm2+GDh2k+tW8eWKXqyg5OTl88MEHtL/lFhbVrYszT6z+iuQWdfGca96x0cWMYyAmd0BqUU6aVPFJ+UQ9oHmRo61by+/Kd5yI7NdM1MCuKFWIYRgM/HQg3xz5hiyn79mQNquNlrktSZuXxt8/+Dv9+1evrLudO3cyYMAAZsyYwciRIwExvb/zjlSIcTrFGlf4qWSzybEHHoA5c6RcZHnIyspi0aJFzJw5k7Zt2zJlyhTu6NEDU4cOcPRoxb9IQIAo8scfV3wMn1mAYUzEZCpHkegy6Q18WwXjXJ+o8ClKFWN32rl/2f1s+2UbmY7Msm/II8gviOim0Xw14it+2v4Tw4cPJy4ujhkzZlS+TNe/EYcOHaJv3748/fTTPProCwwYYOLgwfIX/Q8MhCVL4MEHS74uPT2d+fPnM3v2bLp168ZLL71EdHS0+4KkJCk7U54PLYzVKimUSUlQq5bv91eQjRtXExk5iEaNcis5kg3YAnSr/KSuU3SpU1GqmABrABse3cCLt72IzWrDai59K91qtmKz2njxthf55rFvCLAG0KtXLxISEti3bx8xMTGcOHHiGs3+6tO2bVt++OEHFi1aT9u2l0lKMsqtPw4HpKfDsGGSnFmYtLQ0pk2bRqtWrUhMTOTrr79m9erV3qIHEBkJGzdK/TUf/qgwbDYxq2/bds1E7/z584wYMYLRo8dx4sSriHBVlCCkKk/NFT1Q4VOUq4LVbGXqHVNJejqJJzs/SZBfECH+IYT6hxLsF0yofygh/iHYrDae6PwEP4/5mal3TPUSyfr167NmzRoGDx5Mt27d+OKLL36/L1TFNG7clMDAf5CZGYTT6XuptcxMGDlS6oQCnD17lkmTJtGmTRtOnTrFjz/+yPLly0vPIu3RQxzgPXtKdkgpZnLDz49sk4mDvXrJhzZu7POcfcUwDD788EMiIiJo2rQpycnJdOs2EXgLETBfCUL29V6vymlel+hSp6JcA3JduRz87SBJ55LIdGQS5BdERMMIwuuHYzGXnBSSz/bt24mLiyM2NpbXXnvNh4LT/568/bYUua7ISmM+JhO0bu3g3nvHs3z5UkaMGMELL7xAC1/LhxmGRHCzZknbCadTLA+GAdnZUKcOxMWxs0cPHp40iYMHD5ZeCLsKSElJYfTo0Vy6dImFCxfSuXPnQlesRCqeZ+Pp7SsZG/AkYtTQZH4VPkW5Trhw4QIjR47k1KlTrFix4t/DEF4BHA5o1EjS8AUT0pfpZo+rpiF9m/rhzq/MRQz0ntHOGQYPXsHcuQ9UTXUYw5C28efOgcUiZrl69QpODxo0iKioKCZPnlz5zyoGh8PBrFmzeOONN5gyZQrPP/98KXVazwIvIFVE/ZCGs56P86C895GI4BVXPqhmosKnKNcRhmEwZ84cpk+fzrx58xhcXHfYf3NWr5aqI+kFPv/ShG+Jx7EtSAWZX7zG69NHtuuuBYcPH6ZHjx7s27ePhg3d1QcMwyDXyMVislS4S0Z8fDyjRo2iadOmzJ8/v8RC3EW5CGxA+ijuQf5AaIq4E+9CCsYqnqjwKcp1yM6dOxk6dCh9+/blzTffJDDw+mkv89xz4stzP3kqJ3zBwSKi16QlHvDnP/8Zu93Oc//1HPN3zmfTsU0cSTuC0+XEZDLRonYLerXoxZiuY+jZvGeZQpiens6UKVP47LPPmD17NkOHDq3CFlNKcWhyi6Jch0RFRZGQkEBqairdu3fn0KFDpd+wf784wyMixA9gNss+Vng4jB4NCQnXZuLIdlpV/rntcsnq5LXiifFPsMi5iK5/68p7O9/jQOoBHC4HBgYuw8Xxi8dZmrSUvkv60nFeR34+W1K9OlizZg0dO3YkIyODvXv3EhcXp6J3DVDhU5TrlNq1a/Ppp58yevRobrvtNpYtW1b0olOn4O67pWX6vHmSkWi3i/I4HHDwoNS9uv12KQFy8OBVn/fFi1U7np+f537h1WX94fX0WNKD3Ga52HPtOI3i64QZGGQ4MjiQeoAei3owJ36O1/kzZ84wePBgJk6cyOLFi1m0aBH1PPYSlauLCp+iXMeYTCaefvppNm7cyLRp0xg1ahSZ+a24162TfjVbt0ox5ZKKOebmij8gMRE6d4YPP7yqc/YvUonNQtHMRAeSsFE2ubmuYsasejakbGDIiiFkODJw4SrXPQYGWc4sXtz0Im9vfxuXy8V7771HZGQk4eHhJCUlceedd17lmSuF0T0+RakmpKenM2bMGJKSklj/7LM0Hz9eBM9XgoJg7lz4j/+osrnZ7XZ2795NfHw8s2Z159QpTwN1K6QzXj+PY8ORpIxpHse2UNweHzho1Ohm/vCHcCIiIoiMjCQiIoL27dtX2d7n2StnaTunLek56WVfXAIBlgDa/9iewAuBLFy4kFsq2NVBqTwqfIpSjTAMg0/efJMBEycSUpmBbDbYtUsixgrMISUlhfj4eHbs2EF8fDzJycm0adOG6OhoMjL+HytXdsduz19wmoz0Qv8U6YK3GRiI9E3wFIctFCd8bdoY/OMfp0hOTiYpKang55EjR7jpppsKhDBfFFu2bOnzPtqDyx9kQ8oGHK68yHQ28CBwGViD2xoXDIQhCZX1C/9ioL6lPqcnn8bPWn1K0F2PqPApSnXjvvswNm3ClLe02RtpJHQWCABOAh2KuS0bacWzGSRFMiICdu8uM13yt99+KxC4fLELCgoiOjq64NW1a1eCg4MBOHsWwsJkq1HIAl4GPgMuAK2RSK9wMc4tFBa+oCApbj1hQtF52e12Dh486CWGycnJXL58uUAIPSPEOnXqFPv9Tl46Sbu57ch2unvheQlfAtKgwoU4C35Emps/gbR09yDEP4RVQ1fRp1W5uv0pVwkVPkWpThw5Io1Rs+UhfRyRkdrAe8CQEm5LQrqQr8KjAWtwsFQy6e7u2+a5ZJn/On/+PFFRUQUi161bN5o0aVLqNAcNgrVrJb+mMgQHS/5OmX1cPUhLS/MSwuTkZPbs2UPdunW9hDAiIoJ27drx2rbXmP79dHJyc9yDFCd8nixFosChRT//oXYP8UXcF759UaVKUeFTlOrESy9J6a08Rflv4GsgGjgErCvmlstIh70/Av/pcdwwm0kfMIA1gwcXiNyePXto27atl8i1b98ei6XssmuenDkD7dp5mth9JzhYvuqYMRUfIx+Xy8Xx48e9xDApKYkTJ05gfsJMZoNCXTbKEr4EYBNSWKUQDYMbcm5iJZoLKpVGhU9RqhPdusFPPxW8vRkYjwhfd2SRsHBhr0HIMuc6xEruySmLhfEDBxaInOeSZWVZtQpGjKhY/o3NBr17w5dfXl3jelZWFk3easLFnIveJ8oSvsPAcmQFtxBWs5VLL16qdMNipeJotVJFqU54+PB+AE4gHcXrI0uey4BxHpe/AexCnt3F6Udz4LPly6UHXRUzcCAsXAijRkF2toFhlE/BgoPtxMRYWLXKetWrtdhsNnKpQP+7dErsHmQxWchyZKnw/Y6oj09RqhPujBEWA/fiTi4cnncsnx+AvyAljku0TptMkJNT0tlKM2IExMefom3bY4SGlr7uGRSUQXDwFWbNmsCXXzYjIGDHVZuXJ4HWClgi9gMlNIlwupwqer8zGvEpSnUiIADsdrKAFUi54hvzTtmRpMOf844NBWYh+3slYbhcmK6qO/wwERHR7N2bztdf38OsWROIj5dkGqvViWGYyM4OpGXLE4wevYCRI/9OvXr5ZVruBL5B0nKqjuzsbBISEgr2NdPrpEN52u+5gEuIC+M40gWoGBoENcDmd3XbGimlo3t8ilKdyNvjWw48C+wGPGXrEaBr3vFmwMdlDHfSZKJ3WBhdunTxenl2Jqg42UA74BSe7XQMA06ebMHFi3Xw98+hVaujBASUFHXWQjbUKjYfl8vF4cOHvbJU9+/fT3h4eEECT2JoIgv2LcCe646mS/TxBeH28TUo+nkmTDzc/mH+95H/rdB8lapBhU9RqhN5WZ33ORx0RPbwPFkBxCEyY6PoXkdLYG/+G7MZIy6OQy+/TEJCgtcrODiYLl260LVr1wIxbNKkiY/G8InAPMTHV1H8EQPGl+W6OjU11UvkfvrpJ2rVquXlOezSpYtXo9lfL/9K63daewtfBQnxD2HtsLX0Dutd6bGUiqPCpyjViUI+vkoRHCyN7nr08DpsGAbHjx/3EsJdu3ZhMpmKRIZhYWEliOElZME1m7AwKRV67Jh8JMD778OSJWJ2nzQJRo70vvvtt+Hjj2HnThAJ3wV4V5mx2+0kJiZ6CV1qaiq33nqrl9CVp4HtkBVDWHNojbeXz0dMmAivH87eZ/ZqB4bfGRU+Ralu3HcfbNpUclHq8uBD5RYQMTx9+rSXECYkJJCRkVFEDNu0aYPZPB+YBGQSFiZ+vgkTJGAFt/D17Qtffw1btnh/XlQUPP44PP88gBXDGEVKyjgvkdu7d6+X5zA6Oprw8HDMZt9z+lIzU7n5nZu5ZL/k8735+OHHrjG7iGgUUeExlKpBhU9RqhunT4s7/MqVCg/hCgzEnJBQoVqdnpw7d47ExESv6DA1NZVvvrHSvbskqYSFiQn99dfh6FGoU8ctfEuWyPkjR6BlSxlz3z7o1Em+Zv28lNWjR8307t20SJm0oKCqy57ccnwL/T7uR7bL92g60BJIne11GNJqCLNnz/bZ8K9ULSp8ilId+fJLGDKkQu5wp78/EwICGLhmDb17967yqaWlpREcfDMBAW7he/99aRfYoQNMn+4Wvi1b4J574I474D/zyspMnix9db/4wj2mYVgxmTIpbyujAq5ckXZMe/bI8nBICPzhDxAZKQ17PUhJSaHb0G7YY+04cZLjKnvZ02wyE2AJYE6/OQxqNYghQ4YQEBDA8uXLCQ0N9W2uSpWhwqco1ZV16yAuTrx95Vn2NJvFDvHuu2xu2ZK4uDjmzJnD0KFFC04ahsGOX3ew5uAavjvxHb9e/hUDg6a1mhLTIoYH2z1I92bdS9nLCgEyALfw3Xgj3HYbpKTA6tVu4VuyBF55Rbz5Lpdc//bbYoB34w+cA+qU73cTHw8zZsg6qs0mXsXcXDHqW63yfuhQePFFCA8nNTWVnj17MmHCBGJHxDJq7Sg2Ht2Iy3AVu+9nMVkIsAbQoUEHlgxcQrv67QBwOBw8++yz7Nixg7Vr19K8efMSJpiBFJvbjhhQHMie6G2IjaO4MuNKeVHhU5TqzKlTshm2fbvU7yxOAM1miW7at4elS2WZFEhKSuL+++9n3LhxjB8/vuDyLce3MGbdGH65/AvZzmxyDe/KJmaTGZvVRuPQxiy4fwF3t7q7mInVRrwAbuHr00cM7TfeKFPJF77MTDn2zTfy70cekWVOb3uhFXEpllFOLSMDxo6F5cslGi7t8WexgL8/jvHj6fPtt/S4/XZeffXVgtPHLhzjb7v+xsajGzmQeoBsZzb+Fn9a1W1FTMsYnur6FJ1u7FRkWMMweOONN3jrrbdYvXo1Xbt29Th7EZgCfIg06L2Cp9XDXQ6mHeLCLO53q5SFCp+i1AT274cFC2DzZjh8WKJAPz9o1UrWEZ96CrwewMLJkyfp168f9957L6/PfJ0/bfgTi39eTJazfEuoQX5BDL9lOPMfmI/V7FkvozPiJvQWvpQU6NJFEl2+/dad1DJypGhzVpZkfs6dW/iT6gJppU/m4kXo1Us2DH3Ies22WDhUvz63HD+OuYoa2wKsWrWKp556ioULFxIbG4tUtX4EifbKY50IAgYjfTeqbl41ARU+RamJGEa5qztfuHCBh2If4mjUUS7Uu0CmM7PsmzwI8gvirrC7+CLuCyzm/KSOscBcwOUlfCC1Oz//XJJK84Xvu+/g4YclaN20CW691fszzpzpQEjI9pL3zXJzIToakpMrVILNsNkwDRgAn37q872lsXPnTmJjY3n33T48+OAKTCZf92QDgS6IaKr4lRet1akoNREffGR169alz1/6cDbkrM+iB5DpyGTz8c1M3zq94NiBA9HY7cXP4eWXZUXSk5gYqF0bmjUrKnoORyAffRRIs2bNGDJkCJ9//jnZhSO6mTPhwIEK1x01ZWXJnqlnRk0VEBUVxc6dH3LvvR9VQPRAqt8kUrQ9hFIaGvEpilIqh347RKcFncq9vFkSNquNuZFz+WTOJ+zbt4+EBBcNGpzFZKrsI+gG4DRpaVdYuXIly5cvJzExkYceeohhw4Zxd9euWFu0KMhw/RCpaHMEKXg2EPgrkhYzDZiBdKq3IikkbwAFFv5GjeDXX2X/r0pwApEYxoFK/h6CgM+BvlUzrWqORnyKopTKjO9neGcuJiHbSjOQ/IolSP+jfBIRBdnjPU5WThbjVo1j+PDhHD16lIYNN2AyVXZ5LgiRMn/q1avHqFGj2Lx5M3v37qVTp068/PLL/CUsDHteY943gP8PzERqx2zPm/o9QP43HIqklKQi+ZNeXeszMmDDhkrO2ZN1/PWvR+jf31v02rSBfv0ocuyTT+Tf06ZJ0B4fn382E+m8qJQHjfgURSmRjJwMGsxs4I72fkT6GT2AdLm1ACmIetybd9OHiLOgGTDCe7xASyDnXjhHrYBaeUdmIc2RfF9CFdEbBrxf6lXZkZEEJidzGWgCfICkkORzBbgJeA04mfd1luSd2wd0BM7jUXP6scfgo48qMN/i6Mk//7mN/v0hLU0CyTNnpEpcdrY7uDxzBpo0kfeNG0Pr1nDpkrhV3n03f6wg5D+ncxXNrfqiEZ+iKCWSeDYRP0ueKTwb+Ba4H1kD9EeErx1u0buItOQZgChIoRZ7/lZ/dp3e5XFkIhKD+VphJRjpHf9e6ZcZBoEpKYBodjbwcKFLQoD+wMZCx3OAj5CF1LqeJ7Zv93GuJeEAdnLrrZK0s3u3HP3+e7jzTnGVeB5r3VrE7/vvRQjfeUciQPe2ZS6wuYrmVr3RfnyKopTI7rO7ceTKMiGnkC2p8FJu+BkJqzogIVIy0NN9OtuZze6zu7nzpjsBaQuUmzsZw7gVq/VxTKZMTKaMouPmkZsrPSVOnZrCb7/dQ27uLnJzc3E6neTm5ha88t+b0tPpn5ODGVm6rE/xD73GSJnrdkgHi3WIZtcBVha6x/nLL2z7/nv8/Px8ehU18x8AAvH3dxAdDVu3iqNk61a4/XYROc9jMTFy1+LFMGCA+Bn/9CdYuxYGDQKxQGwFJpTyH6SACp+iKKVwKfsSdmeepywLCcxKy+v4GcjPuozIe+8hfDm5OUx8eSKTtkzCmWemt1gsWK1WgoLMDB5s8NxzZsLDXeTkmHC5ZC8rMNDgl1/8WLIkhC+/vIGsrE+wWD4ruNdisRS8PN+Hulz0dbkwI6KXimh34QffGdyd6h9BljpTkZhyF9Db49qcnBwmT56Mw+Eo98vpdGKxWLyEsHdvgw8+uELt2mKl3LoVxo2TiG7sWBG+995zHxs/Xgz8n30mK61+fjB4sPxbhA9kjVkpCxU+RVFKxN/ij8VsweVySdGQTGRFrTjxOwlcAG7Jex+B2MvOUNDB3GwyM3XyVKasn4LFYimlU4IDf//DyA6cDWjDTTcFMnUqTJ3qwxdwuSAoCOx2eiDZmp9TdI/vK+B/gF88jtcH/oZ0qB/u/goENW/ODz/84MMkpFqL0+n0EkOT6XtCQx8H0omJkb26tDT4178kkaVRIym6k5YmpURjYmDVKqmo1r+/jDtihPgf//UvaNAASv+rRMlHhU9RlBIJrx+Ozc+Gw+6A5sgT4wCS8VGY3Xk/FxQ6/jMFqhHiH0Jk40j8/MoqJu1HldSjNJtlsywpidpIGs3ziI3hbuBX4BkkD+cxxNbgSTvEIPA60nQdECO8j5hMpoJIz003ZJ9PklkuXYKFC6VeKUCtWhL1LVwoP2+6CUaPlrraLVrINYYh+4PLlkmU6P6rQykNFT5FUUokqkmUe6kzEMnvX4+kxbVGAoyjwDGkdfsAoI3HAPuB7xC/gEWWOqOaRF2r6QtDhsChQ5CdzSQkWWUibh9fLLAUiQaL4wXgLmAy0DA01HNdsZI0yfvUbGw26TH45pswZYr7il695FifPpLRuWkTfPWVNI/I5623ZLlz7NgQvNaVlRJRO4OiKKXS/f3uxP8a7z6QBGxDNsH8ked3c2AHMA7v1TYH8CaiLu2g842dSRidcE3mXcD589LMryq60tepI+OVGbGWlzHAIsDJ5Mnw6quwa5fUKwVYsUKaRCxYABcuyP7erl3eI5w+LV8vMdGfW245jUi7UhoqfIqilMrag2sZtnIYGY6Ssy3LQ7BfMItjFzOoQ1VFTD7wwgvS8C+zIn7BPIKDpR/SE1VZHuwAUmuzclVxZGl4ELC80jOqCajwKYpSKoZhcN/S+/j22Lc4XI4KjWE1W+nVoheb/7i5lB59VxG7HTp2hBMnytebsDABAdCzp6w1Vvn8nwX+TuXELxQ4hPTsU8pCDeyKopSKyWTio9iPqGerh9nk+yPDbDJTN7AuSx9e+vuIHohwffedpEr6ukwZGAjh4dId96rMfybQlIqnXAQh9WhU9MqLCp+iKGXSKKQR25/cTpPQJtistrJvyCPQGkij4EZse2IbTUKbXMUZloOmTSExEe66S5Yty0NQEAwbBv/8J5TU8qjS5Jcaa4nvrYVswNtIXz6lvKjwKYpSLsLqhLH/2f08FvkYgdZA/MwlR05+Zj8CrYHEdYzj4HMHaV2v9TWcaSk0aCBpkUuWQOfOYLOJoOVHcmaz+AgCAqRu2FdfwQcflF8oK0wjxPfxR0TMyvLjBSMmjE3Ak1d3atUQ3eNTFMVnjqQd4Z34d1i5fyXnM84TaJVIJduZTYPgBgwMH8jY6LG0uaFNGSP9zhw7Bjt2SIPaK1cka7NTJ/HqNW5c1t1XiWQkFfZTwIQkruSTgbgLJyE2fG0+WxFU+BRFqRTp9nTOXDmDYRg0Dm3s0XlBqRwGYpI8jBRauwGIRKI9pTKo8CmKoig1Ct3jUxRFUWoUKnyKoihKjUKFT1EURalRqPApiqIoNQoVPkVRFKVGocKnKIqi1ChU+BRFUZQahQqfoiiKUqNQ4VMURVFqFCp8iqIoSo1ChU9RFEWpUajwKYqiKDUKFT5FURSlRqHCpyiKotQoVPgURVGUGoUKn6IoilKjUOFTFEVRahQqfIqiKEqNQoVPURRFqVGo8CmKoig1iv8DrlyIDY7EK84AAAAASUVORK5CYII=\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "solution = min_conflicts(usa_csp)\n",
+ "print(solution)\n",
+ "draw_graph(usa_csp, solution, node_size=400)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 31,
+ "id": "74b0aa0a",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'WA': 'R', 'OR': 'G', 'ID': 'B', 'NV': 'R', 'CA': 'B', 'AZ': 'G', 'UT': 'Y', 'MT': 'R', 'WY': 'G', 'CO': 'R', 'ND': 'G', 'SD': 'B', 'NE': 'Y', 'KA': 'G', 'OK': 'B', 'NM': 'Y', 'TX': 'R', 'MN': 'R', 'IA': 'G', 'MO': 'R', 'AR': 'G', 'LA': 'B', 'WI': 'B', 'IL': 'Y', 'KY': 'G', 'TN': 'B', 'MS': 'R', 'MI': 'R', 'IN': 'B', 'OH': 'Y', 'AL': 'G', 'GA': 'R', 'FL': 'B', 'PA': 'R', 'WV': 'B', 'VA': 'R', 'NC': 'G', 'SC': 'B', 'NY': 'G', 'NJ': 'B', 'DE': 'G', 'MD': 'Y', 'DC': 'G', 'VT': 'R', 'MA': 'B', 'CT': 'R', 'NH': 'G', 'RI': 'G', 'ME': 'R'}\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAb4AAAEuCAYAAADx63eqAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAACiNUlEQVR4nOydd3hUVROH320pm4TeQQkdpIP03nuRjoAI6kcTREVQsFBVFDsoFkAQBUPvIL13CB1CBwm9BNI3u/f7Y1I2ySbZ3QSMct7nuU92bz27uXvnnDkzv9FpmqahUCgUCsVTgv6fboBCoVAoFE8SZfgUCoVC8VShDJ9CoVAoniqU4VMoFArFU4UyfAqFQqF4qlCGT6FQKBRPFcrwKRQKheKpQhk+hUKhUDxVKMOnUCgUiqcKZfgUCoVC8VShDJ9CoVAoniqU4VMoFArFU4UyfAqFQqF4qlCGT6FQKBRPFcrwKRQKheKpQhk+hUKhUDxVKMOnUCgUiqcKZfgUCoVC8VShDJ9CoVAoniqU4VMoFArFU4Xxn26A4r+JTbOx48oOdl7Zyc6rOwmJDMHsYaZagWrUfqY2zYo2w2Qw/dPNVCgUTyE6TdO0f7oRiv8Omqbxy+FfGLtlLA+jHhIVE4XFZonfbtAZMJvMGHQG3qz1Ju/WfRcPg8c/2GKFQvG0oQyfIsO4/ug6nQI6cezmMcIsYWnubzaZyeebj+U9llM2T9kn0EKFQqFQhk+RQVx7eI1qP1fjdthtYrQYl4718/Bj68tbqZy/8mNqnUKhUCSgDJ8i3cTYYqjwQwXO3jtLjM01oxdHdq/snBt2jhzeOTK4dQqFQpEYFdWpSDefbP+EyyGX3TZ6AOGWcAasGJCBrVIoFArHqBGfIl2ERYeRZ0oewi3h8BVgAYYDcfEqB4GjQD9gLBAXyGkE8gFVgXKyysvoxbFBxyieo7h7jXnwAJYvh5074ehRiI6G3Lmhfn1o1Ahq1gSdzr1zKxSK/wwqnUGRLv488Sd6e8eBBuwB6qdwwEAgJxAGnANWA3eAhmC1WZm6bypft/zatUbcuQNvvw0BAWA0Qmho4u2bNsHHH4sR/Pxz6NLFtfMrFIr/FMrVqUgXy88sJ9RiZ2hqA7uAiDQO9AEqAm2A7UA4WGwWVp1d5VoDVq+G4sVh/nyIjExu9AAsFggLg0uX4OWXoU0bePjQtesoFIr/DMrwKdLFweCDiVcUAPwR4+cMpQEbcE3eXn5wGYvVktoRCfz5p4zeQkLErekMYWGwcSPUrq2Mn0LxlKIMnyJdPIh6kHxlI2Af4s5MCwNgJn6EqNfpeRT9KO3jjh6Ffv0gIq2hpQOiouDcOejZ0/VjFQrFvx5l+BTpwqAzJF+ZFygJ7HDiBFYgHPCWtzbNhlGfxtRzTAx07SquTXeJioKtW2HBAvfPoVAo/pUow6dIF4WzFXa8oSES0ZnW4O00chcWlLeaRePHb39k27ZthDqarwNYuRKCg/HXNDyQ2Bh7KgM64BLwcuzrfXbbz8WuIywM3nkHVGCzQvFUoQyfIl3Ue7Yeep2D2ygnkqawN4UDw5E0h9VAHcTdCRQxF+HKlSuMHDmSvHnzUq5cOfr168cPP/zAgQMHiI6OhilT4oNYigDz7E57LPbU9uQA3k/pA9y9C7ucnZBUKBT/BVQ6gyJd9K7Qm5mHZxIR42CurQFwJMm66bF/DUgeXwuggqzy9fBldMvRvFzpZQCio6M5duwY+/fvZ//+/fzwww9cOHuWe1FR8WmCfYA5wNDY97OBl0hs6PoCfwBbY5uUiMhISXeoUyfNz3rnDmzbBvv3w9WrYDDAc89BtWpQty54KK1theJfgUpgV7jNxYsXGT9hPHP85mDLYUv3+fw8/Lg54ibeJu8U9wk/eBCPevUwRkTgD/wCDAGWItOKhYGdSGDpRSRnvhCQBwhAph3PASWQlEMAmjaF9etTvObp0zB6NKxZI8YtNBRssR/XwwO8vOT1wIEwZgxkyeL6Z1coFE8O5epUuMzVq1cZOHAgzz//PIUKFmLtwLV4G1M2Vs7gY/Lh+zbfp2r0AMwRERiTDK3iRn3rgTLETxcmYgBwBVjj6KS3bzu8lqbBJ59AlSqwbJkMDh8+TDB6IFkUDx/K8u23klK4eXOqH0GhUPzDKMOncJrr168zbNgwKlasSNasWTlz5gwTJkygWZlmvFXrLcwms1vn9TZ607RoU3qV75X2zqbkxWv7IK7MXxE3pyM8gQ9iF2fOqWnQvz9MnCgZEzYnBrSRkWJD27SBRYvS3l+hUPwzqDm+/xLR0fDXXxKssX+/PLGzZZP5q7p1ZXFDq/L27dtMnjyZmTNn8vLLL3Pq1Cny5s2baJ8JjSbwKPoRvxz6RXQ7ncTH5EO9wvUI6BqAzpm2FS+eLHevMBLkshqYkcqh/YDJwOKkG8qXT7bvxx+LAlq48x8lnogIeOklKFJERosKhSJzoQzff4HISJg0SXxtkHgSCsQYenpC1qwwbpwMZZwwMvfu3WPKlCn8+OOP9OzZk+PHj1OgQAGH++p0Or5p+Q0NCjeg/7L+WGyWVA2gp8ETg97AxMYTGVZjmOPIUEfkzCnG/NatRKtnAPcRJbSUakQYgXHAMLt1kUYjl3PnpoTNhl4vbThxQr5Od3Lj4wgPl1TDU6dU0ItCkdlQrs5/O0eOQOnS8MUXCZNNSf1yFosYw2vX4I03oF49uHkzxVOGhIQwduxYSpYsyZ07dzh8+DBTp05N0ejZ06lMJy4Pv8ykxpPwz+aPUWfEEGMgq2dWsnpmxdPgSR5zHt6p/Q5nh55leM3hzhu9WLSXXsJqTNxnKwY878SxPYH8du+NwP9WreKZZ57hzTffZN++fYwcqdnlxn8CtEpylhIprJuPZAieA8Q2z5/vRKMUCsWTRVP8e9m3T9N8fTVNpqScX4xGTStYUNOCgxOd7uHDh9rEiRO1XLlyaX379tXOnz+f7iZ+/cPXWutBrbXVQau1zRc3a7dCb7l9LpvNpv31119ah0qVtAidzvXPnXQxmTStRw9N0zTt5MmT2kcffaQVLVpb0+ki7HbboUEWDWJi3wdrUFiDvEnWocG12L9n448vWzbdX6FCochgVDrDv5Xbt6FkSalB5w5GI5QpA4cPEx4VxbRp05gyZQpNmjTho48+olSpUm6dNiZGwv+PHRNhlGXL5lGkSChffvkaxnQ41rdv387777/PzZs3GTduHF2PHkX/9dfuTcLFkSULBAWB3XzlH39ovPaajfDwOCm2aCAbUkKiKpIUsQa4AHxpt240CZowZwGpKWgyyb8qa1b3m6lQKDIWNcf3b+WVV9L30I+JQTt/np0dO9Lt4EFq167Nxo0bKVeunFunO3tWvK2//QZ6vUwhWq0QHd0Bo9HEL79Ar14wYgS4YlP37dvHBx98wNmzZ/noo4/o1asXRqMROnWSxLqTJ0V301W8vWH27ERGD2DvXh0REfb6ox5ADWAbYuS2AfWQMhT26xwXIPT2hsOHoWFD15uoUCgeE//0kFPhBidPapq3t6aBVhg0E2i3k7jxKkl+ttYSNJ/YxRi7b9z7AaCFGwza4V273G6KxaJpEyZIc4zGtD2s3t6a9sEHmhYdnfp5AwMDtfbt22uFChXSpk+frkVFRSXf6cEDTatcWdPMZtdcnN7emjZ7tsPrduzo6JCPNOgY+7qCBkEarEmy7tfY14ldnX5+mjZ/vttfr0KheAyo4JZ/I99+KwErsaSmV/kDEBq79AJG2r2fDnh7e1Pp3Dm3mhEVBa1aSZJ3RIS4OVMjJkb2++ILaNbMcXGFU6dO0a1bN1q2bEmTJk04e/YsAwYMwMNRaGTWrLBnDwwfLkOrtMInfX2haFHYsUPyDRygd/iLqI9ovtwDbiOBLHEVd+8Bx0m55HxK51QoFP8U6if5b2TNmkRWJk65JI44vUqnCA2FVS5WPY/lxRdh507XPa7h4bBvH3TunFAY4fz587z00ks0aNCA559/nnPnzjFs2DC84vTAUsLDQ3IPTp6EoUMhVy5ZlzUrYSYTFi8vmWirXh1mzZIJyFSS68qUEQ3OxNQCQoCfEUVtgCyIu/Pn2L9FHJ5Pp5N8PoVCkXlQhu/fRmSkpCXYURN4CJxCytvNB3q7cs59+9LeJwkBAbBunfu5bhERUg7vm2/u8Nprr1GjRg2KFy/OuXPnGDlyJD4+Pq6d0N9fqjbcvg1//w2rVjG1SRNWvPuuRNns3SvV2h2otNhTowYkv7Q3kizxJTK/F0fd2HUpj/YiIhzmxysUin8QZfj+bYSE4Cg80hm9yhRxMTLUYoFBg8SeCDsQ119WpAhQHWA/IiJmAHxjlyKIfkoQIMe/9ZYHOXLkJygoiA8//JAsGaHwnDs31KnDjdKlueTnl6axs6dRo5Rctg2AW4ixi6Ne7LqUDV/9+qIdoFAoMg+Z3/BFRcEff0Dr1hKBZzDIpEmOHPKU+v57eJRWtdP/EEajw8KpzuhVpkSUxcKuXbu4ceMGmhPZLcuW2U8xPgTaIoWB7gHXgI8QdUwQN2Eo4ircgIyeqiLzYmA2+1Kx4nhy5MjhYqvTJmvWrISEhLh0jK8v9O7taLrwEyReyN5N2i123QC7dRoJqQxRDBuWjirxmiYjfHeiVhUKRYpkXsOnaRJunicPDBgg81q3bokqiabB/fuwZQuMHCkGcdKktKMr/gvkyOFoEiqRXmUnF0/5t4cHb775JuXLl8fX15fy5cvTsWNH3nrrLaZOncqaNWs4c+YMUbEP4Llz7fsaQbF/eyKjO2+gOfFF9uIxIPoq3yOjp7EAhIXpmTOHx4I7hg/kVvL2Tl96q9GokSPHWYYMKcmCBQuc6lAAco9PmgRVq4rP1dcXzGaRaWvQAGbMSF8ai0KhyKSGLzxcRnhDhogEV2y1bYeEhclEyiefyMMihRIz/xl0Oihb1uGmGcAmRK/SafR6ivXrx969e7l9+zbBwcH89ttv9OnTh/z583PixAm++uor2rRpQ5YsWXj22WdZs8b+Oy6JGLW+SGL3fScu2glJCBcOHXKlwc7jruHz84uicuWv0encF+v089Nx+HA5fv99LhMmTKB58+acPn065QMiI+Gtt+DZZ8XwHTok97XVKp29kBCpgjt8uHQGf/rJ4chfoVA4wT+dT5GMqChNq11b07y83JOgKlJE0+7e/ac/xePlxx81m49PfB7fegffhSU2j++i3bq+oI1Juq/ZrGkHDzp1WYvFol24cEEzGKxJLndSg74aFNTAoEE7DW5oMEuDOg7+VWs0MMa/1+k0zWbL+K9pwYIF2gsvvODSMXfu3NHq16+vvfDCC9q0aZEupwgajZqWPbumHT+ecE6LxaJ9/fXXWq5cubR33nlHe/jwYeKLXr4s960rF/Px0bQmTTQtLCwDvimF4uki8xm+kSNdT0i2Xzw8NK19+3/6Uzw2oqKitB+mTNEeZYRWJWha+fIut8FgSO2UpzSoqkGPVAzfLxrkSbTOas2Y78dms2k7Lu/QPtz0oVbhywqa+R2zVu77clrnPztr3+75Vrvy4EqKxwYFBWklSpTQRowYoVljG7R1q6blz+/cLenjo2kNGmja3387Pv/169e1l156SStUqJA2b948zWaziV5q3rxpfamOFy8vTatZUzqLCoXCaTKX4Tt2TPvYaNRaJvmBFweH6+bFvv4odnSzx34Us2LFP/1pMhSr1arNnz9fK1asmNayZUvt8tix8qRNj9Hz9ta0Q4dcbkuOHGmd+jsNyqVi+Npo0Dn+vZ9fxnxHS08t1fy/9td8JvlohnEGjbEkWrwmemmeEzy1ZnOaaefvJRbg3rZtm5Y3b15t+vTpyc4bGqppU6dqWuHCmubpqWlZs8pX7+uraVmyaJpOZ9FKl76prVzp3Mh1x44dWsWKFbVGDRtqoVWqpC15k9piNmvau+9mzBeoUDwlZC6R6t692TlvHq1tNu4hM0fXkbjASCReMG5dgdj3+ZGQiRCgBzAt7lxVq8KBA0+2/Y+JTZs2MXLkSAA+++wzGjduLI+9tm1h82b3kunMZnj3XfjAYU3yVGnSBDZtint3GlgFdAcKAVeR/8RzSFrDL0i6gxW4guS9zQJ2A5LgVq5cCIGBvhgcBO04Q7glnD6L+7D2/FqniuAadAY8jZ582eJLBlQdwNy5c3nrrbeYO3cuzZs3T/XYGzfg4EGJQTEYRAjm4MEZ7N27kT/++MPpNsfExLDp1VepM3t2/JysPxAcu+Sy27cyEAhcREKCCgET7U/m7S33+nPPOX19heJpJvMYvqgoyJaN6MhIl7TwtwEtkMfrMMQoeoA8DI4flyfTv5QjR44watQozp49y8cff0zXrl3ji6UC8p21aycV1xOS6tLGbJbAocmT3arI/v33Ekwrl7wGvAnsBB4glQzaAp8jtc5fQSI9NeRx3hB4F8k2BJMpmty5v8Vi+YwOHTrQqVMnGjdujKeTyW/hlnAa/tqQY7eOERnjWuqA2WSmVlQtzs85z4oVK9wW6A4ODqZcuXLcvHkTk7M5g5omat1nz8av8keSQF5HkkNA5Oe6ILGzKRo+g0Ek2GbOdKv9CsXTRuaJ6jx6FDw8EmnhQ4IWft0k6+JShmcD7ZCMKoAVceczGkWt41/I5cuX6dOnDy1atKBt27acOnWK7t27JzZ6IJnRa9fC+PFizNIyFmYzZM8O8+bBZ5+5ZfRA8twSat0WRLoi14Cw2L8/IpJeLyMjvdDYbZeR/1iZ+HMZDB4cPz6CvXv3UqZMGSZNmkS+fPl48cUXWbBgAaGpRfQCA1YMcMvogRjNzbbNfLrgU7eNHkCBAgUoUaIEW7dudf6gEycgODjZarfk56xW+Z8+Dek8CkUGkHkM3/Hj8gNGsrzijNx2xPDVS7KuASLEvAB4ETAhPeP4h0ZoKAQGPoGGZxx3797l7bffpkqVKhQtWpSgoCBef/11xwLNcej1EgYfFCQ1f3LnFgOYNSshOh22OOWSokVlhHfpErRvn652+vhYqVdvO2LM3MdslqZnzw5FihThrbfeYseOHZw6dYoGDRowY8YMChQoQPv27fn111+5e/duouPXn1/P4tOL3TJ6cdiMNl7f/DqPotIngtChQweWLVvm/AF7Ymekk+C2/JzJJHqlCoUiTTKP4QsLizd8zmrhL0EKCraOPUUvxC16G+Sh4kYOlzPcvQt//SW5xL/8kpBb7y4RERF8+umnlCpVivDwcE6cOMG4ceNck+8qWBAmTpSGXLkCS5cyLHdurs+YIQ0+fx5ef12Kr6aD06dPU7duXaKixlGypMnt4rJGIxQqBB99lHxbvnz5GDBgAGvXruXKlSt0796dFStWULRoUZo0acLUqVP5+++/GbVhVPI5va+A83bv4/yDO1JuS7glnNlHZrv3QWKJM3xOzxwcOpRiIrrb8nPHjzu7p0LxVJN5DJ+PT7wiibNa+LMRJ9qzQD6gK2BBpLvQ6TK07LXVCr//DhUqQIEC0K0bvPGGLD17St5xyZJiDKOjnTtnTEwMM2bMoESJEhw4cIBdu3bxww8/kC9fvvQ1Nk8eaNiQPdmyEVqhAvj5pe98gNVq5YsvvqBu3br06dOHTZv+Yts2DwoUcEkKE5D98+SRuJy0Kglly5aNXr16sWjRIq5fv87QoUPZv38/5RqW48i1I2lf7AgyxZjKruGWcL7Y/YUrHyEZzz33HB4eHgQ662VIRWbPLfk5q1UpuigUTpJ5DF+5cvGGzxkt/GvARmAlEvEWiDzbRiG9ZavZjFaxYoY07dQpqFRJlNOOHRPDFhIig9TwcHkdFSVxCm+8IaVtUlMj0TSN5cuXU7FiRebMmcPChQtZuHAhJUuWzJD2xmEymYh21gqnQlBQEPXr12fFihXs27ePwYMHo9fryZtXIhybNHFU0cAxPj4i3Hz4sHQgXMFsNtOxY0dmz57Nx79/nHYgSTRwEnEJ3EVumhQIfhTMvYh7rjXIDp3Oypgxz+Hh0RsRkPOKXfIDbRAzZhd9my1biucqjGvycxrwUJ+NEH12u7lXhUKREpnH8FWokGio1IDUtfB/AyohqpD57JZhwFHgcFgYDd99lzfffJNNmzZhsSvc6gpbtkC1ahKL4EzgZFgYXLgA9erBihXJt+/evZv69eszevRoJk+ezJYtW6hZs6ZbbUsLDw8Ptz83gM1m4+uvv6Z27dr06NGDTZs2UTRJlGyuXLB6NcyZI+V3zGaRl7RHrw/H09PKc89JSbz162XElx72Xt9LlC0N8eZTSIhvWUQ3OpVRn7fRm8AbgW62ZgGQlz59NlK27EkkbSMqdrmBmLChQB7EF2uTdJukX5QdacnPPcSPqQyhOnvwJZRcoRfJM/AFzGb5KY0dK6kXCoUiOW7O0DwGPD2lMun8+WC18gmih29PNxKiN0GC4pNSAHF3alWr8u2MGSxfvpxRo0Zx/vx5WrZsSbt27WjVqhXZUulxx3H8uKTKuZIpEEd4OPToARs2QK1acObMGUaPHs2+ffsYP348L730ktt5a2mhaRqXQy4TmTuSg7cOkvdhXgr4FUDnQhTnuXPn6N+/P5qmsWfPHooXL57ivjoddOoky+nTErdx4ICMhLNkgQsXVlG06C2mTRuSER8PgNthTmiyBiJGT4+kDK5Bcl8cfO0amhsjvigkZ/EvIDyN+c646NQPgHlQe2r8nLYjiqWwXgP2Up18bEaPjTDsjGdsH+fYMfE+TJ4MAweKjG1a9XwViqeJzJPHB2Jpqld3v7ppHGYz/PmnWK1YgoODWblyJStWrGDr1q08//zztG/fnnbt2lGsWPLHjMUiI5igIIfBd06TL5+V1q2Hs3z5fN555x2GDh2Kt7e3+ydMAU3T2HV1F1N2TWH9hfVoaESFR+Hl5YVVZ8XD4EGHUh14q9ZbVMpXKcXz2Gw2pk2bxrhx43j//fcZNmxY8jQKF1m5ciVff/01GzZsSNd57Ok4vyPLzjiIovwKaI+kDH4NvIpEh0QDU4AXsM+miCerZ1bmvDCH9qWcjXi1AC2RRHxX71cPwB8qecAR5wNSHuJHC9ZxjPKJDV4qeHtL8ZKtW2UeWqFQZDbDBzBqFHz3nfvGz8MDWrSA5ctT3CUsLIyNGzeyfPlyVq5cSc6cOeONYI0aNTAYDPzyiwjhJx7t+SOp8n+TkJgNkBtJzH4PqVZgTzh1625h2bKaj6XmHMD1R9d5aclL7P57N+GWcDQc/0vjFEvalWzH9LbTyeaVLdH2Cxcu0L9/fywWC7NmzcqwOcf79+/z7LPPcu/ePecTvNNg3JZxTNw2kRgtSe5anOG7RnJfYQTy7+mR/Hxeei+2997O80Wed7IFHwJfIEk17uAJy5+HnoedCkqJwIta7OY0pYnCteGbwSBZLocPQ3rjphSK/wKZZ44vjgkToHJl93wzJpOE9f/6a6q7+fj40L59e3755ReCg4OZOXMmer2egQMHkj9/fl5+uR8ffBCahosz9QKrCZg5c6Y1WbM+HqN3MPggZaaVYevlrYRZwlI0egBWzUq4JZylp5dSemppzt07BySM8mrUqEH79u3Ztm1bhgbaZM+eHX9/f+cjHp2gRqEamD3MKe9wBJkoHmi3dAPO4tBWRVuiaVihITVr1mT06NFs2LCB8BQN0mlk+Jh4u7+/uLZ//RXq1nVwWCKioP1haFw+7dBW4B0+I4iSLhs9EI/qnTvies9k3VyF4h8h8xk+Dw95ejRs6HyoIIh7s0wZUWtxYWSl1+upUaMGkyZN4ujRo+zduxd///rcuuXsyMRxgVV7IiNFmCajOXPnDI1mNyIkKgSLzfkglihrFLfDb1NrRi32n9pP06ZNmTt3Ljt27OCtt956LHOP9erVY/v27Wnv6CSNizROeePfiHpadcDPbikN5EB0wOww6Az0qtyLO7fv8Omnn2I0Ghk7dix58uShYcOGTJgwgZ07d9pFyE5GfKfpJRzmxMAzz6Rq/A5TiZm8QgT2ht4f6XD9CuiAz5IcVQjYEv8uJkbmXQMCMqDZCsW/nMxn+EAmJlavhmnTJDoileg3fHxk/9GjJbY+d+50XbpIkSJUqNAPX1/ntCITk7jAahw2mzQtI4mxxdA5oDOh0alLeqWETbNxP/w+dabUoWXLluzYsYNSpUplbCPtyGjD52HwYEi1IXgbk8yXvon0Pz7AcUjkEEQTL8m5RtQegZeXFw0bNmT8+PHs2LGD69evM2rUKB4+fMiwYcPIlSsX7dq1wGKZi+iqZADZT8CeBZLOk0JH7xPeJYrU7scciOFLXX0mLEzU7RSKp53MafhAQgX79hUlkunToVUrQgvmZkdhHbMrwKxa3qzpVJ6bn74PN2/CmDG4LSOShEuXZJTmOgUQbZnEhIWJcEpGMuPQDIKWBaHNTeK7+haYS/J132I/AADAGmglZkkMxVoUe2wRpnHUq1ePHTt2OK9s4gSNDI2Ifpi+kZe30ZuXK71MhbwVkm3z8/OjVatWfP755xw8eJBLly7x5ptNiYlxT+PUMSbIFQT79kkOgo9Poo5eBF4spwM2R6Go8ZRBXO9fpnm1S5ck8laheJrJvIYvFs3DgzXVc9CwWzg5BjygzUA/+rXT8XobHT2rXaHwg7EUmVmB7/d/71RJGqeuqbk7F3IN6X0n5/TpM+zbt49r164Rk04xYU3T+GTHJ1gKWaQKUFzS8iNkIHI9ybp7SMDHbiQREkRm8y/Q2mt8eTDtB2Z6KVSoEL6+vpw5cybd57JYLHzwwQe81PMlJleZjNmUylxfKpj0Jp7J+gxTmk9xav8cOXLQuHEuvL3TnpNznlDgsESgjBghHb1vv5WqG/nzc9SjGp6kka8IwAQkjDX1lAy9XmysQvE0k3ny+BwQ/CiY3ot7s+/aPsIsEmliibKACcJjwiHWflx6cIl31r/DxG0T+bPLn9QrXC+Vs6ZNvnySVuh67vcSEmvNCAZDNOfObWPw4B+5du0ad+7cIXfu3BQsWJCCBQtSoEABh6+zZs3qMPfuxO0T3Am/IwNMK5IjXQApflAEuJ9kXXZkSqg+sAwJSF2DDBSKwIHgA9wNv0tOc05XP7BL1K1bl+3bt1O6dGm3z3H+/Hl69epFtmzZOHz4MPny5aPyxcq0n9eeyJhIrJpzLkiz0cyz2Z5le7/tLhrOMOJvvAxBY+PGxfz55z28vLzw9vbGy8sLr1q18GrUiEOHKhG1wEzatq8S0AyZf5yc4l6hoXDECaU3heK/TKY1fCdunaDerHo8in5EjC3tB024JZxwSzgt57bku9bf0b9yf7euGxoayv37e4mMrANORdDZF1jdggyrEuPj48H06a9Rp85rgIxYbt68ybVr17h27RrBwcFcu3aNTZs2xb++du0aVqvVoVEM8gnCarPKf68QYtzijNyzSCCH/brCsQ2phUh4BSDVTmPzyb2N3hy8fpDmxVIvwpo+LvDmm3fJmvU94B3kSe4JlAKaItY45dqJmqbFF4wdM2ZMovzCxkUac3zwcXos7MGJ2ycIi045ulVv06PX6xlcfTATG03E0+jqXK4Z+eKdGYWljc0GefMWp2rVqkRGRsYvDx8+5NatW1y6lI+YGGfdD+ORiJ63Ut0rjUpPCsV/nkxp+K4/uk79WfW5H3nf5WPDY8J5ffXr5Dbnpl2pdk4dc/HiRVatWsXKlSvZtWsX1arVwNNzWRrlzXYDviQusLofR9nRtliFqjhMJhOFChWiUKFCqbbr0aNH8YYw7u+FCxfYaNtIZO7YScjCiHGrhdjfmojhO2i3rlbsCfVAByQAtQfExUtEWaMIuhv0mAxfMJJFvplKlWLQ6+2/1EhgH3AY6Tg0AGYiFjuBkJAQBg0axJEjR9iwYQMVHWiw+mfzZ/cru9l6eSuf7/qcrZe2omkaJoMJDY0ISwQ5vHPQPF9z1o5fy4RRE9wweiBSMGnPh2pa8nliRxk6er0f5cr1oly5Xg7PM2eOVNdyzliVRgKsJqW4RwZrtysU/0oyneHTNI0+S/rwKNr9+mgRMRH0WdKH88POO3TfxcTEsGvXLlauXMmqVau4c+cOrVu35rXXXiMgIIAsWbIwcSJ8/HHSPPpLdq9fdqotJhP07+9eWqKfnx+lSpVKFm05fO1wgvYGyZvCiL0NR7xwOZFoxqWx626RMOIDkYsEybmPxabZsFjd1/RMmdVAd8TAxZCyAIwldtmIjADnI8LOsHPnTnr37k3r1q3Zv38/ZnPKbkmdTkdD/4Y09G+IpmlcCbnCrbBbGPQGimYvGp+w3+r3VsydO5dXX33Vjc9UEWdGe7t2SbBxok9pcRR/FUOyMFM7KlRwtV7wR0AFSGHE6+ubuBP2pLgXcY/AG4E8iHyASW+idK7SFMtRDL0u04cZKP6DZDrDt+HCBvb8vSchL+0wMri6h4xQygBNkHzxzUj2gAEZzeRGtBifEeP3/qb3+aHtD4AUeV27di2rVq1i3bp1FC5cmLZt2zJr1iyef/75ZLJcQ4fC11+nXz3Nywveey9950hKHp88GPVGcQE/g9iVQ4ibE8RD6xe7zg+Z40sFI0ayemb0MGA1UhrYlS8wBgn26IrVOo/x4w/x448/8tNPP9HexeK5Op2OwtkKUzhb4WTbRo0axYABA+jXr58b0axeyLB5IQkRRMKlSwmvX37Z2fOVRBS0HVO2bKqSng4oghQ2+sHhVosFHpMmejIeRj1k1uFZfLnnS248uoG3yTveBW21WdHQ6FGuB2/Xepvncj/3ZBqlUJAJJcuazmnKxosb5c0uYCfQEZn+eQisQkYy/RGjdw/ojEy1bUGEid+Ww70MXrxneI/1q9dz5MgRGjVqRNu2bWndujUFC6Zd3nPtWhFedtf4mc3w88/w4ovuHZ9iu86tpfvC7jyMeigrfkECWuohrk4Qu3MC+d46JznBWKRYQOxgWG/R4znXk8oFK1OjRo34pXDhwi4JWydwDXG7uT+ZFB6u57XX6jBlyp/kz5/f7fM4QtM0atasyahRo+jUyZnCP0kJREojp7NXhA9SZ+SFVPcaOFDqPKYzGBgQwfRdu9J/nrRYFbSKPkv6EGWNSjXa2qAz4GHwYEDVAXzS9BO8jEpNW/H4yVR+hsiYSLZd3hb7BhnRtUJKsBuQkUtXRJUjqRKKAVHgf4S4/ICoiCj23t7LmDFjuHXrFsuWLeO1115zyugBtGwJn38O3t6u9w3MZpEdzWijB1CjYA2iYuzcbf7IZ7YXIX42dl3yAU8yfHx8+DvwbyZMmEDu3LmZN28etWrVIn/+/LRv355JkyaxYcMGQpyuaN8XiMTfX8oP2Uu//fKLiPKAuPDi0tbils9iBUg8PWHuXEOGGz25ro5Ro0YxefJkN/MKKwEDSNBqdZ3oaLh/vyzSq0udESNcL/brCLP5ySSwj9syjm4Lu3E/8n6aKUZWzUpETAQ/HvyRaj9X436E6/P6CoWrZCrDd/Tm0QQljquI5ytprIgnYggvJFkfQ0K17dhOo95TT9V2VWnZsiVebtZlGTxYo2zZj/HwiHBGUhGdLgYPjyh++AE+/NCtS6ZJdu/stCvVLmF+pCkyirOPCSkXu86R5vJY4kd7HgYPBj4/kBzZctC4cWPee+89li5dSnBwMPv27aNPnz7cv3+fcePGUbBgQZ577jn69evH9OnTCQwMdJCTeBoZqst6qxW++Sblz3LkiARuxC0jR8p6g8GGTrcXKaqX8XTo0IEHDx6wdetWN8/wCRLo4k6AjBGrNRe1a5/nl19mpLl38eLwwQdiuNzF0xM6dICmTd0/hzN8s/cbPtv1mcs5tRExEQTdDaLxnMaPab5ZoUggUxm+Sw8uJYShhyOR446mYHxJ0Ac+gTyDJiFzWt0SjrFqVk7ePpmuNk2dOhVYysWLBv73PxmhZMmSuAduNMo6b2/o1i0Ss7kqDRpcTtd102Jcw3GY9OkfBngYPHiz5pvJ1ut0Op599lm6du3KlClT2L59O/fv3+f333+nRo0a7N27lxdffJHs2bNTv3593nnnHRYuXMijR5+jaQkPrnfegSlT4MEDd1pnIaW5qvRiMBgYMWIEkyennPOWOl6IS6IGKZeLdYQZKIq391GWLt3J559/zrBhw9IsGDxypIyU3TF+np5QrBj8+KPrx7rC6TuneW/De24LSURbowm6G8TEbRMzuGUKRWIyleFL5HYyI8bN0cR+aOx2kE73e8AIJGLxeuJdrTb3NRWPHDnC+PHjmTdvHgUKePDddyKssWiRuIz69ZMghg8/lPJ/N2/C/Pm+DB/elZFxQ5fHgKZp7Fy6E/0uPR4691VEfEw+fNfqO/L7OedONJlMVK5cmYEDBzJr1ixOnjzJ33//zYcffki2bNmYM2cOf/89G50uYRT4/PPywJ7inDhKEmKQ2kKPhz59+nDkyBGOuJ3R7YtMLH+OxeJJRERqgTJxrojhiEp2fkqVKsXevXs5e/YsLVu25O7duykebTDA0qUy5+yK8fPxgWrVZF7Pz8/549xhwIoBRFmjpDTUROBjpFP6CxJ5bB8L9DcirfcJ8CnwE3BY8nE/2/UZwY+CH29jFU81mcrw5fHJkxBM8QwSc5rU0xWFlJYpkmS9D9AOeQ7FZkLo0PFsVveqb4aFhdGjRw+++uqrRNXHzWZxF737LsycCbNmiRuqZcuEB8s777zD3r170+FGS5mQkBB69uzJd999x/4p+2lbqq1bkl1mk5n+lfvTt2LfdLUna9asNG3alDFjxrB8+XJKl04+Ch0/Xkos3nZQNL1KFciWLWFZty7pHufS1b7U8PLy4o033uDzzz9Px1l0aNpAatcuysWLwxB5nKxIxQQ9cmNWR5LLryGuiYTOSrZs2Vi5ciVVqlShRo0anDhxIsUrmUzw22/SycqXL3VD5usrXogpU2Dbtsefu3f+3nn2Be/DpsVat57AaEQ0vC4SpBZXIvMqMBuZmx4GjALaIr9rpGM3/cD0x9tgxVNNpjJ8lfNXJsISGynnheQzr0F+EFYkcnEBkAVJp0pKLqRC0E556+vhS61najnYMW3eeOMNqlevTu/evV0+1mw28/nnn/PGG29gdS0WPVX2799PlSpVyJEjB3v37qXsc2UJ6BrA/6r+L3mVghTQocPb6M379d/nm5bfuBm1mcr5dclz3MqVg7Zt4dNPk+9/6JC4QeOWFi2S7hFFSjlpGcHAgQNZs2YNl+xzEVxk48aNREToKVPmC2ArEn0VhUR9PgL2Ii4JxzquBoOBzz//nI8++oiGDRuyPJUiyiDf5bVrUmLo5ZfBy+sy8AgfH428eSPJkWMDP/8sHY2BA13NA3SPRacWJRg9e7yQAN8uSDDsTeAvJD6oLtIv0CHz093kkChrFLOPzH7sbVY8vWQqw5fNKxslcpRIWFEXydn7iwSXSVYkaDClDMQ6iGpJqMwZNPRvmHh7cLAMKxYvlnyFa9eSKVL/+eefbN26NXZ+zz26dOlCtmzZ+Pnnn5HwyllISGpRxELni/2AHwCpCzdrmsaXX35JmzZtmDx5Mt9//z3esdnRBr2Br1p8xcaXNlIlfxW8jd54GpIHXHgZvfDQe+Bxw4Pd/XfzXt33MtzoCY7nHceNk9SOa9fcOd/je3JnzZqVV199lS+/dF+o+5tvvmH48OFJvk8TMrJzvu19+vRh5cqVDB48mI8//jjFiNMISwRzjv7K1HttWVs2P5Z3i8H7Wcg+4VlqftmD0Gfb0LZ9qFPBWBnFlktbiLamUimjENJhvYy4OdNI2wt+FExYdKqVoBUKt8l0eXyzA2czZPWQeFFqd9Gho3WJ1qx8cSVcvw7ffy/ljUJDZbZf06QrHBUl/svXXoOhQ7kYHU2NGjVYs2YNVdMpcXH06AE2bGjAm29q6HQGHOe1GZGHZGXEOCaufH7nzh1efvll7ty5w7x58yhSJKmPNzEnb59kzdk1bL28lasPr6JDR9HsRalfuD5tS7alb/u+DBo0iBcfR54FIN17MeT+/pK+EBdJ+Npr0t8oXx62bJGv/+xZiVpMmZKk1TFIL9evX6ds2bIEBQWRK1cul449e/YsderU4fLly/GdkfQSHBxMx44dKVq0KDNnzoxXq7FpNr7d+y3vb3ofnU6XYi1GvUWPr9mXn9r/RLey3R5TBycxJb8rydl7sb7Kr5BqIMWS7PQzIsyzCdGJTaV0pp+HH3te3aMS2xWPhUxn+KJioigzrQwXH1xM13m8jd7sf3UfZZfskEQoqzX1InuenmgGA1/lzo02ZAhvv/NOuq4v8mbNiYq6iKenM5nHeiQ0/iskRwy2bt1K79696dmzJ5MmTcKUAclca9asYdSoURw5cuQxPRAHIkNzazLDd/UqlCghyiFxhs9sTuyKe/VVUcwBsNn06PWvIJEPj5e4/M6xY8e6dNzQoUPJkiULkyalrI/pDhEREfzvf//j5MmTLF26FN9cvrSc21JEuJ3sFPqYfGhatCnzu8x/7InhRb8pmvCbTcnwfYk4OdYAL5F8nt6OLJ5Z2NFvB+Xzln8MrVU87WQ6wwdwMPgg9WfVl9JD7mCBLjlfYMEeE6xalTiDOg0i9Hq82rRBt2hROrKGLyMJdPdIKmuVNmZstglMmPCI6dOnM3PmTFq1auVmO5KjaRpVqlRhwoQJtG3bNsPOm8AhREIm/bURw8N1DBtWkRYtRtOxY8cMMfwpcebMGerVq8fFixfxSaESelIePHhAkSJFOH78uNOiCK6gaRpTpkzhi6lf4Pm6JzeibqTuTnSAt9GbGgVr8FefvzAZHt/3V/OXmuy9tlfeODJ815AR3yBgJeLpb5Py+TwNnlwafol8vvkeT4MVTzWZao4vjqoFqvJrx1+dDtiwx2wy06FEB7p+uJ7oJUtcMnoA3jYbuo0b4aWXXL62EAO0xj2jBxBOdPQ73LmznIMHD2ao0QPJz3v33XdTnUNKH1WQCZz03lp6vLzE6H333XcUKVKEiRMncvPmzQxoY3JKlSpF3bp1mTEj7YTyOGbMmOG0/J076HQ63nnnHUq8XYIrD6+4bPRAEsP3Be9j3NZxj6GFCdQrXM+x4HQk4qleiGhn50XKBgYiQWhx/aMbSOBaLN4mb2X0FI+NTDnii2PTxU10X9id0KhQIq2puCmROT0voxcf1P+Adx9WQOvaFX16FKbNZpg7F15IXUcxOZ8iSUzpm6PUtILodBewD33PKKxWK6VLl+aXX36hQYMGGX5+CELTKqHTpUfL0hsZPUrR2iNHjjB16lQWLlxI27Ztef3116lRI+WqBu6wd+9eunfvztmzZ9McXcbExFC8eHECAgKoXr16hrbDnr/O/8ULf76QkBSedDR1DNGvjUTKHMYNVmOA6Uh+fTUZ+R3434HHNme24cIGXvjzBZl3/Aq5/fVIbE9uxOg9T0J/6G8k9ehq7D45pZ1Ukt9ypzKdWNht4WNpq0KRKUd8cTQu0pjzw84ztMZQ/Dz8yOKZJZFaiR49WTyz4GnwpEOpDhz830Heqz0S3SuvoI+IwB/Jabc3Qb8glfNKI5XfkvINsSpf4eEy4eRSGfZoxPDJFXU6OJckDW3sWOjdG37/PUGf0tsb9PrEmpU6XQhSWyjjMRgMjBo1ik8++eSxnP/iRRPvvpuF6Gh3i3+YganEGT2AihUr8vPPP3P+/HkqVqxIjx49qF69OnPmzCEqKmOKwtaoUQN/f38CAgLS3Hf58uUULFjwsRo9gI+2fJSyEkogIkb+IhIbtdZu2zYkvz5Wsi7aGs3kne6q1KRN4yKN8fOITSx8E3gfyeN7DynHWJ3ET5tCQO/Y7e8CryEpDojX5u1abz+2tioUmdrwgUxyf9bsM26/c5tF3RYxvtF4jCeMdCnVhRG1RzCrwyyuvnmVJT2WUCZ3GUlRCE94UFgRY5aUvsAcB+t/i90GiNFLI6cqMatx1r3Zq1eCPuWaNVCgQGLNSokA/cKFa7tGnz59OH78OIcOHcrQ8wYGBlK3bl2eeeZ9PDx+REZuzgbR6GL3/xYpv5GcHDlyMGLECM6dO8cHH3zA77//zrPPPsuYMWP4+++/093+UaNG8dlnn4kb+M4dSX35/nvJwJ8/H4KCwGbj66+/Zvjw4em+XmpcCblC4I1AxxsPAOsQ4/EsUo7rEhCE5MrtQ0aGOvlWrZqVgBMBicXNM4qQEPTfTeWL3X74uO6NTYRRb6RqgarULPSEaicpnkoytavTETabDZPJRHR0tONaal27wkJxkfgjMYafIZrW2ZAR39zYxR84T0IBg5NIpzMYybQDoE0bWLnSydYNQ0Yq8pU6CtcfO1ZGgXPnJqzbskVGgcmf257I6NHVmnHO8eWXX7Jnzx6nRjjOsGnTJnr06MG0adPo2rVr7NqTSLn3C8iETvLbTdN06HSiYSlFaF1zx50+fZrvv/+euXPn0rhxY4YOHUr9+vXdilrVbDZGFCnChx4eZL1yRQoqRkdL+ouHB9hsWIxGvtE0hp87hzF3KjH56STgRACvLn81cVHmr5Bk7ytI2T37abAzwCrwzQntO8OE0fBsVjDoINoGF+/rye7Vlby+45C8gnRisUi15k8/Bb0eLTyc1r1gsz9EuRlH4+vhy6khpyiUpVD62/cEiIyEo0cT8lMLFpTiwW5q4iueEJl+xJeUR48e4ePjk3IB0b17E719HnFtJpWKLAQ0QkZ4cfyGhKUkyuQ6cMCF1u0hY1VGTIhpfjz873//Y/PmzZw5k/48uYCAAHr06EFAQICd0QMxYkeA9YiO1bOIITcCeu7d8+XUqYqISsERXDV6AKVLl+bbb7/l0qVLNGrUiIEDB1KxYkV++uknwlwJbrpyBV3dunx68yZZz50Tg/fwoTzdoqLg0SMIC8MUEsIb4eEYS5WCFStcbq+zBN4IdJyrdx65gfMkXl2hPjRvACWyw6+fQNHsYNRLB8zTAKVz2chlXoD4RZsjXTw3uXEDKlaUOlKRkRAejg4IWACl7oKXGwUWfEw+rH5xdaY3ejab/Nvr1hXZuGbNREHn5ZfltZ+fbFuxQvZVZD4yXQX2tHj48CFZsmRJeYcbN5KtGo8IuryRZH1fYAIyHWEDfie5W1S7eZPR775LjNWKxWIhJiYGi8WS6HXc36lTT1IoQ3+zBqT67uPB19eX119/nc8++ywhmtFmExdfTIyIZzqhiPztt9/y2WefsWHDBipUqOBgDx1QK3YBibyIAjzZvHkZM2fOZNWq2un+PFmyZGHIkCEMHjyYDRs2MHXqVEaPHk3fvn0ZMmQIRYsWTfngI0dETfvRI0xOyMyZYmLg/n3o0QM++iihnlIGEhIZklCtxJ62yBzecqQYvA6GVYdPmsLk63A+C5hS+GUb9DZESm0zMupbhBhBF7hzB2rUEBWkJGWp/KJh50zo3wFWlYBwJ2KzvI3e5DTnZGn3pVQtkD7RiMfNxYvQvTucOhU3JSF9o6Ts3Cm1OMuUEW3VNHQnFE+Yf53hCwkJIWtqirsOuljlkGfFpyQu79cJGIyM08Jjl6SpRTrAz9cXo4cHJpMJk8mE0WhM9tpoNOLndwT7UBqDIXlsjMXiSnqgjfjigo+JoUOHUrFYMe4XL072RYsgTiRZp5PG5ssnCtxvvCGim3ZomhZfv2/nzp0ULuxE1VtAbju59erXr88rr7xClCWK2xG30TSNnOacbglvx6HT6WjWrBnNmjXj4sWL/PDDD1SvXp2aNWsydOhQmjVrhl5v5+wIDhaj507tpPBw0WPLly8dKTCOMRvN6NAlN34+SAL4r8AqGD4BJjYGs8kVXc4YZB65I7AMyTFwAk0Tv/z16ymWhPeNlpHf6hLwXhM4FytRam8EjZoes5cvOnQMrT6U0fVG421yPn3p9J3T7Pl7D4evHyYkKoSsnlmpkr8KtZ6pRcmcJdM+gRvs2iU/hfBw0cNIi9BQ0aKtUEGmimunv2+nyCD+FYbv1i3YvVtuomPHcnL//hhmzpRyK+XKJfmx+/k5fICNQzLM7GPFzIh27hykD9wDB8kDPj6Mfv99J1u6HHkaCc8+C5cuSa8vjosXoaSTv0ubLZzQ0DykNsBNF5pGjsWLORcWhvbRR44jWP/+W0pQ/P47NGokr/PkwWKx8OqrrxIUFMTOnTvJmTOny5e/HXabn0//TMQrEfh+4ouHwQN0EoGY3zc/7Uu1Z1iNYel6kBUpUoTPPvuMsWPHMm/ePEaNGsWwYcMYMmQIffv2JWuWLPIgD3XgUnSW8HAYPBgaN8bdIX9ISAhHjhzh8OHDBAYGcvjwYU7qT4rv3VFHKQvwEnj8BpY14NPS3cZHoGld0OnOkaqGWBxLl8KOHbS0WOJrTtizDNEd+hswn4WjZ+FNHyhRBnY/A7fM4GWFKrf11Bgzhcb1X3Y6sV7TNBafWszYLWM5f/88ep0+kYqNr8kXq2alRI4SjGs0jg6lOmSYOtHJkyKg7uptYrXKMS1ayCzMc0qBLVOQqYNbDh2Skj8bN4q8ZlhYQk8rTlwjTx4YPVpq4xkMSM89thyQPxLMEld0+jVgMVAeSSEC0dLvhJQ83YikEiWievVk84YpMwsYStyo7733pCTMn39K1OamTZIWuHt34sFTSsEtf//tTenSeipWrEjTpk1p2rQpNWrUwCMj1IcjI6W427Ztzif5e3iAtzfhixfT+fPPMRqN/Pnnn/Faks4SY4vhk+2f8PGOj9GhIyLGcb6fSW/CoDfQsVRHfmj7A9m8srl0HUdomsbOnTv57rvvWL9+PWPr1uXLlSsJ1rTEQU3ITFggcBG5l3YhbvH9yOR4fWAysbOSRqMEVv3xR5rXDw4OTmTgAgMDuXnzJuXLl6dy5cpUqlSJSpUq4fuML1VnViUyxi6H1S6PTwds7gC928n9U6oUjBoFd+9Crlxyr33yiXisHQVVgXQaT5yAmzdzsGhRTypXrkyVKlUoW7as4/usYkU4epR5wBhkutHetHRBgsW+APohXcF8SL3oRBiN0KeP1PZygjvhd+i1uBc7r+x0SrLNx+RD/cL1+e2F38hpdr1TZk9MjIzaTp9OpmfvNDqddICPHJGPrvhnyZSGz2IRo/H99/J8TquFPj6iAblwIRRb/hW8/z6EhyczfFeBEkBNEgyfhuQCeyHxh4nw9pZzjR7tZMsfAPmRbGKIiJAitQsWyHRQsWLyAGrfPvFRjg2fGfiYiIj/sXPnTtavX8+GDRs4e/Ys9erVo2nTpjRr1oyyZcu63qu1WsVns3OnNNJFwvV6PmvXjvcXLsTo4q/4fsR9msxpQtDdIKc1Jz0Nnvh5+rH15a0ZmoB97do1IurVo+nFi3gCryPdFpC88C5IdsBFpL5xM6SaXn+ko/QlMA0pBlIUJJTv2jXIIb49q9VKUFBQIgN3+PBhdDpdvIGL+1uiRAmHAVtVfqzC4RuHHba/eTFY2BX8POGLLyTOZPZsaNJEmjF4sJQm2rlTgi9TMnxnz0KRIh7MmPEeO3Zc4NChQ1y4cIHSpUvHG8LKlStTyWzGXKcOhIcTgRi0FUgHAKRqWH6kCFPx2O0/I17ZXcSnFCbg5SUTZGn4/q8/uk6NX2pwI/QGFpvzUTMeBg/y++Zn76t7yeub1+njkvLzz/Dmm/b9wx3ASMScG5AJlK+RbvN1pHu0GnElFwS6AyPx8fHhyy/hf/9zuymKDCLTGb7oaGjdWkZFdul4aaLXi5dz+6oQyjfNl7ogtbN4ecHlyzKsdJpXkWSJ9OZL+SKmOluitXfu3GHz5s1s2LCBDRs2EBYWFj8abNq0KYWccbVNmSIW2EU5N3u0Z55BFxTkUtx2uCWc6j9X5+y9sy7Lb+nQkdUrKwdeO0CxHEnVj90kOhp8ffG3WHgVcdPtj900AsiOPMIuIpkD5YHvk5yiFeIgnAPEmM1sefFFFhmNHD58mOPHj5MvX75Eo7jKlSuTP39+pzsry04vo9fiXg47Cct7QLtSYjsKFJDBU7duCdtDQyWoYvJkuHIldcNXvLgn8BGSUQ7h4eEcO3aMw4cPc+jQIQ4fPkzFI0f4JiYGn9hHxmtIx/GX2HP9CPyAjJJ/Q0zD38gsoj/wXdIP4OcnHodKlVL8/BarhYrTK3L23llibM6IvSfGqDdSOldpDg84jFHv+lBL06TDejFeM/8hEpn8A1JAMBrYjpj5QsiESm2k/Lw/8hueArwCVKBoUfk/PIkaiYqUyXTpDK++KpPIrhg9kJiWkBBo2D4Layo2Tr9Esre3NMYlowdykzsncpwyPshYIluyLbly5aJr1678+OOPnD9/nl27dtGgQQNWr15NpUqVKF26NK+//jpLly4lJCQk+amvXZMoxFij9wfSE/dFeuutkP4syAi4PVIC0Q9J/9gVu0135w5MnOjSpxrx1wgu3L/gluakhsbDqId0DuiM1ZZBxX1PnIg33DWRR9opRPRgPpIbDhL0tAupppiUbkiiBoAuPBzbrl0899xzfP755wQHB3Pu3DkWLFjAmDFjaNOmDQUKFHBphN6+VHvqF64v859JqBnbx9m1K8FzbY+vr3Qi169PdqgDooAN8e/MZjM1atRg4MCB/PTTT+zfv58fBw7EbNdP7otIcMZ1MeeQIP4wGxnnGBBhmfnIKDkRmgbHjqXaqgnbJnA55LJbRg/ErX7h/gU+3eGgCrITnD8PieVhg2L/9kQ+nTcSFVsB8QH4kZAlDPAMEisu0c43biRXc1I8eTKV4Vu3DhYtcsv7Fs/9+9H0uzAa07PPxk76uYFeL5Mkn33mxsHZgCWIq9IdzEhEQx+n9i5atCivvfYaAQEB3Lp1iz/++INnn32W77//nkKFClGrVi0++OADtm7dKtJe06bFT5R+CQxHlKVuIjnRg5GRz3kkBaQ8MuIJBl5AfuK7Qf5J330n+W1OcPj6YX4N/FXm874icXriMSTk9lLs+4vAWBIscCw2zca5e+f46VAGlSm6ciVR17sP8vBejziv4qSn4+TG8zs4RX7gTuxrA9Dc35+hQ4dSr1691NNunESn0/HbC7+RzydfohGLrwdkjR1s37kjt6sjr3P+/LIdpGJ7tmyJl8Qkm4lLhCE0NNF8Xl1kTnQp8u/chxi5q0iyRK/Y/TogxnFV0hNaran2cB9EPuDzXZ+LZNtXiBKFfZ/pIDKtDjL03IP0Fychk4wBwE3xNHy8/WMeRdkJATjJgQNJHyMlkf90X6S+0n27bRuQiIGUH6sGAxw86HIzFBlMpjF8mgavv570d5DaeAQkglIH/Gl3Hk8ehdXm5PTdkDOnyzPJMYA1SxbYvFlGfW5RH3kc+GC1uvIV+yCPiT9wp+q4Xq+nSpUqjBw5kr/++ovbt28zadIkrFYrI0aMIFeuXDyYMgWioggBPkSeE51ir2wC2gGfI3anFvIMyYH0Y4chxmFU3AU1Df76y6m2Td45mSirAyMZSILepH/suiNIR/pI8t3DLGF8sv2TdFWWsFgsXL58mZMnThBtF8naB/nmf0XmpeLIjvxQrjs413WSCB48hozlnOac7Hl1D8VzFI9P8zCbICb2UrlyJaReJmvfddkO4gZ98CDxkpg0pgeSW0peQjoLcxHVtLyIm9OG3Ev5kPnPSGQUaE+U1cr+kyc5deoUFgcRxbMDZyeu+BBn3ByxBplcbIXcoEMRqdfYAZpep+e3o7+lcHDKXLiQdEYgC/IM0iHO3tyIX+QmcBfH3aMEwsJkFKn4Z8k08UV79siPNIEvkWHAdOQn5YGo8C5D+pogP6UcyE+ve/yRUVE6vvqzAL8ePAidO4tLy5n5LB8f7mTNyv9y5SKgYMF0ZtA1IyzsAMeOVaRaNT0GQzQp63j6Io/WnxHnWcbg5eVF48aNady4MR9//DH3z5zBLzacdDfyMEqp9sR6wJGEdTckWCgC8A4Lk8nYdu1SbUe0NZolp5dg05J8/gNIKG1vEoZX0YiPtR0ycL5mty2W+5H3OXj9IM8XSBYugdVq5ebNm1y9ejXF5fbt2+TJk4cW2bLxnd0DtzBSG3U1YF+cyAfpBCxA3L32BABN7Fc8pkzl/H75OTrwKOO3jmfK7iloNh0mvbhGatWSqOfFi5PP8a1ZI4EtzsmYehMSAsuWwfbtEoEYHS2xOnXrQg/PypTx9UVnF9P/ElKL5CgyKAP5VX6EyAXGsQ9xFd9FCjGA2LHfAgNZ0749V69epUiRIpQpUyZ+mXVvVmKB7tpIKaNqSMcojrvI5OwryDRbHHZaCmGWMBaeXMjgaoMdfnKbzcb9+/e5ffs2d+7c4fbt29y+fZuNG0ths9UncUe0DAlpS6eRG3h47Cdz1D1KQNOUmktmINMYvlWr7ONR4sYjs5DxSBztYheQYq9bkcdRd6SglwgXWq1yPn4tJA/mGTNg/Hjp4losid1zHh6y+PnB+++Td8AAzL16MWjQIGbOnJmuPKDJk//g/Pku/P77m4iffyNwGzHiVsRlUh6pztmNxL/mjCf7jRsSAhsSwl1kpJLSDXCHlF17NsT9V9Bmg/37HeyVmBO3TuBp8Ew8t3cA8a32JbHe5Cnk6ymLuECPkMzwWWIs/LLmF/ZE7Elm1K5fv062bNl45plnEi3Vq1ePf12gQAGJRo2IIGmS5AzEeeWDjP7j+BTpfpVGwvRjEG/abhICYqI9PQkrXZrsaX4j7mEymJjQeAJv1XqLWYGzCI0eRXbvGLJmlWnboUPl49hHdRYqJFkDaRXiuHcvOyNGzGTePHGSJM1X27YNlnvWZFeENZET3x+xR0eQcc8e5Jc5hMRZge2RSM95SPQsgJdez7cbNoDJRGRkJGfPnuXUqVOcPn2aVatWcazYscQ5jAVIyCux721cQAZiacR17b28l7Fjx8YbNfvl3r17+Pj4kDt37kSLyZQbk8mCxZJSClFp4GUktKcD0lv7iJScaV5e8BjlXRVOkmkM39at9moIaY1HQEZ5zwOdkR7Y79inpz98GDf3oYfXXpNAlT17xBDu3i07+PmJ9FKtWiKroNejQwqM1q5dm2nTpvH66687vHpaXLlyhWnTphEYGIhMcMe5WUIRw+6BmJ4nGN5lF+maEzFuMTi+CXKRsmtPD/EP9yN79/Jm48Z4e3vj5eUV/9f+9RnPM8kDWs4jw6uksUOBiNHTI32CNYjFsZtnibJFsfrQanQ2Hc888wzlypWLN2qFChXC09PTmW9DXNlVqsC+ffGrUooXrYsUQ4irtqNH6szvQFJkALBYqPPhh+QICKBLly506tSJZ5991rm2uEB27+y8VestpOMn1UNGjhTP/ogR4krLkgU6dhTdgbS+jh07avPmmysJD/cjOoW4I6sVjoSXIIiSVErig95i97omKTtME80gGgyi6RWbyuDl5UX58uUpX748IPmOf47/M/lJGiH1xOyLN0QgTpM0iLBFYLPZ4osO2xu4XLlyOcxb3LdPHhcJjoHTyGxld8TSXkXMeU3gLcTp2xcZBxdGXBZfIMaxAiaT3HKKf5ZMk85QvLi97zvOiCXX3UygBNKvHI445eZjPymUJQvs2AGxvyOXuXDhArVr1yYgIID69eunfUASXnzxRUqUKMG4cY+38rVL7N4t+XsPHxKCdKBnI/lqSemNjOpWJ1k/CBmIxc203qtVi8MTJhAZGUlERITDv3uj9/KX8S9idLFjqK+QHvs25NkRqzdJCJIO9SoyyotGgmRfILHWHNCrfC/mdkoSm+8OixdD377pU24BCZJp2ZKoJUvYuHEjixYtYtmyZRQrVowuXbrQuXPn1LVC3WID8uW43/Zly9rTs+c8IiKcC8ZqzzJ+pxe+6Sy0jLe3KFSULu1ws6ZpGMYbEuTa7AvwLkIMXS7Ex1oOuSHfTP2SBp2BmA9diw6NipI50oTb41rshXYiebvZEEHEz5FhZzAJeXxhyI3cE6kSbMbXVzrkzvbNFI+HTDPiS+xRTGs8shMJ/esR+/5FREcikLhqlpqWvlyZokWL8ttvv9GjRw/27t3LM888A0iE2NLTS9l8cTP7g/cTGh2Kt9Gbyvkr08i/EZ2f68zxg8fZtm0bP//8s/sNeByUKxcfMpsVkZsagnzDzRGv0gYkIu8jZCplDNIFMSGzGnOQOgoAmEzkaNeOJk0SzXIlY+HJhexYvoOHUXZqvkn0JmmL9Fs0JMIkjpjY9UkMX07v9KlxxNOhA1EFCmAMCkpf8ScvL5gyBU9PT1q3bk3r1q2ZPn06W7ZsYdGiRdSqVYuCBQvGG8FSpTKgLBCNEefzOdypCnLmTElefPEPp40ewHI6sJUGNGUDnqQwPEwLsxnefjtFowcSzZrLnIvb4beTb2yIeBbjtC+LInbGwXywPXl8XE1NEgP16qvw/fca0dG62AukVsarAI5LXMuMyquvKqOXGcg0hq9wYfv8llpILbqlOB6PzEZ+6JUcrJd1kZEQa6vcplmzZgwfPpxOnTrx16a/mLx3MlP3TUWn0yUrF3P89nEWn1rMkNVD8Dvnx4RJE/CJ01XLLPj5iYBo7ND6bWR6bSISeu4HVEWMXQmkE/0uMq1iQxzL65A0B0B+wXXrkhaV8lVynHsXqzfJr0jc0lmgAYklPq4h07jhxGeI+Hr4Uq1gMnE5t5gXEMA3t26x3cMDQ0p+vrQwm0XhJ4kQo8lkihfLnjZtGjt27GDhwoU0atSInDlz0rlzZ7p06eKe+g4gDtcAxAK4lgNks+no1i2AyEjXQ7heYg4HqEpBgvFInp2XOt7eIgP4wQep7nbv3j3y2vJyGweGLycyytuLuMpzIr20RUgIwDPI4+E0MiirJ4c5CoZyhv79bzN1qg/upygJHh6PpYiHwg0yTTpDw4b2ykX245GlyFPPgkz4jER+7D8hI7y45TtkqCCuDIPhPqtXz+P+ffs8G9d55513yFUmF89Mfobv9n5HmCXMcY00JHIsIiaC24Vu88GtD9j7t7Man0+QN99MEDpFDN4BxClzAxl8xXWkywErkcTuUGQuJ5GZy5rVKcNXLHuxlFUzsiFTIvuQ6LzqiAWOW0ojgbt2ec5Wm5Xaz6RP6j4iIoL//e9/fPTRR0zfvBnTqlVOlWBKho8P9OoF776b6m4Gg4EGDRrw3Xff8ffff/Pjjz/y8OFD2rRpQ+nSpRkzZgyHDx92I02jEuJmc63tGzc24fTpJdhsbZNsKYHkBCRdV5q4kcw9clKDfZyhFJ9hSi5FlhJmMzRtKqGmDmTKbt26xU8//USLFi3w9/fH64wXXroUDHMDEuf0tULundVIJNK3iOGLHVj7efjRu0JvXGXBggU0a1aeVq1WYja7PytkNsMPP0hepeKfJ9PM8Z04IdUWEiev/44490+RMB6pgxi5KyQO+YpAJoxmYzK1oW7dY/j4jGHr1q1UrVqVtm3b0q5dO0o6WxohlmM3j1FnZh1JfnWxU242mfmr91/UebZO2js/KR49kuF1OjsEYcCGDh1o+eefTgWTvLvhXb7a85Vbqi1JqVGwBnteTSmhK21Onz5N165dKV++PD/++CN+fn6y4cABSX+5fTttFQWDQUa8kyZJySY3/eqapnHgwAEWLlzIwoUL0TSNLl260KVLF6pVq+bCSPBHZO4pEmfcni1brmXdOjPiY76HRA9dR7wtkchQO25dAcQvsB77UBYDMeSmMO9wm4F6MKeko+nnJ6IQ338PPXsm+q6uXbvGkiVLWLRoEYcPH6Zly5Z07tyZVq1aYfIykWdKnsQucjfJ7pWdmyNuOl0J4s6dO7z++usEBgYye/ZsatSowejR8M03rqtKmc0wbFjakbWKJ0emMXwAVavKfHd68fKC48dFYy88PJyNGzeyYsUKVq5ciZ+fH+3ataNdu3bUqVMnVZHl0OhQin9bnJthN1PcJy2yeGbh3NBz5PbJRDHMq1ZJwperv+A4jEYiK1emZ4ECnDh5ku+//56mTZumekjwo2BKflfSaWHqlDCbzCzrsYymRVO/XkrMmTOHt99+m48//phXX301uWGJjIRvvxXV54iIxOoiRiNhgKdOh7F7d9E7LZZBuqGIETxy5Ei8EQwPD493h9aqVStxDUGHnETCks4gxit5wpjNZiQyMoZcucKIiDAiQ+7tSKcyAPGqXEDyaOPWjUYMnj+ensepVOkBBQoEExLyN5s3v0120zF6RL/P0AK7KR0ZKWlDOp3I/VWtKgrsL7wgvj7g0qVLLF68mIULF3L69Gnatm1L586dad68Od5JRCPmHJnD4FWD03Xf+ETDL5t86FGkPbz1Fjyf+hh1+fLlDBw4kJ49ezJx4sREbfrhB4mcjYpKuyZfXN/o888ltUSRechUhu/AAahfP32SZd7e8PLL0rlMis1m49ChQ6xcuZIVK1Zw8eJFWrZsSbt27WjZsiXZsyfOwBqwcgBzjsxJXBbGRTwMHrQo1oLlPZe7fY7HwnvvyQPeVeNnNErR1YMHIU8eVq5cydChQ6lZsyZffvkl+VPx5fx86GfeXPum2w8xL4MXnZ/r7FY0Z1hYGEOHDmX37t0EBATEh82niM0mvbADB6QeTUwMFCjAqlu3WBoczM8BqQU4pB9N0zh58iSLFi1i4cKF3Llzh06dOtG5c2fq1auXRlWMg4gYwjbEiMUg9UdKERHRjNq1mxMY2AhxYTRCwiXfRDLsqiC5Jrns1oXRqVNbrl7tT5s2oQwfLrkD48ZFcuaMjSVLdOzYUYGiRV/F338AjlwjQUFBLFq0iEWLFnH58mU6dOhAly5daNy4capltjRNo+0fbdl8aXOK5atSw9sCzc7D0vmg0+ulV1ynDsyZI/exHQ8ePOCNN95g586dzJo1i3r16jk854ULMle3apV4bENDEyrI6HSikWqxiE7q559DhgfzKtJNpjJ8AGPGiDvBncIBBoMEtJw44dx0zbVr11i5ciUrV66Md4nGjQazFcjGs18/m9jozUKUiUYgYUEPEM2vpMQgKTwvy1svoxdHBx6lRM4SDnb+h9A0+PRTmDDBudpPIPNZxYvD2rWJHhrh4eFMnDiRn3/+mY8++ohBgwY5LLGjaRr9l/Un4GRAYkUOJ/A0eFI6V2l29t+Jj4drQUMnTpygW7duPP/880ybNg1fXyeSvlLgypUrVK1alZs3bzoxAss44gzHwoULuXr1Kh07dqRLly40atQIUxplfeK4e1fSVi9f1oiJiTNOY5Gw2SVARUR2+jziOl2Ch0dp3n8/jOHDH7BsWSgTJsCZM9Iv8PeX3+oL8em2Pojh/ANNK8jJkydZuHAhixYt4vbt2/GGu379+i6Vs4qwRNBybksOBB8gPMb5+8YcDTWuwerfwcs+i8Fkkh7yunVQUxIC161bx6uvvkr79u2ZPHmyU/fInTuwYYOkB8cF5hUvLqds2jRBKk6R+ch0hk/TpF7VH3+4Nhjx8BDPyu7d7hXBTuoStVS38KDSg4Tcs/vIhLknEjlWNoUT3UBiALoTnw1t0psYXG0wX7f82vWGPW6OHJEqvmfOpOy/8fWVruz770sYegri3ydPnmTw4MGEhoYyffp0nnfgUrJpNkauH8n3+793ugfvY/Kh9jO1WdRtEX6efk5/NE3TmDVrFqNGjeLzzz/n5ZdfdvrY1Chbtiy//vor1aplTGSpq1y8eDHeCJ47d4527drRpUsXmjZtmuJ8q80mGg2HDtknYwNsQm7WM0g4UzASzlSCevWms3NnJ86c0VG8uEZ4uPR3/vpLfpvdukFwcLwHM/Y6BqKijPTqlY8DB2x07tyZzp07U6tWLYedIWexWC2M3zqeL3Z/QbQ1GquWsp/RaAWTDUbtgDHbwZiiUqAvYevW8dbs2axdu5YZM2ak6bJX/DfIdIYPxPj9/LO44y0WUlSTiMPHB1q0kGNia4CmC5vNRrVp1Th0z27CcQvSES6IRB/2cnBgJBJsWhGJOrOjdK7SnBpyKv2Ne1wcOQJ//MGVuXPJGRKCj5eXiBJXrw5t20rQhxNBLJqm8dtvvzFq1Cg6d+7MxIkTyeZA3HjX1V28svwVroZcJcISgc3BfJSfhx+eRk++aP4FfSr0cSnkPzQ0lEGDBnHo0CEWLFjAc0lSDdLD22+/TbZs2fggjZD8J8HVq1dZvHgxixYt4tixY7Rp04YuXbrQokWLRHNTU6dK4GlyT0oEEkU9AYnvXQCAt3dp3nvvAj/9ZOHq1YS9+/cXb2FEhPzupk513K6YGB8MhiPodBk3Bwpw+s5ppuyawu/HfscUbUWzWLDpwBD7FIvRQ++jMGIXlLyb+rk04KrRyMe9e/PZN99kSDUNxb+DTGn44rh2Db76Cn76KcETZ7HIgMNoFA9d/fpSIL1RUvXgdJJjcg7uR9pFPn6DBLwVQipvvkVymaQ/ETfniySb5jDpTUS+H5lYbT4T0qtXL1q2bEmfPs6VRUqJe/fu8d5777FixQqmTJlCz549HRqu/df2E3AygG2Xt3H5wWU0NLJGPceFRSWpU3AU1vtFAB3+/pI50aJF2jrQR48epVu3btSpU4fvvvsOsztpCqmwYcMGPvzwQ3bt2pX2zk+Q69evx0dIHjhwgJYtW9KlSxeaNGlFsWK+PHhgf8OGI+4LAwmaX7WBtRgMc+nVaxBr1z6icWOYP18Ksfr7i7Rgp07yO9y4USKxHWMAKiPJdhl/z1uOHuZku1oczxpFmAccvQVbr8OFGHG4FkGyZAaR8FMcC4xD9ERrxK6L8fTE+P774s1QPD1o/wIsFk07dkzT5szRtG+/1bTp0zVtyxZNCwl5fNf0nOCpMRZZ+qGhR+Od2Pc50WhBwvaxaDRHIysaI5Osj10M4wxaeHT442twBlGnTh1t69atGXa+3bt3axUrVtSaNGminT59OtV9z5zRtBYtNM3LS9P0+nBNujsJi9ks2+rX17TAwOTH22w27ccff9Ry5cqlzZkzJ8M+Q1IiIiI0Pz8/7e7du4/tGunl1q1b2k8//aS1aNFC8/Z+STMaw5J8n4U1WB/7+l0N0OB/GuTQcuTIo+XMiQZokyfL34sX0TQNrVIleV+sGFrfvmgmE5qvryxly6K9+y7agweyr6b5aJo2//F8wL59Nc1g0DTQpoCWB7QFoD0EzQbaIdBeBC129lqzgVYEtBygDU56Y+XIIQ8ZxVND5h5+xGI0itpWnz6iQD9gADRokExYP0Mx6O3mI44g83VxMRXlkZz5OC4jOl/dSDGP2KbZnM4h+ie5dOkShQsXzrDz1axZkwMHDtC2bVvq1KnDhx9+SESSsF1Ng6+/hkqVpFp4ZCTYbMkrVYSHy7bt20VXfOzYBE/Aw4cPefHFF5k6dSrbt29P94g1Nby8vKhfvz4bNmxIe+d/iNy5c/Paa6+xdu1aOnT4iZiY1Ea9nyCOv/xAC/LluwdAyZKJ5++OHUuYd4/76CNHSmro7dswa5YEetSpE+dSDcNxcat0YrNJVV2rNb6Oy/eIxpMfMsKrjGQBxznntyMZid8iqr6JZk8sFik/oXhq+FcYvn8C/2z+8sKCyMpfQgQyPkd8JTeRQJZQJBCuOanqBOb1yZuyekkmITo6mlu3blGwYCofxA2MRiPDhw8nMDCQU6dOUb58edauXRu/feRIieaNiHCuVpmmyb6ffy5zTocOHaZq1apkyZKFvXv3UjoVDciMolWrVqxZs+axXycjOHTIeXHI7Nkf8OGHRkJCpHjCXLvMkdmz4aWXHB/n5SVuz+XLJXp0VlxldE6Tuti8GwQFSUI8UsclCtE5T43ZSExaXLnCFfYbo6ISVehQ/PfJ3E/if5B6z9bj9J3T2E7bpAs5hESlcViAjPpuIBMKaQT4Wa9amT59Ou3bt6dAgQKPp9Hp5O+//yZ//vwuhZq7QqFChViwYAFr1qxhyJAhVK1albp1p/P99zncyqUPD4c//rAQELCYGTMm0KNHj7QPyiBatmzJxIkT0TQtXTUbnwT37jm/b86cd2nTRo9eL8c9eiTrrVaZ69u5M/XpMD8/aNZMRuWvvy4j9BUr3uPSpecwGAzo9fo0/6a1T949eyivaRgRKfukdSVrI6n8UYi27PPIz3UOovXUJfZ157gDoqMzRjlD8a9BGb4U6F+5P78d/Y3wwHDxm2RLskN1ZKQH8i0mDdjMhhhLwNfkyyuVXmHHxh2MHj2akiVL8sILL9CxY8cMUunPGC5fvoy/v/9jv06rVq04fvw4o0d/yxtvpJy87AzR0Sb0+nFUq/ZknRfFihXD19eXo0ePUrFixSd6bVdxJd3Qz+8Rvr7hZM8utfwGD5ZUzx07oEwZcMYZUKCA6BsAGAwxeHhc5ebNnNhsNqxWa6p/ndmnTnAwJaOiMOK4jktcyFEhRLtmSey21rHrewFNkZLQ8XpK6VHNUPzrUIYvBaoVqEaRbEU42edkQk0we8rFLk7g5+nHxL4TMfQzEB0dzdatW1m6dCmNGzcmS5YsdOzYkY4dO1KtWrUnmhSdgAV4RHDwKQoXzvjCqY7w9vbGaByFyWSzyyv7FSnaeR4p3fACMkeUDYnJO4cU+gTRkmwCNCc6+hvGjxdX3JMkzt2Z2Q1fkSJw65Zz++p04mv28hIN8rj/zcKFKbs5k3LtWkJakclkoEOHtnToMNy1RqfGunXQvTuEhMTXcVmG3QguCbORGYm4O1tD7vg/gDfidlJl0Z8q1BxfCuh0OuZ2mouX0fWyLfaYjWbmdpobHyzj4eERX6bm6tWrzJkzB71eT//+/SlUqBCDBg1i3bp1RLtbIsdpziFFfEsgETkF6NFjKD///CciBD4TCXl/PMTEwI8/gsUSdwt+AYxCJlFDkInUy0AzSFb37TJQH5Ha+habTUdAQIJb7knRsmXLRHOVmZHo6GgKFToPpCEsGUtEhJmoKBmF9+snubEAW7ZIGkNahIZK4EuC2pcHduOqjKFSJfGhIl2ij4DBiAPmETLKC0RCa64BG5EqI4GxyxHkTpsTdz6zWaKlFE8NyvClQqV8lRjXcBxmk3t5YGaTmQHPD6BxkcYOt+v1eqpVq8akSZM4ceIEW7ZsoUiRIowbN468efPy4osvEhAQwMOH6VenT+A+MsVfHomFO4c4iqIwGGx4eloQZ9EbSLW+ObhT5DQtTpywf/cQeXx9B7REZmL8EYHkSySM8kBGg/URh9Vn8Ws9PUVW80nSsGFDDh48mMH/n/RjsVhYu3Yt/fv3J3/+/Jw7NwmTyYmoIeD+/RxEREhnr1w50S8AcXumVl4yKkrcmx07QvbsYjQFDZExy0Dy5k2kVDESkdT+DMgbuwwAJiN3SyUk9iyf3TIMKd5+PO4kTpTXUvx3UIYvDd6p8w7v1nnXZeNnNpnpV6kfXzT/wuljSpYsyciRI9m1axcnT56kYcOG/PrrrxQqVIjWrVvz008/ceNGeiLkAoHiwHJEZia1IqKhSP95MBIzF5WO6ybn0CH7CM5dse1JOqTwRWZm1se+v4AYvQFIvcYEIiIS5pWeFGazmdq1a7Nx48Yne2EHxMTEsH79el577TXy58/PuHHjqFChAkeOHCEwcCZlyiRNpbmEzHTZM5ZHj5bi4ZFwX6xeLVG07ds7vu5nn0lAS86c4gqtWhV27bI3kp6Aa6XAnGL4cNHbjKUXUtIxHJm72wv8D0l1cHRbFEDu/nIgeRtlymR8GxWZlkyt3JKZ2HJpCz0W9ki1EC1IIIvJYGJ2x9m0K9UuQ6798OFD1qxZw9KlS1m7di1lypShY8eOvPDCC5Qo4azw9UlEesad0Yk3UsZ6DRnVV/r8c1HciYkBGdGNwHHY+7vIo6sO0q/Xx75PLoU1YoSc90nyyZefsPXSVmq8UINz985hw0bx7MWpVrAaDQo3IKtX1sd2bavVytatWwkICGDx4sX4+/vTvXt3unTpkiwX8+BBcT86E8MxY0Z/+vSZg8nknHs0ZbyQ/99H6TyPA+7fl7IHDx6k6zRWLy8MS5ZAy5aOt1ulCsO8ebB3L9y4IR2BnDnFyHfpAl27ypyo4t+DMnwuEG2NZtHJRXy15yuO3jyKUW/EoDdgs9mIskZRJncZ3qjxBj3K9XDbPZoWUVFRbNmyhaVLl7Js2TKyZ88eHxxTtWrVFIJjooHnkBGTu/9uM6Ln+Jabxyfmq6/g3Xc1oqN1wFqkIGokyeOt+iLtL4W4ZfMAi5CSO4kf7qNHS13YJ0Hwo2De3/Q+847NIyoiCr2nPl442aAz4OPhQ7Q1mu5luzOx8UQKZXFDOd0BVquVHTt2EBAQwKJFiyhYsCDdu3ena9euFElDy23cOOkYpFX5pHDhS5w4URYfn/TO8WZDnI3OCehGWCIIvBFI4I1AQqJC8DR4UiZ3GZ4v8Dy5zA5KHSxZgu3FF9FHulc2zGoysVyv59jo0YwZMyaZiPaSJSKWERmZ8vxxnH77pEkwZIhrEbSKfw5l+NzEarNy6cElQqND8TZ5UzR70SeeoG6z2di/fz9Lly5lyZIlhIaG0qFDBzp27EiDBg3s6pxNwt//A8LDNS5eTHBD/fKLJChv2SI/3ty5RW0/Lo3PYpHw9du34xRSzEAQqWbqOyAsLIyTJ09y/Phxjh8/zrFjxzhwIB/373+HCCSHIM6nWSSkGIO4W4sCHwN/kxDVOQQxltvi22IyRfHGG0F88EHhxy42/MexPxiwcgBRMVFYUqo6HotRZ8TL6MXUNlPpW7GvW9ez2Wzs2rWLgIAAFi5cSN68eenWrRtdu3alePHiTp9H00T4/aef0q58MnjwNCZPHomvr7vGz4zETaaVWg5Bd4P4ePvH/HniTzwMHlisFqKt0Rj0BryMXkTGRFKzYE3G1B9D82LN448LDAxkW506DIqJweRqMJinJ5QuzfUFC+g1YABWq5Xff/+dQoUKER0ttXNXrXK+QoyPD5QvD2vWiLa7InOjDN9/iNOnT7N06VKWLl1KUFAQrVq1olOndnTqNIgiRR7w6JFUFRo9WvZPavhKloQpU6BdrId2+XJ45x0RypC7xBMpTupYhspisXD27Nl44xb399q1a5QqVYry5ctTrlw5ypcvT548FahbtyBRUXHJ358hkZ2zkTSFa8j84g1En+MTEgyfBrwG7AC2AnkxmaKoWHEAp04tpESJEtStW5d69epRt27dDBUMmLxjMuO3jXe5nqDZZObdOu/yQQPnKjrYbDb27t1LQEAACxYsIEeOHPHGLr25nwsXwquvQnS0RkRESsn3GlOnDubll3/Dx8e14pjh4bB/f0uqVl2Qal07q83Kpzs+ZdL2SWmWGgIpT9W0aFNmtJ/BuWPnaN++PVO/+46uly6Jfp0rdSXr1oUFC8DPD6vVyuTJk/nmm2/44YefmT69PTt2uJ7a5+Eh3te9ex+vnKIi/SjD9x8lODiY5cuXc/Xqz4wadYgKFWDgQAlGuHBBeqVJDd+ECVKdaIFUpqFLF6hcWZQ6Eu6SnGjaba5cuZLIuB0/fpygoCAKFSqUyMCVK1eOEiVKOFSDqVIFDh+2XzMD+IqEPL6OwKdAdpLn8dmQSr+Hgc0ULpyLixfBYonm0KFD7Nixg+3bt7Nz506yZMlC3bp145fSpUu7lS+55NQSei/p7bLRi8NsMjOrwyy6le3mcLumaezfv5+AgAACAgLw9fWNd2NmZFklkCmyDz64zI8/eqHX58HbW4emyX0gFVA0dLrZbNlymMqVf0aCm9KKDDUCnly9+h4jRhxly5YtvPHGG7z++uvJRuExthi6BHRh/YX1Ln2fHgYPshqzEjM9ht+m/UabNm1kw/Hj8NprEBgoE3OWJCNxnU4Mnp+f9O569pR1duzevZtWrXYTFjaEmBjnZd7s8fSUyNb58906XPGEUIbvP89HaNokihSx8ssv8P338NxzMHFicsN37Bg0aSI1aTUNSpeW0jPlyycYvuhoHc89ZyYiImsi41a+fHnKlCnjUgmgBQsk7D2tOae0MJvlWTZoUPJtNpuNM2fOsGPHjvglJCSEOnXqxBvCqlWr2rmFHXMn/A7Fvy1OSFRIutqaxTMLZ4eeJY9PHkCM3aFDh+KNnYeHB927d6dbt26UK+ekQoKbDB8+nOzZszNkyEccOQIhIRKk8dxzULgw/PrrLObMmcPmzdOBEVgsa7BYdHh5xcTPZVmtYDD4ITGSLyAjd5nPPHXqFJMmTWLdunUMHTqUYcOGxddmfG35a/xx7A+XKqrHY4X8Pvm58PaF5Hm2Z87AokVyU587J6HDuXNLZE+rVnKDp9DpOXMGKlXSiIy0N4j+iDCv/fzfX0iwlQVHGiBms8wPNm+ebJMik6AM33+e1sAa/P3F0OXLJ+r5587BsmWJDd/Zs/DppyI2rGkSCThqFJQokWD4YmJ8CAv7jaxZX0h3yzRN2rJvn+PC786g04mBPno0YW4yLYKDgxMZwqCgoFjdUHGP1qpVi6xZE0djvrfhPb7a8xVRVru0jlnIM3EECc+/JcAx5DlpQKYuWxGfw+2h92BojaH0ztM73tgB8cauQoUKT0T702q18swzz7Bp06YURb1jYmIoU6YMP/30Ew0bNqRGjcLMmdOXrVsn8+qrTQgPj2DhwqP06zcdERrI7vA8Z8+e5eOPP2bFihUMGjSIyp0r02d1H7dHzgDeRm8GVB3AVy2/cvscSXnlFVH/SXwv+iMFOO1TPy4hAr2ODR9AzZqwe3eGNU2RwSjD95+nIbA13vA1bQq9eokBLFMmueELDob33hOjNHky5M+f2PBJMMrvQJsMad3lyyLE4W5Uuq+vzKmkxxP48OFD9uzZE+8e3b9/P8WLF48fEdaoXYPKf1ROPNq7j9S48URk/8vGrl+CeGmbIM/FlcA94JWEQ3UWHYXnF6Z7l+50796dSpUqPXGh661bt/LGG28QGBiY6n5z585l+vTpTJ06lU6dOnH+/Hlq167NxIkTqVWrFjly5CA8PNwp1/GFCxf4+JOPmeU3C1vWJG7TlDoRcd+lA7yMXgS9HsQzWZ9J89ppER0t7v/k83r+uGP4vL3h1CkZOSsyHyr49j9PtmRrxo0TKapr15LvXa8eXL8ON2+mJmbhl2GtK1xYlPxz5Ehc+y0tjEaZrtmwIX1GDyBLliw0b96c8ePHs3nzZu7du8ePP/5IkSJF+PPPP6nSogoPHyXJfzyCePQqkbg2oz0mxCAmSU80e5uZv2U+n376KZUrV/5HqjvMnz/fqWoWPXv25O7du0yZMoUXXngBnU5HixYtWLduHWazmezZsxMcHOzUNYsWLcrLH7yMV84k7sn7wJXY12ec/wyapjFt/zTnD0iF48ed9xg4g9EotQkVmRNl+P7z1EL0EhMoXlw0fr/9NvneOh2sWCERnY6fx+FAhQxtYbly0jtu0kTiD9KyAz4+4ko6cQJq1MjQpgCip1qjRg3efvttlixZwue/f46Xd5KH9RFE9a0CEovjSNMgGtHESpLGpuk0Dl3/58rgxMTEsGjRIrp3757mvgaDgbFjx7J48WJeeEHc282bN+evv/4CpErF+fPnnb72klNLiIhJMqxyphPhgChrFAEnApw/IBWOHk2tFmRHpAOZLfZ12oSGJg3cUmQmVHWG/zx1EcOXOM/pww/ht98cH1G2rOP1AKGhfuh0plR1G90hTx6Rx9q5UwJV1q4FgyGhF261aoSGRtOkiYF33zXSpEnaBjKjuBl6kyib3dzeZST1sCzgg0xtHUP6GCAKbPuQQMhsQJKBVbglnJthNx9vo1Nh06ZNFClSJM2E9zgqV66MxWLh/v37AFSvXp3Lly9z48YNihYtyoULF2jQoIFT59p2eVvyaidHkO+uEOJVDEXU6pzg6sOrRMZExge5WK1WIiIiCA8PJzw8PNFr+yXp+p07KxMZ2YaknURhKcldnamjaekWlVE8RpTh+89TG8jGpUuJhyTPPBMvcA+knP5UvLh9YIsnf/6ZlxEjCtGlSxdeeeUVatSokaGuujp1ZLHZJADn6lW5foECOgYNasXbb79D06atMux6zqDX6dFh9xmPIIppcca/PDJSiTN8tZF5qQdI9sVdRBk5Fh06DLrEKiFPEmfdnHEsW7aMxo0bM3bsWNq2bYvRaKRx48asX7/e5RFf8KMkbtG0OhFpYI2yUrhsYSy3LYSHhxMdHY23tzdmsznZktr6nDm9MBh0bgdZOcIv42YEFBmMMnz/eXTAOESPPn15A0ajF6+8spNWrSKYPXs2ffr0wcPDg1deeYU+ffqQOwNrmun1klBf0k7fuHHjBmzevJlWrZ6s4SuSvQhmk5lH0Y8knuEEktIWpwtqRdTWkkqNZkMiOpcgOs2xOtE+Hj74Z/N/vI2+eBFWroStW+H8eelJFCpETJ06BC1axPjx49M+RyyLFy/mww8/ZPTo0SxbtoyOHTvSvHlz1q1bR4sWLVizZo3T53I42kutE5EGXl5eLF26lFJ5S2E2m/H09HSrI7Z3r5T5c00AJgqpbBKHB3GzR76+kMnLND7VqDm+p4J+QEXS188xI36o7BQoUID33nuPoKAgfvjhB44cOUKJEiXo3Lkzq1evxpqR3WY7GjVqxKZNmx7LuVOjav6qWKyxCdGnkb7EEGBg7DIEqXJ6xMHBxZBYILsSAREREVzee5nbt29nfGNPnoSGDSXiZ+RIyWkLDJRJrNWr0X30ERtCQynUtq1EFaVBcHAwZ86coUmTJowfP56PPvoIm81G8+bNWb9+Pf7+/ly4cMHp5uX2tuscxXUiLiGdiM+RMow3caxX7gCLZqFi8YrkyJEDLy8vt70PFSpIaSXX8EUE3OOWhHvTan0888+KjEEZvqcCHSLsnAf3jJ8Z6A90SXxWnY769esze/ZsLl++TPPmzRk3bhyFCxfm/fffd8kFlibR0dS6coUJgYHY8uWTyT+DQWTyGzeGH37I8Eq09+7dY/r06fRp24fo+7FDgUCgMjKa87NbqiMF3hwFSNQBdhI/OMjqkZXA9YEUL16cBg0a8OWXX7pkPByiaSLL8/zzsG2b+LEdiDcbYmLwstlEoqdFC1FWjolxcEJh6dKltG7dGg8PD9q2bYuHhweLFi2iSJEiZM2alcjIyFT/z9evXycgIIChQ4dSsWJFTq09laCT7kwnIq5cetySpKkF/QpmiCC8tzd06OAot/0Sycs3+cc2LOmSsF+JErIoMicqj++pIhgpyXkJ592e3og+50TAud70sWPHmDlzJnPnzqVcuXK88sordO7cGW+7+mlOo2nwxx/w+uvSjU7JuPn4iDtvzBjJunczNj2uiOvs2bNZv349LVu2pG/fvlzKeYmRG0cSZkmfu9hsMvNJk08YVmMYkZGRbNy4kaVLl7J8+XLy5s0bLzJepUoV10YvI0aI8XdWVTm+QWYJp12yRDoSSWjWrBmDBg2iU2z59TVr1jBixAiOHj3K8OHDKViwIBMmTOD69ev4+flx8eJFtm3bxvbt29m2bRt3796NFwaoX78+ITlC6Lyws5T2+g3pi7VIctHjSAWsosh8nz3PEJ8T6WHw4PVqr/NFC+drXqZGYCDUru26RmdSfHwkEb5z5wxpluIxoAzfU0cMUps6Tmja0YNcjxi8QohotHs+m6ioKFasWMGMGTPYt28f3bt3p3///lStWtW5h3pkpBQ727zZeV0zHx9RCt6wQUJFnUDTNA4fPsycOXOYN28eJUqU4KWXXqJbt27xElsWq4Wy35fl3L1zyeepXKBo9qKcGnIKD0Pi6EGr1crevXvjRcYjIyPp0KEDHTp0oEGDBphMSQvJ2jF3rtTPcdXoxWE2w5tvio6dHffu3aNIkSIEBwfjExvGq2kaderUYejQofgZDGz48EMKXLvG835+PHjwgKt6PZZKlcjWvj01WrWibNmyiZLbNU2j8NeFufrwqntttcPL6MXJwScpkt256FRnGDZMhB7cNX4mk3ia1617clHHCtdRhu+pJRz4E5EW2YeE1ukRN05doDdi8DLm13v16lV+/fVXZs6cSZYsWXjllVfo1asXOXPmdHyAxQLNmomematPIZNJ6ikdPCiZ8SkQHBzM77//zpw5cwgNDeWll16iT58+KZb6OXrzKLVn1HZ71Gc2mdnRbweV81dOdT9N0xJV2jh79iytW7emY8eOtGjRAj/7cMGbN8Wnll43r7e3ZFxXSMjRnDNnDkuWLGHJkiWAjIYPHz7M/GnTKPXHH/SOiSEGcYTHmWVNr0fn6ytRIh06wMcfS0fEjpVBK+m+sHu6Jct6V+jNT+1+cvscjoiMlKjiEydcn/MzGiFvXjh0yOk+l+IfQhk+xRPFZrOxefNmZs6cyapVq2jRogWvvPIKTZs2TSx79cEH8OWX7o9iPDxEJXjFikSrw8PDWbZsGbNnz2bfvn106tSJl156ibp16zolu7Xl0hba/tGWiJgIbFpa1QoEHTq8Td4s67GMpkWTzhelzbVr11i+fDnLli1j165d1KtXj44dO9KuXTvyffMNfPUV/lFRBCPObPuSrZWRacmLyOzuG0ghJwviNRyB1LhAp5N6VMuWxR/bvn17ypYti9lsZtu2bezdu5e+OXIw+fp1DNHRpFm/wGCQcgWTJ8tcot0Q6MVFL7L09NLkyexOoNfpye+bnzOvn8HHI4MTSpE+RKtW4vp01tFgNkOBAiL/V9C1cpWKfwBl+BT/GPfv3+ePP/5gxowZ3L17l379+tGvXz8KR0RAlSr42o30whFZzLhZqB+BQ8gU0F925xyOFC9aCfI0mj8fW5s27Nixgzlz5rB48WKqV69O37596dChg0vVJOI4c+cM3RZ04/z982mO/nxMkroQ0DWA53Knv7RQSEgIa9asYenSpaxfu5ZLoaH4Wa34I9/P68DQ2H2PIeFIQYjhi4vtnRS77zEkeDIuOUTz9GTDrFlsOnqUzZs3s3fvXqpWrUqjRo2oX78+jc6fx3fMGPfmEf/3P+nIxBq/qJgoWv/emj3X9rg08jPqjeTwzsGeV/ZkqIszKTYbTJsG774rTU7JAHp7y75vvAHjx4udV2R+lOFTZAoOHz7MzJkzmTdvHr97eNDs5k30dhpS/iSXCo4TTxuDPNR3I7UojhFXGAeC8+Wjbmzict++fenVq1eGFKa12qwsPLmQyTsnc/zWccwmMw9DH+Lt5Y3JaCLcEk6Z3GUYVWcU3cp2w6jP+JTZ6CNH0NesiTEyEn/gVWAZsD92+wgkH/x9xPCVQ0r3VkrhfCHA5PLlMcVqcm7bti0hfWTzZmjbNn3ziF98IUUhY7FYLYzZNIap+6YSGROZ5typj8mH6gWr83un38nvl9+9drhIaKhMoc6dKxkh4eFiCE0myRjp0kWK+ubKlfa5FJkHZfgUmYrIhw8x5sqFMUkhUX+SGz6Azcio5hDQEhnxDbDbHm00cnbhQp5r3/6xiUGHRIZw6Pohur7SldGjR1OpWCWq5K9CNq9sj+V68fzxhxiSR4/iv58hiMBWSaAwkkXhjxi+V4EIZERYG8kasEczGNC9/z6MHUvv3r2pXbs2gwcPlqd/sWJw61b62uvjI2rQ/v6JVgfeCGT81vGsPrsaL6MX4ZZwLDYLOnT4efoRbY2mTK4yjKk3hk5lOv0jot4gAcZRUfLXy0sFr/ybUcotikyF1/nz8lRJWkE7BRohhq8qIvrxvyTbPby9Kfvo0WN9SmX1ykqjIo0wnDDwYrkXyZcvX9oHZQT37iX7nvoAc4AGQBnAfrppARLPOwFJoSsP/AxUi92us1rh5k2io6NZvXo1n332mWz46adEwTP+JJRm9UFcpVORdO5fkdH3fCCZBHZkJIwdC7/+mmh1pXyVWNx9Mfcj7rM/eD+BNwK5H3Efb5M3ZXKVoVrBao9f6cYJdDq5NRX/fpThU2Qujh1LWTg0BeoBPwEv4iAG9dEjkcnv3Ttj2pcKERER7uUquovJlCzjug9QHxnhvZRk9+zAp7HLHcQV2hH4G7vvzdOTzZs3U6pUKXEJa5q4KJNE1q5ARt/XkDS8ibHnnY0Uo5iDA8NntcKff0pZkCxZkn2c7N7ZaV6sOc2LqdLliseLMnyKzEVYmEvl2O8iD/DhwIdAVxxUIAwJSbrmsRAeHu5WsIzblCyZLFG/MFIidTUwI5VDcwE9/WD2IxjcEMKzgbdmoLL/Hdav+Dm+BBGXL0NsVQZHFERGfMcRvemtyMiyOxI4k2zs6+EhpclbJM1aVyieHMrwKTIXPj4OFURSYjgyt/cVEso/ApnrSkTWrBnUuAQ0TaQu58+HHTvg6lUNq/UOpUubqFkT2reHF15wrbiuK0RGRrLpxg2ah4Ym+xHPQGq7+pBY4WsUMiK87g9j6sGhk6C7AD/WB00PYMUcuoiIrFHs1u0m+8HsvHIpO3qTKcVcyquIke2EjPKeBzojbtbfgbeTHhAeDgcOKMOn+EdRhk+RuShXzun5uNXAeuBk7PvvgOeAXsjcH4DNxwd9pUoZ2sQtW6B/f4n1CA+P88zqgGxcuAAXLkj64IAB8MknEn+SEVOMERERrF27loULF7J69WoqVqxIxaJFKXjuXKL9iqVwfIgeanvDo2uIdGtBxD9s5y0Nt0aCBwSHB/PmujeZruVgoTmKIkkK0HdEHh5ZgTbAaCTCdkjs9hcRQ5jM8MXESK0pheIfREV1KjIX0dEyQksisOxP4qjOR0gJtylAN7v9ZiPzTUcR0bVwoHupUlTu1o0OHTq4roFpR1y+1owZzovJ+PhIeZpVqyBW/cwlwsPDWbNmDQsWLGDt2rVUrVqVLl268MILL0gQzbp1IgqZRqZ1qAfU6wenc0FkKupnSdGjI2uExq4ZUPqOrPMneYTtTiSg5m/EvXkZcbkewkH6xODBkiSnUPxDqOoMisyFhwd0757M3XmJxA9aP+AKiY0eQF/gLGL0ALwrVGDkzz8TERFBz549eeaZZxg8eDDr1q0jygVNKk2Dl16CmTNdU1ALCxPPXs2azk81hoWFERAQQLdu3cifPz/Tp0+ncePGBAUFsXHjRgYNGpQQOdqiBTRoIIEuKbUd6NQdTrlo9ABsaDzwhAYvQ0gqydmzY69TCTF8NezWJ8LLC0qVcq0RCkUGo0Z8iszHyZNSXie9MvlmM/z+O3TsCCRoYC5btozly5dz8uRJWrRoQfv27WndujXZs2dP8VQ//CAFENzN3/b0hDZtpDyeI0JDQ1m5ciULFixgw4YN1KpViy5dutCxY0dypZUdfeuWaGzevi3D0iT8VgEGtYWwdMw3elmgy0n4bUnyEV8kYuy+QNyecSwCxiORn/FzKlmywOrVIoipUPxDKMOnyJyMHg3ffOO+pTGZoGlT8TGm4Nq8ceMGK1euZPny5WzZsoVq1arRoUMH2rdvj79dkvW1azJISfAm+uM4nR5k3FMM8CJh9lEwmyEgQAwgwMOHD+ON3aZNm6hTpw5du3alffv2KYt3p8TFi2JM7t9P5Ca26iDfCLjjg0QAhSF+Hh2QG9Ewqxq7bgkie2M/2M4BDJKXXhY4/j00uZ/4089HClddIUGsGiRZPq6+R9u4ldmyiaFOrdqEQvGYUYZPkTmJjpY6cQcOOCyomiomE+TPL9UZnNSSCgsLY/369SxbtoyVK1dSoECBeCMYEFCVb77RER0dt7c/KRu+rci4JwbYTkJ6uFC+fAzvvDOPBQsWsGXLFho0aECXLl1o3759qiNOpwgJgaFDYeFCSWyPiWFlSXixMzzyRAxfe8QuRyL+47WxH6cjYviyAE0cn94UAwMPwLdr3Wyflxe8846IWioU/yDK8CkyLxER0KmT5A24IpPv7w+bNkmNGDewWq3s3r2bZcuWsXTpMs6fP4Cm2Sdc+5Oy4esPRCHjnQKIpok94TRu/Db9+tWhXbt2ZH0MqRYcOyaC0EuW8L+Gj/i5cqz7097wxfE38lEGAbtI1fAB+N+Hi9+42a68eeHcOfD1dfMECkXGoAyfInOjaTBnjlQItdlEN9IRZrPsO2qUuEkzyJV27hxUqGAjIsI+Dswfx4YvHJntmo8YvgFIdmHC5JrZrDF1qo5+/TKkeWlS7ttSnLgfJG8cGT6ALxH5m79J0/AZrfDwE/COSXkfh3h7w9q1UL++iwcqFBmPiupUZG50OujbV+aFfvhBohhz55b1Op2kPtSvLwlz16/DRx9l6PzR0aNgMjn7M1mMFPxpjrg7LcCqRHuEh+vYvz/5kY+L29EP0t7JD7HTIKO+T+yWJYl39bDBXV/nHxsaSKdk7lxl9BSZBpXArvh34OkpeptxmptxjorHLJH/6JErCmqzkQQLY+zSOXbdC4n2uncvAxuYETwiIf+jNqmO+PDyQle+NBw+l/LoO5YYLy+CY2LI/ddfeKsoTkUmQo34FP9O4kZ8jxkvr2Q60CnwN7AJmIu4O/MBCxF9mTuJ9vTJ+KLhKfJslqTFh5JwDXhI8hpFKRCDjbyb9sJvv0GNGjK6zpqVML0eq7e3jMA9PKBUKYzTpjHmhReYuHp1ej+GQpGhKMOnUKTCc8+lVCzCgoRGxi2zkCp4Z4DA2CUICeifF3+UtzdUrfo4W5yY+oXro0tes0KafAaxzRUAJ+OAimUvhtHoIbmRe/bA3buwfDmTChTg2ujRkq8RHAynT0P//kz++mt+/PFHTp8+nWGfSaFIL8rVqVCkQpkyIi+ZnNZJ3hcD3iB5PYKBiLtzKCCCNNWrZ3AjU6Fr2a78ePBHwiyxUbHzSJzHVwtRlo5jJ7DH7r0RUbcGvI3e9K6QpLyTnx/Ur88CLy/6de8OJUok2lygQAE++OADhgwZwoYNG/6xIrIKhT0qqlOhSIOXX5bYDBeqJaXIs8/CpUtPrnq3pmmUnlaaoLtB6T6Xl9GLK8OvkNsnd7JtBQsWZO/evRQqVCjZtpiYGJ5//nlGjRpFz549090OhSK9KFenQpEG77yTMeWFfHwk0+JJDnp0Oh2/tPsFb2P6CuT6mHwYXXe0Q6MHqdciNBqN/PDDD4wYMYKQJ1QbUaFIDWX4FIo0KFsWBg2S+Tl30etF9uy11zKuXc5Sr3A9/lf1f5hN7hXJ9TB4UCJnCd6r916K+6RVfb5WrVq0atWKDz/80K02KBQZiXJ1KhROEBUFtWvDiRPy2hV0OsieXRTU7CRAnyg2zcbLS19m0alFhFuc1z/11HtSLGcxdvTbQXZvx5JqVqsVk8mE1WpNdQ7vzp07lC1blnXr1lEpg2skKhSuoEZ8CoUTeHpKAdqqVV1LR/Dygjx5YNeuf87oAeh1emZ3nM0Xzb/Ax+SDhyF1361ep8eEiWyXsrGn/54UjR5INXgvL680A1dy5crFpEmTGDRoEDYHVSQUiieFMnwKhZP4+Yls6MSJ4vZMYUoLkDlBLy/o2RPOns0cJeh0Oh0Dnx/I6ddPM6zGMLJ4ZMHH5IOfhx9mkxlfD1/8PPzwMHjQpUwXdr66k5JnSzLrp1mpnje1+b2k9O/fH4CZM2em+/MoFO6iXJ0KhRuEhIiE6KxZcOqU5PrpdBL56e8PHTrA669D4cL/dEtTxqbZOHfvHIE3AnkY9RBPgyfP5X6OcnnK4WmUqrNBQUHUrl2bAwcOJCrVZM+VK1eoU6cOV69edeq6gYGBtGjRghMnTqRda1CheAwow6dQpBObDR48EKOXLdt/r9Tcp59+yubNm1m7dq1Dd+bp06fp0KEDZ86ccfqcw4cPJzQ0lF9++SUjm6pQOIVydSoU6USvhxw5RDv7v2b0AN5++21u377NnDlzHG5PK6LTEePHj2fNmjXs2rUrI5qoULiEGvEpFIo0OXz4MC1atODo0aOYzfn47Tepd3vkCDx4oKFpNvLlM/D889CnD7zwQtqdgHnz5vHpp59y8OBBjEYlIqV4cijDp1AonGLUqDGsXFmBixe7o9enXBvYzw+MRpg2DXr0SDlhX9M0mjZtSvv27XnjjTceX8MViiQow6dQKNLk5k1o1MjG6dORaJpzEZxmMzRrBn/+Kekgjjh9+jR169bl6NGjFChQIANbrFCkjDJ8CoUiVe7ckfzF4OCUBLtTxtsbatWCdetkFOiIMWPGcOHCBebNm+d4B4Uig1HBLQqFIkU0TWr/Xr/uutEDiIiQ6kUff5zyPmPGjGHPnj1s2LDB/YYqFC6gDJ9CoUiRJUtgxw6wWOzX+gN5APtJvl+AhnbbE4xYeDh8+ikEpVAgwmw28+233zJkyBCiXNWDUyjcQBk+hUKRIh99lFIQixX4xunzWCzwxRcpb2/Xrh2lS5dmypQprjZRoXAZZfgUCoVDTp+GCxdS2voOMAV44NS5YmLgt99Sd5d+8803fPXVV1y8eNG1hioULqIMn0KhcMiePZKc75jnEdem8yM0o1GMaUr4+/vz1ltvqdQGxWNHGT6FQuGQgwchNDS1PcYD3wG3nT7n0aOpb3/77bcJCgpi+fLlTp9ToXAVZfgUCoVDHj5Ma49yQFvgU6fOZ7WmnPQeh6enJ9OmTWPYsGGEpbWzQuEmyvApFAqHZMnizF7jgJ+Ba2nuaTA4V8uwSZMm1K5dm0mTJjnTAIXCZZThUygUDqlSxRlDVRzoDnzr1DnLl3fu2l988QU///wzp06dcu4AhcIFlOFTKBQOqVlTEtjT5kMS5/QBJBfojImBMmWcu3b+/Pn54IMPGDJkCEpcSpHRKMOnUCgcUqYMFCniaMsloKnd+2eASGBL7PuHQM5ERxiN0KtXyrJljhg8eDD3799XUmaKDEcZPoVCkSJjxzo3L5fAX0hye4lEaw0GGyNGuHZto9HI999/z4gRIwgJCXHtYIUiFZThUygUKdK5M9Su7WyB3R7AACTYJcFaenjEYDB8yZ9/jseSWPssTWrVqkWbNm348MMPXTpOoUgNVZ1BoVCkyu3bEuhy44Z71RmqV4dff73GgAH9uX//Pr/99hulSpVy+hx3797lueeeY+3atVSuXNnF1isUyVEjPoVCkSq5c8O+fVC8uNTYcxYfH2jcGNauBX//gqxdu5aXX36ZOnXq8N1332Gz2Zw6T86cOfn4448ZNGiQ08coFKmhDJ9CoUiT/PlFdeXtt8HLK3UD6OcHWbPC9OmwYoXsD6DT6Rg8eDC7d+/mjz/+oHnz5ly9etWp6/fr1w+9Xs+MGTMy4NMonnaUq1OhULjEgwcwZw4sXCjGME7hJXduKVjbp4/MDXp4pHyOmJgYPvvsM77++mu+/PJLevXqhU6XPAXCniNHjtCsWTNOnDhB7ty5M+4DKZ46lOFTKBTpIu4Jkobdcsjhw4fp06cPpUuXZvr06eTKlSvV/d98800ePnyoRn6KdKFcnQqFIl3odO4ZPYDKlStz4MABihQpQoUKFVi5cmWq+48bN461a9eyc+dO9y6oUKBGfAqFIpOwbds2+vbtS9OmTfnyyy/x8/NzuN/8+fP55JNPOHjwIEZXMuIViliU4VMoFJmGhw8f8tZbb7Fp0yZmz55NvXr1ku2jaRrNmjWjbdu2DB8+nEsPLrH8zHK2Xd7GuXvn0NAo6FeQBoUb0LJ4Syrmq/gPfBJFZkYZPoVCkelYsWIFAwYMoHfv3owfPx6vuNDQWM6cOUONtjV47p3nOHz7MACRMZGJ9vEweGDUGymavShTW02lgX+DJ9Z+ReZGzfEpFIpMR7t27Thy5Ajnz5+nWrVqBAYGxm/TNI2V91YS1iuM3cG7iYyJTGb0AKKt0YRbwjl+6zitfm/FwJUDibG5mIGv+E+iRnwKhSLTomkac+fO5a233uLNN99k5MiRjN48mmn7pxFuCXfpXGaTmQaFG7C853KMejU3+DSjDJ9Cocj0XLlyhX79+nEl6xWuVblGhDXCrfOYTWZer/Y6k5tNzuAWKv5NKMOnUCj+Fdx8dJPCXxYmiqh0ncfb6M3O/jupnF/pfj6tqDk+hULxr2Dq/qnojLEJg18BnwHRdjscBGYBM0koDRhHIPCN7B8ZE8kHmz94zK1VZGaU4VMoFJkem2Zj2v5piYNYNGCPg53bA7uBW7Hvw5Ayge0BD9DQ2HBhA7fCbjk4WPE0oAyfQqHI9Jy7d45oa3TilbWBXUDS6b5cQH1gGWAD1gBlALtq8p5GT3ZeUeovTyvK8CkUikzP4euH0euSPK4KAP6I8UtKrdi/AcAVoHnizaHRoRwIPpDBrVT8W1CGT6FQZHruR953nIPXCNiHuDPt0QMdgNNAa8Az8WabZuNm2M3H0FLFvwFl+BQKRabHpDc5LluUFygJ7HBwUJ7YvylUMPI0eDreoPjPowyfQqHI9JTIWSLlpPOGSETnI+fPZzaaKZenXAa0TPFvRBk+hUKR6amcrzIRlhSS1nMC5YC9zp9Pr9fzfIHnM6Jpin8hyvApFIpMj5+nH/UL1095hwYkzulL63weflQtUDXd7VL8O1HKLQqF4l/Bxgsb6TC/A2GWpJEsLmKBbjm78cewPzAYDBnTOMW/CjXiUygU/wqaFG1C4yKN8TB4uH0OHTqezfYsfy/5m2rVqrF9+/YMbKHi34IyfAqF4l/DzA4zyemdM3lOn5P4mHxY/dJqdmzdwahRo+jVqxc9evTgypUrGdxSRWZGGT6FQvGvIZc5F7tf2U1+3/x4Gb3SPiAWo86I3qKnD30om6csOp2O7t27c/r0aUqXLk3lypUZO3Ys4eGulTpS/DtRhk+hUPyrKJytMKeGnKJH2R54G70x6FKZp9NklFe3cF32vrSXldNX8ueff8ZvNpvNjB07lsOHD8cbwfnz56NCH/7bqOAWhULxr+XErRN8uedLlpxaQrglPH4UaLFaAIg+Hc3KMStpXqo5Op2Oo0eP0rRpUxYvXkzdunWTnW/79u0MGzYMX19fvvnmG6pUqeJ+4yIjISQEjEbIkQMcJeAr/hGU4VMoFP8JboTe4PKDy2ho/L+9O4+OqsoWOPxLVaVSVQkJQx4GCAbFkMYGmdVAICK2IIYWZQqDIoOg0Ubpth3wSRsacImPoQG1WxQBhdAPULohQWQSEhkj8kJsBgFRkHkQQlJJje+PU4QKGWpIwFi1v7VqrVTdc0+dG9bK5tx7zt4xETHERcWRkpLCkCFDGDp0aGm7tWvXMnz4cLKzs4mPjy/Xj91uZ/78+bz++uv06dOHKVOm0LBhw3LtKrRvH8yeDZ9/DsePq6DndIJWC61bw1NPweDBYDLV1GULP0jgE0IErE8++YSlS5eyevXqMp/PmzePadOmsW3bNqKjoys89+eff+avf/0rixYt4tVXX+W5555Dr69kRenZszBqFKxfD1Yr2CrIKwoQEaFmfnPmwBNPyCzwFyKBTwgRsAoKCoiNjeXIkSM0aNCgzLFXX32VLVu2sGHDBgyGyhfKHDhwgPHjx3P48GFmzpxJ7969yzbYuRMefBDMZrB4uYs+PBy6d4flyyFMcobebBL4hBABbeDAgTzwwAOMGTOmzOcOh4MhQ4YAsGTJEjSaqtf6ZWVlMX78eO644w5mzJhBQkIC7NkDXbvClSu+D8xohG7dICsLPHy3qFny2xZCBLTBgweTkZFR7nONRsOCBQs4duwYr732msd+evfuzd69e+nRowdJSUm8/PzzOFJS/At6oGaIOTnqmaC4qWTGJ4QIaMXFxTRq1Ij8/HyaNGlS7vi5c+dITEzkpZde4qmnnvKqz9OnT5Pbqxfd9+zhMeBuYNJ1bf4F9AXCXe9LgBDg6lPCYcDfQS10OXQIGjXy8cqEv2TGJ4QIaAaDgUceeYRly5ZVeDw6OpqsrCxef/111q5d61Wft9Sty8OHD2MChgOfANfPID4G/ghccb2GAi+5vf/71YZ2O7z3nm8XJapFAp8QIuBVdrvzqvj4eJYvX87jjz9OXl6e5w7dAmRf4DzgnvXzIrAaeMKbwZWUwPvve9NS1BAJfEKIgNejRw+OHj3K4cOHK22TlJTE7NmzSUlJ4cSJE1V3+NVXUKiqRBiBgcAit8P/C/wGaOPtAC9ehHPnvG0tqkkCnxAi4Ol0Ovr378/SpUurbJeamkpaWhoPP/wwBQVVlHTPzQWHo/TtcGA5UOx6v8j1mdeMRvjPf3w5Q1SDBD4hRFDwdLvzqpdffpmOHTuSmpqKrbKN6Oay1eCTgGhgJXAY2AkM8XWAxcWe24gaIYFPCBEUOnfuzOXLl9m7d2+V7UJCQnj33Xex2WyMGzeu4oTVdeuW++gJ1EzvE6AncIuvA4yM9PUM4ScJfEKIoKDRaEhNTfVq1hcaGsqyZcvIyclhxowZ5Rt07qzycLp5AlgPzMPH25wARUXQqpWvZwk/SeATQgSNwYMHe112KDIykszMTGbOnMmKFSvKHuzaFVxpzgqI4AAtKCaBu9FSCPze14HFxak8nuKmkMAnhAgabdu2Ra/Xs2PHDq/aN23alFWrVvH000+zffv20s+PNOnKC47pxHKMBpynE7u4m53spAgDJ3iBdzlAizJ9LQAmV/QlJhO88IK/lyT8IJlbhBBBJT09nQsXLvC3v/3N63MyMzMZPXo069ZtZe7c21i4EOxWO1Z7xUVwdVgIxUY/VvAOzxJJFStE69WDH36AOnV8vRThJwl8QoigcvDgQZKTkzl+/DhabRXV268zefIi0tMfQKdrRHGxd+WEDJiJ4hLZdCWeQ+WOFwH/HjaMgQsXekySLWqOBD4hRNDp0KED0ydO5L7ISLV/rrhYraps0wbuuqv0+d1VZ8+qQ6dO2XE6vQ+WACHYqc9F9tCWWH66dsBkouDJJ+mdl0dkZCQff/wx9evXr4nLEx7oPDcRQogAkp3N8itXiH3sMbWgxGJR+TJDQ9VKTasVUlPhlVeghXpON2KESqzia9ADcKLlElEMJoMtdCME1Ib1CROoM2ECG2220r2Dy5Yto0OHDjV7vaIcmfEJIYLD5cvwzDOwciXOoiKqvFmp1YJeDxMmsKbtqwxI1VJY2Aw44Xq5V21vB+wBvgeauT57A0gHtgP3ABDOFT7UpzEoYQ8sXAjt2pX5ymXLlpGWlsabb77J6NGjq3etokoS+IQQge/sWUhMhOPHVVJob5lMbA27j+SLK7ERD4QBzwF/cDXYC/QHDnIt8DmB5sAlIBV4p7S71neYyfvOWOnX7d+/n379+nHPPffwzjvvYDRW3tbusLPzp53sOrGLvNN5lNhLiImIoVPjTiTdmkTjOo29v84gI4FPCBHYrFY1uzp4UP3so0JMLKM/I9gMjEZV2tvlOvoiUA/4b64Fvi2o3C0fAOOAk1ytwmc0Qn4+3H575d935coVxowZw759+1i+fDnNmzcvc9xitzBr+yymb5uO2WrG6rBSbFPpzkIIIUIfgdVhJenWJKbeP5VOTTr5fM2BTpYRCSECW3o6fP+9X0EPIJwiBrAcA2bgXuAysA+wA0tRJWXdLQT6oGo2AKwqPaLTwa5dVCkiIoLFixczatQoEhMTWbXq2vl5p/No+U5L0jenc6bwDAWWgtKgB+DEWfrZ+iPrSV6QzPjPx2O1+3ftgUpmfEKIwHXmjMqK4pYAegkwA9gP1AHaAlbU0zgAC+pmZZjrfVdgDdAULcdZA+wACoFkYLrraChqxtcQiEFl7ewLjAVOoWaJEBICEyfCG294N/xt27YxaNAghg0bxkNjHuKhJQ9RaC306Vdg1Bnp0rQLmUMz0Wv1nk8IAjLjE0IErnnzyrydAbwATABOAz8CaajlKVcro08ABrm9X+M6V4ODNuwBHkeFzwWULzX7GWqxfG/X+6GuHs4C4HT6VoQhMTGRr7/+mi17ttD9w+4+Bz0As83M1mNbeWb1Mz6fG6gk8AkhAtfixaWR5hIwEbXU5DEgHDVP6wO87UVXITjpRjYQB9wGZLl6crcQFS5vRc38BqDmk0sA0GodmExmfBEdHY1mgAan1v+bc0W2IjLyM9hwZIPffQQSCXxCiMBks4FbxfVtqEKxj1ajy1bku376ENiICp9X/QRsAFajtjfsAf4PeJlr9dmLePPNgSQkJDB06FBmzZpFTk4OhYWVz+Syf8xm98ndOGY5YBrqXuxVXwMfuX5+Azh/3cmbAFd+bbPNzLjPx3l9rYFMNrALIQLT+fPglgbsPGr3XXX+6DXgnOun5hUczUY9MXzwus/HoZ4F5qPTteLYsc84eXIfubm55ObmkpGRQX5+PrfddhsdO3YsfbVp0waj0cj0rdMpshaprpyoh5Hd/Bv/0Z+Psvvkbto3au9fBwFCAp8QIjA5nWo1iUsD4Bxgw78/fEeBc1S0OESHikgAr1RwvDFgRaOBlBSIjtYRHd2a1q1bM2LECAAsFgv5+fmlwXD+/Pns37+fFgkt+Pb33+LUuPrvDHwFdAIq3+JXKavdyheHvwj6wCe3OoUQgalBA3W70yURtVJzZTW6PENDv88NC4O//KXiY3q9nvbt2zNmzBjef/99du/ezYULF0iflU6Ixi3HTGPUVsGt/o3B6rDy5dEv/Ts5gMiMTwgRmEJDoVkz+O47AKKAScCzqD98D6IWt6xHPQqb5kWXX9HZr6FcLbnXurX35xgMBmKax2DaZuJSyaVrB7oD81FbCq/3DyiTi80G3Fm2yYmCE94PIkBJ4BNCBK7+/WHGjNI0ZX9CrbWcjNpoUAfoALzmRVdFujqs0T4KPmQ8AxX0unVT++h9FRISgpPrVnPeArQAciibMhTUtsEGbu83ARfK9xns5FanECJwpaWVec4HKuDloragnwIyocw87g3gkwq6MtYzEDuqF1Wkzyx/jhEGDYJ//1tlbfFVs7rNKLFVEGnvQ63orKK+bWVa1G/huVGAkxmfECJwxcbCyJHw0Udg9m3/XBnh4YTMmcPsQVoGpMLYsapoekmJqmjkTqNRAS8mBt57D373O/+/tmF4Q8L14ZSYrwt+DYBWqCQyPjx2NOgMdIvzc0mou2++gc2bISdHJQDX61U+1MRE6NlTTXNrMQl8QojA9vbbkJmpKjNcH6W8YTBA9+4wUOXe7NpV1a7NzYWVKyE7G3buPElUVF2aNzfSrRv06aNiQE3cVex/Z3/mfzMfG7ayB5JR2wR9YLFYCPshDFsHGzp/pqCrVsFLL8GPP6rfpXuli40bITwcHA4YNQomT4Y6dXz/jptAcnUKIQLfDz/AvfeqarI2m+f2Lna9Hm27duqPehWzmOTkZCZNmkRycnJNjLaMfWf30eH9Dpht1ZixApoQDb8x/IaolVH89NNPpKWlMWrUKKKjr39QWIGCAhg+HNauhaIiz+0NBhX0VqxQ/1OoZeQZnxAi8MXFqdtzXbuqWYkX7Ho9i/V6Lv3rXx5v3ZWUlKDX35gE0C3/qyXD7hqGQWeoVj9h2jA+HfkpW7du5dNPP2X//v3Ex8czcuRIdu/eXfmJBQXQpQtkZXkX9ECliTt7Fnr1UsGylpHAJ4QIDjExsGGDqn7epo16EFenzrX7kVotREaqDXc9e6LdvJltw4bx3IsveuzaYrEQFhbmsZ2/ZvacyS3ht6AN0fp1vinUxJQeU0iITgCgQ4cOfPTRRxw8eJAWLVrQt29funTpQkZGBhaLW040p1Otzjl40LcCvlcVFUG/fnDokF/jvlHkVqcQIjgdOaKK4+3dq/5A16unFmjcfTc0VCtGCgsLad++PZMmTWLQoEGVdvXb3/6Wf/7zn7Rq1eqGDff45eMkfpDI2aKzlNi9D0KmUBPP3/M8U3tMrbSNzWZj1apVzJkzh/379zNmzBjGjh1Lo+xsGDHC+5leRTQa9XvdtatmHnrWAAl8QghRhdzcXHr37s3u3buJjY2tsE18fDxZWVnEx8ff0LFcNF9k7OqxZH6XidlqLr/Hz41BZyBMG8YHv/+A/nf29/o7vv32W+bOncvSjAwOWSw0MJtpBpxwvdyfCLZDpeL+HrUNZAmUSerWHNf6m4gItRKoRw+vx3EjSeATQggPJk+ezKZNm1i3bh0ajQaL3cL6I+vZfnw7uSdy2bhlI90Tu/NgwoMk3ZpEx8Ydb+hG8S0/bOGtnLdYd2QdxlAjDqcDp9OJVqPFarcSrg9n3N3jSOuURgNTA88dVqAgM5Owfv3Ql5TQDJXu7TngD67je4H+wEGuBb5YVHKACvXsCZ9/7tdYapoEPiGE8MBms5GcnMwj/R6hoG0Bc3bOwYmTQkshdue1LRJh2jB0Gh0xETFM7TGVAXcOuKEB0Gw1k3c6jwPnD2C1W6lvrE+7Ru2Ii4qr/ve+9hq89RbY7TQDRqPqyO9yHX4RqAf8N14GvvBwtVCmFtzulMAnhBBeWJW7ir5L+6KP0lPs8FxGPTw0nKRbk8jol0E9Y72bMMIalpwMW7YAKi/2B6g8pytRGdPiUIUimuFl4DOZ1AbIuLgbN2YvyapOIYTwYNuxbQz+YjCOOg6vgh5AobWQTd9votO8TlwwX/B8Qm1z5ky5jx5HldRdB7QEmlx3/H+Aum6v4e4HQ0PVFodaQAKfEEJU4dSVU/Ra3ItCa+VV0itjcVg4dvkYKUtS+NXdXNOW3zrxOGoBywLgiQpOeRH42e210P2g0+lfwtIbQAKfEEJUYfhnwzFb/c+aYrFbyDudxz++/kcNjuomaNmy3EdxwG1AFvCYr/2ZzXD77dUfVw2QwCeEEJX45uQ35BzLweqwlj0wE/UwawrwNvAZ18oVfQZsKNu80FrIhA0TsDm8T5f2i0tOpqJSFB8CGwHv8t+4iY5WCQJqAQl8QghRiZnbZ1ZcFghgMKqQ39Oo+kY5Vfdlc9hYfXB1zQ7wRnr0UXV78jrNgY6VnDINiHB7le75CwtTuT5rCQl8QghRiS8Of1Fmu0KF6qCiwamqmxVYCsj6LqumhnbjNWkC998PWi1HgQcqaKIDnKiVnQsAC3DF7XXuakONRtVGrCUk8AkhRAUuFV/ybjXmJeAQUN9z063HtlZ3WDfXu++qSgvVYTLBn/4ETZvWzJhqgAQ+IYSowHnzecJ0VSSeXgpMRT3vC0dVRffgV7etIS4O5s71v7CsXg/x8TBxYs2Oq5pqx9pSIYSoZbQhWhxOR+UNUlG3OI8CK4AioPxakDI0Ib/CucaTT8Lly/DKK75VsTcaVdD78ku1h68W+RX+KwghxI3XJLIJVrvVc8NmQFvgC89N76h/R/UG9UsZNw7WrFGlnTzVMwwNVUHv2Wdh506oW/emDNEXEviEEKICOo3O+0B1L3CEKhe46DQ6kuNqvkL7TZOcrEo5zZ6t9vjpdGp7QlSUel2tbzh6NOzZA2+/rVZz1kJyq1MIISoxqt0oJn45kSKrh3p04UAbYDNl6/K4CdWEktoqtYZHeJMZjTBypHoVFkJeHly8qJ7lJSRAbGytSELtiSSpFkKISlw0XyR2ZqznwOdBCCF0atyJHU/tqKGRieqQW51CCFGJesZ6TL5/MuGhPucpKcOgM/DhIx/W0KhEdUngE0KIKjx/z/O0a9QOg86//WymUBPp96XTqmGrGh6Z8JcEPiGEqIImRMOaoWtoG9MWU6hv+9lMoSbG3zueP3f58w0anfCHPOMTQggvWO1WpmRPYdpX07A5bOUTV7sxhZoI04ax6NFFpLRIuYmjFN6QwCeEED44cvEIs3fMZsGeBVjsFvTaa8s4i6xFNIlswh/v/SPD2w4nMqx2VCMQZUngE0IIPzidTo5fPs6+c/sosZUQZYjirlvuoq6h7i89NOGBBD4hhBBBRRa3CCGECCoS+IQQQgQVCXxCCCGCigQ+IYQQQUUCnxBCiKAigU8IIURQkcAnhBAiqEjgE0IIEVQk8AkhhAgqEviEEEIEFQl8QgghgooEPiGEEEFFAp8QQoigIoFPCCFEUJHAJ4QQIqhI4BNCCBFUJPAJIYQIKhL4hBBCBBUJfEIIIYKKBD4hhBBB5f8BrswztEM6Fd8AAAAASUVORK5CYII=\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "solution = backtracking_search(usa_csp)\n",
+ "print(solution)\n",
+ "draw_graph(usa_csp, solution, node_size=400)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 32,
+ "id": "4e2c7f5e",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'WA': 'R', 'OR': 'G', 'ID': 'B', 'NV': 'R', 'CA': 'B', 'AZ': 'G', 'UT': 'Y', 'WY': 'G', 'MT': 'R', 'ND': 'G', 'MN': 'R', 'SD': 'B', 'IA': 'G', 'NE': 'Y', 'CO': 'R', 'KA': 'G', 'MO': 'R', 'OK': 'B', 'NM': 'Y', 'TX': 'R', 'AR': 'G', 'MS': 'R', 'TN': 'B', 'AL': 'G', 'GA': 'R', 'FL': 'B', 'NC': 'G', 'SC': 'B', 'VA': 'R', 'KY': 'G', 'IL': 'Y', 'WI': 'B', 'MI': 'R', 'OH': 'Y', 'PA': 'R', 'NY': 'G', 'NJ': 'B', 'DE': 'G', 'MD': 'Y', 'DC': 'G', 'WV': 'B', 'VT': 'R', 'NH': 'G', 'ME': 'R', 'MA': 'B', 'RI': 'G', 'CT': 'R', 'IN': 'B', 'LA': 'B'}\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAb4AAAEuCAYAAADx63eqAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAACgDElEQVR4nOyddXiTVxuH70glqVC0xQvF3Rkw3BkyGOzDfUMmMMPGBgO2AWPYcNcxBgMGQ4a7uzvFrVhdkrzfH6dpkzRtk7ZAGefmeq8mr5ycpOX95XnOIypFURQkEolEInlLUL/uCUgkEolE8iqRwieRSCSStwopfBKJRCJ5q5DCJ5FIJJK3Cil8EolEInmrkMInkUgkkrcKKXwSiUQieauQwieRSCSStwopfBKJRCJ5q5DCJ5FIJJK3Cil8EolEInmrkMInkUgkkrcKKXwSiUQieauQwieRSCSStwopfBKJRCJ5q5DCJ5FIJJK3Cil8EolEInmrkMInkUgkkrcKKXwSiUQieauQwieRSCSStwrt656ARCKRpDUmxcSuwF3sv72f/Xf2ExwZjKerJ5VyVqJq7qrUzV8XrVre/t5WVIqiKK97EhKJRJIWmBQT049MZ+TukYTHhBNhiMBgMsQd16g06F30uGhc+Lrq13xd5WtcNC6vccaS14EUPolE8p/g9ovbvP/H+1x6comwmLBkz9e76MntnZu/2/5N4SyFX8EMJekFKXwSieSNJ/B5IJVmV+JpxFOMitHh61So8HbzZm/3vZTIVuIlzlCSnpDCJ5FI3miijdEUnVqUm89vOiV6ZlSoyKLPwtXPr+Lt5v0SZihJb8ioTolE8kbz/Y7veRDyIEWiB6CgEBIdwucbP0/jmUnSK9Lik0gkbywvIl/g96sfkYZI6wMTgDBABbgCBYAmgBuwGvAG6lpf4qZx4+rnV8nlneulz1vyepEWn0QieWNZfHoxalUit7F2wLdAb+ABsDf58aYdmZZ2k5OkW6TwSSSSN5a/L/5NeEx40id5AQEI8UuCKGMU/1z+J62mJknHSOGTSCRvLCcfnkz+pBfAVSBT8qdefnIZufrz30eWLpBIJG8sIVEhiR/8A7HGFw3kA2olP57BZCDSEInORZcm85OkT6TwSSSSV0dwMBw5AidPwrNn4OoKhQtDxYqQP7/TwyW6vgfQFuHiDAT+AsKBZPTMpJhkKbO3APkblkgkL58LF2DECFizRohdZCRER4NKBZ6eYDAI4fv2W2jbVux3gFzeubjy9ErSJ/kDZYDNiICXJMikyyRLmL0FyDU+iUTy8jAaYeRIKF8e/vxTCF5wsBA9AEWBkBCIiIBz5+Cjj6BaNbh926Hhq+auigoHRPId4DrJBriUy17OodeVvNlI4ZNIJC8HgwFat4bRo4WwmUzJXxMWBocPQ5kycPFikqdevHiR4N3BKNEOBKN4AKWBXYmf4uXqRc9yPZMfS/LGI4VPIpG8HD7/HDZvhvBk0g1sMRrF+l+NGuKnBQaDgVWrVlGvXj1q1apFUX1RcmWyk3D+BWJ9z5KmwP+AliRIXgfQqrW8X+R95+YqeSORwieRSNKe3bthwQLnRc+MogiXaO/eADx48IBRo0aRL18+xo8fT/fu3bl58yY/jvqRpa2XotOmLgpT76JnTvM5uGpcUzWO5M1ACp9EIkl7+vQR7s1YfgcqAJ5AdqAxUC/2uSeiqpiLxfPGAFFRGP/+m28aN6Zo0aLcunWLdevWsXfvXtq3b4+bmxsANfLWoHeF3uhd9Cmaqt5FT4vCLWhVtFUK36zkTUNGdUokkrTl+HEIDIx7Oh4YDcwAGiJEbhOwG9gae85wRI75EpuhlKgouj59yrc3buDj45PoS/7a4FdCo0P5/czvDvXiM+Ph4kH9/PVZ1HKRw9dI3nykxSeRSNKWdeviojZfAN8DU4FWiBgTF6AZ8IsDQ2mB4tevJyl6ALduqahwfybl7s5GY/BCbUza9emuccfDxYNxDcax6n+rZO7eW4b8bUskkrRl1y4R0QkcACIR8SQpJjgYgoIgS5YEh06fhv794cABUKtVhIe3A11DKDsXKv8Gng8gRo9WCzodRJkiyOiekb4V+9KrfC98PX1TMzPJG4oUPolEkrbcuRP38AmQhVTeaNzd4e5dK+FTFPjhBxg7VqQGWpXXjMgE+78Rm/tzyHYGk3so0So9Iz8tzoBPEwqo5O1CCp9EIklbLKquZAaCAAOpvNlYjKko0L27yIe3iJ+xT6QP3KqOCYgCfhgIoY9EERnJ24tc45NIJGlLnjxxD6sger+uSc14kZGQKz5Xb8IEWLEiZZkS4eHw66/iesnbixQ+iUSSttSsCVph32UARgCfIMQvHIgBNgIDHBzO6OUFmURPoatXYehQUeAlpYSHQ8+e8PhxyseQvNlI4ZNIJGlL8+aiEHUsXyFSGkYBWYHcwBTgfQeGMqhULA4NpUaNGsyYMYMhQyJjA0b9EYkRQTZXlEX0Igq02Dc8dt+huD1RUTB5shPvSfKfQqXIrosSiSStKVMGTp1K/Tg6HdEHD/LvzZssXLiav/6aiugt5I9won4KfBZ78hmgNXAZuBF7joKoXfYC0adoatzQPj4iWFSjSf00JW8W0uKTSCRpzosxY4hSp/L24u4ObdrgWqoUzZo1o1eveXh7u1uc0AmwTDxfCHS2GWQPcB+YjOhMGx13xGCAS5dSN0XJm4kUPolEkqbs2rWLEj17cqBsWRR9ysqIoVZDxozw229xu44fh4gIyxZE7wDBwAXAiBC2jjYDLUSky38Y+3yd1dHjx1M2vbTgWcQzxh8Yz7vz3sVntA/qH9RoRmjI/mt2mi1rxsrzK4kxxry+Cf6HkekMEokkTTAYDIwYMYI5c+Ywb948ajVoAJ06wd9/OxeN4uIiRG/vXvD2jtt9/z7EJNABs9VXEygK5LQ4Fg6siD3ugnCDLgI+AERxmdcR4BJtjGbYjmFMPDQRNWrCDfHhqYqi8CD0Af9c/oddgbtwUbsws9lMWhdr/eon+h9GCp9EIkk1N2/epH379nh6enL8+HH8/PzEgcWLYdIkEYoZHR1X0SVRPDygShVxnXmMWFztNk7oBNRArOnZujlXI25xTWKfd0CUxn4MZEWligs+fWXcfnGbOovqcC/kHpGGyCTPDYkOAaDLmi78ee5PlrRaIrtHpBHS1SmRSFLFihUrqFixIi1btmTjxo3xogfCZfnFF3DmjMg61+uFFafXi6gSV1fx3M0NKleG338XPfxsRA8gf34D7u5Gm715gXzABkQ1UEsWAqFAHsAPaINIpvgdgJjoFyxc+B2DBw/mzz//5PLly5gcaZabQu6H3KfSnErceHaD8BjHkxDDY8JZf3k9Lf5ogdFk+/4lKUFGdUokbzGKovAi6gUGk4EMbhlw0bg4fG1YWBhffPEFO3bs4Pfff6dixYrJXxQZKaI9T5wQTWZdXaFIEahQAXyt62aaTCZOnz7Ntm3b2Lp1K7t3BxMZuQWTSY+I2JyDsOCuAc8QjY8MCLfmXoQluBEoZTHqRGALcAxXolgy9g8uRNzkxIkTnDx5kqCgIEqVKkXZsmUpU6YMZcuWpUSJEnEtkFKKoijUWFCDg7cPYlCSsXoTQe+iZ3jN4XxT7ZtUzUUihU8ieesIiw5j2dllzD0+lzOPzhBjjEGlUmFSTOTJkIemhZryWaXPCMhk28I8nlOnTtG2bVsqVqzI1KlT8fLySpO5Xb9+na1bt7Jt2za2b99OpkyZqFu3LnXr1qVWrdqULp2Ju3fBWvgsMQvfz4j1vWM2x+8hrMQTVCCCI77N4OJFkdsAPHv2jFOnTnHixIk4Mbxy5QoFCxa0EsPSpUuTMWNGh9/X4lOL6bO+D2Fjw4TR2R+RhkjsFE8D3RAph58har2Z2QE8BT4AnVbH+U/O4+/j7/BrSxIihU8ieUtQFIX5J+fTb1M/UCA0JtTueS5qFzRqDS0Kt2D6e9PJqMtoNcbUqVP54YcfGD9+PJ06dUrVnB49esT27dvjxC4yMpJ69erFiV3u3Lmtzp80CYYMSXljdzMehLCQrnzgth5atoRlyxI9NzIyknPnzsUJ4YkTJzh9+jRZsmSJE0Lzz1y5cqFSqayuVxSFApMLcP35dZiAyKiogjBIwSnhc9W40qdCHyY2mpi6D+AtRwqfRPIWEGmIpNXyVuy+udvhRq1uGjc8XT3Z1nkbpf1KExQURPfu3bl//z7Lli2jQIECTs8jJCSE3bt3x7kvb926Rc2aNalbty716tWjaNGiCYTDkuhoKF4crl2z7MjQCKiEKI5myd+I+jAesc+jEBVcXFFjoicRzASx3rh3L5Qt6/D7MJlMXL16NU4IzZvRaKRMmTJWghjmHUadxXXE5z4B4ZHdB/RD5OI7IXwAnq6eBA8KTvJzeuk8fw6HDgmX9ZMnwmVdtKhwWRcubFVUPD0ihU8i+Y9jNBlpsLgBB+4cIMKQXDuDhHi7eTOp5CS+6/0d7dq1Y9SoUbjaD7FMQHR0NAcPHmTbtm1s27aNkydPUqlSpTiLrkKFCmidDK08cwaqvGMiLNwcm7cM+Bax1md5w22NcGv+Gvu8K5CTjHzFKUqTm9j2SRoNtG0LS2z7vzvP/fv348TQ/POm700MtQ0oWkUIX3PgCKJ+W12cFj69i55TvU9RIJPzXzxSzblzMHw4/POPCEgKC4uP1PX0BJMJcuQQZnmXLiK4KR0ihU8i+Y8zeu9oRu4e6VQkoRUKaF5oWNtwLU0aNUnyVHNAitl1uW/fPgoVKhRn0VWrVg19SpPaLdj71Woaj69HBDqMxCCiNtcR7z98BmRH1OcsDYCaTriSjSP8SwnOWQ/o5QUvXrwUS6Xjio4sPb9UPDELnycwD/gcuIi18Llird8GoBhxwuft5s2CFgtoWTRV7X2dw2iEUaNgzBhR6DS56FcPD2H5rVgB+fO/mjk6gczjk0hSgckk3G7HjsGDB+K+6e8P5ctbddJ5bdx6cYsRu0YIS28CiQdWKEB+oJbFxSeBXUAfcM3iyinPUzTBWvgUReH69etxFp1lQErPnj1ZunQpmWI7K6Ql795fwWm+pC1/cJ5ihPIhIjndLHx/AkWA0qgwoSecDDzgQ1ZRAjtfAAwG0UDXZk3RZDIRERERt4WHhzv9eI/XnnhvqxlfoBAi+NS2L24v7Ft85jkpppR/iUkJBgO0bg1btjjQADGWsDA4eRLKlYM9e6BkyZc6RWeRwieRpICQEJg+HcaPF481GvFFWKUSHqDoaNGWbtAgUbzkVSdKm/nt8G8YFYvcLwU4SLw+mGkOzEZYFtmAMGAzIvXNFSIMEfy6/1e+qfoNTx4/Yfv27XFiZw5Iady4MePGjUsQkPJSuHKFfARygCr8S0O+pREnGIYnP6HBlVDmoeF/qIikPpsZwC/MZW8C/TETEh3Np7VqsU+lshKv6Oho3N3d0el06HQ69Hq9w499fHzQ6/WcCT/DrbBbCV+0FjATqOrcWzdEG7h07hK3M962G0yT5vTrJ0TP2Ygik0lY0bVqiaKoWWwV/vUhXZ0SiZNs2wbt2kFoaPJfgD08hACuWCGCMl4liqKQaWwmnkc+FzuSC6zYB5wHegCrEM0PmsWP52pyJce+HDw7+sypgJTkMBqNBAcH8/z5c54/f86LFy/sPrZ8/tvBgxS3+fALAB+Rm6z48zF72Ul+qnADDcIt1xXIhWiPZIvB05PAyZNR3n3XSrzc3d1TLSxTD0/lmy3fxFvdzRENIwDWIkqNZsPhNT6toqXi0YoEHg8kJCSEokWLUrRoUYoVK0axYsUoWrQo+fLlQ5MWbSd274ZGjRy39Ozh6goNG8LatamfTxohLT6JxAnmzIHPP3fO43PxoihKsn696NH6qrgbcjdhWawciBS4/YjACkuqIITvT0S62yfWhw1qA/W71WfapmlWASlRUVFJClZyj8PCwvD29sbHx4cMGTLg4+OT4HHu3LkpWbJk3P4co0bBzp1W8+sM7OI2lblNI+Bdrjn8WWkVhQLVq0MKIlWTo0ruKqhViQR51ASc7N7k7ubOvnX7UKlUPH/+nAsXLnD+/HkuXLjA9OnTOX/+PI8ePaJQoUIJBLFAgQIOByYB8MknEBGBP+JP4h7WntmyCI/4DYRm/068Fx2Evp+KjhbfFo8dE2sA6QApfBKJg6xf75zomVEUIYDvvQdHjoio71fB+cfncdO4JRS/2ojAindsLlADLYBpiNZ1NsVKTJhYc3gNp387bSVeRqMxgVDZPi9cuLDd/RkyZMDLywu1s9F/p0/DgQPCvxxLZ4Q1dxphWDmFyQQBiSfsp4ayfmXx9fTl+rPr8IXNwQzAdxbPh9sZoHb8Q1eNKz3K9oizQn18fKhSpQpVqlSxuiQ0NJRLly7FCeLixYs5f/48t2/fxt/f30oMixUrRuHChdHpdNave/IkXL8e9zQfIn7WsvuhrfNzAPYtaqKixLrA0qX2jr5ypPBJJA7w9Cl07Jg6j094OHz4obifvIrmp5GGSBTsrGQkFViRLfZnVvtj5vDPwYS2E6yES6fTvfqcskaN4NtvrXb5I5bLTiG8iQ6jUkGdOi8t90ylUjG85nBRucXBHMrE0Kg09H+nf7LneXp6Ur58ecrbWFiRkZFcuXIlThDXrFnDTz/9xLVr18iRI4eVINY9dIhcMTFxAabmPhhm4TN3PxzqyMSNRtiwwcF3+fKRwid5o1AUhWvPrnHm4RnCY8LxcPWgZLaS5M+Y/6XefEeOtCd6/ojvvDeID9ubAywBdmJbVktR4MYN+OMP6NAh7eb24sULAgMDuXnzptV2OuQ0IeVCElhuQIoDKwJyBiSwLl4LRYtCsWLCfWbBziQuWZDYAb0evv46beaVCB1LdWTW8VlpUqszNeXK3N3dKVmyJCVtoixjYmK4fv16nCBu3bqVImvXktuiD9Q7wGLEkmQhRPfDfTgofCD+Az14YLcA+atGCp/kjeDGsxtMODiB+SfnY1JMaNVaTIoJtUqNwWRAq9LSs1xP+r3TjzwZ8qTpa0dGirU9C6+aBUZgEjDEobHCwmD0aMeFT1EUHj9+HCdm9gTOaDSSN2/euM3f35+KFSvSM3tPmu1qRozJTjPTzEAJRJpbtoSH7eGmcaNa7mqOnfwqmDwZ6tVLnRmu1YqQ+5e8+KpSqVjRZgVlZ5blcdhj60hbB9Br9dTMW5Mvq3z5Uubn4uJC4cKFKVy4MC1bxuYHFisGFy5YnZdU90OAccAUi+ctEJYhIMKd796VwieRJIfRZGTs/rGM3DUSg8lg/yYey5QjU5hxdAYj64yk/zv9Ew8ocJIDB5IqQPENMBboC/g4NN7lyxAUJKK7jUYj9+7dSyBmZpG7desWOp0Of3//OGELCAigTp06cfsyZsyYqLWb6WAmHkY8tD8RJwMrXDQu6Uv4qlaFjz4S30pSWrxTpxPrTq/AVevn6ceRj45Qe2Ft7oXcczgXT++ip2nBpixutRiN+hX4yM3Y+UyS6n4I8DWJrPElMebrQAqfJN0SZYii+R/N2Xtrr0OltqKN0UQTzfc7vmdX4C5WfrjSqTY7iXHkiLD67FMB4TccRzL/5eNQlHDq1h1OSMhK7t69S+bMma2stTJlytCiRYu4fZ6enk7N12g0smHDBqZNm0aIMQRtVS0GlSH5wAozw+2Pm0WXhUo5Kzk1l5fO+PFw+zb8+69z4qdSiVyTzZsTJK2/THJ55+Jc33MM3zmcCQcnJOjAbomXqxcuGhdmNZ3FB8U+eGVzjCNvXjh/3noX8d0P5zo7XmTkK/2sk0IKnyRdoigK7f5qx56be5yuLxkWE8bW61vpuqYrSz9IfRTZ1asiIT1xRgDVEMlxyaNSuVC3blf69v2Y3Llzp7rXm5mHDx8yd+5cZs6cSfbs2enbty9zms6h2KxiBEcFp2psDxcPfqj9w+stjGwPjUYkSY4YAb/8Im6uyaUm6/WirM6qVa8+uRIRmflT3Z/4puo3LDi5gFUXV3Hm4RmCo4JRq9Rk88hGhRwV6FqmK80KNUuTL28polYtkYZg88c/F1EQzgNRTc1hvLwgayJRU68YKXySdMmf5/7k32v/pqioMkC4IZw1l9aw9tJamhd2KsYvAck35S4BNAVGI1Y+kkardaFIkWJpkjKmKAp79+5l2rRpbNq0idatW7N69WrKlSsXd86sprPovrZ7istcuahdqJCjAp1Kpa4F0UtDo4EffhBltYYNg40bRdJ0WJiIJgQhdmq16PY+YAD07Qsur0lQYsmoy8gXVb7giyq2png6oXlzUZDahqSSPsYiWv2acQeCQKylvv9+2s0tlcjKLZJ0R7Qxmmy/ZONF1AuRkBWGyDFTIcLsSwPlY/etRiQUWS59ZAL6iIdZ9Fl48NUDp9ZGgoODOX/+POfPn+fcuXOsXVuSq1c7IBqcWuJPfNTmVaAc8BWi1MZOEmuW6u0tlpWaNnV4SnbnuGTJEqZPn05MTAx9+vShS5cu+MQ2VLVEURQ+3fApC04tcFr8tGot2T2zc/Tjo2TzcDAK5nXz5IlYmD16FB4+FCJYvLhomVO2bLpZZ3ojqFwZDh9O/Tg6nVgzeA0Wtj2kxSdJd6y6sMo66q0d4mtmJBAIbALuIlqtgfAy2lYhiSXKEMX6K+vtWn0hISFx4mb+ee7cOZ48eRKX2Fu8eHE6dSrKL79oCLXftzWWAsD/gMlA0gV5o6NTXsDizJkzTJ8+nWXLllG3bl0mTZpE7dq1k3RBqlQqpjSZQgb3DEw8ONFhK9rDxYOATAFs7rj5zRE9gMyZxbeK1HyzkAimTYPq1VMXOevuLqzxdCJ6IIVPkg5ZeGohodF2VMYdUXDfE2FIOZBOFhIdwrxj8/B74RcnbGaRCwoKokiRIhQvXpxixYrRt29fihcvjr+/v1UlkdBQkYKQPN8jMp0sSShIOXJA9uyOjCeIiopi1apVTJs2jevXr/Pxxx9z9uxZcua0DSZPHJVKxU91f6J54eZ0WdOFu8F3iTBEYFIS+nE9XUUwzbfVv+Wbqt+82khCSfqifHn48kuYOFG4jp1FrYaMGWHKlOTPfYVIV6ck3ZHtl2w8Dn8sntgW9TUzHqgO3AG8SdTiA1AFqyizowzFixeP24oVK4a/v7/DhXw/+ggWLoSYxLMp7JAJ2A6Uidvj4QHjxkHv3slfffPmTWbOnMm8efMoUaIEffr0oXnz5rikcm1KURQO3T3EktNL2HtrL7de3MKoGPFx96Fijoo0L9ycNsXaoHPRJT+Y5L+Pooj/AH/84Zz4ubgI0TtwIN315JPCJ0lXKIqCZoQmvtRWYsI3GygMPAHOYu27KAJY9Oh0UbsQ/V2SYZnJcvcuFClCMu5OS8w9fe5h2Ywtb15RtNrd3f5VJpOJzZs3M23aNPbt20enTp3o3bs3RYoUSdX8JZJUoSgwc6aocBMdnfw3QA8PqFYNFi0CX99XM0cnkK5OSbpCif2XLCGItjogym4lYfHZc+c5S86cMHUq9OmjEB6eXHBEW0RJlNlYip5eD3/+aV/0goKCmD9/PjNmzCBDhgx88sknLFu2DA+PxDrISSSvEJVKuCnee0+4LObNE/tMJiGEarX4w46MFO7RIUOgSZN0G0gkLT5JusPrZ6/4NT57Ft9dhKb0QbTXScbVmck9E08GPkn1vBRFoXLlDRw7VgeTyTk3oE4HixfDBxZ5yIqicOjQIaZNm8a6deto0aIFffr0oVKlSukvX04isSQ6Gs6dgxMnRAV3V1coXFiIXjpqOJsY0uKTpDuKZy3OobuHEh6IBG4iojpLIboMOECZ7GXSZF4jR47EYFjDzJm1+fJL8eU2OY+PTgcZMghLr3p1sS8sLIzff/+d6dOnExwcTJ8+fZgwYQKZM2dOejCJJL3g6ipSQ8qWfd0zSRFS+CTpjpZFWnL64en4sPtlWOfxVUFUCjOzDzho8VwLDBQPPVw8aFnEYsEvhUyfPp3Fixezd+9efH31vPce/PgjLFgg8qejouKLWOv1Yp+rK/TrJ4LiPDzg4sWLTJ8+nSVLllC9enV+/vln6tev73wvOolEkiqkq1OS7ggKDyLX+FxEGe22Q3AKnVbH/a/uk8E9Q4rHWLFiBV988QW7d+8mv010WkSEyMs9dgzu3BFLHfnzC49PuXKgKDH8/fffTJs2jQsXLtCjRw8+/vhj8uRJ2w4SEonEcaTwSdIl/Tb0Y9rhaaK4cgrRu+j5qspXjKg9In7n5cuwejXs2gXXroloNV9fqFEDGjcWkWgW62tbt26lQ4cObNmyhVKlSjn82nfu3GH27NnMmTOHAgUK0LdvX1q2bImrq2uK349EIkkbpPBJ0h0XL16kTbs2XG9ynSi3KKd7lwFghHw++bjU75Io8nv2LPTqBcePx0eiWaLRiKi0bNlg0iRo1oyjR4/SpEkT/vrrL6qbF+iSQFEUtm3bxvTp09mxYwft27end+/elChRwvn5SySSl4YUPkm6YuHChXz99df8+OOPNGjTgMpzK/Mk/IlT4qdVa/HAA/dF7vy7YhOlN20S1fsdqdwPoNcTXKMGpU6cYPKsWTRvnnSR62fPnrFw4UKmT5+Om5sbffv2pUOHDnh5eTk8Z4lE8uqQwidJY0yIZiUu2CvXlRihoaH07duXo0ePsnz5ckqWFPUu7wbfpc2KNpx+eJqwmOSrRni4eFAhRwWWt17O7o27edSlC70VBU3iDfXsEqFSERwQgO/Zs6JztB2OHTvGtGnTWLVqFU2aNKFv375UrVpVpiJIJOkcGU4mSSUmRH5BKyAnQvB0gBtQHNGt4FqSI5w8eZLy5cvj4uLCkSNH4kQPIKd3TvZ138eUJlPw9/HHw8UDndY6h06n1eHh4kGBTAWY1WwWO7rswNfTlzaKQi+TyWnRA9ApCr5378Lnn1vtj4iIYMGCBVSuXJkPPviAggULcunSJZYuXUq1atWk6EkkbwDS4ntDCYkK4eSDk9wJvoNKpSKXdy7K+JWJKzD8atgNdACeA4nV8nJB9AxqiMg6j29EqSgK06ZNY/jw4UyaNIn27dsn+WqKonD8/nEO3jnI4XuHCYkKIYNbBirlrESV3FUo7Vs6XniCgiAgAIJT14AVnQ42b+aqnx8zZsxg4cKFVKpUiT59+tC4cWOHa31KJJL0gxS+NwijychfF/5izN4xnHl0Bp2LDvOvT6VSERETQRm/MgysNpCWRVuiVr0sg14BBgG/AY62K3FFWIIbgKo8e/aMnj17cuPGDZYvX07BggXTdoojR8JPP4l1PURnvIcICfYAGgNTEI0eFgDdgD8QjYVsOePjQ10XF7p160avXr0SpDRIJJI3Cyl8bwgXgy7y4YoPufHsBqExSVdK9nT1pGCmgixvvZyCmdNYUADhvpwBpKSjtwdnz06iadORNG/enF9++QW3RNbQUoyiiOjMoKC4Xf7Et4S9i7A/zT3TawOngXeA9XaGM7i4YDhzBvfChdN2nhKJ5LUg1/jeAHbc2EGFWRU49/hcsqIHEBodyqmHpyg3qxx7b+1N49lsIOWiBxCGr+9HTJnyM5MnT0570QO4dSvJ9ik5ERbfWUQFtF3ALOBf4IGd87VubrgfPZr285RIJK8FKXzpnFMPTtF0WVPCYsKc6jJgUkyERofSaEkjzj06l0aziQA64e8fjqurlUEFiLJ9KhUEBkLXrqJkl5eX2EqUgMGD4cULyJzZjaZNd6fRnOxw8qToBZYItxHyXRZYhKh+9gFQFFhq74LQUFGeRSKR/CeQwpeOiTZG88GfHxAek1LrCsJjwmmzog0GU8oroMTzJyASv/Plg2XL4o+cOQPhNtMcMABCQuDxY5g/Hw4eFIVRIiIigYVAKgNPEuPZMxRjwry/9wEf4F2gJjAEIXzmkJr2sc/t8vBhGk9SIpG8LmSR6nTMzKMzuR96X7TmCcO6UHNpoDzxX13uADsR5owK0fy7IihlFW69uMW8E/P4uPzHqZzRZMzRm506iR6Tn30mjixcCJ07w9ChCa9yd4eKFWHtWihUSIjgp5+qgZVAd4df3WQy8eTJEx49esTDhw/jflo+fvToEZWvX2dUWBjeNtevQazxmdkH3EB0zwMhfN8CJ7HsmW7xJiQSyX8CKXzpFEVRGLt/bLy11w7Rky4SCESkzt1FmDG3EaZKTUTncT1wH9gLlIWwmDDG7hvLR+U+SkWemRGId5m+847oL3fhghCzP/6AffvsC58ZLy+oXx/27IFPPw0DdhId3TGBkCUmaEFBQXh7e+Pr60u2bNmsflauXDnuca6HD/Hq1EmYm0mwEBGfWsbOfqt9bm5QxvYsiUTypiKFL51yMegizyKeJTzgDhRBxOHPQbTo2Yy4U79rcV4O4MP4p/dC7nHj+Q3yZ0xpKH4g4s8lvmOC2eqrWROKFhVdypMjRw7RyQDg4sWllCy5jKxZs+Lr62slZH5+fpQuXdpqX5YsWRwr8hwdHd8jKBEiEY7bWcB7Fvv/AkYAv2Dxn8PFRZisEonkP4EUvnTK0XtHk7bOciE6j99EuDnrJD2ei9qFY/eOxQmfoihERUURGhpKWFgYoaGhVpvtPi+vQHr3jkZnUTSlUyfR1ODGDeHmdIS7dyFTJvG4YMFcREXdSPt+dK6u0LSp6MKQSLbOGkRWYWdEir2Z7sD3CIO6qXmnXi9MXIlE8p9ACl865cbzG4RGJ5O64IUwXRSEBZgEwZHB9P22L/2P9I8TNa1Wi4eHB56ennFbYs91uqxotdZCnDevCHLZsAHmzk3+PYWGwtat8O234rlG481Li68aOBBl40ZUESLBPtDmcFvi1/Ys0QFPLHfo9fD116LRnkQi+U8ghS+dYjQ50I0gBOH6VCFiTrImfqparaZj5458NeWrOEFzSSLkPyEmYFKCvXPnwrNnosO4IZHA0ago0RVo4EDImBG6dTMfeXnuw38ePSIcaKnR4GInwtMhVCrhv+3fPy2nJpFIXjPya2w6xdfTN0ExZivuIrIB8iLcnueTHk/noqOEfwly5cqFj4+Pk6IH4k+ldIK9AQFQoYL9K8aOFQEtmTMLV2j58rB/vxBJYaLWdnIOyRMSEsJHH33E559/Ts5Vq3DJkwdTSutpengId6nTn5VEIknPSOFLp5TLXk40ULUlEriEyAQoBfgC9REx+PuIL6jyAFgRf5lapaZ8jvKpnFV/wJPAQKhXL+FRrVYsqfn7w4IFIsYkJES4OM+dgzFjwMfHfLYJ0dEh7di9ezelSwtxPnXqFNUaNeL41KncUBRMzlSIcXEBb2/Ytg2KF0/TOUokktePdHWmU8r6lbWu1LIM6zy+KoiSIwB5gC6IPL7dsedkxsqTqFapKZ41tTfxD4AvSLwTg6PogN6IctGpJzIyku+++46lS5cya9YsmjYVYSm3bt2iWc+ezFy+nIADB2DaNPvd182o1aIbQ5UqIlfDzy9N5ieRSNIXskh1Oqb/pv5MPzqdaGMiN2oHcdW48uU7X/JzvZ/TYFY7EQkAKa8mI6plXkEIYOo4ceIEnTp1okiRIsyYMYMsWbIAEBwczLvvvkvXrl358ssvxcmBgTB1KixdKuqtubuLdbyoKCF4DRqIQBaZuiCR/KeRwpeOeRD6gEK/FSIkOulE7OTI4JaBK59dIatHEtEvTjECo/FnNBrnG7yKUNS9CD9tyjEYDIwdO5aJEycyfvx4OnToEJf+YTAYaN68Oblz52bGjBn200KCg0Uxa6MRfH2ldSeRvEVI4Uvn/H7mdz5a91GK63XqXfQsen8RHxT7IM3mdPPmTZYsKcmgQVFoNI5ZowaDC1qtD0bjZi5eLMOpU2Ltz91dFLAuUUKk3znClStX6Ny5Mx4eHsyfP5/cuXNbHf/888+5cOECGzZsSEEQj0Qi+a8j1/jSOe1Ltudi0EV+PfCr0+Knd9EzpPqQNBW9kJAQmjVrRrduP6DR1EJ0YL+F6Nxgr3uEO0ajkTVrMrN//3lmzcqISiU8jEajWFZTq4W38YMPRMpDqUSMQUVRmD59Ot9//z3Dhg3jk08+SZD8PnXqVLZu3cr+/ful6EkkErtIi+8NYc7xOfTf1J9IQyRGJem8NDVqMMDcVnPpWrZrms3BZDLRsmVLsmXLxqxZs2JdiApwCJiLcGHeBAyIgqElMJkaM2NGdz77LCMqlQtGY+KpBWq1KIvZqxf8/LN1Xei7d+/SvXt3nj17xqJFiyhSpEiC6zdt2kS3bt3Yt2+f7JIukUgSRaYzvCH0LNeTc33P8WHxD3HXuuPt5i0ELha1So23mzfuWnfal2xPuf3liDyUkjW4xBkyZAgvXrxg6tSpFutmKkTv8tnABUTQSzTwHINhL61afcuAAdkxmdyTFD0QAZcRETBzJlStKlIhFEVh2bJllC1blmrVqrF//367onf27Fk6d+7MypUrpehJJJIkkRbfG8iziGfsDNzJwTsHufbsGmqVmgKZClApZyVq+9cmg3sGzp49S506dTh9+jR+aRC4sXDhQkaMGMGhQ4fiIieTo2tXWLEiYZ8+R3Bzg9KlY8ibtxNnz55m0aJFVEgkU/7Bgwe88847/PTTT7Rv397uORKJRGJGCt9/mMGDBxMYGMgyy46xKWD//v28//777Ny5k2LFijl0zcaN0Lp1ykTPjEoVRs2am9mwoRE6nf3Uh4iICGrXrk2jRo0YPnx4yl9MIpG8NUjh+w8THh5OiRIlmD59Og0bNkzRGDdv3qRKlSrMnTuXxo0bO3SNyQQ+Pj8TErIb2GhxpCBQwM4+DTCAhE1pJ6FWL+bZs6N423aVRaw5tm3bFq1Wy9KlS1PRa1AikbxNyDW+/zB6vZ5p06bRt29fImK7FADw9Klok7B4MSxZIjrDhiasxmKO4BwwYIDDogdiaIOhBrAf0cAWRGfcGOCEzb6rQCdEJ11bFqPVdmGRvUPA999/z927d5k3b54UPYlE4jDS4nsLaNu2LYX8/RlRtKgomHntmgiZNMWmH6jVIqqkfHmRT9C8OUZFoVWrVvj6+jJz5kynhKV7d5g/PxrwAfYA5RFtXzcC14HxFvuGIKrB+APXEFW3QVTdLgPco2LFLBw+bP0aixYtYvjw4Rw6dIisWdMqMV8ikbwNSOF7C3i8eTOhjRuTx80NjaXlZw9PTyhenNGlS7Pp0iU2b97sWNdzCwoXhsuXQXRfaI6o7/kpUA4hblks9oUD8xCVtmsCQ2NHGYyIEl2DXi8MUrP27t69m9atWzu15iiRSCRmpKvzv87atWRt2RJ/kyl50QMIDcV05Aifzp7Nmm+/dVr0AO7dMz+qiaiaDcLyqx67We6rGfu4C7A49rEJWBq7D2JiRGoDwNWrV/nwww9ZunSpFD2JRJIipMX3X2bvXlF42RHBs4eXF5w4IZruOXmZWDLcDvwP0UepBHAP0USwIMKay4pY48uHsPz8gM2xjz+MPd8VV1d49AiMxqdUqVKFL7/8kl69eqXsPUkkkrceKXz/VcLCoEABePAg5WOo1VC2LBw+LB47gNFoJFcuIw8euCLKmGUARgJHiW8QWBZoC0wBbltc3R3RUj4C0bJoCiBqeD5/Hs177zWibNmy/Prrryl/TxKJ5K1Hujr/q4wbBy9e0Aj43s7hvxH2lQERWqICxtieZDLBxYsiCz0RgoKC+Oeffxg6dCh169YlY8aMhIZujz2qQzQNHI9wcZp5N3ZfDZvRugDLgb8wuzkBChVS+PTTPnh5eTF27Ngk3rREIpEkjxS+/yIGA0yeDBERdAGWICpqWrIYUV5aCywEMmE/oYCwMBg9GhDW3KlTp5gxYwZdunShUKFCBAQEMHHiRFQqFV999RWBgYHMmtUILy/zADWBRwixM1M9dp+t8NVAWIi5MHfRdXcHX9/9HD9+nKVLl6LRJF32TCKRSJJDujr/ixw4AA0bQkgIEQjLbh3xMvMMyI4oLV0g9vhsoDMi8862MJhBo6HNO++w7fRpcuTIQZUqVeK2YsWKJRCjqCjImjU+ICU1uLgYyZy5EkeO/E2uXLlSP6BEInnrkW2J/oscPSpCIRHOxg8R1pxZ+P4EigClEZafJ9AGEUe5EDvCp9UyuEED5q5dS6ZMmZJ9eTc30V1h4EBhMKYUNzcjKtV8/vlnlhQ9iUSSZkhX53+Ry5chMr4zQxdgJWDes4j4FbSFiLhLDdAe+ANRX8USd7WaSlmzOiR6Zvr0EX31UpANAYBarWAw3GfBgmyUL18+ZYNIJBKJHd4Y4QsOFpW11q2Df/+FmzdBOmkTwWTdEPZdRMr4GkT6+GGEyN0GdiDW+gBaIMRxve14ipJgzORQq2HDBsifX8HNzeDUtRqNglr9lAEDNvC//zV36lqJRCJJjnTt6gwNFeUkx48XQqfXxx+LiQGNBjp0gC++gEKFXt88LXkY+pBdN3dx+O5hbr24hUatoWiWolTKWYmaeWuic7HfZSBNyZULXFzi3J0g1u8WITLqGgK+wE+IVPFmFpdGIqzA9y3Hc3EBX1+np+HjE82hQ1356KNW/PNPY8LDPZK9xsMjlJIlT1G79mx+/HG+068pkUgkyZFug1u2bIH27UXudVLrRFqtuC9/+imMHCnWl14HFx5fYNDWQWy+thkXjQuh0aEosbGUWrUWvYsek8lEj3I9GFZzGBl1GV/KPJ49e8apX36h0rhx6C2ELxAoBGQDJiDW9AoD7YDeFtcfjj12D8hs3qnXw9mzkC+fEzMxS+oOIIJNmxry/fcjOHu2BBqNgdBQT8wOBw+PUBQFcua8x/ffj6BDh6WAByrVThKuOEokEknqSJfCN3q0EDFnernp9cLq27kTMmR4aVNLgKIojN47mpG7RxJpiIwTu8Rw07ihd9Gz7INlNCyQslZBtq9//vx5/vnnH9avX8/JkydpWLUqy7ZvRxtjvVpXCzgFPED0SKiFcHfalnguDvRBVNIEwM9P1CFzqgPCb4h6m9bfWq5fz8eBA1U4dqw8z5754OkZStmyJ6lU6TDFi5+zeYkcwBVAj0QikaQV6U74pk+Hr79OedfuEiXg4EFhCb5sFEWh29/dWHF+BeExzk1Yp9Uxq9ksOpbq6PTrRkREsGPHDtavX8/69etRFIX33nuPpk2bUrt2bdG0tVs34Sc2GpMfMMmJ6uCHH+Cbb5y46CGQH1F6DBYsgF9/FU0hvL2hZUsR9enjA8OHw9WrojuSJSoVXLniRoECnwG/pO49SCQSiQXpKrjlyhX46quUd+2OioILF8RN9VUweu/oFIkeQIQhgo/XfczBOwcdOv/WrVtMnz6dpk2b4uvry+jRo8mTJw///PMPgYGBTJs2jSZNmsR3Kh8+XGR/pxZPT3C6LuZMhKtTCN7AgfDLL/DihfhScvMm1K8P0dHJjRMFzECUMJNIJJK0IV1ZfHXqwK5dlgGEexGduc8hAu6LAhMRVT3uI1rYbABCgZyIwPwBuLt7cP06ZM/+8uZ64fEFys8qT4QhdTfl3N65ufzZZdy11iJlMBg4cOBAnFX34MEDGjVqxHvvvUfDhg3JmNGBNcIZM1L1TSJSrSZy+XJ8Wrd28sqcwD2CgyFHDpg3Dz78MP5oaKhYLhwzBm7dSsrigwIFvID5wAcpeg8SiURiS7qx+AIDRcGReNELBpoCnwFPgbvAMMAt9nkVhCVwAAgBtgDPEQH7MHPmy53voG2DiDREikiRsYCl9XIMca8GUSvsIDAV+BH4FZFB/lAcfhrxlCWnxV0/KCiIJUuW0K5dO3x9ffn888/RarXMmjWLBw8esHjxYtq2beuY6IGw1D7+2Doc1kEUnY5/GzSg4uDBXLt2zYkrnwGPAdi/X6QTtmplfYanJzRpIgKYkicU2OfE60skEknSpBvhW7nSNi/vcuzPdghrTwc0AEohChx7IapQ+seelxuYBJQiMlKsK70sHoU9YvPVzfGBLGZxs8dGRG2wxsBAhI4XIe7thcWEMWjdIKpVq0b+/PlZuXIlderU4fTp05w4cYJRo0ZRpUqVlNWoVKlELsiYMUL8HBnD1RUyZED1+++02LiRr7/+murVq3PkyBEHX/Qi5mCUoCDIksX+emv27OI4wJ9/ivU+yy0eBXD0tSUSiSR50o3w7dwp1ujiKYQQvC4I9XhmcWwr0Iqkpn/3bsrXCpNjZ+BOXDQu8TuqIopc2no9nyDu2R8gYj20gCtCuy2aFTxTntF/cH8ePXrEmjVr+Oijj8iZM2faTFalErkeZ87ABx+IdT9vb6s2QzGA0cNDiGP37sLH+P77APTq1YsZM2bQpEkT1q9PkNpuh/iKMVmyCHEz2Mlfv39fHAfhBn3+3HpLbEyJRCJJLelG+K5csd3jjVjjUwEfIYLumyN8hE8QZZYTx83NyK5dNwkMDOTOnTs8ePCAoKAgnj9/TmhoKJGRkRgMBlKyxHn47mFCo0Pjd+RAGJ77bU68Hvs2kikz6eXuhU9RH9zTIhglMfLnh+XLxTeCBQtElOb//gdt27KmeHF29uolur1Ony4qTFvQvHlz1q1bR48ePZg7d24yL+SFuRdElSoi0nbVKuszQkNh40aoW9fRyb/C/BSJRPKfJ91UbrFnFYhglgWxjy8CHYH+iNTq+0mOFxERzscf90GjOY/BYEh0MxqNaDQatFqt3c3FxSXBvpuVbqLksBHM2sA84B3LSSAqQCeDUTHyMOxh8iemBZkyiXyCli3jdl0fM4YDDx9S1yPxyirvvPMOu3fvpnHjxty+fZthw4ahspvXVxxzGkOGDDBsGHz2mTAy69YVutu3rygu06mTIxG4GqCas+9SIpFIEiXdCF/WrHD9elJnFAG6IkLlWwCrEcEu9o1WV1cvDh/ekGxkp6IoGI1GKzGMiYlJUiwHHRnE5vubrQfyRXhn9yIKY4JYlgwlWVSoUKten/FdunRpfvkl+Vy5QoUKsX//ft577z3u3LnD9OnTcXFxsTlLh2h2dBGAAQMgc2aRm2nO43v/fVi61NEqO3qsm9hKJBJJ6kg3rs5337VadkLcOH8F7sQ+vw0sQ5hUXyKiPrsAN2OP343dfxoQN1VH0hlUKhVarRZ3d3c8PT3x8fEha9asZPfzI7eikO/UKQpu3UrRXbsoeecOZXPmpFrhamjVdr4z1EJEdJr70OWPnebd5OeQz8eZcmBpS5kyZTh58qRDbl9fX1927tzJvXv3aNGiBaGh9pT9CyDeeuzRQ1Q8i4iAhw9FxK05MHX48ISpDCACnQoUACGkdZx/UxKJRJII6Ub4Gja0jbr3QoRDVkbcRN8BSiDEMBNiQc0l9rgXUBexFlQAlcpEtWpWkTKOEx4Ov/0G/v5QpAh06SJy4b78Etq1g9y5qTRyHnrF1tJBeGBLxE7b/Lwi8BdwAzAgIknOAHssXjImnNJ+pVM23zTAz88PrVbLnTt3kj8Z8PT05O+//8bPz4/atWvz6NEjmzM6AGmxXulBUla9RCKRpIR0c0epWxe8vCz35EQkvN1F1Hu8i3Bzescez4FYVHuAMLEuIm6SejSaaHbvbkHv3r25ePGi45PYtw8KFoRBg0RmdUSE6IcUESG2Fy8gOpqau25iikokcb0m1jl9jYFKiDz70cDk2KkWjj9FfVvNqGGjuHr1quNzTWPKlCnDqVOnHD7fxcWFuXPn0qRJE6pWrcoVq+gkD0zKYgymFDbjA4QXvhjWJbQlEokk9aQb4VOrYexYSCK+wiG0WqhY0Z3Llxfg6+tLzZo1adKkCVu2bEnalbdkiaijde9esnkQOgP0OAZuMQivXoDFwQzAd0C32OcqhLH6CaLQzFeI9gfZxGEPFw8mt51MVFQUVatWpU6dOixdupSIiFdbpsvs7nQGlUrFDz/8wMCBA6lRowaHDglT9/qz67wzZxi/7FMIS7YsmT20xHcQTDd/ohKJ5D9CuipZpijC5bl7t21On+N4eMD585Anj3geGRnJ0qVLmThxIgD9+/enQ4cO1qkDW7dC8+bCqnOQZ+4Q0A+epaK9nlatpXqe6mzrvA2VSkV0dDRr165lzpw5HDlyhPbt29OzZ09Kl375btDff/+d1atXs2LFihRd/88//9CtWzcG/jaQETdGEB4TjlEx8nUV+KE2uGts13ATwwPIC2xGWP0SiUSStqQr4QPhWaxaVdRvdFb89Hr45x+oXTvhMUVR2LZtGxMmTODo0aP06tWLvn374qfTQUAAPHni9Fz/DYCWbSHCznKfI2R0z8jZvmfJ4ZUjwbGbN28yf/585s2bh6+vLz169KBdu3ZkeEk9l86fP0+LFi1sXJbO8deOv2iztQ2Kq/WfVMlsML8FFMkCblrQ2hHAkCiRa/8orDv5M84kHQUcSySS/xjpTvgAQkJEjteWLY5VX9HpRJmr1auhcuXkz7948SKTJk3ijz/+YHGuXDS5fBl1bKuAPxDlN88ibI98iNjRPgivJcBw4AdElbIrJeHjZhDhxHKWVq3Fy9WL3d12UyJbiSTPNRqNbN26lTlz5rBlyxbef/99evbsSbVq1RLJo3Oee/dg0SIj3367HT+/usTEqPHwgLJloUEDaNvWtoxYQkyKiYqzKnLy4UlMisnuOSWzQYeSUNMfAjKCRg0vIuHQXdhwBVacB2+3bFz97Cpebl52x5BIJJLUki6Fz8zff8fHmZhMouCxGY1GuDUVBXr3FonSzq4PPrl/H498+XCPNS1/RdSbngo0ROSenwTGIcJo3BA1SQKAF0Db2HMP5oIP28BTvZowF/s3fTMeLh5UylmJJa2W2LX0kuLRo0csXryYOXPmoCgKPXr0oHPnzvj6+jo1jpmHD6FPH1FFBaw/XzN6vfjse/QQJT8T+4yXn11Oj7U9CIuJbTw7AVFox7z+eQZYj6g+9g3x2Q4GROehykBFcNe681WVrxhVZ1SK3pNEIpEkR7oWPjMnTsCePbB3r6j96O4O5coJ665+/VS0nduzB5o2heBgXiDiRBeRdAOc3QhRnAN8jqgf4wpEamFpWS1j2ufmZuhddFodRsWIChUqlYrwmHCq56nOgGoDaBjQMFXWmqIoHDhwgDlz5rBq1Srq1q1Lz549adCggcPFrDdsEJZcZCTYNGq3i9mq3rgR7C05lp1RlpMPT8bvsBS+k8C/iHrjJxBiZ/6QtwO3EGZ17Efi4+7Do68fWddDlUgkkjTijRC+l8bEicKkjIpiE6IJUiRJry71QCRPLAX8gFlYCGWGDLBsGUE1K3Li/gkehj1Eo9KQL2M+SvmWQu/ifHug5AgODuaPP/5gzpw53L9/n27dutG9e3f8/f0TvWbtWiF6KQkc9fISwUdlysTvCwoPIuf4nEQbLUI4zcL3DNiGqDaXE/EBTwWaISJg5wMfI1IzY/F29WZ9h/W8m+dd5ycokUgkyfBGRhAYjXDpEhw/Do8fi2jB/PmhfHnR+NRhrlyJi6AJQgTQW34gVYHziD7g/wIVgBUIq9AFaI2NhRgdDTdvkkXfmPoB9RN9WUVR2HtrL7tv7mbvrb08iXiCu9adctnLUS13Nd4r9J7DIunt7c3HH3/Mxx9/zOnTp5k7dy4VKlSgXLly9OzZkxYtWuBmURvsxg2Rh5/SbImQEGjUSAQfecbWIT127xjuWndr4QM4Srw15xe7zx3xDeMfhC+5JlaiBxBljOLYvWNS+CQSyUvhjRK+Z89g0iRRWCU2FoXoaBEN6OYmNKxgQRg8WFg0yYbPx3e9JTNC/AzEfyjmZgu5ABOiOqgWaBK7vwNQD9F2NSsQHRPD3m3beOTjg6+vL35+fvj5+eHj44NKpUJRFBaeWsh3O77jeeRzIg2RGEzx1bn33trLvBPzMCkmepTrwajao5wK8ihVqhSTJk1izJgxrF69mpkzZ/LJJ5/QsWNHevToQYkSJWjfPuWpImYeP4YKFURBmxo1IDAkkBijHX/pNUR0UDab/YWBUwhr0E4wUpQxiktPLqVukhKJRJIIb4yrc+1aUT0sMtJ+EIYlHh5QuLDowiPqPSbC6NHw/fcQE8NzhCfO3hpfLkTL25+AncQbKArwCJgI9AMi3dxYWq8emz08ePDgQdwWFRVFljxZCG4UTLhPOEaNMdn36651x9vNm9X/W03V3FWTPT8xrl27xvz585k/fz6ZMjXk8uWZREdbdnAPR4TtmNcGZwJXEHGry4EPY/cbEHbuDczNf/V6EVyUJc9jHlbpRrS/Rb++CYgqcrsRH2AL4sNiAXYATxEftvkv0OL4x+U/ZmbTmSl+3xKJRJIYb4TwjR0LP/zgXGNZtVoI4LZtULFiIidt2QKtW4vkQURE56/ER3V6IEpe1wamAJ0RLXFLWQwxEdiCqE2NTid8sLlzW73M7Se3qbqgKg/CHmBQ7PZfShStoqWTphPVclSLsyB9fX3Jli0brq6O51AYDAbq13/Azp3ZiRc5ECI2B2G7mhkO/IYw1c7Gnp9Q+KwnGgZFV0Ozj8E1In6NLyuis1R+hIsTcI+Bwish811YboRMsW7XZzo46QsrSqrI/8l3DGj4g8PvTyKRSBwl3bs6lyxxXvRAeDFDQqBePTh9GvLmtT4eExPDhkePaBgaGldOeQDC6huLEDkPxP16DMJrVwZoYPM6nyPE8iyQU6PhcXg4hSznoZhos7oND8MfOi16AAaVgSXGJYQeDCX0bmicFfn48WMyZMgQJ4aWm6Wb1c/Pj8yZM6PVarl6NZmOuFY0in1XSxCLdMlN1AMufABBRaFbDcw9+fBGfJgLgI3QJzOM2Qo/GeC2Kb6DE0DmCKgbCJXvKbhvHQOjMkD//o6WfJFIJBKHSNcW3927okGC3c43DqLVQqVKIhVCpYLr168zZ84c5s+fT8GCBZmrVlNg3z5U9jvhOoxJp2N9tWr0PH2aEiVK0KdPH1q0aMHsk7MZsGVAfH5bSt6DWkvlnJXZ021PXBqE0WjkyZMnPHz40MqtarmZjwUHB5MlSy7u379Mwu86/ti3+K4i3Jz9gUsIP2QSFl/cZCMg/xZ42MIqj0//EDxmQScFfjXFv4KdjkTxeHhAsWLw77/xfYzSMdHRsGYNrFsHBw/C06dCs/PmhZo1RcP7SpVe9ywlEkm6Fr7OnWHZMsvu7P7AQ6xddZsRHbpjSMyA9fBQ+OyzvRw9OoKTJ0/SqVMnPvroI4oWLQp37gh1DUu5MAEinPTKFaI0GlavXs306dO5fO0yz3s+J1Jlsyg5P/ZtfG0x5dUI66iu/eE9XDzY2nkr7+R6x/4JSRAdHc3Fi0FUrOhHdLSt9eRP4sK3BBF90hX4CIeED8AlFFp2gWKrANBFw755UOQx6JJf3rTG1VWE7B4+bNu+I91gMsG0afDtt2LNMyQk4Tlqtcg3zZsX5s93rMKQRCJ5OaRbH9Lz57BihaXomVmHaGtu3pLPXwgLUzF9ujfdu3fn9u3bjB8/XogeQK5cMGWKbTNA59DrRSSNXo+bmxtt27Zl165dDJk/BKNic6d/hgjxB2FIOUh4TDjjD4x37NzwcC5dusTWrVuZN28eP/30E+PG/UhMTNJVZexzE9FuYk7s8xk2x3MhQn4siPGETRPjglbG/wuFg1IgeiDMqBs3oG/fFFz88nn6VNSWHTRILBXbEz0Q4hgeDhcuiFqyQ4YIkZRIJK+edLvGt22b+LKfXASno4SFleb990vbr/LStStcvw6//ur8YqJOBzNmiBbyNpyLOkeM2ibM/xRCK3IiKpoUd+xlFBS239iO0Wjk/v373L59m1u3bnHr1q0Ej0NCQsidOzd58uSJ+1mjRllWrzalwG3sjsg03x77fBbwLaL5bxJE+kBgTSq57KLTaShmgHuIzXJdryziY7iB+GPsB+xC2O+5EUZx16goWLVK1E2rVcvZN/DSePZMuC5v345Pr3GEiAiRlvPsmbAU06jkqkQicZB0K3yHDqVubc8WvV4EuSTqYhoxAvLlg88+E4luya35ubuLNahly0TdNDscuH0g4c5TQBWE+M1BGK2ejr2HJ6FP0GXWkUWfxUrUAgICqFWrFnny5CFPnjxkzZrVbkm0FStg82bHXsuabohmgiCkajyi6W8SROvhakOGPt6FLlb78wHLgM9iTzlDXAgMAJ2A0ggb0y32+APzwfBw8TtKJ8KnKNChg/OiZyY8HBYtEt+XOnRI+/lJJJLESbfCd+WKVX65Be8TP+1aiISC5ImMjGTs2NUULnwGRVEwmUxWP82PvT/8kIaHDlHx8mWMajUuBgPa2InEqNXExNbC3F6gAP+UKEHYokUoCxcmGM9kMnGl8BVRyNPMTUR16+KIkNGMiLt7Fcc+EzetG5PmTKK4X3E8PDwSbC4uSde27NMHDhxI3B2XOCUQ8a1nEJ10OyDkK1MS12jQ3KhJ/Yfx/vROiDxJs/AtRAR8miX1CCILwly/uqztkPv3i8raKSzKnZasWiVKt6VE9MyEh4vfScOGkCVL8udLJJK0Id0Kn33RA9GV2zIQI9Ch8VQqcHFxxcPDA7VajUqlivtp+VitVnOsTBnOxsTgd+MGvrdv4/XsGahUBPv5EZQ3L08KFEBxcaGKzTi2P3df2U1EjEVtsFOIKEfznb0kws/noPAZDAYWLViE8lQhPDycsLAwq02lUtkVRL1ej4eHBzqdFwbDbwjXZVKf33A7+75EmKhNgPqIJI8xSc7X7akvkVpwj13bewdYDFwACiFaQO0jXvjMjeo/Q5SLy5NgQDc4ckQUFn/NDB1qGQ/lT8IAITPmfh7uiAJ41sTEwMyZIjBGIpG8GtKt8OXPL8QqrQIA3Nzc+eyzD6hWLW3Gc4Q5i+ew+XqsbzEGOIeoffZL7AlGRNHmB/auTojaRc3Ov3fa7VqgKArR0dGEhYXZFUXz/mzZdjFtWmNiYlLT+WAEUAkhhomTSeOOZ5QWkfwuMFt9NYGiWPdYX4GQ0pHARcT3gtlAXP2BsDA4cybNhU9RFE49PMX+2/s5cvcIz6Oe4+3mTYXsFXgn1ztUyFHBynV86pRoleUYuxH1fQwIm9a6mkJkpCjBJ4VPInl1pFvhe+cdmDvXGbdcFJY3WOFjjA9aDQ+37ijwKqjlX4sdgTuIMcWIO7kKYdJYZmOsQFiCIIwDy1gYFVa/oYCMAYm26lGpVLi5ueHm5kamTIm7IDt1EkFDU6dax/G4EUEMrpisJpcYRYBWwI9JnuXnehNVmPVaaSegBiKYpbPN+RmB0bFbECKw5X3gDrHVzIxGNq5YwZbHj9Hr9U5vOp3Oqm2ToigsP7ec73d8z72Qe5gUExGGeAv9z3N/olVryazLzNAaQ+letjtqlZp9+5z5QrYQUa8tIvZxwjJCz5/D/fuQPbujY0okktSQboWvTh3H+sTFYxshsgVL11Pp0s43qk0tHxb/kBG7RwjhO4lYtPKxOakSog5afmBv7GYmN6IPEqB30dOzXM80mdeYMeLGPW2aED89YeygFq1YzV0cre4yDFG8zb4CuLpCm3eNaDa7WVXFzosIctkAzE1i9CwI4VuIKOmZGTCp1WTKk4dcuXIRHh5OaGgojx49Ijw83GozW7e2W0REBK6uwt3tlsmN5/WeE5UlCpPWvl890iBCikOjQ/lk3Sf89O9PfJX7K1auaE5ERG6711gTDqxEOHUjgF6IwCDrUnPu7sKKlMInkbwa0q3wZc0KjRuLLuzx632Bds70J7GbrxlPTxg4ME2n5xABmQKolLMSe2/txdQpkUXLErEbJN0BF+hWtluazEulgl9+EUEV7dspLH3WmpLGs3RkMRPpTxQ6B0bJh7Dfpts9qigGWrXRwG73BO0g5iLSGT2wttEHxo5YBCET04ECCNEDiNRo0JQpQ9++fXFPQfdhRVGIjIzk+uPr1F9en5iIGEyKY7mN0UQTGBnIl5e+xOtCOcS3kuRYhYhPbYB4pzGINvQtrc4ymeLKxUokkldAuk1gB1Gc2qKVXIpQq8HfH1q1SpMpOc2cZnNw06TuTXi4ePBz3Z/JpEsqitJ56tWDe+N+p7Z2Dzoi+ZSpqBJ8iQhEWM5dsTZHAaYhvnTUstqrUplwcztNr0mfY7KTFxmA6G1oSzhCEnwQBvBNYK3FcXVMDM1GjMDT05P8+fPTq1cv9u3bh9HoWGa8SqXCxc2F//3zPx5HPna6dqqiVjC4GAj3e+LgFQsRZd+0iOCWD2L32c4L+/mlEonkpZCuha9AAfj559QVVXF3hz//BI0jS1cvgYKZCzK+4fgUd19317pTKWclPq30aRrPDDAY0H7VD22UCE/MxV3cyIlwxQXZnFwWsdIWiBDBoSSGu7uaQ4fK0LVfP7ZqNJiIl09btAjp9Ef0g7iCSG18jOhVG1tfBwVwr1OHS8+fs2zZMkqXLs2aNWuoUaMG7u7uFC9enK+//pqzZ8+SVBW+n/f8zI3nN6z6IDqDSTER47cftTa56+8gkv6XILrw+iHcnhuw/WyNRijuYCEDiUSSetK18AF8/jl89FHKxE+vF0WDzdXJXhe9K/RmWM1h6LSOuBDj8XDxoGKOivzT/h/Uqpfwq1q/PkEimg/PcSUnahZb7LVNNU8cvR5+/BGKFVPTqVMnamzejDGZ/EJHiABud+uGt7c3bdq0YfXq1Tx8+JAnT54wZ84c8uTJw/z58ylVqhQ6nY7y5cszfPhwblmEX4ZEhfDz3p8Jj7F4L/MR0TSWOrYaEbj6Y+yxRQgljsWQfR8mte3nEYMI0TVv8xFJG5cQC7wngcuIygXLEry//Pmd/kgkEkkKSffCp1LBhAkwfrwITtE6sCqp14tiwLt3J1pU5ZUzoNoA1rdfj6+HLx4uSUfZuGnc0Gl1DK0xlB1ddqTYWkyWVavshs1+xUNcmYcuTuzMqeZJo1eF89VX8MUX8fvcq1fHpWdPTKnxWbu7c7dKFWoNG8ajR4+sDvn4+NClSxc2btzIkydPePz4Mb/++ive3t5MmDCBvHnz4unpybvvvkvX8V1RWXa7TapuajVEZbavENXZLH2uefaC1raWXhNAZ7EtBPoSb+2Zt95YuztjqFz5EgaDU5FcEokkFaTr7gy23LoFI0fC0qUiajAiIt5g0evFep6nJ3z5pag8lh7XTSJiIlh+bjnj9o/j0pNL6F30cTfjCEMEGdwy0LNcT/pW7Esub2f656WAQoVEiRwL/BGp2H1RUZ4hrGEAkRRDpJr7IxIRhiMsl1GAiAp1I4r5mp60iPwz4beTiAiiK1bEdO4cTv9KXF2Fz/vgQb4bO5bNmzezY8cO9A66AB48eMDChQtZs2YNhwsfxpTPIphlJ6LRYk7gCaIgDSTslHEZkXZimWu37yvUu0ZiinbOirfF1dVI2bJdefhwL9988w3dunVDp0vdmAQFwbFjcPGiCCzKkEHk8pQunT7/U0gkr5g3SvjMhIaKAh7Hj8O9e2L9rlAhKF9e/N9+U/qWRsREcO7xOV5EvsBN60aRLEXIon+FtasyZhRJZBb4I4TvIBAG5MGfEXjwjANE4Y0np4hkNBpyAKPIQhBfMJ4ezEOvDsH1wQMRkmvD5WPHeF69OpXUasdbQHl4QIkSsGkT+PigKApdunQhODiYv/76yyonzxF8x/nyKMzCYpyEdd3ULxFZMZbCF41YbHwI9LEYzKhFNf0sPCmEoqSsyrReL6zjUaPg4MGD/Pzzzxw+fJj+/fvTp08fvL29nRtw82Yx2KFDQuCiosQCoqur+DISEwPt28PgwRAQkKI5SyT/CRTJ20vGjIoiUvritrygbAElEJQ8oPwPlEWgRKJSAGUG9ZUa+CvtyKc8JKvVtZEqlbJpyRK7L3Xs2DGlbJkyijJ9uqJ4eorN5rXjNg8PsU2YoChGo9U4UVFRSu3atZXPPvtMMZlMTr1d15GuCsMRWzcU1Ch8E/s8MwoNYx+XRkGDghsKoOCDQm/ir43dVJ8WVby8TYm+jaQ2d3dFqVxZUaKirOd4+vRppX379krmzJmVb7/9Vnn06FHybywoSFGaNROfWXIvrNEoik6nKGPHJvhsJZK3hTfENpK8FPz8Ej1kmWjeCtDEpjk0ZAv5CCQ/N8hmGfEBuGi1fDJ0KBERETajhWAyXSNffg307gGPHokeiA0bQtasKGo1JuCJSsX1gACif/lFnNO/fwLz3dXVlVWrVrF9+3YmTpzo1Nu1ChBKrG6qmarAYEQDei3CFWpLlovs3GUkc2bn0m48PKBixfjWW5aULFmSpUuXcujQIYKCgihcuDD9+vXj9u3b9ge7c0e4Of791zFL2mgUawQ//CBawjuYCiKR/JeQwvc2k0zh0rmIgHxHC96oixShfKVKjB49GjgL9EQsoGWmTJnOLFlyQoymKwtd7sGmJfDoESqjEbWi8PzKFQaWLUuBn39m6erVmBKpVO7j48OGDRv49ddfWblypaPvluyesaVRzHVTAxF1U39B+HYfkrBuqg/QGFFdxyb+RIlQaNEsHyVLtiJPnhO4uBjQJlIFBoRrU6eDn36CnTuTriQUEBDAjBkzOHfuHG5ubpQpU4bu3btz6ZJFFE54OFSvDg8eON8mIiwMNmwQYdMSyVvGG7nGJ0kjtmwRmf0WjQ/9sd9nwAC4YC+0JRadDoYN416nxpw8WYFGjTSo1TGIStz2MAdwDEXUbIlfr9u7dy9ffikKYI8fP5537TT5BThx4gQNGjTg77//pmrVqtYHo6JEHbATJ0THVxcX2rusZdmz3SI7Yz0iwNK2bmpOROaGZXALwExEs8B34nfV8a/DnBpzuHDhAhcuXODgwSfs2VOWx48rYjLlRK02olJpUKlU5MkTTufOBvr1y4iPj/Nrgk+fPmXKlClMmTKFmjVrMnjwYMrNmwfz5gkLLqXodLBxI9SsmfIxJJI3DCl8bzMmE+TOLSKEUou7O9zZAJk/wGAIRqt11IXmgUhT34pluySTycSyZcsYMmQIFStWZMyYMQTYCcjYuHEj3bp1Y8+ePRQsWBBu3oTRo0WXV61WNBSOigK1mg3FtLRtEkHIn0A2oKHNYGeJr5vqg7XwnQX+RbSI14KH1oMZzWbQsVTHBHNSFIWbNx9y9Og1rl27zK1bx7l48TwXLlwgJCSEIkWKULRoUastICAArQO5OqGhocyePZvlY8aw6/Fj3Ewmqyq14YgiaWY9nwkcR2i9ZQ/i/sBVRNwOhQvDhQuyFbzkrUEK39vO+vXw4YfWrRqcRa+HAd1g2CLA6S63iFt1EYS/0TrcPiIiggkTJjB+/Hi6du3K0KFD8fHxsTpn9uzZjBk9mhMffYTXyJEietFOhXOjCnJ9CQ+8UjBFG1TRKjrc78CI70aQL18+h697/vw5Fy9e5Pz583GW4oULF7h37x4BAQEJBLFw4cJ20xsMX3wBv/2G1maNzp+EFns4opz4t0A34AAi6/AMwnLHw0MsOFau7MxHIJG8sUjhk0DHjrB6dcrEz8UFihSG41GgvUpyBcMTR4fwPY63e/TBgwd8//33/P3333z33Xf06tUrvuO8onC0TBmKnz2LLvEOxgBsLACtP4Rw1yRPSxIPFw/G1x7P3U13mTp1Kh988AHffvstefIkaJ3rMBEREVy6dMlKDC9cuMC1a9fIkSNHAkGs/OGHqO/cSTCOP/Zd1TuA1gjrrxHC4utlPqhWw4ABoj6gRPIWIIVPIqyj5s1FqRtnxM/NTZTI2d8eMo/FtqyZvz/MmSMCD+fMgb22Na4ToEM0a028cOXp06f56quvuH37NuPGjeO9995DNXQoysSJqByce/cWsLx4ysRPp9VRN19d1rZbi0ql4smTJ4wbN45Zs2bRrl07Bg8eTM6cOZMfyEEMBgPXrl2zEsMbZ8+y/cQJ7BWC8yfxXvC9gL8QAazbASvHZtWqsG9fms1bIknPSOGTCAwG8Y3/55+FEBqSKMKsUomgiNatYcok8CqM6DJujfPCp0U0JpqX5FmKorBx40a+/vpranp6MvX0adQ2rY+SwqCG/7WGTQWcEz+9i553cr7D+g7rcddau2QfPXrE2LFjmTdvHl26dGHQoEH4+vo6PrgzXL2KUrYsKougJDP+JC58SxCf7izgI9uDuXM701ZeInmjkekMEoFWC999J6IgO3YUwSre3mL9ztUVdDoMHh5EAzRqJKqELFwIXmcQJaTTAgOiaWvSgTEqlYomTZpw+vRphj9+TP6oqGT7SQDsB+oAGU2w9U/INw3c74JrMo0WXNQu6LQ6hrw7hH87/ZtA9ACyZcvGuHHjOHfuHCaTiWLFijFw4ECCgmxnlQYoCs6GoTxBNPbtD3wPPLczpkTytiCFT2JN4cIwf75IAdiyBSZOFFbguHGo162jaJYsBE6bZpEDeBhw3NpKHg2iOGbyaK9dw/fhQ0Ak21v2PLDtJ3EA0Q62BXAPkZbx/nNwmw1dt0OGSNCbNHi7eePl6oW3mzd6Fz0eLh70rtCbs33P8m2Nb9Gqk468zJ49O5MmTeLUqVMEBwdTuHBhhg4dytOnTx17+8mgKBCV0Q/FCQsXhOA1AiYANRAiaEWOHGkxPYnkjSDddmCXvGbc3aFSJbHFogaqNW7Mxo0b6dPHXLjyGKKgZVqhBi4Q34kvCdatEykZCBfeIuCz2EPmfhLmroEDYp/3s7h8FGL2Efvh2X4IzKPn9L+LCIsJQ6fVUdK3JPkz5k9RS6hcuXIxffp0Bg4cyKhRoyhUqBCfffYZ/fv3J0OGDMkPYMHjxzB3LqxcCefPQ1SUF7dMWcmJY2koG4AtwPnY578BxRA1uWuDcF3XqOHUnCSSNxkpfBKnaNy4McuWLbMQvrRyc8aOFhHOihWzuHz5ON7e3nGbl5eX1XNvb28ybd+OJtbyeQdYjJDMQgiH6T6E8IUj3Jwj7Lzeh8AQhEs038No8vlUTrKUm7P4+/szZ84cBg8ezIgRIyhQoABffPEFn3/+OZ6enkleGxUFQ4fCb7+JwEvLPPVVtKIXM3G1LSdjQwgiVnYykCl2XzbgV+Bj4DSg0+tFcJNE8pYghU/iFA0aNKB3795ERUXh5uYGZE7T8TUaFzJkyIO7uztBQUFcv36d4OBgQkJCCA4OjttCQkLYHhRECYtrzVZfTYS9aI6tfAqYgOx2Xi87FmuDbm5w+3aaCp+ZgIAAFi5cyMWLFxkxYgQBAQF888039O3b126Lpdu3oVYtUY3MnldzMp/TgzkJhC/Q5jwv4lsOWtIldgMwZcmCOpHqOBLJfxEpfBKnyJw5M8WKFWPPnj3Uq1cPqIywr5IukKwoEGnTu9VeazhXV4UWLYbRooUDKQElSsC5c3FPOyHWr25g3TY3I8KBeh+RJm/JfcDcCMqkKKhMJqcDR5yhSJEi/P7775w9e5bhw4czfvx4Bg4cSK9evXCP/UAePBC55I8eJV5D+ioF+ZP/8T+Wo8O2Ka7jRGo0fGYw0G7HDurUqZPicSSSNwkZ3CJxmsax63yC6gh7Kmn27xcZEJab/YwJL8DBQAubhHHbjhJmPBBt91bYGeJP4iuTRYeEUKhOHcqWLcuHH37IkCFDmD9/Pnv27OHBgwekZeZPiRIlWLlyJRs2bGD79u0UKFCAadOmERkZRdu2Yl0vucYJn/Ebz/HBmNL/xjod7u3a0WzaNLp160anTp0SdLiXSP6LyDw+idMcOXKELl26cP68OVyiDKLPT2pxRxTWGprciYIxY+D77/GPjo7LXbsGPAMqYF1Y+w6iNOfPiLJdBsQ61xREynxBgAwZeB4YyNWrV7ly5UqCn5GRkRQoUIACBQpQsGBBq59+fn6oUlHr8siRIwwbNozDh/MREjKR6GhzevqC2JleQ1TObhn7LnyA4Xhyguvsx4fnPMJAXUT06iRI2nLV60Vk7j//gKsroaGhDB8+nEWLFvHjjz/So0cP1G9KR2eJxEmk8EmcxmQy4efnx5EjR8ibNy/CxmqDbeUW5/ECrhPvfEyGc+egYkX8IyKS7SjhD+xFSOpRhKujOjAGKIHIHAyqU4dsW7cmKmDPnz/n2rVrdkUxPDzcriAWLFjQKVH09w/n5k3zmt+vwFhEjGpd4C7QF3iMCN35CbhKDsYwgfcZxDFaozA2qRdQqYSPuV8/GDFClJyz4NSpU/Tq1QutVsuMGTMoUaJEIgNJJG8uUvgkKaJTp05Uq1aN3r17x+5pA6wj5Tl9HoiaIu2du6xcOZF0n0piXF1pmz071zNmpH///rRt2zY2eMcxXrx4wdWrV+1ai2FhYYlaitmzZ48TxfPnRYNaUXktGOHynYeIPTUTinDojkGErVwFfgDqUIwK/MFlArhGDFq8CEWNIooTeHiIRdYmTWDYMNG8NhFMJhOzZs3iu+++o0ePHnz//fd2A3AkkjcVKXySFPH777+zfPly/v7779g9IYiVtKs4K35RURpcXfugUk0mGQddQg4ehDp1UteTztUVGjfGtGoVmzdvZuLEiZw8eZI+ffrQu3fvVJcee/HiRaKWYlhYGAEBARQsWJDw8LZs396CqCgXYBPQFIgkYQxaF0TuZGFEs6GbwCeIxAzIx3UqcoQyLufp1j4Sv6KZoEwZkZOZMaPD837w4AFffvklBw4cYOrUqTRp0iRVn4NEkm5QJJIUEBQUpHh7eyuRkZEWe18oilJbURQPRVFwaDOZ3JWZM/2UUaNGpnwyX3yhKHq9oojgUac2IyiRnp6K8vix1ZDnzp1TevXqpfj4+ChdunRRTpw4kfL5JcGLFy+UY8eOKcuXL1feeeewxdQWK+CbyLQHKlBPgWEKeCmQQYGrCc7z9FSUxYtTP8d///1XCQgIUFq3bq3cvXs39QNKJK8ZuXotSRGZM2fG378pX399gw4doGFDaNHCm+HDt3H69G+EhemIjLTXPwBEWTI9UAqVai9Nmx5j5sxZLF++PGWTGTcOmjYV7jxn0GhQvLxootcz7c8/rQ4VK1aMGTNmcPXqVYoUKULTpk2pVasWa9aswZhcuGUyGEwGVl1YRefVnamwsAL1ttSjT2AfLllVYsmCyDC0F/pqmYTRHOiOqEJ60+oskyl1bRbNNGjQgDNnzlCkSBFKly7Nb7/9loLPwARcRMTWzgeWA+dIri6rRPJSeN3KK3nzWL9eUUqUUBQXlyhFq42ysjK0WkXx8jIpGs1TZcqUpUpMTG9FUUooiuKnKEpORVGqKYoyRFGUk1Zjnjx5UsmSJYuyb9++lE3KaFSUn35SFJ1OUTSa5K09Dw9FqVhRUa5fV65du6bky5dP+fnnnxMdPjo6Wlm2bJlSqVIlJV++fMqECROUFy9eODVFk8mkzDk+R8k4OqPi9ZOXwnCst8rjFTDGTvG5AnoFlttMPUSBrArMjrX4OsTu76tAfgXuxJ3r5WVSli5N2ceZGOfPn1dq1qyplC9fXjl69KgDV9xQFOVzRXgBPBRF8bL46akoik5RlJ6KolxM24lKJEkghU/iMCEhitK6teNeRZ1OUXLmVJTDhx0bf/369Yqfn59y7dq1lE/y0iVF6dhRidJolAg3N0VxdRWTUakUxctLTKpoUeEDNBrjLrtz545StGhRZeDAgYrJZEryJQ4cOKD873//UzJmzKj069dPuXr1arLTCo4MVmovqK14/OiRUPDM2/udFFyDLT7DMQpkU2CjAtEK3FCgsQJlFYi0ET6TAj0UKKzAg9i3HKLUrv25MmbMGGX37t1KeHh4yj9XC0wmkzJ//nwlW7Zsyueff57IFwCDoii/KELYXJSkXd7a2POGKooSnSZzlEiSQga3SBwiJATefRcuXbJfQisp9HrYsAFq1kz+3ClTpjB16lT2799PRicCMWwpExDAysGDKRAcDEFBIoS/cGGoUAECAuxeExQURKNGjahUqRJTpkxJNo/t9u3bTJ06lTlz5vDuu+/Sv39/atasmSB1ITQ6lKpzq3L5yWWijEl8eE8CYPppMFhGUM5F9FQw5/G9D4xG1KMZjggmWhJ7rgnoCpwAdqDTZWL27BUcPryfAwcOcO7cOYoXL06VKlWoUqUKVatWJXfu3CnOPwwKCmLgwIFxAUGtWrWKHSsGUUJgB8lV9LFGD5QH/kU0JZZIXg5S+CTJoijw3nuwfbvzomfG01Ok3dkUW7FLv379OHv2LBs3bsTV1fk26VeuXKFWrVrcuXPH6Zv6ixcvaNasGXny5GH+/Pm4uCS2ThlPWFgYixcvZtKkSbi7uydIh+iwqgN/nf8radEzM+MYPCjn1JztodVCz54wfXr8vvDwcI4dO8aBAwfYv1+IoVartRLCcuXKOZXGAbB792569+5N/vz5mTJlCv7+Q4HVpCyv0x1RbXUjTkf4SiQOIoVPkix//CFuomHOfHm3QauFd96B3btFDnVSGI1G3n//fbJly8acOXOcFq+JEydy7tw5Zs+enaK5hoeH07p1a1xdXfnjjz/iamgmh8lkSpAOUbxpcbr824XwGAdF4NJ7sPIPiEm6c0Ny6HRw5kyixi0gOtnfuHHDSggvXbpEqVKl4oSwSpUq5MyZfN3U6Ojo2Ea8o5k/PxJX16S7RiSNB6KfRPdUjCGRJI4UPkmSmEyQOzfcuweiVNZuxLdxMwWBAnb2jQTaAVdij4ugy82boWrV5F83NDSU6tWr87///Y9BgwY5Nef69evzySef8P777zt1nSXR0dF07NiRp0+fsmbNmmRbCNly/vx5Jk+ezBzmYMweG7k4ARGEaRajM8B6oC2itMwNRJGWLJ3g2WwwOmd5mdHrRTujwYOdvzY0NJQjR45w4MCBuE2v18eJYJUqVShTpkwilrgRg8GXAgWeEB4ON27EB9rOmQNLlsDOneKLT9as4m9KG5uiGBMDOXOKGqXijuQFPES6PCUvA5nOIEmSHTsgONj8rAais505BP0+Yj3nhM2+q7HnWhMeLjIPHMHT05N169YxdepUVqywV17aPqGhoRw8eJC6desmf3ISuLq6smzZMvz9/alfvz7Pnj1z6vpixYoxaPQgXHIl4io9iaj01h4heiDKneoAZSlkuAXqlPiVwylePIgBA1JwKeJzr127NkOGDGHdunU8fvyYrVu30rhxYy5cuMBHH31EpkyZqF69OgMGDGD16tU8ePAg9upNaLWiKbHRCJMmJf46GTPCRovvShs32ubWK9gvKy6RpB4pfJIk+fdfy1ywigihOxn7fA+ih3dhm30B2OuwoChindBRcuXKxdq1a+nbty8HDx60OnYn+A6TDk6i5fKWFJ1SlAKTC1B5dmU6LOpAgUYF0HukvsSWRqNh9uzZVKlShVq1avHw4UOnrt9/ez8uGjvCdxQRv9ERMK95RiNapDcBnpngvQrgewZcQh1+Pb0e6tQJ48aNUhw8uM+puSaGSqWiUKFCdOnShRkzZnDq1Cnu3bvHsGHD8PLyYvbs2RQtWpT8+fNz4EBfRAUf+OYb8SXn+XP743bqBIsWxT9ftAg6W/aSIhSR7yeRpD1S+CRJsmePcHcKXBH993bHPt+NKPX8rs2+hNaemagouH/f8dcvW7Ys8+bNo1WrVgQGBnLz+U2aLG1CgckFGLRtEGsuruHik4tce3aNw/cOs/bRWi6UuECO8TmYe2JuqlsJqVQqfv31V1q1akX16tW5dcteW1f7HLt/jNBoG+E6igh27EJ8p1wQreNdgeIIz/ClYPioMtQeJsTPNSTR1/HyEq7DpUth27asLFkyn5YtW3L8+HGH5+oM3t7e1KtXj++++44NGzbw5MkT1q9fT4kS8YvAFSqIRrqJWfjvvy/We58/h2fPxN9Zixa2Z6VFxw+JJCFS+CRJ8vix7Z6axIvcHoTwVbfZl3jegqurvTGTplmzZgwcOJBqfapRbGoxNl/bTJQxikiDnQasKogiikdhj+i3sR81F9TkacRT517QdkiVimHDhtG3b1+qV6/O5cuXHbruafhTFGyE9xqQC8hmc/JJhOipgZLAWUAxQdXx8E02aPw56sIb8M4chpubyM7w94f//U+snd2/L8QEoGHDhsyYMYP33nuPCxcupPRtO4xaraZo0aJ4eVmL/IgR8Ntv9n/f7u7QrBksXy625s3tNSZ+DqQmSEYisY/swC5JEo3Gdk8NYCrwFNEepyDgizBhniLu2IlbfIpib8zk0VbR8ujZIwz2u9faJSwmjEN3D1F5TmUO9zxMRl3K8wIB+vfvj7e3N7Vq1WLjxo2UTqLDAYCHq50Sak0R3xHWAi0QEfsvgEDi+yoVRjS6uAwUBVwjoOwC9JVXMrnxFLqU6ZLsXFu1akVoaCgNGjRg9+7d5MuXz8F3mXaUKCEqyY0eDUWLJjzeubMIwFEU0VoxISocaXIskTiLtPgkSVKwoO2eKog79WygWuw+b8Sa3uzYn4nfZMPDTfj52bHUkmD/7f18s+UbDCrHRc9MtDGaWy9u0WZFmzTpoN69e3cmTZpEgwYNOHDgQJLnlvErg4eLjfh5AJ0RHYXWx+47hYjl+B34BdFF1kACT58KFcWzFXd4rp07d2bQoEHUq1ePe/fuJX9BqvFJsOeHH2D2bLh7N+HZ1asLS/XhQ1EcISFuCP+vRJK2SOGTJEmtWmCdz6xD9Dcfj3Bxmnk3dl/i1h6ARvOIvHmzULt2bYYPH87OnTuJjExcCKMMUXy44kMiDClvOxRtjObgnYP8fub3FI9hSZs2bViwYAHNmzdn69atiZxlpHJONSJqxQZvhPhdRXQfOoXwDve22D5EZIJYpP9FGiIpma2kU3P95JNP6NmzJ/Xr1ycoKCjpk589EwrlZARrPGUT7ClQQLhjJ09OeLZKBevWwdq1ieV2FkMmsUteBlL4JEnywQf2bko1gUcIsTNTPXZf4sLn5gYDBvhx7949BgwYQEREBIMGDSJLlizUqlXLrhCuPL+SF1EvrAcyV/AycwNRvWtv4u8jLCaMIduGpInVB9C4cWP++usv2rdvz5o1ayyOGBBfALJTIls//DwTWaPyQXiHDwNPgEqI1DXzVgTIhMj1A1SKCtVFFS2atmD16tXExDi+9jV48GCaN29Oo0aNePHC4rM0GkUtuUaNRC6Bnx8UKiR+Zswo9m/YYBndlAytgYT5jt9/n3jxg+LFxZYQHaLsmUSS9sgEdkmy1K4tIvAcvv8lgk4HV69CDptMh5CQEPbt28fOnTvZuXMnZ8+epXz58tSqVYvfvX7nathV6wtsE8HXAJcQ99xPEn99T1dPNnbYyLt57PrVUsSxY8d47733+OWXX+jUqSqiluYNzDUqF5yETzdAWCpjNPRaPVvab+H6vuvMmjWLq1ev0rVrV3r27En+/PmTvV5RFD799FPOnDnDpk2b0J89K0yxoCAITSJlwtMTsmQRESiVKiX5GleunCR37gq4u6e+1VB0tJoHDw6TJ0/5VI8lkdgiLT5JssycaevudB69XuR22YoegJeXF40aNWL06NEcPHiQ+/fvM2TIEMKjw7kWci3hBZZY5r89AeysJZmJMkSxK3BXyt+EHcqXL8/27duZO/cbIiNLxk4m3rzpXBpKZANNKjx2Oq2OrmW6UjVfVTp27Mju3bvZtm0bkZGRVK5cmQYNGvDXX38laQWqVCp+++03/P39WVKuHEqtWhAYmLTogTgeGCh83r/+aveUO3fu8PHHH1O1an0OHKiLoqQuh1JRdBw9WpGyZRvwxRdfJO+ilUicRAqfJFkKFYJffhHilRK0WiMFC4oyWo7g5eVFw4YN6dCvA57uyZQKs81/SyL1K8YUw55bexybhBMUK5aHrVtNuLpGYBuFqFbBijbg4y4eO4urxpWATAH80uAXq/1FixZl/Pjx3L59m65duzJ58mRy587NoEGDuHr1qt2x1Go188uUofPVq6ginFwzjYgQPkuLcixPnjzhm2++oXTp0mTKlIlLly5Ru/YGVKqCQPLFve2jQaXypWrVnZw7d47o6GiKFCnCqFGjCEtNsViJxAIpfBKH+OQTEXrurPi5uRlRlEuMGXMYBxodWPEs4hlqVTJ/oidJmP+WhKctKPxlWA/90WpDSKyLUe4McLAn+HmCuxMJRB4uHpTMVpI93fagd7H/wbu7u9O+fXt27drFzp07MRgMVKlShXr16rFixQqioy2Ca06dQjN0KO4p7SAfHg6DBxN+8CCjRo2icOHChIaGcubMGUaPHk2mTJkADbAZkZ3vbESmBsgM7ATc8fPzY+rUqRw8eJCzZ89SsGBBZsyY4dT6pkRiDyl8EocZOhRWroRMmZIXQK1WrOn17avhr79u06VLcy5duuTU67lqkrlxmvPfSsU+L4yILUkiv/zhvYfMnz+fnTt3cvPmTafyAu1zB1gKROLvD9myWQdyzJkjvIQFMsG9r8AwEvgpdvsRuwE5ehc97lp3htYYyqGeh/Bx93FoJkWKFGHcuHHcuXOHnj17Mm3aNHLnzs3AgQO5cvkytG8PsYFDvyNicz2B7EBji6mcRyyhZkDE2dRGVGgFMEVEcOvddzl39iwHDhxg+vTp5Ejgv86GKFFTF5G/4QgeiFSZE0BeqyMFChTgjz/+YN26daxcuZLixYuzYsWKNAtUkrx9yOAWidOEhMDChWLJ5+5dIYLmvyKzjrRrB199FZ+4PH/+fEaMGMGBAwfw8/Nz6HWCwoPIOT4n0UablABzcMtdYDvW99YIoBCi44EdKioVKXK9CIGBgdy4cYNHjx6RM2dO8uXLh7+/v9XPfPny4efnl0xD2u8QyXdR+PuLz+arr2DIEHHUtivBlSvgkgWmHoE1FyHwOWjVIo1PUaBwlpx0KtWf7mW7k0mXyaHPKSkuX77M7NmzOT9nDitDQtAZjYxHtLKdATRE2GWbEHn1vRGC2Bf4CuGwnA8MAbYgpMmo06HZvl30mUoSBRF59D1wHZGaYOmu1Mfuyw4MAzrgSPrCli1bGDhwIFqtltGjR1OnTp3kPwiJxAIpfJJU8ewZnDwpai66ukKRIpA/v/28rJEjR7J69Wp27dqFl5eXQ+Nn+yUbj8Ntal6ZhW8DUAJxpzZzF1HU/yvEfdUCL1cvZjadSbuS7eL2RUVFcfv2bW7cuBEnhpaPX7x4QZ48eRIIovlxliz1UKlOA6KEWO/eMHYsXL8OPj72ha9Agfg5RRvheaS43WfSgUbdCOsWT2mDsXNnVEuWEKIo5ESIWRs753VCxAhtsNnfBzhHbGE6tRq6dIF585yYwQWE3XgUUYrMGygHvIMw2Z1bADWZTPz55598++23FCxYkNGjR1OmTBmnxpC8vUjhk7wyFEWhd+/eBAYGsm7dOoe6qw/cMpCJhyZaW30TEPfM3cCXJPSmTUWIYWXr3TqtjodfP8TLzTHRBdGU9ubNmwkEUTy+wd27z+JqTPr7C6GbNg2KFYNRo5IXvoRkQ/ShS2MKFIBr19iEqJoWif16hX6IrovdbPbvQFRUCyW2Q17BguBgzdKXSXR0NLNmzWLUqFHUrVuXkSNHOpTeIXm7kcIneaUYDAZatWpFxowZWbBgQbLd1W+9uEWRKUVSVbkFwE3jRpcyXZjZdGaqxrEmAkXxQqUSwSJm4fPzg2rVRM7i339bC5+XF1ZBMMuXQ8OG8c9jYjQMHfoVWq0WjUaT4Ke9fY6cU6dRI9RGI0sRxvAD7KMF/gEa2ey/iCgbeofYphIuLhBt44J+jYSEhDB+/HgmT55Mx44dGTp0KFmzZn3d05KkU2SRaskrRavV8scff1CnTh2GDh3Kjz/+mOT5eTLkYfC7gxm9bzThMeFJnpsUKoOKH2sl/VrOo0GlSvi9ManizMePJ2fxqcmYMSNGoxGDwYDBYCAyMjLuudFotHqc3E/z43qxkZyZgSBEDJC9//xZEK2EbbmPiISLK/Od6qCgtMXLy4thw4bRp08fRo0aRZEiRejXrx9ffvklnp7JpMRI3jqkxSd5LTx+/Jhq1arRv39/+vbtm+S5BpOB6vOrc+L+CaKMzncld9e6U+JUCfQP9Sxfvtzh4BrHyASI2pZmi69ePWHtlSsnAl127HDG1VmQJMNSU4pOB5GRvECUEV+IKDBmS0dEjw17a3xnsAhC1eksOxSnO65du8Z3333Hjh07GDp0KB999JFDrnVbjCYjl55c4vj94zwMfYhapcbfx5/yOcqTJ0Oe5AeQpEtkOoPktZA1a1Y2bdrEqFGjWL16dZLnatVatnTaQvkc5RN2O0gCtUqN3kXPyjYrObjsILVr16Z8+fLs2ZOWSewJCzND0sWZk6ZKqmdkl0KFAJGiMAJR2W0NogZ2DCKcZgAitnI/8C1CAEOA34BFwBg746VXAgIC+P3331m/fj1r166lWLFi/PHHH5gcrLv3PPI5I3eNxG+cH5VnV6bP+j4M3jaYQdsG0fXvrhSeUpgiU4qw4OQCDKb0Zf1KkkcKn+S1kT9/ftatW8fHH3/M/v37Ez9RUfAMjmR3oz/5rupgdFod2mS89J4unpT2Lc3JXid5r9B7aDQahg8fzpw5c2jdujUTJkxIozywHtgrzAz2izOXLi3KX5q3/v3jjymKJ6Jy9UugQQPMFQS+QpTRHgVkBXIDUxBVRgsirLpTgD8i0eAv4F/im1Dh4iLGewMoV64c//77LzNmzGDcuHFUrFgxiY4agg1XNhAwOYCf9v5EUEQQoTGhhEaHEmOKIdoYTXBUMJGGSC49ucSnGz6lzIwyXHj88hv+StIO6eqUvHY2bdpE165d2blzJ0WKFBE7w8Jg6VLhOzx7VlTIVqshJoaHAX70y/eU3dV0PFZeoNPqUKlUxBhj0Kq1vJvnXb6u+jW1/WvbDZ4JDAykdevW5MuXj3nz5jmcWmGfKEQj3hfJnZgs9+5p2bdvKa1bt0k26Mdprl0Ti49JtIBylGi1mmt//03Rpk3TYGKvDpPJxMqVKxkyZAj58uVj9OjRlC9vXQR70sFJDNk+xKn1ZBUqPFw82NgxbQugS14eUvgk6YIFCxbwww8/sH/fPrJv2gT9+omM7kTqM8YAWp2OiPq1uDF2MIYM3mTSZSKXdy6HRCMyMpJ+/fqxa9cuVq1aRbFixVIx++UIyy81tST1HDv2Ax9/vAyNRsPYsWOpVatWKsazQ9OmsHkzpKLkl+LqyvUCBXj36VOqVq3K999/n2wn+vRGTEwMs2fPZuTIkdSqVYtRo0YREBDAyvMr6bKmS4qDqDxdPTn+8XEKZk7QvVmSzpDCJ0k3/Dx8ONUmTKC6wYDK0cAJV1dROubff5Ntm2OPBQsW8M033zB58mTatWuX/AV2URChIhsRpWOcRQ90B36zSswuXLgwP//8c9oJy8OHIv8uJCTlY3h7w5UrhHt6MnPmTMaOHfvGCmBoaCgTJkxg4sSJtGjfghXZVxAak0y3iiRQq9SU8i3F0Y+OolFr0nCmkjRHkUjSA0ajYqpfX4nSaBRF2HrObZ6einLyZIpe+sSJE0r+/PmVzz77TImKikrhG4hSFKWxoigeiqLgxOahKEpnRVGM1qNFRSm//fab4uvrq3Tq1Em5ceNGCudlw44diqLXp+wz1uvF9RaEhYUp48ePV/z8/JSWLVsqJ06cSJt5vkIePXqklBhcQuE7FIZbbHlRcEdhaOzz/ii42NlUKPiLczx/8lT+PPvn635LkmSQwS2S9MHEiaj278c1pZ0DQkOhefMUrWGVKVOGY8eOERgYSK1atbhz547TYyiKKyL1eySgJzo6uf9a7oigmCnAAmzjzFxdXfn000+5cuUK+fLlo3z58nz55Zep701XqxZs3Cg6rDvaZNHNTZy/caO43gK9Xs8XX3zBtWvXqF69Oo0bN6ZVq1acPHkydfN8hegz6LnueV00hzDzDLgV+9hcW90HEe5qufVAFDStLk4JjQ5l9L7RL3/SklQhhU/y+rl3D777Dv+wMFwRCdaWlEVUcgwEusY+Pmxx/GrsPoKCIJmE+MTw8fFhzZo1NGvWjIoVK7J9+/ZEzzWZhAa0aQO5c4tOFGo1eHioqVjxC4YNO8TUqZlQlIwIgcuAqE2ZAXBDBMN8iyjcbH5H9vHy8uKHH37g3LlzREVFUaRIEX766SfCU5NDV6OGSDRs1Qrc3YmruWaL+dgHH4jza9RIdEhLAaxRowZNmjR5YwRw181daNU2UcKngFxAGUTrK3tEAn8iwl0D4nefeXiGF5GpD3aSvDyk8EleP9OmQayllw9YZnHoDCLXzJJMgN2etuHhInEuhaW01Go1gwcPZsmSJXTo0IHRo0cnyPvasUOI3YcfihZNd+7ETZ3wcDh6FH78sTDffHOPHj2eEhp6DXF3XAisRJgRD2LfgeMltcy96Q4cOMCpU6coVKgQs2fPTnlbpUyZ4PffMd24zvOh3xBcuxp3VaBkzgw5c0KjRqLY6M2bIro2k2OdIvR6Pf379+fq1atpJIBBiO4X7yJMLg3CxMoL/A/RV8Kx3LzEOHL3COHRNn9lpxD9HUsB1xBFSm35G1EKx+b7gM5Fx4kHJ1I1J8nLRQqf5PUzaxZEiYosnRDJ0mYWAp1tTu8CnAZ2JTbev/+majp169blyJEj/P3337Rs2ZLnz59jMomcu6ZNhYEamkQMhNHogtHowrJlEBCQg7NnGyCy5OohilCnnIIFC7J8+XJWr17NsmXLKFGiBKtXr3YqJzE8Jpz5J+ZTcXZFPObmJwfjyF73BLmGQsavDbw3pjRbpnyJ6csvRIPBFJB6AYwAPkdkGQ4D9iFSRkyIgmu3EF8o2sSek3RuXlJceXoFg2LxBeJm7EsVR5S5yYj4BmbJfuAe0JIEBrtJMXHrxS0k6RcpfJLXy6NHEBwc9/QdIBjRxMYI/IEoo2WJHtEf7lt744WGwoEDqZ5Wrly52LVrF3nz5qVChQp8+GEQs2c7V6UrMlK8vWrV4EIa5zdXrFiRbdu2MWnSJH744QeqVq3qUEWa1RdWk3N8Tj7f9DlH7x0l0hBJhCGCcEM4aOBF1As2XN1Aqz9bUWJaCc49OpeqedoTwJYtWyYjgFcRXYXnIPyJSUXKhiIUqDmii6Dz1l+CLw2nEK5Lc5Ggkli7O28i2lV8SILWV2JAO2NK0hVS+CSvlwsXEqwxma2+LYiOADntXNYL8Z0/Qec6kwmOHEmTqbm6ujJ58mTee28Bf/2lS3FpypAQYSmmdTMDlUpFw4YNOX78OJ988gmdOnWiefPmnD17NsG5JsVEj7970HF1R55HPic0Oumw/dDoUC4GXaTi7IosPr041XM1C+C1a9eoWbNmEgJ4A9FP6i7OpYZEIPwD3RDpJY6TL2M+NKrYyJYYROPBQISH9RfgIKJT1AOEzq4EGmD/DxPhMs/pnchBSbpACp/k9WInCrMT8Dsi1tHWzWnGDdH7/Dt7ByNS18LIkuBgWLDgXeK//u8FqiICVTIhIhuOxM5Wg4jU9ESsVnYDLqMo8OAB/PRTmk3LCrVaTceOHbl06RJ16tShbt26dO/endu3b8ed8/G6j/nj3B9OJWcrKEQYIui1rhcrzq1Ik7nqdLo4AaxVq1acAJ44cQJh47dANKpNybpdOKLA2hKHzr5z5w7z589n97LdmCJjX+8iwnX5CaIdfe/Yx3kQVt9KxK+2YuLjRhoiKZe9XArmL3lVSOGTvF7slAvLi7i3bABaJXFpN8QtcpXN/v3nz9OpUyeGDRvGggUL2L17N7dv38aYglSJhQvjg1eEE7Yp8BmihPNdxPqTOS2gCsIkeIFYc9IB5YGzhIfDhAkvt4Wdm5sb/fv35/Lly+TIkYMyZcowYMAAFh9ZzLKzy1JckSTCEEG3v7txJ9j5NI/E0Ol09OvXL04A33vvPebNK4PReBUwoVKJQFJLhg+Hjh1FrI251qlOJyJq4+ufhiFcnk8SvGZYWBgbNmygf//+FCtWjDJlyrBp0ybaVGqDqz62c8NJRBixD+BlsVVCWH6BwHngR5ttavzrFMhYgEw6x4KBJK8HWblF8noJCYHMmSEmBn/Eqk49RCDdM0QjdQMiju8GMBwRZT4q9vKliBCIpwgHl6LVcqNrV3ZXq8b169fjuqVfv36dp0+fkidPHvLly0f+/PkT/MyYMSO2FCxoeQM+Gju753beyILY2e+12d8UkdKwEi8vWLQI3n/f2Q8pZdy7d4/vR3zP3ItzhUZbLpZORhistvtARDLWsth/EtgF9X+pz+Yem1/KXCMiQlEUP/R6UfbNXgun4cPF72KJhUG3c6cQQ+vUSx0wHJPpa06cOMHmzZvZsmULR44coXz58jRo0IAGDRpQtmxZNBrh4uy0uhPLzizDqKQwjzQWVbSKjpk6MuezOSlqgyR5NchGtJLXi5eXyA+4ft1qd0Aip9vSDvgZIXwAKnd38nfqRH47OWcREREEBgbGCeGNGzc4ePAg169f5/r166jVaisxzJWrEDdu9CTeMVII4c7sArRFhOIkFEtrWgGDARF3s2fPqxO+HDlyUKNPDZZMXULUwSjhPVQjeg0ZEd1lLfc9RaQVLgOKIQJQw4DNQBvY82APt17ceil96HS6g6SdAyqCJ0+GU6TIL2TJkoUGDRrw1VdfUbNmzUSb0v5Y50dWX1hNWEzK662qUJE7Y24ebntIkalFGDlyJO3atUOtlo619IYUPsnr54svYOBAAhOJHtESH66wwOaYGrAK5ciQAapXtzuOTqejaNGiFLVti46Iwnv69KmVKO7Z8xgRNGFe3/NGWHRjgI8Q0Q5NgNlJvLkcmGVZUeDQoSROfQlMOzKNKN8oIXQPYqdzE+FLfmazLyOiF1ENRI5aD0T0UFFxvqIo/H7mdwa9O+glzHQfKatzah8fn2hOnDhErlwlHTo/T4Y8TGw0kX6b+qXYJaxz0bGu0zpKfV2KnTt3MnjwYMaOHctPP/1EkyZN0r7jhiTFSOGTvH46dxbN61LZ0duo06EZPlz4yZxEpVKROXNmMmfOTIUKFQBhnW3bBi+sinAUJV5+LyJ8hf2BhomMfBfhUxRcuHCLzz8fh06nQ6/XJ7nZO8fNzc3hG6iiKJx+eFr8L8+FEDezyOVBrF1Z7ssbe2EVxDrWn4hMgU/E7ihjFDtu7HhJwncQ4dROGzQaT3Lleu7UNT3L9eTm85uMPzjeafHTu+hZ0WYFpXxLAVCrVi3279/P2rVrGTBgAKNHj2b06NFUq1YtmZES8uIF/PMP7N8Pp06BwQBZsojvd7VrQ8WKKfqTf6uRwid5/Xh7iyiStm1TLH5GtZqjMTGcURR6KEqafLv28BBWWuIUQfgGZ5K48K0mrpAjkCmTKwUKFCA8PJzw8HAePnxIeHg4ERERcfsS2yIiIoiOjk5WHM2b4qEQ4xMjohTzIsStCiIP5B2E8B2z2Gdu/q5GBFdOQ3h0LUp6Hrl5hIULFxITE5PkFh0dnew5ludOnXqaMmXiX0ejSdg9KSYmrpeugzjvthxZZySFMhei74a+RBmiiDEl3cJJb9KQyejKyrAWVD4eAl4PwM8PEF+mWrRoQdOmTVmyZAnt27endOnS/Pjjj5QsmbwlGhQEAwbAsmXifds21diyRezPnh3GjYMWLZx+u28tUvgk6YNmzeCTT2DqVOfFT6tF4+tLxmXLmNS3L9u2b2fmzJl4e3unakpFi9pO5SKwHlEqKxdwG7Eg9o7NlUaEkowHdgIioV6thhYt/Pj8889TPCej0ZisSJqP3w65jTokdn0pLyLrIhyhB5kRHtw1sfseEW/xQXyBGZuqauFR4Wzbtg0XF5dEN3d3d1xdXZM8x3JzdXXF3/9rIN4PnCcPBAaK34GZGzegUCFnPi2P5E+xQ6fSnaibvy4/7fmJBScXoFFriDJEEWUU1YX00aBWwCMGvjxg5LNDEeiMf4DnP0Kda9eG0aOhlLD+NBoNXbp0oW3btsyYMYP69etTv359RowYQb58+ezOYeNGaNdOZOZER9uvvR4dLbarV6F9e2jQABYvFtGtkmR4fY0hJBIbTCZFGTlSUXQ6x1vleHgoSokSinLvnqIoihIeHq707t1bCQgIUI4cOZLqKRUoYPlydxRoo0AOBfSxPz9W4IUC85XY22HssTwKdFbgfNz1Xl6Ksnp1qqfkME/DnyquI11FS51vUVCjUA+FYhatd/xi93nbtOQZLoJk+cx6X8CkgJc022GKomgUc7umQYNQqlZFuX0bxWhE2bIFxdMT5cwZ67ZOO3ag5MyZsN2T0ahVoqMfpnpW4dHhyu7A3cqExZ8o3zTXKYMaaJTZ5VCO+6EYVYn8TapU4m/4u+8UxWhMMGZwcLAyfPhwJVOmTMqnn36qPHjwwOr48uUp6xzl5qYopUsrSkhIqt/2fx4pfJL0x7FjilKqlPjfr1Yn3n/P01NRfv5ZUQyGBEP8+eefStasWZVff/1VMdq5+TjKb78JbU1J+zrbzd09Qnn6NDQ1n4zTZB6TOV64cqHggUIjCzGrFLuvpGPC13ZF25c0038VRfFSzMIVHo7y9dcoefOieHujlC2L8vffCQUuMeF7+NBF8fHxUVq1aqXMnj1buX37dsqntmaNc1/GLPsXtm5tV/wURfQB7N+/v5IpUyZl6NChyvPnz5VTp1L2Upbi16JFyt/q24KMs5WkP8qVE6v4e/aIiM+KFcVqfsaMkC8f/O9/oqPDo0cwaJBYELKhTZs2HDp0iD///JNmzZrx+PFjh18+OCqYA7cPsPX6VgrXOYRGk/pUV3d3I/nzr6VIkfyMHTuW0KSqXKch7+Z5F5W5irI/ws1pmY2QJ3ZfXtsrE+KiuFA2Q9m0nmIsdYD4vDedDn75Rbg7X7yA48dFu0VbatWyzeED0JEt23AuXrxIixYt2LZtG6VLl6ZUqVIMHDiQnTt3Eu1oJYHTp4UfMSXVgMLDYcMG+NZuVVmyZs3KhAkTOH78OHfu3KFAgSLUq/eUyMiU/71FRYm1vzVr/t/emYc3WWV//JM0XZKWRZFFAVtpi9Aqm6BFoQiiCENdUNFBkK2IuICKOOOjIAwgjCguMCPWhRFBUPgpWpFFECggICo7Vso2RVosAlbpQpP0/f1xEpqmaZuWgjg5n+fp07w373tzk/Z5v7n3nvM91e4iINAEduV/GrvdztixY5k7dy5z587lRq9Cqm5OFpzk3a3vMuObGWT9noUtuMR9+NS2HhR/PBvD7suRuHJMJoiOht27ISNjNxMnTmT16tU8+eSTPPLII+XmltUEaw+tpff83pV6c/qDxbBQe1Zt2rduz/Dhw0lKSiK4atEmlTANmEB1glJKE4HUOizZoHQ6nXzzzTcsXbqUZcuWsXfvXrp27UrPnj3p2bMnTZs2LduN3Q5XXSWZ9Gdzm7RaYf16+UJXAa+9lsno0ZfgdHr+n32A7BWnI9FIbRB79k6u5/+DeBgtQPaehehoGbZGe/pGhU8JCJYvX86gQYMYPnw4Y8eOPePYYRgG83fN56HPH8JR7KDAUc43+8//BdsHgr1qARMmk+Tob94MLVqUtO/Zs4eJEyeyatWqMwJYy4d9m18Yhph9b9kiv4uKZIbcrh3GtdfS9qNu7MzZSbFR/bp1VouVkdeNZHyn8SxatIiUlBQyMjIYMmQIw4YNIyoqqtp9l+AAWiM3+eqONRyxoBlS4Vk5OTmsWLGCpUuXsnz5cho1anRGBDt16iSuKwsWwLBhcOoUUUgM0EFKQmbeRlxBjwJP+3jF14D3Eb8funaFCoobA1x/vXdhkenAVGAWEjUcgtQfTEO+JAB0RYp0JSCBV65PIVxSca67rsKXDFhU+JSAITs7m/79++NwOJg3bx6XNb5MzJt3LajcscMAVkyDLQ+Dw7+ZX1iY5NOvWgXx8b7P8RTAJ554gkcffdR/AXQ6YfZsmDJFXLDN5pJCgRYL2GxQVMSPdybSNi6NAqeP0EA/MGEism4k6Y+kE2opyW3Ys2cPKSkpzJ07lw4dOvDggw/Su3fvs5wF7kccoH+lqlUWpEbQbcgsyf+pjtPp5Ntvv2Xp0qUsXbqU9PR0unbtytvff88lLqPvKMTcZjRSEgtKhK8HsByJ3/WkPeLx8xjIP0N6OkT6XlN2OOTPVZLCkYuUf5iN1Bz0hduJYCEy2/sJkFSK4GCYMAGeecbPDyHAUOFTAgqn08nUqVOZMWMGHcZ14Ktfv6pasvKhRPj4fSi8CIrC8WWzFRYmk7ABA8SY2p+VzD179jBp0iRWrlzpnwDu2wf33CPrWXmViLbZzEetghh4WzGF5qp5UZowUTesLpuSN9G8nu9cgoKCAhYtWsSbb77JwYMHGTJkCMnJyUSWc5OvnB+Rmcyv+O/mYkOSDlMQW7nqc+zYMValpnJ3cjIW1+0xCinU8CKyiFqXEuGb63p+PyVbpXuQRcks4BKQf4LXX4fBg32+5u7dkJDgWeB4GeLzWkj5WWcTgVTgG6Ro4CBEmoVbb5W0CKUsGtyiBBRBQUE8++yzPJPyDEuyl1TdnioqDR6Pgnv7EHT1Iho2zsdiKVnSTEiQWIZDh+Ctt/zPqYqLi+ODDz5g7dq17Nq1i+joaF544QV+8yjSe4bt26F9ewm8qEz0AIqL6bvNznsfOolwBBFs9m9GZrPYiKobVaHogVjBDRgwgPXr17N8+XJyc3Np164dvXr1YvHixTgcVXVkuRLIQApUhWEYYeWe+fvvtcjJacCUKQv59tt3OFvRAwk6uS8uDovXF4/2iHf3S17nN0Fk2rNq4fuImd0l7oZTp3CkpXH8+HEOHz7Mjz/+yNatW9mwYQNffvkln366nuJiz4Cb466rK0q1ngP0cz3u5zouISen4vcZyOiMTwk4io1iLn/lco78fgReQYqPPk5JUOF3yLbJYKQchFsnLMhK0jXAVdLUMLwhR548QpD57G+4nvzwww9MmjSJFStW8Pjjj/PYY49JQn5OjmwWnjxZrX6z61t5KLkRK8KzwYBCH8ufEcERFFPMyGtHMv7G8aWWN/0lPz+fhQsXkpKSwqFDhxg6dCjJyclcfnnVDK5XrTrK5s1vccstqbRosYeIiDyKi01kZ1/Kli0dePfdISxZ8hcgiLAw6NtXJlbV3S49w+LFMHCgFGSEM5VDGiEVGPchdqZzkSXOucj860dkdzIK2eO706PLL00m7q1bF5vNRnh4eCmXncLCdmzePA77mT3kymZ8G4AulCxvupc9v0fmmrK/t2nTWX4O/6Ooc4sScKw8sJLc0x4GnAZiFVm2oIPwEOJ0kofc8b4AfgFuhHx7Pkv3LaV38941OsaWLVsyb9480tPTmTRpEtHR0YwaNYq/rV9P8FmkQlx6rIBPXz1K1mcfMN92gNWHVrM7ZzennaepFVqLay+7lpujb+buuLtLRbZWFZvNxsCBAxk4cCA7d+4kJSWFtm3bkpCQwPDhw+nVqxcWS8W3n6lTYeLERuTnj+XZZ90lh93f08vu4eXnSzzK2rXia+lyDqse5VRUuAqRo6mIa6ubPkgVwE1IEEw+8Beva2/u2ZMTS5bgi2PHoEkTz5aOiFfcYuBuH1e8h3wWbXy0S5sfrmiByx+UP6gofxj3Lry3JCm7DgY3YRCGwd9cbUkYRJafxM09GARh8LQc3zH/jnM+5vT0dGPsrbcaea5M5UgwgsE45pXB3EbuhsatYIS7fiyuc93Hw8Ewrr76nI/Zm7y8PGP27NlGQkKC0bhxY2PcuHFGZmamz3NnzaqeewkYhsViGNHRhpGfX/2xHl+zxigKCzvTaSQYX7oeZ4BRC4zxYHTxeOHBYIwAYxAYj3gPymw2jKeeqvA169Xzfi8vGdDAgE8MyDOgyIAvDBhjQB0D3jYg2+Nnput8uxEebhizZ1f//f+vo3t8SsCx6Sev9Z/LkLWpr/3soAWynnVEDrdkbampoZXLlVdeyT9q18bqMRO5AnEKdbMTmWkAvIHUgj8F3I+E27uPZwHs3y97hecRm83GoEGD2LhxI1988QXHjx+ndevWJCUlkZqaitNV6v7AAXjyyeoX63A4ICtLDJ79JTMzk3nz5jF8+HDi4uKISUqSbHAfxCAxlK97tQ8EPgT+z/W4FOHhleYW9O/vbcI9GklpmITkJDYFZiKhNVbgAWSZ0/0zBEkJWYbT6TvhXxFU+JSAI+v3rLKNXZHgOH9yp4OQIMKCkv6Mc71VbhiwbBmm4pL8tgGUDmd4D7kV+oXd/oeG/LVq1YqZM2dy+PBh+vTpw+TJk4mKimLChAkMHVrgpTlRwEokWTsISVCPQKR/MLC3TP8FBfDOOxL06o1hGKSnp5OSksKAAQOIjIykffv2fPzxx8TFxTF37lyOnTxJcO/e5WaAj6Psv0oiUAcJdungfYHDIS7SFTBypGShlOZ+JBMwD8kYXIIkVGRTsvnsxgocJySkN336wMUXo5SD7vEpAYfT8BHS3xApsL4ej1C88jpAplZWOTQwiI6JJtwWXqZUUGWP/Tk3NDQUU1aWJKZ7kIBED/7gGvoCJOThOX8+BLtdNsP+fi5q6/lPeHg4gwcPZvDgwWzfvp2XX/6QNWsqysHriPyRnMAh4GUk2mgjZyKOXDgcEujy6qtOtm/fTlpaGuvWrWPdunXYbDYSExNJTEzkueeeo3nz5mVLWT39tCSd5+VxyGsUTZGwE09MSKqDN/YgE6mtgnn8nauwBltp26gt3a7oRt/4vtQNq3vmvGbN4NFHYebMYgoKqj8nCQuD6dOrfXlAoMKnBBy1QmqVDm5xcyNSWu/6SjpIR9ZKGsuh1WJlxfIVZerqlff4xIkTZdoruq6oqIgbQkL4vKiIOl5Dcc/6uiDBFo2r8DkUZmTw83//W0pszeUEdZwPWrduTUJCaxYtMvywxgwCopGigZlI+O2iUmfY7fDmm7nMmXM5jRs3JjExkT59+vDKK6/4F13aqRN06wbLl5f50lEV8i0GIzr/Ro4rQnTv8b2k7k1l1LJRDGg1gJdueYnaoVJCa+DAfbz6qoOgoBiczqrfnq1W+M9/oGHDag83IFDhUwKO+AbxfH3Yx4ZePWTSsJmSenSe5CNRncuRmHZX0GN8/XhiYmLOzWCRpPvTGzYQ1rt3mWqkA5AltoNUYZnTRebhw3Tv3LmU+IaEhFRY5Na7zZ9zfM1my4voTEuDgoKqGkz2AXxblBhGBN98c4Arr6xXxT5dvPsuxMVJVdhqLGfnWWDIbZDjlc/pzh99f/v7fJL+Cal/TcWcZeb2229n2rQXefvtFhw4ULV9TqsV3ngD7ryz8nMDHRU+JeC4rfltbM3e6tuXswvgHfMxy/U7CIkh6AFIjVHCLGEkXZl0roYqLxsUhK1FC5+zjkhkp+sL4J0q9tu8Rw8yP/vszLFhGBQWFvosdFtRW25uLtnZ2X5d5z4OCgryKY67d88FYqv4Ti4DTvh8Jjw8iNzcaooeiOfphg1ipJmbW7YsfAXkBcOTt8DH5djVgeRRFuYX0nV2V0I/CuX9lPdJSkrioYfgueekLrPDUfHLRkRA/fqwcCFcc00V3lsAo8KnBBxD2g7h+TXPy8ETXk/WAcZ6HI+vuC/DMBjWbljNDa48GjSQyEAfkYbvACcR82S/PVJCQ6FLl1JNJpMJq9WK1Wrl4nMYGWEYBkVFRT7FsV+/Rhw8WNUejwDljdeguPgsSxTExoqn2KBBMiWtxC3nVDCcCoH77oa1vgusl6GwuJCg+4LoeFNHQP4806bB8OEwYwbMmSMBO2EuE5viYqnK3qqVbEXeead3RKhSESp8SsBRP7w+ye2SeXfru+VXY/CDMEsY9199P5fWurQGR1cBd9wB770n5tQeRFenL7MZetds0r2/mEwmQkNDCQ0N5aKLLir1XGws1RC+T4DOPp/JzS3gwQf7cdVVNmJjY2nevDmxsbHExsaWee0KadAAliyRYJepUyUwyGo9k3KX7zyNuchOdgRMuwHeawP5IZX2Wgq7YSf5s2QW37f4TFtMDLz2mvxkZ0uUqsMhEZtxcRBSxddQBLUsUwKSfHs+zWc0l1SEKlcBEPPmhhENyXgsg4iQc1dPrxS7dsG111avKKonJpPklJWugXNBMHkyjB8vN/cSohDDsJ9cv91RnZlInttsJKqzrFVJWJjBV19tZt++DDIyMti7dy8ZGfI4JCSklBC6hTEmJqbyChkFBeKVun8/J04dY9CGMWxqYOdYBLDVNZwTiPlKS+AmJAp4NbAOWTY3I+l5PZAwUeTL1K4Ru4i+uFpfZxQ/UeFTApa9x/eS8HYCuadzq1SrzoSJOqF1+Hro17Ss37LyC2qSBx6QzZzC6pUYAmSm8vXX0KZNjQ2rptiyRUrXlV5NjKJE+IYiCmIgeSc3An+ntIFYCT16wLJlZdsNwyAnJ6eUELqFcf/+/dSuXbvMDDE2NpaYmBisVmupviasmcCU9VM47TwtJggbgDuAZsBvSOpdPpJfvg4RxLsQ7V4DbONMUYVgczCjrhvFtFumoZw7VPiUgObAyQPcNv82Dv16qPKafIAt2EbT2k357K+fVVix4Jzx229iUv3zz7LRU1VsNtkUev75mh9bDWAY8vb2ls1JrzI2WzGpqWa6davadcXFxWRlZfkUxYMHD9KgQYNSM8Q3nW+yN3+vJPa9DNxO6ZTC04hjdXekzJ5b+ABykIyMMZypcHt1g6vZMWJHtd+3Ujm6x6cENM0uasa2h7YxfeN0/rnhn9iddvLt+aWS3M0mM+HB4VjMFsZcP4anrn+K4KA/KJKgdm1Yvx46dpQKDVWIMsRmkyKB48adu/GdJSaT7GfddVf1LcukHyenT29j27Y0EhMfq9QQ2xOz2UyTJk1o0qQJ3bxU0+l0kpmZWWrZdH+d/bJ0eRiJLvKefIYigaoHkJQZNw4kgtgKeFRe2nu8BlRfqRCd8SmKC0exg5UHVrIhcwObftrEqaJThIeEk9AkgRua3kD3Zt3/OMHz5uefpWzO+vWV1+QLDpYoiOnTYdiwcm24LiT69ZPKQNXdzgwPh08/PcCUKQ/yyy+/MGvWLBISEmp0jG4s/7DIF6XtwApk9ubNl4jLWFNkuTMYKEIEry+Sk+KBY6yjxktdKSWo8CnKnxXDEL/NyZPh229l7+70aVkCDQ6WyE3DgORkGD3au+7NBU1hIdx8M3z3XdXFz2aDzz+XvULDMJg/fz5PPfUUSUlJTJkypcZTNcImhcn+XgbwAeIZ561ZnyB7evUoWerMAz5C6u56uAWZTWYcYx1lLdSUGkNNqhXlz4rJBL16SYJ1VhZ89BG8+CJMmQIzZ8K6dXDiBLzyyp9K9EDy1VaulIoFXrEk5WK1QuPGsHq1iB5I6kS/fv3Ys2cPwcHBxMfHM2fOnBo1FY+sGykPmiKbRz94nXAaEUXvnL5wIAkJcPEw5Glcq7GK3jlGZ3yKolzQpKWJl/a2bRAUBJ51eIODRfDMZnjsMXjmmYqFcsuWLYwYMYKIiAj+/e9/ExcX5/9Adu2CNWtkeTknR5aPW7dmaOPvmH3yK0mLWY+kMtxB6ajOU0AypaM63XyIGCfcKod94/vy4d0f+j8upcqo8CmK8qdg/34RwU2b4OhRmRW2aQMdOogJjb/OJU6nkzfeeIMJEyaQnJzM2LFjsdkqqDa/fDmMGSMDMIzSa69mMxtjw7j5rnzy3Mnk3yPidxIJbGmBRHS68/i8he8npKbUKIi4OILF9y7mpmY3+fdmlGqhwqcoSkCSnZ3N6NGj2bhxIzNmzKC3t5NNfr7sj376aYUhpgYQ/zD8UB+pTXQWRNWN4sDIA7rUeY5R4VMUJaBZuXIlDz/8MPHx8bz22mtSsig/X6aRu3b5ZRawtRHcMBQKziLo12qxsuqBVXRs2rH6nSh+ocEtiqIENN27d2fHjh20bduWdu3a8dJLL1Hcv7/fogfQ9iiMXw22apbtswXbGHP9GBW984TO+BRFUVzs27ePOffcwzPbt2Otxq1xYiJM6QQFVTCPtlqsjLpuFC/c9IIucZ4ndManKIriIiY6mrDMTPp4iV4s0NPr3FhggevxeGR775Y0WDoPLv0dapWtIFWKiJAI6tvq89lfP2NK9ykqeucRnfEpiqK42byZDTfeSK/CQk4geejZQEfEivOIR9tlruNLkdJQucB9wL8AuxkWt4BXe9Rmaz2xlbOYxeGl2CimdcPWjLpuFH1a9iHUEnq+32XAo16diqIoblaupIPdjh0pmnANknrXFbHa9GyLRsQvDRHCt4GRwCtASDHcswfu2X8aIy+Pw6eOkFeUJybndZpiNuli2x+JfvqKoihu0tIIcTq5DhE0XL87A5282hJdj99DDFj6uo5TPfuzWDDt38/ldS6nZf2WRNaNVNG7ANC/gKIoipujRwHoQonIrUOEr7NXWxekzN5CoB/iO303MMezP4sFfvnlXI9aqSIqfIqiKG5c5YsSEfexE8AxJJDleqTO7Algl+ucT5D9ol6uy+8HlrquOUOQVlm40FDhUxRFcePy7uyIBKu8Bdzgeqo2sqf3luv3Fcgy5yngcqARcA9gR4o0AGJvFhNzfsau+I0Kn6IoipvOncFmwwq0B6YjS5xuOrnaEpGIzlXA50jQyzakJN/f8FjurF0b6nlWn1UuBFT4FEVR3Nx+u9QzRPbwchCxc9PZ1ZYIvA+0AW5BZnvun5HADmCXxQL333++Rq5UAc3jUxRF8aRPH0hNBYfj7PqxWmHnToiOrplxKTWGzvgURVE8ef11CD3LpHKbDUaMUNG7QFHhUxRF8aRJE5g1S8SrOgQHQ2QkTJ5cs+NSagwVPkVRFG/694cXX6y4nLsvrFZo1kwq5oaFnZuxKWeNCp+iKIovHnlEqq9feimEh1d8blCQiN7QobB1K1xyyfkZo1ItNLhFURSlIgoKYMECmQHu21daBO12MJngvvvgiScgPv6PG6fiNyp8iqIo/nLqFOzYAcePy15e8+ZwxRUifsqfBhU+RVEUJaDQPT5FURQloFDhUxRFUQIKFT5FURQloFDhUxRFUQIKFT5FURQloFDhUxRFUQIKFT5FURQloFDhUxRFUQIKFT5FURQloFDhUxRFUQIKFT5FURQloFDhUxRFUQIKFT5FURQloFDhUxRFUQIKFT5FURQloFDhUxRFUQIKFT5FURQloFDhUxRFUQIKFT5FURQloFDhUxRFUQKK/wftg9N2fPpT7gAAAABJRU5ErkJggg==\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "solution = tree_csp_solver(usa_csp)\n",
+ "print(solution)\n",
+ "draw_graph(usa_csp, solution, node_size=400)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 33,
+ "id": "da1fb579",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'AL': 'B', 'LO': 'Y', 'FC': 'R', 'AQ': 'G', 'MP': 'B', 'LI': 'Y', 'PC': 'R', 'AU': 'G', 'CE': 'B', 'BO': 'Y', 'RA': 'B', 'LR': 'R', 'IF': 'R', 'CA': 'G', 'BR': 'B', 'NB': 'R', 'PL': 'Y', 'PI': 'Y', 'NH': 'G', 'PA': 'G', 'NO': 'R'}\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAb4AAAEuCAYAAADx63eqAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAAB3PUlEQVR4nO2dd3RURRuHn03PJqGGUAOhI72EIh2lCEoVUUClCqigIMUG+ikoTZp0VJqIIoIURZr0Tui9S+8QSM9md74/JgECKVvuliTznHNPttw779zN7v3dmXmLTgghUCgUCoUii+Dm7A4oFAqFQuFIlPApFAqFIkuhhE+hUCgUWQolfAqFQqHIUijhUygUCkWWQgmfQqFQKLIUSvgUCoVCkaVQwqdQKBSKLIUSPoVCoVBkKZTwKRQKhSJLoYRPoVAoFFkKJXwKhUKhyFIo4VMoFApFlkIJn0KhUCiyFB7O7oBCoci8CCG4EH6Bfdf2cebeGaIN0Xi4eZDdOzuV8lWiav6q5PDJ4exuKrIYSvgUCoXm7L++n/E7x7Ps5DIEAg83D6LiozAKIwBe7l74ePgQY4ghr19e+tboS4+qPQjUBzq554qsgE4VolUoFFqx68oueq7oyYXwC8QlxD0SuvTw9fBFIHit7GtMemkSOX1z2rmniqyMEj6FQmEzsQmxfLz+Y37Y9wMxCTFWt+Pt7o3eU8+8NvNoWbqlhj1UKB6jhE+hUNjEzcib1JtTjysPr9gkek+i99TTs2pPJjabiE6n06RNhSIJJXwKhcJqbkbeJHRWKDejbmIwGTRt28/Tj47lOzKr5SwlfgpNUeEMCoWDEAISEpzdC+2ITYil3px6dhE9gChDFL8e/ZWvN3+teduKrI0SPoXCDsTHw9Kl8OGHULUq6PXg5gZeXuDuDgUKQOvWMH48nDnj7N5ax2f/fsbVh1ftInpJRBmiGL19NAdvHLSbDUXWQ011KhQacuUKfP89zJwpR3iRkfJvanh7S0GsVAk+/hhatZLPXZ09V/fQcG5Dzdb00qN4zuIcf/84Xu5eDrGnyNxkgJ+YQuH6mEwwcSKULg2TJsHDhxARkbboAcTFQUwM7NoFb70FNWvC+fMO6bJN9FrZy2GiB3Aj8gZzDsxxmD1F5kYJn0JhI1euSMEaOhSio+U0pzVERsKBA1ChAkybpm0fteTwzcOcuefY+dmkKU81QaXQAiV8CoUNnD0L1apJwYqKsr09o1GK5+DBcurTFa/zE3ZOIC4hzuF2b0XdYsflHQ63q8h8qJRlCoWVXLkCderAnTtyqlNLoqNh6lTw9YX//U/btm1BCMHSk0vNy8gyB7gJDCL5leYAsBO4B3gDzwGNAZ+0m4s2RPP7sd+pU7iONV1XKB6hRnwKhRWYTNIR5e5d7UUviagoGDsW1q61T/vWcC3iGvFGM+Zy7wOXEh+feuL1HcB6oAnwKdATCAd+BtLRUoFg66WtFvZYoXgWJXwKhRVMmACnT8upSXsSHQ2dO0tnGVcg7FqYeZ6Vh4BCQGXgYOJrscBGoDlQEnAHcgKvIYXySPrNnrhzApOw052GIsughE+hsJD//oNhw7RZ0zOHyEjo398xttLj7L2zxCbEpr/jIaACUBE4B0QCl4EE5NTmk3gjhfCceX24HXXb3O4qFCmihE+hsJAJExybgSU2FhYulNOqziYmIYYEYzonfxF4AJQDCiBHdUeAaECPHOk9jT9gxo2Eu87doWEUisyJEj6FwgJiYmD2bDDYL1lJiri5SbvORAhBXGwcOtLJm3kIKA74JT6vgJzu1CPFL6Xp4cjE99PrQ2JtP4XCFtQ3SKGwgOXLzdkrBLiWuD1ZWLUKUgEuAP8DFgJeiVs1YDJQJsUWY2JkYPzgwVZ1O02EEISHh3P9+nWuXbuWbHvytevXr+NW0w1TfVPqVw4DcAwwAWMTXzMi1/cCkMedAMo/cUwccAZ4If2+GowGsnlns+o8FYoklPApFBawfr1cc0ufosCvQL/E50lzfU8yBBiR+Po7QFdgV6ot3r4tpztz5zavr0IIHj58mKKIPf3cy8uLAgUKPNry589PsWLFqFu37qPn+fPn59DdQ7z0y0s8jEvF2+YkoAPeJ/mU5mLkSLAB8A9yXa8Y8BD4Gznaq5j+OeX0zamET2EzSvgcwJ3oO4RdC2Pv1b3svLKT8NhwhBDoPfVUyV+FmgVrEloglJAcIRm7/MqxY7B1K2zbBrt3Q3i4dHv08oLgYKhfX6Y4efFF86/eLsYOs+On3wLm81j45gFvA0NT2FcPdAJeT7NFX1/Ytw+aNoWIiIhURezJ5+7u7uTPnz+ZqBUuXJhatWolEzk/P780bSdRybMS0YanBfwJDiIHtjmeer0GUvA+Sjzdtcg4PiNQBPnRmOEsWjV/VbP6qVCkhRI+O2ESJtaeW8uY7WPYcXkH3h7eRBuiSTAldwzYdHET/l7+GIwGgrMH83Gdj3mj/BvoPc1Y8HAFYmPhjz9g9OjHSSajU7gw3rwpr9r+/nKBrGVLGDhQCmEGwWSSmVrMoxYyOO0EUAr4DdhOysIXCfyCVIzUefDAQKdOE4mN/QohBAULFnwkXAUKFKBgwYJUr1790fP8+fMTEBBgbofNQu+pJyRHCGfvpfJBvJXKgeV5PL1ZNXEDGcy+ETk1mg4+Hj40KdbEgt4qFCmjqjPYgR2Xd9BxSUfuxdwjMt6sebFH+Hv5AzCh2QR6VOnh2iPATZvgjTekX79583+PcXMDHx85Cpw7F/LmtUcPNSU6GrJnN8ejMwT4ETltGYWc3xuHHPJ48niN7zdkuhIf5JBoAtIrJHW6dr3HpEkeBAQEOO27MWXPFD5Z/wlRBo3iOQ4h3ewqpL2bj4cPF/tfJMgvSBu7iiyL8urUkBhDDH1X9aXx/MZcenDJYtEDiIyPJDI+kv6r+9NwXkOuPLyifUdtJSYGevaEFi3kSM5S0QM5fIqOhn//hZIl4fffte+nxiQkgGVa8xbSgWUuci7vaQYh05bcAFaQnugB+PnlIlu2bE69IXq70tvaBpFXIl3R06GjeYnmSvQUmqCETyPCY8N5/qfnmX1gtiZxRlGGKHZc3kHF6RU5ctOMlBaO4uFDOUr75RcpgLZiMMj6Pd26wahRtrdnR3x8LM3UUgTp5LIKaKdJHzSeubSKbN7Z6FKpCz4e6STX1BAfDx8+rfupw+wpMjdK+DQgIi6COrPrcOLOCU2DaxNMCdyPvU/dOXU5fvu4Zu1aTXQ0NGoER47ItT2t2x4+HL77Ttt2NUSnM+DnZ2nk+k/ABh4HtVmPnx8UT39Q6BDGNBnjMO9KXw9fulbuSvWC1R1iT5H5UcJnI0II2i5qy7l758xL3msFEXERNJjbgPDYcLu0bzbvvAPHj8vqqfYgOhq+/FJOfzqZmJgYdu/ezYwZM+jVqxfVq1cne/bsJCTss7Cl4kCoJn1yc4NQbZqymQDvAH599VeHOGHl9MnJd01d94ZIkfFQzi02Mu/gPN5f9b52C/2p4O3uTbvn2rHw1YV2tZMqq1fDq6+m7LGpNUFB0n3SQfN6Dx484ODBg+zfv58DBw6wf/9+zp07R5kyZahSpQpVq1alSpUqVKpUie++8+ebbxybsiwJT0/pR+Tp6XjbqfHlxi/5bud3aYc42IC/pz9bu2+lcr7KdmlfkTVRwmcD1yKuUXpKaaucWKxB76lnSYclvFTiJYfYe0REBBQt6rhkkT4+0KkT/PST5k3fvHmTAwcOPBK4AwcOcOPGDSpWrJhM5MqVK4e3t/czx+/fD/XqOUb/n+aFF1xiMJwMIQRD1g1hWtg0zcXP38ufNW+uoXZwbU3bVSiU8NnAB/98wIywGRhMjkvcWDp3aU72Pekwe4CsiDpkiGOv9j4+cPGiHP1ZgRCCS5cuPRK3JKGLjo5OJnBVq1alVKlSuLunlDk5ZcqVkzO+jsTfX4ZLNmvmWLvmMn7HeAavHoxwFwhsu6R44klQQBB/dfpLjfQUdkEJn5XEGGLIMzaP3ac4n0bvqWdTl02OW+gXQo72Ll50jL0kfHzg889haEoB38kxGo2cOXMm2SjuwIEDeHl5JRO4KlWqEBJie3ac+fPhvfccV5YIIF8+uHpVrvO5IuPGjeOXNb9gaGPgQvgFq34Xbjo3vNy8YD8cmXCEEkVK2KGnCoUSPquZd3Aeff/pm/405wRkDLMOmZKpBNACmavwALAcaE/ypL1p4KZzo33Z9ixqv8jarlvG9u3w0kvpxuqFIEO2Gz/x2iZk3mE98vQLAJ8A3cy1HRgIt24lC56Lj4/n+PHjydbjDh8+TJ48eZIJXJUqVcifP7+5lizCYIDy5eHMGXlfYG88PeP5+Wcdr7/uQot7T3Do0CGaNGnC7t27KVykML8e/ZXR20ZzPvw8cQlxGEXaMSC+Hr6YhIlWpVvxSd1PWDZ9GceOHWPJkiUOOgNFVkOlLLOSpSeXmr+21xHp3PcQmcVqC9AEmbHCN/GvmcJnEibWnVtncX+tZtMmm7w4CwBXAIHMW9IKqA2UNuNYERXF/j//ZPeNG4+E7sSJExQtWvSRuLVr147KlSuTM2dOq/toKZ6esHgx1KqlTShjWnh5CXLlOsDXX3enaNE51KhRw74GLSQmJobOnTszbtw4ihYtCsCbFd/kzYpvcuD6ARYfX8zmi5s5cvMIsQmxuLu5I4QgwZRAPv98hBYIpXGxxnQs35Hcepm/texnZalUqRLLly+ndevWzjw9RSZFCZ+VhF0Ls/ygbMhK07eQCTv+AzogM9dHIMu2mEG0IZobkTfI55/P8j5YyqZNmhSf0yEHurmAw5gnfA9jYvh10CAevPgiVatWpWfPnlSsWBG93vl5TCtWhE8+kSlK7bX0qdNBQICOw4dr8O+/w2jZsiVdu3blq6++wsfHccHjafHpp59Srlw53nzzzWfeq5K/ClXyy/yjQggexj18JH5+nn74evqm2KaPjw8zZsygS5cuvPDCC5rnG1UoXHTFwLV5GPeQ21G3LT/wAbLuWH7kKK8AUBbIg6xaYyY+Hj7su2ZpPJmVHDyoSTMmZFKuO8jZXnPI5ubGd6+9xg8//MB7771HrVq1XEL0khg2DF5/HezRJSl6sHkz5Mmj44033uDw4cOcO3eOKlWqsGtX6uWLzMeETJw9DjkWL4KsH5gL+SVtAHwB/MWzJZVg7dq1LF26lOnTp6e7bqrT6cjuk528/nkJ1AemKnpJNGrUiMaNGzPUjDVehcJS1IjPCq5HXMfHwwdDvJkjod+Qtxg+yBFfPWA6kOSfUgEphGZ6bRtMBq5GXLWozyDvupO2J5+n9Z7vgwfp1dtOk2vICjUxQAIwnvRqEDxGZzLBFRfMVZqITgc//ij9cObN027k5+X1WPTKlXv8et68efnjjz9YvHgxbdq04a233uLrr7/G1zdtEXmW+8BspOBFIKvHpjSdfQMpjH7I+kFdgQ+Bkty5c4du3brx888/kytXLktP0SzGjh1LuXLl6Ny5s8tN8SoyNmrEZwVxxjjLPAPfAD4FBgCvANeR156kdb0KwM3E180gOiaa9z58Dx8fH7y9vfHy8sLT0xNPT088PDxwd3fH3d0dNzc3dDrdo83NzQ13d3c8PT3x8vLC29sbX19f9Ho9fn5+BAQEkD17dnLkyEHOnDnJnTs3JhunOQsgZ3UfAh8gk3dZhNap0TTGzQ2mTZMFJrJlsz24XK+HJk3gxInkovckr732GkeOHOHSpUtUrlyZHWYXCRRIwSuMHMldR5ZESmsN14j870UBs4CKCPE+/fr1oGPHjrzwghll060kd+7cfPfdd/Tq1QuDBtPtCkUSSviswNPNE5ucYQ8m/p0BjAV+SHx+yLzDfX18GT9mPOHh4Tx48ICIiAiioqKIjo4mJiaGuLg44uPjMRgMGI1GTCZTshGdyWTCaDRiNBpJSEjAYDBgMBiIj48nLi6O2NhYYmNjiYmJwd3LjOqgZuANjEbO6C6z5EAXmtpMi9dek16er7wCXl4mwDLBDgiQTqxz58Jff0GePGnvnydPHhYtWsS3337Lq6++ysCBA4lOc8h5A2iEvP2IJKWpy/QxALEYjT8wceIqvv22lRVtWEbnzp0JCgpi4sSJdrelyDoo4bOCIL8g4oxWejoagGNAS6DPE1sLpCqYkf3f092TQjkL4ePjY/aoz2oCA83eVV4WH29PZ/XyAgYCX5vboIeH62RlNoOgIFi6FDp2/JI6dfaQM6esmp4t27Pxd0mve3hAnTqy2MWNG1JALeHVV1/lyJEjXL9+ncqVK7Nt27YU9jqPnGDejhy52YaHh4G8eRPw8mqOXP+zHzqdjunTpzN69GguXLhgV1uKrINa47OC3PrcZPPKxp2YO5YffBJZi7QS8GSykCrIStRnSdflMcGYQLX81Sy3bQ2hobBihVm7tnjqeZ0U9umOLMG6Eqn9aeLnBxlsbScyMpKVK6dx6FBvChaES5dk4fl9+2RIYny8zMLy3HPyo61Y0fZBbWBgIAsXLuTPP/+kQ4cOdOjQgW+++QY/Pz9kMEkt4C5mlTm3iGjgdWApYL+UMsWLF2fQoEG89957rFq1yrWLMysyBCqA3Uqa/NyE9efXO8W2n6cfEZ9GOOYCMH48fPaZ/SoypIW3t8wYkwGqsycxc+ZM1qxZw9KlS51i/+7du3z44Yfs2rWL2bNnUb/+B8i7LYsKCVqIH3AUmcbAPhgMBqpVq8Znn33GG2+8YTc7iqyBmuq0kldKvoLewznrT3WC6zjurrdpU7Agj6WmFCiQoURPCMG0adN47733nNaH3Llzs2DBAsaNG8eOHW2IizuFfUUP5MR2R7AxR2daeHp6MmvWLAYMGMC9e/fsZkeRNVDCZyVvV3obk+ZTR+nj7+XPwNoDHWewfHkoVcpx9pLw85OJsTMQO3fuJDY21q6ejubSunUZPv7YgLe3I+onGZEL1LPsaqVWrVq8+uqrfPzxx3a1o8j8KOGzkpy+OWlbpi1uOsd+hAFeATQu1jj9HbVkyBC5MOVITCZIIRuIKzNt2jTeffdd3Fwik/RwdDpHhgBEAV+i/Tpicr799lv++ecftm7dalc7isyNWuOzgRO3T1BtVjViEuycsDERP08/JjWfRI8qPRxi7xEGA5QtK4vDOoBonY5Lr79OmV9/dYg9Lbh16xalS5fm/PnzDs0bmjLhyMwrjo6BDAAWAc3tamXp0qV8/vnnHDx4MHnNRJNJfkf37YPdu+X6cGysdKEtXlwmV61WDYoUSZb4XJH1UMJnI8M3D2fU9lF2q0CdhIebB7UK1WJL1y3O8Wo7eBBq17Z/VmadjqhChajh60upsmX5/vvvCQ4Otq9NDRg1ahRnzpzhJzsUz7Wcycg6GOZ9J0NCZAaaxk9MJGzaJAfclifOeQGwb7VcIQRt27alatWqfPHFF3DtGsyYAVOmSLdZNzdZTeTJS5ubm5y1MBggRw746CPo3h3slHVG4dq4wpxMhubTep9SJHsR3HX2dQDxdvdmYbuFznPlrlwZBg60f0C5ry9+q1ax//BhKleuTJUqVZg0aRJGo70dNKzHaDQyY8YMpzq1JOdvrAtQ14Kd2NPJBWRs3+TJk5k9cSIP2raFYsVg7Fi4f18WSYyIeLZelMkEDx/KG7fr1+HLL6FgQRg0yDkeywqnooTPRjzcPFjz5hpy+eay23qfr4cvy99YTnB2J498vvoKXn7ZfuLn6wu//Qbly+Pt7c2XX37J9u3bWbZsGTVr1mTfPgcl5raQ1atXkzdvXqpVc1BsZbrsd6JtHTJg3r4EnzjBifh4fJYvl8JlaWq76Gh5zPTpULo07Nljn44qXBIlfBoQnD2YXT13EeQXhIebtjkBdAk6XjO9xovFXtS0Xatwc4OFC6F1a+l1qSV6Pfz6K7RMHtZeunRpNmzYQL9+/WjRogUDBgwgIiJCW9s2kuTU4hrcR5YBcRbu2F14x4yBtm3xjYrC29aVmuhouRbYsKH8/imyBEr4NKJYzmIc6H2AOsF18PO0XRR8PXwJzhbM3+3/ZuucrcyePVuDXmqAh4fMrzV6tBQrW2P89Ho5VbV1qxTUFNDpdHTp0oVjx44RHh5OuXLlWL58uW12NeL8+fPs2bOH119/3dldSeQ2MjmcszAk9sFOjBolZx60LoIYEwM9esCCBdq2q3BJlPBpSD7/fGzsspHvm3+Pv6e/VQHunm6e+Hr48k61dzjV9xTNKzVn9erVfP755/z999926LUV6HTw/vtw9CjUqEGsuzsmS134fX1lPZ9+/WQpgqpV0z0kMDCQOXPmMH/+fIYMGULbtm25fPmylSehDTNnzqRLly5WlAayF/FgUyEpWzEl9sEOLFkCw4fbr/JvTAz07g3bt9unfYXLoLw67UR4bDizD8xm3I5xPIx/iMFoSDWxtYfOA72XHpMw0aNKD/rV6EfxXMmTM+/evZuWLVuycuVKatas6YhTMIvjx4/zYb16/NO0KR7LlslicnFxKTsMJMUC6vXSq65HD4uSYD9JXFwco0aNYvLkyQwbNoy+ffvirkGGGSEE+67vY+/VvWy9tJWDNw4SZZCJnf08/aiSrwr1itSjeoHqlM1ZliJFirBjxw5KlDC3vK69OQNURVZgMA9tvTp9kXX+NJ76vXULSpaUDir2pkABWWojg1QGUViOEj47YxImdl3ZxZ6re9h8cTMHr8sLqUmY8PbwpnTu0jQo0oDqBavTKKRRmpWp//77b3r27MnmzZsp5YxsKinQvXt3ihUrJitlR0XBgQMyjmrrVrh5U7qP+/pKB4I6dWQcVZkyz5YrsJJTp07Rp08fIiIimDlzptUOJvdj7jPn4BzG7RzHw7iHGE3GVOMz9Z563HRueBo9CTobxK4Zu8jhk8OGs9CSKCAncsrRPEJCpI9Ho0aPX9u2Dbp2tVz4hMiGTrcAM1KQW8bLL8P69TJcwd74+sqTnzbN/rYUTkEJXwZj9uzZjBgxgu3bt5M/f36n9uXq1atUqFCBs2fP2q0KtzkIIR5Nf3bq1Inhw4fjb2amGSEE08OmM3jdYACL4zG9dd54eHjwXdPv6F2tt4tUDghGVmUwj5AQ6d/xJHXqwH//WS58sbHQrFkJCheuRbVq1ahWrRpVqlQx+/+RIvv2Qf369pviTAlvbzh3ToY8KDIdSvgyICNGjGDJkiVs3ryZbNmyOa0fH3/8MbGxsUyaNMlpfXiSO3fuMHjwYP79918mT55M61ScZZK49OASHRZ34Oito4+mM63Fz9OPinkrsqj9IqeFnURGRvLvv/8SHNyfqlX/c0ofhMjGoUOb2bdv36Pt6NGjFClS5JEQWiyGnTvLMBeTA3PjenvD4MFyTVGR6VDClwERQvD+++9z+vRpVq1ahZdGVdIt4eHDhxQtWpR9+/YREhLicPtpsXHjRvr06UPZsmWZPHkyhQoVemafo7eOUn9OfTmtKbQJjnfXuZPdJztbum6hXFA5TdpMCyEEp06dYtWqVaxatYrdu3dTq1YtPvooiKZNl+Hu7uggdjegHbA42asGg4Hjx4+zb98+wsLCHolh4cKFnxHDgICA5E2Gh0P+/JbH6WlBjhxybdHT0/G2FXZFCV8GxWg08tprr+Hj48OCBQscnhj5u+++Y//+/SxcuNChds0lNjaWUaNGMWXKFL744gvef//9R84vp+6couaPNXkQp328mw4d2X2ys7vnbkrl1n4dNjo6mk2bNj0SO4PBQIsWLWjRogUvvPBConDEAnmwxMFFG/yQ6crSd756UgyTtiNHjhAcHEy1atUIDQ2lWrVqVL92Dd/evdN1agkBbiKjCP2Q2UKnAP7AGuAb4ADgA5QFBgKt0utkQID08jHD41iRsVDCl4GJiYmhadOm1KhRg3HjxjnMbnx8PMWKFWPlypVUqVLFYXat4eTJk/Tp04fIyEhmzZpF6fKlKTWlFNcjriPslFpLh44CAQU43e80ek/bPQPPnTv3SOi2b99O1apVadGiBc2bN6d8+fKprCt+BEzFbqEFKVIKWfTWunVOg8HAiRMnkolhu7AwPkpIID1/3RDgR6AxcBVZD/4VIBToDowHXkOm0d4KLAB+SK9Dej1MmAC9ell1PgrXRQlfBuf+/fvUrVuX7t27M3CgY+r0zZ07l4ULF7J27VqH2LMVIQTz5s3j448/Jm+PvJzxO0Nsgn2nznw9fOlWuRtTX55q8bFxcXFs2bLlkdg9fPiQ5s2b06JFCxo3bkyOHDnMaOUmUBJwVJYbPXKKs4WmrZpq18Zt58509wvhsfABDAaOI6sE9kt8bhVvvQXz51t7tMJF0Ta/lsLh5MyZk9WrV1OnTh3y589Pp06d7GrPZDLx3XffMWHCBLva0RKdTkfXrl3JXTU3bZe0xZhg/4TXMQkxzDk4h84VO1M7uHa6+1+6dIlVq1bxzz//sGnTJsqVK0eLFi349ddfqVy5shVT2XmB6UBvZIiDPfFGhi9oK3oAblYkKLgMrEJOaV4G2tvSgTNnbDla4aIo4csEBAcHs2rVKl588UWCgoJo3Nh+hWr/+ecfPD097WrDXowKG4XRzXFVHmISYvhk/Sds6bblmfcMBgPbt29/NKq7efMmL730Em+88QazZ88md+7cGvSgE3JSbxP2q82nQ04gTrdP8xbE7bVBXtCyAy8DnYE/kJUJrcbeZbgUTkEJXyahfPnyLF68mPbt27NmzRq7rb2NHTuWwYMHu0i8mvmcvXeW/dcdX7Vg77W9nL9/nmI5i3Ht2jX++ecf/vnnH9avX0+pUqVo3rw5P/30E6GhoZpknkmODjn9WBs4Ddij/E4AsBkZNG8HPMy/RC3j8VQnyNVGgOtAUWvtO8FjWmF/VK7OTET9+vWZMWMGr7zyCufPa18aZvfu3fz333+89tprmrdtb6bsmYLRZOZobw4wCkh46rWnqyJdQGbnSoMEYwIdJ3SkSpUqlC9fnnXr1tGqVStOnTrFnj17+Oqrr6hZs6YdRC8Jf6Q7RzlkOjGt8ECK3TbkpKKdsGHkWxoZyr/EFvtBQbYcrXBR1Igvk9GuXTtu3LjBSy+9xPbt28mTJ0+q+96+DZs3w+7dsGWLLGQdHy/DloKCoG5dqFVLJs0oVEiO9gYMGIBnBoxrWnVmFQaTGWm87gOXkMtWp5B6YQMJIoFzunMsm7yMWrVq4WHBCEY7sgPbgc+AGYCt03d+yHygC4FnYyQ15fnn4cgRqw7VIb05ewC5gVeRtwE7gPnArPQa8PKSX35FpkMJXybkvffe4+rVq7z88sts3LgRvydq5wkhk8+PHQtr18rfdmTks0kxrl6Fgwdh7lyZbrNy5WiOH3dj9uweDj0XLYg3xvNf+H/m7XwIeS0vCBzEZuEDeOjxkJrP18TD3Zk/Nx+kDLwOdESWDrI0zi8p08pEZJCAA6a7a9eWNSAjrYtJbI/s9TdI705f5L/ULC9PX18IDbXKrsK1UVOdmZQRI0ZQrlw5OnTogMEgRzqXLkG9evDSS7BypUyG8fBh6pmghICICLnfrl16YmJ+pnZtf44fd+CJaMCxW8fw8fAxb+dDQAWgInAOTWLAfTx8OH7bVT60msBZ4E+gCXJomw14dhRvNJL4ni9QBpgM3EKOoRy0xlu3blJH0uQ/kq/vPclLyMneSKTcb0I6v6RLXJwSvkyKEr5Mik6nY9asWQgh6NWrF7NmCcqWldOaUVFS1CzFYPDm+HF5LfjmG8emTrSFG5E3cNOZ8VW/iCxeXg4ogFzCsm6WLRluOjduRt20vSHNcEPKxFrgGtL38StkyHdd4HmMxkZMnOiO0fgjMiLuBNAVbdcJzaB4cahQwbE2QVYPadUKnJgLV2E/lPBlYjw9Pfn998X8808T+vY1EBUFCQnpH5cWQkgP72+/hddft709RxBvjDcvS8shoDhyCQvkyO9g4mM3ZI3VJzFBuilFEolLsIdHpRbkQo78PgVWIsdGO3B338CkSQW4dCkUGR7uRD7++HEtR0fh6wuDBjnWpsJhKOHL5HzxhR8REW9gMGjrlh0dDatWQceOrj/y83L3Qpfe1JwBOIacMxubuO1CJkC5gfQPCX/qmPuJr5uBt4e32f11FUqWLMkZVwjgbtUKHFn2yt0dypWD6tUdZ1PhUJTwZWIWLICZMyE62j7/5iTxGznSLs1rQmxsLA+vPSQuPp0RV1KKyfeBPonb+0Bh5EiwPDLL8RVAAHeQwlg+/T6YhIkCAQWsPQWn4TLC5+EBixfLUZgj8PaGX391jC2FU1BenZmU69fh3XftX7szOlqu97VtC2XtGM6VHgkJCZw9e5ajR48m2y5evEjxksWJaxeXtj/GQaAKkOOp12sA/yCXxBoDy5HrgEke/WYUfI8zxlEmsIylp+R0XEb4AGrUgD59YMYM+2ZT8fOTX+hixexnQ+F0VJLqTEqzZrBxowxFsDc6nRS9w4elT4A9EUJw6dKlZwTu1KlTFChQgPLlyyfbSpUqhZeXF2WmlOHU3VP27VwqlM1TlmPvHXOKbVtYuXIl06dPZ9WqVc7uiiQ+HuOLL2LYsQMfO8yvGzw98WzfXk6VOLjMl8KxqBFfJuTIEdi61TGiB9Lh5eJFWLdOCq5W3Lp16xmBO3bsGP7+/o+E7YUXXuDDDz/kueeeSxav+DStSrdi0u5JxBsdWaZHri+2LNXSoTa1wqVGfECsycRrXl6MDQykdEQEOg1HfiZfX9YAtxs1opsSvUyPGvFlQrp3h59/drzH5QsvwL//Wn7cw4cPOXbs2CNxO3LkCEePHiUhIeGRwFWoUIHy5ctTrlw5clnh6PBf+H88N+U5Yo2OreTt4+HDqb6nKJy9sEPtakF8fDzZsmUjIiLC6dl64uPjadeuHf7+/iyYPRuPgQNh3jzbpz11OvDxgcGDOd2xIw1feIGJEyfSoUMHbTqucEmU8GUyoqIgTx5zrgchPK5Z7Y8M802qWQ0y3DcfUA+5yJU+Pj6yikuhVLJYxcbGcvLkyWTidvToUe7cuUPZsmUfiVvSlj9/fk2TYTea14hN/23SrD1zaFi4IRu7bXSoTS0pVqwYq1evplQp7avJm4vBYOD1119HCMHvv//+WIS3bpUxNRER1mV28feHAgWk40zFigAcPnyYJk2aMHv2bF5+2awwd0UGRE11ZjL27ZNpyMy7EV6J9Ni4gaxZPRKZ3Alkal9vYF3i+/nSbc3TU+b87NAhgXPnzj0jcBcvXqREiRKPhK1Xr16UL1+eokWLWlFvznJGNx5Nw7kNiUlwTKkZd5M7x78/znz3+bz55psOOUetKVWqFGfOnHGa8CUkJPDWW28RFxfH0qVLk48869WD8+dh0SIYPVqmJkpIkBlXUiPJM7R8eRkf2Lp1sgoQFStWZMWKFbRs2ZJFixbRqFEjO52ZwpmoEV8mY8IE+PTTtH/7khCS16weggxk+zvx+QvA88jRXifAnGBeE4GBi4iK6pGmo4kzGbB6ALP2zSI6wb7urnpPPe+GvsurAa8yYMAADAYDEyZMoH4GS3rcr18/ihcvTv/+/R1u22Qy0bVrV65fv87KlSvx8Ukn7dyBA7Bpk8y8HhYG9+9LIfTwkNMgtWpJsXzxRSiTtpftpk2b6NChAytWrKBWrVranZTCJVDCl8lo2xaWLTNnzxAeC98VoDlS7CYhc3cVBY4ihW8ecNgs+6VLR7FvH2k6mjiT2IRYykwpw+WHlzEJ+0Teu+vcKZy9MCfeP4G3hzdCCBYtWsQnn3xCtWrVGD16NCVKlLCLba35/vvvOXXqFFOnTnWoXZPJRO/evTlz5gyrVq1Cr9c71D7AqlWr6NatG2vWrKFy5coOt6+wHxlv7kWRJlevWrJ3G2Qh0WAgCJmvEeBnZJbmssAbyJHgAbNajIz0c1nRA+lssqnrJnL65DQvf6eFuOncyOGTg41dNj7K1qLT6XjjjTc4ceIEoaGh1KpVi4EDB3L//n3N7WtNqVKlOH36tENtCiH44IMPOH78OH/99ZdTRA+gRYsWTJkyhRYtWnDqlHNCYRT2QQlfJiPeIm/9ZUAEMl/9SWQ6EpDVyjonPi4INECO+tLHUSEUthCSI4SdPXYSqA/E0007b0VPN0/y6POwq+cuiuQo8sz7vr6+fPrppxw7dozIyEjKlCnDlClTHlXPcEUcHdIghGDQoEHs2bOHVatW4e/oHJ1P8dprr/Htt9/SpEkT/vvvP6f2RaEdSvgyGdYtoTVAZt4fhCzTeQbp6JIvcduNLDqafnyEk5fwzKZk7pIc6nOIBkUa4Odp+whV76mnUdFGHOpziBK50p7GzJs3LzNnzmT9+vWsWLGCChUq8Ndff+GKqw5FihThxo0bxMbaPwxECMHQoUPZsGEDa9asIXt2MxOh2pmuXbsyZMgQGjduzLVr15zdHYUGKOHLZBQtau2R/ZEenJ8js/UfR+bxOohc64vBnLCGAhkoJWU+/3ysfWstM16ZQYBXAD5uZtbsewJ/T38CvAL4oeUPrO68mrz+ec0+tkKFCqxZs4bx48czePBgmjRpwqFDhyzugz3x8PCgSJEinDt3zu62RowYwfLly1m7di05c+a0uz1L6Nu3Lz169KBJkybcuXMn/QMULo0SvkxGvXrW5vLNA3RACl0/Ho/28iEdXd4ivelONzfIYE6L6HQ63qz4JtcHXqfsxbLkcc+D3lOPv1fqU2wBXgHoPfWUyl2KSc0ncWPQDTpV6GRVzKFOp6NFixYcPnyYdu3a0bRpU9555x1u3Lhhy2lpSlJIgz0ZM2YMv/zyC+vXrydPnjx2tWUtn376Ka1bt6ZZs2Y8ePDAzKPigf3AD8AwYCAwFPge2IYmlY4VFqPi+DIZoaEyni79OL7/UnhtTuKWEtPSte3nBzVrprubSxJ+O5wLSy/w33//cT3+Onuv7WXn5Z2EXQsjMj4SdHJ0F1oglNrBtQktEErpwNKa2ff09OS9996jU6dOfPvtt5QvX54BAwbw0Ucf4euoqgSpYO91vkmTJjFr1iw2b95Mvnzpx4s6k2+++YaIiAhefvll1qxZk4ojlxEZFjQa2Av4JL72ZAiND+CV+FoJ5DJDR8A5jjxZDRXOkMmIi4PAQOsSWdiKj4/M2RkU5HjbtvL1119z/fp1pk+f7uyuAHDu3Dk++eQTdu/ezciRI+nYsaPTAuCnT5/OgQMHmDVrluZtz5gxg1GjRrF582aKFHnWIcgVMZlM9OjRg6tXr7JixYon4gsFMBcZExuHdBwzF//E4/sDXyBFUWE3hCLT8cEHQnh6CiHTRztm0+mEaNXK2WduHQaDQRQqVEgcPHjQ2V15hq1bt4rQ0FBRo0YNsW3bNqf0Yf369aJBgwaatzt79mxRqFAhcfbsWc3btjcGg0G0b99etG7dWsTHxwshrgghGggh/IQQ2LDphRDFhRD7HXk6WQ61xpcJ+eADWUTakej1MHiwY21qxd9//01wcDCVKlVydleeoW7duuzevZt+/frRsWNHOnTowIULFxzaB3tMdS5cuJChQ4eyfv16ihcvrmnbjsDDw4NffvkFg8HAiBGvIERZYDsQZWPL0cA5oA7mhhAprMDZyquwD6+/LoS3t2NGe+7uQtSuLYTJ5Oyzto5mzZqJ+fPnO7sb6RIVFSWGDx8ucufOLYYMGSLCw8MdYtdoNApfX18RERGhSXuLFy8W+fLlE0ePHtWkPWcSG7tBREe7CdtGealtvkKIHxx4NlkHNeLLpMyYIZ1NHIGXl4lff5UVXjIa58+fZ9++fbRv397ZXUkXvV7P0KFDOXLkCHfv3qV06dJMnz6dBDvXn3Jzc6NYsWKcPXsWkwmMRuvbWrFiBe+//z6rV6+mXLly2nXSKZzF27s1vr72SX0nQ4g+wNzqKArzUcKXScmRQ9bks3e2Jy8vA25ugwkLW2pfQ3Zi5syZvP322073nLSE/Pnz8+OPP7J69WoWL15MpUqV+Ocf7S+OkZHwyy/QuzdcurSK6tUr4O4ucz57eECRItChA0ydal6qvNWrV9OzZ0/+/vtvl5xWtgwT8Dq2T22mRwwyi5Lrp7fLUDh7yKmwL999J4Reb58pTr1eiH79hNizZ68oUqSIGDx4sDAYDM4+ZbOJjY0VefLkEadOnXJ2V6zGZDKJFStWiFKlSolmzZqJI0eO2NzmyZNC9Ool/7/+/ul/D3x9hfDxEaJZMyE2bEh5ynv9+vUiMDBQ7Nixw+b+uQbjhO2OLOZu3kKI1xxzWlkEJXxZAHuIn5+fEP37P77I3b59WzRt2lQ0bNhQ3Lhxw7knbCa//PKLePHFF53dDU2Ij48XkyZNEnny5BG9e/e26n8QFyfEJ59IIfPwsP570by5EDdvPm53y5YtIk+ePGLz5s0anrEzeSik96UjRC9p0wshDjjg3LIGSviyCH//LUTOnLY7vHh6ylHAvHnP2khISBBDhw4VhQoVyhB39vXq1RN//PGHs7uhKXfv3hUDBgwQuXPnFiNHjhQxMTFmHXfsmBDFimlzg+TlJUS2bEL8+acQO3fuFHny5BHr1q2z74k7lGnCcaO9pM1dCPGWI04uS6CELwtx75709vTxEcLDw2jRxczDQ44EGjcW4tq1tO2sWLFC5MmTR0yePFmYXNTV88iRIyJ//vyJMViZj9OnT4u2bduKkJAQ8dtvv6X5f9izRwqVTqfdjAAI4e1tFP7+A8Xff//twDO3NyYhRIhwrOglbT5CiPt2P8OsgBK+LMjZs0KUKbNGeHnFiWzZpKClfOESInt2+X63bkIcPmyJjbOiUqVKonPnziIyMtJu52Itffv2FcOGDXN2N+zOxo0bRZUqVcTzzz8vdu7c+cz7hw8LERCgreAl/w4ZxNy5Tjhxu3FOyDCD9IWqSBGEjw/Czw8RFITo0gUREYFo0ADxww/WCF+AEGKx4041E6NSlmVBIiIiCA4O5siR01y9GsS+fbBlC1y4IFOeeXlBwYLQoAFUqyY3a0IjoqOjeffddzlw4ABLliyhZMmS2p+MFURGRlK4cGEOHTpEcHCws7tjd0wmEz///DOff/459evXZ+TIkRQpUoToaChZEuxdacfXF/bsgfLl7WvHMSwGemBOOrKQEPjxR2jcWHq9NmsGr7wCu3bBm29Cz56W2nYDPgLGWnqg4ilUkuosyB9//EGDBg0IDg4iOBhq1YL339fejl6vZ+7cucycOZM6derwww8/0Lp1a+0NWchvv/1GvXr1soTogYzD69KlC+3bt+e7776jatWq9O7dm5s3v+T+fW+724+NlWEPhw/LMIiMzW6sqahQsCA0bw5Hj9pi2wRssaUBRSIqji8LMnfuXLp27eoQWzqdjj59+rBy5Ur69evHZ599htGWCGgbEUIwffp0+vTp47Q+OAs/Pz++/PJLDh8+zKFDvsyebTSjioftCCGTl4/NFAOVw4Dlk2SXL8OqVVCliq32L9jagAIlfFmOc+fOcfz4cV5++WWH2q1Zsyb79u1j9+7dvPTSS9y+fduh9pMICwvj3r17NGvWzCn2XYGCBQsixDB0OscF7UdHw5gxYDA4zKSdsOxOoU0bmUyibl25dPDZZ7baj7O1AQVK+LIc8+fPp1OnTnh5Ob7sSZ48eVizZg2hoaGEhoayZ88eh/dh+vTp9O7d22klflyBa9dgwwYQwrE55oxGWLHCoSZtwmg0cuvWLY4dO8amTZtYvHgxV69aViB42TIID5cj3mnTrC0S/SQOzj6fScnwM+4K8zGZTMybN48///zTaX3w8PBg5MiR1KpVi1deeYWvv/6a3r17W1W93FLu37/P0qVLOX36tN1tuTJz5liy90JgPHASCAAqA58D64FvgCfXCD2A8FRbioiA8ePh1Vct6q5mxMfHc+fOHW7fvm3WFh4eTo4cOciTJ8+jrVgxIwULOqf/kgBnGs80KOHLQmzevJns2bNTuXJlZ3eF1q1bU7ZsWdq1a8euXbuYPn26lfkyTcBpYB+wEzgPxCIvyEWA2kA1oAzz58+nefPmBGXESrkasnq19N5Nn/HAKGAG0AxZHHU1sBzwQ+aqXGCR7X37wGQCLQbcMTExZovY7du3iYqKInfu3MmELGmrWLHiM6/lzp0b92fqe00APsXWKceEBOn0k4S7O3h6mnNkVZvsKiRK+LIQSU4tjhhdmUPJkiXZtWsXvXr1onbt2ixZsoRixYqZefRNYCbwPVLodKTsbfcLAEK44+PjzocfztSi6xmaI0fM2esBshL4HKDdE6+3TNz+Z5VtDw84cwZKl07+uhCCyMhIi4TMYDCkKGJ58uShaNGiz7yWI0cODaa4qyFvqmwTvnfflVsSnTvDgnTvIbyBBjbZVUhUHF8WISl27/Tp0y434hFCMHXqVIYPH87s2bPTcbyJQsYyzU98HpvGvsmJi9Ph5eWFTtcemApkt7rPGZUbN2R8WfojvtXAK8jPN6X74/8BZ7F0xOftHccLLywiV661zwiZu7t7qkKW0hYQEOCEm7hIIBDnOJn4I6eYazrBduZCjfiyCEmxe64meiBDHvr27UvVqlV5/fXX6datG19++WUK00xbgDeQ60jmC14S3t4CecFagryw/4Kcwss63L8vExSkL3x3kRf4tC4RvwN/PfG8CrAxzVaNRh2+vgVo2rTpM0Kmt3cNLU3wR94Q/ImcZnccsbH++PjUcKjNzErWdW3LYjgyds9aateuTVhYGFu2bOHll1/m7t27T7w7C3gJuI6lLuXPEou8sLcjq2XBSEgwt2BwbuAOkFaR2w7Im5CkLW3RA3B396JBg8a8/fbbNG/enNDQUIoUKZJBRC+JwYBj6zfGx3vxzTfx1Kr1PIsWLbJ78WFziIuT2Z5OnJDT18l+ri6OEr4sgLNi96whb968rF+/nooVKxIaGkpYWBjSuWIAtgve00Qjp+xGadyu6+LtDUajOasbzyPXlJZpat/dHXx8NG3SCdQASiDXlR2Dl5cv//vfOT7++GOmTZtGsWLFGDNmDPfv33dYH4xGWLkS3n5bproLCIAKFaBmTahaFQoUgNy54cUXZczmzZsO65rFqDW+LMCXX35JeHg4kyZNcnZXLGLJkiUsXNidRYti8PCwZ+SzHviZ5E4cGZvo6GjOnz/PmTNnOHv27KPt9OnLXLlyDDDHhXAcMAbpRNQ08Zj1yJGdHmvW+LJlgyVLZP7KjM0JpKOLA1LfoEeuaT+OA9m3bx8TJ07kr7/+olOnTnz44YeUKlXKLtYjImDSJLnFxcnn6ZF0c9OsGQwbJvP9uhJK+DI5JpOJYsWK8eeff1LF9nxJDuYhCQkheHg44q42O3AGyOMAW9oQERHBuXPnkglb0nb37l2KFi1KiRIlntleeKEoFy+aO1r5BenCfwIZQ1YNGce3lmfj+ECGk6S+juzlBdevQ65clp6tK/It8jOItqMNL+Q6dMqR/9euXWPatGnMmjWLmjVr0r9/f1544QXNnH7Wr4dOnSAyEqvS2+l0UgTfeQdGjdIigF8blPBlcjZu3Ej//v05ePCgy4QxmM/byGz4ljuyWI4XclSz0gG2zCc8PDxFYTt79iwPHz6kePHizwhbyZIlKViwYArOQZI33oBFixx8IonkyQO3bjnHtvYYkY4um7HPyM8DKAyEATnT3DM6OppffvmFiRMn4uHhQf/+/enYsSM+Vs4rJyTIcIuFC2W6OVvR6+XNzpo1ULas7e3ZihK+TE6XLl2oXLkyAwYMcHZXLOQ8UA7HiF4SemAHUMlhFoUQ3Lt375GYPT01GRcXl+KorUSJEuTPn9+quLSlS6FrV/OmrLTFQK1ax1m2LB958+Z1tHE7EQe8jPzeaCl+nkChxHbzmX2UEIK1a9cyceJEDhw4QJ8+fXj33Xct+rwNBmjVSpYq00L0ktDp5Lrgxo1yTdCZKOHLxLhy7F76DEDG2jkyq7E70BmYp2mrQghu3bqV6shNCEHJkiVTFLegoCDNR+oJCRAUJEMbHImXl5EWLYayceN06tevT7du3Xj55ZedkjdWWwzAe8j0bloohR8yQ8sywPo54ePHj/P999+zaNEi2rRpw4ABA6hYsWKaxwghU8qtXm3d1KY5ZMsGu3dDmTL2ad8clPBlYubMmcOyZctYvny5s7tiIXHIGDLL657Zjg9wA0uD200mE9evX09V3Ly9vR9NQz4tbrly5XL4NPQXX8gyQbEOHFCHhsLevfKG7I8//mDu3LmcOHGCTp060bVrV5dIpWcbG4COyO+tNQLojRzpTQS6o5XX6N27d5k5cyZTp06lTJkyDBgwgBYtWqQ4WzBtGgwZAlFRmphOEZ0OSpSAY8fMTdNmhz4o4cu8NGjQgP79+9O2bVtnd8VCtgMtgIep7hESIt2lk3Ic1q4NM2ZAUm3ZuXNh3Dg4d07eYbZtCyNHyhIxaZMN+DXRfnJMJhNXrlxJUdjOnTtHQEBAiqO24sWLkzNn2ms0jubBAyhe3HGxV76+sGkT1Hgq/vrcuXPMmzePefPmkStXLrp160anTp0IDAx0TMc0JxL4CRhLVNR19HqBTpfeJTYAGVnWB/gQyG+XnsXHx7N48WImTJjAw4cP+fDDD+nSpQv+/v4A/PcflCun7fRmauj18NFHMHy4/W2liFBkSs6ePSsCAwNFXFycs7tiBZOEED5CCFLdihRBrFsnH8fEILp1Q7RuLZ9/9x0iKAjxzz+I+HjEhQuI5s0RoaGIuLjU2xQCYTJ5iLt3PxRr1qwRU6dOFQMGDBAtW7YUzz33nPDx8REFCxYUDRo0ED169BAjR44UixcvFgcOHBAPHz50+KdkK6tWCaHXCyEnuOy3+foK8dFHaffFaDSK9evXi86dO4vs2bOLdu3aiRUrVoj4+HjHfBjWYDIJER4uxPXrQty6JUR09KO3zpw5LV59NYcwGvsLIUKFEL5CCA8hhLcQwlMI4SWEKCuEeEcI8bsQwnG/U5PJJLZs2SLatWsncufOLQYPHiwuXbokGjUSwt3d/t+HJ78Xp0877LSToUZ8mZSMGrsnaY9MK5Y6ISHw44+P48FWrYL+/SEsTAbSzp4NHTo83j8yEooWhdGjoXv3tK3v3OnNsGF1nxm5FStWLINlGEmft9+WcXX2usv38IAiReS0lvfTkQ+p8ODBA37//XfmzJnD+fPnefPNN+nWrRvlypWzTyct4cgR6RK7aZN8HBMjpx1ALp7myQOhoawTgnWBgYx5VANKIPPMxiE9iPW4Qm29CxcuMHnyZGbP3kpExHZMJsett3p4yDCHadMcZvIxztFbhT0xGo2iSJEiYv/+/c7uipVUFmmNyp4e8UVFId5+G/HWW3KU5+6OMBiePebttxFvvJF2u3Ir5siTdSrx8UI0bmwS7u6xmt/Re3gIkT+/EFevWt+/kydPik8++UQUKFBAhIaGiqlTp4q7d+9q9wGYg9EoxK+/ClGpkhwie3ike/IxOp1I8PISol07IfbscWx/raBnz1jh5pbgsNFe0qbXCxEZ6fjzVSnLMiGuVHfPOuLN2qtNG7lmlz07rFsHgwfDnTsQGCjvJp8mf375fvo4I/O+c/D0hBo1vsbffw96vXaTPz4+ULCgdGYpUMD6dkqXLs3IkSO5dOkSw4cPZ8uWLRQrVozXX3+d1atXYzQaNetzipw9K71yevaEQ4fk0NiMPJk+QuAeHw9//gkNG0Lv3vb1GLEBkwl+/dUbkym9EWgIMkepPzKu8GXgcuJ7XZEjWX+kJ2oTZPHitHF3B2f43inhy4S4Wt09yzGvaMiyZRAeLj0Tp0yBBg2k4N25k/K16fp1KYrp4yRXMycwffp0fv99ASdPlmbkSB16/eOZO2vR62W2j6NH0axaubu7Oy+99BK//fYbFy5coEGDBnzxxRcULlyYTz/9lFOnTmlj6EmmT4eKFaXgWStaQkix/Pln6coYFqZtHzXg3DlL9l6JdOC5DuQF+j3x3pDE964CBYEe6bYWEQFbt1piXxuU8GUyIiIiWL58OZ07d3Z2V2zA/IBdkBfqdu3k37g4uZa0dGnyfSIj4Z9/ZALd9MmoHoWWsXTpUoYPH86aNWvIly+IDz6Qy1a1a8sRW0qj5tTQ6cDfX67n/fUX/PSTfG4PcubMyXvvvceePXtYs2YNCQkJNGjQgNq1azNr1iwePHhgu5Fhw2DQILmGZ9Kg/FBMjCyG2LAhbN5se3saEhYGludB8EGuxR9P4T1fZOWOg2a1tG2bpbY1wPGzqwqriIsTYt8+IWbNEqJXLyFee02IV18VomtXISZNEmLbNiEiI8Xs2bNFq1atnN1bGxkupOebeWt8JhNi2TK5tnf0KGL06JS9OqtUQcTGpre+pxNC9Hf0CTucLVu2iMDAQBEWFpbi+ydPCvHuu0L4+cktIEAInS75+oy3t0G4u0cKT08hWrQQYtMm6ejoDOLj48XKlStFu3btRPbs2UXnzp3FunXrhNFotLyxkSPt6+7q5+dS636DBj37v015KyJgXeLjKAFvC3gr8XkXAZ8nPo4U8KaAimZ9HN7ejj9nJXyuTliYEB07ym9HQEDKP0gfHyGyZRPC01PszZFDbPviC7kgn8GIiIgQf/31l5g+vY14+NBNpCd8Pj4IPz+Evz+iXDnEggWP3//xR/maj48UwV69EPfupSd6CCEChBCLHHzmjuXo0aMiKChIrF27Nt19jUbpcr5wobxAdu8uRJcuQvTtK8To0fdF9uyNRGysk9QuFW7fvi0mTZokqlSpIoKDg8XQoUPF2bNnzTt42zbpZ29vr46gICFcJASme3dzu11EgJ+A7AI8BOQXcPgJ4fNOfE8nIETAIbM/DkffMCnhc1WOHHnsRebmZvYPygjC5O8vRMGCQqxb5+yzSJOEhASxe/duMWLECNGgQQPh7+8vGjZsKMaNGyqMRi+RvkjZY/MRQlx2wNk7h0uXLong4GCxYMECTdorUKCAuHDhgiZt2YODBw+KDz/8UOTJk0fUq1dPzJ49O/WYy6goIQoUsL/oJd2sduvm2A8jFbp2tUT4kkZ8CQKWCMgp4PpTI76LAp4T8LvZH0dCgmPPWQmfq2EwCPHVV/Ku07z5h9Q3vV6It98W4sEDZ5/VI86fPy9mzpwp2rdvL3LlyiXKlSsnBgwYIFatWiUik/k1txNy2tHRwtfIjmfvXO7duyfKli0rvvvuO83abNWqlVi8eLFm7dmLuLg4sXTpUtGqVSuRPXt20aVLF7Fx48bkU6EDBzpmtPfk73PbNud9KIn06mVuKMuTwpe0BQpY/JTwCQFrhRwRRqfbrru7489ZBbC7ElFR8NJLsH+/dhHFPj6QNy9s366di50FhIeHs3HjRtatW8fatWuJjIykSZMmNGnShMaNG1MgVV/3nUiXaEe6gPsjyyC95ECbjiEmJoamTZtSo0YNxo0bp1m7X3/9NdHR0YwalXGq2N+8eZNffvmFOXPmEBUVRdeuXenSvj1Fqld3TL6uJ2nWTGaEtjP3799/pvpH0uOIiE7Ex49CiPSK5YUAPwKNAYGsEfgqcAgYi6wmMeKJ/UOBt5Bp2FKncGG4eNGq07IaJXyuQkwM1K8vfcC1zhzs7i7T8e/bJ4PZ7IjBYGD37t2sXbuWdevWcfToUerUqfNI7CpUqGBmmIUAagD7AQ286tJFB5REFlzNXM7ORqOR9u3b4+vry4IFC6wqZZQaq1atYvz48axfv16zNh2FEIL9+/czZ84c3OfOZWRsLHp7xwU+jY+PjBXU4Kb07t27KZa3OnPmDAaDIVmC9CcfX76cl8aNdTxMPTVuIiHATWTGGR1QBPgUWdGkK88K3yLgI2SJsdTT9rRvD4sXW3fO1qKEzxUQAlq3llHY9kqX7+Eh83wdPWp+7igzEEJw+vTpR0K3efNmSpQo8Ujo6tSpY3UxTDiLrI3niLtwX2AXkHbZloyGEIL33nuPM2fO8Pfff+Ot4f8e5OipTJky3Lt3LwPHjYKpXDncjqfkmi8JQX4LLyCLBoEc+ywANiFlQJ/41wc5VzEdyJGeYW9vGTrx+efp9lEIwd27d1MctZ09exaj0fhI0J7+mydPnlT/P3Fxsk6ewZEVwBLx9ZVpBPv1S39fLVHC5wosWgQ9etg/s4NeD++/D2PG2NTMnTt3WL9+PevWrWPdunUAj4TuxRdfJE+ePFr0NpEJwDDsOeUZHa0jLKwedetu1HQ05AqMGDGCJUuWsHnzZrJly2YXG4ULF2bDhg2UKFHCLu3bnfh4GXSYxpU/BIgABgKfJb72tPCdAUoga4p0AMogCwylS4MGMvcnUtxu376d6rSkTqdLdeQWGBho9c1H8+YOmXF9Bh8fOHMGChVyrF0lfM7m1i0oWRIz5hm0wddXpkqoVs3sQ2JjY9m+ffsjoTt79iwNGjR4JHalS5e2492+QE6lLMc+Iz9fYmNr07hxFHnzFmDevHmPyrRkdH788Ue+/fZbduzYQb58liUFsIR27drx+uuv8/rrr9vNhl05cECKTxol6UOQRYPGICfucpC68AFMQ5aRXWuG+Rhvb7q2bv1I5Dw8PJ4RtaTH9qrduGGDnHSKdHAJzKZNYc0ax9oEc3NDKezHN984thpoTAx88IF0dkkFIQRHjhx5JHQ7duygXLlyNGnShEmTJlGzZk08HVZBUgfMR4rfX2grfnqgAT4+f/Lvv/D+++/z/PPPs3z5cooVK6ahHcezcuVKhg0bxubNm+0qegChoaGEhYVlXOE7dMis7CyhQEPgO5KvZD3NfaTo1TLTvGdCAh0aNSJ44MBH4uZoGjWCXLkcK3x+frLorVNwvCOp4hHR0UL4+zvOffrJGKIzZ5J15dq1a2LevHnizTffFHnz5hXFixcXffr0EUuXLhX37993zueTDKMQ4msh65ppEebgK4QYJIQwPLJgMpnE5MmTRVBQkFi/fr1Dzsoe7NixQwQGBordu3c7xN6aNWtEw4YNHWLLLowfL4SXV5q/mSIg1oE4AiIbiFsgfgDRIPF9QASAyA7CDURpEFfM/T36+z/ze3QGa9c6pj4jCOHpKUTTps7L9KOEz5nMnesc4fP0FPF9+ohVq1aJAQMGiPLly4ucOXOKV199VcycOVOcP3/e2Z9MGhwRQpQRQvgL6wTPXwgRIoTYm6qFDRs2iLx584qJEycKk7N+mVZy4sQJkTdvXrFq1SqH2bxz547Ili2bdenBXIGxY+WV2AzhEyA6gfgoBeE7k/g4HsREEEVBxJjzewwIEOLECWd/CkIIGfbr42P/S1BAgKzf6yyU8DmT5s3N+pYUAeEDwu+J7SqIOBBfgigBQp+4XzcQF8xo84pOJ+rXry9GjBghdu/eLRIcnTrBJgxCiGXizJk8Ij7eQwihF2mLnW/iVlXIdGTpV/U+f/68qFixoujatauIiYmxy1lozdWrV0VISIiYM2eOw20XLVpUnDx50uF2NWHKlHQD158UvjPI0d3/UhE+ASIy8bW95qiAn58Q//3n7E9BCCFzXQQH27cSu6+vEM7OeZC5XNgyGvv3m71rUjGQpK0AMjf6CmAh8AAZRloN+NeM9gq4u7P577/5/PPPqVGjBu621qJxKB5ERTWmenUD9+9vRnp+voV0LciOXLvLBhQDOgLjgH2JWwfMKTtUtGhRduzYQWRkJA0bNuTatWv2ORWNePDgAc2bN6dXr1507drV4faT1vkyJCVKgJf5lcdLAK8D36fyvhGYgwyQMWulOD7eKcklUiJbNrn8nzu37eWpUiIpfKF9e+3btgQlfM7i/n24d8/qw9cD65C+jtWRXkrZgfcxpwoW6PR66c2WQVmyZAl16tQhKKg20AvpAHMGCEeGPjwAziFvC94FnrPYhp+fH7///jstW7akRo0a7Nq1S6vua0pcXBxt2rShfv36fPLJJ07pQ4YWvmrVpNOXBXzBswE2lXhconUe8CeyJGu6lChhWQ0oOxMcLHNdBAdLodICnU629f33jo/ZSwklfM7i0iWbvlXrkXlNgq1twGSC//6z2r6zmTNnjkNGNjqdjs8//5xp06bRsmVL5s6da3eblmAymXjrrbcIDAxk4sSJTgsir1atWsYVvsBAOdRJg/+QibqSCAZikaEMIOc1o5CzMQ+BvUAzc+3XqWN2Vx1FoUJw/LgML7ZV/PR6qe07d8pC9q6AEj5nERsrb4PMpA0ydihH4uO7gE3Jx0wmx4ZRaMiFCxc4cuQILVu2dJjNVq1asWXLFr799lv69+9PQkol3h2MEIIBAwZw69Ytfv75Z6dOV1etWpUDBw5gdHTKL6147TXnjLr8/eGNNxxv1wx8fWHyZFi/HipVks8t+Yr5+8v7iSFD4Ngx2YaroITPWXh4yLVeM1mGnMQLT3ycG7hui32dDhwWi6ct8+bNo2PHjpqn30qP5557jt27d3Py5EmaNWvG3bt3LW9ECHkVmD8feveWd/tVq0L16jJh8ddfy1Lxd+6k29TYsWPZuHEjy5YtsyEtnDbkzJmT/Pnzc/LkSaf2wxqEEOysUYM4LSqtW0r27PDCC463awG1a8PBg7B7N7z9toz38/aWoubjIy8j3t5S6Pz95XJptWowa5bMz/Hll653qXGdieWsRu7cYMOooTEwCbiCTA1rMe7usg8ZDJPJxLx581iyZIlT7OfMmZO///6bTz/9lBo1arBs2TIqVKiQ/oH378OcOTBuHDx4IG88UooW3rBBzg3Fxcmk5UOGyAvjU6nU5s+fz7Rp09i+fTs5cuTQ5uRsJGmdr1y5cs7uilkkJCSwZMkSxowZQ0xMDJtDQgi8cAGdBTekNqHXw6BBFs38OJMKFWD2bPn41i25Dnj+vJw48vSEnDmhShUoU8allixTxrlOpVkYk8nsaNEnXamf3FqCCAURBsIA4iGI6SB+Msen2MdHiCtXnP0pWMyGDRtEhQoVXCK+bsGCBSIwMFAsWbIk9Z0SEoT49lv5eVsTHezvL0Tx4kKEhT1q8p9//hF58+YVx48fd8BZms93330n+vXr5+xupEtUVJSYMmWKKFq0qKhbt65YsWKFjEE8cMCx9fiCg4XIIKEymQ0lfM6kenWbhC8OxBcgiiPj+AqD6AHiojk/umzZnJc2wQbefvttMX78eGd34xF79+4VwcHB4osvvng2gPvECSHKl9cmHYavrxCDB4u927eLwMBAsX37dueccBps2rRJPP/8887uRqrcuXNHfPXVVyIoKEi0adMm5c/ws88ck77E11eIXbsc/yEohBCqEK1zGTYMMWYMuvh4x9t2UAFMLYmIiCA4OJjTp08TFBTk7O484saNG7Rv357AwEB+/vlnAgICYMsWePllWdhUo7Ujk48PYUYjtxcs4OUOHTRpU0sePnxIvvz5CDsfxn8P/yPaEI27zp0cPjmolK8SuXwdn4MSpDPU+PHj+eWXX3j11VcZOHAgZcqUSXnn+Hg5X3fmjP3q9GhUJUVhPa4+E5tp2bdvH4vPneN/8fE43C3B3x8GDHC0VZtZvHgxDRs2dCnRA8iXLx8bNmygb9++PP/886z54gsKduumeTVvt9hYqnp44DFuHLRqJT0LXIDw2HDmHZzHvEPziB0YS+gPoXh5eCGQ99Q6dMQkxJDNOxu1C9Wmb42+vFjsRdx09vWtO3DgAGPGjGHdunW88847HDt2jPzpFWL28oLNm6Wz0dWr2oufXg9t28ooboXTUCM+BxIZGcmvv/7KzJkzuXPnDu+88w6DVq/Ge9s2h/ZD5MuH7urVZxwmXJ169eoxcOBA2rRp4+yupIgQgp9HjqTt0KEE2PNn5eMjhW/RIvvZMINrEdf4ZP0nLD6+GDedG9EG84Te38ufAK8APq/3OX1C++Dupl0YhhCCf//9lzFjxnD8+HEGDBjAO++8Y3ktwtu3Zamiixe1u4Hx84POnWH69Az328tsKOFzAAcPHmTmzJksWrSI+vXr07t3b5o2bSrjrrZvl0WpNB4dpEa0TscPpUrR6PffqVgx41QbP3v2LLVr1+bq1asOLIlkIUJAgwaYduzAzd7xbHo9/PYbODCWMQkhBD8f/pn3V71PXEIcBpN1oyI/Tz9K5i7J7+1/p2Tukjb1KSEhgT/++IMxY8YQFxfHkCFD6NixI14WpCJ7hrg4GDoUpk61OLNLMry8ZBDc7NnQrp317Sg0Q9122ImoqChmz55NzZo1adWqFQUKFODIkSMsW7aM5s2bPw42rlNH3gVqlRsoLdzd8alWDc++fWnSpAm9evXi5s2b9rerAXPnzqVz586uK3ogL2z799tf9EDeKHXpIsMkHEhsQiyv/PoK7/39HpHxkVaLHkCUIYrDNw9TaUYlFhxeYF0bUVFMmTKFkiVLMn36dIYPH86RI0fo0qWLbaIHMjht7Fi5XlupkrzZsCSC28dHbm3bwtmzSvRcCDXi05jDhw8za9Ysfv31V+rUqUPv3r156aWX0s6qERUlc/rcuGHfzun1cPQoFC1KeHg4w4cPZ968eQwaNIj+/fs7PQg6NYxGI0WLFuWvv/5y3VGq0Qj58pkVeK4ZPj5yRPL55w4xF2OI4YX5L3DoxiFiEmwYAaWA3kPP+JfG07tab7P2v3PnDlOmTGHatGnUq1ePwYMHU6uWuaVfreTQIZgwAf74Q47uPTzkbzfpRidpZBcTI9OgvfcevPMOuNiatMLFhe/aNVi7Vs4Gbt8u15oTEuT0eLZsMuFFgwZQty7UrOm8ONDo6Gh+//13Zs6cyeXLl+nZsyc9evQgONiCTJqHD8sTiYiwTyd9feXUWKtWyV4+c+YMQ4YM4eDBg4wePZrXXnvNafkeU2PdunV8/PHH7LegmoXDWblSjtzt9f9LjcBAecNk53RlJmGi2c/N2H55u+ail4TeU8+8NvNoXzb11P3nz59n/PjxLFy4kPbt2zNw4EBKly5tl/6kihAy125YGJw+LcXP3V1mYalUSV6YcuZ0bJ8UFuFywicEbNokZxg2bHh8U5UaXl5yCwyEwYPhrbcgIMAxfT127BgzZ87kl19+oVatWvTu3ZsWLVrgYW3agr17oXFjefHU8t/i6wtz50IaLvAbN27ko48+ws/PjwkTJlC9enXt7NtI586dqVWrFv1cIa17atSrBxY4KYUAPyIz7/RAlrBJoiswxdyGAgJg4UJ45RWzbVvD97u/57N/PyPKkMaPUQP8vfw51fcUBQIKJHt93759jB07lvXr19OrVy8++OAD8uXLZ9e+KDIvLiV8V65Ap06yTF10tOXXfj8/KYLz5tlvzT8mJoY//viDmTNncv78eXr06EHPnj0pUqSINgZOnIDWreXw1laHFx8f+aH8/rtZ+QCNRiPz5s1j6NChvPjii4wcOZJChaxKiGYRcQlxRMRHYDQZ8fX0JcAr4NGoMzw8nJCQEM6ePUtgYKDd+2IVCQlyGtkC1/cQHgvfj4BNfr19+khPQTtx/v55KkyvYLbXpi14uHlQt3BdNry9AZCj/TFjxnDq1Ck++ugjevbsKeMkFQobcBnhmzsX+vaVjlS2Jr7X66FFC+lroNVv5OTJk8ycOZOff/6Z0NBQevfuzSuvvGIfZwuDgfhhwzCOHo23hwduln4gbm5S9Fq3lhfE7NktOjwiIoLRo0czffp0+vXrx+DBg/Hz87OsD2kQHhvOoqOLWHd+HXuu7uFaxDU83DzQ6XQYTUZ8PHyoEFSBBiEN0J3UcWrjKf744w/N7GuOFdPUIWgofOXLw5EjtrSQJo3nN2bTf5swCsdUXvDz9KN3YG/+nfYvCQkJDBkyhDfeeMN2ZxWFIhGXEL4vvpC5e7X06Pf2huLFpUOWtbmY4+LiWLJkCTNnzuT06dN0796dnj17UrRoUe06mgqjRo3iyubNTClVSip4UlLjtP5d/v7yrqFNGxg4EEJDberDxYsX+eSTT9i6dSvffvstb775Jm42xB8duXmE0dtHs+TEErPivtx17giDoIB/AUY0G0Hnip3xcHPBnAuzZ8MHH6Q9J/8UIWgofN7ej9eZNOa/8P94bspzxBodW8Iq4EEAvzX+jebNm7vcmrMi4+N04Rs+HEaNsk8Ym6endJbctSvdOpPJOHXqFD/88APz58+ncuXK9O7dm1atWjnMlf7u3buULl2aHTt2UKpUKekl9vff0sNn61Y4dUqmRBdCzu2GhMgRR+3a0nkll7apoXbu3MmAAQMwGo1MmDCBunXrWnR8XEIcQzcOZeqeqcQb460aOfh5+lE4e2EWv7aYckEulv1/+HBZe8WCn1IIj4WvJ7JydxKrAYv8E729pSeYxv93gEFrBzF5z2TijY5Nq+fr4cuhPodsju9TKFLCqcK3ejW8+qp9Y7e9veGll2DZsrT3i4uL488//2TmzJkcP36cbt268c4771C8eHH7dS4VBg0aRFRUFNPtuG5jKUIIfvvtNz755BNq1KjBmDFjzBr5Hr99nJcXvsytqFs2rxHp0OHj4cOXDb5kSJ0hrjMS+OwzGDnSokNC0HDE5+sL585Beum4rCDP2DzciU4jRGMCYAD6A0kzkfuAw0A34H9AP2QBySQ2AveAV1Nv1tPNk8/qfcb/Gv7Pyp4rFKnjtHmjBw/gzTftn7AkLg7WrYM//5RxpE9z9uxZZs2axbx58yhfvjzvvvsubdq0cdp6wsWLF5kzZw5Hjx51iv3U0Ol0dOzYkTZt2jBu3DiqV69Ojx49+Pzzz1NNB7Xv2j5emP8CEXERj/I22oJAEJMQw9dbvubyw8tMbj7ZNcTPyfGP8XFxDBs2DH1wMHny5Hlmy507t1XV2W9H3eZh3MP0dxTALqC+xSZSxWAysPHCRiV8CrvgNOHr18+iJRGbiI6Gbt2gUSPIkQPi4+NZvnw5M2fO5PDhw3Tp0oVt27ZRsqTzp1W+/PJL3nvvvfST6ToJX19fhg4dSvfu3Rk6dCilS5fmq6++okePHskursdvH+eF+S+Yd+G0kGhDNHMOzkHvqWdMExfIcJ83r/SoclDauadx1+kILleOm/fucfjwYe7cucPt27cfbffv3yd79uwpimJqm5eXF/uu78PXwzf9ac7awHagOsnjMmzk0M1D2jWmUDyBU4Tvxg3pYR8X5zib8fEwZsxdhPiOOXPmUKZMGXr37k27du3w9vZ2XEfS4MiRI/zzzz+cOXPG2V1JlwIFCjB79mz279/PRx99xJQpUxg/fjyNGzcmLiGOlxe+TESc/YK5ow3RTN07lUYhjWhesrnd7KTGgwcP2L9/P/v27ePe2rV8GhODs5zs3YsXp28a1TaMRiP37t1LJoZJ29mzZ9m5c2ey1+7cuYNer8ezvicPqzyE9AaLBZBztzuAF7U7r2hDNOGx4eTwyaFdowoFThK+mTMdn2UlJgZGjTLQv7+BTZs2pV6PS3vLwBkgGtABAUAJHi+IPObTTz/ls88+szyTvBOpWrUqGzduZNmyZfTp04fnnnuOoM5B3Iq8pcn0ZlpEG6J58883OffBObteHCMiIjhw4ABhYWHs27ePsLAwrl69SqVKlQgNDaXGG2/gv3GjRXE4/z3xuKutHaxdO8233d3dH43kzEEIwYMHD/hyw5d8f+R78/rQCJhNyl45M5Ff/SQSgLLpN+np7klUfJQSPoXmOFz4hIDJk6VTonk0BA4BN4CkkVlXoBAwwiLbfn55adnyO+yreSZgPfIqsAu4ipz/cXvi/VjkLXI9oBdQg82bt3Ds2DGWLFliz87ZBZ1OR9u2bWnRogWfT/qccUfHgYNySUfFRzFg9QDmtJmjTXtRURw8eDCZyF28eJGKFStSrVo1mjRpwqeffkqZMmWSZ+iZPBkOHtSkDxYRECC9tzREp9ORI0cOAnMHokNn3g1MXqAU0kvn6TwDvUnZucXMvigUWuNw4bt40ZIKH/8BW4HswArgNZtsx8To2LRJrvVpTzwwFRgLRACRT7yX0pTfGeAcsAghCrB5s5ERI752mWlXa/D29uZGiRu4H3V3WLBznDGO3479xrhm4yyu8B0TE8OhQ4cICwt7JHTnz5+nXLlyhIaG0qBBAwYOHEjZsmXTD2UZPBh695axlo5Ep5Nxm3bA38sfT3dP80MZGiJHd2kPQM3GYDTg56ld4gSFIgmHC9++fTL/pnnMR86d1ATmYavwGY2yuLL27Ef27QZyStNcTEAUOt0ZBg3S4ev7PVAHKGaHPtqf8NhwlpxY4jDRS0KHjp8O/MTg2oNT3ScuLo7Dhw8nE7nTp0/z3HPPERoaSu3atfnggw8oX768dR69r74K775rw1lYgZeXFFs73SyVCypnnnNLErmB8sBuQIOCBP5e/mT3sSzrkEJhDg4XvrAwS26K5wMfIYWvFnATOadiPYcP23T4UwjgG+Bb5Fqe9ej1AjgAVABmAG/Z2jmHs+joItx0ZmZ2OQzsBO4gZ7DzIWd+k1KeHgCWA+2RF9M0iEmIYfLuyY+ELz4+nqNHjz4SubCwME6ePEmpUqUIDQ2levXq9OnThwoVKmhXisnbW8bzDR/uOHdlLy9Iw6nFVqrlr2Z5JYYGyJUJDaicr7I2DSkUT+Fw4btyBUwmc/bcBlwEOiAXDYoDCwHbfujaVY0RyKjdH7FV9B5jRI4YewMPgL4atesY1p1fZ16Q+g7kv/cVpJ+PO3AWOMVj4TuEXBo9RLrCB3Dt4TW6v9edI3uPcPz4cYoVK0ZoaCihoaH06NGDihUr4mvvYr+DBsGCBXD8uLlfcuvx84NJk+wStJ5Ebn1ucvjk4FbUrdR3evrnmB0Y9sTz/6VwjBlLDV7uXjQKscuahELheOGLNzvz0TygKY9Xyjslvmab8GlXHPt/SNGzR+xWDPAx8iqScUZ+e67uSX+nWKRzQxuSe/aVTtwAwpHLux2Axcgl0nRiBdyMbvgV92PSm5OoVKmSpkm1zcbdHRYvhmrV7BvT5+Ul87B262Y/G4l0r9ydCbsmEGd0YOwR4KZzo3PFzg61qcg6WJ9x2ErMu+mOAX4HNiPnwPIhcyMdwtZ5FGtL5SVnG9KJxZ4By9FAH6QDjOsTlxDHtYhr6e94GenOnpZn7SFkbFhZIA9gRuEBnZeOYrWLUbt2beeIXhJlyshRn71Gl56eUKiQTEXkAI/H92u8b3cbKVGjQA2K5cyYa90K18fhwleqlPztps0y5PzXceBg4nYCuQg0P3EfI3L4kLSZN5Q0M5QpDaKB19FuejMt4oA3kE4wrk1EfASebmbEMMQAetIOij6EXOok8a8Z9zrxxnjux95Pf0dH0LatrLOltfh5e8uE5Dt3OqzCd6FshXix2IsOrYrh5+nHp/U+dZg9RdbD4cIXGmrO9WAeMsNtYR6P+PIh17x+QQ4ZRiEXgZK29AutAmTLdppNmzYRbfVU1FeAoy6wRqTgz09vR6djNBmTBymnhi/y3iG1KedLyI83aV2vAtKn6Xr6TRuM5heCtTsdOsCaNZAvnza5PPV6WXlj714I0sBl0gJmvDwDb3fHhNl4uXnRIKQBL5XQNjZRoXgSh6/xVatmTvD66lRe75C4ASyw2Lanp5G8eU/y6acjOXz4MOXLl6dOnTqPtnz58qXTQiwwHceM9pKIQgbqd8E8ZXEM0dHRXL16lStXrnDlyhXOXj5LvCE+/S4GI791J4GUqgsdTPw746nXDwFp+HHo0OHn5WIxX/Xqwdmz0vNywQKZ2cWCKu2ArLHo6Qnz5kHLlvbpZzoEZw9m7Itj+WDVByS42VglOh18PH2Y01qbZAQKRWo4XPhy54aiRWVJOUfj4eHO1KmtKFeuFTExMezdu5ft27czZ84c3nnnHXLlypVMCJ977rmnCq8uBjun4UqZG8gsMM/b3ZIQgocPHyYTtae3q1evEhUVRaFChShUqBAFCxakYKGCeOo9iSMdJwgfpFffKuR8Q3HktOd54AJwDGgJPJkv/ARyubcJqU6R+nv5UzKX85OMP4OfH8yaJQPcv/8e5syRTjDR0amnONPr5fpdwYLwySfw+uvyNSdx48YNfv7oZwJrBfIg1wPLQxzMxNfDl4XtFhLk59gRrSLr4ZR6fHPmyILVjk5yUbWqDKBPCZPJxIkTJ9i+fTvbt29n27ZthIeH8/zzz1OnTh3q1q1L7doDcXffm6aNkBD48Udo3Dj56zt2wNChcqbKzQ3q14fRo6GsGTkLpUK8Ddh2JyyE4O7du8kELCVhE0IQHBz8SNiSxO3J57lz534mnVSdn+qw48oO8zrzZByfF9KZJRjYg3TcfVLgDMB4pCdoaVJE76nnUJ9DlMhVwvwPxBlER8ssCnv3yr9nzkBcHA8iIzH5+5OzaVNZVPj556FiRWf3ln379tG2bVt69OjBx599zMsLX2bXlV1EJ2jr2OXr4cvMljN5q2LG8WJWZFycInzR0XKZwlFxviBnjH76SS69mMv169fZsWNHohBuZdOmsHRvvFMSvp07oUkT+OYb6N5dznaNHw9Tp0ohLmaW81oJZJqzlDEajdy6dSvVEVrSX19f32QClpKwZcuWzaociZ/9+xljto9xeOYWkBfOqM+iMmxux2HDhuHl5cWwYcPS39lB/Prrr3zwwQfMmDGDV1+VVWMNRgNv/fkWK0+vtLmwMICHmwfe7t4saLeANmXa2NyeQmEOTqvAPm4cfPmlY8RPp4PSpeHIEVvCGc4hREV0urR/7CkJX716UKECTJuWfN/mzaWX6XwzfFeE8GDnzrVcuXI7RXG7ceMGuXLlemZk9rS46e04Zbbv2j7qz62vyQXREtx0brR7rh2LX1vsULtaMmHCBC5evMjEiROd3RWMRiNDhw7lt99+Y/ny5VRMYeT554k/6ba8GzGGGOJNZgfnJsPP04/K+Sqz8NWFFM5e2NZuKxRm47RCtP37y/X+w4ftn+TCx0fGFdsWw3cEnc7yBqKj5TTn118/+16HDjLLlTlERhqZNq0/sbElHwlZjRo1Hj3Onz+/0xNcVytQjSLZi3DizgmH2vV2804zT2dGIFeuXBw4cMDZ3eDhw4d06tSJyMhI9u7dS2Dg06UWJG2fa0v9IvX536b/MefgHHQ6HZHx6a9duOnc8PXwJZ9/Pv7X8H90rtA5w47SFRkXpwmfu7ssRlulin1HfX5+8PHHUN6MtFdpE4E18XT37klhTymzVP78cOeOee0EBGRjwYIZOMLBxRY+rvMx7696nyiD4+ax4+/EM/XzqeQelpvixYs7zK6W5MqVi3v3zKzVYyfOnDlD69atadSoERMnTky3IkVufW4mt5jMmCZjWHRsEXMOzuHQjUPEGeOShT8IBNGGaAoEFKB+4fq8X+N9ahasqQRP4TScJnwAJUvC8uUyPMkeGZ70emjXTjqV2I51M8I5c0pnluvXeaYO4PXrkMoNdSq4fiB754qdGb19NCfvnLR7IVqQa3uL31lM2B9h1KxZk9atWzN06FCKFi1qd9ta4mzhW7t2LW+99RZff/01vXv3tuhYX09fulbuStfKXQG4HnGd03dPE5sQi7ubO9m9s1MuqBx6T+d5pioUT+LwAPanefFFWLFCjsy0vAHU6+GNN2QCDW3a1WPNx+XnJx30Fqew/PT77/L8zUMk9sG18XDzYPFri/Hx0KjqQRr4evjyVqW3eLncy3z55ZecOXOGggULUr16dXr16sXFixft3getcJbwCSGYMGECXbp0YfHixRaLXkrkD8hPg5AGNCvRjMbFGlO9YHUlegqXwunCB/LiHxYmpyNtTbPo4SE9OKdMkU4mbpqdYRnMHXEZDDJIP2kbNUrGH3//vawOcf++HIXu3CkdfMwjGlni2vUpF1SO/zX8n10vdu46d4L8ghjfdPyj13LmzMnXX3/N6dOnCQoKomrVqvTp04fLly/brR9akTt3bocLX1xcHN27d2fevHns2rWL+vXrO9S+QuEsXEL4QE4DHjgAn38uU5pZKoAeHvK4hg3h5EmZuF7bJYQymJsPtEUL2ZekbfVqmb1q6VK5rlekiDzXbdvkdK955AdcLDNJGgyuPZjulbvbRfzcde4E6gPZ1n1bitlacuXKxYgRIzh16hQ5c+akcuXKvP/++1y5ckXzvmhFzpw5uX//Po5ysr5+/ToNGzYkMjKS7du3U6RIkfQPUigyCU4LZ0iLiAj4+WcYOxZu3pQZmyIjn/X+1Oulk4zRCG+/DR9++Ow6mrZUAI7a00AatEdmjsk4CCH4eP3HTN07VbMQB18PX4L8gtjWfRuFshUy65jbt28zduxYfvrpJzp37swnn3xCgQIFNOmPlmTLlo0rV66QLVs2u9rZu3cv7dq1o1evXgwdOlQ5mSiyHC4pfEkIAZcvyyDv3btlfc+YGCmE+fJB7doy92e5crJEmf2ZBHyGfcsRpYQ/sAho4WC72vDPmX948883iYqPsqmum6+HL29XeptxTcdZlZfz5s2bjBkzhjlz5tClSxc+/vhjM/KzOo6QkBA2bdpESEiI3Wz88ssv9O/fn1mzZtG2bVu72VEoXBmXFj7X4wGySkS6WbY1JghZnsBlZqYtJjw2nAGrB/Db0d/Q6XRm53tMivsqmK0gP7T8gfpFbF+HunHjBqNHj2b+/Pl07dqVIUOGkDdvXpvbtZWqVavy448/UrVqVc3bNhqNfPbZZyxevJjly5dToUKF9A9SKDIpGfdK6hSyI2vxmVF3TjN8gYFk9H9VDp8czGkzh6sDr/JVo68IzhaMp5sn2b2zJ4v5csONbN7Z8PP0w9fDl3bPtWNDlw2cfP+kJqIHkC9fPiZMmMCRI0cwGAyULVuWIUOGcPv2bU3atxZ7eXY+ePCAVq1asXfvXvbu3atET5HlUSM+i7mFLB3w0EH2CgOnkGUNMhfhseEcuH6AgzcOcj/2PgajAT8vP0rmKkm1AtUonrO4Q9afrly5wsiRI/ntt9/o1asXgwYNInfu3Ha3+zQdOnSgffv2dLAkoWw6nD59mlatWtGkSRPGjx+fblC6QpEVUMJnFYuRhXLtnZ3EF9gE1LCzHQXA5cuX+fbbb/n999/p06cPAwcOJFeuXHa0KIADyJIUW7l+fRX+/joCAvyRHrwVgXpA9cTNslH/mjVrePvttxkxYgTvvPOOtl1XKDIwSvis5g1gJfZzdNEjpzhTSPKpsCsXL17km2++YenSpbz33nsMGDCAnDlzamjhATAfGIssN28k9eLGvsgES37Iek09gLRHo0IIxo8fz7hx4/j999+pW7euVh1XKDIFSvisxgC8AmxDe/HTI+vvTcOVqq5nNS5cuMCIESNYvnw5/fr1o3///mTPnt2GFgXwE1LABJbPGPgivw8jgA9JaQQYGxtLr169OHr0KMuWLaNwYVX1QKF4moztMeFUPIG/kOKnZWC5L9AXJXrOp2jRovz000/s3r2b//77jxIlSjB8+HAePrRmffcq0ADoD0Ri3TR5DPImaxhy6vN8snevXbtGgwYNiIuLY9u2bUr0FIpUUMJnE57I+LrZQDZs8/b0AfICfwOjUaLnOhQvXpw5c+awY8cOzpw5Q4kSJfj222+JiIgws4VTQGVkyXkt1oWjgINAVeQaIezZs4caNWrQunVrfvvtN7vWXVQoMjpK+DShA7I6+htIAbPkouOfuL0LnAUaad47hTaULFmS+fPns3XrVo4dO0bx4sUZPXo0kZFp1aG7ANQG7gIJGvbGhFwrbMjKlSN55ZVXmDZtGp999pnKxKJQpINa49OccGAe8ANwGvBGjt6S8q25I50ZjEA55LTm68gpTkVG4vjx43z99dds2rSJQYMG8e677+KXLMlsLPAccAl7lZQymeD+fTdu3drBc8/VtIsNhSKzoYTPriQAx4ETyLUZN+TorgJQAjXgzhwcO3aMr776iq1btzJ48GD69OmTONU4EJiBvVPcCeGNTvc68oZLoVCkhxI+hUIjDh8+zFdffcXOnTsZN64jb7wxHZ3OvNRstqMHlgONHWRPoci4KOFTKDTm4MGDmExNqVz5tob1IM2hGhDmSIMKRYZECZ9CoTlXkFPZ1leisA5fYC9y7VihUKSGWmRSKDRnhkV7h4TIgsX+/pA3L3TtKutPNmwIP/5oSUsG4HuLbCsUWRElfAqF5vyFpaO9lSul2O3fD2FhMGKENXYTgNXWHKhQZCmU8CkUmmICTlp9dMGC0Lw5HD1qbQvXcHyhZIUiY6GET6HQlLPIpNLWcfkyrFoFVapY24IeOGS1fYUiK6CET6HQlOtYI3xt2kCOHFC3LjRoAJ99ZksfbthysEKR6bH+1lShUKRAvFVHLVsGjTUJwRNW90GhyCqoEZ9CoSneTravc4E+KBSujRI+hUJTCqBtMmpr+6BQKFJDCZ9CoSnFsVdCavOIBio60b5C4fqozC0KheZUA/Y7yXZRni5Qq1AokqNGfAqF5rRG1mV0NJ7Ay06wq1BkLNSIT6HQnBtACM7J1XkQKOVguwpFxkKN+BQKzckHNEF6WDqSSijRUyjSR434FAq7cASoCTiqHp8vsBao6yB7CkXGRY34FAq7UAFZgV3vAFu+QBeU6CkU5qFGfAqF3TAgBfAc9ovtcwPyA6dxjMgqFBkfNeJTKOyGJ/AvkBtwt0P7OiA7sAklegqF+SjhUyjsSkFgN9LhxUvDdj2AXMAOZLV3hUJhLkr4FAq7UwQZZtAUbUZmfkAd4DBQRoP2FIqshVrjUygcyh9AT8AIRFp4rB9yevN7oCuOD5dQKDIHSvgUCocTC/wOjAYuIKctI5ElhR5jMkFCgjdeXu7IqdKPgc5IAVQoFNaihE+hcCpngL3AzsS/SQLox7FjvuzYIXjnnZnIKU01wlMotEAJn0LhouzZs4devXpx8OBBZ3dFochUKOFTKFyUmJgYcuXKRXh4ON7eqrisQqEVyqtToXBRfH19KV68OMeOHXN2VxSKTIUSPoXChalSpQoHDhxwdjcUikyFEj6FwoWpWrWqEj6FQmOU8CkULowa8SkU2qOcWxQKFyY8PJzg4GDCw8Nxd7dHvk+FIuuhRnwKhQuTI0cO8uTJw9mzZ53dFYUi06CET6FwcdR0p0KhLUr4FAoXRwmfQqEtSvgUChenSpUq7N+/39ndUCgyDcq5RaFwca5du0bFihW5ffs2Op3K16lQ2Ioa8SkULk7+/Plxd3fnypUrzu6KQpEpUMKnULg4Op1OrfMpFBqihE+hyAAo4VMotEMJn0KRAVDCp1BohxI+hSIDoIRPodAOJXwKRQagePHi3L9/n7t37zq7KwpFhkcJn0KRAXBzc6Ny5cqqGrtCoQFK+BSKDIKa7lQotEEJn0KRQVAZXBQKbVDCp1BkENSIT6HQBpWyTKHIIBji4qiWPTt7pk/H5+ZNiIsDT08IDIQqVaBiRfD2dnY3FQqXRwmfQuHKCAFbtsDYsfDvv0THx+Pl44NHfDwkJICbG/j4gIcHxMRAmTIwcCB06AC+vs7uvULhkijhUyhclRUroF8/uHcPoqKkCJqDv7/8O2AADB0KXl7266NCkQFRwqdQuBr37sE778Dq1RAdbX07ej0UKACLF0Plypp1T6HI6CjhUyhciWPHoEEDiIiA+Hht2vT1halToVs3bdpTKDI4yqtToXAVjhyB2rXliE8r0QO59te3L0yfrl2bCkUGRo34FApX4Pp1KFcO7t+3nw1fX/jtN2jVyn42FIoMgBI+hcLZCAFNm8LmzWAw2NdW9uxw9qwMgVAosihqqlOhcDYLFsDOnfYXPZDTnj162N+OQuHCqBGfQuFM4uMhKAgePHCcTb0e1q+H5593nE2FwoVQIz6Fwpn8+ScYjY61GRMD48Y51qZC4UKoEZ9C4UyqVgVn5N/08YHLl9VanyJLokZ8CoWzuHtXxu2lQQgQBEQ98dqPQMPExwIYC5QEfIHCwKdAXHq2PTxg1SpLe6xQZAqU8CkUzmLfPrPyaRqBSam89wEwC5gPRAD/AP8CHdJrNDISduwwu6sKRWZCCZ9C4Sz27pU5ONNhMPAdEP7U62eAacAvwPOAB1AOWAKsBjak1/C2bRZ1V6HILCjhUyicxeHDssJCOoQipza/e+r1f4FCQI2nXg8GagHr0mv44kVzeqlQZDqU8CkUziIy0uxdvwYmA7efeO0OkD+V/fMnvp8mjogbVChcECV8CoWzcHc3e9fywCvAqCdeCwSup7L/9cT300SnM9u+QpGZUMKnUDiLPHks2v0r4AfgauLzF4DLwJ6n9rsM7AJeTK9BPz+L7CsUmQUlfAqFs6hZU2ZRMZMSwOvA94nPSwF9gM5IoTMCx4BXgcaJW5pUqGBZfxWKTIISPoXCWVSrZtF0J8AXJI/pmwL0BN4E/IGXkI4wS9JryN1d1v1TKLIgKnOLQuEs4uNltYTYWMfbDgiAP/6QVSEUiiyGGvEpFM7Cywtee83iUZ8meHvDi+muAioUmRIlfAqFM/noIylCjsTHBz74wDmCq1C4AGqqU6FwNjVrQlgYmEyOsefnB+fOQd68jrGnULgYasSnUDibBQscN+rz84PvvlOip8jSKOFTKJxNyZIwfLj94+o8PKBSJejd2752FAoXR011KhSugMkErVrBhg2yUKzWuLnJgPn9+6FAAe3bVygyEGrEp1C4Am5usGQJ1KljUVC7Wbi7y4Kz27cr0VMoUMKnULgO3t6yOGynTtqJn58flCsna/8VL65NmwpFBkcJn0LhSnh6wg8/wMqVEBRkVqHaFPHwkMcOGyanNwsV0rafCkUGRq3xKRSuSkQEzJgB48fLgrUREekf4+cn1wvfegsGD4YSJezfT4Uig6GET6FwdUwmWLcOVqyArVvh9GlZUsjNDYSQdfUKFpTxgM2aQYcO4O/v7F4rFC6LEj6FIqNhNMK9ezLHp5eXzPfp4+PsXikUGQYlfAqFQqHIUijnFoVCoVBkKZTwKRQKhSJLoYRPoVAoFFkKJXwKhUKhyFIo4VMoFApFlkIJn0KhUCiyFEr4FAqFQpGlUMKnUCgUiiyFEj6FQqFQZCmU8CkUCoUiS6GET6FQKBRZCiV8CoVCochSKOFTKBQKRZZCCZ9CoVAoshT/B+DTXcKm6mjhAAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "solution = min_conflicts(france_csp)\n",
+ "print(solution)\n",
+ "draw_graph(france_csp, solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 34,
+ "id": "3559ec32",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'AL': 'R', 'LO': 'G', 'FC': 'B', 'AQ': 'R', 'MP': 'G', 'LI': 'B', 'PC': 'G', 'AU': 'R', 'CE': 'Y', 'BO': 'G', 'RA': 'Y', 'LR': 'B', 'IF': 'R', 'CA': 'Y', 'BR': 'R', 'NB': 'G', 'PL': 'B', 'PI': 'G', 'NH': 'B', 'PA': 'R', 'NO': 'R'}\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAb4AAAEuCAYAAADx63eqAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAAB6PklEQVR4nO2dd3iTVRuH7yRdSVsoG8oqssum7KlMAWXIXrLkE0QBByqoIDhQHCiiIiJDZO+hbGTKLJuypwyhBQrdzTjfH6eU2TZpVse5r+u9oMmb85w3TfN7n3OeoRFCCBQKhUKhyCZo3T0BhUKhUChciRI+hUKhUGQrlPApFAqFIluhhE+hUCgU2QolfAqFQqHIVijhUygUCkW2QgmfQqFQKLIVSvgUCoVCka1QwqdQKBSKbIUSPoVCoVBkK5TwKRQKhSJboYRPoVAoFNkKJXwKhUKhyFYo4VMoFApFtsLD3RNQKKzGYoEzZyA0FM6fh/h48PSE3LmhalWoVg38/Nw9S4VCkcFRwqfI2AgBO3bAV1/B+vXg4QFaLcTESCEE8PEBLy+IjYWgIHjzTejdG/z93Tp1hUKRMdGoRrSKDMvatTB4MISHS1Gz9qPq6ytFceBAGD8eDAbnzlOhUGQqlPApMh5370rBW7FCCl560eshIAAWLoQGDRw2PYVCkblRwqfIWJw5Aw0bQmQkJCQ4Zky9HsaOhREjHDOeQqHI1CjhU2QczpyB2rWlx3d//85RGAzw/vvw0UeOHVehUGQ6lPApMga3b0P58nI/z1kfSYMBJk+Gfv2cM75CocgUKOFTZAw6doTVqyEx0bl2fH0hLAyKFXOuHYVCkWFRCewK97NihYzgdLbogdw37N7deV6lQqHI8CiPT+FeLBYIDIQbN1xn088PFiyA1q1dZ1OhUGQYlMencC/r1tmXspAeoqNhwgTX2lQoFBkG5fEp3Mtzz8GWLa636+Mj9/pKlHC9bTuIM8Zx5MYRjtw4QlRiFBZhQe+hp2zesoQUCiGXPpe7p6hQZHhUyTKF+4iLk+XIrOBZ4DDwH+D90OMzgW+Ac0AO4CVgPJDTmkFXroRhw6yerruIjI9k1qFZTN43mYuRFzF4GjBZTBjNRgB0Wh1eOi/ijHHk0ueiV6VevF7rdUrkylyirlC4CuXxKdzHnj3QogXcu5fqaReBkkgx+wXonPT4N8AEYBbQFLgKvAbcAnYAnmnZ79ABli5N5+SdT2R8JCPWj+CPo3+g1WiJNVq3JOyl80Kr0VKnSB2mtJlC2bxlnTxThSJzofb4FO5j/34wGtM87XegDtAXKXIA94AxwA/A80iRCwIWAueBudbY37fPxgm7jjVn1lByUklmH5lNvCneatEDSDQnEm+KZ9ulbVT7pRpf7vwSs8XsxNkqFJkLJXwK9xEWJpc70+B3oGfSsQ64AfwDxCOXNh/GD2gNrLfG/rVrNkzWNQghGL52OJ0WdeJ23G0SzOkv22YRFuJMcXyy9RMazGhAVEKUA2eqUGRelPAp3Ed0dJqn7AAuAV2AEOSS51wgAsjL0zepCwHh1tgXAkwmKyfrfIQQvLLyFX498KtNHl5axBhjOHj9IPWm11Pip1CghE/hTnS6NE+ZBbRAihxAj6TH8iLF72mydf2h81NFCKvm4CpG/z2a+cfnO1T07pNgTuDMrTO0/KOlWvZUZHuU8CncR/78sqlsCsQh9+y2AgWTjonI6M5CyOjOx0NTooE1yCjQtBA+PqDR2DxtZ7Dv6j6+2fWNU0TvPgnmBI7cOMJ3u79zmg2FIjOgojoV7mPRInjllRSjOucBQ4BDgNdDj3cBagIFkJGdj0d1XgT2Ab5pmD+s0dC9XDkqVqz4yFGyZEl0LvQEE0wJlJ1clkt3L7nEnt5Dz+FBhymdp7RL7CkUGQ2Vx6dwHyEhqe6xzQL6AY+Xk34dGApcAfIA7wBngQSgMbCRtEUPjYYKgwYxf9Agjh07xrFjx5g5cybHjh3jv//+o9xjglihQgWKFSuGxgke4k/7fiI81qpdSYeQYE7g9b9eZ13vdS6zqVBkJJTHp3AfQsgO6Wnk8VnLDGA0sJMnxfIJ/P1h+nTo1OmJp6KjowkLC+PYsWMcP348WRijoqKoUKHCEx5i/vz50y2IQgiKTCzCtSjXRph667w5O/QsRXIUcaldhSIjoIRP4V7eeQd++MFhnRlmI3P6uqV1op+f7P3n42P12Ldv335ECI8dO8bRo0fR6XRPiGGFChUICAhIc8yN5zfSYUEHohPTjnB1JN46b4bXGc4Xzb5wqV2FIiOghE/hXi5elA1o4+NdZ9PLC4YMgW+/tXsoIQT//fffI2J431MMCAh4QhDLly+Pr++Dhdi+y/sy6/CsVCwgI3qigLd5dA13CrKG2zBgC3AU0CUdgUArIF/Kwxb2L8yVt67YfM0KRWZHCZ/C/bRuDRs3WlXFxSHo9XDiBBQv7jQTFouFy5cvPyGIp06donDhwslC+JvhN/4z/pf6YBORu/G1gNpJj91Ahrze4oHw5UBG+SQCq4DbwMCUh/XQenD73dv4e/vbcaUKReZDBbco3M+0aVC2rGuEz9cXPvrIqaIHoNVqCQoKIigoiBdeeCH5cZPJxNmzZzl27BiHjx3mRuINsGZ7sDIyj+O+8B0CqgCbn3KuF1AJWJT6kAZPA4f+O0TD4g2tmIBCkXVQeXwK9xMYCD/+KEXJmWi1ULKk3Fd0Ex4eHpQrV45OnTrx8hsv4+tt5TUXQYathgMW4BhSDJ9GAnAEmeyYCmaLmdO3TltnX6HIQiiPT5Ex6N0bNm+WuX3OaEyr0cgI0hUrMky1ljhTHFqNDfee972+4si9u8dXKP8B9iL/qgsD7VMfzizMxJnSrpWqUGQ1lPApMgYaDfz2G8TFYVy+HE8HRXkC0tMLCJC9/4KCHDeuneg0NgpwFWTOxp2k/z9OPeQen5Vo0Ng+hwxCQgJcvixjonQ6yJULChbMMIV4FBkcJXyKjINOx7bBgzm8ahVDvL3RJqS/M0EyBgMUKwZ//ZXhuq3n8M6R3EzWKgKSjjNAO/vt67S6TBPYYjbDmjUwfz7s3i1Fz9tb3tMIIbeHPT2hUiVo3hz695e/doXiaag9PkWG4fLly3Tt3p2yy5ej3bZNfnMZDOkay6zRkKDTwXvvwdGjGU70AIrkKGJ74ns7oA+P1nCzgyoFnuY6Zhyio+Hzz6FQIejRA+bMgXPnpNBFR8vaB1FR0vOLioJ//oEvvpCxUs2awbZt7r4CRUZECZ8iQxAbG0uHDh14++23adGiBdSqBadOwVdfyeVJX1/r1rF8fUGvx9K7N83z5GFfq1bgkTEXNjQaDcH5gm17UW7k/p0DiE2I5fze80RFZcxWRVu3QunS8OmnstaAtdNMSJBCuGkTtGoFffo4rDiQIoug8vgUbkcIQa9evdBoNMyePftJL0gI2LkTli+Xt/DHjsm1L50OLBb5/yJFoHZtuc7VpQv4+zN16lTmz5/Ppk2bnFJj0xG8v/F9vt31LUaLi3IYH6IgBQneFszevXupWrUqzZs3p1mzZtSsWRNPT0+Xz+c+ZjMMHy4ryjkizsnHR1ao+/NPqFnT/vFcSkKCXLEIC5MurkYjb+4qVJDrul4Ocv2zGUr4FG7n66+/Zt68eezYsQO9Xp/2C4SAu3flbb2npyw/5u39xGkmk4kKFSowadIkWrZs6YSZ28+ZW2eoPKUy8SYXVq4B/Dz9+L7V9/Sv1p/Y2Fh27NjBhg0b2LhxIxcuXKBx48Y0a9aM5s2bU7ZsWZfdOJhM8r5l3TrHB/f6+sqt3kaNHDuuw7l9W6r+1KmyspGPj/zMm5P6KOp0UgDj4+US/quvyk1NK0rkKSRK+BRuZd26dfTt25c9e/ZQzAnRCEuXLmXcuHEcOHAAbSq9/9xJrV9qse+/fS616evpy80RNzF4PrmHGh4ezqZNm9i4cSMbNmzAYrHQrFkzmjVrRtOmTSlYsKBT5iQE9OolHXtnZLSAFL+tW2VjkAzHzZvw1luwZImM2rH2TTAY5MpHly7wzTeQ16o2zNkaJXwKt3H27Fnq16/P4sWLadjQOdVDhBDUrVuXN954g549ez7y3N27cPCgjBBMSJDOY968UL26zKl3NrGxsUyePJnPFnxG7AuxmLQpt2hyJHoPPYNrDOablt+kea4QgrNnzyZ7g3///TdFixZN9gYbNWr0SO1Re5g9GwYPhpgYhwyXIoUKwdmz6Y6bcg4LF8LAgRAXl/4KRl5eshzf9Onw0kuOnV8WQwmfwi1ERUVRp04d3njjDQYNGuRUW1u3bqVv376cPHmS8+e9+e47WLUKIiLk94TFIg+NRq4iJSbKldP69eUNeJMmjs0PMxqNTJ8+nXHjxlG3bl0++eQT3j/8PmvPriXR7MD8xRQo5FeIM2+cwdfLdsEymUyEhoYme4OhoaGEhIQkC2FISAge6Qgmun5dRmK6Is5Gr4e+feGnn5xvK01MJhl9s2KF4xTfYIDOnWVebAYp1pDRUMKncDkWi4WXXnqJAgUK8Msvv7jEZr16I7hy5W0iIgpiNKba//YR/PwgZ04YO1Zuo9gjgBaLhQULFjB69GiCgoL4/PPPqZkUbRERG0GpSaW4m3A3/QasQO+hZ12vdQ6rzxkTE8O2bdvYuHEjGzdu5PLlyzz77LPJgTKlS5e2an+wXTuZp+eqOuUGA2zfLr17t2EyQfv28Pffjl/bNRigRQtYvFiJ31NQwqdwOR9//DEbN25k8+bNeDk5Ki02FkaMgOnTLcTHp3+Pz9cXqlWDuXOhaFHbXiuEYM2aNYwaNQovLy/Gjx9P06ZPlljZfGEzL8x9wWllxAyeBt6t9y5jnh3jlPEB/vvvPzZv3syGDRvYsGEDOp0u2Rts0qQJ+fPnf+I1V67ItAVXdqbSamUP4gULXGfzCfr0kcLkrA1NgwF69pRBMopHUMKncCnLli1j2LBh7N2712lBEve5dElG8IWHy60Te/HwkEugy5bJrAlr2LlzJyNHjiQiIoLPPvuM9u3bp+oBrTy1km6Luzlc/AyeBl6r8RoTmk9wWYSmEIJTp04lL4tu3bqVoKCgZG+wYcOGGAwGRo2SrREdUajHFnx8pOjmyeNau4Bca+/WzXmidx+DAZYuhQwa1ewulPApXMaxY8d47rnnWLNmDTVq1HCqrfPnZQ78nTty/86R6PUyFuGhbkNPcOTIEUaNGsXRo0cZO3YsvXv3RmflktPmC5vpuLAjscZYu/f8NGjw8fDhk+c+4e16b9s1lr2YTCb27t2bvCx68OBBatasyZ49q4mNTSvSJAiYBjR76LEtQBPAgOztFAi8D/Szaj4Gg6yP8NprNl6Ivdy+DaVKyQ+nK8iTR5a7yZnTNfYyAUr4FGlyK/YWq06vYuflnez4dweXIi8lfyHrPfWUzl2aRsUbUb9ofV4o8wJ6zydz8W7fvk2tWrUYM2YMvXv3du58b0HFijI63NGidx+DATZsgHr1Hn383LlzjB49mk2bNjFy5EgGDRqE91NyDNPidtxtBq4cyLpz64gxpi/owdfTl2I5i7Go8yIq5K+QrjGcSVRUFCtW7KFv38aYzWklzAfxdOHrBVwBBLAGaAscB8paNYdOnWRDEJfyxhvw66+uc3G9veH11+Hrr11jLxOghE+RIvuv7eernV+x4tQKPLQeqX4Ba9Dg5+WHRVjoV7Ufw+oMo1TuUoC802/dujWVKlXim2/SDqG3lw4dZKKyIxs8PI1CheDMGbn/d/36dT755BMWLlzI0KFDefPNN/H3t78A9MbzG/l026fsuboHi7Ck7QEK8PXypaBfQUY2GEmfqn3w0GbMkm0gq6n06GFNSbEgUhe+++QHfgQ6W2W/WDG5JO4yYmMhf37n52w8jr+/XPNPx01YViTj/kUo3Mbd+LsM/nMwK06tIN4Uj0VYSDCnfncqEEQlylj0X0J/4beDv/FW3bcY3Xg0o94fBcCXX37p9LkvXw7r1ztf9AAiI+H11xMoWPBjfvnlF/r378/JkyfJ68AE4mbPNKPZM824cOcCMw/NZPPFzRy9cZR4UzyeOuklmS1mLMJCyZwlOff3OdZNXEe9YvUybJm2hzlyxFHbXBZgNRABlLL6VVevPujs4BLmz3dP7yQhZCDNY7ms2RXl8SkeYfOFzXRZ1IUYY4zdZbQMngb88cdzsSeHNx4md+7cDprl0zGZZE+2W7ecauYxYunYcTwTJ/6PoraGe9pBeEw4UYlRmC1mDJ4GCvkXQqvRUrFiRaZPn06tWrVcNhd7eO89mDDBmjODSHmPLwcQB5iAb4DhVtv38pKOUI4cVr/EPurVg1270jwtCLgB6ABfoBUwGfADZiJ3MecDXW2x3bgxbNliyyuyLBmzhpPCLSw4toAX5r7ArbhbDqkdGWuM5UbCDe50vMPZuLMOmGHqrFzpGk/vYXQ6PXnyfOJS0QPI55uPZ3I9Q+k8pSmco3ByJ/eWLVuyfv16l87FHuzfgw0EIoF7wFBgs432zaxc+Sdbtmzh0KFDXLx4kbt372JxxuawENLFtZJVQDRwANgPfJr0+Cxkk47fbbV/+LCtr8iyqKVOBSDD6Put6Of4HDItxJhiaPZ7M3b030HlApUdO/5DfPGFayp/PIzZrGH2bFki0c/PtbafRosWLfj000/58MMP3T0Vq/Dzkyt/9q87eQNfIoNalgPtrXqV2axhwYKZREWFExkZyZ07d4iMjCQmJgZ/f38CAgLIlSsXAQEByYc1PxsMhieXmi9fTpfSF0Z6fMeAS8BWYBHS2/sPsDopKC4O/vtPLotkc5TwKbhw5wI9lvRwWuI0QFRiFC3/aMnZN86mq1RWWkREpOeGNgjrAiZSx8MD1q6VEYLupmHDhhw6dIh79+6Rw2Xrd+mnbFkpftbdsBiBh1ciHi+/4wW8DYzDWuHLk0fLqlVPhnWazWbu3buXLIT3j4d/Pn36dIrPJyYmPiGMjeLjectsxtYSof8CfwEvIb28GkBHoDwwJ+mKrcLHB06eVMKHEr5sj0VY6Lq4q0va4tyNv8ub695k6ouOryQRGir/rl291AkyQG/PnowhfAaDgTp16vD333/Trl07d08nTUJCbHGCWj/2c/2nnNMf+Bi5UPhimiNWrfr0x3U6Hbly5SJXrlzWTu4REhMTuXv37iPCaNiwAd0+67twtEd+QecE2gCjgMrAkKTneyCF0KbsTGcnzGcSlPBlc6aGTiUsPAyzMDvdVpwpjj+O/EGfKn2oX+xpX1rpZ/9+9/1NWyyy1U1GoWXLlqxbty5TCF/JktYK30UrRzQgIzvTxtMTnn3WymFtxMvLi3z58pEvX74HD8bHy/JhVtZmW86jaxE7gQtAt6SfewAfAIeAqtZOLIO25nI16l3IxliEhbFbx6Y7QTo9xJni+Hjrxw4fNzTU+sLTzuCs82N3rKZFixaZJsBFq5V1mt1RR9nDQzYxcBk5ctiVyjALmaZfFbmvV/uhx63GAbmlWQElfNmYDec2EJPo4kRaYMflHfx791+Hjhkd7dDhbMbVdSZTo1KlSsTExHDu3Dl3T8Uq3nkHvL1dn1VVpQqUKeNCg5UqpbtobDywEJiK9PDuHz8Ac3lyt/OpxMbKkkYKJXzZmW93f5ucdJ4iE5Fx1J8BXwHLgPtf8meB6cDnwARgBnAybbtCCKaGOnafz9252hlpBUmj0dCiRQs2bNjg7qmkidls5siRmRiNp5FJ6K7Bzw/ef99l5iR58qQ7YXA5oAdeRnp794/+SNFba80gefOqep1JqD2+bIoQgl3/pp1IC0B3oCQyVWo2sA2ZPrUCaIncbPACLgNHgHKpD5dgTmDduXV80uQTq+d6584drl69+shx7dq15P+HhY3G2kg+Z+Dj4zbTT6VFixYsXrzY6U1+04sQguXLl/PBBx+QJ08eJk+uyvDhWod00UgLDw+oXBnatnW+rSeoVUvW00uDi4/93I0He3sPowesrtdQp461Z2Z5lPBlU65GXcVosbHrZw6gNHATOAo0BkIeej4o6bCC4+HHEUKQmJj4iIA9/P+HH/P29qZw4cLJR2BgIJUrV6ZVq1YULlyYP/8sw/jxgoQEW12/tELkrSOjrSA1a9aMIUOGYDQa8XRZPS7r2LRpE6NGjSIhIYGvv/6aVq1aodFoOHkSpkxxTAup1PD2hnnz3LRKMGQIbNvm+rV5Pz9pWwEo4cu2HLx+EC+dl21pDHeBM0A+pPcXnH77cXFx5CmZh5irMRQsWDBZzO4LW7Vq1R4ROV/f1HP/YmPT29PNmhD51PHwkNWgMhIFChSgRIkS7N27l/r1HRtBm1727dvHyJEjuXjxIp9++ildunRB+9Aa8eefyy7s5845rxO7Xg8//SSLU7uF55+XrT1cLXw5c0KTJq61mYFRwpdNuRV3C7PFyhSG+cjdYB+kx1cZCEMWDkwnBh8DC1YuoGlw00e+/NJLtWrp6eB90W67AF5eJmrW1CArK2YcWrZsyd9//kl9rRYOHJBVO+Lj5bpskSIyia5SJadX7D9x4gQffvghe/bs4aOPPqJ///5P9UJ9fKQzVLMmXLvmePEzGGDMGHj5ZceOaxNaLbz7Lowe7br8G19fuaHp7o3wDIQSvmyKyWJCYGUkXTfkHt99wpP+jQbSl9+Lh86DHAE5HCJ6IKO0mzeX2yeuLruekBDL//5XmZ49u9C7d28qVark2gk8Tnw8LFrEhwsX4nPxIvz4o1SRh9cQDQbpqsbFybuGd9+Vm14OXBa9fPkyH3/8MatWrWLEiBHMnj0bgyH1uiX58smczOeek82EHaUNej18+aVsS+d2hg6V/fhOn3b+h1WrhWeegcGDnWsnk5GBYtEUrsRb551c2Nhm8iL3+8LSb18g8PZwrKcxYoS8uXUl3t4wcmQO1q1bjU6no02bNlSpUoWvv/6aq1evunYyJhN89plUj9dew+/CBTyEkM3uHt84i42VjxuNsHcv9OsHBQrIdUA7CzTfvHmT4cOHU61aNQIDAzlz5gzvvvtumqJ3n7x5pYP61ltSsOxxVAwGKFECtm/PIKIH8uZi0SLXRER5e8PChe5JlMzAKOHLpgQFBKVf+DTIaM5twEFkbIgFWUF3pXVDxBnjKJ6zePrsp0CjRrI5rCvR6eTNdMWKFRk/fjwXL17k+++/5+TJk1SqVIlmzZoxa9YsopxdPfv4cZmYNn683D+ydQ8pKgru3JGeX716cPGizVO4d+8eY8aMoXz58pjNZo4fP86nn35KQECAzWN5esInn8gOPvXrS42wxRn18UnE3x/efhtOnJCruhmKSpXY8PzzxDpz+dFggB9+gHJphFlnQ5TwZVOqFapGnNGO8LkKQCek8H0DfI3sCGPl31hufW5y6dO5TpoCGg3MnSu9BFfg6wtjx0Jg4IPHtFotzz77LNOmTePq1au8+uqrLF26lCJFitC9e3f++usvjI7evFqyRG6MnThhf2fvmBi51lixotW92+Lj4/nmm28oXbo0Fy9eZP/+/fzwww8UdEAx5CpVpLd29Ci8+qqsr+zpKdPhDAbp0Oj1cqnbz0/+/MwztylV6mvCw2HcuIzXdNxisfDOO+8w/NQpEt97T16Io9Hr5Z3DgAGOHzsLoBrRZmOKfFuEq1EuXo5LolWpVvzVM+18pvTwzjtyxc6ZYfFarcwF27/fulWkiIgIFi5cyOzZszl//jxdu3ald+/e1KhRw75O6QsWyGVKZ1yswSCbHDZt+tSnTSYTM2fOZOzYsYSEhPDpp59S0QV5HZGRcPCgLBMXFye3KgMC5FZlmTKQmBhHYGAgYWFhFHL1EkAaGI1GBgwYwLlz51i1apVszvzrrzBsmAxJtrcPoE4nlf7HH6FvX4fMOSuihC8bM3TNUKbsn2J7Pp+d+Hn5MbnVZPpU7eOU8RMS5PLYsWPOKyWWK5cUvWeesf21Z8+eZc6cOcyePRsPDw969epFz549KVGihG0Dbdsmw+OdqfAGg2w98ZCgWSwWlixZwocffkhgYCDjx4+nTgZLju7bty9Vq1Zl+PDh7p5KMjExMXTu3BmdTseCBQse3fM8cwa6dpUBL+n12n19ITgY5s9P3wczG6GELxtz9vZZKv1cySUtiR7Gz8uP8BHh+Hg4b3P/3j1o0EB+n9ie5pAyGo1cZtu+XWYC2IMQgj179vDHH3+wYMECypUrR69evejcubP0BFIjOhpKlYIbN+ybRFpoNNKNOnoU4eHB+vXrGTVqFBqNhs8//5zmzZvb57E6iQ0bNvDBBx+wd+9ed08FgFu3btGmTRuCg4OZOnUqHh5PCag3m2H2bJnQeO2avKFJywPUauUGaPHiMHIk9OyZsernZVCU8GVzGkxvwM5/d7rMnpfOi0E1BvH989873VZ0NHToIAMk7N36ArltkjcvbNzo+OLGiYmJrFu3jtmzZ7Nu3TqaNm1Kr169aNOmDd5P26QaOBD++MOxqp4SBgP/du/Oy+fOcf36dT799FM6duyYIQXvPiaTiaJFi7Jt2zZKly7t1rlcvnyZli1b0r59ez7//PO03zchYN8+mD4dduyQd2+eng/W1M1mGcFburSM6OrXD2rUcP6FZCGU8GVzQq+F0nBGQ6d2X38Yfy9/zrxxhgJ+BVxiTwj4/XcZyp6QkL6kaI1G3lS/+qoMmnR2FPrdu3dZsmQJs2fP5siRI3Tq1IlevXpRv359mfd45oyM+nBFYcsk4oHF331HtyFDnu6tZECGDx9Orly5GDNmjNvmcPz4cVq1asVbb72V/mVXs1lG2cbEyA+jr6/08FSKQrpRwqfg3Q3vMmn3JBIszu2tY/A0ML3tdLpW7OpUO0/j2jWZ4jZrFoAgJiZtb8XHRwpns2bw8cfuuam+fPkyc+fOZfbs2cTGxtKzZ0/eunCB3IsWOa+u11MQej2ajz+W6Q6ZhL1799KrVy9OnTrlFu90586dvPTSS0ycOJEePXq43L4iZdRicDZHCEHO0JyYbpvQaZx3B6n30NO0RFO6VOjiNBupERgoA91u3oThwy/i67udfPnAy0vu2eXMKf+9Hxpfty6MGgUXLsDq1e5bSSpWrBjvv/8+x44dY9myZRjv3cN73jyXih6AJi5OFkO1N+rQhdSsWRMhBKGhoS63vWrVKjp06MDs2bOV6GVAlPBlY2JjY+nRowfLlyxnz+A95PfNj4fW8ctYPh4+VMxfkQWdFrh9X8hgAB+fOQwcuJSbN+H6dRkcuX49bN0qg+ru3oV//oGPPnJ9QnxKaDQaqlatypdt2mCwsov2s8iKcgmPPTbtsfO2AEWsGTAmRibUZRI0Gg09evRgzpw5LrU7Y8YM/ve//7F69WpatGjhUtsK61DCl025dOkSDRo0wNPTk23bthFSJoR9A/dR2L+wY6MtjVDGrwx/9/kbvaeLMsvTYN26dbRs2RKA3LnldlmtWlC1qqzdnIFjNmD/ful9pcFFYDuyyI6VxXTSRghwg/dkDz169GD+/PmYzVYWZLcDIQRffPEF48aNY8uWLdSqVcvpNhXpQwlfNmTr1q3UqVOH3r17M2vWLPRJpU4K5yjM0cFH6VahGwZP+6pJaNCg99DTo1gPwr8K596te46Yut3cu3ePQ4cO0ahRI3dPJX1s2WLVMufvQB2gLzDLUbZjYmCn6yKAHUHZsmUpXLgwf//9t1PtWCwW3nrrLebMmcPOnTspW7asU+0p7EMJXzZCCMGPP/5Ily5d+P3333nzzTefWHr09/ZnRvsZrOy2ksL+hfHzsq33kFajxeBpoHKByuwduJc5/5vDqwNfpVOnTiQmJjryctLF5s2bqVu3rtUFkzMcZ89addrvQM+kYx3gsGy/48cdNZLL6NmzJ3PnznXa+ImJifTu3Zv9+/ezbds2Ah+uYafIkKiozmxCQkICQ4YMYffu3axYsYKSJUum+RqLsLDp/CYm/DOBrRe3ovfUk2hOfCLh3eBpQKfRkWhOpGP5jrxV9y1CAh9UBbZYLLRv356iRYvy448/OvzabGHw4MGULFmSd955x63zSDeFCsm+eqmwA3gOuI5spFEOeBV4E7nH1wt45aHztyQ9dsUa+5UqwZEjNk7avVy7do2KFSty7dplfHwuAKHAPuAWYEI2lqwChADVAOv2UAGio6Pp2LEjPj4+zJ8/P3n1RJGxyRwJOQq7uH79Oh07dqRgwYLs2rULfyuDI7QaLc1LNqd5yebEGmM5/N9h9l/bz8H/DhKVEIVWoyWXPhc1AmtQI7AGFfJVwFP3ZAl9rVbL7NmzqVmzJjNnzqSvm2oICiFYt24dK1ascIt9h2BF7tYsoAVS9AB6JD32JvIP/vGFUiNgdeODTJLD9zCBgXf44w89np55AC9AAI9XNPBOOuKA2sB7QCtSay4cHh5OmzZtqFy5MlOmTMk0+Y0KQCgyDBaLEPHxQiQkyP87gj179ogiRYqIsWPHCrPZ7JhB08mxY8dE3rx5xb59+9xi//Tp0yIwMFBYHPXmuoPgYCFkmMlTj1gQOUD4giiQdATIb3pxCEQ/EO8+9ppfQDROZcxHjqZN3f0O2MBZIUQ9IYRemM1aIQQ2HP5CiPxCiBVPHfnixYuiTJky4oMPPsjcn6dsitrjcyM3bsDPP0O3brJZpoeHDLfX62WFopIlZem9qVPh1i3bx581axZt2rRh8uTJjB492mHdztNLhQoV+Pnnn+nYsSPh4eFpv8DBrF+/nhYtWrg9pcIuatdO9enlSB8lDDiUdJwAGiL3/boCM4C9SDU8DUwEullh2qLTYa5bN13Tdi0W4DugMrAbiEOrtTX/MAq4CXQHOgK3k585evQoDRo04PXXX+fTTz/N3J+n7Iq7lTc7snOnEG3bCuHjI4Ren/ZNtsEgz+3SRQhrnCWj0SiGDx8uSpUqJY4dO+b8C7KR9957TzRp0kQYjUaX2n3xxRfF3LlzXWrT4UybJoSvb4oflpYg3nrK4wuSvD8jiN9ABIPwB1ESxHgQZiu8vXtareik14umTZuKMWPGiA0bNoioqCh3vyOPkSCEaCOE8BW2eXipHV5CiAJCiDNi27ZtIn/+/GLevHkuvCaFo1HBLS7kzh0YNEhWAomLk98mtnC/EHvXrjBpkmy8+Ti3bt2ia9eu6HQ65s+fT65cjm326gjMZjOtWrWiSpUqfPXVVy6xmZiYSL58+Th37hx58+ZN+wUZlbAw2XQ2Ntb1tr29iTx6lH/OnGH79u3s2LGDgwcPUq5cORo0aJB8OKIBbfowAq2Bnci9OkeiJTHRQP36Xowfv4BmzZo5eHyFK1HC5yI2bYLOneX3lb094nx8ZHmtpUtl37n7HD16lHbt2tGpUyfGjx+PLgMXsb116xY1atTgiy++oGtX59fu3LJlCyNGjGDfvn1Ot+VMhBDElCiB36VLrjfevLkscfMQ8fHxhIaGsmPHDnbs2MHOnTvJkyfPI0JYpkwZFy0H9gcWAM65KTCbwWzOh5fXeWQkqCLT4lZ/M5uwcKF1S5q2HgaDEH/9JW0sXrxY5M2bV8yZM8e9F2sDBw4cEHnz5hVHjhxxuq33339ffPDBB0634yxiY2PFtGnTRKVKlcS7gYEiwdvb8R+o1A4/PyE2bEhznmazWRw7dkz8/PPPomfPnqJ48eIib968on379uLrr78Wu3fvFomJiU54h9YLIQzCccubKR0+Qoh+Tpi/wpUo4XMyq1c7R/QeiJ9F9Oo1TRQrVkzs37/f3ZdrM7NnzxYlS5YUt2/fdqqd6tWri23btjnVhjO4evWq+OCDD0T+/PlF69atxfr164UlNlaIvHldK3wlSwqRzqjgy5cvi3nz5okhQ4aIKlWqCD8/P/Hcc8+Jjz76SKxbt07cvXvXznfprhAir3C+6N0/DEKIjXbOWeFO1FKnE7l8GYKDHdMENTV0umgOH46jQoV8zjXkJIYNG8bZs2dZtWqVUyJPb968SZkyZQgPD8fT0+qMNbeyb98+vv/+e/7880969uzJG2+88WgZrHXr4KWXXLPXp9fLlvMhIWmfawWRkZHs2rUreXk0NDSUMmXKPLI8alv1k8+SDtf1J5RlAU640J7CkSjhcxJCQMOGsGePbJbsTDw9Bc2ba/jzT+facRZGo5FmzZrRuHFjxo0b5/Dx58yZw6JFi1i+fLnDx3YkJpOJpUuX8v3333P16lXeeOMNBgwYQEBAwNNf0KsXLFni3C7sBoPs4vvll04zkZCQwIEDB5KFcMeOHQQEBDwihOXKlUthn9AMFAQinDa/p+ML/A3UdLFdhSNQwuckZs2CIUOc7+3dx9cX/vgD2rd3jT1Hc+PGDWrUqMHkyZNp166dQ8d++eWXqVu3LoMHD3bouI7i9u3bTJs2jcmTJxMUFMTw4cNp27Zt2pVAoqKgTh3Zkd0Z/fl8fGQjwk2bZONCF2GxWDh58uQjQnjv3j3q169PgwYNaNiwIdWrV8fLywtYjaxNE+Wy+Um0QGdgvovtKhyCO9dZsyoWixDFi7t2CwaEqFzZ3VduH7t37xb58uUTJ0+edNiYFotFFChQQJw7d85hYzqKsLAwMWjQIBEQECBefvllERoaavsgERFClC0rhJeXYz9Mer0QdeoIER3t+AtPB1euXBELFiwQb7zxhqhWrZrw9fUVjRs3Fvv3VxZp7ckVL47w8UH4+iIKFED06YOIinrwfFSUfO75523d6/MXQqiqLZkRJXxOYNu2VHOMnRjoIsShQ+6+evuYOnWqKF++vLh3755Dxjt06JAoVaqUQ8ZyBGazWfz111+iZcuWokCBAmLMmDHi+vXr9g16964QLVvKD4CjPkjduwsRF+eYi3YCkZGRYu3atSI8PLewRvg2bJD/v34dUbkyYtSoB8/PnInInRuh08nnrRc+HyHEvy68aoWjUCXLnMCkSdbGHAQBemROUAFk97Ront4nO20SEsDNzQ/sZuDAgTRo0IC+ffsihP2r8OvWrcsQXbCjo6P56aefCA4OZtSoUXTr1o2LFy/y8ccf25/wnSMHrFkDv/4K/v7g7Z2+cfR62Zl30SKYO1cudWZQcubMScuWTcib17YlzoIFoWVLOHTowWOzZsnCEpUry+0C6/FCdnpQZDaU8DmB7dvlrbN1rEKK3QFgP/Bpuu2azeDkfpsu4YcffuDKlSt88cUXNr7Sggx2eMDD3dbdwaVLl3j33XcJCgpi48aNTJ06lQMHDtC3b198HCksGg306CH79b37LuTKJUUwDSyASa+HAgXg44/h/Hlo3dpx83Iq/2FDXwkArlyR9wilSsmfL12SvX179pTH77/bMloCcMEm+4qMgRI+BxMZCbdvp3naUyiMbINyzC77ly7ZXxnG3Xh7e7NkyRJ++OEH1q1bl8JZMcBcYBBQEfBBlmf2SDqKYzJ1oGrVHTRpUsYl876PEIIdO3bQuXNnqlevjtlsZt++fSxdupRGjRo5t4pJ/vwwbpysgP777/Dqq1CxogxO8fSU3qCnp/TmqlVjd0gIf7RtC9euScHMmdN5c3M4CVj7Fda+vbwPKFpUvkVjx8rHZ8+Wnl5wsCwWf/w4HDxorX1z0hwUmQ53r7VmNbZsESJnTmu3U4oL2JD0/8sCggV8KKCxgF/TtT3j7y/EgQPufhccw5YtW0T+/PkfC0w5LYQYJGQSsb9Iax8mLk4rhPAWQjQXMunYecEICQkJ4vfffxchISGiVKlS4ocffnDYXqXdmExyLzA8XIh795KT0bdv3y6qVq3q5smllwvCmmLUD+/xbdmCCAxEnDkjfy5dGjFhwoNzn3sOMWyYtXt8nkKIb1x2tQrHoYTPwSxdKkSOHLYIn6+AnAKKCRgsINYu4cuZU4hNm9z9LjiO7777TlSpUkXExNwRQnwghNALITyE9QEIDx++QogWQgg7g0ke48aNG2LcuHGiUKFColmzZmLVqlVu731oLUajUeTKlUtcuXLF3VNJB3eFFB/rhU8IGdjSrh1i507ZpzBXLhntWaAAwmBA5MuHMBqt+Tz5CSFmuPKCFQ5CtQx2MLYnqy8HHFvp3RkpXe5i6NChXLmykXv3iqLXW9Bo7KnOEYNMOi4DTAc62TW3w4cP8/3337Ns2TI6d+7M+vXrqVixol1juhoPDw9atGjB2rVrGTBggLunYyM5gNzADZteNXw4BAXB3buy7vbD+3pxcXLpc80aePHFtEbSANVtsq3IGGQO4UtMlIvvFy7IDSwPD8iTB6pWlVFoGQgfHxln4E70evfadyQazQEmTNiKENEOel+NScfLyOCI1216tdlsZtWqVXz//fecOXOGIUOGcObMmUzd6qh169asWLEiEwofSOFZY9Mr8uWDLl1g+XIpeo8H1fbuLSM90xa+eCDYJtuKjEHGrdxy9apsT75wIVy8+EBR7k9Xo5GlmnLmlLXBhg2T/7pZdY4fl8U0oqOtOTsImbbwuMf3LLIndt+HHtNhTQSbVpvAkCHfU6dOEYKDgylbtiz6TKuEx4F6wD0njW8AJgFpf+Hfu3eP6dOnM2nSJPLnz8+wYcPo1KlTpqn9mRr3a5nevHkzqRpKZmISMBJntSJKneqodIbMScYTvrAwePttGWMshHUhihqNrCmYN6+MaOvd220CaDbLqSQmWnN2ECkL39bHHusJpJ1kpNcbeffdzzlxIoywsDDOnj1L4cKFCQ4OfuQoV64cfk/rZJthiEMuSV4FnPkR1QO7gCpPffbs2bP88MMPzJ49m5YtWzJs2DDq1KnjxPm4h1q1avHll1/y3HPPuXsqNnIbGRHtxHqlT8UP+AVZLk2R2cg4wmcywRdfwOefS08uvdPy9YXq1WUCbpEijp2jFdy4cYPq1T25ds09S7D168OOHQ9+NhqNnDt3jrCwsEeO06dPU6BAgScEsXz58uTIkcMtc3+UN4DfcH7FfQ1QCuldSu9NCMHmzZv5/vvv2bVrFwMHDuS1116jiBs+T67i448/JiYmhq+++srdU0kH3YGFyKxEV5EDuAmks1iAwq1kDOG7dQuaNpXJt46o6uzhIfOVFi+G55+3f7w0OHfuHMuXL2fZsmUcO3aMYsV+5tSpziQmunYL1dcXJkyA115L+1yz2cyFCxeeEMQTJ06QO3fuJwQxODiYXLlyOf8iAJnI3wjXtZkxAO8TF/cOc+fO5bvvvsNisTB8+HB69uyJwWBw0Tzcx969e+nXrx/Hjx9391TSwTGEqIlG4yqvzwC8B4x2kT2Fo3G/8IWHQ82acP26teuD1qPXw7x54OBq/0IIDh48mCx24eHhtGvXjvbt29OkSRPu3fOmWDHndot5Gnq9zFu2omBHilgsFi5duvSEIIaFheHv7/9UQXR8YEc7ZEUb13004+O9KVnSn2rVajNs2DCaNWvm3ETzDIbFYqFgwYLs3buXoKAgd0/HaoQQzJs3j/DwgQwenIiXl5N7gKEBSiMLTWT+/d3sinuFLzZWLkueP++8GHy9HtauhUaN7BrGZDKxY8cOli1bxvLly/H09KRDhw506NCB2rVro9PpHjm/Y0dYsULu+bkCT0+5tfnbb84ZXwjBlStXnhDD48eP4+Xl9YgQVqhQgeDgYPLnz58O8biB3Pt07V1DfLwnd+58SaFCb7rUbkYio7dvepyrV68yaNAgLl68yIwZv1CjRh/gPM5d8tQDu4HKTrShcDbuFb4hQ2DGDJk840zy5YNz52x2hWJjY9mwYQPLli1j9erVBAUF0b59ezp06EBwcHCqX+rnz0OlSq5pkA3g5wenToFNjasdgBCC//77j+PHjz8hiMBTPcTAwMBU3rsJwBisEb65c+Hbb+HkSfmrrVoVPvgANm6Ezz57tFazh4csJ5c6NYB9adrNqsyfP585c+awatUqd08lVYQQTJs2jVGjRjFkyBBGjRqVFI16DtkYNhLnrBbogZ94NNpakRlxn/Dt2AEtWjhf9ECmQnTtCjNnpnnq7du3Wb16NcuXL2fTpk3UqFGD9u3b065dO4oVK2aT2e+/l1/Ezm5G6+sLP/0EL7/sXDu2IIQgPDz8qUumcXFxT3iHwcHBFC1aFI2mKTLJPHW+/VbGQk2ZIqvte3lJx37bNvl+nD1ra6V9kNX2Y5GpI9mP27dvExQUxM2bNx1bQNuBnD9/noEDByanl1SqVOmxM8KABsBdHOv56YFvkbVhFZkeF1aJeYDFIsQzz9hej8veHmMpNPq8fPmymDRpkmjSpInw9/cX7du3F7NmzRIRERF2XabZLETdukJ4ezvvsnx8ZCs2SybqhxkRESG2b98ufvnlFzF06FDRrFkzERgYKPz8/ERkpE6kVSoqMlI2Dl248OnPjxmD6NkzPSXN/IQQx1z0LmRM6tevL9auXevuaTyByWQSEydOFHny5BETJkwQRqMxlbPPCyEqC2vqeKZ9eAkhcgghljvjshRuwj2VW7Zvl1EYriQ+Hr7+GubORQhBWFhY8n7dxYsXeeGFF3jjjTdo0aKFw6L4tFrphdSu/aDojCPx8ZFV5ZcudXvevk3kyZOHBg0a0KBBg0cev3v3PP7+ZdN8/a5d8tfZoYMzZncQqOCMgTMFrVu35q+//nJrK6fHOXHiBAMGDMDDw4N//vmHMmXS6rZRAtnm62tgLLKLgq2Bcxpk9OZzyPJ2+Wx8vSIj4562RF995brNr/tYLFiWLGHM0KGUKVOGVq1aER4ezldffcV///3HzJkzad++vcND13PkkF/UwcEysd1RGAwQEiKX9rJKtH3OnGa02rSX2G7dkrUKPFK5bVu4EAICHhzW5WUbgTtWzTWrcl/4MgJGo5HPP/+chg0b0qtXL7Zs2WKF6N1Hh0w5OAkMA/yTjtS/8uLjdZhMHsALyFJoq1Cil/VwvfDFx8O6dWkmqAfxoDd5LqAN8G/Sc32RuzF+yBK1zZEf77SIMxqpcvEiCxYs4NKlS3z//fc899xzeKT2DeoAAgJg925ZVc3e6mEajRxj1ChZ3MbX1xEzzCiYkHfaqZMnD0REpF4QvEsXGcxy/7CuQa9Ail/2pUqVKsTExHDmzBm3zuPgwYPUqlWLrVu3EhoaymuvvYZWm56vq2LIgKlw4HfgLWQAjD+yVLEOmYReGniZsLCB9OhRF1gJNHTEpSgyIK4XvqNHrf72v9+b/DpQAFnL4z7vJj13FVmwyJryur5C8FL+/FSvXt3lOVpeXrIozc6dsvq7wQA6G2IodDr5ttWoAfv3y6AZJ+u1G/DGmoCEunVlxOby5Y62r0U2tM2+aDQat3p98fHxfPDBB8nl4dauXUvx4sUdMLI30B74CtiLrP9qRN5sxQOngVmULfs169Yd5nb6ukkrMgmuF77QUJt79/ggG8iEPeU5PdAFOGTtYP/8Y5NtR1OtGhw+LLc5u3WTX+B+fvJ4GI0GdLpYfHxM6PXQpw/s3SuP4CxbEL4w1uzF5MwpS7IOGSLFLzZWpoGuWSObiKcfL+AZewbIErhL+Hbt2kW1atU4ceIEhw8fpm/fvi6/QfX19aVJkyYZPqVDYR+uT2d49VWYOjXN04J4UL45FhiMXIj6HbnUWQT4FNlhbRBwBDhsjX0fH9ekUFiJ2Szz70JD4cgR2SNMo5HLo8eOzeGZMnfo+0594swxCCHw9fKlbJ6y+HplqTXOZCyWkmi15606d84cmDgRTpyQeXwhIdITXr/+yTw+kLmV+fOnPF5iIgwb1pEKFZ6lTp06VKlSJUt0X7CVG7dvENQsiIHjBrLr2i5O3TpFvCkegcBb502JXCVoWKwh9YrW44UyLxDgE2CXvZiYGD788EPmz5/PpEmT6NSpk1ur5syePZslS5aw3PFLCooMguuFr1s3WLAgzdOCgAjkKnwMcnt5HVAJKXzzkZ7gPaA4sAIraylota4rp5IOhBD8ffFvfg39lQ2nNnDbeBt/H380SXtfQghiTbEU8itEnSJ1eKX6KzR7phlajXvilOzFYrFw6NAhNmzYwIYNGxgwYAvdu7vn92My5eT3379l9+7d7N69m/Pnz1O1alXq1KlD3bp1qVOnDoULF3bL3FzBudvn+G7Pd8w8OJO4uDgsHhZEKongfl5+mCwmOpbvyDv13qFqwao229y8eTMDBw6kXr16fPfdd+TJk8eOK3AMd+7coXjx4ly/fh3frLWJrkjC9cLXvTvMn5/maUE88PjMSGF7Bbnc+T4PPL7LwPPIoOXO1tjPoMJnspj4Zf8vfLHzCyLjI4lOtKqhH35efvh7+TOi3giG1BqCly7j91P7999/k4Vu06ZN5MqVi+bNm9O8eXOaNYvD1/d/QJSLZ6VDNqednvzIvXv32LdvX7IQ7t69Gx8fH+rUqZN8VK9ePRP3O5QkmhMZt3Uc3+76FpPFhNFiW4CPTqPDS+dF1wpdmdRqEv7eaVdIunv3LiNGjGDNmjVMmTKFNm3apHf6TqFFixa8+uqrdOzY0d1TUTgB1wvfkCGyzEgaBPFkp7p8wM/Aah4IH8AGoA+yYFGaX0F6vetTKdLg+M3jdF7Umct3LxNjTF+ZF4OngUD/QBZ1XpSuO29nEhUVxZYtW5LFLjw8nKZNm9KiRQuaN2/+WEUcM1AQ6e+7Ej0y6KFiimcIITh//vwjQhgWFkZwcPAjYvjMM89kmgLXYeFhtJvfjmtR14g12vd34ePhQw7vHCzqvIhGxVOujbt69WoGDx5M69atmTBhAjlz5rTLrjOYMmUK27dvZ86cOe6eisIJuF74pk2D4cPTrOMVxAPhE8jg4o7IfbyveFT4QFZZ7I3M2EmVSpXkZloG4Yc9P/DexveS91DsQYMGHw8fPn72Y96tb1eUh12YTCb279+fLHQHDhygVq1ayUJXrVq1NELTPwU+w7WFqqsik9dtIy4ujgMHDrBr1y52797Nrl27MBqNjwhhzZo18benZYaT2HNlD81nNyc6Mdruz97D6D30zO04l/bl2j/yeEREBMOGDWP37t1MmzYtQze9vX79OsHBwdy4cSMTdqVXpIXrhe/QIdkpISr1pawgZJ1+HTKzqzgwEtmHvC9PCt8CZIbOeVJuDWkBVhcpwuH//Y9GjRpRu3Ztt9YkHLtlLBP+mWD3nfbjGDwNvFHrDb5o9oVDx02Nc+fOsWHDBtavX8/ff/9N0aJFk5cvGzZsaONeyT1kc9hwJ832cfTAJqCuQ0a7cuXKI17hwYMHKVmy5CNiWK5cuXTmpTmGQ/8douGMhlYvqduK3kPPki5LaFW6FUIIFi1axLBhw+jevTuffPJJptg7q1+/Ph999BHPu6Cnp8K1uF74jEYZu+/o3ntWYPH15dCgQczTaNi2bRvHjx+nevXqNGrUiEaNGlG3bl2X3Zl/t/s7Ptj8gcNF7z4GTwMfNvqQkQ1GOmX827dvs3nz5mSvLi4u7qF9umYUKlTITgsbkX35nL0srUfuHk9ymoXExESOHDnyiBhGRERQq1at5KCZ2rVrkzt3bqfN4WGiE6MpOakkN2NuOtWOr6cvf3f+m8/f/ZxTp04xffp06tSp41SbjuSbb77h1KlTTLUiCl2RuXBPd4Zu3WDRIrA4s2/WU9Dr4ebN5KS56Ohodu3axbZt29i2bRuhoaEEBwcnC2GDBg2c8mV05MYR6kyrQ5zJuWkVeg89W/tupWbhmnaPlZiYyK5du5KF7sSJE9SvXz9Z7CpWrOiEfa1XgHk4T/x0yMoex7Fid9ih3Lx5kz179iQL4b59+yhUqNAjXmGlSpWcUlWo/4r+zDs2j3iTc5eStWjRXtPyXv73+OjDj/B+PL8kg3P+/Hnq1q3LtWvXnui3qcjcuEf49u+Hxo1dG2Ti4QF9+8Kvv6Z4Snx8PPv27UsWwl27dhEUFJQshA0bNrTbkzGajVT8qSJnbp9x6L5KShTPWZxTr5/C28O2Lx0hBCdOnEgWuu3bt1O6dGmaN29OixYtqFevngu+yEzImonbcbz46YC8wH7kwrl7MZvNhIWFPeIVXr58merVqyenU9SuXdvuz9+2S9toNaeV01YaHsdH58OPbX6kf7X+LrHnaKpWrcoPP/xAw4aqfFlWwn39+CpXhmPH0qzZ6TD0epklXr681S8xGo0cOnQoWQi3b99O3rx5k4WwUaNGFC9e3CZP55td3zD679Eu++IxeBp4v/77fNT4ozTPvXnzJhs3bkwWO51OlxyQ0qRJE/LmzeuCGT+OEVmbZwMyo9N+4uLAw6MQnp57gKIOGdMZREZGsm/fvuTAmd27d5MjR45HvMJq1arZdAPy7Mxn2XppqxNn/SRFchTh8vDLmSbS9WHGjh1LZGQkEydOdPdUFA7EfcJ3+LAsuuiKKioGg6wY8+23dg1jsVg4duxYshBu27YNLy+vR4SwbNmyKf6BW4SFwG8CuRHj2pZMuXxycXPETTy0jy6bxcXFsWPHjuSglIsXL/Lss88mL1+WLl06g3xZCWAKMAIZ6WlPHqaBEycqMWBADJs27c1UOXhCCM6cOfOIV3jq1CkqVar0iBimdDN24c4Fgn8KdvoS5+P4efmxsttKniuRcaM4U+Lo0aO8+OKLXLhwIYP8LSgcgfuED+DDD2XNKWcveRYrJuuCOTiC8/4X0cNCGBsb+4gQVqpUKXl/YO3ZtXRe1NlpkXQp4e/lz6z2s2hXth1HjhxJFrrdu3dTuXLlZKGrVatWBi/RdRHoB+xGCBMajS01X+/38piOEE3o0aMHfn5+/JrK0ndmICYmhtDQ0GQh3LVrF8AjQlijRg18fX15f+P7TNw9kURzKoFlE5GOtQa5GlwUudp8P9XuILALuI0Mny4PNCXVLVINGl4s8yIruq+w72LdgBCCMmXKsGDBAqpXr+7u6SgchHuFz2iEBg2k9+foLq338fWVFaGrVXPO+I9x6dIltm/fniyEN27coEGDBjRq1IhVvqvYHr499QEmIlf3hiNrJgOEIouR9gM+Bu5rkwdQEtmzKQ3HpUBMASwzLQQEBCTv0z377LMZMnk4bc5w+PAAypbdhY+PN7LWejQ8smdqQL5Bcchs0BHAs9xvexQVFUXNmjUZOXIkffr0ceXknYoQgsuXLz/iFR45coQyZcpwpc0VIjzTKAwwEWiL/FwZgT+Rb2F34B9gJ7LJwTPIrJM/kduv/ZFvdwrk8snF7fcyZ8eDd999Fy8vLz799NO0T1ZkCtwrfCDz+Ro0gNOnZa8+R2IwwF9/yUAaN3Hjxo1kIfzZ92dMPml4KRORDQrqAveLXzwufG8AeZCrfouQMRqtUh/WoDEQ1ifMQS1e3M+zzz7LW28Np23bCsg36ADSDTEhe61VAkKQlVievgd27NgxnnvuOTZv3kylSpVcM3E3kJCQwIGDB2i0rhEmrPj83Rc+kN161gL/A75BZpg8XNwmAfgeeW+RikPkrfPm8puXye+bSpXwDMru3bsZMGAAx48fd/dUFA7C/ZWN/f1lq6AGDRzXVdXbG3Lnhs2b3Sp6AAUKFKBTp058MuETNAYr9wjqIe+u09r+9AHKYlWet1lrxidP1ug1999//3H48GFatHge2UC0G7LZ6DRgJvAD8ps6hJTLGUDFihX55ptv6Ny5M1FpFFTIzHh7e5OvTD68PW2Mwk1EZnoUQXaBNiGXNh8ZHPkrSKOhho+HDweuH7DNfgahVq1aREZGcurUKXdPReEg3C98IAVv/XqYNEnm2NmTu2QwQPv2cO4c1K7tsCnay7Gbx9B7WhlIEYgsXZNW68A4ZOt5K6LxfTx8OHrzqHX2MzhLly6ldevWDqm68/LLL9OwYUMGDhyIuxc/nElEbMQTwU0pMh8YD3yBLIBbH7mcaUDu+z2OH2lmm5iFmVuxt6yeb0ZCq9XSvn17li1b5u6pKBxExhA+kE3o+veHkydl11W93noP0MNDBq7Urg3LlsnuDwEBTp2urUQnRie3FrKK55A1k58Wwf8L8otpAnAXWag0DQSCmETHpAO4m8WLF9O5s1W9OKxi0qRJnDp1ip+sKJ6eWTGabei40A1ZH/BDoDUwA/lNEcvTA2qjkaKYCkIIm7s+ZCReeuklli5d6u5pKBxExhG++xQuLAtZ37gBEybIup45c0phy5nzweHnB15esh35a6/JGqC7d0OLFu6+gqdic7J6AaAMsOMpz73Kgy+mmshOOlZ8p1iEiyvlOIGbN29y4MABWrZs6bAx9Xo9ixYtYuzYsezbt89h42YkfDzS4R1rgeCkf83I4JUTj52TAJwBSqQxlEabvjlkEBo1asS5c+f4999/3T0VhQNwfD0kR+HvLwXttdfkz9evw4ULMgDG01Pu4ZUta9+yqAsxeKZxS/w0nkV6d/VSeF6HDChYC9wEUumRqkGTJbq2L126lFatWjk8/65UqVJMmTKFLl26EBoa6rK6ma4iKCDI9vw9AZxCLqkHAo2BNch9vYejOnMAVVIfSqPREBQQZJv9DISnpycvvvgiy5cv54033nD3dBR2kjlUA6BQIXlkUsrnLW97bc48yAi6PcDTguEsyLwqDyBX6kMlmhMpn9f6qjUZlcWLF/Pa/ZshB/PSSy+xY8cOXn75ZVauXOnW7gmOJp9vPny9fEmIsyJtaB4y60ODzN/rgPz85Ucuaa4H7iAFsByyX1ga3ySxxliqFEhDHTM4L730EhMnTlTClwVwfzpDNiLPhDzcjksjl+nxcPK7yMYBRXgyj0+DTGVoguzikwr+Xv7cff9upq4+ER4eTunSpbl+/brTKq4YjUYaN25M27Ztef/9951iw100/b0pmy9sdovtQoZCXH3naqb+/MXFxVGwYEHOnTvnpvJ9CkeRdW5pMwEhhULSPulNHogeyDvuj5CiB1L4Pkg6RiGj9tMQPYDKBSpn6i8dgGXLlvH88887tcyYp6cnCxYs4LvvvmPrVtfWtHQ2XSt0xc/Tz+V2tUJL9N5oypYty8iRIwkNDc2UEbR6vZ4WLVqwcuVKd09FYSdK+FzIwOoD8fdyfSduPy8//hfyP5fbdTSLFi2iU6dOTrdTtGhRZs2aRY8ePfjvv/+cbs9V9KzUEwuuD3Dy8vTi0C+HmDNnDkIIunXrxjPPPMPbb7/Nrl27sLi6PZkddOjQQUV3ZgHUUqcLMZqN5P8qP5EJkS616+flR/iI8EwdVRcREUHJkiW5fv06BkM6AoXSwejRo9mxYwfr1693Sl88dzBo9SCmH5zu0tSCRsUasbXfA+9ZCMHRo0dZvHgxS5YsITIykpdeeomOHTvSsGHDDN377u7duxQpUoytW69y8qQfu3fLMsDx8TLIvFAhqF8fQkKgUiVZS0OR8VDC52JG/z2ar//52ulNaJMxQau8rfhz6J+Zeqlz2rRprF+/noULF7rMptlspmXLltSuXZvPPvvMZXadybWoa5T6vhRxZtd8/vQeenb230m1QinXyj158iRLlixh8eLFXLt2jfbt29OxY0eee+65DFU0/dYt+O03+OijO2g0/nh5eRAd/WRnNYMBdDowm+Hll2H4cBmArsg4KOFzMTGJMZT+oTTXo6+7xF5Oz5wErQhCr9Xz7bffUrduXZfYdTQtW7ZkwIABdOnSxaV2b968SUhICL/88gutW7d2qW1HExMTw8iRI/n9yO/EN40nweKkwvBJGDwNDKs9jM+bfm71a86dO8fSpUtZvHgxZ8+epW3btnTs2JHmzZu7rYN7QgKMHi0LS2k0tnVS8/CQR+PGMGNGpg5Mz1KoPT4X4+vly4JOC9B7OL8PnMHTwMKuCzmw6wCDBw+mc+fOdO/enUuXLjndtiO5desWu3fvpk2bNi63nT9/fubNm0e/fv24fPmyy+07iq1bt1K5cmXu3LnDuSXnaBzU2KlL3x5aD4rmKMrHz35s0+tKlizJiBEj2LNnD4cOHaJq1apMmDCBggUL0qNHD5YuXUqss9uYPcT93tWTJ8vlTFvbh5pM8nWbN0OZMjB7tut6bytSRgmfG2hYvCFDag5JX1K7lRg8DfSp0ocWJVug1Wp5+eWXOXXqFOXKlaN69eqMGjWKe/fuOc2+I1mxYgXNmzfH11FFzG2kQYMGvPPOO3Tp0oXExFR62WVAYmJieOONN+jRowcTJ05k9uzZ5MmTh6Vdl1I2T1m8dY73ojy0HuT3zc+Wvlvw0nml/YIUKFq0KMOGDWPbtm2cOHGChg0b8tNPP1GoUCE6derEvHnznPoZXrpUFo66cMH+lqFGI0RHw+DBMHSoEj93o4TPTUxoPoHOwZ3x9XT8l7nB08CLZV5kcuvJjzzu6+vLmDFjOHLkCNeuXaNs2bJMnToVs9mejubOx1XRnKnxzjvvUKBAAUaMGOHWedjCli1bqFy5Mnfv3uXo0aO0bds2+TlfL1+299tO1YJVHXoD5uPhQxH/IuwbuI+CfgUdNm7BggUZPHgwGzdu5Ny5c7Rq1YrZs2dTpEgR2rZty6xZs7hz547D7C1ZAr16Ob5HdkwMTJ8uBVCJn/tQe3xuRAjBW+vfYmroVGKNjvkLM3gYeLnKy/zY5ke0mtTva0JDQ3nrrbe4c+cO33zzDc2bN3fIHBzJ7du3KVGiBFevXsXPz/U5aA9z584dQkJC+PLLLx1aJNvRREdHM3LkSJYuXcqUKVN48cUXUzw30ZzI2C1jmbh7ot0BV3oPPV0rdGVSq0n4e7smbScyMpLVq1ezePFiNm/eTL169ejYsSPt27cnX7586Rrz4EHZJc2ZK6oGA3z6Kbz5pvNsKFJGCV8GYNP5TfRY2oN7Cfdsr6eYhLfOG18vX/7o8AetSqfRlfYhhBAsX76cESNGUK5cOb766ivKl884pc1mzpzJypUrM0zuVGhoKM8//zw7d+6kTJky7p7OE2zZsoUBAwbQoEEDJk6caHXN0UP/HaLn0p5cirxEnCnOpoLmfl5+5PTOyaz2s2j6TNP0Tt1uoqOj+euvv1iyZAlr166levXqdOrUiQ4dOhAYGGjVGImJsu79uXNOniyyAc3hw1C6tPNtKR5FCV8GISohijFbxvBr6K+gkW2MrMHX0xeBoF/Vfnza5FMCfALSZT8hIYEff/yR8ePH061bN8aMGZMhyjK1adOGXr160b17d3dPJZkpU6bw008/sXv3bpflFKZFdHQ077//PsuWLUvTy0sJIQR7r+7l611fs/LUSnw8fDCZTcSaHnV9fDx88NJ5ERUXRUieED5v8zlNn2ma5gqDK4mLi2PdunUsWbKE1atXExwcTKdOnXjppZcoXrx4iq8bNQq+/9653t59tFqoUgX275f/V7gOJXwZjDhjHAuOL+CnfT9x7OYxtBotOq0u+Q5cq9FitpgxCzMV8lVgcI3BdKvYzWGdFyIiIhg7dizz58/n/fff5/XXX3dKGLnFIu+qQ0Pl0tLt2zLvyd8fKlSAGjWgSJFISpUqxtWrV/H3d33Fm5QQQtCrVy+8vb2ZPn36kydERcHKlbB9O+zcKS80IUFu6nh5QVAQ1KsHDRtCu3ay04gd/P333wwYMICGDRvy3XffkStXGhXLrSDBlMDRm0cJvRbKvmv7uBN/ByEE/t7+VC9YnRqBNVj922rMcWYmTJhgtz1nkpCQwKZNm1iyZAkrVqygRIkSdOzYkY4dO1L6IXfrzh0IDJRRmK7Czw8WLIBMnimT+RCKDIvFYhFnbp0Ry08sF3OOzBF/HP5DLDuxTJyOOC3MFrNTbYeFhYk2bdqIkiVLiiVLlgiLxeKQcU+dEuK114Tw9ZWHv78QGo0QUhXkYTDIx3U6syhQYJ/4+28hHGTeYURFRYny5cuL6dOnP3jw+HEh+vcXQq8Xws/v0Yt62uHrK4SPjxDdugmxf3+65vDaa6+JwoULi1WrVjnw6qxj//79okyZMi63aw+JiYliw4YNYtCgQaJAgQKicuXKYuzYseL48ePi66/lZy+tX5ujj8aN3f2uZD+U8ClSZf369aJSpUqiUaNGYn86vpzvc/68/AP38RHC09OWLwaz8PMTIihIiM2bHXddjuD48eMib9684vCePUIMHSoFT6ez/ZtPq5XfuH36CHHvnlW2N2/eLEqUKCH69Okjbt++7dwLTQGLxSIKFy4sTp486Rb79mIymcS2bdvE0KFDReHCRYSHx38uFz2QfxMXLrj73cheKOFTpInJZBJTp04VBQsWFH369BFXrlyx+rVmsxCTJ8vv9fRowsOHXi8dqqgoJ16sjfz56afiqoeHsOj1jvkGzJdPiK1bU7T3sJe3evVqF17p0xk8eLCYMGGCu6dhN2fOmIW3t8mKX1NxAT4CfB86rgpIEDBGQCkBhqTz+gm4kOaYvr5C/Pqru9+B7IXaUlWkiU6nY+DAgZw6dYrAwEAqV67Mxx9/TExMTKqvS0yE9u3hvfdksIC96YJxcTB3riz+e/WqfWM5hC1baD1+PIEmExpbS3o8jfh4CA+H55+H5cufeHrz5s1UrlyZ2NhYjh496pZKNo/Ttm1bVqxY4e5p2M3Bg1q8vKwtjr0KiH7oCAQ6ASuBucgmmoeBEGBTmqPFxMCOHemYtCL9uFt5FZmPCxcuiG7duonChQuLmTNnCrP5yf3GxEQhmjeXXpqjl4Y8PIQoVEiIa9fccPH32bXLuRtCer0Qa9YIIaSXN3jwYFGkSBHx559/uvGinyQ+Pl7kzJlT3Lx5091TsYu3335yrzllj2/DY49tSPICL6f71126tLvfgeyF8vgUNhMUFMS8efNYtGgRP//8MzVr1mTbtm2PnPPqqzKg0RGO0OOYTNIxatjQtRF4ydy5A23aODfmPS4OOndm54IFVKpUibi4OI4ePZrhCmV7e3vTvHlz/vzzT3dPxS5On5YSlD42ArWAoum2f+NGul+qSAdK+BTppm7duuzatYsRI0bw8ssv07FjR86ePcu6dTJE25m6YDLB9evwwQfOs5Eir74q16ecjCk2Ft3LL/Pj5MnMmDGDgIAAp9tMD1lhudO2G6j2QEDS0R64BdjXdsHouvaICpTwKexEo9HQrVs3Tpw4QY0aNahVqznt28e4JAE4NhZ+/hn27nW+rWTWrYM//5R5eU7Gw2KhtocHrW/fdrote2jdujWbN28mzhnuvYuwre3fciAy6VgO5AHsazOWgXvvZkmU8Ckcgl6vZ+TIkfTvfwSj0XXNQ+PiYMgQl5mDjz5yTVmPJDSxsbIZXPrX4ZxOnjx5qFatGps3b3b3VNJNkSL2vLoZsBe4ku4RMqgzn2VRwqdwGCYTzJjhj9mc/lY06eH4cThxwgWGTpyAY8dcYOgxwsPlhmkGJrMvd9atC+nvetUMaA50AEIBExAFTAGeUtnnKdSsmV7bivSghE/hMFavds9ehdEI333nAkM//WTTBQYhwx5mAjrA76HjdVvsxsa66ALTT9u2bVm1ahUWi/XFrTMSISGyu3r6WQy0BroCOYGKwH6kKKaOt7fs+6dwHUr4FA5jwQJZpjJlgoD8wMOBIdOAZ5P+rwHOPvaaj4Feqdo1mWDZMuvnmW42bpTG0kFdHs38mpz66Y8iBDwWNZvRKFWqFLlz52b//v3unkq6KF/eWuG7yNPFzAsYi/z8xgCXkJ/tYmmO6OGhhM/VKOFTOIw9e6w5ywx873Dbd+/KQtdOw2RyTa+alLh7V6ZRZGAy83Knhwf07WtEp0vfjY095M+fQPXqLjebrVHCp3AIcXHw77/WnDkC+BoZEec49HrZ6cFpnDwJPj5ONJAGej0cOuQ++1bQrl07Vq5c6e5p2MytW7cYN24cc+fWQ9jQh9AReHklEBHxLu3atWPHjh2IDBzElJVQwqdwCFeuWKsLNZBLm1871L7RCBcu2P46IQQWiwWz2YzRaCQhIYG4uDhiYmKIiori3r17REZGcu/CBSx2bALt5kHmV0DSzzZhscCtW+m27wpq1apFeHg458+fd/dUrOLixYsMHTqU0qVLc/nyZXbsmE27dl54uTA2KyDAmwsXxvP888/Tt29f6tWrx9KlSzHbW99PkSpK+BQOIT7elmaa44AfgPCnPFedRyXiC6tGjI2N5513PiR//vzky5ePPHnykCtXLnLmzIm/vz++vr4YDAZ8fHzw8vLCw8MDrVaLVqtFp9Ph5eWFwWAgR44c5M6dm/z581OoUCGKFClCUFAQL/foQVTqG5ipUocHmV+RST/bTAbPctZqtbzwwgsZ3us7dOgQPXv2JCQkBIPBwLFjx5g2bRrlypVj6lTpXLsCvR7mz4c8eQwMHjyYU6dO8c477zBhwgTKlSvHlClTMnVuZEZGCZ/CIXh42JJqVhF4gaeL2gEelYj3rRrRx8eLUaNGcPToUcLCwjh9+jTnz5/n8uXLXLt2jRs3bhAREUFkZCTR0dHEx8djMpmwWCwIIZ7q8UVHRyd7fMvXriVnjhzWXqDj0Whc941sB+3atWP16hVAGDAbGAb0REY7voLc393BowFOzkcIwebNm2nZsiVt2rShatWqnD9/ni+++ILAwMDk8/LmhenTwWBw7nz0eujeHZ577sFjOp2Ojh07smvXLqZPn86aNWsoUaIE48aNIyIiwrkTymZ4uHsCiqxB7tyyG4P1jEV6d287xL6np5bixXNSoEBOh4z3BEFBLqnWkiJCyDlkaE7y/PMraNp0C0LUQqPRIGNYH8YHGQEZh/R73wVaIRM+HI/JZGLp0qVMmDCBmJgY3n33XXr06IG3t3eKr3npJVkNaPJk51Sm8/GBypXhxx+f/rxGo6Fhw4Y0bNiQkydP8s0331CmTBm6d+/OW2+9RcmSJR0/qWyG8vgUDqFAAVtjP0ohvYBJDrEvBM6NjAsMxKWbP48h4uOhQgW32U+di0BjoDqenrMwGECjieFJ0QOIB+4BRmA70APZ1sex0aBxcXH89NNPlC1blkmTJjF69GiOHz9Ov379UhW9+4wfD4MGOd7z0+uhShWZGWPN30u5cuX49ddfCQsLIyAggNq1a9O5c2f2urROXxbEvc0hFFmJRo1sbelyWYC3gMZJPyPgzGOvGSOgZ5ptXby9ZdNbp9KggfPaEKVxnNZqRYcOHcTPP/8szp8/7+QLtRazEGKyEMIghNAJIbDjMAghXhJC3LJrRhEREWLcuHEif/78om3btmLHjh12jTd1qmwUa28T5fudpgYOFCIuLv3zuXfvnpg4caIoVqyYaNSokVi1atVT24I5jchIIZYtE2LkSCHq1RMiMFCIvHmFKFBAiLJlhejdW4hffhHi+HHXzSkdKOFTOIzPPpNNxN2hDbVru+ACf/xRfgu6+uK8vUXUm2+K2bNni969e4sCBQqIUqVKiSFDhogVK1aIe/fuueDiHydRCNFeCOEr7BO8hw8vIUR+IcQZm2dz8eJFMWzYMJErVy7Rv39/ERYWZs/FPTa2/I5P76/e2ztRFCwoxJYtDpuSSExMFHPnzhXVqlUT5cuXF7/99puIj493nIHHOXRIipqPjxA5cgih1aZ8wQaDPCpWFGL2bPuU3kko4VM4jKtXpeflal3w8xNi4UIXXOC9e87prGuF8ImrV5OnYTabxaFDh8SXX34pmjZtKvz8/ESjRo3EZ599Jvbt2+cCD8AohGglpJfmKNG7f2iFELmFEGetmsnhw4dFz549Re7cucW7774rrly54phLfAyLRYjNm4V4/nn53e/nl/qvTK+X3/3Fi0eJwoXfF7GxFifNyyI2btwoWrZsKQoVKiTGjx8v7ty54zgDt24J8dJL8oLS4/b6+QmRP78QmzY5bk4OQAmfwqG0bm1tJ2vHHTlzyo7vLqF/f9kC3lUXp9EI0apVqlOKiYkRf/31lxg+fLgoX768yJs3r+jWrZuYPn26k4TgVeEc0XtY/AoJIZ7uyVosFrF582bx/PPPi8DAQPHll1+KyMhIJ1zn07l6VYjffxfi1VelU5M7t/x+z5VLiBIlhOjaVYjJk4U4fFjOtVKlSmLdunVOn9fhw4dF7969Ra5cucSbb74pLl26ZN+Aq1YJERAghJeX/Z9jvV6Ifv2EiIlxzMXaiRI+hUPZvdu1TpHBIJdYXcaVK2nf7jvy0OuFsHHZ7vLly2LatGmiS5cuInfu3KJChQrirbfeEmvXrhWxsbF2vgGbhRB64TzRu3/4CCH6PGLZZDKJhQsXiho1aoiyZcuKadOmOXd5z0HMmDFDtGjRwmX2Ll++LN5++22RO3du0bNnT3Ho0CHbB5k8Wf5xOfKz7OMjRLVqcp/QzSjhUzicwYNdI34ajdxPd5m3d59p01yz1+fra7eqm0wmsWfPHvHJJ5+IBg0aCD8/P9G8eXPx9ddfiyNHjgiLxZYluCghRAHhfNG7fxiEEBtEbGys+Pnnn0XJkiVF3bp1xfLly10b0GEn8fHxolChQuLo0aMutXvnzh3x5ZdfisDAQNG8eXOxfv16637fU6Y4XvTuH97eQlSpIkR0tNOvPzWU8CkcTkyMDPZyvjNkEUeOuOECLRYhmjVzbiSPp6cQVasKYTI5dOqRkZFi2bJlYvDgweKZZ54RhQoVEn369BFz584VN2/eTOPVE4RrvL0HR0REHlGgQH7x4osviu3btzvsfXA1n376qejfv79bbCckJIgZM2aIChUqiKpVq4o//vhDJKZ0t/jPP86/a/XxEaJTJ9e+CY+hhE/hFA4fFsLf33l/OxpNrGjRYq777vyjooSoXNk50TyennKzKCLC6Zdx9uxZ8eOPP4p27dqJnDlzipCQEDFy5EixZcsWkZCQ8NCZZiFEQeFK0RMCERfnIc6dm+fMt8AlhIeHi4CAAHH9+nW3zcFisYg///xTPPvss6JYsWLi22+/fTQiODZWiCJFnCt69w+DQYiVK932XmiEEMLduYSKrMnevdCsGURHy0+7o9DrYdy4GJYta0GpUqWYNm0anp6ejjNgLffuyQs8flw2i3UEej0UKwbbt0O+fI4Z00qMRiO7d+9m3bp1rF+/nlOnTtGoUSNatmxJ+/Z6ChcejkbztKR0Z6IFXgIWudiu4xk8eDD58uVj3Lhx7p4K+/fv56uvvmLTpk0MHDiQoUOHUujLL2HqVNlqxRXkyiUry+fM6Rp7D6GET+FUjh+Hdu3g+nX7tcHTU1a7mDlTlpWKiYmhU6dOeHp6smDBAvTuqGVpNMLYsfDtt7JStz1/Tno99O8PX32VIepy3rp1i40bN7J+/Xqee24+PXrEplmIfO5c+VacPAn+/lC1KnzwATRoIJ+fORP69ZPFmbt2tXYmfshqL3a1SHc7p0+fpkGDBly6dAm9Xk94TDih10PZd3Ufp2+fJs4Yh5fOi8I5ClMzsCY1AmtQIqBEUuk353D+/HkmTpzIqtmzOR0djZcru0IYDPDJJ/DWW66zmYQSPoXTSUyEjz+G776TOpGeJua+vvLLc9YsWR7twdiJ9O3bl6tXr7Jy5UpyuuHuEYDDh6F3bzh/Xt4xW6zs66bRyC+AAgVg9myoV8+580wnQlRAowlL9Zxvv4UvvoApU6BlS1nhbe1a2Tz+q6/kOc89B0eOQJ068Oef1lrXAyeA4nZcQcagdbvW5H02L3s893Ax8iI+Hj7EGmMxWR78UWjQ4Oflh1mY8dZ583qt1xlcYzCF/As5bV4xn32G59ixeLm6A0ihQrKnmfWtXRyCEj6Fyzh1Sn45zp4NOp1cAk0NvV46UI0awbvvQpMmUicex2KxMHToUHbu3MnatWsp8LAyupp9++RFLluG8PIiJioKv8fPMRhkO4u4OHj+eXlx9es//eIyBCbAF0i5Cvndu1C4MMyYAZ07P/2cS5egRAlYtEh6e1euQMGC1tjPAcxALnlmTswWM9/u/pbRm0aTkJCA8LT+a9fHwwchBJ2COzG59WQCfAIcP8GiReUvxAqeBQ4D/wH3q572BYoAn9pq198fli+Xf9wuRAmfwuVER8vP+rZtsHMnnD0rvUKNRt74FS4MtWpJwevQAYoUSXtMIQRjx45lzpw5bNiwgSB3dzIwGjm7YgUzXn+dzzp2hMhI6QXmzAnVqkFICFSqBFYUTHY/14GSyI4KT2ftWnjhBbna65FCz5dPPoFVq+Teb6VK0LcvvG1Vcw4vYDzg+iUxR3D61mm6LOrC2dtniTGmv92Dt84bXy9fZneYTevSrR03wRs3oHhxq7qPXER+EnICvwD373H6kk7h02rh/ffhs89sfaVdqLZECpfj5we9esnjPhaLPFL60kwLjUbDxx9/TJ48eWjYsCFr1qyhYsWKjplwevD0JNRs5mT9+in3n8k0xJNWI5dbt2Qvu9R+f7//DkOGyP/36CF/tk74TKQmuhmZjec30n5+e+JMcViElcvfKZBgTiAhLoHOizozot4IxjQe45j9v9BQeQNmhfD9jmwmVRuYxQPhSzcWC2zdau8oNqPaEikyBFpt+kXvYd544w2++OILmjZtyq5du+wf0A6OHz9OhQzbSsgWPIDUF4by5IGIiJT3b3fulAF83brJn3v0gKNH4dAha+xrATdE7drJxvMbaTe/HTHGGLtF72FijbF8/c/XfLj5Q8cMuH+/1ZFnvyPbCvcE1gE3HGH/6FFHjGITSvgUWY6ePXsyY8YM2rZty7p169w2j7CwMIKDg91m33HkQvbPS5m6daXTsHz505+fNUvu11atKvf1atd+8HhaGI06rl9PxOjqwAs7OBF+gvbz2xNrdFCay2PEGGP4bs93/HbwN/sHu3LFqoizHcAloAsQglzynGu/dYiKcmy+kxUo4VNkSVq3bs2yZcvo3bs3CxYscMscso7H5wfkTfWMnDlh3Di5lLl8uXQgjEZYs0bG7ixcKFPEDh16cPzwg0x/SOs712g0M2jQL+TIkYOKFSvSuXNnxowZw4IFCzh69CgJVizRuRKzxUyXRV2cJnr3iTXGMmzNMC7fvWzfQFa+f7OAFjz4JPRIeswhuDKNAhXcosjiHDlyhFatWvHhhx8yePBgl9lNSEggICCAyMhIqzp+Z3zaAqvSPGvOHJg4EU6ckAF7ISEyYPWHH+DyZZmLeZ+4OBm4NGuWDIxJGU8gmrg4M6dPnyYsLIywsDBOnDhBWFgYFy5coGjRogQHBycf5cuXp1y5cvj6+tp53bbz+fbP+Xz753YFsliLh9aD2oVrs73f9vTv9w0aBL/8kuopcUBBwAzJUcoJQCRwCJhIOoNbQEa1mc0ujWpWwqfI8pw7d44WLVrQr18/PvjgA6cmBN/n6NGjdOnShRMnTjjdlmv4CYvlHbRadwSZVEYG0D+dxMREzp49+4gYhoWFcfr0aQoWLPiIGN7/11n5nlEJURT4ugBxJte9T35efizvupymzzRN3wBffokYPRpNYsrpKvOAIUiR83ro8S5ATeAWUAgY89Bz2sfOTZH7G8QuREV1KrI8JUuWZMeOHbRs2ZKIiAi+/fZbtE5OmA0LC8sSy5yJiYmsWrWKefOWMnt2nBsKyvgBqYd+enl5JYvbw5hMJi5cuJAshlu2bOGnn37i5MmTBAQEPCKG9488efLYNdvZR2aj1bh2Byk6MZqv//naauGLjY3l0KFDhIaGsn//fjy2buXbxERSuxWYBfQDij32+OvAUKAZ8EXScZ/6yH3BNKla1ap5OxLl8SmyDXfu3OHFF1+kRIkSTJ8+3an1PUePHg2QIeoypodTp07x22+/MWvWLMqVK8fAgQPp1m01Hh6LkQtersIPCAd8HDaixWLh33//TfYMH/YUHxbRhz3FggULprlSIISgxPcluHT3ksPmai0+Oh/ODj1L4RyFH3k8NjaWw4cPs3//fkJDQwkNDeXcuXMEBwdTo0YNQkJCqFW6NJVbtEDjjuAhDw8YPRo++silZpXwKbIVsbGxdOrUCZ1Ox8KFC51W37Njx4506dKFrtYXpHQ7sbGxLF68mGnTpnH69Gn69OnDgAEDKFOmTNIZYUANXJdTZ0AmrX/iEmtCCK5fv/6EGB4/fhyz2fzEkmlwcDBFixZNFsRLkZco/2P5tJc5JyK3TEs+9vhlYDNwDVmWtDjSlcqf9tx9PX35ptk3VLFUeUTkzp49S3BwMCEhIYSEhFCjRg0qVqyIl9dji5Dly8sCq67GYIC//5YVK1yIEj5FtsNoNNK3b1/+/fdfVq5cSUBAgMNtlCtXjsWLF7s3id5KDh48yLRp05g/fz61a9dm4MCBvPDCCyl4xB8iv7mdG7EoeQZZo9OqnSKnEh4e/sj+4f0jKiqK8uXLU758eSxlLSw1LyXWksZ78zTh+xeZJNcUqIZ0qncB+4D/AbnTnqPusI4ql6o8IXJWBVfNmAFDh6ZdR9DRlCkjBdfF5fqU8CmyJRaLhWHDhrF9+3bWrl1LQeuKRlpFQkICOXPm5N69e0/eWWcQ7t69y9y5c5k2bRoREREMGDCAfv36UbRo0TReaQQqAOcAxyVlP4keuUNU3Yk27CcyMjJZEKecm8J+r/1pN5F4mvBNR3p2j0e3/oF0fK0oU1ouTzlOvJ7OYKq4OMif37XC5+sLkybJjiQuRuXxKbIlWq2WSZMm8dJLL9GgQQMuXLjgsLFPnz5NiRIlMpzoCSHYsWMHffv2pXjx4mzevJnx48dz/vx5Ro8ebYXogUwtWIOs1uisu3QD8B0ZXfQAAgICqFu3LgMGDCCwcmD63pJEpMf3tFioCsB564a5Fn0tHcaT0Otl/yhXpn/kyiVL+LgBFdWpyLZoNBpGjx79SH3PSpUqWfXa4zePs+nCJrZd2sbeq3u5FXcLk8WEh9YDH+GDTysfvtv9HU1KNKFygcpOvpLUCQ8P5/fff2fatGkIIRg4cCATJkwgf34rNo+eSkmkN9YQmcnlSM9PjyxI/T8Hjuka4ozp3PuMQ1aEe6KNR9JjVq4qJ5pTTkewihEjZEWB48etb6uVXvR6WdXAx3FBS7aghE+R7RkyZAi5c+emWbNmLFu2jHop9MRLNCey9MRSvtzxJadunUIgiDfFP3FOLLGQE0ZuGolWo6VkrpK8V/89OgV3wtvDNcnsFouFDRs2MG3aNDZs2ED79u359ddfqV+/voPyGIOB/UB75LKnvcnansjIzelAJzvHcg8e2nR+neqRnmI0kO+x56KRDrAz7d9Hp5NiFBJif9fo1DAY4JVXZJ07N6GWOhUKoHv37sycOZN27dqxdu3aJ54PvRZKucnlGLhqIIduHCLOFPeE6D1OvCmeWGMsR28eZdCfgyj9Q2n2XNnjrEsA4N9//2XcuHE888wzjBo1iiZNmnDp0iVmzpxJgwYNHJy8XwI4AHyE/PZOz9KuBtnrrwlwhswqegCF/NLZKNYLWfbk+FOeO458m60gh3eO9Nl/mHLlYMkSnJawqddD48ayZ6UbUcKnUCTRqlUrVqxYQZ8+fZg3bx4g6y6+t+E9Gs5oyIXIC0Qnpm/zPzoxmn/v/ctzs57jrXVvPdJx216MRiNLly6ldevWVKlShRs3brB06VJCQ0MZPHiwk7vS64D3gJPIVGb/pCMtgTUgPbznkaXQ1gBubCDsAOoWrYvB00r3zIKME7p/NEMWp9mNrAUWB2xC7v09a92QIYVCbJtwSjz/PCxeLD0zR2IwQPPmspirTufYsW1ELXUqFA9Rr149Nm7cSKtWrYi4HcGG3BvYdGGTw0pQxZni+GX/LxwPP87KbivtWvo8ffp0cpJ5mTJleOWVV1i8eDEGR39hWUUx4Ctktca/gO1Jx0nkt7gFuZxZFNnRrQEytDHQDXN1DiGFQtBprPxCn/PYzw2BXsg8vk08yOPrD1hRTMZL50Xj4o2tn2xatG4te0l16gTXr9u39KnVytYdo0fDO++4XfRApTMoFE/lzNkzVB1fFWMxI8Y0WvKkB72HnsZBjVnVfZVNezNxcXHJSeYnT55MTjIvW7asw+eosI1EcyK5vszl9K4MT8PPy4+NvTdSu0htxw6cmAgffywrj2s0Mu3BWrRaubRZujTMnw8Z6DOqljoViqew6PoixDPCKaIH0vPbdmkbY7eMter8Q4cO8frrr1OkSBHmzp3L0KFD+ffff5kwYYISvQyCl86LPlX62B9kkg7yGvJSq7ATqp94ecHnn8vWGqNHQ7584Ocnj5TOz5FDengdOsDGjXDgQIYSPVAen0LxBCfCTxAyNcQlFfb1Hnp2v7L7qSkP9+7dS04yv3nzJv3796d///4UK/Z4qWBFRuFUxCmq/lI1zcAnR+Lr6ctXzb9icE0XtN2yWCAsDEJD5VLoiRPSC/T0hLx5oWFDqFFDRoY6dW/ZPpTwKRQPIYSgypQqHLt5DIHz/zQ0aCidpzQnhpxAq9EihOCff/5h2rRpLFu2jGbNmvHKK6/QvHlzdBlgb0SRNi1nt2Tzxc0ODWBKjVw+ubg0/BL+3v4usZcVUMEtCsVDbL20lQuRF1wiegACwbWoayw6sIirW68ybdo0zGYzr7zyCl988QUFCmTuSMfsyIz2Myg7uWy6I4BtweBp4PcOvyvRsxHl8SkUD9FmThvWnF3jMuEDQIDuXx09jD0YOHCgE/LtFK5m1qFZDPlriFO7sHvrvGlbti0LOy90mo2sihI+hSKJ8Jhwik4sSoI5wboXTEQWLNEgk5BLAa2Bucim4TakVXnrvDk/7DyB/lknvD87I4Rg0OpB/HH0D6dEeXrpvCiduzS7BuxS3l46UFGdCkUSu6/stj2vrjvwAfAqso/atvTZ9tZ588+//6TvxYoMh0aj4ecXfqZLcBfrk9qtxFvnTancpdjad6sSvXSihE+hSGLftX3EJKZzaSoHUBq4mb6XRxuj2XPVueXMFK5Fq9Eyvd10Pmz4IXoPPRoHdLMweBpoVboVuwfsJo/Bisx2xVNRwqdQJLH98nbMwpy+F99FlppMZ7lGi7Cw/dL29L1YkWHRaDSMbDiSfQP3UT5fefy8Ush/SwODp4EA7wDmvDSHZV2XKU/PTlRUp0KRxM2YdLhr85G3jz5Ij68hcCl99m/F3UrfCxUZngr5K3B40GFWnFzBlzu/5NjNY1iEJdX9ZA+NBz6ePuTwzsE7dd+hX7V+BPgEuG7SWRglfApFEiZzOvKuuvFoJ207MJqdUyVGkTHw0HrQMbgjHYM7cjLiJOvOrpP9HK/t5WbMTUwWEzqNDn9vf6oUqELj4o1pHNSYxsUbqyhfB6OET6FIwsvDvR3TvXWu6dWncD/l8pajXN5yDKszzN1TyZaoPT6FIomSuRzkuqWTErmsbLymUCjsQgmfQpFE4+KN3eZ1eWo9HdtWRqFQpIha6lQokggJDMHbw9v6BPY3U3i8n+229Z56agTWsP2FCoXCZpTHp1AkUatwLSzC4hbbJouJekXrucW2QpHdUMKnUCTh4+FD/6r98dR6utSuh9aDXpV74evl61K7CkV2RQmfQvEQQ2sPRad1bfsfT60nw2sPd6lNhSI7o4RPoXiIkrlL0jm4Mz46H5fY89Z580KZFyifr7xL7CkUCtWdQaF4gnsJ9yg5qSQRsRFOt5XLJxfnhp4jlz6X020pFAqJ8vgUisfI4Z2DeR3nYfBwbFX9xzF4GpjdYbYSPYXCxSjhUyieQrNnmvHd8985vKXMfQyeBr5o+gVtyrRxyvgKhSJl1FKnQpEK0w5MY+iaocSZ4hw2psHDwFctvuK1mq85bEyFQmE9SvgUijTYeXknXRZ34U7cHbsEUO+hJ6d3TuZ3mk/jIFWlRaFwF0r4FAoriDXG8u6Gd/nt4G9o0NgkgD4eMkL05cov823Lb1W+nkLhZpTwKRQ2EB4Tzm8Hf2PchnGYtCZ8vHyIToxG8ODPSIMGPy8/zMKMwdPAsNrD+F/I/8jvm9+NM1coFPdRwqdQ2IgQgpKlSjLp90nEBcSx5+oeLty5QLwpHm8Pb4oHFKdO4TrUCKzBM7meUb3UFIoMhhI+hcJGTpw4QcuWLbl06ZISNYUiE6LSGRQKG1m1ahUvvPCCEj2FIpOihE+hsJFVq1bx4osvunsaCoUinailToXCBm7dukWJEiW4efMmPj6uqeepUCgci/L4FAob+Ouvv2jSpIkSPYUiE6OET6GwAbXMqVBkftRSp0JhJYmJieTPn5+TJ09SsGBBd09HoVCkE+XxKRRWsm3bNsqWLatET6HI5CjhUyisZPXq1WqZU6HIAijhUyisQAih9vcUiiyCEj6FwgpOnDiB0WikcuXK7p6KQqGwEyV8CoUV3Pf2VLUWhSLzo4RPobACtcypUGQdVDqDQpEGERERlCxZkhs3bqjEdYUiC6A8PoUiDVS1FoUia6GET6FIA7XMqVBkLdRSp0KRCvertZw6dYoCBQq4ezoKhcIBKI9PoUiFbdu2Ua5cOSV6CkUWQgmfQpEKaplToch6KOFTKFJAVWtRKLImSvgUihQICwvDbDZTqVIld09FoVA4EA93T0ChcBv37sHBg3DkCNy9CxYL6PVQpgyEhLBq5UpVrUWhyIIo4VNkL27dgt9+gx9/hOvXwWCAhAR5CAGenlL8EhN53WgkslkzOH4cKlRw98wVCoWDUOkMiuzBnTswbBgsWgQaDcTFWfUyodOh8fKC4GCYOhWqV3fyRBUKhbNRwqfI+qxaBX36QGys9OzSi14PQ4fCuHHg5eW4+SkUCpeihE+RdRFCenm//SZFzxEYDFCiBGzZAnnzOmZMhULhUpTwKbImQkD//rBwoeNE7z5eXlC4MOzbB3nyOHZshULhdFQ6gyJrMnq03M9ztOgBJCbC1avw7LNgNDp+fIVC4VSU8CmyHvv3wzffQEyM82wkJsL583K/T6FQZCrUUqcia5GQAOXKwcWLrrGn18OuXVClimvsKRQKu1EenyJr8euvcPOm6+zFx8OgQa6zp1Ao7EZ5fIqsgxAQFASXL7vWrl4Phw7Jii8KhSLDozw+RdZh2za4fdv1dk0m+P5719tVKBTpQgmfIuswb16qAS1BQH7g4TOmAc8m/V8AXwGlAT1QDBgJpJnybjTCggXpmbFCoXADSvgUWYedO+VyZyqYgZR8s6HAVOB3IApYA2wCulhjOyoKIiKsnqpCoXAfSvgUWQOzGU6fTvO0EcDXQORjj58BfgLmAHWR1dsrAEuAtcDmtAb28YHQUJumrFAo3IMSPkXW4Pp18Ei72UgN5NLm1489vgkoAtR67PGiQB1gQ1oDJybCmTPWzFShULgZJXyKrEFsLGit+ziPA34Awh96LAIolML5hZKeTxWTyeqODwqFwr0o4VNkDXQ6q0+tCLwAfPHQY3mB6ymcfz3p+VTRaGyag0KhcB9K+BRZg4AAudxoJWOBX4GrST83Af4F9j523r/AbqBpWgN6eUHOnFbbVygU7kMJnyJrkCcP+PpafXopoCswKennMsAgoCdS6MzAcaAj0CzpSBWdTpUtUygyCUr4FFkHG4VnNI/m9E0GXgF6AX7A88hAmCXWDBYXB5Uq2WRfoVC4h7TD4BSKzELz5rJgdApd1i8+9nNRIP6hn7XAe0mHzZQqBd7e6XmlQqFwMcrjU2QdXn5ZBpm4Gl9f2eldoVBkCpTwKbIORYpA48aut2uxQM+errerUCjShRI+Rdbiww/BYHCdPb0eXnkF/PxcZ1OhUNiFakukyHr07SuLRsfHp3mq3RQsCGfP2hRRqlAo3IsSPkXW4949GWwSHp72ufag18OaNe5ZXlUoFOlGLXUqsh45csCqVc5d8jQY4L33lOgpFJkQJXyKrEnt2rB6tXOWIA0GGDIERo92/NgKhcLpqKVORdZm715o2xbu3rV/z0+rlbl6n30Gb77pmPkpFAqXo4RPkfWJjpZ5dvPnywor6fnI+/rCM8/AwoVQrpzj56hQKFyGEj5F9mH3bvj8c9iQ1F0vLQ9Qq5UNZoOC5H5ez56qA4NCkQVQwqfIfvz3H8ydCxs3woEDcPs2eHrK50wm+f+KFaFRI+jaFUJC3DtfhULhUJTwKRTR0RAVBWazDFzJlcs9pc8UCoVLUMKnUCgUimyFSmdQKBQKRbZCCZ9CoVAoshVK+BQKhUKRrVDCp1AoFIpshRI+hUKhUGQrlPApFAqFIluhhE+hUCgU2QolfAqFQqHIVijhUygUCkW2QgmfQqFQKLIVSvgUCoVCka1QwqdQKBSKbIUSPoVCoVBkK5TwKRQKhSJb8X8mP4FACjA2yQAAAABJRU5ErkJggg==\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "solution = backtracking_search(france_csp)\n",
+ "print(solution)\n",
+ "draw_graph(france_csp, solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 35,
+ "id": "3e18cf8d",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "{'AL': 'R', 'LO': 'G', 'CA': 'Y', 'BO': 'G', 'AU': 'R', 'LI': 'B', 'AQ': 'R', 'PC': 'G', 'CE': 'Y', 'PL': 'B', 'BR': 'R', 'NB': 'G', 'NH': 'B', 'IF': 'R', 'PI': 'G', 'NO': 'R', 'MP': 'G', 'LR': 'B', 'RA': 'Y', 'PA': 'R', 'FC': 'B'}\n"
+ ]
+ },
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAb4AAAEuCAYAAADx63eqAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/NK7nSAAAACXBIWXMAAAsTAAALEwEAmpwYAAB8UklEQVR4nO2ddXgUxxvHPxe/S4J7cHcJ7g6luFsLlAIFWmjR0h8ubbHSIi3FCwVKcClQrLi7u7sT4sndze+PAYpE7pK7vch8nmcfyO3uvLMn+92ZeUUnhBAoFAqFQpFEcHJ0BxQKhUKh0BIlfAqFQqFIUijhUygUCkWSQgmfQqFQKJIUSvgUCoVCkaRQwqdQKBSKJIUSPoVCoVAkKZTwKRQKhSJJoYRPoVAoFEkKJXwKhUKhSFIo4VMoFApFkkIJn0KhUCiSFEr4FAqFQpGkUMKnUCgUiiSFi6M7EC958ACOHoWzZyEwEIQAb28oWBBKloSMGR3dQ4VCoVDEEiV8r7l+HaZNgz/+gKAgcHeH4GAwGuV+FxcwGCAsTP7bqRP06gU5cjiy1wqFQqGwEl2SL0R7/Tp06QL79oHZDOHhlp3n5gZOTlC+PMyeDTlz2refCoVCobAJSXeNz2yGKVOgcGHYuRNCQy0XPZDHhobCrl1QpAhMnizbVCgUCkW8JmmO+EJDoVEjOcoLCrJNm56ecvS3di3o9bZpU6FQKBQ2J+kJX2go1KwJx49DSIht29broVgx2L4dPDxs27ZCoVAobELSmuoUAlq3to/ogWzz5Elo2VLaUigUCkW8I2kJ319/wbZt9hG914SEyBHf4sX2s6FQKBSKWJN0pjofPoQ8eSAgQBt73t5w6RJkyKCNvbcIN4UTagzFWeeM3lWPky5pPd8oFApFdCSdOL7Bg+X6nlaEhkqbc+bY3dS5x+dYcW4FO2/u5MSDEzwPfY6zzhmBfKbJkSIH5TKXo2aOmjQv2BwvNy+790mhUCjiK0ljxBcQAOnT23eKMzL0ejnS9Pa2edNmYWb5ueWM2zOO80/OYzQbiTBHRHuOl5sXZmHmkyKf0K9CP/KmzmvzfikUCkV8J2nMgS1cKIPNtcbJCRYssHmzl59eptTMUnRe05ljD44RYgyJUfQAAsMDCY4IZu7xuRT/vTjDtw8nwhTzeQqFQpGYSBojvnLl4OBBiw+vBpwEHgDur17rBGQGxlhru0wZq2zHxNSDU/l267eEmcIwi7gFzBtcDWROlpm/2/5NntR5bNRDhUKhiN8k/hGfEHDmjMWH3wB2AzpgrS3snz1rk9AGIQQDtwxk0LZBhBhD4ix6AMERwVx+epkys8pw6uGpOLenUCgUCYHEL3w3b1olPAuAcsgR3nxb2BcCbtyIczMjd47k18O/EhwRHPc+vYVA8CLsBVXnVeXy08s2bVuhUCjiI4lf+K5cAVdXiw9fALR/tW0CHsbVvqsrXI6boGy7to0JeyfYXPTexj/Mn/qL66s1P4VCkehJ/MJnhSfnHuAm0AooCeQCbBKGHgdv0oCwANquaEuw0X6iB3LkdzfgLiN3jrSrHYVCoXA0iV/4nJ0tPnQ+UAdI8+rvdthoutMl9uGS/bf0JyBcm6D74IhgJu2fxPnH5zWxp1AoFI4g8QtfihQWHRYCLAV2AhlebT8jvTtPatSH93kR+oIFJxcQatQu8D7cFM74veM1s6dQKBRak/iFr0gRWUk9BlYDzsA54MSr7TxQGbnuB2ACQt/aLKneF+Hvz6fjxzN69GjWrVvHrVu3sDSCZO7xuZqnGzMJE0vOLsE/1F9TuwqFQqEVSSOOL3NmuHs32kM+AgoBP733+lKgN1ALWPTevorIdcHoiEiXjuW//MKJEyc4efIkJ0+eJCwsjGLFir2zFSpUCHd393fOzf5Ldm7634zewM9AI+SC5NvcAv4F7iFjM7K9uoh0MXQY8HT1ZFLdSXQr2S3mgxUKhSKBkTSEr00bWLpU+1JBOp0sUeTn987LDx8+fCOCJ0+e5MSJE1y9epXcuXNTrFgxihcvTu5CuWl5pCVGszF6G5EJ323kMLUmUAI5VN0PHAa6Aali7nqrgq3wa+kX84EKhUKRwEgawrdnD3z0ke2qrVuKpyds3AiVK8d4aGhoKOfOnXszMtx5cycnC578L3VMVEQmfHORI7sG7x27EDAAzWLuerbk2bjxzY2YD1QoFIoERtKozlCxIqRNq73wpUkDlSpZdKiHhwe+vr74+voC8MuBXxi0dRBhpjDrbIYjR3zVI9lXCNhmWTN3A+4SZgzD3SUm5VUoFIqEReJ3bgE55ThsmByBaYWnp7Sp08Xq9Ochz60XPZDuqQKIrPKQF2BhOKCzzpmgCI0fFBQKhUIDkobwAXTqJD08rYjrizXOzlC4sLQZSyypthApeqQzS2Ak+wKRU50WoNPpYl5fVCgUigRI0hE+nQ6WLAEPD/vbcneXtuJQCsngakBHLEaLbsgyEmcj2XcWyGFZMyazCQ8XDd4rhUKh0JikI3wA2bLJ+nh6vf1s6PXSRvbscWomV8pclldKNwMRb221kFH3B4Aw5PTnNuTaXzXLmnR3ccfbzfYFdBUKhcLRJA3nlrdp1gxmzIAvvrB9RXa9Hn7/HZo3j3NTJTOVtLz00PsBhpWBT5BxfNv4L46vM5DasiYLpyuMLpbrkwqFQhGfSXrCB/Dpp5AqFbRrJ8UvIm4VCcIAJ4MBVz8/aPB+DEHsyJ0qNyZhivnAPtHs+yx2tp10TlTJWiV2JysUCkU8J2lNdb5N/fqyXFDt2nHz9vT0JLBMGUolS8azChVs1j0nnRP1cteL3TpfHNG76GlWwIJgP4VCoUiAJF3hA0iXDtavh5UroVo16fji5hbzeW5u8tiqVWHFClIfOEC1Vq346quvbNq9/hX6Y3C10A3Thvgk86GMTxnN7SoUCoUWJI3MLZZy4wb89Rfs2AHHjsGLF/+VFDIaZZWF4sWhRg2ZBi3Hfy6SwcHBlChRgjFjxtCyZUubdEcIQZ6pebj6/KpN2rMET1dPJn80mc99P9fMpkKhUGiJEr7oCAqSlR2EkNOhMUyJHjhwgMaNG3Py5EkyZMhgky5svbaVxksa27X6+mt06MiVKhdne57FzdmCka9CoVAkQJL2VGdMeHrKVGfp0lm0DliuXDm6dOlCt27dLC49FBO1ctaiZcGWmsTUebh4sKzlMiV6CoUiUaOEz8YMHz6cmzdv8scff9iszan1ppJan9qutfmcTE7kvJeTfMnz2c2GQqFQxAeU8NkYNzc3/vzzTwYOHMjNmzHU0rMQb3dv9nTeQyp9KruIn8HVQIcSHSjmX4xq1arx4MEDm9tQKBSK+IISPjtQtGhR+vbtS+fOnTGbLQxCj4HsKbJzuOthMnhlwMPZdtOeBlcDnxX/jLlN5rLwz4U0aNCAsmXLcvLkSZvZUCgUiviEcm6xE0ajkcqVK9OuXTt69epls3b9Q/3ptbEXK86viJPDi5uzG3oXPXMbz/0gZs/Pz4+vvvqKuXPn0rBhw7h2WaFQKOIVSvjsyKVLl6hQoQL79u0jb968Nm1789XNdF3XlWchzwgKD0Jg2cfo4eIBAhrlb8RvH/9GakPkOcwOHjxIs2bN6NevH3369FHpyxQKRaJBCZ+dmTp1KosWLWLPnj24uNg2Q5wQgl03dzF+33i2XN2CM85ERERgcv4v1ZmLzgWDm4EwYxjJ3ZPTs3RPvij1BRm8Yg63uHnzJg0bNqR8+fJMmzYNV1dXm/ZfoVAoHIESPjtjNpupXbs2tWrV4rvvvrObHaPZSN8f+3I58DIlapUgIDwAN2c3UnmkokTGEpTMWJL0XumtbjcgIIC2bdsSEhLC8uXLSZkypR16r1AoFNqhhE8Dbt26RcmSJdm6dSvFihWzm5327dtTp04dOnbsaNN2TSYTAwYMYP369axfv57cuXPbtH2FQqHQEuXVqQFZs2ZlwoQJdOjQgbCwMLvZOXPmDIUKFbJ5u87OzkyaNIm+fftSqVIldu7caXMbCoVCoRVqxKcRQggaN25M4cKF+eGHH2zevtFoJFmyZDx+/BjPuFSbiIGtW7fSvn17xo4dy2efxbLukUKhUDgQJXwa8uDBA4oXL87q1aspV66cTdu+ePEiH3/8MVev2j+h9YULF2jQoAEtWrTghx9+wMlJTRwoFIqEg7pjaUiGDBmYNm0aHTt2JDjYtkmn7TXNGRn58+fnwIED7Nu3jxYtWhAUFKSJXYVCobAFSvg0pkWLFpQqVYpBgwbZtN2zZ89SuHBhm7YZHWnSpGHLli0kS5aMKlWqcPfuXc1sKxQKRVxQwucApk6dysqVK9m2bZvN2jx79qxmI77XuLu7M2/ePFq2bEm5cuU4duyYpvYVCoUiNijhcwCpUqVi1qxZdO7cGX9/f5u0qeVU59vodDoGDRrE5MmTqVu3LqtXr9a8DwqFQmENyrnFgXzxxRdEREQwd+7cOLUTHh5O8uTJef78OR4e9q/bFxVHjx6lcePG9O7dmwEDBsQxzZkZCAHCATfAAKi0aQqFIu6oEZ8DmThxIjt27GDdunVxaufSpUtkzZrVoaIHULJkSQ4cOMCSJUv4/PPPCQ8Pt+JsE7AB6AWUADyBFEDGV/8aXr3eG9j46niFQqGwHiV8DsTb25s//viDL774gidPnsS6Ha0dW6Ijc+bM7Nq1i2fPnlGnTh2ePn0awxnPgO+BDEAb4FfgBBAKGIGwV/+Gvnp9GtAayAT8CDy3w1UoFIrEjBI+B1OlShXatm1Ljx49iO2ssyMcW6LDy8uLlStXUrZsWcqVK8fFixejOHI1kBMYAzwBAiDGKhPi1XGPgNGvzo/biFmhUCQtlPDFA77//nvOnj3LkiVLYnW+oxxbosPJyYlx48YxaNAgqlSp8p4HaxDQDGgP+CNHc7EhBHiBHCm2BGwbG6lQKBInyrklnnDkyBE+/vhjTpw4QaZMmaI8TggICICQEHB2Bi8vKFYsHytXrox34veaHTt20Lp1a8aMGUPXrq2BqsAFYi94keEBFAR2AN42bFehUCQ2lPDFI4YPH86hQ4fYsGHDOx6RJ0/CsmWwYwecOiVFz8VFiqDRKDCZ7tGwYQbq1HGmTRtIk8Zx1xAVly9fplmzemzYEEjmzC/Q6eyRrNsdKAbsRAqhQqFQfIgSvnhEREQE5cqVo3v37nTu3JUlS2DcOLhyBcLDwRSDI6NeD2YzNGwI330Hvr7a9NtSQkM7A/Px8DDb0Yoe6AJMsaMNhUKRkFHCF884e/YslSp9TsaMO7l1y53YpMF0cgJ3d/jsM5gwAQwG2/fTenYDH6HNOpwe2AaU18CWQqFIaCjhi2dMnQr9+kUQEeEEOMepLb0eUqaEv/+GEiVs07/YYQSyAfc0tJkZuEFc30OFQpH4UF6d8QQhYNAguUVEuGKLG3ZICNy7B1WqwN69ce9j7FmHDEHQEn9kQLxCoVC8ixrxxRNGj4axY8HG1Yre4OkJu3Y5at2vLHDIAXYrAnscYFehUMRn1IgvHrBzJ/z4o/1EDyAoCBo0IFZrhnHjBnDKoiMXL4ZSpWSIRsaMUK8e7HlLt/74A3Q68POz1PZR4LZVvVUoFIkfJXwOJigI2rSR05L25sUL6NvX/nbe5QDgGuNRkybBN9/A//4HDx/CrVvQsyesWfPfMfPnQ6pUsGCBpbZdgYPWd1mhUCRq1FSng+nVC2bPhlBbxnJHg14P27dD2bLa2INvkKEFUX/N/P3BxwfmzYOWLSM/5uZNyJFDxjO2bg137kCGDDHZdgL6AhNi03GFQpFIUSM+BxIQAHPmaCd6IG19/7129mAfMeXf3L9f9qtp06iPWbBAToM2bw4FCsCiRZbYNgMO9epRKBTxECV8DmThQhlzpyVCwJYt8OCBVhZjrp7w9KnMNuPiEvUxCxZAu3by/+3aWTPdqao3KBSKd1HC50AmT7bE2SQ7MiDb663tHrJA6wggD7J2XXagM9KZJGYWLrS6u7Ek5rp5qVPDkydgNEa+f+9euH5droWCFL7Tp+HECUvsR9GoQqFIskTzjK2wJ6GhcPWqpUevA2q991oj4A6wGFmgNQhYiMxY8nmMtrdsgf79renxu4SFhfH48WMePXrEw4cPefToUaTbkiW3yZMn+rbKl5eZZlavhhYtPtw/f74cqRYv/uHr77/2ISpnp0KheBclfA7i1CmZSuzly9icvRXYAlwCsrx6LTnwpcUtHDv27t9ms5nnz5+/I1rRCVpwcDBp06YlXbp0pE+fnnTp0r3ZChUq9Ob/Pj6Dgc3R9iV5chg1Cr78Uk531qkDrq6wdat0xFm6FGbOhPr1/ztnxQp5zoQJ0U+RQn6L3xOFQpE0UMLnIE6ejHpqL2a2AmX4T/Ss59kzI9WqteD58+s8evSIJ0+e4O3t/Uaw3hazYsWKvSNs6dKlI0WKFO9UkIiaj5DVEqKvxtCvn/TSHDMG2rcHb28oWRIqVpSeqB06SDF8TefOMGwY/POPjE+MHA+gikXvh0KhSDqocAYHMX48DB5sifhlR1Ynf/2MUg1Ii0wBFrvCtQDu7hHMmrWfIkWSkS5dOtKkSYObm1us24ua3UADIFZD2ziSDNgIVHCAbYVCEV9RIz4HYTLJdSvLWM27a3yDkNOcscfV1ZUKFaqQK1ecmrEAzQIGI8EJKO1A+wqFIj6ivDodhF4f09pUdNRC5r68E2v7JpPsg/1xA7q/+lc7zGZ35JpnzFljFApF0kIJn4PInVt6MsaOWkBtoCkyH6UROfX5OzDXohbMZksyn9iKL9H6qxYeHsbQofd4oF3AokKhSCAo4XMQJUtCWPT+HjGwHPgYaI306CwMHOHDsIfIyZdPy+D5rMiq6JoMMQEDZvMXBAWloFChQnz77bc8ffpUI9sKhSK+o4TPQWTMaOlU4w0iFzM3YCRwBRnDdxOYjRSZ6NHpoFIlS3tqK8YDqTWylRaD4RcmTZrEqVOnePnyJfny5WP48OH4+/tr1AeFQhFfUcLnQJo1A2cHFAj39IRWrbS2qkeOUg12tSKEAVjG68B1Hx8fpk+fzuHDh7l16xZ58uRh7NixBGlfn0mhUMQTlPA5kD59wC4RBDGQOrWsyq49ZYFF2GvKMzTUiUmTSmM0lvhgX44cOZg3bx67d+/mxIkT5M6dm8mTJxOqZYZwhUIRL1DC50AKF5aVBrTEYIABA+R0p2NoAixFjvxs9fVzAgzodMvZvNmdTz/9FGMUAZL58uVjyZIlbNq0iX///Zc8efIwY8YMIiIibNQXhUIR31EB7A7myBE5+tKiEC3Imnbnz8fFo9RWXABaAdeQa5SxxRPIjRTTvISGhtK0aVO8vLxYvHgxrq7RhzMcOnSIoUOHcuXKFYYPH0779u1xdsT8s0Kh0Aw14nMwpUrJHJUG+y59AeDqamTpUhEPRA9kDs3jwFDAG1l1whq8Xp03AhnSkRcADw8PVq9eTUhICK1btyY8PDzaVsqUKcOmTZuYN28es2fPpnDhwixduhSz2WxlfxQKRUJBjfjiAWFhUKwYXLsG9ppx0+vNeHnNokGDg/z22294eMSnqgVhSMeX8cA55DRoBPD2MFiPDEYPBgoB3wLNgMhVPCwsjNatW2M2m1m2bBnuFqi9EIItW7YwZMgQwsPDGT16NA0aNLAwJ6lCoUgoKOGLJzx6JEd/9+/HJXl15BgM0otzypRAunT5nKtXr7Jy5UqyZo059EF7goGTyFHcPS5fPs3Jk5do0aI3UBIohqXOMeHh4bRt25bQ0FBWrFhhsdgLIVi7di1Dhw7FYDAwZswYatasqQRQoUgkKOGLRzx8KNf7bt+23ZqfwQCdOsHUqTJgXQjBpEmTmDBhAosWLaJmzZq2MWQnNm/ezMSJE9m8OfrSRlERERFB+/btCQgIYOXKleityNP2erQ4bNgwMmbMyJgxY6hkzwDIwEDYtQsOHYKdO+UUQFiYjHlJkQLKlpXlKipU0N4rSqFITAhFvCIkRIhvvhFCrxdCprGO3ebmJkSKFEKsXh25nW3btokMGTKI8ePHC7PZrO1FWsGePXtEhQoV4tRGRESEaNu2rahVq5YICgqK1fnz5s0T2bNnFx999JE4fPhwnPrzAefOCdGtm/zQkyUTwsUl6g/W01MIg0GIwoWFWLhQiNBQ2/ZFoUgCKOGLpxw4IO9tBoMQzs6WC55eL4S7uxDt2gnx9Gn0Nm7evClKlSolWrVqJQICArS5MCs5fvy4KFasWJzbMRqN4tNPPxXVq1cXgYGBsWojLCxM/Pbbb8LHx0c0bdpUnD59Om6d8vcX4pNP5IcWndhFtXl5CZE2rRCbN8etHwpFEkNNdcZzjh+HSZNg5Ur5t8kURliYCyBd7t3cwMNDTo2mSyc9RLt0gbRpLWs/NDSUL7/8koMHD7Jq1Sry5MljnwuJJZcvX+bjjz/m8uXLcW7LZDLRpUsXrl27xvr16/HyitmT9GnwUw7cOcDhe4fZdXMXj4MfE24MJ/BFIE+vPqWgZ0H6t+tPs7LN8HCxwmFo2zZo00ZOb8Y1iN5ggBYt4LffZFoehUIRLUr4EghCwI0b0Lv3fIzGHPj6VsHFBZInlx6hvr6QMmVs2xbMnDmToUOHMmfOHBo2bGjTvseFu3fvUrp0ae7du2eT9sxmM1988QXnz59n48aNeHt7f3CMEII9t/YwYd8ENl/djLuLO8HhwRjFh15HLrhgCjPh7OrMJ4U+YUitIeRKFUORwz/+gJ49bRu86eEBefPCjh2x/yIoFEkEJXwJjFatWtGsWTPatGlj87YPHDhAy5Yt6dy5M8OHD8dJu/INUfLixQuyZctm0+TSZrOZnj17curUKTZu3Ejy5Mnf7Lv45CJtlrfh8rPLBEcEI7Di52ECZydnmuRpwtwWc0nmnuzDYxYuhG7d7JOxwM1Nit++fRCJoCsUConj72wKq7h165bdwhDKlSvH4cOH2b59O40aNeLFixd2sWMNnp6eBAUFYcvnMycnJ6ZPn46vry916tThxYsXmIWZcXvHUWJGCU49OkVQRJB1ogfgDCadiRUXVpDhhwwsO7bs3f0nTthP9ADCw+HyZWjXzj7tKxSJBDXiS2D4+Phw4MABsmTJYjcbERER9O/fnw0bNrBy5UqKFCliN1uW4ObmRmBgIG42zugthKBPnz7s3rubzF9nZuutrQRHBNvOQATUc6rH4r6LSWEwQMGCcPWq7dqPCoMB5s+X634KheIDlPAlIMLDw/Hy8iI4OBgXFxe721u4cCF9+vRh6tSpdplatZSUKVNy7do1Utph7cpkNpF/WH6u6q4iXGz/U3A2O+Oxw4N/dKWoePgwumAbCmt0JE8uRTa1VjUQFYqEg5rqTEDcu3ePDBkyaCJ6AJ988glbtmzhf//7H/3794+y4oG9eT3daQ+G7xjOPcM9u4gegMnJhKm2ibCbu7UTPZCB7zNmaGdPoUhAKOFLQNhzfS8qihcvzpEjRzhz5gx16tTh8ePHmtoH+wnfiQcnmLR/km2nNyMh1BTKpy3MBEVfKMLGRkPh55/BZNLQqEKRMFDCl4C4ffu2Xdf2oiJVqlSsX7+e8uXLU6pUKQ4fPqypfXsIX4QpgpbLWhJq1KYQ7Qs36F/HsmOzA1uBP5DRml5vbV9ZYzQsDDZtsuYMhSJJoIQvAXHr1i2HCB+As7Mz33//Pb/88gsff/wxc+bM0cy2PYRvzcU1PAh8YL3nZiwJcYM/isMjK+PLywOBb23TrDk5MBC2bLHOoEKRBFDCl4C4ffu2wysqNG3alN27dzNx4kS6d+9OWFiY3W0aDAabC9+4PeMIDA+0aZuWMLOkhsaEgN27NTSoUCQMtPGSUNiEW7duUbduXUd3g/z583Pw4EE6depEtWrVWL58OT4+PnazZ+sR38UnFzn7+KzlJ/yMLBKvA9yQBd8/BhYDRZHVkiwg1BUml4X/7QYnrXypz52TAqhhSaXwcDh7Fs6cgYAAad7TU0ZzFC0qk8woFI5ECV8CIj6M+F6TLFkyVqxYwdixYyldujRLliyhSpUqdrFla+Hbdn2b9Se1BXIBL4E/gV2xsx3iCldSQd6nlh1/AEjx1t//AOWsMRgWJqsb2zgG8n38/WHBApg+Ha5ckeImhPStEUJWVnJ2huBgyJpV5pPt2hXSpLFrtxSKSFFTnQkIR67xRYZOp+O7775j3rx5tGzZkilTptg0w8prPD09CbZhKMDum7sJMcYye0oyIA/wKHanOwk4mtHy48sBL97arBI9kEUYw8OtPctinj+XIpYhA3z3HZw/L3U2IEAuMYaESAfToCB4+VIWWb52DUaPhsyZoWVLsFEaVoXCYpTwJRACAgIICwsjdTwMSK5bty4HDhxg3rx5fPrppzYVKbD9iO/g3YOxP9kfuAxYIV5vE+gK+zPH3rzVmEzg7m6Xpv/+G3LlkulHX4ubpYSEyMHo6tWQL58cLapUGgqtUMKXQHgdyqDTcK3GGnLkyMHevXvR6XRUqFCBa9eu2axtWwvf4+BYxCIuAX4E5gLZgMqxsy2c4EaK2J0bKzw9wcYJD8xm6N4dWreWI764+DcZjXJk2LMnNGtm18GpQvEGtcaXQIhP63tRYTAYWLBgAdOmTaN8+fLMnz+fjz76yOp2zMLM2UdnOXr/KPtu72Ozy2ZCjaFsmL2BtJ5pqZSlEqUylaJUplIk90gec4PvYTTHIgNNG+Qanw0I1fJXV7iwTR1bzGZo3x7WrpXrdbYiKEiGHH70Efzzj92XJBVJHCV8CYT4tr4XFTqdjl69elGsWDHatGnDV199xaBBgywqcfQk+Alzjs3h5wM/ExQRBAICI16FHDjDw7sPAdh8dTMeLh6EGcOon6c+/Sv0p1zmchaPhl2cHPu1d48hmcqNt/7fKQ52TMC51KnJ8PgxaS2tTBwDffvaXvReExICBw5A27awfLmmjqiKJIaa6kwgJIQR39tUqVKFw4cPs27dOpo3b87Lly+jPDbCFMHQf4eS5ecsjNw5kodBDwkMD/xP9N4j3BTOy7CXhJnCWHVhFbX/rE2JGSW48OSCRX1LrXfgOqmAbC+0MWV2d2fZy5fkzp2bihUr8uOPP3LmzJlYOyDt3AmzZtlH9F4TEiJHfkuX2s+GQqGEL4GQUEZ8b+Pj48OOHTvIkCEDZcqU4fz58x8cc/LBSQr9VohJByYRagy12ttSIAiKCOL0o9P4zvDlxz0/YjJHP6Qq41PGKhu2xCscyt/RxpZrunSM2rmTR48eMXz4cO7du0eDBg3ImTMnvXr1YtOmTRYnIAgKgjZt7Ct6b9vq1g0exdJzVqGICSV8CYSENuJ7jbu7O9OnT2fgwIFUqVKFVatWvdm38fJGKsytwJVnV+KcKNoszIQYQxizawxN/JoQboraS6JKtip4uFgRRd2HyNf3PsPi4PW3KXnf+nOsxmCAAQNAp8Pd3Z06deowdepUrl+/zrp16/Dx8WHUqFGkS5eOZs2aMXfuXB4+fBhlc+PGgZZ1iUNC4NtvtbOnSFqoenwJhDx58rBu3Try58/v6K7EmsOHD9OiRQvat29PpU6VaLGsRezj6aJB76KnSrYq/N3u70jX884+OkvpWaXtYjsmUobAk/EaZG5Jl07W4/Pyivawx48fs3HjRtatW8eWLVvIly8fDRs2pEGDBhQrVgydTkdEhGxOS+EDGQT/8CEkS6atXUXiRwlfAkAIgcFg4MmTJ3h6WpnlOJ7x+PFjGn3WiEO+hzA7m+1mx+Bq4PMSnzOl3pRI95f4vQQnHp6wm/3I8DDpGLhHMHK7fe0EA1/nzIl/yZLky5ePvHnzvvk3RYoUUZ4XHh7Orl27+Pvvv1m3bh3h4eE0aNCAVKm6MGWKL4GB2nqbeHrC2LHwlVUlKRSKmFHClwB49OgRBQoU4OlTC/NcxWNMZhO+M3w5/fA0Qmffr57eRc/WDlupkKXCB/uWnFlC13VdNU1U7e7kxvVpzmR8ZMeRpl5PePPmnP7mGy5evMilS5e4dOnSm/8bDAby5s37jhjmy5ePnDlz4v5WoLsQggsXLrBu3TrGjq3E8+cfvof/kR0pt9eB1w9ms4GFwA5kktPLyCSnrxkBXHl1TNQUKwYnTlhx/QqFBahwhgRAQl3fi4xJ+ydx9flVu4seQIgxhFbLWnG512X0rvp39jUr0IxBWwdpJnweLh60LdyWjAvbQuPGchHL5kY8oGxZ3ObMoaSbGyVLvrsAKYTg/v3774jh7t27uXjxIrdu3cLHx+eDEWK7du2YNMmSBOQmYDLwP5te0oULMnbQgmgYhcJilPAlABKiR2dkhESEMGrXKBmjpxEvQl+w6PQiuvh2eef1gBcBdPLsxOjnozE72W/K9TXJ3JMx+aPJ4O4Nq1bJNCUhIbbL02UwQIUKsG5dlNHfOp2OTJkykSlTJqpVq/bOvoiICK5du/ZGFI8fP46fnx/nz9/n0aPTyLIU0TEAGA/05N202nHD1RUuXYIEvLStiIco4UsAJJYR37JzyzS3GRQRxNg9Y/m8xOdcv36dNWvWsGbNGo4dO0aFChXwTuZNQP4Au6436l30LG62GG93b/lC3bqwfz+0aAF378YtRkCnkyO9/v1h6NBYpydzdXUlX7585MuX753XDx2C2rXNRBOG+YpSQDVgIjAmVn2IDCcnOepTwqewJUr4EgCJZcQ3bm8MxV/frnvnDGQBGgCvs5IdB/YDzwB3oABQE9B/0NI73Hp2i9zVchN4IZCGDRvSr18/PD09+fTTT+nboy/7s+9n582ddvHyNLga+KHGD9TMWfPdHUWLyqJ1I0fCTz9JAbNi+tMM4OmJU5Ys4Ocn27MDwcGg01k6zzgKqAh8Hck+X96NngoFWsTYohDaxA4qkhZq5jwBkBhGfP6h/lx+ejnmA9sCg4F+SD+JDa9e3wdsBWoD3wFdkHV6/gRiSL1pxEj1LtW5d+8es2fP5t69e7Rp04aZM2cybMgw1rRdQ/Uc1TG4GmJ1bVFhcDUwpvoYvi4XmRAg5/HGjIHbt2HYMEibVoYfROW56+Iiffvd3TmVKRPLO3SQhWbtJHpg7dpaYeSTythI9h3j3QJLgyxu1dnZmj4oFDGjRnwJgMQw4jv+4Dh6Vz0RYRGWneAKFERWXg0FtgONkbXwAFICLZH+FKeQA4ooEDrBNfM1jEYjPXv2ZPfu3ezZs4e8efMC4Obsxto2axm1cxQT9k0g1BiKIPZrb27ObhhcDMxvOp9G+RrFfEKaNDBokAw4P3MGjh6FvXulqIWESIFMnRoqV4ZSpaBUKYIvXmRIp060EAInOya1TJbM2mXIkcgPo59N7Ds5gbe3TZpSKN6ghC8B8LokUULm6L2jhBpDLT8hHDgLZAZuI0d1Bd47xh0phNeIVvgAjt8/TvXq1UmfPj0HDhwg2XtR0c5OzoysPpLmBZvTalkr7gbctdrj01nnjJuzGx/l/ojZjWaTSp/KqvNxdpb++8WKQefO0R5avnx59Ho9//77L7Vq1bLOjhXkz2/tVGNuoDUwBSgSZ/thYXYd0CqSKGqqM54TERHBo0ePyJQpk6O7EieuPb8WbRqxN7yuezcWuIpcMgoGDMh1v/fxerU/Bl6EvuCjjz5ixYoVH4je2xRNX5RzX55jRasV1MxREw8XD7zdvHGKYp3LxcmFZO7J0Lvo6VS8E4e7HmZl65XWi56V6HQ6unfvzvTp0+1qx8MDrH/mGoZcrI07rq7gY0k0hUJhBWrEF8+5d+8e6dKlw9XV1dFdiRMW5+J8XffODFwA5gH1keJm4kPxC0SKYgzodDoGDbasPJKTzok6uepQJ1cd7r68y77b+zh49yC7b+7machTIswRuDm7kT1Fdqplq0apTKWokKXCf16bGvHJJ58wePBg7t27Z9cHo0qV4MaN6KY8b7z3dxbk/PRrIjtxhEW2S5ZU5YkUtkcJXzwnMTi2ANYlhQY5F1EQ+BspeC7AeaT/xGvCkAlBan5w9gcIBK5O1j88+CTzoWWhlrQs1NLqc+2Nt7c3rVu3Zvbs2QwbNsxudrp3h5UrZdUELfH2VunKFPZBTXXGcxKDYwtAluRZrCsAK5AjvhAgE1AV2IgUOhPwHFgGJAOKxdyct5u3xYVqExI9evRg1qxZGI2xqCpvIeXLQ/r0dms+SkymMOrVs9AZSqGwAiV88ZzEMuIrmbGkZeECfwHfI9f5tgFNgXRAJeTIbvOrfbOR8X0dsWjeonC6wjEflAApWrQoWbNm5e+//7abDZ0OhgyJOsrCHnh4mEif/i8KF87H3LlziYhQAqiwHUr44jmJZcRXMlPJmL06+wBDkHF8/wO+BN726PN99doQZIashsQYvA7ghBNVslWJRa8TBj169LC7k0vHjlCwoHYxdRkzOnP+fCcWLFjAokWLyJ8/P3/88YddR7aKpIMSvnhOYhnxeeo8SaZzTGE1TzdPauawYCEwgdKiRQuOHTvG1atX7WbDyUkmiHmrgIPd0Oth2TJpq1KlSmzbto25c+cyf/58ChQowIIFC5QAKuKEEr54TkIe8Qkh2L17N127dsXHx4fUl1LjrtPgzvke7jr3D1OGJSI8PDzo1KkTM2bMsKudHDlg1iwpTPbCYIBRo6Q359tUrVqV7du3M3PmTGbPnk2hQoVYuHAhJpPJfp1RJFqU8MVzEuKI79q1a4wcOZLcuXPTvXt38uTJw+nTpzk44yA6Z20dTFxxJXRHKI0aNmLXrl0k1vKTX3zxBX/88QehoVYkCYgF7drBpEn2ET+DAfr1k/m2o6J69ers3LmT3377jd9//51ChQqxePFiJYAKq1DCF48JCgoiODiYNGnSOLorMeLv78/s2bOpUqUKZcuW5enTp/j5+XHmzBkGDhyIj48PyT2S06NUD5vnxIwOT3dPLi25ROPGjenSpQvly5dn5cqVie5GmTt3bkqUKMHy5cvtbqt7d5g3Tzq7xLIYxDvodFJIx42To72Yj9dRs2ZNdu/ezdSpU5k2bRpFihTBz88Ps9n+JabeJ8wYxtPgpzwKekRAWECifbhKTKgK7PGGUOAkMpnvfSCEJ0+CmDx5BaNHr0emf9J+mjA6jEYjW7duZf78+WzYsIGaNWvSsWNH6tWrh1sUNeFCIkLIOy0vd17esXv/DK4GFjVbRJP8TQAwmUysWbOGcePG8fz5c/r370+HDh3w8LAyxjCesnr1aiZMmMDevXs1sXfrFrRqZeLgwVD+q7xuHZ6ecgp16VIo8H5KOgsRQrB582aGDx9OYGAgw4cPp3nz5hYlK4gNL0Jf4HfGj63XtnLo3iHuvryLi5MLOp0Oo9mI3kVPkfRFqJqtKi0KtsA3Ywz59BSao4TPoYQBK5AFPM8iU5BEIIPXZKaM0FAn9HpPpDAWBwYiszU7LpPLmTNnmD9/PosWLSJLlix06NCBNm3akDp1aovOP3DnADXm17BLGaDXuDu7Uy9PPVa1XvXBvtdrj+PHj+fo0aP07t2b7t27kzJlSrv1RwuMRiPZs2dnw4YNFNUoweXIkaPYsiUlL1/24upVmVszpsG0TienNdOnl7m5O3e2jbeoEIKNGzcyfPhwwsLCGD58OE2bNrWZAJ55dIZxe8ex/NxynHROMWYjctY54+7iTvbk2fm20re0K9LOulhWhd1QwucQTMBPyIKdApl3y1K8kXm7RiF9+7WZrX706BF//fUX8+fP5/Hjx3z66ad8+umnFIjlY/rsY7PpvbG3XcTPzdmN/Gnys6/zPjzdoh+JnDlzhokTJ7Ju3To6derEN998k2CdiQBGjhzJw4cP+e233+xu6+HDhxQqVIjDhw+TI0cOTpyAuXNh1y5ZPNbF5T9BM5shPBxy55Yp0Dp1gnLl7JOOTAjB+vXrGTFiBBEREYwYMYImTZrEOoFBmDGModuHMu3QNMJN4ZiE9dPknq6eZEuejaUtl1IoXaFY9UNhO5Twac4FoBWypEBcckB5InN6+QE5bNCvDwkLC2PdunUsWLCAXbt20ahRIzp27Ei1atVwtsEj+m+Hf2PAlgGW5/G0AA8XD/KlzseOTjtI4ZHC4vNu377N5MmTmTdvHg0aNKB///4UKRL36gJac/fuXYoUKcLNmzfxtnM9ny+//BJ3d3cmTZr0wT6zGW7ehMBAOXPh6QnZstlmTdBShBCsW7eOESNGIIRgxIgRNGrUyCoBPP/4PPUX1+dh4EOCjXH7nurQ4eHiwfBqwxlYYWCizCSUUFDCpynrkFmYQ3lVQzuOOAMewGrANqVphBAcPHiQBQsWsHTpUooWLUrHjh1p1qyZXW6k6y+t59NVnxIcEUyYKSxObRlcDbQs2JJfP/41xpFeVLx48YLff/+dyZMn4+vry8CBA6lSpUqCukk1b96c2rVr0717d7vZuHjxIpUqVeLChQsWT3E7CiEEa9asYcSIEbi4uDBixAjq168f42d67P4xqs+vLh1W4lCf8X0MrgY+K/4ZU+tNTVDfq8SEEj7NWAl8wuv1O9tieNV+3Vi3cOvWLf78808WLFiAEIKOHTvyySefkC1btshPMBph61Y5r7VrF5w9K7MYm82ylkymTFC2rCye2qBBtLVtnoU844t1X7D+8vpYTSV5uXmhd9GzuPliauW0zQNAaGgof/75JxMnTiRFihQMHDiQJk2a2GSka2+2bt1Kv379OHHihN1urM2bN6ds2bIMHDjQLu3bA7PZzOrVqxkxYgQeHh6MGDGCevXqRfoenX98nnJzyvEy7KVd+mJwNfBl6S8ZX3u8XdpXRI8SPk3YjxyR2W5K70MMwD4sytj8isDAQFasWMH8+fM5efIkrVq1omPHjpQtWzbqG+ajR/D77zBlily0eS12UXbLIPdXrAgDB0Lt2lEu7Jx8cJKfD/zMktNLCA8NB1dZPT3SZl+FRORMkZNvK31Li4ItrK8AYQEmk4m1a9cybtw4nj59+sYTVG/PKO44YjabyZ8/P/Pnz6d8+fI2b3///v20bt2aixcvxuv3ISrMZjMrVqxg5MiReHl5MWLECOrWrfvmOx9mDKPArwW48eKGTUd672NwNbC85XLq5alnNxuKyFHCZ3eCkWXC72lgKzfSOzTyUAKQN/Lt27ezYMEC1q5dS5UqVejQoQMNGzbEPbp8VELA7NnQp49024tNoLSnJ/j6wqJFUY4AFy9eTK8Bveg8qjNu2d3YeXMn119c55n/M1ydXcmYKiNlfcpSOWtlKmSpoJmjgBCCPXv2MH78eA4fPkyvXr3o0aMHqVLZt+BsbPnpp584efIkCxYssGm7QggqV65M165d6dixo03b1hqz2cyyZcsYOXIkyZMnZ+TIkdSuXZtvt37Lr4d+jfOaniWk0qfiau+rVq1HK+KOEj678yWymqr9XPf/wwB8gyxv8C4XLlxg/vz5LFy4kLRp09KxY0fatm1LunTpYm724UNo2RKOHYt7UTYXF5mEcdo06dr3CqPRyKBBg1i5ciWrV6/+wB2/b9++ZM6cmb59+8bNvg04e/YsEydOZM2aNXTs2JE+ffrEu+w6T58+JXfu3Fy5csWma3Br1qxh2LBhHDt2LEFM+1qCyWRi6dKljBw5En02PecrnSfMHLf1Zktxd3anTeE2/NHkD03sKSQqc4tduQHMRRvRAzm6nAQ8AuTN79dff6Vs2bLUqFEDo9HIhg0bOHbsGF9//bVlonfrlkycuH+/bSqRGo2ynS+/fJOm4+nTp3z00UecOnWKw4cPRxqD5uzsHG8SExcqVIh58+Zx6tQpXFxcKFGiBB06dOD06dOO7tobUqdOTaNGjZg3b57N2jQajXz77beMGzcu0YgeyO9W27ZtOXv2LJ51PAkzaiN6AGGmMPzO+vE0+KlmNhVK+OzMNGzjvWk5QsC5c31o1qwZOXPmZM+ePYwcOZJbt24xYcIE61z0HzyQVUgfPJCCZUuCg2HcOO598w2lS5emRIkSbNiwIcrRibOzc7xLM5Y5c2YmTJjA1atXKVSoEHXr1uXjjz9mx44d8SJtVY8ePfj9999tlsZrzpw5ZM6cmbp1Y+9EFZ8JiAjgaOhRze+KOnTMPT5XW6NJHDXVaTfCgLRAgOaWX7xwYcWKX2nRojXJkyePXSNmM1SoAEeP2l703iIY2D9kCDVHj472uCFDhuDh4cGQIUPs1pe4EhYWxsKFC5kwYQLJkiVj4MCBNG3a1GGjIyEEvr6+jB8/ntq1a8eprcDAQPLmzcu6deso+X7phETCjCMz6Lu5b/RxpT8jkyt9w39L6UeBU8BnwAj+S6rkAuQC6hNj3cjMyTJzu8/t2HZdYSVqxGc39gIxu5Jnzy4T9Hp5QYYMctkr8K1ELoGBcl89Kxy/UqTQ8/nnvrEXPYDp0+HMGbuKHshVyZqzZr170ZEQn6Y6o8Ld3Z3PP/+cc+fOMXjwYCZNmkS+fPn4/fffCQnRarr7P3Q6Hd27d7dJkdpJkyZRvXr1RCt6AFuvbbUsmYIADkSzvzuymPLXyFWOHTE3+TDwIS9CX8R8oMImKOGzG0eQgeoxs26dvO+fOAHHj8OPP/63b8UK6QuyZYuccbQME/IxNJbcuQPffmubNT1L8PePvhYN8XOqMyqcnJxo3Lgx+/bt448//mDDhg3kyJGDMWPG8OzZM0370r59e3bs2MHdu3dj3cbDhw+ZMmUKY8aMsWHP4h+H7h2y7MAKyMihmJ5lPIB8wOOYmzS4Gjh2/5hl9hVxRgmf3dgJhFt1RoYMULeuFMDXzJ8vy8AULQoLF1raUjCwxyrb7zB5MkRExP58awkNlRf6/HmUh7i4uMT7EV9kVKpUibVr1/Lvv/9y7do1cufOzTfffMOtW7c0se/l5UXbtm2ZNWtWJHsFct4u+geKUaNG0aFDB3LksE9qvPhAmDGMuy8tfDjIBGRHil90hCAzFGaOuckQYwgnHpywzL4izijhsxuXrD7jzh3YuFEm8gWZ63DHDmjfXm7WhWSdtdo+INPrz5ghg9O1xMlJFnmLgoQ04ouMggULMnfuXE6fPo2bmxslSpTgk08+4eTJk3a33aNHD2bNmkVExBVgMtAUyIJchHJ/9a8HUBj4AviL18kWLl26xNKlSxk8eLDd++lIAsMDraucUB04ROTpdmcAPyKLrvgDpWJuLtwUzvOQqB/8FLZFCZ/dsNwlukkT8PaWMd3p0sHIkfL1P/+UI72CBaFNG5kV7PhxS1uNZSXutWuj3Z0dSMe7v/fZQLVX/xfABGTIvh7ICnyHBe9GcDD88kuUu11cXBK08L3Gx8eH8ePHc+3aNYoWLUq9evX46KOP+Pfff+3kCSooXPgOa9cG4eRUEBiEzO16B+lx/NpmGPJhaSbQDfkpf8mUKb0ZMGBAvM/HGVdMwmRderf0QF4in1j5AvmlHwKURkY0WTCBEmHWcJYliaOEz25Y7sm3ejUEBMjR3YUL8OSJfH3BAjnSA/DxgapV5Yygre2/w9atsjPRYEKOGyKjN/LWuQDpz7oR2IasRxEjDx/C08jjmRKCc4s1JE+enIEDB3L9+nVatWrFl19+SZkyZVi2bJkNBf4uUANoQcmS/jg7R2DZA1EgEITZPJMJEzbTp89LLLpzJ2A8XDwwmq38flVDLqVH9XNxBnyBF7wOrY0SHTo8XWOXWF1TjEY4fFimLWzfHkqVgsKFoXhxqFULRoyA9ev/u4nFU5Tw2Y0UVp9Rtar06uzfH/btg8uXpaNLhgxyO3gQFi+21NEylkVVLajePQCYiPw9v81l4DdgEVAeOYFWCFlq9x/g35ga1utldphISOhTnVHh7u5O586dOXv2LEOHDuWXX34hb968TJ8+PY6eoIuB/MghSeyclJycjOj1AlfXn4EiyE848eHv78+JgydwFlY+LKZGzg4fjGK/GTiO/CHE8HP0cvMiT+o81tnXkvv3YdgwOSVVsyb07StvRkePyqmokydh2zb4/nto1w4yZ4b69eXTfDyMmFPCZzfKxuqsb76RHpyDB8t8zufOSWeXEydkdEFIiFwHjB4noJL1xoWQahsDpZAPuxPfe30bch2/zHuvZwHKAVtiajg4OMq53MQy1RkVTk5ONGrUiL1797JgwQL++ecfsmfPzujRo3kaxSg4aiYCXZAjN1uMkoORa9algRM2aM8xmM1mrly5wsqVKxk+fDhNmjQhR44c+Pj4MGDAAJKHxiL8pyof+rD9jswaOBY4iaxEZoi+GZPZRMmM8TBUJDRUilyOHDBhgnRACwiQN6LIMBrh5UvpK7BxIzRsCIUKyZtXPEIJn92oAHhZfVbatNCqlRS6Xr3+G+1lyCC/e59+asl0pxcfyo8FhIbKBNQWMAqYyrue2k+AjFEcn/HV/miJiJDTnZGQ2KY6o6NixYqsWbOGHTt2cOPGDfLkycPXX3/NjRs3LDh7GjAc26fJE0hPjWpIV8X4TUBAAPv27eP333+nR48eVKhQgeTJk1OjRg3mzZuHyWSiffv2bNq0CX9/fw4ePMjnNT/HWRfDqK8PMij9NcmBocjgdZAB7INfbf9DLpfmjrm/wSHBtP2oLUOGDGH37t1EaOlVHRWHDkG+fHJaMyzM+sT0Qsg4rQsXoEwZ6bwQT37DKnOL3biMLBGkfeCy9NC7ivS7toKAAEidOtpQhuxIZ5ZaQHsgA1AAWIh8sP0RuBnJeVWRjwI/RrLvHb78Uiawfo+5c+eyZ88e5s5Neqmd7t27x+TJk5k9ezYfffQRAwYMoHjx4pEceRj5TtvzO6cDsiHFL5pqHhohhODGjRucOnWKkydPvtnu3btHwYIFKVas2JutaNGipEwZ9ZzjsfvHqDyvsmVB7DbESedE47yN6Z2hN5s2bWLTpk1cu3aN6tWrU7duXerWrat9KMmqVfDJJ3IWxlYYDLI+55o1MjjZgSjhsyslcMzUUFUsShfxPuHhcp0tmtyO2flP+K4g1+77AduRTi35kUkt3h5v3kY+9K7HgjrxAwbA+A+Lc86fP59t27bZvMxOQsLf35+ZM2fyyy+/ULhwYQYOHEiNGjVeeSOGIaOlI3vssDUGoCfSf1c7goODOXPmzDsCd+rUKby8vN4RuGLFipEnTx5cXKwIT3hFoV8Lce7JOTv0Pmo8XT3Z1mEbZTP/tzzy8OFDtmzZwqZNm9i8eTPJkyenTp061K1bl+rVq+PlZf1sksWsWQNt20Y9nRkX9HqZCnHjRlmw2kEo4bMrS5BzHdrl6wwPdweW4ObWJHYNpEghM6lEQXb+Ez6Arsja70WQUtsTuZb3J3JF6AJyFigtUviixWCAn3+Gbt0+2LVw4UI2btzIokWLLL6UxEpYWBiLFy9m/PjxeHp6MnDgQFq0OIqT0zTsW+z4bfTIAsuWFz62FCEEt2/f/mAUd/v2bfLly/fBKC5NmjQ2s73g5AJ6ru9JUIRGWYuAPKnycPGri1GGU5jNZk6dOvVmNHj48GFKlSr1ZjRYrFgxnJxstGp15gyULWvbkd77GAzQsSP89pv9bMSAEj47IkQYYWHp8PB4qZnNR4/0lC6diiFDhtOpUydcrX2qqloVdu2Kcnd23hW+28iYvXJI4TMjxwGzkM70aYC2yDXBGOuje3vD9u2yDNJ7LFmyhNWrV7NkyRLLryWRYzabWb9+PT///AN//30Qg0HLn7IT0ALwi1MrISEhnD179h2RO3XqFG5ubh+M4vLly2f999lKjGYjRacX5cKTC3atvv4ag6uB9e3WUy17NYvPCQwMZMeOHW+E0N/f/81osE6dOpaVG4sMo1EGDl+4YH9PTL0eNm2SU58OQAmfnTh//jxffvkluXPfZPr0uzg7a1HjSw9s5+BBGDx4MDdv3mTUqFG0bt3a8ifCYcPghx8sdnKxKa6ucp0xkvn/ZcuW4efnx/Lly7XvV7znD0ymnjg7a72e7IEMhI85uF0Iwb179z4YxV2/fp08efJ8MIpLnz693XsfFWcfnaX0rNKEGO37fupd9HxS9BNmNpwZp3auX7/+RgS3b99Ozpw534wGK1SogJubW8yNAIweDWPH2ne09zYZM8KVK3IEqDFK+GxMUFAQo0ePZs6cOQwdOpSePXvi4tIVOe0Zy2wqFqFHpoz4+c0r27ZtY/DgwYSEhPD9999Tv379mLNTHDoENWpol6D6bSpXjnK0uWrVKhYsWMCqVas07lRCoChgWRHcxYth0iT5UO/tLeOOBw+WeQu+//7dZw4XF3jxIrrW9Eif/d7vvBoWFsa5c+c+EDmdTvfBKK5AgQKW35g1ZNzecYzaOcpuji7OOmd8kvlwruc5PN1sF7geERHBgQMH3gjhpUuXqFq16hshzJ07ChfToCBIn17b372np/wyRrK0YW+U8NkIIQSrVq2iT58+VK5cmQkTJpAx42vn/iCkT+MFrE1cbRnuQHFkYux3R0tCCNatW8fgwYPx9vbmhx9+oFq1alE3JQTkzw+XrM81Gie8veVduUGDSHevXbuWWbNmsW7dOm37Fe8JR4avxOz+PmmSfKD//XeZDN3NDf75Rz5reHrKh2/LE6FLQkNrsnPngHdE7sqVK+TMmfMDkcuQIYN1acEciBCC3ht7M/fEXJuLn7POmdSG1BzpeoQsybPYtO33efLkyTtOMnq9/o0IVq9enWTJkskDZ8+GPn1iLA9mc3LlkrHDGn8vlPDZgCtXrtCrVy9u3brFr7/+GoWwPEcGlV/FmjyeMeOBzI+yHfCO8iiTyYSfnx/Dhg0jZ86cfP/995QuXTryg+fNk0GEWj79pU0rs0NEUbR1/fr1/Prrr2zYsEG7PiUIjiEzJke/juzvL9PezZsHLVt+uH/EiNgJ38OHOtq0qfqOwBUsWBAPjxhXdOM9Qgi+3fotvx7+1Wbip3fRk9YzLXs+22N30XsfIQRnzpx5Mxo8cOAAJUqUoG7duvSbMQOP29EXws0OPERmYnNFPsr/jkxQ0QmZK8jt1VYSGeebP6ZOeXrKjB3ly8f+wmKBCmCPAyEhIQwfPpxy5cpRo0YNjh8/Hs1oKiXS0b8GYKupDQPQANhNdKIHMgC8Xbt2nD9/nhYtWtC0aVOaNWvG2bORVHFo316mJtIKT0+ZoDqaSuWJPXNL7DlOTGWFAPbvl/HHTZva1nq6dC5s376GX375hc8++wxfX99EIXogC/mOrz2eZS2XkUqfCnfnuMWevV7TO9fznOaiB/J6ihQpQv/+/dmyZQsPHz7ku+++I+j2bZxjEL3XrEPmA7qPzNPd6619A1/tuwv4AJ9b0mBYGGzebM1l2AQlfLFk/fr1FC5cmHPnznH8+HEGDBhgwVqFN9Kpfw6QjNgHAHsghfQvYBlyrcUyXF1d6datG5cvX6ZixYrUqFGDDh06cO3atf8OcnODZcuk55W9cXWFSpVk3FA0JKXMLdbxDEtmEJ4+hTRp5LpdVCxdKqNZXm/Vq8dsXadz48OsrYmLj/N8zNXeV2lTuA0eLh7oXSz/XTjpnPB09SRPqjxsbL+RmQ1n2nRNLy4YDAbq1avHDy1a4Pp6ytNCPJA+vZFFPOqRSelPWNKQ0Qg7d1pl2xYo4bOSmzdv0qRJE7755ht+++03li1bRpYs1jy96YDWyPDvb5ECFv1o7T+8kQECQ5FTpo2ssPsuer2efv36cfnyZXLlykWZMmXo2bMn9+7dkweULCnn/O3tceXpKXOwxTDHn1iTVMcdI1jgdp86tUyYH92zQ6tW0pnl9bZ9uyX2dST2yg0AKTxS8EeTP7jT5w4jq40kc7LMuDq5ktw9OW7O/z3w6tDh7eaNp6snehc9TfM3ZVuHbVz86iJVs1d14BVEw5EjVgerByMDWcpFsi8I+UhuQaY2yduVt7VCKCwiLCxM/PDDDyJ16tRi1KhRIiQkxEYtRwghVgshugshCgsh3IUQbiI83EVERDi9+ruYEOJLIcTfQgijjey+y+PHj0X//v1FqlSpxIABA8STJ0+EMJmEaNNGCINBCOn2YtvN21uI48ct6t+uXbtExYoV7XLtCZtJQgg3IQTRbi9eIAwGxLJlke8fPhzRvn30bUS+6YUQd7W51HjG85DnYtu1beKnfT+JZlObiXxf5hOjdowSf53+S1x6ckmYzCZHd9EyunWz6PeaDYQniOQgXEBkBHHq1b6OINxf7dOByA7ipKX3AZ1OCLNZ00u2PqdPEmTr1q189dVX5MmTh8OHD9s4b54L0PjVBnK9Jog5cyZz/fo9xo37FS0G5mnSpGHChAl88803jBkzhnz58tG7d2/6TJ+Ot7s7LF9uO2cXFxfw8oJ//5X+9BagRnxRkQM58RS9t3Dy5DBqlEyF6uICderIWeatW+XILvYDexOyaG3SI4VHCmrkqEGNHDXIdDMTLo9dGFp1qKO7ZT1WJJ9ejUxeYQLWIJMjvp7u7A+MAW4BHwEXkYE2FmEyRT8Pb2PUVGc03L17lzZt2tC1a1fGjx/PunXrNEgW64xc/0vLixdmtP6IfHx8mD59OgcPHuTy5cvkzpePSUWKED5pkhSruH45PT3lmt6ZM1CihMWnKeeWyHn8OBtGCwOt+/WTIQ1jxkgn2ixZZD7wJk3kfj8/+RG/vT2KoYBqYGBGgoPtEaKTsBBCJJhQjQ+IhTOSM9Ds1b/vF6HPiixU/TVWpEuPxrHNHsT/EZ/JJKNtjx6F69dlVgE3N7lSX6KE3LwtXSOzjIiICKZOncoPP/xA9+7dmTt3LgaNswvo9fo4FiKNG7ly5eLPP//kzJkzDB06lJ+PHGHs0KG03boVp9275ediTekULy/55f7lF5mnz8qbhHJukTx58oQdO3awfft2tm/fzv3797h7V1j8PNK+vdzep0IFGdJgDWYzbNsWSvv26ShRogTVq1enevXqlC9fPtF4dsaE2Qw3b8KNG8l58SI7ly5B9uzyFpVgyJJFPtBa8fsSwFpkkFYB4O/39tdG1oaZiRTAaEmWTPM4vvi5xmc2C7FtmxB16wrh5iaEl5fc3p4XdncXIlkyIVxdhciVS4hp04Tw94+z6V27donChQuL2rVri4sXL9rgYmKHn5+faNGihcPsv8+BAwdErVq1RO7cucXaSZOEuVcvITw9I/9sQH5uyZPLz6d4cSGWLBEiLMx6w4GBQuzZI66NHy++y5JFCD8/IXbutMlnnRB49uyZWL16tfj6669F0aJFRbJkyUS9evXE+PHjxeHDh4XRaBRCtBNCOAnr1+fiunkJITaJwMBAsWnTJjFo0CBRtmxZ4enpKapVqyZGjBghdu7cKUJDQ+3/RmnIqVNCfP21EMWKyduQwSCEXh8mXF2DhJeX/MrnySNEp05CbN+u+fKV9WzcKO+lFqzxebxa5/MCUQjEwrfW+Aa/d/wSEJlAhMa0xlepkuaXHP+Eb80aIXx8Ir+ZRrd5egqh1wvRu7cQQUFWm33w4IHo0KGDyJw5s1i6dKkwO/jbunbtWlG/fn2H9iEytm3bJsqWLSuKFi0q1q5aJcxnzwrx559C9OolROvWQjRrJsSnnwoxdqwQW7cK8eyZ9UbOnRPiiy+EyJJFCBcXIZIlE0ZPTxHo5CQdYl4/8GTMKO8uJ07Y/kIdhL+/v/j7779Fv379hK+vr/Dy8hK1a9cWP/zwg9i/f78IDw+P5KyjQgiD0F74MgohPnTgePnypdiwYYMYMGCAKFWqlPDy8hI1a9YUY8aMEXv37hVhsXkAcjBmsxDLl8tnOL1eCGdny3w2vLzk13jq1Ng999kbs9kszu7YISIsuSB7bM7OQgwerPl1xx/he/pU3jTj6kGo1wuRKZMQe/ZYZNZoNIpp06aJNGnSiP79+4uXL1/a+UItY8uWLaJGjRqO7kakmM1msWbNGlG4cGFRrlw58e+//9qm4R07hChVSn6GLi6W/3AMBiGKFBFiwwbb9ENDAgICxD///CO+/fZbUaZMGeHp6SmqV68uRo0aJXbv3m2FSBQU2oqeXggxwaKePX/+XKxdu1b07dtXlChRQnh7e4s6deqIH3/8URw4cEBERERYeI2O4e5dIapXl8/Wsb0tGQxC5M5tsROzXQkODhbr168XPXv2FFmzZhXZs2cXT729HSN8Xl5yWKwx8UP4zp4VIk0aOT1mqzdUrxfip5+iNXvgwAHh6+srqlSpIs6cOaPRxVrGnj17RPny5R3djWgxGo1i0aJFIleuXKJWrVri4MGDsWsoIECILl3i/tBjMMhR5/PnNr1OWxIcHCy2bt0qBg8eLCpUqCA8PT1F5cqVxbBhw8T27dvjECazU0gx0kr4MgohAmPV06dPn4pVq1aJ3r17v5m+/fjjj9+bvo0frFkj782WPodFt+l08rb0/ffaT3/euXNHzJgxQzRs2FB4e3uLypUri3HjxomzZ8/K2a0pU+Km7LHdMmd2yFyw44XvzBm5FqTT2f5NNRiE+OGHD0w+efJEdOvWTWTMmFEsWLDA4dOakXH06FFRvHhxR3fDIsLDw8WMGTOEj4+PaNKkiTh9+rTlJ1+8KKcsPTxs85m7uwuROnW8mf4MDQ0VO3bsEMOHDxdVqlQRnp6eonz58uJ///uf2LJliwiKxbR81HQT2oifXgixy2a9fvz4sVi+fLn48ssvRcGCBUWKFClEw4YNxU8//SSOHTsmTCbHxMPNny+Fyh63pd697Xu/N5lM4uDBg2Lo0KGiRIkSImXKlKJt27Zi0aJF4unTpx+e8OKFfS42pjdi8mT7vQnR4Fjhe/hQ3qTsIXpvv7kLFggh5Jdh9uzZIn369KJXr17ieTweGZw7d07ky5fP0d2wiuDgYDFx4kSRLl068emnn4qrV69Gf8LZs0KkSGGfz9/LS4jDh7W58LcICwsTe/bsEaNHjxY1atQQXl5eonTp0mLgwIFi48aNIiAgwI7WA4UQWYQQzsJ+omcQQnxlx2uQ6+1+fn6ie/fuIl++fCJVqlSiSZMmYvLkyeLUqVOaCOHq1fbVAU9PIYYOtW2fX758KVasWCE+++wzkT59elGwYEExcOBAsXPnTsumk/v3t1+yisi2VKkc5qTmOOEzm4WoV8+205vR3ATPbNokypcvL8qWLSuOHTvmsMu2lOvXr4usWbM6uhuxwt/fX4wYMUKkTp1a9OjRQ9y9G0lmjzt35Bffng89yZIJcemSXa81IiJCHDhwQPz444+iTp06wtvbW5QoUUL07dtXrFu3Trx48cKu9j/kphAijbCP+BmEEI2EvbIHRcXdu3fFokWLRNeuXUXu3LlFmjRpRPPmzcW0adP+m6qzIXfuWO9bF5tNr5cOynHhypUrYvLkyaJ27drCy8tL1KlTR0yZMiXmh87ICA0VIls2bUTPYHDomrzjhM/PT7M55QgnJ7HX1VXMmjnTYdMm1vLgwQORNm1aR3cjTkSaBk0I+dBTpYptFk6i25ycpM+5DdeMjEajOHLkiJgwYYL4+OOPRbJkyUSRIkVE7969xapVqyKfRtKc60KITEIID2E70fMUQrQWMsWeY7l165ZYsGCB+Oyzz0SOHDlEunTpRKtWrcT06dPFhQsX4iSEZrMQVatKp2Et7v8ZM8qIHUuJiIgQO3bsEAMGDBAFChQQ6dOnF507dxYrV660jWPeoUP2n/L08BCibdu49zUOOEb4IiLk074W36xXm8nTU4hNmxxyubHB399feHl5ObobNuHOnTuie/fuInXq1GLkyJEieNo07RbSPT2FGD8+1n03mUzixIkT4ueffxaNGjUSKVKkEAUKFBA9e/YUy5YtE48ePbLhO2VLXgghPhFmc9zCHEwmZyFFb5YQIv6thQshZ0fmzZsnOnToILJkySIyZswo2rVrJ2bNmiUuX75slRAuXaqtj4eHhxD9+kXfpydPnoiFCxeKNm3aiJQpUwpfX18xbNgwcejQIfs8yM+bZz/xc3eXntvBwbbvtxU4RvhWrZLxWBoKnwAhatVyyOXGhvDwcOHs7OzobtiUK1euiM9btxYBWn/uer0QFgqU2WwWZ86cEVOnThXNmjUTqVOnFnny5BHdunUTf/31l7h//76d3yXbsnv3EHH/vqswm72EdaLnJoxGV7F/v7cwm286pvOxwGw2iytXrojZs2eL9u3bi0yZMonMmTOLTz/9VMydO1dcv3492vOLFtX+tuTl9a4OvP4Ojh07VlSqVEl4e3uLRo0aiZkzZ4o7d+7Y9w18zezZtl/v0+uFKFtWiHgQMuYY4StXTvtvF8jHq5sJ50fs7Owc72OcrOb334VRywX01z+477+PtDtms1lcuHBBTJ8+XbRq1UqkS5dO5MiRQ3Tu3Fn8+eef4vbt2xq/QbYjIiJC5MuXT/zzz0YhxFYhRB0hhKsQIpn4MOBd99br3kKIb4TJdFkUL15crFixwiH9twVms1lcvHhR/P7776JNmzYiffr0Ilu2bKJTp05i/vz54tatW2+OPXFCW9+Ot4Vv1qww8c8//4ivvvpKZM+eXWTNmlV8+eWXYuPGjTasBGMlmzdL50NbeFzr9UL07CmEo67lPXRCCKFpjrSAAFkczII8j9n5r9S9J1APmAZ4AX8AnwFLkNXtLEKvh4kToWdPq7vtCLy9vbl37x7eNs5F6jCEgNy54e2it1qRNi3cv49wcuLatWtvcl1u374dZ2fnN3kmq1evTvbs2bXvnx2YPXs2ixcvZtu2bW8lUA4DzgBHgLNAADJlbxrAFyiJrPggj9+wYQMDBgzg1KlTOGucSNgeCCG4cOHCm89+x44dJE+enGrVqnHr1gD+/TcvJlNMeSOzE/mdqQHwCdDF6n45OZ2gfPmvaNCgAQ0aNKBQoULxI+m1v78s6bFypbxnW5sv19tb5uJcskQmp48vaC61O3dalBdOIHPDbXn1/zvI3HDfvvq7GohUID629smjTRvNLzm2pE2bVjx8+NDR3bAd585Z/EhdFUQK3s3zVxXErPeO2w7Cx4L2wjw8xMh69USWLFlEhgwZRNu2bcXMmTOtXgNKKAQHB4vMmTOLAwcOxKkds9ksKlSoIP78808b9Sx+YTKZxOnTp8WUKVNEsmQ3LLyNZBOw5dX/7wgoJOBbAVUFzIrVgMjNzWxLHyzb8zqNoMHwX8rA6Iawer1cy1u2TIhI0+w5Fu2rMxw9CmFhVp/mg3yuOgPcBHYCy5CjvQdABksbOnjQatuOwtEVGmzOkSPgFHOZpRvAbiA5MgN8SxuYFuHhVPfyotXmzeTLly9+PE3bkalTp1KmTBnKli0bp3Z0Oh3ff/89n3/+Oa1bt8bV1dVGPYwfODk5UbhwYQoUKMyAAbFp4e07U+xxc9Nx6RIUKBCnZuxHgQLw++/w00+wZ4/8Le/YAVevyvu5iwukSCHLfLzecuVydK+jRHvhO306VsJ3G9iArAG1ACgFNEeWxFgE9LO0oTt3rLbtKBKd8O3fD4GBMR62ACgHlAXmYxvhczebqWw2Q/78NmgtfvP8+XMmTJjA7t27bdJetWrVyJUrF3PnzuWLL76wSZvxjWvX5L3b+lvT23em2L/fOh2cOhWPhe81np5Qt67cBg92dG9ijfaFaK2s4t0ESAFUQlb7/R/yxtju1f52r/62mARU0y3RCd+xYxYdtgBo/2rbhFxNsQmnT9uqpXjN+PHjady4MfltKPJjxoxh9OjRiev7+BYBAdbWQm3Ch3em2GMyyT4otEF74bOygvdq4AVyevM34BhwHWjzan874DRwwtIGLZhqiy8kOuGzYLS3B/lZt0K6WeQCFtvKfnCwrVqKt9y7d4+ZM2cywtqqsjFQpkwZSpcuzfTp023abnzBbLb2jNW8e2fSO6APitiivQqkSxenarvzAQEUR67rlX3rdYvQuJJ6XPDw8EhcwmfB5z4fqIP0MQT5YPP6s3UB3vcFjgAsXnVK5Ot6AKNGjaJz585kzpzZ5m2PHj2acePGEZAIhyYGg/TMcBROTgnq1pTg0X6Nr1Qp8PKK1bg+FFiKLGdf/63XVwCjgAlYcEHxfhL9PxLdiC+GsIwQ5Odr4j9npTDkc/VJICvS8eVtrgPZLLXv6WnpkQmSS5cusWLFCi5evGiX9gsXLkytWrX45ZdfGDp0qF1sOIqcOcE2PzUj8k71GmcseTTT6ZLE8nO8QfsRX6lSsX60Wo2cUOiAvDG+3jojv27/xHC+cHKCqlVjZVsL7t+H5cuhf38oWxZ27pxDp041yJ0batSAkSNhwwZ4+dLRPY0lZcpEO+pajbxNnENOXZ8AzgOVket+rYF5wCHkqP8S8DP/TXvHiK9vbHqdYBg6dCh9+/YlVapUdrMxcuRIJk+ezLNnz+xmwxF4eEDWrLZoqQfyLvV6+8yis0JDoUgRW9hXWITmARQmk2MKHoJ4qdOJP5o1E4cPH443sVsmk0yQUKuWTJDg7S1zK0d2CS4uMoTGw0OIDh3iTck5izCbzeLepEkizN09ys+nLoi+kbzuByI9iAgQc0AUBOENIheIH0GYLPn8DQYhpk939NtgN44cOSIyZcokAq3JeBxLunbtKgYNGmR3O1rTrp1DbksChMiVy9FXn7TQXviEEOKrr7RLf/7WFuHlJQYPHChy584tsmfPLvr37y8OHjzoMBE8c0aIggVjVwLF2Vney+vXtzgNpeY8f/5crFixQnTr1k1ky5ZNlE+fXoQ5OzvmzuLlJcSRI45+S+xGrVq1xHSNhP3WrVsiZcqUCS5vaUxs2qRNOaL3t2gy6inshPYpywCuXJHj+tDQmI+1Fe7u0Lcv/PADQghOnTrF8uXLWbZsGSEhITRv3pyWLVtStmxZnOzs+Wk2w/ffw48/yrcgLp+Am5ucppk7F5o3t10fY4PJZOLw4cNs3ryZTZs2cerUKSpWrEjdunWpU6cOBQsWRFesmGPCCrJkgZs3E6WDy9atW+nRowfnzp3TLMC8T58+mEwmpkyZook9LTCbIXNmueSgJR4ecOuWzKqn0AiHSW7t2vavx/b2ZjDICpPvYTabxenTp8Xw4cNFwYIFRebMmcXXX38tdu/ebZeSH+HhQjRtavtkuAaDY54ab926JWbNmiVatmwpUqVKJQoXLiz69esnNm/eLIIjKz2ycKH2j9WenkJMmaL9m6MBZrNZlCpVSixZskRTuw8fPhSpUqUSN27c0NSuvZk4UQiDwazZV9PFRYhmzRx91UkPxwnf7dva1mSbPNmibp09e1aMHDlSFClSRGTMmFF89dVXYufOncJog0R6RqMQjRvbr9SVwSDE2LFx7ma0BAUFiQ0bNoivv/5aFChQQKROnVq0adNGzJs3L/JK6+8TGipEypSaCp9RrxfC39++b4yDWLp0qfD19XVIgeX//e9/onPnzprbtSdXrtwWev0DASbNbk0JuABIgsVxwieErPlkb/FzdhaidGnpRWIlFy5cEGPGjBHFihUT6dOnFz169BD//vtvrEsFDRli/7InBoMQ69fHqnuRYjabxcmTJ8X48eNFzZo1hZeXl6hSpYoYM2aMOHz4cOxuuKtXa1b/JdzdXfT29hY9evQQz549s90bEw8IDw8XefLkEZscVGD52bNnIk2aNOLixYsOsW9LTCaT+P3330WaNGlE164zhV5v/1Gfp6cQs2Y5+sqTJo4VPrNZiE8+sd9NUKcTIl06mzxSXbp0Sfz444/C19dXpEuXTnzxxRdiy5YtFovg8eP2G+m9v6VKJURc7vEPHz4UixYtEh06dBAZMmQQuXLlEj179hSrV68W/rYaOTVpIoSbm33fCBcXIapWFc+ePhU9e/YU6dOnF3PnznXI6MgezJgxQ9SoUcOhHsrff/+9aJOAKp5ExqVLl0TVqlVF2bJlxZkzZ4QQQgwbZt9nM71eiI8+krdAhfY4VviEkPN/LVrY/lvm7CxE2rRCXL5s8y5fvXpVjBs3TpQuXVqkSZNGdOnSRWzatEmER1F+IyJCiNy5pQ5rIXzu7tZVXwoLCxPbt28XgwYNEr6+viJ58uSicePG4rfffhNXrlyx0bv2Hk+fCpE1q/yc7PEm6HTy839r+vXIkSOiTJkyomLFiuJEQooFiYSgoCDh4+MjDh065NB+BAQEiPTp0yfI9zMiIkKMGzdOpE6dWvz888/vLGeYzUJ062Yf8dPrhShfPt7UZE2SOF74hJDTkP37225I5OkpRNGiQrxVXdleXL9+XUycOFGULVtWpE6dWnTu3Fls2LBBhIWFvTlm5Urt/Tk8PISIyu/AbDaLS5cuialTp4oGDRqIZMmSiVKlSonBgweLXbt2RSngNuf2bSEyZbK9k5OTk6wcfenSByZNJpOYMWOGSJcunfj666/FixcvtLlWGzN27FjRvHlzR3dDCCHEL7/8Iho2bOjobljF8ePHha+vr6hVq5a4du1apMeYzUIMGGDbmRpPTyHq1lWi52jih/C95sABOQqI7bqfq6v8lo4dKxxR1fHmzZti0qRJokKFCiJVqlSiY8eOYt26daJMGW0Wyt/e3Nzkj/Y1L168ECtXrhRffPGFyJ49u8iUKZP47LPPxF9//SUeP36s+Xv1hvv3hShc2HZrvQaDEDlzRq36r3j8+LH4/PPPRcaMGcXChQvjTUIDS3i9tnbhwgVHd0UIIURISIjIkiWL2L9/v6O7EiMhISHiu+++E2nTphVz58616HPfulVOHnh4xP5r6eIiv+IzZ6rpzfhA/BI+IeSj0G+/CZEjh/ymWDI/6OUlb3g9eghx9aqjr0AIIcTt27fF5MmTRcmSbQQEW/DjyCb+q+r8etsuQCfAU4CXgLwC5lqhARFi+PAxomLFisLLy0vUqVNH/PTTT+L06dPx60YfESHE6NHyoSWqtDUxbTqdPH/gQCHeGm3HxP79+0WJEiVEtWrVxNmzZ+14kbbj22+/FV27dnV0N95h1qxZokaNGo7uRrTs2rVL5M2bVzRv3tzq4PuXL2XeDYPBumc0vV4KZpMmmkxAKSwk/gnfa8xmIXbvlsOWMmXkt83VVX6L3NzkI1Tu3NI5Zv58ITRI1RQbZs4UQq+3ZMQXlfD5vPq/WcB6Ac4CLlj0o3NyChCffjpBbNq0KfKYuvjG2bNCNG8uP2NL55c8POSiZv36Qhw7FiuzRqNRTJ06VaRJk0YMGDBABAQE2PjCbMedO3dEqlSpxJ1IYlIdSXh4uMidO7fYunWro7vyAf7+/qJnz54iU6ZMYsWKFXFqKzBQiBkzhChSRN6OvL3lZjDIr6yXl0wr6OIin91HjxbiwQMbXYjCZjgmc0tsEELWcwsJAVdXWeFBoywVcaFjR1hgUaXc7MBsoNZbr+0APgHerhqfDvgVS+qSe3rClCnQubOFnY0vPH4Mc+bA6tVw5gyYzQhXV/xfviRF8uQQESG/DwULQsOG0K0bZMwYZ7MPHz5kwIAB7Nixg0mTJtG8eXN08SzTS7du3UiZMiXjxo1zdFc+YPHixUyZMoX9+/fHm/dt/fr19OjRgzp16jBhwgRSpkxps7aNRjh/XlZODwiQmV88PWWVhaJFQR/3En0Ke+Fo5U3s5M1r6bRITCM+k4A1r6Y+j1k81ZLg44vNZiFu3BBBW7eKuu7uQuzdK8SVK3ZdKNm5c6coXLiwqFOnTryKUbtw4YJIkyZNvI1HNJlMokiRImLt2rWO7op49OiRaNeunciZM2e8HIUqHIv29fiSGI8fx7WFe0AKZLU6IzAJKGHx2bduxdW+g9HpIFs2TKlSscfFBSpUsLvJKlWqcOzYMaZOnUqFChXo3r07//vf/zDYsFKoySRHC0ePwqFD8OCBHEHo9VC4sKzeVbLku/kbhwwZQr9+/Ww6arElTk5OjB49miFDhlC/fv03OW/vB9zn6P2jHL57mPNPzhMSEYKLswuZvDJRNnNZSmYsSf40+XF2co5zH4QQ/PXXX/Tt25f27dtz6tQpPBN5HUaF9SScqc4ESrJkltbczU70U51hwCDgKrDWYvuVK8OuXRYfHm95+fIlPj4+mlf/vnv3Lv369ePgwYNMnjyZRo0axam9y5fl9PO8ef/lyw4MfPcYV1dZjTskBPLkgW+/hRw5jtC6dWMuX75sUwG2NUIIypUrR4+ve2DMb2Tc3nHc9r+Nu4s7QeFBmITpneO93Lze/L+Lbxd6l+lNjpQ5YmX79u3b9OjRg5s3bzJnzhzKlCkTp2tRJF60L0SbxLDdMqQ7MA44jSzZahkeHray71iEEHavmhEZPj4+LFmyhNmzZzNw4EAaNmzItWvXrG7n3j2oW1eu/cyYAUFBUvDeFz2QS5j+/hAeDmfPQs+eUK1aQapWXYJeH39FD8AszBTvUZzO5zrT558+XHl2hTBTGC/DXn4gegCB4YFvtt8O/0bB3wrS6K9GPAx8aLlNs5np06fj6+tL2bJlOXr0qBI9RbQo4bMz6dJZc3QEEPrWZnxvvxvQDxhlcYvZs1tjP/5iNpsd6jBRs2bNN2WWypQpw6hRowi1oKyWEDB/PuTLB//+K8tQRURYZzswEEwmA2vXVqJCBVldKT5y+ellSs0sxaJ7ixCugsCISFQ9GsJN4YQaQ9l0ZRN5p+XF74xfjOdcunSJatWq8eeff7Jz506GDh2Km5tbbC9BkURQwmdnype35uiPAf1b24hIjukM3ALWxdiap6cmS2KaIIRwuKegm5sbgwYN4tixY5w4cYIiRYrwzz//RHm82QxdusCXX0rxMr7/HGMlQUE6Dh+WpSwPHIhbW7Zmx40dlJhRglOPThEUERSntsLN4bwMe0nntZ3pvbE3ka3GREREMHbsWCpUqECLFi3YvXs3BQsWjJNdRdJBCZ+dqVhRClDM3ADEe9se3g1lADAAT4CGMbbo5CQdJBID8UH4XpM1a1ZWrlzJlClT+Oqrr2jevDm33vMiEkKGsixZIqc1bYXJJNeMa9WCgwdt125c2HFjB/UX1ycoIgizMNus3eCIYOYcn0OP9T3eEb9jx45RpkwZtm/fzpEjR+jduzfOznF3jFEkHZTw2ZkaNeTNyhE4O0OBAo6xbWvik/C9pl69epw5c4ZixYrh6+vL2LFjCQ8PB2DkSFi5EoKD7WM7KAjq1IE77z8Xaczlp5dpuLghwRH2udDgiGAWnlrIT/t/IiQkhEGDBlGvXj369OnDP//8Q/bEMpev0BQlfHYmRw7HjLrc3Mz07AkuiSRgxVHOLTHh4eHBsGHDOHToEHv27KFYsWLMmnWI8ePtJ3qvCQ6Gdu3k6NIRmIWZ1stbE2y074UGRQQxZNsQClQqwPXr1zl16hQdOnSIdw9CioRD/LuTJEIGDZKJZrQkPDyca9f6x8oDMT7iaOeWmMiZMyfr1q1jzJhx9OyZlpAQ2035RYXRCMeOySQ3juCXA79w6eklm05vRkWYMQxaweK/FpM+fXq721MkbpTwaUC9epA1639xW/bGwwPattWRJ4+BMmXK8Nlnn3HlyhVtjNuJ+DjV+T46nY6QkEa4u2dHq59WUBAMHGi9p2hcCY4IZtj2YXF2ZLEYJ3hqfsrai5bHsCoUUaGETwOcnWHZMu1i6pIlgxkz3Bk1ahRXrlwhe/bslC9fng4dOnDp0iVtOmFjEoLwAYwbJ70vtcRohLUa64HfGT/NP4/A8EDG7xuvqU1F4kQJn0YULAhDhsiMHPbEYIDFi8HbW/6dIkUKhg8fzpUrV8ibNy8VK1akffv2nD9/3r4dsTEJQfhOnABHzCwHBMDYsdraHLd3HIHh1sXp2YKTD05y6WnCfHhTxB+U8GnId99B48b2Ez+DQY44atb8cF/y5MkZMmQIV69epXDhwlStWpW2bdty9uxZ+3TGxsRX55a3Wb9eZluxnOzA1vde2wFkttr2iRO2DZuIjsdBj7n+4nrMB/4MjAG+ByYAq5CZ9wCuAHOBH4DxwDzgQsxNCgSbrmyKRa8Viv+I33eSRIZOB3/+Cc2a2V78DAb51P/VV9EflyxZMr777juuXr1KiRIlqFmzJq1ateL06dO27ZCNie/OLQA7dsQ9SD22GAxS/LTg6P2jeLhYOG/fFhgMfIHMt74LOAssBYoBfYH+QHXAgoFcqDGUXTcTQfJZhUNRwqcxzs6yPt8PP8ibVVwHMe7ukCoVrFgBvXpZfp63tzcDBw7k6tWrlClThtq1a9O8eXNOnjwZtw7ZiYQy1ekowsNlpQctOHz3sPVxe8mAPMAjYBNQFSgJeCDvQtkBC/N/H7wbTyL3FQkWJXwOQKeDr7+WBSx9fWVmF2vv6a6u0lmmaVO4ehU++ih2ffH09KR/fxn2UKlSJerVq0eTJk04duxY7Bq0E/Fd+ISAp08dZz80FLTyW7r49CJGs5VDW3/gMuAKvATikF3sUdCj2J+sUACJJLw5YZIrl6zFduAATJwo14jc3WVgcmRTZu7ucjOZ4LPPpHjmzm2bvhgMBvr06UP37t2ZNWsWDRs2xNfXl+HDh1OqVCnbGIkD8V34wsPlw4sji3z9+edytm4dYtU5salKdq/yPchi4cFLkI/XHsgRX1HgHBCHuNYIs8axG4pEhxI+B6PTyUTWK1bAs2dSCA8fljX0Hj6U8VlubjIDTNWqMgtM6dKyYKk90Ov19O7dm27dujFnzhyaNm1K0aJFGTZsGGXLlrWPUQuI784tLi4yKbUj+fjjmgwfXtjq86x9oOi7ry8bbm2w7OA2QK63/n5dmDkQiGU9XWedysupiBtK+OIRqVLJKcvYTlvaEg8PD7788ku6dOnC3LlzadmyJQULFmTYsGFU0KDkg3+oP0fuHeHIvSPsubWH289uc6/BPSrNrUSBNAWokKUCpTKVomDagjap3B1XnJ3lw0hIiOPs58+fkvz57V+dPf+N/Gy8tRFBLIa3aZDrfeeAirGz7+3uHbsTFYpXKOFTRIu7uzs9evSgc+fOzJ8/n3bt2pEnTx6GDx9OpUqVbGpLCMGBOweYuG8i6y+vx8PFgxBjCOGmVzECaWDv7b3svb2XJWeXAKB30fNNuW/o6tuVtJ5pbdofaylQQKYQs47XNRhfEzu3UE9P0GpGurRPabzcvAgID7D+ZB1QF1iLLDRSAFlm8jZwEoscXIqlL2a9XYXiLeLv3JEiXuHu7k63bt24dOkSbdq0oUOHDtSoUYOdO3fapP2LTy7iO9OX2n/WZtWFVYSZwvAP8/9P9N7jddXux8GPGbNrDFl/ycp3W7+L8ngtqFIFdDprR0GW1GCMmbAw7ZKhl8xYMtJq6hZTCGgBHAd+AiYC/wL5Yz7VRedC1WxVY29boQB0Ijar24okT0REBIsWLWLMmDH4+PgwfPhwqlevbvV6kclsYuL+iYzaMYpQU2icEh4bXA1k8MrA8pbLKZGxRKzbsQYhBKdOnWLlypXMn/+MW7d+QAjtp+IyZID797WxZRZmUo9LzYuwF9oYfAsvNy/WtllL9RzVNbetSDyoEZ8iVri6utKpUycuXLjA559/Tvfu3alSpQpbt2612FMw3BROM79mjNo5imBjcJyz/AdHBHPt+TUqzavE35f+jlNb0WE2m9m/fz8DBgwgd+7cNGnShMDAQObPb0OKFBqX4UCuLX7zjXb2nHROdC/VHXdnd+2MvsLbzZuq2dWITxE31IhPYRNMJhNLlixh9OjRpEqViuHDh1OnTp0oR4BGs5HGSxqz/fp2Qoy29wjRu+hZ3mo5H+f52CbtRUREsGvXLlauXMmqVatIlSoVzZo1o1mzZhQrVuzNdQ4bBhMmyLg6rfDwgNu3IU0a7WzeeXmH3FNyE2YKi/lgG2FwMTC6xmj6lu+rmU1F4kQJn8KmmEwmli1bxujRo/H29mbYsGHUq1fvAwH85p9vmHV0ll2LmBpcDRzpeoQCaWNXhj4kJIQtW7awcuVK/v77b3LmzEmzZs1o2rQp+fLli/Schw9lbGWgRvmbPTxkMVpH1ORrvaw1qy+u1mxdNbl7cm58c4MUHik0sadIvCjhU9gFs9nM8uXLGT169Jsq5Q0aNECn07H/9n5qLqhpl5He2+jQUShdIU58ccLikIeXL1+yYcMGVq5cyaZNm/D19aVp06Y0adKErFmzWtTG3LnQu7c2SaPTppWZe7wd4OH/LOQZuabk4kXoC7vb8nT1ZEHTBTQr0MzuthSJHyV8CrtiNptZtWoVo0aNwtnZmUFDBtHvZj/uvLyjiX1PV08GVx7Md5W/i/KYJ0+esHbtWlauXMmuXbuoXLkyzZo1o1GjRqRNa32IhBBQvTrs22ffArEGA6xZA7Vq2c9GTIxdNZbvjn4nU5HZCXdnd+rkqsPatqoIrcI2KOFTaILZbGbt2rV8/cfX3C5yG+Gi3dfO09WTRwMeYXD9ryTGnTt3WLVqFStXruTYsWPUqVOHZs2a8fHHH5M8efI423zyRMbV3b1rn4oNnp7wv//JzVHMmTOH7777jupjqrP+yXq7VGN3dXIlV6pcHPj8AMk94v65KBSghE+hIUII8k3Lx+VnlzW16+XqxZR6U6joWfGN2F25coWGDRvStGlT6tSpg94OOeDu3YMKFeS/thz5GQzQvz+MHGm7Nq3BaDTSr18//vnnH9auXUvevHkZsGUA049Mt75qQzS4O7uTI2UOdn+2mzQGDT13FIkeJXwKzTh89zDV51ePfmTwMxAA9AM833r9d+AB8DWyVutpwPnVlgmoB0QzK+n20o1Ui1PRtGlTmjVrRtWqVXF1teP83CuePoW2beW0Z1zX/FxcZJLyqVNlknJH8OzZM1q3bo2zszNLliwhRYoUb/ZNPzKd/pv7E2YMi1uAO9IxqU6uOsxvMp9k7sni2GuF4l1UHJ9CMzZd3WSZ+3tK4Mxbfz9EZvZ6m4rIAqd9kQK5OvomzcnNnLlyht9++41atWppInoAqVPDpk0wY4Z0QIntwNLLC8qVg/PnHSd6586do0yZMhQrVoz169e/I3oAPUr14EyPM/hm9MXLLXbxjAZXAyncU7Co2SJWtV6lRE9hF5TwKTRj542dltVxK4rM2/iaE8hq3ZHhBhRBFjiNBoObgRMPT8Rs2w7odNC+PVy/DiNGQPr0UgRdYsiU6+5uwsNDOq+sXCkrdmSxtByQjVm3bh1Vq1Zl6NChTJw4EWfnyL1kc6TMwYEuB1jaYinVs1fHw9njnbXVyHB1csXLzYvMyTLzY80fufHNDZrkb2KHq1AoJCpJtUIzjj84btmBmYFTyBI2qZGjv8+R+RzfJ+zVsRmjbzIkIoQj945QM2dNi/tra1KnhoED5frcjh2wezfs3CkLEgcGyjqLrq7g4wNubkfJmfM+v/3WwGFiB3Jddty4cUydOpV169ZRrly5GM9x0jlRL0896uWpx40XN9h0ZRN7bu1h/5393A+8T4QpAmcnZ5K5J6N4+uJUzV6VylkrUylrpXhdc1GReFDCp9CM56HPLT/49agvG3Lt7v04tX3AIeQ32AdoEn1zEeYIrj6/arl9O+LkBDVqyC0q1q27x7Rp08iSpYF2HXuP4OBgunTpwuXLlzl06BA+Pj5Wt5E9RXa+KPUFX5T6wg49VChihxI+hSaYzCbrcnEWA+YBz4l8mrMCYOXgzd4B87akQoUKfPLJJxiNRlximhO1A3fu3KFJkybky5ePXbt22cXrVaFwFGqNT6EJTjondFgxjZXi1XYZWbPNBng4e9imIQ1InTo1Pj4+nD59WnPb+/fvp2zZsrRs2ZKFCxcq0VMkOpTwKTRBp9NZ76HXGOiIdGCJIy46FzInyxz3hjSkUqVK7NmzR1Obf/zxB40bN2bGjBl8++23as1NkShRwqfQjCLpilh3Qirk+p0NMLgZKO1T2jaNaYSWwmc0Gunbty/ff/89O3fupEEDx60tKhT2RgmfQjOqZq+Ksy6GZNF9gFyRvO6MLE6eEmiK1et7YcYwSmbUqES5jXgtfPbOMfH8+XPq16/P6dOnOXjwIAUK2GhuWaGIpyjhU2hGzRw10bs6Zr3IHGhm4YyF3L592yH2Y0OOHDkQQnDz5k272Th//jxly5alYMGCbNy4kVSpUtnNlkIRX1BenQrNqJq9KsnckxEYrlGxulcYXAx8WuBTzu8+T/HixcmfPz+tW7emZcuWZMwYQwCgA9HpdFSqUIGTy5eT3ccHbt6EsDAZ7Jc6Nfj6QpEisihfLNiwYQOdOnVi7NixdO7c2ca9VyjiLypXp0JTJu2fxNDtQ22azDgmPFw8uN/vPik8UhAeHs7WrVvx8/Nj7dq1FCtWjDZt2tC8efNYlSCyC0LINC0TJ2LctAmTELjr9RASIks9ODlJsXNxgeBgyJ8f+vWD1q0tyokmhGDChAn88ssvLF++nAoVKmhwUQpF/EEJn0JT/EP9yTE5h3XB7HFA76Knq29XJteb/MG+0NBQ/vnnH/z8/Ni4cSNlypShdevWNG3a1HFTfn//DV99JesaBQdLEbQEr1e5Mb/+GoYNA7fIXWFDQkLo2rUr58+fZ/Xq1WRxZFoYhcJBKOFTaM7fl/6m9fLWmoz6fLx9uNzrcoxri8HBwaxfvx4/Pz+2bNlCpUqVaN26NY0bN7ZJfb4Yef4cvvgC1q+XghdbDAbIkAGWLZNToW9x9+5dmjZtSs6cOZk7dy4GQ/Q5NBWKxIpyblFoToO8Daifp77dA8r1LnqWtlxqkUONwWCgZcuWLF++nDt37tC+fXtWrFhB1qxZadKkCUuWLCEw0E5rk+fOQd68sHZt3EQP5PnXrkGlSjBnzpuXDx48SNmyZWnSpAl//fWXEj1FkkaN+BQOISg8iErzKnH+8XnLShVZicHVwKQ6k+KcI/LFixesXr0aPz8/9u3bR926dWndujUff/yxbTKanD0LFSvCy5eWT2taisEA48ezwNubfv36MWfOHBo1amRbGwpFAkQJn8Jh+If6U2NBDc49PkeoMdRm7epd9IyvPZ6vynxlszYBnj59ysqVK/Hz8+PIkSPUr1+f1q1bU7duXdzd3a1v8OFDKFhQTnPa6WcY7uJC79Sp6bVtG4UKFbKLDYUioaGET+FQgiOC6bWxF0vOLInzmp+bsxsGVwN/Nv2TBnntm3nk4cOHrFixAj8/P06fPk2jRo1o06YNNWvWtKzIrRBQrx78+y9EvF9l17aYvb1xunoV4ovXqkLhYJTwKeIF269vp+2KtgRFBFkd5+esc8bdxZ2Pcn3ErEazSKXX1iPz7t27LFu2DD8/P65cuULTpk1p3bo1VatWjbqywuLF0K0bBAXZv4NublC7tvQYVSgUSvgU8YcwYxgrzq9g3J5xXHl+BSDKUaCTzgkvNy/CTeG0KtSKvuX6UixDVGXatePmzZssXboUPz8/7ty5Q/PmzWndujWVKlXCyemVL1lEhCzD/lybkA4APD1h0ya5nqhQJHGU8CniJecfn2fv7b3svbWXA3cP8CL0BUazETdnN3KkyEGVbFUo41OG6tmrk9xDg3CDWHDlypU3IvjkyRNatmxJmzZtKHvrFrouXSAgQLvO6HTQuDGsWqWdTYUinqKET6HQgPPnz+Pn5ye3a9coGh6ufSc8PGTas3TptLetUMQjlPApFBoinj5FZMyIkwUOLdWAk8AD4G2f0T+An4CrQDKgGfAjEOO418sLpkyBzz6zut8KRWJCBbArFBqiO34cJwvi/24AuwEdsPat138CvgUmAP7AgVfH1gFilNLAQNi3z9ouKxSJDiV8CoWWHDkik03HwAKgHNAJmP/qtZfAcGAq8BHgCmQHlgLXgMWW2N+718oOKxSJDyV8CoWWnDxpUdzeAqD9q20T8BDYB4Qipzbfxgv4GNhsiX071vZTKBIKqh6fQqElFsTt7QFuAq2ANMiC9IuBtK/+juxHmxE4Zol9OwfLKxQJATXiUyi0xNk5xkPmI9fs0rz6u92r19IATwBjJOfcf+v4aHFSP3mFQo34FAotiSFtWAhyzc4EZHj1WhjwAjmqcwdWIkeDrwkENgJjLLGvqjIoFGrEp1BoSpkyMotKFKwGnIFzwIlX23mgMnLdbzjQC/gH6cV5g/+mRNtbYr9w4dj1W6FIRKgRn0KhJSVLRjvdOB/4DMj63utfAb2BO0BqoD9wBTkarApsBaKW01c4O0OVKrHqtkKRmFAB7AqFlkREQLJkEGqbMkzzgGHAXj4Uyw/w9gY/P1kVQqFIwqipToVCS1xdoU0biKpqg5V8BvyADHWwyHbt2jaxq1AkZJTwKRRa07evFCEb8SnQJqaDPDygVy+bCa5CkZBRU50KhSOoUAEOHgSzWRt7BgNcvQoZMsR8rEKRyFEjPoXCEfz5pxyFaYGnJ4wfr0RPoXiFEj6FwhHkygXff2//uDoXFxnC0KOHfe0oFAkINdWpUDgKsxmaNoUtWyxKXG01Tk6QJg0cOwY+PrZvX6FIoKgRn0LhKJycYNkyqFzZ9iM/Z2dInVpWY1Cip1C8gxI+hcKRuLnB+vXwySe2Ez9PTyhQAI4ehdy5bdOmQpGIUMKnUDgaFxeYMQP+/hvSpwcLCtVG2Y5eD4MHw4kTkCWLTbupUCQW1BqfQhGfCAyE33+HSZMgIED+HROennK9sH17GDgQ8uSxfz8VigSMEj6FIj5iNsPWrbBmDezZAxcvgk4n1wWFkKnPfHxk0uu6daF1a/DycnSvFYoEgRI+hSIhYDLBs2cyx6ebGyRPrl0coEKRyFDCp1AoFIokhXJuUSgUCkWSQgmfQqFQKJIUSvgUCoVCkaRQwqdQKBSKJIUSPoVCoVAkKZTwKRQKhSJJoYRPoVAoFEkKJXwKhUKhSFIo4VMoFApFkkIJn0KhUCiSFEr4FAqFQpGkUMKnUCgUiiSFEj6FQqFQJCmU8CkUCoUiSfF/bTRouvEOI4MAAAAASUVORK5CYII=\n",
+ "text/plain": [
+ "
"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "solution = tree_csp_solver(france_csp)\n",
+ "print(solution)\n",
+ "draw_graph(france_csp, solution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94ccd804",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-07-Logical-Agents.ipynb b/Chapter-07-Logical-Agents.ipynb
new file mode 100644
index 000000000..68fecd402
--- /dev/null
+++ b/Chapter-07-Logical-Agents.ipynb
@@ -0,0 +1,66068 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "14ec8738",
+ "metadata": {},
+ "source": [
+ "# Logical Agents"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "d086b439",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from utils import *\n",
+ "from logic import *\n",
+ "from notebook import psource"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b92a436a",
+ "metadata": {},
+ "source": [
+ "## Logical Sentences"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ebe7bcb8",
+ "metadata": {},
+ "source": [
+ "The `Expr` class is designed to represent any kind of mathematical expression. The simplest type of `Expr` is a symbol, which can be defined with the function `Symbol`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "d33eb66c",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "x"
+ ]
+ },
+ "execution_count": 2,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "Symbol('x')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2a0390e7",
+ "metadata": {},
+ "source": [
+ "Or we can define multiple symbols at the same time with the function `symbols`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "ff6b16bb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "(x, y, P, Q, f) = symbols('x, y, P, Q, f')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e847db90",
+ "metadata": {},
+ "source": [
+ "We can combine `Expr`s with the regular Python infix and prefix operators. Here's how we would form the logical sentence \"P and not Q\":"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "53c62fb1",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(P & ~Q)"
+ ]
+ },
+ "execution_count": 4,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "P & ~Q"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1c2f71ba",
+ "metadata": {},
+ "source": [
+ "This works because the `Expr` class overloads the `&` operator with this definition:\n",
+ "\n",
+ "```python\n",
+ "def __and__(self, other): return Expr('&', self, other)```\n",
+ " \n",
+ "and does similar overloads for the other operators. An `Expr` has two fields: `op` for the operator, which is always a string, and `args` for the arguments, which is a tuple of 0 or more expressions. By \"expression,\" I mean either an instance of `Expr`, or a number. Let's take a look at the fields for some `Expr` examples:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "dceaebbb",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'&'"
+ ]
+ },
+ "execution_count": 5,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "sentence = P & ~Q\n",
+ "\n",
+ "sentence.op"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "73c1806a",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(P, ~Q)"
+ ]
+ },
+ "execution_count": 6,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "sentence.args"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "b4fee5db",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'P'"
+ ]
+ },
+ "execution_count": 7,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "P.op"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "ddf61d4f",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "()"
+ ]
+ },
+ "execution_count": 8,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "P.args"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "ed691410",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'P'"
+ ]
+ },
+ "execution_count": 9,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "Pxy = P(x, y)\n",
+ "\n",
+ "Pxy.op"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "54f299db",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(x, y)"
+ ]
+ },
+ "execution_count": 10,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "Pxy.args"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "23aee792",
+ "metadata": {},
+ "source": [
+ "It is important to note that the `Expr` class does not define the *logic* of Propositional Logic sentences; it just gives you a way to *represent* expressions. Think of an `Expr` as an [abstract syntax tree](https://en.wikipedia.org/wiki/Abstract_syntax_tree). Each of the `args` in an `Expr` can be either a symbol, a number, or a nested `Expr`. We can nest these trees to any depth. Here is a deply nested `Expr`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "84852830",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(((3 * f(x, y)) + (P(y) / 2)) + 1)"
+ ]
+ },
+ "execution_count": 11,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "3 * f(x, y) + P(y) / 2 + 1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f6bc2ff7",
+ "metadata": {},
+ "source": [
+ "## Operators for Constructing Logical Sentences\n",
+ "\n",
+ "Here is a table of the operators that can be used to form sentences. Note that we have a problem: we want to use Python operators to make sentences, so that our programs (and our interactive sessions like the one here) will show simple code. But Python does not allow implication arrows as operators, so for now we have to use a more verbose notation that Python does allow: `|'==>'|` instead of just `==>`. Alternately, you can always use the more verbose `Expr` constructor forms:\n",
+ "\n",
+ "| Operation | Book | Python Infix Input | Python Output | Python `Expr` Input\n",
+ "|--------------------------|----------------------|-------------------------|---|---|\n",
+ "| Negation | ¬ P | `~P` | `~P` | `Expr('~', P)`\n",
+ "| And | P ∧ Q | `P & Q` | `P & Q` | `Expr('&', P, Q)`\n",
+ "| Or | P ∨ Q | `P` | `Q`| `P` | `Q` | `Expr('`|`', P, Q)`\n",
+ "| Inequality (Xor) | P ≠ Q | `P ^ Q` | `P ^ Q` | `Expr('^', P, Q)`\n",
+ "| Implication | P → Q | `P` |`'==>'`| `Q` | `P ==> Q` | `Expr('==>', P, Q)`\n",
+ "| Reverse Implication | Q ← P | `Q` |`'<=='`| `P` |`Q <== P` | `Expr('<==', Q, P)`\n",
+ "| Equivalence | P ↔ Q | `P` |`'<=>'`| `Q` |`P <=> Q` | `Expr('<=>', P, Q)`\n",
+ "\n",
+ "Here's an example of defining a sentence with an implication arrow:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "0e066e66",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(~(P & Q) ==> (~P | ~Q))"
+ ]
+ },
+ "execution_count": 12,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "~(P & Q) |'==>'| (~P | ~Q)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "296655d0",
+ "metadata": {},
+ "source": [
+ "## `expr`: a Shortcut for Constructing Sentences\n",
+ "\n",
+ "If the `|'==>'|` notation looks ugly to you, you can use the function `expr` instead:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "586daf85",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(~(P & Q) ==> (~P | ~Q))"
+ ]
+ },
+ "execution_count": 13,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "expr('~(P & Q) ==> (~P | ~Q)')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8a44c0e8",
+ "metadata": {},
+ "source": [
+ "`expr` takes a string as input, and parses it into an `Expr`. The string can contain arrow operators: `==>`, `<==`, or `<=>`, which are handled as if they were regular Python infix operators. And `expr` automatically defines any symbols, so you don't need to pre-define them:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "c6466edf",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "sqrt(((b ** 2) - ((4 * a) * c)))"
+ ]
+ },
+ "execution_count": 14,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "expr('sqrt(b ** 2 - 4 * a * c)')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "14f45754",
+ "metadata": {},
+ "source": [
+ "For now that's all you need to know about `expr`. If you are interested, we explain the messy details of how `expr` is implemented and how `|'==>'|` is handled in the appendix."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "37e44f37",
+ "metadata": {},
+ "source": [
+ "## Propositional Knowledge Bases: `PropKB`\n",
+ "\n",
+ "The class `PropKB` can be used to represent a knowledge base of propositional logic sentences.\n",
+ "\n",
+ "We see that the class `KB` has four methods, apart from `__init__`. A point to note here: the `ask` method simply calls the `ask_generator` method. Thus, this one has already been implemented, and what you'll have to actually implement when you create your own knowledge base class (though you'll probably never need to, considering the ones we've created for you) will be the `ask_generator` function and not the `ask` function itself.\n",
+ "\n",
+ "The class `PropKB` now.\n",
+ "* `__init__(self, sentence=None)` : The constructor `__init__` creates a single field `clauses` which will be a list of all the sentences of the knowledge base. Note that each one of these sentences will be a 'clause' i.e. a sentence which is made up of only literals and `or`s.\n",
+ "* `tell(self, sentence)` : When you want to add a sentence to the KB, you use the `tell` method. This method takes a sentence, converts it to its CNF, extracts all the clauses, and adds all these clauses to the `clauses` field. So, you need not worry about `tell`ing only clauses to the knowledge base. You can `tell` the knowledge base a sentence in any form that you wish; converting it to CNF and adding the resulting clauses will be handled by the `tell` method.\n",
+ "* `ask_generator(self, query)` : The `ask_generator` function is used by the `ask` function. It calls the `tt_entails` function, which in turn returns `True` if the knowledge base entails query and `False` otherwise. The `ask_generator` itself returns an empty dict `{}` if the knowledge base entails query and `None` otherwise. This might seem a little bit weird to you. After all, it makes more sense just to return a `True` or a `False` instead of the `{}` or `None` But this is done to maintain consistency with the way things are in First-Order Logic, where an `ask_generator` function is supposed to return all the substitutions that make the query true. Hence the dict, to return all these substitutions. I will be mostly be using the `ask` function which returns a `{}` or a `False`, but if you don't like this, you can always use the `ask_if_true` function which returns a `True` or a `False`.\n",
+ "* `retract(self, sentence)` : This function removes all the clauses of the sentence given, from the knowledge base. Like the `tell` function, you don't have to pass clauses to remove them from the knowledge base; any sentence will do fine. The function will take care of converting that sentence to clauses and then remove those."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a3491fa9",
+ "metadata": {},
+ "source": [
+ "## Wumpus World KB\n",
+ "Let us create a `PropKB` for the wumpus world with the sentences mentioned in `section 7.4.3`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "34d39dc6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wumpus_kb = PropKB()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0e385d7a",
+ "metadata": {},
+ "source": [
+ "We define the symbols we use in our clauses.
\n", + "$P_{x, y}$ is true if there is a pit in `[x, y]`.
\n", + "$B_{x, y}$ is true if the agent senses breeze in `[x, y]`.
" + ] + }, + { + "cell_type": "code", + "execution_count": 16, + "id": "deab110e", + "metadata": {}, + "outputs": [], + "source": [ + "P11, P12, P21, P22, P31, B11, B21 = expr('P11, P12, P21, P22, P31, B11, B21')" + ] + }, + { + "cell_type": "markdown", + "id": "4a8cc36a", + "metadata": {}, + "source": [ + "Now we tell sentences based on `section 7.4.3`.
\n", + "There is no pit in `[1,1]`." + ] + }, + { + "cell_type": "code", + "execution_count": 17, + "id": "c934db1d", + "metadata": {}, + "outputs": [], + "source": [ + "wumpus_kb.tell(~P11)" + ] + }, + { + "cell_type": "markdown", + "id": "ed62f7d9", + "metadata": {}, + "source": [ + "A square is breezy if and only if there is a pit in a neighboring square. This has to be stated for each square but for now, we include just the relevant squares." + ] + }, + { + "cell_type": "code", + "execution_count": 18, + "id": "c6b48305", + "metadata": {}, + "outputs": [], + "source": [ + "wumpus_kb.tell(B11 | '<=>' | ((P12 | P21)))\n", + "wumpus_kb.tell(B21 | '<=>' | ((P11 | P22 | P31)))" + ] + }, + { + "cell_type": "markdown", + "id": "7a021616", + "metadata": {}, + "source": [ + "Now we include the breeze percepts for the first two squares leading up to the situation in `Figure 7.3(b)`" + ] + }, + { + "cell_type": "code", + "execution_count": 19, + "id": "4a14d380", + "metadata": {}, + "outputs": [], + "source": [ + "wumpus_kb.tell(~B11)\n", + "wumpus_kb.tell(B21)" + ] + }, + { + "cell_type": "markdown", + "id": "4e5befbf", + "metadata": {}, + "source": [ + "We can check the clauses stored in a `KB` by accessing its `clauses` variable" + ] + }, + { + "cell_type": "code", + "execution_count": 20, + "id": "4fe8296f", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "[~P11,\n", + " (~P12 | B11),\n", + " (~P21 | B11),\n", + " (P12 | P21 | ~B11),\n", + " (~P11 | B21),\n", + " (~P22 | B21),\n", + " (~P31 | B21),\n", + " (P11 | P22 | P31 | ~B21),\n", + " ~B11,\n", + " B21]" + ] + }, + "execution_count": 20, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "wumpus_kb.clauses" + ] + }, + { + "cell_type": "markdown", + "id": "58d0b2be", + "metadata": {}, + "source": [ + "We see that the equivalence $B_{1, 1} \\iff (P_{1, 2} \\lor P_{2, 1})$ was automatically converted to two implications which were inturn converted to CNF which is stored in the `KB`.
\n", + "$B_{1, 1} \\iff (P_{1, 2} \\lor P_{2, 1})$ was split into $B_{1, 1} \\implies (P_{1, 2} \\lor P_{2, 1})$ and $B_{1, 1} \\Longleftarrow (P_{1, 2} \\lor P_{2, 1})$.
\n", + "$B_{1, 1} \\implies (P_{1, 2} \\lor P_{2, 1})$ was converted to $P_{1, 2} \\lor P_{2, 1} \\lor \\neg B_{1, 1}$.
\n", + "$B_{1, 1} \\Longleftarrow (P_{1, 2} \\lor P_{2, 1})$ was converted to $\\neg (P_{1, 2} \\lor P_{2, 1}) \\lor B_{1, 1}$ which becomes $(\\neg P_{1, 2} \\lor B_{1, 1}) \\land (\\neg P_{2, 1} \\lor B_{1, 1})$ after applying De Morgan's laws and distributing the disjunction.
\n", + "$B_{2, 1} \\iff (P_{1, 1} \\lor P_{2, 2} \\lor P_{3, 2})$ is converted in similar manner." + ] + }, + { + "cell_type": "markdown", + "id": "a9733937", + "metadata": {}, + "source": [ + "## Inference in Propositional Knowledge Base\n", + "In this section we will look at two algorithms to check if a sentence is entailed by the `KB`. Our goal is to decide whether $\\text{KB} \\vDash \\alpha$ for some sentence $\\alpha$.\n", + "### Truth Table Enumeration\n", + "It is a model-checking approach which, as the name suggests, enumerates all possible models in which the `KB` is true and checks if $\\alpha$ is also true in these models. We list the $n$ symbols in the `KB` and enumerate the $2^{n}$ models in a depth-first manner and check the truth of `KB` and $\\alpha$." + ] + }, + { + "cell_type": "code", + "execution_count": 21, + "id": "ead34986", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(tt_check_all)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9bb77b2b",
+ "metadata": {},
+ "source": [
+ "The algorithm basically computes every line of the truth table $KB\\implies \\alpha$ and checks if it is true everywhere.\n",
+ "
\n", + "If symbols are defined, the routine recursively constructs every combination of truth values for the symbols and then, \n", + "it checks whether `model` is consistent with `kb`.\n", + "The given models correspond to the lines in the truth table,\n", + "which have a `true` in the KB column, \n", + "and for these lines it checks whether the query evaluates to true\n", + "
\n", + "`result = pl_true(alpha, model)`.\n", + "
\n", + "
\n", + "In short, `tt_check_all` evaluates this logical expression for each `model`\n", + "
\n", + "`pl_true(kb, model) => pl_true(alpha, model)`\n", + "
\n", + "which is logically equivalent to\n", + "
\n", + "`pl_true(kb, model) & ~pl_true(alpha, model)` \n", + "
\n", + "that is, the knowledge base and the negation of the query are logically inconsistent.\n", + "
\n", + "
\n", + "`tt_entails()` just extracts the symbols from the query and calls `tt_check_all()` with the proper parameters.\n" + ] + }, + { + "cell_type": "code", + "execution_count": 22, + "id": "289de55a", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(tt_entails)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b95486be",
+ "metadata": {},
+ "source": [
+ "Keep in mind that for two symbols P and Q, P => Q is false only when P is `True` and Q is `False`.\n",
+ "Example usage of `tt_entails()`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 23,
+ "id": "42910682",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "KB: (P & Q)\n",
+ "alpha: Q\n",
+ "symbols: [P, Q]\n",
+ "model:{}\n",
+ "model:{P: True}\n",
+ "model:{P: True, Q: True}\n",
+ "When KB is True, alpha is True\n",
+ "model:{P: True, Q: False}\n",
+ "When KB is False, return True\n",
+ "model:{P: False}\n",
+ "model:{P: False, Q: True}\n",
+ "When KB is False, return True\n",
+ "model:{P: False, Q: False}\n",
+ "When KB is False, return True\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "True"
+ ]
+ },
+ "execution_count": 23,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "tt_entails(P & Q, Q)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "909002c3",
+ "metadata": {},
+ "source": [
+ "P & Q is True only when both P and Q are True. Hence, (P & Q) => Q is True"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 24,
+ "id": "15a5469c",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "KB: (P | Q)\n",
+ "alpha: Q\n",
+ "symbols: [P, Q]\n",
+ "model:{}\n",
+ "model:{P: True}\n",
+ "model:{P: True, Q: True}\n",
+ "When KB is True, alpha is True\n",
+ "model:{P: True, Q: False}\n",
+ "When KB is True, alpha is False\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "False"
+ ]
+ },
+ "execution_count": 24,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "tt_entails(P | Q, Q)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 25,
+ "id": "9381dc63",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "KB: (P | Q)\n",
+ "alpha: P\n",
+ "symbols: [P, Q]\n",
+ "model:{}\n",
+ "model:{P: True}\n",
+ "model:{P: True, Q: True}\n",
+ "When KB is True, alpha is True\n",
+ "model:{P: True, Q: False}\n",
+ "When KB is True, alpha is True\n",
+ "model:{P: False}\n",
+ "model:{P: False, Q: True}\n",
+ "When KB is True, alpha is False\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "False"
+ ]
+ },
+ "execution_count": 25,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "tt_entails(P | Q, P)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b2f54c1f",
+ "metadata": {},
+ "source": [
+ "If we know that P | Q is true, we cannot infer the truth values of P and Q. \n",
+ "Hence (P | Q) => Q is False and so is (P | Q) => P."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 26,
+ "id": "baa7f6a3",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "KB: ((((A & (B | C)) & D) & E) & ~(F | G))\n",
+ "alpha: ((((A & D) & E) & ~F) & ~G)\n",
+ "symbols: [F, C, D, G, A, E, B]\n",
+ "model:{}\n",
+ "model:{F: True}\n",
+ "model:{F: True, C: True}\n",
+ "model:{F: True, C: True, D: True}\n",
+ "model:{F: True, C: True, D: True, G: True}\n",
+ "model:{F: True, C: True, D: True, G: True, A: True}\n",
+ "model:{F: True, C: True, D: True, G: True, A: True, E: True}\n",
+ "model:{F: True, C: True, D: True, G: True, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: True, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: True, A: True, E: False}\n",
+ "model:{F: True, C: True, D: True, G: True, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: True, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: True, A: False}\n",
+ "model:{F: True, C: True, D: True, G: True, A: False, E: True}\n",
+ "model:{F: True, C: True, D: True, G: True, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: True, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: True, A: False, E: False}\n",
+ "model:{F: True, C: True, D: True, G: True, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: True, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: False}\n",
+ "model:{F: True, C: True, D: True, G: False, A: True}\n",
+ "model:{F: True, C: True, D: True, G: False, A: True, E: True}\n",
+ "model:{F: True, C: True, D: True, G: False, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: False, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: False, A: True, E: False}\n",
+ "model:{F: True, C: True, D: True, G: False, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: False, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: False, A: False}\n",
+ "model:{F: True, C: True, D: True, G: False, A: False, E: True}\n",
+ "model:{F: True, C: True, D: True, G: False, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: False, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: False, A: False, E: False}\n",
+ "model:{F: True, C: True, D: True, G: False, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: True, G: False, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False}\n",
+ "model:{F: True, C: True, D: False, G: True}\n",
+ "model:{F: True, C: True, D: False, G: True, A: True}\n",
+ "model:{F: True, C: True, D: False, G: True, A: True, E: True}\n",
+ "model:{F: True, C: True, D: False, G: True, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: True, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: True, A: True, E: False}\n",
+ "model:{F: True, C: True, D: False, G: True, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: True, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: True, A: False}\n",
+ "model:{F: True, C: True, D: False, G: True, A: False, E: True}\n",
+ "model:{F: True, C: True, D: False, G: True, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: True, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: True, A: False, E: False}\n",
+ "model:{F: True, C: True, D: False, G: True, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: True, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: False}\n",
+ "model:{F: True, C: True, D: False, G: False, A: True}\n",
+ "model:{F: True, C: True, D: False, G: False, A: True, E: True}\n",
+ "model:{F: True, C: True, D: False, G: False, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: False, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: False, A: True, E: False}\n",
+ "model:{F: True, C: True, D: False, G: False, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: False, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: False, A: False}\n",
+ "model:{F: True, C: True, D: False, G: False, A: False, E: True}\n",
+ "model:{F: True, C: True, D: False, G: False, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: False, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: False, A: False, E: False}\n",
+ "model:{F: True, C: True, D: False, G: False, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: True, D: False, G: False, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False}\n",
+ "model:{F: True, C: False, D: True}\n",
+ "model:{F: True, C: False, D: True, G: True}\n",
+ "model:{F: True, C: False, D: True, G: True, A: True}\n",
+ "model:{F: True, C: False, D: True, G: True, A: True, E: True}\n",
+ "model:{F: True, C: False, D: True, G: True, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: True, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: True, A: True, E: False}\n",
+ "model:{F: True, C: False, D: True, G: True, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: True, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: True, A: False}\n",
+ "model:{F: True, C: False, D: True, G: True, A: False, E: True}\n",
+ "model:{F: True, C: False, D: True, G: True, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: True, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: True, A: False, E: False}\n",
+ "model:{F: True, C: False, D: True, G: True, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: True, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: False}\n",
+ "model:{F: True, C: False, D: True, G: False, A: True}\n",
+ "model:{F: True, C: False, D: True, G: False, A: True, E: True}\n",
+ "model:{F: True, C: False, D: True, G: False, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: False, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: False, A: True, E: False}\n",
+ "model:{F: True, C: False, D: True, G: False, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: False, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: False, A: False}\n",
+ "model:{F: True, C: False, D: True, G: False, A: False, E: True}\n",
+ "model:{F: True, C: False, D: True, G: False, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: False, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: False, A: False, E: False}\n",
+ "model:{F: True, C: False, D: True, G: False, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: True, G: False, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False}\n",
+ "model:{F: True, C: False, D: False, G: True}\n",
+ "model:{F: True, C: False, D: False, G: True, A: True}\n",
+ "model:{F: True, C: False, D: False, G: True, A: True, E: True}\n",
+ "model:{F: True, C: False, D: False, G: True, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: True, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: True, A: True, E: False}\n",
+ "model:{F: True, C: False, D: False, G: True, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: True, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: True, A: False}\n",
+ "model:{F: True, C: False, D: False, G: True, A: False, E: True}\n",
+ "model:{F: True, C: False, D: False, G: True, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: True, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: True, A: False, E: False}\n",
+ "model:{F: True, C: False, D: False, G: True, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: True, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: False}\n",
+ "model:{F: True, C: False, D: False, G: False, A: True}\n",
+ "model:{F: True, C: False, D: False, G: False, A: True, E: True}\n",
+ "model:{F: True, C: False, D: False, G: False, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: False, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: False, A: True, E: False}\n",
+ "model:{F: True, C: False, D: False, G: False, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: False, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: False, A: False}\n",
+ "model:{F: True, C: False, D: False, G: False, A: False, E: True}\n",
+ "model:{F: True, C: False, D: False, G: False, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: False, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: False, A: False, E: False}\n",
+ "model:{F: True, C: False, D: False, G: False, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: True, C: False, D: False, G: False, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False}\n",
+ "model:{F: False, C: True}\n",
+ "model:{F: False, C: True, D: True}\n",
+ "model:{F: False, C: True, D: True, G: True}\n",
+ "model:{F: False, C: True, D: True, G: True, A: True}\n",
+ "model:{F: False, C: True, D: True, G: True, A: True, E: True}\n",
+ "model:{F: False, C: True, D: True, G: True, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: True, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: True, A: True, E: False}\n",
+ "model:{F: False, C: True, D: True, G: True, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: True, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: True, A: False}\n",
+ "model:{F: False, C: True, D: True, G: True, A: False, E: True}\n",
+ "model:{F: False, C: True, D: True, G: True, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: True, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: True, A: False, E: False}\n",
+ "model:{F: False, C: True, D: True, G: True, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: True, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: False}\n",
+ "model:{F: False, C: True, D: True, G: False, A: True}\n",
+ "model:{F: False, C: True, D: True, G: False, A: True, E: True}\n",
+ "model:{F: False, C: True, D: True, G: False, A: True, E: True, B: True}\n",
+ "When KB is True, alpha is True\n",
+ "model:{F: False, C: True, D: True, G: False, A: True, E: True, B: False}\n",
+ "When KB is True, alpha is True\n",
+ "model:{F: False, C: True, D: True, G: False, A: True, E: False}\n",
+ "model:{F: False, C: True, D: True, G: False, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: False, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: False, A: False}\n",
+ "model:{F: False, C: True, D: True, G: False, A: False, E: True}\n",
+ "model:{F: False, C: True, D: True, G: False, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: False, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: False, A: False, E: False}\n",
+ "model:{F: False, C: True, D: True, G: False, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: True, G: False, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False}\n",
+ "model:{F: False, C: True, D: False, G: True}\n",
+ "model:{F: False, C: True, D: False, G: True, A: True}\n",
+ "model:{F: False, C: True, D: False, G: True, A: True, E: True}\n",
+ "model:{F: False, C: True, D: False, G: True, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: True, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: True, A: True, E: False}\n",
+ "model:{F: False, C: True, D: False, G: True, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: True, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: True, A: False}\n",
+ "model:{F: False, C: True, D: False, G: True, A: False, E: True}\n",
+ "model:{F: False, C: True, D: False, G: True, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: True, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: True, A: False, E: False}\n",
+ "model:{F: False, C: True, D: False, G: True, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: True, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: False}\n",
+ "model:{F: False, C: True, D: False, G: False, A: True}\n",
+ "model:{F: False, C: True, D: False, G: False, A: True, E: True}\n",
+ "model:{F: False, C: True, D: False, G: False, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: False, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: False, A: True, E: False}\n",
+ "model:{F: False, C: True, D: False, G: False, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: False, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: False, A: False}\n",
+ "model:{F: False, C: True, D: False, G: False, A: False, E: True}\n",
+ "model:{F: False, C: True, D: False, G: False, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: False, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: False, A: False, E: False}\n",
+ "model:{F: False, C: True, D: False, G: False, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: True, D: False, G: False, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False}\n",
+ "model:{F: False, C: False, D: True}\n",
+ "model:{F: False, C: False, D: True, G: True}\n",
+ "model:{F: False, C: False, D: True, G: True, A: True}\n",
+ "model:{F: False, C: False, D: True, G: True, A: True, E: True}\n",
+ "model:{F: False, C: False, D: True, G: True, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: True, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: True, A: True, E: False}\n",
+ "model:{F: False, C: False, D: True, G: True, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: True, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: True, A: False}\n",
+ "model:{F: False, C: False, D: True, G: True, A: False, E: True}\n",
+ "model:{F: False, C: False, D: True, G: True, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: True, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: True, A: False, E: False}\n",
+ "model:{F: False, C: False, D: True, G: True, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: True, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: False}\n",
+ "model:{F: False, C: False, D: True, G: False, A: True}\n",
+ "model:{F: False, C: False, D: True, G: False, A: True, E: True}\n",
+ "model:{F: False, C: False, D: True, G: False, A: True, E: True, B: True}\n",
+ "When KB is True, alpha is True\n",
+ "model:{F: False, C: False, D: True, G: False, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: False, A: True, E: False}\n",
+ "model:{F: False, C: False, D: True, G: False, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: False, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: False, A: False}\n",
+ "model:{F: False, C: False, D: True, G: False, A: False, E: True}\n",
+ "model:{F: False, C: False, D: True, G: False, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: False, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: False, A: False, E: False}\n",
+ "model:{F: False, C: False, D: True, G: False, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: True, G: False, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False}\n",
+ "model:{F: False, C: False, D: False, G: True}\n",
+ "model:{F: False, C: False, D: False, G: True, A: True}\n",
+ "model:{F: False, C: False, D: False, G: True, A: True, E: True}\n",
+ "model:{F: False, C: False, D: False, G: True, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: True, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: True, A: True, E: False}\n",
+ "model:{F: False, C: False, D: False, G: True, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: True, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: True, A: False}\n",
+ "model:{F: False, C: False, D: False, G: True, A: False, E: True}\n",
+ "model:{F: False, C: False, D: False, G: True, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: True, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: True, A: False, E: False}\n",
+ "model:{F: False, C: False, D: False, G: True, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: True, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: False}\n",
+ "model:{F: False, C: False, D: False, G: False, A: True}\n",
+ "model:{F: False, C: False, D: False, G: False, A: True, E: True}\n",
+ "model:{F: False, C: False, D: False, G: False, A: True, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: False, A: True, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: False, A: True, E: False}\n",
+ "model:{F: False, C: False, D: False, G: False, A: True, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: False, A: True, E: False, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: False, A: False}\n",
+ "model:{F: False, C: False, D: False, G: False, A: False, E: True}\n",
+ "model:{F: False, C: False, D: False, G: False, A: False, E: True, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: False, A: False, E: True, B: False}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: False, A: False, E: False}\n",
+ "model:{F: False, C: False, D: False, G: False, A: False, E: False, B: True}\n",
+ "When KB is False, return True\n",
+ "model:{F: False, C: False, D: False, G: False, A: False, E: False, B: False}\n",
+ "When KB is False, return True\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "True"
+ ]
+ },
+ "execution_count": 26,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "(A, B, C, D, E, F, G) = symbols('A, B, C, D, E, F, G')\n",
+ "tt_entails(A & (B | C) & D & E & ~(F | G), A & D & E & ~F & ~G)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a7c91a63",
+ "metadata": {},
+ "source": [
+ "We can see that for the KB to be true, A, D, E have to be True and F and G have to be False.\n",
+ "Nothing can be said about B or C."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "89b04f01",
+ "metadata": {},
+ "source": [
+ "Coming back to our problem, note that `tt_entails()` takes an `Expr` which is a conjunction of clauses as the input instead of the `KB` itself. \n",
+ "You can use the `ask_if_true()` method of `PropKB` which does all the required conversions. \n",
+ "Let's check what `wumpus_kb` tells us about $P_{1, 1}$."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 27,
+ "id": "2718c7ec",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "KB: (~P11 & (~P12 | B11) & (~P21 | B11) & (P12 | P21 | ~B11) & (~P11 | B21) & (~P22 | B21) & (~P31 | B21) & (P11 | P22 | P31 | ~B21) & ~B11 & B21)\n",
+ "alpha: ~P11\n",
+ "symbols: [P11, P12, P22, P31, B21, P21, B11]\n",
+ "model:{}\n",
+ "model:{P11: True}\n",
+ "model:{P11: True, P12: True}\n",
+ "model:{P11: True, P12: True, P22: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False}\n",
+ "model:{P11: True, P12: False, P22: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False}\n",
+ "model:{P11: False, P12: True}\n",
+ "model:{P11: False, P12: True, P22: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False}\n",
+ "model:{P11: False, P12: False, P22: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is True, alpha is True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is True, alpha is True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is True, alpha is True\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: False}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: False}\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: True}\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: False}\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "KB: (~P11 & (~P12 | B11) & (~P21 | B11) & (P12 | P21 | ~B11) & (~P11 | B21) & (~P22 | B21) & (~P31 | B21) & (P11 | P22 | P31 | ~B21) & ~B11 & B21)\n",
+ "alpha: P11\n",
+ "symbols: [P11, P12, P22, P31, B21, P21, B11]\n",
+ "model:{}\n",
+ "model:{P11: True}\n",
+ "model:{P11: True, P12: True}\n",
+ "model:{P11: True, P12: True, P22: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False}\n",
+ "model:{P11: True, P12: False, P22: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False}\n",
+ "model:{P11: False, P12: True}\n",
+ "model:{P11: False, P12: True, P22: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False}\n",
+ "model:{P11: False, P12: False, P22: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is True, alpha is False\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "(True, False)"
+ ]
+ },
+ "execution_count": 27,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "wumpus_kb.ask_if_true(~P11), wumpus_kb.ask_if_true(P11)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "02016e47",
+ "metadata": {},
+ "source": [
+ "Looking at Figure 7.9 we see that in all models in which the knowledge base is `True`, $P_{1, 1}$ is `False`. It makes sense that `ask_if_true()` returns `True` for $\\alpha = \\neg P_{1, 1}$ and `False` for $\\alpha = P_{1, 1}$. This begs the question, what if $\\alpha$ is `True` in only a portion of all models. Do we return `True` or `False`? This doesn't rule out the possibility of $\\alpha$ being `True` but it is not entailed by the `KB` so we return `False` in such cases. We can see this is the case for $P_{2, 2}$ and $P_{3, 1}$."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 28,
+ "id": "70f4230a",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "KB: (~P11 & (~P12 | B11) & (~P21 | B11) & (P12 | P21 | ~B11) & (~P11 | B21) & (~P22 | B21) & (~P31 | B21) & (P11 | P22 | P31 | ~B21) & ~B11 & B21)\n",
+ "alpha: ~P22\n",
+ "symbols: [P11, P12, P22, P31, B21, P21, B11]\n",
+ "model:{}\n",
+ "model:{P11: True}\n",
+ "model:{P11: True, P12: True}\n",
+ "model:{P11: True, P12: True, P22: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False}\n",
+ "model:{P11: True, P12: False, P22: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False}\n",
+ "model:{P11: False, P12: True}\n",
+ "model:{P11: False, P12: True, P22: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False}\n",
+ "model:{P11: False, P12: False, P22: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is True, alpha is False\n",
+ "KB: (~P11 & (~P12 | B11) & (~P21 | B11) & (P12 | P21 | ~B11) & (~P11 | B21) & (~P22 | B21) & (~P31 | B21) & (P11 | P22 | P31 | ~B21) & ~B11 & B21)\n",
+ "alpha: P22\n",
+ "symbols: [P11, P12, P22, P31, B21, P21, B11]\n",
+ "model:{}\n",
+ "model:{P11: True}\n",
+ "model:{P11: True, P12: True}\n",
+ "model:{P11: True, P12: True, P22: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: True, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False}\n",
+ "model:{P11: True, P12: False, P22: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: True, P12: False, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False}\n",
+ "model:{P11: False, P12: True}\n",
+ "model:{P11: False, P12: True, P22: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: True, P22: False, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False}\n",
+ "model:{P11: False, P12: False, P22: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is True, alpha is True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: True, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: True, P21: False, B11: False}\n",
+ "When KB is True, alpha is True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: True}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: False}\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: True, P31: False, B21: False, P21: False, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: True}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: True, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: True, B11: False}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: False}\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: False, B11: True}\n",
+ "When KB is False, return True\n",
+ "model:{P11: False, P12: False, P22: False, P31: True, B21: True, P21: False, B11: False}\n",
+ "When KB is True, alpha is False\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "(False, False)"
+ ]
+ },
+ "execution_count": 28,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "wumpus_kb.ask_if_true(~P22), wumpus_kb.ask_if_true(P22)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5cc4adc1",
+ "metadata": {},
+ "source": [
+ "### Proof by Resolution\n",
+ "Recall that our goal is to check whether $\\text{KB} \\vDash \\alpha$ i.e. is $\\text{KB} \\implies \\alpha$ true in every model. Suppose we wanted to check if $P \\implies Q$ is valid. We check the satisfiability of $\\neg (P \\implies Q)$, which can be rewritten as $P \\land \\neg Q$. If $P \\land \\neg Q$ is unsatisfiable, then $P \\implies Q$ must be true in all models. This gives us the result \"$\\text{KB} \\vDash \\alpha$ if and only if $\\text{KB} \\land \\neg \\alpha$ is unsatisfiable\".
\n", + "This technique corresponds to proof by contradiction, a standard mathematical proof technique. We assume $\\alpha$ to be false and show that this leads to a contradiction with known axioms in $\\text{KB}$. We obtain a contradiction by making valid inferences using inference rules. In this proof we use a single inference rule, resolution which states $(l_1 \\lor \\dots \\lor l_k) \\land (m_1 \\lor \\dots \\lor m_n) \\land (l_i \\iff \\neg m_j) \\implies l_1 \\lor \\dots \\lor l_{i - 1} \\lor l_{i + 1} \\lor \\dots \\lor l_k \\lor m_1 \\lor \\dots \\lor m_{j - 1} \\lor m_{j + 1} \\lor \\dots \\lor m_n$. Applying the resolution yields us a clause which we add to the KB. We keep doing this until:\n", + "\n", + "* There are no new clauses that can be added, in which case $\\text{KB} \\nvDash \\alpha$.\n", + "* Two clauses resolve to yield the empty clause, in which case $\\text{KB} \\vDash \\alpha$.\n", + "\n", + "The empty clause is equivalent to False because it arises only from resolving two complementary\n", + "unit clauses such as $P$ and $\\neg P$ which is a contradiction as both $P$ and $\\neg P$ can't be True at the same time." + ] + }, + { + "cell_type": "markdown", + "id": "5a03ae78", + "metadata": {}, + "source": [ + "There is one catch however, the algorithm that implements proof by resolution cannot handle complex sentences. \n", + "Implications and bi-implications have to be simplified into simpler clauses. \n", + "We already know that *every sentence of a propositional logic is logically equivalent to a conjunction of clauses*.\n", + "We will use this fact to our advantage and simplify the input sentence into the **conjunctive normal form** (CNF) which is a conjunction of disjunctions of literals.\n", + "For eg:\n", + "
\n", + "$$(A\\lor B)\\land (\\neg B\\lor C\\lor\\neg D)\\land (D\\lor\\neg E)$$\n", + "This is equivalent to the POS (Product of sums) form in digital electronics.\n", + "
\n", + "Here's an outline of how the conversion is done:\n", + "1. Convert bi-implications to implications\n", + "
\n", + "$\\alpha\\iff\\beta$ can be written as $(\\alpha\\implies\\beta)\\land(\\beta\\implies\\alpha)$\n", + "
\n", + "This also applies to compound sentences\n", + "
\n", + "$\\alpha\\iff(\\beta\\lor\\gamma)$ can be written as $(\\alpha\\implies(\\beta\\lor\\gamma))\\land((\\beta\\lor\\gamma)\\implies\\alpha)$\n", + "
\n", + "2. Convert implications to their logical equivalents\n", + "
\n", + "$\\alpha\\implies\\beta$ can be written as $\\neg\\alpha\\lor\\beta$\n", + "
\n", + "3. Move negation inwards\n", + "
\n", + "CNF requires atomic literals. Hence, negation cannot appear on a compound statement.\n", + "De Morgan's laws will be helpful here.\n", + "
\n", + "$\\neg(\\alpha\\land\\beta)\\equiv(\\neg\\alpha\\lor\\neg\\beta)$\n", + "
\n", + "$\\neg(\\alpha\\lor\\beta)\\equiv(\\neg\\alpha\\land\\neg\\beta)$\n", + "
\n", + "4. Distribute disjunction over conjunction\n", + "
\n", + "Disjunction and conjunction are distributive over each other.\n", + "Now that we only have conjunctions, disjunctions and negations in our expression, \n", + "we will distribute disjunctions over conjunctions wherever possible as this will give us a sentence which is a conjunction of simpler clauses, \n", + "which is what we wanted in the first place.\n", + "
\n", + "We need a term of the form\n", + "
\n", + "$(\\alpha_{1}\\lor\\alpha_{2}\\lor\\alpha_{3}...)\\land(\\beta_{1}\\lor\\beta_{2}\\lor\\beta_{3}...)\\land(\\gamma_{1}\\lor\\gamma_{2}\\lor\\gamma_{3}...)\\land...$\n", + "
\n", + "
\n", + "The `to_cnf` function executes this conversion using helper subroutines." + ] + }, + { + "cell_type": "code", + "execution_count": 29, + "id": "f7120f00", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(to_cnf)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "38d9ac74",
+ "metadata": {},
+ "source": [
+ "`to_cnf` calls three subroutines.\n",
+ "
\n", + "`eliminate_implications` converts bi-implications and implications to their logical equivalents.\n", + "
\n", + "`move_not_inwards` removes negations from compound statements and moves them inwards using De Morgan's laws.\n", + "
\n", + "`distribute_and_over_or` distributes disjunctions over conjunctions.\n", + "
\n", + "Run the cell below for implementation details." + ] + }, + { + "cell_type": "code", + "execution_count": 30, + "id": "0bb9acf4", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(eliminate_implications)\n",
+ "psource(move_not_inwards)\n",
+ "psource(distribute_and_over_or)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e5b762a0",
+ "metadata": {},
+ "source": [
+ "Let's convert some sentences to see how it works\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 31,
+ "id": "938707c4",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "((A | ~B) & (B | ~A))"
+ ]
+ },
+ "execution_count": 31,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "A, B, C, D = expr('A, B, C, D')\n",
+ "to_cnf(A |'<=>'| B)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 32,
+ "id": "2ff1d653",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "((A | ~B | ~C) & (B | ~A) & (C | ~A))"
+ ]
+ },
+ "execution_count": 32,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "to_cnf(A |'<=>'| (B & C))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 33,
+ "id": "99d19f03",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(A & (C | B) & (D | B))"
+ ]
+ },
+ "execution_count": 33,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "to_cnf(A & (B | (C & D)))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 34,
+ "id": "050f76a3",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "((B | ~A | C | ~D) & (A | ~A | C | ~D) & (B | ~B | C | ~D) & (A | ~B | C | ~D))"
+ ]
+ },
+ "execution_count": 34,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "to_cnf((A |'<=>'| ~B) |'==>'| (C | ~D))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "53dae7eb",
+ "metadata": {},
+ "source": [
+ "Coming back to our resolution problem, we can see how the `to_cnf` function is utilized here"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 35,
+ "id": "83ddcfaf",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(pl_resolution)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 36,
+ "id": "0083c5f6",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(True, False)"
+ ]
+ },
+ "execution_count": 36,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "pl_resolution(wumpus_kb, ~P11), pl_resolution(wumpus_kb, P11)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 37,
+ "id": "705a54f9",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(False, False)"
+ ]
+ },
+ "execution_count": 37,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "pl_resolution(wumpus_kb, ~P22), pl_resolution(wumpus_kb, P22)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9c48f7ef",
+ "metadata": {},
+ "source": [
+ "### Forward and backward chaining\n",
+ "Previously, we said we will look at two algorithms to check if a sentence is entailed by the `KB`. Here's a third one. \n",
+ "The difference here is that our goal now is to determine if a knowledge base of definite clauses entails a single proposition symbol *q* - the query.\n",
+ "There is a catch however - the knowledge base can only contain **Horn clauses**.\n",
+ "
\n", + "#### Horn Clauses\n", + "Horn clauses can be defined as a *disjunction* of *literals* with **at most** one positive literal. \n", + "
\n", + "A Horn clause with exactly one positive literal is called a *definite clause*.\n", + "
\n", + "A Horn clause might look like \n", + "
\n", + "$\\neg a\\lor\\neg b\\lor\\neg c\\lor\\neg d... \\lor z$\n", + "
\n", + "This, coincidentally, is also a definite clause.\n", + "
\n", + "Using De Morgan's laws, the example above can be simplified to \n", + "
\n", + "$a\\land b\\land c\\land d ... \\implies z$\n", + "
\n", + "This seems like a logical representation of how humans process known data and facts. \n", + "Assuming percepts `a`, `b`, `c`, `d` ... to be true simultaneously, we can infer `z` to also be true at that point in time. \n", + "There are some interesting aspects of Horn clauses that make algorithmic inference or *resolution* easier.\n", + "- Definite clauses can be written as implications:\n", + "
\n", + "The most important simplification a definite clause provides is that it can be written as an implication.\n", + "The premise (or the knowledge that leads to the implication) is a conjunction of positive literals.\n", + "The conclusion (the implied statement) is also a positive literal.\n", + "The sentence thus becomes easier to understand.\n", + "The premise and the conclusion are conventionally called the *body* and the *head* respectively.\n", + "A single positive literal is called a *fact*.\n", + "- Forward chaining and backward chaining can be used for inference from Horn clauses:\n", + "
\n", + "Forward chaining is semantically identical to `AND-OR-Graph-Search` from the chapter on search algorithms.\n", + "Implementational details will be explained shortly.\n", + "- Deciding entailment with Horn clauses is linear in size of the knowledge base:\n", + "
\n", + "Surprisingly, the forward and backward chaining algorithms traverse each element of the knowledge base at most once, greatly simplifying the problem.\n", + "
\n", + "
\n", + "The function `pl_fc_entails` implements forward chaining to see if a knowledge base `KB` entails a symbol `q`.\n", + "
\n", + "Before we proceed further, note that `pl_fc_entails` doesn't use an ordinary `KB` instance. \n", + "The knowledge base here is an instance of the `PropDefiniteKB` class, derived from the `PropKB` class, \n", + "but modified to store definite clauses.\n", + "
\n", + "The main point of difference arises in the inclusion of a helper method to `PropDefiniteKB` that returns a list of clauses in KB that have a given symbol `p` in their premise." + ] + }, + { + "cell_type": "code", + "execution_count": 38, + "id": "af23d674", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(PropDefiniteKB.clauses_with_premise)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "310af58d",
+ "metadata": {},
+ "source": [
+ "Let's now have a look at the `pl_fc_entails` algorithm."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 39,
+ "id": "e5fad13d",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(pl_fc_entails)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "78b31c1a",
+ "metadata": {},
+ "source": [
+ "The function accepts a knowledge base `KB` (an instance of `PropDefiniteKB`) and a query `q` as inputs.\n",
+ "
\n", + "
\n", + "`count` initially stores the number of symbols in the premise of each sentence in the knowledge base.\n", + "
\n", + "The `conjuncts` helper function separates a given sentence at conjunctions.\n", + "
\n", + "`inferred` is initialized as a *boolean* defaultdict. \n", + "This will be used later to check if we have inferred all premises of each clause of the agenda.\n", + "
\n", + "`agenda` initially stores a list of clauses that the knowledge base knows to be true.\n", + "The `is_prop_symbol` helper function checks if the given symbol is a valid propositional logic symbol.\n", + "
\n", + "
\n", + "We now iterate through `agenda`, popping a symbol `p` on each iteration.\n", + "If the query `q` is the same as `p`, we know that entailment holds.\n", + "
\n", + "The agenda is processed, reducing `count` by one for each implication with a premise `p`.\n", + "A conclusion is added to the agenda when `count` reaches zero. This means we know all the premises of that particular implication to be true.\n", + "
\n", + "`clauses_with_premise` is a helpful method of the `PropKB` class.\n", + "It returns a list of clauses in the knowledge base that have `p` in their premise.\n", + "
\n", + "
\n", + "Now that we have an idea of how this function works, let's see a few examples of its usage, but we first need to define our knowledge base. We assume we know the following clauses to be true." + ] + }, + { + "cell_type": "code", + "execution_count": 40, + "id": "0b621bbf", + "metadata": {}, + "outputs": [], + "source": [ + "clauses = ['(B & F)==>E', \n", + " '(A & E & F)==>G', \n", + " '(B & C)==>F', \n", + " '(A & B)==>D', \n", + " '(E & F)==>H', \n", + " '(H & I)==>J',\n", + " 'A', \n", + " 'B', \n", + " 'C']" + ] + }, + { + "cell_type": "markdown", + "id": "5b5bb2c6", + "metadata": {}, + "source": [ + "We will now `tell` this information to our knowledge base." + ] + }, + { + "cell_type": "code", + "execution_count": 41, + "id": "d2617082", + "metadata": {}, + "outputs": [], + "source": [ + "definite_clauses_KB = PropDefiniteKB()\n", + "for clause in clauses:\n", + " definite_clauses_KB.tell(expr(clause))" + ] + }, + { + "cell_type": "markdown", + "id": "8cfdea81", + "metadata": {}, + "source": [ + "We can now check if our knowledge base entails the following queries." + ] + }, + { + "cell_type": "code", + "execution_count": 42, + "id": "81e1582c", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "queue:[A, B, C]\n", + "C poped from queue [A, B]\n", + "queue:[A, B]\n", + "B poped from queue [A]\n", + "premises in clauses: ((B & C) ==> F) are all true\n", + "conclusion F are added to queue\n", + "queue:[A, F]\n", + "F poped from queue [A]\n", + "premises in clauses: ((B & F) ==> E) are all true\n", + "conclusion E are added to queue\n", + "queue:[A, E]\n", + "E poped from queue [A]\n", + "premises in clauses: ((E & F) ==> H) are all true\n", + "conclusion H are added to queue\n", + "queue:[A, H]\n", + "H poped from queue [A]\n", + "queue:[A]\n", + "A poped from queue []\n", + "premises in clauses: (((A & E) & F) ==> G) are all true\n", + "conclusion G are added to queue\n", + "premises in clauses: ((A & B) ==> D) are all true\n", + "conclusion D are added to queue\n", + "queue:[G, D]\n", + "D poped from queue [G]\n", + "queue:[G]\n", + "G poped from queue []\n", + "G is the same with query, return True\n" + ] + }, + { + "data": { + "text/plain": [ + "True" + ] + }, + "execution_count": 42, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pl_fc_entails(definite_clauses_KB, expr('G'))" + ] + }, + { + "cell_type": "code", + "execution_count": 43, + "id": "78b9b0fe", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "queue:[A, B, C]\n", + "C poped from queue [A, B]\n", + "queue:[A, B]\n", + "B poped from queue [A]\n", + "premises in clauses: ((B & C) ==> F) are all true\n", + "conclusion F are added to queue\n", + "queue:[A, F]\n", + "F poped from queue [A]\n", + "premises in clauses: ((B & F) ==> E) are all true\n", + "conclusion E are added to queue\n", + "queue:[A, E]\n", + "E poped from queue [A]\n", + "premises in clauses: ((E & F) ==> H) are all true\n", + "conclusion H are added to queue\n", + "queue:[A, H]\n", + "H poped from queue [A]\n", + "H is the same with query, return True\n" + ] + }, + { + "data": { + "text/plain": [ + "True" + ] + }, + "execution_count": 43, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pl_fc_entails(definite_clauses_KB, expr('H'))" + ] + }, + { + "cell_type": "code", + "execution_count": 44, + "id": "a4d2c858", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "queue:[A, B, C]\n", + "C poped from queue [A, B]\n", + "queue:[A, B]\n", + "B poped from queue [A]\n", + "premises in clauses: ((B & C) ==> F) are all true\n", + "conclusion F are added to queue\n", + "queue:[A, F]\n", + "F poped from queue [A]\n", + "premises in clauses: ((B & F) ==> E) are all true\n", + "conclusion E are added to queue\n", + "queue:[A, E]\n", + "E poped from queue [A]\n", + "premises in clauses: ((E & F) ==> H) are all true\n", + "conclusion H are added to queue\n", + "queue:[A, H]\n", + "H poped from queue [A]\n", + "queue:[A]\n", + "A poped from queue []\n", + "premises in clauses: (((A & E) & F) ==> G) are all true\n", + "conclusion G are added to queue\n", + "premises in clauses: ((A & B) ==> D) are all true\n", + "conclusion D are added to queue\n", + "queue:[G, D]\n", + "D poped from queue [G]\n", + "queue:[G]\n", + "G poped from queue []\n" + ] + }, + { + "data": { + "text/plain": [ + "False" + ] + }, + "execution_count": 44, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pl_fc_entails(definite_clauses_KB, expr('I'))" + ] + }, + { + "cell_type": "code", + "execution_count": 45, + "id": "c60592c4", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "queue:[A, B, C]\n", + "C poped from queue [A, B]\n", + "queue:[A, B]\n", + "B poped from queue [A]\n", + "premises in clauses: ((B & C) ==> F) are all true\n", + "conclusion F are added to queue\n", + "queue:[A, F]\n", + "F poped from queue [A]\n", + "premises in clauses: ((B & F) ==> E) are all true\n", + "conclusion E are added to queue\n", + "queue:[A, E]\n", + "E poped from queue [A]\n", + "premises in clauses: ((E & F) ==> H) are all true\n", + "conclusion H are added to queue\n", + "queue:[A, H]\n", + "H poped from queue [A]\n", + "queue:[A]\n", + "A poped from queue []\n", + "premises in clauses: (((A & E) & F) ==> G) are all true\n", + "conclusion G are added to queue\n", + "premises in clauses: ((A & B) ==> D) are all true\n", + "conclusion D are added to queue\n", + "queue:[G, D]\n", + "D poped from queue [G]\n", + "queue:[G]\n", + "G poped from queue []\n" + ] + }, + { + "data": { + "text/plain": [ + "False" + ] + }, + "execution_count": 45, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pl_fc_entails(definite_clauses_KB, expr('J'))" + ] + }, + { + "cell_type": "markdown", + "id": "7c62c31e", + "metadata": {}, + "source": [ + "### Effective Propositional Model Checking\n", + "\n", + "The previous segments elucidate the algorithmic procedure for model checking. \n", + "In this segment, we look at ways of making them computationally efficient.\n", + "
\n", + "The problem we are trying to solve is conventionally called the _propositional satisfiability problem_, abbreviated as the _SAT_ problem.\n", + "In layman terms, if there exists a model that satisfies a given Boolean formula, the formula is called satisfiable.\n", + "
\n", + "The SAT problem was the first problem to be proven _NP-complete_.\n", + "The main characteristics of an NP-complete problem are:\n", + "- Given a solution to such a problem, it is easy to verify if the solution solves the problem.\n", + "- The time required to actually solve the problem using any known algorithm increases exponentially with respect to the size of the problem.\n", + "
\n", + "
\n", + "Due to these properties, heuristic and approximational methods are often applied to find solutions to these problems.\n", + "
\n", + "It is extremely important to be able to solve large scale SAT problems efficiently because \n", + "many combinatorial problems in computer science can be conveniently reduced to checking the satisfiability of a propositional sentence under some constraints.\n", + "
\n", + "We will introduce two new algorithms that perform propositional model checking in a computationally effective way.\n", + "
\n" + ] + }, + { + "cell_type": "markdown", + "id": "16f137d2", + "metadata": {}, + "source": [ + "### 1. DPLL (Davis-Putnam-Logeman-Loveland) algorithm\n", + "This algorithm is very similar to Backtracking-Search.\n", + "It recursively enumerates possible models in a depth-first fashion with the following improvements over algorithms like `tt_entails`:\n", + "1. Early termination:\n", + "
\n", + "In certain cases, the algorithm can detect the truth value of a statement using just a partially completed model.\n", + "For example, $(P\\lor Q)\\land(P\\lor R)$ is true if P is true, regardless of other variables.\n", + "This reduces the search space significantly.\n", + "2. Pure symbol heuristic:\n", + "
\n", + "A symbol that has the same sign (positive or negative) in all clauses is called a _pure symbol_.\n", + "It isn't difficult to see that any satisfiable model will have the pure symbols assigned such that its parent clause becomes _true_.\n", + "For example, $(P\\lor\\neg Q)\\land(\\neg Q\\lor\\neg R)\\land(R\\lor P)$ has P and Q as pure symbols\n", + "and for the sentence to be true, P _has_ to be true and Q _has_ to be false.\n", + "The pure symbol heuristic thus simplifies the problem a bit.\n", + "3. Unit clause heuristic:\n", + "
\n", + "In the context of DPLL, clauses with just one literal and clauses with all but one _false_ literals are called unit clauses.\n", + "If a clause is a unit clause, it can only be satisfied by assigning the necessary value to make the last literal true.\n", + "We have no other choice.\n", + "
\n", + "Assigning one unit clause can create another unit clause.\n", + "For example, when P is false, $(P\\lor Q)$ becomes a unit clause, causing _true_ to be assigned to Q.\n", + "A series of forced assignments derived from previous unit clauses is called _unit propagation_.\n", + "In this way, this heuristic simplifies the problem further.\n", + "
\n", + "The algorithm often employs other tricks to scale up to large problems.\n", + "However, these tricks are currently out of the scope of this notebook. Refer to section 7.6 of the book for more details.\n", + "
\n", + "
\n", + "Let's have a look at the algorithm." + ] + }, + { + "cell_type": "code", + "execution_count": 46, + "id": "d6cdf0ba", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(dpll)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "742b708c",
+ "metadata": {},
+ "source": [
+ "The algorithm uses the ideas described above to check satisfiability of a sentence in propositional logic.\n",
+ "It recursively calls itself, simplifying the problem at each step. It also uses helper functions `find_pure_symbol` and `find_unit_clause` to carry out steps 2 and 3 above.\n",
+ "
\n", + "The `dpll_satisfiable` helper function converts the input clauses to _conjunctive normal form_ and calls the `dpll` function with the correct parameters." + ] + }, + { + "cell_type": "code", + "execution_count": 47, + "id": "0e4afb2c", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(dpll_satisfiable)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bd537b61",
+ "metadata": {},
+ "source": [
+ "Let's see a few examples of usage."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 48,
+ "id": "5c7d8a38",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "A, B, C, D = expr('A, B, C, D')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 49,
+ "id": "63e49642",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "clauses: [A, B, ~C, D]\n",
+ "symbols: {D, B, C, A}\n",
+ "model: {}\n",
+ "check pl_true of clause A with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause B with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause ~C with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause D with model {}\n",
+ "Check Results: None\n",
+ "Finding pure symbol with symbols {D, B, C, A} and clauses [A, B, ~C, D]\n",
+ "Pure symbol results P: D value: True\n",
+ "clauses: [A, B, ~C, D]\n",
+ "symbols: {B, C, A}\n",
+ "model: {D: True}\n",
+ "check pl_true of clause A with model {D: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause B with model {D: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause ~C with model {D: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause D with model {D: True}\n",
+ "Check Results: True\n",
+ "Finding pure symbol with symbols {B, C, A} and clauses [A, B, ~C]\n",
+ "Pure symbol results P: B value: True\n",
+ "clauses: [A, B, ~C, D]\n",
+ "symbols: {A, C}\n",
+ "model: {D: True, B: True}\n",
+ "check pl_true of clause A with model {D: True, B: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause B with model {D: True, B: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause ~C with model {D: True, B: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause D with model {D: True, B: True}\n",
+ "Check Results: True\n",
+ "Finding pure symbol with symbols {A, C} and clauses [A, ~C]\n",
+ "Pure symbol results P: A value: True\n",
+ "clauses: [A, B, ~C, D]\n",
+ "symbols: {C}\n",
+ "model: {D: True, B: True, A: True}\n",
+ "check pl_true of clause A with model {D: True, B: True, A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause B with model {D: True, B: True, A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause ~C with model {D: True, B: True, A: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause D with model {D: True, B: True, A: True}\n",
+ "Check Results: True\n",
+ "Finding pure symbol with symbols {C} and clauses [~C]\n",
+ "Pure symbol results P: C value: False\n",
+ "clauses: [A, B, ~C, D]\n",
+ "symbols: set()\n",
+ "model: {D: True, B: True, A: True, C: False}\n",
+ "check pl_true of clause A with model {D: True, B: True, A: True, C: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause B with model {D: True, B: True, A: True, C: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause ~C with model {D: True, B: True, A: True, C: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause D with model {D: True, B: True, A: True, C: False}\n",
+ "Check Results: True\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "{D: True, B: True, A: True, C: False}"
+ ]
+ },
+ "execution_count": 49,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "dpll_satisfiable(A & B & ~C & D)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5ffd81b5",
+ "metadata": {},
+ "source": [
+ "This is a simple case to highlight that the algorithm actually works."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 50,
+ "id": "0f7c41c3",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n",
+ "symbols: {D, B, C, A}\n",
+ "model: {}\n",
+ "check pl_true of clause (B | C | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~D | C | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (B | ~A | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~D | ~A | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (B | C | B) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~D | C | B) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (B | ~A | B) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~D | ~A | B) with model {}\n",
+ "Check Results: None\n",
+ "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n",
+ "Pure symbol results P: D value: False\n",
+ "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n",
+ "symbols: {B, C, A}\n",
+ "model: {D: False}\n",
+ "check pl_true of clause (B | C | A) with model {D: False}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~D | C | A) with model {D: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (B | ~A | A) with model {D: False}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~D | ~A | A) with model {D: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (B | C | B) with model {D: False}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~D | C | B) with model {D: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (B | ~A | B) with model {D: False}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~D | ~A | B) with model {D: False}\n",
+ "Check Results: True\n",
+ "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n",
+ "Pure symbol results P: B value: True\n",
+ "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n",
+ "symbols: {A, C}\n",
+ "model: {D: False, B: True}\n",
+ "check pl_true of clause (B | C | A) with model {D: False, B: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (B | C | B) with model {D: False, B: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n",
+ "Check Results: True\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "{D: False, B: True}"
+ ]
+ },
+ "execution_count": 50,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "dpll_satisfiable((A & B) | (C & ~A) | (B & ~D))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d1fc46f8",
+ "metadata": {},
+ "source": [
+ "If a particular symbol isn't present in the solution, \n",
+ "it means that the solution is independent of the value of that symbol.\n",
+ "In this case, the solution is independent of A."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 51,
+ "id": "2b7c7511",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "clauses: [(A | ~B), (B | ~A)]\n",
+ "symbols: {B, A}\n",
+ "model: {}\n",
+ "check pl_true of clause (A | ~B) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (B | ~A) with model {}\n",
+ "Check Results: None\n",
+ "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n",
+ "Pure symbol results P: None value: None\n",
+ "clauses: [(A | ~B), (B | ~A)]\n",
+ "symbols: {A}\n",
+ "model: {B: True}\n",
+ "check pl_true of clause (A | ~B) with model {B: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (B | ~A) with model {B: True}\n",
+ "Check Results: True\n",
+ "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n",
+ "Pure symbol results P: A value: True\n",
+ "clauses: [(A | ~B), (B | ~A)]\n",
+ "symbols: set()\n",
+ "model: {B: True, A: True}\n",
+ "check pl_true of clause (A | ~B) with model {B: True, A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (B | ~A) with model {B: True, A: True}\n",
+ "Check Results: True\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "{B: True, A: True}"
+ ]
+ },
+ "execution_count": 51,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "dpll_satisfiable(A |'<=>'| B)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 52,
+ "id": "8ef690ba",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "clauses: [(~B | ~A | C), (A | ~A | C), (~B | B | C), (A | B | C), (~B | ~A | ~A), (A | ~A | ~A), (~B | B | ~A), (A | B | ~A)]\n",
+ "symbols: {C, A, B}\n",
+ "model: {}\n",
+ "check pl_true of clause (~B | ~A | C) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (A | ~A | C) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~B | B | C) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (A | B | C) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~B | ~A | ~A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (A | ~A | ~A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~B | B | ~A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (A | B | ~A) with model {}\n",
+ "Check Results: None\n",
+ "Finding pure symbol with symbols {C, A, B} and clauses [(~B | ~A | C), (A | ~A | C), (~B | B | C), (A | B | C), (~B | ~A | ~A), (A | ~A | ~A), (~B | B | ~A), (A | B | ~A)]\n",
+ "Pure symbol results P: C value: True\n",
+ "clauses: [(~B | ~A | C), (A | ~A | C), (~B | B | C), (A | B | C), (~B | ~A | ~A), (A | ~A | ~A), (~B | B | ~A), (A | B | ~A)]\n",
+ "symbols: {A, B}\n",
+ "model: {C: True}\n",
+ "check pl_true of clause (~B | ~A | C) with model {C: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (A | ~A | C) with model {C: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~B | B | C) with model {C: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (A | B | C) with model {C: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~B | ~A | ~A) with model {C: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (A | ~A | ~A) with model {C: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~B | B | ~A) with model {C: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (A | B | ~A) with model {C: True}\n",
+ "Check Results: None\n",
+ "Finding pure symbol with symbols {A, B} and clauses [(~B | ~A | ~A), (A | ~A | ~A), (~B | B | ~A), (A | B | ~A)]\n",
+ "Pure symbol results P: None value: None\n",
+ "clauses: [(~B | ~A | C), (A | ~A | C), (~B | B | C), (A | B | C), (~B | ~A | ~A), (A | ~A | ~A), (~B | B | ~A), (A | B | ~A)]\n",
+ "symbols: {B}\n",
+ "model: {C: True, A: True}\n",
+ "check pl_true of clause (~B | ~A | C) with model {C: True, A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (A | ~A | C) with model {C: True, A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~B | B | C) with model {C: True, A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (A | B | C) with model {C: True, A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~B | ~A | ~A) with model {C: True, A: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (A | ~A | ~A) with model {C: True, A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~B | B | ~A) with model {C: True, A: True}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (A | B | ~A) with model {C: True, A: True}\n",
+ "Check Results: True\n",
+ "Finding pure symbol with symbols {B} and clauses [(~B | ~A | ~A), (~B | B | ~A)]\n",
+ "Pure symbol results P: None value: None\n",
+ "clauses: [(~B | ~A | C), (A | ~A | C), (~B | B | C), (A | B | C), (~B | ~A | ~A), (A | ~A | ~A), (~B | B | ~A), (A | B | ~A)]\n",
+ "symbols: set()\n",
+ "model: {C: True, A: True, B: False}\n",
+ "check pl_true of clause (~B | ~A | C) with model {C: True, A: True, B: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (A | ~A | C) with model {C: True, A: True, B: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~B | B | C) with model {C: True, A: True, B: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (A | B | C) with model {C: True, A: True, B: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~B | ~A | ~A) with model {C: True, A: True, B: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (A | ~A | ~A) with model {C: True, A: True, B: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~B | B | ~A) with model {C: True, A: True, B: False}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (A | B | ~A) with model {C: True, A: True, B: False}\n",
+ "Check Results: True\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "{C: True, A: True, B: False}"
+ ]
+ },
+ "execution_count": 52,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "dpll_satisfiable((A |'<=>'| B) |'==>'| (C & ~A))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 53,
+ "id": "8877c80c",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n",
+ "symbols: {A, C, B}\n",
+ "model: {}\n",
+ "check pl_true of clause (~A | ~A | B | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~C | ~A | B | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~A | ~B | B | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~C | ~B | B | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~A | ~A | C | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~C | ~A | C | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~A | ~B | C | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~C | ~B | C | A) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~A | A | B) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~B | ~C | A | B) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~A | A | C) with model {}\n",
+ "Check Results: None\n",
+ "check pl_true of clause (~B | ~C | A | C) with model {}\n",
+ "Check Results: None\n",
+ "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n",
+ "Pure symbol results P: None value: None\n",
+ "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n",
+ "symbols: {C, B}\n",
+ "model: {A: True}\n",
+ "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~A | A | B) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~A | A | C) with model {A: True}\n",
+ "Check Results: True\n",
+ "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n",
+ "Check Results: True\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "{A: True}"
+ ]
+ },
+ "execution_count": 53,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "dpll_satisfiable((A | (B & C)) |'<=>'| ((A | B) & (A | C)))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6c3a72af",
+ "metadata": {},
+ "source": [
+ "### 2. WalkSAT algorithm\n",
+ "This algorithm is very similar to Hill climbing.\n",
+ "On every iteration, the algorithm picks an unsatisfied clause and flips a symbol in the clause.\n",
+ "This is similar to finding a neighboring state in the `hill_climbing` algorithm.\n",
+ "
\n", + "The symbol to be flipped is decided by an evaluation function that counts the number of unsatisfied clauses.\n", + "Sometimes, symbols are also flipped randomly to avoid local optima. A subtle balance between greediness and randomness is required. Alternatively, some versions of the algorithm restart with a completely new random assignment if no solution has been found for too long as a way of getting out of local minima of numbers of unsatisfied clauses.\n", + "
\n", + "
\n", + "Let's have a look at the algorithm." + ] + }, + { + "cell_type": "code", + "execution_count": 54, + "id": "fca2582f", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(WalkSAT)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "50b9a890",
+ "metadata": {},
+ "source": [
+ "The function takes three arguments:\n",
+ "
\n", + "1. The `clauses` we want to satisfy.\n", + "
\n", + "2. The probability `p` of randomly changing a symbol.\n", + "
\n", + "3. The maximum number of flips (`max_flips`) the algorithm will run for. If the clauses are still unsatisfied, the algorithm returns `None` to denote failure.\n", + "
\n", + "The algorithm is identical in concept to Hill climbing and the code isn't difficult to understand.\n", + "
\n", + "
\n", + "Let's see a few examples of usage." + ] + }, + { + "cell_type": "code", + "execution_count": 55, + "id": "66e3030e", + "metadata": {}, + "outputs": [], + "source": [ + "A, B, C, D = expr('A, B, C, D')" + ] + }, + { + "cell_type": "code", + "execution_count": 56, + "id": "cedb5b0b", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{D: True, B: True, C: False, A: True}" + ] + }, + "execution_count": 56, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "WalkSAT([A, B, ~C, D], 0.5, 100)" + ] + }, + { + "cell_type": "markdown", + "id": "afb2f3bf", + "metadata": {}, + "source": [ + "This is a simple case to show that the algorithm converges." + ] + }, + { + "cell_type": "code", + "execution_count": 57, + "id": "55dc9097", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{C: True, A: True, B: True}" + ] + }, + "execution_count": 57, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "WalkSAT([A & B, A & C], 0.5, 100)" + ] + }, + { + "cell_type": "code", + "execution_count": 58, + "id": "d06d2fb0", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{D: True, C: True, A: True, B: True}" + ] + }, + "execution_count": 58, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "WalkSAT([A & B, C & D, C & B], 0.5, 100)" + ] + }, + { + "cell_type": "code", + "execution_count": 59, + "id": "22899b09", + "metadata": {}, + "outputs": [], + "source": [ + "WalkSAT([A & B, C | D, ~(D | B)], 0.5, 1000)" + ] + }, + { + "cell_type": "markdown", + "id": "1663811b", + "metadata": {}, + "source": [ + "This one doesn't give any output because WalkSAT did not find any model where these clauses hold. We can solve these clauses to see that they together form a contradiction and hence, it isn't supposed to have a solution." + ] + }, + { + "cell_type": "markdown", + "id": "c7e34352", + "metadata": {}, + "source": [ + "One point of difference between this algorithm and the `dpll_satisfiable` algorithms is that both these algorithms take inputs differently. \n", + "For WalkSAT to take complete sentences as input, \n", + "we can write a helper function that converts the input sentence into conjunctive normal form and then calls WalkSAT with the list of conjuncts of the CNF form of the sentence." + ] + }, + { + "cell_type": "code", + "execution_count": 60, + "id": "73409b93", + "metadata": {}, + "outputs": [], + "source": [ + "def WalkSAT_CNF(sentence, p=0.5, max_flips=10000):\n", + " return WalkSAT(conjuncts(to_cnf(sentence)), 0, max_flips)" + ] + }, + { + "cell_type": "markdown", + "id": "5e78c07c", + "metadata": {}, + "source": [ + "Now we can call `WalkSAT_CNF` and `DPLL_Satisfiable` with the same arguments." + ] + }, + { + "cell_type": "code", + "execution_count": 61, + "id": "e8cdf715", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{D: True, B: True, C: True, A: True}" + ] + }, + "execution_count": 61, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "WalkSAT_CNF((A & B) | (C & ~A) | (B & ~D), 0.5, 1000)" + ] + }, + { + "cell_type": "markdown", + "id": "3ec86268", + "metadata": {}, + "source": [ + "It works!\n", + "
\n", + "Notice that the solution generated by WalkSAT doesn't omit variables that the sentence doesn't depend upon. \n", + "If the sentence is independent of a particular variable, the solution contains a random value for that variable because of the stochastic nature of the algorithm.\n", + "
\n", + "
\n", + "Let's compare the runtime of WalkSAT and DPLL for a few cases. We will use the `%%timeit` magic to do this." + ] + }, + { + "cell_type": "code", + "execution_count": 62, + "id": "c8f6feb7", + "metadata": {}, + "outputs": [], + "source": [ + "sentence_1 = A |'<=>'| B\n", + "sentence_2 = (A & B) | (C & ~A) | (B & ~D)\n", + "sentence_3 = (A | (B & C)) |'<=>'| ((A | B) & (A | C))" + ] + }, + { + "cell_type": "code", + "execution_count": 63, + "id": "d7e665a9", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}" + ] + }, + { + "name": "stderr", + "output_type": "stream", + "text": [ + "IOPub data rate exceeded.\n", + "The notebook server will temporarily stop sending output\n", + "to the client in order to avoid crashing it.\n", + "To change this limit, set the config variable\n", + "`--NotebookApp.iopub_data_rate_limit`.\n", + "\n", + "Current values:\n", + "NotebookApp.iopub_data_rate_limit=1000000.0 (bytes/sec)\n", + "NotebookApp.rate_limit_window=3.0 (secs)\n", + "\n" + ] + } + ], + "source": [ + "%%timeit\n", + "dpll_satisfiable(sentence_1)\n", + "dpll_satisfiable(sentence_2)\n", + "dpll_satisfiable(sentence_3)" + ] + }, + { + "cell_type": "code", + "execution_count": 64, + "id": "97c61f2b", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "889 µs ± 17.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)\n" + ] + } + ], + "source": [ + "%%timeit\n", + "WalkSAT_CNF(sentence_1)\n", + "WalkSAT_CNF(sentence_2)\n", + "WalkSAT_CNF(sentence_3)" + ] + }, + { + "cell_type": "markdown", + "id": "0c7ac46a", + "metadata": {}, + "source": [ + "On an average, for solvable cases, `WalkSAT` is quite faster than `dpll` because, for a small number of variables, \n", + "`WalkSAT` can reduce the search space significantly. \n", + "Results can be different for sentences with more symbols though.\n", + "Feel free to play around with this to understand the trade-offs of these algorithms better." + ] + }, + { + "cell_type": "markdown", + "id": "86264a6d", + "metadata": {}, + "source": [ + "### SATPlan\n", + "\n", + "In this section we show how to make plans by logical inference. The basic idea is very simple. It includes the following three steps:\n", + "1. Constuct a sentence that includes:\n", + " 1. A colection of assertions about the initial state.\n", + " 2. The successor-state axioms for all the possible actions at each time up to some maximum time t.\n", + " 3. The assertion that the goal is achieved at time t.\n", + "2. Present the whole sentence to a SAT solver.\n", + "3. Assuming a model is found, extract from the model those variables that represent actions and are assigned true. Together they represent a plan to achieve the goals.\n", + "\n", + "\n", + "Lets have a look at the algorithm" + ] + }, + { + "cell_type": "code", + "execution_count": 65, + "id": "6035b73c", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(SAT_plan)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3589ab6f",
+ "metadata": {},
+ "source": [
+ "Let's see few examples of its usage. First we define a transition and then call `SAT_plan`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 66,
+ "id": "3eb78c86",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "['Right', 'Right']\n",
+ "['Right']\n",
+ "['Left', 'Left']\n"
+ ]
+ }
+ ],
+ "source": [
+ "transition = {'A': {'Left': 'A', 'Right': 'B'},\n",
+ " 'B': {'Left': 'A', 'Right': 'C'},\n",
+ " 'C': {'Left': 'B', 'Right': 'C'}}\n",
+ "\n",
+ "\n",
+ "print(SAT_plan('A', transition, 'C', 2)) \n",
+ "print(SAT_plan('A', transition, 'B', 3))\n",
+ "print(SAT_plan('C', transition, 'A', 3))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d82dc7d",
+ "metadata": {},
+ "source": [
+ "Let us do the same for another transition."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 67,
+ "id": "16a6b5ed",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "['Right', 'Down']\n"
+ ]
+ }
+ ],
+ "source": [
+ "transition = {(0, 0): {'Right': (0, 1), 'Down': (1, 0)},\n",
+ " (0, 1): {'Left': (1, 0), 'Down': (1, 1)},\n",
+ " (1, 0): {'Right': (1, 0), 'Up': (1, 0), 'Left': (1, 0), 'Down': (1, 0)},\n",
+ " (1, 1): {'Left': (1, 0), 'Up': (0, 1)}}\n",
+ "\n",
+ "\n",
+ "print(SAT_plan((0, 0), transition, (1, 1), 4))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "726521d5",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-09-Inference-in-First-Order-Logic.ipynb b/Chapter-09-Inference-in-First-Order-Logic.ipynb
new file mode 100644
index 000000000..724216a23
--- /dev/null
+++ b/Chapter-09-Inference-in-First-Order-Logic.ipynb
@@ -0,0 +1,1282 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "0f51464a",
+ "metadata": {},
+ "source": [
+ "## First-Order Logic Knowledge Bases: `FolKB`\n",
+ "\n",
+ "The class `FolKB` can be used to represent a knowledge base of First-order logic sentences. You would initialize and use it the same way as you would for `PropKB` except that the clauses are first-order definite clauses. We will see how to write such clauses to create a database and query them in the following sections."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "b8638386",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from utils import *\n",
+ "from logic import *\n",
+ "from notebook import psource"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "70198f3c",
+ "metadata": {},
+ "source": [
+ "## Criminal KB\n",
+ "In this section we create a `FolKB` based on the following paragraph.
\n", + "The law says that it is a crime for an American to sell weapons to hostile nations. The country Nono, an enemy of America, has some missiles, and all of its missiles were sold to it by Colonel West, who is American.
\n", + "The first step is to extract the facts and convert them into first-order definite clauses. Extracting the facts from data alone is a challenging task. Fortunately, we have a small paragraph and can do extraction and conversion manually. We'll store the clauses in list aptly named `clauses`." + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "a18f6282", + "metadata": {}, + "outputs": [], + "source": [ + "clauses = []" + ] + }, + { + "cell_type": "markdown", + "id": "aaa5bb71", + "metadata": {}, + "source": [ + "“... it is a crime for an American to sell weapons to hostile nations”
\n", + "The keywords to look for here are 'crime', 'American', 'sell', 'weapon' and 'hostile'. We use predicate symbols to make meaning of them.\n", + "\n", + "* `Criminal(x)`: `x` is a criminal\n", + "* `American(x)`: `x` is an American\n", + "* `Sells(x ,y, z)`: `x` sells `y` to `z`\n", + "* `Weapon(x)`: `x` is a weapon\n", + "* `Hostile(x)`: `x` is a hostile nation\n", + "\n", + "Let us now combine them with appropriate variable naming to depict the meaning of the sentence. The criminal `x` is also the American `x` who sells weapon `y` to `z`, which is a hostile nation.\n", + "\n", + "$\\text{American}(x) \\land \\text{Weapon}(y) \\land \\text{Sells}(x, y, z) \\land \\text{Hostile}(z) \\implies \\text{Criminal} (x)$" + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "id": "b7161c61", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"(American(x) & Weapon(y) & Sells(x, y, z) & Hostile(z)) ==> Criminal(x)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "03cd5efd", + "metadata": {}, + "source": [ + "\"The country Nono, an enemy of America\"
\n", + "We now know that Nono is an enemy of America. We represent these nations using the constant symbols `Nono` and `America`. the enemy relation is show using the predicate symbol `Enemy`.\n", + "\n", + "$\\text{Enemy}(\\text{Nono}, \\text{America})$" + ] + }, + { + "cell_type": "code", + "execution_count": 4, + "id": "7c3fcff2", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"Enemy(Nono, America)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "0c1c557b", + "metadata": {}, + "source": [ + "\"Nono ... has some missiles\"
\n", + "This states the existence of some missile which is owned by Nono. $\\exists x \\text{Owns}(\\text{Nono}, x) \\land \\text{Missile}(x)$. We invoke existential instantiation to introduce a new constant `M1` which is the missile owned by Nono.\n", + "\n", + "$\\text{Owns}(\\text{Nono}, \\text{M1}), \\text{Missile}(\\text{M1})$" + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "id": "986af6ca", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"Owns(Nono, M1)\"))\n", + "clauses.append(expr(\"Missile(M1)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "fa12ffc5", + "metadata": {}, + "source": [ + "\"All of its missiles were sold to it by Colonel West\"
\n", + "If Nono owns something and it classifies as a missile, then it was sold to Nono by West.\n", + "\n", + "$\\text{Missile}(x) \\land \\text{Owns}(\\text{Nono}, x) \\implies \\text{Sells}(\\text{West}, x, \\text{Nono})$" + ] + }, + { + "cell_type": "code", + "execution_count": 6, + "id": "59b18b23", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"(Missile(x) & Owns(Nono, x)) ==> Sells(West, x, Nono)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "082b73ef", + "metadata": {}, + "source": [ + "\"West, who is American\"
\n", + "West is an American.\n", + "\n", + "$\\text{American}(\\text{West})$" + ] + }, + { + "cell_type": "code", + "execution_count": 7, + "id": "c821092c", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"American(West)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "75a45247", + "metadata": {}, + "source": [ + "We also know, from our understanding of language, that missiles are weapons and that an enemy of America counts as “hostile”.\n", + "\n", + "$\\text{Missile}(x) \\implies \\text{Weapon}(x), \\text{Enemy}(x, \\text{America}) \\implies \\text{Hostile}(x)$" + ] + }, + { + "cell_type": "code", + "execution_count": 8, + "id": "ac043c98", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"Missile(x) ==> Weapon(x)\"))\n", + "clauses.append(expr(\"Enemy(x, America) ==> Hostile(x)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "c25fdefb", + "metadata": {}, + "source": [ + "Now that we have converted the information into first-order definite clauses we can create our first-order logic knowledge base." + ] + }, + { + "cell_type": "code", + "execution_count": 9, + "id": "7e3fc1a3", + "metadata": {}, + "outputs": [], + "source": [ + "crime_kb = FolKB(clauses)" + ] + }, + { + "cell_type": "markdown", + "id": "f5c34921", + "metadata": {}, + "source": [ + "The `subst` helper function substitutes variables with given values in first-order logic statements.\n", + "This will be useful in later algorithms.\n", + "It's implementation is quite simple and self-explanatory." + ] + }, + { + "cell_type": "code", + "execution_count": 10, + "id": "7df0639e", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(subst)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4b619e7e",
+ "metadata": {},
+ "source": [
+ "Here's an example of how `subst` can be used."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "3e63d2e5",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "Owns(Nono, M1)"
+ ]
+ },
+ "execution_count": 11,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "subst({x: expr('Nono'), y: expr('M1')}, expr('Owns(x, y)'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5cdbc8ac",
+ "metadata": {},
+ "source": [
+ "## Inference in First-Order Logic\n",
+ "In this section we look at a forward chaining and a backward chaining algorithm for `FolKB`. Both aforementioned algorithms rely on a process called unification, a key component of all first-order inference algorithms."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d7def74e",
+ "metadata": {},
+ "source": [
+ "### Unification\n",
+ "We sometimes require finding substitutions that make different logical expressions look identical. This process, called unification, is done by the `unify` algorithm. It takes as input two sentences and returns a unifier for them if one exists. A unifier is a dictionary which stores the substitutions required to make the two sentences identical. It does so by recursively unifying the components of a sentence, where the unification of a variable symbol `var` with a constant symbol `Const` is the mapping `{var: Const}`. Let's look at a few examples."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "296b57a8",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "x: x, y: 3, s: {}\n",
+ "Expression x: x is variable\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "{x: 3}"
+ ]
+ },
+ "execution_count": 12,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "unify(expr('x'), 3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "6acc37e6",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "x: A(x), y: A(B), s: {}\n",
+ "Expression x and y are Expr, return Unify((x,), (B,), Unify(A, A, {}))\n",
+ "x: A, y: A, s: {}\n",
+ "Expressions x: A == Expressions y: A, return Substitution: {}\n",
+ "x: (x,), y: (B,), s: {}\n",
+ "Expression x: (x,) and y: (B,) are list\n",
+ "Return Unify(x[1:]:(), y[1:]):(), Unify(x[0]:x, y[0]:B, s:{})\n",
+ "x: x, y: B, s: {}\n",
+ "Expression x: x is variable\n",
+ "x: (), y: (), s: {x: B}\n",
+ "Expressions x: () == Expressions y: (), return Substitution: {x: B}\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "{x: B}"
+ ]
+ },
+ "execution_count": 13,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "unify(expr('A(x)'), expr('A(B)'))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "d9556684",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "x: (Cat(x) & Dog(Dobby)), y: (Cat(Bella) & Dog(y)), s: {}\n",
+ "Expression x and y are Expr, return Unify((Cat(x), Dog(Dobby)), (Cat(Bella), Dog(y)), Unify(&, &, {}))\n",
+ "x: &, y: &, s: {}\n",
+ "Expressions x: & == Expressions y: &, return Substitution: {}\n",
+ "x: (Cat(x), Dog(Dobby)), y: (Cat(Bella), Dog(y)), s: {}\n",
+ "Expression x: (Cat(x), Dog(Dobby)) and y: (Cat(Bella), Dog(y)) are list\n",
+ "Return Unify(x[1:]:(Dog(Dobby),), y[1:]):(Dog(y),), Unify(x[0]:Cat(x), y[0]:Cat(Bella), s:{})\n",
+ "x: Cat(x), y: Cat(Bella), s: {}\n",
+ "Expression x and y are Expr, return Unify((x,), (Bella,), Unify(Cat, Cat, {}))\n",
+ "x: Cat, y: Cat, s: {}\n",
+ "Expressions x: Cat == Expressions y: Cat, return Substitution: {}\n",
+ "x: (x,), y: (Bella,), s: {}\n",
+ "Expression x: (x,) and y: (Bella,) are list\n",
+ "Return Unify(x[1:]:(), y[1:]):(), Unify(x[0]:x, y[0]:Bella, s:{})\n",
+ "x: x, y: Bella, s: {}\n",
+ "Expression x: x is variable\n",
+ "x: (), y: (), s: {x: Bella}\n",
+ "Expressions x: () == Expressions y: (), return Substitution: {x: Bella}\n",
+ "x: (Dog(Dobby),), y: (Dog(y),), s: {x: Bella}\n",
+ "Expression x: (Dog(Dobby),) and y: (Dog(y),) are list\n",
+ "Return Unify(x[1:]:(), y[1:]):(), Unify(x[0]:Dog(Dobby), y[0]:Dog(y), s:{x: Bella})\n",
+ "x: Dog(Dobby), y: Dog(y), s: {x: Bella}\n",
+ "Expression x and y are Expr, return Unify((Dobby,), (y,), Unify(Dog, Dog, {x: Bella}))\n",
+ "x: Dog, y: Dog, s: {x: Bella}\n",
+ "Expressions x: Dog == Expressions y: Dog, return Substitution: {x: Bella}\n",
+ "x: (Dobby,), y: (y,), s: {x: Bella}\n",
+ "Expression x: (Dobby,) and y: (y,) are list\n",
+ "Return Unify(x[1:]:(), y[1:]):(), Unify(x[0]:Dobby, y[0]:y, s:{x: Bella})\n",
+ "x: Dobby, y: y, s: {x: Bella}\n",
+ "Expression y: y is variable\n",
+ "x: (), y: (), s: {x: Bella, y: Dobby}\n",
+ "Expressions x: () == Expressions y: (), return Substitution: {x: Bella, y: Dobby}\n",
+ "x: (), y: (), s: {x: Bella, y: Dobby}\n",
+ "Expressions x: () == Expressions y: (), return Substitution: {x: Bella, y: Dobby}\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "{x: Bella, y: Dobby}"
+ ]
+ },
+ "execution_count": 14,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "unify(expr('Cat(x) & Dog(Dobby)'), expr('Cat(Bella) & Dog(y)'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "01f130a0",
+ "metadata": {},
+ "source": [
+ "In cases where there is no possible substitution that unifies the two sentences the function return `None`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "04910a78",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "x: Cat(x), y: Dog(Dobby), s: {}\n",
+ "Expression x and y are Expr, return Unify((x,), (Dobby,), Unify(Cat, Dog, {}))\n",
+ "x: Cat, y: Dog, s: {}\n",
+ "Expression x: Cat or y: Dog are str, return None\n",
+ "x: (x,), y: (Dobby,), s: None\n",
+ "Substitution None is None, return None\n",
+ "None\n"
+ ]
+ }
+ ],
+ "source": [
+ "print(unify(expr('Cat(x)'), expr('Dog(Dobby)')))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fc902c73",
+ "metadata": {},
+ "source": [
+ "We also need to take care we do not unintentionally use the same variable name. Unify treats them as a single variable which prevents it from taking multiple value."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "id": "5c1fbf5b",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "x: (Cat(x) & Dog(Dobby)), y: (Cat(Bella) & Dog(x)), s: {}\n",
+ "Expression x and y are Expr, return Unify((Cat(x), Dog(Dobby)), (Cat(Bella), Dog(x)), Unify(&, &, {}))\n",
+ "x: &, y: &, s: {}\n",
+ "Expressions x: & == Expressions y: &, return Substitution: {}\n",
+ "x: (Cat(x), Dog(Dobby)), y: (Cat(Bella), Dog(x)), s: {}\n",
+ "Expression x: (Cat(x), Dog(Dobby)) and y: (Cat(Bella), Dog(x)) are list\n",
+ "Return Unify(x[1:]:(Dog(Dobby),), y[1:]):(Dog(x),), Unify(x[0]:Cat(x), y[0]:Cat(Bella), s:{})\n",
+ "x: Cat(x), y: Cat(Bella), s: {}\n",
+ "Expression x and y are Expr, return Unify((x,), (Bella,), Unify(Cat, Cat, {}))\n",
+ "x: Cat, y: Cat, s: {}\n",
+ "Expressions x: Cat == Expressions y: Cat, return Substitution: {}\n",
+ "x: (x,), y: (Bella,), s: {}\n",
+ "Expression x: (x,) and y: (Bella,) are list\n",
+ "Return Unify(x[1:]:(), y[1:]):(), Unify(x[0]:x, y[0]:Bella, s:{})\n",
+ "x: x, y: Bella, s: {}\n",
+ "Expression x: x is variable\n",
+ "x: (), y: (), s: {x: Bella}\n",
+ "Expressions x: () == Expressions y: (), return Substitution: {x: Bella}\n",
+ "x: (Dog(Dobby),), y: (Dog(x),), s: {x: Bella}\n",
+ "Expression x: (Dog(Dobby),) and y: (Dog(x),) are list\n",
+ "Return Unify(x[1:]:(), y[1:]):(), Unify(x[0]:Dog(Dobby), y[0]:Dog(x), s:{x: Bella})\n",
+ "x: Dog(Dobby), y: Dog(x), s: {x: Bella}\n",
+ "Expression x and y are Expr, return Unify((Dobby,), (x,), Unify(Dog, Dog, {x: Bella}))\n",
+ "x: Dog, y: Dog, s: {x: Bella}\n",
+ "Expressions x: Dog == Expressions y: Dog, return Substitution: {x: Bella}\n",
+ "x: (Dobby,), y: (x,), s: {x: Bella}\n",
+ "Expression x: (Dobby,) and y: (x,) are list\n",
+ "Return Unify(x[1:]:(), y[1:]):(), Unify(x[0]:Dobby, y[0]:x, s:{x: Bella})\n",
+ "x: Dobby, y: x, s: {x: Bella}\n",
+ "Expression y: x is variable\n",
+ "x: Bella, y: Dobby, s: {x: Bella}\n",
+ "Expression x and y are Expr, return Unify((), (), Unify(Bella, Dobby, {x: Bella}))\n",
+ "x: Bella, y: Dobby, s: {x: Bella}\n",
+ "Expression x: Bella or y: Dobby are str, return None\n",
+ "x: (), y: (), s: None\n",
+ "Substitution None is None, return None\n",
+ "x: (), y: (), s: None\n",
+ "Substitution None is None, return None\n",
+ "x: (), y: (), s: None\n",
+ "Substitution None is None, return None\n",
+ "None\n"
+ ]
+ }
+ ],
+ "source": [
+ "print(unify(expr('Cat(x) & Dog(Dobby)'), expr('Cat(Bella) & Dog(x)')))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "950af96b",
+ "metadata": {},
+ "source": [
+ "### Forward Chaining Algorithm\n",
+ "We consider the simple forward-chaining algorithm presented in Figure 9.3. We look at each rule in the knowledge base and see if the premises can be satisfied. This is done by finding a substitution which unifies each of the premise with a clause in the `KB`. If we are able to unify the premises, the conclusion (with the corresponding substitution) is added to the `KB`. This inferencing process is repeated until either the query can be answered or till no new sentences can be added. We test if the newly added clause unifies with the query in which case the substitution yielded by `unify` is an answer to the query. If we run out of sentences to infer, this means the query was a failure.\n",
+ "\n",
+ "The function `fol_fc_ask` is a generator which yields all substitutions which validate the query."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "id": "b81bf447",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(fol_fc_ask)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2b05beb0",
+ "metadata": {},
+ "source": [
+ "Let's find out all the hostile nations. Note that we only told the `KB` that Nono was an enemy of America, not that it was hostile."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "id": "606e15cc",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[{x: Nono}]\n"
+ ]
+ }
+ ],
+ "source": [
+ "answer = fol_fc_ask(crime_kb, expr('Hostile(x)'))\n",
+ "print(list(answer))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "155bbd7f",
+ "metadata": {},
+ "source": [
+ "The generator returned a single substitution which says that Nono is a hostile nation. See how after adding another enemy nation the generator returns two substitutions."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 19,
+ "id": "db959f52",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[{x: Nono}, {x: JaJa}]\n"
+ ]
+ }
+ ],
+ "source": [
+ "crime_kb.tell(expr('Enemy(JaJa, America)'))\n",
+ "answer = fol_fc_ask(crime_kb, expr('Hostile(x)'))\n",
+ "print(list(answer))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e5bbf5cb",
+ "metadata": {},
+ "source": [
+ "Note: `fol_fc_ask` makes changes to the `KB` by adding sentences to it."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "974d96a2",
+ "metadata": {},
+ "source": [
+ "### Backward Chaining Algorithm\n",
+ "This algorithm works backward from the goal, chaining through rules to find known facts that support the proof. Suppose `goal` is the query we want to find the substitution for. We find rules of the form $\\text{lhs} \\implies \\text{goal}$ in the `KB` and try to prove `lhs`. There may be multiple clauses in the `KB` which give multiple `lhs`. It is sufficient to prove only one of these. But to prove a `lhs` all the conjuncts in the `lhs` of the clause must be proved. This makes it similar to And/Or search."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "73a6ea02",
+ "metadata": {},
+ "source": [
+ "#### OR\n",
+ "The OR part of the algorithm comes from our choice to select any clause of the form $\\text{lhs} \\implies \\text{goal}$. Looking at all rules's `lhs` whose `rhs` unify with the `goal`, we yield a substitution which proves all the conjuncts in the `lhs`. We use `parse_definite_clause` to attain `lhs` and `rhs` from a clause of the form $\\text{lhs} \\implies \\text{rhs}$. For atomic facts the `lhs` is an empty list."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 20,
+ "id": "0e1f0cba",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(fol_bc_or)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fd0f7532",
+ "metadata": {},
+ "source": [
+ "#### AND\n",
+ "The AND corresponds to proving all the conjuncts in the `lhs`. We need to find a substitution which proves each and every clause in the list of conjuncts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 21,
+ "id": "f980abab",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(fol_bc_and)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b612077d",
+ "metadata": {},
+ "source": [
+ "Now the main function `fl_bc_ask` calls `fol_bc_or` with substitution initialized as empty. The `ask` method of `FolKB` uses `fol_bc_ask` and fetches the first substitution returned by the generator to answer query. Let's query the knowledge base we created from `clauses` to find hostile nations."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 22,
+ "id": "5cd0fb95",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "((((American(x) & Weapon(y)) & Sells(x, y, z)) & Hostile(z)) ==> Criminal(x))\n",
+ "Enemy(Nono, America)\n",
+ "Owns(Nono, M1)\n",
+ "Missile(M1)\n",
+ "((Missile(x) & Owns(Nono, x)) ==> Sells(West, x, Nono))\n",
+ "American(West)\n",
+ "(Missile(x) ==> Weapon(x))\n",
+ "(Enemy(x, America) ==> Hostile(x))\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Rebuild KB because running fol_fc_ask would add new facts to the KB\n",
+ "crime_kb = FolKB(clauses)\n",
+ "for c in crime_kb.clauses:\n",
+ " print(c)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 23,
+ "id": "01e9fc67",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Starting Back Or with (KB, Goal: Hostile(x), theta: {})\n",
+ "Processing Rule: ((((American(x) & Weapon(y)) & Sells(x, y, z)) & Hostile(z)) ==> Criminal(x))\n",
+ "lhs: [American(v_0), Weapon(v_1), Sells(v_0, v_1, v_2), Hostile(v_2)], rhs: Criminal(v_0)\n",
+ "Starting Back And with (KB, Goals: [American(v_0), Weapon(v_1), Sells(v_0, v_1, v_2), Hostile(v_2)], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Enemy(Nono, America)\n",
+ "lhs: [], rhs: Enemy(Nono, America)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Owns(Nono, M1)\n",
+ "lhs: [], rhs: Owns(Nono, M1)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Missile(M1)\n",
+ "lhs: [], rhs: Missile(M1)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: ((Missile(x) & Owns(Nono, x)) ==> Sells(West, x, Nono))\n",
+ "lhs: [Missile(v_3), Owns(Nono, v_3)], rhs: Sells(West, v_3, Nono)\n",
+ "Starting Back And with (KB, Goals: [Missile(v_3), Owns(Nono, v_3)], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: American(West)\n",
+ "lhs: [], rhs: American(West)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: (Missile(x) ==> Weapon(x))\n",
+ "lhs: [Missile(v_4)], rhs: Weapon(v_4)\n",
+ "Starting Back And with (KB, Goals: [Missile(v_4)], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: (Enemy(x, America) ==> Hostile(x))\n",
+ "lhs: [Enemy(v_5, America)], rhs: Hostile(v_5)\n",
+ "Starting Back And with (KB, Goals: [Enemy(v_5, America)], theta: {v_5: x})\n",
+ "first: Enemy(v_5, America) for Back Or, rest: [] for Back And\n",
+ "Starting Back Or with (KB, Goal: Enemy(x, America), theta: {v_5: x})\n",
+ "Processing Rule: ((((American(x) & Weapon(y)) & Sells(x, y, z)) & Hostile(z)) ==> Criminal(x))\n",
+ "lhs: [American(v_6), Weapon(v_7), Sells(v_6, v_7, v_8), Hostile(v_8)], rhs: Criminal(v_6)\n",
+ "Starting Back And with (KB, Goals: [American(v_6), Weapon(v_7), Sells(v_6, v_7, v_8), Hostile(v_8)], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Enemy(Nono, America)\n",
+ "lhs: [], rhs: Enemy(Nono, America)\n",
+ "Starting Back And with (KB, Goals: [], theta: {v_5: Nono, x: Nono})\n",
+ "Length(goals)=0, yield theta: {v_5: Nono, x: Nono}\n",
+ "Starting Back And with (KB, Goals: [], theta: {v_5: Nono, x: Nono})\n",
+ "Length(goals)=0, yield theta: {v_5: Nono, x: Nono}\n"
+ ]
+ },
+ {
+ "data": {
+ "text/plain": [
+ "{v_5: Nono, x: Nono}"
+ ]
+ },
+ "execution_count": 23,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "crime_kb.ask(expr('Hostile(x)'))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c445eb42",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-11-Automated-Planning.ipynb b/Chapter-11-Automated-Planning.ipynb
new file mode 100644
index 000000000..50986a0ea
--- /dev/null
+++ b/Chapter-11-Automated-Planning.ipynb
@@ -0,0 +1,2666 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "c66c550f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from planning import *\n",
+ "from notebook import psource"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "89ede26a",
+ "metadata": {},
+ "source": [
+ "# Hierarchical Search \n",
+ "\n",
+ "Hierarchical search is a a planning algorithm in high level of abstraction.
\n", + "Instead of actions as in classical planning (chapter 10) (primitive actions) we now use high level actions (HLAs) (see planning.ipynb)
\n", + "\n", + "## Refinements\n", + "\n", + "Each __HLA__ has one or more refinements into a sequence of actions, each of which may be an HLA or a primitive action (which has no refinements by definition).
\n", + "For example:\n", + "- (a) the high level action \"Go to San Fransisco airport\" (Go(Home, SFO)), might have two possible refinements, \"Drive to San Fransisco airport\" and \"Taxi to San Fransisco airport\". \n", + "
\n", + "- (b) A recursive refinement for navigation in the vacuum world would be: to get to a\n", + "destination, take a step, and then go to the destination.\n", + "
\n", + "\n", + "
\n", + "- __implementation__: An HLA refinement that contains only primitive actions is called an implementation of the HLA\n", + "- An implementation of a high-level plan (a sequence of HLAs) is the concatenation of implementations of each HLA in the sequence\n", + "- A high-level plan __achieves the goal__ from a given state if at least one of its implementations achieves the goal from that state\n", + "
\n", + "\n", + "The refinements function input is: \n", + "- __hla__: the HLA of which we want to compute its refinements\n", + "- __state__: the knoweledge base of the current problem (Problem.init)\n", + "- __library__: the hierarchy of the actions in the planning problem\n", + "\n" + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "3d2af2cf", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(RealWorldPlanningProblem.refinements)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1baa5053",
+ "metadata": {},
+ "source": [
+ "## Hierarchical search \n",
+ "\n",
+ "Hierarchical search is a breadth-first implementation of hierarchical forward planning search in the space of refinements. (i.e. repeatedly choose an HLA in the current plan and replace it with one of its refinements, until the plan achieves the goal.) \n",
+ "\n",
+ "
\n", + "The algorithms input is: problem and hierarchy\n", + "- __problem__: is of type Problem \n", + "- __hierarchy__: is a dictionary consisting of all the actions and the order in which they are performed. \n", + "
\n", + "\n", + "In top level call, initialPlan contains [act] (i.e. is the action to be performed) " + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "id": "b8142cd9", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(RealWorldPlanningProblem.hierarchical_search)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "edd61974",
+ "metadata": {},
+ "source": [
+ "## Example\n",
+ "\n",
+ "Suppose that somebody wants to get to the airport. \n",
+ "The possible ways to do so is either get a taxi, or drive to the airport.
\n", + "Those two actions have some preconditions and some effects. \n", + "If you get the taxi, you need to have cash, whereas if you drive you need to have a car.
\n", + "Thus we define the following hierarchy of possible actions.\n", + "\n", + "##### hierarchy" + ] + }, + { + "cell_type": "code", + "execution_count": 4, + "id": "cf7f1e3b", + "metadata": {}, + "outputs": [], + "source": [ + "library = {\n", + " 'HLA': ['Go(Home,SFO)', 'Go(Home,SFO)', 'Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)', 'Taxi(Home, SFO)'],\n", + " 'steps': [['Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)'], ['Taxi(Home, SFO)'], [], [], []],\n", + " 'precond': [['At(Home) & Have(Car)'], ['At(Home)'], ['At(Home) & Have(Car)'], ['At(SFOLongTermParking)'], ['At(Home)']],\n", + " 'effect': [['At(SFO) & ~At(Home)'], ['At(SFO) & ~At(Home) & ~Have(Cash)'], ['At(SFOLongTermParking) & ~At(Home)'], ['At(SFO) & ~At(LongTermParking)'], ['At(SFO) & ~At(Home) & ~Have(Cash)']] }\n", + "\n" + ] + }, + { + "cell_type": "markdown", + "id": "25cb5f05", + "metadata": {}, + "source": [ + "\n", + "the possible actions are the following:" + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "id": "bc4c515d", + "metadata": {}, + "outputs": [], + "source": [ + "go_SFO = HLA('Go(Home,SFO)', precond='At(Home)', effect='At(SFO) & ~At(Home)')\n", + "taxi_SFO = HLA('Taxi(Home,SFO)', precond='At(Home)', effect='At(SFO) & ~At(Home) & ~Have(Cash)')\n", + "drive_SFOLongTermParking = HLA('Drive(Home, SFOLongTermParking)', 'At(Home) & Have(Car)','At(SFOLongTermParking) & ~At(Home)' )\n", + "shuttle_SFO = HLA('Shuttle(SFOLongTermParking, SFO)', 'At(SFOLongTermParking)', 'At(SFO) & ~At(LongTermParking)')" + ] + }, + { + "cell_type": "markdown", + "id": "6243f681", + "metadata": {}, + "source": [ + "Suppose that (our preconditionds are that) we are Home and we have cash and car and our goal is to get to SFO and maintain our cash, and our possible actions are the above.
\n", + "##### Then our problem is: " + ] + }, + { + "cell_type": "code", + "execution_count": 6, + "id": "da7691f9", + "metadata": {}, + "outputs": [], + "source": [ + "prob = RealWorldPlanningProblem('At(Home) & Have(Cash) & Have(Car)', 'At(SFO) & Have(Cash)', [go_SFO])" + ] + }, + { + "cell_type": "markdown", + "id": "12c48b0c", + "metadata": {}, + "source": [ + "##### Refinements\n", + "\n", + "The refinements of the action Go(Home, SFO), are defined as:
\n", + "['Drive(Home,SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)'], ['Taxi(Home, SFO)']" + ] + }, + { + "cell_type": "code", + "execution_count": 7, + "id": "bb9ca2c5", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "[Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)]\n", + "[{'name': 'Drive', 'args': (Home, SFOLongTermParking), 'precond': [At(Home), Have(Car)], 'effect': [At(SFOLongTermParking), NotAt(Home)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}, {'name': 'Shuttle', 'args': (SFOLongTermParking, SFO), 'precond': [At(SFOLongTermParking)], 'effect': [At(SFO), NotAt(LongTermParking)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}] \n", + "\n", + "[Taxi(Home, SFO)]\n", + "[{'name': 'Taxi', 'args': (Home, SFO), 'precond': [At(Home)], 'effect': [At(SFO), NotAt(Home), NotHave(Cash)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}] \n", + "\n" + ] + } + ], + "source": [ + "for sequence in RealWorldPlanningProblem.refinements(go_SFO, library):\n", + " print (sequence)\n", + " print([x.__dict__ for x in sequence ], '\\n')" + ] + }, + { + "cell_type": "markdown", + "id": "2df36745", + "metadata": {}, + "source": [ + "Run the hierarchical search\n", + "##### Top level call" + ] + }, + { + "cell_type": "code", + "execution_count": 8, + "id": "24e6ecfb", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "hiearchy: {'HLA': ['Go(Home,SFO)', 'Go(Home,SFO)', 'Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)', 'Taxi(Home, SFO)'], 'steps': [['Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)'], ['Taxi(Home, SFO)'], [], [], []], 'precond': [['At(Home) & Have(Car)'], ['At(Home)'], ['At(Home) & Have(Car)'], ['At(SFOLongTermParking)'], ['At(Home)']], 'effect': [['At(SFO) & ~At(Home)'], ['At(SFO) & ~At(Home) & ~Have(Cash)'], ['At(SFOLongTermParking) & ~At(Home)'], ['At(SFO) & ~At(LongTermParking)'], ['At(SFO) & ~At(Home) & ~Have(Cash)']]}\n", + "frontier: [{'state': [At(Home), Have(Cash), Have(Car)], 'parent': None, 'action': [Go(Home, SFO)], 'path_cost': 0, 'depth': 0}]\n", + "Plan [Go(Home, SFO)] poped from frontier: []\n", + "Find HLA, get hla: Go(Home, SFO) and index: 0\n", + "prefix: []\n", + "Outcome: [At(Home), Have(Cash), Have(Car)]\n", + "suffix: []\n", + "Refinement(hla: Go(Home, SFO)) got sequence: [Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)]\n", + "frontier Added: {'state': [At(Home), Have(Cash), Have(Car)], 'parent':, 'action': [Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)], 'path_cost': 0, 'depth': 1}\n",
+ "Refinement(hla: Go(Home, SFO)) got sequence: [Taxi(Home, SFO)]\n",
+ "frontier Added: {'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Taxi(Home, SFO)], 'path_cost': 0, 'depth': 1}\n",
+ "Plan [Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)] poped from frontier: [{'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Taxi(Home, SFO)], 'path_cost': 0, 'depth': 1}]\n",
+ "Find HLA, get hla: None and index: 2\n",
+ "prefix: [Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)]\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFOLongTermParking), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(LongTermParking), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(LongTermParking)\n",
+ "lhs: [], rhs: NotAt(LongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Outcome: [Have(Cash), Have(Car), At(SFOLongTermParking), NotAt(Home), At(SFO), NotAt(LongTermParking)]\n",
+ "suffix: []\n",
+ "Outcome: [Have(Cash), Have(Car), At(SFOLongTermParking), NotAt(Home), At(SFO), NotAt(LongTermParking)] Goal Test Success, return Plan:1\n",
+ "[Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)] \n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "plan= RealWorldPlanningProblem.hierarchical_search(prob, library)\n",
+ "print (plan, '\\n')\n",
+ "# print ([x.__dict__ for x in plan])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ae143c3",
+ "metadata": {},
+ "source": [
+ "#### Example 2"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "0d401bf5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "library_2 = {\n",
+ " 'HLA': ['Go(Home,SFO)', 'Go(Home,SFO)', 'Bus(Home, MetroStop)', 'Metro(MetroStop, SFO)' , 'Metro(MetroStop, SFO)', 'Metro1(MetroStop, SFO)', 'Metro2(MetroStop, SFO)' ,'Taxi(Home, SFO)'],\n",
+ " 'steps': [['Bus(Home, MetroStop)', 'Metro(MetroStop, SFO)'], ['Taxi(Home, SFO)'], [], ['Metro1(MetroStop, SFO)'], ['Metro2(MetroStop, SFO)'],[],[],[]],\n",
+ " 'precond': [['At(Home)'], ['At(Home)'], ['At(Home)'], ['At(MetroStop)'], ['At(MetroStop)'],['At(MetroStop)'], ['At(MetroStop)'] ,['At(Home) & Have(Cash)']],\n",
+ " 'effect': [['At(SFO) & ~At(Home)'], ['At(SFO) & ~At(Home) & ~Have(Cash)'], ['At(MetroStop) & ~At(Home)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(MetroStop)'] , ['At(SFO) & ~At(MetroStop)'] ,['At(SFO) & ~At(Home) & ~Have(Cash)']] \n",
+ " }"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "e39ea556",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "hiearchy: {'HLA': ['Go(Home,SFO)', 'Go(Home,SFO)', 'Bus(Home, MetroStop)', 'Metro(MetroStop, SFO)', 'Metro(MetroStop, SFO)', 'Metro1(MetroStop, SFO)', 'Metro2(MetroStop, SFO)', 'Taxi(Home, SFO)'], 'steps': [['Bus(Home, MetroStop)', 'Metro(MetroStop, SFO)'], ['Taxi(Home, SFO)'], [], ['Metro1(MetroStop, SFO)'], ['Metro2(MetroStop, SFO)'], [], [], []], 'precond': [['At(Home)'], ['At(Home)'], ['At(Home)'], ['At(MetroStop)'], ['At(MetroStop)'], ['At(MetroStop)'], ['At(MetroStop)'], ['At(Home) & Have(Cash)']], 'effect': [['At(SFO) & ~At(Home)'], ['At(SFO) & ~At(Home) & ~Have(Cash)'], ['At(MetroStop) & ~At(Home)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(Home) & ~Have(Cash)']]}\n",
+ "frontier: [{'state': [At(Home), Have(Cash), Have(Car)], 'parent': None, 'action': [Go(Home, SFO)], 'path_cost': 0, 'depth': 0}]\n",
+ "Plan [Go(Home, SFO)] poped from frontier: []\n",
+ "Find HLA, get hla: Go(Home, SFO) and index: 0\n",
+ "prefix: []\n",
+ "Outcome: [At(Home), Have(Cash), Have(Car)]\n",
+ "suffix: []\n",
+ "Refinement(hla: Go(Home, SFO)) got sequence: [Bus(Home, MetroStop), Metro(MetroStop, SFO)]\n",
+ "frontier Added: {'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Bus(Home, MetroStop), Metro(MetroStop, SFO)], 'path_cost': 0, 'depth': 1}\n",
+ "Refinement(hla: Go(Home, SFO)) got sequence: [Taxi(Home, SFO)]\n",
+ "frontier Added: {'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Taxi(Home, SFO)], 'path_cost': 0, 'depth': 1}\n",
+ "Plan [Bus(Home, MetroStop), Metro(MetroStop, SFO)] poped from frontier: [{'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Taxi(Home, SFO)], 'path_cost': 0, 'depth': 1}]\n",
+ "Find HLA, get hla: Metro(MetroStop, SFO) and index: 1\n",
+ "prefix: [Bus(Home, MetroStop)]\n",
+ "Starting Back Or with (KB, Goal: NotAt(MetroStop), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Outcome: [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)]\n",
+ "suffix: []\n",
+ "Refinement(hla: Metro(MetroStop, SFO)) got sequence: [Metro1(MetroStop, SFO)]\n",
+ "frontier Added: {'state': [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)], 'parent': , 'action': [Bus(Home, MetroStop), Metro1(MetroStop, SFO)], 'path_cost': 0, 'depth': 2}\n",
+ "Refinement(hla: Metro(MetroStop, SFO)) got sequence: [Metro2(MetroStop, SFO)]\n",
+ "frontier Added: {'state': [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)], 'parent': , 'action': [Bus(Home, MetroStop), Metro2(MetroStop, SFO)], 'path_cost': 0, 'depth': 2}\n",
+ "Plan [Taxi(Home, SFO)] poped from frontier: [{'state': [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)], 'parent': , 'action': [Bus(Home, MetroStop), Metro1(MetroStop, SFO)], 'path_cost': 0, 'depth': 2}, {'state': [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)], 'parent': , 'action': [Bus(Home, MetroStop), Metro2(MetroStop, SFO)], 'path_cost': 0, 'depth': 2}]\n",
+ "Find HLA, get hla: None and index: 1\n",
+ "prefix: [Taxi(Home, SFO)]\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: Have(Cash), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Outcome: [Have(Car), At(SFO), NotAt(Home), NotHave(Cash)]\n",
+ "suffix: []\n",
+ "Plan [Bus(Home, MetroStop), Metro1(MetroStop, SFO)] poped from frontier: [{'state': [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)], 'parent': , 'action': [Bus(Home, MetroStop), Metro2(MetroStop, SFO)], 'path_cost': 0, 'depth': 2}]\n",
+ "Find HLA, get hla: None and index: 2\n",
+ "prefix: [Bus(Home, MetroStop), Metro1(MetroStop, SFO)]\n",
+ "Starting Back Or with (KB, Goal: NotAt(MetroStop), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(MetroStop), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Outcome: [Have(Cash), Have(Car), NotAt(Home), At(SFO), NotAt(MetroStop)]\n",
+ "suffix: []\n",
+ "Outcome: [Have(Cash), Have(Car), NotAt(Home), At(SFO), NotAt(MetroStop)] Goal Test Success, return Plan:1\n",
+ "[Bus(Home, MetroStop), Metro1(MetroStop, SFO)] \n",
+ "\n",
+ "[{'name': 'Bus', 'args': (Home, MetroStop), 'precond': [At(Home)], 'effect': [At(MetroStop), NotAt(Home)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}, {'name': 'Metro1', 'args': (MetroStop, SFO), 'precond': [At(MetroStop)], 'effect': [At(SFO), NotAt(MetroStop)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}]\n"
+ ]
+ }
+ ],
+ "source": [
+ "plan_2 = RealWorldPlanningProblem.hierarchical_search(prob, library_2)\n",
+ "print(plan_2, '\\n')\n",
+ "print([x.__dict__ for x in plan_2])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f783d6b5",
+ "metadata": {},
+ "source": [
+ "# Angelic Search \n",
+ "\n",
+ "Search using angelic semantics (is a hierarchical search), where the agent chooses the implementation of the HLA's.
\n", + "The algorithms input is: problem, hierarchy and initialPlan\n", + "- problem is of type Problem \n", + "- hierarchy is a dictionary consisting of all the actions. \n", + "- initialPlan is an approximate description(optimistic and pessimistic) of the agents choices for the implementation.
\n", + " initialPlan contains a sequence of HLA's with angelic semantics" + ] + }, + { + "cell_type": "markdown", + "id": "5aaf33f1", + "metadata": {}, + "source": [ + "The Angelic search algorithm consists of three parts. \n", + "- Search using angelic semantics\n", + "- Decompose\n", + "- a search in the space of refinements, in a similar way with hierarchical search\n", + "\n", + "### Searching using angelic semantics\n", + "- Find the reachable set (optimistic and pessimistic) of the sequence of angelic HLA in initialPlan\n", + " - If the optimistic reachable set doesn't intersect the goal, then there is no solution\n", + " - If the pessimistic reachable set intersects the goal, then we call decompose, in order to find the sequence of actions that lead us to the goal. \n", + " - If the optimistic reachable set intersects the goal, but the pessimistic doesn't we do some further refinements, in order to see if there is a sequence of actions that achieves the goal. \n", + " \n", + "### Search in space of refinements\n", + "- Create a search tree, that has root the action and children it's refinements\n", + "- Extend frontier by adding each refinement, so that we keep looping till we find all primitive actions\n", + "- If we achieve that we return the path of the solution (search tree), else there is no solution and we return None.\n", + "\n", + " \n" + ] + }, + { + "cell_type": "code", + "execution_count": 11, + "id": "9b887131", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(RealWorldPlanningProblem.angelic_search)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e8acbb7b",
+ "metadata": {},
+ "source": [
+ "\n",
+ "### Decompose \n",
+ "- Finds recursively the sequence of states and actions that lead us from initial state to goal.\n",
+ "- For each of the above actions we find their refinements,if they are not primitive, by calling the angelic_search function. \n",
+ " If there are not refinements return None\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "e03db010",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(RealWorldPlanningProblem.decompose)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "801c154f",
+ "metadata": {},
+ "source": [
+ "## Example\n",
+ "\n",
+ "Suppose that somebody wants to get to the airport. \n",
+ "The possible ways to do so is either get a taxi, or drive to the airport.
\n", + "Those two actions have some preconditions and some effects. \n", + "If you get the taxi, you need to have cash, whereas if you drive you need to have a car.
\n", + "Thus we define the following hierarchy of possible actions.\n", + "\n", + "##### hierarchy" + ] + }, + { + "cell_type": "code", + "execution_count": 13, + "id": "97ffa15f", + "metadata": {}, + "outputs": [], + "source": [ + "library = {\n", + " 'HLA': ['Go(Home,SFO)', 'Go(Home,SFO)', 'Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)', 'Taxi(Home, SFO)'],\n", + " 'steps': [['Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)'], ['Taxi(Home, SFO)'], [], [], []],\n", + " 'precond': [['At(Home) & Have(Car)'], ['At(Home)'], ['At(Home) & Have(Car)'], ['At(SFOLongTermParking)'], ['At(Home)']],\n", + " 'effect': [['At(SFO) & ~At(Home)'], ['At(SFO) & ~At(Home) & ~Have(Cash)'], ['At(SFOLongTermParking) & ~At(Home)'], ['At(SFO) & ~At(LongTermParking)'], ['At(SFO) & ~At(Home) & ~Have(Cash)']] }\n", + "\n" + ] + }, + { + "cell_type": "markdown", + "id": "d912e517", + "metadata": {}, + "source": [ + "\n", + "the possible actions are the following:" + ] + }, + { + "cell_type": "code", + "execution_count": 14, + "id": "87d6db03", + "metadata": {}, + "outputs": [], + "source": [ + "go_SFO = HLA('Go(Home,SFO)', precond='At(Home)', effect='At(SFO) & ~At(Home)')\n", + "taxi_SFO = HLA('Taxi(Home,SFO)', precond='At(Home)', effect='At(SFO) & ~At(Home) & ~Have(Cash)')\n", + "drive_SFOLongTermParking = HLA('Drive(Home, SFOLongTermParking)', 'At(Home) & Have(Car)','At(SFOLongTermParking) & ~At(Home)' )\n", + "shuttle_SFO = HLA('Shuttle(SFOLongTermParking, SFO)', 'At(SFOLongTermParking)', 'At(SFO) & ~At(LongTermParking)')" + ] + }, + { + "cell_type": "markdown", + "id": "832cedc9", + "metadata": {}, + "source": [ + "Suppose that (our preconditionds are that) we are Home and we have cash and car and our goal is to get to SFO and maintain our cash, and our possible actions are the above.
\n", + "##### Then our problem is: " + ] + }, + { + "cell_type": "code", + "execution_count": 15, + "id": "9e61456f", + "metadata": {}, + "outputs": [], + "source": [ + "prob = RealWorldPlanningProblem('At(Home) & Have(Cash) & Have(Car)', 'At(SFO) & Have(Cash)', [go_SFO, taxi_SFO, drive_SFOLongTermParking,shuttle_SFO])" + ] + }, + { + "cell_type": "markdown", + "id": "a809fea4", + "metadata": {}, + "source": [ + "An agent gives us some approximate information about the plan we will follow:
\n", + "(initialPlan is an Angelic Node, where: \n", + "- state is the initial state of the problem, \n", + "- parent is None \n", + "- action: is a list of actions (Angelic HLA's) with the optimistic estimators of effects and \n", + "- action_pes: is a list of actions (Angelic HLA's) with the pessimistic approximations of the effects\n", + "##### InitialPlan" + ] + }, + { + "cell_type": "code", + "execution_count": 16, + "id": "984769d1", + "metadata": {}, + "outputs": [], + "source": [ + "angelic_opt_description = AngelicHLA('Go(Home, SFO)', precond = 'At(Home)', effect ='$+At(SFO) & $-At(Home)' ) \n", + "angelic_pes_description = AngelicHLA('Go(Home, SFO)', precond = 'At(Home)', effect ='$+At(SFO) & ~At(Home)' )\n", + "\n", + "initialPlan = [AngelicNode(prob.initial, None, [angelic_opt_description], [angelic_pes_description])] \n" + ] + }, + { + "cell_type": "markdown", + "id": "65bbf9dd", + "metadata": {}, + "source": [ + "We want to find the optimistic and pessimistic reachable set of initialPlan when applied to the problem:\n", + "##### Optimistic/Pessimistic reachable set" + ] + }, + { + "cell_type": "code", + "execution_count": 17, + "id": "0ee43042", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "[[At(Home), Have(Cash), Have(Car)], [Have(Cash), Have(Car), At(SFO), NotAt(Home)], [Have(Cash), Have(Car), NotAt(Home)], [At(Home), Have(Cash), Have(Car), At(SFO)], [At(Home), Have(Cash), Have(Car)]] \n", + "\n", + "[[At(Home), Have(Cash), Have(Car)], [Have(Cash), Have(Car), At(SFO), NotAt(Home)], [Have(Cash), Have(Car), NotAt(Home)]]\n" + ] + } + ], + "source": [ + "opt_reachable_set = RealWorldPlanningProblem.reach_opt(prob.initial, initialPlan[0])\n", + "pes_reachable_set = RealWorldPlanningProblem.reach_pes(prob.initial, initialPlan[0])\n", + "print([x for y in opt_reachable_set.keys() for x in opt_reachable_set[y]], '\\n')\n", + "print([x for y in pes_reachable_set.keys() for x in pes_reachable_set[y]])" + ] + }, + { + "cell_type": "markdown", + "id": "811d4137", + "metadata": {}, + "source": [ + "##### Refinements\n" + ] + }, + { + "cell_type": "code", + "execution_count": 18, + "id": "d4987f07", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "[Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)]\n", + "[{'name': 'Drive', 'args': (Home, SFOLongTermParking), 'precond': [At(Home), Have(Car)], 'effect': [At(SFOLongTermParking), NotAt(Home)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}, {'name': 'Shuttle', 'args': (SFOLongTermParking, SFO), 'precond': [At(SFOLongTermParking)], 'effect': [At(SFO), NotAt(LongTermParking)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}] \n", + "\n", + "[Taxi(Home, SFO)]\n", + "[{'name': 'Taxi', 'args': (Home, SFO), 'precond': [At(Home)], 'effect': [At(SFO), NotAt(Home), NotHave(Cash)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}] \n", + "\n" + ] + } + ], + "source": [ + "for sequence in RealWorldPlanningProblem.refinements(go_SFO, library):\n", + " print (sequence)\n", + " print([x.__dict__ for x in sequence ], '\\n')" + ] + }, + { + "cell_type": "markdown", + "id": "1a3efdb7", + "metadata": {}, + "source": [ + "Run the angelic search\n", + "##### Top level call" + ] + }, + { + "cell_type": "code", + "execution_count": 19, + "id": "41f17476", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "\n", + "\n", + "Plan [Go(Home, SFO)] poped from frontier: []\n", + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Opt Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(SFO), NotAt(Home)], [Have(Cash), Have(Car), NotAt(Home)], [At(Home), Have(Cash), Have(Car), At(SFO)], [At(Home), Have(Cash), Have(Car)]]}\n", + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Pes Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(SFO), NotAt(Home)], [Have(Cash), Have(Car), NotAt(Home)]]}\n", + "Opt Reachable Set intersects with Goal.\n", + "Pes Reachable Set intersects with Goal, get Guaranteed: [[Have(Cash), Have(Car), At(SFO), NotAt(Home)]]\n", + "Running Making-Progress: Plan: is same with Initial Plan: []\n",
+ "Find HLA: Go(Home, SFO) in plan: \n",
+ "Prefix: []\n",
+ "suffix: []\n",
+ "Outcome: [At(Home), Have(Cash), Have(Car)]\n",
+ "Refinement(hla: Go(Home, SFO)) got sequence: [Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)]\n",
+ "frontier Added: {'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)], 'path_cost': 0, 'depth': 1, 'action_pes': [Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)]}\n",
+ "Refinement(hla: Go(Home, SFO)) got sequence: [Taxi(Home, SFO)]\n",
+ "frontier Added: {'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Taxi(Home, SFO)], 'path_cost': 0, 'depth': 1, 'action_pes': [Taxi(Home, SFO)]}\n",
+ "\n",
+ "\n",
+ "Plan [Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)] poped from frontier: [{'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Taxi(Home, SFO)], 'path_cost': 0, 'depth': 1, 'action_pes': [Taxi(Home, SFO)]}]\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFOLongTermParking), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(LongTermParking), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(LongTermParking)\n",
+ "lhs: [], rhs: NotAt(LongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Opt Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(SFOLongTermParking), NotAt(Home)]], 2: [[Have(Cash), Have(Car), At(SFOLongTermParking), NotAt(Home), At(SFO), NotAt(LongTermParking)]]}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFOLongTermParking), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(LongTermParking), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(LongTermParking)\n",
+ "lhs: [], rhs: NotAt(LongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Pes Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(SFOLongTermParking), NotAt(Home)]], 2: [[Have(Cash), Have(Car), At(SFOLongTermParking), NotAt(Home), At(SFO), NotAt(LongTermParking)]]}\n",
+ "Opt Reachable Set intersects with Goal.\n",
+ "Plan is premitive, return plan\n",
+ "[Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)] \n",
+ "\n",
+ "[{'name': 'Drive', 'args': (Home, SFOLongTermParking), 'precond': [At(Home), Have(Car)], 'effect': [At(SFOLongTermParking), NotAt(Home)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}, {'name': 'Shuttle', 'args': (SFOLongTermParking, SFO), 'precond': [At(SFOLongTermParking)], 'effect': [At(SFO), NotAt(LongTermParking)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}]\n"
+ ]
+ }
+ ],
+ "source": [
+ "plan= RealWorldPlanningProblem.angelic_search(prob, library, initialPlan)\n",
+ "print (plan, '\\n')\n",
+ "print ([x.__dict__ for x in plan])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "697a8471",
+ "metadata": {},
+ "source": [
+ "## Example 2"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 20,
+ "id": "5e2b4d76",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "HLA:['Go(Home,SFO)', 'Go(Home,SFO)', 'Bus(Home, MetroStop)', 'Metro(MetroStop, SFO)', 'Metro(MetroStop, SFO)', 'Metro1(MetroStop, SFO)', 'Metro2(MetroStop, SFO)', 'Taxi(Home, SFO)'] \n",
+ "\n",
+ "steps:[['Bus(Home, MetroStop)', 'Metro(MetroStop, SFO)'], ['Taxi(Home, SFO)'], [], ['Metro1(MetroStop, SFO)'], ['Metro2(MetroStop, SFO)'], [], [], []] \n",
+ "\n",
+ "precond:[['At(Home)'], ['At(Home)'], ['At(Home)'], ['At(MetroStop)'], ['At(MetroStop)'], ['At(MetroStop)'], ['At(MetroStop)'], ['At(Home) & Have(Cash)']] \n",
+ "\n",
+ "effect:[['At(SFO) & ~At(Home)'], ['At(SFO) & ~At(Home) & ~Have(Cash)'], ['At(MetroStop) & ~At(Home)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(Home) & ~Have(Cash)']] \n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "library_2 = {\n",
+ " 'HLA': ['Go(Home,SFO)', 'Go(Home,SFO)', 'Bus(Home, MetroStop)', 'Metro(MetroStop, SFO)' , 'Metro(MetroStop, SFO)', 'Metro1(MetroStop, SFO)', 'Metro2(MetroStop, SFO)' ,'Taxi(Home, SFO)'],\n",
+ " 'steps': [['Bus(Home, MetroStop)', 'Metro(MetroStop, SFO)'], ['Taxi(Home, SFO)'], [], ['Metro1(MetroStop, SFO)'], ['Metro2(MetroStop, SFO)'],[],[],[]],\n",
+ " 'precond': [['At(Home)'], ['At(Home)'], ['At(Home)'], ['At(MetroStop)'], ['At(MetroStop)'],['At(MetroStop)'], ['At(MetroStop)'] ,['At(Home) & Have(Cash)']],\n",
+ " 'effect': [['At(SFO) & ~At(Home)'], ['At(SFO) & ~At(Home) & ~Have(Cash)'], ['At(MetroStop) & ~At(Home)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(MetroStop)'], ['At(SFO) & ~At(MetroStop)'] , ['At(SFO) & ~At(MetroStop)'] ,['At(SFO) & ~At(Home) & ~Have(Cash)']] \n",
+ " }\n",
+ "for l in library_2:\n",
+ " print(f\"{l}:{library_2[l]}\", \"\\n\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 21,
+ "id": "652f3c41",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\n",
+ "\n",
+ "Plan [Go(Home, SFO)] poped from frontier: []\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Opt Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(SFO), NotAt(Home)], [Have(Cash), Have(Car), NotAt(Home)], [At(Home), Have(Cash), Have(Car), At(SFO)], [At(Home), Have(Cash), Have(Car)]]}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Pes Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(SFO), NotAt(Home)], [Have(Cash), Have(Car), NotAt(Home)]]}\n",
+ "Opt Reachable Set intersects with Goal.\n",
+ "Pes Reachable Set intersects with Goal, get Guaranteed: [[Have(Cash), Have(Car), At(SFO), NotAt(Home)]]\n",
+ "Running Making-Progress: Plan: is same with Initial Plan: []\n",
+ "Find HLA: Go(Home, SFO) in plan: \n",
+ "Prefix: []\n",
+ "suffix: []\n",
+ "Outcome: [At(Home), Have(Cash), Have(Car)]\n",
+ "Refinement(hla: Go(Home, SFO)) got sequence: [Bus(Home, MetroStop), Metro(MetroStop, SFO)]\n",
+ "frontier Added: {'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Bus(Home, MetroStop), Metro(MetroStop, SFO)], 'path_cost': 0, 'depth': 1, 'action_pes': [Bus(Home, MetroStop), Metro(MetroStop, SFO)]}\n",
+ "Refinement(hla: Go(Home, SFO)) got sequence: [Taxi(Home, SFO)]\n",
+ "frontier Added: {'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Taxi(Home, SFO)], 'path_cost': 0, 'depth': 1, 'action_pes': [Taxi(Home, SFO)]}\n",
+ "\n",
+ "\n",
+ "Plan [Bus(Home, MetroStop), Metro(MetroStop, SFO)] poped from frontier: [{'state': [At(Home), Have(Cash), Have(Car)], 'parent': , 'action': [Taxi(Home, SFO)], 'path_cost': 0, 'depth': 1, 'action_pes': [Taxi(Home, SFO)]}]\n",
+ "Starting Back Or with (KB, Goal: NotAt(MetroStop), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(MetroStop), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Opt Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(MetroStop), NotAt(Home)]], 2: [[Have(Cash), Have(Car), NotAt(Home), At(SFO), NotAt(MetroStop)]]}\n",
+ "Starting Back Or with (KB, Goal: NotAt(MetroStop), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(MetroStop), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Pes Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(MetroStop), NotAt(Home)]], 2: [[Have(Cash), Have(Car), NotAt(Home), At(SFO), NotAt(MetroStop)]]}\n",
+ "Opt Reachable Set intersects with Goal.\n",
+ "Pes Reachable Set intersects with Goal, get Guaranteed: [[Have(Cash), Have(Car), NotAt(Home), At(SFO), NotAt(MetroStop)]]\n",
+ "Running Making-Progress: Plan: is same with Initial Plan: []\n",
+ "Find HLA: Metro(MetroStop, SFO) in plan: \n",
+ "Prefix: [Bus(Home, MetroStop)]\n",
+ "suffix: []\n",
+ "Starting Back Or with (KB, Goal: NotAt(MetroStop), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Outcome: [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)]\n",
+ "Refinement(hla: Metro(MetroStop, SFO)) got sequence: [Metro1(MetroStop, SFO)]\n",
+ "frontier Added: {'state': [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)], 'parent': , 'action': [Bus(Home, MetroStop), Metro1(MetroStop, SFO)], 'path_cost': 0, 'depth': 2, 'action_pes': [Bus(Home, MetroStop), Metro1(MetroStop, SFO)]}\n",
+ "Refinement(hla: Metro(MetroStop, SFO)) got sequence: [Metro2(MetroStop, SFO)]\n",
+ "frontier Added: {'state': [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)], 'parent': , 'action': [Bus(Home, MetroStop), Metro2(MetroStop, SFO)], 'path_cost': 0, 'depth': 2, 'action_pes': [Bus(Home, MetroStop), Metro2(MetroStop, SFO)]}\n",
+ "\n",
+ "\n",
+ "Plan [Taxi(Home, SFO)] poped from frontier: [{'state': [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)], 'parent': , 'action': [Bus(Home, MetroStop), Metro1(MetroStop, SFO)], 'path_cost': 0, 'depth': 2, 'action_pes': [Bus(Home, MetroStop), Metro1(MetroStop, SFO)]}, {'state': [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)], 'parent': , 'action': [Bus(Home, MetroStop), Metro2(MetroStop, SFO)], 'path_cost': 0, 'depth': 2, 'action_pes': [Bus(Home, MetroStop), Metro2(MetroStop, SFO)]}]\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: Have(Cash), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Opt Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Car), At(SFO), NotAt(Home), NotHave(Cash)]]}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: Have(Cash), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Pes Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Car), At(SFO), NotAt(Home), NotHave(Cash)]]}\n",
+ "\n",
+ "\n",
+ "Plan [Bus(Home, MetroStop), Metro1(MetroStop, SFO)] poped from frontier: [{'state': [Have(Cash), Have(Car), At(MetroStop), NotAt(Home)], 'parent': , 'action': [Bus(Home, MetroStop), Metro2(MetroStop, SFO)], 'path_cost': 0, 'depth': 2, 'action_pes': [Bus(Home, MetroStop), Metro2(MetroStop, SFO)]}]\n",
+ "Starting Back Or with (KB, Goal: NotAt(MetroStop), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(MetroStop), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Opt Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(MetroStop), NotAt(Home)]], 2: [[Have(Cash), Have(Car), NotAt(Home), At(SFO), NotAt(MetroStop)]]}\n",
+ "Starting Back Or with (KB, Goal: NotAt(MetroStop), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(Home), theta: {})\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: NotAt(Home)\n",
+ "lhs: [], rhs: NotAt(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(MetroStop), theta: {})\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Car)\n",
+ "lhs: [], rhs: Have(Car)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(MetroStop)\n",
+ "lhs: [], rhs: At(MetroStop)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Pes Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(MetroStop), NotAt(Home)]], 2: [[Have(Cash), Have(Car), NotAt(Home), At(SFO), NotAt(MetroStop)]]}\n",
+ "Opt Reachable Set intersects with Goal.\n",
+ "Plan is premitive, return plan\n",
+ "[Bus(Home, MetroStop), Metro1(MetroStop, SFO)] \n",
+ "\n",
+ "[{'name': 'Bus', 'args': (Home, MetroStop), 'precond': [At(Home)], 'effect': [At(MetroStop), NotAt(Home)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}, {'name': 'Metro1', 'args': (MetroStop, SFO), 'precond': [At(MetroStop)], 'effect': [At(SFO), NotAt(MetroStop)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}]\n"
+ ]
+ }
+ ],
+ "source": [
+ "plan_2 = RealWorldPlanningProblem.angelic_search(prob, library_2, initialPlan)\n",
+ "print(plan_2, '\\n')\n",
+ "print([x.__dict__ for x in plan_2])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e99a8fed",
+ "metadata": {},
+ "source": [
+ "## Example 3 \n",
+ "\n",
+ "Sometimes there is no plan that achieves the goal!"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 22,
+ "id": "73ac184b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "library_3 = {\n",
+ " 'HLA': ['Shuttle(SFOLongTermParking, SFO)', 'Go(Home, SFOLongTermParking)', 'Taxi(Home, SFOLongTermParking)', 'Drive(Home, SFOLongTermParking)', 'Drive(SFOLongTermParking, Home)', 'Get(Cash)', 'Go(Home, ATM)'],\n",
+ " 'steps': [['Get(Cash)', 'Go(Home, SFOLongTermParking)'], ['Taxi(Home, SFOLongTermParking)'], [], [], [], ['Drive(SFOLongTermParking, Home)', 'Go(Home, ATM)'], []],\n",
+ " 'precond': [['At(SFOLongTermParking)'], ['At(Home)'], ['At(Home) & Have(Cash)'], ['At(Home)'], ['At(SFOLongTermParking)'], ['At(SFOLongTermParking)'], ['At(Home)']],\n",
+ " 'effect': [['At(SFO)'], ['At(SFO)'], ['At(SFOLongTermParking) & ~Have(Cash)'], ['At(SFOLongTermParking)'] ,['At(Home) & ~At(SFOLongTermParking)'], ['At(Home) & Have(Cash)'], ['Have(Cash)'] ]\n",
+ " }\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 23,
+ "id": "0d61b5c9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "shuttle_SFO = HLA('Shuttle(SFOLongTermParking, SFO)', 'Have(Cash) & At(SFOLongTermParking)', 'At(SFO)')\n",
+ "prob_3 = RealWorldPlanningProblem('At(SFOLongTermParking) & Have(Cash)', 'At(SFO) & Have(Cash)', [shuttle_SFO])\n",
+ "# optimistic/pessimistic descriptions\n",
+ "angelic_opt_description = AngelicHLA('Shuttle(SFOLongTermParking, SFO)', precond = 'At(SFOLongTermParking)', effect ='$+At(SFO) & $-At(SFOLongTermParking)' ) \n",
+ "angelic_pes_description = AngelicHLA('Shuttle(SFOLongTermParking, SFO)', precond = 'At(SFOLongTermParking)', effect ='$+At(SFO) & ~At(SFOLongTermParking)' ) \n",
+ "# initial Plan\n",
+ "initialPlan_3 = [AngelicNode(prob.initial, None, [angelic_opt_description], [angelic_pes_description])] "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 24,
+ "id": "ea782bd5",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\n",
+ "\n",
+ "Plan [Shuttle(SFOLongTermParking, SFO)] poped from frontier: []\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(SFOLongTermParking), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: At(SFOLongTermParking), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Opt Reachable Set: {0: [[At(SFOLongTermParking), Have(Cash)]], 1: [[Have(Cash), At(SFO), NotAt(SFOLongTermParking)], [Have(Cash), NotAt(SFOLongTermParking)], [At(SFOLongTermParking), Have(Cash), At(SFO)], [At(SFOLongTermParking), Have(Cash)]]}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: At(SFOLongTermParking), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Starting Back Or with (KB, Goal: At(SFOLongTermParking), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Pes Reachable Set: {0: [[At(SFOLongTermParking), Have(Cash)]], 1: [[Have(Cash), At(SFO), NotAt(SFOLongTermParking)], [Have(Cash), NotAt(SFOLongTermParking)]]}\n",
+ "Opt Reachable Set intersects with Goal.\n",
+ "Pes Reachable Set intersects with Goal, get Guaranteed: [[Have(Cash), At(SFO), NotAt(SFOLongTermParking)]]\n",
+ "Running Making-Progress: Plan: is same with Initial Plan: []\n",
+ "Find HLA: Shuttle(SFOLongTermParking, SFO) in plan: \n",
+ "Prefix: []\n",
+ "suffix: []\n",
+ "Outcome: [At(SFOLongTermParking), Have(Cash)]\n",
+ "Refinement(hla: Shuttle(SFOLongTermParking, SFO)) got sequence: [Get(Cash), Go(Home, SFOLongTermParking)]\n",
+ "frontier Added: {'state': [At(SFOLongTermParking), Have(Cash)], 'parent': , 'action': [Get(Cash), Go(Home, SFOLongTermParking)], 'path_cost': 0, 'depth': 1, 'action_pes': [Get(Cash), Go(Home, SFOLongTermParking)]}\n",
+ "\n",
+ "\n",
+ "Plan [Get(Cash), Go(Home, SFOLongTermParking)] poped from frontier: []\n",
+ "Starting Back Or with (KB, Goal: NotAt(Home), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: NotHave(Cash), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: NotAt(Home), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: NotHave(Cash), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Opt Reachable Set: {0: [[At(SFOLongTermParking), Have(Cash)]], 1: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]], 2: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(Home), Have(Cash)], [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)]]}\n",
+ "Starting Back Or with (KB, Goal: NotAt(Home), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: NotHave(Cash), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: NotAt(Home), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: NotHave(Cash), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Pes Reachable Set: {0: [[At(SFOLongTermParking), Have(Cash)]], 1: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]], 2: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(Home), Have(Cash)], [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)]]}\n",
+ "Opt Reachable Set intersects with Goal.\n",
+ "Pes Reachable Set intersects with Goal, get Guaranteed: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)]]\n",
+ "guaranteed: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)]] not empty and Making-Progress\n",
+ "final_state: [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)]\n",
+ "Running Decompose with hierarchy, plan: , final_state: [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)], reachable_set: {0: [[At(SFOLongTermParking), Have(Cash)]], 1: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]], 2: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(Home), Have(Cash)], [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)]]}\n",
+ "Pop action: Go(Home, SFOLongTermParking) from Plan: [Get(Cash)]\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Find Previous state: [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]\n",
+ "Define problem with initial s_i: [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)] and goal s_f: [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)]\n",
+ "\n",
+ "\n",
+ "Plan [Go(Home, SFOLongTermParking)] poped from frontier: []\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Opt Reachable Set: {0: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]], 1: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)]]}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFO)\n",
+ "lhs: [], rhs: At(SFO)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Pes Reachable Set: {0: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]], 1: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)]]}\n",
+ "Opt Reachable Set intersects with Goal.\n",
+ "Pes Reachable Set intersects with Goal, get Guaranteed: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash), At(SFO)]]\n",
+ "Running Making-Progress: Plan: is same with Initial Plan: []\n",
+ "Find HLA: Go(Home, SFOLongTermParking) in plan: \n",
+ "Prefix: []\n",
+ "suffix: []\n",
+ "Outcome: [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]\n",
+ "Refinement(hla: Go(Home, SFOLongTermParking)) got sequence: [Taxi(Home, SFOLongTermParking)]\n",
+ "frontier Added: {'state': [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)], 'parent': , 'action': [Taxi(Home, SFOLongTermParking)], 'path_cost': 0, 'depth': 2, 'action_pes': [Taxi(Home, SFOLongTermParking)]}\n",
+ "Refinement(hla: Go(Home, SFOLongTermParking)) got sequence: []\n",
+ "frontier Added: {'state': [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)], 'parent': , 'action': [], 'path_cost': 0, 'depth': 2, 'action_pes': []}\n",
+ "\n",
+ "\n",
+ "Plan [Taxi(Home, SFOLongTermParking)] poped from frontier: [{'state': [At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)], 'parent': , 'action': [], 'path_cost': 0, 'depth': 2, 'action_pes': []}]\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFOLongTermParking), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: Have(Cash), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Opt Reachable Set: {0: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]], 1: [[At(SFOLongTermParking), At(Home), Have(Cash), At(SFOLongTermParking), NotHave(Cash)]]}\n",
+ "Starting Back Or with (KB, Goal: NotAt(SFOLongTermParking), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(Home)\n",
+ "lhs: [], rhs: At(Home)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Starting Back Or with (KB, Goal: Have(Cash), theta: {})\n",
+ "Processing Rule: At(SFOLongTermParking)\n",
+ "lhs: [], rhs: At(SFOLongTermParking)\n",
+ "Starting Back And with (KB, Goals: [], theta: None)\n",
+ "theta is None, pass\n",
+ "Processing Rule: Have(Cash)\n",
+ "lhs: [], rhs: Have(Cash)\n",
+ "Starting Back And with (KB, Goals: [], theta: {})\n",
+ "Length(goals)=0, yield theta: {}\n",
+ "Pes Reachable Set: {0: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]], 1: [[At(SFOLongTermParking), At(Home), Have(Cash), At(SFOLongTermParking), NotHave(Cash)]]}\n",
+ "\n",
+ "\n",
+ "Plan [] poped from frontier: []\n",
+ "Opt Reachable Set: {0: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]]}\n",
+ "Pes Reachable Set: {0: [[At(SFOLongTermParking), Have(Cash), At(Home), Have(Cash)]]}\n",
+ "Run Angelic Search, get None\n",
+ "None\n"
+ ]
+ }
+ ],
+ "source": [
+ "plan_3 = RealWorldPlanningProblem.angelic_search(prob_3, library_3, initialPlan_3)\n",
+ "print(plan_3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fac09de7",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-12-Quantifying-Uncertainty.ipynb b/Chapter-12-Quantifying-Uncertainty.ipynb
new file mode 100644
index 000000000..68d24b820
--- /dev/null
+++ b/Chapter-12-Quantifying-Uncertainty.ipynb
@@ -0,0 +1,1165 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "ecfa97b0",
+ "metadata": {},
+ "source": [
+ "# Probability "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "96757cab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from probability import *\n",
+ "from utils import print_table\n",
+ "from notebook import psource, pseudocode, heatmap"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6e6f77d0",
+ "metadata": {},
+ "source": [
+ "## PROBABILITY DISTRIBUTION\n",
+ "\n",
+ "Let us begin by specifying discrete probability distributions. The class **ProbDist** defines a discrete probability distribution. We name our random variable and then assign probabilities to the different values of the random variable. Assigning probabilities to the values works similar to that of using a dictionary with keys being the Value and we assign to it the probability. This is possible because of the magic methods **_ _getitem_ _** and **_ _setitem_ _** which store the probabilities in the prob dict of the object. You can keep the source window open alongside while playing with the rest of the code to get a better understanding."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "28642c83",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(ProbDist)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "8d55ab6f",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "0.75"
+ ]
+ },
+ "execution_count": 3,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "p = ProbDist('Flip')\n",
+ "p['H'], p['T'] = 0.25, 0.75\n",
+ "p['T']"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fb5ea1d5",
+ "metadata": {},
+ "source": [
+ "The first parameter of the constructor **varname** has a default value of '?'. So if the name is not passed it defaults to ?. The keyword argument **freqs** can be a dictionary of values of random variable: probability. These are then normalized such that the probability values sum upto 1 using the **normalize** method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "e96d3d76",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'?'"
+ ]
+ },
+ "execution_count": 4,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "p = ProbDist(freq={'low': 125, 'medium': 375, 'high': 500})\n",
+ "p.var_name"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "5adea957",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(0.125, 0.375, 0.5)"
+ ]
+ },
+ "execution_count": 5,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "(p['low'], p['medium'], p['high'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cf293052",
+ "metadata": {},
+ "source": [
+ "Besides the **prob** and **varname** the object also separately keeps track of all the values of the distribution in a list called **values**. Every time a new value is assigned a probability it is appended to this list, This is done inside the **_ _setitem_ _** method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "fa1f668c",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "['low', 'medium', 'high']"
+ ]
+ },
+ "execution_count": 6,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "p.values"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d7c75b27",
+ "metadata": {},
+ "source": [
+ "The distribution by default is not normalized if values are added incrementally. We can still force normalization by invoking the **normalize** method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "dc213655",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(50, 114, 64)"
+ ]
+ },
+ "execution_count": 7,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "p = ProbDist('Y')\n",
+ "p['Cat'] = 50\n",
+ "p['Dog'] = 114\n",
+ "p['Mice'] = 64\n",
+ "(p['Cat'], p['Dog'], p['Mice'])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "1869cb51",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(0.21929824561403508, 0.5, 0.2807017543859649)"
+ ]
+ },
+ "execution_count": 8,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "p.normalize()\n",
+ "(p['Cat'], p['Dog'], p['Mice'])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ad19565f",
+ "metadata": {},
+ "source": [
+ "It is also possible to display the approximate values upto decimals using the **show_approx** method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "65acdbe0",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'Cat: 0.219, Dog: 0.5, Mice: 0.281'"
+ ]
+ },
+ "execution_count": 9,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "p.show_approx()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "834e464e",
+ "metadata": {},
+ "source": [
+ "## Joint Probability Distribution\n",
+ "\n",
+ "The helper function **event_values** returns a tuple of the values of variables in event. An event is specified by a dict where the keys are the names of variables and the corresponding values are the value of the variable. Variables are specified with a list. The ordering of the returned tuple is same as those of the variables.\n",
+ "\n",
+ "\n",
+ "Alternatively if the event is specified by a list or tuple of equal length of the variables. Then the events tuple is returned as it is."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "732b67fe",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(8, 10)"
+ ]
+ },
+ "execution_count": 10,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "event = {'A': 10, 'B': 9, 'C': 8}\n",
+ "variables = ['C', 'A']\n",
+ "event_values(event, variables)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c483d4c8",
+ "metadata": {},
+ "source": [
+ "_A probability model is completely determined by the joint distribution for all of the random variables._ (**Section 13.3**) The probability module implements these as the class **JointProbDist** which inherits from the **ProbDist** class. This class specifies a discrete probability distribute over a set of variables. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "869a737e",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(JointProbDist)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d53928a5",
+ "metadata": {},
+ "source": [
+ "Values for a Joint Distribution is a an ordered tuple in which each item corresponds to the value associate with a particular variable. For Joint Distribution of X, Y where X, Y take integer values this can be something like (18, 19).\n",
+ "\n",
+ "To specify a Joint distribution we first need an ordered list of variables."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "c440f67d",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "P(['X', 'Y'])"
+ ]
+ },
+ "execution_count": 12,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "variables = ['X', 'Y']\n",
+ "j = JointProbDist(variables)\n",
+ "j"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bdd8cadc",
+ "metadata": {},
+ "source": [
+ "Like the **ProbDist** class **JointProbDist** also employes magic methods to assign probability to different values.\n",
+ "The probability can be assigned in either of the two formats for all possible values of the distribution. The **event_values** call inside **_ _getitem_ _** and **_ _setitem_ _** does the required processing to make this work."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "4f2034e8",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(0.2, 0.5)"
+ ]
+ },
+ "execution_count": 13,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "j[1,1] = 0.2\n",
+ "j[dict(X=0, Y=1)] = 0.5\n",
+ "\n",
+ "(j[1,1], j[0,1])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8b991730",
+ "metadata": {},
+ "source": [
+ "It is also possible to list all the values for a particular variable using the **values** method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "3bac4b86",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "[1, 0]"
+ ]
+ },
+ "execution_count": 14,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "j.values('X')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d6ef62ac",
+ "metadata": {},
+ "source": [
+ "## Inference Using Full Joint Distributions\n",
+ "\n",
+ "In this section we use Full Joint Distributions to calculate the posterior distribution given some evidence. We represent evidence by using a python dictionary with variables as dict keys and dict values representing the values.\n",
+ "\n",
+ "This is illustrated in **Section 13.3** of the book. The functions **enumerate_joint** and **enumerate_joint_ask** implement this functionality. Under the hood they implement **Equation 13.9** from the book.\n",
+ "\n",
+ "$$\\textbf{P}(X | \\textbf{e}) = \\alpha \\textbf{P}(X, \\textbf{e}) = \\alpha \\sum_{y} \\textbf{P}(X, \\textbf{e}, \\textbf{y})$$\n",
+ "\n",
+ "Here **α** is the normalizing factor. **X** is our query variable and **e** is the evidence. According to the equation we enumerate on the remaining variables **y** (not in evidence or query variable) i.e. all possible combinations of **y**\n",
+ "\n",
+ "We will be using the same example as the book. Let us create the full joint distribution from **Figure 13.3**. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "9b20e254",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "full_joint = JointProbDist(['Cavity', 'Toothache', 'Catch'])\n",
+ "full_joint[dict(Cavity=True, Toothache=True, Catch=True)] = 0.108\n",
+ "full_joint[dict(Cavity=True, Toothache=True, Catch=False)] = 0.012\n",
+ "full_joint[dict(Cavity=True, Toothache=False, Catch=True)] = 0.016\n",
+ "full_joint[dict(Cavity=True, Toothache=False, Catch=False)] = 0.064\n",
+ "full_joint[dict(Cavity=False, Toothache=True, Catch=True)] = 0.072\n",
+ "full_joint[dict(Cavity=False, Toothache=False, Catch=True)] = 0.144\n",
+ "full_joint[dict(Cavity=False, Toothache=True, Catch=False)] = 0.008\n",
+ "full_joint[dict(Cavity=False, Toothache=False, Catch=False)] = 0.576"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "83777f3c",
+ "metadata": {},
+ "source": [
+ "Let us now look at the **enumerate_joint** function returns the sum of those entries in P consistent with e,provided variables is P's remaining variables (the ones not in e). Here, P refers to the full joint distribution. The function uses a recursive call in its implementation. The first parameter **variables** refers to remaining variables. The function in each recursive call keeps on variable constant while varying others."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "id": "c4cda6e5",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(enumerate_joint)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d7bdcec",
+ "metadata": {},
+ "source": [
+ "Let us assume we want to find **P(Toothache=True)**. This can be obtained by marginalization (**Equation 13.6**). We can use **enumerate_joint** to solve for this by taking Toothache=True as our evidence. **enumerate_joint** will return the sum of probabilities consistent with evidence i.e. Marginal Probability."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "id": "a0466cd1",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "0.19999999999999998"
+ ]
+ },
+ "execution_count": 17,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "evidence = dict(Toothache=True)\n",
+ "variables = ['Cavity', 'Catch'] # variables not part of evidence\n",
+ "ans1 = enumerate_joint(variables, evidence, full_joint)\n",
+ "ans1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4ae8c9e4",
+ "metadata": {},
+ "source": [
+ "You can verify the result from our definition of the full joint distribution. We can use the same function to find more complex probabilities like **P(Cavity=True and Toothache=True)**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "id": "156e63a7",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "0.12"
+ ]
+ },
+ "execution_count": 18,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "evidence = dict(Cavity=True, Toothache=True)\n",
+ "variables = ['Catch'] # variables not part of evidence\n",
+ "ans2 = enumerate_joint(variables, evidence, full_joint)\n",
+ "ans2"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6e440e1e",
+ "metadata": {},
+ "source": [
+ "Being able to find sum of probabilities satisfying given evidence allows us to compute conditional probabilities like **P(Cavity=True | Toothache=True)** as we can rewrite this as $$P(Cavity=True | Toothache = True) = \\frac{P(Cavity=True \\ and \\ Toothache=True)}{P(Toothache=True)}$$\n",
+ "\n",
+ "We have already calculated both the numerator and denominator."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 19,
+ "id": "5f437a3b",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "0.6"
+ ]
+ },
+ "execution_count": 19,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "ans2/ans1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cf19f1d4",
+ "metadata": {},
+ "source": [
+ "We might be interested in the probability distribution of a particular variable conditioned on some evidence. This can involve doing calculations like above for each possible value of the variable. This has been implemented slightly differently using normalization in the function **enumerate_joint_ask** which returns a probability distribution over the values of the variable **X**, given the {var:val} observations **e**, in the **JointProbDist P**. The implementation of this function calls **enumerate_joint** for each value of the query variable and passes **extended evidence** with the new evidence having **X = xi**. This is followed by normalization of the obtained distribution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 20,
+ "id": "42617655",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(enumerate_joint_ask)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "af4230d2",
+ "metadata": {},
+ "source": [
+ "Let us find **P(Cavity | Toothache=True)** using **enumerate_joint_ask**."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 21,
+ "id": "8ae91cac",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "(0.6, 0.39999999999999997)"
+ ]
+ },
+ "execution_count": 21,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "query_variable = 'Cavity'\n",
+ "evidence = dict(Toothache=True)\n",
+ "ans = enumerate_joint_ask(query_variable, evidence, full_joint)\n",
+ "(ans[True], ans[False])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "33e62340",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-13-Probabilistic-Reasoning.ipynb b/Chapter-13-Probabilistic-Reasoning.ipynb
new file mode 100644
index 000000000..220b92527
--- /dev/null
+++ b/Chapter-13-Probabilistic-Reasoning.ipynb
@@ -0,0 +1,3532 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "18cee36f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from probability import *\n",
+ "from utils import print_table\n",
+ "from notebook import psource, pseudocode, heatmap"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2a9441d2",
+ "metadata": {},
+ "source": [
+ "## BAYESIAN NETWORKS\n",
+ "\n",
+ "A Bayesian network is a representation of the joint probability distribution encoding a collection of conditional independence statements.\n",
+ "\n",
+ "A Bayes Network is implemented as the class **BayesNet**. It consisits of a collection of nodes implemented by the class **BayesNode**. The implementation in the above mentioned classes focuses only on boolean variables. Each node is associated with a variable and it contains a **conditional probabilty table (cpt)**. The **cpt** represents the probability distribution of the variable conditioned on its parents **P(X | parents)**.\n",
+ "\n",
+ "Let us dive into the **BayesNode** implementation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "3a6e47a7",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(BayesNode)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "55046353",
+ "metadata": {},
+ "source": [
+ "The constructor takes in the name of **variable**, **parents** and **cpt**. Here **variable** is a the name of the variable like 'Earthquake'. **parents** should a list or space separate string with variable names of parents. The conditional probability table is a dict {(v1, v2, ...): p, ...}, the distribution P(X=true | parent1=v1, parent2=v2, ...) = p. Here the keys are combination of boolean values that the parents take. The length and order of the values in keys should be same as the supplied **parent** list/string. In all cases the probability of X being false is left implicit, since it follows from P(X=true).\n",
+ "\n",
+ "The example below where we implement the network shown in **Figure 14.3** of the book will make this more clear.\n",
+ "\n",
+ " \n",
+ "\n",
+ "The alarm node can be made as follows: "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "f73b4ad4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "alarm_node = BayesNode('Alarm', ['Burglary', 'Earthquake'], \n",
+ " {(True, True): 0.95,(True, False): 0.94, (False, True): 0.29, (False, False): 0.001})"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c1e5d1bc",
+ "metadata": {},
+ "source": [
+ "It is possible to avoid using a tuple when there is only a single parent. So an alternative format for the **cpt** is"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "0858d78e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "john_node = BayesNode('JohnCalls', ['Alarm'], {True: 0.90, False: 0.05})\n",
+ "mary_node = BayesNode('MaryCalls', 'Alarm', {(True, ): 0.70, (False, ): 0.01}) # Using string for parents.\n",
+ "# Equivalant to john_node definition."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4ead9a7",
+ "metadata": {},
+ "source": [
+ "The general format used for the alarm node always holds. For nodes with no parents we can also use. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "bd8802db",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "burglary_node = BayesNode('Burglary', '', 0.001)\n",
+ "earthquake_node = BayesNode('Earthquake', '', 0.002)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d8d2281f",
+ "metadata": {},
+ "source": [
+ "It is possible to use the node for lookup function using the **p** method. The method takes in two arguments **value** and **event**. Event must be a dict of the type {variable:values, ..} The value corresponds to the value of the variable we are interested in (False or True).The method returns the conditional probability **P(X=value | parents=parent_values)**, where parent_values are the values of parents in event. (event must assign each parent a value.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "09cc7d77",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "0.09999999999999998"
+ ]
+ },
+ "execution_count": 6,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "john_node.p(False, {'Alarm': True, 'Burglary': True}) # P(JohnCalls=False | Alarm=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "306a0b5c",
+ "metadata": {},
+ "source": [
+ "With all the information about nodes present it is possible to construct a Bayes Network using **BayesNet**. The **BayesNet** class does not take in nodes as input but instead takes a list of **node_specs**. An entry in **node_specs** is a tuple of the parameters we use to construct a **BayesNode** namely **(X, parents, cpt)**. **node_specs** must be ordered with parents before children."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "959f4974",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "The alarm node can be made as follows: "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "f73b4ad4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "alarm_node = BayesNode('Alarm', ['Burglary', 'Earthquake'], \n",
+ " {(True, True): 0.95,(True, False): 0.94, (False, True): 0.29, (False, False): 0.001})"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c1e5d1bc",
+ "metadata": {},
+ "source": [
+ "It is possible to avoid using a tuple when there is only a single parent. So an alternative format for the **cpt** is"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "0858d78e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "john_node = BayesNode('JohnCalls', ['Alarm'], {True: 0.90, False: 0.05})\n",
+ "mary_node = BayesNode('MaryCalls', 'Alarm', {(True, ): 0.70, (False, ): 0.01}) # Using string for parents.\n",
+ "# Equivalant to john_node definition."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4ead9a7",
+ "metadata": {},
+ "source": [
+ "The general format used for the alarm node always holds. For nodes with no parents we can also use. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "bd8802db",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "burglary_node = BayesNode('Burglary', '', 0.001)\n",
+ "earthquake_node = BayesNode('Earthquake', '', 0.002)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d8d2281f",
+ "metadata": {},
+ "source": [
+ "It is possible to use the node for lookup function using the **p** method. The method takes in two arguments **value** and **event**. Event must be a dict of the type {variable:values, ..} The value corresponds to the value of the variable we are interested in (False or True).The method returns the conditional probability **P(X=value | parents=parent_values)**, where parent_values are the values of parents in event. (event must assign each parent a value.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "09cc7d77",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "0.09999999999999998"
+ ]
+ },
+ "execution_count": 6,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "john_node.p(False, {'Alarm': True, 'Burglary': True}) # P(JohnCalls=False | Alarm=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "306a0b5c",
+ "metadata": {},
+ "source": [
+ "With all the information about nodes present it is possible to construct a Bayes Network using **BayesNet**. The **BayesNet** class does not take in nodes as input but instead takes a list of **node_specs**. An entry in **node_specs** is a tuple of the parameters we use to construct a **BayesNode** namely **(X, parents, cpt)**. **node_specs** must be ordered with parents before children."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "959f4974",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(BayesNet)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4629bcf3",
+ "metadata": {},
+ "source": [
+ "The constructor of **BayesNet** takes each item in **node_specs** and adds a **BayesNode** to its **nodes** object variable by calling the **add** method. **add** in turn adds node to the net. Its parents must already be in the net, and its variable must not. Thus add allows us to grow a **BayesNet** given its parents are already present.\n",
+ "\n",
+ "**burglary** global is an instance of **BayesNet** corresponding to the above example.\n",
+ "\n",
+ " T, F = True, False\n",
+ "\n",
+ " burglary = BayesNet([\n",
+ " ('Burglary', '', 0.001),\n",
+ " ('Earthquake', '', 0.002),\n",
+ " ('Alarm', 'Burglary Earthquake',\n",
+ " {(T, T): 0.95, (T, F): 0.94, (F, T): 0.29, (F, F): 0.001}),\n",
+ " ('JohnCalls', 'Alarm', {T: 0.90, F: 0.05}),\n",
+ " ('MaryCalls', 'Alarm', {T: 0.70, F: 0.01})\n",
+ " ])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "1eef44c7",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "BayesNet([('Burglary', ''), ('Earthquake', ''), ('Alarm', 'Burglary Earthquake'), ('JohnCalls', 'Alarm'), ('MaryCalls', 'Alarm')])"
+ ]
+ },
+ "execution_count": 8,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "burglary"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "699d9c1f",
+ "metadata": {},
+ "source": [
+ "**BayesNet** method **variable_node** allows to reach **BayesNode** instances inside a Bayes Net. It is possible to modify the **cpt** of the nodes directly using this method."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "e82c0fda",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "probability.BayesNode"
+ ]
+ },
+ "execution_count": 9,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "type(burglary.variable_node('Alarm'))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "ab020cbd",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "{(True, True): 0.95,\n",
+ " (True, False): 0.94,\n",
+ " (False, True): 0.29,\n",
+ " (False, False): 0.001}"
+ ]
+ },
+ "execution_count": 10,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "burglary.variable_node('Alarm').cpt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ae22de06",
+ "metadata": {},
+ "source": [
+ "## Exact Inference in Bayesian Networks\n",
+ "\n",
+ "A Bayes Network is a more compact representation of the full joint distribution and like full joint distributions allows us to do inference i.e. answer questions about probability distributions of random variables given some evidence.\n",
+ "\n",
+ "Exact algorithms don't scale well for larger networks. Approximate algorithms are explained in the next section.\n",
+ "\n",
+ "### Inference by Enumeration\n",
+ "\n",
+ "We apply techniques similar to those used for **enumerate_joint_ask** and **enumerate_joint** to draw inference from Bayesian Networks. **enumeration_ask** and **enumerate_all** implement the algorithm described in **Figure 14.9** of the book."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "1af7bbf8",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(enumerate_all)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "78f7c0da",
+ "metadata": {},
+ "source": [
+ "**enumerate_all** recursively evaluates a general form of the **Equation 14.4** in the book.\n",
+ "\n",
+ "$$\\textbf{P}(X | \\textbf{e}) = α \\textbf{P}(X, \\textbf{e}) = α \\sum_{y} \\textbf{P}(X, \\textbf{e}, \\textbf{y})$$ \n",
+ "\n",
+ "such that **P(X, e, y)** is written in the form of product of conditional probabilities **P(variable | parents(variable))** from the Bayesian Network.\n",
+ "\n",
+ "**enumeration_ask** calls **enumerate_all** on each value of query variable **X** and finally normalizes them. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "79c9e687",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(enumeration_ask)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f77e21ed",
+ "metadata": {},
+ "source": [
+ "Let us solve the problem of finding out **P(Burglary=True | JohnCalls=True, MaryCalls=True)** using the **burglary** network. **enumeration_ask** takes three arguments **X** = variable name, **e** = Evidence (in form a dict like previously explained), **bn** = The Bayes Net to do inference on."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "a4fd3712",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "0.2841718353643929"
+ ]
+ },
+ "execution_count": 13,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "ans_dist = enumeration_ask('Burglary', {'JohnCalls': True, 'MaryCalls': True}, burglary)\n",
+ "ans_dist[True]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a1929844",
+ "metadata": {},
+ "source": [
+ "### Variable Elimination\n",
+ "\n",
+ "The enumeration algorithm can be improved substantially by eliminating repeated calculations. In enumeration we join the joint of all hidden variables. This is of exponential size for the number of hidden variables. Variable elimination employes interleaving join and marginalization.\n",
+ "\n",
+ "Before we look into the implementation of Variable Elimination we must first familiarize ourselves with Factors. \n",
+ "\n",
+ "In general we call a multidimensional array of type P(Y1 ... Yn | X1 ... Xm) a factor where some of Xs and Ys maybe assigned values. Factors are implemented in the probability module as the class **Factor**. They take as input **variables** and **cpt**. \n",
+ "\n",
+ "\n",
+ "#### Helper Functions\n",
+ "\n",
+ "There are certain helper functions that help creating the **cpt** for the Factor given the evidence. Let us explore them one by one."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "7a1e8f66",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(make_factor)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "469eab34",
+ "metadata": {},
+ "source": [
+ "**make_factor** is used to create the **cpt** and **variables** that will be passed to the constructor of **Factor**. We use **make_factor** for each variable. It takes in the arguments **var** the particular variable, **e** the evidence we want to do inference on, **bn** the bayes network.\n",
+ "\n",
+ "Here **variables** for each node refers to a list consisting of the variable itself and the parents minus any variables that are part of the evidence. This is created by finding the **node.parents** and filtering out those that are not part of the evidence.\n",
+ "\n",
+ "The **cpt** created is the one similar to the original **cpt** of the node with only rows that agree with the evidence."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "6211eae9",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(all_events)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5bf7918e",
+ "metadata": {},
+ "source": [
+ "The **all_events** function is a recursive generator function which yields a key for the orignal **cpt** which is part of the node. This works by extending evidence related to the node, thus all the output from **all_events** only includes events that support the evidence. Given **all_events** is a generator function one such event is returned on every call. \n",
+ "\n",
+ "We can try this out using the example on **Page 524** of the book. We will make **f**5(A) = P(m | A)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "id": "8960356a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "f5 = make_factor('MaryCalls', {'JohnCalls': True, 'MaryCalls': True}, burglary)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "id": "6260ec26",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ ""
+ ]
+ },
+ "execution_count": 17,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "f5"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "id": "116eca34",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "{(True,): 0.7, (False,): 0.01}"
+ ]
+ },
+ "execution_count": 18,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "f5.cpt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 19,
+ "id": "d324c58f",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "['Alarm']"
+ ]
+ },
+ "execution_count": 19,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "f5.variables"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a3f379a6",
+ "metadata": {},
+ "source": [
+ "Here **f5.cpt** False key gives probability for **P(MaryCalls=True | Alarm = False)**. Due to our representation where we only store probabilities for only in cases where the node variable is True this is the same as the **cpt** of the BayesNode. Let us try a somewhat different example from the book where evidence is that the Alarm = True"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 20,
+ "id": "123d8d9f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "new_factor = make_factor('MaryCalls', {'Alarm': True}, burglary)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 21,
+ "id": "86f02fd1",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "{(True,): 0.7, (False,): 0.30000000000000004}"
+ ]
+ },
+ "execution_count": 21,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "new_factor.cpt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "20a2f1c2",
+ "metadata": {},
+ "source": [
+ "Here the **cpt** is for **P(MaryCalls | Alarm = True)**. Therefore the probabilities for True and False sum up to one. Note the difference between both the cases. Again the only rows included are those consistent with the evidence.\n",
+ "\n",
+ "#### Operations on Factors\n",
+ "\n",
+ "We are interested in two kinds of operations on factors. **Pointwise Product** which is used to created joint distributions and **Summing Out** which is used for marginalization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 23,
+ "id": "b8852099",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(Factor.pointwise_product)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "54ceac8d",
+ "metadata": {},
+ "source": [
+ "**Factor.pointwise_product** implements a method of creating a joint via combining two factors. We take the union of **variables** of both the factors and then generate the **cpt** for the new factor using **all_events** function. Note that the given we have eliminated rows that are not consistent with the evidence. Pointwise product assigns new probabilities by multiplying rows similar to that in a database join."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 25,
+ "id": "db745a04",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(pointwise_product)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b7ec1f25",
+ "metadata": {},
+ "source": [
+ "**pointwise_product** extends this operation to more than two operands where it is done sequentially in pairs of two."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 26,
+ "id": "778cde0e",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(Factor.sum_out)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a6a4af3a",
+ "metadata": {},
+ "source": [
+ "**Factor.sum_out** makes a factor eliminating a variable by summing over its values. Again **events_all** is used to generate combinations for the rest of the variables."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 27,
+ "id": "97b498a8",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(sum_out)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6dff486e",
+ "metadata": {},
+ "source": [
+ "**sum_out** uses both **Factor.sum_out** and **pointwise_product** to finally eliminate a particular variable from all factors by summing over its values."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2bfcdd79",
+ "metadata": {},
+ "source": [
+ "#### Elimination Ask\n",
+ "\n",
+ "The algorithm described in **Figure 14.11** of the book is implemented by the function **elimination_ask**. We use this for inference. The key idea is that we eliminate the hidden variables by interleaving joining and marginalization. It takes in 3 arguments **X** the query variable, **e** the evidence variable and **bn** the Bayes network. \n",
+ "\n",
+ "The algorithm creates factors out of Bayes Nodes in reverse order and eliminates hidden variables using **sum_out**. Finally it takes a point wise product of all factors and normalizes. Let us finally solve the problem of inferring \n",
+ "\n",
+ "**P(Burglary=True | JohnCalls=True, MaryCalls=True)** using variable elimination."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 28,
+ "id": "be62db37",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(elimination_ask)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 29,
+ "id": "8553ef93",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'False: 0.716, True: 0.284'"
+ ]
+ },
+ "execution_count": 29,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "elimination_ask('Burglary', dict(JohnCalls=True, MaryCalls=True), burglary).show_approx()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0afdcad0",
+ "metadata": {},
+ "source": [
+ "#### Elimination Ask Optimizations\n",
+ "\n",
+ "`elimination_ask` has some critical point to consider and some optimizations could be performed:\n",
+ "\n",
+ "- **Operation on factors**:\n",
+ "\n",
+ " `sum_out` and `pointwise_product` function used in `elimination_ask` is where space and time complexity arise in the variable elimination algorithm (AIMA3e pg. 526).\n",
+ "\n",
+ ">The only trick is to notice that any factor that does not depend on the variable to be summed out can be moved outside the summation.\n",
+ "\n",
+ "- **Variable ordering**:\n",
+ "\n",
+ " Elimination ordering is important, every choice of ordering yields a valid algorithm, but different orderings cause different intermediate factors to be generated during the calculation (AIMA3e pg. 527). In this case the algorithm applies a reversed order.\n",
+ "\n",
+ "> In general, the time and space requirements of variable elimination are dominated by the size of the largest factor constructed during the operation of the algorithm. This in turn is determined by the order of elimination of variables and by the structure of the network. It turns out to be intractable to determine the optimal ordering, but several good heuristics are available. One fairly effective method is a greedy one: eliminate whichever variable minimizes the size of the next factor to be constructed. \n",
+ "\n",
+ "- **Variable relevance**\n",
+ " \n",
+ " Some variables could be irrelevant to resolve a query (i.e. sums to 1). A variable elimination algorithm can therefore remove all these variables before evaluating the query (AIMA3e pg. 528).\n",
+ "\n",
+ "> An optimization is to remove 'every variable that is not an ancestor of a query variable or evidence variable is irrelevant to the query'."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84214647",
+ "metadata": {},
+ "source": [
+ "#### Runtime comparison\n",
+ "Let's see how the runtimes of these two algorithms compare.\n",
+ "We expect variable elimination to outperform enumeration by a large margin as we reduce the number of repetitive calculations significantly."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 30,
+ "id": "82cf2f6b",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "130 µs ± 962 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)\n"
+ ]
+ }
+ ],
+ "source": [
+ "%%timeit\n",
+ "enumeration_ask('Burglary', dict(JohnCalls=True, MaryCalls=True), burglary).show_approx()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 31,
+ "id": "69e54658",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "227 µs ± 919 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)\n"
+ ]
+ }
+ ],
+ "source": [
+ "%%timeit\n",
+ "elimination_ask('Burglary', dict(JohnCalls=True, MaryCalls=True), burglary).show_approx()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5450b938",
+ "metadata": {},
+ "source": [
+ "In this test case we observe that variable elimination is slower than what we expected. It has something to do with number of threads, how Python tries to optimize things and this happens because the network is very small, with just 5 nodes. The `elimination_ask` has some critical point and some optimizations must be perfomed as seen above.\n",
+ "
\n", + "Of course, for more complicated networks, variable elimination will be significantly faster and runtime will drop not just by a constant factor, but by a polynomial factor proportional to the number of nodes, due to the reduction in repeated calculations." + ] + }, + { + "cell_type": "markdown", + "id": "b7b3e9e6", + "metadata": {}, + "source": [ + "## Approximate Inference in Bayesian Networks\n", + "\n", + "Exact inference fails to scale for very large and complex Bayesian Networks. This section covers implementation of randomized sampling algorithms, also called Monte Carlo algorithms." + ] + }, + { + "cell_type": "code", + "execution_count": 32, + "id": "e65b26e9", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(BayesNode.sample)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "883cb48a",
+ "metadata": {},
+ "source": [
+ "Before we consider the different algorithms in this section let us look at the **BayesNode.sample** method. It samples from the distribution for this variable conditioned on event's values for parent_variables. That is, return True/False at random according to with the conditional probability given the parents. The **probability** function is a simple helper from **utils** module which returns True with the probability passed to it.\n",
+ "\n",
+ "### Prior Sampling\n",
+ "\n",
+ "The idea of Prior Sampling is to sample from the Bayesian Network in a topological order. We start at the top of the network and sample as per **P(Xi | parents(Xi)** i.e. the probability distribution from which the value is sampled is conditioned on the values already assigned to the variable's parents. This can be thought of as a simulation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 33,
+ "id": "8395ce4c",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(prior_sample)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d630c64f",
+ "metadata": {},
+ "source": [
+ "The function **prior_sample** implements the algorithm described in **Figure 14.13** of the book. Nodes are sampled in the topological order. The old value of the event is passed as evidence for parent values. We will use the Bayesian Network in **Figure 14.12** to try out the **prior_sample**\n",
+ "\n",
+ " \n",
+ "\n",
+ "Traversing the graph in topological order is important.\n",
+ "There are two possible topological orderings for this particular directed acyclic graph.\n",
+ "
\n",
+ "\n",
+ "Traversing the graph in topological order is important.\n",
+ "There are two possible topological orderings for this particular directed acyclic graph.\n",
+ "
\n", + "1. `Cloudy -> Sprinkler -> Rain -> Wet Grass`\n", + "2. `Cloudy -> Rain -> Sprinkler -> Wet Grass`\n", + "
\n", + "
\n", + "We can follow any of the two orderings to sample from the network.\n", + "Any ordering other than these two, however, cannot be used.\n", + "
\n", + "One way to think about this is that `Cloudy` can be seen as a precondition of both `Rain` and `Sprinkler` and just like we have seen in planning, preconditions need to be satisfied before a certain action can be executed.\n", + "
\n", + "We store the samples on the observations. Let us find **P(Rain=True)** by taking 1000 random samples from the network." + ] + }, + { + "cell_type": "code", + "execution_count": 34, + "id": "bb74c5b4", + "metadata": {}, + "outputs": [], + "source": [ + "N = 1000\n", + "all_observations = [prior_sample(sprinkler) for x in range(N)]" + ] + }, + { + "cell_type": "markdown", + "id": "0a98b37f", + "metadata": {}, + "source": [ + "Now we filter to get the observations where Rain = True" + ] + }, + { + "cell_type": "code", + "execution_count": 35, + "id": "7f650ab7", + "metadata": {}, + "outputs": [], + "source": [ + "rain_true = [observation for observation in all_observations if observation['Rain'] == True]" + ] + }, + { + "cell_type": "markdown", + "id": "5e221f71", + "metadata": {}, + "source": [ + "Finally, we can find **P(Rain=True)**" + ] + }, + { + "cell_type": "code", + "execution_count": 36, + "id": "cf7f8977", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "0.485\n" + ] + } + ], + "source": [ + "answer = len(rain_true) / N\n", + "print(answer)" + ] + }, + { + "cell_type": "markdown", + "id": "45dc4b09", + "metadata": {}, + "source": [ + "Sampling this another time might give different results as we have no control over the distribution of the random samples" + ] + }, + { + "cell_type": "code", + "execution_count": 37, + "id": "d9e5d9d4", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "0.508\n" + ] + } + ], + "source": [ + "N = 1000\n", + "all_observations = [prior_sample(sprinkler) for x in range(N)]\n", + "rain_true = [observation for observation in all_observations if observation['Rain'] == True]\n", + "answer = len(rain_true) / N\n", + "print(answer)" + ] + }, + { + "cell_type": "markdown", + "id": "4ce63752", + "metadata": {}, + "source": [ + "To evaluate a conditional distribution. We can use a two-step filtering process. We first separate out the variables that are consistent with the evidence. Then for each value of query variable, we can find probabilities. For example to find **P(Cloudy=True | Rain=True)**. We have already filtered out the values consistent with our evidence in **rain_true**. Now we apply a second filtering step on **rain_true** to find **P(Rain=True and Cloudy=True)**" + ] + }, + { + "cell_type": "code", + "execution_count": 38, + "id": "8663f5fe", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "0.8149606299212598\n" + ] + } + ], + "source": [ + "rain_and_cloudy = [observation for observation in rain_true if observation['Cloudy'] == True]\n", + "answer = len(rain_and_cloudy) / len(rain_true)\n", + "print(answer)" + ] + }, + { + "cell_type": "markdown", + "id": "b820bb77", + "metadata": {}, + "source": [ + "### Rejection Sampling\n", + "\n", + "Rejection Sampling is based on an idea similar to what we did just now. \n", + "First, it generates samples from the prior distribution specified by the network. \n", + "Then, it rejects all those that do not match the evidence. \n", + "
\n", + "Rejection sampling is advantageous only when we know the query beforehand.\n", + "While prior sampling generally works for any query, it might fail in some scenarios.\n", + "
\n", + "Let's say we have a generic Bayesian network and we have evidence `e`, and we want to know how many times a state `A` is true, given evidence `e` is true.\n", + "Normally, prior sampling can answer this question, but let's assume that the probability of evidence `e` being true in our actual probability distribution is very small.\n", + "In this situation, it might be possible that sampling never encounters a data-point where `e` is true.\n", + "If our sampled data has no instance of `e` being true, `P(e) = 0`, and therefore `P(A | e) / P(e) = 0/0`, which is undefined.\n", + "We cannot find the required value using this sample.\n", + "
\n", + "We can definitely increase the number of sample points, but we can never guarantee that we will encounter the case where `e` is non-zero (assuming our actual probability distribution has atleast one case where `e` is true).\n", + "To guarantee this, we would have to consider every single data point, which means we lose the speed advantage that approximation provides us and we essentially have to calculate the exact inference model of the Bayesian network.\n", + "
\n", + "
\n", + "Rejection sampling will be useful in this situation, as we already know the query.\n", + "
\n", + "While sampling from the network, we will reject any sample which is inconsistent with the evidence variables of the given query (in this example, the only evidence variable is `e`).\n", + "We will only consider samples that do not violate **any** of the evidence variables.\n", + "In this way, we will have enough data with the required evidence to infer queries involving a subset of that evidence.\n", + "
\n", + "
\n", + "The function **rejection_sampling** implements the algorithm described by **Figure 14.14**" + ] + }, + { + "cell_type": "code", + "execution_count": 39, + "id": "8c060094", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(rejection_sampling)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "637cf61a",
+ "metadata": {},
+ "source": [
+ "The function keeps counts of each of the possible values of the Query variable and increases the count when we see an observation consistent with the evidence. It takes in input parameters **X** - The Query Variable, **e** - evidence, **bn** - Bayes net and **N** - number of prior samples to generate.\n",
+ "\n",
+ "**consistent_with** is used to check consistency."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 40,
+ "id": "5be075a1",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(consistent_with)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "00d50857",
+ "metadata": {},
+ "source": [
+ "To answer **P(Cloudy=True | Rain=True)**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 41,
+ "id": "9d6d798d",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "0.8141414141414142"
+ ]
+ },
+ "execution_count": 41,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "p = rejection_sampling('Cloudy', dict(Rain=True), sprinkler, 1000)\n",
+ "p[True]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5461f576",
+ "metadata": {},
+ "source": [
+ "### Likelihood Weighting\n",
+ "\n",
+ "Rejection sampling takes a long time to run when the probability of finding consistent evidence is low. It is also slow for larger networks and more evidence variables.\n",
+ "Rejection sampling tends to reject a lot of samples if our evidence consists of a large number of variables. Likelihood Weighting solves this by fixing the evidence (i.e. not sampling it) and then using weights to make sure that our overall sampling is still consistent.\n",
+ "\n",
+ "The pseudocode in **Figure 14.15** is implemented as **likelihood_weighting** and **weighted_sample**."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 42,
+ "id": "041e22e7",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(weighted_sample)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "be6d4b4d",
+ "metadata": {},
+ "source": [
+ "\n",
+ "**weighted_sample** samples an event from Bayesian Network that's consistent with the evidence **e** and returns the event and its weight, the likelihood that the event accords to the evidence. It takes in two parameters **bn** the Bayesian Network and **e** the evidence.\n",
+ "\n",
+ "The weight is obtained by multiplying **P(xi | parents(xi))** for each node in evidence. We set the values of **event = evidence** at the start of the function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 43,
+ "id": "b4829294",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "({'Rain': True, 'Cloudy': False, 'Sprinkler': True, 'WetGrass': True}, 0.2)"
+ ]
+ },
+ "execution_count": 43,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "weighted_sample(sprinkler, dict(Rain=True))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 44,
+ "id": "ed5eb7fb",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(likelihood_weighting)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "af6447d5",
+ "metadata": {},
+ "source": [
+ "**likelihood_weighting** implements the algorithm to solve our inference problem. The code is similar to **rejection_sampling** but instead of adding one for each sample we add the weight obtained from **weighted_sampling**."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 45,
+ "id": "a5c07330",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'False: 0.191, True: 0.809'"
+ ]
+ },
+ "execution_count": 45,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "likelihood_weighting('Cloudy', dict(Rain=True), sprinkler, 200).show_approx()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8767b05a",
+ "metadata": {},
+ "source": [
+ "### Gibbs Sampling\n",
+ "\n",
+ "In likelihood sampling, it is possible to obtain low weights in cases where the evidence variables reside at the bottom of the Bayesian Network. This can happen because influence only propagates downwards in likelihood sampling.\n",
+ "\n",
+ "Gibbs Sampling solves this. The implementation of **Figure 14.16** is provided in the function **gibbs_ask** "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 46,
+ "id": "408663ca",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(gibbs_ask)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71636f33",
+ "metadata": {},
+ "source": [
+ "In **gibbs_ask** we initialize the non-evidence variables to random values. And then select non-evidence variables and sample it from **P(Variable | value in the current state of all remaining vars) ** repeatedly sample. In practice, we speed this up by using **markov_blanket_sample** instead. This works because terms not involving the variable get canceled in the calculation. The arguments for **gibbs_ask** are similar to **likelihood_weighting**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 47,
+ "id": "106d4db8",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'False: 0.175, True: 0.825'"
+ ]
+ },
+ "execution_count": 47,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "gibbs_ask('Cloudy', dict(Rain=True), sprinkler, 200).show_approx()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "60a4c9e6",
+ "metadata": {},
+ "source": [
+ "#### Runtime analysis\n",
+ "Let's take a look at how much time each algorithm takes."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 48,
+ "id": "200c9f0b",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "6.8 ms ± 47.3 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n"
+ ]
+ }
+ ],
+ "source": [
+ "%%timeit\n",
+ "all_observations = [prior_sample(sprinkler) for x in range(1000)]\n",
+ "rain_true = [observation for observation in all_observations if observation['Rain'] == True]\n",
+ "len([observation for observation in rain_true if observation['Cloudy'] == True]) / len(rain_true)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 49,
+ "id": "7e62ce2f",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "8.47 ms ± 57.3 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n"
+ ]
+ }
+ ],
+ "source": [
+ "%%timeit\n",
+ "rejection_sampling('Cloudy', dict(Rain=True), sprinkler, 1000)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 50,
+ "id": "2d631d72",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "7.09 ms ± 14.7 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n"
+ ]
+ }
+ ],
+ "source": [
+ "%%timeit\n",
+ "likelihood_weighting('Cloudy', dict(Rain=True), sprinkler, 1000)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 51,
+ "id": "73c85878",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "182 ms ± 752 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)\n"
+ ]
+ }
+ ],
+ "source": [
+ "%%timeit\n",
+ "gibbs_ask('Cloudy', dict(Rain=True), sprinkler, 1000)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4a07d999",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/Chapter-14-Probability-Reasoning-over-Time.ipynb b/Chapter-14-Probability-Reasoning-over-Time.ipynb
new file mode 100644
index 000000000..91c6c432e
--- /dev/null
+++ b/Chapter-14-Probability-Reasoning-over-Time.ipynb
@@ -0,0 +1,1189 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "ed5e78cd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from probability import *\n",
+ "from utils import print_table\n",
+ "from notebook import psource, pseudocode, heatmap"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "321ad1f3",
+ "metadata": {},
+ "source": [
+ "## HIDDEN MARKOV MODELS"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f37e8593",
+ "metadata": {},
+ "source": [
+ "Often, we need to carry out probabilistic inference on temporal data or a sequence of observations where the order of observations matter.\n",
+ "We require a model similar to a Bayesian Network, but one that grows over time to keep up with the latest evidences.\n",
+ "If you are familiar with the `mdp` module or Markov models in general, you can probably guess that a Markov model might come close to representing our problem accurately.\n",
+ "
\n", + "A Markov model is basically a chain-structured Bayesian Network in which there is one state for each time step and each node has an identical probability distribution.\n", + "The first node, however, has a different distribution, called the prior distribution which models the initial state of the process.\n", + "A state in a Markov model depends only on the previous state and the latest evidence and not on the states before it.\n", + "
\n", + "A **Hidden Markov Model** or **HMM** is a special case of a Markov model in which the state of the process is described by a single discrete random variable.\n", + "The possible values of the variable are the possible states of the world.\n", + "
\n", + "But what if we want to model a process with two or more state variables?\n", + "In that case, we can still fit the process into the HMM framework by redefining our state variables as a single \"megavariable\".\n", + "We do this because carrying out inference on HMMs have standard optimized algorithms.\n", + "A HMM is very similar to an MDP, but we don't have the option of taking actions like in MDPs, instead, the process carries on as new evidence appears.\n", + "
\n", + "If a HMM is truncated at a fixed length, it becomes a Bayesian network and general BN inference can be used on it to answer queries.\n", + "\n", + "Before we start, it will be helpful to understand the structure of a temporal model. We will use the example of the book with the guard and the umbrella. In this example, the state $\\textbf{X}$ is whether it is a rainy day (`X = True`) or not (`X = False`) at Day $\\textbf{t}$. In the sensor or observation model, the observation or evidence $\\textbf{U}$ is whether the professor holds an umbrella (`U = True`) or not (`U = False`) on **Day** $\\textbf{t}$. Based on that, the transition model is \n", + "\n", + "| $X_{t-1}$ | $X_{t}$ | **P**$(X_{t}| X_{t-1})$| \n", + "| ------------- |------------- | ----------------------------------|\n", + "| ***${False}$*** | ***${False}$*** | 0.7 |\n", + "| ***${False}$*** | ***${True}$*** | 0.3 |\n", + "| ***${True}$*** | ***${False}$*** | 0.3 |\n", + "| ***${True}$*** | ***${True}$*** | 0.7 |\n", + "\n", + "And the the sensor model will be,\n", + "\n", + "| $X_{t}$ | $U_{t}$ | **P**$(U_{t}|X_{t})$| \n", + "| :-------------: |:-------------: | :------------------------:|\n", + "| ***${False}$*** | ***${True}$*** | 0.2 |\n", + "| ***${False}$*** | ***${False}$*** | 0.8 |\n", + "| ***${True}$*** | ***${True}$*** | 0.9 |\n", + "| ***${True}$*** | ***${False}$*** | 0.1 |\n" + ] + }, + { + "cell_type": "markdown", + "id": "f965ae34", + "metadata": {}, + "source": [ + "HMMs are implemented in the **`HiddenMarkovModel`** class.\n", + "Let's have a look." + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "41d68262", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(HiddenMarkovModel)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8681fa9a",
+ "metadata": {},
+ "source": [
+ "We instantiate the object **`hmm`** of the class using a list of lists for both the transition and the sensor model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "7ca3a72f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "umbrella_transition_model = [[0.7, 0.3], [0.3, 0.7]]\n",
+ "umbrella_sensor_model = [[0.9, 0.2], [0.1, 0.8]]\n",
+ "hmm = HiddenMarkovModel(umbrella_transition_model, umbrella_sensor_model)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "597431ff",
+ "metadata": {},
+ "source": [
+ "The **`sensor_dist()`** method returns a list with the conditional probabilities of the sensor model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "5c60c31a",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "[0.9, 0.2]"
+ ]
+ },
+ "execution_count": 4,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "hmm.sensor_dist(ev=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dd2f1d16",
+ "metadata": {},
+ "source": [
+ "Now that we have defined an HMM object, our task here is to compute the belief $B_{t}(x)= P(X_{t}|U_{1:t})$ given evidence **U** at each time step **t**.\n",
+ "
\n", + "The basic inference tasks that must be solved are:\n", + "1. **Filtering**: Computing the posterior probability distribution over the most recent state, given all the evidence up to the current time step.\n", + "2. **Prediction**: Computing the posterior probability distribution over the future state.\n", + "3. **Smoothing**: Computing the posterior probability distribution over a past state. Smoothing provides a better estimation as it incorporates more evidence.\n", + "4. **Most likely explanation**: Finding the most likely sequence of states for a given observation\n", + "5. **Learning**: The transition and sensor models can be learnt, if not yet known, just like in an information gathering agent\n", + "
\n", + "
\n", + "\n", + "There are three primary methods to carry out inference in Hidden Markov Models:\n", + "1. The Forward-Backward algorithm\n", + "2. Fixed lag smoothing\n", + "3. Particle filtering\n", + "\n", + "Let's have a look at how we can carry out inference and answer queries based on our umbrella HMM using these algorithms." + ] + }, + { + "cell_type": "markdown", + "id": "50b30b66", + "metadata": {}, + "source": [ + "### FORWARD-BACKWARD\n", + "This is a general algorithm that works for all Markov models, not just HMMs.\n", + "In the filtering task (inference) we are given evidence **U** in each time **t** and we want to compute the belief $B_{t}(x)= P(X_{t}|U_{1:t})$. \n", + "We can think of it as a three step process:\n", + "1. In every step we start with the current belief $P(X_{t}|e_{1:t})$\n", + "2. We update it for time\n", + "3. We update it for evidence\n", + "\n", + "The forward algorithm performs the step 2 and 3 at once. It updates, or better say reweights, the initial belief using the transition and the sensor model. Let's see the umbrella example. On **Day 0** no observation is available, and for that reason we will assume that we have equal possibilities to rain or not. In the **`HiddenMarkovModel`** class, the prior probabilities for **Day 0** are by default [0.5, 0.5]. " + ] + }, + { + "cell_type": "markdown", + "id": "cfa89c75", + "metadata": {}, + "source": [ + "The observation update is calculated with the **`forward()`** function. Basically, we update our belief using the observation model. The function returns a list with the probabilities of **raining or not** on **Day 1**." + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "id": "a585a325", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(forward)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "411eb34e",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "The probability of raining on day 1 is 0.82\n"
+ ]
+ }
+ ],
+ "source": [
+ "umbrella_prior = [0.5, 0.5]\n",
+ "belief_day_1 = forward(hmm, umbrella_prior, ev=True)\n",
+ "print ('The probability of raining on day 1 is {:.2f}'.format(belief_day_1[0]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5c67103a",
+ "metadata": {},
+ "source": [
+ "In **Day 2** our initial belief is the updated belief of **Day 1**.\n",
+ "Again using the **`forward()`** function we can compute the probability of raining in **Day 2**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "3797dd05",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "The probability of raining in day 2 is 0.88\n"
+ ]
+ }
+ ],
+ "source": [
+ "belief_day_2 = forward(hmm, belief_day_1, ev=True)\n",
+ "print ('The probability of raining in day 2 is {:.2f}'.format(belief_day_2[0]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7808bf86",
+ "metadata": {},
+ "source": [
+ "In the smoothing part we are interested in computing the distribution over past states given evidence up to the present. Assume that we want to compute the distribution for the time **k**, for $0\\leq k\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(backward)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "f0590cb4",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "[0.6272727272727272, 0.37272727272727274]"
+ ]
+ },
+ "execution_count": 9,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "b = [1, 1]\n",
+ "backward(hmm, b, ev=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "17eb46df",
+ "metadata": {},
+ "source": [
+ "Some may notice that the result is not the same as in the book. The main reason is that in the book the normalization step is not used. If we want to normalize the result, one can use the **`normalize()`** helper function.\n",
+ "\n",
+ "In order to find the smoothed estimate for raining in **Day k**, we will use the **`forward_backward()`** function. As in the example in the book, the umbrella is observed in both days and the prior distribution is [0.5, 0.5]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "3ced7b0b",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "The probability of raining in Day 0 is 0.65 and in Day 1 is 0.88\n"
+ ]
+ }
+ ],
+ "source": [
+ "umbrella_prior = [0.5, 0.5]\n",
+ "prob = forward_backward(hmm, ev=[T, T])\n",
+ "print ('The probability of raining in Day 0 is {:.2f} and in Day 1 is {:.2f}'.format(prob[0][0], prob[1][0]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f9c894e4",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Since HMMs are represented as single variable systems, we can represent the transition model and sensor model as matrices.\n",
+ "The `forward_backward` algorithm can be easily carried out on this representation (as we have done here) with a time complexity of $O({S}^{2} t)$ where t is the length of the sequence and each step multiplies a vector of size $S$ with a matrix of dimensions $SxS$.\n",
+ "
\n", + "Additionally, the forward pass stores $t$ vectors of size $S$ which makes the auxiliary space requirement equivalent to $O(St)$.\n", + "
\n", + "
\n", + "Is there any way we can improve the time or space complexity?\n", + "
\n", + "Fortunately, the matrix representation of HMM properties allows us to do so.\n", + "
\n", + "If $f$ and $b$ represent the forward and backward messages respectively, we can modify the smoothing algorithm by first\n", + "running the standard forward pass to compute $f_{t:t}$ (forgetting all the intermediate results) and then running\n", + "backward pass for both $b$ and $f$ together, using them to compute the smoothed estimate at each step.\n", + "This optimization reduces auxlilary space requirement to constant (irrespective of the length of the sequence) provided\n", + "the transition matrix is invertible and the sensor model has no zeros (which is sometimes hard to accomplish)\n", + "
\n", + "
\n", + "Let's look at another algorithm, that carries out smoothing in a more optimized way." + ] + }, + { + "cell_type": "markdown", + "id": "c8a2d25a", + "metadata": {}, + "source": [ + "### FIXED LAG SMOOTHING\n", + "The matrix formulation allows to optimize online smoothing with a fixed lag.\n", + "
\n", + "Since smoothing can be done in constant, there should exist an algorithm whose time complexity is independent of the length of the lag.\n", + "For smoothing a time slice $t - d$ where $d$ is the lag, we need to compute $\\alpha f_{1:t-d}$ x $b_{t-d+1:t}$ incrementally.\n", + "
\n", + "As we already know, the forward equation is\n", + "
\n", + "$$f_{1:t+1} = \\alpha O_{t+1}{T}^{T}f_{1:t}$$\n", + "
\n", + "and the backward equation is\n", + "
\n", + "$$b_{k+1:t} = TO_{k+1}b_{k+2:t}$$\n", + "
\n", + "where $T$ and $O$ are the transition and sensor models respectively.\n", + "
\n", + "For smoothing, the forward message is easy to compute but there exists no simple relation between the backward message of this time step and the one at the previous time step, hence we apply the backward equation $d$ times to get\n", + "
\n", + "$$b_{t-d+1:t} = \\left ( \\prod_{i=t-d+1}^{t}{TO_i} \\right )b_{t+1:t} = B_{t-d+1:t}1$$\n", + "
\n", + "where $B_{t-d+1:t}$ is the product of the sequence of $T$ and $O$ matrices.\n", + "
\n", + "Here's how the `probability` module implements `fixed_lag_smoothing`.\n", + "
" + ] + }, + { + "cell_type": "code", + "execution_count": 11, + "id": "bffc317e", + "metadata": {}, + "outputs": [], + "source": [ + "umbrella_transition_model = [[0.7, 0.3], [0.3, 0.7]]\n", + "umbrella_sensor_model = [[0.9, 0.2], [0.1, 0.8]]\n", + "hmm = HiddenMarkovModel(umbrella_transition_model, umbrella_sensor_model)" + ] + }, + { + "cell_type": "code", + "execution_count": 12, + "id": "815660dc", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Processing e_t: True, t is: 1\n", + "f is: [0.5, 0.5], B is: [[0.63 0.06]\n", + " [0.27 0.14]]\n", + "Processing e_t: False, t is: 2\n", + "f is: [0.5, 0.5], B is: [[0.0459 0.1848]\n", + " [0.0231 0.1432]]\n", + "Processing e_t: True, t is: 3\n", + "f is: [0.8181818181818181, 0.18181818181818182], B is: [[0.1089 0.0378]\n", + " [0.1701 0.0802]]\n", + "Processing e_t: False, t is: 4\n", + "f is: [0.17380352644836272, 0.8261964735516373], B is: [[0.0459 0.1848]\n", + " [0.0231 0.1432]]\n", + "Processing e_t: True, t is: 5\n", + "f is: [0.7250810038991707, 0.27491899610082926], B is: [[0.1089 0.0378]\n", + " [0.1701 0.0802]]\n" + ] + } + ], + "source": [ + "e_t = F\n", + "evidence = [T, F, T, F, T]\n", + "fl_smoother = FixedLagSmoother(evidence, hmm, d=2)\n", + "fl_smoother.fit()" + ] + }, + { + "cell_type": "code", + "execution_count": 13, + "id": "7436e178", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Processing e_t: False, t is: 6\n", + "f is: [0.15247208886151503, 0.847527911138485], B is: [[0.0459 0.1848]\n", + " [0.0231 0.1432]]\n" + ] + }, + { + "data": { + "text/plain": [ + "[0.1508998635320297, 0.8491001364679702]" + ] + }, + "execution_count": 13, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "fl_smoother.smoothing(e_t)" + ] + }, + { + "cell_type": "code", + "execution_count": 14, + "id": "0d4f8b53", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Processing e_t: True, t is: 1\n", + "f is: [0.5, 0.5], B is: [[0.63 0.06]\n", + " [0.27 0.14]]\n", + "Processing e_t: False, t is: 2\n", + "f is: [0.5, 0.5], B is: [[0.0459 0.1848]\n", + " [0.0231 0.1432]]\n", + "Processing e_t: True, t is: 3\n", + "f is: [0.8181818181818181, 0.18181818181818182], B is: [[0.1089 0.0378]\n", + " [0.1701 0.0802]]\n", + "Processing e_t: False, t is: 4\n", + "f is: [0.17380352644836272, 0.8261964735516373], B is: [[0.0459 0.1848]\n", + " [0.0231 0.1432]]\n", + "Processing e_t: True, t is: 5\n", + "f is: [0.7250810038991707, 0.27491899610082926], B is: [[0.1089 0.0378]\n", + " [0.1701 0.0802]]\n" + ] + } + ], + "source": [ + "e_t = T\n", + "evidence = [T, F, T, F, T]\n", + "fl_smoother = FixedLagSmoother(evidence, hmm, d=2)\n", + "fl_smoother.fit()" + ] + }, + { + "cell_type": "code", + "execution_count": 15, + "id": "4ee1a762", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Processing e_t: True, t is: 6\n", + "f is: [0.15247208886151503, 0.847527911138485], B is: [[0.4131 0.0462]\n", + " [0.2079 0.0358]]\n" + ] + }, + { + "data": { + "text/plain": [ + "[0.8648251560751015, 0.13517484392489867]" + ] + }, + "execution_count": 15, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "fl_smoother.smoothing(e_t)" + ] + }, + { + "cell_type": "markdown", + "id": "95f6e55c", + "metadata": {}, + "source": [ + "### PARTICLE FILTERING\n", + "The filtering problem is too expensive to solve using the previous methods for problems with large or continuous state spaces.\n", + "Particle filtering is a method that can solve the same problem but when the state space is a lot larger, where we wouldn't be able to do these computations in a reasonable amount of time as fast, as time goes by, and we want to keep track of things as they happen.\n", + "
\n", + "The downside is that it is a sampling method and hence isn't accurate, but the more samples we're willing to take, the more accurate we'd get.\n", + "
\n", + "In this method, instead of keping track of the probability distribution, we will drop particles in a similar proportion at the required regions.\n", + "The internal representation of this distribution is usually a list of particles with coordinates in the state-space.\n", + "A particle is just a new name for a sample.\n", + "\n", + "Particle filtering can be divided into four steps:\n", + "1. __Initialization__: \n", + "If we have some idea about the prior probability distribution, we drop the initial particles accordingly, or else we just drop them uniformly over the state space.\n", + "\n", + "2. __Forward pass__: \n", + "As time goes by and measurements come in, we are going to move the selected particles into the grid squares that makes the most sense in terms of representing the distribution that we are trying to track.\n", + "When time goes by, we just loop through all our particles and try to simulate what could happen to each one of them by sampling its next position from the transition model.\n", + "This is like prior sampling - samples' frequencies reflect the transition probabilities.\n", + "If we have enough samples we are pretty close to exact values.\n", + "We work through the list of particles, one particle at a time, all we do is stochastically simulate what the outcome might be.\n", + "If we had no dimension of time, and we had no new measurements come in, this would be exactly the same as what we did in prior sampling.\n", + "\n", + "3. __Reweight__:\n", + "As observations come in, don't sample the observations, fix them and downweight the samples based on the evidence just like in likelihood weighting.\n", + "$$w(x) = P(e/x)$$\n", + "$$B(X) \\propto P(e/X)B'(X)$$\n", + "
\n", + "As before, the probabilities don't sum to one, since most have been downweighted.\n", + "They sum to an approximation of $P(e)$.\n", + "To normalize the resulting distribution, we can divide by $P(e)$\n", + "
\n", + "Likelihood weighting wasn't the best thing for Bayesian networks, because we were not accounting for the incoming evidence so we were getting samples from the prior distribution, in some sense not the right distribution, so we might end up with a lot of particles with low weights. \n", + "These samples were very uninformative and the way we fixed it then was by using __Gibbs sampling__.\n", + "Theoretically, Gibbs sampling can be run on a HMM, but as we iterated over the process infinitely many times in a Bayesian network, we cannot do that here as we have new incoming evidence and we also need computational cycles to propagate through time.\n", + "
\n", + "A lot of samples with very low weight and they are not representative of the _actual probability distribution_.\n", + "So if we keep running likelihood weighting, we keep propagating the samples with smaller weights and carry out computations for that even though these samples have no significant contribution to the actual probability distribution.\n", + "Which is why we require this last step.\n", + "\n", + "4. __Resample__:\n", + "Rather than tracking weighted samples, we _resample_.\n", + "We choose from our weighted sample distribution as many times as the number of particles we initially had and we replace these particles too, so that we have a constant number of particles.\n", + "This is equivalent to renormalizing the distribution.\n", + "The samples with low weight are rarely chosen in the new distribution after resampling.\n", + "This newer set of particles after resampling is in some sense more representative of the actual distribution and so we are better allocating our computational cycles.\n", + "Now the update is complete for this time step, continue with the next one.\n", + "\n", + "
\n", + "Let's see how this is implemented in the module." + ] + }, + { + "cell_type": "code", + "execution_count": 16, + "id": "150ab16c", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(particle_filtering)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "57906a4c",
+ "metadata": {},
+ "source": [
+ "Here, `scalar_vector_product` and `vector_add` are helper functions to help with vector math and `weighted_sample_with_replacement` resamples from a weighted sample and replaces the original sample, as is obvious from the name.\n",
+ "
\n", + "This implementation considers two state variables with generic names 'A' and 'B'.\n" + ] + }, + { + "cell_type": "markdown", + "id": "5cb54907", + "metadata": {}, + "source": [ + "Here's how we can use `particle_filtering` on our umbrella HMM, though it doesn't make much sense using particle filtering on a problem with such a small state space.\n", + "It is just to get familiar with the syntax." + ] + }, + { + "cell_type": "code", + "execution_count": 17, + "id": "77c34d22", + "metadata": {}, + "outputs": [], + "source": [ + "umbrella_transition_model = [[0.7, 0.3], [0.3, 0.7]]\n", + "umbrella_sensor_model = [[0.9, 0.2], [0.1, 0.8]]\n", + "hmm = HiddenMarkovModel(umbrella_transition_model, umbrella_sensor_model)" + ] + }, + { + "cell_type": "code", + "execution_count": 18, + "id": "6bcf289c", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "['A', 'A', 'A', 'A', 'A', 'B', 'A', 'A', 'B', 'A']" + ] + }, + "execution_count": 18, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "particle_filtering(T, 10, hmm)" + ] + }, + { + "cell_type": "code", + "execution_count": 19, + "id": "40299792", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "['B', 'B', 'B', 'B', 'B', 'B', 'A', 'B', 'B', 'B']" + ] + }, + "execution_count": 19, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "particle_filtering([F, T, F, F, T], 10, hmm)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d8b5760b", + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.7.10" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/Chapter-17-Making-Complex-Decisions.ipynb b/Chapter-17-Making-Complex-Decisions.ipynb new file mode 100644 index 000000000..deccaa7aa --- /dev/null +++ b/Chapter-17-Making-Complex-Decisions.ipynb @@ -0,0 +1,1323 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "53b9fb22", + "metadata": {}, + "source": [ + "# Making Complex Decisions\n", + "---\n", + "\n", + "This Jupyter notebook acts as supporting material for topics covered in **Chapter 17 Making Complex Decisions** of the book* Artificial Intelligence: A Modern Approach*. We make use of the implementations in mdp.py module. This notebook also includes a brief summary of the main topics as a review. Let us import everything from the mdp module to get started." + ] + }, + { + "cell_type": "code", + "execution_count": 1, + "id": "5ba2e22a", + "metadata": {}, + "outputs": [], + "source": [ + "from mdp import *\n", + "from notebook import psource, pseudocode, plot_pomdp_utility" + ] + }, + { + "cell_type": "markdown", + "id": "dd807ed2", + "metadata": {}, + "source": [ + "## MDP\n", + "\n", + "To begin with let us look at the implementation of MDP class defined in mdp.py The docstring tells us what all is required to define a MDP namely - set of states, actions, initial state, transition model, and a reward function. Each of these are implemented as methods. Do not close the popup so that you can follow along the description of code below." + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "64f4c2a7", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(MDP)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2ff56bb2",
+ "metadata": {},
+ "source": [
+ "The **_ _init_ _** method takes in the following parameters:\n",
+ "\n",
+ "- init: the initial state.\n",
+ "- actlist: List of actions possible in each state.\n",
+ "- terminals: List of terminal states where only possible action is exit\n",
+ "- gamma: Discounting factor. This makes sure that delayed rewards have less value compared to immediate ones.\n",
+ "\n",
+ "**R** method returns the reward for each state by using the self.reward dict.\n",
+ "\n",
+ "**T** method is not implemented and is somewhat different from the text. Here we return (probability, s') pairs where s' belongs to list of possible state by taking action a in state s.\n",
+ "\n",
+ "**actions** method returns list of actions possible in each state. By default it returns all actions for states other than terminal states.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1d522d7a",
+ "metadata": {},
+ "source": [
+ "Now let us implement the simple MDP in the image below. States A, B have actions X, Y available in them. Their probabilities are shown just above the arrows. We start with using MDP as base class for our CustomMDP. Obviously we need to make a few changes to suit our case. We make use of a transition matrix as our transitions are not very simple.\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "689233b6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Transition Matrix as nested dict. State -> Actions in state -> List of (Probability, State) tuples\n",
+ "t = {\n",
+ " \"A\": {\n",
+ " \"X\": [(0.3, \"A\"), (0.7, \"B\")],\n",
+ " \"Y\": [(1.0, \"A\")]\n",
+ " },\n",
+ " \"B\": {\n",
+ " \"X\": {(0.8, \"End\"), (0.2, \"B\")},\n",
+ " \"Y\": {(1.0, \"A\")}\n",
+ " },\n",
+ " \"End\": {}\n",
+ "}\n",
+ "\n",
+ "init = \"A\"\n",
+ "\n",
+ "terminals = [\"End\"]\n",
+ "\n",
+ "rewards = {\n",
+ " \"A\": 5,\n",
+ " \"B\": -10,\n",
+ " \"End\": 100\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "e64cc8b2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class CustomMDP(MDP):\n",
+ " def __init__(self, init, terminals, transition_matrix, reward = None, gamma=.9):\n",
+ " # All possible actions.\n",
+ " actlist = []\n",
+ " for state in transition_matrix.keys():\n",
+ " actlist.extend(transition_matrix[state])\n",
+ " actlist = list(set(actlist))\n",
+ " MDP.__init__(self, init, actlist, terminals, transition_matrix, reward, gamma=gamma)\n",
+ "\n",
+ " def T(self, state, action):\n",
+ " if action is None:\n",
+ " return [(0.0, state)]\n",
+ " else: \n",
+ " return self.t[state][action]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "17a9872e",
+ "metadata": {},
+ "source": [
+ "Finally we instantize the class with the parameters for our MDP in the picture."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "3233a2cf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "our_mdp = CustomMDP(init, terminals, t, rewards, gamma=.9)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ffaf0fce",
+ "metadata": {},
+ "source": [
+ "With this we have successfully represented our MDP. Later we will look at ways to solve this MDP."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bbb4246d",
+ "metadata": {},
+ "source": [
+ "## GRID MDP\n",
+ "\n",
+ "Now we look at a concrete implementation that makes use of the MDP as base class. The GridMDP class in the mdp module is used to represent a grid world MDP like the one shown in in **Fig 17.1** of the AIMA Book. We assume for now that the environment is _fully observable_, so that the agent always knows where it is. The code should be easy to understand if you have gone through the CustomMDP example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "16431f75",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "689233b6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Transition Matrix as nested dict. State -> Actions in state -> List of (Probability, State) tuples\n",
+ "t = {\n",
+ " \"A\": {\n",
+ " \"X\": [(0.3, \"A\"), (0.7, \"B\")],\n",
+ " \"Y\": [(1.0, \"A\")]\n",
+ " },\n",
+ " \"B\": {\n",
+ " \"X\": {(0.8, \"End\"), (0.2, \"B\")},\n",
+ " \"Y\": {(1.0, \"A\")}\n",
+ " },\n",
+ " \"End\": {}\n",
+ "}\n",
+ "\n",
+ "init = \"A\"\n",
+ "\n",
+ "terminals = [\"End\"]\n",
+ "\n",
+ "rewards = {\n",
+ " \"A\": 5,\n",
+ " \"B\": -10,\n",
+ " \"End\": 100\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "e64cc8b2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class CustomMDP(MDP):\n",
+ " def __init__(self, init, terminals, transition_matrix, reward = None, gamma=.9):\n",
+ " # All possible actions.\n",
+ " actlist = []\n",
+ " for state in transition_matrix.keys():\n",
+ " actlist.extend(transition_matrix[state])\n",
+ " actlist = list(set(actlist))\n",
+ " MDP.__init__(self, init, actlist, terminals, transition_matrix, reward, gamma=gamma)\n",
+ "\n",
+ " def T(self, state, action):\n",
+ " if action is None:\n",
+ " return [(0.0, state)]\n",
+ " else: \n",
+ " return self.t[state][action]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "17a9872e",
+ "metadata": {},
+ "source": [
+ "Finally we instantize the class with the parameters for our MDP in the picture."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "3233a2cf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "our_mdp = CustomMDP(init, terminals, t, rewards, gamma=.9)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ffaf0fce",
+ "metadata": {},
+ "source": [
+ "With this we have successfully represented our MDP. Later we will look at ways to solve this MDP."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bbb4246d",
+ "metadata": {},
+ "source": [
+ "## GRID MDP\n",
+ "\n",
+ "Now we look at a concrete implementation that makes use of the MDP as base class. The GridMDP class in the mdp module is used to represent a grid world MDP like the one shown in in **Fig 17.1** of the AIMA Book. We assume for now that the environment is _fully observable_, so that the agent always knows where it is. The code should be easy to understand if you have gone through the CustomMDP example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "16431f75",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(GridMDP)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "09fc7d52",
+ "metadata": {},
+ "source": [
+ "The **_ _init_ _** method takes **grid** as an extra parameter compared to the MDP class. The grid is a nested list of rewards in states.\n",
+ "\n",
+ "**go** method returns the state by going in particular direction by using vector_add.\n",
+ "\n",
+ "**T** method is not implemented and is somewhat different from the text. Here we return (probability, s') pairs where s' belongs to list of possible state by taking action a in state s.\n",
+ "\n",
+ "**actions** method returns list of actions possible in each state. By default it returns all actions for states other than terminal states.\n",
+ "\n",
+ "**to_arrows** are used for representing the policy in a grid like format."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bd0bc41a",
+ "metadata": {},
+ "source": [
+ "We can create a GridMDP like the one in **Fig 17.1** as follows: \n",
+ "\n",
+ " GridMDP([[-0.04, -0.04, -0.04, +1],\n",
+ " [-0.04, None, -0.04, -1],\n",
+ " [-0.04, -0.04, -0.04, -0.04]],\n",
+ " terminals=[(3, 2), (3, 1)])\n",
+ " \n",
+ "In fact the **sequential_decision_environment** in mdp module has been instantized using the exact same code."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "519f5ccc",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ ""
+ ]
+ },
+ "execution_count": 7,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "sequential_decision_environment"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f5bdca31",
+ "metadata": {},
+ "source": [
+ "# VALUE ITERATION\n",
+ "\n",
+ "Now that we have looked how to represent MDPs. Let's aim at solving them. Our ultimate goal is to obtain an optimal policy. We start with looking at Value Iteration and a visualisation that should help us understanding it better.\n",
+ "\n",
+ "We start by calculating Value/Utility for each of the states. The Value of each state is the expected sum of discounted future rewards given we start in that state and follow a particular policy $\\pi$. The value or the utility of a state is given by\n",
+ "\n",
+ "$$U(s)=R(s)+\\gamma\\max_{a\\epsilon A(s)}\\sum_{s'} P(s'\\ |\\ s,a)U(s')$$\n",
+ "\n",
+ "This is called the Bellman equation. The algorithm Value Iteration (**Fig. 17.4** in the book) relies on finding solutions of this Equation. The intuition Value Iteration works is because values propagate through the state space by means of local updates. This point will we more clear after we encounter the visualisation. For more information you can refer to **Section 17.2** of the book. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "47eb95f5",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(value_iteration)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6584d0dd",
+ "metadata": {},
+ "source": [
+ "It takes as inputs two parameters, an MDP to solve and epsilon, the maximum error allowed in the utility of any state. It returns a dictionary containing utilities where the keys are the states and values represent utilities.
Value Iteration starts with arbitrary initial values for the utilities, calculates the right side of the Bellman equation and plugs it into the left hand side, thereby updating the utility of each state from the utilities of its neighbors. \n", + "This is repeated until equilibrium is reached. \n", + "It works on the principle of _Dynamic Programming_ - using precomputed information to simplify the subsequent computation. \n", + "If $U_i(s)$ is the utility value for state $s$ at the $i$ th iteration, the iteration step, called Bellman update, looks like this:\n", + "\n", + "$$ U_{i+1}(s) \\leftarrow R(s) + \\gamma \\max_{a \\epsilon A(s)} \\sum_{s'} P(s'\\ |\\ s,a)U_{i}(s') $$\n", + "\n", + "As you might have noticed, `value_iteration` has an infinite loop. How do we decide when to stop iterating? \n", + "The concept of _contraction_ successfully explains the convergence of value iteration. \n", + "Refer to **Section 17.2.3** of the book for a detailed explanation. \n", + "In the algorithm, we calculate a value $delta$ that measures the difference in the utilities of the current time step and the previous time step. \n", + "\n", + "$$\\delta = \\max{(\\delta, \\begin{vmatrix}U_{i + 1}(s) - U_i(s)\\end{vmatrix})}$$\n", + "\n", + "This value of delta decreases as the values of $U_i$ converge.\n", + "We terminate the algorithm if the $\\delta$ value is less than a threshold value determined by the hyperparameter _epsilon_.\n", + "\n", + "$$\\delta \\lt \\epsilon \\frac{(1 - \\gamma)}{\\gamma}$$\n", + "\n", + "To summarize, the Bellman update is a _contraction_ by a factor of $gamma$ on the space of utility vectors. \n", + "Hence, from the properties of contractions in general, it follows that `value_iteration` always converges to a unique solution of the Bellman equations whenever $gamma$ is less than 1.\n", + "We then terminate the algorithm when a reasonable approximation is achieved.\n", + "In practice, it often occurs that the policy $pi$ becomes optimal long before the utility function converges. For the given 4 x 3 environment with $gamma = 0.9$, the policy $pi$ is optimal when $i = 4$ (at the 4th iteration), even though the maximum error in the utility function is stil 0.46. This can be clarified from **figure 17.6** in the book. Hence, to increase computational efficiency, we often use another method to solve MDPs called Policy Iteration which we will see in the later part of this notebook. \n", + "
For now, let us solve the **sequential_decision_environment** GridMDP using `value_iteration`." + ] + }, + { + "cell_type": "code", + "execution_count": 9, + "id": "250c5543", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{(0, 1): 0.3984432178350045,\n", + " (1, 2): 0.649585681261095,\n", + " (3, 2): 1.0,\n", + " (0, 0): 0.2962883154554812,\n", + " (3, 0): 0.12987274656746342,\n", + " (3, 1): -1.0,\n", + " (2, 1): 0.48644001739269643,\n", + " (2, 0): 0.3447542300124158,\n", + " (2, 2): 0.7953620878466678,\n", + " (1, 0): 0.25386699846479516,\n", + " (0, 2): 0.5093943765842497}" + ] + }, + "execution_count": 9, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "value_iteration(sequential_decision_environment)" + ] + }, + { + "cell_type": "markdown", + "id": "f4298c27", + "metadata": {}, + "source": [ + "The pseudocode for the algorithm:" + ] + }, + { + "cell_type": "markdown", + "id": "2bd29969", + "metadata": {}, + "source": [ + "# POLICY ITERATION\n", + "\n", + "We have already seen that value iteration converges to the optimal policy long before it accurately estimates the utility function. \n", + "If one action is clearly better than all the others, then the exact magnitude of the utilities in the states involved need not be precise. \n", + "The policy iteration algorithm works on this insight. \n", + "The algorithm executes two fundamental steps:\n", + "* **Policy evaluation**: Given a policy _πᵢ_, calculate _Uᵢ = U(πᵢ)_, the utility of each state if _πᵢ_ were to be executed.\n", + "* **Policy improvement**: Calculate a new policy _πᵢ₊₁_ using one-step look-ahead based on the utility values calculated.\n", + "\n", + "The algorithm terminates when the policy improvement step yields no change in the utilities. \n", + "Refer to **Figure 17.6** in the book to see how this is an improvement over value iteration.\n", + "We now have a simplified version of the Bellman equation\n", + "\n", + "$$U_i(s) = R(s) + \\gamma \\sum_{s'}P(s'\\ |\\ s, \\pi_i(s))U_i(s')$$\n", + "\n", + "An important observation in this equation is that this equation doesn't have the `max` operator, which makes it linear.\n", + "For _n_ states, we have _n_ linear equations with _n_ unknowns, which can be solved exactly in time _**O(n³)**_.\n", + "For more implementational details, have a look at **Section 17.3**.\n", + "Let us now look at how the expected utility is found and how `policy_iteration` is implemented." + ] + }, + { + "cell_type": "code", + "execution_count": 10, + "id": "2f676ec7", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(expected_utility)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "1c4109cd",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(policy_iteration)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8b754a05",
+ "metadata": {},
+ "source": [
+ "
Fortunately, it is not necessary to do _exact_ policy evaluation. \n", + "The utilities can instead be reasonably approximated by performing some number of simplified value iteration steps.\n", + "The simplified Bellman update equation for the process is\n", + "\n", + "$$U_{i+1}(s) \\leftarrow R(s) + \\gamma\\sum_{s'}P(s'\\ |\\ s,\\pi_i(s))U_{i}(s')$$\n", + "\n", + "and this is repeated _k_ times to produce the next utility estimate. This is called _modified policy iteration_." + ] + }, + { + "cell_type": "code", + "execution_count": 12, + "id": "a3f87f07", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "psource(policy_evaluation)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "23e59d12",
+ "metadata": {},
+ "source": [
+ "Let us now solve **`sequential_decision_environment`** using `policy_iteration`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "3ec785da",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "{(0, 1): (0, 1),\n",
+ " (1, 2): (1, 0),\n",
+ " (3, 2): None,\n",
+ " (0, 0): (0, 1),\n",
+ " (3, 0): (-1, 0),\n",
+ " (3, 1): None,\n",
+ " (2, 1): (0, 1),\n",
+ " (2, 0): (0, 1),\n",
+ " (2, 2): (1, 0),\n",
+ " (1, 0): (1, 0),\n",
+ " (0, 2): (1, 0)}"
+ ]
+ },
+ "execution_count": 13,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "policy_iteration(sequential_decision_environment)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "04f390e2",
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.10"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/README.md b/README.md
index 17f1d6085..f6593b0f3 100644
--- a/README.md
+++ b/README.md
@@ -35,14 +35,14 @@ Features from Python 3.6 and 3.7 that we will be using for this version of the c
- [`dataclasses` module](https://docs.python.org/3.7/library/dataclasses.html#module-dataclasses): replace `namedtuple` with `dataclass`.
-[//]: # (There is a sibling [aima-docker]https://github.com/rajatjain1997/aima-docker project that shows you how to use docker containers to run more complex problems in more complex software environments.)
+[//]: # "There is a sibling [aima-docker]https://github.com/rajatjain1997/aima-docker project that shows you how to use docker containers to run more complex problems in more complex software environments."
## Installation Guide
To download the repository:
-`git clone https://github.com/aimacode/aima-python.git`
+`git clone https://github.com/shengmincui/aima-python.git`
Then you need to install the basic dependencies to run the project on your system:
diff --git a/agents.ipynb b/agents.ipynb
index 636df75e3..d50b7a785 100644
--- a/agents.ipynb
+++ b/agents.ipynb
@@ -11,7 +11,7 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
@@ -43,9 +43,151 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 2,
"metadata": {},
- "outputs": [],
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
"source": [
"psource(Agent)"
]
@@ -75,9 +217,221 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 3,
"metadata": {},
- "outputs": [],
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " "
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
"source": [
"psource(Environment)"
]
@@ -114,9 +468,17 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 4,
"metadata": {},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Can't find a valid program for BlindDog, falling back to default.\n"
+ ]
+ }
+ ],
"source": [
"class BlindDog(Agent):\n",
" def eat(self, thing):\n",
@@ -137,9 +499,17 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 5,
"metadata": {},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "True\n"
+ ]
+ }
+ ],
"source": [
"print(dog.alive)"
]
@@ -163,7 +533,7 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
@@ -217,7 +587,7 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
@@ -264,7 +634,7 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
@@ -287,9 +657,21 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 9,
"metadata": {},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "BlindDog decided to move down at location: 1\n",
+ "BlindDog decided to move down at location: 2\n",
+ "BlindDog decided to move down at location: 3\n",
+ "BlindDog decided to move down at location: 4\n",
+ "BlindDog ate Food at location: 5\n"
+ ]
+ }
+ ],
"source": [
"park = Park()\n",
"dog = BlindDog(program)\n",
@@ -313,9 +695,19 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 10,
"metadata": {},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "BlindDog decided to move down at location: 5\n",
+ "BlindDog decided to move down at location: 6\n",
+ "BlindDog drank Water at location: 7\n"
+ ]
+ }
+ ],
"source": [
"park.run(5)"
]
@@ -329,9 +721,25 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 11,
"metadata": {},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "BlindDog decided to move down at location: 7\n",
+ "BlindDog decided to move down at location: 8\n",
+ "BlindDog decided to move down at location: 9\n",
+ "BlindDog decided to move down at location: 10\n",
+ "BlindDog decided to move down at location: 11\n",
+ "BlindDog decided to move down at location: 12\n",
+ "BlindDog decided to move down at location: 13\n",
+ "BlindDog decided to move down at location: 14\n",
+ "BlindDog drank Water at location: 15\n"
+ ]
+ }
+ ],
"source": [
"park.add_thing(water, 15)\n",
"park.run(10)"
@@ -357,7 +765,7 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 12,
"metadata": {},
"outputs": [],
"source": [
@@ -423,9 +831,22 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 13,
"metadata": {},
- "outputs": [],
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "
"
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
"source": [
"park = Park2D(5,20, color={'BlindDog': (200,0,0), 'Water': (0, 200, 200), 'Food': (230, 115, 40)}) # park width is set to 5, and height to 20\n",
"dog = BlindDog(program)\n",
@@ -482,7 +903,7 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 14,
"metadata": {},
"outputs": [],
"source": [
@@ -553,7 +974,7 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 15,
"metadata": {},
"outputs": [],
"source": [
@@ -618,9 +1039,22 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 16,
"metadata": {},
- "outputs": [],
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "
"
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
"source": [
"park = Park2D(5,5, color={'EnergeticBlindDog': (200,0,0), 'Water': (0, 200, 200), 'Food': (230, 115, 40)})\n",
"dog = EnergeticBlindDog(program)\n",
@@ -654,7 +1088,7 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 17,
"metadata": {},
"outputs": [],
"source": [
@@ -696,9 +1130,30 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 18,
"metadata": {},
- "outputs": [],
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "
"
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[[], [None], [], [None], [None]]\n",
+ "Bump\n"
+ ]
+ }
+ ],
"source": [
"step()"
]
@@ -713,7 +1168,7 @@
],
"metadata": {
"kernelspec": {
- "display_name": "Python 3",
+ "display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
@@ -727,7 +1182,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.6.4"
+ "version": "3.7.10"
}
},
"nbformat": 4,
diff --git a/agents.py b/agents.py
index d29b0c382..3f6e65b34 100644
--- a/agents.py
+++ b/agents.py
@@ -65,7 +65,7 @@ def display(self, canvas, x, y, width, height):
# Do we need this?
pass
-
+
class Agent(Thing):
"""An Agent is a subclass of Thing with one required instance attribute
(aka slot), .program, which should hold a function that takes one argument,
diff --git a/arc_consistency_heuristics.ipynb b/arc_consistency_heuristics.ipynb
index fb2241819..d794b22e7 100644
--- a/arc_consistency_heuristics.ipynb
+++ b/arc_consistency_heuristics.ipynb
@@ -1977,7 +1977,7 @@
],
"metadata": {
"kernelspec": {
- "display_name": "Python 3",
+ "display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
@@ -1991,7 +1991,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.7.5rc1"
+ "version": "3.7.10"
}
},
"nbformat": 4,
diff --git a/csp.ipynb b/csp.ipynb
index 5d490846b..389d4efb1 100644
--- a/csp.ipynb
+++ b/csp.ipynb
@@ -59,33 +59,44 @@
"text/html": [
"\n",
- "\n",
+ "\n",
"\n",
"\n",
" "
- ]
- },
- "metadata": {},
- "output_type": "display_data"
- }
- ],
+ "outputs": [],
"source": [
"psource(policy_evaluation)"
]
@@ -1396,70 +1359,18 @@
},
{
"cell_type": "code",
- "execution_count": 18,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "{(0, 0): (0, 1),\n",
- " (0, 1): (0, 1),\n",
- " (0, 2): (1, 0),\n",
- " (1, 0): (1, 0),\n",
- " (1, 2): (1, 0),\n",
- " (2, 0): (0, 1),\n",
- " (2, 1): (0, 1),\n",
- " (2, 2): (1, 0),\n",
- " (3, 0): (-1, 0),\n",
- " (3, 1): None,\n",
- " (3, 2): None}"
- ]
- },
- "execution_count": 18,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
+ "outputs": [],
"source": [
"policy_iteration(sequential_decision_environment)"
]
},
{
"cell_type": "code",
- "execution_count": 19,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "data": {
- "text/markdown": [
- "### AIMA3e\n",
- "__function__ POLICY-ITERATION(_mdp_) __returns__ a policy \n",
- " __inputs__: _mdp_, an MDP with states _S_, actions _A_(_s_), transition model _P_(_s′_ | _s_, _a_) \n",
- " __local variables__: _U_, a vector of utilities for states in _S_, initially zero \n",
- " _π_, a policy vector indexed by state, initially random \n",
- "\n",
- " __repeat__ \n",
- " _U_ ← POLICY\\-EVALUATION(_π_, _U_, _mdp_) \n",
- " _unchanged?_ ← true \n",
- " __for each__ state _s_ __in__ _S_ __do__ \n",
- " __if__ max_a_ ∈ _A_(_s_) Σ_s′_ _P_(_s′_ | _s_, _a_) _U_\\[_s′_\\] > Σ_s′_ _P_(_s′_ | _s_, _π_\\[_s_\\]) _U_\\[_s′_\\] __then do__ \n",
- " _π_\\[_s_\\] ← argmax_a_ ∈ _A_(_s_) Σ_s′_ _P_(_s′_ | _s_, _a_) _U_\\[_s′_\\] \n",
- " _unchanged?_ ← false \n",
- " __until__ _unchanged?_ \n",
- " __return__ _π_ \n",
- "\n",
- "---\n",
- "__Figure ??__ The policy iteration algorithm for calculating an optimal policy."
- ],
- "text/plain": [
- ""
- ]
- },
- "execution_count": 19,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
+ "outputs": [],
"source": [
"pseudocode('Policy-Iteration')"
]
@@ -1524,115 +1435,9 @@
},
{
"cell_type": "code",
- "execution_count": 20,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "data": {
- "text/html": [
- "\n",
- "\n",
- "\n",
- "\n",
- " "
- ]
- },
- "metadata": {},
- "output_type": "display_data"
- }
- ],
+ "outputs": [],
"source": [
"psource(GridMDP.T)"
]
@@ -1668,114 +1473,9 @@
},
{
"cell_type": "code",
- "execution_count": 21,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "data": {
- "text/html": [
- "\n",
- "\n",
- "\n",
- "\n",
- " "
- ]
- },
- "metadata": {},
- "output_type": "display_data"
- }
- ],
+ "outputs": [],
"source": [
"psource(GridMDP.to_arrows)"
]
@@ -1790,115 +1490,9 @@
},
{
"cell_type": "code",
- "execution_count": 22,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "data": {
- "text/html": [
- "\n",
- "\n",
- "\n",
- "\n",
- " "
- ]
- },
- "metadata": {},
- "output_type": "display_data"
- }
- ],
+ "outputs": [],
"source": [
"psource(GridMDP.to_grid)"
]
@@ -1921,10 +1515,8 @@
},
{
"cell_type": "code",
- "execution_count": 23,
- "metadata": {
- "collapsed": true
- },
+ "execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"# Note that this environment is also initialized in mdp.py by default\n",
@@ -1946,10 +1538,8 @@
},
{
"cell_type": "code",
- "execution_count": 24,
- "metadata": {
- "collapsed": true
- },
+ "execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"pi = best_policy(sequential_decision_environment, value_iteration(sequential_decision_environment, .001))"
@@ -1964,19 +1554,9 @@
},
{
"cell_type": "code",
- "execution_count": 25,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "> > > .\n",
- "^ None ^ .\n",
- "^ > ^ <\n"
- ]
- }
- ],
+ "outputs": [],
"source": [
"from utils import print_table\n",
"print_table(sequential_decision_environment.to_arrows(pi))"
@@ -2005,10 +1585,8 @@
},
{
"cell_type": "code",
- "execution_count": 26,
- "metadata": {
- "collapsed": true
- },
+ "execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"sequential_decision_environment = GridMDP([[-0.4, -0.4, -0.4, +1],\n",
@@ -2019,19 +1597,9 @@
},
{
"cell_type": "code",
- "execution_count": 27,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "> > > .\n",
- "^ None ^ .\n",
- "^ > ^ <\n"
- ]
- }
- ],
+ "outputs": [],
"source": [
"pi = best_policy(sequential_decision_environment, value_iteration(sequential_decision_environment, .001))\n",
"from utils import print_table\n",
@@ -2065,10 +1633,8 @@
},
{
"cell_type": "code",
- "execution_count": 28,
- "metadata": {
- "collapsed": true
- },
+ "execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"sequential_decision_environment = GridMDP([[-4, -4, -4, +1],\n",
@@ -2079,19 +1645,9 @@
},
{
"cell_type": "code",
- "execution_count": 29,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "> > > .\n",
- "^ None > .\n",
- "> > > ^\n"
- ]
- }
- ],
+ "outputs": [],
"source": [
"pi = best_policy(sequential_decision_environment, value_iteration(sequential_decision_environment, .001))\n",
"from utils import print_table\n",
@@ -2124,10 +1680,8 @@
},
{
"cell_type": "code",
- "execution_count": 30,
- "metadata": {
- "collapsed": true
- },
+ "execution_count": null,
+ "metadata": {},
"outputs": [],
"source": [
"sequential_decision_environment = GridMDP([[4, 4, 4, +1],\n",
@@ -2138,19 +1692,9 @@
},
{
"cell_type": "code",
- "execution_count": 31,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "> > < .\n",
- "> None < .\n",
- "> > > v\n"
- ]
- }
- ],
+ "outputs": [],
"source": [
"pi = best_policy(sequential_decision_environment, value_iteration(sequential_decision_environment, .001))\n",
"from utils import print_table\n",
@@ -2338,221 +1882,9 @@
},
{
"cell_type": "code",
- "execution_count": 32,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "data": {
- "text/html": [
- "\n",
- "\n",
- "\n",
- "\n",
- " "
- ]
- },
- "metadata": {},
- "output_type": "display_data"
- }
- ],
+ "outputs": [],
"source": [
"psource(POMDP)"
]
@@ -2599,7 +1931,7 @@
},
{
"cell_type": "code",
- "execution_count": 33,
+ "execution_count": null,
"metadata": {},
"outputs": [],
"source": [
@@ -2619,7 +1951,7 @@
},
{
"cell_type": "code",
- "execution_count": 34,
+ "execution_count": null,
"metadata": {},
"outputs": [],
"source": [
@@ -2665,40 +1997,9 @@
},
{
"cell_type": "code",
- "execution_count": 35,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "data": {
- "text/markdown": [
- "### AIMA3e\n",
- "__function__ POMDP-VALUE-ITERATION(_pomdp_, _ε_) __returns__ a utility function \n",
- " __inputs__: _pomdp_, a POMDP with states _S_, actions _A_(_s_), transition model _P_(_s′_ | _s_, _a_), \n",
- " sensor model _P_(_e_ | _s_), rewards _R_(_s_), discount _γ_ \n",
- " _ε_, the maximum error allowed in the utility of any state \n",
- " __local variables__: _U_, _U′_, sets of plans _p_ with associated utility vectors _αp_ \n",
- "\n",
- " _U′_ ← a set containing just the empty plan \\[\\], with _α\\[\\]_(_s_) = _R_(_s_) \n",
- " __repeat__ \n",
- " _U_ ← _U′_ \n",
- " _U′_ ← the set of all plans consisting of an action and, for each possible next percept, \n",
- " a plan in _U_ with utility vectors computed according to Equation(__??__) \n",
- " _U′_ ← REMOVE\\-DOMINATED\\-PLANS(_U′_) \n",
- " __until__ MAX\\-DIFFERENCE(_U_, _U′_) < _ε_(1 − _γ_) ⁄ _γ_ \n",
- " __return__ _U_ \n",
- "\n",
- "---\n",
- "__Figure ??__ A high\\-level sketch of the value iteration algorithm for POMDPs. The REMOVE\\-DOMINATED\\-PLANS step and MAX\\-DIFFERENCE test are typically implemented as linear programs."
- ],
- "text/plain": [
- ""
- ]
- },
- "execution_count": 35,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
+ "outputs": [],
"source": [
"pseudocode('POMDP-Value-Iteration')"
]
@@ -2712,137 +2013,9 @@
},
{
"cell_type": "code",
- "execution_count": 36,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "data": {
- "text/html": [
- "\n",
- "\n",
- "\n",
- "\n",
- " "
- ]
- },
- "metadata": {},
- "output_type": "display_data"
- }
- ],
+ "outputs": [],
"source": [
"psource(pomdp_value_iteration)"
]
@@ -2881,7 +2054,7 @@
},
{
"cell_type": "code",
- "execution_count": 37,
+ "execution_count": null,
"metadata": {},
"outputs": [],
"source": [
@@ -2909,7 +2082,7 @@
},
{
"cell_type": "code",
- "execution_count": 38,
+ "execution_count": null,
"metadata": {},
"outputs": [],
"source": [
@@ -2918,20 +2091,9 @@
},
{
"cell_type": "code",
- "execution_count": 39,
+ "execution_count": null,
"metadata": {},
- "outputs": [
- {
- "data": {
- "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYEAAAD8CAYAAACRkhiPAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMS4yLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvNQv5yAAAIABJREFUeJzsnXd81dX9/5+fm733JiEBEkYYYRNkrwABW9yjWq2tP7WuVq24v0WtiKNaF1K0al3ggNIEhIDKEhlhRCBkD7L33rnn98eH+ykrZN2bm3Gej0cekuQzziee+359zjnv83orQggkEolEMjDRmbsBEolEIjEfUgQkEolkACNFQCKRSAYwUgQkEolkACNFQCKRSAYwUgQkEolkACNFQCKRSAYwUgQkEolkACNFQCKRSAYwluZuwPl4enqK4OBgczdDIpFI+hTx8fElQgivrpzbq0QgODiYI0eOmLsZEolE0qdQFCWrq+fK6SCJRCIZwEgRkEgkkgGMFAGJRCIZwEgRkEgkkgGMFAGJRCIZwEgRkEgkkgGMFAGJRCIZwEgRkEgkkgGMFAGJRCIZwEgRkEgkkgHMgBaBF198kfDwcMaOHUtERAQHDx40d5MkfYBNmzahKApnzpy54nGOjo491CJJW1hYWBAREUF4eDjjxo3j9ddfR6/XX/GczMxMRo8e3e4xn3/+uTGbajYGrAgcOHCAmJgYjh49SkJCAjt37iQwMNDczZL0Ab744gtmzJjBl19+ae6mSNrBzs6O48ePc+rUKeLi4ti6dSt//etfu31dKQL9gPz8fDw9PbGxsQHA09MTf39/Vq1axeTJkxk9ejR33303QggSExOZMmWKdm5mZiZjx44FID4+ntmzZzNx4kSioqLIz883y/NIeoaamhr279/PBx98oIlAfn4+s2bNIiIigtGjR7N3794LzikpKSEyMpLY2FhzNFlyDm9vb9atW8fbb7+NEILW1lYee+wxJk+ezNixY3n//fcvOaetY1auXMnevXuJiIjg73//e4eu1WsRQvSar4kTJ4qeorq6WowbN06EhoaKe++9V/z4449CCCFKS0u1Y37zm9+ILVu2CCGEGDdunEhLSxNCCLF69Wrx/PPPi6amJhEZGSmKioqEEEJ8+eWX4s477+yxZ5D0PP/+97/F7373OyGEEJGRkSI+Pl68+uqr4oUXXhBCCNHS0iKqqqqEEEI4ODiIgoICMWXKFLFjxw6ztXkg4+DgcMnPXF1dRUFBgXj//ffF888/L4QQoqGhQUycOFGkp6eLjIwMER4eLoQQbR7zww8/iOjoaO2abR3XUwBHRBfjrlGspBVF+RBYBhQJIUaf+5k7sAEIBjKBG4QQ5ca4nzFwdHQkPj6evXv38sMPP3DjjTeyevVqnJycWLNmDXV1dZSVlREeHs7y5cu54YYb2LhxIytXrmTDhg1s2LCBpKQkTp48ycKFCwH1rcHPz8/MTyYxJV988QUPP/wwADfddBNffPEFy5cv53e/+x3Nzc38+te/JiIiAoDm5mbmz5/PO++8w+zZs83ZbMl5qDETduzYQUJCAl9//TUAlZWVpKSkEBYWph3b1jHW1tYXXLOt40JCQnrikbpHV9Xj/C9gFjABOHnez9YAK8/9eyXwcnvXCRsdJhpbGk2ilO3x1VdfiQULFghvb2+RnZ0thBDiueeeE88995wQQojU1FQxfvx4kZSUJCZMmCCEECIhIUFMmzbNLO2V9DwlJSXC1tZWBAUFicGDB4tBgwaJwMBAodfrRW5urli3bp0YPXq0+Pjjj4UQQtjb24vbb79dPPHEE2Zu+cDl4pFAWlqacHd3F3q9XlxzzTXiu+++u+Sc80cCbR1z8UigreN6gvz87o0EjLImIITYA5Rd9ONfAR+f+/fHwK/bu05yaTKeazy5buN1fHT8IwprCo3RvMuSlJRESkqK9v3x48cZPnw4oK4P1NTUaKoOMHToUCwsLHj++ee58cYbARg+fDjFxcUcOHAAUN/8Tp06ZbI2S8zL119/ze23305WVhaZmZmcPXuWkJAQ9uzZg7e3N3/4wx+46667OHr0KACKovDhhx9y5swZVq9ebebWS4qLi7nnnnu4//77URSFqKgo3nvvPZqbmwFITk6mtrb2gnPaOsbJyYnq6up2jzMlubnw0EPQ3cGGKSuL+Qgh8gGEEPmKoni3d8JQ96HMGz2P2JRYvkn8BgWFyQGTWRa6jOiwaMb7jkdRFKM0rqamhgceeICKigosLS0ZNmwY69atw9XVlTFjxhAcHMzkyZMvOOfGG2/kscceIyMjAwBra2u+/vprHnzwQSorK2lpaeHhhx8mPDzcKG2U9C6++OILVq5cecHPrr32Wu644w4cHBywsrLC0dGRTz75RPu9hYUFX375JcuXL8fZ2Zn77ruvp5s9oKmvryciIoLm5mYsLS257bbb+POf/wzA73//ezIzM5kwYQJCCLy8vNi8efMF57d1zNixY7G0tGTcuHHccccdPPTQQ+1ey1hkZ8PLL8P69aDXw223wb/+1fXrKeLc/Fh3URQlGIgR/1sTqBBCuJ73+3IhhNtlzrsbuBsgKChoYlZWFkIIjhccJyY5htiUWA7lHkIg8HfyZ+mwpSwLW8aCIQtwsHYwStslEomkt5OZCS+99L+Af+edsHKlOhJQFCVeCDGpK9c1pQgkAXPOjQL8gB+FEMOvdI1JkyaJy9UYLqwpZFvqNmJTYtmeup3qpmpsLGyYEzyHZWHLiA6NJsStDyzAmIGdZeos3QJ3dzO3RCLpOgO5H6elwd/+Bp98Ajod/P738PjjEBT0v2N6qwi8ApQKIVYrirIScBdC/OVK12hLBM6nqbWJfdn7iEmOISY5hpQydV5/lNcookOjWRa2jOmB07HUmXKmq+8w59gxAH4cP97MLZFIus5A7MdJSWrw/+wzsLKCu++Gv/wFAgIuPdbsIqAoyhfAHMATKASeAzYDG4EgIBu4Xghx8eLxBXREBC4muTSZ2ORYYlNi2Z21mxZ9C662riwetphloctYPGwxHvYeXXiq/sFA/PBI+h8DqR+fPg0vvghffgk2NnDvvfDoo3Cl7PPuiIBRXpeFEDe38av5xrj+lQjzCCMsMow/Rf6JqsYq4tLiiEmJYWvKVr48+SU6RUfkoEhtlDDae7TRFpclEonEWPzyC7zwAnz1Fdjbq4H/kUfAu92Umu7Rr+ZMnG2cuXbUtVw76lr0Qs+RvCPa4vKT3z/Jk98/SZBLkCYIc4PnYmdlZ+5mSySSAczx4/D88/Dtt+DkBE88AX/6E3h69sz9e5UItOfu1xl0io4pAVOYEjCFVXNXkVedx9aUrcQkx/DxiY9578h72FnaMX/IfC0FdZDzIKPdXyKRSK7EkSNq8N+yBVxc4Nln1bz/nl77NtrCsDFQFEUA6HQ6fH19iYqK4qmnnmLo0KFGvU9DSwO7M3eri8spMWRWZAIwzmecNkqYEjAFC52FUe9rDpLq6gAYbm9v5pZIJF2nP/Xjn3+GVatg2zZwc1Pf+h94AFxd2z+3Lcy+MGwsDCLQFs7OzkRERPDII4+wfPlyo8ztCyFILEnUpo32Z++nVbTiae/JkmFLWBa2jEVDF+Fq243/QxKJZMCzb58a/OPiwMNDnfO/7z5wdu7+tfuNCLi6uopp06aRnZ1NWloaTU1N7Z5jZWVFSEgIt9xyC3/6059w7uZftLy+nO1p24lJjmFb6jbK6suwUCyYOXimNkoY7jG8zywu/7ekBIDlPTXBKJGYgL7aj4WA3bvV4P/DD+oi72OPwT33gDFrDvUbETh/JGBjY4OXlxe+vr5YW1tTX19PRkYGlZWVtNdmRVHw9PRk9uzZPPfcc+1WCWqLVn0rP+f8TGxKLDHJMfxS9AsAQ9yGaOsIswfPxsbSpkvX7wkGUmqdpP/S1/qxELBrlxr89+4FX191g9fdd6uZP8am34hASEiIWLRoEQkJCWRkZFBWVqYZMhmwtrbGw8MDV1dXdDod5eXlFBYW0tra2u717ezsGD16NA888AC33HILFhadm/PPrswmNjmWmJQYvs/4noaWBhysHFg0dBHRodEsDV2Kn1PvspLuax8eieRy9JV+LARs364G/wMH1I1dK1fCXXeBnQkTEfuNCFxus1hZWRlxcXHs2bOH48ePk5GRQUlJySXiYGVlhYuLC/b29uj1ekpLS6mvr2/3nhYWFvj7+3Pttdfy7LPP4uZ2ib3RZalrruP7jO81UcipygFgot9EloUtY1nYMib4TUCnmLd4W1/58EgkV6K392MhIDZWDf6HD6uWDk88ofr72PTAREG/FoG2qKqqYufOnezZs4djx46RlpZGSUkJjY2NFxxnaWmJg4MDNjY21NfXU1tb26FUVFdXVyIjI3n22WeZNm3aFY8VQpBQmKBNG/2c8zMCgY+DD9Gh0USHRbNwyEKcbJw69GzGpLd/eCSSjtBb+7Fer6Z4rloFx46pZm5PPgm33w4X1Z0xKQNSBNqitraW77//nt27d3P06FFSU1MpLi6moaHhguMsLCywtbVFp9NRX19PS0tLu9e2sbFh2LBh3H333dx3331YWl5+m0VxbTHfpX5HbEos36V+R2VjJVY6K+YEz9EWl4e6GzfttS1664dHIukMva0f6/Xq5q7nn4eEBBg2DJ56Cm69VfX56WmkCHSAhoYGdu/ezY8//kh8fDwpKSkUFhZeMmWk0+mwsrJCr9dfMuV0OXQ6Hd7e3ixdupQXXnjhkvKSza3N/HT2J21PwpmSMwAM9xiuOaDOCJqBlYVpes7Zc+IXaGtrkutLJD1Bb+nHra2wcaNq73D6NAwfDk8/DTfdBG28E/YIUgS6QVNTE/v27eOHH37gyJEjJCcnU1BQQN25zSkGFEVBp9Oh1+vbzU4CcHBwYMKECTz11FNERUVpP08rSyM2RTW8+zHzR5pam3C2cSZqaBTLwpaxZNgSvBy8jP6cEomk67S0wBdfqMZuSUkwahQ88wxcfz10Mr/EJPQbEXBxcRGPP/44V199NeHh4WbNxW9paeHgwYPs3LmTw4cPk5ycTF5e3mVLximK0iFhsLS0JCgoiN/+9rc8/vjjNNHEzvSdmigU1BSgoDB10FQtBXWcz7hu/R02FBUBcKOpXagkEhNirn7c3AyffqoG/7Q0GDtWDf7XXKN6+/cW+o0IXGnHsJWVFa6urvj7+zN27FiWL1/OwoULce3OXusuoNfriY+PZ+fOnRw8eJAzZ86Ql5d3Qb3RzqAoCi4uLsybN49bH7qVX/S/EJMSw5E8dUQ0yHmQurgcGs38IfOxt+pcknFvm0uVSLpCT/fjpib4+GPVzz8zEyZMUIP/1Vf3ruBvYECIQEfQ6XTY2dnh6elJSEgIM2bMYMWKFYwbN67TewI6i16vJyEhgbi4OA4ePEhiYiI5OTlUV1d3aJRwMVbWVvgM9sF3iS9nfM9Q01SDraUtc4PnamsJg10Ht3sdKQKS/kBP9ePGRvjwQ7WM49mzMHkyPPccLF0KvdkkoF+JgCFrx9bWFmtray0Dp7GxkZqaGhobGzu0MexKGAqC+/v7M3r0aBYvXszVV1+Nuwns+4QQJCYmsmPHDn7++WdOnz7N2bNnqaqq6rxrqgI6Bx36kXqYD6ODRmvTRtMGTbtsNTUpApL+gKn7cX29Wrj95ZchNxciI9Xgv2hR7w7+BvqNCDg4OAhfX18qKyupra2lqanpioHS0tISKyurC8SiqamJhoYGWlpauvQGbkBRFGxtbXFzc2PIkCFMnTqVa6+9lsmTJ7eZGtpZkpOTiYuL48CBA5w6dYrs7GwqKio6Lw6WoAvUMf+e+dy55E6ihkXhbqcKmhQBSX/AVP24rg7efx/WrIGCApg5Uw3+8+b1jeBvoN+IwOWygxobG0lOTubMmTOkpKSQlZVFTk4OhYWFlJaWUlVVpQnGlZ7FwsICS0tLLYC3tLTQ0tLS7VGFhYUFjo6O+Pn5MXLkSKKiorjmmmvw8up6hk9WVhbbt29n//79nDx5kuzsbMrLyzvXVh24ertif+2vCPntH9k3eXKX2yORmBtji0BNDbz3Hrz6KhQVqUH/2Wdh9myjXL7H6dci0Bnq6+s5c+YMiYmJpKWlkZmZSV5eHgUFBZSVlVFVVUVdXR3Nzc3tCoZhDaG1tbXDaaFtoSgKVlZWuLm5MXjwYCZPnsy1117LzJkzOzWqyM3NJS4ujn379pGQkEBmZiZlZWWdEgdnZ2eioqJ4++238ZYZQ5I+Qsk5R2HPbm7DraqCd96B116D0lJ1uueZZ2DGDGO00nxIEegC1dXVJCYmkpSURGpqKtnZ2eTk5FBUVERZWRnV1dWaYFwJ3blUASFEt4TCcC07Ozt8fHwYOXIk8+bN44YbbmDQoCtXPCsqKiIuLo69e/eSkJCgWWh0dFrJysqK4cOHs3r1aqKjo7v1DBJJb6SiAt56C/7+dygvVxd6n3kG2nGE6bVUVFTw1VdfsWvXLk6fPs0vv/wiRcCUlJeXc/r0aZKSkkhLSyM7O5u8vDyKioooLy+nurqa+vr6Du0wNgaWlpY4OzszePBgJkyYwIoVK4iKirpkVFFWVsZTGzeSfPAg9clJnDx9kuqKjqeyenp6cvPNN/Paa69hZY698BLJOT7KzwfgDr/OufSWlcGbb6pflZVqiuczz8CkLoXLnqG5uZm9e/eyefNm4uPjtenghoaGK436pQj0FoqLizXBSE9P1wSjuLhYEwzDwrUpURQFGxsbWp2csAsO5rGrr+bWW28lJCSEyspK/vXtv/h629ecOHqCmuwa6KB+2djYMHHiRN577z3Gjh1r0meQSAx0dk2gpER963/rLaiuVjd3Pf009Ib8iIyMDDZu3MjevXtJSUmhqKiI2traDiezWFpaYm9vj4eHB8HBwQwdOpT169f3DxFQFEVYWVlhZWWFjY0Ntra22Nvb4+joiKOjIy4uLri6uuLm5oanpydeXl54e3vj6+uLv78/fn5+2NnZ9YmqX0IICgoKNMHIyMjQBKOkpITy8nJqamraU/9uY2FhgZ2dHU4eTuj8dRRZFdHc2AzpQCnQgRklRVHw8fHhkUce4dFHHzVZWyUDl46KQFGROt//zjtq5s/116vBf8yYnmgl1NXVsWXLFrZv384vv/xCTk4OlZWV7WY6GtDpdNjY2ODg4ICzs7MW7ywsLCgtLaW4uJiKigrq6uoufpHsHyJga2srvL29qa+vp7Gxkaampi5l8Oh0OiwsLC4REwcHh0vExMPDAy8vL3x8fPD19cXPzw8/Pz8cHBx6jZjo9XrOnj3L6dOnSUlJISMjg7Nnz5Kfn09JSQkVFRVG20PRJjrQWejQt+ihg13G2tqa6dOn8/nnn19irCeRdIb2RCA/H155BdauVTd83XST6uo5apTx2iCE4MiRI3z77bccOnSI9PR0rW5JR0b2Bv8xQ1q7ra0tlpaWtLS0UFtb290Xvt4rAoqiZALVQCvQcqWGXmk6qLm5mZKSEvLz88nPz6ewsJDi4mJKSkooLS2lvLycyspKqqurqampoa6ujrq6ugvEpLNZPoqiXLAX4XJi4uLigru7uyYm3t7e+Pj44OfnR0BAAI6Ojj0qJnq9noyMDE0wXjt0iMbCQkIbGjTBqK2tpbGxsfP7EYyAoih4eHjw2GOP8eijj2oL6xLJlWhLBHJy1Bz/detUk7dbb1WDf1hY5+9RXFzMV199xffff09iYiKFhYVUV1e3m01owBDkDZ93vV5v9M+Y4QXX1tYWJycnfHx8GDZsGF999VWvF4FJQoiS9o7tiTWBlpYWSktLLxCToqIiSkpKKCsr08SkqqqKmpoaamtrLxiZNDc3d0lMzh+Z2NjYtDkycXd3v0BM/P398ff3x9nZuUticqU3qJaWFlJTU0lMTCQlJYXMzExycnIoKCigtLSUyspKampq2t2DYQysrKwYO3Ysr7/+OjNmzJDiILmAi/txdjasXg0ffKB6+99+u1rJa9iwy5/f0tJCXFwcMTExHD16VNuY2dDQYJaXofOxsrLC1tYWZ2dnfHx8CA0NZcKECUyePJkJEybg4uLS7jV6dYpobxMBY6HX6ykrKyMvL4+8vLwLRiYGMamoqLhETBoaGi6Y5uqqmBhGJnZ2djg4OODk5ISTk9Ml01wuHh54+/gQHBDAoEGDcHFx6ZKYNDU1kZycTGJiIqmpqWRkZJCYnkja2TRKS0tpqmlSF5dN8Hny9vbm1ltv5emnnzaJtYek91N3bpqkMNuCl16Cjz5Sf/6736k1fJubU9iwYQM//fQTKSkpFBcXa/PmPT3lbWFhgb29Pc7Ozvj6+hIaGsqkSZOYOnUqERERODo6Gv2evV0EMoBy1Jnk94UQ69o6ti+JgLHQ6/WUl5dfMjIpLi6+YJqrLTFpbm7usphYWlpqIxODmDg6Ol6wIOXh4YGnp+cF01z+/v64u7tfICZFtUVsS9lGbEos2xK3UZNbg0WZBcH6YLyavbCutaaqrIrCwkLKy8tpbGw02ofTwcEBb29vJk+ezF133cX8+fNNbhgo6TlqampYu3Yna9e6k5Y2HWjFwuJftLb+DThr8vsbpl9cXFzw8/MjNDSUqVOnEhkZybhx47DtBQWbersI+Ash8hRF8QbigAeEEHvO+/3dwN0AQUFBE7Oyskzanv6KEILKykry8vI0QSkuLmZ7Rga15eX4NzVdMDKpqakxqphYW1trYmLvYA/WUKfUUSbKqNHVgD14eXoxMXQi88bMY96YeQwOHIy1tTVJSUnaLm+DLUhqaio5OTlGW+jW6XQ4OzsTHBzMwoULeeihhwgICDDKtSVdRwjBgQMH2LRpE4cOHSIlJYWysrLzpiDDgKeAW4Em4H3gFSCvy/c0vPwYgnpYWBjTp0/nqquuIjw8HOueLA5sJHq1CFxwM0X5P6BGCPHq5X4/EEcCpqaz+dVCCKqrq8nNzb1kzcSQutqemHR2CH5x1oQmJufSg52dnXFxccHOzk6zBbm4LKixsLS0xMXFhbFjx3Lbbbdxyy23YGNjY5J7DQSys7N588032bJlCzk5OZ0YAY5CDf43AfXAe8CrQOElRxrSKl1cXPD399eC+rx58xg+fLjRDB97M71WBBRFcQB0Qojqc/+OA1YJIb673PFSBIyPuVxEhRDU1tZqI5OCggKKiorIyc/hRMYJknOTyS3KpamuCRrBRthgrbeGFmhtbtVGJuZetGsLa2tr3N3dmTJlCo8//jjTp083d5N6jMrKSj788EO2bt1KQkICZWVlRtz8OAZ4GrgOqMPLayPTp//ML2GuuE6bxpEVK3pN6nZvojeLwBBg07lvLYHPhRAvtnW8FAHj05utpPVCT3xePDHJMcSmxBKfHw9AoHOgVjhnXsg89E168vPzNTNAw8iktLSUsrIyKioqtPTg2tpa6urqqK+vp6amxuQ7s6+EoihYW1vj5eVFZGQkDz/8MNOmTet1mU/19fVs2bKF//znPxw/fpzCwkItjdiYWFtb4+Pjw4QJE5g7dy7R0dEMHToURVE4dgyefx42bQInJ3jwQXj4YfD0VM/tzf24N9BrRaCzSBEwPn3pw5NXncfWlK3EpsQSlxZHbXMtdpZ2zAuZp4lCoEtgl6+vLjCu5b333iMrK8ukO7E7i8GSfPjw4cyZM4fIyEjGjx+Pv79/p32b6urq2L59O9u3byc+Pl4rYtTU1GT0Z9bpdDg4ODBixAjuvfdebrvttk5Nvxw+rAb///4XXFzUwP/QQ+DmduFxfakfmwMpApI26asfnsaWRnZn7SYmOYaY5BgyKjIAGOszVqumNjVgKha67mcBnTp1imeffZbvv/+eysrKTq1nGIKgYa+Hs7MzDg4OVFRUkJaWRlVVlVlHI11Fp9Ph6OjIoEGDCA8PZ86cOVx//fXdqpNxPgcOqMF/2zY14P/5z/DAA6oQXI6+2o97CikCkn6NEIIzJWe0aaN92ftoFa142HmwJHQJy0KXETUsCldbV6Pds7a2ljVr1vDvf/+bs2fPdjqQW1hY4O7uTnBwMGPHjuWqq65i0aJFBAQEUFVVRVxcHDt37uTHH38kPT2dpnN++T2JYUe8g4MDnp6e+Pn5aenBHh4eF+yC9/X1JSAgAF9f326lRO7dC6tWwc6d6lTPI4/AH/+oTgFJuo4UAcmAory+nB1pO4hJiWFrylbK6suwUCyYETRDmzYa4TnC6AuIQgj++9//smbNGo4dO0ZdXZ1Rr9+X0Ol0mqWKwZ/Lzs7uArNHNze3c7vgPaioiGDXrumcOuWNh0cLjzwieOABK0ywb2pAIkVA0iavZmcD8GhQkJlbYhpa9a0czD2ojRISChMAGOI2RJs2mj14NjaWHUvzNLi77tu3jz179mhOkGVlZVoZU3Nx/pu7t7c3YWFhzJw5kxtuuIHAwEAOHjzIp59+yp49e8jJyaG6utpo2VXn+2hZWFhc4o/T2trahtnjAuBZYCZqbv/LwD9R0z6vbPbo5OSkjUyyrKywd3Pj6qFD8fb21jYt+vv7Y29vb5Rn7MtIEZC0yUCbS82uzGZrylZikmPYlbGLhuYGbOtsCW8Mx7nAmfrceory1WJABk8oY38GDEHSWAZijo6OBAcHEx4ezrRp01i4cCGjRo3q0kinoqKCr7/+mi1btnDixAmKi4tpaGgw2t9ADejW2Nr+moaGx2hoGI+1dSEhIRsJCfkea2v171FdXX2B2aNhr0lzc3OX/LnOF5OLzR7PF5OLnYPP3wXf02aPxkSKgKRN+psI6PV60tLSOHToED/99BMnT54kNzeXsrIyzSvGmBkwhk1shsVfRVEuCVodCfSGdFFbW1taW1s7VVhIUZRLAqKiKDg5OTFo0CBGjhzJlClTWLhwIePGjet2CqoQgmPHjrFhwwZ2795NWloalZWVHayctwz1zX8ykAX8DfgIdbfvhZz/d/Xw8NDWHYKDgxk2bBhhYWF4enpSUlLCbfv20Vxayl329hQXF3fI7LGr/lyWlpYXWKpcSUwutlQZNGgQTk5OPS4mUgQkbdLbRaClpYWkpCQOHTrE4cOHOXXqFDk5OZSXl2s1no2+YUwHWAD2YOliqQYe72DsmuwoLfnqFwU+AAAgAElEQVRf4Y6uVnsaNmwY06ZN47rrrmPMmDHtBoS8vDxeeukltmzZQm5ubodEzGBZfPGxiqLg6OiIv78/I0aMYMqUKSxYsIBJkyYZfX9CbW3tuf0F/2XPHjcKC/+AXh+BWpHoReDfdLhk3RVQFAWsrLCwsyPo3IK1j48PgwYNIiQkhGHDhjFy5EhCQ0Mvm54qhLjA7LGgoMDsZo+GXfDni4mhpolBDDtj9ihFQNImPS0CjY2NnDp1imPHjhEfH8+pU6c4e/asVg3JFEFdURTtrdLDw0ObMw4MDCQkJISAgABycnKIj4/n5MmT5OXlUVlZ2eGpIIMtgaurK4MGDSIiIoKlS5eyZMkSk1lKNDc38/HHH7N27VpOnz7dIZsMw9/BcP7Fz+bg4ICfnx/Dhw9n0qRJLFiwgMjIyC6b7en18M03aqrnL7+oNs5PPw233AKGrQ1CCJKSkti4cSO7d+8mMTHR6AaC53N+ZS4XFxc8PT3x9fUlMDCQ4OBgQkNDGTVqFEOGDOm0KAohKC8v13bBn2+pYti42BNmj/b29tjb21/gHPz1119LEZBcniUJ6kLpti7WA66vrychIYFjx45x4sSJC97U6+vrTfOmzv9qJDs6OuLu7q6lMBre/sLCwhg5ciSBgYHEx8dfUO2prKysU9WerKyssLGzwcrZiibXJmr8aiAchg8ZTnRoNMvCljEjaAZWFp3btGUKDh8+zOrVq9mzZw+lpaUdCiiGRdeWlpbLBl97e3t8fX0JCwtj4sSJzJ07l1mzZrW5Sa21FTZuhBdegNOnYcQINfjfeCN01aanvr6eHTt28J///Efz+6+urjbpHgsLCwtNMFxdXfHy8tIEw9DHRo0aRWBgoFFHURebPRYWFlJYWHhJgSxDPQ/DLvh2xESKgKRj1NTUcPz4cY4dO8bJkyc5ffo0OTk5VFRUmDSow//e0gxvL+cH9uDgYO1DFxQUpH3oioqKtLnpxMRECgoKqKmp6XC1J0MNZXd3dwYPHszkyZP51a9+dcXCNenl6cQmxxKTEsOPmT/S1NqEs40zUUOjWBa2jCXDluDlYJxNU8agpKSEN954gw0bNpCVldWhuXuD572VlRVNTU3U1dVd8v/d1tYWX19fhg0bxsSJE5k5cy6FhXN5+WVrkpMhPByeeQauuw56yrk7NTWVb7/9lh9//JEzZ85QWFjYI4VhDHbSjo6OmmD4+fkRFBRESEgIw4cPZ+TIkfj5+fWYLcj5Zo+jRo2SIjAQEUJQUVGhvaWfPn2axMRE8vLyTP6mbkCn013w4bg4sIeGhhIeHn5BYDfQ0tLC9u3biY2N5dixY52u9mRYtHV2dsbf35/Ro0ezYMECVqxY0aFqTB2hpqmGnek7iU2OJTYllvyafBQUpg6aqo0SxvmM63VZJS0tLXz77be89dZbnDhxgurq6g6dZyhwDurbeXV1Na2tCvAbVFfPYShKAu7u7zBmTCoTJkQwZ84c5s2bh4ODg8mepzM0NDSwZ88eNm/ezJEjR8jKyqKioqLH0nstLS21z4RhFOvv709QUBBDhw4lNDSU0aNHG233Ncg1gX6DEIKSkhKOHj3KiRMnOHPmDMnJyeTm5mpz6oZayabk/GGym5ubtmgVFBSkBfaRI0cSHBx8xbee06dP880331xQ7ckwTdNevzNkadjb2+Pp6cmwYcO46qqruO666xgxwvgbwTqCXug5XnBcs7I4nHcYgACnAE0Q5oXMw8G6dwTDy3Hy5EleeeUV4uLiKCgoaOf/gxXwW+BJIAQbm5O4uPyD1tbNVFaWXzJVYzDLGzJkCOPHj2fWrFksXLhQE5Xu8HxmJgDPBAd3+1oGzp49y5YtW4iLi9NGmbW1td3OLju/b7bXzw2lJZ2cnHBzc8Pb2xt/f38GDx7MkCFDGD58OOHh4bhdbKZ06T2lCPRG9Ho9BQUFxMfH88svv3DmzBnS0tK0oG4IiD1hl3y5+U8fHx9t/rOjgd1AZWUlmzdvJi4ujpMnT5Kfn6+ZlHXkeQztcXV1JSgoiHHjxrF8+XIWLFjQZ/z7C2oKtGpq29O2U9NUg42FDfNC5hEdGk10WDTBrsHmbma7VFVVsXbtWj755BPS0tJoaBDA74CVQBBwEFgFbNXOURQFNzc3fH19sbGxoampidLSUkpLSy+ZjrKyssLT05OQkBAiIiKYOXMmixYt6lSpUHNluTU3N7N//37+85//cPDgQTIyMqioqDDKwrZOp9M+a0KIdsXHysoKOzs7nJ2dtVrkhpTaVatWSRHoCVpbW8nNzeXIkSMkJCSQmppKeno6ubm5VFZWatMvPfU3vTiwn58JYQjsf9XrsfX3Z8/EiR2+bmtrq9bxjxw5QmZmprbY2pG3JMNiq6OjIz4+PowaNUozIPPx8enOI/damlqb2JO1R1tLSC1LBSDcK5xlYctYFraMaYOmYanrvQVO6uvhn/+El1+GvDwYObIMO7tXSE9/n4qK8g5dw9bWlkGDBuHj44O1tTW1tbXk5uZSXFx8yXSMpaUlHh4emr/SjBkziIqKumwf6e2pznl5eWzbto0dO3ZoGWjGsDI/P9UU1BfLNvbCSBHoCk1NTWRlZWmpjKmpqWRmZpKXl3fBm3pP/o2uFNjPT3Hr6Bv75T48Z8+e5ZtvvtEWW4uKiqitre2wgBnmPD08PAgJCWHKlCmsWLGCKVOm9DqvfHORXJqsWVnsydpDi74FN1s3loQuITo0msXDFuNu1/E3YVNSWwvvvw9r1kBhIcyaBc89B3PnwsWzbqmpqbz++uvExsaSn5/foUVoRVHw9PQkNDQULy8vLC0tKSkpIT09naKiokvqFhjM9wYPHsyYMWO46qqrWB8QgI2PT68VgY7Q3NzM4cOHiYmJ4aeffiI9PZ3S0lLq6+uNEWOkCIC6IJSenk58fDynT58mPT2drKwsLagbdmka45k7M+/XkcBumIrpboH0hoYGtm3bxrZt2zhx4gTH0tJoqalB6eACsU6nw9raGmdnZwICAhgzZgxRUVEsX74cJ2n12CUqGyqJS48jJlk1vCuuK0an6Lgq8CptLWGUV9dsILpDTQ28+y68+ioUF8P8+Wq2z+zZnbtObW0tH3/8MR988AFJSUnU1tZ26DxbW1sGDx5MeHg4vr6+6PV6UlJSSE1N1bJ+LkCnw8PNjaCgIMaMGcP06dOJiooi2IjrBL2B4uJidu7cydatWzlx4gT5+fkd2bHdP0WgtraW1NRULahnZGSQk5Oj/VGM+aZuqHMLalA3fLVFW4H9/F2Mhjf27gZ2A0IIjh8/zubNmzlw4ACpqamUlpZqC8YdeUbDYqvBgGz69OnccMMNWoUniWnRCz2Hcw9ro4RjBepIbbDLYG3aaE7wHGwtu27X3B5VVfD22/D661BaClFRavC/6irj3UMIwe7du3nzzTfZu3cv5eXlHX4J8fDwICwsjAkTJuDn50dlZSX/2rePmqwsOGcPcvE5Li4uBAYGEh4eTmRkJIsWLWL48OHGe6BeRktLCydOnCA2Npa9e/eyc+fO/iECOp1OQPtv1h28lra13mDm1d5uPUO6oyGwG/xMLjcVY6zAfj6lpaVs2rSJXbt2cerUKfLz86murqapqanDOfG2tra4ubkRGBjIhAkTuPrqq5k9e3afWWwdaORU5WjV1Ham76SuuQ57K3sWDFmgLi6HRhPgHGCUe1VUwD/+AX//u/rv6Gg1+E+dapTLd4js7GzefvttNm3aRHZ2dofTNm1tbbURwLRp0wgICCApKYnDhw+TnJxMfn7+JSMQRVFwcXHR/JWmTZvGokWLCA8P73cvPP0mO0hRlMs2xvCWbmFhcYFDY2tra7vFyA0blAx57BcHdsMbe0hIiEkCu4GWlhZ2797Nli1biI+PJysri/LychoaGjq12Ork5ISvry/h4eHMnTuXa665Bm9vb5O1W9JzNLQ08GPmj1oKalZlFgARvhGaLfZk/8mdrqZWVgZvvAFvvqmOAn71KzX4dyJXwKQ0NjbyxRdfsH79ehISEqipqemwnYe7uzuhoaFMmjSJefPm4e7uzt69ezl06BBnzpzRFmjPx2C+FxAQwIgRI5g6dSoLFy4kIiKiz65p9RsRsLCwEJaWlu2mTbYV2C82lBoyZIhJA/v5pKWl8c0337Bv3z6SkpK0xdbOGJDZ2dnh4eHB0KFDmTp1Ktdccw3jx4/vVsd8Ij0dgJeGDOnyNSQ9jxCC08WntWmj/Wf3oxd6vOy9WBq6lOjQaBYNXYSLbdub4kpK1Cmft95S5/+vvVa1d4iI6MEH6SJCCA4cOMC7777Lrl27KCwqQnQwldqQoRQeHs6MGTOIjo6mvr6enTt38vPPP3PmzBlyc3Oprq6+5LPp5OSEn5+fZr43f/58Jk+e3GNxpKv0GxHQ6XTC09PzAuMncwZ2A7W1tcTGxrJt2zYSEhK0lNCO5sQbFlsNQ9Nx48axePFilixZgqOJSyv19tQ6Sccoqy9je+p2YlJi2JayjfKGcix1lswMmqmtJYR5hAFqhs9rr6mLvnV1cMMNavAfPdrMD9ENDP34Sz8/1q5dy1dffUV6evqli8dtoCgK7u7uDB06lEmTJjF//nwWLVpEZmYmO3bs4Oeff9YsVKqqqi5rvufr68uIESO08yMjIy/rWmoO+o0ImGOfQGtrK0ePHmXTpk0cPHjwgrStzhiQOTg44OXlxfDhw5k1axbXXHMNISEhZp97lCLQ/2jRt/Bzzs/aKOFk0UkAgi0icTv6N05vm0lzk46bb1Z46ikYOdLMDTYCV+rHTU1NbNq0iX/+85/Ex8dTWVnZ4XVFW1tb/P39GTVqFNOnT2f58uWEh4eTnJysicOpU6fIzs6msrLykpc+e3t7fHx8NPO9efPmMXPmTKytrbv/0J1AisAVKCgoYNOmTfzwww+cOnWKwsJCampqurTYGhwczMSJE1m+fPkVXRZ7E1IE+j8/n8ph5V/L2Lt5BPpWHYz5FIf5/yBqagjLQpexNHQpPo59e5NeZ/uxoTDO2rVr+e6778jPz+9UER83NzdCQkK0wL5kyRKcnZ1JT09nx44dWkEjg9/Vxet6tra2+Pj4aOZ7c+bMYc6cOdjZ2XXuwTvIgBWB5uZmdu7cSUxMDMeOHdOMohobGzu82GrIiff19dUMyK6++mo8PT278yi9BikC/ZesLFi9Gj78UPX2/+1v4aFH6sjU7dJGCbnVuQBM9p/MsrBlRIdGM95vPDqlby2AGqsfl5WVsX79er788kuSkpI6tVHLxsYGPz8/Ro4cSWRkJMuWLdMquZ09e5YdO3awf/9+fvnlF7KysigrK7skDtnY2ODt7c3QoUOZMGECs2fPZt68ed2eFu7VIqAoymLgTdRaTuuFEKvbOvZ8ERBCcObMGTZt2sS+ffs0AzJDTnxnqj0ZDMimTZvGihUrGDNmTK9f6DEWvzl9GoBPR40yc0skxiI9HV56CT76SN3R+7vfwcqVcPGeKSEEJwpPaFYWB3MOIhD4OfqxNHQpy8KWsWDIAhytTbsuZQxM2Y9bW1v573//ywcffMCBAwc6vKcB/peGGhISwvjx45k3bx5Lly7VDN8KCgqIi4tj7969JCQkkJmZSWlp6RXN9yIiIpg1axYLFizA1dW1o+3onSKgKIoFkAwsBHKAw8DNQojTlztep9MJQ/pnexhy+g2LrREREURHRzN//nyTL7ZKJOYgJQX+9jf497/V4i2//z08/jgEBnbs/OLaYralqoZ336V+R1VjFdYW1swJnqOloA5xk1lkBk6dOsW6deuIiYnh7NmzHayxrGJtba0tJEdGRrJ06dILSnyWlpZq4nD8+HEyMjIoKSm5rPmeh4cHQ4YMYdy4ccycOZOFCxdeMlPRm0UgEvg/IUTUue+fABBCvNTG8eLcfzUDMm9vb0aMGMHs2bO55pprCAwMNPtiq0TSk5w5Ay++CJ9/DtbWcM898Nhj4O/f9Ws2tzazL3sfsSmxxCTHkFSaBMBIz5GalcX0wOm9oppab6KqqopPPvmEzz77jJMnT1JbW9vh6SRFUXB2diY4OJhx48Yxd+5coqOjL6grUFlZyc6dO9mzZw/Hjh0jPT29TfM9d3d3zXxv/fr1vVYErgMWCyF+f+7724CpQoj7L3f8xIkTRXx8vMnaMxB5OCUFgDdCQ83cEklnOXVKLeG4YQPY2cF998Ejj4Cvr/HvlVqWqk0b7c7cTbO+GVdbV62a2uJhi/G0N986WW/ux3q9nri4OD788EN2795NSUlJp2oSWFlZaRlGkZGRLF68mOnTp1+wP6i2tpZdu3axe/dujh07RmpqKsXFxeenyPZaEbgeiLpIBKYIIR4475i7gbsBgoKCJmZlZZmsPQMRuTDc9zhxQg3+X38Njo5w//3w5z+DEQtRXZHqxmri0uO0amqFtYXoFB3TBk3Tpo3GeI/p0RF5X+zHaWlprF+/ns2bN5ORkXGJW2p7ODs7a7U2Zs+ezdVXX32JzXZDQwM//PADS5cu7bUi0KnpoN5eT6Av0hc/PAOVo0fh+edh82ZwdoYHH4SHHwYPD/O1SS/0xOfFa9NG8fnqSD3QOfCCamp2VqZJfTTQX/pxXV0dn3/+OZ999hlHjx697K7lK2FlZYWXlxdhYWFMnTqVqKgoZs6ciZWVVa8VAUvUheH5QC7qwvAtQohTlzteioDx6S8fnv7MoUNq8I+JAVdXNfA/+CC0U1HQLORX52uGdzvSdlDbXIutpS3zQ+Zr1dSCXIKMft/+3I/1ej379+9n/fr1qkVGYWFXitF0WQRMuudZCNGiKMr9wHbUFNEP2xIAiWSgceAArFoF330H7u7qFND994NL23ZAZsfPyY+7JtzFXRPuorGlkT1Ze1TDuxR1XwJbYazPWG2UMDVgaqcN7wYaOp2OmTNnMnPmzAt+npOTwwcffMCmTZtITk6mvr7eJPfv05vFJO1zd5Ka9bGuH3ur9zX27FHf/HfuBE9PePRRddG3L9fsEUKQVJqkbVLbm7WXVtGKh52HVk0tamgUbnZdG97IfqxSX1/P119/zWeffcbhw4cpLy83TCf1zumgziJFQNJfEQJ+/BH++lfYvRt8fNQ0z3vuAQcHc7fO+FQ0VLA9dTuxKbFsTdlKaX0pFooFM4JmaKOEEZ4jZLq3ERBCoNPppAhIJL0RIdQ3/lWrYN8+8PNTN3j94Q9gb2/u1vUMrfpWDuUe0kYJJwpPABDiGqI5oM4ePBsbS1n4qKv02s1inUWKgPGRw2jzIARs26YG/4MHYdAg1drhrrvA1nSVI/sEZyvPEpuipp/uSt9FfUs9DlYOLBy6kOjQaJaGLsXf6cKdcLIfX5nuiEDvMMOWmIzki+qxSkyLEPDf/6rBPz4eBg+G999Xzd1khU+VQJdA7pl0D/dMuof65np+yPxBGyVsPrMZgAl+E7Q9CZP8J8l+bEKkCEgkRkCvV/P7n38ejh+HIUPggw/gttugDziOmw07KzuWhi5laehShBCcLDqp7Ul4Ye8LrNqzCh8HHxT3qbj7zKRq1FCcbZzN3ex+hZwO6uf05/zq3kBrK3zzjRr8T56E0FC1itctt6gmb5KuU1pXynep3xGTEsPXSbG0NFdjpbNi1uBZ2lrCMPdh5m5mr0CuCUjaRIqAaWhtVT19XngBEhNhxAi1ePuNN8IAcSnvUWbHH6ay/ASLRDKxKbGcLlaNiMM8wrRpoxlBM7C26NmKXr0FuSYgaZMIaattVFpaVDfPF1+E5GS1bu+GDWoRdxn8Tcd4Z1dwns2a0N+zZuEaMsoztGmjtw+/zes/v46zjTNRQ6OIDo1mSegSvB28zd3sPoEcCUgkHaC5WfXxf/FFtajLuHHw7LPw61+Drm8V6ep31DTVsCt9lyYK+TX5KChMCZiiVVOL8I3o13sS5HSQRGIiGhvh44/VYi5ZWTBxohr8ly9Xq3pJehdCCI4VHNNssQ/nHkYgCHAK0LyN5ofMx8G6f+3QkyIgaRNZXrJrNDSotXtXr4azZ2HqVDX4L1kig7856Go/LqwpZFvqNmKSY9iRtoPqpmpsLGyYGzJXW0sIdg02QYt7FrkmIGmTnE56mA906uth3TpYswby8uCqq2D9eli4UAZ/c9LVfuzj6MMdEXdwR8QdNLU2sTdrrzZtdP+2+7l/2/2Ee4VrVhaRgZFY6gZWWBxYTyuRtEFtLaxdC6+8AoWFMHs2fPopzJkjg39/wdrCmvlD5jN/yHxej3qd5NJkbdro9Z9fZ81Pa3CzdWPxsMVaNTV3O3dzN9vkSBGQDGiqq+Hdd+HVV6GkBObPV7N9Zs82d8skpibMI4ywyDD+FPknKhsq1WpqKbHEJsfyxckv0Ck6pgdO16aNwr3C++XishQByYCkshLefhtefx3KymDxYjXPf/p0c7dMYg5cbF24btR1XDfqOvRCz5G8I2qdhOQYVu5aycpdKxnsMlibNpobMhdby/5hAiVFoJ8T2ZsrlJiB8nL4xz/gjTegogKWLVOD/5Qp5m6Z5Er0ZD/WKTqmBExhSsAUVs1dRW5VrlZN7aMTH/HukXext7Jnfsh8LQU1wDmgx9pnbGR2kGRAUFqqBv5//AOqqtT8/qefVlM+JZKO0tDSwO7M3Vo1tcyKTAAifCO0UcJk/8k9Xk1NpohKJG1QXKxO+bz9NtTUwHXXqcF/3Dhzt0zS1xFCkFiSqDmg7s/eT6toxcveiyWhS1gWuoxFQxfhYmv6UYwUAUmbXHvyJADfjB5t5pb0LIWF6mLvu++qaZ833ghPPaXaPEj6Hn2hH5fVl2nV1LalbqOsvgxLnSUzg2Zqo4QwjzCTLC7LfQKSNiltbjZ3E3qUvDw1zXPtWmhqUt08n3pKNXiT9F36Qj92t3Pn5jE3c/OYm2nVt/Jzzs/aKOHRuEd5NO5RhroN1RxQZw2e1SsM76QISPoFOTnw8svwz3+qJm+33QZPPqlaO0skPY2FzoKrgq7iqqCreGnBS2RVZLE1ZSsxKTG8H/8+bx58E0drRxYNXaRVU/N19DVLW6UISPo0WVmqtcOHH6qFXe64A554Qi3qIpH0Fga7Dubeyfdy7+R7qWuu4/uM77VRwreJ3wIw2X+yNm003m88OqVnnAmlCEj6JOnpqqnbxx+rO3rvukut4Tt4sLlbJpFcGXsre21KSAhBQmGCJgh/3f1X/m/3/+Hr6KsJwoIhC3C0Np0lvBSBfs58NzdzN8GopKSods6ffqpW7rrnHvjLXyAw0Nwtk5iS/taPDSiKwjjfcYzzHcdTs56iuLb4f9XUTn/NB8c+wNrCmjnBc1QX1NBohroPNW4bTJUdpCjK/wF/AIrP/ehJIcTWK50js4MkbZGYqAb/L75QC7b/v/8Hjz0G/v7mbplEYhqaW5vZf3a/5m90puQMACM8R2hWFlcFXoWVhVXvTBE9JwI1QohXO3qOFAHJxZw8qZZw3LgR7Ozgj3+ERx4BHx9zt0wi6VnSytI0B9TdWbtpam3CxcaFxcMWs+H6DTJFVHJ5liQkALBt7Fgzt6RznDihFm//5htwdFTn+//0J/DyMnfLJOagr/ZjYzLUfSgPTn2QB6c+SHVjNTvTd6qGdymx3bquqUXgfkVRbgeOAI8IIcpNfD/JRdS3tpq7CZ0iPl4N/v/5Dzg7q74+Dz0EHh7mbpnEnPS1fmxqnGycWDFyBStGrkAv9Fg82nWbim7lICmKslNRlJOX+foV8B4wFIgA8oHX2rjG3YqiHFEU5UhxcfHlDpEMAA4eVM3cJk2C3bvhr39V0z9XrZICIJFcie6mknZrJCCEWNCR4xRF+ScQ08Y11gHrQF0T6E57JH2Pn35SA/327eDuri7+3n+/OgqQSCSmx2S7ERRF8Tvv2xXASVPdS9L32LMHFixQyzceParu9s3MVHf5SgGQSHoOU64JrFEUJQIQQCbw/0x4L0kbLOtFcylCwA8/qG/+u3erGT6vvaamezo4mLt1kt5Mb+rH/Q3pIioxOUJAXJwa/PfvV3P7H38c/vAHNe1TIpF0j+7sE+gZcwrJgEQI2LoVIiMhKkpd6H3nHUhLgwcflAIgkfQGpAj0c+YcO8acY8d69J5CqCmekydDdDQUFMD770NqKtx3H9j2j9Kskh7EHP14oCBFQGI09Hp1c9f48Wr5xooK1d0zJQXuvlu1e5BIJL0LKQKSbtPaChs2wNixavnGujrV3fPMGbjzTrCyMncLJRJJW0gRkHSZlhb47DO1ZONNN6kjgc8+U83ebr9ddfmUSCS9GykCkk7T0qK+6Y8aBb/5jRrsN25Uzd5uuQUsur6DXSKR9DDyXa2fc4O3t9Gu1dQE//63WswlPR0iIuDbb+FXvwKdfJ2QmBBj9mPJhUgR6OfcFxDQ7Ws0NsJHH8FLL6lpnpMmwRtvqF4/itL9Nkok7WGMfiy5PPL9rZ9T19pKXRcdGBsa1Lz+YcPUCl6+vmre/6FDsHy5FABJz9Gdfiy5MnIk0M9Zes6H/cfx4zt8Tl0d/POfqp9Pfr7q7/Phh6rXjwz8EnPQlX4s6RhSBCQatbWwdi288goUFsKcOWq2z5w5MvhLJP0VKQISqqvVaZ/XXoOSEvWNf+NGmDXL3C2TSCSmRorAAKayEt56C/7+dygrg8WL1Upe06ebu2USiaSnkCIwACkvhzffVL8qKtRF3qefhilTzN0yiUTS00gR6Ofc4eur/bu0VH3rf+stqKqCFSvU4D9hghkbKJF0gPP7scS4SBHo59zh50dxMaxcqc7719aq/j5PP616/UgkfYE7/PzaP0jSJaQI9GMKCuD5l1v5aJ2O+nqFm26Cp56C8HBzt0wi6RwlTU0AeFpbm7kl/Q8pAv2QvDxYs0b18G9o0uGzpJz4V90ZMcLcLZNIusZ1p04Bcp+AKZAi0I84e1bd4LV+vWrydvvtcOpXp7ELamLECHdzN08ikfRCpG1EPyAzU2czTncAAA2TSURBVLV1GDpUffu//XZITlZ3+doFNZm7eRKJpBcjRwJ9mLQ01dTt449VF8/f/14t4D54sLlbJpFI+gpSBPogycnw4ouqpYOlJdx7L/zlLzBokLlbJpFI+hpSBPoQiYlq8P/iC7Ve74MPwmOPwZWy5+6VFrySfoDsx6ZDikAf4Jdf4IUX4KuvwN4eHnlE/fLxaf/cG2UxDkk/QPZj09GthWFFUa5XFOWUoih6RVEmXfS7JxRFSVUUJUlRlKjuNXNgcvw4XHutuqlr2zZ44gl1EXjNmo4JAMDZhgbONjSYtJ0SiamR/dh0dHckcBK4Bnj//B8qijIKuAkIB/yBnYqihAkhZFWIDnDkCDz/PGzZAi4u8Oyz8NBD4N6FLM/bEhMBmV8t6dvIfmw6uiUCQohEAOVSs/lfAV8KIRqBDEVRUoEpwIHu3K+/c/AgrFqlVu9yc1P//cAD4Opq7pZJJJL+iqnWBAKAn8/7PufczySXYf9+NeDv2AEeHmoh9z/+EZydzd0yiUTS32lXBBRF2QlczsLvKSHEf9o67TI/E21c/27gboCgoKD2mtOv2L1bDf7ffw9eXupc/733gqOjuVsmkUgGCu2KgBBiQReumwMEnvf9ICCvjeuvA9YBTJo06bJC0Z8QQg36q1bBnj1q8fbXX4e77wYHB3O3TiKRDDRMNR20BfhcUZTXUReGQ4FDJrpXn0AIdbpn1Sr46Sfw94d//EPd5WtnZ7r7PhIY2P5BEkkvR/Zj09EtEVAUZQXwFuAFxCqKclwIESWEOKUoykbgNNAC/HGgZgYJoS70rloFhw5BYCC8+y7ceSfY2pr+/ss9PU1/E4nExMh+bDq6mx20CdjUxu9eBF7szvX7MkKoKZ6rVsHRoxAcDOvWwW9/Cz1piZ5UVwfAcHv7nrupRGJkZD82HXLHsJHR6+Hbb9UdvidOqM6eH34Iv/kNWFn1fHv+X1ISIPOrJX0b2Y9Nh7SSNhKtrfDll+ru3uuvh/p6+OQTOHNGnfoxhwBIJBJJe0gR6CYtLfDpp2rJxptvVkcCn38Op0/DbbepLp8SiUTSW5Ei0EWam+Gjj2DkSDXYW1vDxo1w8qQqBhYW5m6hRCKRtI98T+0kTU3qNM/f/gYZGTB+PGzaBFdfrRZ2kUgkkr6EFIEO0tgI//qXWskrOxsmTVLz/KOj4VLrpN7D07LMmKQfIPux6ZAi0A4NDWrh9tWrITcXpk1T6/hGRfXu4G9gQVesRyWSXobsx6ZDikAb1NWpef1r1kB+PsyYoa4BzJ/fN4K/gePV1QBEODmZuSUSSdeR/dh0SBG4iJoaWLsWXnkFiopg7lw122f27L4V/A08nJoKyPxqSd9G9mPTIUXgHNXV8M478NprUFICCxfCM8/AzJnmbplEIpGYjgEvApWV8NZb8Pe/Q1kZLFmiBv/ISHO3TCKRSEzPgBWB8nJ44w14801VCJYvV4P/5MnmbplEIpH0HANOBEpL1bf+f/xDnQJasUIN/nKqUSKRDEQGjAgUFanz/e+8o2b+XH89PP00jBlj7paZlr8NGWLuJkgk3Ub2Y9PR70WgoEDN9HnvPXXD1003wVNPwahR5m5ZzzDdxcXcTZBIuo3sx6aj34pAbq6a479unWr18JvfwJNPwvDh5m5Zz/JTZSUgP0SSvo3sx6aj34lAdja8/LK6y1evh9tvhyeegGHDzN0y8/Bkejog86slfRvZj01HvxGBzEzV1+df/1K/v/NOWLkSQkLM2iyJRCLp1fR5EUhLUx09P/lEdfH8wx/g8cchKMjcLZNIJJLeT58VgaQkNfh/9plateu+++Avf4GAAHO3TCKRSPoOfU4ETp+GF19USzna2MBDD8Gjj/L/27vfGCuuMo7j31+pQAh/w9qUWBAaoeFPiVZC2jdVQ6MNUYhNVUwaW20kFOUFEqMNSW3AvrFpNEZrwdigjVr+NBTQEixarTFuBUNKKRUC2BYQslIUX7Si4OOLmXY3ZHfv7M7OzN6Z3ychmd2Ze+6Th3Pvs3PmzBmmTKk6MjOz9tM2ReCll5KHt2/dCmPGJF/8a9bANddUHdnw9p2mXhG3WnE/Ls6wLwIHDsD69cnTu8aNS2b6rF4NHR1VR9YevPSu1YH7cXGGbRHYty/58t+1CyZMgAceSIZ+/GyJgdl7/jzgh3JYe3M/Lk6uIiDpU8CDwGxgYUTsT38/HXgFOJIe2hkRK7K02dkJ69bB7t0waVKyvWoVTJyYJ9Lm+uZrrwH+8Fh7cz8uTt4zgUPAHcCGXvYdj4j3D6Sxo0eTJZwnT07m/K9cCePH54zQzMz6lKsIRMQrABqiR2699Vayzs+KFTB27JA0aWZm/biqwLZnSDog6XeSMj2f68Ybk1k/LgBmZuVoeSYgaS9wbS+71kbEjj5edgaYFhFvSPog8LSkuRHxr17aXw4sB5jm23zNzErVsghExG0DbTQiLgIX0+0/SzoOzAL293LsRmAjwIIFC2Kg72X929C0ZVOtltyPi1PIFFFJ7wbOR8RlSdcDM4ETRbyX9e+GMWOqDsEsN/fj4uS6JiDpk5JOAbcAv5S0J911K3BQ0ovANmBFRJzPF6oNxq5z59h17lzVYZjl4n5cnLyzg7YD23v5/VPAU3natqHxyMmTAHzCt1hbG3M/Lk6Rs4PMzGyYcxEwM2swFwEzswZzETAza7Bhu4qoDY0nZs+uOgSz3NyPi+MiUHNTR4+uOgSz3NyPi+PhoJrb3NXF5q6uqsMwy8X9uDg+E6i5H5w+DcBn/BxOa2Pux8XxmYCZWYO5CJiZNZiLgJlZg7kImJk1mC8M19y2uXOrDsEsN/fj4rgI1FzHyJFVh2CWm/txcTwcVHObzpxh05kzVYdhlov7cXFcBGpu09mzbDp7tuowzHJxPy6Oi4CZWYO5CJiZNZiLgJlZg7kImJk1mKeI1twz8+dXHYJZbu7HxXERqLkxI0ZUHYJZbu7HxfFwUM09evo0j6bL8Jq1K/fj4rgI1NyWri62+GEc1ubcj4uTqwhIeljSXyQdlLRd0sQe++6XdEzSEUkfyx+qmZkNtbxnAs8C8yJiPnAUuB9A0hxgGTAXuB14VJIH9czMhplcRSAifhURl9IfO4Hr0u2lwJMRcTEi/gocAxbmeS8zMxt6Q3lN4AvA7nT7PcDJHvtOpb8zM7NhpOUUUUl7gWt72bU2Inakx6wFLgE/fftlvRwffbS/HFie/nhR0qFWMTVEB3BuqBrr7T+kjQxpLtpco3NxRT9udC6ucMNgX9iyCETEbf3tl3Q38HFgUUS8/UV/Cpja47DrgL/10f5GYGPa1v6IWJAh7tpzLro5F92ci27ORTdJ+wf72ryzg24HvgYsiYg3e+zaCSyTNErSDGAm8Kc872VmZkMv7x3D3wNGAc9KAuiMiBUR8bKkLcBhkmGiL0XE5ZzvZWZmQyxXEYiI9/Wz7yHgoQE2uTFPPDXjXHRzLro5F92ci26DzoW6h/HNzKxpvGyEmVmDVVIEJN2eLidxTNLXe9k/StLmdP8LkqaXH2U5MuTiK5IOp0tz/FrSe6uIswytctHjuDslhaTazgzJkgtJn077xsuSflZ2jGXJ8BmZJuk5SQfSz8niKuIsmqTHJXX1NY1eie+meToo6aZMDUdEqf+AEcBx4HpgJPAiMOeKY1YCj6Xby4DNZcc5jHLxEWBMun1fk3ORHjcOeJ7kDvUFVcddYb+YCRwAJqU/X1N13BXmYiNwX7o9B3i16rgLysWtwE3AoT72Lya5YVfAzcALWdqt4kxgIXAsIk5ExH+AJ0mWmehpKfDjdHsbsEjp9KOaaZmLiHguuqff9lyao26y9AuA9cC3gH+XGVzJsuTii8D3I+IfABFR1yU2s+QigPHp9gT6uCep3UXE88D5fg5ZCvwkEp3ARElTWrVbRRHIsqTEO8dEsjbRBWByKdGVa6DLa9xL99IcddMyF5I+AEyNiF+UGVgFsvSLWcAsSX+Q1Jnes1NHWXLxIHCXpFPAM8CqckIbdga1XE8VTxbLsqRE5mUn2txAlte4C1gAfKjQiKrTby4kXQV8G7inrIAqlKVfXE0yJPRhkrPD30uaFxH/LDi2smXJxWeBTRHxiKRbgCfSXPyv+PCGlUF9b1ZxJpBlSYl3jpF0NckpXn+nQe0q0/Iakm4D1pLcmX2xpNjK1ioX44B5wG8lvUoy5rmzpheHs35GdkTEfyNZqfcISVGomyy5uBfYAhARfwRGk6wr1DSZl+vpqYoisA+YKWmGpJEkF353XnHMTuDudPtO4DeRXvmomZa5SIdANpAUgLqO+0KLXETEhYjoiIjpETGd5PrIkogY9Jopw1iWz8jTJJMGkNRBMjx0otQoy5ElF68DiwAkzSYpAn8vNcrhYSfwuXSW0M3AhYg40+pFpQ8HRcQlSV8G9pBc+X88kmUm1gH7I2In8COSU7pjJGcAy8qOswwZc/EwMBbYml4bfz0illQWdEEy5qIRMuZiD/BRSYeBy8BXI+KN6qIuRsZcrAF+KGk1yfDHPXX8o1HSz0mG/zrS6x/fAN4FEBGPkVwPWUzy/JY3gc9nareGuTIzs4x8x7CZWYO5CJiZNZiLgJlZg7kImJk1mIuAmVmDuQiYmTWYi4CZWYO5CJiZNdj/AfYEjbWN5IUkAAAAAElFTkSuQmCC\n",
- "text/plain": [
- ""
- ]
- },
- "metadata": {},
- "output_type": "display_data"
- }
- ],
+ "outputs": [],
"source": [
"%matplotlib inline\n",
"plot_pomdp_utility(utility)"
@@ -2974,7 +2136,7 @@
],
"metadata": {
"kernelspec": {
- "display_name": "Python 3",
+ "display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
@@ -2988,7 +2150,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.6.4"
+ "version": "3.7.10"
},
"widgets": {
"state": {
diff --git a/mdp_apps.ipynb b/mdp_apps.ipynb
index da3ae7b06..07c1c1a26 100644
--- a/mdp_apps.ipynb
+++ b/mdp_apps.ipynb
@@ -1803,7 +1803,7 @@
],
"metadata": {
"kernelspec": {
- "display_name": "Python 3",
+ "display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
@@ -1817,7 +1817,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.6.4"
+ "version": "3.7.10"
}
},
"nbformat": 4,
diff --git a/notebook.py b/notebook.py
index 7f0306335..4e2aa5ef5 100644
--- a/notebook.py
+++ b/notebook.py
@@ -1063,13 +1063,14 @@ def plot_NQueens(solution):
height = im.size[1]
im = np.array(im).astype(np.float) / 255
fig = plt.figure(figsize=(7, 7))
+ print(fig)
ax = fig.add_subplot(111)
ax.set_title('{} Queens'.format(n))
plt.imshow(board, cmap='binary', interpolation='nearest')
# NQueensCSP gives a solution as a dictionary
if isinstance(solution, dict):
for (k, v) in solution.items():
- newax = fig.add_axes([0.064 + (k * 0.112), 0.062 + ((7 - v) * 0.112), 0.1, 0.1], zorder=1)
+ newax = fig.add_axes([(0.064 + (k * 0.112)), (0.062 + ((7 - v) * 0.112)), 0.1, 0.1], zorder=1)
newax.imshow(im)
newax.axis('off')
# NQueensProblem gives a solution as a list
@@ -1080,6 +1081,7 @@ def plot_NQueens(solution):
newax.axis('off')
fig.tight_layout()
plt.show()
+
# Function to plot a heatmap, given a grid
diff --git a/planning.ipynb b/planning.ipynb
index 7b05b3c20..9525c1095 100644
--- a/planning.ipynb
+++ b/planning.ipynb
@@ -281,7 +281,9 @@
{
"cell_type": "code",
"execution_count": 81,
- "metadata": {},
+ "metadata": {
+ "scrolled": false
+ },
"outputs": [
{
"data": {
@@ -2694,7 +2696,9 @@
{
"cell_type": "code",
"execution_count": 129,
- "metadata": {},
+ "metadata": {
+ "scrolled": false
+ },
"outputs": [
{
"data": {
@@ -3845,7 +3849,7 @@
],
"metadata": {
"kernelspec": {
- "display_name": "Python 3",
+ "display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
@@ -3859,7 +3863,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.5.3"
+ "version": "3.7.10"
}
},
"nbformat": 4,
diff --git a/planning.py b/planning.py
index 1e4a19209..dbb90f86e 100644
--- a/planning.py
+++ b/planning.py
@@ -1558,7 +1558,9 @@ def refinements(self, library): # refinements may be (multiple) HLA themselves
['At(SFO) & ~At(Home)']
]}
"""
+# print(self.name)
indices = [i for i, x in enumerate(library['HLA']) if expr(x).op == self.name]
+# print(f"indices: {indices}")
for i in indices:
actions = []
for j in range(len(library['steps'][i])):
@@ -1577,25 +1579,36 @@ def hierarchical_search(self, hierarchy):
The problem is a real-world problem defined by the problem class, and the hierarchy is
a dictionary of HLA - refinements (see refinements generator for details)
"""
+ print(f"hiearchy: {hierarchy}")
act = Node(self.initial, None, [self.actions[0]])
frontier = deque()
frontier.append(act)
+ print(f"frontier: {[x.__dict__ for x in frontier]}")
while True:
if not frontier:
return None
plan = frontier.popleft()
+ print(f"Plan {plan.action} poped from frontier: {[x.__dict__ for x in frontier]}")
# finds the first non primitive hla in plan actions
(hla, index) = RealWorldPlanningProblem.find_hla(plan, hierarchy)
+ print(f"Find HLA, get hla: {hla} and index: {index}")
prefix = plan.action[:index]
+ print(f"prefix: {prefix}")
outcome = RealWorldPlanningProblem(
RealWorldPlanningProblem.result(self.initial, prefix), self.goals, self.actions)
+ print(f"Outcome: {outcome.initial}")
suffix = plan.action[index + 1:]
+ print(f"suffix: {suffix}")
if not hla: # hla is None and plan is primitive
if outcome.goal_test():
+ print(f"Outcome: {outcome.initial} Goal Test Success, return Plan:{ 1}")
return plan.action
else:
for sequence in RealWorldPlanningProblem.refinements(hla, hierarchy): # find refinements
+ print(f"Refinement(hla: {hla}) got sequence: {sequence}")
frontier.append(Node(outcome.initial, plan, prefix + sequence + suffix))
+ print(f"frontier Added: {frontier[-1].__dict__}")
+
def result(state, actions):
"""The outcome of applying an action to the current problem"""
@@ -1626,24 +1639,39 @@ def angelic_search(self, hierarchy, initial_plan):
if not frontier:
return None
plan = frontier.popleft() # sequence of HLA/Angelic HLA's
+ print('\n')
+ print(f"Plan {plan.action} poped from frontier: {[x.__dict__ for x in frontier]}")
opt_reachable_set = RealWorldPlanningProblem.reach_opt(self.initial, plan)
+ print(f"Opt Reachable Set: {opt_reachable_set}")
pes_reachable_set = RealWorldPlanningProblem.reach_pes(self.initial, plan)
+ print(f"Pes Reachable Set: {pes_reachable_set}")
if self.intersects_goal(opt_reachable_set):
+ print(f"Opt Reachable Set intersects with Goal.")
if RealWorldPlanningProblem.is_primitive(plan, hierarchy):
+ print(f"Plan is premitive, return plan")
return [x for x in plan.action]
guaranteed = self.intersects_goal(pes_reachable_set)
+ print(f"Pes Reachable Set intersects with Goal, get Guaranteed: {guaranteed}")
if guaranteed and RealWorldPlanningProblem.making_progress(plan, initial_plan):
+ print(f"guaranteed: {guaranteed} not empty and Making-Progress")
final_state = guaranteed[0] # any element of guaranteed
- return RealWorldPlanningProblem.decompose(hierarchy, final_state, pes_reachable_set)
+ print(f"final_state: {final_state}")
+ return RealWorldPlanningProblem.decompose(hierarchy, plan, final_state, pes_reachable_set)
# there should be at least one HLA/AngelicHLA, otherwise plan would be primitive
hla, index = RealWorldPlanningProblem.find_hla(plan, hierarchy)
+ print(f"Find HLA: {hla} in plan: {plan}")
prefix = plan.action[:index]
+ print(f"Prefix: {prefix}")
suffix = plan.action[index + 1:]
+ print(f"suffix: {suffix}")
outcome = RealWorldPlanningProblem(
RealWorldPlanningProblem.result(self.initial, prefix), self.goals, self.actions)
+ print(f"Outcome: {outcome.initial}")
for sequence in RealWorldPlanningProblem.refinements(hla, hierarchy): # find refinements
+ print(f"Refinement(hla: {hla}) got sequence: {sequence}")
frontier.append(
AngelicNode(outcome.initial, plan, prefix + sequence + suffix, prefix + sequence + suffix))
+ print(f"frontier Added: {frontier[-1].__dict__}")
def intersects_goal(self, reachable_set):
"""
@@ -1724,20 +1752,27 @@ def making_progress(plan, initial_plan):
"""
for i in range(len(initial_plan)):
if plan == initial_plan[i]:
+ print(f"Running Making-Progress: Plan: {plan} is same with Initial Plan: {initial_plan}")
return False
return True
def decompose(hierarchy, plan, s_f, reachable_set):
solution = []
i = max(reachable_set.keys())
+ print(f"Running Decompose with hierarchy, plan: {plan}, final_state: {s_f}, reachable_set: {reachable_set}")
while plan.action_pes:
action = plan.action_pes.pop()
+ print(f"Pop action: {action} from Plan: {plan.action_pes}")
if i == 0:
return solution
- s_i = RealWorldPlanningProblem.find_previous_state(s_f, reachable_set, i, action)
+ s_i = RealWorldPlanningProblem.find_previous_state(
+ s_f, reachable_set, i, action)
+ print(f"Find Previous state: {s_i}")
problem = RealWorldPlanningProblem(s_i, s_f, plan.action)
- angelic_call = RealWorldPlanningProblem.angelic_search(problem, hierarchy,
- [AngelicNode(s_i, Node(None), [action], [action])])
+ print(f"Define problem with initial s_i: {s_i} and goal s_f: {s_f}")
+ angelic_call = RealWorldPlanningProblem.angelic_search(
+ problem, hierarchy, [AngelicNode(s_i, Node(None), [action], [action])])
+ print(f"Run Angelic Search, get {angelic_call}")
if angelic_call:
for x in angelic_call:
solution.insert(0, x)
diff --git a/planning_angelic_search.ipynb b/planning_angelic_search.ipynb
index 71408e1d9..9259061ac 100644
--- a/planning_angelic_search.ipynb
+++ b/planning_angelic_search.ipynb
@@ -57,33 +57,44 @@
"text/html": [
"\n",
- "\n",
+ "\n",
"\n",
"\n",
"
\n", + "$P_{x, y}$ is true if there is a pit in `[x, y]`.
\n", + "$B_{x, y}$ is true if the agent senses breeze in `[x, y]`.
" + ] + }, + { + "cell_type": "code", + "execution_count": 16, + "id": "deab110e", + "metadata": {}, + "outputs": [], + "source": [ + "P11, P12, P21, P22, P31, B11, B21 = expr('P11, P12, P21, P22, P31, B11, B21')" + ] + }, + { + "cell_type": "markdown", + "id": "4a8cc36a", + "metadata": {}, + "source": [ + "Now we tell sentences based on `section 7.4.3`.
\n", + "There is no pit in `[1,1]`." + ] + }, + { + "cell_type": "code", + "execution_count": 17, + "id": "c934db1d", + "metadata": {}, + "outputs": [], + "source": [ + "wumpus_kb.tell(~P11)" + ] + }, + { + "cell_type": "markdown", + "id": "ed62f7d9", + "metadata": {}, + "source": [ + "A square is breezy if and only if there is a pit in a neighboring square. This has to be stated for each square but for now, we include just the relevant squares." + ] + }, + { + "cell_type": "code", + "execution_count": 18, + "id": "c6b48305", + "metadata": {}, + "outputs": [], + "source": [ + "wumpus_kb.tell(B11 | '<=>' | ((P12 | P21)))\n", + "wumpus_kb.tell(B21 | '<=>' | ((P11 | P22 | P31)))" + ] + }, + { + "cell_type": "markdown", + "id": "7a021616", + "metadata": {}, + "source": [ + "Now we include the breeze percepts for the first two squares leading up to the situation in `Figure 7.3(b)`" + ] + }, + { + "cell_type": "code", + "execution_count": 19, + "id": "4a14d380", + "metadata": {}, + "outputs": [], + "source": [ + "wumpus_kb.tell(~B11)\n", + "wumpus_kb.tell(B21)" + ] + }, + { + "cell_type": "markdown", + "id": "4e5befbf", + "metadata": {}, + "source": [ + "We can check the clauses stored in a `KB` by accessing its `clauses` variable" + ] + }, + { + "cell_type": "code", + "execution_count": 20, + "id": "4fe8296f", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "[~P11,\n", + " (~P12 | B11),\n", + " (~P21 | B11),\n", + " (P12 | P21 | ~B11),\n", + " (~P11 | B21),\n", + " (~P22 | B21),\n", + " (~P31 | B21),\n", + " (P11 | P22 | P31 | ~B21),\n", + " ~B11,\n", + " B21]" + ] + }, + "execution_count": 20, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "wumpus_kb.clauses" + ] + }, + { + "cell_type": "markdown", + "id": "58d0b2be", + "metadata": {}, + "source": [ + "We see that the equivalence $B_{1, 1} \\iff (P_{1, 2} \\lor P_{2, 1})$ was automatically converted to two implications which were inturn converted to CNF which is stored in the `KB`.
\n", + "$B_{1, 1} \\iff (P_{1, 2} \\lor P_{2, 1})$ was split into $B_{1, 1} \\implies (P_{1, 2} \\lor P_{2, 1})$ and $B_{1, 1} \\Longleftarrow (P_{1, 2} \\lor P_{2, 1})$.
\n", + "$B_{1, 1} \\implies (P_{1, 2} \\lor P_{2, 1})$ was converted to $P_{1, 2} \\lor P_{2, 1} \\lor \\neg B_{1, 1}$.
\n", + "$B_{1, 1} \\Longleftarrow (P_{1, 2} \\lor P_{2, 1})$ was converted to $\\neg (P_{1, 2} \\lor P_{2, 1}) \\lor B_{1, 1}$ which becomes $(\\neg P_{1, 2} \\lor B_{1, 1}) \\land (\\neg P_{2, 1} \\lor B_{1, 1})$ after applying De Morgan's laws and distributing the disjunction.
\n", + "$B_{2, 1} \\iff (P_{1, 1} \\lor P_{2, 2} \\lor P_{3, 2})$ is converted in similar manner." + ] + }, + { + "cell_type": "markdown", + "id": "a9733937", + "metadata": {}, + "source": [ + "## Inference in Propositional Knowledge Base\n", + "In this section we will look at two algorithms to check if a sentence is entailed by the `KB`. Our goal is to decide whether $\\text{KB} \\vDash \\alpha$ for some sentence $\\alpha$.\n", + "### Truth Table Enumeration\n", + "It is a model-checking approach which, as the name suggests, enumerates all possible models in which the `KB` is true and checks if $\\alpha$ is also true in these models. We list the $n$ symbols in the `KB` and enumerate the $2^{n}$ models in a depth-first manner and check the truth of `KB` and $\\alpha$." + ] + }, + { + "cell_type": "code", + "execution_count": 21, + "id": "ead34986", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def tt_check_all(kb, alpha, symbols, model):\n",
+ " """Auxiliary routine to implement tt_entails."""\n",
+ " print(f"model:{model}")\n",
+ " if not symbols:\n",
+ " if pl_true(kb, model):\n",
+ " result = pl_true(alpha, model)\n",
+ " print(f"When KB is True, alpha is {result}")\n",
+ " assert result in (True, False)\n",
+ " return result\n",
+ " else:\n",
+ " print("When KB is False, return True")\n",
+ " return True\n",
+ " else:\n",
+ " P, rest = symbols[0], symbols[1:]\n",
+ " return (tt_check_all(kb, alpha, rest, extend(model, P, True)) and\n",
+ " tt_check_all(kb, alpha, rest, extend(model, P, False)))\n",
+ "\n", + "If symbols are defined, the routine recursively constructs every combination of truth values for the symbols and then, \n", + "it checks whether `model` is consistent with `kb`.\n", + "The given models correspond to the lines in the truth table,\n", + "which have a `true` in the KB column, \n", + "and for these lines it checks whether the query evaluates to true\n", + "
\n", + "`result = pl_true(alpha, model)`.\n", + "
\n", + "
\n", + "In short, `tt_check_all` evaluates this logical expression for each `model`\n", + "
\n", + "`pl_true(kb, model) => pl_true(alpha, model)`\n", + "
\n", + "which is logically equivalent to\n", + "
\n", + "`pl_true(kb, model) & ~pl_true(alpha, model)` \n", + "
\n", + "that is, the knowledge base and the negation of the query are logically inconsistent.\n", + "
\n", + "
\n", + "`tt_entails()` just extracts the symbols from the query and calls `tt_check_all()` with the proper parameters.\n" + ] + }, + { + "cell_type": "code", + "execution_count": 22, + "id": "289de55a", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def tt_entails(kb, alpha):\n",
+ " """\n",
+ " [Figure 7.10]\n",
+ " Does kb entail the sentence alpha? Use truth tables. For propositional\n",
+ " kb's and sentences. Note that the 'kb' should be an Expr which is a\n",
+ " conjunction of clauses.\n",
+ " >>> tt_entails(expr('P & Q'), expr('Q'))\n",
+ " True\n",
+ " """\n",
+ " assert not variables(alpha)\n",
+ " print(f"KB: {kb}")\n",
+ " print(f"alpha: {alpha}")\n",
+ " symbols = list(prop_symbols(kb & alpha))\n",
+ " print(f"symbols: {symbols}")\n",
+ " return tt_check_all(kb, alpha, symbols, {})\n",
+ "\n", + "This technique corresponds to proof by contradiction, a standard mathematical proof technique. We assume $\\alpha$ to be false and show that this leads to a contradiction with known axioms in $\\text{KB}$. We obtain a contradiction by making valid inferences using inference rules. In this proof we use a single inference rule, resolution which states $(l_1 \\lor \\dots \\lor l_k) \\land (m_1 \\lor \\dots \\lor m_n) \\land (l_i \\iff \\neg m_j) \\implies l_1 \\lor \\dots \\lor l_{i - 1} \\lor l_{i + 1} \\lor \\dots \\lor l_k \\lor m_1 \\lor \\dots \\lor m_{j - 1} \\lor m_{j + 1} \\lor \\dots \\lor m_n$. Applying the resolution yields us a clause which we add to the KB. We keep doing this until:\n", + "\n", + "* There are no new clauses that can be added, in which case $\\text{KB} \\nvDash \\alpha$.\n", + "* Two clauses resolve to yield the empty clause, in which case $\\text{KB} \\vDash \\alpha$.\n", + "\n", + "The empty clause is equivalent to False because it arises only from resolving two complementary\n", + "unit clauses such as $P$ and $\\neg P$ which is a contradiction as both $P$ and $\\neg P$ can't be True at the same time." + ] + }, + { + "cell_type": "markdown", + "id": "5a03ae78", + "metadata": {}, + "source": [ + "There is one catch however, the algorithm that implements proof by resolution cannot handle complex sentences. \n", + "Implications and bi-implications have to be simplified into simpler clauses. \n", + "We already know that *every sentence of a propositional logic is logically equivalent to a conjunction of clauses*.\n", + "We will use this fact to our advantage and simplify the input sentence into the **conjunctive normal form** (CNF) which is a conjunction of disjunctions of literals.\n", + "For eg:\n", + "
\n", + "$$(A\\lor B)\\land (\\neg B\\lor C\\lor\\neg D)\\land (D\\lor\\neg E)$$\n", + "This is equivalent to the POS (Product of sums) form in digital electronics.\n", + "
\n", + "Here's an outline of how the conversion is done:\n", + "1. Convert bi-implications to implications\n", + "
\n", + "$\\alpha\\iff\\beta$ can be written as $(\\alpha\\implies\\beta)\\land(\\beta\\implies\\alpha)$\n", + "
\n", + "This also applies to compound sentences\n", + "
\n", + "$\\alpha\\iff(\\beta\\lor\\gamma)$ can be written as $(\\alpha\\implies(\\beta\\lor\\gamma))\\land((\\beta\\lor\\gamma)\\implies\\alpha)$\n", + "
\n", + "2. Convert implications to their logical equivalents\n", + "
\n", + "$\\alpha\\implies\\beta$ can be written as $\\neg\\alpha\\lor\\beta$\n", + "
\n", + "3. Move negation inwards\n", + "
\n", + "CNF requires atomic literals. Hence, negation cannot appear on a compound statement.\n", + "De Morgan's laws will be helpful here.\n", + "
\n", + "$\\neg(\\alpha\\land\\beta)\\equiv(\\neg\\alpha\\lor\\neg\\beta)$\n", + "
\n", + "$\\neg(\\alpha\\lor\\beta)\\equiv(\\neg\\alpha\\land\\neg\\beta)$\n", + "
\n", + "4. Distribute disjunction over conjunction\n", + "
\n", + "Disjunction and conjunction are distributive over each other.\n", + "Now that we only have conjunctions, disjunctions and negations in our expression, \n", + "we will distribute disjunctions over conjunctions wherever possible as this will give us a sentence which is a conjunction of simpler clauses, \n", + "which is what we wanted in the first place.\n", + "
\n", + "We need a term of the form\n", + "
\n", + "$(\\alpha_{1}\\lor\\alpha_{2}\\lor\\alpha_{3}...)\\land(\\beta_{1}\\lor\\beta_{2}\\lor\\beta_{3}...)\\land(\\gamma_{1}\\lor\\gamma_{2}\\lor\\gamma_{3}...)\\land...$\n", + "
\n", + "
\n", + "The `to_cnf` function executes this conversion using helper subroutines." + ] + }, + { + "cell_type": "code", + "execution_count": 29, + "id": "f7120f00", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def to_cnf(s):\n",
+ " """\n",
+ " [Page 253]\n",
+ " Convert a propositional logical sentence to conjunctive normal form.\n",
+ " That is, to the form ((A | ~B | ...) & (B | C | ...) & ...)\n",
+ " >>> to_cnf('~(B | C)')\n",
+ " (~B & ~C)\n",
+ " """\n",
+ " s = expr(s)\n",
+ " if isinstance(s, str):\n",
+ " s = expr(s)\n",
+ " s = eliminate_implications(s) # Steps 1, 2 from p. 253\n",
+ " s = move_not_inwards(s) # Step 3\n",
+ " return distribute_and_over_or(s) # Step 4\n",
+ "\n", + "`eliminate_implications` converts bi-implications and implications to their logical equivalents.\n", + "
\n", + "`move_not_inwards` removes negations from compound statements and moves them inwards using De Morgan's laws.\n", + "
\n", + "`distribute_and_over_or` distributes disjunctions over conjunctions.\n", + "
\n", + "Run the cell below for implementation details." + ] + }, + { + "cell_type": "code", + "execution_count": 30, + "id": "0bb9acf4", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def eliminate_implications(s):\n",
+ " """Change implications into equivalent form with only &, |, and ~ as logical operators."""\n",
+ " s = expr(s)\n",
+ " if not s.args or is_symbol(s.op):\n",
+ " return s # Atoms are unchanged.\n",
+ " args = list(map(eliminate_implications, s.args))\n",
+ " a, b = args[0], args[-1]\n",
+ " if s.op == '==>':\n",
+ " return b | ~a\n",
+ " elif s.op == '<==':\n",
+ " return a | ~b\n",
+ " elif s.op == '<=>':\n",
+ " return (a | ~b) & (b | ~a)\n",
+ " elif s.op == '^':\n",
+ " assert len(args) == 2 # TODO: relax this restriction\n",
+ " return (a & ~b) | (~a & b)\n",
+ " else:\n",
+ " assert s.op in ('&', '|', '~')\n",
+ " return Expr(s.op, *args)\n",
+ "def move_not_inwards(s):\n",
+ " """Rewrite sentence s by moving negation sign inward.\n",
+ " >>> move_not_inwards(~(A | B))\n",
+ " (~A & ~B)\n",
+ " """\n",
+ " s = expr(s)\n",
+ " if s.op == '~':\n",
+ " def NOT(b):\n",
+ " return move_not_inwards(~b)\n",
+ "\n",
+ " a = s.args[0]\n",
+ " if a.op == '~':\n",
+ " return move_not_inwards(a.args[0]) # ~~A ==> A\n",
+ " if a.op == '&':\n",
+ " return associate('|', list(map(NOT, a.args)))\n",
+ " if a.op == '|':\n",
+ " return associate('&', list(map(NOT, a.args)))\n",
+ " return s\n",
+ " elif is_symbol(s.op) or not s.args:\n",
+ " return s\n",
+ " else:\n",
+ " return Expr(s.op, *list(map(move_not_inwards, s.args)))\n",
+ "def distribute_and_over_or(s):\n",
+ " """Given a sentence s consisting of conjunctions and disjunctions\n",
+ " of literals, return an equivalent sentence in CNF.\n",
+ " >>> distribute_and_over_or((A & B) | C)\n",
+ " ((A | C) & (B | C))\n",
+ " """\n",
+ " s = expr(s)\n",
+ " if s.op == '|':\n",
+ " s = associate('|', s.args)\n",
+ " if s.op != '|':\n",
+ " return distribute_and_over_or(s)\n",
+ " if len(s.args) == 0:\n",
+ " return False\n",
+ " if len(s.args) == 1:\n",
+ " return distribute_and_over_or(s.args[0])\n",
+ " conj = first(arg for arg in s.args if arg.op == '&')\n",
+ " if not conj:\n",
+ " return s\n",
+ " others = [a for a in s.args if a is not conj]\n",
+ " rest = associate('|', others)\n",
+ " return associate('&', [distribute_and_over_or(c | rest)\n",
+ " for c in conj.args])\n",
+ " elif s.op == '&':\n",
+ " return associate('&', list(map(distribute_and_over_or, s.args)))\n",
+ " else:\n",
+ " return s\n",
+ "def pl_resolution(kb, alpha):\n",
+ " """\n",
+ " [Figure 7.12]\n",
+ " Propositional-logic resolution: say if alpha follows from KB.\n",
+ " >>> pl_resolution(horn_clauses_KB, A)\n",
+ " True\n",
+ " """\n",
+ " clauses = kb.clauses + conjuncts(to_cnf(~alpha))\n",
+ " new = set()\n",
+ " while True:\n",
+ " n = len(clauses)\n",
+ " pairs = [(clauses[i], clauses[j])\n",
+ " for i in range(n) for j in range(i + 1, n)]\n",
+ " for (ci, cj) in pairs:\n",
+ " resolvents = pl_resolve(ci, cj)\n",
+ " if False in resolvents:\n",
+ " return True\n",
+ " new = new.union(set(resolvents))\n",
+ " if new.issubset(set(clauses)):\n",
+ " return False\n",
+ " for c in new:\n",
+ " if c not in clauses:\n",
+ " clauses.append(c)\n",
+ "\n", + "#### Horn Clauses\n", + "Horn clauses can be defined as a *disjunction* of *literals* with **at most** one positive literal. \n", + "
\n", + "A Horn clause with exactly one positive literal is called a *definite clause*.\n", + "
\n", + "A Horn clause might look like \n", + "
\n", + "$\\neg a\\lor\\neg b\\lor\\neg c\\lor\\neg d... \\lor z$\n", + "
\n", + "This, coincidentally, is also a definite clause.\n", + "
\n", + "Using De Morgan's laws, the example above can be simplified to \n", + "
\n", + "$a\\land b\\land c\\land d ... \\implies z$\n", + "
\n", + "This seems like a logical representation of how humans process known data and facts. \n", + "Assuming percepts `a`, `b`, `c`, `d` ... to be true simultaneously, we can infer `z` to also be true at that point in time. \n", + "There are some interesting aspects of Horn clauses that make algorithmic inference or *resolution* easier.\n", + "- Definite clauses can be written as implications:\n", + "
\n", + "The most important simplification a definite clause provides is that it can be written as an implication.\n", + "The premise (or the knowledge that leads to the implication) is a conjunction of positive literals.\n", + "The conclusion (the implied statement) is also a positive literal.\n", + "The sentence thus becomes easier to understand.\n", + "The premise and the conclusion are conventionally called the *body* and the *head* respectively.\n", + "A single positive literal is called a *fact*.\n", + "- Forward chaining and backward chaining can be used for inference from Horn clauses:\n", + "
\n", + "Forward chaining is semantically identical to `AND-OR-Graph-Search` from the chapter on search algorithms.\n", + "Implementational details will be explained shortly.\n", + "- Deciding entailment with Horn clauses is linear in size of the knowledge base:\n", + "
\n", + "Surprisingly, the forward and backward chaining algorithms traverse each element of the knowledge base at most once, greatly simplifying the problem.\n", + "
\n", + "
\n", + "The function `pl_fc_entails` implements forward chaining to see if a knowledge base `KB` entails a symbol `q`.\n", + "
\n", + "Before we proceed further, note that `pl_fc_entails` doesn't use an ordinary `KB` instance. \n", + "The knowledge base here is an instance of the `PropDefiniteKB` class, derived from the `PropKB` class, \n", + "but modified to store definite clauses.\n", + "
\n", + "The main point of difference arises in the inclusion of a helper method to `PropDefiniteKB` that returns a list of clauses in KB that have a given symbol `p` in their premise." + ] + }, + { + "cell_type": "code", + "execution_count": 38, + "id": "af23d674", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def clauses_with_premise(self, p):\n",
+ " """Return a list of the clauses in KB that have p in their premise.\n",
+ " This could be cached away for O(1) speed, but we'll recompute it."""\n",
+ " return [c for c in self.clauses if c.op == '==>' and p in conjuncts(c.args[0])]\n",
+ "def pl_fc_entails(kb, q):\n",
+ " """\n",
+ " [Figure 7.15]\n",
+ " Use forward chaining to see if a PropDefiniteKB entails symbol q.\n",
+ " >>> pl_fc_entails(horn_clauses_KB, expr('Q'))\n",
+ " True\n",
+ " """\n",
+ " count = {c: len(conjuncts(c.args[0])) for c in kb.clauses if c.op == '==>'}\n",
+ " inferred = defaultdict(bool)\n",
+ " agenda = [s for s in kb.clauses if is_prop_symbol(s.op)]\n",
+ " while agenda:\n",
+ " print(f"queue:{agenda}")\n",
+ " p = agenda.pop()\n",
+ " print(f"{p} poped from queue {agenda}")\n",
+ " if p == q:\n",
+ " print(f"{p} is the same with query, return True")\n",
+ " return True\n",
+ " if not inferred[p]:\n",
+ " inferred[p] = True\n",
+ " for c in kb.clauses_with_premise(p):\n",
+ " count[c] -= 1\n",
+ " if count[c] == 0:\n",
+ " print(f"premises in clauses: {c} are all true")\n",
+ " print(f"conclusion {c.args[1]} are added to queue")\n",
+ " agenda.append(c.args[1])\n",
+ " return False\n",
+ "\n", + "
\n", + "`count` initially stores the number of symbols in the premise of each sentence in the knowledge base.\n", + "
\n", + "The `conjuncts` helper function separates a given sentence at conjunctions.\n", + "
\n", + "`inferred` is initialized as a *boolean* defaultdict. \n", + "This will be used later to check if we have inferred all premises of each clause of the agenda.\n", + "
\n", + "`agenda` initially stores a list of clauses that the knowledge base knows to be true.\n", + "The `is_prop_symbol` helper function checks if the given symbol is a valid propositional logic symbol.\n", + "
\n", + "
\n", + "We now iterate through `agenda`, popping a symbol `p` on each iteration.\n", + "If the query `q` is the same as `p`, we know that entailment holds.\n", + "
\n", + "The agenda is processed, reducing `count` by one for each implication with a premise `p`.\n", + "A conclusion is added to the agenda when `count` reaches zero. This means we know all the premises of that particular implication to be true.\n", + "
\n", + "`clauses_with_premise` is a helpful method of the `PropKB` class.\n", + "It returns a list of clauses in the knowledge base that have `p` in their premise.\n", + "
\n", + "
\n", + "Now that we have an idea of how this function works, let's see a few examples of its usage, but we first need to define our knowledge base. We assume we know the following clauses to be true." + ] + }, + { + "cell_type": "code", + "execution_count": 40, + "id": "0b621bbf", + "metadata": {}, + "outputs": [], + "source": [ + "clauses = ['(B & F)==>E', \n", + " '(A & E & F)==>G', \n", + " '(B & C)==>F', \n", + " '(A & B)==>D', \n", + " '(E & F)==>H', \n", + " '(H & I)==>J',\n", + " 'A', \n", + " 'B', \n", + " 'C']" + ] + }, + { + "cell_type": "markdown", + "id": "5b5bb2c6", + "metadata": {}, + "source": [ + "We will now `tell` this information to our knowledge base." + ] + }, + { + "cell_type": "code", + "execution_count": 41, + "id": "d2617082", + "metadata": {}, + "outputs": [], + "source": [ + "definite_clauses_KB = PropDefiniteKB()\n", + "for clause in clauses:\n", + " definite_clauses_KB.tell(expr(clause))" + ] + }, + { + "cell_type": "markdown", + "id": "8cfdea81", + "metadata": {}, + "source": [ + "We can now check if our knowledge base entails the following queries." + ] + }, + { + "cell_type": "code", + "execution_count": 42, + "id": "81e1582c", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "queue:[A, B, C]\n", + "C poped from queue [A, B]\n", + "queue:[A, B]\n", + "B poped from queue [A]\n", + "premises in clauses: ((B & C) ==> F) are all true\n", + "conclusion F are added to queue\n", + "queue:[A, F]\n", + "F poped from queue [A]\n", + "premises in clauses: ((B & F) ==> E) are all true\n", + "conclusion E are added to queue\n", + "queue:[A, E]\n", + "E poped from queue [A]\n", + "premises in clauses: ((E & F) ==> H) are all true\n", + "conclusion H are added to queue\n", + "queue:[A, H]\n", + "H poped from queue [A]\n", + "queue:[A]\n", + "A poped from queue []\n", + "premises in clauses: (((A & E) & F) ==> G) are all true\n", + "conclusion G are added to queue\n", + "premises in clauses: ((A & B) ==> D) are all true\n", + "conclusion D are added to queue\n", + "queue:[G, D]\n", + "D poped from queue [G]\n", + "queue:[G]\n", + "G poped from queue []\n", + "G is the same with query, return True\n" + ] + }, + { + "data": { + "text/plain": [ + "True" + ] + }, + "execution_count": 42, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pl_fc_entails(definite_clauses_KB, expr('G'))" + ] + }, + { + "cell_type": "code", + "execution_count": 43, + "id": "78b9b0fe", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "queue:[A, B, C]\n", + "C poped from queue [A, B]\n", + "queue:[A, B]\n", + "B poped from queue [A]\n", + "premises in clauses: ((B & C) ==> F) are all true\n", + "conclusion F are added to queue\n", + "queue:[A, F]\n", + "F poped from queue [A]\n", + "premises in clauses: ((B & F) ==> E) are all true\n", + "conclusion E are added to queue\n", + "queue:[A, E]\n", + "E poped from queue [A]\n", + "premises in clauses: ((E & F) ==> H) are all true\n", + "conclusion H are added to queue\n", + "queue:[A, H]\n", + "H poped from queue [A]\n", + "H is the same with query, return True\n" + ] + }, + { + "data": { + "text/plain": [ + "True" + ] + }, + "execution_count": 43, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pl_fc_entails(definite_clauses_KB, expr('H'))" + ] + }, + { + "cell_type": "code", + "execution_count": 44, + "id": "a4d2c858", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "queue:[A, B, C]\n", + "C poped from queue [A, B]\n", + "queue:[A, B]\n", + "B poped from queue [A]\n", + "premises in clauses: ((B & C) ==> F) are all true\n", + "conclusion F are added to queue\n", + "queue:[A, F]\n", + "F poped from queue [A]\n", + "premises in clauses: ((B & F) ==> E) are all true\n", + "conclusion E are added to queue\n", + "queue:[A, E]\n", + "E poped from queue [A]\n", + "premises in clauses: ((E & F) ==> H) are all true\n", + "conclusion H are added to queue\n", + "queue:[A, H]\n", + "H poped from queue [A]\n", + "queue:[A]\n", + "A poped from queue []\n", + "premises in clauses: (((A & E) & F) ==> G) are all true\n", + "conclusion G are added to queue\n", + "premises in clauses: ((A & B) ==> D) are all true\n", + "conclusion D are added to queue\n", + "queue:[G, D]\n", + "D poped from queue [G]\n", + "queue:[G]\n", + "G poped from queue []\n" + ] + }, + { + "data": { + "text/plain": [ + "False" + ] + }, + "execution_count": 44, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pl_fc_entails(definite_clauses_KB, expr('I'))" + ] + }, + { + "cell_type": "code", + "execution_count": 45, + "id": "c60592c4", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "queue:[A, B, C]\n", + "C poped from queue [A, B]\n", + "queue:[A, B]\n", + "B poped from queue [A]\n", + "premises in clauses: ((B & C) ==> F) are all true\n", + "conclusion F are added to queue\n", + "queue:[A, F]\n", + "F poped from queue [A]\n", + "premises in clauses: ((B & F) ==> E) are all true\n", + "conclusion E are added to queue\n", + "queue:[A, E]\n", + "E poped from queue [A]\n", + "premises in clauses: ((E & F) ==> H) are all true\n", + "conclusion H are added to queue\n", + "queue:[A, H]\n", + "H poped from queue [A]\n", + "queue:[A]\n", + "A poped from queue []\n", + "premises in clauses: (((A & E) & F) ==> G) are all true\n", + "conclusion G are added to queue\n", + "premises in clauses: ((A & B) ==> D) are all true\n", + "conclusion D are added to queue\n", + "queue:[G, D]\n", + "D poped from queue [G]\n", + "queue:[G]\n", + "G poped from queue []\n" + ] + }, + { + "data": { + "text/plain": [ + "False" + ] + }, + "execution_count": 45, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pl_fc_entails(definite_clauses_KB, expr('J'))" + ] + }, + { + "cell_type": "markdown", + "id": "7c62c31e", + "metadata": {}, + "source": [ + "### Effective Propositional Model Checking\n", + "\n", + "The previous segments elucidate the algorithmic procedure for model checking. \n", + "In this segment, we look at ways of making them computationally efficient.\n", + "
\n", + "The problem we are trying to solve is conventionally called the _propositional satisfiability problem_, abbreviated as the _SAT_ problem.\n", + "In layman terms, if there exists a model that satisfies a given Boolean formula, the formula is called satisfiable.\n", + "
\n", + "The SAT problem was the first problem to be proven _NP-complete_.\n", + "The main characteristics of an NP-complete problem are:\n", + "- Given a solution to such a problem, it is easy to verify if the solution solves the problem.\n", + "- The time required to actually solve the problem using any known algorithm increases exponentially with respect to the size of the problem.\n", + "
\n", + "
\n", + "Due to these properties, heuristic and approximational methods are often applied to find solutions to these problems.\n", + "
\n", + "It is extremely important to be able to solve large scale SAT problems efficiently because \n", + "many combinatorial problems in computer science can be conveniently reduced to checking the satisfiability of a propositional sentence under some constraints.\n", + "
\n", + "We will introduce two new algorithms that perform propositional model checking in a computationally effective way.\n", + "
\n" + ] + }, + { + "cell_type": "markdown", + "id": "16f137d2", + "metadata": {}, + "source": [ + "### 1. DPLL (Davis-Putnam-Logeman-Loveland) algorithm\n", + "This algorithm is very similar to Backtracking-Search.\n", + "It recursively enumerates possible models in a depth-first fashion with the following improvements over algorithms like `tt_entails`:\n", + "1. Early termination:\n", + "
\n", + "In certain cases, the algorithm can detect the truth value of a statement using just a partially completed model.\n", + "For example, $(P\\lor Q)\\land(P\\lor R)$ is true if P is true, regardless of other variables.\n", + "This reduces the search space significantly.\n", + "2. Pure symbol heuristic:\n", + "
\n", + "A symbol that has the same sign (positive or negative) in all clauses is called a _pure symbol_.\n", + "It isn't difficult to see that any satisfiable model will have the pure symbols assigned such that its parent clause becomes _true_.\n", + "For example, $(P\\lor\\neg Q)\\land(\\neg Q\\lor\\neg R)\\land(R\\lor P)$ has P and Q as pure symbols\n", + "and for the sentence to be true, P _has_ to be true and Q _has_ to be false.\n", + "The pure symbol heuristic thus simplifies the problem a bit.\n", + "3. Unit clause heuristic:\n", + "
\n", + "In the context of DPLL, clauses with just one literal and clauses with all but one _false_ literals are called unit clauses.\n", + "If a clause is a unit clause, it can only be satisfied by assigning the necessary value to make the last literal true.\n", + "We have no other choice.\n", + "
\n", + "Assigning one unit clause can create another unit clause.\n", + "For example, when P is false, $(P\\lor Q)$ becomes a unit clause, causing _true_ to be assigned to Q.\n", + "A series of forced assignments derived from previous unit clauses is called _unit propagation_.\n", + "In this way, this heuristic simplifies the problem further.\n", + "
\n", + "The algorithm often employs other tricks to scale up to large problems.\n", + "However, these tricks are currently out of the scope of this notebook. Refer to section 7.6 of the book for more details.\n", + "
\n", + "
\n", + "Let's have a look at the algorithm." + ] + }, + { + "cell_type": "code", + "execution_count": 46, + "id": "d6cdf0ba", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def dpll(clauses, symbols, model, branching_heuristic=no_branching_heuristic):\n",
+ " """See if the clauses are true in a partial model."""\n",
+ " print(f"clauses: {clauses}")\n",
+ " print(f"symbols: {symbols}")\n",
+ " print(f"model: {model}")\n",
+ " unknown_clauses = [] # clauses with an unknown truth value\n",
+ " for c in clauses:\n",
+ " print(f"check pl_true of clause {c} with model {model}")\n",
+ " val = pl_true(c, model)\n",
+ " print(f"Check Results: {val}")\n",
+ " if val is False:\n",
+ " return False\n",
+ " if val is None:\n",
+ " unknown_clauses.append(c)\n",
+ " if not unknown_clauses:\n",
+ " return model\n",
+ " print(f"Finding pure symbol with symbols {symbols} and clauses {unknown_clauses}")\n",
+ " P, value = find_pure_symbol(symbols, unknown_clauses)\n",
+ " print(f"Pure symbol results P: {P} value: {value}")\n",
+ " if P:\n",
+ " return dpll(clauses, remove_all(P, symbols), extend(model, P, value), branching_heuristic)\n",
+ " P, value = find_unit_clause(clauses, model)\n",
+ " if P:\n",
+ " return dpll(clauses, remove_all(P, symbols), extend(model, P, value), branching_heuristic)\n",
+ " P, value = branching_heuristic(symbols, unknown_clauses)\n",
+ " return (dpll(clauses, remove_all(P, symbols), extend(model, P, value), branching_heuristic) or\n",
+ " dpll(clauses, remove_all(P, symbols), extend(model, P, not value), branching_heuristic))\n",
+ "\n", + "The `dpll_satisfiable` helper function converts the input clauses to _conjunctive normal form_ and calls the `dpll` function with the correct parameters." + ] + }, + { + "cell_type": "code", + "execution_count": 47, + "id": "0e4afb2c", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def dpll_satisfiable(s, branching_heuristic=no_branching_heuristic):\n",
+ " """Check satisfiability of a propositional sentence.\n",
+ " This differs from the book code in two ways: (1) it returns a model\n",
+ " rather than True when it succeeds; this is more useful. (2) The\n",
+ " function find_pure_symbol is passed a list of unknown clauses, rather\n",
+ " than a list of all clauses and the model; this is more efficient.\n",
+ " >>> dpll_satisfiable(A |'<=>'| B) == {A: True, B: True}\n",
+ " True\n",
+ " """\n",
+ " return dpll(conjuncts(to_cnf(s)), prop_symbols(s), {}, branching_heuristic)\n",
+ "\n", + "The symbol to be flipped is decided by an evaluation function that counts the number of unsatisfied clauses.\n", + "Sometimes, symbols are also flipped randomly to avoid local optima. A subtle balance between greediness and randomness is required. Alternatively, some versions of the algorithm restart with a completely new random assignment if no solution has been found for too long as a way of getting out of local minima of numbers of unsatisfied clauses.\n", + "
\n", + "
\n", + "Let's have a look at the algorithm." + ] + }, + { + "cell_type": "code", + "execution_count": 54, + "id": "fca2582f", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def WalkSAT(clauses, p=0.5, max_flips=10000):\n",
+ " """Checks for satisfiability of all clauses by randomly flipping values of variables\n",
+ " >>> WalkSAT([A & ~A], 0.5, 100) is None\n",
+ " True\n",
+ " """\n",
+ " # Set of all symbols in all clauses\n",
+ " symbols = {sym for clause in clauses for sym in prop_symbols(clause)}\n",
+ " # model is a random assignment of true/false to the symbols in clauses\n",
+ " model = {s: random.choice([True, False]) for s in symbols}\n",
+ " for i in range(max_flips):\n",
+ " satisfied, unsatisfied = [], []\n",
+ " for clause in clauses:\n",
+ " (satisfied if pl_true(clause, model) else unsatisfied).append(clause)\n",
+ " if not unsatisfied: # if model satisfies all the clauses\n",
+ " return model\n",
+ " clause = random.choice(unsatisfied)\n",
+ " if probability(p):\n",
+ " sym = random.choice(list(prop_symbols(clause)))\n",
+ " else:\n",
+ " # Flip the symbol in clause that maximizes number of sat. clauses\n",
+ " def sat_count(sym):\n",
+ " # Return the the number of clauses satisfied after flipping the symbol.\n",
+ " model[sym] = not model[sym]\n",
+ " count = len([clause for clause in clauses if pl_true(clause, model)])\n",
+ " model[sym] = not model[sym]\n",
+ " return count\n",
+ "\n",
+ " sym = max(prop_symbols(clause), key=sat_count)\n",
+ " model[sym] = not model[sym]\n",
+ " # If no solution is found within the flip limit, we return failure\n",
+ " return None\n",
+ "\n", + "1. The `clauses` we want to satisfy.\n", + "
\n", + "2. The probability `p` of randomly changing a symbol.\n", + "
\n", + "3. The maximum number of flips (`max_flips`) the algorithm will run for. If the clauses are still unsatisfied, the algorithm returns `None` to denote failure.\n", + "
\n", + "The algorithm is identical in concept to Hill climbing and the code isn't difficult to understand.\n", + "
\n", + "
\n", + "Let's see a few examples of usage." + ] + }, + { + "cell_type": "code", + "execution_count": 55, + "id": "66e3030e", + "metadata": {}, + "outputs": [], + "source": [ + "A, B, C, D = expr('A, B, C, D')" + ] + }, + { + "cell_type": "code", + "execution_count": 56, + "id": "cedb5b0b", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{D: True, B: True, C: False, A: True}" + ] + }, + "execution_count": 56, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "WalkSAT([A, B, ~C, D], 0.5, 100)" + ] + }, + { + "cell_type": "markdown", + "id": "afb2f3bf", + "metadata": {}, + "source": [ + "This is a simple case to show that the algorithm converges." + ] + }, + { + "cell_type": "code", + "execution_count": 57, + "id": "55dc9097", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{C: True, A: True, B: True}" + ] + }, + "execution_count": 57, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "WalkSAT([A & B, A & C], 0.5, 100)" + ] + }, + { + "cell_type": "code", + "execution_count": 58, + "id": "d06d2fb0", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{D: True, C: True, A: True, B: True}" + ] + }, + "execution_count": 58, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "WalkSAT([A & B, C & D, C & B], 0.5, 100)" + ] + }, + { + "cell_type": "code", + "execution_count": 59, + "id": "22899b09", + "metadata": {}, + "outputs": [], + "source": [ + "WalkSAT([A & B, C | D, ~(D | B)], 0.5, 1000)" + ] + }, + { + "cell_type": "markdown", + "id": "1663811b", + "metadata": {}, + "source": [ + "This one doesn't give any output because WalkSAT did not find any model where these clauses hold. We can solve these clauses to see that they together form a contradiction and hence, it isn't supposed to have a solution." + ] + }, + { + "cell_type": "markdown", + "id": "c7e34352", + "metadata": {}, + "source": [ + "One point of difference between this algorithm and the `dpll_satisfiable` algorithms is that both these algorithms take inputs differently. \n", + "For WalkSAT to take complete sentences as input, \n", + "we can write a helper function that converts the input sentence into conjunctive normal form and then calls WalkSAT with the list of conjuncts of the CNF form of the sentence." + ] + }, + { + "cell_type": "code", + "execution_count": 60, + "id": "73409b93", + "metadata": {}, + "outputs": [], + "source": [ + "def WalkSAT_CNF(sentence, p=0.5, max_flips=10000):\n", + " return WalkSAT(conjuncts(to_cnf(sentence)), 0, max_flips)" + ] + }, + { + "cell_type": "markdown", + "id": "5e78c07c", + "metadata": {}, + "source": [ + "Now we can call `WalkSAT_CNF` and `DPLL_Satisfiable` with the same arguments." + ] + }, + { + "cell_type": "code", + "execution_count": 61, + "id": "e8cdf715", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{D: True, B: True, C: True, A: True}" + ] + }, + "execution_count": 61, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "WalkSAT_CNF((A & B) | (C & ~A) | (B & ~D), 0.5, 1000)" + ] + }, + { + "cell_type": "markdown", + "id": "3ec86268", + "metadata": {}, + "source": [ + "It works!\n", + "
\n", + "Notice that the solution generated by WalkSAT doesn't omit variables that the sentence doesn't depend upon. \n", + "If the sentence is independent of a particular variable, the solution contains a random value for that variable because of the stochastic nature of the algorithm.\n", + "
\n", + "
\n", + "Let's compare the runtime of WalkSAT and DPLL for a few cases. We will use the `%%timeit` magic to do this." + ] + }, + { + "cell_type": "code", + "execution_count": 62, + "id": "c8f6feb7", + "metadata": {}, + "outputs": [], + "source": [ + "sentence_1 = A |'<=>'| B\n", + "sentence_2 = (A & B) | (C & ~A) | (B & ~D)\n", + "sentence_3 = (A | (B & C)) |'<=>'| ((A | B) & (A | C))" + ] + }, + { + "cell_type": "code", + "execution_count": 63, + "id": "d7e665a9", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | C) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | C) with model {A: True}\n", + "Check Results: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {B, A}\n", + "model: {}\n", + "check pl_true of clause (A | ~B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {B, A} and clauses [(A | ~B), (B | ~A)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: {A}\n", + "model: {B: True}\n", + "check pl_true of clause (A | ~B) with model {B: True}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A) with model {B: True}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {A} and clauses [(A | ~B)]\n", + "Pure symbol results P: A value: True\n", + "clauses: [(A | ~B), (B | ~A)]\n", + "symbols: set()\n", + "model: {B: True, A: True}\n", + "check pl_true of clause (A | ~B) with model {B: True, A: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A) with model {B: True, A: True}\n", + "Check Results: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {D, B, C, A}\n", + "model: {}\n", + "check pl_true of clause (B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (B | ~A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {D, B, C, A} and clauses [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "Pure symbol results P: D value: False\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {B, C, A}\n", + "model: {D: False}\n", + "check pl_true of clause (B | C | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | A) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | C | B) with model {D: False}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False}\n", + "Check Results: None\n", + "check pl_true of clause (~D | ~A | B) with model {D: False}\n", + "Check Results: True\n", + "Finding pure symbol with symbols {B, C, A} and clauses [(B | C | A), (B | ~A | A), (B | C | B), (B | ~A | B)]\n", + "Pure symbol results P: B value: True\n", + "clauses: [(B | C | A), (~D | C | A), (B | ~A | A), (~D | ~A | A), (B | C | B), (~D | C | B), (B | ~A | B), (~D | ~A | B)]\n", + "symbols: {A, C}\n", + "model: {D: False, B: True}\n", + "check pl_true of clause (B | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | A) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | C | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (B | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "check pl_true of clause (~D | ~A | B) with model {D: False, B: True}\n", + "Check Results: True\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {A, C, B}\n", + "model: {}\n", + "check pl_true of clause (~A | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | B | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~A | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~C | ~B | C | A) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | B) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~A | A | C) with model {}\n", + "Check Results: None\n", + "check pl_true of clause (~B | ~C | A | C) with model {}\n", + "Check Results: None\n", + "Finding pure symbol with symbols {A, C, B} and clauses [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "Pure symbol results P: None value: None\n", + "clauses: [(~A | ~A | B | A), (~C | ~A | B | A), (~A | ~B | B | A), (~C | ~B | B | A), (~A | ~A | C | A), (~C | ~A | C | A), (~A | ~B | C | A), (~C | ~B | C | A), (~A | A | B), (~B | ~C | A | B), (~A | A | C), (~B | ~C | A | C)]\n", + "symbols: {C, B}\n", + "model: {A: True}\n", + "check pl_true of clause (~A | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | B | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~A | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~C | ~B | C | A) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~A | A | B) with model {A: True}\n", + "Check Results: True\n", + "check pl_true of clause (~B | ~C | A | B) with model {A: True}" + ] + }, + { + "name": "stderr", + "output_type": "stream", + "text": [ + "IOPub data rate exceeded.\n", + "The notebook server will temporarily stop sending output\n", + "to the client in order to avoid crashing it.\n", + "To change this limit, set the config variable\n", + "`--NotebookApp.iopub_data_rate_limit`.\n", + "\n", + "Current values:\n", + "NotebookApp.iopub_data_rate_limit=1000000.0 (bytes/sec)\n", + "NotebookApp.rate_limit_window=3.0 (secs)\n", + "\n" + ] + } + ], + "source": [ + "%%timeit\n", + "dpll_satisfiable(sentence_1)\n", + "dpll_satisfiable(sentence_2)\n", + "dpll_satisfiable(sentence_3)" + ] + }, + { + "cell_type": "code", + "execution_count": 64, + "id": "97c61f2b", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "889 µs ± 17.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)\n" + ] + } + ], + "source": [ + "%%timeit\n", + "WalkSAT_CNF(sentence_1)\n", + "WalkSAT_CNF(sentence_2)\n", + "WalkSAT_CNF(sentence_3)" + ] + }, + { + "cell_type": "markdown", + "id": "0c7ac46a", + "metadata": {}, + "source": [ + "On an average, for solvable cases, `WalkSAT` is quite faster than `dpll` because, for a small number of variables, \n", + "`WalkSAT` can reduce the search space significantly. \n", + "Results can be different for sentences with more symbols though.\n", + "Feel free to play around with this to understand the trade-offs of these algorithms better." + ] + }, + { + "cell_type": "markdown", + "id": "86264a6d", + "metadata": {}, + "source": [ + "### SATPlan\n", + "\n", + "In this section we show how to make plans by logical inference. The basic idea is very simple. It includes the following three steps:\n", + "1. Constuct a sentence that includes:\n", + " 1. A colection of assertions about the initial state.\n", + " 2. The successor-state axioms for all the possible actions at each time up to some maximum time t.\n", + " 3. The assertion that the goal is achieved at time t.\n", + "2. Present the whole sentence to a SAT solver.\n", + "3. Assuming a model is found, extract from the model those variables that represent actions and are assigned true. Together they represent a plan to achieve the goals.\n", + "\n", + "\n", + "Lets have a look at the algorithm" + ] + }, + { + "cell_type": "code", + "execution_count": 65, + "id": "6035b73c", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def SAT_plan(init, transition, goal, t_max, SAT_solver=cdcl_satisfiable):\n",
+ " """\n",
+ " [Figure 7.22]\n",
+ " Converts a planning problem to Satisfaction problem by translating it to a cnf sentence.\n",
+ " >>> transition = {'A': {'Left': 'A', 'Right': 'B'}, 'B': {'Left': 'A', 'Right': 'C'}, 'C': {'Left': 'B', 'Right': 'C'}}\n",
+ " >>> SAT_plan('A', transition, 'C', 1) is None\n",
+ " True\n",
+ " """\n",
+ "\n",
+ " # Functions used by SAT_plan\n",
+ " def translate_to_SAT(init, transition, goal, time):\n",
+ " clauses = []\n",
+ " states = [state for state in transition]\n",
+ "\n",
+ " # Symbol claiming state s at time t\n",
+ " state_counter = itertools.count()\n",
+ " for s in states:\n",
+ " for t in range(time + 1):\n",
+ " state_sym[s, t] = Expr('S_{}'.format(next(state_counter)))\n",
+ "\n",
+ " # Add initial state axiom\n",
+ " clauses.append(state_sym[init, 0])\n",
+ "\n",
+ " # Add goal state axiom\n",
+ " clauses.append(state_sym[first(clause[0] for clause in state_sym\n",
+ " if set(conjuncts(clause[0])).issuperset(conjuncts(goal))), time]) \\\n",
+ " if isinstance(goal, Expr) else clauses.append(state_sym[goal, time])\n",
+ "\n",
+ " # All possible transitions\n",
+ " transition_counter = itertools.count()\n",
+ " for s in states:\n",
+ " for action in transition[s]:\n",
+ " s_ = transition[s][action]\n",
+ " for t in range(time):\n",
+ " # Action 'action' taken from state 's' at time 't' to reach 's_'\n",
+ " action_sym[s, action, t] = Expr('T_{}'.format(next(transition_counter)))\n",
+ "\n",
+ " # Change the state from s to s_\n",
+ " clauses.append(action_sym[s, action, t] | '==>' | state_sym[s, t])\n",
+ " clauses.append(action_sym[s, action, t] | '==>' | state_sym[s_, t + 1])\n",
+ "\n",
+ " # Allow only one state at any time\n",
+ " for t in range(time + 1):\n",
+ " # must be a state at any time\n",
+ " clauses.append(associate('|', [state_sym[s, t] for s in states]))\n",
+ "\n",
+ " for s in states:\n",
+ " for s_ in states[states.index(s) + 1:]:\n",
+ " # for each pair of states s, s_ only one is possible at time t\n",
+ " clauses.append((~state_sym[s, t]) | (~state_sym[s_, t]))\n",
+ "\n",
+ " # Restrict to one transition per timestep\n",
+ " for t in range(time):\n",
+ " # list of possible transitions at time t\n",
+ " transitions_t = [tr for tr in action_sym if tr[2] == t]\n",
+ "\n",
+ " # make sure at least one of the transitions happens\n",
+ " clauses.append(associate('|', [action_sym[tr] for tr in transitions_t]))\n",
+ "\n",
+ " for tr in transitions_t:\n",
+ " for tr_ in transitions_t[transitions_t.index(tr) + 1:]:\n",
+ " # there cannot be two transitions tr and tr_ at time t\n",
+ " clauses.append(~action_sym[tr] | ~action_sym[tr_])\n",
+ "\n",
+ " # Combine the clauses to form the cnf\n",
+ " return associate('&', clauses)\n",
+ "\n",
+ " def extract_solution(model):\n",
+ " true_transitions = [t for t in action_sym if model[action_sym[t]]]\n",
+ " # Sort transitions based on time, which is the 3rd element of the tuple\n",
+ " true_transitions.sort(key=lambda x: x[2])\n",
+ " return [action for s, action, time in true_transitions]\n",
+ "\n",
+ " # Body of SAT_plan algorithm\n",
+ " for t in range(t_max + 1):\n",
+ " # dictionaries to help extract the solution from model\n",
+ " state_sym = {}\n",
+ " action_sym = {}\n",
+ "\n",
+ " cnf = translate_to_SAT(init, transition, goal, t)\n",
+ " model = SAT_solver(cnf)\n",
+ " if model is not False:\n",
+ " return extract_solution(model)\n",
+ " return None\n",
+ "\n", + "The law says that it is a crime for an American to sell weapons to hostile nations. The country Nono, an enemy of America, has some missiles, and all of its missiles were sold to it by Colonel West, who is American.
\n", + "The first step is to extract the facts and convert them into first-order definite clauses. Extracting the facts from data alone is a challenging task. Fortunately, we have a small paragraph and can do extraction and conversion manually. We'll store the clauses in list aptly named `clauses`." + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "a18f6282", + "metadata": {}, + "outputs": [], + "source": [ + "clauses = []" + ] + }, + { + "cell_type": "markdown", + "id": "aaa5bb71", + "metadata": {}, + "source": [ + "“... it is a crime for an American to sell weapons to hostile nations”
\n", + "The keywords to look for here are 'crime', 'American', 'sell', 'weapon' and 'hostile'. We use predicate symbols to make meaning of them.\n", + "\n", + "* `Criminal(x)`: `x` is a criminal\n", + "* `American(x)`: `x` is an American\n", + "* `Sells(x ,y, z)`: `x` sells `y` to `z`\n", + "* `Weapon(x)`: `x` is a weapon\n", + "* `Hostile(x)`: `x` is a hostile nation\n", + "\n", + "Let us now combine them with appropriate variable naming to depict the meaning of the sentence. The criminal `x` is also the American `x` who sells weapon `y` to `z`, which is a hostile nation.\n", + "\n", + "$\\text{American}(x) \\land \\text{Weapon}(y) \\land \\text{Sells}(x, y, z) \\land \\text{Hostile}(z) \\implies \\text{Criminal} (x)$" + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "id": "b7161c61", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"(American(x) & Weapon(y) & Sells(x, y, z) & Hostile(z)) ==> Criminal(x)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "03cd5efd", + "metadata": {}, + "source": [ + "\"The country Nono, an enemy of America\"
\n", + "We now know that Nono is an enemy of America. We represent these nations using the constant symbols `Nono` and `America`. the enemy relation is show using the predicate symbol `Enemy`.\n", + "\n", + "$\\text{Enemy}(\\text{Nono}, \\text{America})$" + ] + }, + { + "cell_type": "code", + "execution_count": 4, + "id": "7c3fcff2", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"Enemy(Nono, America)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "0c1c557b", + "metadata": {}, + "source": [ + "\"Nono ... has some missiles\"
\n", + "This states the existence of some missile which is owned by Nono. $\\exists x \\text{Owns}(\\text{Nono}, x) \\land \\text{Missile}(x)$. We invoke existential instantiation to introduce a new constant `M1` which is the missile owned by Nono.\n", + "\n", + "$\\text{Owns}(\\text{Nono}, \\text{M1}), \\text{Missile}(\\text{M1})$" + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "id": "986af6ca", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"Owns(Nono, M1)\"))\n", + "clauses.append(expr(\"Missile(M1)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "fa12ffc5", + "metadata": {}, + "source": [ + "\"All of its missiles were sold to it by Colonel West\"
\n", + "If Nono owns something and it classifies as a missile, then it was sold to Nono by West.\n", + "\n", + "$\\text{Missile}(x) \\land \\text{Owns}(\\text{Nono}, x) \\implies \\text{Sells}(\\text{West}, x, \\text{Nono})$" + ] + }, + { + "cell_type": "code", + "execution_count": 6, + "id": "59b18b23", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"(Missile(x) & Owns(Nono, x)) ==> Sells(West, x, Nono)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "082b73ef", + "metadata": {}, + "source": [ + "\"West, who is American\"
\n", + "West is an American.\n", + "\n", + "$\\text{American}(\\text{West})$" + ] + }, + { + "cell_type": "code", + "execution_count": 7, + "id": "c821092c", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"American(West)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "75a45247", + "metadata": {}, + "source": [ + "We also know, from our understanding of language, that missiles are weapons and that an enemy of America counts as “hostile”.\n", + "\n", + "$\\text{Missile}(x) \\implies \\text{Weapon}(x), \\text{Enemy}(x, \\text{America}) \\implies \\text{Hostile}(x)$" + ] + }, + { + "cell_type": "code", + "execution_count": 8, + "id": "ac043c98", + "metadata": {}, + "outputs": [], + "source": [ + "clauses.append(expr(\"Missile(x) ==> Weapon(x)\"))\n", + "clauses.append(expr(\"Enemy(x, America) ==> Hostile(x)\"))" + ] + }, + { + "cell_type": "markdown", + "id": "c25fdefb", + "metadata": {}, + "source": [ + "Now that we have converted the information into first-order definite clauses we can create our first-order logic knowledge base." + ] + }, + { + "cell_type": "code", + "execution_count": 9, + "id": "7e3fc1a3", + "metadata": {}, + "outputs": [], + "source": [ + "crime_kb = FolKB(clauses)" + ] + }, + { + "cell_type": "markdown", + "id": "f5c34921", + "metadata": {}, + "source": [ + "The `subst` helper function substitutes variables with given values in first-order logic statements.\n", + "This will be useful in later algorithms.\n", + "It's implementation is quite simple and self-explanatory." + ] + }, + { + "cell_type": "code", + "execution_count": 10, + "id": "7df0639e", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def subst(s, x):\n",
+ " """Substitute the substitution s into the expression x.\n",
+ " >>> subst({x: 42, y:0}, F(x) + y)\n",
+ " (F(42) + 0)\n",
+ " """\n",
+ " if isinstance(x, list):\n",
+ " return [subst(s, xi) for xi in x]\n",
+ " elif isinstance(x, tuple):\n",
+ " return tuple([subst(s, xi) for xi in x])\n",
+ " elif not isinstance(x, Expr):\n",
+ " return x\n",
+ " elif is_var_symbol(x.op):\n",
+ " return s.get(x, x)\n",
+ " else:\n",
+ " return Expr(x.op, *[subst(s, arg) for arg in x.args])\n",
+ "def fol_fc_ask(kb, alpha):\n",
+ " """\n",
+ " [Figure 9.3]\n",
+ " A simple forward-chaining algorithm.\n",
+ " """\n",
+ " # TODO: improve efficiency\n",
+ " kb_consts = list({c for clause in kb.clauses for c in constant_symbols(clause)})\n",
+ "\n",
+ " def enum_subst(p):\n",
+ " query_vars = list({v for clause in p for v in variables(clause)})\n",
+ " for assignment_list in itertools.product(kb_consts, repeat=len(query_vars)):\n",
+ " theta = {x: y for x, y in zip(query_vars, assignment_list)}\n",
+ " yield theta\n",
+ "\n",
+ " # check if we can answer without new inferences\n",
+ " for q in kb.clauses:\n",
+ " phi = unify_mm(q, alpha)\n",
+ " if phi is not None:\n",
+ " yield phi\n",
+ "\n",
+ " while True:\n",
+ " new = []\n",
+ " for rule in kb.clauses:\n",
+ " p, q = parse_definite_clause(rule)\n",
+ " for theta in enum_subst(p):\n",
+ " if set(subst(theta, p)).issubset(set(kb.clauses)):\n",
+ " q_ = subst(theta, q)\n",
+ " if all([unify_mm(x, q_) is None for x in kb.clauses + new]):\n",
+ " new.append(q_)\n",
+ " phi = unify_mm(q_, alpha)\n",
+ " if phi is not None:\n",
+ " yield phi\n",
+ " if not new:\n",
+ " break\n",
+ " for clause in new:\n",
+ " kb.tell(clause)\n",
+ " return None\n",
+ "def fol_bc_or(kb, goal, theta):\n",
+ " print(f"Starting Back Or with (KB, Goal: {goal}, theta: {theta})")\n",
+ " for rule in kb.fetch_rules_for_goal(goal):\n",
+ " print(f"Processing Rule: {rule}")\n",
+ " lhs, rhs = parse_definite_clause(standardize_variables(rule))\n",
+ " print(f"lhs: {lhs}, rhs: {rhs}")\n",
+ " for theta1 in fol_bc_and(kb, lhs, unify_mm(rhs, goal, theta)):\n",
+ " yield theta1\n",
+ "def fol_bc_and(kb, goals, theta):\n",
+ " print(f"Starting Back And with (KB, Goals: {goals}, theta: {theta})")\n",
+ " if theta is None:\n",
+ " print(f"theta is None, pass")\n",
+ " pass\n",
+ " elif not goals:\n",
+ " print(f"Length(goals)=0, yield theta: {theta}")\n",
+ " yield theta\n",
+ " else:\n",
+ " first, rest = goals[0], goals[1:]\n",
+ " print(f"first: {first} for Back Or, rest: {rest} for Back And")\n",
+ " for theta1 in fol_bc_or(kb, subst(theta, first), theta):\n",
+ " for theta2 in fol_bc_and(kb, rest, theta1):\n",
+ " yield theta2\n",
+ "\n", + "Instead of actions as in classical planning (chapter 10) (primitive actions) we now use high level actions (HLAs) (see planning.ipynb)
\n", + "\n", + "## Refinements\n", + "\n", + "Each __HLA__ has one or more refinements into a sequence of actions, each of which may be an HLA or a primitive action (which has no refinements by definition).
\n", + "For example:\n", + "- (a) the high level action \"Go to San Fransisco airport\" (Go(Home, SFO)), might have two possible refinements, \"Drive to San Fransisco airport\" and \"Taxi to San Fransisco airport\". \n", + "
\n", + "- (b) A recursive refinement for navigation in the vacuum world would be: to get to a\n", + "destination, take a step, and then go to the destination.\n", + "
\n", + "\n", + "
\n", + "- __implementation__: An HLA refinement that contains only primitive actions is called an implementation of the HLA\n", + "- An implementation of a high-level plan (a sequence of HLAs) is the concatenation of implementations of each HLA in the sequence\n", + "- A high-level plan __achieves the goal__ from a given state if at least one of its implementations achieves the goal from that state\n", + "
\n", + "\n", + "The refinements function input is: \n", + "- __hla__: the HLA of which we want to compute its refinements\n", + "- __state__: the knoweledge base of the current problem (Problem.init)\n", + "- __library__: the hierarchy of the actions in the planning problem\n", + "\n" + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "3d2af2cf", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def refinements(self, library): # refinements may be (multiple) HLA themselves ...\n",
+ " """\n",
+ " State is a Problem, containing the current state kb library is a\n",
+ " dictionary containing details for every possible refinement. e.g.:\n",
+ " {\n",
+ " 'HLA': [\n",
+ " 'Go(Home, SFO)',\n",
+ " 'Go(Home, SFO)',\n",
+ " 'Drive(Home, SFOLongTermParking)',\n",
+ " 'Shuttle(SFOLongTermParking, SFO)',\n",
+ " 'Taxi(Home, SFO)'\n",
+ " ],\n",
+ " 'steps': [\n",
+ " ['Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)'],\n",
+ " ['Taxi(Home, SFO)'],\n",
+ " [],\n",
+ " [],\n",
+ " []\n",
+ " ],\n",
+ " # empty refinements indicate a primitive action\n",
+ " 'precond': [\n",
+ " ['At(Home) & Have(Car)'],\n",
+ " ['At(Home)'],\n",
+ " ['At(Home) & Have(Car)'],\n",
+ " ['At(SFOLongTermParking)'],\n",
+ " ['At(Home)']\n",
+ " ],\n",
+ " 'effect': [\n",
+ " ['At(SFO) & ~At(Home)'],\n",
+ " ['At(SFO) & ~At(Home)'],\n",
+ " ['At(SFOLongTermParking) & ~At(Home)'],\n",
+ " ['At(SFO) & ~At(SFOLongTermParking)'],\n",
+ " ['At(SFO) & ~At(Home)']\n",
+ " ]}\n",
+ " """\n",
+ "# print(self.name)\n",
+ " indices = [i for i, x in enumerate(library['HLA']) if expr(x).op == self.name]\n",
+ "# print(f"indices: {indices}")\n",
+ " for i in indices:\n",
+ " actions = []\n",
+ " for j in range(len(library['steps'][i])):\n",
+ " # find the index of the step [j] of the HLA\n",
+ " index_step = [k for k, x in enumerate(library['HLA']) if x == library['steps'][i][j]][0]\n",
+ " precond = library['precond'][index_step][0] # preconditions of step [j]\n",
+ " effect = library['effect'][index_step][0] # effect of step [j]\n",
+ " actions.append(HLA(library['steps'][i][j], precond, effect))\n",
+ " yield actions\n",
+ "\n", + "The algorithms input is: problem and hierarchy\n", + "- __problem__: is of type Problem \n", + "- __hierarchy__: is a dictionary consisting of all the actions and the order in which they are performed. \n", + "
\n", + "\n", + "In top level call, initialPlan contains [act] (i.e. is the action to be performed) " + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "id": "b8142cd9", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def hierarchical_search(self, hierarchy):\n",
+ " """\n",
+ " [Figure 11.5]\n",
+ " 'Hierarchical Search, a Breadth First Search implementation of Hierarchical\n",
+ " Forward Planning Search'\n",
+ " The problem is a real-world problem defined by the problem class, and the hierarchy is\n",
+ " a dictionary of HLA - refinements (see refinements generator for details)\n",
+ " """\n",
+ " print(f"hiearchy: {hierarchy}")\n",
+ " act = Node(self.initial, None, [self.actions[0]])\n",
+ " frontier = deque()\n",
+ " frontier.append(act)\n",
+ " print(f"frontier: {[x.__dict__ for x in frontier]}")\n",
+ " while True:\n",
+ " if not frontier:\n",
+ " return None\n",
+ " plan = frontier.popleft()\n",
+ " print(f"Plan {plan.action} poped from frontier: {[x.__dict__ for x in frontier]}")\n",
+ " # finds the first non primitive hla in plan actions\n",
+ " (hla, index) = RealWorldPlanningProblem.find_hla(plan, hierarchy)\n",
+ " print(f"Find HLA, get hla: {hla} and index: {index}")\n",
+ " prefix = plan.action[:index]\n",
+ " print(f"prefix: {prefix}")\n",
+ " outcome = RealWorldPlanningProblem(\n",
+ " RealWorldPlanningProblem.result(self.initial, prefix), self.goals, self.actions)\n",
+ " print(f"Outcome: {outcome.initial}")\n",
+ " suffix = plan.action[index + 1:]\n",
+ " print(f"suffix: {suffix}")\n",
+ " if not hla: # hla is None and plan is primitive\n",
+ " if outcome.goal_test():\n",
+ " print(f"Outcome: {outcome.initial} Goal Test Success, return Plan:{ 1}")\n",
+ " return plan.action\n",
+ " else:\n",
+ " for sequence in RealWorldPlanningProblem.refinements(hla, hierarchy): # find refinements\n",
+ " print(f"Refinement(hla: {hla}) got sequence: {sequence}")\n",
+ " frontier.append(Node(outcome.initial, plan, prefix + sequence + suffix))\n",
+ " print(f"frontier Added: {frontier[-1].__dict__}")\n",
+ "\n", + "Those two actions have some preconditions and some effects. \n", + "If you get the taxi, you need to have cash, whereas if you drive you need to have a car.
\n", + "Thus we define the following hierarchy of possible actions.\n", + "\n", + "##### hierarchy" + ] + }, + { + "cell_type": "code", + "execution_count": 4, + "id": "cf7f1e3b", + "metadata": {}, + "outputs": [], + "source": [ + "library = {\n", + " 'HLA': ['Go(Home,SFO)', 'Go(Home,SFO)', 'Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)', 'Taxi(Home, SFO)'],\n", + " 'steps': [['Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)'], ['Taxi(Home, SFO)'], [], [], []],\n", + " 'precond': [['At(Home) & Have(Car)'], ['At(Home)'], ['At(Home) & Have(Car)'], ['At(SFOLongTermParking)'], ['At(Home)']],\n", + " 'effect': [['At(SFO) & ~At(Home)'], ['At(SFO) & ~At(Home) & ~Have(Cash)'], ['At(SFOLongTermParking) & ~At(Home)'], ['At(SFO) & ~At(LongTermParking)'], ['At(SFO) & ~At(Home) & ~Have(Cash)']] }\n", + "\n" + ] + }, + { + "cell_type": "markdown", + "id": "25cb5f05", + "metadata": {}, + "source": [ + "\n", + "the possible actions are the following:" + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "id": "bc4c515d", + "metadata": {}, + "outputs": [], + "source": [ + "go_SFO = HLA('Go(Home,SFO)', precond='At(Home)', effect='At(SFO) & ~At(Home)')\n", + "taxi_SFO = HLA('Taxi(Home,SFO)', precond='At(Home)', effect='At(SFO) & ~At(Home) & ~Have(Cash)')\n", + "drive_SFOLongTermParking = HLA('Drive(Home, SFOLongTermParking)', 'At(Home) & Have(Car)','At(SFOLongTermParking) & ~At(Home)' )\n", + "shuttle_SFO = HLA('Shuttle(SFOLongTermParking, SFO)', 'At(SFOLongTermParking)', 'At(SFO) & ~At(LongTermParking)')" + ] + }, + { + "cell_type": "markdown", + "id": "6243f681", + "metadata": {}, + "source": [ + "Suppose that (our preconditionds are that) we are Home and we have cash and car and our goal is to get to SFO and maintain our cash, and our possible actions are the above.
\n", + "##### Then our problem is: " + ] + }, + { + "cell_type": "code", + "execution_count": 6, + "id": "da7691f9", + "metadata": {}, + "outputs": [], + "source": [ + "prob = RealWorldPlanningProblem('At(Home) & Have(Cash) & Have(Car)', 'At(SFO) & Have(Cash)', [go_SFO])" + ] + }, + { + "cell_type": "markdown", + "id": "12c48b0c", + "metadata": {}, + "source": [ + "##### Refinements\n", + "\n", + "The refinements of the action Go(Home, SFO), are defined as:
\n", + "['Drive(Home,SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)'], ['Taxi(Home, SFO)']" + ] + }, + { + "cell_type": "code", + "execution_count": 7, + "id": "bb9ca2c5", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "[Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)]\n", + "[{'name': 'Drive', 'args': (Home, SFOLongTermParking), 'precond': [At(Home), Have(Car)], 'effect': [At(SFOLongTermParking), NotAt(Home)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}, {'name': 'Shuttle', 'args': (SFOLongTermParking, SFO), 'precond': [At(SFOLongTermParking)], 'effect': [At(SFO), NotAt(LongTermParking)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}] \n", + "\n", + "[Taxi(Home, SFO)]\n", + "[{'name': 'Taxi', 'args': (Home, SFO), 'precond': [At(Home)], 'effect': [At(SFO), NotAt(Home), NotHave(Cash)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}] \n", + "\n" + ] + } + ], + "source": [ + "for sequence in RealWorldPlanningProblem.refinements(go_SFO, library):\n", + " print (sequence)\n", + " print([x.__dict__ for x in sequence ], '\\n')" + ] + }, + { + "cell_type": "markdown", + "id": "2df36745", + "metadata": {}, + "source": [ + "Run the hierarchical search\n", + "##### Top level call" + ] + }, + { + "cell_type": "code", + "execution_count": 8, + "id": "24e6ecfb", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "hiearchy: {'HLA': ['Go(Home,SFO)', 'Go(Home,SFO)', 'Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)', 'Taxi(Home, SFO)'], 'steps': [['Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)'], ['Taxi(Home, SFO)'], [], [], []], 'precond': [['At(Home) & Have(Car)'], ['At(Home)'], ['At(Home) & Have(Car)'], ['At(SFOLongTermParking)'], ['At(Home)']], 'effect': [['At(SFO) & ~At(Home)'], ['At(SFO) & ~At(Home) & ~Have(Cash)'], ['At(SFOLongTermParking) & ~At(Home)'], ['At(SFO) & ~At(LongTermParking)'], ['At(SFO) & ~At(Home) & ~Have(Cash)']]}\n", + "frontier: [{'state': [At(Home), Have(Cash), Have(Car)], 'parent': None, 'action': [Go(Home, SFO)], 'path_cost': 0, 'depth': 0}]\n", + "Plan [Go(Home, SFO)] poped from frontier: []\n", + "Find HLA, get hla: Go(Home, SFO) and index: 0\n", + "prefix: []\n", + "Outcome: [At(Home), Have(Cash), Have(Car)]\n", + "suffix: []\n", + "Refinement(hla: Go(Home, SFO)) got sequence: [Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)]\n", + "frontier Added: {'state': [At(Home), Have(Cash), Have(Car)], 'parent':
\n", + "The algorithms input is: problem, hierarchy and initialPlan\n", + "- problem is of type Problem \n", + "- hierarchy is a dictionary consisting of all the actions. \n", + "- initialPlan is an approximate description(optimistic and pessimistic) of the agents choices for the implementation.
\n", + " initialPlan contains a sequence of HLA's with angelic semantics" + ] + }, + { + "cell_type": "markdown", + "id": "5aaf33f1", + "metadata": {}, + "source": [ + "The Angelic search algorithm consists of three parts. \n", + "- Search using angelic semantics\n", + "- Decompose\n", + "- a search in the space of refinements, in a similar way with hierarchical search\n", + "\n", + "### Searching using angelic semantics\n", + "- Find the reachable set (optimistic and pessimistic) of the sequence of angelic HLA in initialPlan\n", + " - If the optimistic reachable set doesn't intersect the goal, then there is no solution\n", + " - If the pessimistic reachable set intersects the goal, then we call decompose, in order to find the sequence of actions that lead us to the goal. \n", + " - If the optimistic reachable set intersects the goal, but the pessimistic doesn't we do some further refinements, in order to see if there is a sequence of actions that achieves the goal. \n", + " \n", + "### Search in space of refinements\n", + "- Create a search tree, that has root the action and children it's refinements\n", + "- Extend frontier by adding each refinement, so that we keep looping till we find all primitive actions\n", + "- If we achieve that we return the path of the solution (search tree), else there is no solution and we return None.\n", + "\n", + " \n" + ] + }, + { + "cell_type": "code", + "execution_count": 11, + "id": "9b887131", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def angelic_search(self, hierarchy, initial_plan):\n",
+ " """\n",
+ " [Figure 11.8]\n",
+ " A hierarchical planning algorithm that uses angelic semantics to identify and\n",
+ " commit to high-level plans that work while avoiding high-level plans that don’t.\n",
+ " The predicate MAKING-PROGRESS checks to make sure that we aren’t stuck in an infinite regression\n",
+ " of refinements.\n",
+ " At top level, call ANGELIC-SEARCH with [Act] as the initialPlan.\n",
+ "\n",
+ " InitialPlan contains a sequence of HLA's with angelic semantics\n",
+ "\n",
+ " The possible effects of an angelic HLA in initialPlan are:\n",
+ " ~ : effect remove\n",
+ " $+: effect possibly add\n",
+ " $-: effect possibly remove\n",
+ " $$: possibly add or remove\n",
+ " """\n",
+ " frontier = deque(initial_plan)\n",
+ " while True:\n",
+ " if not frontier:\n",
+ " return None\n",
+ " plan = frontier.popleft() # sequence of HLA/Angelic HLA's\n",
+ " print('\\n')\n",
+ " print(f"Plan {plan.action} poped from frontier: {[x.__dict__ for x in frontier]}")\n",
+ " opt_reachable_set = RealWorldPlanningProblem.reach_opt(self.initial, plan)\n",
+ " print(f"Opt Reachable Set: {opt_reachable_set}")\n",
+ " pes_reachable_set = RealWorldPlanningProblem.reach_pes(self.initial, plan)\n",
+ " print(f"Pes Reachable Set: {pes_reachable_set}")\n",
+ " if self.intersects_goal(opt_reachable_set):\n",
+ " print(f"Opt Reachable Set intersects with Goal.")\n",
+ " if RealWorldPlanningProblem.is_primitive(plan, hierarchy):\n",
+ " print(f"Plan is premitive, return plan")\n",
+ " return [x for x in plan.action]\n",
+ " guaranteed = self.intersects_goal(pes_reachable_set)\n",
+ " print(f"Pes Reachable Set intersects with Goal, get Guaranteed: {guaranteed}")\n",
+ " if guaranteed and RealWorldPlanningProblem.making_progress(plan, initial_plan):\n",
+ " print(f"guaranteed: {guaranteed} not empty and Making-Progress")\n",
+ " final_state = guaranteed[0] # any element of guaranteed\n",
+ " print(f"final_state: {final_state}")\n",
+ " return RealWorldPlanningProblem.decompose(hierarchy, plan, final_state, pes_reachable_set)\n",
+ " # there should be at least one HLA/AngelicHLA, otherwise plan would be primitive\n",
+ " hla, index = RealWorldPlanningProblem.find_hla(plan, hierarchy)\n",
+ " print(f"Find HLA: {hla} in plan: {plan}")\n",
+ " prefix = plan.action[:index]\n",
+ " print(f"Prefix: {prefix}")\n",
+ " suffix = plan.action[index + 1:]\n",
+ " print(f"suffix: {suffix}")\n",
+ " outcome = RealWorldPlanningProblem(\n",
+ " RealWorldPlanningProblem.result(self.initial, prefix), self.goals, self.actions)\n",
+ " print(f"Outcome: {outcome.initial}")\n",
+ " for sequence in RealWorldPlanningProblem.refinements(hla, hierarchy): # find refinements\n",
+ " print(f"Refinement(hla: {hla}) got sequence: {sequence}")\n",
+ " frontier.append(\n",
+ " AngelicNode(outcome.initial, plan, prefix + sequence + suffix, prefix + sequence + suffix))\n",
+ " print(f"frontier Added: {frontier[-1].__dict__}")\n",
+ " def decompose(hierarchy, plan, s_f, reachable_set):\n",
+ " solution = []\n",
+ " i = max(reachable_set.keys())\n",
+ " print(f"Running Decompose with hierarchy, plan: {plan}, final_state: {s_f}, reachable_set: {reachable_set}")\n",
+ " while plan.action_pes:\n",
+ " action = plan.action_pes.pop()\n",
+ " print(f"Pop action: {action} from Plan: {plan.action_pes}")\n",
+ " if i == 0:\n",
+ " return solution\n",
+ " s_i = RealWorldPlanningProblem.find_previous_state(\n",
+ " s_f, reachable_set, i, action)\n",
+ " print(f"Find Previous state: {s_i}")\n",
+ " problem = RealWorldPlanningProblem(s_i, s_f, plan.action)\n",
+ " print(f"Define problem with initial s_i: {s_i} and goal s_f: {s_f}")\n",
+ " angelic_call = RealWorldPlanningProblem.angelic_search(\n",
+ " problem, hierarchy, [AngelicNode(s_i, Node(None), [action], [action])])\n",
+ " print(f"Run Angelic Search, get {angelic_call}")\n",
+ " if angelic_call:\n",
+ " for x in angelic_call:\n",
+ " solution.insert(0, x)\n",
+ " else:\n",
+ " return None\n",
+ " s_f = s_i\n",
+ " i -= 1\n",
+ " return solution\n",
+ "\n", + "Those two actions have some preconditions and some effects. \n", + "If you get the taxi, you need to have cash, whereas if you drive you need to have a car.
\n", + "Thus we define the following hierarchy of possible actions.\n", + "\n", + "##### hierarchy" + ] + }, + { + "cell_type": "code", + "execution_count": 13, + "id": "97ffa15f", + "metadata": {}, + "outputs": [], + "source": [ + "library = {\n", + " 'HLA': ['Go(Home,SFO)', 'Go(Home,SFO)', 'Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)', 'Taxi(Home, SFO)'],\n", + " 'steps': [['Drive(Home, SFOLongTermParking)', 'Shuttle(SFOLongTermParking, SFO)'], ['Taxi(Home, SFO)'], [], [], []],\n", + " 'precond': [['At(Home) & Have(Car)'], ['At(Home)'], ['At(Home) & Have(Car)'], ['At(SFOLongTermParking)'], ['At(Home)']],\n", + " 'effect': [['At(SFO) & ~At(Home)'], ['At(SFO) & ~At(Home) & ~Have(Cash)'], ['At(SFOLongTermParking) & ~At(Home)'], ['At(SFO) & ~At(LongTermParking)'], ['At(SFO) & ~At(Home) & ~Have(Cash)']] }\n", + "\n" + ] + }, + { + "cell_type": "markdown", + "id": "d912e517", + "metadata": {}, + "source": [ + "\n", + "the possible actions are the following:" + ] + }, + { + "cell_type": "code", + "execution_count": 14, + "id": "87d6db03", + "metadata": {}, + "outputs": [], + "source": [ + "go_SFO = HLA('Go(Home,SFO)', precond='At(Home)', effect='At(SFO) & ~At(Home)')\n", + "taxi_SFO = HLA('Taxi(Home,SFO)', precond='At(Home)', effect='At(SFO) & ~At(Home) & ~Have(Cash)')\n", + "drive_SFOLongTermParking = HLA('Drive(Home, SFOLongTermParking)', 'At(Home) & Have(Car)','At(SFOLongTermParking) & ~At(Home)' )\n", + "shuttle_SFO = HLA('Shuttle(SFOLongTermParking, SFO)', 'At(SFOLongTermParking)', 'At(SFO) & ~At(LongTermParking)')" + ] + }, + { + "cell_type": "markdown", + "id": "832cedc9", + "metadata": {}, + "source": [ + "Suppose that (our preconditionds are that) we are Home and we have cash and car and our goal is to get to SFO and maintain our cash, and our possible actions are the above.
\n", + "##### Then our problem is: " + ] + }, + { + "cell_type": "code", + "execution_count": 15, + "id": "9e61456f", + "metadata": {}, + "outputs": [], + "source": [ + "prob = RealWorldPlanningProblem('At(Home) & Have(Cash) & Have(Car)', 'At(SFO) & Have(Cash)', [go_SFO, taxi_SFO, drive_SFOLongTermParking,shuttle_SFO])" + ] + }, + { + "cell_type": "markdown", + "id": "a809fea4", + "metadata": {}, + "source": [ + "An agent gives us some approximate information about the plan we will follow:
\n", + "(initialPlan is an Angelic Node, where: \n", + "- state is the initial state of the problem, \n", + "- parent is None \n", + "- action: is a list of actions (Angelic HLA's) with the optimistic estimators of effects and \n", + "- action_pes: is a list of actions (Angelic HLA's) with the pessimistic approximations of the effects\n", + "##### InitialPlan" + ] + }, + { + "cell_type": "code", + "execution_count": 16, + "id": "984769d1", + "metadata": {}, + "outputs": [], + "source": [ + "angelic_opt_description = AngelicHLA('Go(Home, SFO)', precond = 'At(Home)', effect ='$+At(SFO) & $-At(Home)' ) \n", + "angelic_pes_description = AngelicHLA('Go(Home, SFO)', precond = 'At(Home)', effect ='$+At(SFO) & ~At(Home)' )\n", + "\n", + "initialPlan = [AngelicNode(prob.initial, None, [angelic_opt_description], [angelic_pes_description])] \n" + ] + }, + { + "cell_type": "markdown", + "id": "65bbf9dd", + "metadata": {}, + "source": [ + "We want to find the optimistic and pessimistic reachable set of initialPlan when applied to the problem:\n", + "##### Optimistic/Pessimistic reachable set" + ] + }, + { + "cell_type": "code", + "execution_count": 17, + "id": "0ee43042", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "[[At(Home), Have(Cash), Have(Car)], [Have(Cash), Have(Car), At(SFO), NotAt(Home)], [Have(Cash), Have(Car), NotAt(Home)], [At(Home), Have(Cash), Have(Car), At(SFO)], [At(Home), Have(Cash), Have(Car)]] \n", + "\n", + "[[At(Home), Have(Cash), Have(Car)], [Have(Cash), Have(Car), At(SFO), NotAt(Home)], [Have(Cash), Have(Car), NotAt(Home)]]\n" + ] + } + ], + "source": [ + "opt_reachable_set = RealWorldPlanningProblem.reach_opt(prob.initial, initialPlan[0])\n", + "pes_reachable_set = RealWorldPlanningProblem.reach_pes(prob.initial, initialPlan[0])\n", + "print([x for y in opt_reachable_set.keys() for x in opt_reachable_set[y]], '\\n')\n", + "print([x for y in pes_reachable_set.keys() for x in pes_reachable_set[y]])" + ] + }, + { + "cell_type": "markdown", + "id": "811d4137", + "metadata": {}, + "source": [ + "##### Refinements\n" + ] + }, + { + "cell_type": "code", + "execution_count": 18, + "id": "d4987f07", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "[Drive(Home, SFOLongTermParking), Shuttle(SFOLongTermParking, SFO)]\n", + "[{'name': 'Drive', 'args': (Home, SFOLongTermParking), 'precond': [At(Home), Have(Car)], 'effect': [At(SFOLongTermParking), NotAt(Home)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}, {'name': 'Shuttle', 'args': (SFOLongTermParking, SFO), 'precond': [At(SFOLongTermParking)], 'effect': [At(SFO), NotAt(LongTermParking)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}] \n", + "\n", + "[Taxi(Home, SFO)]\n", + "[{'name': 'Taxi', 'args': (Home, SFO), 'precond': [At(Home)], 'effect': [At(SFO), NotAt(Home), NotHave(Cash)], 'domain': None, 'duration': 0, 'consumes': {}, 'uses': {}, 'completed': False}] \n", + "\n" + ] + } + ], + "source": [ + "for sequence in RealWorldPlanningProblem.refinements(go_SFO, library):\n", + " print (sequence)\n", + " print([x.__dict__ for x in sequence ], '\\n')" + ] + }, + { + "cell_type": "markdown", + "id": "1a3efdb7", + "metadata": {}, + "source": [ + "Run the angelic search\n", + "##### Top level call" + ] + }, + { + "cell_type": "code", + "execution_count": 19, + "id": "41f17476", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "\n", + "\n", + "Plan [Go(Home, SFO)] poped from frontier: []\n", + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Opt Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(SFO), NotAt(Home)], [Have(Cash), Have(Car), NotAt(Home)], [At(Home), Have(Cash), Have(Car), At(SFO)], [At(Home), Have(Cash), Have(Car)]]}\n", + "Starting Back Or with (KB, Goal: NotAt(SFO), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Cash)\n", + "lhs: [], rhs: Have(Cash)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: Have(Car)\n", + "lhs: [], rhs: Have(Car)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Processing Rule: At(SFO)\n", + "lhs: [], rhs: At(SFO)\n", + "Starting Back And with (KB, Goals: [], theta: None)\n", + "theta is None, pass\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Starting Back Or with (KB, Goal: At(Home), theta: {})\n", + "Processing Rule: At(Home)\n", + "lhs: [], rhs: At(Home)\n", + "Starting Back And with (KB, Goals: [], theta: {})\n", + "Length(goals)=0, yield theta: {}\n", + "Pes Reachable Set: {0: [[At(Home), Have(Cash), Have(Car)]], 1: [[Have(Cash), Have(Car), At(SFO), NotAt(Home)], [Have(Cash), Have(Car), NotAt(Home)]]}\n", + "Opt Reachable Set intersects with Goal.\n", + "Pes Reachable Set intersects with Goal, get Guaranteed: [[Have(Cash), Have(Car), At(SFO), NotAt(Home)]]\n", + "Running Making-Progress: Plan:
class ProbDist:\n",
+ " """A discrete probability distribution. You name the random variable\n",
+ " in the constructor, then assign and query probability of values.\n",
+ " >>> P = ProbDist('Flip'); P['H'], P['T'] = 0.25, 0.75; P['H']\n",
+ " 0.25\n",
+ " >>> P = ProbDist('X', {'lo': 125, 'med': 375, 'hi': 500})\n",
+ " >>> P['lo'], P['med'], P['hi']\n",
+ " (0.125, 0.375, 0.5)\n",
+ " """\n",
+ "\n",
+ " def __init__(self, var_name='?', freq=None):\n",
+ " """If freq is given, it is a dictionary of values - frequency pairs,\n",
+ " then ProbDist is normalized."""\n",
+ " self.prob = {}\n",
+ " self.var_name = var_name\n",
+ " self.values = []\n",
+ " if freq:\n",
+ " for (v, p) in freq.items():\n",
+ " self[v] = p\n",
+ " self.normalize()\n",
+ "\n",
+ " def __getitem__(self, val):\n",
+ " """Given a value, return P(value)."""\n",
+ " try:\n",
+ " return self.prob[val]\n",
+ " except KeyError:\n",
+ " return 0\n",
+ "\n",
+ " def __setitem__(self, val, p):\n",
+ " """Set P(val) = p."""\n",
+ " if val not in self.values:\n",
+ " self.values.append(val)\n",
+ " self.prob[val] = p\n",
+ "\n",
+ " def normalize(self):\n",
+ " """Make sure the probabilities of all values sum to 1.\n",
+ " Returns the normalized distribution.\n",
+ " Raises a ZeroDivisionError if the sum of the values is 0."""\n",
+ " total = sum(self.prob.values())\n",
+ " if not np.isclose(total, 1.0):\n",
+ " for val in self.prob:\n",
+ " self.prob[val] /= total\n",
+ " return self\n",
+ "\n",
+ " def show_approx(self, numfmt='{:.3g}'):\n",
+ " """Show the probabilities rounded and sorted by key, for the\n",
+ " sake of portable doctests."""\n",
+ " return ', '.join([('{}: ' + numfmt).format(v, p) for (v, p) in sorted(self.prob.items())])\n",
+ "\n",
+ " def __repr__(self):\n",
+ " return "P({})".format(self.var_name)\n",
+ "class JointProbDist(ProbDist):\n",
+ " """A discrete probability distribute over a set of variables.\n",
+ " >>> P = JointProbDist(['X', 'Y']); P[1, 1] = 0.25\n",
+ " >>> P[1, 1]\n",
+ " 0.25\n",
+ " >>> P[dict(X=0, Y=1)] = 0.5\n",
+ " >>> P[dict(X=0, Y=1)]\n",
+ " 0.5"""\n",
+ "\n",
+ " def __init__(self, variables):\n",
+ " self.prob = {}\n",
+ " self.variables = variables\n",
+ " self.vals = defaultdict(list)\n",
+ "\n",
+ " def __getitem__(self, values):\n",
+ " """Given a tuple or dict of values, return P(values)."""\n",
+ " values = event_values(values, self.variables)\n",
+ " return ProbDist.__getitem__(self, values)\n",
+ "\n",
+ " def __setitem__(self, values, p):\n",
+ " """Set P(values) = p. Values can be a tuple or a dict; it must\n",
+ " have a value for each of the variables in the joint. Also keep track\n",
+ " of the values we have seen so far for each variable."""\n",
+ " values = event_values(values, self.variables)\n",
+ " self.prob[values] = p\n",
+ " for var, val in zip(self.variables, values):\n",
+ " if val not in self.vals[var]:\n",
+ " self.vals[var].append(val)\n",
+ "\n",
+ " def values(self, var):\n",
+ " """Return the set of possible values for a variable."""\n",
+ " return self.vals[var]\n",
+ "\n",
+ " def __repr__(self):\n",
+ " return "P({})".format(self.variables)\n",
+ "def enumerate_joint(variables, e, P):\n",
+ " """Return the sum of those entries in P consistent with e,\n",
+ " provided variables is P's remaining variables (the ones not in e)."""\n",
+ " if not variables:\n",
+ " return P[e]\n",
+ " Y, rest = variables[0], variables[1:]\n",
+ " return sum([enumerate_joint(rest, extend(e, Y, y), P) for y in P.values(Y)])\n",
+ "def enumerate_joint_ask(X, e, P):\n",
+ " """\n",
+ " [Section 13.3]\n",
+ " Return a probability distribution over the values of the variable X,\n",
+ " given the {var:val} observations e, in the JointProbDist P.\n",
+ " >>> P = JointProbDist(['X', 'Y'])\n",
+ " >>> P[0,0] = 0.25; P[0,1] = 0.5; P[1,1] = P[2,1] = 0.125\n",
+ " >>> enumerate_joint_ask('X', dict(Y=1), P).show_approx()\n",
+ " '0: 0.667, 1: 0.167, 2: 0.167'\n",
+ " """\n",
+ " assert X not in e, "Query variable must be distinct from evidence"\n",
+ " Q = ProbDist(X) # probability distribution for X, initially empty\n",
+ " Y = [v for v in P.variables if v != X and v not in e] # hidden variables.\n",
+ " for xi in P.values(X):\n",
+ " Q[xi] = enumerate_joint(Y, extend(e, X, xi), P)\n",
+ " return Q.normalize()\n",
+ "class BayesNode:\n",
+ " """A conditional probability distribution for a boolean variable,\n",
+ " P(X | parents). Part of a BayesNet."""\n",
+ "\n",
+ " def __init__(self, X, parents, cpt):\n",
+ " """X is a variable name, and parents a sequence of variable\n",
+ " names or a space-separated string. cpt, the conditional\n",
+ " probability table, takes one of these forms:\n",
+ "\n",
+ " * A number, the unconditional probability P(X=true). You can\n",
+ " use this form when there are no parents.\n",
+ "\n",
+ " * A dict {v: p, ...}, the conditional probability distribution\n",
+ " P(X=true | parent=v) = p. When there's just one parent.\n",
+ "\n",
+ " * A dict {(v1, v2, ...): p, ...}, the distribution P(X=true |\n",
+ " parent1=v1, parent2=v2, ...) = p. Each key must have as many\n",
+ " values as there are parents. You can use this form always;\n",
+ " the first two are just conveniences.\n",
+ "\n",
+ " In all cases the probability of X being false is left implicit,\n",
+ " since it follows from P(X=true).\n",
+ "\n",
+ " >>> X = BayesNode('X', '', 0.2)\n",
+ " >>> Y = BayesNode('Y', 'P', {T: 0.2, F: 0.7})\n",
+ " >>> Z = BayesNode('Z', 'P Q',\n",
+ " ... {(T, T): 0.2, (T, F): 0.3, (F, T): 0.5, (F, F): 0.7})\n",
+ " """\n",
+ " if isinstance(parents, str):\n",
+ " parents = parents.split()\n",
+ "\n",
+ " # We store the table always in the third form above.\n",
+ " if isinstance(cpt, (float, int)): # no parents, 0-tuple\n",
+ " cpt = {(): cpt}\n",
+ " elif isinstance(cpt, dict):\n",
+ " # one parent, 1-tuple\n",
+ " if cpt and isinstance(list(cpt.keys())[0], bool):\n",
+ " cpt = {(v,): p for v, p in cpt.items()}\n",
+ "\n",
+ " assert isinstance(cpt, dict)\n",
+ " for vs, p in cpt.items():\n",
+ " assert isinstance(vs, tuple) and len(vs) == len(parents)\n",
+ " assert all(isinstance(v, bool) for v in vs)\n",
+ " assert 0 <= p <= 1\n",
+ "\n",
+ " self.variable = X\n",
+ " self.parents = parents\n",
+ " self.cpt = cpt\n",
+ " self.children = []\n",
+ "\n",
+ " def p(self, value, event):\n",
+ " """Return the conditional probability\n",
+ " P(X=value | parents=parent_values), where parent_values\n",
+ " are the values of parents in event. (event must assign each\n",
+ " parent a value.)\n",
+ " >>> bn = BayesNode('X', 'Burglary', {T: 0.2, F: 0.625})\n",
+ " >>> bn.p(False, {'Burglary': False, 'Earthquake': True})\n",
+ " 0.375"""\n",
+ " assert isinstance(value, bool)\n",
+ " ptrue = self.cpt[event_values(event, self.parents)]\n",
+ " return ptrue if value else 1 - ptrue\n",
+ "\n",
+ " def sample(self, event):\n",
+ " """Sample from the distribution for this variable conditioned\n",
+ " on event's values for parent_variables. That is, return True/False\n",
+ " at random according with the conditional probability given the\n",
+ " parents."""\n",
+ " return probability(self.p(True, event))\n",
+ "\n",
+ " def __repr__(self):\n",
+ " return repr((self.variable, ' '.join(self.parents)))\n",
+ "\n",
+ "\n",
+ "The alarm node can be made as follows: "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "f73b4ad4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "alarm_node = BayesNode('Alarm', ['Burglary', 'Earthquake'], \n",
+ " {(True, True): 0.95,(True, False): 0.94, (False, True): 0.29, (False, False): 0.001})"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c1e5d1bc",
+ "metadata": {},
+ "source": [
+ "It is possible to avoid using a tuple when there is only a single parent. So an alternative format for the **cpt** is"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "0858d78e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "john_node = BayesNode('JohnCalls', ['Alarm'], {True: 0.90, False: 0.05})\n",
+ "mary_node = BayesNode('MaryCalls', 'Alarm', {(True, ): 0.70, (False, ): 0.01}) # Using string for parents.\n",
+ "# Equivalant to john_node definition."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4ead9a7",
+ "metadata": {},
+ "source": [
+ "The general format used for the alarm node always holds. For nodes with no parents we can also use. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "bd8802db",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "burglary_node = BayesNode('Burglary', '', 0.001)\n",
+ "earthquake_node = BayesNode('Earthquake', '', 0.002)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d8d2281f",
+ "metadata": {},
+ "source": [
+ "It is possible to use the node for lookup function using the **p** method. The method takes in two arguments **value** and **event**. Event must be a dict of the type {variable:values, ..} The value corresponds to the value of the variable we are interested in (False or True).The method returns the conditional probability **P(X=value | parents=parent_values)**, where parent_values are the values of parents in event. (event must assign each parent a value.)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "09cc7d77",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "0.09999999999999998"
+ ]
+ },
+ "execution_count": 6,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "john_node.p(False, {'Alarm': True, 'Burglary': True}) # P(JohnCalls=False | Alarm=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "306a0b5c",
+ "metadata": {},
+ "source": [
+ "With all the information about nodes present it is possible to construct a Bayes Network using **BayesNet**. The **BayesNet** class does not take in nodes as input but instead takes a list of **node_specs**. An entry in **node_specs** is a tuple of the parameters we use to construct a **BayesNode** namely **(X, parents, cpt)**. **node_specs** must be ordered with parents before children."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "959f4974",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " class BayesNet:\n",
+ " """Bayesian network containing only boolean-variable nodes."""\n",
+ "\n",
+ " def __init__(self, node_specs=None):\n",
+ " """Nodes must be ordered with parents before children."""\n",
+ " self.nodes = []\n",
+ " self.variables = []\n",
+ " node_specs = node_specs or []\n",
+ " for node_spec in node_specs:\n",
+ " self.add(node_spec)\n",
+ "\n",
+ " def add(self, node_spec):\n",
+ " """Add a node to the net. Its parents must already be in the\n",
+ " net, and its variable must not."""\n",
+ " node = BayesNode(*node_spec)\n",
+ " assert node.variable not in self.variables\n",
+ " assert all((parent in self.variables) for parent in node.parents)\n",
+ " self.nodes.append(node)\n",
+ " self.variables.append(node.variable)\n",
+ " for parent in node.parents:\n",
+ " self.variable_node(parent).children.append(node)\n",
+ "\n",
+ " def variable_node(self, var):\n",
+ " """Return the node for the variable named var.\n",
+ " >>> burglary.variable_node('Burglary').variable\n",
+ " 'Burglary'"""\n",
+ " for n in self.nodes:\n",
+ " if n.variable == var:\n",
+ " return n\n",
+ " raise Exception("No such variable: {}".format(var))\n",
+ "\n",
+ " def variable_values(self, var):\n",
+ " """Return the domain of var."""\n",
+ " return [True, False]\n",
+ "\n",
+ " def __repr__(self):\n",
+ " return 'BayesNet({0!r})'.format(self.nodes)\n",
+ "def enumerate_all(variables, e, bn):\n",
+ " """Return the sum of those entries in P(variables | e{others})\n",
+ " consistent with e, where P is the joint distribution represented\n",
+ " by bn, and e{others} means e restricted to bn's other variables\n",
+ " (the ones other than variables). Parents must precede children in variables."""\n",
+ " if not variables:\n",
+ " return 1.0\n",
+ " Y, rest = variables[0], variables[1:]\n",
+ " Ynode = bn.variable_node(Y)\n",
+ " if Y in e:\n",
+ " return Ynode.p(e[Y], e) * enumerate_all(rest, e, bn)\n",
+ " else:\n",
+ " return sum(Ynode.p(y, e) * enumerate_all(rest, extend(e, Y, y), bn)\n",
+ " for y in bn.variable_values(Y))\n",
+ "def enumeration_ask(X, e, bn):\n",
+ " """\n",
+ " [Figure 14.9]\n",
+ " Return the conditional probability distribution of variable X\n",
+ " given evidence e, from BayesNet bn.\n",
+ " >>> enumeration_ask('Burglary', dict(JohnCalls=T, MaryCalls=T), burglary\n",
+ " ... ).show_approx()\n",
+ " 'False: 0.716, True: 0.284'"""\n",
+ " assert X not in e, "Query variable must be distinct from evidence"\n",
+ " Q = ProbDist(X)\n",
+ " for xi in bn.variable_values(X):\n",
+ " Q[xi] = enumerate_all(bn.variables, extend(e, X, xi), bn)\n",
+ " return Q.normalize()\n",
+ "def make_factor(var, e, bn):\n",
+ " """Return the factor for var in bn's joint distribution given e.\n",
+ " That is, bn's full joint distribution, projected to accord with e,\n",
+ " is the pointwise product of these factors for bn's variables."""\n",
+ " node = bn.variable_node(var)\n",
+ " variables = [X for X in [var] + node.parents if X not in e]\n",
+ " cpt = {event_values(e1, variables): node.p(e1[var], e1)\n",
+ " for e1 in all_events(variables, bn, e)}\n",
+ " return Factor(variables, cpt)\n",
+ "def all_events(variables, bn, e):\n",
+ " """Yield every way of extending e with values for all variables."""\n",
+ " if not variables:\n",
+ " yield e\n",
+ " else:\n",
+ " X, rest = variables[0], variables[1:]\n",
+ " for e1 in all_events(rest, bn, e):\n",
+ " for x in bn.variable_values(X):\n",
+ " yield extend(e1, X, x)\n",
+ " def pointwise_product(self, other, bn):\n",
+ " """Multiply two factors, combining their variables."""\n",
+ " variables = list(set(self.variables) | set(other.variables))\n",
+ " cpt = {event_values(e, variables): self.p(e) * other.p(e) for e in all_events(variables, bn, {})}\n",
+ " return Factor(variables, cpt)\n",
+ "def pointwise_product(factors, bn):\n",
+ " return reduce(lambda f, g: f.pointwise_product(g, bn), factors)\n",
+ " def sum_out(self, var, bn):\n",
+ " """Make a factor eliminating var by summing over its values."""\n",
+ " variables = [X for X in self.variables if X != var]\n",
+ " cpt = {event_values(e, variables): sum(self.p(extend(e, var, val)) for val in bn.variable_values(var))\n",
+ " for e in all_events(variables, bn, {})}\n",
+ " return Factor(variables, cpt)\n",
+ "def sum_out(var, factors, bn):\n",
+ " """Eliminate var from all factors by summing over its values."""\n",
+ " result, var_factors = [], []\n",
+ " for f in factors:\n",
+ " (var_factors if var in f.variables else result).append(f)\n",
+ " result.append(pointwise_product(var_factors, bn).sum_out(var, bn))\n",
+ " return result\n",
+ "def elimination_ask(X, e, bn):\n",
+ " """\n",
+ " [Figure 14.11]\n",
+ " Compute bn's P(X|e) by variable elimination.\n",
+ " >>> elimination_ask('Burglary', dict(JohnCalls=T, MaryCalls=T), burglary\n",
+ " ... ).show_approx()\n",
+ " 'False: 0.716, True: 0.284'"""\n",
+ " assert X not in e, "Query variable must be distinct from evidence"\n",
+ " factors = []\n",
+ " for var in reversed(bn.variables):\n",
+ " factors.append(make_factor(var, e, bn))\n",
+ " if is_hidden(var, X, e):\n",
+ " factors = sum_out(var, factors, bn)\n",
+ " return pointwise_product(factors, bn).normalize()\n",
+ "\n", + "Of course, for more complicated networks, variable elimination will be significantly faster and runtime will drop not just by a constant factor, but by a polynomial factor proportional to the number of nodes, due to the reduction in repeated calculations." + ] + }, + { + "cell_type": "markdown", + "id": "b7b3e9e6", + "metadata": {}, + "source": [ + "## Approximate Inference in Bayesian Networks\n", + "\n", + "Exact inference fails to scale for very large and complex Bayesian Networks. This section covers implementation of randomized sampling algorithms, also called Monte Carlo algorithms." + ] + }, + { + "cell_type": "code", + "execution_count": 32, + "id": "e65b26e9", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def sample(self, event):\n",
+ " """Sample from the distribution for this variable conditioned\n",
+ " on event's values for parent_variables. That is, return True/False\n",
+ " at random according with the conditional probability given the\n",
+ " parents."""\n",
+ " return probability(self.p(True, event))\n",
+ "def prior_sample(bn):\n",
+ " """\n",
+ " [Figure 14.13]\n",
+ " Randomly sample from bn's full joint distribution.\n",
+ " The result is a {variable: value} dict.\n",
+ " """\n",
+ " event = {}\n",
+ " for node in bn.nodes:\n",
+ " event[node.variable] = node.sample(event)\n",
+ " return event\n",
+ "\n",
+ "\n",
+ "Traversing the graph in topological order is important.\n",
+ "There are two possible topological orderings for this particular directed acyclic graph.\n",
+ "\n", + "1. `Cloudy -> Sprinkler -> Rain -> Wet Grass`\n", + "2. `Cloudy -> Rain -> Sprinkler -> Wet Grass`\n", + "
\n", + "
\n", + "We can follow any of the two orderings to sample from the network.\n", + "Any ordering other than these two, however, cannot be used.\n", + "
\n", + "One way to think about this is that `Cloudy` can be seen as a precondition of both `Rain` and `Sprinkler` and just like we have seen in planning, preconditions need to be satisfied before a certain action can be executed.\n", + "
\n", + "We store the samples on the observations. Let us find **P(Rain=True)** by taking 1000 random samples from the network." + ] + }, + { + "cell_type": "code", + "execution_count": 34, + "id": "bb74c5b4", + "metadata": {}, + "outputs": [], + "source": [ + "N = 1000\n", + "all_observations = [prior_sample(sprinkler) for x in range(N)]" + ] + }, + { + "cell_type": "markdown", + "id": "0a98b37f", + "metadata": {}, + "source": [ + "Now we filter to get the observations where Rain = True" + ] + }, + { + "cell_type": "code", + "execution_count": 35, + "id": "7f650ab7", + "metadata": {}, + "outputs": [], + "source": [ + "rain_true = [observation for observation in all_observations if observation['Rain'] == True]" + ] + }, + { + "cell_type": "markdown", + "id": "5e221f71", + "metadata": {}, + "source": [ + "Finally, we can find **P(Rain=True)**" + ] + }, + { + "cell_type": "code", + "execution_count": 36, + "id": "cf7f8977", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "0.485\n" + ] + } + ], + "source": [ + "answer = len(rain_true) / N\n", + "print(answer)" + ] + }, + { + "cell_type": "markdown", + "id": "45dc4b09", + "metadata": {}, + "source": [ + "Sampling this another time might give different results as we have no control over the distribution of the random samples" + ] + }, + { + "cell_type": "code", + "execution_count": 37, + "id": "d9e5d9d4", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "0.508\n" + ] + } + ], + "source": [ + "N = 1000\n", + "all_observations = [prior_sample(sprinkler) for x in range(N)]\n", + "rain_true = [observation for observation in all_observations if observation['Rain'] == True]\n", + "answer = len(rain_true) / N\n", + "print(answer)" + ] + }, + { + "cell_type": "markdown", + "id": "4ce63752", + "metadata": {}, + "source": [ + "To evaluate a conditional distribution. We can use a two-step filtering process. We first separate out the variables that are consistent with the evidence. Then for each value of query variable, we can find probabilities. For example to find **P(Cloudy=True | Rain=True)**. We have already filtered out the values consistent with our evidence in **rain_true**. Now we apply a second filtering step on **rain_true** to find **P(Rain=True and Cloudy=True)**" + ] + }, + { + "cell_type": "code", + "execution_count": 38, + "id": "8663f5fe", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "0.8149606299212598\n" + ] + } + ], + "source": [ + "rain_and_cloudy = [observation for observation in rain_true if observation['Cloudy'] == True]\n", + "answer = len(rain_and_cloudy) / len(rain_true)\n", + "print(answer)" + ] + }, + { + "cell_type": "markdown", + "id": "b820bb77", + "metadata": {}, + "source": [ + "### Rejection Sampling\n", + "\n", + "Rejection Sampling is based on an idea similar to what we did just now. \n", + "First, it generates samples from the prior distribution specified by the network. \n", + "Then, it rejects all those that do not match the evidence. \n", + "
\n", + "Rejection sampling is advantageous only when we know the query beforehand.\n", + "While prior sampling generally works for any query, it might fail in some scenarios.\n", + "
\n", + "Let's say we have a generic Bayesian network and we have evidence `e`, and we want to know how many times a state `A` is true, given evidence `e` is true.\n", + "Normally, prior sampling can answer this question, but let's assume that the probability of evidence `e` being true in our actual probability distribution is very small.\n", + "In this situation, it might be possible that sampling never encounters a data-point where `e` is true.\n", + "If our sampled data has no instance of `e` being true, `P(e) = 0`, and therefore `P(A | e) / P(e) = 0/0`, which is undefined.\n", + "We cannot find the required value using this sample.\n", + "
\n", + "We can definitely increase the number of sample points, but we can never guarantee that we will encounter the case where `e` is non-zero (assuming our actual probability distribution has atleast one case where `e` is true).\n", + "To guarantee this, we would have to consider every single data point, which means we lose the speed advantage that approximation provides us and we essentially have to calculate the exact inference model of the Bayesian network.\n", + "
\n", + "
\n", + "Rejection sampling will be useful in this situation, as we already know the query.\n", + "
\n", + "While sampling from the network, we will reject any sample which is inconsistent with the evidence variables of the given query (in this example, the only evidence variable is `e`).\n", + "We will only consider samples that do not violate **any** of the evidence variables.\n", + "In this way, we will have enough data with the required evidence to infer queries involving a subset of that evidence.\n", + "
\n", + "
\n", + "The function **rejection_sampling** implements the algorithm described by **Figure 14.14**" + ] + }, + { + "cell_type": "code", + "execution_count": 39, + "id": "8c060094", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def rejection_sampling(X, e, bn, N=10000):\n",
+ " """\n",
+ " [Figure 14.14]\n",
+ " Estimate the probability distribution of variable X given\n",
+ " evidence e in BayesNet bn, using N samples.\n",
+ " Raises a ZeroDivisionError if all the N samples are rejected,\n",
+ " i.e., inconsistent with e.\n",
+ " >>> random.seed(47)\n",
+ " >>> rejection_sampling('Burglary', dict(JohnCalls=T, MaryCalls=T),\n",
+ " ... burglary, 10000).show_approx()\n",
+ " 'False: 0.7, True: 0.3'\n",
+ " """\n",
+ " counts = {x: 0 for x in bn.variable_values(X)} # bold N in [Figure 14.14]\n",
+ " for j in range(N):\n",
+ " sample = prior_sample(bn) # boldface x in [Figure 14.14]\n",
+ " if consistent_with(sample, e):\n",
+ " counts[sample[X]] += 1\n",
+ " return ProbDist(X, counts)\n",
+ "def consistent_with(event, evidence):\n",
+ " """Is event consistent with the given evidence?"""\n",
+ " return all(evidence.get(k, v) == v for k, v in event.items())\n",
+ "def weighted_sample(bn, e):\n",
+ " """\n",
+ " Sample an event from bn that's consistent with the evidence e;\n",
+ " return the event and its weight, the likelihood that the event\n",
+ " accords to the evidence.\n",
+ " """\n",
+ " w = 1\n",
+ " event = dict(e) # boldface x in [Figure 14.15]\n",
+ " for node in bn.nodes:\n",
+ " Xi = node.variable\n",
+ " if Xi in e:\n",
+ " w *= node.p(e[Xi], event)\n",
+ " else:\n",
+ " event[Xi] = node.sample(event)\n",
+ " return event, w\n",
+ "def likelihood_weighting(X, e, bn, N=10000):\n",
+ " """\n",
+ " [Figure 14.15]\n",
+ " Estimate the probability distribution of variable X given\n",
+ " evidence e in BayesNet bn.\n",
+ " >>> random.seed(1017)\n",
+ " >>> likelihood_weighting('Burglary', dict(JohnCalls=T, MaryCalls=T),\n",
+ " ... burglary, 10000).show_approx()\n",
+ " 'False: 0.702, True: 0.298'\n",
+ " """\n",
+ " W = {x: 0 for x in bn.variable_values(X)}\n",
+ " for j in range(N):\n",
+ " sample, weight = weighted_sample(bn, e) # boldface x, w in [Figure 14.15]\n",
+ " W[sample[X]] += weight\n",
+ " return ProbDist(X, W)\n",
+ "def gibbs_ask(X, e, bn, N=1000):\n",
+ " """[Figure 14.16]"""\n",
+ " assert X not in e, "Query variable must be distinct from evidence"\n",
+ " counts = {x: 0 for x in bn.variable_values(X)} # bold N in [Figure 14.16]\n",
+ " Z = [var for var in bn.variables if var not in e]\n",
+ " state = dict(e) # boldface x in [Figure 14.16]\n",
+ " for Zi in Z:\n",
+ " state[Zi] = random.choice(bn.variable_values(Zi))\n",
+ " for j in range(N):\n",
+ " for Zi in Z:\n",
+ " state[Zi] = markov_blanket_sample(Zi, state, bn)\n",
+ " counts[state[X]] += 1\n",
+ " return ProbDist(X, counts)\n",
+ "\n", + "A Markov model is basically a chain-structured Bayesian Network in which there is one state for each time step and each node has an identical probability distribution.\n", + "The first node, however, has a different distribution, called the prior distribution which models the initial state of the process.\n", + "A state in a Markov model depends only on the previous state and the latest evidence and not on the states before it.\n", + "
\n", + "A **Hidden Markov Model** or **HMM** is a special case of a Markov model in which the state of the process is described by a single discrete random variable.\n", + "The possible values of the variable are the possible states of the world.\n", + "
\n", + "But what if we want to model a process with two or more state variables?\n", + "In that case, we can still fit the process into the HMM framework by redefining our state variables as a single \"megavariable\".\n", + "We do this because carrying out inference on HMMs have standard optimized algorithms.\n", + "A HMM is very similar to an MDP, but we don't have the option of taking actions like in MDPs, instead, the process carries on as new evidence appears.\n", + "
\n", + "If a HMM is truncated at a fixed length, it becomes a Bayesian network and general BN inference can be used on it to answer queries.\n", + "\n", + "Before we start, it will be helpful to understand the structure of a temporal model. We will use the example of the book with the guard and the umbrella. In this example, the state $\\textbf{X}$ is whether it is a rainy day (`X = True`) or not (`X = False`) at Day $\\textbf{t}$. In the sensor or observation model, the observation or evidence $\\textbf{U}$ is whether the professor holds an umbrella (`U = True`) or not (`U = False`) on **Day** $\\textbf{t}$. Based on that, the transition model is \n", + "\n", + "| $X_{t-1}$ | $X_{t}$ | **P**$(X_{t}| X_{t-1})$| \n", + "| ------------- |------------- | ----------------------------------|\n", + "| ***${False}$*** | ***${False}$*** | 0.7 |\n", + "| ***${False}$*** | ***${True}$*** | 0.3 |\n", + "| ***${True}$*** | ***${False}$*** | 0.3 |\n", + "| ***${True}$*** | ***${True}$*** | 0.7 |\n", + "\n", + "And the the sensor model will be,\n", + "\n", + "| $X_{t}$ | $U_{t}$ | **P**$(U_{t}|X_{t})$| \n", + "| :-------------: |:-------------: | :------------------------:|\n", + "| ***${False}$*** | ***${True}$*** | 0.2 |\n", + "| ***${False}$*** | ***${False}$*** | 0.8 |\n", + "| ***${True}$*** | ***${True}$*** | 0.9 |\n", + "| ***${True}$*** | ***${False}$*** | 0.1 |\n" + ] + }, + { + "cell_type": "markdown", + "id": "f965ae34", + "metadata": {}, + "source": [ + "HMMs are implemented in the **`HiddenMarkovModel`** class.\n", + "Let's have a look." + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "41d68262", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
class HiddenMarkovModel:\n",
+ " """A Hidden markov model which takes Transition model and Sensor model as inputs"""\n",
+ "\n",
+ " def __init__(self, transition_model, sensor_model, prior=None):\n",
+ " self.transition_model = transition_model\n",
+ " self.sensor_model = sensor_model\n",
+ " self.prior = prior or [0.5, 0.5]\n",
+ "\n",
+ " def sensor_dist(self, ev):\n",
+ " if ev is True:\n",
+ " return self.sensor_model[0]\n",
+ " else:\n",
+ " return self.sensor_model[1]\n",
+ "\n", + "The basic inference tasks that must be solved are:\n", + "1. **Filtering**: Computing the posterior probability distribution over the most recent state, given all the evidence up to the current time step.\n", + "2. **Prediction**: Computing the posterior probability distribution over the future state.\n", + "3. **Smoothing**: Computing the posterior probability distribution over a past state. Smoothing provides a better estimation as it incorporates more evidence.\n", + "4. **Most likely explanation**: Finding the most likely sequence of states for a given observation\n", + "5. **Learning**: The transition and sensor models can be learnt, if not yet known, just like in an information gathering agent\n", + "
\n", + "
\n", + "\n", + "There are three primary methods to carry out inference in Hidden Markov Models:\n", + "1. The Forward-Backward algorithm\n", + "2. Fixed lag smoothing\n", + "3. Particle filtering\n", + "\n", + "Let's have a look at how we can carry out inference and answer queries based on our umbrella HMM using these algorithms." + ] + }, + { + "cell_type": "markdown", + "id": "50b30b66", + "metadata": {}, + "source": [ + "### FORWARD-BACKWARD\n", + "This is a general algorithm that works for all Markov models, not just HMMs.\n", + "In the filtering task (inference) we are given evidence **U** in each time **t** and we want to compute the belief $B_{t}(x)= P(X_{t}|U_{1:t})$. \n", + "We can think of it as a three step process:\n", + "1. In every step we start with the current belief $P(X_{t}|e_{1:t})$\n", + "2. We update it for time\n", + "3. We update it for evidence\n", + "\n", + "The forward algorithm performs the step 2 and 3 at once. It updates, or better say reweights, the initial belief using the transition and the sensor model. Let's see the umbrella example. On **Day 0** no observation is available, and for that reason we will assume that we have equal possibilities to rain or not. In the **`HiddenMarkovModel`** class, the prior probabilities for **Day 0** are by default [0.5, 0.5]. " + ] + }, + { + "cell_type": "markdown", + "id": "cfa89c75", + "metadata": {}, + "source": [ + "The observation update is calculated with the **`forward()`** function. Basically, we update our belief using the observation model. The function returns a list with the probabilities of **raining or not** on **Day 1**." + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "id": "a585a325", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def forward(HMM, fv, ev):\n",
+ " prediction = vector_add(scalar_vector_product(fv[0], HMM.transition_model[0]),\n",
+ " scalar_vector_product(fv[1], HMM.transition_model[1]))\n",
+ " sensor_dist = HMM.sensor_dist(ev)\n",
+ "\n",
+ " return normalize(element_wise_product(sensor_dist, prediction))\n",
+ "def backward(HMM, b, ev):\n",
+ " sensor_dist = HMM.sensor_dist(ev)\n",
+ " prediction = element_wise_product(sensor_dist, b)\n",
+ "\n",
+ " return normalize(vector_add(scalar_vector_product(prediction[0], HMM.transition_model[0]),\n",
+ " scalar_vector_product(prediction[1], HMM.transition_model[1])))\n",
+ "\n", + "Additionally, the forward pass stores $t$ vectors of size $S$ which makes the auxiliary space requirement equivalent to $O(St)$.\n", + "
\n", + "
\n", + "Is there any way we can improve the time or space complexity?\n", + "
\n", + "Fortunately, the matrix representation of HMM properties allows us to do so.\n", + "
\n", + "If $f$ and $b$ represent the forward and backward messages respectively, we can modify the smoothing algorithm by first\n", + "running the standard forward pass to compute $f_{t:t}$ (forgetting all the intermediate results) and then running\n", + "backward pass for both $b$ and $f$ together, using them to compute the smoothed estimate at each step.\n", + "This optimization reduces auxlilary space requirement to constant (irrespective of the length of the sequence) provided\n", + "the transition matrix is invertible and the sensor model has no zeros (which is sometimes hard to accomplish)\n", + "
\n", + "
\n", + "Let's look at another algorithm, that carries out smoothing in a more optimized way." + ] + }, + { + "cell_type": "markdown", + "id": "c8a2d25a", + "metadata": {}, + "source": [ + "### FIXED LAG SMOOTHING\n", + "The matrix formulation allows to optimize online smoothing with a fixed lag.\n", + "
\n", + "Since smoothing can be done in constant, there should exist an algorithm whose time complexity is independent of the length of the lag.\n", + "For smoothing a time slice $t - d$ where $d$ is the lag, we need to compute $\\alpha f_{1:t-d}$ x $b_{t-d+1:t}$ incrementally.\n", + "
\n", + "As we already know, the forward equation is\n", + "
\n", + "$$f_{1:t+1} = \\alpha O_{t+1}{T}^{T}f_{1:t}$$\n", + "
\n", + "and the backward equation is\n", + "
\n", + "$$b_{k+1:t} = TO_{k+1}b_{k+2:t}$$\n", + "
\n", + "where $T$ and $O$ are the transition and sensor models respectively.\n", + "
\n", + "For smoothing, the forward message is easy to compute but there exists no simple relation between the backward message of this time step and the one at the previous time step, hence we apply the backward equation $d$ times to get\n", + "
\n", + "$$b_{t-d+1:t} = \\left ( \\prod_{i=t-d+1}^{t}{TO_i} \\right )b_{t+1:t} = B_{t-d+1:t}1$$\n", + "
\n", + "where $B_{t-d+1:t}$ is the product of the sequence of $T$ and $O$ matrices.\n", + "
\n", + "Here's how the `probability` module implements `fixed_lag_smoothing`.\n", + "
" + ] + }, + { + "cell_type": "code", + "execution_count": 11, + "id": "bffc317e", + "metadata": {}, + "outputs": [], + "source": [ + "umbrella_transition_model = [[0.7, 0.3], [0.3, 0.7]]\n", + "umbrella_sensor_model = [[0.9, 0.2], [0.1, 0.8]]\n", + "hmm = HiddenMarkovModel(umbrella_transition_model, umbrella_sensor_model)" + ] + }, + { + "cell_type": "code", + "execution_count": 12, + "id": "815660dc", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Processing e_t: True, t is: 1\n", + "f is: [0.5, 0.5], B is: [[0.63 0.06]\n", + " [0.27 0.14]]\n", + "Processing e_t: False, t is: 2\n", + "f is: [0.5, 0.5], B is: [[0.0459 0.1848]\n", + " [0.0231 0.1432]]\n", + "Processing e_t: True, t is: 3\n", + "f is: [0.8181818181818181, 0.18181818181818182], B is: [[0.1089 0.0378]\n", + " [0.1701 0.0802]]\n", + "Processing e_t: False, t is: 4\n", + "f is: [0.17380352644836272, 0.8261964735516373], B is: [[0.0459 0.1848]\n", + " [0.0231 0.1432]]\n", + "Processing e_t: True, t is: 5\n", + "f is: [0.7250810038991707, 0.27491899610082926], B is: [[0.1089 0.0378]\n", + " [0.1701 0.0802]]\n" + ] + } + ], + "source": [ + "e_t = F\n", + "evidence = [T, F, T, F, T]\n", + "fl_smoother = FixedLagSmoother(evidence, hmm, d=2)\n", + "fl_smoother.fit()" + ] + }, + { + "cell_type": "code", + "execution_count": 13, + "id": "7436e178", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Processing e_t: False, t is: 6\n", + "f is: [0.15247208886151503, 0.847527911138485], B is: [[0.0459 0.1848]\n", + " [0.0231 0.1432]]\n" + ] + }, + { + "data": { + "text/plain": [ + "[0.1508998635320297, 0.8491001364679702]" + ] + }, + "execution_count": 13, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "fl_smoother.smoothing(e_t)" + ] + }, + { + "cell_type": "code", + "execution_count": 14, + "id": "0d4f8b53", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Processing e_t: True, t is: 1\n", + "f is: [0.5, 0.5], B is: [[0.63 0.06]\n", + " [0.27 0.14]]\n", + "Processing e_t: False, t is: 2\n", + "f is: [0.5, 0.5], B is: [[0.0459 0.1848]\n", + " [0.0231 0.1432]]\n", + "Processing e_t: True, t is: 3\n", + "f is: [0.8181818181818181, 0.18181818181818182], B is: [[0.1089 0.0378]\n", + " [0.1701 0.0802]]\n", + "Processing e_t: False, t is: 4\n", + "f is: [0.17380352644836272, 0.8261964735516373], B is: [[0.0459 0.1848]\n", + " [0.0231 0.1432]]\n", + "Processing e_t: True, t is: 5\n", + "f is: [0.7250810038991707, 0.27491899610082926], B is: [[0.1089 0.0378]\n", + " [0.1701 0.0802]]\n" + ] + } + ], + "source": [ + "e_t = T\n", + "evidence = [T, F, T, F, T]\n", + "fl_smoother = FixedLagSmoother(evidence, hmm, d=2)\n", + "fl_smoother.fit()" + ] + }, + { + "cell_type": "code", + "execution_count": 15, + "id": "4ee1a762", + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Processing e_t: True, t is: 6\n", + "f is: [0.15247208886151503, 0.847527911138485], B is: [[0.4131 0.0462]\n", + " [0.2079 0.0358]]\n" + ] + }, + { + "data": { + "text/plain": [ + "[0.8648251560751015, 0.13517484392489867]" + ] + }, + "execution_count": 15, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "fl_smoother.smoothing(e_t)" + ] + }, + { + "cell_type": "markdown", + "id": "95f6e55c", + "metadata": {}, + "source": [ + "### PARTICLE FILTERING\n", + "The filtering problem is too expensive to solve using the previous methods for problems with large or continuous state spaces.\n", + "Particle filtering is a method that can solve the same problem but when the state space is a lot larger, where we wouldn't be able to do these computations in a reasonable amount of time as fast, as time goes by, and we want to keep track of things as they happen.\n", + "
\n", + "The downside is that it is a sampling method and hence isn't accurate, but the more samples we're willing to take, the more accurate we'd get.\n", + "
\n", + "In this method, instead of keping track of the probability distribution, we will drop particles in a similar proportion at the required regions.\n", + "The internal representation of this distribution is usually a list of particles with coordinates in the state-space.\n", + "A particle is just a new name for a sample.\n", + "\n", + "Particle filtering can be divided into four steps:\n", + "1. __Initialization__: \n", + "If we have some idea about the prior probability distribution, we drop the initial particles accordingly, or else we just drop them uniformly over the state space.\n", + "\n", + "2. __Forward pass__: \n", + "As time goes by and measurements come in, we are going to move the selected particles into the grid squares that makes the most sense in terms of representing the distribution that we are trying to track.\n", + "When time goes by, we just loop through all our particles and try to simulate what could happen to each one of them by sampling its next position from the transition model.\n", + "This is like prior sampling - samples' frequencies reflect the transition probabilities.\n", + "If we have enough samples we are pretty close to exact values.\n", + "We work through the list of particles, one particle at a time, all we do is stochastically simulate what the outcome might be.\n", + "If we had no dimension of time, and we had no new measurements come in, this would be exactly the same as what we did in prior sampling.\n", + "\n", + "3. __Reweight__:\n", + "As observations come in, don't sample the observations, fix them and downweight the samples based on the evidence just like in likelihood weighting.\n", + "$$w(x) = P(e/x)$$\n", + "$$B(X) \\propto P(e/X)B'(X)$$\n", + "
\n", + "As before, the probabilities don't sum to one, since most have been downweighted.\n", + "They sum to an approximation of $P(e)$.\n", + "To normalize the resulting distribution, we can divide by $P(e)$\n", + "
\n", + "Likelihood weighting wasn't the best thing for Bayesian networks, because we were not accounting for the incoming evidence so we were getting samples from the prior distribution, in some sense not the right distribution, so we might end up with a lot of particles with low weights. \n", + "These samples were very uninformative and the way we fixed it then was by using __Gibbs sampling__.\n", + "Theoretically, Gibbs sampling can be run on a HMM, but as we iterated over the process infinitely many times in a Bayesian network, we cannot do that here as we have new incoming evidence and we also need computational cycles to propagate through time.\n", + "
\n", + "A lot of samples with very low weight and they are not representative of the _actual probability distribution_.\n", + "So if we keep running likelihood weighting, we keep propagating the samples with smaller weights and carry out computations for that even though these samples have no significant contribution to the actual probability distribution.\n", + "Which is why we require this last step.\n", + "\n", + "4. __Resample__:\n", + "Rather than tracking weighted samples, we _resample_.\n", + "We choose from our weighted sample distribution as many times as the number of particles we initially had and we replace these particles too, so that we have a constant number of particles.\n", + "This is equivalent to renormalizing the distribution.\n", + "The samples with low weight are rarely chosen in the new distribution after resampling.\n", + "This newer set of particles after resampling is in some sense more representative of the actual distribution and so we are better allocating our computational cycles.\n", + "Now the update is complete for this time step, continue with the next one.\n", + "\n", + "
\n", + "Let's see how this is implemented in the module." + ] + }, + { + "cell_type": "code", + "execution_count": 16, + "id": "150ab16c", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def particle_filtering(e, N, HMM):\n",
+ " """Particle filtering considering two states variables."""\n",
+ " dist = [0.5, 0.5]\n",
+ " # Weight Initialization\n",
+ " w = [0 for _ in range(N)]\n",
+ " # STEP 1\n",
+ " # Propagate one step using transition model given prior state\n",
+ " dist = vector_add(scalar_vector_product(dist[0], HMM.transition_model[0]),\n",
+ " scalar_vector_product(dist[1], HMM.transition_model[1]))\n",
+ " # Assign state according to probability\n",
+ " s = ['A' if probability(dist[0]) else 'B' for _ in range(N)]\n",
+ " w_tot = 0\n",
+ " # Calculate importance weight given evidence e\n",
+ " for i in range(N):\n",
+ " if s[i] == 'A':\n",
+ " # P(U|A)*P(A)\n",
+ " w_i = HMM.sensor_dist(e)[0] * dist[0]\n",
+ " if s[i] == 'B':\n",
+ " # P(U|B)*P(B)\n",
+ " w_i = HMM.sensor_dist(e)[1] * dist[1]\n",
+ " w[i] = w_i\n",
+ " w_tot += w_i\n",
+ "\n",
+ " # Normalize all the weights\n",
+ " for i in range(N):\n",
+ " w[i] = w[i] / w_tot\n",
+ "\n",
+ " # Limit weights to 4 digits\n",
+ " for i in range(N):\n",
+ " w[i] = float("{0:.4f}".format(w[i]))\n",
+ "\n",
+ " # STEP 2\n",
+ " s = weighted_sample_with_replacement(N, s, w)\n",
+ "\n",
+ " return s\n",
+ "\n", + "This implementation considers two state variables with generic names 'A' and 'B'.\n" + ] + }, + { + "cell_type": "markdown", + "id": "5cb54907", + "metadata": {}, + "source": [ + "Here's how we can use `particle_filtering` on our umbrella HMM, though it doesn't make much sense using particle filtering on a problem with such a small state space.\n", + "It is just to get familiar with the syntax." + ] + }, + { + "cell_type": "code", + "execution_count": 17, + "id": "77c34d22", + "metadata": {}, + "outputs": [], + "source": [ + "umbrella_transition_model = [[0.7, 0.3], [0.3, 0.7]]\n", + "umbrella_sensor_model = [[0.9, 0.2], [0.1, 0.8]]\n", + "hmm = HiddenMarkovModel(umbrella_transition_model, umbrella_sensor_model)" + ] + }, + { + "cell_type": "code", + "execution_count": 18, + "id": "6bcf289c", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "['A', 'A', 'A', 'A', 'A', 'B', 'A', 'A', 'B', 'A']" + ] + }, + "execution_count": 18, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "particle_filtering(T, 10, hmm)" + ] + }, + { + "cell_type": "code", + "execution_count": 19, + "id": "40299792", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "['B', 'B', 'B', 'B', 'B', 'B', 'A', 'B', 'B', 'B']" + ] + }, + "execution_count": 19, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "particle_filtering([F, T, F, F, T], 10, hmm)" + ] + }, + { + "cell_type": "code", + "execution_count": null, + "id": "d8b5760b", + "metadata": {}, + "outputs": [], + "source": [] + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.7.10" + } + }, + "nbformat": 4, + "nbformat_minor": 5 +} diff --git a/Chapter-17-Making-Complex-Decisions.ipynb b/Chapter-17-Making-Complex-Decisions.ipynb new file mode 100644 index 000000000..deccaa7aa --- /dev/null +++ b/Chapter-17-Making-Complex-Decisions.ipynb @@ -0,0 +1,1323 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "id": "53b9fb22", + "metadata": {}, + "source": [ + "# Making Complex Decisions\n", + "---\n", + "\n", + "This Jupyter notebook acts as supporting material for topics covered in **Chapter 17 Making Complex Decisions** of the book* Artificial Intelligence: A Modern Approach*. We make use of the implementations in mdp.py module. This notebook also includes a brief summary of the main topics as a review. Let us import everything from the mdp module to get started." + ] + }, + { + "cell_type": "code", + "execution_count": 1, + "id": "5ba2e22a", + "metadata": {}, + "outputs": [], + "source": [ + "from mdp import *\n", + "from notebook import psource, pseudocode, plot_pomdp_utility" + ] + }, + { + "cell_type": "markdown", + "id": "dd807ed2", + "metadata": {}, + "source": [ + "## MDP\n", + "\n", + "To begin with let us look at the implementation of MDP class defined in mdp.py The docstring tells us what all is required to define a MDP namely - set of states, actions, initial state, transition model, and a reward function. Each of these are implemented as methods. Do not close the popup so that you can follow along the description of code below." + ] + }, + { + "cell_type": "code", + "execution_count": 2, + "id": "64f4c2a7", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
class MDP:\n",
+ " """A Markov Decision Process, defined by an initial state, transition model,\n",
+ " and reward function. We also keep track of a gamma value, for use by\n",
+ " algorithms. The transition model is represented somewhat differently from\n",
+ " the text. Instead of P(s' | s, a) being a probability number for each\n",
+ " state/state/action triplet, we instead have T(s, a) return a\n",
+ " list of (p, s') pairs. We also keep track of the possible states,\n",
+ " terminal states, and actions for each state. [Page 646]"""\n",
+ "\n",
+ " def __init__(self, init, actlist, terminals, transitions=None, reward=None, states=None, gamma=0.9):\n",
+ " if not (0 < gamma <= 1):\n",
+ " raise ValueError("An MDP must have 0 < gamma <= 1")\n",
+ "\n",
+ " # collect states from transitions table if not passed.\n",
+ " self.states = states or self.get_states_from_transitions(transitions)\n",
+ "\n",
+ " self.init = init\n",
+ "\n",
+ " if isinstance(actlist, list):\n",
+ " # if actlist is a list, all states have the same actions\n",
+ " self.actlist = actlist\n",
+ "\n",
+ " elif isinstance(actlist, dict):\n",
+ " # if actlist is a dict, different actions for each state\n",
+ " self.actlist = actlist\n",
+ "\n",
+ " self.terminals = terminals\n",
+ " self.transitions = transitions or {}\n",
+ " if not self.transitions:\n",
+ " print("Warning: Transition table is empty.")\n",
+ "\n",
+ " self.gamma = gamma\n",
+ "\n",
+ " self.reward = reward or {s: 0 for s in self.states}\n",
+ "\n",
+ " # self.check_consistency()\n",
+ "\n",
+ " def R(self, state):\n",
+ " """Return a numeric reward for this state."""\n",
+ "\n",
+ " return self.reward[state]\n",
+ "\n",
+ " def T(self, state, action):\n",
+ " """Transition model. From a state and an action, return a list\n",
+ " of (probability, result-state) pairs."""\n",
+ "\n",
+ " if not self.transitions:\n",
+ " raise ValueError("Transition model is missing")\n",
+ " else:\n",
+ " return self.transitions[state][action]\n",
+ "\n",
+ " def actions(self, state):\n",
+ " """Return a list of actions that can be performed in this state. By default, a\n",
+ " fixed list of actions, except for terminal states. Override this\n",
+ " method if you need to specialize by state."""\n",
+ "\n",
+ " if state in self.terminals:\n",
+ " return [None]\n",
+ " else:\n",
+ " return self.actlist\n",
+ "\n",
+ " def get_states_from_transitions(self, transitions):\n",
+ " if isinstance(transitions, dict):\n",
+ " s1 = set(transitions.keys())\n",
+ " s2 = set(tr[1] for actions in transitions.values()\n",
+ " for effects in actions.values()\n",
+ " for tr in effects)\n",
+ " return s1.union(s2)\n",
+ " else:\n",
+ " print('Could not retrieve states from transitions')\n",
+ " return None\n",
+ "\n",
+ " def check_consistency(self):\n",
+ "\n",
+ " # check that all states in transitions are valid\n",
+ " assert set(self.states) == self.get_states_from_transitions(self.transitions)\n",
+ "\n",
+ " # check that init is a valid state\n",
+ " assert self.init in self.states\n",
+ "\n",
+ " # check reward for each state\n",
+ " assert set(self.reward.keys()) == set(self.states)\n",
+ "\n",
+ " # check that all terminals are valid states\n",
+ " assert all(t in self.states for t in self.terminals)\n",
+ "\n",
+ " # check that probability distributions for all actions sum to 1\n",
+ " for s1, actions in self.transitions.items():\n",
+ " for a in actions.keys():\n",
+ " s = 0\n",
+ " for o in actions[a]:\n",
+ " s += o[0]\n",
+ " assert abs(s - 1) < 0.001\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "689233b6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Transition Matrix as nested dict. State -> Actions in state -> List of (Probability, State) tuples\n",
+ "t = {\n",
+ " \"A\": {\n",
+ " \"X\": [(0.3, \"A\"), (0.7, \"B\")],\n",
+ " \"Y\": [(1.0, \"A\")]\n",
+ " },\n",
+ " \"B\": {\n",
+ " \"X\": {(0.8, \"End\"), (0.2, \"B\")},\n",
+ " \"Y\": {(1.0, \"A\")}\n",
+ " },\n",
+ " \"End\": {}\n",
+ "}\n",
+ "\n",
+ "init = \"A\"\n",
+ "\n",
+ "terminals = [\"End\"]\n",
+ "\n",
+ "rewards = {\n",
+ " \"A\": 5,\n",
+ " \"B\": -10,\n",
+ " \"End\": 100\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "e64cc8b2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class CustomMDP(MDP):\n",
+ " def __init__(self, init, terminals, transition_matrix, reward = None, gamma=.9):\n",
+ " # All possible actions.\n",
+ " actlist = []\n",
+ " for state in transition_matrix.keys():\n",
+ " actlist.extend(transition_matrix[state])\n",
+ " actlist = list(set(actlist))\n",
+ " MDP.__init__(self, init, actlist, terminals, transition_matrix, reward, gamma=gamma)\n",
+ "\n",
+ " def T(self, state, action):\n",
+ " if action is None:\n",
+ " return [(0.0, state)]\n",
+ " else: \n",
+ " return self.t[state][action]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "17a9872e",
+ "metadata": {},
+ "source": [
+ "Finally we instantize the class with the parameters for our MDP in the picture."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "3233a2cf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "our_mdp = CustomMDP(init, terminals, t, rewards, gamma=.9)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ffaf0fce",
+ "metadata": {},
+ "source": [
+ "With this we have successfully represented our MDP. Later we will look at ways to solve this MDP."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bbb4246d",
+ "metadata": {},
+ "source": [
+ "## GRID MDP\n",
+ "\n",
+ "Now we look at a concrete implementation that makes use of the MDP as base class. The GridMDP class in the mdp module is used to represent a grid world MDP like the one shown in in **Fig 17.1** of the AIMA Book. We assume for now that the environment is _fully observable_, so that the agent always knows where it is. The code should be easy to understand if you have gone through the CustomMDP example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "16431f75",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "text/html": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ " class GridMDP(MDP):\n",
+ " """A two-dimensional grid MDP, as in [Figure 17.1]. All you have to do is\n",
+ " specify the grid as a list of lists of rewards; use None for an obstacle\n",
+ " (unreachable state). Also, you should specify the terminal states.\n",
+ " An action is an (x, y) unit vector; e.g. (1, 0) means move east."""\n",
+ "\n",
+ " def __init__(self, grid, terminals, init=(0, 0), gamma=.9):\n",
+ " grid.reverse() # because we want row 0 on bottom, not on top\n",
+ " reward = {}\n",
+ " states = set()\n",
+ " self.rows = len(grid)\n",
+ " self.cols = len(grid[0])\n",
+ " self.grid = grid\n",
+ " for x in range(self.cols):\n",
+ " for y in range(self.rows):\n",
+ " if grid[y][x]:\n",
+ " states.add((x, y))\n",
+ " reward[(x, y)] = grid[y][x]\n",
+ " self.states = states\n",
+ " actlist = orientations\n",
+ " transitions = {}\n",
+ " for s in states:\n",
+ " transitions[s] = {}\n",
+ " for a in actlist:\n",
+ " transitions[s][a] = self.calculate_T(s, a)\n",
+ " MDP.__init__(self, init, actlist=actlist,\n",
+ " terminals=terminals, transitions=transitions,\n",
+ " reward=reward, states=states, gamma=gamma)\n",
+ "\n",
+ " def calculate_T(self, state, action):\n",
+ " if action:\n",
+ " return [(0.8, self.go(state, action)),\n",
+ " (0.1, self.go(state, turn_right(action))),\n",
+ " (0.1, self.go(state, turn_left(action)))]\n",
+ " else:\n",
+ " return [(0.0, state)]\n",
+ "\n",
+ " def T(self, state, action):\n",
+ " return self.transitions[state][action] if action else [(0.0, state)]\n",
+ "\n",
+ " def go(self, state, direction):\n",
+ " """Return the state that results from going in this direction."""\n",
+ "\n",
+ " state1 = vector_add(state, direction)\n",
+ " return state1 if state1 in self.states else state\n",
+ "\n",
+ " def to_grid(self, mapping):\n",
+ " """Convert a mapping from (x, y) to v into a [[..., v, ...]] grid."""\n",
+ "\n",
+ " return list(reversed([[mapping.get((x, y), None)\n",
+ " for x in range(self.cols)]\n",
+ " for y in range(self.rows)]))\n",
+ "\n",
+ " def to_arrows(self, policy):\n",
+ " chars = {(1, 0): '>', (0, 1): '^', (-1, 0): '<', (0, -1): 'v', None: '.'}\n",
+ " return self.to_grid({s: chars[a] for (s, a) in policy.items()})\n",
+ "def value_iteration(mdp, epsilon=0.001):\n",
+ " """Solving an MDP by value iteration. [Figure 17.4]"""\n",
+ "\n",
+ " U1 = {s: 0 for s in mdp.states}\n",
+ " R, T, gamma = mdp.R, mdp.T, mdp.gamma\n",
+ " while True:\n",
+ " U = U1.copy()\n",
+ " delta = 0\n",
+ " for s in mdp.states:\n",
+ " U1[s] = R(s) + gamma * max(sum(p * U[s1] for (p, s1) in T(s, a))\n",
+ " for a in mdp.actions(s))\n",
+ " delta = max(delta, abs(U1[s] - U[s]))\n",
+ " if delta <= epsilon * (1 - gamma) / gamma:\n",
+ " return U\n",
+ "Value Iteration starts with arbitrary initial values for the utilities, calculates the right side of the Bellman equation and plugs it into the left hand side, thereby updating the utility of each state from the utilities of its neighbors. \n", + "This is repeated until equilibrium is reached. \n", + "It works on the principle of _Dynamic Programming_ - using precomputed information to simplify the subsequent computation. \n", + "If $U_i(s)$ is the utility value for state $s$ at the $i$ th iteration, the iteration step, called Bellman update, looks like this:\n", + "\n", + "$$ U_{i+1}(s) \\leftarrow R(s) + \\gamma \\max_{a \\epsilon A(s)} \\sum_{s'} P(s'\\ |\\ s,a)U_{i}(s') $$\n", + "\n", + "As you might have noticed, `value_iteration` has an infinite loop. How do we decide when to stop iterating? \n", + "The concept of _contraction_ successfully explains the convergence of value iteration. \n", + "Refer to **Section 17.2.3** of the book for a detailed explanation. \n", + "In the algorithm, we calculate a value $delta$ that measures the difference in the utilities of the current time step and the previous time step. \n", + "\n", + "$$\\delta = \\max{(\\delta, \\begin{vmatrix}U_{i + 1}(s) - U_i(s)\\end{vmatrix})}$$\n", + "\n", + "This value of delta decreases as the values of $U_i$ converge.\n", + "We terminate the algorithm if the $\\delta$ value is less than a threshold value determined by the hyperparameter _epsilon_.\n", + "\n", + "$$\\delta \\lt \\epsilon \\frac{(1 - \\gamma)}{\\gamma}$$\n", + "\n", + "To summarize, the Bellman update is a _contraction_ by a factor of $gamma$ on the space of utility vectors. \n", + "Hence, from the properties of contractions in general, it follows that `value_iteration` always converges to a unique solution of the Bellman equations whenever $gamma$ is less than 1.\n", + "We then terminate the algorithm when a reasonable approximation is achieved.\n", + "In practice, it often occurs that the policy $pi$ becomes optimal long before the utility function converges. For the given 4 x 3 environment with $gamma = 0.9$, the policy $pi$ is optimal when $i = 4$ (at the 4th iteration), even though the maximum error in the utility function is stil 0.46. This can be clarified from **figure 17.6** in the book. Hence, to increase computational efficiency, we often use another method to solve MDPs called Policy Iteration which we will see in the later part of this notebook. \n", + "
For now, let us solve the **sequential_decision_environment** GridMDP using `value_iteration`." + ] + }, + { + "cell_type": "code", + "execution_count": 9, + "id": "250c5543", + "metadata": {}, + "outputs": [ + { + "data": { + "text/plain": [ + "{(0, 1): 0.3984432178350045,\n", + " (1, 2): 0.649585681261095,\n", + " (3, 2): 1.0,\n", + " (0, 0): 0.2962883154554812,\n", + " (3, 0): 0.12987274656746342,\n", + " (3, 1): -1.0,\n", + " (2, 1): 0.48644001739269643,\n", + " (2, 0): 0.3447542300124158,\n", + " (2, 2): 0.7953620878466678,\n", + " (1, 0): 0.25386699846479516,\n", + " (0, 2): 0.5093943765842497}" + ] + }, + "execution_count": 9, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "value_iteration(sequential_decision_environment)" + ] + }, + { + "cell_type": "markdown", + "id": "f4298c27", + "metadata": {}, + "source": [ + "The pseudocode for the algorithm:" + ] + }, + { + "cell_type": "markdown", + "id": "2bd29969", + "metadata": {}, + "source": [ + "# POLICY ITERATION\n", + "\n", + "We have already seen that value iteration converges to the optimal policy long before it accurately estimates the utility function. \n", + "If one action is clearly better than all the others, then the exact magnitude of the utilities in the states involved need not be precise. \n", + "The policy iteration algorithm works on this insight. \n", + "The algorithm executes two fundamental steps:\n", + "* **Policy evaluation**: Given a policy _πᵢ_, calculate _Uᵢ = U(πᵢ)_, the utility of each state if _πᵢ_ were to be executed.\n", + "* **Policy improvement**: Calculate a new policy _πᵢ₊₁_ using one-step look-ahead based on the utility values calculated.\n", + "\n", + "The algorithm terminates when the policy improvement step yields no change in the utilities. \n", + "Refer to **Figure 17.6** in the book to see how this is an improvement over value iteration.\n", + "We now have a simplified version of the Bellman equation\n", + "\n", + "$$U_i(s) = R(s) + \\gamma \\sum_{s'}P(s'\\ |\\ s, \\pi_i(s))U_i(s')$$\n", + "\n", + "An important observation in this equation is that this equation doesn't have the `max` operator, which makes it linear.\n", + "For _n_ states, we have _n_ linear equations with _n_ unknowns, which can be solved exactly in time _**O(n³)**_.\n", + "For more implementational details, have a look at **Section 17.3**.\n", + "Let us now look at how the expected utility is found and how `policy_iteration` is implemented." + ] + }, + { + "cell_type": "code", + "execution_count": 10, + "id": "2f676ec7", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def expected_utility(a, s, U, mdp):\n",
+ " """The expected utility of doing a in state s, according to the MDP and U."""\n",
+ "\n",
+ " return sum(p * U[s1] for (p, s1) in mdp.T(s, a))\n",
+ "def policy_iteration(mdp):\n",
+ " """Solve an MDP by policy iteration [Figure 17.7]"""\n",
+ "\n",
+ " U = {s: 0 for s in mdp.states}\n",
+ " pi = {s: random.choice(mdp.actions(s)) for s in mdp.states}\n",
+ " while True:\n",
+ " U = policy_evaluation(pi, U, mdp)\n",
+ " unchanged = True\n",
+ " for s in mdp.states:\n",
+ " a = max(mdp.actions(s), key=lambda a: expected_utility(a, s, U, mdp))\n",
+ " if a != pi[s]:\n",
+ " pi[s] = a\n",
+ " unchanged = False\n",
+ " if unchanged:\n",
+ " return pi\n",
+ "Fortunately, it is not necessary to do _exact_ policy evaluation. \n", + "The utilities can instead be reasonably approximated by performing some number of simplified value iteration steps.\n", + "The simplified Bellman update equation for the process is\n", + "\n", + "$$U_{i+1}(s) \\leftarrow R(s) + \\gamma\\sum_{s'}P(s'\\ |\\ s,\\pi_i(s))U_{i}(s')$$\n", + "\n", + "and this is repeated _k_ times to produce the next utility estimate. This is called _modified policy iteration_." + ] + }, + { + "cell_type": "code", + "execution_count": 12, + "id": "a3f87f07", + "metadata": {}, + "outputs": [ + { + "data": { + "text/html": [ + "\n", + "\n", + "\n", + "\n", + "
def policy_evaluation(pi, U, mdp, k=20):\n",
+ " """Return an updated utility mapping U from each state in the MDP to its\n",
+ " utility, using an approximation (modified policy iteration)."""\n",
+ "\n",
+ " R, T, gamma = mdp.R, mdp.T, mdp.gamma\n",
+ " for i in range(k):\n",
+ " for s in mdp.states:\n",
+ " U[s] = R(s) + gamma * sum(p * U[s1] for (p, s1) in T(s, pi[s]))\n",
+ " return U\n",
+ "class Agent(Thing):\n",
+ " """An Agent is a subclass of Thing with one required instance attribute \n",
+ " (aka slot), .program, which should hold a function that takes one argument,\n",
+ " the percept, and returns an action. (What counts as a percept or action \n",
+ " will depend on the specific environment in which the agent exists.)\n",
+ " Note that 'program' is a slot, not a method. If it were a method, then the\n",
+ " program could 'cheat' and look at aspects of the agent. It's not supposed\n",
+ " to do that: the program can only look at the percepts. An agent program\n",
+ " that needs a model of the world (and of the agent itself) will have to\n",
+ " build and maintain its own model. There is an optional slot, .performance,\n",
+ " which is a number giving the performance measure of the agent in its\n",
+ " environment."""\n",
+ "\n",
+ " def __init__(self, program=None):\n",
+ " self.alive = True\n",
+ " self.bump = False\n",
+ " self.holding = []\n",
+ " self.performance = 0\n",
+ " if program is None or not isinstance(program, collections.abc.Callable):\n",
+ " print("Can't find a valid program for {}, falling back to default.".format(self.__class__.__name__))\n",
+ "\n",
+ " def program(percept):\n",
+ " return eval(input('Percept={}; action? '.format(percept)))\n",
+ "\n",
+ " self.program = program\n",
+ "\n",
+ " def can_grab(self, thing):\n",
+ " """Return True if this agent can grab this thing.\n",
+ " Override for appropriate subclasses of Agent and Thing."""\n",
+ " return False\n",
+ "class Environment:\n",
+ " """Abstract class representing an Environment. 'Real' Environment classes\n",
+ " inherit from this. Your Environment will typically need to implement:\n",
+ " percept: Define the percept that an agent sees.\n",
+ " execute_action: Define the effects of executing an action.\n",
+ " Also update the agent.performance slot.\n",
+ " The environment keeps a list of .things and .agents (which is a subset\n",
+ " of .things). Each agent has a .performance slot, initialized to 0.\n",
+ " Each thing has a .location slot, even though some environments may not\n",
+ " need this."""\n",
+ "\n",
+ " def __init__(self):\n",
+ " self.things = []\n",
+ " self.agents = []\n",
+ "\n",
+ " def thing_classes(self):\n",
+ " return [] # List of classes that can go into environment\n",
+ "\n",
+ " def percept(self, agent):\n",
+ " """Return the percept that the agent sees at this point. (Implement this.)"""\n",
+ " raise NotImplementedError\n",
+ "\n",
+ " def execute_action(self, agent, action):\n",
+ " """Change the world to reflect this action. (Implement this.)"""\n",
+ " raise NotImplementedError\n",
+ "\n",
+ " def default_location(self, thing):\n",
+ " """Default location to place a new thing with unspecified location."""\n",
+ " return None\n",
+ "\n",
+ " def exogenous_change(self):\n",
+ " """If there is spontaneous change in the world, override this."""\n",
+ " pass\n",
+ "\n",
+ " def is_done(self):\n",
+ " """By default, we're done when we can't find a live agent."""\n",
+ " return not any(agent.is_alive() for agent in self.agents)\n",
+ "\n",
+ " def step(self):\n",
+ " """Run the environment for one time step. If the\n",
+ " actions and exogenous changes are independent, this method will\n",
+ " do. If there are interactions between them, you'll need to\n",
+ " override this method."""\n",
+ " if not self.is_done():\n",
+ " actions = []\n",
+ " for agent in self.agents:\n",
+ " if agent.alive:\n",
+ " actions.append(agent.program(self.percept(agent)))\n",
+ " else:\n",
+ " actions.append("")\n",
+ " for (agent, action) in zip(self.agents, actions):\n",
+ " self.execute_action(agent, action)\n",
+ " self.exogenous_change()\n",
+ "\n",
+ " def run(self, steps=1000):\n",
+ " """Run the Environment for given number of time steps."""\n",
+ " for step in range(steps):\n",
+ " if self.is_done():\n",
+ " return\n",
+ " self.step()\n",
+ "\n",
+ " def list_things_at(self, location, tclass=Thing):\n",
+ " """Return all things exactly at a given location."""\n",
+ " if isinstance(location, numbers.Number):\n",
+ " return [thing for thing in self.things\n",
+ " if thing.location == location and isinstance(thing, tclass)]\n",
+ " return [thing for thing in self.things\n",
+ " if all(x == y for x, y in zip(thing.location, location)) and isinstance(thing, tclass)]\n",
+ "\n",
+ " def some_things_at(self, location, tclass=Thing):\n",
+ " """Return true if at least one of the things at location\n",
+ " is an instance of class tclass (or a subclass)."""\n",
+ " return self.list_things_at(location, tclass) != []\n",
+ "\n",
+ " def add_thing(self, thing, location=None):\n",
+ " """Add a thing to the environment, setting its location. For\n",
+ " convenience, if thing is an agent program we make a new agent\n",
+ " for it. (Shouldn't need to override this.)"""\n",
+ " if not isinstance(thing, Thing):\n",
+ " thing = Agent(thing)\n",
+ " if thing in self.things:\n",
+ " print("Can't add the same thing twice")\n",
+ " else:\n",
+ " thing.location = location if location is not None else self.default_location(thing)\n",
+ " self.things.append(thing)\n",
+ " if isinstance(thing, Agent):\n",
+ " thing.performance = 0\n",
+ " self.agents.append(thing)\n",
+ "\n",
+ " def delete_thing(self, thing):\n",
+ " """Remove a thing from the environment."""\n",
+ " try:\n",
+ " self.things.remove(thing)\n",
+ " except ValueError as e:\n",
+ " print(e)\n",
+ " print(" in Environment delete_thing")\n",
+ " print(" Thing to be removed: {} at {}".format(thing, thing.location))\n",
+ " print(" from list: {}".format([(thing, thing.location) for thing in self.things]))\n",
+ " if thing in self.agents:\n",
+ " self.agents.remove(thing)\n",
+ "def policy_evaluation(pi, U, mdp, k=20):\n",
- " """Return an updated utility mapping U from each state in the MDP to its\n",
- " utility, using an approximation (modified policy iteration)."""\n",
- " R, T, gamma = mdp.R, mdp.T, mdp.gamma\n",
- " for i in range(k):\n",
- " for s in mdp.states:\n",
- " U[s] = R(s) + gamma * sum([p * U[s1] for (p, s1) in T(s, pi[s])])\n",
- " return U\n",
- " def T(self, state, action):\n",
- " if action is None:\n",
- " return [(0.0, state)]\n",
- " else:\n",
- " return self.transitions[state][action]\n",
- " def to_arrows(self, policy):\n",
- " chars = {\n",
- " (1, 0): '>', (0, 1): '^', (-1, 0): '<', (0, -1): 'v', None: '.'}\n",
- " return self.to_grid({s: chars[a] for (s, a) in policy.items()})\n",
- " def to_grid(self, mapping):\n",
- " """Convert a mapping from (x, y) to v into a [[..., v, ...]] grid."""\n",
- " return list(reversed([[mapping.get((x, y), None)\n",
- " for x in range(self.cols)]\n",
- " for y in range(self.rows)]))\n",
- "class POMDP(MDP):\n",
- "\n",
- " """A Partially Observable Markov Decision Process, defined by\n",
- " a transition model P(s'|s,a), actions A(s), a reward function R(s),\n",
- " and a sensor model P(e|s). We also keep track of a gamma value,\n",
- " for use by algorithms. The transition and the sensor models\n",
- " are defined as matrices. We also keep track of the possible states\n",
- " and actions for each state. [page 659]."""\n",
- "\n",
- " def __init__(self, actions, transitions=None, evidences=None, rewards=None, states=None, gamma=0.95):\n",
- " """Initialize variables of the pomdp"""\n",
- "\n",
- " if not (0 < gamma <= 1):\n",
- " raise ValueError('A POMDP must have 0 < gamma <= 1')\n",
- "\n",
- " self.states = states\n",
- " self.actions = actions\n",
- "\n",
- " # transition model cannot be undefined\n",
- " self.t_prob = transitions or {}\n",
- " if not self.t_prob:\n",
- " print('Warning: Transition model is undefined')\n",
- " \n",
- " # sensor model cannot be undefined\n",
- " self.e_prob = evidences or {}\n",
- " if not self.e_prob:\n",
- " print('Warning: Sensor model is undefined')\n",
- " \n",
- " self.gamma = gamma\n",
- " self.rewards = rewards\n",
- "\n",
- " def remove_dominated_plans(self, input_values):\n",
- " """\n",
- " Remove dominated plans.\n",
- " This method finds all the lines contributing to the\n",
- " upper surface and removes those which don't.\n",
- " """\n",
- "\n",
- " values = [val for action in input_values for val in input_values[action]]\n",
- " values.sort(key=lambda x: x[0], reverse=True)\n",
- "\n",
- " best = [values[0]]\n",
- " y1_max = max(val[1] for val in values)\n",
- " tgt = values[0]\n",
- " prev_b = 0\n",
- " prev_ix = 0\n",
- " while tgt[1] != y1_max:\n",
- " min_b = 1\n",
- " min_ix = 0\n",
- " for i in range(prev_ix + 1, len(values)):\n",
- " if values[i][0] - tgt[0] + tgt[1] - values[i][1] != 0:\n",
- " trans_b = (values[i][0] - tgt[0]) / (values[i][0] - tgt[0] + tgt[1] - values[i][1])\n",
- " if 0 <= trans_b <= 1 and trans_b > prev_b and trans_b < min_b:\n",
- " min_b = trans_b\n",
- " min_ix = i\n",
- " prev_b = min_b\n",
- " prev_ix = min_ix\n",
- " tgt = values[min_ix]\n",
- " best.append(tgt)\n",
- "\n",
- " return self.generate_mapping(best, input_values)\n",
- "\n",
- " def remove_dominated_plans_fast(self, input_values):\n",
- " """\n",
- " Remove dominated plans using approximations.\n",
- " Resamples the upper boundary at intervals of 100 and\n",
- " finds the maximum values at these points.\n",
- " """\n",
- "\n",
- " values = [val for action in input_values for val in input_values[action]]\n",
- " values.sort(key=lambda x: x[0], reverse=True)\n",
- "\n",
- " best = []\n",
- " sr = 100\n",
- " for i in range(sr + 1):\n",
- " x = i / float(sr)\n",
- " maximum = (values[0][1] - values[0][0]) * x + values[0][0]\n",
- " tgt = values[0]\n",
- " for value in values:\n",
- " val = (value[1] - value[0]) * x + value[0]\n",
- " if val > maximum:\n",
- " maximum = val\n",
- " tgt = value\n",
- "\n",
- " if all(any(tgt != v) for v in best):\n",
- " best.append(tgt)\n",
- "\n",
- " return self.generate_mapping(best, input_values)\n",
- "\n",
- " def generate_mapping(self, best, input_values):\n",
- " """Generate mappings after removing dominated plans"""\n",
- "\n",
- " mapping = defaultdict(list)\n",
- " for value in best:\n",
- " for action in input_values:\n",
- " if any(all(value == v) for v in input_values[action]):\n",
- " mapping[action].append(value)\n",
- "\n",
- " return mapping\n",
- "\n",
- " def max_difference(self, U1, U2):\n",
- " """Find maximum difference between two utility mappings"""\n",
- "\n",
- " for k, v in U1.items():\n",
- " sum1 = 0\n",
- " for element in U1[k]:\n",
- " sum1 += sum(element)\n",
- " sum2 = 0\n",
- " for element in U2[k]:\n",
- " sum2 += sum(element)\n",
- " return abs(sum1 - sum2)\n",
- "def pomdp_value_iteration(pomdp, epsilon=0.1):\n",
- " """Solving a POMDP by value iteration."""\n",
- "\n",
- " U = {'':[[0]* len(pomdp.states)]}\n",
- " count = 0\n",
- " while True:\n",
- " count += 1\n",
- " prev_U = U\n",
- " values = [val for action in U for val in U[action]]\n",
- " value_matxs = []\n",
- " for i in values:\n",
- " for j in values:\n",
- " value_matxs.append([i, j])\n",
- "\n",
- " U1 = defaultdict(list)\n",
- " for action in pomdp.actions:\n",
- " for u in value_matxs:\n",
- " u1 = Matrix.matmul(Matrix.matmul(pomdp.t_prob[int(action)], Matrix.multiply(pomdp.e_prob[int(action)], Matrix.transpose(u))), [[1], [1]])\n",
- " u1 = Matrix.add(Matrix.scalar_multiply(pomdp.gamma, Matrix.transpose(u1)), [pomdp.rewards[int(action)]])\n",
- " U1[action].append(u1[0])\n",
- "\n",
- " U = pomdp.remove_dominated_plans_fast(U1)\n",
- " # replace with U = pomdp.remove_dominated_plans(U1) for accurate calculations\n",
- " \n",
- " if count > 10:\n",
- " if pomdp.max_difference(U, prev_U) < epsilon * (1 - pomdp.gamma) / pomdp.gamma:\n",
- " return U\n",
- "