Visualize your assembly with IGV
IGV: Integrative Genomics Viewer.
We will use this software to evaluate our assemblies, among others to view how the reads map to the assembly.
We will also add tracks with genome annotation and gaps.
Read mapping is aligning each of your reads to a/the matching locus on a longer sequence (assembly). You could think of it at the location of where your read would hybridize to your genome if you could do this experiment.
Usually few mismatches are allowed (think about the consequences). A portion of the reads may map to several loci in your genome (ie. in repeated regions).
Reads can be mapped as paired or single. If paired is used, then the matching regions are defined by the insert size and the length of each read
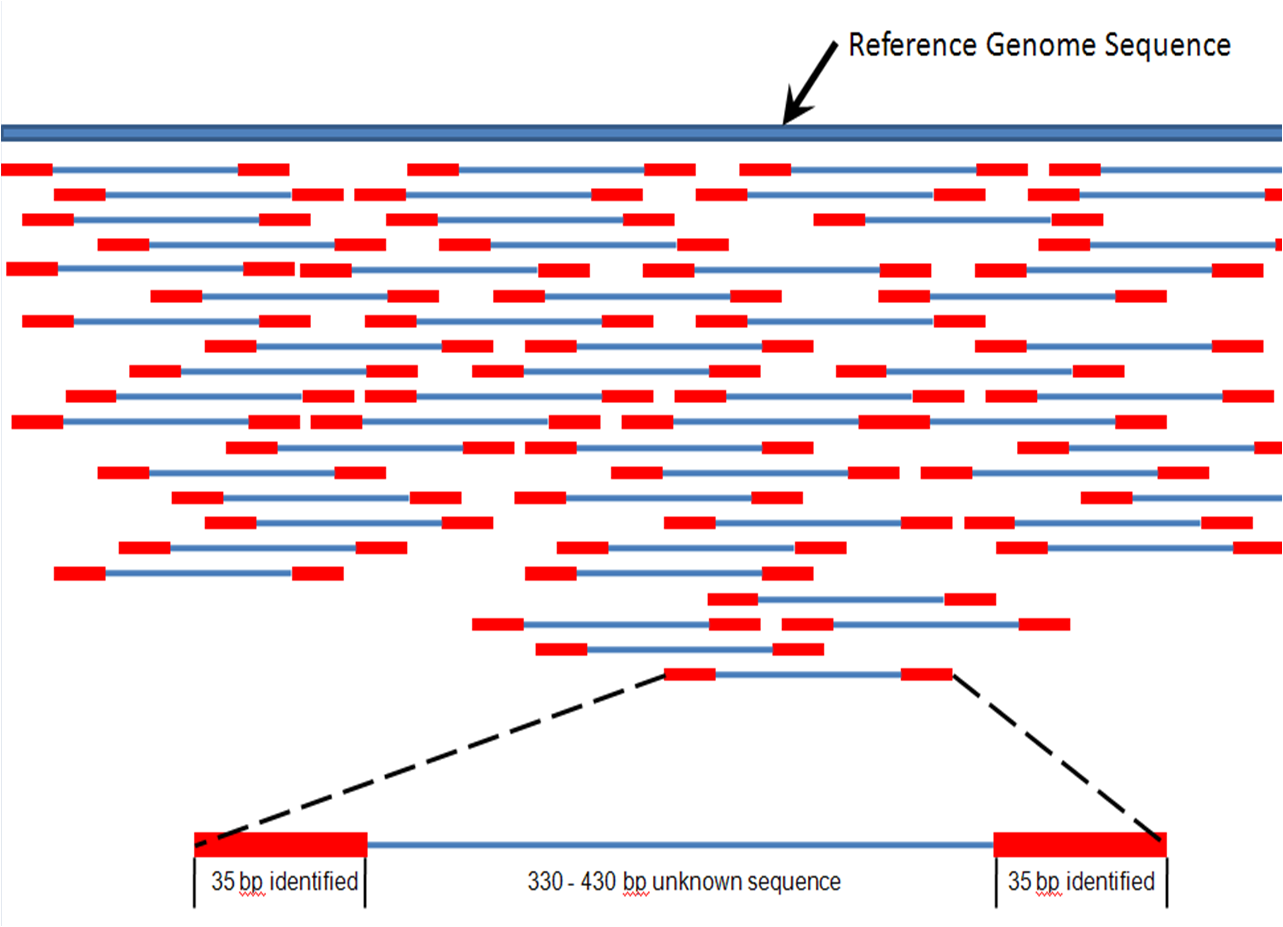
Read mapping techniques are used for several purposes. Some examples:
-
To evaluate the quality of an assembly (or to compare different methods used to assemble your reads). Read mapping can help identifying problematic areas in your assembly process. Indeed, statistics are necessary but might not be sufficient to evaluate the quality of your assembly.
We want to look at:
- the coverage regularity (ex: some repeated regions might have increased coverage)
- the coverage at the beginning and end of scaffolds - is it good enough?
- are they positions where pileup of reads show polymorphism?
- ...
-
Assembly polishing software such as
pilonandreapruse mapped reads to identify potential positions where your assemblies should be improved. It is good to visualize what information they are using.Softwares can use variation in coverage, wrong read pairs orientation, discrepancy between expected insert size and actual insert size obtained from read mapping (ie. longer than expected) to improve assembly.
-
To identify SNPs: some methods use reads mapping against a reference genome to identify and type variants/SNPs (e.g. snippy)
We use bwa mem option from bwa tools software.
We have assembled reads and annotated using Bifrost pipeline. The data for today's practical are found in /cluster/projects/nn9305k/tutorial/20210412_mapping_visualization
Mapping can be done either with raw reads or trimmed reads. If you are interested to see if there are positions with SNPs, it is easier to use trimmed-reads (avoiding the visualization noise provide by adapters)
You will use the files provided in this folder: /cluster/projects/nn9305k/tutorial/20210412_mapping_visualization/practical, to be able to visualize the assembly with IGV.
- the raw_reads:
MiSeq_Ecoli_MG1655_50x_R{1,2}.fastq.gz - the trimmed-reads:
MiSeq_Ecoli_MG1655_50x_{R1,R2,S}_concat_stripped_trimmed.fq.gz - the assembly (polished with Pilon, output during prokka annoation):
MiSeq_Ecoli_MG1655_50x.fna(fasta format) - the genome annotation file(.gff) provided by
Prokka:MiSeq_Ecoli_MG1655_50x.gff - A script that will allow to create a
.bedfiles, to easily identify scaffolds limitsscaffoldgap2bed_py3.py(more information bellow)
NB: Note that scaffold names between assembly and annotations have to be consistent to link the genome annotation to the assembly and to reads tracks for the visualization in IGV. This is why we used the assembly that prokka output (this is the sequence is the same as .fasta assembly polished by pilon. However, Prokka transforms scaffold names from the assembly used as input. If scaffold names in the annotation file and sequence file are not consistent, IGV will not manage to link the information of both files. If you encounter such case, the solution is to use an alias file, file that will provide IGV the correspondance between contigs of your sequence/assembly and the annotation file. This is described here
PRACTICAL EXERCISE:
NB: Convention: means <change_me>
In your `home` directory make a directory for today's work and a folder called `mapping` where you will **copy** the input files
cd <home>
mkdir mapping
cd mapping
rsync -rauPW /cluster/projects/nn9305k/tutorial/20210412_mapping_visualization/practical/* .You can look at the file content e.g. (one reads-file, the assembly file):
head MiSeq_Ecoli_MG1655_50x.fna
gunzip -cd MiSeq_Ecoli_MG1655_50x_S_concat_stripped_trimmed.fq.gz | headThe mapping tool is called bwa tools. It is installed in the Bifrost pipeline conda environment.
Here are options:
- You can use the raw_reads for mapping
- You can use the trimmed reads for mapping
- You can perform 2 mappins with raw_reads and trimmed reads (2 times). This might be interesting if you want to look at the effect of trimming or not on the mapping visually.
For the tutorial, you will chose one solution 1 or 2. (Solution 3 is if you are curious and want to repeat the exercise)
You will ask for interactive ressources in saga and activate the bifrost environment. (We use the queue for testing purposes: devel)
srun --account=nn9305k --mem-per-cpu=4G --cpus-per-task=2 --qos=devel --time=0:30:00 --pty bash -i
conda activate bifrostTo map the reads to an assembly/reference we need to:
- Index the reference: we are in this case using the assembly as reference
bwa index <reference.fna>- We map the reads (attribute the position of the reads according to the index) and sort the mapped reads by index position
- for paired reads (PE).
NB: Here
-means that the output of the pipe|is used as input in samtools. And\is used to indicate that your code (instructions) continues on the next line
bwa mem -t 4 <reference.fna> <in1:read1.fq.gz> <in2:read2.fq.gz> \
| samtools sort -o <out:PE_mapped_sorted.bam> -- If you used trimmed reads (follow bellow)
-- you also have unpaired reads (called S here) we map as such:
bwa mem -t 4 <reference.fna> <in:S_reads.fq.gz> \
| samtools sort -o <out:S_mapped_sorted.bam> --- you need to merged the mapped PE and S reads as such:
samtools merge <out:all_merged.bam> <in1:S_mapped_sorted.bam> <in2:PE_mapped_sorted.bam>-- we need to be sure merged reads are still sorted by index: we resort
samtools sort -o <out:final_all_merged.bam> <in:all_merged.bam>OPTIONAL
NB: Some software like Pilon need and updated index after merging bam files). You do that by running:
samtools index <final_all_merged.bam>1.4 The sam/bam file format
You can also have a look at Samtools article and at Samtools manual
.bam files are in a compressed binary format. We need to transform the .bam (to a .sam file) to be able to see how mapped-reads are represented in the file.
PRACTICAL EXERCISE:
To decompress: chose f.eks. PE_mapped_sorted.bam that we did in the first step:
samtools view -h -o <out.sam> <in.bam>Look at your .sam file using:
less <filename.sam>1.5 looking at how the reads maps against the reference with Samtools tview module
- looking at the reads pileup with SAMtools
- use
-p <position>if you want to see a specific position - type
?to view the navigation help while samtools is running - type
qto quit
- use
PRACTICAL EXERCISE:
samtools tview <final_all_merged.bam> --reference <assembly>We use a little python script from sequencetools repository to insert gap locations into a file and load it as a track in IGV. This will allow to easily locate the different scaffolds and potentially problematic regions. This is how we generate the file:
Using this script requires Biopython. On Saga: we use biopython that is installed in bifrost environment to generate the .bed file
PRACTICAL EXERCISE:
path_script="path"
conda activate bifrost
python scaffoldgap2bed_py3.py -i <assembly.fna> > <gap_file>.bedIf you can install IGV on your pc do so. Otherwise use the rescue solution to work with SAGA.
If want to do that at your PC you can install IGV as such
PRACTICAL EXERCISE:
conda create -n <envname> -c bioconda igv
conda activate <IGV:envname>From the folder you want to work in transfer the following files from Saga to your pc:
- the assembly
.fnaand annotation files.gff - the final
.bamfile - the
.bedfile
scp <user_name>:<your_mapping_folder_assembly_AND_annotation_files> .It is possible to use graphical interface on Saga.
Login to saga using the -Y option
PRACTICAL EXERCISE:
ssh -Y <username>@saga.sigma2.noDo a simple test that to check that it is working
xeyestype ctrl+C to kill xeyes
Ask for ressources on Saga to use IGV (do not forget --x11)
srun --account=nn9305k --mem-per-cpu=16G --cpus-per-task=1 --qos=devel \
--time=0:30:00 --x11 --pty bash -i
conda activate igv
igvA window with IVG should open. You will see several error messages that it tries to load a genome file, ignore those (it is because there are some server data that try to be loaded but we do not need those)
2.3 Loading files in IGV

PRACTICAL EXERCISE:
- Create a
genome filethis allows associating tracks to the assembly :Genomes > create.genome file. Use the menu to select your assembly file.fastaand the annotation-gene file:.gff.
NB: You need to fill the
unique identifierANDdescriptive namefileds.
- Locate and Load your
mapped readsand thegap fileusing:file > load from file
- if you use SAGA here: you need to navigate throught the file structure: cluster>projects>nn9305k>active> and your own folder
- To be able to easily re-open (without re-importing everything you can do):
file > save session
- be carrefull where you save in the navigator when using SAGA
Now you are ready to navigate and explore your assembly.
Try to find a gap.
NB: To zoom while staying centered on the gap: click above menu (position within the scaffold - at the gap - top track) then click with the mouse at the gap position on the gap track (until appropriate zoom is obtained).
You can look here for Options and interpretation, and here: PE orientations.
Have a look at:
- coverage
- gaps positions
- some strange scaffolds?
- PE orientations: in detail how the reads map to your assembly (you will need to zoom a lot)
- are some PE reads miss-oriented? reported as having abnormal insert sizes?
You can look here at the Uio course for more details or if you want to do things slightly differently. We reuse some of their scripts.