|
| 1 | +原文:https://mp.weixin.qq.com/s/qci10h9rJx_COZbHV3aygQ |
| 2 | + |
| 3 | + |
| 4 | + |
| 5 | +# MySQL自增主键一定是连续的吗 |
| 6 | + |
| 7 | +众所周知,自增主键可以让聚集索引尽量地保持递增顺序插入,避免了随机查询,从而提高了查询效率。 |
| 8 | + |
| 9 | +但实际上,MySQL 的自增主键并不能保证一定是连续递增的。 |
| 10 | + |
| 11 | +下面举个例子来看下,如下所示创建一张表: |
| 12 | + |
| 13 | +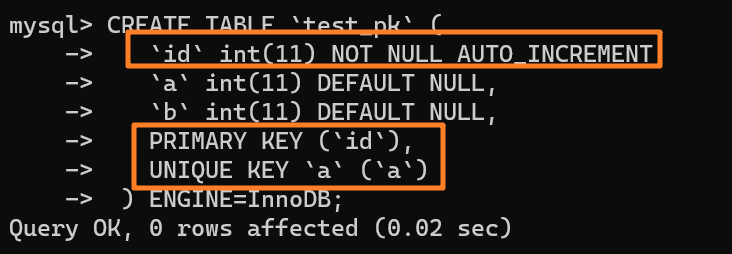 |
| 14 | + |
| 15 | + |
| 16 | + |
| 17 | +## [自增值保存在哪里?](https://javaguide.cn/database/mysql/mysql-auto-increment-primary-key-continuous.html#自增值保存在哪里) |
| 18 | + |
| 19 | +使用 `insert into test_pk values(null, 1, 1)` 插入一行数据,再执行 `show create table` 命令来看一下表的结构定义: |
| 20 | + |
| 21 | +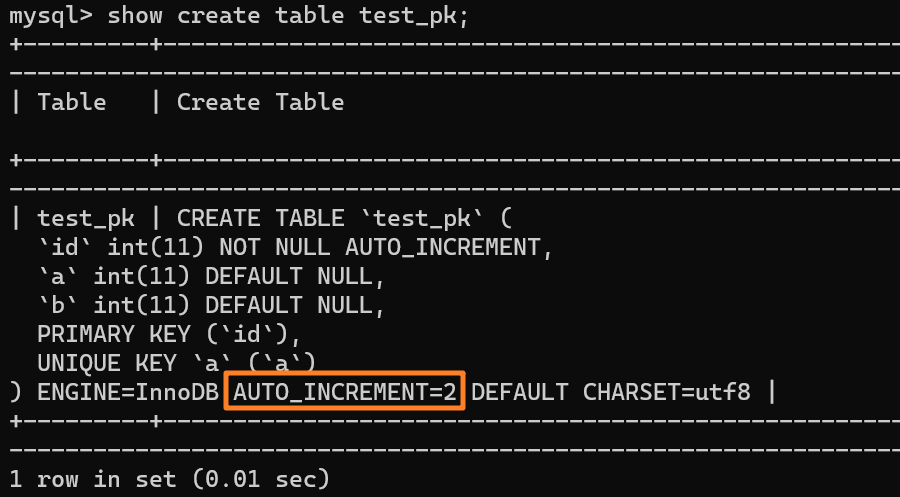 |
| 22 | + |
| 23 | +上述表的结构定义存放在后缀名为 `.frm` 的本地文件中,在 MySQL 安装目录下的 data 文件夹下可以找到这个 `.frm` 文件: |
| 24 | + |
| 25 | +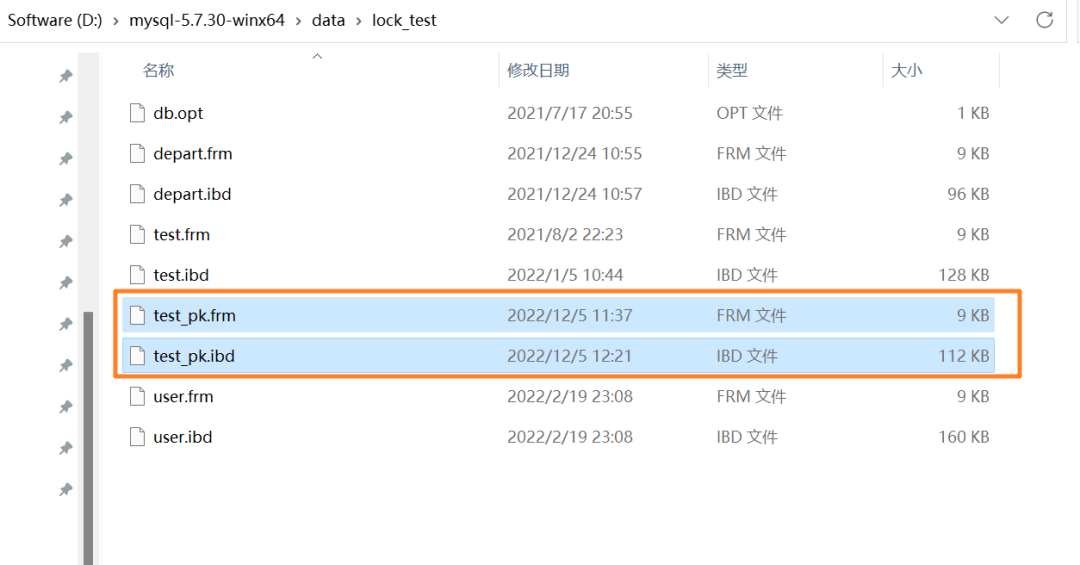 |
| 26 | + |
| 27 | +从上述表结构可以看到,表定义里面出现了一个 `AUTO_INCREMENT=2`,表示下一次插入数据时,如果需要自动生成自增值,会生成 id = 2。 |
| 28 | + |
| 29 | +但需要注意的是,自增值并不会保存在这个表结构也就是 `.frm` 文件中,不同的引擎对于自增值的保存策略不同: |
| 30 | + |
| 31 | +1)MyISAM 引擎的自增值保存在数据文件中 |
| 32 | + |
| 33 | +2)InnoDB 引擎的自增值,其实是保存在了内存里,并没有持久化。第一次打开表的时候,都会去找自增值的最大值 `max(id)`,然后将 `max(id)+1` 作为这个表当前的自增值。 |
| 34 | + |
| 35 | +举个例子:我们现在表里当前数据行里最大的 id 是 1,AUTO_INCREMENT=2,对吧。这时候,我们删除 id=1 的行,AUTO_INCREMENT 还是 2。 |
| 36 | + |
| 37 | +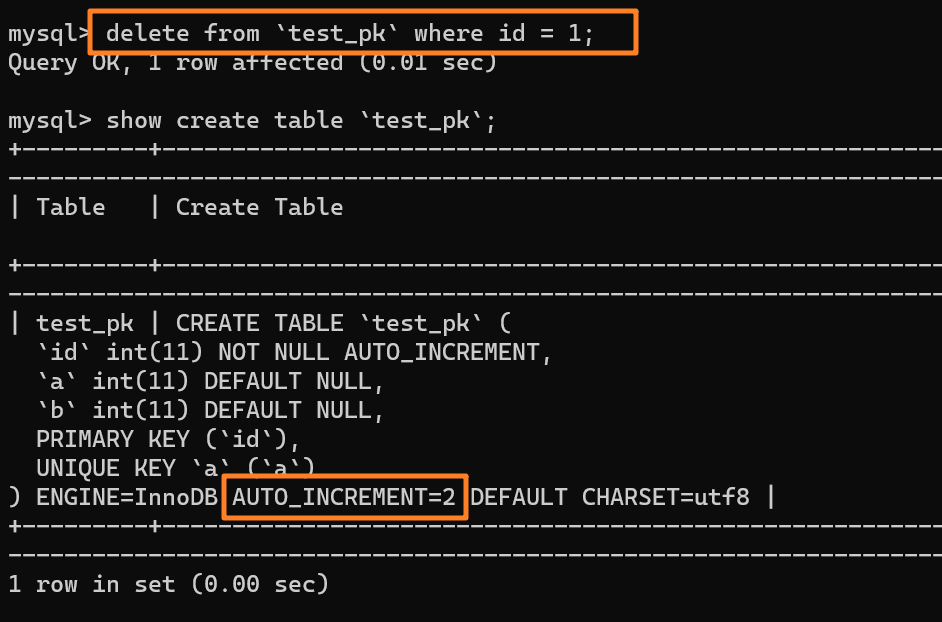 |
| 38 | + |
| 39 | +但如果马上重启 MySQL 实例,重启后这个表的 AUTO_INCREMENT 就会变成 1。 也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。 |
| 40 | + |
| 41 | + |
| 42 | + |
| 43 | +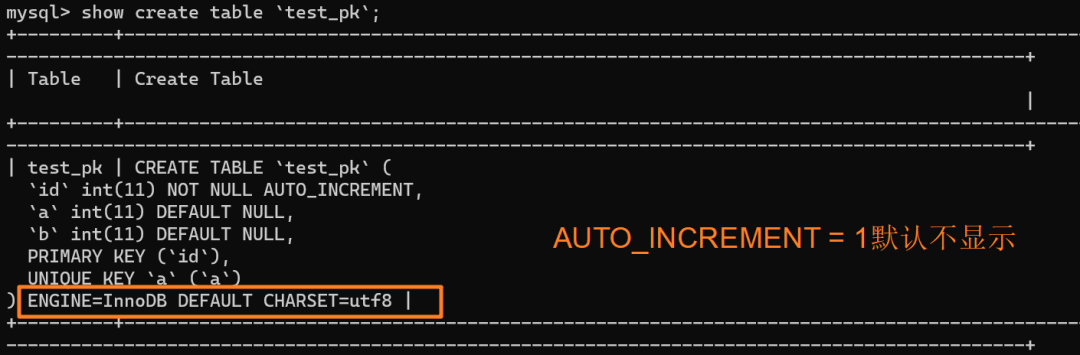 |
| 44 | + |
| 45 | +以上,是在我本地 MySQL 5.x 版本的实验,实际上,**到了 MySQL 8.0 版本后,自增值的变更记录被放在了 redo log 中,提供了自增值持久化的能力** ,也就是实现了“如果发生重启,表的自增值可以根据 redo log 恢复为 MySQL 重启前的值” |
| 46 | + |
| 47 | +也就是说对于上面这个例子来说,重启实例后这个表的 AUTO_INCREMENT 仍然是 2。 |
| 48 | + |
| 49 | +理解了 MySQL 自增值到底保存在哪里以后,我们再来看看自增值的修改机制,并以此引出第一种自增值不连续的场景。 |
| 50 | + |
| 51 | + |
| 52 | + |
| 53 | +## [自增值不连续的场景](#自增值不连续的场景) |
| 54 | + |
| 55 | +### [自增值不连续场景 1](#自增值不连续场景-1) |
| 56 | + |
| 57 | +在 MySQL 里面,如果字段 id 被定义为 AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下: |
| 58 | + |
| 59 | +- 如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段; |
| 60 | +- 如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。 |
| 61 | + |
| 62 | +根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设某次要插入的值是 `insert_num`,当前的自增值是 `autoIncrement_num`: |
| 63 | + |
| 64 | +- 如果 `insert_num < autoIncrement_num`,那么这个表的自增值不变 |
| 65 | +- 如果 `insert_num >= autoIncrement_num`,就需要把当前自增值修改为新的自增值 |
| 66 | + |
| 67 | +也就是说,如果插入的 id 是 100,当前的自增值是 90,`insert_num >= autoIncrement_num`,那么自增值就会被修改为新的自增值即 101 |
| 68 | + |
| 69 | +一定是这样吗? |
| 70 | + |
| 71 | +非也~ |
| 72 | + |
| 73 | +了解过分布式 id 的小伙伴一定知道,为了避免两个库生成的主键发生冲突,我们可以让一个库的自增 id 都是奇数,另一个库的自增 id 都是偶数 |
| 74 | + |
| 75 | +这个奇数偶数其实是通过 `auto_increment_offset` 和 `auto_increment_increment` 这两个参数来决定的,这俩分别用来表示自增的初始值和步长,默认值都是 1。 |
| 76 | + |
| 77 | +所以,上面的例子中生成新的自增值的步骤实际是这样的:从 `auto_increment_offset` 开始,以 `auto_increment_increment` 为步长,持续叠加,直到找到第一个大于 100 的值,作为新的自增值。 |
| 78 | + |
| 79 | +所以,这种情况下,自增值可能会是 102,103 等等之类的,就会导致不连续的主键 id。 |
| 80 | + |
| 81 | +更遗憾的是,即使在自增初始值和步长这两个参数都设置为 1 的时候,自增主键 id 也不一定能保证主键是连续的 |
| 82 | + |
| 83 | + |
| 84 | + |
| 85 | +### [自增值不连续场景 2](https://javaguide.cn/database/mysql/mysql-auto-increment-primary-key-continuous.html#自增值不连续场景-2) |
| 86 | + |
| 87 | +举个例子,我们现在往表里插入一条 (null,1,1) 的记录,生成的主键是 1,AUTO_INCREMENT= 2,对吧 |
| 88 | + |
| 89 | +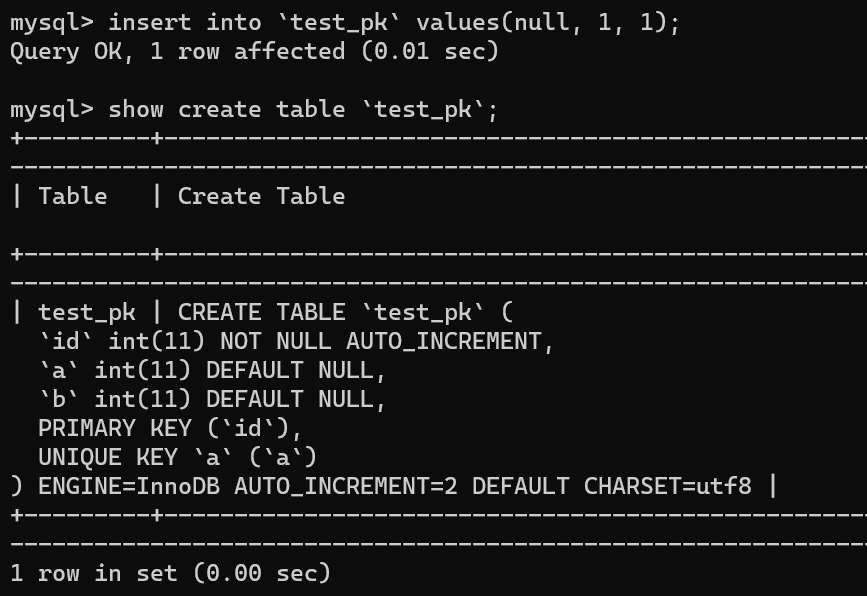 |
| 90 | + |
| 91 | +这时我再执行一条插入 `(null,1,1)` 的命令,很显然会报错 `Duplicate entry`,因为我们设置了一个唯一索引字段 `a`: |
| 92 | + |
| 93 | +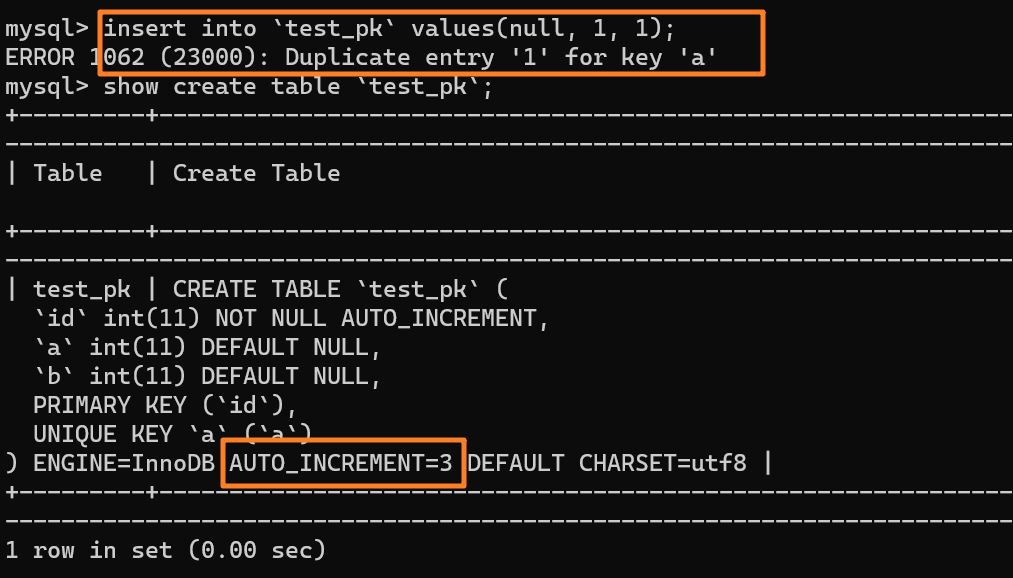 |
| 94 | + |
| 95 | +但是,你会惊奇的发现,虽然插入失败了,但自增值仍然从 2 增加到了 3! |
| 96 | + |
| 97 | +这是为啥? |
| 98 | + |
| 99 | +我们来分析下这个 insert 语句的执行流程: |
| 100 | + |
| 101 | +1. 执行器调用 InnoDB 引擎接口准备插入一行记录 (null,1,1); |
| 102 | +2. InnoDB 发现用户没有指定自增 id 的值,则获取表 `test_pk` 当前的自增值 2; |
| 103 | +3. 将传入的记录改成 (2,1,1); |
| 104 | +4. 将表的自增值改成 3; |
| 105 | +5. 继续执行插入数据操作,由于已经存在 a=1 的记录,所以报 Duplicate key error,语句返回 |
| 106 | + |
| 107 | +可以看到,自增值修改的这个操作,是在真正执行插入数据的操作之前。 |
| 108 | + |
| 109 | +这个语句真正执行的时候,因为碰到唯一键 a 冲突,所以 id = 2 这一行并没有插入成功,但也没有将自增值再改回去。所以,在这之后,再插入新的数据行时,拿到的自增 id 就是 3。也就是说,出现了自增主键不连续的情况。 |
| 110 | + |
| 111 | +至此,我们已经罗列了两种自增主键不连续的情况: |
| 112 | + |
| 113 | +1. 自增初始值和自增步长设置不为 1 |
| 114 | +2. 唯一键冲突 |
| 115 | + |
| 116 | +除此之外,事务回滚也会导致这种情况 |
| 117 | + |
| 118 | + |
| 119 | + |
| 120 | +### [自增值不连续场景 3](https://javaguide.cn/database/mysql/mysql-auto-increment-primary-key-continuous.html#自增值不连续场景-3) |
| 121 | + |
| 122 | +我们现在表里有一行 `(1,1,1)` 的记录,AUTO_INCREMENT = 3: |
| 123 | + |
| 124 | +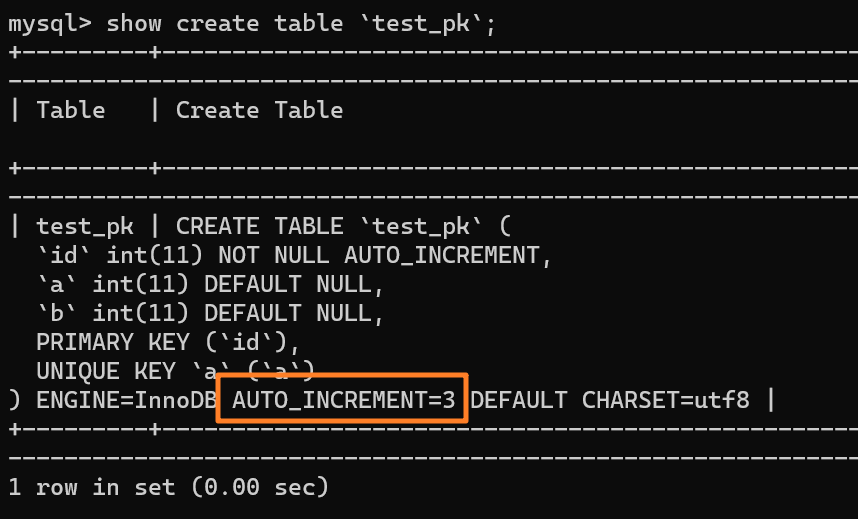 |
| 125 | + |
| 126 | +我们先插入一行数据 `(null, 2, 2)`,也就是 (3, 2, 2) 嘛,并且 AUTO_INCREMENT 变为 4: |
| 127 | + |
| 128 | +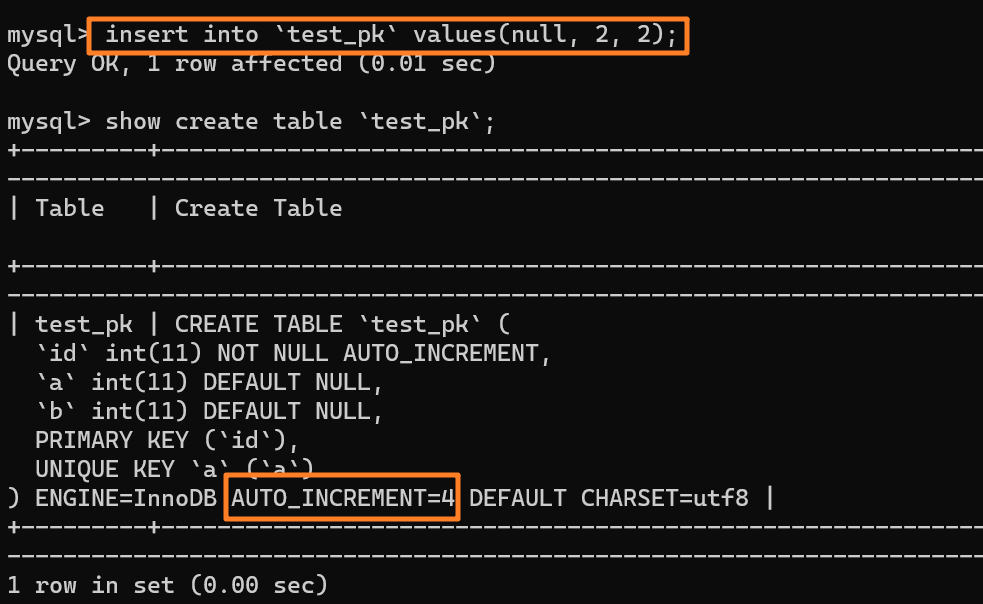 |
| 129 | + |
| 130 | +再去执行这样一段 SQL: |
| 131 | + |
| 132 | +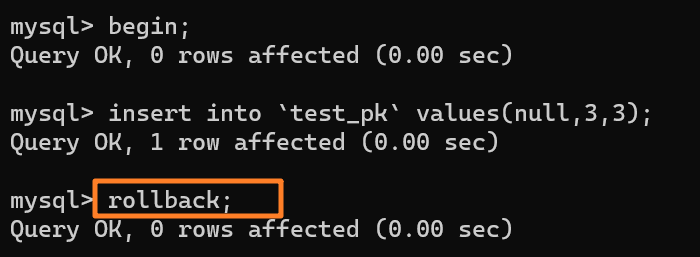 |
| 133 | + |
| 134 | +虽然我们插入了一条 (null, 3, 3) 记录,但是使用 rollback 进行回滚了,所以数据库中是没有这条记录的: |
| 135 | + |
| 136 | +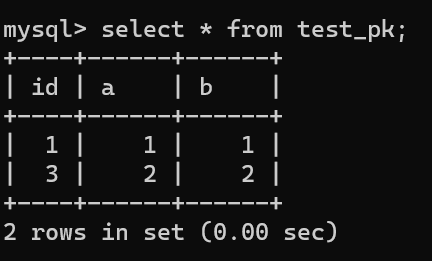 |
| 137 | + |
| 138 | +在这种事务回滚的情况下,自增值并没有同样发生回滚!如下图所示,自增值仍然固执地从 4 增加到了 5: |
| 139 | + |
| 140 | +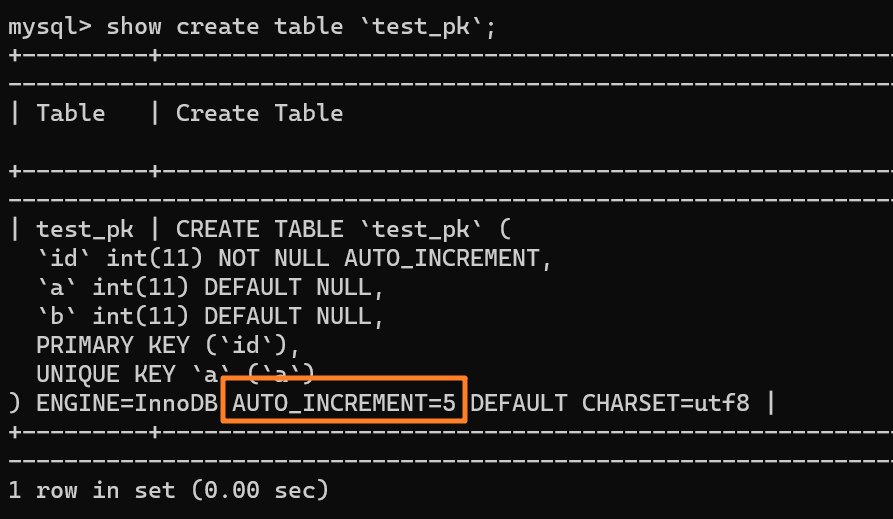 |
| 141 | + |
| 142 | +所以这时候我们再去插入一条数据(null, 3, 3)的时候,主键 id 就会被自动赋为 `5` 了: |
| 143 | + |
| 144 | +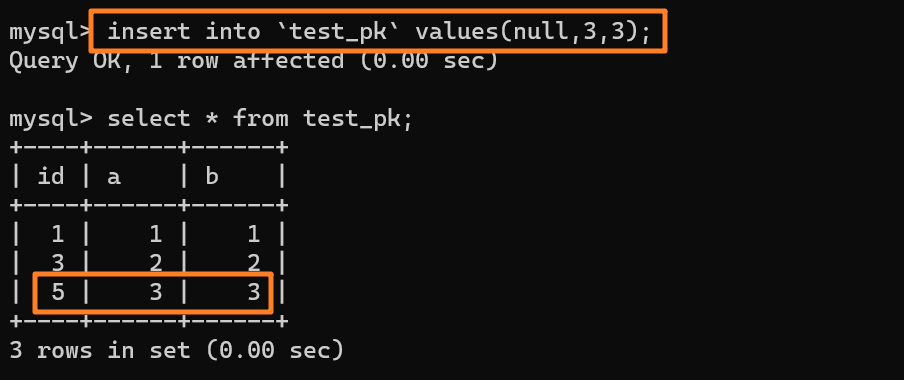 |
| 145 | + |
| 146 | +那么,为什么在出现唯一键冲突或者回滚的时候,MySQL 没有把表的自增值改回去呢?回退回去的话不就不会发生自增 id 不连续了吗? |
| 147 | + |
| 148 | +事实上,这么做的主要原因是为了提高性能。 |
| 149 | + |
| 150 | +我们直接用反证法来验证:假设 MySQL 在事务回滚的时候会把自增值改回去,会发生什么? |
| 151 | + |
| 152 | +现在有两个并行执行的事务 A 和 B,在申请自增值的时候,为了避免两个事务申请到相同的自增 id,肯定要加锁,然后顺序申请,对吧。 |
| 153 | + |
| 154 | +1. 假设事务 A 申请到了 id = 1, 事务 B 申请到 id=2,那么这时候表 t 的自增值是 3,之后继续执行。 |
| 155 | +2. 事务 B 正确提交了,但事务 A 出现了唯一键冲突,也就是 id = 1 的那行记录插入失败了,那如果允许事务 A 把自增 id 回退,也就是把表的当前自增值改回 1,那么就会出现这样的情况:表里面已经有 id = 2 的行,而当前的自增 id 值是 1。 |
| 156 | +3. 接下来,继续执行的其他事务就会申请到 id=2。这时,就会出现插入语句报错“主键冲突”。 |
| 157 | + |
| 158 | + |
| 159 | + |
| 160 | +而为了解决这个主键冲突,有两种方法: |
| 161 | + |
| 162 | +1. 每次申请 id 之前,先判断表里面是否已经存在这个 id,如果存在,就跳过这个 id |
| 163 | +2. 把自增 id 的锁范围扩大,必须等到一个事务执行完成并提交,下一个事务才能再申请自增 id |
| 164 | + |
| 165 | +很显然,上述两个方法的成本都比较高,会导致性能问题。而究其原因呢,是我们假设的这个 “允许自增 id 回退”。 |
| 166 | + |
| 167 | +因此,InnoDB 放弃了这个设计,语句执行失败也不回退自增 id。也正是因为这样,所以才只保证了自增 id 是递增的,但不保证是连续的。 |
| 168 | + |
| 169 | +综上,已经分析了三种自增值不连续的场景,还有第四种场景:批量插入数据。 |
| 170 | + |
| 171 | + |
| 172 | + |
| 173 | +### [自增值不连续场景 4](#自增值不连续场景-4) |
| 174 | + |
| 175 | +对于批量插入数据的语句,MySQL 有一个批量申请自增 id 的策略: |
| 176 | + |
| 177 | +1. 语句执行过程中,第一次申请自增 id,会分配 1 个; |
| 178 | +2. 1 个用完以后,这个语句第二次申请自增 id,会分配 2 个; |
| 179 | +3. 2 个用完以后,还是这个语句,第三次申请自增 id,会分配 4 个; |
| 180 | +4. 依此类推,同一个语句去申请自增 id,每次申请到的自增 id 个数都是上一次的两倍。 |
| 181 | + |
| 182 | +注意,这里说的批量插入数据,不是在普通的 insert 语句里面包含多个 value 值!!!,因为这类语句在申请自增 id 的时候,是可以精确计算出需要多少个 id 的,然后一次性申请,申请完成后锁就可以释放了。 |
| 183 | + |
| 184 | +而对于 `insert … select`、replace …… select 和 load data 这种类型的语句来说,MySQL 并不知道到底需要申请多少 id,所以就采用了这种批量申请的策略,毕竟一个一个申请的话实在太慢了。 |
| 185 | + |
| 186 | +举个例子,假设我们现在这个表有下面这些数据: |
| 187 | + |
| 188 | + |
| 189 | + |
| 190 | +我们创建一个和当前表 `test_pk` 有相同结构定义的表 `test_pk2`: |
| 191 | + |
| 192 | +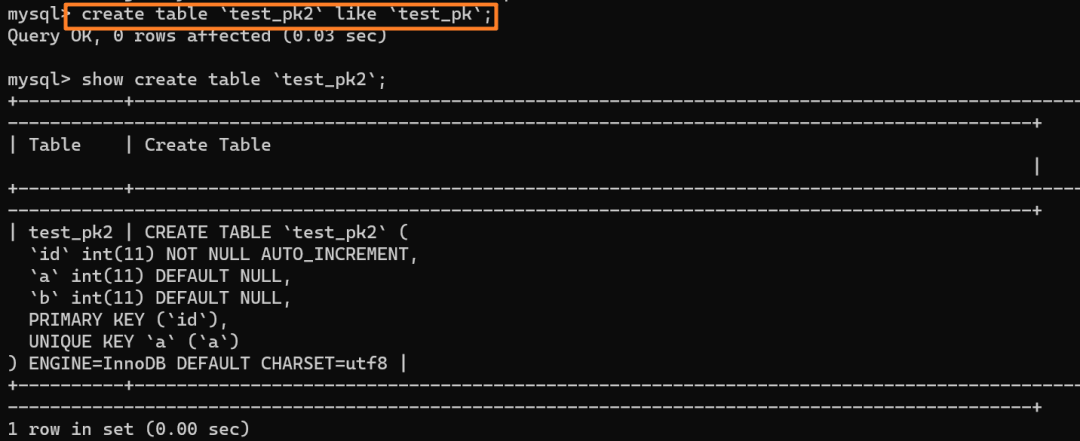 |
| 193 | + |
| 194 | +然后使用 `insert...select` 往 `teset_pk2` 表中批量插入数据: |
| 195 | + |
| 196 | +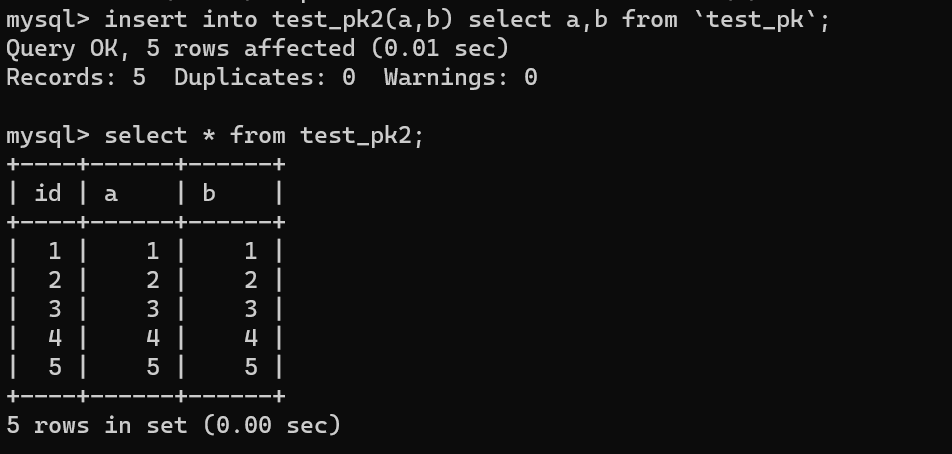 |
| 197 | + |
| 198 | +可以看到,成功导入了数据。 |
| 199 | + |
| 200 | +再来看下 `test_pk2` 的自增值是多少: |
| 201 | + |
| 202 | +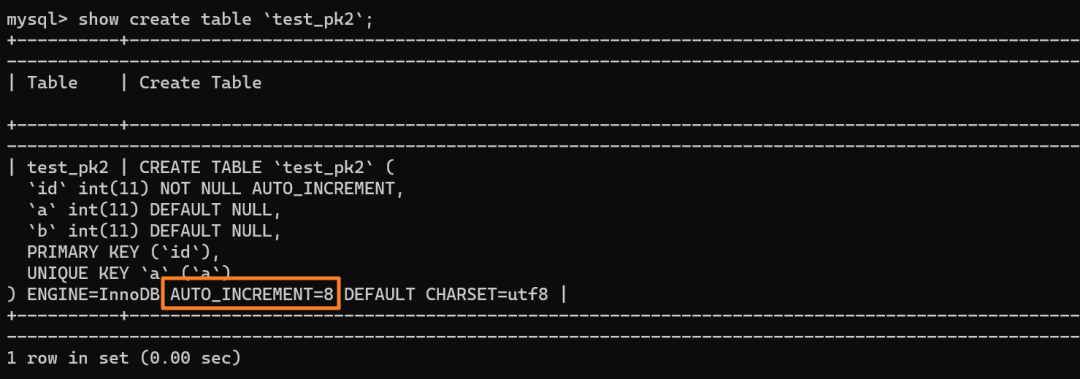 |
| 203 | + |
| 204 | +如上分析,是 8 而不是 6 |
| 205 | + |
| 206 | +具体来说,insert……select 实际上往表中插入了 5 行数据 (1 1)(2 2)(3 3)(4 4)(5 5)。但是,这五行数据是分三次申请的自增 id,结合批量申请策略,每次申请到的自增 id 个数都是上一次的两倍,所以: |
| 207 | + |
| 208 | +- 第一次申请到了一个 id:id=1 |
| 209 | +- 第二次被分配了两个 id:id=2 和 id=3 |
| 210 | +- 第三次被分配到了 4 个 id:id=4、id = 5、id = 6、id=7 |
| 211 | + |
| 212 | +由于这条语句实际只用上了 5 个 id,所以 id=6 和 id=7 就被浪费掉了。之后,再执行 `insert into test_pk2 values(null,6,6)`,实际上插入的数据就是(8,6,6): |
| 213 | + |
| 214 | +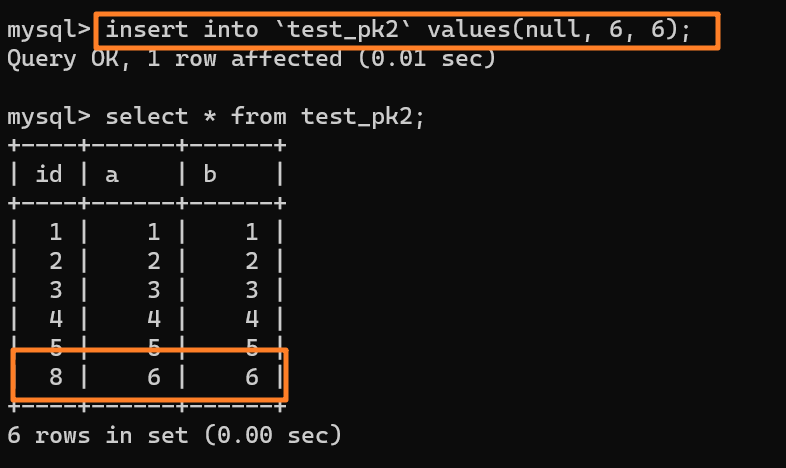 |
| 215 | + |
| 216 | + |
| 217 | + |
| 218 | +## [小结](https://javaguide.cn/database/mysql/mysql-auto-increment-primary-key-continuous.html#小结) |
| 219 | + |
| 220 | +本文总结下自增值不连续的 4 个场景: |
| 221 | + |
| 222 | +1. 自增初始值和自增步长设置不为 1 |
| 223 | +2. 唯一键冲突 |
| 224 | +3. 事务回滚 |
| 225 | +4. 批量插入(如 `insert...select` 语句) |
0 commit comments