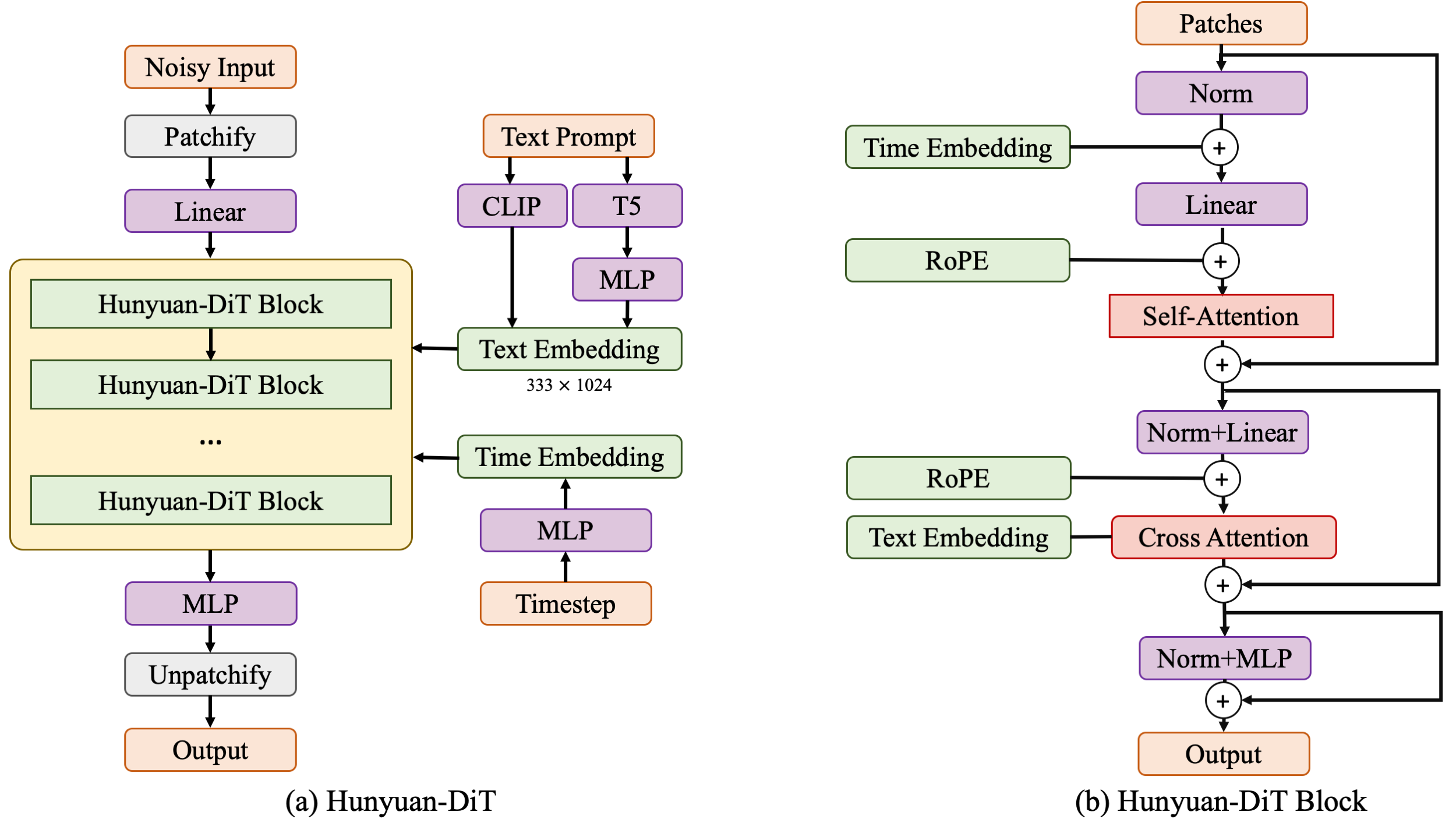
+ ![]() +
+
 +
+  +
+  +
+  +
+  +
+  +
+  +
+
+  +
+
+  +
+
+
| Model | Open Source | Text-Image Consistency (%) | Excluding AI Artifacts (%) | Subject Clarity (%) | Aesthetics (%) | Overall (%) | +
|---|---|---|---|---|---|---|
| SDXL | ✔ | 64.3 | 60.6 | 91.1 | 76.3 | 42.7 | +
| PixArt-α | ✔ | 68.3 | 60.9 | 93.2 | 77.5 | 45.5 | +
| Playground 2.5 | ✔ | 71.9 | 70.8 | 94.9 | 83.3 | 54.3 | +
| SD 3 | ✘ | 77.1 | 69.3 | 94.6 | 82.5 | 56.7 | + +
| MidJourney v6 | ✘ | 73.5 | 80.2 | 93.5 | 87.2 | 63.3 | +
| DALL-E 3 | ✘ | 83.9 | 80.3 | 96.5 | 89.4 | 71.0 | +
| Hunyuan-DiT | ✔ | 74.2 | 74.3 | 95.4 | 86.6 | 59.0 | +
+  +
+
+  +
+
| 训练数据示例 | +|||
 |
+  |
+  |
+  |
+
| 青花瓷风格,一只蓝色的鸟儿站在蓝色的花瓶上,周围点缀着白色花朵,背景是白色 (Porcelain style, a blue bird stands on a blue vase, surrounded by white flowers, with a white background. +) | +青花瓷风格,这是一幅蓝白相间的陶瓷盘子,上面描绘着一只狐狸和它的幼崽在森林中漫步,背景是白色 (Porcelain style, this is a blue and white ceramic plate depicting a fox and its cubs strolling in the forest, with a white background.) | +青花瓷风格,在黑色背景上,一只蓝色的狼站在蓝白相间的盘子上,周围是树木和月亮 (Porcelain style, on a black background, a blue wolf stands on a blue and white plate, surrounded by trees and the moon.) | +青花瓷风格,在蓝色背景上,一只蓝色蝴蝶和白色花朵被放置在中央 (Porcelain style, on a blue background, a blue butterfly and white flowers are placed in the center.) | +
| 推理结果示例 | +|||
 |
+  |
+  |
+  |
+
| 青花瓷风格,苏州园林 (Porcelain style, Suzhou Gardens.) | +青花瓷风格,一朵荷花 (Porcelain style, a lotus flower.) | +青花瓷风格,一只羊(Porcelain style, a sheep.) | +青花瓷风格,一个女孩在雨中跳舞(Porcelain style, a girl dancing in the rain.) | +
| Condition Input | +||
| Canny ControlNet | +Depth ControlNet | +Pose ControlNet | +
| 在夜晚的酒店门前,一座古老的中国风格的狮子雕像矗立着,它的眼睛闪烁着光芒,仿佛在守护着这座建筑。背景是夜晚的酒店前,构图方式是特写,平视,居中构图。这张照片呈现了真实摄影风格,蕴含了中国雕塑文化,同时展现了神秘氛围 (At night, an ancient Chinese-style lion statue stands in front of the hotel, its eyes gleaming as if guarding the building. The background is the hotel entrance at night, with a close-up, eye-level, and centered composition. This photo presents a realistic photographic style, embodies Chinese sculpture culture, and reveals a mysterious atmosphere.) |
+ 在茂密的森林中,一只黑白相间的熊猫静静地坐在绿树红花中,周围是山川和海洋。背景是白天的森林,光线充足 (In the dense forest, a black and white panda sits quietly in green trees and red flowers, surrounded by mountains, rivers, and the ocean. The background is the forest in a bright environment.) |
+ 一位亚洲女性,身穿绿色上衣,戴着紫色头巾和紫色围巾,站在黑板前。背景是黑板。照片采用近景、平视和居中构图的方式呈现真实摄影风格 (An Asian woman, dressed in a green top, wearing a purple headscarf and a purple scarf, stands in front of a blackboard. The background is the blackboard. The photo is presented in a close-up, eye-level, and centered composition, adopting a realistic photographic style) |
+
 |
+  |
+  |
+
+
| ControlNet Output | +||
 |
+  |
+  |
+
