| title | 零拷贝详解:mmap、sendfile 与 splice | |||||||
|---|---|---|---|---|---|---|---|---|
| description | 零拷贝高频面试题总结,讲清传统 read/write、mmap、sendfile、splice 的拷贝路径、上下文切换、SG-DMA、Java NIO、Kafka 和 RocketMQ 的应用场景。 | |||||||
| category | 计算机基础 | |||||||
| tag |
|
|||||||
| head |
|
面试里有个很常见的套路:先问你“Kafka 为什么快”“RocketMQ 为什么扛得住堆积”,等你答出顺序写、Page Cache、零拷贝之后,面试官顺势往下挖:“零拷贝具体省掉了哪几次拷贝?”“mmap 和 sendfile 有什么区别?”“splice 又是干嘛的?”
到这一步,很多人就开始打太极了。能背出“零拷贝就是不经过用户态”的不少,能把四次拷贝、两次 DMA、几次上下文切换的账算清楚的不多。
Guide 这篇就把这本账捋一遍:传统 I/O 到底拷了几次,零拷贝的“零”到底零在哪,mmap、sendfile、splice 三条路线各自省了什么、又各自有什么代价。
后面“几次拷贝、几次切换”的数字都是在一个简化模型下算的,脱离前提就不准。先把假设摆明:
- 场景是把一个普通文件通过 TCP socket 发出去,且数据初始不在 Page Cache 里(需要真正读盘)。
- 不涉及 TLS 加密、压缩、格式转换这类要在用户态碰数据的处理。
- 设备支持常见的 DMA 与 scatter-gather。
- 数到的“拷贝次数”只算数据本身(payload),不含描述符、元数据。
- 下文说的“上下文切换”,准确讲是用户态和内核态之间的模式切换(一次系统调用进出各算一次),它和线程被调度器换上换下的“线程上下文切换”不是一回事;只有系统调用真的阻塞、线程被换出时,才会额外发生线程上下文切换。
Page Cache 命中、走 TLS、硬件不支持 SG-DMA,这些数字都会变。模型是用来理解机制的,不是放之四海皆准的常数。
先看一个最常见的场景:一个文件下载接口,服务端要把磁盘上的文件,通过已经建立好的 socket 发给客户端。最直接的写法就是一个 read 加一个 write:
while ((n = read(file_fd, buf, BUF_SIZE)) > 0)
write(socket_fd, buf, n);看着只有两行,底层却折腾得不轻。一次完整的“读磁盘 + 发网络”,CPU 和 DMA 一共要搬四趟数据,用户态和内核态之间还要来回切四次。
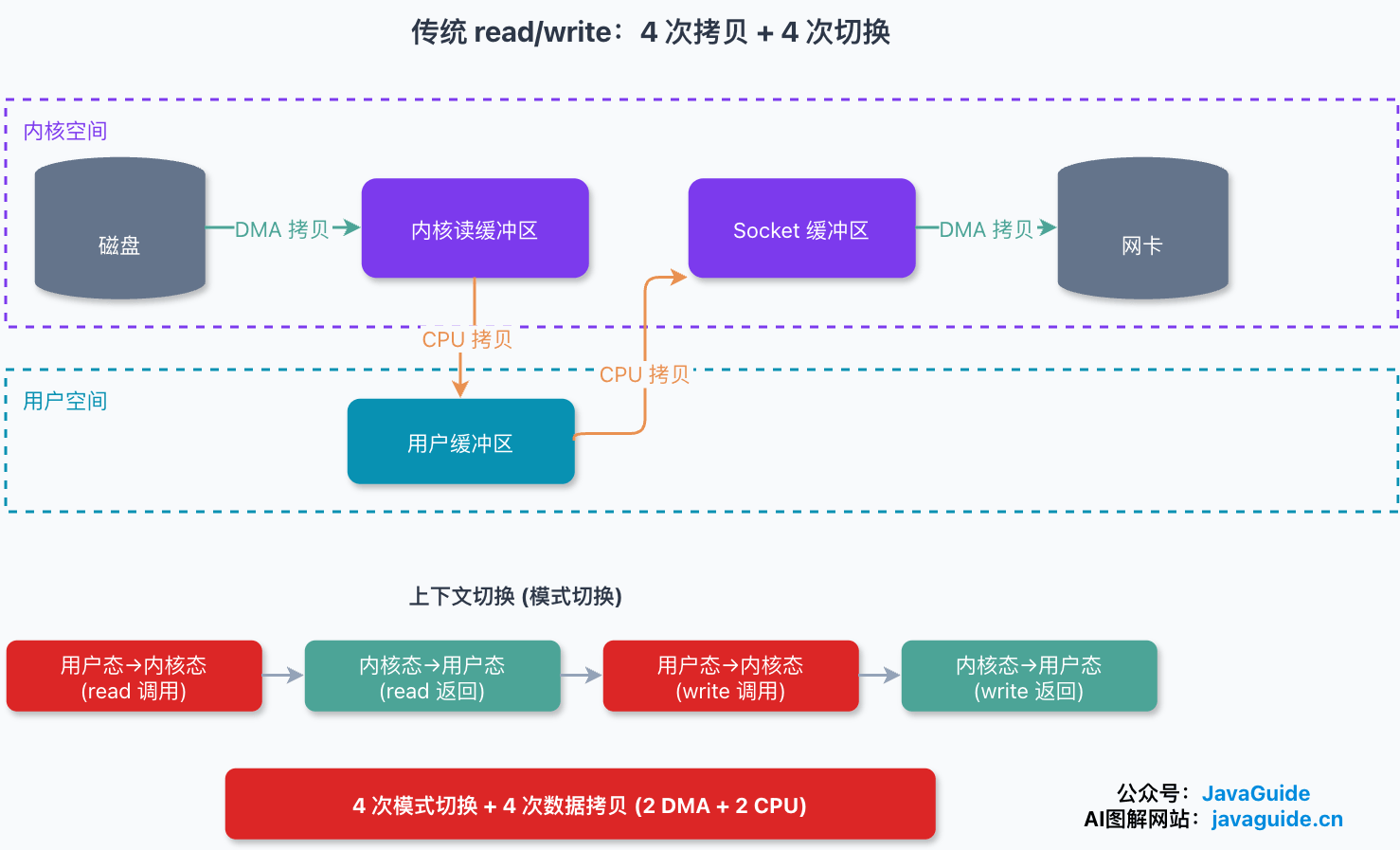
把这两行拆开看,read 这一半发生了什么:
- 应用进程调用 read,发起系统调用,上下文从用户态切到内核态(第 1 次切换)。
- DMA 控制器把数据从磁盘读进内核读缓冲区(第 1 次拷贝,DMA 拷贝)。
- CPU 把内核读缓冲区的数据拷到用户缓冲区(第 2 次拷贝,CPU 拷贝),上下文切回用户态(第 2 次切换),read 返回。
write 这一半是对称的:
- 应用进程调用 write,发起系统调用,上下文切到内核态(第 3 次切换)。
- CPU 把用户缓冲区的数据拷到 socket 缓冲区(第 3 次拷贝,CPU 拷贝)。
- DMA 把 socket 缓冲区的数据拷到网卡(第 4 次拷贝,DMA 拷贝),上下文切回用户态(第 4 次切换),write 返回。
数一下:4 次模式切换,4 次数据拷贝,其中 2 次是 DMA 拷贝、2 次是 CPU 拷贝。(严格说,write 把数据复制进 socket 发送缓冲区后通常就返回了,网卡的排队、分段和 DMA 发送是协议栈异步完成的,并不需要等 DMA 真正发完才切回用户态。这里把它画进一次调用里,只是为了把账算齐。)
这里插一句 DMA(Direct Memory Access,直接内存访问)。它是设备控制器或系统里的 DMA 引擎提供的能力,能在外设和内存之间直接搬数据,全程基本不用 CPU 盯着(现代硬件里它通常集成在设备控制器、SoC 或芯片组中,未必是一块独立芯片)。磁盘到内核缓冲区、socket 缓冲区到网卡这种纯体力活交给它,CPU 就能腾出手算别的,所以 DMA 拷贝并不烧 CPU。
真正难受的是那两次 CPU 拷贝。数据从内核读缓冲区拷到用户缓冲区,再从用户缓冲区原样拷回 socket 缓冲区,可我们这个下载接口压根没碰过它的内容,数据只是路过用户空间打了个转。CPU 全程在做无意义的搬运,外加四次切换的寄存器保存恢复开销。高并发、大文件场景下,这部分浪费会被放大得很明显。
零拷贝要省的,就是这部分。
先纠正一个常见误解:零拷贝不是真的一次拷贝都没有。
数据从磁盘到网卡,物理上的搬运绕不开。准确说,零拷贝省掉的是 CPU 拷贝,以及随之减少的上下文切换;那两次 DMA 拷贝(磁盘到内核、内核到网卡)是硬件的事,谁也省不掉。
所以零拷贝更精确的定义是:在 I/O 操作中让 CPU 不再参与数据在内存之间的复制,从而减少 CPU 拷贝和用户态/内核态切换的次数。它是一类技术的统称,下面三条路线都是在围着“怎么干掉 CPU 拷贝”做文章。
第一个思路来自虚拟内存。现代操作系统用虚拟地址替代物理地址,这里有个关键特性:多个虚拟地址可以指向同一块物理内存。
mmap 用的正是这一点。它的函数签名长这样:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);其中 fd 是要映射的文件描述符,length 是映射长度,offset 是文件偏移。调用之后,内核读缓冲区会和用户空间的一段虚拟地址映射到同一块物理内存上。换句话说,内核缓冲区和用户缓冲区“共享”了同一份数据,不再各存一份。
于是原来的 read + write 就变成了 mmap + write。这里要先破除一个常见误区:mmap 调用本身只是建立文件到一段虚拟地址的映射,并不会立刻把文件读进内存。真正的读盘发生在后面访问到尚未驻留的映射页、触发缺页中断时,由内核从 Page Cache(没有就从磁盘)按页加载。流程大致是:
- 应用进程调用
mmap,内核建立文件到虚拟地址区间的映射,进出内核态各一次,调用返回。此时还没有任何文件数据被搬进来。 - 后续访问这段映射区(典型是把它当作
write的数据源),首次碰到未驻留的页就触发缺页中断;若 Page Cache 里没有该页,DMA 把数据从磁盘读进 Page Cache(DMA 拷贝)。 - 页表建立映射后,这段内核 Page Cache 页同时映射进了用户地址空间,两边共享同一份物理内存。
- 应用调用
write,CPU 把这份数据从内核 Page Cache 拷进 socket 缓冲区(CPU 拷贝)——因为共享物理内存,省掉了传统方式里“内核到用户、再回内核”那次多余的 CPU 拷贝。 - DMA 把 socket 缓冲区的数据发往网卡(DMA 拷贝),
write返回。
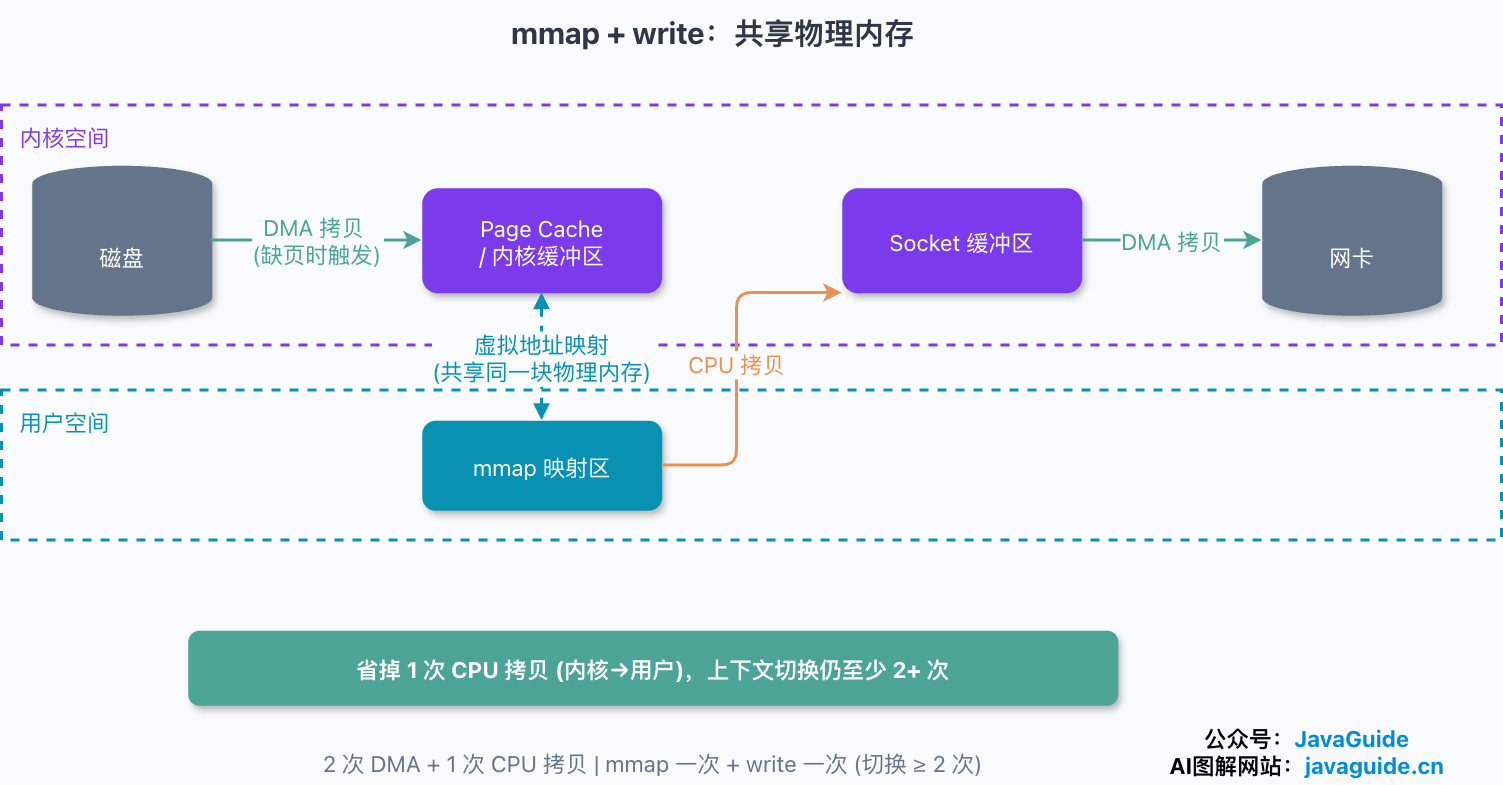
算账(缓存未命中、走完整路径时):大致 2 次 DMA + 1 次 CPU 拷贝;切换上 mmap 一次、write 一次,外加首次访问的缺页处理。和传统方式比,mmap 干掉的是“内核到用户”那次 CPU 拷贝。
所以“mmap + write 固定是 4 次切换、3 次拷贝”只能当教学简化模型——Page Cache 命中与否、缺页发生在哪,都会让真实数字浮动。
mmap 还有个附带好处:用户进程不必再维护一份和 Page Cache 内容重复的用户态读缓冲区,省掉了这块额外的缓冲和复制。至于到底省多少物理内存,取决于处理窗口、缓冲区大小和访问模式,不能一概而论说“省一半”。
不过 mmap 不是没有坑。映射本身有成本,建立和拆除页表、处理缺页中断都要花时间,文件很小的时候,这点开销摊下来可能比老老实实 read/write 还慢,所以 mmap 更适合大文件、反复读写。还有个更隐蔽的雷:如果你映射的文件被另一个进程截断(truncate),你再去访问被截掉的那段映射区,会直接吃一个 SIGBUS 信号,程序当场挂掉。这类问题在生产环境里排查很费劲,用 mmap 时得心里有数。
mmap 省了一次 CPU 拷贝,但它仍然绕不开 mmap 和 write 两类系统调用;如果只是把文件原样发出去,能不能用一次系统调用把内核内的数据传输做完?
Linux 2.1 内核引入的 sendfile 就是干这个的:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);- in_fd:数据来源,必须是支持 mmap 式读取的对象(通常是普通文件),不能是 socket。
- out_fd:数据去向,在 Linux 2.6.33 之前只能是 socket,之后可以是任意文件。具体限制要绑定内核版本看。
- offset:从文件哪个位置开始读,传 NULL 表示用文件当前偏移。
- count:传输多少字节。
它的语义是:在两个文件描述符之间直接传数据,整个过程都在内核里完成,数据完全不经过用户空间。流程缩短成:
- 应用进程调用 sendfile,切到内核态(第 1 次模式切换)。
- DMA 把数据从磁盘拷到内核读缓冲区(DMA 拷贝)。
- CPU 把内核读缓冲区的数据拷到 socket 缓冲区(CPU 拷贝)。
- DMA 把 socket 缓冲区的数据拷到网卡(DMA 拷贝),切回用户态(第 2 次模式切换),sendfile 返回。
算账:2 次模式切换,3 次数据拷贝(2 次 DMA + 1 次 CPU)。
对比 mmap,sendfile 的核心优势是把文件到 socket 的转发收进一次系统调用里,通常少了一轮用户态/内核态来回;代价是它比 mmap“死板”:数据全程在内核里走,用户态根本看不到也碰不到这份数据。如果你需要在传输前改一改文件内容,sendfile 帮不上忙,这种场景只能用 mmap。
走到这里还剩一次 CPU 拷贝(内核读缓冲区到 socket 缓冲区)。能不能连这一次也干掉?
Linux 2.4 给 sendfile 做了升级,关键是引入了 SG-DMA(scatter/gather DMA,分散/聚集 DMA)。这项硬件能力让 DMA 可以直接从内核读缓冲区把数据搬到网卡,不必先经过 socket 缓冲区。
升级后的流程:
- 应用进程调用 sendfile,切到内核态(第 1 次模式切换)。
- DMA 把数据从磁盘拷到内核读缓冲区(DMA 拷贝)。
- CPU 不再拷贝数据本身,只把这份数据在内核缓冲区里的描述信息(内存地址 + 偏移量长度)写进 socket 缓冲区。
- SG-DMA 根据这些描述信息,直接把数据从内核读缓冲区搬到网卡(DMA 拷贝),切回用户态(第 2 次模式切换),sendfile 返回。
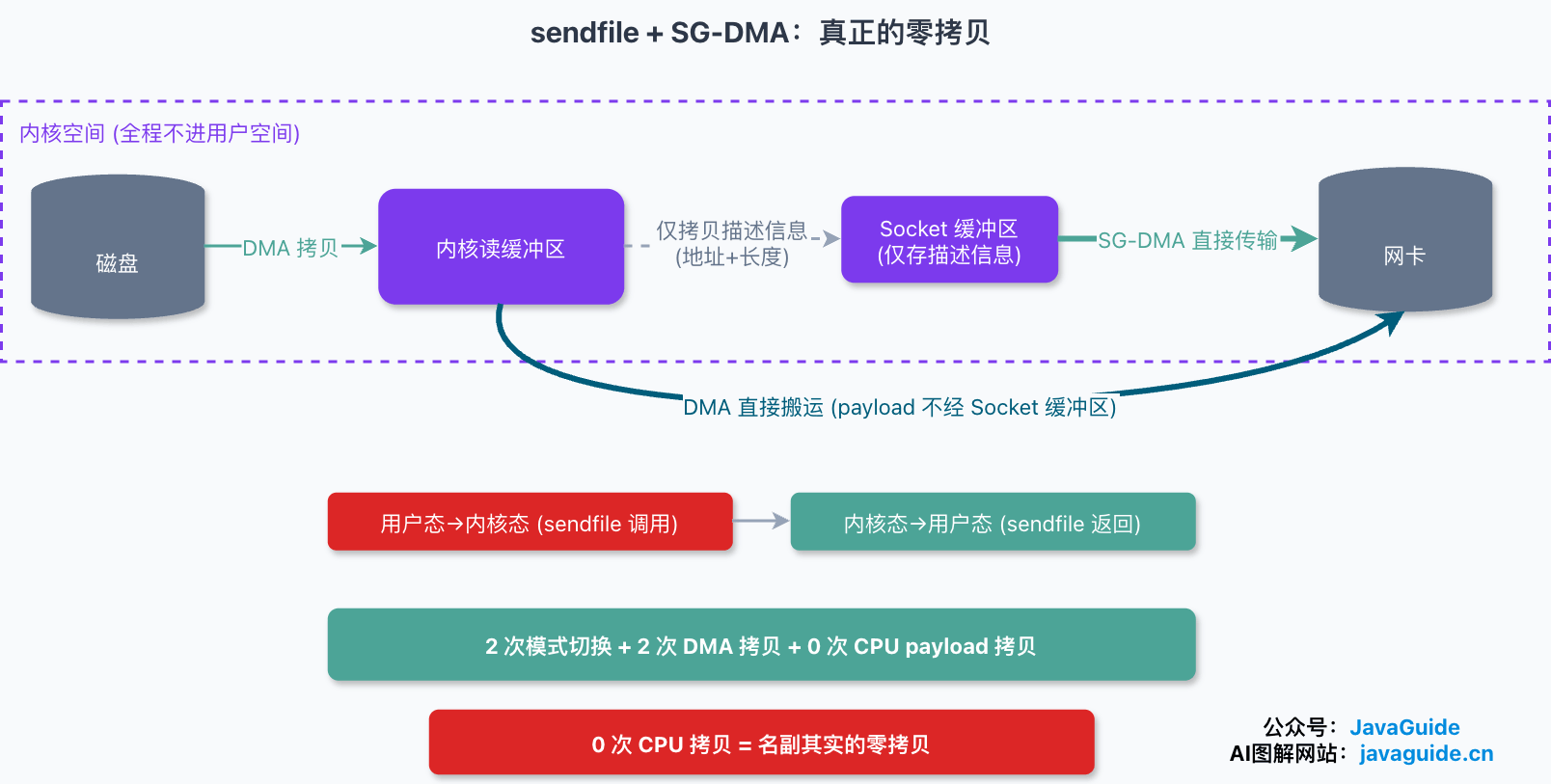
算账:2 次模式切换,2 次数据拷贝,且两次都是 DMA 拷贝,payload 的 CPU 拷贝为 0。
这才是名副其实的零拷贝:全程没有任何一次靠 CPU 搬运 payload,磁盘到网卡完全由 DMA 完成。第 3 步 CPU 写的那点描述信息只是几个字节的元数据,不算数据拷贝。不过能不能真走到这条路径有前提:网卡得支持 scatter-gather、内核版本够、协议栈中途不需要碰数据。一旦开启用户态 TLS 加密、要做格式转换,内核就得真正读到 payload,这条 0 CPU 拷贝的路就走不通了。
sendfile 已经很好了,但它有个硬限制:in_fd 得是支持 mmap 式读取的对象(通常是普通文件),不能是 socket,out_fd 早期也只能是 socket。如果想在两个 socket 之间、或者更一般的两个描述符之间做零拷贝转发,sendfile 就不够用了。
Linux 2.6.17 内核引入的 splice(由 Jens Axboe 提交,需要 glibc 2.5 支持)补上了这块。它的思路是借道管道(pipe):
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out,
size_t len, unsigned int flags);splice 要求 fd_in 和 fd_out 中至少有一个是管道。它为什么要绑着管道?因为 Linux 的管道底层是一组引用计数的页指针:管道缓冲区里存的不是数据本身,而是指向内核内存页的指针,外加每页的引用计数。所谓“把数据从管道挪到另一端”,多数情况下只是复制指针、给对应的页引用计数加一,不真正搬动 payload。要提醒的是,SPLICE_F_MOVE 只是给内核的一个提示,并非硬保证——遇到某些文件系统、设备或缓冲区形态无法直接移动页时,内核仍可能退化成真正的复制。
用 splice 实现文件到 socket 的传输,得两步走、两次系统调用:
splice(file_fd, NULL, pipe_w, NULL, len, SPLICE_F_MOVE); // 文件 → 管道写端
splice(pipe_r, NULL, socket_fd, NULL, len, SPLICE_F_MOVE); // 管道读端 → socket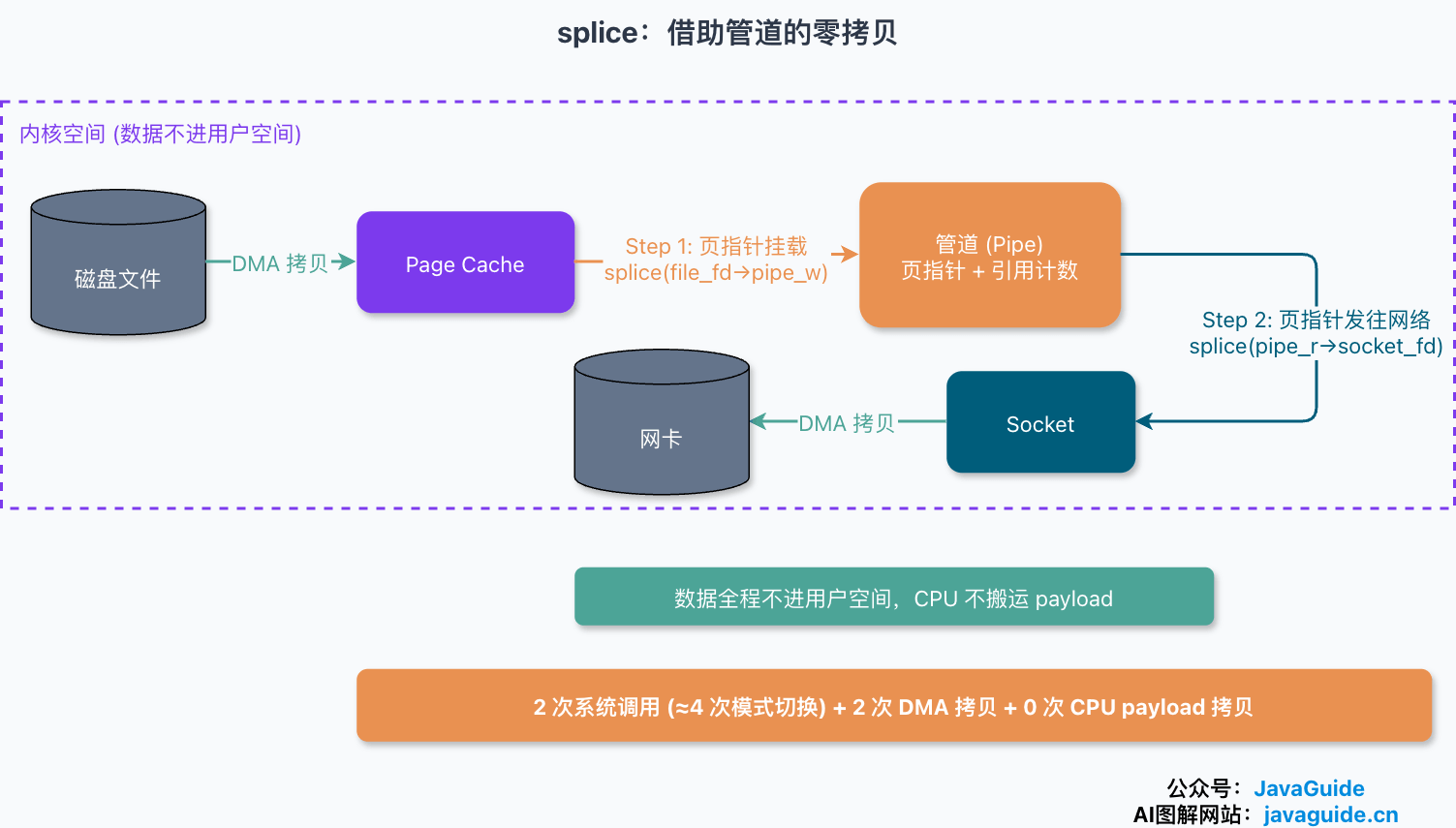
第一次把 Page Cache 里的页挂到管道缓冲区上,第二次把这些页指针当作网络包的分片发往 socket。数据全程不进用户空间,CPU 不搬运 payload。但要看清楚:这是两次 splice 调用,进出内核态各算一次,合计大约 4 次模式切换,并不是有些文章说的“和 sendfile 一样只有一次系统调用、两次切换”。实际工程里两个 fd 还得设非阻塞、配合 epoll,并处理短传输和 EAGAIN。
splice 和前面几位的区别可以这么理解:
- 比 sendfile 通用:sendfile 更专注于内核内 fd 到 fd 的传输(典型是文件到 socket);splice 借助管道,能在更广的描述符之间转发数据,包括 socket 到 socket。有些内核版本内部会复用相关实现,但两者是独立的系统调用,参数限制和演进各不相同,别简单理解成严格的父子继承关系。
- 和 mmap 取向相反:mmap 把数据映射到用户空间,让你能改;splice 的全部意义就在于数据压根不碰用户空间,你看不见也改不了。
补一个版本细节:在 Linux 2.6.30 及更早,fd_in 和 fd_out 必须恰好有一个是管道;从 2.6.31 开始,两端可以都是管道。
把上面四条路线放一起看,账就一目了然了:
| 方式 | CPU payload 拷贝 | DMA 拷贝 | 模式切换 | 典型系统调用 |
|---|---|---|---|---|
| 传统 read + write | 2 | 2 | 4 | read + write |
| mmap + write | 1 | 2 | 映射后发送通常至少 2,首次访问另有缺页 | mmap 一次 + write 多次 |
| sendfile | 0 或 1(取决于发送路径) | 通常 2 | 2 | sendfile |
| splice(文件→管道→socket) | 通常可避免 | 通常 2 | 4 | splice 两次 |

(mmap 那行的拷贝/切换次数随 Page Cache 命中与缺页时机浮动,不宜钉成固定值;sendfile 在网卡支持 SG-DMA 时,CPU payload 拷贝降到 0。)
两个结论:
第一,2 次 DMA 拷贝在所有方式里都省不掉。 因为它们是硬件完成的,分别对应“磁盘到内核”和“内核到网卡”这两段物理搬运。很多朋友会误以为零拷贝优化的是 DMA,实际省的是 CPU 拷贝和模式切换。
第二,选哪条路,先看数据要不要被应用碰一下。 传输前要改内容,用 mmap 更顺手;只是把文件原样发出去,sendfile 更合适,网卡支持 SG-DMA 时还能把 CPU payload 拷贝压到 0。splice 的位置更靠后:只有文件到 socket 之外的 fd 转发需求,比如 socket 到 socket,才值得把管道这层搬出来,同时也要接受两次系统调用的成本。
零拷贝也不是开关一拧就永远赚。开了 TLS、要压缩、要做格式转换,payload 迟早要进用户态处理;内容过滤、加水印、限速也是同一类问题。文件很小或者访问很随机时,映射、缺页、管道这些固定开销可能反而更显眼。
mmap 还要小心文件被 truncate 后访问旧映射触发 SIGBUS;零拷贝发送量很大时,Page Cache 被挤占、内存回收变重,也会把收益吃掉一部分。
Java NIO 把这两条主线都封装了,对应关系很清楚。
MappedByteBuffer 对应 mmap。 通过 FileChannel.map 拿到一个 MappedByteBuffer,底层调用的就是 Linux 的 mmap,把文件(或文件的一部分)映射进内存,之后直接操作内存就行,不用再走 read/write 系统调用:
FileChannel channel = FileChannel.open(
Paths.get("./data.bin"),
StandardOpenOption.READ, StandardOpenOption.WRITE);
// 把文件映射到内存,底层是 mmap
MappedByteBuffer buffer = channel.map(
FileChannel.MapMode.READ_WRITE, 0, channel.size());FileChannel.transferTo / transferFrom 可能用到 sendfile。 注意是“可能”:Java API 只承诺把字节送到目标 Channel,并不保证用哪个系统调用。在支持的平台上,当目标是 socket 时,JDK 可能走 sendfile 这类内核传输路径;目标是普通文件或别的 Channel 时,又可能走别的路径,甚至退化成用户态复制。所以下面这个示例把目标写成 SocketChannel,才更贴近零拷贝的场景:
FileChannel source = FileChannel.open(
Paths.get("./in.dat"), StandardOpenOption.READ);
// socketChannel 是一条已连接的 SocketChannel
// 文件 → socket,JDK 在支持的平台上可能使用零拷贝优化(如 sendfile)
source.transferTo(0, source.size(), socketChannel);这里有个容易踩的坑:transferTo 不保证一次就传完,调用方必须根据返回值循环处理剩余数据。底层若走 Linux sendfile,单次上限是 0x7ffff000(约 2 GB)字节;但 Java 层暴露的具体上限、以及到底走没走零拷贝路径,都要结合 JDK 版本和目标平台验证——比如 Windows 上的行为就和 Linux 不完全一致。
零拷贝最常被拿来解释 Kafka、RocketMQ 为什么快,但这两家选的路线其实不一样,背后是各自读写模式的差异。
Kafka 消费端用零拷贝发送。 消费者来拉消息时,Kafka 要把日志段文件(log segment)从磁盘发到网络,这是典型的“只转发、不修改内容”,于是它用 FileChannel.transferTo 把日志直接从 Page Cache 送进 socket,数据不进 JVM 堆。再叠加生产端的顺序写和 Page Cache,高吞吐就是这么攒出来的。(顺带一提,Kafka 的索引文件用的是 mmap。)但零拷贝不是无条件生效:一旦需要做消息格式转换、解压重压缩,或开启了 TLS 要在用户态加密,payload 就得被读出来处理,这条路径会退化——能不能用零拷贝,要结合 Kafka、JDK 和操作系统版本判断。
RocketMQ 主要走 mmap。 RocketMQ 的 CommitLog 用 MappedByteBuffer 做内存映射来读写文件,这也是它把 CommitLog 设计成固定大小文件的原因之一,固定大小便于映射管理。选 mmap 而不是 sendfile,是因为它的读写模式需要更灵活地操作映射出来的这段内存,而不只是把文件原样转发出去。
一句话区分:单纯转发选 sendfile,需要操作映射内存选 mmap,这正好呼应前面那条“要不要改数据”的判断标准。
搜"zerocopy"很容易搜到 Google 维护的一个 Rust 库 google/zerocopy,由 Google 工程师持续维护,下载量很大、活跃度没问题。它的版本号更新很快(写作时已到 0.8.x 系列),这里就不钉死某个具体数字了,以 crates.io 和 GitHub Release 为准。
但要提醒一句:这个 crate 和本文讲的操作系统零拷贝不是一个概念,别混淆。OS 层面的零拷贝说的是 I/O 过程中减少 CPU 在内核/用户缓冲区之间的数据搬运;而 Rust 的 zerocopy crate 解决的是类型安全的内存转换,在字节序列和结构体之间做安全转换(safe transmutation),不必拷贝、也不写 unsafe。两者都叫"zero copy",一个在讲系统调用和 DMA,一个在讲语言层面的内存布局与类型安全,别在面试里混为一谈。
面试里问“零拷贝是什么”,先把“零”说准:它不是没有任何拷贝,磁盘到内存、内存到网卡这两段 DMA 搬运通常还在;零拷贝主要省的是 CPU 在内核缓冲区和用户缓冲区之间搬 payload 的那几次,以及随之减少的模式切换。
传统 read + write 可以按 4 次拷贝来讲:磁盘到内核缓冲区是 DMA,内核到用户缓冲区是 CPU,用户缓冲区到 Socket 缓冲区还是 CPU,Socket 缓冲区到网卡是 DMA。这里最浪费的是两次 CPU 拷贝,因为应用并没有改数据,只是让数据经过用户空间转了一圈。
几种方案的回答顺序可以这么排:mmap + write 让用户空间和 Page Cache 映射同一批物理页,省掉“内核到用户”那次 CPU 拷贝,但还要 write 到 Socket 缓冲区;sendfile 把文件到 socket 的转发放进一次系统调用,数据不进用户态;配合 SG-DMA 时,Socket 缓冲区只放描述信息,payload 可以直接由 DMA 从内核缓冲区送到网卡;splice 则借助 pipe 传递页引用,更适合一般 fd 之间的转发,但通常要两次系统调用。
如果面试官把话题拉到 Kafka、RocketMQ,答案也不要混。Kafka 消费端把日志段文件原样发给消费者,适合走 FileChannel.transferTo 这类 sendfile 路线;RocketMQ 的 CommitLog 需要更灵活地读写映射内存,所以更常和 mmap 绑定。再补一句边界:TLS、压缩、格式转换、内容过滤这些场景需要应用真正处理 payload,零拷贝路径就会退化。