VLMEvalKit: 大規模視覚言語モデルの評価ツールキット





🏆 OpenCompass Learderboard • 📊Datasets & Models • 🏗️Quickstart • 🛠️Development • 🎯Goal • 🖊️Citation
VLMEvalKit(pythonパッケージ名はvlmeval)は、大規模視覚言語モデル(LVLMs)のオープンソース評価ツールキットです。このツールキットは、複数のリポジトリでのデータ準備という重労働なしに、さまざまなベンチマークでLVLMsのワンコマンド評価を可能にします。VLMEvalKitでは、すべてのLVLMsに対して生成ベースの評価を採用し、正確なマッチングとLLMベースの回答抽出の両方で得られた評価結果を提供します。
PS: 日本語の README には最新のアップデートがすべて含まれていない場合があります。英語版をご確認ください。
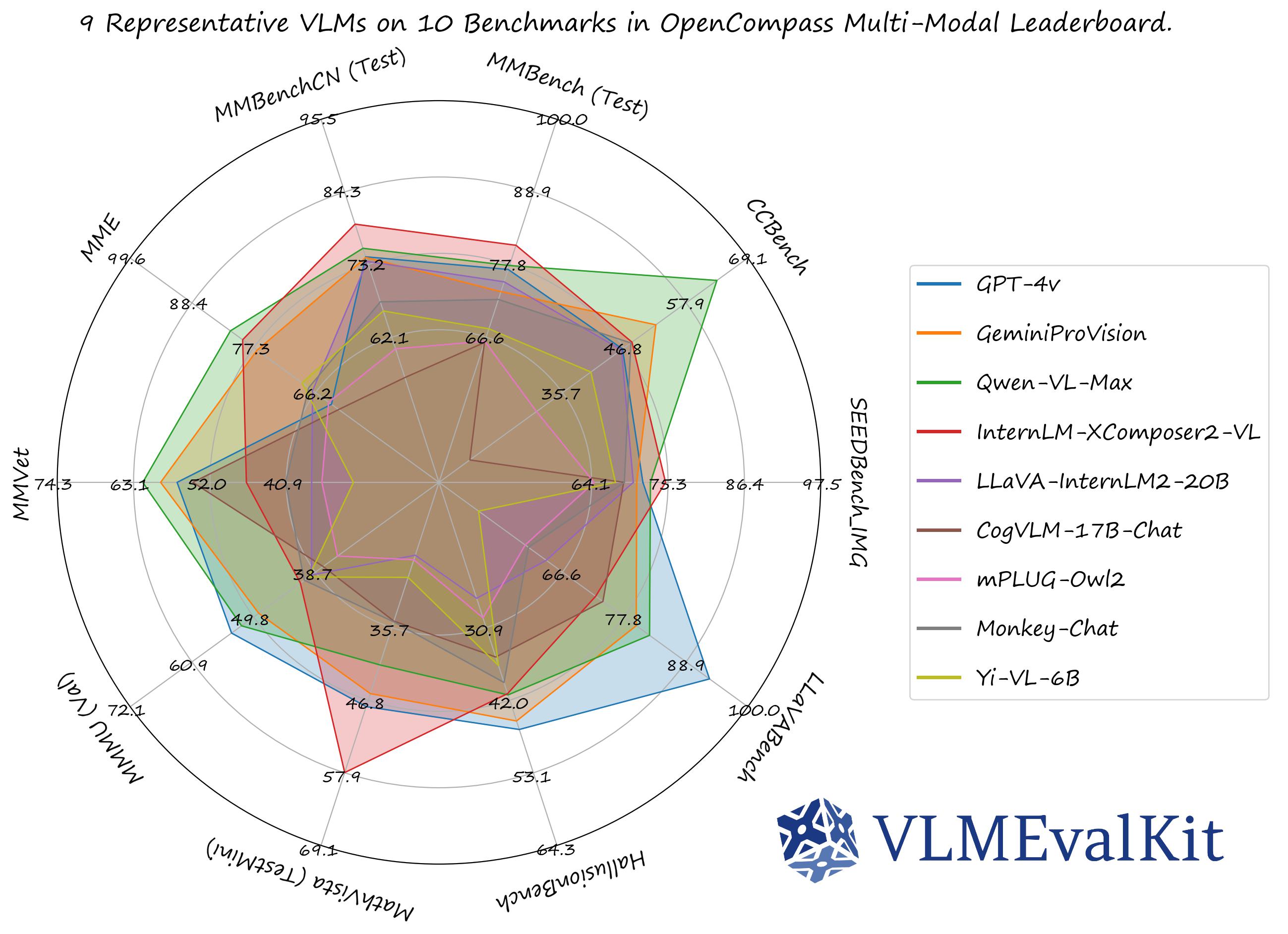
公式のマルチモーダルリーダーボードでのパフォーマンス数値は、ここからダウンロードできます!
OpenVLM Leaderboard: すべての詳細な結果をダウンロード。
Supported Image Understanding Dataset
- デフォルトでは、すべての評価結果はOpenVLM Leaderboardに表示されます。
| データセット | データセット名 (run.py用) | タスク | データセット | データセット名 (run.py用) | タスク |
|---|---|---|---|---|---|
| MMBench シリーズ: MMBench, MMBench-CN, CCBench |
MMBench_DEV_[EN/CN] MMBench_TEST_[EN/CN] MMBench_DEV_[EN/CN]_V11 MMBench_TEST_[EN/CN]_V11 CCBench |
多肢選択問題 (MCQ) | MMStar | MMStar | MCQ |
| MME | MME | はい/いいえ (Y/N) | SEEDBench シリーズ | SEEDBench_IMG SEEDBench2 SEEDBench2_Plus |
MCQ |
| MM-Vet | MMVet | VQA | MMMU | MMMU_[DEV_VAL/TEST] | MCQ |
| MathVista | MathVista_MINI | VQA | ScienceQA_IMG | ScienceQA_[VAL/TEST] | MCQ |
| COCO Caption | COCO_VAL | キャプション | HallusionBench | HallusionBench | Y/N |
| OCRVQA* | OCRVQA_[TESTCORE/TEST] | VQA | TextVQA* | TextVQA_VAL | VQA |
| ChartQA* | ChartQA_TEST | VQA | AI2D | AI2D_TEST | MCQ |
| LLaVABench | LLaVABench | VQA | DocVQA+ | DocVQA_[VAL/TEST] | VQA |
| InfoVQA+ | InfoVQA_[VAL/TEST] | VQA | OCRBench | OCRBench | VQA |
| RealWorldQA | RealWorldQA | MCQ | POPE | POPE | Y/N |
| Core-MM- | CORE_MM | VQA | MMT-Bench | MMT-Bench_[VAL/VAL_MI/ALL/ALL_MI] | MCQ |
| MLLMGuard - | MLLMGuard_DS | VQA | AesBench | AesBench_[VAL/TEST] | MCQ |
| VCR-wiki + | VCR_[EN/ZH]_[EASY/HARD]_[ALL/500/100] | VQA | MMLongBench-Doc+ | MMLongBench_DOC | VQA |
| BLINK + | BLINK | MCQ | MathVision+ | MathVision MathVision_MINI |
VQA |
| MT-VQA+ | MTVQA_TEST | VQA | MMDU+ | MMDU | VQA (multi-turn) |
* ゼロショット設定で合理的な結果を出せないVLMの一部の評価結果のみを提供しています
+ 評価結果はまだ利用できません
- VLMEvalKitでは推論のみがサポートされています
VLMEvalKitは、キーを設定すると判定LLMを使用して出力から回答を抽出し、それ以外の場合は正確なマッチングモード(出力文字列で「はい」、「いいえ」、「A」、「B」、「C」...を検索)を使用します。正確なマッチングは、はい/いいえのタスクと多肢選択問題にのみ適用できます。
Supported Video Understanding Dataset
| Dataset | Dataset Names (for run.py) | Task | Dataset | Dataset Names (for run.py) | Task |
|---|---|---|---|---|---|
| MMBench-Video | MMBench-Video | VQA | Video-MME | Video-MME | MCQ |
Supported API Models
| GPT-4v (20231106, 20240409) 🎞️🚅 | GPT-4o 🎞️🚅 | Gemini-1.0-Pro 🎞️🚅 | Gemini-1.5-Pro 🎞️🚅 | Step-1V 🎞️🚅 |
|---|---|---|---|---|
| Reka-[Edge / Flash / Core]🚅 | Qwen-VL-[Plus / Max] 🎞️🚅 | Claude-3v-[Haiku / Sonnet / Opus] 🎞️🚅 | GLM-4v 🚅 | CongRong 🎞️🚅 |
| Claude3.5-Sonnet 🎞️🚅 | GPT-4o-Mini 🎞️🚅 | Yi-Vision🎞️🚅 |
Supported PyTorch / HF Models
🎞️: 複数の画像を入力としてサポートします。
🚅: 追加の設定/操作なしで使用できるモデルです。
🎬: 入力としてビデオをサポート。
Transformersバージョンの推奨事項:
特定のtransformerバージョンで一部のVLMが実行できない可能性があることに注意してください。各VLMを評価するために、以下の設定を推奨します:
transformers==4.33.0を使用してください:Qwenシリーズ,Monkeyシリーズ,InternLM-XComposerシリーズ,mPLUG-Owl2,OpenFlamingo v2,IDEFICSシリーズ,VisualGLM,MMAlaya,ShareCaptioner,MiniGPT-4シリーズ,InstructBLIPシリーズ,PandaGPT,VXVERSE,GLM-4v-9B.transformers==4.37.0を使用してください:LLaVAシリーズ,ShareGPT4Vシリーズ,TransCore-M,LLaVA (XTuner),CogVLMシリーズ,EMU2シリーズ,Yi-VLシリーズ,MiniCPM-[V1/V2],OmniLMM-12B,DeepSeek-VLシリーズ,InternVLシリーズ,Cambrianシリーズ,VILA-VLシリーズ.transformers==4.40.0を使用してください:IDEFICS2,Bunny-Llama3,MiniCPM-Llama3-V2.5,360VL-70B,Phi-3-Vision,WeMM.transformers==latestを使用してください:LLaVA-Nextシリーズ,PaliGemma-3B,Chameleon-VLシリーズ,Video-LLaVA-7B-HF,Ovis1.5-Llama3-8B.
# デモ
from vlmeval.config import supported_VLM
model = supported_VLM['idefics_9b_instruct']()
# 単一画像のフォワード
ret = model.generate(['assets/apple.jpg', 'この画像には何がありますか?'])
print(ret) # この画像には葉がついた赤いリンゴがあります。
# 複数画像のフォワード
ret = model.generate(['assets/apple.jpg', 'assets/apple.jpg', '提供された画像にはリンゴが何個ありますか?'])
print(ret) # 提供された画像にはリンゴが2個あります。クイックスタートガイドについては、クイックスタートを参照してください。
カスタムベンチマーク、VLMsを開発するか、単にVLMEvalKitに他のコードを貢献する場合は、開発ガイドを参照してください。
コミュニティからの共有を奨励し、それに応じたクレジットを共有するために、次回のレポート更新では以下のことを実施します:
- 全ての貢献に対して感謝の意を示します
- 新しいモデル、評価セット、または主要な機能への3つ以上の主要な貢献を持つ貢献者は、テクニカルレポートの著者リストに加わることができます。適格な貢献者は、issueを作成するか、またはVLM評価キット ディスコードチャンネルで kennyutc にDMを送ることができます。私たちはそれに応じてフォローアップします。
このコードベースは以下を目的として設計されています:
- 研究者や開発者が既存のLVLMsを評価し、評価結果を簡単に再現できるようにするための使いやすい、オープンソースの評価ツールキットを提供します。
- VLMの開発者が自分のモデルを簡単に評価できるようにします。複数のサポートされているベンチマークでVLMを評価するには、単一の
generate_inner()関数を実装するだけで、他のすべてのワークロード(データのダウンロード、データの前処理、予測の推論、メトリックの計算)はコードベースによって処理されます。
このコードベースは以下を目的として設計されていません:
- すべての第三者ベンチマークの元の論文で報告された正確な精度数値を再現すること。その理由は2つあります:
- VLMEvalKitは、すべてのVLMに対して生成ベースの評価を使用します(オプションでLLMベースの回答抽出を使用)。一方、一部のベンチマークは異なるアプローチを使用する場合があります(SEEDBenchはPPLベースの評価を使用します)。これらのベンチマークについては、対応する結果で両方のスコアを比較します。開発者には、コードベースで他の評価パラダイムをサポートすることをお勧めします。
- デフォルトでは、すべてのVLMに対して同じプロンプトテンプレートを使用してベンチマークを評価します。一方、一部のVLMには特定のプロンプトテンプレートがある場合があります(現時点ではコードベースでカバーされていない場合があります)。VLMの開発者には、現在カバーされていない場合でも、VLMEvalKitで独自のプロンプトテンプレートを実装することをお勧めします。これにより、再現性が向上します。
この作業が役立つ場合は、このリポジトリにスター🌟を付けてください。サポートありがとうございます!
研究でVLMEvalKitを使用する場合、または公開されたオープンソースの評価結果を参照する場合は、以下のBibTeXエントリと、使用した特定のVLM/ベンチマークに対応するBibTexエントリを使用してください。
@misc{duan2024vlmevalkit,
title={VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models},
author={Haodong Duan and Junming Yang and Yuxuan Qiao and Xinyu Fang and Lin Chen and Yuan Liu and Xiaoyi Dong and Yuhang Zang and Pan Zhang and Jiaqi Wang and Dahua Lin and Kai Chen},
year={2024},
eprint={2407.11691},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.11691},
}