 @@ -36,22 +41,14 @@ Welcome to our web-based [**Tencent Hunyuan Bot**](https://hunyuan.tencent.com/b
You can use simple prompts similar to natural language text
-> 画一只穿着西装的猪
->
> draw a pig in a suit
->
-> 生成一幅画,赛博朋克风,跑车
>
> generate a painting, cyberpunk style, sports car
or multi-turn language interactions to create the picture.
-> 画一个木制的鸟
->
> draw a wooden bird
>
-> 变成玻璃的
->
> turn into glass
## 📑 Open-source Plan
@@ -82,6 +79,7 @@ or multi-turn language interactions to create the picture.
- [🔑 Inference](#-inference)
- [Using Gradio](#using-gradio)
- [Using Command Line](#using-command-line)
+ - [Using ComfyUI](#-using-comfyUI)
- [More Configurations](#more-configurations)
- [🚀 Acceleration (for Linux)](#-acceleration-for-linux)
- [🔗 BibTeX](#-bibtex)
@@ -110,7 +108,7 @@ and output the new text prompt for image generation.
## 📈 Comparisons
-In order to comprehensively compare the generation capabilities of HunyuanDiT and other models, we constructed a 4-dimensional test set, including Text-Image Consistency, Excluding AI Artifacts, Subject Clarity, Aesthetic. More than 50 professional evaluators performs the evaluation.
+In order to comprehensively compare the generation capabilities of Hunyuan-DiT and other models, we constructed a 4-dimensional test set, including Text-Image Consistency, Excluding AI Artifacts, Subject Clarity, Aesthetic. More than 50 professional evaluators performs the evaluation.
@@ -36,22 +41,14 @@ Welcome to our web-based [**Tencent Hunyuan Bot**](https://hunyuan.tencent.com/b
You can use simple prompts similar to natural language text
-> 画一只穿着西装的猪
->
> draw a pig in a suit
->
-> 生成一幅画,赛博朋克风,跑车
>
> generate a painting, cyberpunk style, sports car
or multi-turn language interactions to create the picture.
-> 画一个木制的鸟
->
> draw a wooden bird
>
-> 变成玻璃的
->
> turn into glass
## 📑 Open-source Plan
@@ -82,6 +79,7 @@ or multi-turn language interactions to create the picture.
- [🔑 Inference](#-inference)
- [Using Gradio](#using-gradio)
- [Using Command Line](#using-command-line)
+ - [Using ComfyUI](#-using-comfyUI)
- [More Configurations](#more-configurations)
- [🚀 Acceleration (for Linux)](#-acceleration-for-linux)
- [🔗 BibTeX](#-bibtex)
@@ -110,7 +108,7 @@ and output the new text prompt for image generation.
## 📈 Comparisons
-In order to comprehensively compare the generation capabilities of HunyuanDiT and other models, we constructed a 4-dimensional test set, including Text-Image Consistency, Excluding AI Artifacts, Subject Clarity, Aesthetic. More than 50 professional evaluators performs the evaluation.
+In order to comprehensively compare the generation capabilities of Hunyuan-DiT and other models, we constructed a 4-dimensional test set, including Text-Image Consistency, Excluding AI Artifacts, Subject Clarity, Aesthetic. More than 50 professional evaluators performs the evaluation.
| Playground 2.5 | ✔ | 71.9 | 70.8 | 94.9 | 83.3 | 54.3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SD 3 | ✘ | 77.1 | 69.3 | 94.6 | 82.5 | 56.7 | -||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MidJourney v6 | ✘ | 73.5 | 80.2 | 93.5 | 87.2 | 63.3 | @@ -314,6 +310,10 @@ python sample_t2i.py --prompt "渔舟唱晚" --load-4bit ``` +### Using ComfyUI + +ComfyUI for Hunyuan-DiT: [HunyuanDiT-ComfyUI](https://github.com/city96/ComfyUI_ExtraModels) + More example prompts can be found in [example_prompts.txt](example_prompts.txt) ### More Configurations @@ -337,7 +337,7 @@ We list some more useful configurations for easy usage: ## 🚀 Acceleration (for Linux) -We provide TensorRT version of HunyuanDiT for inference acceleration (faster than flash attention). +We provide TensorRT version of Hunyuan-DiT for inference acceleration (faster than flash attention). See [Tencent-Hunyuan/TensorRT-libs](https://huggingface.co/Tencent-Hunyuan/TensorRT-libs) for more details. diff --git a/README_zh.md b/README_zh.md new file mode 100644 index 0000000..58e5344 --- /dev/null +++ b/README_zh.md @@ -0,0 +1,364 @@ +






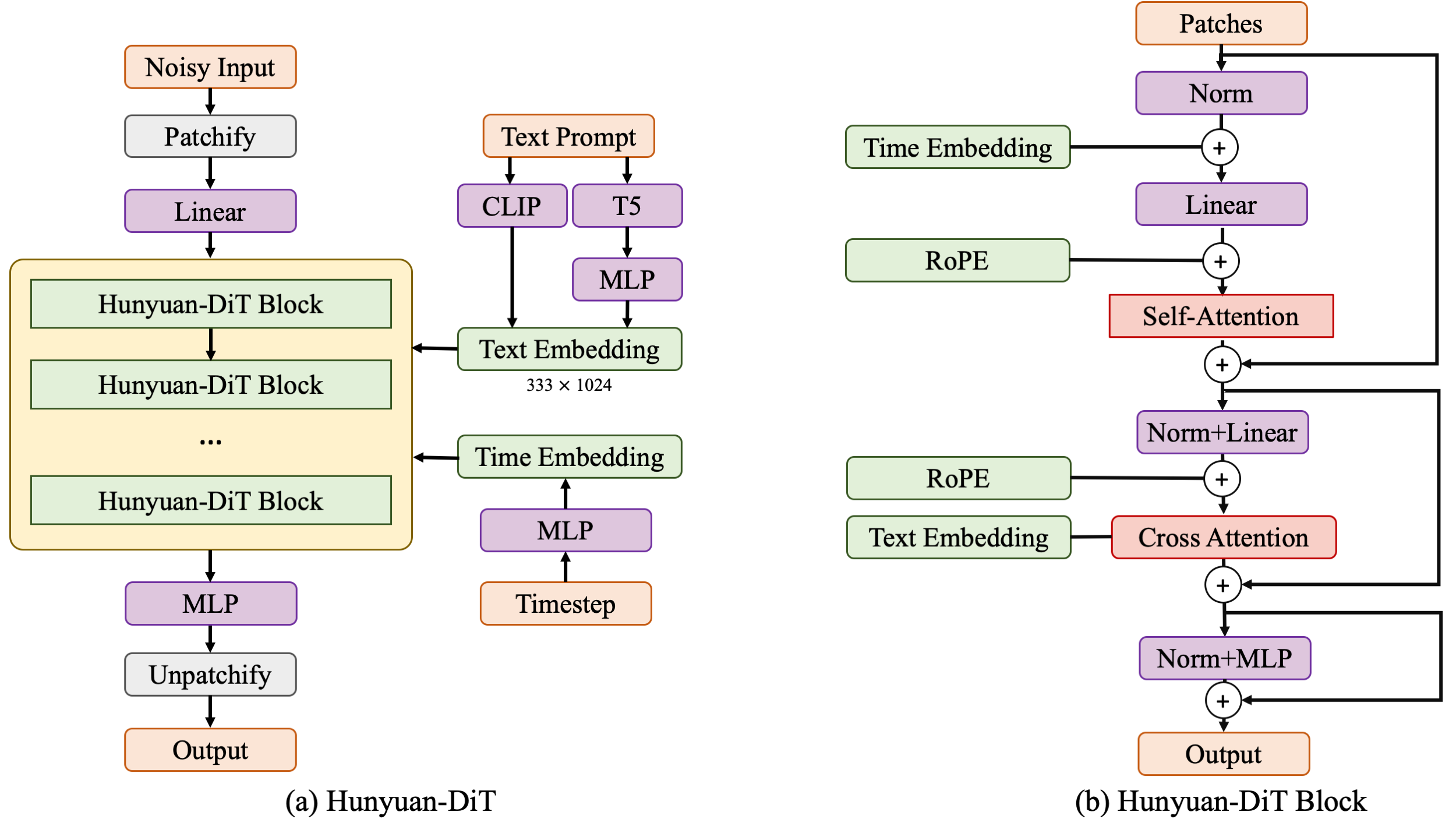 +
+ +
+| 模型 | 是否开源 | 文本与图像一致性 (%) | 排除AI痕迹 (%) | 主体清晰度 (%) | 美学 (%) | 总体 (%) | +
|---|---|---|---|---|---|---|
| SDXL | ✔ | 64.3 | 60.6 | 91.1 | 76.3 | 42.7 | +
| PixArt-α | ✔ | 68.3 | 60.9 | 93.2 | 77.5 | 45.5 | +
| Playground 2.5 | ✔ | 71.9 | 70.8 | 94.9 | 83.3 | 54.3 | +
| SD 3 | ✘ | 77.1 | 69.3 | 94.6 | 82.5 | 56.7 | +
| MidJourney v6 | ✘ | 73.5 | 80.2 | 93.5 | 87.2 | 63.3 | +
| DALL-E 3 | ✘ | 83.9 | 80.3 | 96.5 | 89.4 | 71.0 | +
| Hunyuan-DiT | ✔ | 74.2 | 74.3 | 95.4 | 86.6 | 59.0 | +
+  +
+
+  +
+
+
+
+---
+
+所有模型将会自动下载。有关模型的更多信息,请访问[Hugging Face代码库](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT)。
+
+| 模型 | 参数规格 | 下载地址 |
+|:------------------:|:-------:|:-------------------------------------------------------------------------------------------------------:|
+| mT5 | 1.6B | [mT5](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/mt5) |
+| CLIP | 350M | [CLIP](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/clip_text_encoder) |
+| DialogGen | 7.0B | [DialogGen](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/dialoggen) |
+| sdxl-vae-fp16-fix | 83M | [sdxl-vae-fp16-fix](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/sdxl-vae-fp16-fix) |
+| Hunyuan-DiT | 1.5B | [Hunyuan-DiT](https://huggingface.co/Tencent-Hunyuan/HunyuanDiT/tree/main/t2i/model) |
+
+
+## 🔑 推理
+### 使用 Gradio
+我们提供了一个基于 Gradio 的 Web 界面,用于快速运行推理。请运行以下命令以启动 Gradio 服务。
+
+```shell
+# 默认情况下,我们启动一个中文用户界面。
+python app/hydit_app.py
+
+# 使用 Flash Attention 进行加速。
+python app/hydit_app.py --infer-mode fa
+
+# 如果 GPU 内存不足,您可以禁用提示词增强模型(DialogGen)。
+# 直到您不使用`--no-enhance` 标志来重新启动应用程序之前,提示词增强模型(DialogGen)将不可用。
+python app/hydit_app.py --no-enhance
+
+# 以英文用户界面启动
+python app/hydit_app.py --lang en
+
+# 启动多轮文本图像生成用户界面。
+# 如果您的 GPU 内存少于 32GB,请使用 '--load-4bit' 启用 4 位量化,这需要至少 22GB 的内存。
+python app/multiTurnT2I_app.py
+```
+然后可以通过 http://0.0.0.0:443 访问演示。
+
+### 使用命令行
+
+您也可以使用命令行工具运行推理,我们提供了几个命令来快速启动:
+
+```shell
+# 使用提示词增强模型 + 文生图模型
+python sample_t2i.py --prompt "渔舟唱晚"
+
+# 仅使用文生图模型
+python sample_t2i.py --prompt "渔舟唱晚" --no-enhance
+
+# 仅使用文生图模型并用Flash Attention 进行加速
+python sample_t2i.py --infer-mode fa --prompt "渔舟唱晚"
+
+# 使用指定图像尺寸生成图像
+python sample_t2i.py --prompt "渔舟唱晚" --image-size 1280 768
+
+# 使用提示词增强模型 + 文生图模型。提示词增强模型以4位量化方式加载,可能会降低效果
+python sample_t2i.py --prompt "渔舟唱晚" --load-4bit
+
+```
+
+### 使用 ComfyUI
+
+ 混元-DiT的ComfyUI: [HunyuanDiT-ComfyUI](https://github.com/city96/ComfyUI_ExtraModels)
+
+更多提示词示例可以在[example_prompts.txt](example_prompts.txt)查看。
+
+### 更多配置
+
+我们列出了一些常用的配置参数,以便更简单的上手使用:
+
+| 参数名称 | 默认值 | 描述 |
+|:---------------:|:---------:|:---------------------------------------------------:|
+| `--prompt` | None | 用于生成图像的文本提示语 |
+| `--image-size` | 1024 1024 | 生成图像的像素大小 |
+| `--seed` | 42 | 用于生成图像的随机种子 |
+| `--infer-steps` | 100 | 采样步数 |
+| `--negative` | - | 用于生成图像的负向提示语 |
+| `--infer-mode` | torch | 推理模式(torch、fa 或 trt) |
+| `--sampler` | ddpm | 扩散采样器(ddpm、ddim 或 dpmms) |
+| `--no-enhance` | False | 禁用提示词增强模型 |
+| `--model-root` | ckpts | 模型检查点的根目录 |
+| `--load-key` | ema | 加载module模型或 ema 模型(ema 或 module) |
+| `--load-4bit` | Fasle | 使用 4 位量化加载 DialogGen 模型 |
+
+## 🚀 加速(适用于 Linux)
+
+我们提供了混元-DiT的TensorRT版本,用于推理加速(比Flash Attention更快)。
+更多详情请查看[Tencent-Hunyuan/TensorRT-libs](https://huggingface.co/Tencent-Hunyuan/TensorRT-libs)
+
+## 🔗 BibTeX
+
+如果您发现[Hunyuan-DiT](https://arxiv.org/abs/2405.08748)或[DialogGen](https://arxiv.org/abs/2403.08857)对您的研究和应用有帮助,请使用以下BibTeX引用::
+
+```BibTeX
+@misc{li2024hunyuandit,
+ title={Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding},
+ author={Zhimin Li and Jianwei Zhang and Qin Lin and Jiangfeng Xiong and Yanxin Long and Xinchi Deng and Yingfang Zhang and Xingchao Liu and Minbin Huang and Zedong Xiao and Dayou Chen and Jiajun He and Jiahao Li and Wenyue Li and Chen Zhang and Rongwei Quan and Jianxiang Lu and Jiabin Huang and Xiaoyan Yuan and Xiaoxiao Zheng and Yixuan Li and Jihong Zhang and Chao Zhang and Meng Chen and Jie Liu and Zheng Fang and Weiyan Wang and Jinbao Xue and Yangyu Tao and Jianchen Zhu and Kai Liu and Sihuan Lin and Yifu Sun and Yun Li and Dongdong Wang and Mingtao Chen and Zhichao Hu and Xiao Xiao and Yan Chen and Yuhong Liu and Wei Liu and Di Wang and Yong Yang and Jie Jiang and Qinglin Lu},
+ year={2024},
+ eprint={2405.08748},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+
+@article{huang2024dialoggen,
+ title={DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation},
+ author={Huang, Minbin and Long, Yanxin and Deng, Xinchi and Chu, Ruihang and Xiong, Jiangfeng and Liang, Xiaodan and Cheng, Hong and Lu, Qinglin and Liu, Wei},
+ journal={arXiv preprint arXiv:2403.08857},
+ year={2024}
+}
+```
+
+## github获赞里程碑
+
+
+