Action localization is the process of recognizing an action of one or more agents from a series of observations on the agent from a video. We all know an action is made of multiple semantic sub-actions in a consistent order(while sub-actions may vary in appearance and duration). So, our main aim is to recognize the sub-actions of the main action in every frame. From the perspective of applications, action localization has a wide range of real-life applications, like- automatic human action monitoring, video surveillance and video captioning.
This paper gives us a state-of-the-art action recognition model, different features of the proposed model go something like that,
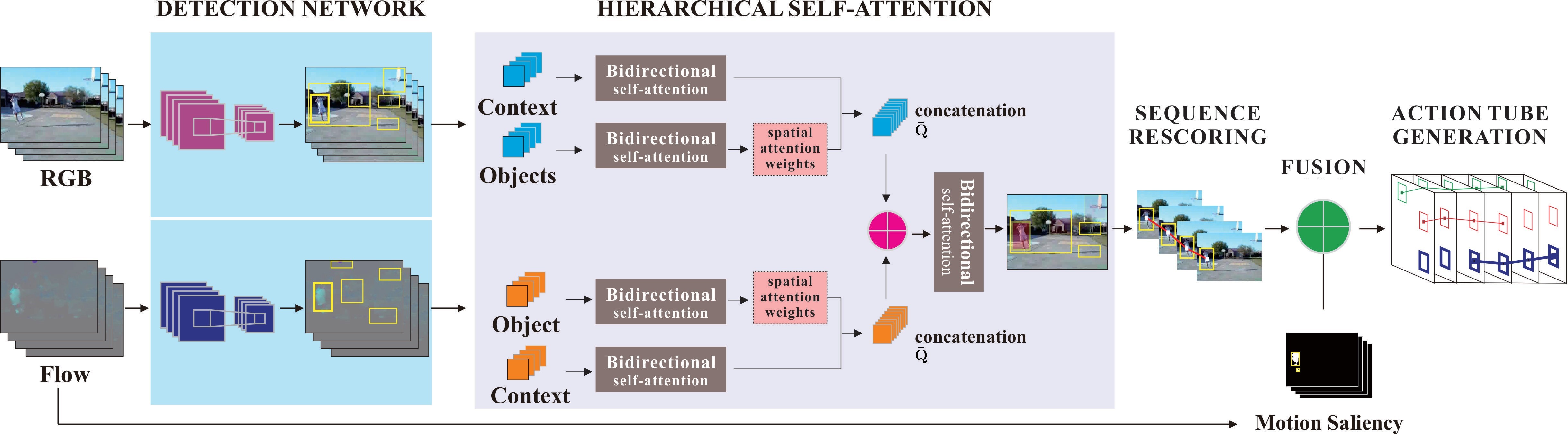
Fig:1 The pipeline of the proposed architecture
-
Use of Faster R-CNN as the first building block of their architecture for action detection, which is composed of a two-stream convolution layer as spatial and motion CNNs.As you can see the spatial-CNN takes RGB images as input while the motion-CNN takes optical flow images as their input.
-
Ability to capture the sub-actions and surroundings and use them to increase the localization accuracy(Like- improvement in video mAP for UCF101-24 and J-HMDB by 2.5% to 5% and 5% to 12% respectively ) through hierarchical self-attention network.
-
SR algorithm(Sequence rescoring algorithm) is used to rectify the inconsistent detection scores due to occlusion at the output of the HISAN.
-
Another important part of the proposed architecture is the fusion strategy which includes motion saliency. Motion saliency is added to avoid the consequences of false detection from motion-CNN which occurs due to small camera movements.
Fig:2- Overview of the motion saliency: (a) the key actor inside the yellow box; (b) the bounding boxes from the motion-CNN; (c) the salient region in white.
-
To simulate the output of the model action tube is generated which helps us to attain superior performance and visualize the output after the fusion scheme.A link of a video on generation of action tube is here.

you can find the slideshare slides here
Two dataset are used for experiment which are UCF101-24 and J-HMDB. Both of the action localization datasets are consist of varity of charcteristics, which is suitable for the experiments.
This dataset contains 3194 annotated videos and 24 action classes. It encompasses several viewpoints of actors, illumination conditions, and camera movements. Most of the videos in this dataset are untrimmed.You can find the dataset overhere
This dataset is composed of 928 trimmed videos and 21 action classes. Several challenges encountered in this dataset include occlusion, background clutter, and high inter-class similarity.You can find the dataset overhere
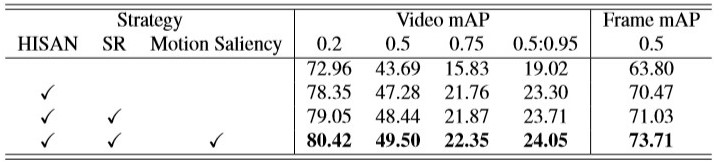
Action localization results on UCF101-24 with various combinations of
strategies.
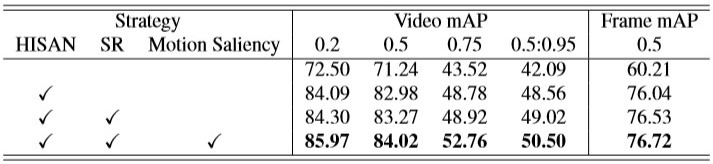
Action localization results on J-HMDB with various combinations of strategies.
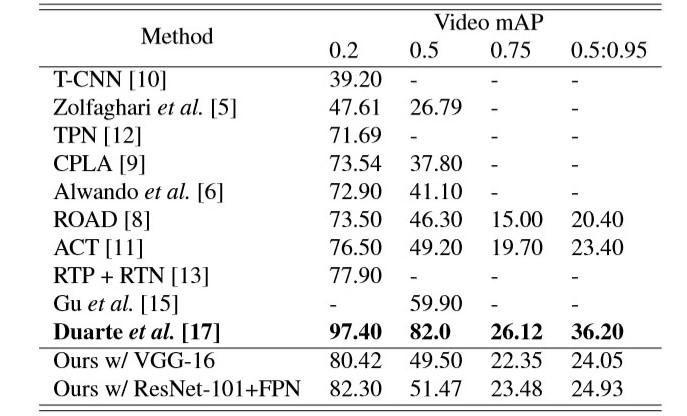
The comparison of the proposed architecture with ten baselines, including Zolfaghari et al. [5], Alwando et al.[5], Singh et al. [8], CPLA [9], T-CNN [10], ACT [11], TPN [12], RTP + RTN [13], Gu et al. [15], and Duarte et al. [17], in terms of video mAP for different IoU’s on UCF101-24 and J-HMDB are provided below in the form of a table.
please note '[x]' is the reference number for the baselines.
Comparison of the action localization performance on UCF101-24. The best results are bold-faced.
Comparison of the action localization performance on J-HMDB. The best results are bold-faced.
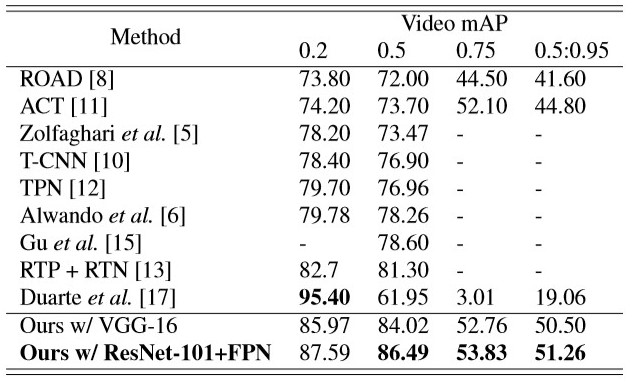
Except [15,17] proposed model outperforms all of the prementioned methods because of the bidirectional self-attention and the fusion strategy which is really boosted the performance of the model.
- Reviewed by Soumtadip Sarkar