A practical example of Apache Spark using the Stack Exchange dataset.
Skip to..
- Project & Demo
- Running the full Mesos demo
- Output - See the output of the "Top Co-Occurring Scala Tags" & "Scala Questions by Month" jobs
- References - Links to resources I used for this project
This project contains an Apache Spark driver application called StackAnalysis. Instructions are provided on how to run the driver application locally or on an Apache Mesos cluster.
Continue reading for more details or check out the accompanying presentation I gave at the Scala Toronto (type p in presentation to see notes).
The Spark driver application itself is a relatively short StackAnalysis.scala file in the respository.
I've bundled a 100k line sample of the StackOverflow.com posts data in this repository. To use the full StackOverflow.com dataset you must download the BitTorrent from the Internet Archive.
More information about the Stack Exchange data dump.
To run the local example download the Spark binaries and set the SPARK_HOME variable in the bin\run-stackanalysis-local.sh script. Package the app (sbt package) and then run the script.
Or, to run the example with Spark's provided spark-submit shell script. Set or replace $SPARK_HOME with where you unpacked your Spark binaries.
git clone https://github.com/seglo/learning-spark.git
cd learning-spark
LS_HOME=$(pwd)
sbt package
# run locally on all cores
$SPARK_HOME/bin/spark-submit --class "StackAnalysis" --master local[*] $LS_HOME/target/scala-2.10/learning-spark_2.10-0.1.0.jar \
--input-file file://$LS_HOME/data/stackexchange/stackoverflow.com-Posts/Posts100k.xml \
--output-directory file://$LS_HOME/data/output Output is persisted to the local file system at data/output/
You can run Spark applications on a cluster using several different technologies. Consult Spark's documentation for more details.
In my presentation I used an Apache Mesos cluster generated for me by Mesosphere. You may take advantage of Google Cloud Compute's deal where you can get $300 or 60 days of any of their services for free (28/03/15).
Sign up on Google Cloud Compute and click the "Start your free trial" button. A credit card is required, but they guarantee that they won't charge it without your expressed permission. I interpretted this as once your $300 or 60 days are up they will ask if you want to upgrade your account, but I haven't yet reached this point, so proceed at your own risk!
Create a new project you will use for your development cluster.
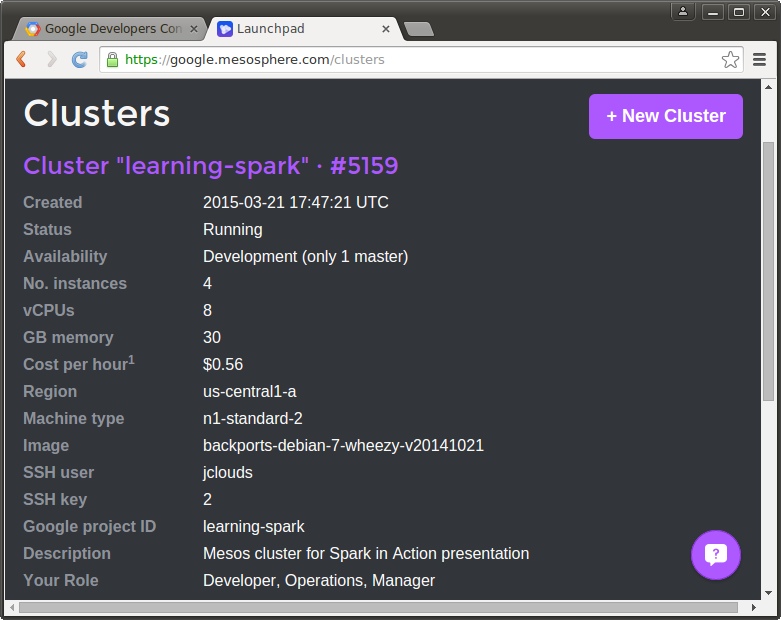
Mesosphere can automatically setup and configure a basic mesos cluster for you by using your Google Cloud Compute's API and your access key. To read more about the process check out Getting Started with Mesosphere for Google Cloud Platform. Once you're ready to proceed you can proceed with the setup with this link.
https://google.mesosphere.com/
After the cluster is setup you should have 4 VM's setup of type n1-standard-2 each with 2 vCPU, 7.5GB RAM, 10GB boot disk. You can manage them with Google Cloud Compute's web console or using their gcloud CLI tool
$ gcloud compute instances list --project learning-spark
NAME ZONE MACHINE_TYPE INTERNAL_IP EXTERNAL_IP STATUS
development-5159-d3d us-central1-a n1-standard-2 10.217.7.180 146.148.xxx.xxx RUNNING
development-5159-b61 us-central1-a n1-standard-2 10.144.195.205 104.197.xxx.xxx RUNNING
development-5159-d9 us-central1-a n1-standard-2 10.173.40.36 104.197.xxx.xxx RUNNING
development-5159-5d7 us-central1-a n1-standard-2 10.8.67.247 104.154.xxx.xxx RUNNINGA handy reference page from mesosphere with pertinent details about your cluster. It also contains details on how to establish an OpenVPN VPN connection to it.
The default n1-standard-2 image only comes with a boot disk of 10GB. Mesosphere will configure HDFS to run on this disk, which with HDFS replication isn't a whole lot of space to work with on your cluster. I attached new fresh 500GB local storage to each node in my cluster (including master), so I could work with the entire stackexchange dataset.
Spark supports AWS S3 which would make this work a lot easier, but AFAIK it doesn't support Google equivalent Cloud Storage or Cloud Datastore features.. this may make for an interesting project for someone!
Add a new persistent disk to each of your VM's using the Console or gcloud CLI tool.
Once you've attached the new drive you need to mount it and make it accessible for HDFS.
# Find out the device name (i.e. /dev/sdb)
sudo fdisk -l
# Create your mount point and mount the device
sudo mkdir /hdfs
sudo /usr/share/google/safe_format_and_mount -m "mkfs.ext4 -F" /dev/sdb /hdfs
# Give the HDFS daemon ownership of the drive
sudo chown hdfs:hadoop /hdfs
# Update your /etc/fstab to mount the device on boot
sudo echo "/dev/sdb /hdfs ext4 defaults 0 0" >> /etc/fstabUpdate your HDFS config to use the new drive or create a symlink. Edit /etc/hadoop/conf/hdfs-site.xml.
NOTE: There's certainly a way to do this without destroying anything on your HDFS partition, but as there's very little on the partition anyhow I decided to proceed in creating a new one and formatting it.
<property>
<name>dfs.datanode.data.dir</name>
<!-- <value>/var/lib/hadoop-hdfs/data</value> -->
<value>/hdfs</value>
</property>Restart the hdfs datanode service.
sudo /etc/init.d/hadoop-hdfs-datanode restartPerform the same steps as with the slaves above (except for restarting the datanode service, as it's not running on master).
NOTE: After you format HDFS you will need to re-add your spark binaries to the HDFS filesystem as mentioned in the "Uploading Spark Package" section on the Run on Mesos cluster guide.
# Restart the namenode service
sudo /etc/init.d/hadoop-hdfs-namenode restart
# Format the HDFS filesystem.
hadoop namenode -format
# Exit safe mode
hdfs dfsadmin -safemode leave
# Check the health of the HDFS
hdfs dfsadmin -reportAfter running the report you should see something like this, along with stats on each data node.
jclouds@development-5159-d9:~$ hdfs dfsadmin -report
Configured Capacity: 1584938655744 (1.44 TB)
Present Capacity: 1406899326976 (1.28 TB)
DFS Remaining: 1310000644096 (1.19 TB)
DFS Used: 96898682880 (90.24 GB)
DFS Used%: 6.89%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
... datanode statsDownload the StackOverflow.com dataset directly to the new drive you mounted on your namenode. I suggest this because I made the unfortunate mistake of downloading it locally and attempting to upload it to my development cluster with a mere 1mbps connection.
Unpack the archive and add the stackoverflow.com-Posts/Posts.xml file to HDFS.
hdfs dfs -mkdir -p /stackexchange/stackoverflow.com-Posts
hdfs dfs -put stackoverflow.com-Posts/Posts.xml /stackexchange/stackoverflow.com-Posts/Posts.xmlI scripted some of the configuration I used to run the StackAnalysis application on mesos. To use this setup the necessary configuration (SPARK_HOME, MASTER_HOST, and SPARK_EXECUTOR_URI) in conf/mesos/mesos-env.sh and run the job with bin/run-stack-analysis-mesos.sh or the spark-shell with bin/run-spark-shell-mesos.sh.
To run StackAnalysis using Spark's provided spark-submit then you must have configured Spark appropriately as discussed in Spark's Run on Mesos cluster guide (setup spark-defaults.xml and spark-env.sh). Then you can submit the job.
# NOTE: input-file and output-directory could also point to local filesystem with URI convention (i.e. file:///home/foo)
$SPARK_HOME/bin/spark-submit --class "StackAnalysis" --master mesos://mesos-host:5050 target/scala-2.10/learning-spark_2.10-0.1.0.jar \
--input-file hdfs://mesos-host/stackexchange/stackoverflow.com-Posts/Posts100k.xml \
--output-directory hdfs://mesos-host/outputYou can also run spark-shell and play with the dataset on the whole cluster using a standard Scala REPL.
$SPARK_HOME/bin/spark-submit --master mesos://mesos-host:5050 --jars target/scala-2.10/learning-spark_2.10-0.1.0.jarThis is the output of the StackAnalysis jobs.
$ cat data/output/ScalaQuestionsByMonth.txt/*
(2008-09,6)
(2008-10,8)
(2008-11,5)
(2008-12,3)
(2009-01,12)
(2009-02,12)
(2009-03,17)
(2009-04,27)
(2009-05,12)
(2009-06,64)
(2009-07,59)
(2009-08,71)
(2009-09,67)
(2009-10,101)
(2009-11,95)
(2009-12,84)
(2010-01,105)
(2010-02,115)
(2010-03,115)
(2010-04,163)
(2010-05,169)
(2010-06,176)
(2010-07,185)
(2010-08,170)
(2010-09,232)
(2010-10,218)
(2010-11,212)
(2010-12,228)
(2011-01,254)
(2011-02,274)
(2011-03,301)
(2011-04,275)
(2011-05,329)
(2011-06,336)
(2011-07,427)
(2011-08,436)
(2011-09,421)
(2011-10,470)
(2011-11,458)
(2011-12,376)
(2012-01,361)
(2012-02,393)
(2012-03,463)
(2012-04,405)
(2012-05,424)
(2012-06,446)
(2012-07,490)
(2012-08,464)
(2012-09,535)
(2012-10,540)
(2012-11,554)
(2012-12,482)
(2013-01,579)
(2013-02,594)
(2013-03,671)
(2013-04,690)
(2013-05,661)
(2013-06,693)
(2013-07,706)
(2013-08,691)
(2013-09,796)
(2013-10,872)
(2013-11,873)
(2013-12,842)
(2014-01,794)
(2014-02,880)
(2014-03,986)
(2014-04,973)
(2014-05,883)
(2014-06,975)
(2014-07,950)
(2014-08,922)
(2014-09,398)$ cat data/output/ScalaTagCount.txt/* | head -n 100
(2687,java)
(2205,playframework)
(1972,sbt)
(1846,playframework-2.0)
(1309,akka)
(884,lift)
(851,functional-programming)
(669,types)
(665,actor)
(650,scala-collections)
(639,json)
(544,intellij-idea)
(532,slick)
(530,generics)
(462,eclipse)
(453,pattern-matching)
(437,scala-2.10)
(418,reflection)
(376,playframework-2.1)
(374,mongodb)
(367,playframework-2.2)
(362,list)
(360,scalaz)
(346,scala-2.8)
(336,collections)
(318,xml)
(318,map)
(318,implicit)
(297,future)
(290,scalatest)
(263,maven)
(261,parsing)
(255,spray)
(250,apache-spark)
(240,implicit-conversion)
(237,android)
(236,concurrency)
(223,regex)
(220,case-class)
(218,scala-macros)
(214,specs2)
(198,jvm)
(191,arrays)
(191,performance)
(188,haskell)
(186,inheritance)
(182,swing)
(170,type-inference)
(170,scala-java-interop)
(168,unit-testing)
(168,scala-ide)
(167,traits)
(167,recursion)
(166,macros)
(166,trait)
(165,shapeless)
(165,function)
(164,anorm)
(159,immutability)
(158,multithreading)
(158,monads)
(157,casbah)
(157,parser-combinators)
(151,scalatra)
(151,string)
(143,constructor)
(143,testing)
(143,tuples)
(142,serialization)
(141,syntax)
(134,class)
(129,javascript)
(124,read-eval-print-loop)
(121,parallel-processing)
(121,squeryl)
(115,spring)
(114,algorithm)
(112,mysql)
(107,compiler)
(105,typeclass)
(103,hadoop)
(103,stream)
(100,lazy-evaluation)
(99,type-erasure)
(98,reactivemongo)
(98,clojure)
(97,forms)
(97,database)
(96,scala-2.9)
(96,templates)
(95,for-comprehension)
(94,oop)
(93,iterator)
(93,asynchronous)
(92,rest)
(91,sql)
(91,python)
(90,type-parameter)
(90,dsl)
(90,postgresql)- Spark Documentation
- Spark: Cluster Computing with Working Sets - University of Berkely paper introducing Spark - Much of the introduction of this talk is paraphrased from this paper.
spark-workshopby Dean Wampler - Spark impl. examples in a Typesafe activator project- Cloudera: Introduction to Apache Spark developer training
- Google Cloud Compute
- Mesosphere in the Cloud - Tutorials to setup mesosphere on IaaS (Amazon, DigitalOcean, Google)
- Google Cloud Compute setup
- Running Spark on Mesos - Mesosphere docs are out-of-date, use this once mesosphere sets up cluster for you.
- Spark atop Mesos on Google Cloud Platform
- Running Spark on Mesos
- YARN Architecture
- HDFS Architecture
docker-sparkby SequenceIQ - If you want to play around with a YARN cluster config