| description |
|---|
A node is a computer contributing computing power to the presearch network. In exchange, you earn pre tokens. |
{% embed url="https://www.youtube.com/watch?v=9NzK3hF_4WE" %}
Search engines are complicated, and building a decentralized search engine provides some unique challenges which do not apply to centralized search engines. For example: how do you prevent malicious actors from running nodes and either stealing user information or returning dangerous or unwanted content? How do you get fast (hundreds of milliseconds) response times across a massively distributed network of servers with drastic variability in performance and reliability? How do you properly incentivize people to run nodes and fairly balance supply and demand for both nodes and searches within the network? Some of these issues Presearch has already solved, and some will require continued experimentation and innovation over time, but Presearch will roll out both the platform and the decentralization of the platform incrementally to ensure an optimal ongoing search experience for the amazing Presearch community. This is what it looks like at the top of the page for the term “Bitcoin”.

There are six core layers of the Presearch search engine architecture:
• Core Services: Advertising API, Account Management API, Search Rewards Tracking, Keyword Staking, Marketplace, and other critical Presearch services which are centrally managed by Presearch.
• Web Server: Receives Search Requests from Presearch users and passes them on to the Gateway to generate results. Returns a final, rendered results page to the user.
• Node Registry: Manages the identity of all nodes, node stats, and any rewards payouts to node operators.
• Node Gateway: Receives requests from the Web Server, removes personally identifiable information from the search requests, and passes the search to one or more healthy nodes.
• Nodes: Decentralized search “workers” which connect to the Node Gateway and perform search operations. Each node is required to have a unique publicly-facing IP address.
• Search Packages: Open source plugins which return intelligent answers and info boxes in response to specific queries.
The following diagram shows the interactions between the major components within the Presearch Search Architecture.

Node operators will be compensated in PRE for the value of the work and capacity they provide to the network. There are at least seven different kinds of operations that a node can perform (with more likely in the future):
1) Registering (all nodes). Registering with a Node Gateway, which can then route queries to the node if it passes health and security validation.
2) Validating (all nodes). Coordinating with a Node Validator to ensure that each node is only running trusted Presearch software (to avoid security issues from potential bad actors).
3) Coordinating. Processing and distributing queries sent by Node Gateways. This may require routing to multiple serving nodes and aggregating the results.
4) Federating. Proxying other data sources and returning their data as part of search results.
5) Serving. Hosting portions of the search index used to process queries.
6) Crawling. Crawling websites to build out search indices.
7) Indexing. Writing federated or crawled data to search indexes to be served by serving nodes.
Different kinds of servers will work better for powering these different use cases. For example:
1) Coordinating will work best on nodes with low network latency, high network bandwidth, and high memory (disk space unimportant, CPU useful, but can vary).
2) Federating will work best on nodes with: low networking latency (CPU, memory, and disk space unimportant; high bandwidth preferred).
3) Serving will work best on nodes with high memory, high uptime, and low network latency (CPU and disk space useful, but can vary).
4) Crawling will work best on nodes with: high disk space, high network bandwidth (CPU, memory, network latency, and uptime unimportant).
5) Indexing will work best on nodes with: high disk space, high network bandwidth, low network latency, and reasonable CPU, memory, and uptime.
The first component of the Presearch decentralized search engine to be released will be the nodes, with a beta program in September 2020 and a production launch in Q4 2020. For this first release, Presearch will be focused only on the following node operations: • Registering • Validating • Federating This means that Presesarch will initially aim for a network of as many nodes as possible, provided as cheaply as possible, so long as their network latency is low. When Preserach later adds Serving and Coordinating operations (enabling the Presearch search index to be decentralized), this will introduce the need for different and more powerful servers to join the network. When Crawling becomes fully decentralized and supported by nodes, the capacity of the network to crawl the web and refresh data will then be tied directly to the size of the network and its growth. Presearch will continue to implement the remaining node operations over time, as detailed in the later Product Roadmap section
When node operators provide server capacity to the Presearch network, they add value and will be compensated in PRE for the value they add. Presearch’s Tokenomics Engine will determine the aggregate amount to be paid out across all node operators based upon needs of the network.
Additionally, in order to for a node operator to receive rewards for running a node in the Presearch network, Presearch will require them to stake PRE to reserve their right to provide that capacity. This stake will also acts as a deposit to ensure that the node operator does not violate the Presearch Terms of Service while operating their node.
Node operators request a node registration code on the Node's dashboard page. This connects their Presearch account to their node(s) for security and node-reward purposes and is necessary to run a node.
After registering, operators download and install Docker, an industry-standard way to deploy software in a quick, convenient, and controlled environment that minimizes configuration steps and errors for those running it.
Docker works on Linux, Mac, and Windows computers, as well as any modern server environment, and is often even preinstalled with commercial hosting accounts.
Node operators then simply run a command that downloads, installs and runs the Presearch Node software in one step. Once a node is running, it connects to and registers with the Presearch gateway, and the gateway then monitors the node and begins routing search requests to it as long as the node remains healthy.
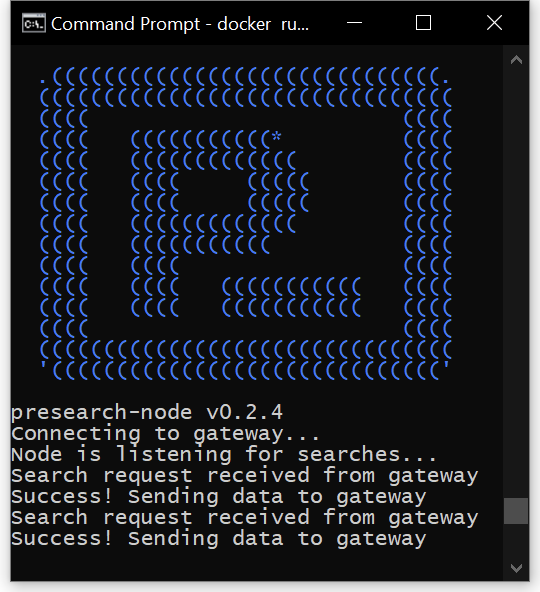
Console output for a search node running and serving search requests.
Searchers use the new Presearch Engine powered by decentralized Presearch nodes just like they normally would any other search engine. The difference is in how queries are processed on the back end.
When a query is submitted, it is received by the Presearch gateway which then redirects it to an active node for processing. The search is anonymized to prioritize user privacy, ensuring that personally identifying information (like IP addresses, account information, or other sensitive information) is not passed through to the search node.
The node sends the query out to a range of search engines and APIs that return results that are then combined into the search results page, complete with on-page search snippets and extended information, as well as Presearch keyword staking ads.
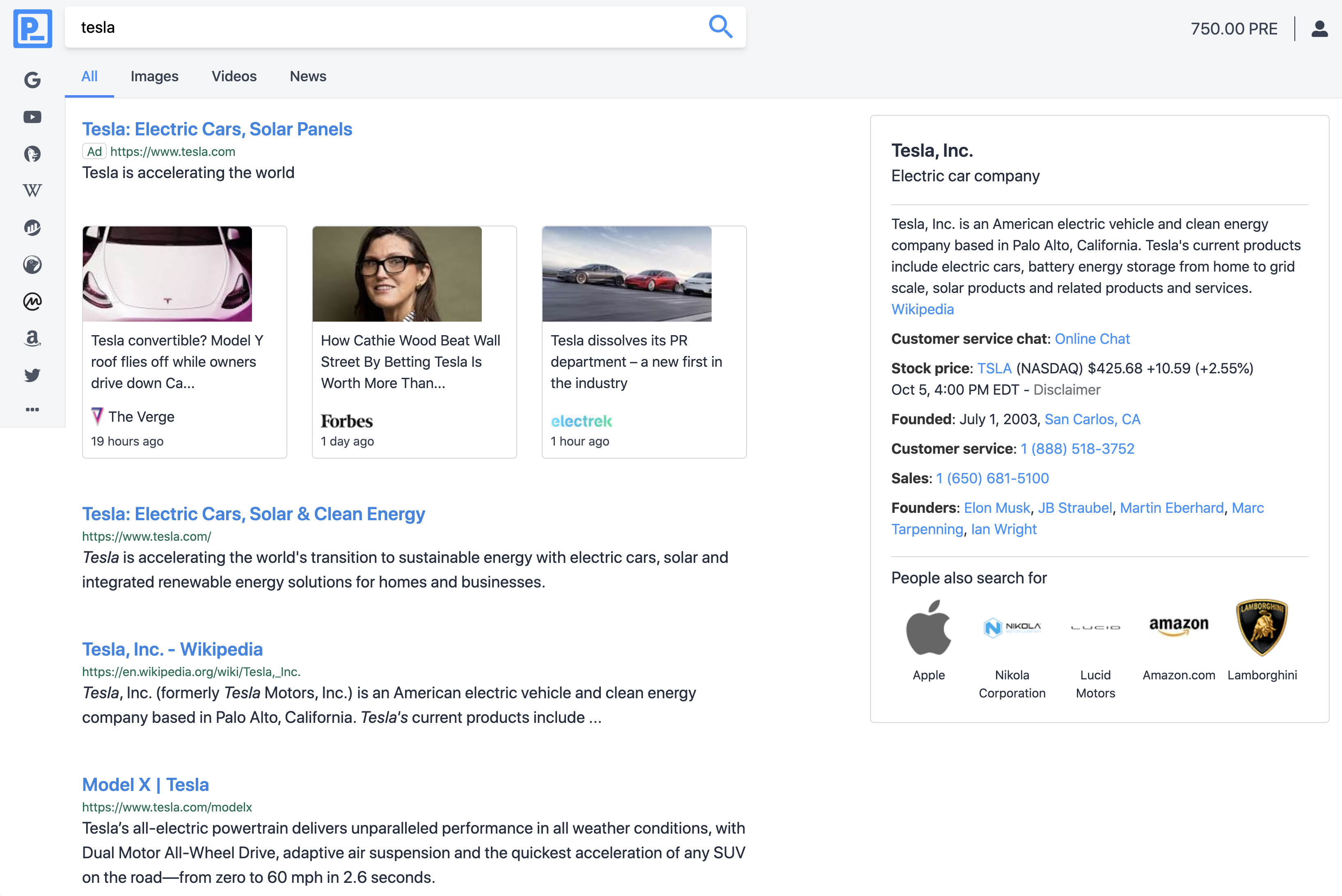
Search results from the new Presearch Engine, powered by decentralized search nodes.
After pushing through some initial challenges faced by less technical team members, everyone was able to run a node on their machines, having it register with the gateway and serve search results.
Considering this was the first time many of the initial testers had ever installed Docker or used the current command line interface needed to start a node, it went well and everyone agreed that even in a still somewhat unpolished state, setup was straightforward and simple.
Search results served were found to be very high-quality, comparable to the world’s best search engines, with the added benefit of privacy and token rewards.
Now that we’ve progressed to the point of having a working system and a small group of initial beta testers, the development team will continue to refine the platform, optimize its performance, and improve usability for both node operation and the end-user search experience until they are ready to be released to a wider tester audience ahead of public launch later in 2020.
We will keep all of those who signed up to be beta testers posted via email as well as our social channels to let them know as we continue to expand the test to more people on different platforms to ensure performance and compatibility.
We can’t wait to release this new platform to the world, and we believe that this is going to significantly improve the Presearch search experience, enabling us to begin aggressively targeting user growth, particularly in geographic areas like North America and Europe where user expectations are higher and retention is more challenging.
At this time, we’d like to thank our development team for all of the time they’ve put into getting us to this initial beta stage and enabling us to begin realizing the project’s ultimate vision of building a globally-decentralized search engine.
Please follow our progress on Presearch search nodes on our social channels:
Telegram
https://t.me/presearchnews
https://t.me/presearch
Twitter
https://twitter.com/presearchnews
https://twitter.com/teampresearch