In the case of image classification implementation of deep neural networks plays an important in order to achieve high accuracy and performance and Convolutional Neural Network(CNN) is one of the well known deep neural networks for image classification. Training a CNN by labeling images in a supervised manner as in “input image belongs to this label”, known as Positive Learning, which yields great results at the output, but the problem starts when inaccurate labels or noisy labels appear in a training dataset, which leads the downfall of the accuracy and overfitting. So, to encounter this issue a team of School of Electrical Engineering, KAIST, South Korea published a paper in the ICCV19 conference, which focuses on achieving a state-of-the-art model for image classification in noisy input labels.
The main contributions of this paper are as follows:
- Negative Learning is introduced to resolve the problem of noisy data classification and to save the model from overfitting. In Negative Learning CNNs are trained using a complimentary label as in "input image does not belong to this complimentary label" which furthermore helps to improve convergence.

Figure 1: Given the noisy label:car, PL classifies that as a car (Red balloon) which is wrong,on the other hand NL classifies that as not a bird(Blue balloon) which is somehow right.
- A new framework has been introduced which is mentioned as Selective Negative Learning and Positive Learning (SelNLPL). In this framework, they used PL and NP both, but in a selective manner. They used PL selectively on the part of the input data which has a high probability to be clean and noise-free whose choices become possible as NL progresses and NL is used on the part of the data that has a high probability to be noisy and incorrect.
- The introduced method is simple and applicable in real file. This method does not require any prior knowledge of tuning of hyper-parameters and type or number of noisy data points, which makes the method more convenient.
- As the optimization of NL and PL is different, NL optimizes the output probability based on the complementary label but PL not, so they introduced a loss function.
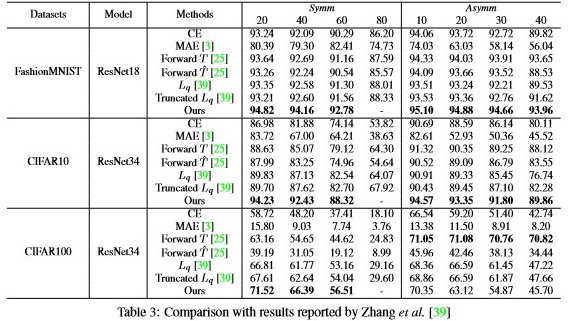
A set of experiments had been conducted in different experiment settings like-different CNN architecture, dataset, and type of noise in the training data to compare their method with other existing methods. They used CIFAR10, CIFAR100, FashionMNIST and MNIST datasets and symmetric and asymmetric noise for experiment purposes.
Shows the performance of their model in all cases, from CNN architecture, dataset, noise type, or noise ratio. Their models outperform other models by a maximum of 5%, but their model fails to converge when symm-exc noise is 80%.
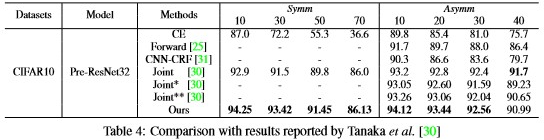
: Table 4 shows the comparison of the produced results between the method proposed in Tanaka et al. [30] and their method, which goes to their fever as the hyper-parameters do not vary according to noise type and ratio.
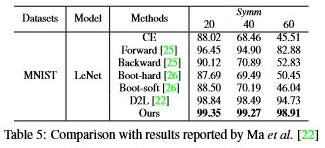
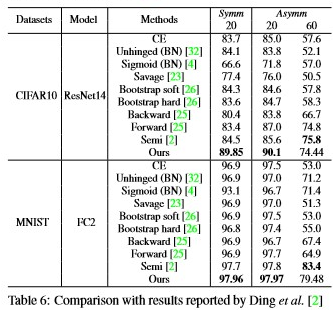
Tables 3 and 4 are taken from [22] and [2], respectively. While Table 3 adopted the structure of LeNet5 for MNIST, Table 4 used a 2-layer fully connected network for MNIST and a 14-layer ResNet for CIFAR10. Both tables show the proposed method surpassed most of the other comparable results for all CNN architectures, datasets, noise types, and ratios. In some cases, the performance of the proposed method exceeded those of other methods by up to 4∼5%, demonstrating the superiority of our method. The proposed method only performed second best for 60% asymmetric noise in Table 4, but we believe this is unimportant because such a scenario is unrealistic.
As a conclusion it is clear that their Semi-supervised Learning model achieves state-of-the-art results based on their SelNLPL framework and their attempt to resolve the issue of the existence of noisy labels and inaccurate labels in classification task goes well.
Code of the paper can be found in this Github repo.
- Reviewed by Soumyadip Sarkar