the tag generation feature can only read english parts? #551
Comments
|
Hi, I've been trying the scenarios you described but I couldn't replicate them, in my case it's working fine, it adds all the variations correctly.
It occurs to me that the error may be caused by the OBS_TAG_REGEXP regex. const OBS_TAG_REGEXP = /#(\w+)/gThis regex is unable to select Chinese characters.
To fix this you have to add a new range that allows you to correctly select chinese characters, the new regex looks like this: const OBS_TAG_REGEXP = /#([\w\u4e00-\u9fa5]+)/gI created a PR with the new value of the variable, but I would like to know if this solution solves your problem @panAtGitHub ? |


|
Thank you for your response; it seems like it should solve the issue with Chinese recognition. However, I downloaded the Obsidian to Anki plugin from Obsidian's built-in "Third-party Plugins" section, and I'm not sure how to update it to the latest version on GitHub before it's updated on the official platform. 谢谢您的回复,看起来应该可以解决中文识别的问题。只不过我的obsidian to anki插件是从obsidian自带的“第三方插件”中下载使用的,在官方平台没有更新前,我不知如何进行更新到github中的最新版本 |
If you want to try the new changes:
|

 That's cool, Chinese tags can now be displayed correctly. Thank you for your response, and I wish you a good mood~
太酷了,中文标签可以正常显示了,谢谢您的回复,祝您好心情~
That's cool, Chinese tags can now be displayed correctly. Thank you for your response, and I wish you a good mood~
太酷了,中文标签可以正常显示了,谢谢您的回复,祝您好心情~
|
|
It is worth mentioning that this new regex will select the most common chinese characters, but it will still fail with any other language containing non-latin characters. Personally, I would change the regex to make it more versatile, but my concern is that it will break something else, some alternatives that would work better might be something like this: To match any unicode letter of any language. const OBS_TAG_REGEXP = /#(\p{L}+)/guor To match anything that is not whitespace. const OBS_TAG_REGEXP = /#([\S]+)/g |
|
谢谢,但标签系统主要涉及分类,一般以简短词组呈现,故对我而言常用语足够使用了。 Thank you, but the tagging system mainly involves categorization, typically presented as short phrases, so common language is sufficient for my use. Although it occurred to me while typing this that emojis could be used as tags—I currently have no plans to use them in my note-taking system. Of course, from the perspective of the program's versatility, making the regular expression adaptable to a wider range of expressions is certainly a good thing~ |
|
当然,看起来这个表达式更加简洁些
but it seems not good now i use this regexp 

|

|
Interesting, that's what I was worried about. That's the problem with regex, any slight change and it can break everything.
Now to get the best of both groups I opted to use the unicode categories, that should give us the best result. const OBS_TAG_REGEXP = /#([\p{L}\p{N}\p{Emoji}\p{M}_-]+)/gu;Now the regex will match any word, number, emoji, mark character, underscore, or dash character after the const OBS_TAG_REGEXP = /#([\p{L}\p{N}\p{Emoji}\p{M}_-]+)/gu;
// Example 1: English words and numbers with underscore and dash
const str1 = "This is a #sample_123-string with #hashtags_and_more.";
const matches1 = str1.match(OBS_TAG_REGEXP).map(match => match.substring(1));
console.log(matches1); // Output: ["sample_123-string", "hashtags_and_more"]
// Example 2: Mixed languages, emojis, symbols, and marks with underscore and dash
const str2 = "This is a #Пример123_string_with #한국어_and #😊, as well as #symbols-and-dashes.";
const matches2 = str2.match(OBS_TAG_REGEXP).map(match => match.substring(1));
console.log(matches2); // Output: ["Пример123_string_with", "한국어_and", "😊", "symbols-and-dashes"]
// Example 3: Only underscores and dashes
const str3 = "This is a #____-__- string with #____-__-.";
const matches3 = str3.match(OBS_TAG_REGEXP).map(match => match.substring(1));
console.log(matches3); // Output: ["____-__-", "____-__-"]
// Example 4: Mixed characters with underscores and dashes
const str4 = "This is a #sample-123_string_with-#한국어_and-<asda#😊";
const matches4 = str4.match(OBS_TAG_REGEXP).map(match => match.substring(1));
console.log(matches4); // Output: ["sample-123_string_with-", "한국어_and-", "😊"]
They can also be nested if you use
It is worth mentioning that I intentionally left out the I add also the links to the official mozilla and unicode documentation in case you want to modify it to your liking. https://unicode.org/Public/UCD/latest/ucd/PropertyValueAliases.txt |



|
哇,你进一步对表达式的修改实在太酷了,我只会些非常基本的正则表达式,所以非常感谢你的持续修改。 Wow, your further modifications to the expression are really cool. I only know some very basic regular expressions, so I am very grateful for your continuous modifications. 当然,我也只是按您讲的将正则表达式进行了修改,并没有修改其他东西,所以早已想过现在这个嵌套语句不会成功 Of course, I simply modified the regular expression as you instructed and didn't change anything else, so I've already considered that the current nested statement would not be successful. 


|
Not necessarily, if you want to add support for obisidan nested tags you would only need to add the const OBS_TAG_REGEXP = /#([\p{L}\p{N}\p{Emoji}\p{M}_/-]+)/gu;
// New character "/" added here ⬆️
If you want the tags to be nested you have to use the More info can be found in the wiki for tag formatting Example using Both will yield the same result:
Here is a working example on a personal deck using IMPORTANT: If you use the For example:
|



|
哦,抱歉,我的表述可能有问题,导致您的理解出现偏差 Oh, sorry, there might have been an issue with how I expressed myself, leading to a misunderstanding on your part. In Anki, the nested expression is like this: Programming::Code, and its logical representation in the program is as follows: That's why I mentioned the need for a format conversion, to make the nested tags from Obsidian display correctly in Anki, that is, converting the "/" read from Obsidian into "::" used in Anki. 在我的目前笔记系统中其实并不需要嵌套标签的系统。因为我对每个信息块,只需要至少三个并列的标签而已,所以现在的正则表达式语法其实也是满足要求的。我只是想到嵌套标签就给您提及了,希望不要增加您的困扰,祝开心~ In my current note system, I actually don't need a nested tag system. For each piece of information, I only need at least three parallel tags, so the current regular expression syntax actually meets my requirements. I just thought of nested tags and mentioned them to you, hoping not to add to your troubles. Wishing you happiness~ 
|


|
Ohh, I see, maybe in the future the plugin will have the ability to transform obsidian nested tags into anki nested tags without the need to modify the original note. It's easy to achieve, but I don't know what the repository maintainers will think. |
|
Haha, the tagging feature is already pretty good now. Thank you for your patience in answering these past few days. Thank you, and wish you happiness and joy. Previously, my answers were all translated using ChatGPT. I hope it didn't cause any misunderstandings, haha. |
Hello, I used ChatGPT to solve this conversion problem today, and I made three modifications. 2,Modified such logic in the AbstractNote and RegexNote classes. RegexNote classes The code style here looks strange, this is the answer given by ChatGPT. The effect is as follows,The image above shows the multi-level tag style in Obsidian, and the image below shows the multi-level tag style in Anki: |



|
It looks great! Maybe you could include the code in a new pull request so the maintainers can evaluate it and possibly include it in the next version of the plugin. But for that you would have to convert the changes to typescript and then find the file |
Thank you so much for your encouragement. With your support, I've tried submitting a pull request. Also, thanks to ChatGPT, I've experienced the joy of being a newbie programmer, haha. |
TARGET DECK
[[2024-03-17,关于标签的试验]]
对作者的交流
你好,我在使用 obsidian to anki 的标签生成功能时,发现其只能读取英文部分,不能读取中文部分,不知这是否是个 bug,可否修复下,谢谢。
PS:我的试验过程如下文所示:
Hello, I've noticed when using the tag generation feature from Obsidian to Anki that it can only read the English part and fails to read the Chinese part. I'm not sure if this is a bug, but could it be fixed, please? Thank you.
P.S. My experimental process is as described in the following text:
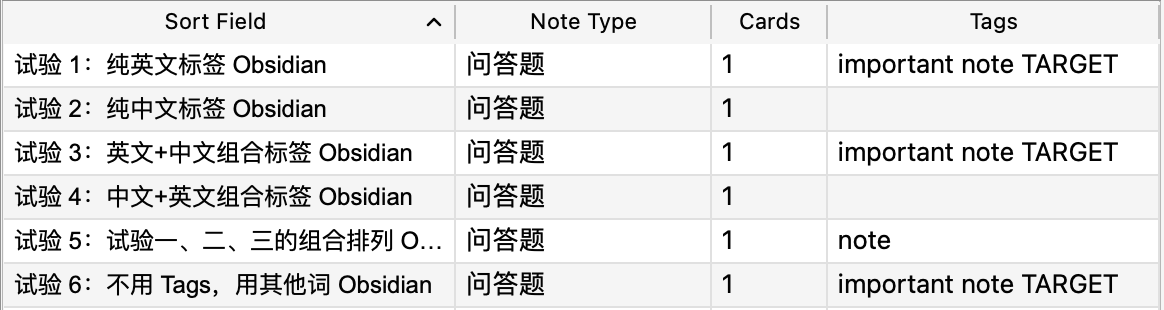
试验 1:纯英文标签
结果:anki 可以正常读取英文标签
Results: Anki can properly read English tags.
Tags: #note #TARGET #important
试验 2:纯中文标签
结果:不行,不能读取中文标签
Results: No, it cannot read Chinese tags.
Tags: #目标 #笔记 #重要
试验 3:英文+中文组合标签
结果:anki 读取英文部分,不能读取中文部分
Results: Anki reads the English part, cannot read the Chinese part.
Tags: #note笔记 #TARGET目标 #important重要
试验 4:中文+英文组合标签
结果:anki 不能读取相关标签,即中文在前时不能进行识别
Results: Anki cannot recognize the related tags when Chinese comes first.
Tags: #目标target #笔记note #重要important
试验 5:试验一、二、三的组合排列
结果:混合标签情况下,还是试验一、二的标签可以正常读取,试验三的标签样式不得行
Results: In the case of mixed tags, only the tags from experiments 1 and 2 can be properly read; the tag style from experiment 3 does not work.
Tags: #note #note笔记 #笔记note #笔记
试验 6:不用 Tags,用其他词
结果:正常生成英文标签
Results: English tags are generated normally.
T: #note #note笔记 #笔记note
标签: #note笔记 #TARGET目标 #important重要
试验结论
推荐使用:英文、或英文+中文组合标签,即试验 1 与 3 两种形式。
Recommendation: Use English or English + Chinese combination tags, namely the forms from experiments 1 and 3.
The text was updated successfully, but these errors were encountered: