This guide demonstrates:
- How to install IPEX-LLM for Intel NPU on Intel Core™ Ultra Processors
- Python and C++ APIs for running IPEX-LLM on Intel NPU
Important
IPEX-LLM currently only supports Windows on Intel NPU.
- Install Prerequisites
- Install
ipex-llmwith NPU Support - Runtime Configurations
- Python API
- C++ API
- llama.cpp Support
- Accuracy Tuning
Important
It is highly recommended to update your NPU driver to 32.0.100.3104, which has been thoroughly verified.
To update driver for Intel NPU:
-
Download the NPU driver
- Visit the official Intel NPU driver page for Windows and download the driver zip file.
- Extract the driver zip file
-
Install the driver
- Open Device Manager and locate Neural processors -> Intel(R) AI Boost in the device list
- Right-click on Intel(R) AI Boost and select Update driver
- Choose Browse my computer for drivers, navigate to the folder where you extracted the driver zip file, and select Next
- Wait for the installation finished
-
(Optional) Uninstall and update the driver
Please skip this if you have successfully installed. This is required when the driver to be installed is lower than current version.
- Open Device Manager and locate Neural processors -> Intel(R) AI Boost in the device list
- Right-click on Intel(R) AI Boost and select Uninstall driver
- Choose Attempt to remove the driver for this device and select Uninstall
- Locate and click Add Drivers in the toolbar, choose the folder where you extracted the driver zip file, and select Next
- Wait for the installation finished, locate and click Scan for hardware changes in the toolbar
A system reboot is necessary to apply the changes after the installation is complete.
Note
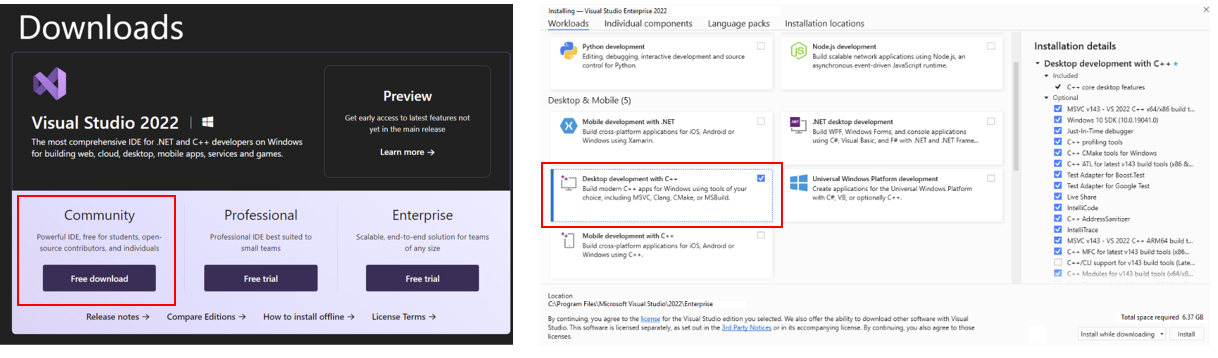
To use IPEX-LLM C++ API on Intel NPU, you are required to install Visual Studio 2022 on your system. If you plan to use the Python API, skip this step.
Install Visual Studio 2022 Community Edition and select "Desktop development with C++" workload:
Visit Miniforge installation page, download the Miniforge installer for Windows, and follow the instructions to complete the installation.

After installation, open the Miniforge Prompt, create a new python environment llm-npu:
conda create -n llm-npu python=3.11Activate the newly created environment llm-npu:
conda activate llm-npuTip
ipex-llm for NPU supports Python 3.10 and 3.11.
Note
Cmake installation is for IPEX-LLM C++ API on Intel NPU. If you plan to use the Python API, skip this step.
With the llm-npu environment active, install CMake:
conda activate llm-npu
pip install cmakeWith the llm-npu environment active, use pip to install ipex-llm for NPU:
conda activate llm-npu
pip install --pre --upgrade ipex-llm[npu]For ipex-llm NPU support, please set the following environment variable with active llm-npu environment based on your device:
-
For Intel Core™ Ultra Processors (Series 2) with processor number 2xxV (code name Lunar Lake):
-
For Intel Core™ Ultra 7 Processor 258V:
No runtime configuration required.
-
For Intel Core™ Ultra 5 Processor 228V & 226V:
set IPEX_LLM_NPU_DISABLE_COMPILE_OPT=1
-
-
For Intel Core™ Ultra Processors (Series 2) with processor number 2xxK or 2xxH (code name Arrow Lake):
set IPEX_LLM_NPU_ARL=1
-
For Intel Core™ Ultra Processors (Series 1) with processor number 1xxH (code name Meteor Lake):
set IPEX_LLM_NPU_MTL=1
IPEX-LLM offers Hugging Face transformers-like Python API, enabling seamless running of Hugging Face transformers models on Intel NPU.
Refer to the following table for examples of verified models:
Tip
You could refer to here for full IPEX-LLM examples on Intel NPU.
IPEX-LLM also provides Python API for saving/loading models with low-bit optimizations on Intel NPU, to avoid repeated loading & optimizing of the original models. Refer to the Save-Load example for usage in details.
IPEX-LLM also provides C++ API for running Hugging Face transformers models.
Refer to the following table for examples of verified models:
| Model | Model link | Example link | Verified Platforms |
|---|---|---|---|
| LLaMA 2 | meta-llama/Llama-2-7b-chat-hf | link | Meteor Lake, Lunar Lake, Arrow Lake |
| LLaMA 3 | meta-llama/Meta-Llama-3-8B-Instruct | link | Meteor Lake, Lunar Lake, Arrow Lake |
| LLaMA 3.2 | meta-llama/Llama-3.2-1B-Instruct, meta-llama/Llama-3.2-3B-Instruct | link | Meteor Lake, Lunar Lake, Arrow Lake |
| Qwen 2 | Qwen/Qwen2-1.5B-Instruct, Qwen/Qwen2-7B-Instruct | link | Meteor Lake, Lunar Lake, Arrow Lake |
| Qwen 2.5 | Qwen/Qwen2.5-3B-Instruct | link | Lunar Lake |
| Qwen/Qwen2.5-7B-Instruct | link | Meteor Lake, Lunar Lake, Arrow Lake | |
| DeepSeek-R1 | deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B, deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | link | Meteor Lake, Lunar Lake, Arrow Lake |
| MiniCPM | openbmb/MiniCPM-1B-sft-bf16, openbmb/MiniCPM-2B-sft-bf16 | link | Meteor Lake, Lunar Lake, Arrow Lake |
Tip
You could refer to here for full IPEX-LLM examples on Intel NPU.
IPEX-LLM provides llama.cpp compatible API for running GGUF models on Intel NPU.
Refer to the following table for verified models:
| Model | Model link | Verified Platforms |
|---|---|---|
| LLaMA 3.2 | meta-llama/Llama-3.2-3B-Instruct | Meteor Lake, Lunar Lake, Arrow Lake |
| DeepSeek-R1 | deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B, deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | Meteor Lake, Lunar Lake, Arrow Lake |
First, you should create a directory to use llama.cpp, for instance, use following command to create a llama-cpp-npu directory and enter it.
mkdir llama-cpp-npu
cd llama-cpp-npuThen, please run the following command with administrator privilege in Miniforge Prompt to initialize llama.cpp for NPU:
init-llama-cpp.batBefore running, you should download or copy community GGUF model to your current directory. For instance, DeepSeek-R1-Distill-Qwen-7B-Q6_K.gguf of DeepSeek-R1-Distill-Qwen-7B-GGUF.
Please refer to Runtime Configurations before running the following command in Miniforge Prompt.
llama-cli-npu.exe -m DeepSeek-R1-Distill-Qwen-7B-Q6_K.gguf -n 32 --prompt "What is AI?"And you could use llama-cli-npu.exe -h for more details about meaning of each parameter.
IPEX-LLM also supports llama.cpp C++ API for running GGUF models on Intel NPU. Refer to Simple Example for usage in details.
Note:
- Warmup on first run: When running specific GGUF models on NPU for the first time, you might notice delays up to several minutes before the first token is generated. This delay occurs because the blob compilation.
IPEX-LLM provides several optimization methods for enhancing the accuracy of model outputs on Intel NPU. You can select and combine these techniques to achieve better outputs based on your specific use case.
You could set environment variable IPEX_LLM_NPU_QUANTIZATION_OPT=1 before loading & optimizing the model with from_pretrained function from ipex_llm.transformers.npu_model Auto Model class to further enhance model accuracy of low-bit models.
IPEX-LLM on Intel NPU currently supports sym_int4/asym_int4/sym_int8 low-bit optimizations. You could adjust the low-bit value to tune the accuracy.
For example, you could try to set load_in_low_bit='asym_int4' instead of load_in_low_bit='sym_int4' when loading & optimizing the model with from_pretrained function from ipex_llm.transformers.npu_model Auto Model class, to switch from sym_int4 low-bit optimizations to asym_int4.
When loading & optimizing the model with from_pretrained function of ipex_llm.transformers.npu_model Auto Model class, you could try to set parameter mixed_precision=True to enable mixed precision optimization when encountering output problems.
IPEX-LLM low-bit optimizations support both channel-wise and group-wise quantization on Intel NPU. When loading & optimizing the model with from_pretrained function of Auto Model class from ipex_llm.transformers.npu_model, parameter quantization_group_size will control whether to use channel-wise or group-wise quantization.
If setting quantization_group_size=0, IPEX-LLM will use channel-wise quantization. If setting quantization_group_size=128, IPEX-LLM will use group-wise quantization with group size 128.
You could try to use group-wise quantization for better outputs.